
An Oversampling Method for Class Imbalance Problems on Large Datasets


Abstract
:1. Introduction
2. Related Work
| Algorithm 1 SMOTE |
| Input: A minority class, N - Percent of oversampling (integer multiple of 100), k - number of nearest neighbors. Output: An oversampled minority class. Number of objects to be generated for each object of the minority class for each object O in the minority class do Compute the k-nearest neighbors of O in the minority class for do Randomly select one of the k-nearest neighbors of O Initialize an empty object for each feature f do Compute the feature difference between and feature difference end for Add to the minority class end for end for |
3. Proposed Method
| Algorithm 2 Fast-SMOTE |
| Input: A minority class, N - number of synthetic objects to be generated. Output: An oversampled minority class. Minimum value for each feature into the minority class. Maximum value for each feature into the minority class. Mode value for each feature into the minority class. Absolute difference between the mode and the minimum value for each feature into the minority class. Absolute difference between the mode and the maximum value for each feature into the minority class. for do Initialize an empty object for each feature f do if then else end if end for Add to the minority class. end for |
4. Experimental Results
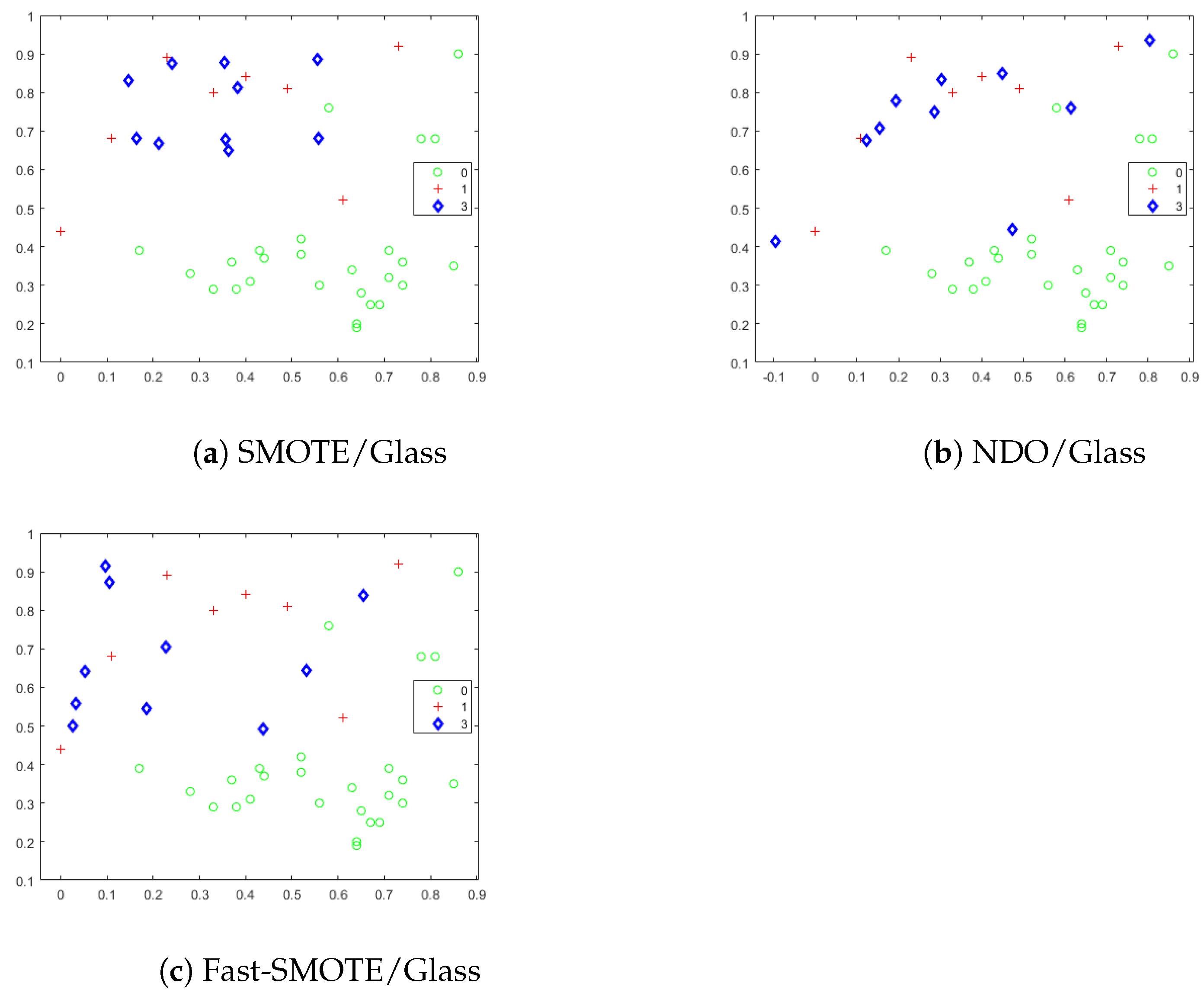
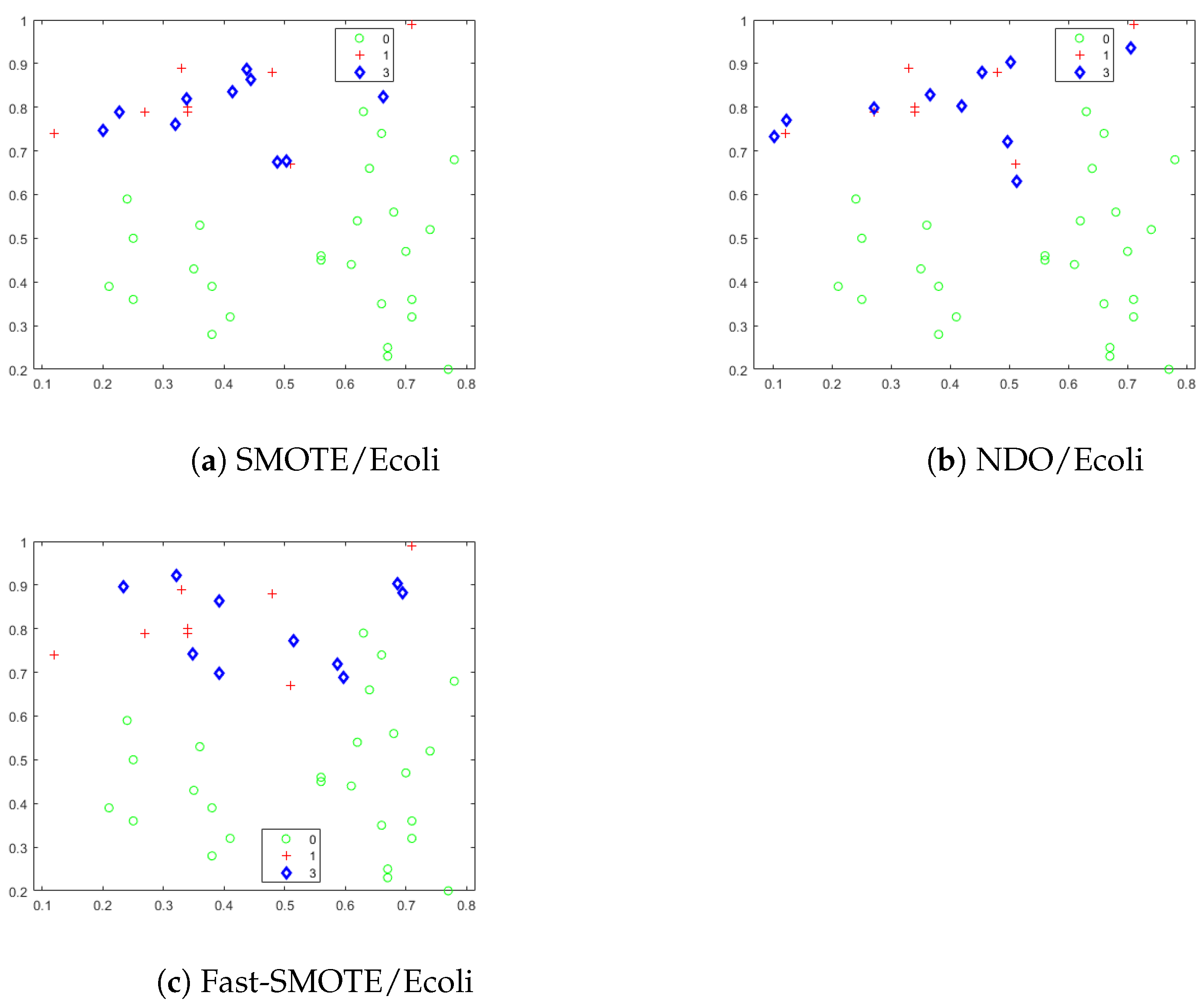
4.1. Synthetic Objects Generated by SMOTE, NDO and Fast-SMOTE
4.2. Comparison against State of the Art Oversampling Methods
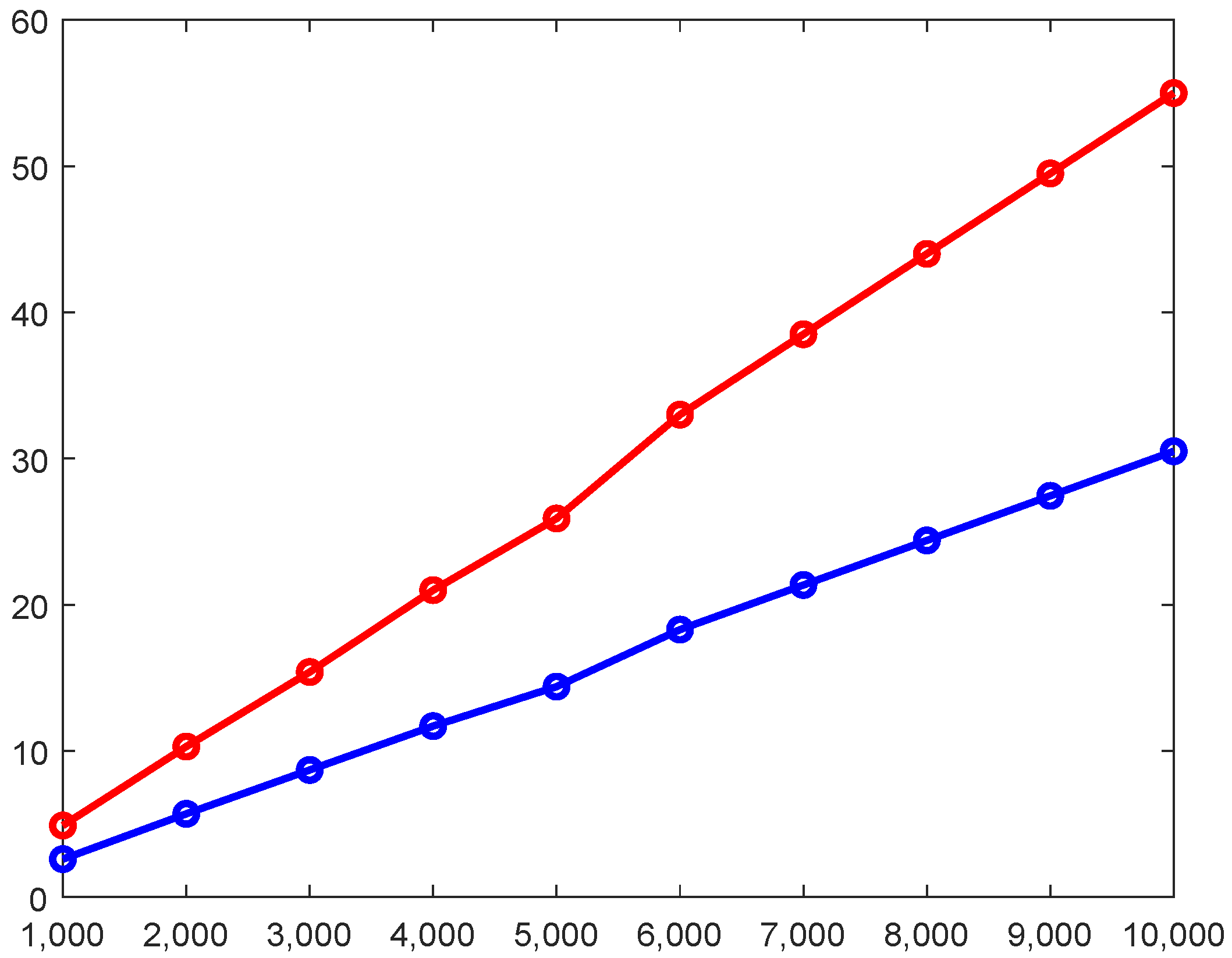
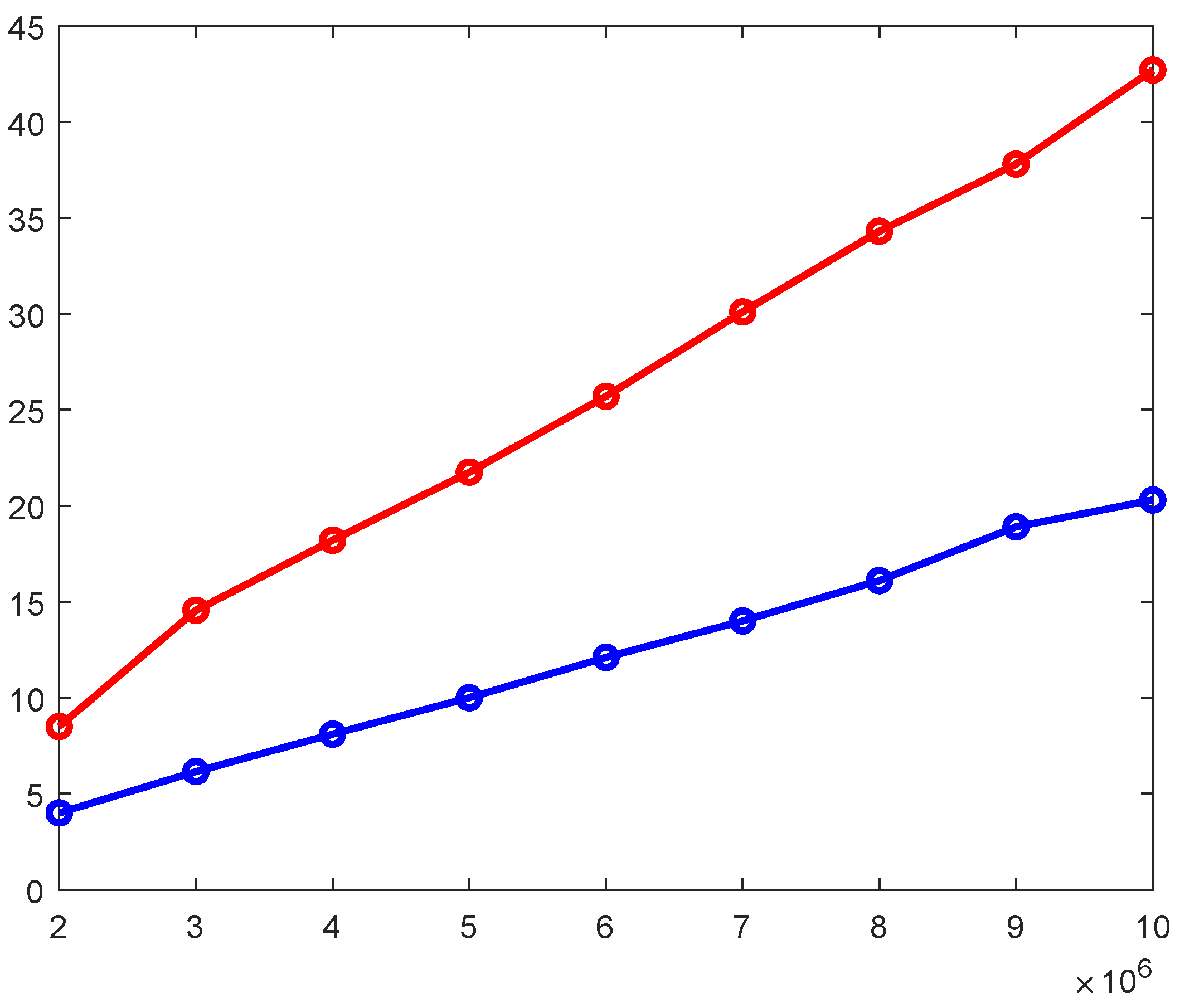
4.3. Assessing the Proposed Method in Large Datasets
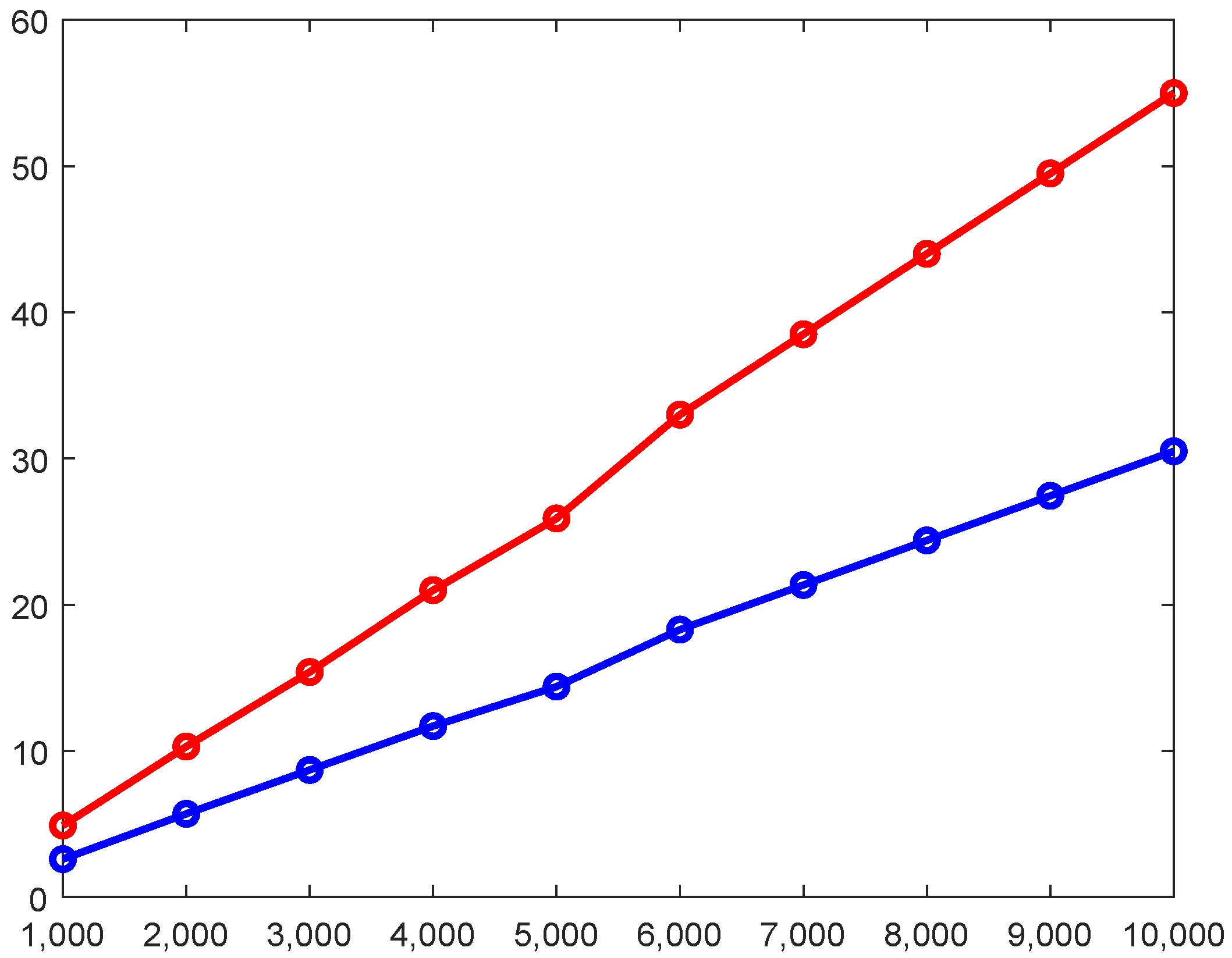
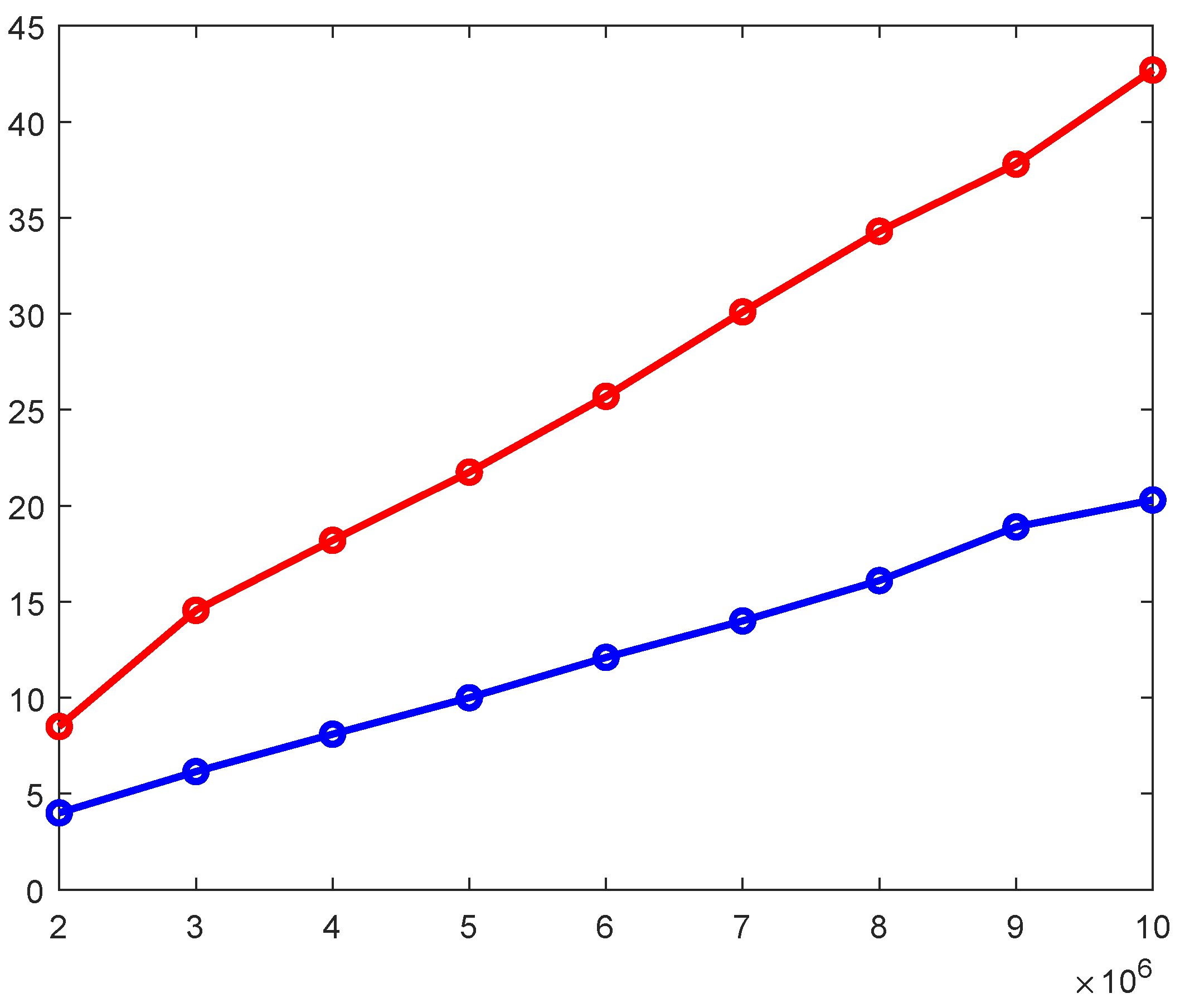
4.4. Scalability
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moscato, V.; Picariello, A.; Sperlí, G. A benchmark of machine learning approaches for credit score prediction. Expert Syst. Appl. 2021, 165, 113986. [Google Scholar] [CrossRef]
- Du, G.; Zhang, J.; Li, S.; Li, C. Learning from class-imbalance and heterogeneous data for 30-day hospital readmission. Neurocomputing 2021, 420, 27–35. [Google Scholar] [CrossRef]
- Eivazpour, Z.; Keyvanpour, M.R. CSSG: A cost-sensitive stacked generalization approach for software defect prediction. Softw. Test. Verif. Reliab. 2021, 31, e1761. [Google Scholar] [CrossRef]
- Srinivasan, R.; Subalalitha, C. Sentimental analysis from imbalanced code-mixed data using machine learning approaches. Distrib. Parallel Databases 2021, Volume 39, 1–16. [Google Scholar] [CrossRef]
- Hussin, S.K.; Abdelmageid, S.M.; Alkhalil, A.; Omar, Y.M.; Marie, M.I.; Ramadan, R.A. Handling Imbalance Classification Virtual Screening Big Data Using Machine Learning Algorithms. Complexity 2021, 2021, 6675279. [Google Scholar] [CrossRef]
- Vilalta, R.; Rish, I. A decomposition of classes via clustering to explain and improve naive bayes. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 444–455. [Google Scholar]
