
An Efficient Algorithm for Mapping Deep Learning Applications on the NoC Architecture




Abstract
:1. Introduction
2. Related Work
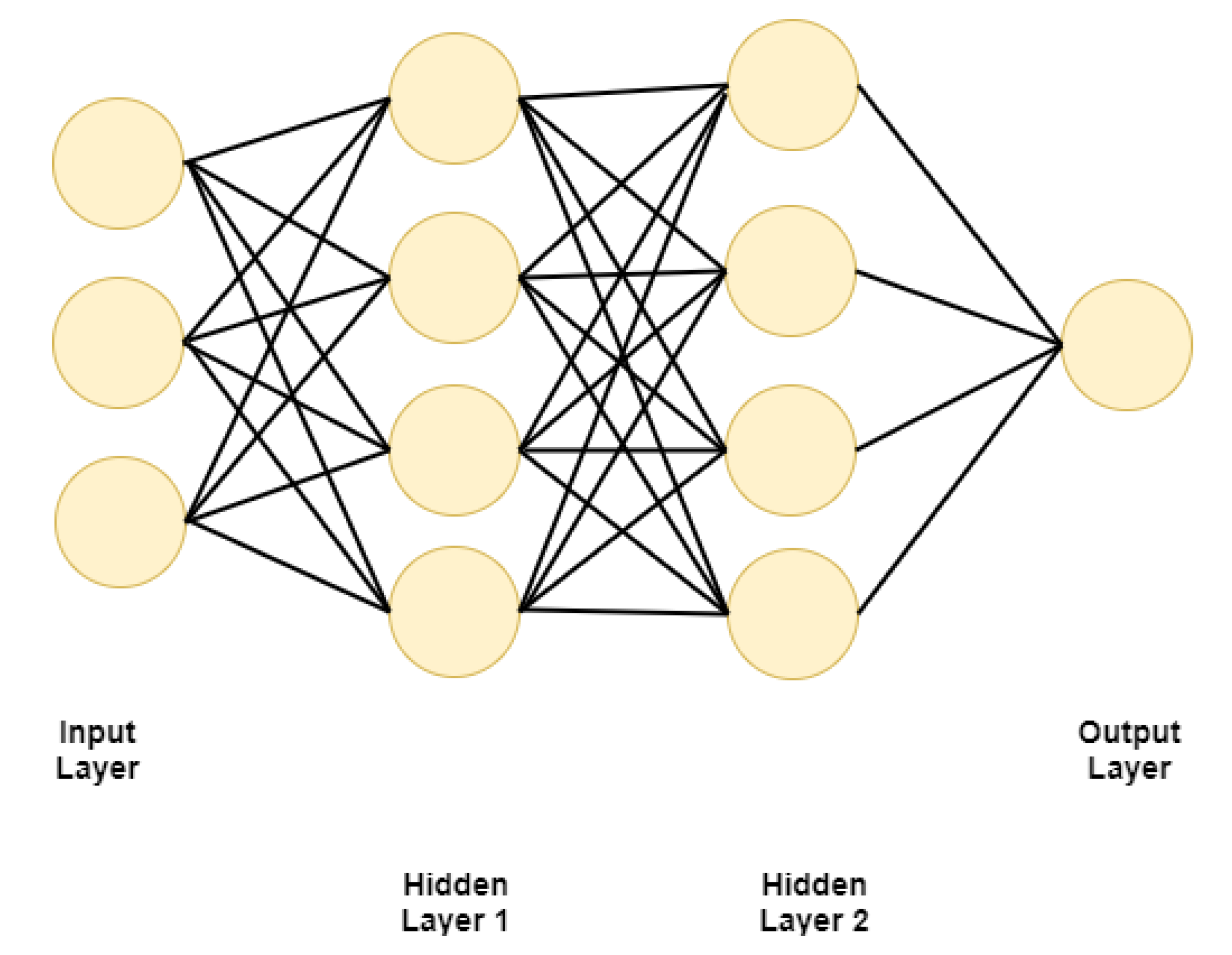
2.1. Machine Learning, Deep Learning, and Neural Networks
