1. Introduction
In In the field of artificial intelligence, an inference engine is a system component that applies logical rules to a knowledge base to infer new information, where the first inference engines are expert systems. Conventional expert systems comprise knowledge bases and inference engines. A knowledge base stores information about the actual world, and an inference engine applies logical rules to the knowledge base and new inferred knowledge. In this process, each piece of new information in the knowledge base can generate additional rules from the inference engine. These expert systems include fuzzy inference systems. Fuzzy inference systems are the core units of fuzzy logic system, which perform decision making as a basic task and employ logical gates such as “OR”, “AND”, and “IF-THEN” rules to generate the required decision rules.
Fuzzy inference systems are broadly divided into Mamdani and Sugeno types. Mamdani-type inference systems are created by combining a series of language control rules obtained from experts, and the output of each rule has a fuzzy set form. Because they have an intuitive and easily understood rule base, they are suitable in fields that employ expert systems that are created from the expert knowledge of humans, such as medical diagnoses. Sugeno-type inference systems are also called Takagi-Sugeno-Kang inference systems, and they use single output membership functions, which are a form of linear function, of a constant or an input value. Sugeno-type inference systems include a defuzzification process, and rather than calculating the center of a 2D region, they adopt a weighted average or weighted sum of several data points; hence, they have the advantage of exhibiting a higher computational efficiency than Mamdani-type inference systems. These fuzzy inference systems are used in various forecasting fields and are actively being studied [
1,
2,
3,
4,
5,
6,
7,
8,
9]. A previous study [
10] proposed a Fuzzy convolutional neural network (F-CNN) that combines fuzzy inference with a CNN to predict traffic flow, which is a core part of predicting traffic volume. Yeom [
11] proposed adaptive neuro-fuzzy inference system (ANFIS), which has an incremental structure and adopts context-based fuzzy clustering. Parsapoor [
12] proposed brain emotional learning-based fuzzy inference system (BELFIS) to predict solar activity. Kannadasan [
13] proposed an intelligent prediction model for predicting performance indices such as surface roughness and geometric tolerance in computer numerical control (CNC) operations, which plays an important role in machine product manufacturing. Guo [
14] proposed a model called backpropagation-based (BP) kernel function Granger causality, which adopts symmetry geometry to embed dimensions and fuzzy inference systems for time-series predictions; in addition, this model was utilized to examine the causal relationships between brain regions. Hwang [
15] proposed a motion cue-based fuzzy inference system to predict the normal walking speeds of sudden pedestrian movements at the initial walking stage when the heel is lifted.
Neural network expert systems are expert systems that mimic human intelligence by combining artificial neural networks (ANNs) and expert systems. In conventional expert systems, human inference methods are designed using decision trees and logical inferences, while ANNs focus on the structure and learning capacity of the human brain and reflect this in their knowledge expression. If these two systems are combined, the process of deriving results can be confirmed by the expert system, while learning can be performed by the ANN without user intervention. Accordingly, it is possible to create a system that is capable of more effective inferences than existing individual systems. The following studies on such neural network expert systems have been conducted [
16,
17,
18,
19,
20]. Liu [
21] proposed recurrent self-evolving fuzzy neural network (RSEFNN), which adopts online gradient descent learning rules to solve brainwave regression problems in brain dynamics, to predict driving fatigue. Dumas [
22] proposed prediction neural network (PNN), which is based on fully connected neural networks and CNNs, and is used for internal image prediction. Lin [
23] proposed an embedded backpropagation neural network comprising two hidden layers for earthquake magnitude prediction.
The aforementioned fuzzy inference systems and ANNs have different processes and solve various prediction problems. In addition, studies are being conducted on solving problems by combining two or more different methods, rather than using one method. Inference systems that combine different methods are called hybrid systems, and the granular computing (GrC) [
24,
25] method is adopted as a method for constructing hybrid systems. GrC is a computing theory related to the processing of information objects, called “information granules” (IG), that occur during the process of extracting knowledge from data and information, as well as abstractifying the data.
In the computing performed in general-used fuzzy inference systems, ANNs, and deep learning methods, the model output appears in a crisp form or as numbers. If the model output is in a crisp form or a number with a clear value, the numerical error relative to the actual output value can be calculated; however, difficulties occur when the difference between the model and actual output is expressed linguistically. However, in GrC, the model output is expressed in a soft form or as a fuzzy set; hence, GrC is effective at handling and processing data and information that are uncertain, incomplete, or with vague boundaries. In the actual world, people mainly use linguistic expressions rather than numerical expressions, and the brain, which makes inferences in uncertain and incomplete environments, utilizes linguistic values instead of numerical values to perform inferences and make decisions. Accordingly, GrC can represent the process by which humans think and make decisions. The following studies on GrC have been conducted [
26,
27,
28,
29]. Zhu [
30] proposed a novel approach that develops and analyzes a granular input space and designed a granular model accordingly. Truong [
31] proposed fuzzy possibilistic C-means (FPCM) clustering and a GrC method to solve anomalous value-detection problems. Zuo [
32] proposed three types of granular fuzzy regression-domain adaptative methods, to apply GrC to transfer learning. Hu [
33] proposed a method that adopts GrC to granularize fuzzy rule-based models and assess the proposed models. Zhao [
34] made long-term predictions about energy systems in the steel industry by designing a granular model based on IGs created via fuzzy clustering. By analyzing the aforementioned research, it has become possible to create IGs that are generated via GrC, and to use these to design a granular model (GM), as well as calculate soft form output and express it linguistically. In addition, performance evaluation methods are proposed to evaluate the prediction performance of soft form output. However, studies are required to improve the prediction performance of granular models by creating optimal IGs, including methods for generating IGs and setting their form and size.
Conventional fuzzy clustering creates circle-shaped clusters starting at the cluster’s center in the input space. However, when the input space’s data exhibits geometric features, a problem emerges in which the clustering is not properly performed. To address this problem, Gustafuson-Kessel (GK) clustering is employed, as it can generate clusters while considering the geometric features of the data. This study proposes context-based GK (CGK) clustering, which considers both the input space and also the output space during existing GK clustering to generate geometrically-shaped clusters. This study also designed a CGK-based granular model that utilizes the proposed context-based GK clustering to generate context-shaped IGs in the output space and geometrically-shaped IGs in the input space. In addition, to resolve the problem of geometric increases in the numbers of rules when large amounts of data are adopted, this study proposes a CGK-based granular model with a hierarchical structure that combines the CKG-based granular model and the normal prediction model into an aggregate structure, such that meaningful rules can be generated. The remainder of this paper is organized as follows.
Section 2 describes fuzzy clustering and GK clustering, while
Section 3 describes IGs, existing granular models, the proposed context-based GK clustering, and the CGK-based granular model.
Section 4 describes the hierarchical CGK-based granular model that is combined into an aggregate structure, and
Section 5 verifies the validity of the proposed method by analyzing its performance using prediction-related benchmarking data. Finally,
Section 6 presents this paper’s conclusions and future research plans.
2. Data Clustering
Clustering is the task of placing data sets into clusters, such that the data in the same cluster are more mutually similar than data in other clusters. It is mainly used in data search and analysis, and as a data analysis method, it is adopted in various fields such as image analysis, bioinformatics, pattern recognition, and machine learning. Because the concept of clustering cannot be precisely defined, various clustering algorithms exist. These include connectivity based clustering, centroid based clustering, distribution based clustering, density based clustering, and grid based clustering, while a typical clustering method is fuzzy clustering.
2.1. Fuzzy Clustering
Fuzzy clustering is a method that was developed by Dunn and improved by Bezdek [
35], which exhibits the feature of allowing the given data to belong to two or more clusters. In non-fuzzy clustering, the given data can only belong to exactly one cluster; hence, it is divided into separate clusters. In fuzzy clustering, data can belong to two or more clusters according to the membership values. For example, a banana can be yellow or green (non-fuzzy clustering criteria, or it can be yellow and green (fuzzy clustering criteria). Here, certain parts of the entire banana can be yellow, and they can be green. The banana can belong to green (green = 1), and it can belong to yellow (yellow = 0.5) and green (green = 0.5), which is not yellow (yellow = 0). The membership values can be between zero and one, while the sum of the membership values is 1. Membership values are assigned to the given data. These membership values numerically indicate the extent to which the data belongs to each cluster. If the data has a low membership value, it can be known that it is on the edge of the cluster; conversely, if it has a high membership value, it can be deduced that it is in the center part of the cluster.