- Elyan, E.; Gaber, M.M. A fine-grained random forests using class decomposition: An application to medical diagnosis. Neural Comput. Appl. 2016, 27, 2279–2288. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- Hu, S.; Liang, Y.; Ma, L.; He, Y. MSMOTE: Improving classification performance when training data is imbalanced. In Proceedings of the 2009 Second International Workshop on Computer Science and Engineering, Qingdao, China, 28–30 October 2009; Volume 2, pp. 13–17. [Google Scholar]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Safe-level-smote: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Pacific-Asia Conference on Knowledge Discovery and data Mining; Springer: Berlin/Heidelberg, Germany, 2009; pp. 475–482. [Google Scholar]
- Maciejewski, T.; Stefanowski, J. Local neighbourhood extension of SMOTE for mining imbalanced data. In Proceedings of the 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011; pp. 104–111. [Google Scholar]
- Ramentol, E.; Caballero, Y.; Bello, R.; Herrera, F. SMOTE-RSB*: A hybrid preprocessing approach based on oversampling and undersampling for high imbalanced data-sets using SMOTE and rough sets theory. Knowl. Inf. Syst. 2012, 33, 245–265. [Google Scholar] [CrossRef]
- Abdi, L.; Hashemi, S. To Combat Multi-Class Imbalanced Problems by Means of Over-Sampling Techniques. IEEE Trans. Knowl. Data Eng. 2016, 28, 238–251. [Google Scholar] [CrossRef]
- Torres, F.R.; Carrasco-Ochoa, J.A.; Martínez-Trinidad, J.F. SMOTE-D a deterministic version of SMOTE. In Mexican Conference on Pattern Recognition; Springer: Cham, Switzerland, 2016; pp. 177–188. [Google Scholar]
- Borowska, K.; Stepaniuk, J. Imbalanced data classification: A novel re-sampling approach combining versatile improved SMOTE and rough sets. In IFIP International Conference on Computer Information Systems and Industrial Management; Springer: Cham, Switzerland, 2016; pp. 31–42. [Google Scholar]
- Gong, C.; Gu, L. A Novel SMOTE-Based Classification Approach to Online Data Imbalance Problem. Math. Probl. Eng. 2016, 2016, 5685970. [Google Scholar] [CrossRef]
- Jiang, K.; Lu, J.; Xia, K. A novel algorithm for imbalance data classification based on genetic algorithm improved SMOTE. Arab. J. Sci. Eng. 2016, 41, 3255–3266. [Google Scholar] [CrossRef]
- Yun, J.; Ha, J.; Lee, J.S. Automatic determination of neighborhood size in SMOTE. In Proceedings of the 10th International Conference on Ubiquitous Information Management and Communication, Danang, Vietnam, 4–6 January 2016; p. 100. [Google Scholar]
- Pérez-Ortiz, M.; Gutiérrez, P.A.; Tino, P.; Hervás-Martínez, C. Oversampling the minority class in the feature space. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 1947–1961. [Google Scholar] [CrossRef] [PubMed]
- Rivera, W.A.; Xanthopoulos, P. A priori synthetic over-sampling methods for increasing classification sensitivity in imbalanced data sets. Expert Syst. Appl. 2016, 66, 124–135. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodriguez, L.; López, A.; Castilla, J.R.; Trueba, A. PSO-based method for SVM classification on skewed data sets. Neurocomputing 2017, 228, 187–197. [Google Scholar] [CrossRef] [Green Version]
- Douzas, G.; Bacao, F. Self-Organizing Map Oversampling (SOMO) for imbalanced data set learning. Expert Syst. Appl. 2017, 82, 40–52. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F.; Last, F. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inf. Sci. 2018, 465, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Nekooeimehr, I.; Lai-Yuen, S.K. Adaptive semi-unsupervised weighted oversampling (A-SUWO) for imbalanced datasets. Expert Syst. Appl. 2016, 46, 405–416. [Google Scholar] [CrossRef]