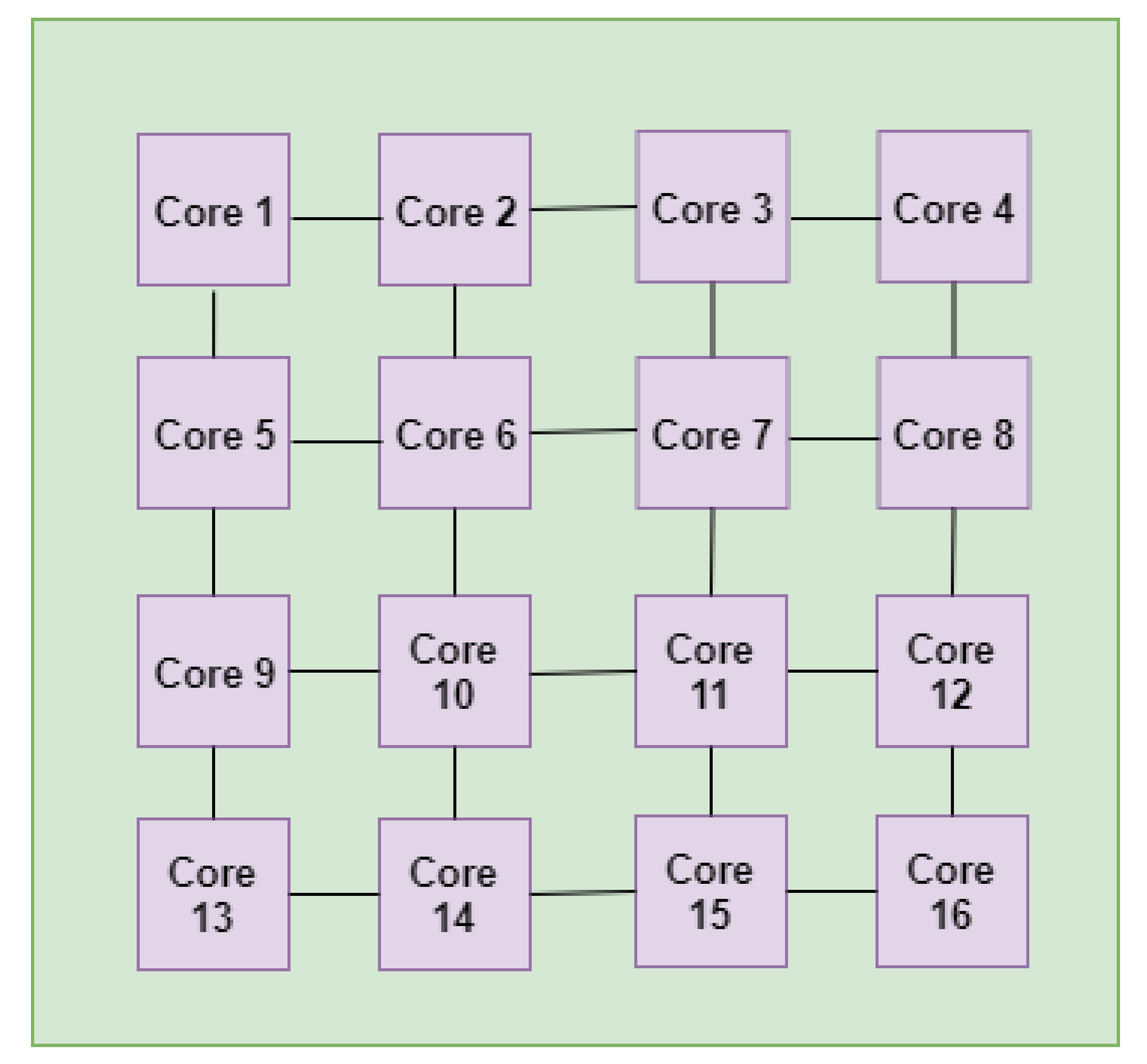
2.2. Network-on-Chip (NoC)
2.3. Application Mapping on the Network-on-Chip (NoC)
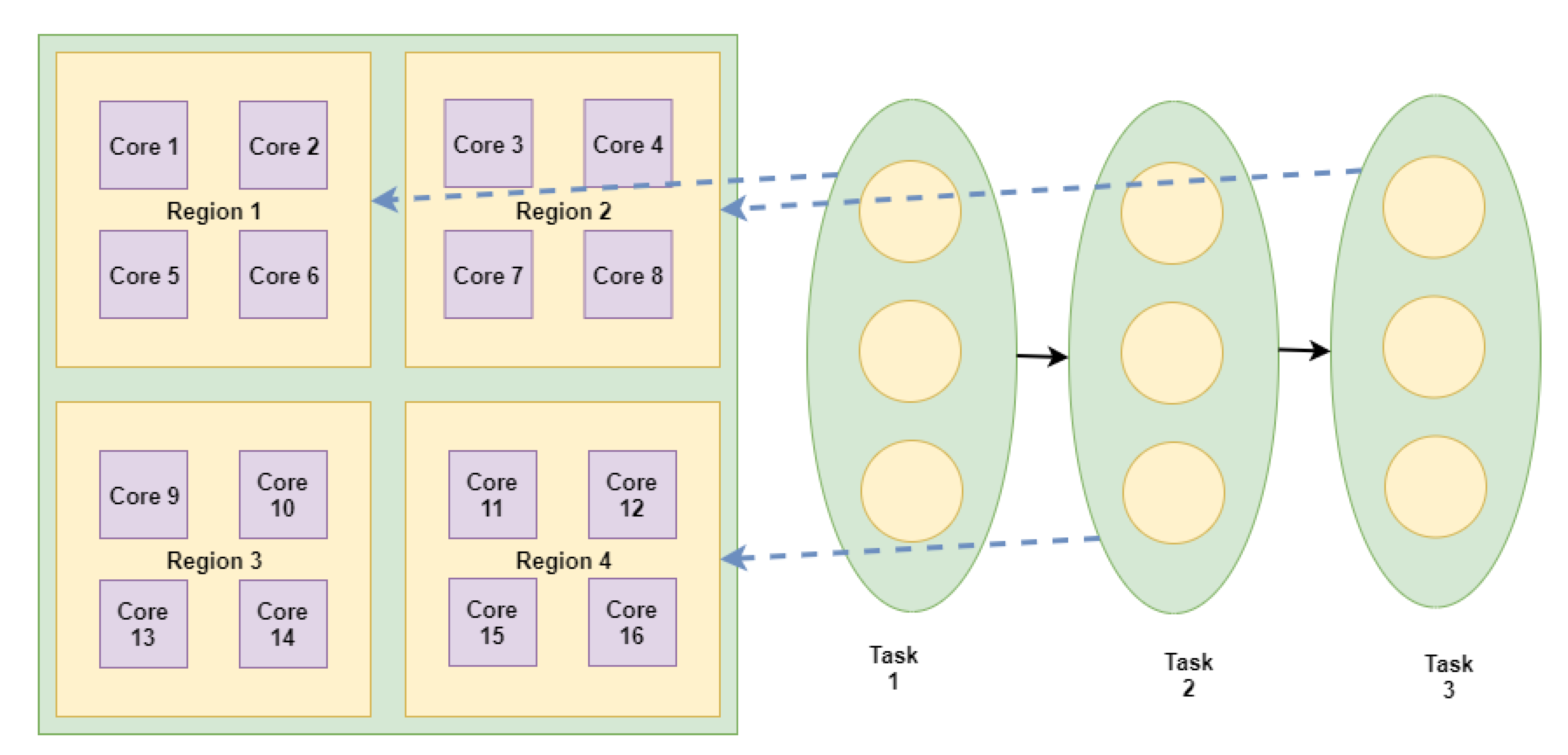
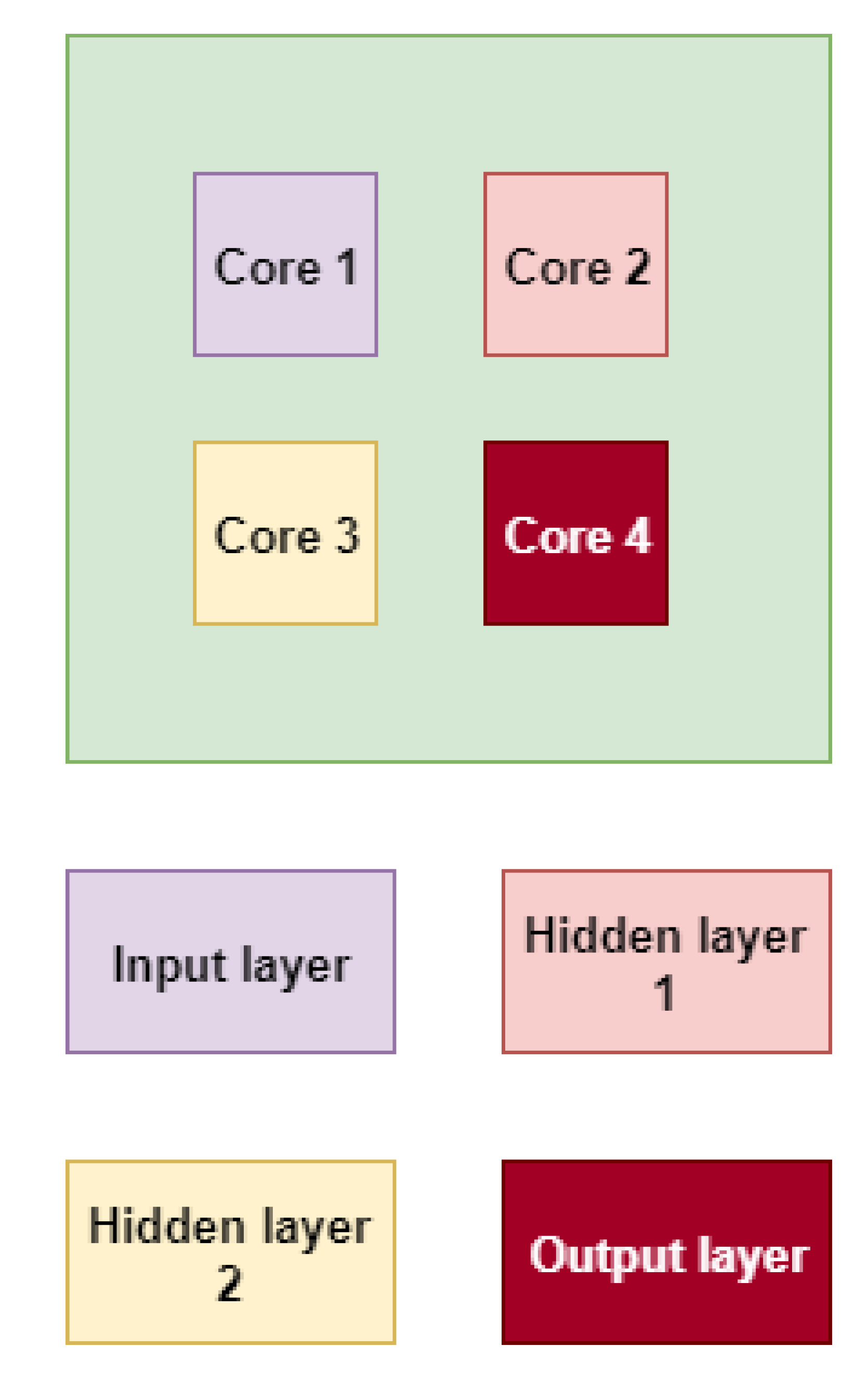
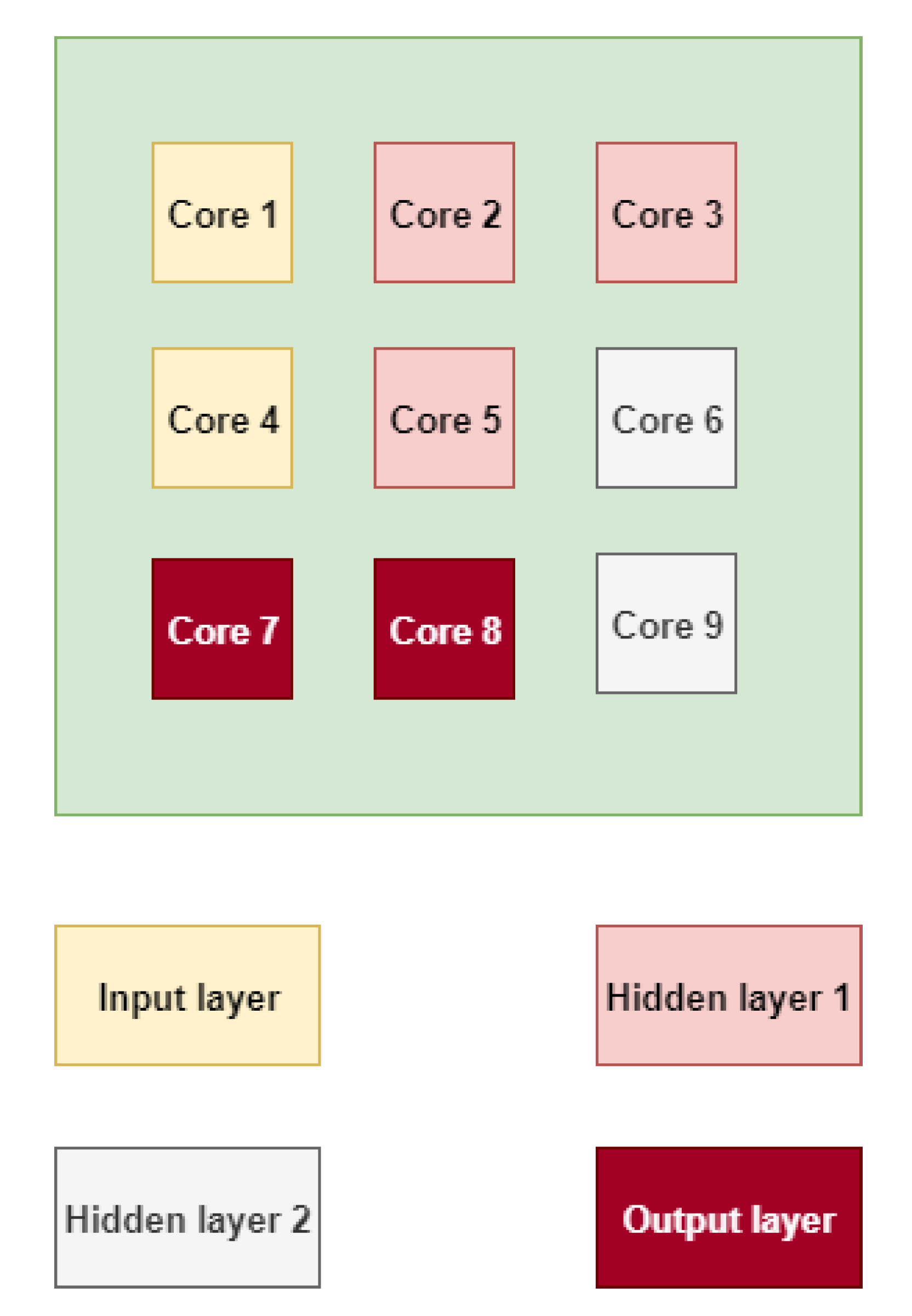
