
Applying ANN and TM to Build a Prediction Model for the Site Selection of a Convenience Store


Abstract
:1. Introduction
2. Literature Review
3. Methodology
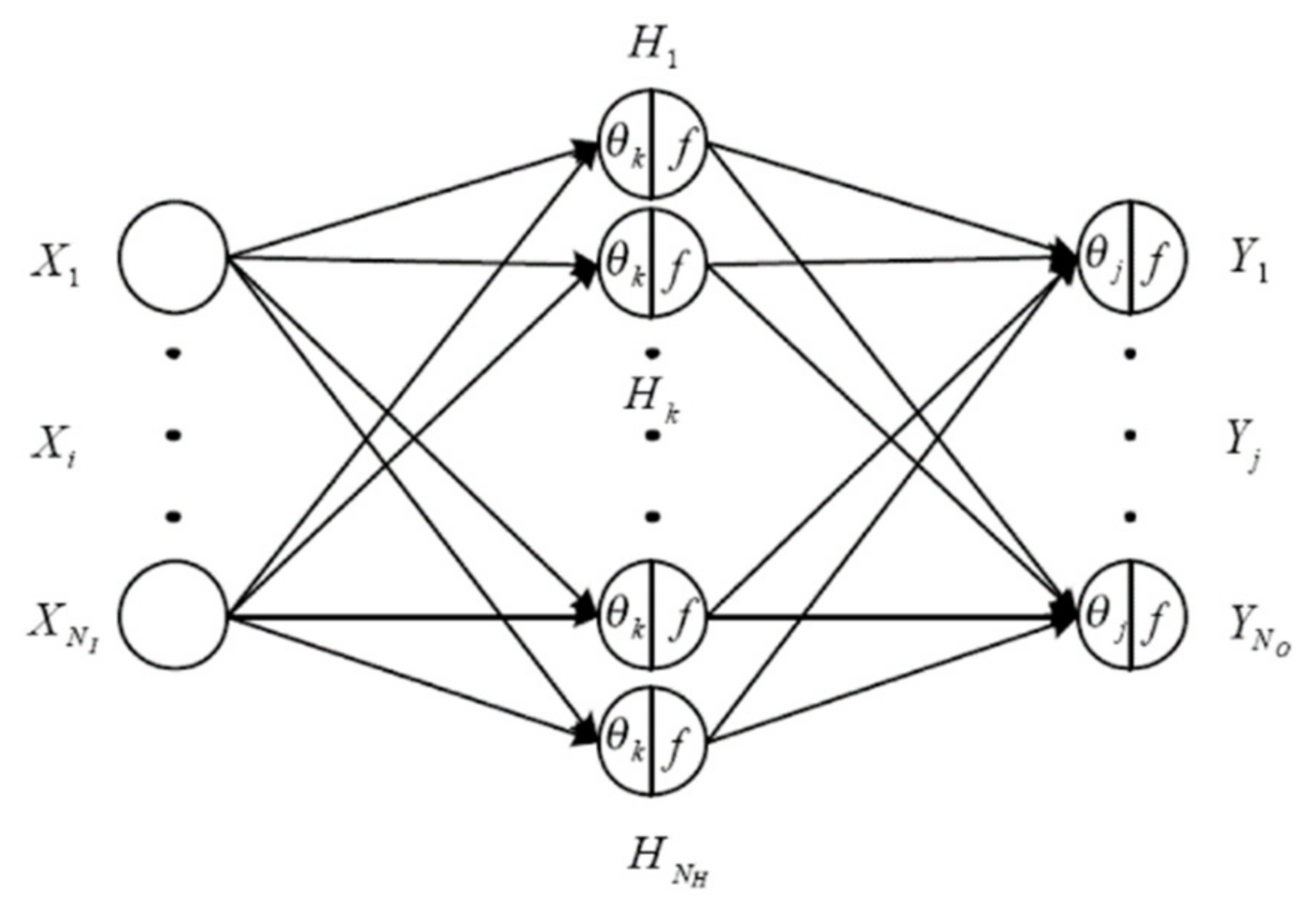
3.1. BPN Network
- Yj: output data;
- f: transfer function;
- Wij: weighting of connecting node i to node j;
- Xi: input data;
- θj: threshold.
3.2. TM
4. Case Study
4.1. Data Collection
4.2. Neural Network Parameter Design
- Neural network design (number of units in the hidden layer)
- 2.
- Learning iterations
- 3.
- Learning rate and momentum term
- 4.
- Transfer function
4.3. TM Analytical Results
4.4. Experimental Results and Validation
4.5. Robustness Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, W.I. The Use of Analytical Network Process (ANP) in Selecting the Location of Convenience Stores. Master’s Thesis, National Chin-Yi University of Technology, Taichung, Taiwan, 2011. [Google Scholar]
- Chou, S.P. Analysis of Chinese Restaurant Location in Taipei Urban Area. Master’s Thesis, National Taipei University of Technology, Taipei, Taiwan, 2011. [Google Scholar]
- Erbıyık, H.; Özcan, S.; Karaboğa, K. Retail Store Location Selection Problem with Multiple Analytical Hierarchy Process of Decision Making an Application in Turkey. Procedia-Soc. Behav. Sci. 2012, 58, 1405–1414. [Google Scholar] [CrossRef] [Green Version]
- Roig-Tierno, N.; Baviera-Puig, A.; Buitrago-Vera, J.; Mas-Verdu, F. The retail site location decision process using GIS and the analytical hierarchy process. Appl. Geogr. 2013, 40, 191–198. [Google Scholar] [CrossRef]
- Hernández, T.; Bennison, D. The art and science of retail location decisions. Int. J. Retail Distrib. Manag. 2000, 28, 357–367. [Google Scholar] [CrossRef]
- Kuo, R.J.; Chi, S.C.; Kao, S.S. A decision support system for selecting convenience store location through integration of fuzzy AHP and artificial neural network. Comput. Ind. 2002, 47, 199–214. [Google Scholar] [CrossRef]
- Pokonieczny, K. Using artificial neural networks to determine the location of wind farms: Miedzna district case study. J. Water Land Dev. 2016, 30, 101–111. [Google Scholar] [CrossRef]
- Abujayyab, S.K.M.; Ahamad, M.S.S.; Yahyac, A.S.; Saad, A.M.H.Y. A new framework for geospatial site selection using artificial neural networks as decision rule: A case study on landfill sites. In Proceedings of the Joint International Geoinformation Conference, Kuala Lumpur, Malaysia, 28–30 October 2015; pp. 28–30. [Google Scholar]
- Fallah, M.; Vagharfard, H.; Farajzadeh, M.; Kheslat, N. Assessment of Spatial multi-criteria decision-making with process of the artificial neural networks Method to Site Selection of the Wastewater Treatment Plant (Case study: Qeshm Island). Int. J. Adv. Biol. Biomed. Res. 2014, 2, 2061–2066. [Google Scholar]
- Satman, M.H.; Altunbey, M. Selecting Location of Retail Stores Using Artificial Neural Networks and Google Places API. Int. J. Stat. Probab. 2014, 3, 67–77. [Google Scholar] [CrossRef]
- Khaw, J.F.C.; Lim, B.S.; Lim, L.E.N. Optimal design of neural networks using the Taguchi method. Neurocomputing 1995, 7, 225–245. [Google Scholar] [CrossRef]
- Rajiv, P.D.; Grünhagen, M. International franchising research: Some thoughts on the what, where, when, and how. J. Mark. Channels 2014, 21, 124–132. [Google Scholar]
- Teller, C.; Reutterer, T. The evolving concept of retail attractiveness: What makes retail agglomerations attractive when customers shop at them? J. Retail. Consum. Serv. 2008, 15, 127–143. [Google Scholar] [CrossRef] [Green Version]
- Widaningrum, D.L. A GIS-based approach for Catchment area analysis of convenience store. Procedia Comput. Sci. 2015, 72, 511–518. [Google Scholar] [CrossRef] [Green Version]