- Li, J.; Fong, S.; Wong, R.K.; Chu, V.W. Adaptive multi-objective swarm fusion for imbalanced data classification. Inf. Fusion 2018, 39, 1–24. [Google Scholar] [CrossRef]
- Gosain, A.; Sardana, S. Farthest SMOTE: A Modified SMOTE Approach. In Computational Intelligence in Data Mining; Springer: Singapore, 2019; pp. 309–320. [Google Scholar]
- Douzas, G.; Bacao, F. Geometric SMOTE: Effective oversampling for imbalanced learning through a geometric extension of SMOTE. arXiv 2017, arXiv:1709.07377. [Google Scholar]
- Maldonado, S.; López, J.; Vairetti, C. An alternative SMOTE oversampling strategy for high-dimensional datasets. Appl. Soft Comput. 2019, 76, 380–389. [Google Scholar] [CrossRef]
- Elyan, E.; Moreno-Garcia, C.F.; Jayne, C. CDSMOTE: Class decomposition and synthetic minority class oversampling technique for imbalanced-data classification. Neural Comput. Appl. 2021, 33, 2839–2851. [Google Scholar] [CrossRef]
- Zhang, Y.; Zuo, T.; Fang, L.; Li, J.; Xing, Z. An Improved MAHAKIL Oversampling Method for Imbalanced Dataset Classification. IEEE Access 2020, 9, 16030–16040. [Google Scholar] [CrossRef]
- Kaya, E.; Korkmaz, S.; Sahman, M.A.; Cinar, A.C. DEBOHID: A differential evolution based oversampling approach for highly imbalanced datasets. Expert Syst. Appl. 2021, 169, 114482. [Google Scholar] [CrossRef]
- Fajardo, V.A.; Findlay, D.; Jaiswal, C.; Yin, X.; Houmanfar, R.; Xie, H.; Liang, J.; She, X.; Emerson, D. On oversampling imbalanced data with deep conditional generative models. Expert Syst. Appl. 2021, 169, 114463. [Google Scholar] [CrossRef]
- Sadhukhan, P. Learning minority class prior to minority oversampling. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Zhang, H.; Wang, Z. A normal distribution-based over-sampling approach to imbalanced data classification. In International Conference on Advanced Data Mining and Applications; Springer: Berlin/Heidelberg, Germany, 2011; pp. 83–96. [Google Scholar]
- Rashu, R.I.; Haq, N.; Rahman, R.M. Data mining approaches to predict final grade by overcoming class imbalance problem. In Proceedings of the 2014 17th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–23 December 2014; pp. 14–19. [Google Scholar]
- Bennin, K.E.; Keung, J.; Phannachitta, P.; Monden, A.; Mensah, S. Mahakil: Diversity based oversampling approach to alleviate the class imbalance issue in software defect prediction. IEEE Trans. Softw. Eng. 2017, 44, 534–550. [Google Scholar] [CrossRef]
- Gong, L.; Jiang, S.; Jiang, L. Tackling class imbalance problem in software defect prediction through cluster-based over-sampling with filtering. IEEE Access 2019, 7, 145725–145737. [Google Scholar] [CrossRef]
- Huda, S.; Liu, K.; Abdelrazek, M.; Ibrahim, A.; Alyahya, S.; Al-Dossari, H.; Ahmad, S. An ensemble oversampling model for class imbalance problem in software defect prediction. IEEE Access 2018, 6, 24184–24195. [Google Scholar] [CrossRef]
- García, V.; Sánchez, J.S.; Martín-Félez, R.; Mollineda, R.A. Surrounding neighborhood-based SMOTE for learning from imbalanced data sets. Prog. Artif. Intell. 2012, 1, 347–362. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Fan, S. CURE-SMOTE algorithm and hybrid algorithm for feature selection and parameter optimization based on random forests. BMC Bioinform. 2017, 18, 169. [Google Scholar] [CrossRef] [Green Version]