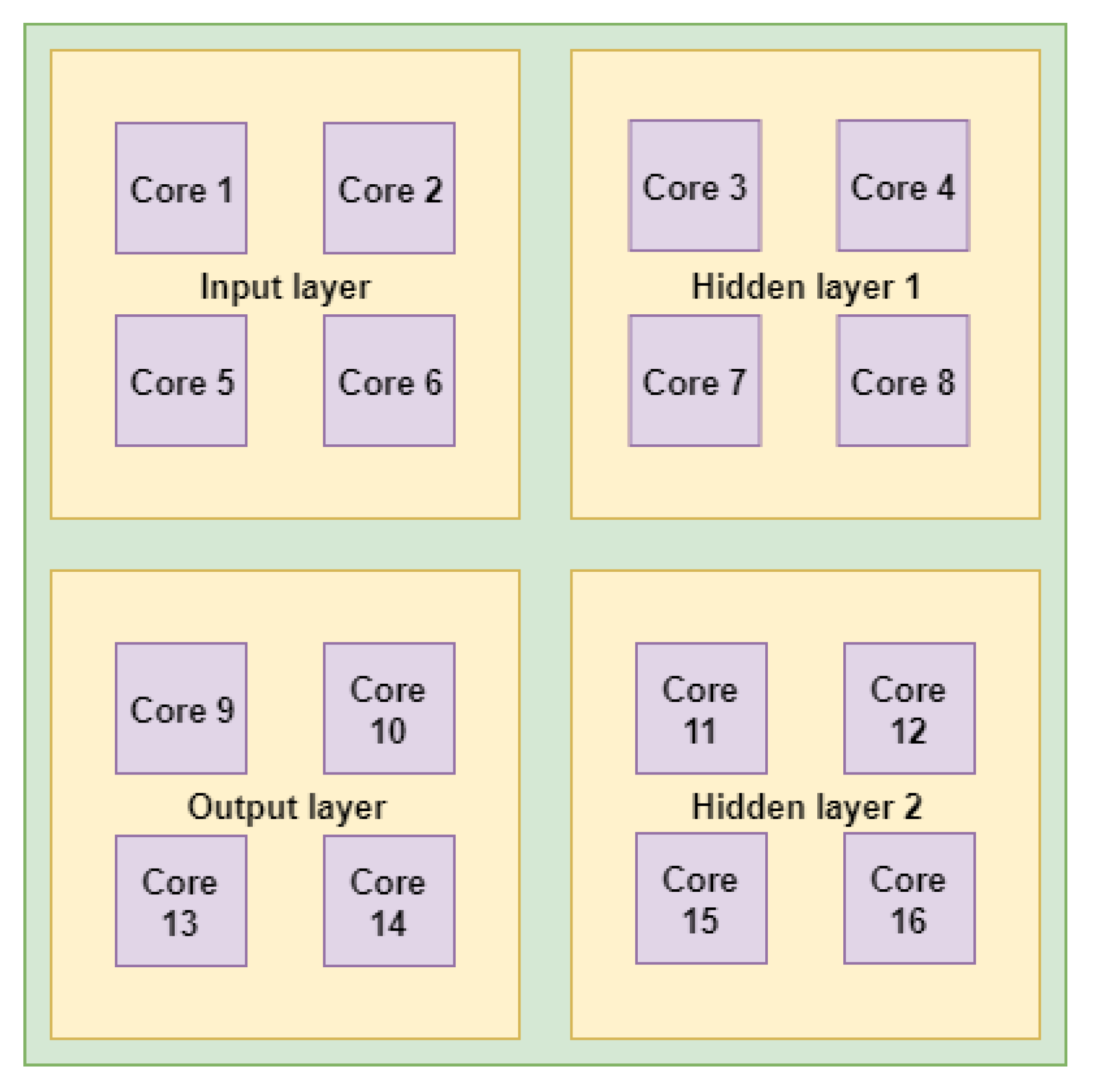
3. Multilevel Task Mapping for NN Applications
| Algorithm 1: AI application mapping on mesh-based NoC. |
|
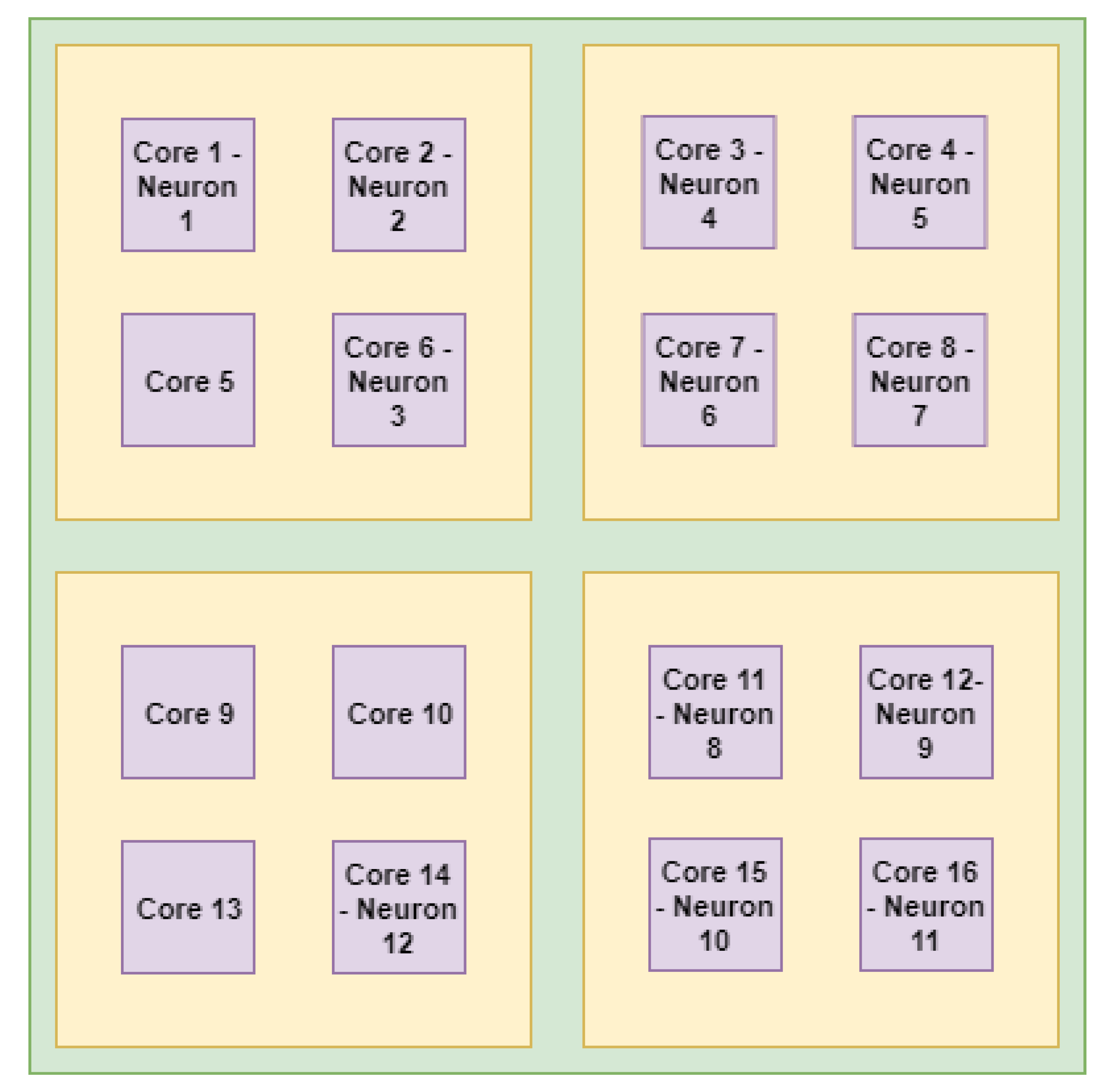
3.1. Level 1 Mapping: Region Mapping