- Kaufmann, P.J.; Donthu, N.; Brooks, C.M. Multi-unit retail site selection processes: Incorporating opening delays and unidentified competition. J. Retail. 2000, 76, 113–127. [Google Scholar] [CrossRef]
- Goodchild, M.F. ILACS: A location-allocation model for retail site selection. J. Retail. 1984, 60, 84–100. [Google Scholar]
- Ganesha, H.R.; Aithal, P.S.; Kirubadevi, P. Ideal store locations for Indian retailers—An empirical study. Int. J. Manag. Technol. Soc. Sci. 2002, 5, 215–226. [Google Scholar] [CrossRef]
- Ahedo, V.; Santos, J.I.; Galán, J.M. Knowledge transfer in commercial feature extraction for the retail store location problem. IEEE Access 2021, 9, 132967–132979. [Google Scholar] [CrossRef]
- Aversa, J.; Doherty, S.; Hernandez, T. Big data analytics: The new boundaries of retail location decision making. Appl. Geogr. 2018, 4, 390–408. [Google Scholar] [CrossRef]
- Lin, G.; Chen, X.; Liang, Y. The location of retail stores and street centrality in Guangzhou, China. Appl. Geogr. 2018, 100, 12–20. [Google Scholar] [CrossRef]
- Rohani, A.M.B.M.; Chua, F.-F. Location analytics for optimal business retail site selection. In Proceedings of the Computational Science and Its Applications, ICCSA 2018, Melbourne, VIC, Australia, 2–5 July 2018. [Google Scholar] [CrossRef]
- Mendes, A.B.; Themido, I.H. Multi-outlet retail site location assessment. Int. Trans. Oper. Res. 2004, 11, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.X.; Wang, M.Y.; Wang, Q.B. Retail Management; Wu Nan Publishing Co., Ltd.: Taipei, Taiwan, 2009. [Google Scholar]
- Li, L. Data visualization and retrieval based convenience store location model of fresh products. J. Digit. Inf. Manag. 2017, 15, 125–134. [Google Scholar]
- Achabal, D.D.; Gorr, W.L.; Mahajan, V. MULTILOC: A multiple store location decision model. J. Retail. 1982, 58, 5–25. [Google Scholar]
- Johnston, R.J.; Kissling, C.C. Establishment use patterns within central places. Aust. Geogr. Stud. 1971, 9, 116–132. [Google Scholar] [CrossRef]
- McArthur, E.; Weaven, S.; Dant, R. The evolution of retailing: A meta review of the literature. J. Macromark. 2016, 36, 272–286. [Google Scholar] [CrossRef] [Green Version]
- Applebaum, W. The analog method for estimating potential store sales. In Guild to Store Location Research; Kornblau, Ed.; Addison-Wesley: Boston, MA, USA, 1968. [Google Scholar]
- Chen, K.; Kuang, C.; Wang, L.; Chen, K.; Han, X.; Fan, J. Storm Surge Prediction Based on Long Short-Term Memory Neural Network. Appl. Sci. 2022, 12, 181. [Google Scholar] [CrossRef]
- Yang, X.; Chen, Y.; Teng, S.; Chen, G. Method for Predicting Local Site Amplification Factors Using 1-D Convolutional Neural Networks. Appl. Sci. 2021, 11, 11650. [Google Scholar] [CrossRef]
- Yeh, Y.C. Neural Network Mode Application and Implementation; Scholars Books Co., Ltd.: Taipei, Taiwan, 2009. [Google Scholar]
- Montgomery, D.C. Design and Analysis of Experiments, 6th ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2005. [Google Scholar]
- Thakur, A.G.; Rao, T.E.; Mukhedkar, M.S.; Nandedkar, V.M. Application of Taguchi Method for Resistance Spot Welding of Galvanized Steel. J. Eng. Appl. Sci. 2010, 5, 22–26. [Google Scholar]
- Taguchi, G.; Chowdhury, S.; Wu, Y. Taguchi’s Quality Engineering Handbook; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| No | Factor | Definition | |
|---|---|---|---|
| A | Customer source | A1 | Residential area (dominated by the residential population surrounding the site, with fixed consumption and higher turnover on holidays and non-work-days compared with weekdays) |
| A0 | Business area (dominated by transient populations surrounding the site engaging in commercial activities in the area, with a higher number of customers on weekdays) | ||