- Guo, S.; Liu, Y.; Chen, R.; Sun, X.; Wang, X. Improved SMOTE algorithm to deal with imbalanced activity classes in smart homes. Neural Process. Lett. 2019, 50, 1503–1526. [Google Scholar] [CrossRef]
- Liang, X.; Jiang, A.; Li, T.; Xue, Y.; Wang, G. LR-SMOTE—An improved unbalanced data set oversampling based on K-means and SVM. Knowl.-Based Syst. 2020, 196, 105845. [Google Scholar] [CrossRef]
- Chen, B.; Xia, S.; Chen, Z.; Wang, B.; Wang, G. RSMOTE: A self-adaptive robust SMOTE for imbalanced problems with label noise. Inf. Sci. 2021, 553, 397–428. [Google Scholar] [CrossRef]
- de Carvalho, A.M.; Prati, R.C. DTO-SMOTE: Delaunay Tessellation Oversampling for Imbalanced Data Sets. Information 2020, 11, 557. [Google Scholar] [CrossRef]
- Wei, J.; Huang, H.; Yao, L.; Hu, Y.; Fan, Q.; Huang, D. NI-MWMOTE: An improving noise-immunity majority weighted minority oversampling technique for imbalanced classification problems. Expert Syst. Appl. 2020, 158, 113504. [Google Scholar] [CrossRef]
- Wang, X.; Yang, Y.; Chen, M.; Wang, Q.; Qin, Q.; Jiang, H.; Wang, H. AGNES-SMOTE: An Oversampling Algorithm Based on Hierarchical Clustering and Improved SMOTE. Sci. Program. 2020, 2020, 8837357. [Google Scholar] [CrossRef]
- Hemalatha, P.; Amalanathan, G.M. FG-SMOTE: Fuzzy-based Gaussian synthetic minority oversampling with deep belief networks classifier for skewed class distribution. Int. J. Intell. Comput. Cybern. 2021, 14, 270–287. [Google Scholar] [CrossRef]
- Mukherjee, M.; Khushi, M. SMOTE-ENC: A novel SMOTE-based method to generate synthetic data for nominal and continuous features. Appl. Syst. Innov. 2021, 4, 18. [Google Scholar] [CrossRef]
- Bej, S.; Davtyan, N.; Wolfien, M.; Nassar, M.; Wolkenhauer, O. Loras: An oversampling approach for imbalanced datasets. Mach. Learn. 2021, 110, 279–301. [Google Scholar] [CrossRef]
- Guan, H.; Zhang, Y.; Xian, M.; Cheng, H.; Tang, X. SMOTE-WENN: Solving class imbalance and small sample problems by oversampling and distance scaling. Appl. Intell. 2021, 51, 1394–1409. [Google Scholar] [CrossRef]
- Zheng, S.; Mogusu, E.; Veeranki, S.P.; Quinn, M.; Cao, Y. The relationship between the mean, median, and mode with grouped data. Commun. Stat.-Theory Methods 2017, 46, 4285–4295. [Google Scholar] [CrossRef]
- Hu, F.; Li, H.; Lou, H.; Dai, J. A parallel oversampling algorithm based on NRSBoundary-SMOTE. J. Inf. Comput. Sci. 2014, 11, 4655–4665. [Google Scholar] [CrossRef]
- Woods, K.S.; Doss, C.C.; Bowyer, K.W.; Solka, J.L.; Priebe, C.E.; Kegelmeyer, W.P., Jr. Comparative evaluation of pattern recognition techniques for detection of microcalcifications in mammography. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 1417–1436. [Google Scholar] [CrossRef]
- Alcalá-Fdez, J.; Fernández, A.; Luengo, J.; Derrac, J.; García, S.; Sánchez, L.; Herrera, F. Keel data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework. J. Mult.-Valued Log. Soft Comput. 2011, 17, 255–287. [Google Scholar]
- Luengo, J.; Fernández, A.; García, S.; Herrera, F. Addressing data complexity for imbalanced data sets: Analysis of SMOTE-based oversampling and evolutionary undersampling. Soft Comput. 2011, 15, 1909–1936. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. University of California, Irvine, School of Information and Computer Sciences. Available online: http://archive.ics.uci.edu/ml (accessed on 20 March 2022).