Fuzzy clustering can be generalized by the following formulas.
where
and
represents the data and data items, respectively.
denotes the number of data items, and
is the number of clusters, which is
.
represents the membership value of the
kth
, and
is the fuzzification coefficient for the fuzzy membership values.
The cluster center and fuzzy membership function are obtained via an iterative process by minimizing Equation (1) according to the constraint conditions defined in Equation (2). Therefore, the objective function is modified using Lagrange multipliers and expressed as:
where
denotes the Lagrange multiplier. Therefore, the clustering problem involves identifying the cluster center set
and the fuzzy membership function set
by minimizing Equation (3). The minimization of cluster centers
can be obtained via Equation (4), and the minimization of the fuzzy membership functions can be obtained using Equation (5), which are expressed as:
Equations (4) and (5) are computed repeatedly to obtain the final cluster centers and fuzzy membership functions.
2.2. Fuzzy Clustering That Considers the Output Space
The aforementioned fuzzy clustering is a clustering that considers the features of the data in the input space. A fuzzy clustering that considers the output space generates clusters by considering both the features of the data in the input space and also the similarity and features of the data in the output space. This clustering type includes context-based fuzzy C-means (CFCM) clustering and interval-based fuzzy C-means (IFCM) clustering [
36], which differ according to how the output space is divided.
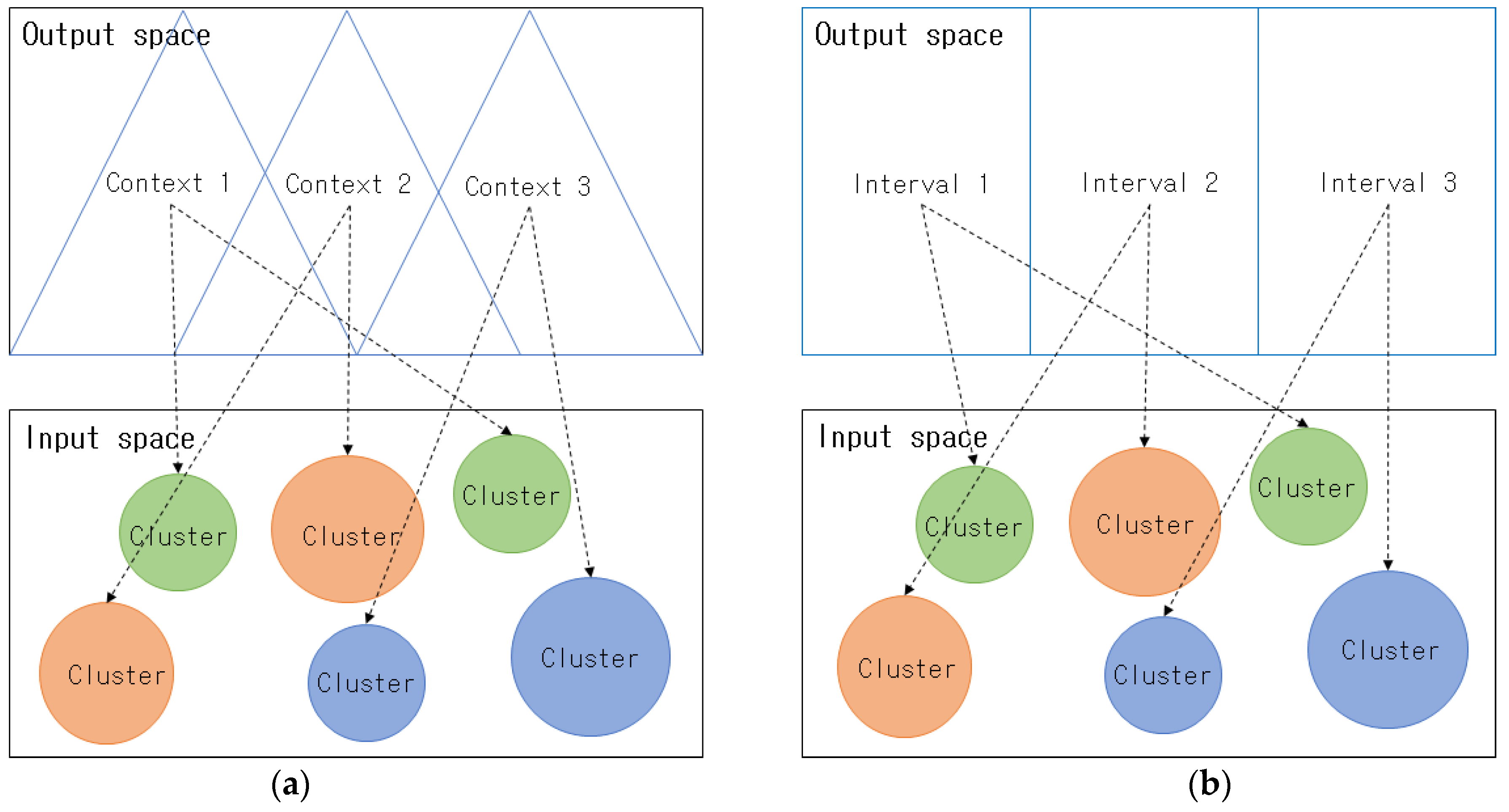
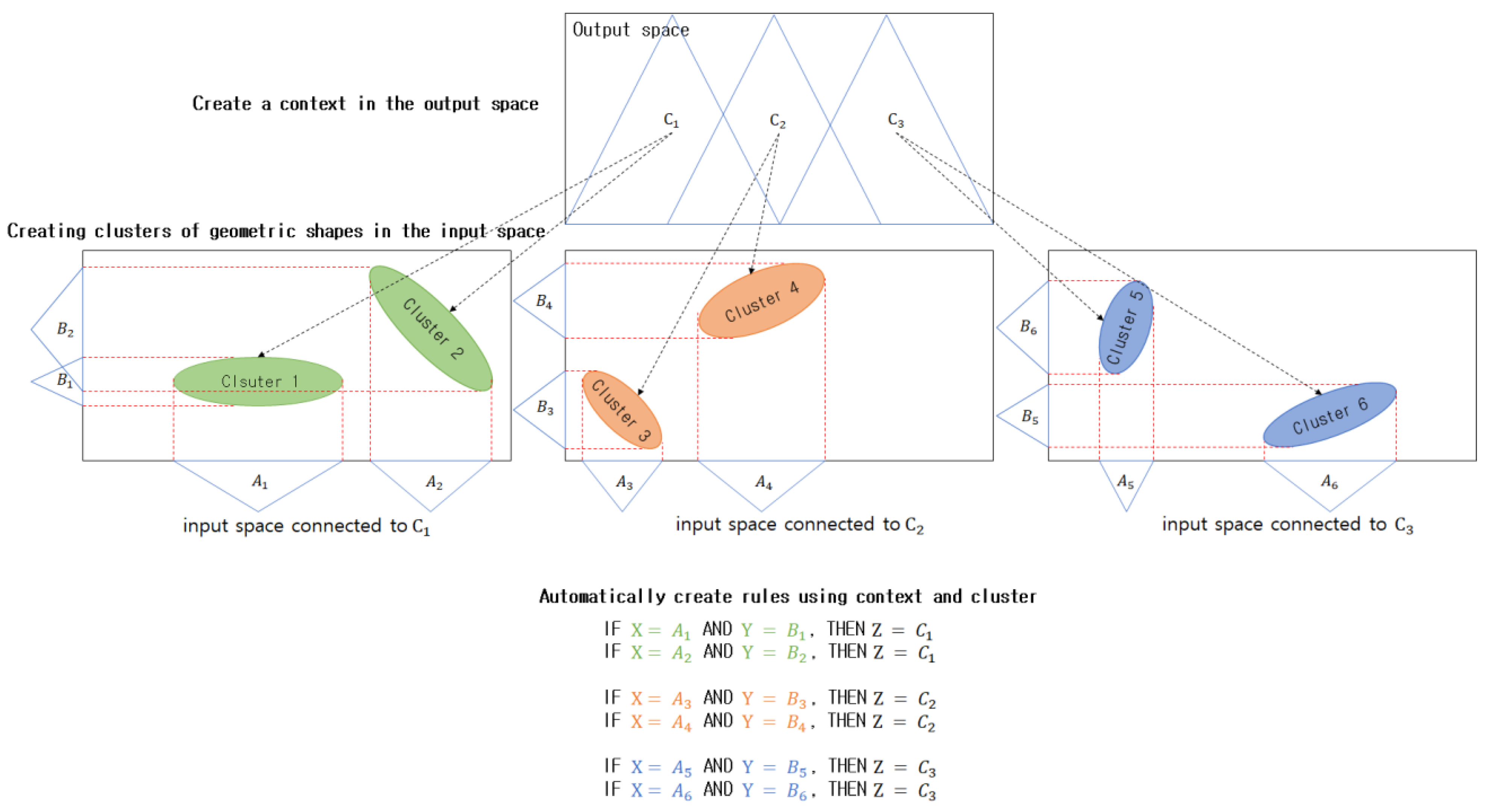
Figure 1. illustrates the fuzzy clustering that considers the output space. In
Figure 1a. triangle-shaped contexts (fuzzy sets), which are IGs, are created in the output space, while clusters that correspond to each context are created in the input space. In
Figure 1b interval-shaped IGs are created in the output space, and clusters that correspond to each interval are created in the input space.