| B | Competitiveness of other CVSs | The number of other chain CVSs within a radius of 200 M + self-owned CVSs within a radius of 100 M | |
| C | Competitiveness of supermarkets | The number of supermarkets and other types of retail stores within a radius of 200 M | |
| D | Customer flow | Pedestrian flow through the site + the number of motorcycles passing through the site | |
| E | Major customer type | (1) Workers (2) Students (3) Pedestrian flow (4) Nearby residents | |
| F | The number of households | The number of effective households within a radius of 100M | |
| G | Store location | (1) Intersection of two parkways (between main streets) (2) Intersection of one parkway and byway (between minor streets) (3) Off intersection | |
| H | Visibility | The signboard is visible from 100 m away | |
| I | Usable area | The area of the store (greater than 75 m2 or not) | |
| No | A1 | A2 | B | C | D | E | F | G | H | I | Predict | No | A1 | A2 | B | C | D | E | F | G | H | I | Predict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 100 | 60 | 15.16 | 100 | 17.16 | 80 | 50 | 1.1 | 70,400 | 49 | 1 | 0 | 100 | 100 | 14.58 | 80 | 21.32 | 80 | 50 | 1.1 | 52,790 |
| 2 | 1 | 0 | 20 | 100 | 14.83 | 80 | 30.52 | 50 | 100 | 1.1 | 60,300 | 50 | 1 | 0 | 10 | 20 | 7.53 | 100 | 3.28 | 80 | 100 | 1.1 | 47,500 |
| 3 | 1 | 0 | 65 | 55 | 12.83 | 80 | 14.44 | 80 | 50 | 1.1 | 43,040 | 51 | 1 | 0 | 100 | 100 | 13.44 | 0 | 5.4 | 70 | 100 | 1.1 | 60,800 |
| 4 | 1 | 0 | 10 | 100 | 5.54 | 100 | 8.56 | 80 | 100 | 1.1 | 49,700 | 52 | 1 | 0 | 20 | 100 | 9.13 | 100 | 15.48 | 50 | 100 | 1.1 | 73,200 |
| 5 | 1 | 0 | 100 | 40 | 0.05 | 80 | 2.88 | 100 | 100 | 1.1 | 65,000 | 53 | 1 | 0 | 100 | 100 | 10.07 | 100 | 6.48 | 80 | 100 | 1.1 | 69,600 |
| 6 | 1 | 0 | 100 | 100 | 10.30 | 100 | 28.92 | 80 | 100 | 1.1 | 87,200 | 54 | 1 | 0 | 10 | 0 | 11.41 | 80 | 13.88 | 80 | 100 | 1.1 | 33,500 |
| 7 | 0 | 1 | 20 | 100 | 11.76 | 80 | 6.75 | 80 | 50 | 1.1 | 32,550 | 55 | 1 | 0 | 65 | 100 | 6.30 | 80 | 7.96 | 80 | 100 | 1.1 | 63,000 |
| 8 | 1 | 0 | 15 | 5 | 12.73 | 100 | 3.68 | 50 | 100 | 1.1 | 34,700 | 56 | 1 | 0 | 100 | 50 | 7.89 | 80 | 5.96 | 50 | 100 | 1.1 | 39,020 |
| 9 | 1 | 0 | 100 | 100 | 1.54 | 80 | 0 | 100 | 100 | 1.1 | 47,050 | 57 | 1 | 0 | 20 | 75 | 6.84 | 80 | 26.88 | 80 | 50 | 1.1 | 54,600 |
| 10 | 1 | 0 | 0 | 50 | 5.44 | 80 | 4.12 | 50 | 0 | 1.1 | 32,900 | 58 | 1 | 0 | 30 | 100 | 9.49 | 100 | 4.28 | 50 | 100 | 1.1 | 44,200 |
| 11 | 1 | 0 | 100 | 100 | 4.06 | 80 | 3.12 | 50 | 50 | 1.1 | 55,000 | 59 | 1 | 0 | 40 | 100 | 12.70 | 100 | 7.04 | 50 | 50 | 1.1 | 39,100 |
| 12 | 1 | 0 | 30 | 100 | 14.80 | 80 | 28.2 | 80 | 50 | 1.1 | 68,000 | 60 | 1 | 0 | 60 | 100 | 6.69 | 100 | 50.08 | 80 | 50 | 1.1 | 85,200 |
| 13 | 1 | 0 | 10 | 50 | 6.15 | 80 | 32.04 | 20 | 50 | 1.1 | 33,000 | 61 | 1 | 0 | 30 | 75 | 9.03 | 100 | 13.72 | 50 | 50 | 1.1 | 49,000 |
| 14 | 1 | 0 | 100 | 100 | 3.21 | 80 | 4.16 | 50 | 0 | 1.1 | 52,600 | 62 | 1 | 0 | 5 | 75 | 5.35 | 80 | 19.44 | 50 | 100 | 1.1 | 43,800 |
| 15 | 1 | 0 | 25 | 100 | 10.50 | 100 | 4.8 | 50 | 50 | 1.1 | 40,700 | 63 | 1 | 0 | 10 | 100 | 7.10 | 80 | 10.8 | 80 | 50 | 1.1 | 32,520 |
| 16 | 1 | 0 | 25 | 100 | 24.80 | 100 | 27.48 | 80 | 100 | 1.1 | 49,080 | 64 | 1 | 0 | 10 | 100 | 5.63 | 80 | 4.96 | 80 | 50 | 1.1 | 50,000 |
| 17 | 1 | 0 | 10 | 35 | 14.48 | 100 | 13.44 | 80 | 50 | 1.1 | 49,000 | 65 | 1 | 0 | 100 | 100 | 6.91 | 80 | 20.68 | 80 | 50 | 0.9 | 46,750 |
| 18 | 1 | 0 | 20 | 60 | 12.59 | 100 | 19.92 | 80 | 100 | 1.1 | 59,100 | 66 | 1 | 0 | 10 | 100 | 5.48 | 80 | 14.28 | 50 | 100 | 1.1 | 41,500 |
| 19 | 1 | 0 | 100 | 100 | 11.05 | 80 | 17.8 | 50 | 50 | 0.9 | 50,000 | 67 | 1 | 0 | 15 | 100 | 13.49 | 100 | 14.72 | 100 | 50 | 1.1 | 43,300 |