- Bhagat, R.C.; Patil, S.S. Enhanced SMOTE algorithm for classification of imbalanced big-data using random forest. In Proceedings of the 2015 IEEE International Advance Computing Conference (IACC), Banglore, India, 12–13 June 2015; pp. 403–408. [Google Scholar]
- Gutiérrez, P.D.; Lastra, M.; Benítez, J.M.; Herrera, F. SMOTE-GPU: Big data preprocessing on commodity hardware for imbalanced classification. Prog. Artif. Intell. 2017, 6, 347–354. [Google Scholar] [CrossRef]
- Fernández, A.; del Río, S.; Chawla, N.V.; Herrera, F. An insight into imbalanced big data classification: Outcomes and challenges. Complex Intell. Syst. 2017, 3, 105–120. [Google Scholar] [CrossRef] [Green Version]
- Leevy, J.L.; Khoshgoftaar, T.M.; Bauder, R.A.; Seliya, N. A survey on addressing high-class imbalance in big data. J. Big Data 2018, 5, 1–30. [Google Scholar] [CrossRef]
- Basgall, M.J.; Hasperué, W.; Naiouf, M.; Fernández, A.; Herrera, F. SMOTE-BD: An Exact and Scalable Oversampling Method for Imbalanced Classification in Big Data. In VI Jornadas de Cloud Computing & Big Data (JCC & BD) (La Plata, Argentina, 2018); Universidad Nacional de La Plata: La Plata, Argentina, 2018. [Google Scholar]
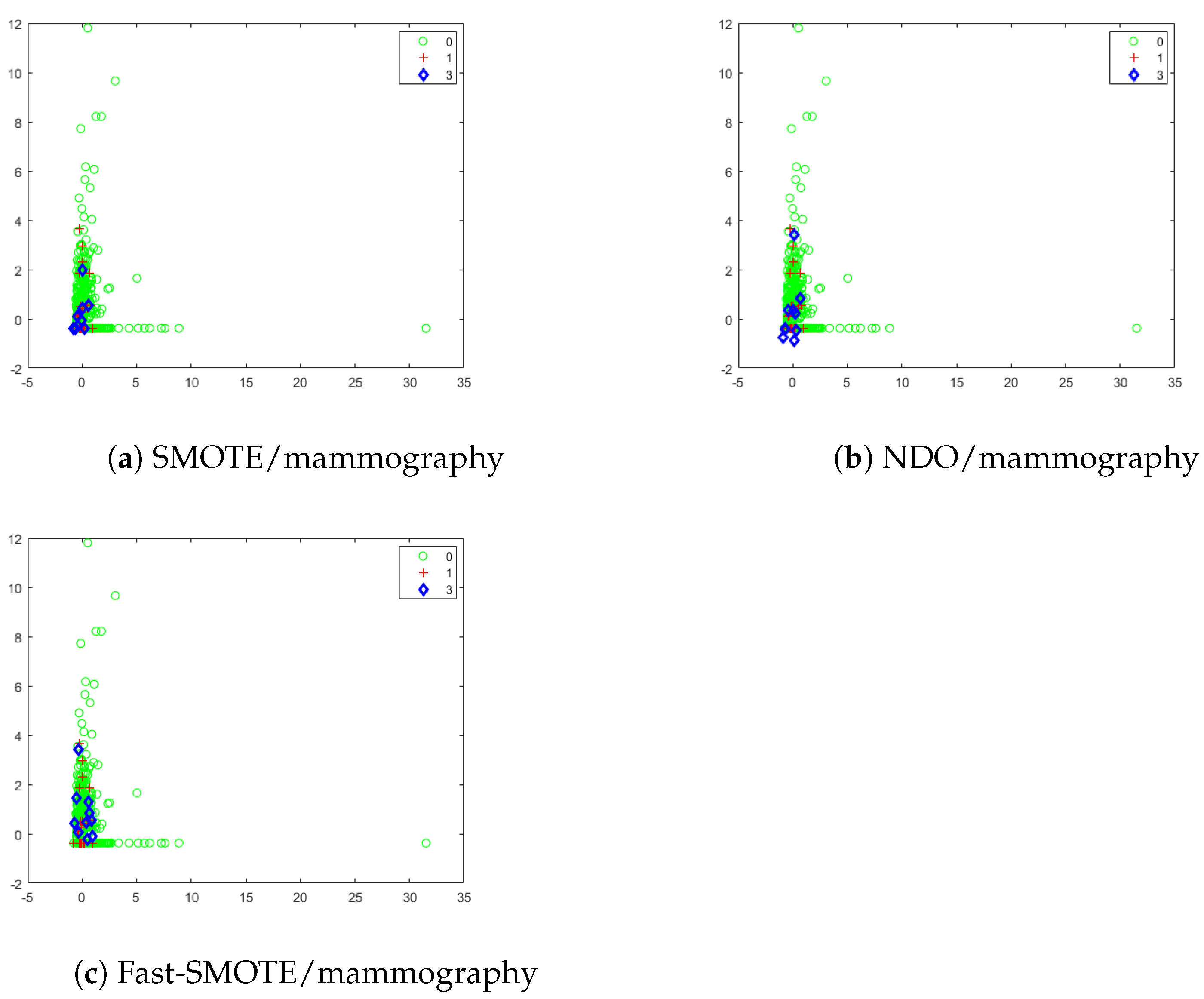



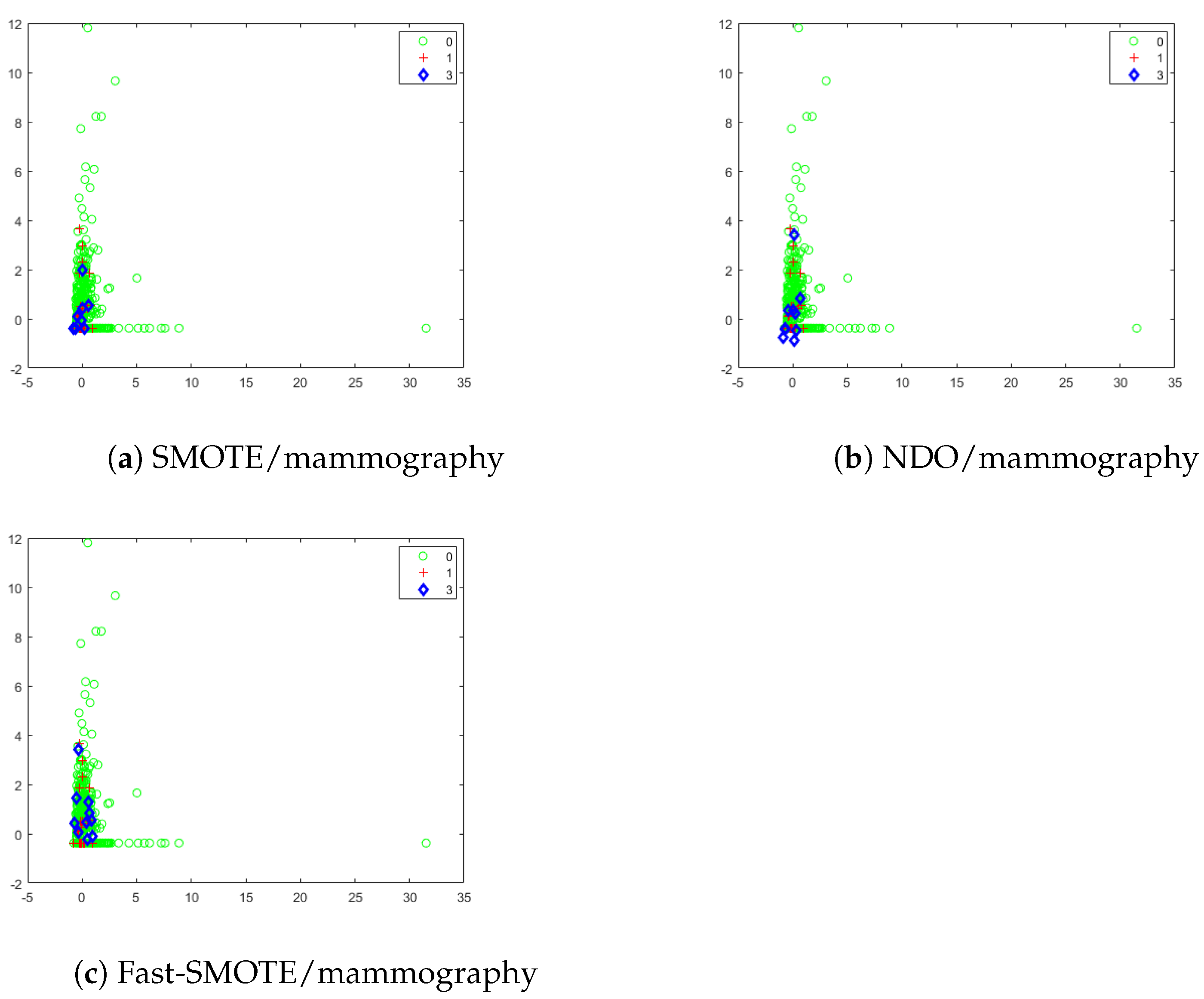{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features Mode | ||
|---|---|---|
| mamography | −0.55 | 0.06 |
| glass | 0.42 | 0.73 |
| ecoli | 0.32 | 0.79 |
| Dataset | # Features | # Objects | IR | Dataset | # Features | # Objects | IR |
|---|---|---|---|---|---|---|---|
| glass1 | 9 | 214 | 1.82 | glass-0-4_vs_5 | 9 | 92 | 9.22 |
| ecoli-0_vs_1 | 7 | 220 | 1.86 | ecoli-0-3-4-6_vs_5 | 7 | 205 | 9.25 |
| wisconsin | 9 | 683 | 1.86 | ecoli-0-3-4-7_vs_5-6 | 7 | 257 | 9.28 |
| pima | 8 | 768 | 1.87 | yeast-0-5-6-7-9_vs_4 | 8 | 528 | 9.35 |
| iris0 | 4 | 150 | 2.00 | vowel0 | 13 | 988 | 9.98 |
| glass0 | 9 | 214 | 2.06 | ecoli-0-6-7_vs_5 | 6 | 220 | 10.00 |
| yeast1 | 8 | 1484 | 2.46 | glass-0-1-6_vs_2 | 9 | 192 | 10.29 |
| haberman | 3 | 306 | 2.78 | ecoli-0-1-4-7_vs_2-3-5-6 | 7 | 336 | 10.59 |
| vehicle2 | 18 | 846 | 2.88 | led7digit-0-2-4-5-6-7-8-9_vs_1 | 7 | 443 | 10.97 |
| vehicle1 | 18 | 846 | 2.90 | glass-0-6_vs_5 | 9 | 108 | 11.00 |
| vehicle3 | 18 | 846 | 2.99 | ecoli-0-1_vs_5 | 6 | 240 | 11.00 |
| glass-0-1-2-3_vs_4-5-6 | 9 | 214 | 3.20 | glass-0-1-4-6_vs_2 | 9 | 205 | 11.06 |
| vehicle0 | 18 | 846 | 3.25 | glass2 | 9 | 214 | 11.59 |
| ecoli1 | 7 | 336 | 3.36 | ecoli-0-1-4-7_vs_5-6 | 6 | 332 | 12.28 |
| new-thyroid1 | 5 | 215 | 5.14 | cleveland-0_vs_4 | 13 | 177 | 12.62 |
| new-thyroid2 | 5 | 215 | 5.14 | ecoli-0-1-4-6_vs_5 | 6 | 280 | 13.00 |
| ecoli2 | 7 | 336 | 5.46 | shuttle-c0-vs-c4 | 9 | 1829 | 13.87 |
| segment0 | 19 | 2308 | 6.02 | yeast-1_vs_7 | 7 | 459 | 14.30 |
| glass6 | 9 | 214 | 6.38 | glass4 | 9 | 214 | 15.47 |
| yeast3 | 8 | 1484 | 8.10 | ecoli4 | 7 | 336 | 15.80 |
| ecoli3 | 7 | 336 | 8.60 | page-blocks-1-3_vs_4 | 10 | 472 | 15.86 |
| page-blocks0 | 10 | 5472 | 8.79 | abalone9-18 | 8 | 731 | 16.40 |
| ecoli-0-3-4_vs_5 | 7 | 200 | 9.00 | glass-0-1-6_vs_5 | 9 | 184 | 19.44 |
| yeast-2_vs_4 | 8 | 514 | 9.08 | shuttle-c2-vs-c4 | 9 | 129 | 20.50 |
| ecoli-0-6-7_vs_3-5 | 7 | 222 | 9.09 | yeast-1-4-5-8_vs_7 | 8 | 693 | 22.10 |
| ecoli-0-2-3-4_vs_5 | 7 | 202 | 9.10 | glass5 | 9 | 214 | 22.78 |
| glass-0-1-5_vs_2 | 9 | 172 | 9.12 | yeast-2_vs_8 | 8 | 482 | 23.10 |
| yeast-0-3-5-9_vs_7-8 | 8 | 506 | 9.12 | yeast4 | 8 | 1484 | 28.10 |
| yeast-0-2-5-7-9_vs_3-6-8 | 8 | 1004 | 9.14 | yeast-1-2-8-9_vs_7 | 8 | 947 | 30.57 |