In normal fuzzy clustering, clusters are created using only the Euclidean distance between the cluster centers and the data in the input space, without considering the features of the data in the output space. However, in context-based fuzzy clustering, triangle-shaped contexts (fuzzy sets) are created in the output space using the method proposed by Pedrycz [
37,
38], while clusters are created via fuzzy clustering in each context; hence, clusters can be created in a more sophisticated manner than in conventional fuzzy clustering.
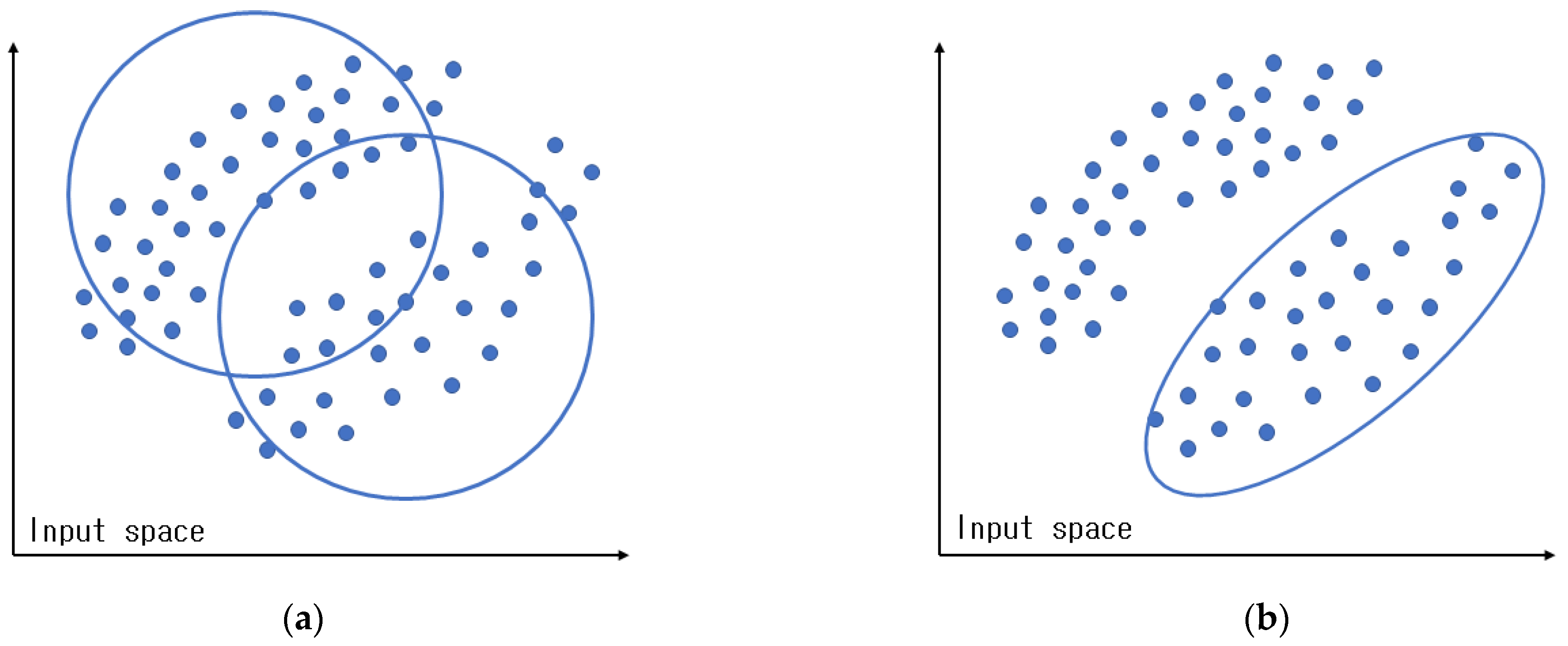
Figure 2a presents normal fuzzy clustering, and
Figure 2b shows clusters that were created in context-based fuzzy clustering by considering the features of the output space.
As illustrated in
Figure 2, fuzzy clustering creates clusters using the distance between the cluster centers and the data in the input space without considering the properties of the data in the output space. In contrast, context-based fuzzy clustering creates clusters by considering the properties of the data in the output space; hence, it can create clusters more efficiently than conventional fuzzy clustering.
The context of the data in the output space can be expressed as
. D represents all of the data in the output space. Here, it is assumed that the context for the given data can be adopted.
represents the extent to which the kth data belongs in the context created in the output space.
can be a value between zero and one, and the requirements for the membership matrix are as expressed in Equation (6) owing to the aforementioned properties.
The membership matrix updated by Equation (6) can be expressed as Equation (7). Here, m is the fuzzification coefficient, and is generally used. For the contexts, the output space is uniformly divided into fuzzy set forms, while the degree of membership is obtained. Usually, the output space is divided uniformly; however, it can be divided flexibly according to a Gaussian probability distribution according to the features of the data. The sequence in which the context-based fuzzy clustering is performed is presented below.
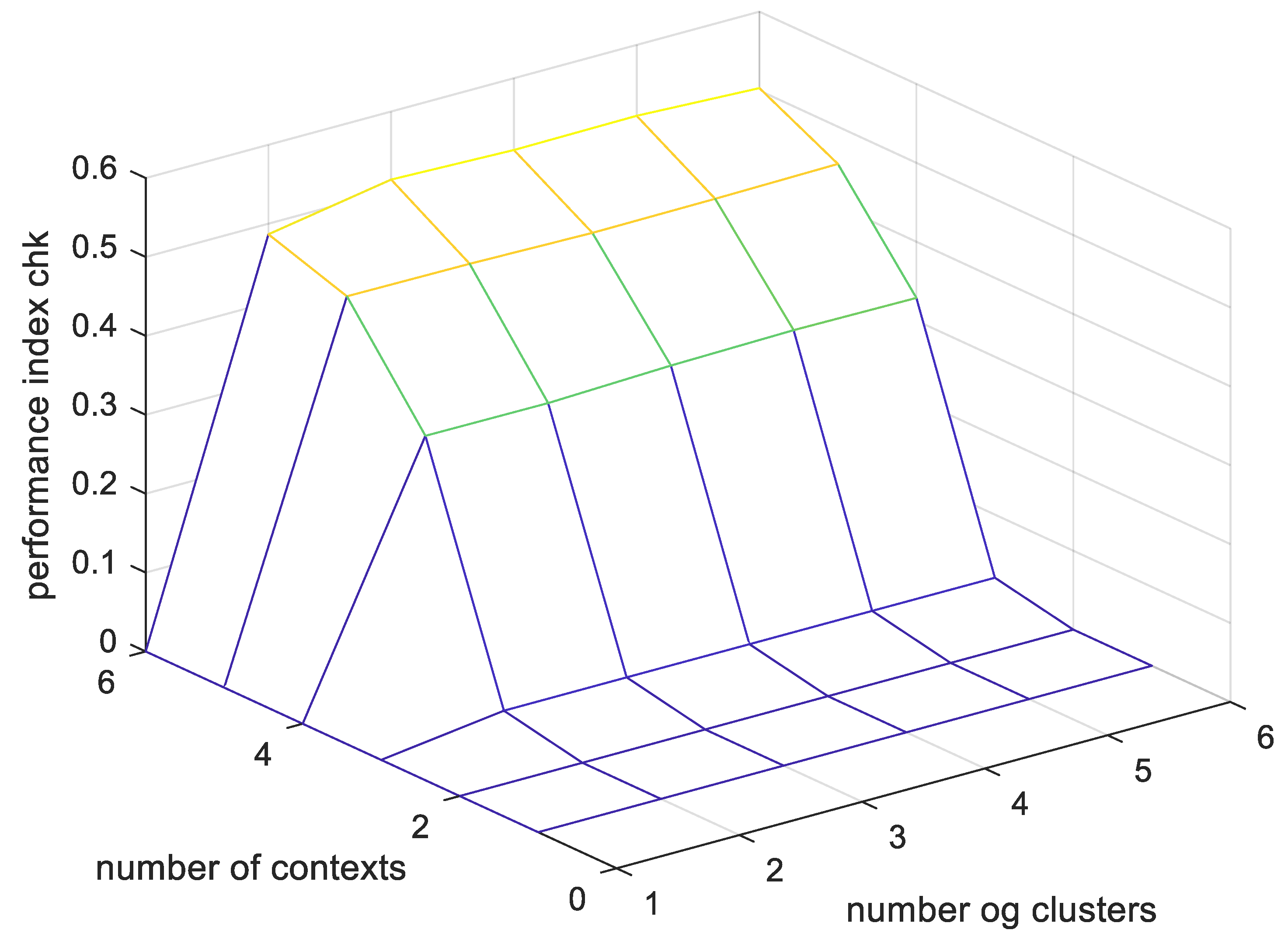
[Step 1] Select the number of contexts that can be expressed linguistically and the number of clusters that can be created in each context, and then initialize the membership matrix U with arbitrary values between zero and one. The numbers of the contexts and clusters can be set as the same number, or different values can be set by the user.