| Algorithm 2: Neural-network-level mapping on the NoC region. |
|
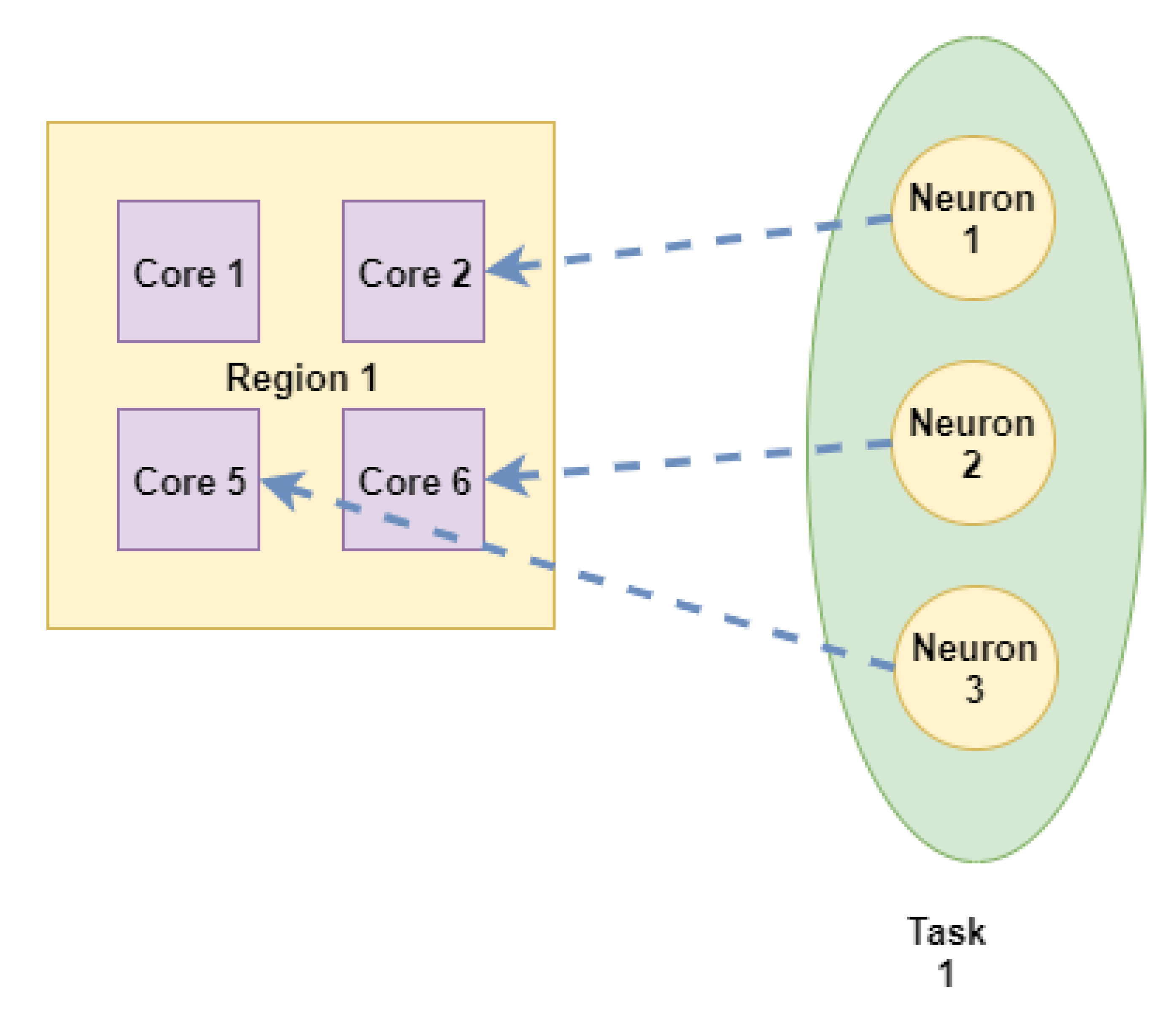
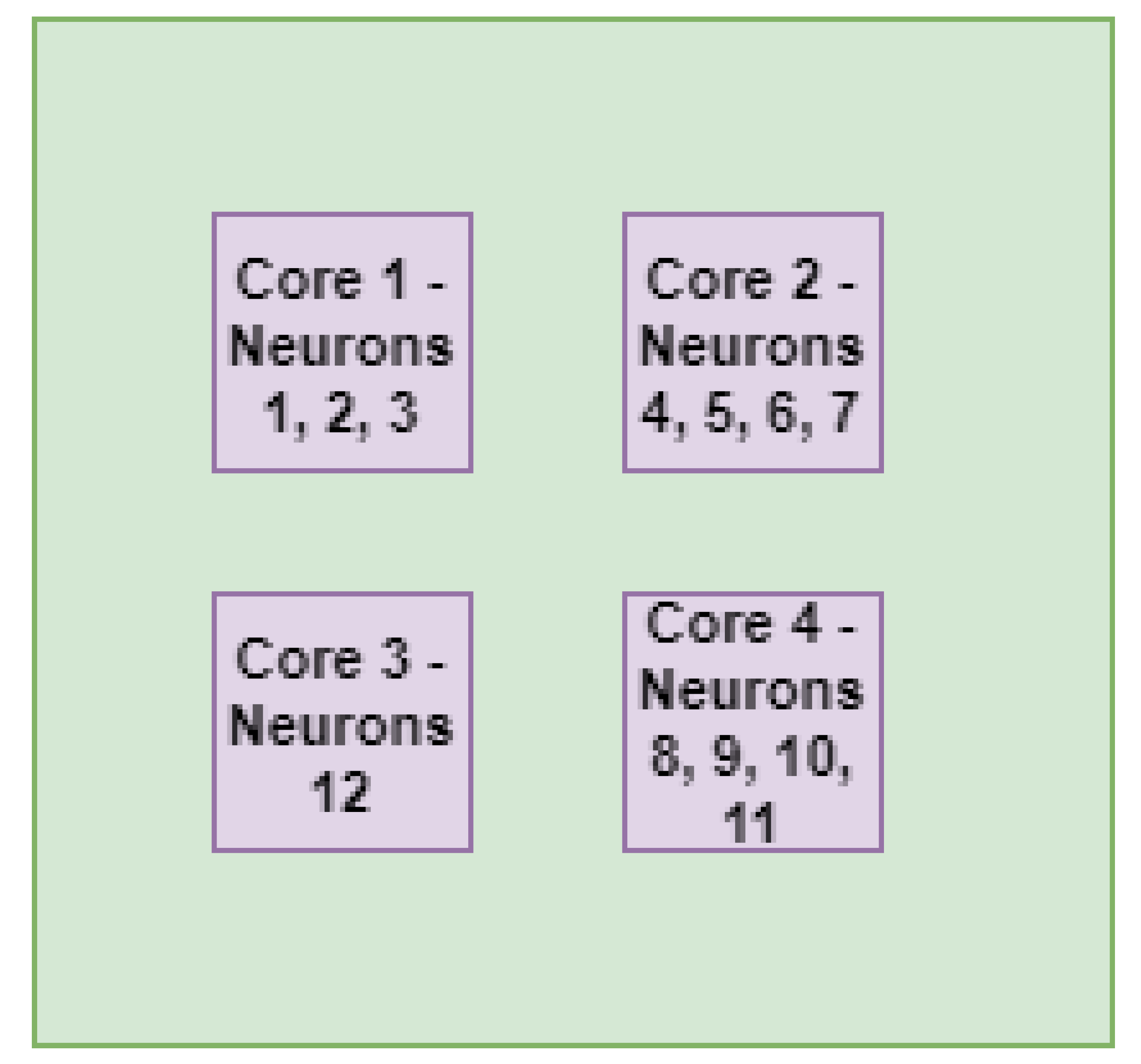
3.2. Level 2 Mapping: Neurons Mapping on the Cores