| yeast-0-2-5-6_vs_3-7-8-9 | 8 | 1004 | 9.14 | yeast5 | 8 | 1484 | 32.73 |
| ecoli-0-4-6_vs_5 | 6 | 203 | 9.15 | ecoli-0-1-3-7_vs_2-6 | 7 | 281 | 39.14 |
| ecoli-0-1_vs_2-3-5 | 7 | 244 | 9.17 | yeast6 | 8 | 1484 | 41.40 |
| ecoli-0-2-6-7_vs_3-5 | 7 | 224 | 9.18 | abalone19 | 8 | 4174 | 129.44 |
| Classifier | Oversampling Method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SMOTE | Borderline | SafeLevel | LNE | NDO | S-RSB* | K-Means-S | Farthest-S | G-SMOTE | S-SF | Fast-SMOTE | |
| CART | 0.825 | 0.807 | 0.808 | 0.814 | 0.817 | 0.824 | 0.802 | 0.819 | 0.798 | 0.821 | 0.801 |
| KNN | 0.857 | 0.842 | 0.822 | 0.836 | 0.853 | 0.857 | 0.789 | 0.840 | 0.800 | 0.854 | 0.822 |
| Naïve Bayes | 0.808 | 0.775 | 0.776 | 0.802 | 0.786 | 0.807 | 0.755 | 0.801 | 0.731 | 0.808 | 0.772 |
| Dataset | Oversampling Method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SMOTE | Borderline | SafeLevel | LNE | NDO | S-RSB* | K-Means-S | Farthest-S | G-SMOTE | S-SF | Fast-SMOTE | |
| glass-0-4_vs_5 | 0.0027 | 0.0006 | 0.0056 | 0.0040 | 0.0002 | 0.0045 | 0.0035 | 0.0025 | 0.0037 | 0.0003 | 0.0001 |
| glass-0-6_vs_5 | 0.0033 | 0.0007 | 0.0069 | 0.0048 | 0.0003 | 0.0054 | 0.0040 | 0.0031 | 0.0044 | 0.0002 | 0.0001 |
| shuttle-c2-vs-c4 | 0.0041 | 0.0004 | 0.0094 | 0.0058 | 0.0004 | 0.0067 | 0.0052 | 0.0040 | 0.0062 | 0.0003 | 0.0002 |
| iris0 | 0.0017 | 0.0016 | 0.0039 | 0.0038 | 0.0002 | 0.0030 | 0.0028 | 0.0017 | 0.0024 | 0.0011 | 0.0001 |
| glass-0-1-5_vs_2 | 0.0052 | 0.0011 | 0.0113 | 0.0076 | 0.0004 | 0.0083 | 0.0068 | 0.0049 | 0.0070 | 0.0004 | 0.0002 |
| cleveland-0_vs_4 | 0.0054 | 0.0009 | 0.0124 | 0.0081 | 0.0005 | 0.0096 | 0.0078 | 0.0051 | 0.0072 | 0.0004 | 0.0002 |
| glass-0-1-6_vs_5 | 0.0059 | 0.0007 | 0.0136 | 0.0083 | 0.0005 | 0.0101 | 0.0069 | 0.0057 | 0.0080 | 0.0004 | 0.0002 |
| glass-0-1-6_vs_2 | 0.0056 | 0.0010 | 0.0132 | 0.0084 | 0.0005 | 0.0102 | 0.0070 | 0.0057 | 0.0076 | 0.0005 | 0.0002 |
| ecoli-0-3-4_vs_5 | 0.0062 | 0.0009 | 0.0132 | 0.0083 | 0.0005 | 0.0091 | 0.0086 | 0.0055 | 0.0076 | 0.0005 | 0.0002 |
| ecoli-0-2-3-4_vs_5 | 0.0062 | 0.0009 | 0.0136 | 0.0092 | 0.0005 | 0.0097 | 0.0088 | 0.0055 | 0.0082 | 0.0005 | 0.0002 |
| ecoli-0-4-6_vs_5 | 0.0060 | 0.0009 | 0.0132 | 0.0091 | 0.0005 | 0.0091 | 0.0079 | 0.0055 | 0.0080 | 0.0005 | 0.0002 |
| ecoli-0-3-4-6_vs_5 | 0.0061 | 0.0009 | 0.0136 | 0.0091 | 0.0005 | 0.0093 | 0.0081 | 0.0057 | 0.0082 | 0.0005 | 0.0002 |
| glass-0-1-4-6_vs_2 | 0.0066 | 0.0012 | 0.0144 | 0.0092 | 0.0005 | 0.0107 | 0.0082 | 0.0062 | 0.0088 | 0.0004 | 0.0002 |
| glass1 | 0.0023 | 0.0032 | 0.0052 | 0.0062 | 0.0002 | 0.0061 | 0.0035 | 0.0022 | 0.0031 | 0.0026 | 0.0001 |
| glass2 | 0.0065 | 0.0010 | 0.0152 | 0.0099 | 0.0005 | 0.0113 | 0.0087 | 0.0065 | 0.0087 | 0.0005 | 0.0003 |
| glass0 | 0.0026 | 0.0031 | 0.0059 | 0.0092 | 0.0002 | 0.0068 | 0.0038 | 0.0026 | 0.0036 | 0.0024 | 0.0001 |
| glass4 | 0.0066 | 0.0008 | 0.0156 | 0.0101 | 0.0006 | 0.0117 | 0.0087 | 0.0065 | 0.0090 | 0.0005 | 0.0003 |
| glass-0-1-2-3_vs_4-5-6 | 0.0041 | 0.0022 | 0.0093 | 0.0090 | 0.0003 | 0.0089 | 0.0051 | 0.0040 | 0.0056 | 0.0014 | 0.0002 |
| glass5 | 0.0070 | 0.0006 | 0.0161 | 0.0100 | 0.0006 | 0.0125 | 0.0085 | 0.0067 | 0.0094 | 0.0004 | 0.0003 |
| glass6 | 0.0055 | 0.0009 | 0.0125 | 0.0092 | 0.0005 | 0.0095 | 0.0067 | 0.0054 | 0.0076 | 0.0007 | 0.0002 |
| new-thyroid1 | 0.0051 | 0.0017 | 0.0116 | 0.0091 | 0.0004 | 0.0074 | 0.0063 | 0.0050 | 0.0069 | 0.0008 | 0.0002 |
| newthyroid2 | 0.0051 | 0.0016 | 0.0114 | 0.0091 | 0.0004 | 0.0073 | 0.0066 | 0.0050 | 0.0068 | 0.0008 | 0.0002 |