[Step 2] Divide the output space uniformly into fuzzy set forms and create fixed-sized contexts that can be expressed linguistically. In addition, a Gaussian probability distribution can be used to flexibly divide the output space and create contexts of different sizes.
[Step 3] Use Equation (8) to calculate the centers of the clusters in each context.
[Step 4] Use Equations (9) and (10) to calculate the objective function. Here, the calculated value is compared to the previous objective function value, and the above process is repeated, provided it is greater than the threshold value that was set, or the process ends if it is less than the threshold value.
where
denotes the Euclidean distance between the kth data and
th cluster center, and
h repress nets the number of iterations.
[Step 5] Equation (7) is adopted to update the membership function U, and Step 3 is performed.
2.3. GK Clustering
Regardless of the data in the input space belonging to a cluster, the cluster is normally determined by the distance between the data and the center of each cluster. As described in
Section 1, fuzzy clustering adopts Euclidean distance to create clusters. Euclidean distance is primarily used when circle-shaped clusters are created, and it has the problem of being unable to create clusters that are not circle-shaped. To resolve this problem, GK clustering was proposed [
39,
40,
41], as it can create geometrically-shaped clusters. GK clustering employs Mahalanobis distance, rather than Euclidean distance, to calculate the distance between cluster centers and data.
Figure 3 illustrates clusters that were created in fuzzy and GK clustering, and Equation (11) presents the Mahalanobis distance.
where
denotes the square of the distance between the ith cluster’s center
and the kth data
, while
is the variance matrix of the ith cluster. In GK clustering, Equation (12) is used to calculate the variance matrix
in Equation (11).
The variance matrix that is calculated using Equation (12) is adopted when calculating the distance between the cluster center and the data in Equation (13):
where
denotes the volume of each cluster. When
is calculated in Equation (13), the matrix may become zero if the number of data is insufficient; hence, the minimum value is limited using Equation (14).
where
is the variance matrix that is calculated using all data, while
I and
denote the unit matrix and weight value constant, respectively. The eigen value and eigen vector can be calculated from the variance matrix. The calculated maximum eigen value is used to limit the minimum eigen value, such that the shape of the cluster can be maintained geometrically.
3. IG Creation and Granular Model Design
3.1. Creating Rational IG
Computing and inferences in GrC are centered on IGs, which are considered fundamental concepts and algorithms, rather than being centered on numbers. IGs are a core element in GrC because they play an important role in knowledge representation and processing [
42,
43,
44]. Although IGs created using various types of clustering are relatively limited, they can reflect the general structure of some original data. Original data comprising numbers cannot depict the features and connections in the data, but IGs make this possible. Rational IG creation is focused on using the original data to create meaningful IGs. To create rational IGs, two requirements must be satisfied: coverage and specificity.
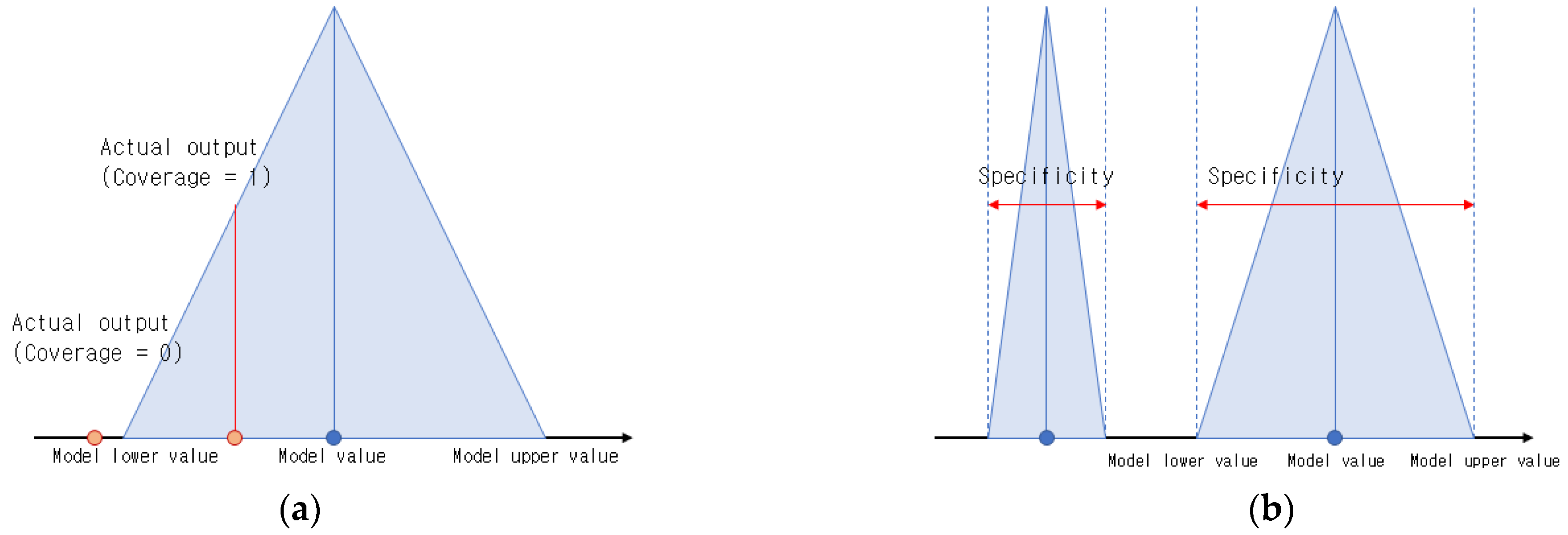
Figure 4. Presents the coverage and specificity in IGs.
Coverage refers to whether the target data is included in the formed IG. In other words, it shows how much of the overall target data has accumulated within the IG’s range, including the extent of the accumulation. The more data that accumulates in the IG, the higher the coverage value. This can verify the validity of the IG, and the model may be better in terms of modeling functions. incl, which is the degree of inclusion and is specified according to the form in which the IG
is created. When
is in context form, incl has a value close to one when
is included in
, and it has a value close to zero when it is not included. In other words, coverage can be adopted to count the number that includes the data
in the granularized output of the granular model, while an average value can be calculated for all data. Ideally, the coverage has a value that is close to one, and all data is included in the granular model’s output.
Specificity represents how specifically and semantically the IG
can be described. In general, the specificity of a given IG
must satisfy Equation (16). In other words, the IG must be created with as much detail as possible, and each IG must have a meaning that can be described. When an IG is in context form, the specificity becomes higher as the interval, i.e., the distance between the upper and lower bounds, becomes narrower. If the IG
is reduced to point form, the specificity arrives at a value close to one.
A continuous decreasing function of the interval length can be considered instead of the exponential function used in Equation (17). Coverage and specificity can be adopted to evaluate the IG’s validity and the granular model’s prediction performance. In other words, the granular model can be evaluated by considering the coverage and specificity of the IG, and a method that can simultaneously maximize coverage and specificity should be determined. These two properties have a trade-off relationship. This implies that the higher the coverage value, the lower the specificity value. Rational IGs can be represented by Equation (18), and this is called the PI.