| 20 | 0 | 1 | 10 | 100 | 10.08 | 100 | 13.25 | 50 | 100 | 1.1 | 45,000 | 68 | 1 | 0 | 100 | 60 | 10.54 | 100 | 6 | 20 | 100 | 1.1 | 51,100 |
| 21 | 1 | 0 | 100 | 100 | 6.50 | 100 | 13.24 | 50 | 100 | 1.1 | 61,600 | 69 | 1 | 0 | 100 | 100 | 3.91 | 100 | 6.92 | 80 | 100 | 1.1 | 63,200 |
| 22 | 1 | 0 | 10 | 100 | 6.06 | 100 | 5.24 | 80 | 50 | 1.1 | 43,800 | 70 | 1 | 0 | 0 | 45 | 6.71 | 100 | 10.96 | 70 | 50 | 1.1 | 38,500 |
| 23 | 1 | 0 | 30 | 75 | 4.56 | 0 | 52.4 | 80 | 50 | 1.1 | 74,500 | 71 | 1 | 0 | 20 | 100 | 10.17 | 80 | 36.96 | 50 | 50 | 1.1 | 59,100 |
| 24 | 1 | 0 | 20 | 80 | 2.81 | 100 | 2.08 | 50 | 100 | 1.1 | 42,500 | 72 | 1 | 0 | 20 | 100 | 4.38 | 100 | 8.56 | 80 | 100 | 1.1 | 55,200 |
| 25 | 1 | 0 | 10 | 100 | 9.20 | 100 | 13.48 | 80 | 50 | 1.1 | 45,100 | 73 | 1 | 0 | 40 | 100 | 4.74 | 0 | 15.68 | 80 | 50 | 1.1 | 45,700 |
| 26 | 1 | 0 | 100 | 100 | 24.48 | 100 | 25.88 | 80 | 100 | 1.1 | 73,700 | 74 | 1 | 0 | 20 | 55 | 5.51 | 0 | 25.76 | 80 | 100 | 1 | 41,800 |
| 27 | 1 | 0 | 30 | 100 | 8.80 | 80 | 22.56 | 80 | 100 | 1.1 | 68,400 | 75 | 1 | 0 | 40 | 100 | 8.65 | 80 | 23.2 | 80 | 50 | 1.1 | 63,200 |
| 28 | 1 | 0 | 40 | 55 | 6.17 | 80 | 11 | 50 | 100 | 1.1 | 44,100 | 76 | 1 | 0 | 20 | 100 | 8.75 | 80 | 16.76 | 50 | 100 | 1.1 | 51,000 |
| 29 | 1 | 0 | 20 | 55 | 7.43 | 100 | 14.32 | 80 | 100 | 1.1 | 56,100 | 77 | 1 | 0 | 10 | 65 | 9.47 | 0 | 42 | 20 | 100 | 1.1 | 39,500 |
| 30 | 1 | 0 | 20 | 100 | 2.62 | 100 | 10.64 | 80 | 100 | 1.1 | 51,300 | 78 | 1 | 0 | 20 | 100 | 10.31 | 80 | 19.72 | 80 | 100 | 1.1 | 50,700 |
| 31 | 1 | 0 | 100 | 100 | 7.24 | 100 | 5.44 | 50 | 100 | 1.1 | 52,100 | 79 | 1 | 0 | 100 | 100 | 6.91 | 80 | 22.72 | 80 | 0 | 1.1 | 64,800 |
| 32 | 1 | 0 | 30 | 100 | 8.32 | 80 | 8.52 | 50 | 50 | 1.1 | 70,100 | 80 | 0 | 1 | 25 | 35 | 10.27 | 100 | 27.95 | 20 | 100 | 1.1 | 44,500 |
| 33 | 1 | 0 | 10 | 60 | 3.68 | 80 | 3.12 | 80 | 50 | 1.1 | 40,800 | 81 | 1 | 0 | 0 | 100 | 13.06 | 80 | 15.48 | 50 | 50 | 1.1 | 40,700 |
| 34 | 1 | 0 | 10 | 100 | 9.82 | 80 | 17.64 | 80 | 100 | 1 | 33,870 | 82 | 0 | 1 | 20 | 55 | 3.35 | 100 | 12.4 | 20 | 100 | 1.1 | 40,000 |
| 35 | 1 | 0 | 15 | 100 | 20.45 | 100 | 1.44 | 100 | 100 | 1.1 | 64,200 | 83 | 1 | 0 | 100 | 100 | 4.75 | 0 | 4.24 | 80 | 100 | 1.1 | 42,000 |
| 36 | 1 | 0 | 15 | 100 | 3.86 | 100 | 27.8 | 20 | 100 | 1 | 24,800 | 84 | 1 | 0 | 15 | 100 | 14.95 | 100 | 17.16 | 50 | 50 | 1.1 | 43,600 |
| 37 | 1 | 0 | 40 | 100 | 4.15 | 100 | 7.92 | 50 | 100 | 1.1 | 44,000 | 85 | 1 | 0 | 100 | 100 | 6.28 | 80 | 9.04 | 50 | 50 | 1.1 | 52,600 |
| 38 | 1 | 0 | 100 | 100 | 1.21 | 0 | 37.08 | 50 | 50 | 1.1 | 73,600 | 86 | 1 | 0 | 100 | 90 | 13.03 | 80 | 15.88 | 50 | 100 | 1.1 | 45,460 |
| 39 | 1 | 0 | 30 | 100 | 15.83 | 80 | 17.85 | 80 | 50 | 1.1 | 57,200 | 87 | 1 | 0 | 15 | 100 | 8.33 | 0 | 41 | 80 | 100 | 1.1 | 60,100 |
| 40 | 1 | 0 | 40 | 75 | 2.52 | 100 | 29.6 | 20 | 50 | 1.1 | 39,100 | 88 | 1 | 0 | 10 | 85 | 6.28 | 80 | 1.4 | 50 | 100 | 1.1 | 34,900 |
| 41 | 1 | 0 | 20 | 100 | 9.21 | 100 | 10 | 80 | 100 | 1.1 | 43,300 | 89 | 1 | 0 | 30 | 100 | 7.88 | 100 | 9.28 | 100 | 50 | 1.1 | 59,300 |
| 42 | 1 | 0 | 100 | 100 | 22.02 | 80 | 5.84 | 50 | 50 | 1 | 36,280 | 90 | 1 | 0 | 40 | 100 | 18.76 | 100 | 18.72 | 80 | 50 | 1.1 | 66,300 |
| 43 | 1 | 0 | 20 | 35 | 12.96 | 80 | 4.72 | 80 | 50 | 1.1 | 48,000 | 91 | 1 | 0 | 40 | 50 | 8.64 | 80 | 28.76 | 80 | 100 | 1.1 | 60,900 |
| 44 | 1 | 0 | 10 | 100 | 15.92 | 80 | 12.72 | 50 | 100 | 1.1 | 35,600 | 92 | 1 | 0 | 55 | 55 | 8.80 | 80 | 17.32 | 80 | 50 | 1.1 | 62,000 |
| 45 | 1 | 0 | 100 | 100 | 7.18 | 80 | 13.84 | 50 | 50 | 1.1 | 71,000 | 93 | 1 | 0 | 30 | 40 | 20.87 | 100 | 29.6 | 80 | 50 | 1.1 | 40,100 |