| ecoli-0_vs_1 | 0.0109 | 0.0028 | 0.0069 | 0.0176 | 0.0002 | 0.0058 | 0.0047 | 0.0024 | 0.0049 | 0.0026 | 0.0001 |
| ecoli-0-6-7_vs_5 | 0.0066 | 0.0010 | 0.0149 | 0.0090 | 0.0005 | 0.0098 | 0.0084 | 0.0061 | 0.0087 | 0.0005 | 0.0003 |
| ecoli-0-6-7_vs_3-5 | 0.0066 | 0.0011 | 0.0150 | 0.0098 | 0.0005 | 0.0102 | 0.0085 | 0.0061 | 0.0088 | 0.0005 | 0.0003 |
| ecoli-0-2-6-7_vs_3-5 | 0.0066 | 0.0012 | 0.0153 | 0.0099 | 0.0005 | 0.0105 | 0.0089 | 0.0063 | 0.0093 | 0.0006 | 0.0003 |
| ecoli-0-1_vs_5 | 0.0077 | 0.0010 | 0.0170 | 0.0100 | 0.0006 | 0.0112 | 0.0093 | 0.0069 | 0.0094 | 0.0005 | 0.0003 |
| ecoli-0-1_vs_2-3-5 | 0.0073 | 0.0012 | 0.0172 | 0.0111 | 0.0006 | 0.0113 | 0.0100 | 0.0068 | 0.0096 | 0.0006 | 0.0003 |
| ecoli-0-3-4-7_vs_5-6 | 0.0082 | 0.0014 | 0.0177 | 0.0117 | 0.0006 | 0.0126 | 0.0104 | 0.0071 | 0.0099 | 0.0006 | 0.0003 |
| ecoli-0-1-4-6_vs_5 | 0.0088 | 0.0010 | 0.0209 | 0.0118 | 0.0007 | 0.0137 | 0.0122 | 0.0082 | 0.0113 | 0.0006 | 0.0003 |
| ecoli-0-1-3-7_vs_2-6 | 0.0096 | 0.0006 | 0.0224 | 0.0132 | 0.0008 | 0.0152 | 0.0111 | 0.0092 | 0.0127 | 0.0005 | 0.0004 |
| haberman | 0.0052 | 0.0042 | 0.0124 | 0.0099 | 0.0004 | 0.0186 | 0.0059 | 0.0050 | 0.0069 | 0.0027 | 0.0002 |
| ecoli-0-1-4-7_vs_5-6 | 0.0104 | 0.0013 | 0.0257 | 0.0151 | 0.0008 | 0.0166 | 0.0139 | 0.0096 | 0.0137 | 0.0007 | 0.0004 |
| ecoli4 | 0.0105 | 0.0012 | 0.0269 | 0.0150 | 0.0009 | 0.0179 | 0.0121 | 0.0101 | 0.0141 | 0.0007 | 0.0004 |
| ecoli1 | 0.0072 | 0.0035 | 0.0170 | 0.0148 | 0.0005 | 0.0118 | 0.0079 | 0.0074 | 0.0096 | 0.0028 | 0.0003 |
| ecoli-0-1-4-7_vs_2-3-5-6 | 0.0105 | 0.0015 | 0.0255 | 0.0147 | 0.0008 | 0.0172 | 0.0139 | 0.0096 | 0.0136 | 0.0008 | 0.0004 |
| ecoli2 | 0.0086 | 0.0018 | 0.0207 | 0.0143 | 0.0007 | 0.0160 | 0.0096 | 0.0083 | 0.0115 | 0.0017 | 0.0003 |
| ecoli3 | 0.0092 | 0.0021 | 0.0235 | 0.0147 | 0.0008 | 0.0164 | 0.0107 | 0.0092 | 0.0127 | 0.0010 | 0.0004 |
| led7digit-0-2-4-5-6-7-8-9_vs_1 | 0.0138 | 0.0019 | 0.0369 | 0.0215 | 0.0011 | 33.1945 | 0.0162 | 0.0129 | 0.0189 | 0.0012 | 0.0005 |
| yeast-1_vs_7 | 0.0142 | 0.0021 | 0.0424 | 0.0225 | 0.0012 | 0.0294 | 0.0171 | 0.0140 | 0.0192 | 0.0011 | 0.0006 |
| page-blocks-1-3_vs_4 | 0.0153 | 0.0020 | 0.0443 | 0.0244 | 0.0013 | 0.0386 | 0.0171 | 0.0148 | 0.0203 | 0.0012 | 0.0007 |
| yeast-2_vs_8 | 0.0167 | 0.0016 | 0.0471 | 0.0244 | 0.0013 | 0.0369 | 0.0199 | 0.0155 | 0.0218 | 0.0011 | 0.0007 |
| yeast-0-3-5-9_vs_7-8 | 0.0154 | 0.0032 | 0.0431 | 0.0253 | 0.0012 | 0.0339 | 0.0180 | 0.0142 | 0.0197 | 0.0018 | 0.0006 |
| yeast-2_vs_4 | 0.0155 | 0.0030 | 0.0451 | 0.0254 | 0.0013 | 0.0358 | 0.0196 | 0.0146 | 0.0226 | 0.0018 | 0.0006 |
| yeast-0-5-6-7-9_vs_4 | 0.0159 | 0.0035 | 0.0471 | 0.0255 | 0.0013 | 0.0352 | 0.0178 | 0.0151 | 0.0225 | 0.0019 | 0.0006 |
| wisconsin | 0.0079 | 0.0119 | 0.0306 | 0.0271 | 0.0006 | 10.9796 | 0.0095 | 0.0077 | 0.0106 | 0.0241 | 0.0003 |
| yeast-1-4-5-8_vs_7 | 0.0235 | 0.0032 | 0.0901 | 0.0428 | 0.0020 | 0.0630 | 0.0305 | 0.0227 | 0.0312 | 0.0017 | 0.0010 |
| abalone9-18 | 0.0243 | 0.0037 | 0.0929 | 0.0436 | 0.0021 | 0.0700 | 0.0267 | 0.0233 | 0.0320 | 0.0021 | 0.0010 |
| pima | 0.0091 | 0.0170 | 0.0346 | 0.0338 | 0.0007 | 0.0332 | 0.0107 | 0.0087 | 0.0118 | 0.0289 | 0.0003 |
| vehicle2 | 0.0175 | 0.0167 | 0.0745 | 0.0507 | 0.0016 | 0.0877 | 0.0205 | 0.0175 | 0.0232 | 0.0236 | 0.0008 |
| vehicle1 | 0.0178 | 0.0184 | 0.0750 | 0.0501 | 0.0016 | 0.0877 | 0.0185 | 0.0174 | 0.0234 | 0.0230 | 0.0008 |
| vehicle3 | 0.0181 | 0.0190 | 0.0767 | 0.0483 | 0.0016 | 0.0898 | 0.0202 | 0.0179 | 0.0238 | 0.0221 | 0.0008 |