The PI plays an important role in evaluating the model’s accuracy and clarity, and various methods for evaluating model performance have been developed. General performance evaluation methods include root-mean-square error (RMSE) and mean absolute percentage error (MAPE). RMSE evaluates performance by subtracting the model’s predicted values from the actual predicted values, calculating the mean of the squares, and squaring the obtained value. MAPE evaluates performance by subtracting the model’s predicted value from the actual output value and dividing by the model’s predicted value. These performance evaluation methods are mainly used when the model’s output value is a numerical value. However, in the case of granular models comprise IGs, the model output is not a numerical value but an IG; hence, it is difficult to evaluate the model using general performance evaluation methods. To address this issue, studies are actively being conducted on adopting coverage and specificity as performance evaluation methods for granular models [
45,
46,
47,
48,
49]. The higher the PI, the more meaningful the IG, and granular models with excellent performance can be designed.
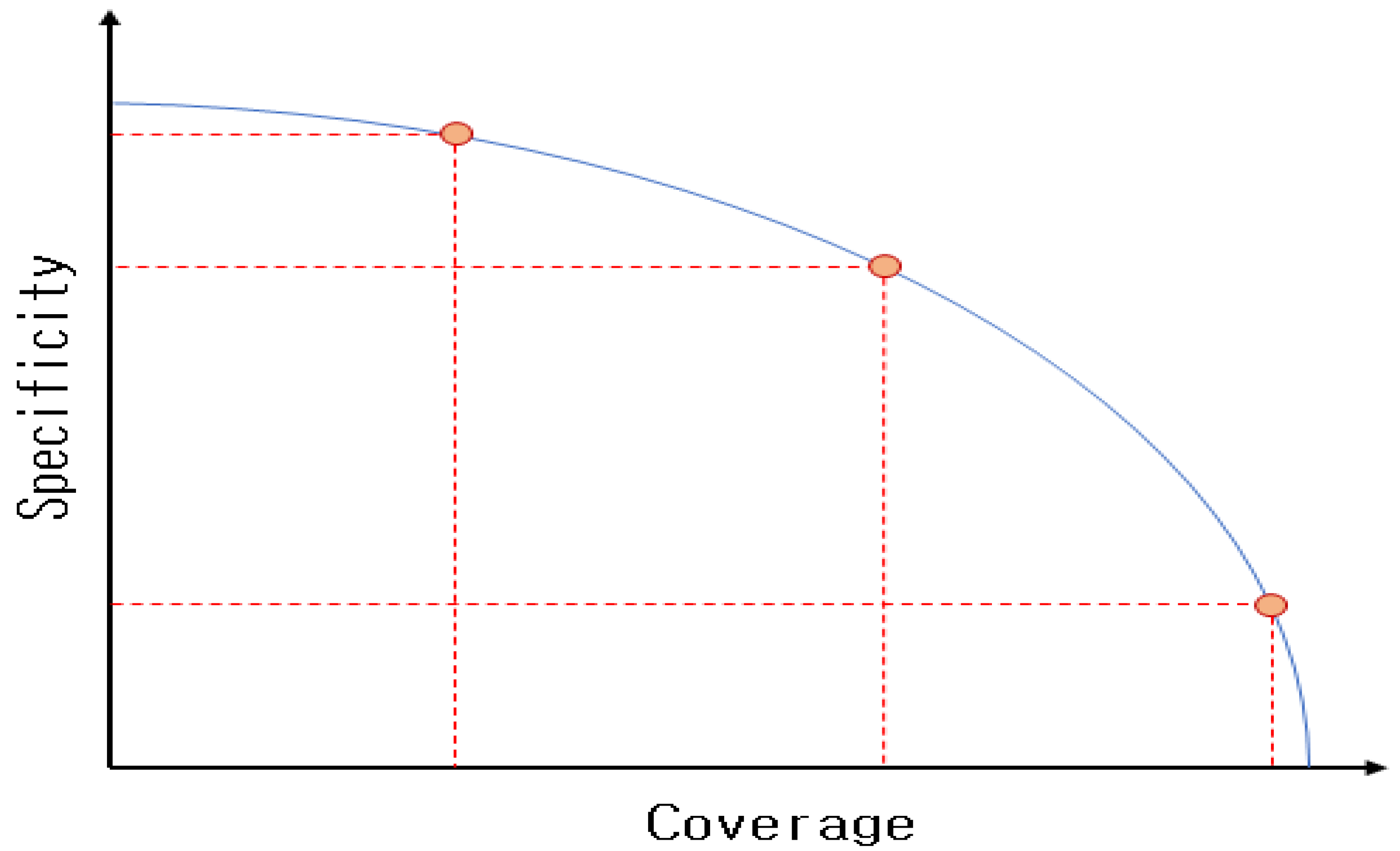
The PI value obtained from a granular model can be adopted to represent the relationship between coverage and specificity as coordinates, and the changes in model performance, which are related to changes in the PI value, can be observed.
Figure 5 illustrates the trade-off relationship between coverage and specificity. If coverage approaches zero, specificity approaches one, and the shape of the IG approaches a point. It can be observed that as the coverage increases, the size of the IG increases, but the specificity decreases.
3.2. Fuzzy-Based Granular Model
Because the inference values of fuzzy rule-based inference systems used in various real-world fields of application are numeric values, there are limitations to describing these results linguistically. Fuzzy granular models, which are designed based on IGs that are created using fuzzy clustering, can express and process knowledge because their output values are IGs. Fuzzy granular models are created by granularizing a predetermined level of information in the data included in A. Owing to the granular properties of the data, granularized output is created from the variables of an existing fuzzy model with numerical input and output. This is based on the rational IG creation method described in
Section 3.2. The IGs used in the fuzzy granular model exhibit the shapes of the fuzzy sets. The IG’s level of granularization is assumed to be
. The granularization level creates the IG
with a fuzzy set shape by allowing IGs of the given level
, which can be described as shown below, due to
, which represent the data in each rule’s output space.
Using the same method, the IGs
are created by granularizing
, which represent the data in the output space. A general fuzzy granular model divides the output space uniformly to create triangle-shaped contexts and clusters in each context. The fuzzy granular model’s output value
is expressed in context form, and each fuzzy rule regarding the input
creates the following IG output:
The following method is used to calculate
, which is the IG output in context form that was created based on all fuzzy rules.
where ⊕, ⊗ represent the completed addition and multiplication operations for each IG, respectively.
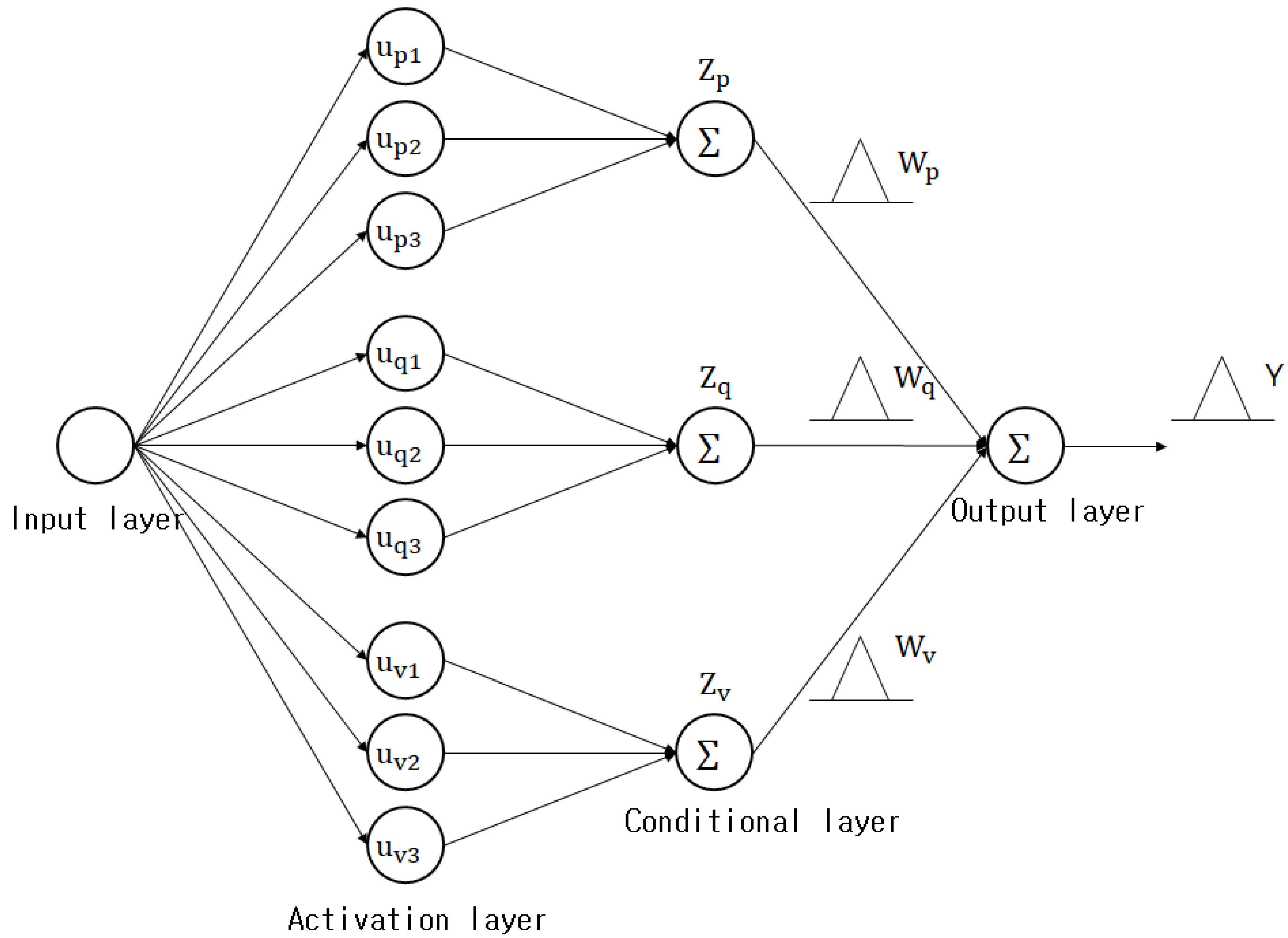
Figure 6. Presents the structure of the fuzzy granular model.