| Algorithm 3: Neuron mapping on the NoC core. |
|
3.3. Discussion about the Proposed Technique
4. Evaluation
4.1. Analytical Model
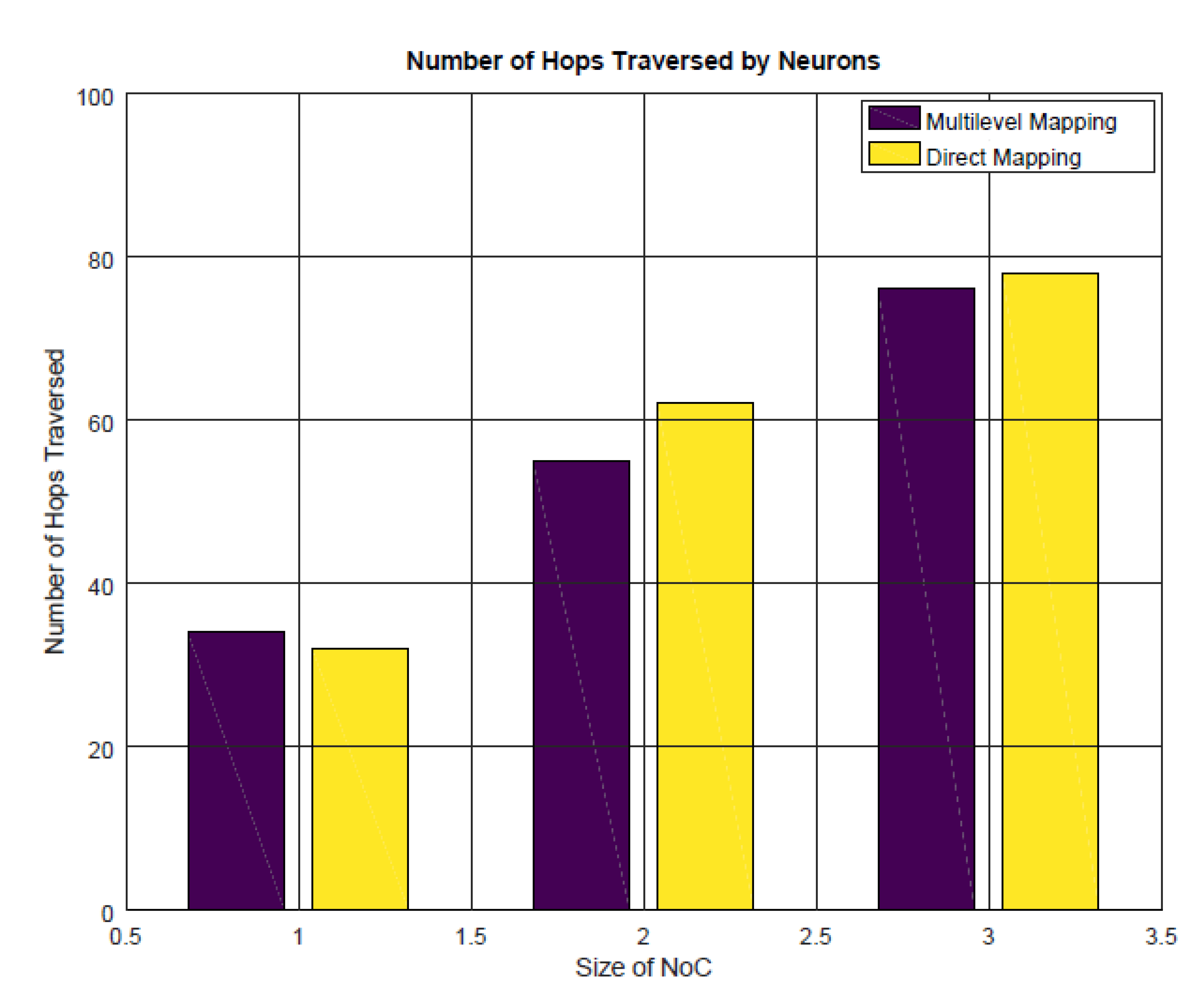
4.2. Simulation Results
4.2.1. Visual Analysis of Application Mapping