| vehicle0 | 0.0192 | 0.0143 | 0.0823 | 0.0625 | 0.0017 | 0.0912 | 0.0221 | 0.0188 | 0.0254 | 0.0199 | 0.0008 |
| yeast-1-2-8-9_vs_7 | 0.0352 | 0.0039 | 0.1494 | 0.0618 | 0.0030 | 0.1203 | 0.0413 | 0.0324 | 0.0444 | 0.0025 | 0.0015 |
| vowel0 | 0.0320 | 0.0076 | 0.1454 | 0.0656 | 0.0032 | 0.1441 | 0.0344 | 0.0310 | 0.0430 | 0.0061 | 0.0016 |
| yeast-0-2-5-7-9_vs_3-6-8 | 0.0316 | 0.0070 | 0.1407 | 0.0654 | 0.0027 | 0.1101 | 0.0363 | 0.0300 | 0.0421 | 0.0059 | 0.0013 |
| yeast-0-2-5-6_vs_3-7-8-9 | 0.0318 | 0.0074 | 0.1427 | 0.0677 | 0.0027 | 0.1092 | 0.0365 | 0.0300 | 0.0411 | 0.0059 | 0.0013 |
| yeast1 | 0.0265 | 0.0347 | 0.1342 | 0.0896 | 0.0020 | 0.1277 | 0.0292 | 0.0260 | 0.0342 | 0.0747 | 0.0010 |
| yeast4 | 0.0567 | 0.0080 | 0.2914 | 0.1046 | 0.0054 | 0.3084 | 0.0742 | 0.0523 | 0.0699 | 0.0052 | 0.0027 |
| yeast5 | 0.0562 | 0.0071 | 0.2921 | 0.1067 | 0.0054 | 0.3100 | 0.0698 | 0.0525 | 0.0706 | 0.0050 | 0.0027 |
| yeast3 | 0.0456 | 0.0136 | 0.2471 | 0.1047 | 0.0043 | 0.2384 | 0.0508 | 0.0448 | 0.0596 | 0.0141 | 0.0021 |
| yeast6 | 0.0566 | 0.0062 | 0.3081 | 0.1069 | 0.0056 | 0.3173 | 0.0803 | 0.0528 | 0.0711 | 0.0048 | 0.0028 |
| shuttle-c0-vs-c4 | 0.0634 | 0.0083 | 0.4022 | 0.1428 | 0.0068 | 0.4615 | 0.0018 | 0.0622 | 0.0864 | 0.0119 | 0.0033 |
| segment0 | 0.0821 | 0.0466 | 0.5992 | 0.3141 | 0.0105 | 1.1618 | 0.0894 | 0.0807 | 0.1045 | 0.0597 | 0.0052 |
| abalone19 | 0.1695 | 0.0255 | 1.8756 | 0.4817 | 0.0270 | 19.3115 | 0.1816 | 0.1679 | 0.2192 | 0.0262 | 0.0134 |
| page-blocks0 | 0.2206 | 0.1040 | 2.5987 | 0.7628 | 0.0344 | 28.2546 | 0.1910 | 0.2177 | 0.2792 | 0.1586 | 0.0171 |
| Sum | 1.3955 | 0.4553 | 8.7356 | 3.3823 | 0.1522 | 96.2835 | 1.5021 | 1.3391 | 0.5366 | 0.5696 | 0.0754 |
| Dataset | # Features | # Objects | IR |
|---|---|---|---|
| Default of credit card clients | 24 | 30,000 | 3.52 |
| Online News Popularity | 61 | 39,797 | 3.90 |
| Statlog (Shuttle) | 9 | 58,000 | 3.67 |
| Skin segmentation | 3 | 245,057 | 3.81 |
| Buzz in social media (Twitter) | 78 | 583,250 | 3.80 |
| Dataset | NDO | Fast-SMOTE |
|---|---|---|
| Default of credit card clients | 0.620 | 0.623 |
| Online News Popularity | 0.551 | 0.551 |
| Statlog (Shuttle) | 0.549 | 0.551 |
| Skin segmentation | 0.990 | 0.999 |
| Buzz in social media (Twitter) | 0.922 | 0.921 |
| Dataset | Oversampling Method | |
|---|---|---|
| NDO | Fast-SMOTE | |
| Default of credit card clients | 0.81 | 0.40 |
| Online News Popularity | 4.94 | 1.95 |
| Statlog (Shuttle) | 1.61 | 0.62 |
| Skin segmentation | 16.47 | 5.80 |
| Buzz in social media (Twitter) | 8771.89 | 2860.40 |
| Sum | 8795.17 | 2869.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Torres, F.; Martínez-Trinidad, J.F.; Carrasco-Ochoa, J.A. An Oversampling Method for Class Imbalance Problems on Large Datasets. Appl. Sci. 2022, 12, 3424. https://doi.org/10.3390/app12073424
Rodríguez-Torres F, Martínez-Trinidad JF, Carrasco-Ochoa JA. An Oversampling Method for Class Imbalance Problems on Large Datasets. Applied Sciences. 2022; 12(7):3424. https://doi.org/10.3390/app12073424
Chicago/Turabian StyleRodríguez-Torres, Fredy, José F. Martínez-Trinidad, and Jesús A. Carrasco-Ochoa. 2022. "An Oversampling Method for Class Imbalance Problems on Large Datasets" Applied Sciences 12, no. 7: 3424. https://doi.org/10.3390/app12073424
APA StyleRodríguez-Torres, F., Martínez-Trinidad, J. F., & Carrasco-Ochoa, J. A. (2022). An Oversampling Method for Class Imbalance Problems on Large Datasets. Applied Sciences, 12(7), 3424. https://doi.org/10.3390/app12073424