3.3. CGK Clustering
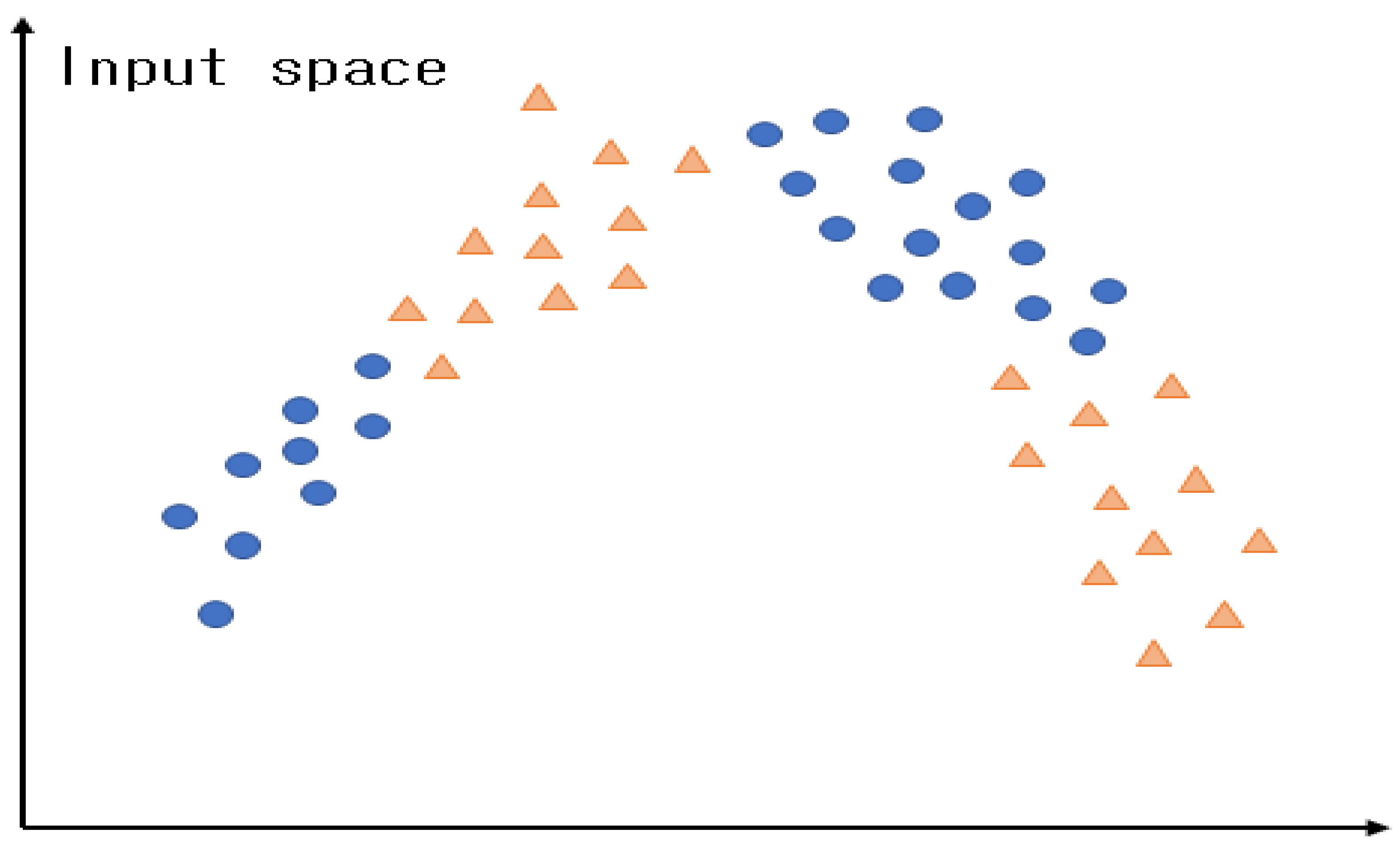
CGK clustering is a clustering method that considers the output space. It creates clusters based on the correlations between the data in the input and output spaces by considering the output space in conventional GK clustering. It is assumed that there are data with two features. The data above can be depicted in red and blue according to the dependent variable.
Figure 7. Presents the data with two features.
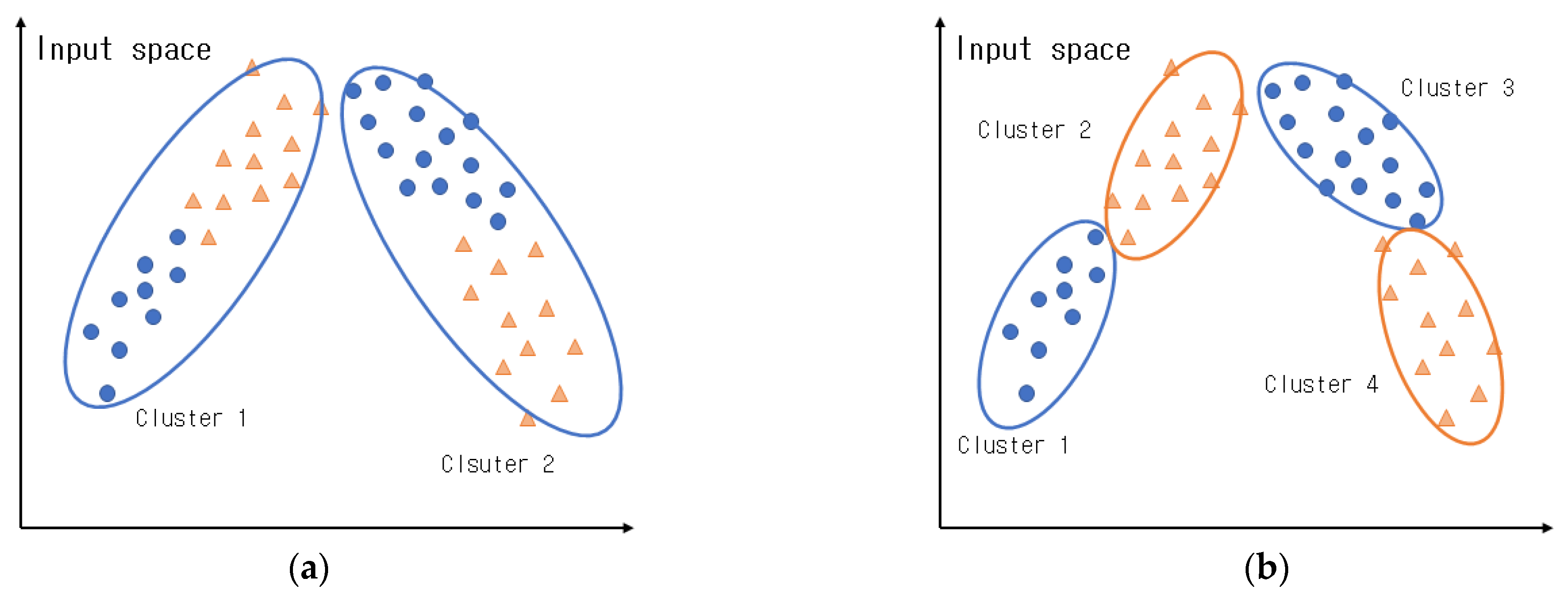
Figure 8a presents clusters created via normal GK clustering. In
Figure 8a, it can be observed that the features of the data in the input space were considered when creating the clusters; however, the features of the output space were not considered.