| 46 | 1 | 0 | 30 | 100 | 9.44 | 80 | 16.16 | 50 | 100 | 1.1 | 46,000 | 94 | 1 | 0 | 10 | 100 | 25.23 | 80 | 3.2 | 80 | 100 | 1.1 | 51,100 |
| 47 | 0 | 1 | 20 | 40 | 18.97 | 80 | 24.12 | 100 | 100 | 1.1 | 55,000 | 95 | 1 | 0 | 100 | 100 | 7.06 | 80 | 39.92 | 80 | 100 | 1.1 | 96,900 |
| 48 | 1 | 0 | 5 | 10 | 7.98 | 100 | 14.68 | 80 | 100 | 1.1 | 43,800 | 96 | 1 | 0 | 100 | 80 | 12.81 | 100 | 15.88 | 50 | 50 | 1.1 | 44,320 |
| Factors | Base | Score | ||||||
|---|---|---|---|---|---|---|---|---|
| B: Competitiveness of other CVSs | ||||||||
| BQ1 | Competitive store category | Major competitive CVS (0) | Minor competitive CVS (20) | Local chain CVS (30) | Self-operated CVS (40) | None (100) | 1 | 100 |
| BQ2 | Relative distance | <50 m (0) | 50–100 m (5) | 100–200 m (10) | >200 m (20) | NA | ||
| BQ3 | Competitive store proximity | good (0) | acceptable (10) | poor (20) | NA | |||
| BQ4 | Competition store opening hours | 24 h | not 24 h | NA | ||||
| C: Competitiveness of Supermarkets: | ||||||||
| CQ1 | Number of stores | ≧4 (0) | 3 (5) | 2 (20) | 1 (40) | none (100) | 20 | |
| CQ2 | Relative distance | <50 m (0) | 50–100 m (10) | 100–200 m (15) | >200 m (35) | 35 | ||
| CQ3 | Competition store closed hours | after 22:00 (0) | 21:00–22:00 (5) | 20:00–21:00 (10) | before 20:00 (15) | 5 | ||
| D: People flow | ||||||||
| DQ1 | Survey time | 07:00–09:00 | 12:00–14:00 | 17:00–19:00 | 21:00–23:00 | |||
| DQ2 | Pedestrian | 264 | 40 | 264/40 = 6.6 | ||||
| DQ3 | Motorcycle | 2568 | 500 | 2568/500 = 5.1 | ||||
| E: Major customer type | ||||||||
| EQ1 | Single source (0) | Two sources (80) | >Two sources (100) | 100 | ||||
| F: Number of households | ||||||||
| FQ2 | Number of households | 429 | 25 | 429/25 = 17.2 | ||||
| G: Store location | ||||||||
| GQ1 | Store location | Off intersection (0) | Between minor streets (30) | Between main streets (50) | 30 | |||
| GQ2 | Width | <6 m (0) | 6–10 m (20) | >10 m (50) | 50 | |||
| H: Visibility | ||||||||
| HQ1 | Visibility | <50 m (0) | 50–100 m (50) | >100 m (100) | 50 | |||
| I: Area | ||||||||
| IQ1 | Usable area | <50 m2 (0.9) | 50–100 m2 (1.0) | >100 m2 (1.1) | ||||
| Factor | Score | Weighting of Residential Area (Factor A) | Sub-Sum |
|---|---|---|---|
| B | 100.0 | 0.29% | 288.5 |
| C | 60.0 | 0.06% | 34.6 |
| D | 11.7 | 0.67% | 79.0 |
| E | 100.0 | 0.08% | 76.9 |
| F | 17.2 | 0.58% | 99.0 |
| G | 80.0 | 0.38% | 307.7 |
| H | 50.0 | 0.06% | 28.8 |
| Sum | 914.5 | ||
| Store | Predict. | Actual | Difference | Ratio | Success | Store | Predict | Actual | Difference | Ratio | Success |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 70,400 | 55,023 | 15,377 | 0.78 | 49 | 52,790 | 47,007 | 5783 | 0.89 | ||
| 2 | 60,300 | 46,923 | 13,377 | 0.78 | 50 | 47,500 | 37,819 | 9681 | 0.80 | ||
| 3 | 43,040 | 39,375 | 3665 | 0.91 | 1 | 51 | 60,800 | 40,152 | 20,648 | 0.66 | |
| 4 | 49,700 | 47,214 | 2486 | 0.95 | 1 | 52 | 73,200 | 46,710 | 26,490 | 0.64 | |
| 5 | 65,000 | 39,669 | 25,331 | 0.61 | 53 | 69,600 | 61,930 | 7670 | 0.89 | ||
| 6 | 87,200 | 91,004 | 3804 | 1.04 | 1 | 54 | 33,500 | 67,507 | 34,007 | 2.02 | 1 |
| 7 | 32,550 | 42,914 | 10,364 | 1.32 | 1 | 55 | 63,000 | 64,056 | 1056 | 1.02 | 1 |
| 8 | 34,700 | 53,743 | 19,043 | 1.55 | 1 | 56 | 39,020 | 36,379 | 2641 | 0.93 | 1 |
| 9 | 47,050 | 43,513 | 3537 | 0.92 | 1 | 57 | 54,600 | 35,050 | 19,550 | 0.64 | |
| 10 | 32,900 | 44,322 | 11,422 | 1.35 | 1 | 58 | 44,200 | 30,780 | 13,420 | 0.70 | |
| 11 | 55,000 | 56,081 | 1081 | 1.02 | 1 | 59 | 39,100 | 37,799 | 1301 | 0.97 | 1 |
| 12 | 68,000 | 48,007 | 19,993 | 0.71 | 60 | 85,200 | 46,564 | 38,636 | 0.55 | ||
| 13 | 33,000 | 35,872 | 2872 | 1.09 | 1 | 61 | 49,000 | 55,184 | 6184 | 1.13 | 1 |