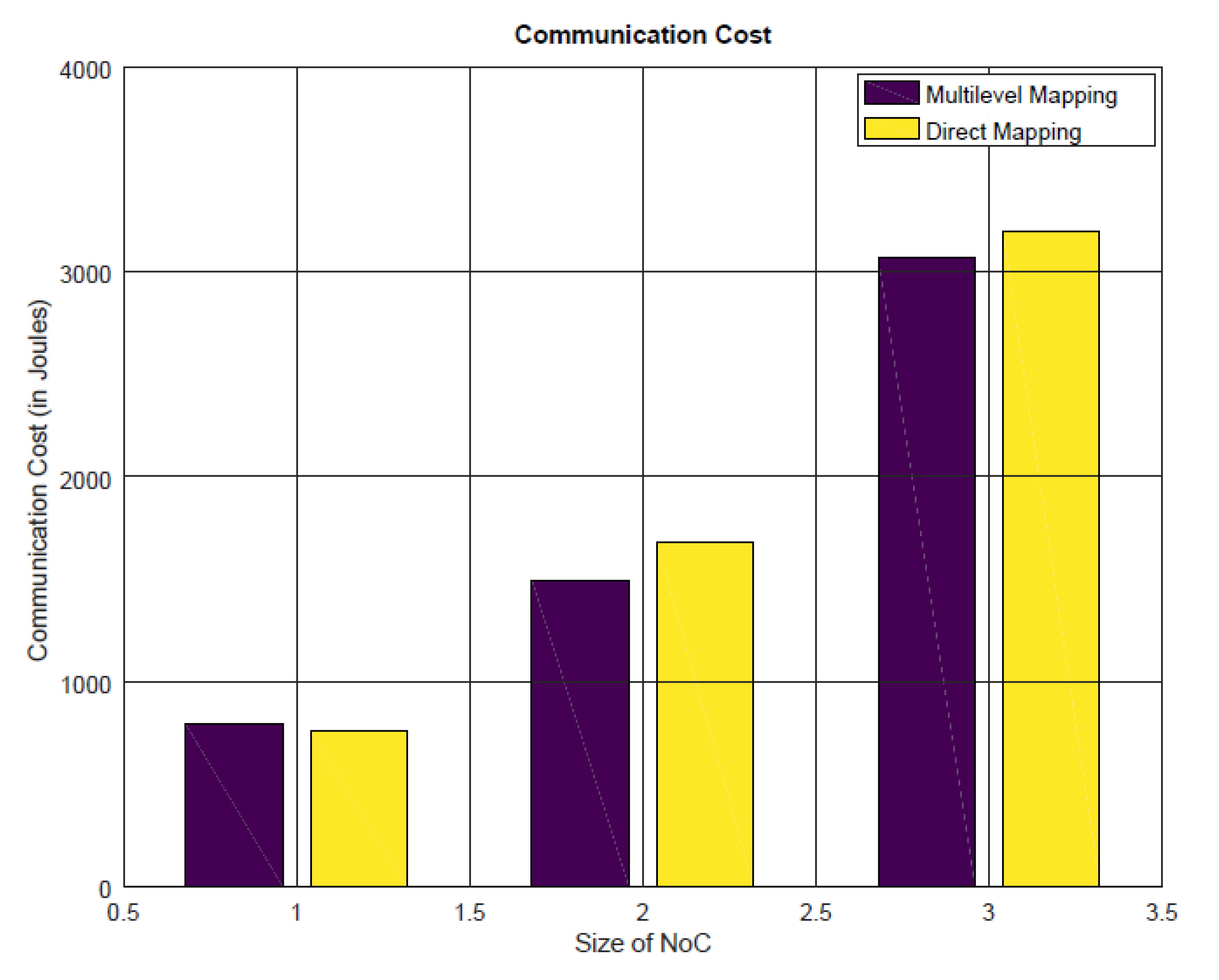
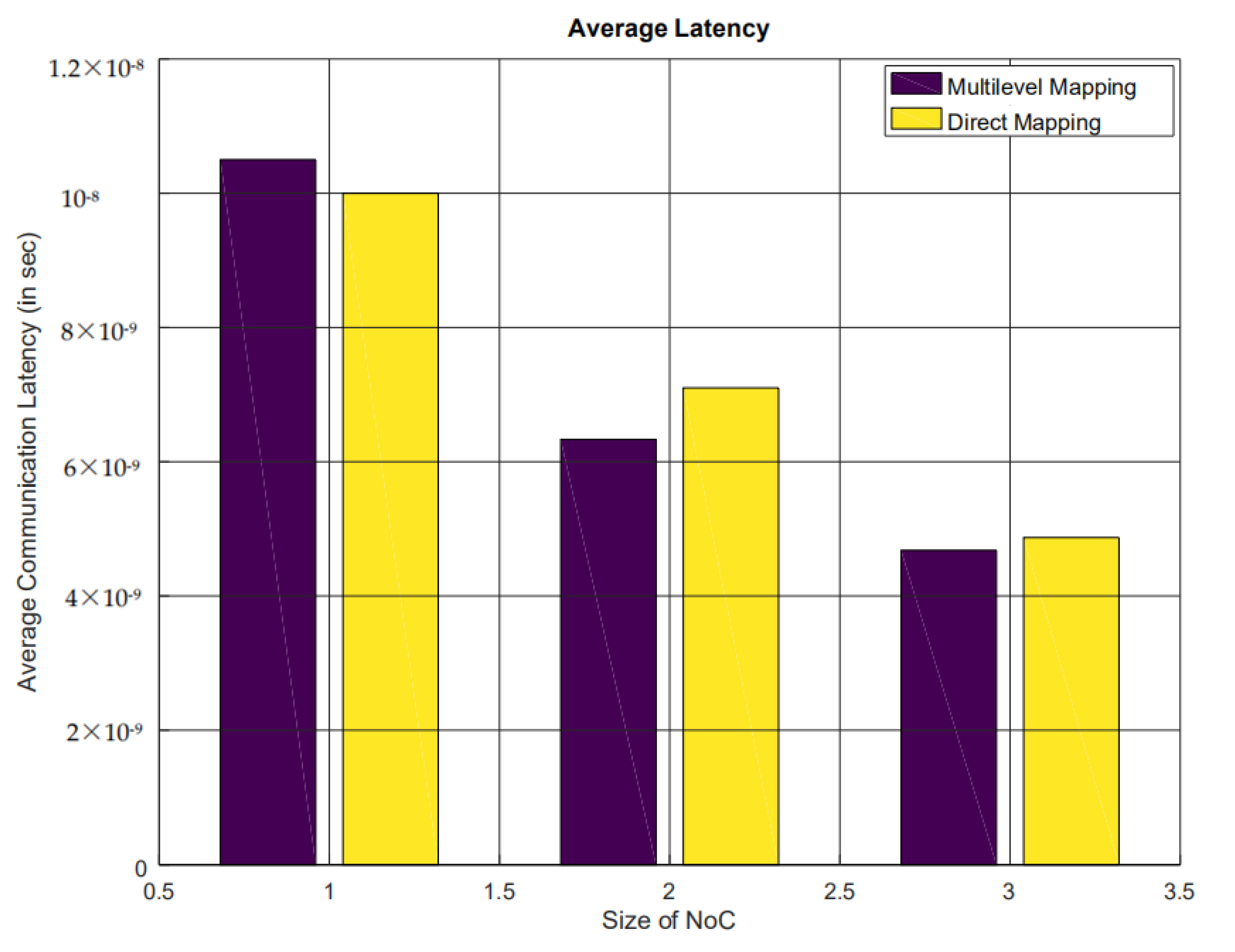
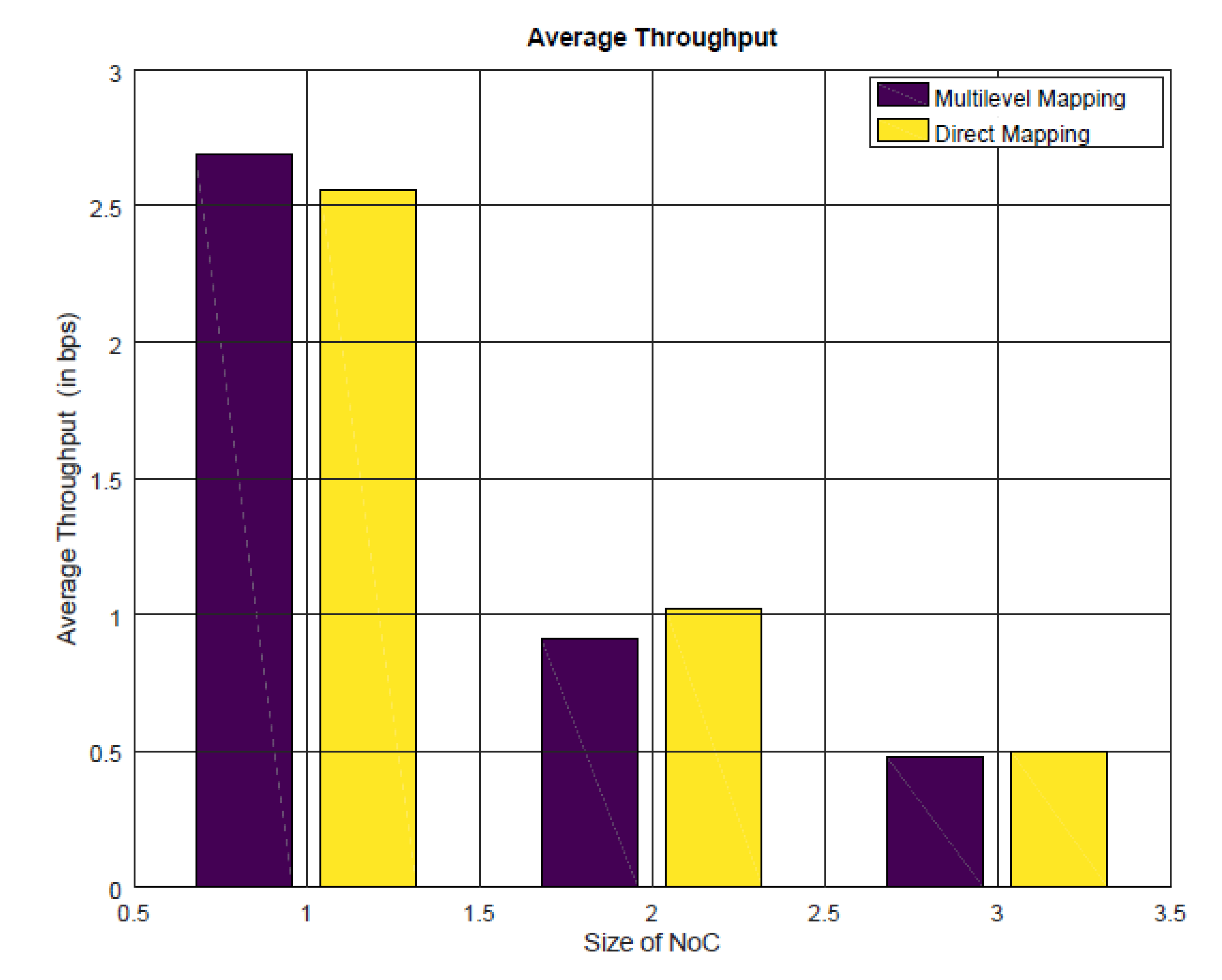
4.2.2. Energy Consumption, Communication Latency, and Throughput Analysis
- 1 indicates four-cores architecture.