Figure 8b presents clusters created via CGK clustering that consider the output space. As illustrated in this figure, clusters are created by considering both the input and output spaces; hence, the features of the data in the output space can be preserved, and more efficient clusters can be created than in normal GK clustering.
Figure 9. Illustrates the concept of CGK that considers the output space.
The context regarding the data in the output space can be expressed as expressed in Equation (22). Here,
D denotes the data in the output space. If it is assumed that a context-shaped IG is adopted for the given data in the output space,
represents the degree to which the context created in the output space belongs to the
kth data.
Fuzzy clustering adopts Euclidean distance to create clusters, while GK clustering improves upon this by creating clusters with Mahalanobis distance using Equation (11).
Where
is a matrix with
, which is a fixed constant for each i. Because fuzzy clustering uses Euclidean distance, it exhibits excellent performance for only problems that create circle-shaped clusters. To circumvent this disadvantage, GK clustering adopts
to extend the Euclidean distance of fuzzy clustering, such that clusters with various geometric shapes can be created, and it allows the distance standard to adapt to local areas. The objective functions are expressed in Equations (23)–(25).
Equations (23)–(25) are repeated in each context generated in the output space to create geometrically-shaped clusters. Below is the sequence in which context-based GK clustering is performed.
[Step 1] The number of contexts that can be expressed linguistically and the number of clusters that are created in each context are selected, as well as ɛ. Here, ɛ sets the degree of the geometric shape, and a value greater than zero must be selected. The membership function U is initialized with values between zero and one. The numbers of contexts and clusters can be set to be the same, or they can be set differently.
[Step 2] Context-shaped IGs with fixed sizes can be created by uniformly dividing the output space, while context-shaped IGs with different sizes can be created by via a Gaussian probability distribution.
[Step 3] Equation (24) is adopted to calculate the centers of the clusters in the contexts in the output space and a membership matrix.
[Step 4] Equations (23) and (26) are adopted to calculate an objective function, and the aforementioned process is repeated if the calculated value is greater than the previous objective-function value. Conversely, if the calculated value is less than the previous objective-function value, the above process ends.
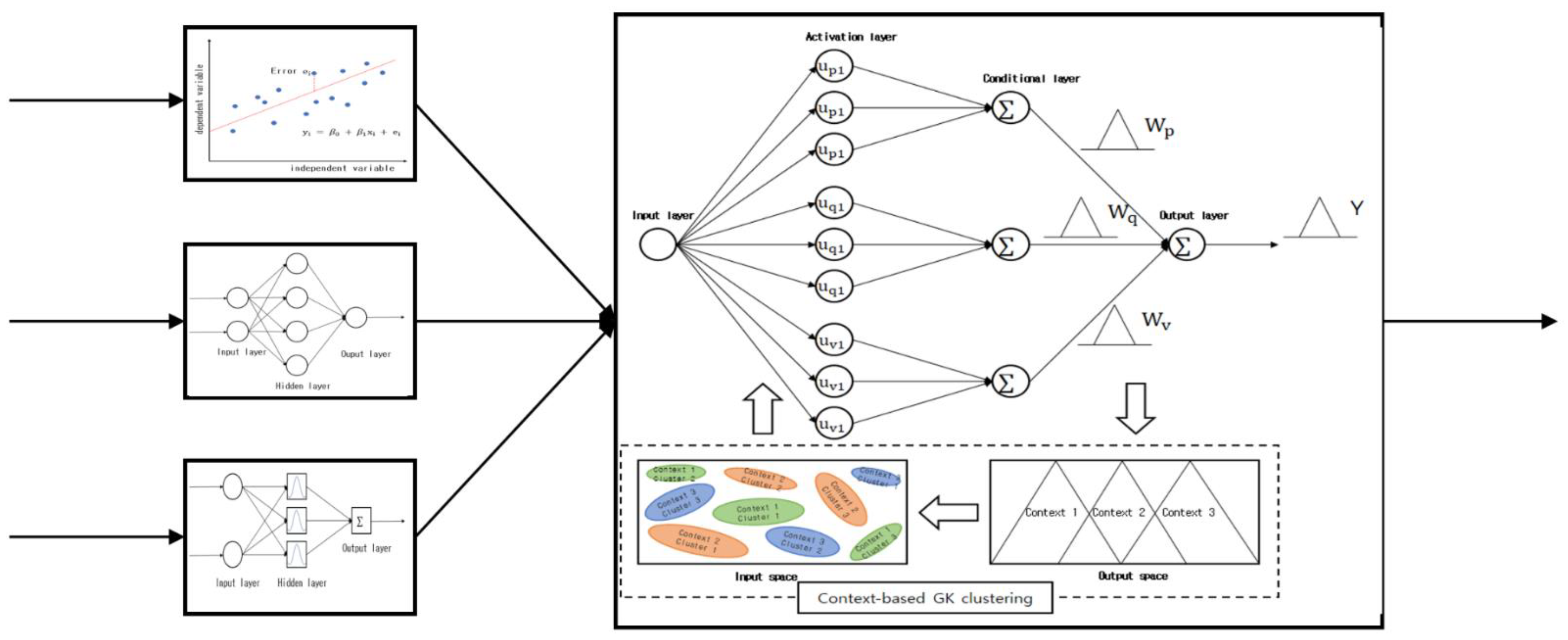
3.4. CGK-Based Granular Model Design
GK granular models are designed to adopt CGK clustering that considers the output space, to create context-shaped IGs in the output space and create geometrically-shaped clusters in each context.
Figure 10. presents the structure of a GK granular model in which three contexts are created in the output space and three clusters are created in each context. As illustrated in the figure, there are conditional and conclusion variables. The conclusion variables represent the context-shaped IGs that are created in the output space, while the conditional variables represent the centers of the clusters that are created in each context, i.e., IGs that are created in the input space. As mentioned above, a uniform creation method and a flexible creation method can be adopted to create the contexts in the output space. The GK granular model’s final output value Y is calculated using Equation (27).
Here, the addition and multiplication symbols ⊕, ⊗ represent the completed addition and multiplication operations for the IGs, respectively. Fuzzy sets are created during the process of handling the GK granular model conditions. At this point, the clusters created via CGK clustering can be represented by the GK granular model’s hidden layer. The area between the hidden and output layers is expressed as a context that can be described linguistically. The sum, which is the GK granular model’s final output, can be expressed using all contexts as expressed in Equation (28):
The GK granular model’s final output is expressed as a triangle-shaped context, and it can be expressed as a fuzzy set:
where
denote the GK granular model’s lower bound, model, and upper bound values, respectively, and they refer to each of the triangle-shaped context’s points. The lower bound, model, and upper bound values can be expressed by Equations (30)–(32):
When CGK clustering is performed, the membership matrix
can be expressed as values between zero and 1, while the membership matrix’s requirements can be expressed as:
Here, the contexts are created by uniformly or flexibly dividing the output space into fuzzy set shapes. The GK granular model’s structure is as follows. In the input layer, data is received and enters the GK granular model. The activation layer is the cluster activation step in which clusters that correspond to the contexts that were created in the output space are created in the input space. The conditional layer performs conditional clustering in each context. The activation and conditional layers are connected, and the data information is adopted in GK clustering when a context is provided. The GK granular model is focused on the activation and conditional layers. The contexts are connected to the GK clustering in the conditional layer, and fuzzy sets are created by considering the features of the data in the input space. A specified number of clusters is created in each context, and the total number of nodes in the output layer is the same as the number of contexts. The final output values that are added up in the output layer are represented as a triangle-shaped context.
6. Conclusions
In this paper, we proposed a CGK-based particle model using context-based GK clustering and a CGK-based particle model with a hierarchical structure. Conventional fuzzy clustering generates clusters by calculating the distance between the center of the cluster and each data using the Euclidean distance. However, there is a problem in that the performance decreases when the data has geometric characteristics. To improve this problem, GK clustering is used. GK clustering uses Mahalanobis distance to calculate the distance between the center of the cluster and each data to generate a geometrical cluster. This paper proposes context-based GK clustering that considers the output space in the existing GK clustering and creates a cluster that considers not only the input space but also the output space. Using the proposed CGK clustering, we designed a CGK-based particle model (CGK-GM) and a CGK-based particle model with aggregated structure (AGM). The advantages of the proposed CGK-based particle model can be summarized as follows.