| 14 | 52,600 | 39,851 | 12,749 | 0.76 | 62 | 43,800 | 39,196 | 4604 | 0.89 | ||
| 15 | 40,700 | 33,121 | 7579 | 0.81 | 63 | 32,520 | 70,667 | 38,147 | 2.17 | 1 | |
| 16 | 49,080 | 52,619 | 3539 | 1.07 | 1 | 64 | 50,000 | 42,152 | 7848 | 0.84 | |
| 17 | 49,000 | 40,460 | 8540 | 0.83 | 65 | 46,750 | 50,033 | 3283 | 1.07 | 1 | |
| 18 | 59,100 | 48,155 | 10,945 | 0.81 | 66 | 41,500 | 46,384 | 4884 | 1.12 | 1 | |
| 19 | 50,000 | 53,140 | 3140 | 1.06 | 1 | 67 | 43,300 | 80,205 | 36,905 | 1.85 | 1 |
| 20 | 45,000 | 53,561 | 8561 | 1.19 | 1 | 68 | 51,100 | 41,517 | 9583 | 0.81 | |
| 21 | 61,600 | 33,410 | 28,190 | 0.54 | 69 | 63,200 | 40,175 | 23,025 | 0.64 | ||
| 22 | 43,800 | 44,622 | 822 | 1.02 | 1 | 70 | 38,500 | 43,788 | 5288 | 1.14 | 1 |
| 23 | 74,500 | 37,861 | 36,639 | 0.51 | 71 | 59,100 | 44,298 | 14,802 | 0.75 | ||
| 24 | 42,500 | 47,955 | 5455 | 1.13 | 1 | 72 | 55,200 | 62,976 | 7776 | 1.14 | 1 |
| 25 | 45,100 | 43,360 | 1740 | 0.96 | 1 | 73 | 45,700 | 30,051 | 15,649 | 0.66 | |
| 26 | 73,700 | 53,278 | 20,422 | 0.72 | 74 | 41,800 | 45,711 | 3911 | 1.09 | 1 | |
| 27 | 68,400 | 67,508 | 892 | 0.99 | 1 | 75 | 63,200 | 47,535 | 15,665 | 0.75 | |
| 28 | 44,100 | 40,352 | 3748 | 0.92 | 1 | 76 | 51,000 | 36,745 | 14,255 | 0.72 | |
| 29 | 56,100 | 42,921 | 13,179 | 0.77 | 77 | 39,500 | 48,996 | 9496 | 1.24 | 1 | |
| 30 | 51,300 | 57,308 | 6008 | 1.12 | 1 | 78 | 50,700 | 73,138 | 22,438 | 1.44 | 1 |
| 31 | 52,100 | 49,883 | 2217 | 0.96 | 1 | 79 | 64,800 | 61,396 | 3404 | 0.95 | 1 |
| 32 | 70,100 | 50,055 | 20,045 | 0.71 | 80 | 44,500 | 20,763 | 23,737 | 0.47 | ||
| 33 | 40,800 | 51,543 | 10,743 | 1.26 | 1 | 81 | 40,700 | 43,101 | 2401 | 1.06 | 1 |
| 34 | 33,870 | 52,791 | 18,921 | 1.56 | 1 | 82 | 40,000 | 58,015 | 18,015 | 1.45 | 1 |
| 35 | 64,200 | 42,554 | 21,646 | 0.66 | 83 | 42,000 | 51,495 | 9495 | 1.23 | 1 | |
| 36 | 24,800 | 51,127 | 26,327 | 2.06 | 1 | 84 | 43,600 | 48,268 | 4668 | 1.11 | 1 |
| 37 | 44,000 | 50,130 | 6130 | 1.14 | 1 | 85 | 52,600 | 56,032 | 3432 | 1.07 | 1 |
| 38 | 73,600 | 44,734 | 28,866 | 0.61 | 86 | 45,460 | 45,805 | 345 | 1.01 | 1 | |
| 39 | 57,200 | 48,733 | 8467 | 0.85 | 87 | 60,100 | 52,036 | 8064 | 0.87 | ||
| 40 | 39,100 | 56,205 | 17,105 | 1.44 | 1 | 88 | 34,900 | 37,717 | 2817 | 1.08 | 1 |
| 41 | 43,300 | 38,257 | 5043 | 0.88 | 89 | 59,300 | 51,201 | 8099 | 0.86 | ||
| 42 | 36,280 | 45,635 | 9355 | 1.26 | 1 | 90 | 66,300 | 39,763 | 26,537 | 0.60 | |
| 43 | 48,000 | 43,643 | 4357 | 0.91 | 1 | 91 | 60,900 | 65,757 | 4857 | 1.08 | 1 |
| 44 | 35,600 | 22,774 | 12,826 | 0.64 | 92 | 62,000 | 45,233 | 16,767 | 0.73 | ||
| 45 | 71,000 | 47,499 | 23,501 | 0.67 | 93 | 40,100 | 44,463 | 4363 | 1.11 | 1 | |
| 46 | 46,000 | 40,230 | 5770 | 0.87 | 94 | 51,100 | 55,101 | −4001 | 1.08 | 1 | |
| 47 | 55,000 | 74,899 | 19,899 | 1.36 | 1 | 95 | 96,900 | 52,973 | 43,927 | 0.55 | |
| 48 | 43,800 | 50,339 | 6539 | 1.15 | 1 | 96 | 44,320 | 39,231 | 5089 | 0.89 | |
| RMSE | 15,791 | Success | 53 | ||||||||
| MAE | 12,155 | Success rate | 55% | ||||||||
| MSE | 249,363,237 | ||||||||||
| Experiment | A | B | C | D | E |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 |
| 2 | 1 | 2 | 2 | 2 | 2 |
| 3 | 1 | 3 | 3 | 3 | 3 |
| 4 | 1 | 4 | 4 | 4 | 4 |
| 5 | 2 | 1 | 2 | 3 | 4 |
| 6 | 2 | 2 | 1 | 4 | 3 |
| 7 | 2 | 3 | 4 | 1 | 2 |
| 8 | 2 | 4 | 3 | 2 | 1 |
| 9 | 3 | 1 | 3 | 4 | 2 |
| 10 | 3 | 2 | 4 | 3 | 1 |
| 11 | 3 | 3 | 1 | 2 | 4 |
| 12 | 3 | 4 | 2 | 1 | 3 |
| 13 | 4 | 1 | 4 | 2 | 3 |
| 14 | 4 | 2 | 3 | 1 | 4 |
| 15 | 4 | 3 | 2 | 4 | 1 |
| 16 | 4 | 4 | 1 | 3 | 2 |
| Factor | Neural Network Design (A) | Learning Iteration (B) | Learning Rate (C) | Momentum Term (D) | Transfer Function (E) | |
|---|---|---|---|---|---|---|
| Level | ||||||