- 2 indicates nine-cores architecture.
- 3 indicates 16-cores architecture.
4.3. Discussion about the Results and Prospective Work
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Marcon, C.; Calazans, N.; Moraes, F.; Susin, A.; Reis, I.; Hessel, F. Exploring NoC mapping strategies: An energy and timing aware technique. In Proceedings of the Design, Automation and Test in Europe, Munich, Germany, 7–11 March 2005; pp. 502–507. [Google Scholar]
- Teehan, P.; Greenstreet, M.; Lemieux, G. A survey and taxonomy of GALS design styles. IEEE Des. Test Comput. 2007, 24, 418–428. [Google Scholar] [CrossRef]
- Charles, S.; Mishra, P. A Survey of Network-on-Chip Security Attacks and Countermeasures. ACM Comput. Surv. 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Mohiz, M.J.; Baloch, N.K.; Hussain, F.; Saleem, S.; Zikria, Y.B.; Yu, H. Application Mapping Using Cuckoo Search Optimization With Lévy Flight for NoC-Based System. IEEE Access 2021, 9, 141778–141789. [Google Scholar] [CrossRef]
- Takai, Y.; Sannai, A.; Cordonnier, M. On the number of linear functions composing deep neural network: Towards a refined definition of neural networks complexity. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Online, 13–15 April 2021; pp. 3799–3807. [Google Scholar]
- Murali, S.; Coenen, M.; Radulescu, A.; Goossens, K.; De Micheli, G. Mapping and Configuration Methods for Multi-Use-Case Networks on Chips. In Proceedings of the 2006 Asia and South Pacific Design Automation Conference, Yokohama, Japan, 24–27 January 2006; pp. 146–151. [Google Scholar]
- Sepúlveda, J.; Strum, M.; Chau, W.J.; Gogniat, G. A multi-objective approach for multi-application NoC mapping. In Proceedings of the 2011 IEEE Second Latin American Symposium on Circuits and Systems (LASCAS), Bogota, Colombia, 23–25 February 2011; pp. 1–4. [Google Scholar]
- Yang, B.; Guang, L.; Xu, T.C.; Yin, A.W.; Säntti, T.; Plosila, J. Multi-application multi-step mapping method for many-core Network-on-Chips. In Proceedings of the NORCHIP 2010, Tampere, Finland, 15–16 November 2010; pp. 1–6. [Google Scholar]
- Khalili, F.; Zarandi, H.R. A Fault-Tolerant Low-Energy Multi-Application Mapping onto NoC-based Multiprocessors. In Proceedings of the 2012 IEEE 15th International Conference on Computational Science and Engineering, Paphos, Cyprus, 5–7 December 2012; pp. 421–428. [Google Scholar]
- Zhu, D.; Chen, L.; Yue, S.; Pinkston, T.M.; Pedram, M. Balancing On-Chip Network Latency in Multi-application Mapping for Chip-Multiprocessors. In Proceedings of the 2014 IEEE 28th International Parallel and Distributed Processing Symposium, Phoenix, AZ, USA, 19–23 May 2014; pp. 872–881. [Google Scholar]
- Khasanov, R.; Castrillon, J. Energy-efficient Runtime Resource Management for Adaptable Multi-application Mapping. In Proceedings of the 2020 Design, Automation Test in Europe Conference Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 909–914. [Google Scholar]
- Ge, F.; Cui, C.; Zhou, F.; Wu, N. A Multi-Phase Based Multi-Application Mapping Approach for Many-Core Networks-on-Chip. Micromachines 2021, 12, 631. [Google Scholar] [CrossRef] [PubMed]
- Domingos, P. Machine Learning for Data Management: Problems and Solutions. In Proceedings of the 2018 International Conference on Management of Data, Guangzhou, China, 18–21 February 2022; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar]
- Li, Y.F.; Guo, L.Z.; Zhou, Z.H. Towards Safe Weakly Supervised Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 334–346. [Google Scholar] [CrossRef] [Green Version]
- Shang, C.; Chang, C.Y.; Chen, G.; Zhao, S.; Lin, J. Implicit Irregularity Detection Using Unsupervised Learning on Daily Behaviors. IEEE J. Biomed. Health Inform. 2020, 24, 131–143. [Google Scholar] [CrossRef]
- Wang, X.; Kihara, D.; Luo, J.; Qi, G.J. EnAET: A Self-Trained Framework for Semi-Supervised and Supervised Learning With Ensemble Transformations. IEEE Trans. Image Process. 2021, 30, 1639–1647. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, D.; Gao, J. Learning Automata-Based Multiagent Reinforcement Learning for Optimization of Cooperative Tasks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1–14. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, D.; Zhang, T.; Cui, Y.; Chen, L.; Liu, S. Novel best path selection approach based on hybrid improved A* algorithm and reinforcement learning. Appl. Intell. 2021, 51, 9015–9029. [Google Scholar] [CrossRef]
- Kaur, R.; Singh, A.; Singla, J. Integration of NIC algorithms and ANN: A review of different approaches. In Proceedings of the 2021 2nd International Conference on Computation, Automation and Knowledge Management (ICCAKM), Dubai, United Arab Emirates, 19–21 January 2021; pp. 185–190. [Google Scholar]
- Zhang, T.; Zhang, D.; Yan, H.R.; Qiu, J.N.; Gao, J.X. A new method of data missing estimation with FNN-based tensor heterogeneous ensemble learning for internet of vehicle. Neurocomputing 2021, 420, 98–110. [Google Scholar] [CrossRef]
- Dong, S.; Wang, P.; Abbas, K. A survey on deep learning and its applications. Comput. Sci. Rev. 2021, 40, 100379. [Google Scholar] [CrossRef]
- Su, R.; Huang, Y.; Zhang, D.; Xiao, G.; Wei, L. SRDFM: Siamese Response Deep Factorization Machine to improve anti-cancer drug recommendation. Brief. Bioinform. 2022, 23, bbab534. [Google Scholar] [CrossRef] [PubMed]
- Lauzon, F.Q. An introduction to deep learning. In Proceedings of the 2012 11th International Conference on Information Science, Signal Processing and their Applications (ISSPA), Montreal, QC, Canada, 2–5 July 2012; pp. 1438–1439. [Google Scholar]
- Playe, B.; Stoven, V. Evaluation of deep and shallow learning methods in chemogenomics for the prediction of drugs specificity. J. Cheminform. 2020, 12, 1–18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bhuvaneshwari, M.; Kanaga, E.G.M.; Anitha, J.; Raimond, K.; George, S.T. Chapter 7—A comprehensive review on deep learning techniques for a BCI-based communication system. In Demystifying Big Data, Machine Learning, and Deep Learning for Healthcare Analytics; Kautish, S., Peng, S.L., Eds.; Academic Press: Cambridge, MA, USA, 2021; pp. 131–157. [Google Scholar]
- Tsai, W.C.; Lan, Y.C.; Hu, Y.H.; Chen, S.J. Networks on chips: Structure and design methodologies. J. Electr. Comput. Eng. 2012, 2012, 2. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Zhang, M.; Qiu, M. A Diffusional Schedule for Traffic Reducing on Network-on-Chip. In Proceedings of the 2018 5th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2018 4th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), Shanghai, China, 22–24 June 2018; pp. 206–210. [Google Scholar]