First, unlike the existing new network, it is possible to automatically generate an explanatory meaningful fuzzy IF-THEN rule that can be expressed verbally by generating information particles in the input space and output space from numerical input and output data. Second, unlike the existing fuzzy clustering, it is effective to process numerical input/output databases with geometric features because it is possible to create a geometrical cluster. Third, meaningful information particles with high abstraction values can be generated by combining the general prediction models, such as linear regression model, neural network, and radiative basis function neural network, with the CGK-based particle model proposed in this paper.
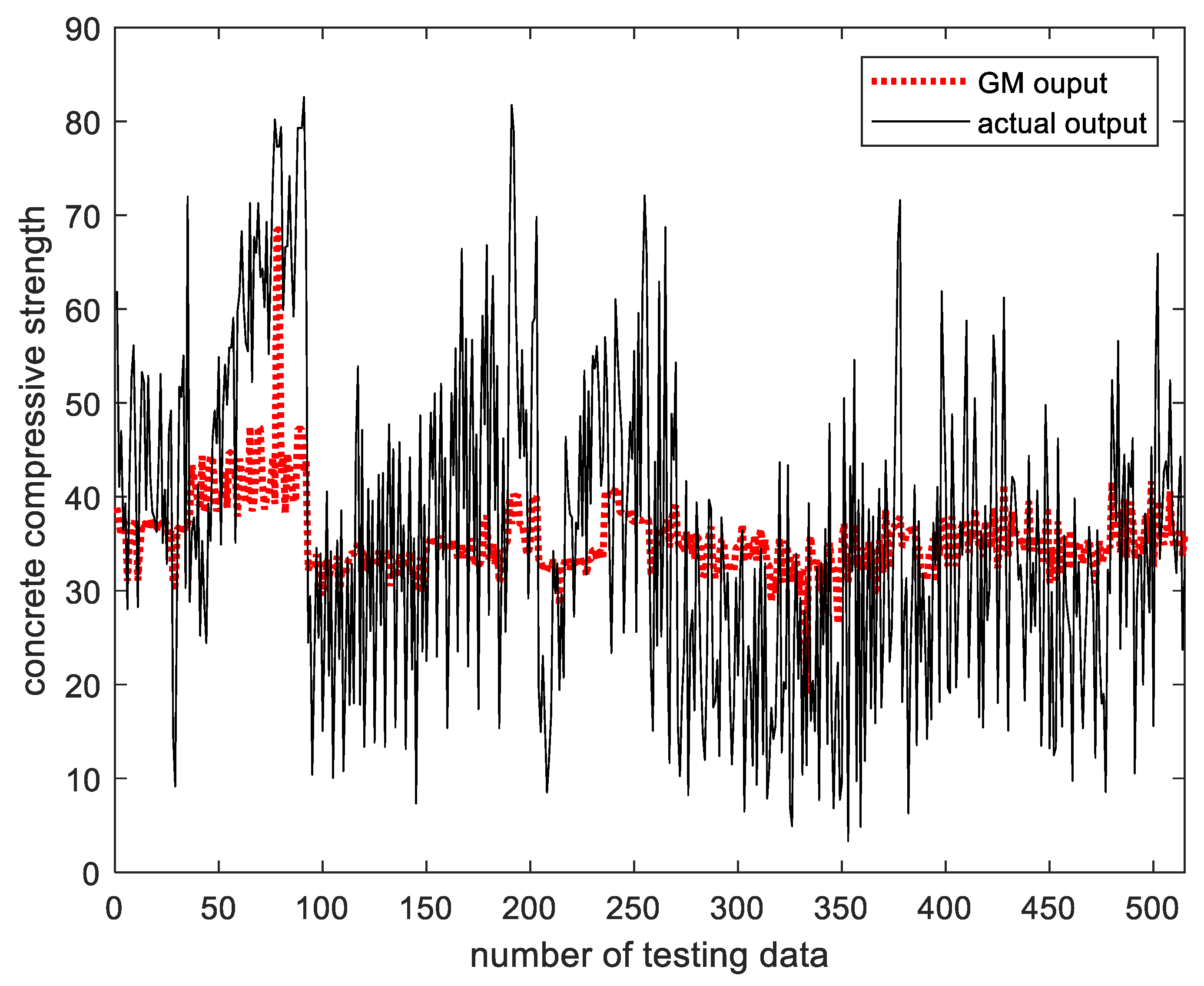
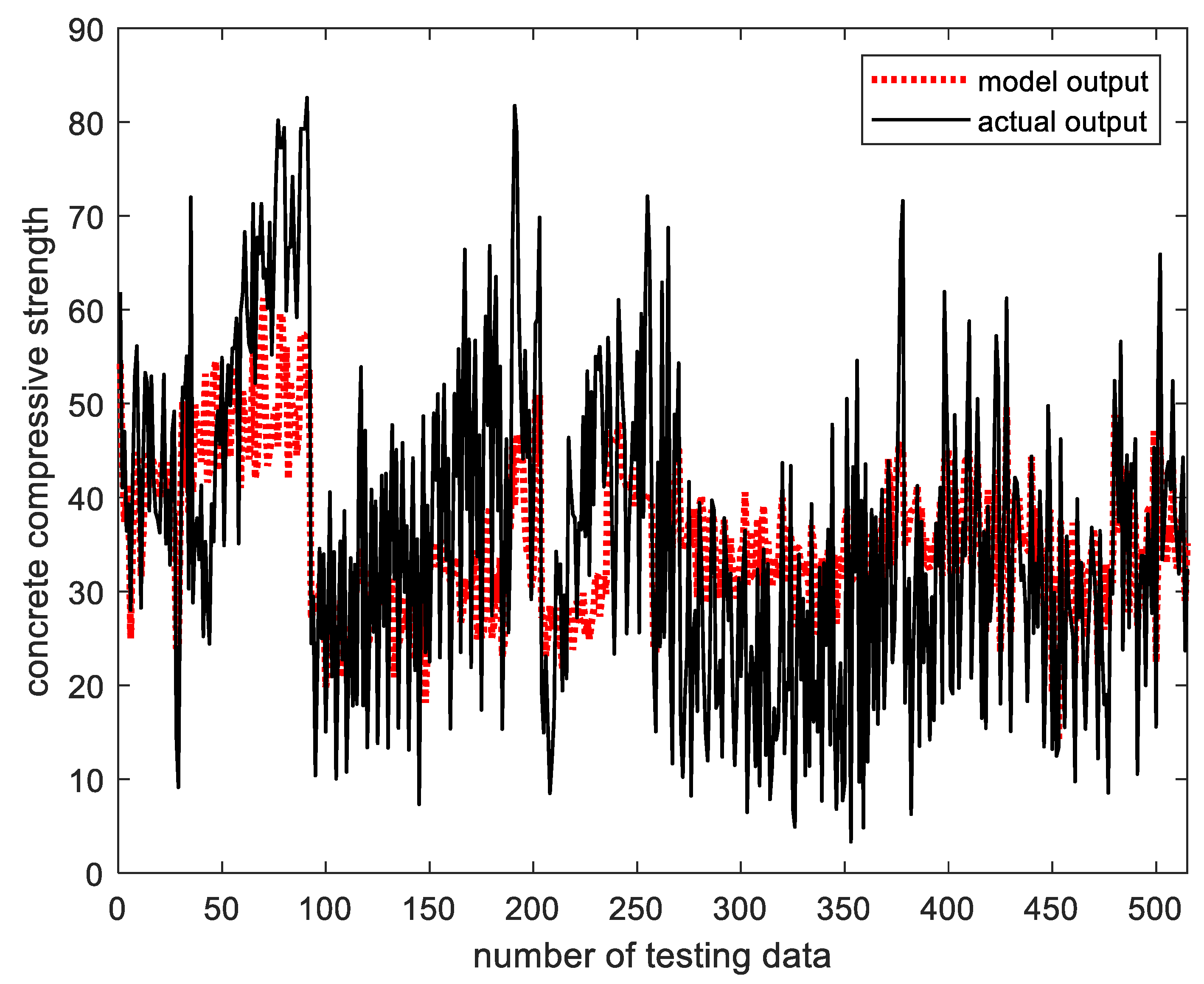
To verify the feasibility of the proposed method, an experiment was conducted using the concrete compressive strength data, a benchmarking database. To evaluate the performance of each particle model, we used a performance index using the scalability and specificity that we consider when generating rational information particles. As a result of the experiment, it was confirmed that the proposed methods were superior to the existing particle models.
In the future, based on the rational information particle generation principle, we plan to conduct research on generating various types of information particles and optimally allocating information particles created in the input space and output space.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}