| Level 1 | Five nodes, one hidden layer | 1000 | 0.1 | 0.1 | Sigmoid | |
| Level 2 | Ten nodes, one hidden layer | 3000 | 0.4 | 0.4 | Gaussian | |
| Level 3 | Five nodes in the first hidden layer; three nodes in the second hidden layer | 6000 | 0.7 | 0.7 | Hyperbolic Tangent | |
| Level 4 | Ten nodes in the first hidden layer; three nodes in the second hidden layer | 10,000 | 0.9 | 0.9 | Hyperbolic Secant | |
| Exp. | Fold 1 | Fold 2 | Fold 3 | Average | St dev | S/N |
|---|---|---|---|---|---|---|
| 1 | 0.122132 | 0.130395 | 0.123223 | 0.12525 | 0.004489 | 23.2695 |
| 2 | 0.147806 | 0.147416 | 0.148411 | 0.147878 | 0.000501 | 21.8307 |
| 3 | 0.114294 | 0.130201 | 0.114288 | 0.119594 | 0.009186 | 23.6575 |
| 4 | 0.114294 | 0.431601 | 0.409061 | 0.318319 | 0.17705 | 14.3572 |
| 5 | 0.409061 | 0.431601 | 0.409061 | 0.416574 | 0.013013 | 12.8321 |
| 6 | 0.166123 | 0.206958 | 0.173732 | 0.182271 | 0.021715 | 19.9735 |
| 7 | 0.186692 | 0.20525 | 0.197209 | 0.196384 | 0.009306 | 19.3602 |
| 8 | 0.167459 | 0.19631 | 0.166127 | 0.176632 | 0.017055 | 20.2605 |
| 9 | 0.114294 | 0.130202 | 0.1142 | 0.119565 | 0.009212 | 23.6565 |
| 10 | 0.147329 | 0.16983 | 0.114294 | 0.143818 | 0.027934 | 21.9647 |
| 11 | 0.161272 | 0.219702 | 0.159119 | 0.180031 | 0.034373 | 20.0176 |
| 12 | 0.158788 | 0.178615 | 0.180458 | 0.17262 | 0.012015 | 20.4729 |
| 13 | 0.114289 | 0.130207 | 0.114303 | 0.1196 | 0.009186 | 23.6571 |
| 14 | 0.212842 | 0.162019 | 0.12926 | 0.16804 | 0.042115 | 20.5424 |
| 15 | 0.226479 | 0.172241 | 0.202408 | 0.200376 | 0.027176 | 19.1389 |
| 16 | 0.231873 | 0.180894 | 0.188176 | 0.200314 | 0.027572 | 19.14 |
| Neural Network Design | Learning Iteration | Learning Rate | Momentum Term | Transfer Function | |
|---|---|---|---|---|---|
| 1 | 20.77873798 | 20.85457474 | 20.60016135 | 20.91125083 | 21.15840307 |
| 2 | 18.10658004 | 21.07781527 | 18.56867528 | 21.44147353 | 20.99761299 |
| 3 | 21.52867521 | 20.54355308 | 22.0299774 | 19.39858585 | 21.94028713 |
| 4 | 20.61961943 | 18.55766957 | 19.83479863 | 19.28230244 | 16.93730947 |
| Effect | 3.422095173 | 2.520145701 | 3.461302121 | 2.159171086 | 5.002977668 |
| Rank | 3 | 4 | 2 | 5 | 1 |
| Best level | A3 | B2 | C3 | D2 | E3 |
| Experiment | Fold 1 | Fold 2 | Fold 3 | S/N | Upper Bond | Lower Bond |
|---|---|---|---|---|---|---|
| Training 1–25 | 0.259155 | 0.13692 | 0.318543 | 14.2625 | ||
| Training 26–50 | 0.125047 | 0.165635 | 0.201135 | 17.7714 | 18.415372 | 14.253997 |
| Training 51–75 | 0.24473 | 0.143677 | 0.141125 | 16.9701 | ||
| Retesting 76–96 | 0.15075 | 0.197292 | 0.236022 | 16.2946 | ||
| Experiment | Fold 1 | Fold 2 | Fold 3 | Average | St. Dev | S/N |
|---|---|---|---|---|---|---|
| Combination of A3:B2:C3:D2:E3 | 0.15075 | 0.197292 | 0.236022 | 0.194688 | 0.042696 | 19.3049 |
| Combination of A1:B3:C3:D3:E3 | 0.257151 | 0.242185 | 0.203655 | 0.23433 | 0.027599 | 17.7922 |
| Store | Target | Prediction | Error Value | Prediction Rate | Accuracy | Store | Target | Prediction | Error Value | Prediction Rate | Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 55,023 | 45,854 | 9169 | 1.20 | 1 | 49 | 47,007 | 49,091 | 2084 | 0.96 | 1 |
| 2 | 46,923 | 49,244 | 2321 | 0.95 | 1 | 50 | 37,819 | 45,503 | 7684 | 0.83 | |
| 3 | 39,375 | 45,845 | 6470 | 0.86 | 51 | 40,152 | 45,367 | 5215 | 0.89 | ||
| 4 | 47,214 | 58,166 | 10,952 | 0.81 | 52 | 46,710 | 47,061 | 351 | 0.99 | 1 | |
| 5 | 39,669 | 58,107 | 18,438 | 0.68 | 53 | 61,930 | 46,147 | 15,783 | 1.34 | 1 | |
| 6 | 91,004 | 87,454 | 3550 | 1.04 | 1 | 54 | 67,507 | 45,464 | 22,043 | 1.48 | 1 |
| 7 | 42,914 | 57,043 | 14,129 | 0.75 | 55 | 64,056 | 46,985 | 17,071 | 1.36 | 1 | |
| 8 | 53,743 | 46,913 | 6830 | 1.15 | 1 | 56 | 36,379 | 45,538 | 9159 | 0.80 | |