- Siast, J.; Łuczak, A.; Domański, M. RingNet: A Memory-Oriented Network-On-Chip Designed for FPGA. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 1284–1297. [Google Scholar] [CrossRef]
- Ahmad, K.; Sethi, M.A.J. Review of network on chip routing algorithms. EAI Endorsed Trans. Context-Aware Syst. Appl. 2020, 7, 167793. [Google Scholar] [CrossRef]
- Abadal, S.; Mestres, A.; Torrellas, J.; Alarcon, E.; Cabellos-Aparicio, A. Medium Access Control in Wireless Network-on-Chip: A Context Analysis. IEEE Commun. Mag. 2018, 56, 172–178. [Google Scholar] [CrossRef] [Green Version]
- Shamim, M.S.; Narde, R.S.; Gonzalez-Hernandez, J.L.; Ganguly, A.; Venkatarman, J.; Kandlikar, S.G. Evaluation of wireless network-on-chip architectures with microchannel-based cooling in 3D multicore chips. Sustain. Comput. Inform. Syst. 2019, 21, 165–178. [Google Scholar] [CrossRef]
- Zhang, W.; Hou, L.; Wang, J.; Geng, S.; Wu, W. Comparison research between xy and odd-even routing algorithm of a 2-dimension 3 × 3 mesh topology network-on-chip. In Proceedings of the 2009 WRI Global Congress on Intelligent Systems, Xiamen, China, 19–21 May 2009; Volume 3, pp. 329–333. [Google Scholar]
- Kadri, N.; Koudil, M. A survey on fault-tolerant application mapping techniques for network-on-chip. J. Syst. Archit. 2019, 92, 39–52. [Google Scholar] [CrossRef]
- Khan, S.; Anjum, S.; Gulzari, U.A.; Afzal, M.K.; Umer, T.; Ishmanov, F. An Efficient Algorithm for Mapping Real Time Embedded Applications on NoC Architecture. IEEE Access 2018, 6, 16324–16335. [Google Scholar] [CrossRef]
- Amin, W.; Hussain, F.; Anjum, S.; Khan, S.; Baloch, N.K.; Nain, Z.; Kim, S.W. Performance evaluation of application mapping approaches for network-on-chip designs. IEEE Access 2020, 8, 63607–63631. [Google Scholar] [CrossRef]
- Zhang, L.; Li, S.; Qu, L.; Kang, Z.; Wang, S.; Chen, J.; Wang, L. MAMAP: Congestion Relieved Memetic Algorithm based Mapping Method for Mapping Large-Scale SNNs onto NoC-based Neuromorphic Hardware. In Proceedings of the 2020 IEEE 22nd International Conference on High Performance Computing and Communications; IEEE 18th International Conference on Smart City; IEEE 6th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Yanuca Island, Cuvu, Fiji, 14–16 December 2020; pp. 640–647. [Google Scholar]
- Mei, L.; Houshmand, P.; Jain, V.; Giraldo, S.; Verhelst, M. ZigZag: Enlarging Joint Architecture-Mapping Design Space Exploration for DNN Accelerators. IEEE Trans. Comput. 2021, 70, 1160–1174. [Google Scholar] [CrossRef]
- Fang, J.; Zong, H.; Zhao, H.; Cai, H. Intelligent mapping method for power consumption and delay optimization based on heterogeneous NoC platform. Electronics 2019, 8, 912. [Google Scholar] [CrossRef] [Green Version]
- Puschini, D.; Clermidy, F.; Benoit, P.; Sassatelli, G.; Torres, L. Game-Theoretic Approach for Temperature-Aware Frequency Assignment with Task Synchronization on MP-SoC. In Proceedings of the 2008 International Conference on Reconfigurable Computing and FPGAs, Cancun, Mexico, 3–5 December 2008; pp. 235–240. [Google Scholar]
- GNU Octave. Available online: https://www.gnu.org/software/octave/index (accessed on 23 January 2021).
- Jones, M. NoCsim: A Versatile Network on Chip Simulator. Ph.D. Thesis, University of British Columbia, Vancouver, BC, Canada, 2005. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AI | Artificial intelligence |
| BB | Branch and bound |
| BEMAP | BB-based exact mapping |
| Bandwidth between two routers and | |
| CC | Communication cost of the NoC |
| DNN | Deep neural network |
| DSE | Design space exploration |
| DVFS | Dynamic voltage and frequency scaling |
| Link energy consumption | |
| Average latency | |
| Latency of packet b | |
| MET | Maximal empty triangle |
| n | Number of neurons |
| N | Number of processing cores |
| Manhattan distance from source to destination tile | |
| NN | Neural network |
| NoC | Network-on-chip |
| Packets received by the core x | |
| PSO | Particle swarm optimization |
| RL | Reinforcement learning |
| SNN | Spiking neural network |
| SoC | System-on-chip |
| SotAs | State-of-the-art |
| Simulation time | |
| VLSI | Very-large-scale integration |
| Article | Mapping Technique | Performance Improvement | AI Application Mapping |
|---|---|---|---|
| [6] | DVFS-based application mapping | Large power savings | ✗ |
| [8] | Multi-application mapping | 18% reduction in latency and energy consumption | ✗ |
| [9] | Fault-tolerant mapping | 9.5% communication energy reductions and 7.94% performance improvement | ✗ |
| [10] | Heuristic-based algorithm | Reduction in the maximum average packet latency by 10.42% | ✗ |
| [11] | Run-time mapping for hard real-time applications | 13% reduction in the energy consumption | ✗ |
| [12] | B*tree-based simulated annealing algorithm/genetic algorithm | 23.45% reduction in power consumption and 24.42% reduction in the latency | ✗ |
| [34] | Branch-bound (BB)-based exact mapping (BEMAP) algorithm | 19.93% reduction in energy consumption and 61.10% depletion in network latency | ✗ |
| [35] | Comparison of most of the reported application mapping techniques for NoC | Conclusion is provided for NoC application mapping-based on algorithm run-time | ✗ |
| [36] | Particle swarm optimization (PSO) algorithm and TABU search | Reduction in average latency by 63% and average energy consumption by 69% | ✓ |
| [37] | Combining uneven and search mapping strategies | Up to 64% more energy-efficient in comparison with SotAs | ✓ |
| [38] | Multilevel genetic algorithm based technique | Reduction in power consumption and delay in comparison with traditional genetic algorithm | ✗ |
| Parameter | Value |
|---|---|
| NoC type | 2D Mesh |
| NoC sizes | 2 × 2, 3 × 3, 4 × 4 |
| Embedded applications | Artificial intelligence (neural network) |
| Packet length | 128 bits (1 flit) |
| Mapping algorithm | Multilevel and direct mapping |
| Simulation time | 1000 s |
| Clock frequency | 2000 MHz |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, Z.A.; Abbasi, U.; Kim, S.W. An Efficient Algorithm for Mapping Deep Learning Applications on the NoC Architecture. Appl. Sci. 2022, 12, 3163. https://doi.org/10.3390/app12063163
Khan ZA, Abbasi U, Kim SW. An Efficient Algorithm for Mapping Deep Learning Applications on the NoC Architecture. Applied Sciences. 2022; 12(6):3163. https://doi.org/10.3390/app12063163
Chicago/Turabian StyleKhan, Zeeshan Ali, Ubaid Abbasi, and Sung Won Kim. 2022. "An Efficient Algorithm for Mapping Deep Learning Applications on the NoC Architecture" Applied Sciences 12, no. 6: 3163. https://doi.org/10.3390/app12063163
APA StyleKhan, Z. A., Abbasi, U., & Kim, S. W. (2022). An Efficient Algorithm for Mapping Deep Learning Applications on the NoC Architecture. Applied Sciences, 12(6), 3163. https://doi.org/10.3390/app12063163