| 9 | 43,513 | 58,137 | 14,624 | 0.75 | 57 | 35,050 | 43,322 | 8272 | 0.81 | ||
| 10 | 44,322 | 41,168 | 3154 | 1.08 | 1 | 58 | 30,780 | 45,571 | 14,791 | 0.68 | |
| 11 | 56,081 | 52,364 | 3717 | 1.07 | 1 | 59 | 37,799 | 45,458 | 7659 | 0.83 | |
| 12 | 48,007 | 45,539 | 2468 | 1.05 | 1 | 60 | 46,564 | 48,266 | 1702 | 0.96 | 1 |
| 13 | 35,872 | 41,905 | 6033 | 0.86 | 61 | 55,184 | 45,607 | 9577 | 1.21 | 1 | |
| 14 | 39,851 | 51,025 | 11,174 | 0.78 | 62 | 39,196 | 47,428 | 8232 | 0.83 | ||
| 15 | 33,121 | 42,860 | 9739 | 0.77 | 63 | 70,667 | 46,256 | 24,411 | 1.53 | 1 | |
| 16 | 52,619 | 56,793 | 4174 | 0.93 | 1 | 64 | 42,152 | 45,659 | 3507 | 0.92 | 1 |
| 17 | 40,460 | 47,130 | 6670 | 0.86 | 65 | 50,033 | 50,749 | 716 | 0.99 | 1 | |
| 18 | 48,155 | 55,865 | 7710 | 0.86 | 66 | 46,384 | 46,644 | 260 | 0.99 | 1 | |
| 19 | 53,140 | 41,386 | 11,754 | 1.28 | 1 | 67 | 80,205 | 51,606 | 28,599 | 1.55 | 1 |
| 20 | 53,561 | 57,164 | 3603 | 0.94 | 1 | 68 | 41,517 | 45,511 | 3994 | 0.91 | 1 |
| 21 | 33,410 | 51,917 | 18,507 | 0.64 | 69 | 40,175 | 47,094 | 6919 | 0.85 | ||
| 22 | 44,622 | 57,347 | 12,725 | 0.78 | 70 | 43,788 | 45,564 | 1776 | 0.96 | 1 | |
| 23 | 37,861 | 45,750 | 7889 | 0.83 | 71 | 44,298 | 52,693 | 8395 | 0.84 | ||
| 24 | 47,955 | 46,572 | 1383 | 1.03 | 1 | 72 | 62,976 | 49,760 | 13,216 | 1.27 | 1 |
| 25 | 43,360 | 54,439 | 11,079 | 0.80 | 73 | 30,051 | 45,444 | 15,393 | 0.66 | ||
| 26 | 53,278 | 48,830 | 4448 | 1.09 | 1 | 74 | 45,711 | 45,511 | 200 | 1.00 | 1 |
| 27 | 67,508 | 55,690 | 11,818 | 1.21 | 1 | 75 | 47,535 | 65,842 | 18,307 | 0.72 | |
| 28 | 40,352 | 41,985 | 1633 | 0.96 | 1 | 76 | 36,745 | 46,789 | 10,044 | 0.79 | |
| 29 | 42,921 | 56,473 | 13,552 | 0.76 | 77 | 48,996 | 45,413 | 3583 | 1.08 | 1 | |
| 30 | 57,308 | 58,213 | 905 | 0.98 | 1 | 78 | 73,138 | 60,417 | 12,721 | 1.21 | 1 |
| 31 | 49,883 | 53,856 | 3973 | 0.93 | 1 | 79 | 61,396 | 52,210 | 9186 | 1.18 | 1 |
| 32 | 50,055 | 42,082 | 7973 | 1.19 | 1 | 80 | 20,763 | 27,751 | 6988 | 0.75 | |
| 33 | 51,543 | 53,754 | 2211 | 0.96 | 1 | 81 | 43,101 | 45,484 | 2383 | 0.95 | 1 |
| 34 | 52,791 | 54,859 | 2068 | 0.96 | 1 | 82 | 58,015 | 46,198 | 11,817 | 1.26 | 1 |
| 35 | 42,554 | 58,567 | 16,013 | 0.73 | 83 | 51,495 | 45,388 | 6107 | 1.13 | 1 | |
| 36 | 51,127 | 41,989 | 9138 | 1.22 | 1 | 84 | 48,268 | 45,612 | 2656 | 1.06 | 1 |
| 37 | 50,130 | 48,448 | 1682 | 1.03 | 1 | 85 | 56,032 | 45,605 | 10,427 | 1.23 | 1 |
| 38 | 44,734 | 39,971 | 4763 | 1.12 | 1 | 86 | 45,805 | 45,853 | 48 | 1.00 | 1 |
| 39 | 48,733 | 45,646 | 3087 | 1.07 | 1 | 87 | 52,036 | 45,553 | 6483 | 1.14 | 1 |
| 40 | 56,205 | 42,024 | 14,181 | 1.34 | 1 | 88 | 37,717 | 45,467 | 7750 | 0.83 | |
| 41 | 38,257 | 57,763 | 19,506 | 0.66 | 89 | 51,201 | 50,338 | 863 | 1.02 | 1 | |
| 42 | 45,635 | 41,986 | 3649 | 1.09 | 1 | 90 | 39,763 | 46,545 | 6782 | 0.85 | |
| 43 | 43,643 | 44,194 | 551 | 0.99 | 1 | 91 | 65,757 | 65,938 | 181 | 1.00 | 1 |
| 44 | 22,774 | 37,175 | 14,401 | 0.61 | 92 | 45,233 | 47,671 | 2438 | 0.95 | 1 | |
| 45 | 47,499 | 45,448 | 2051 | 1.05 | 1 | 93 | 44,463 | 46,158 | 1695 | 0.96 | 1 |
| 46 | 40,230 | 43,343 | 3113 | 0.93 | 1 | 94 | 55,101 | 45,378 | 9723 | 1.21 | 1 |
| 47 | 74,899 | 58,563 | 16,336 | 1.28 | 1 | 95 | 52,973 | 49,800 | 3173 | 1.06 | 1 |
| 48 | 50,339 | 56,292 | 5953 | 0.89 | 96 | 39,231 | 41,638 | 2407 | 0.94 | 1 | |
| RMSE | 9810 | Success | 62 | ||||||||
| MAE | 7750 | Success rate | 65% | ||||||||
| MSE | 96,229,425 | ||||||||||
| Number of Training Instances | Success Rate |
|---|---|
| 16 | 65% |
| 32 | 69% |
| 48 | 72% |
| 64 | 73% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, H.-P.; Yeh, H.-P.; Chang, T.-H.; Teng, Y.-H.; Tsai, C.-C. Applying ANN and TM to Build a Prediction Model for the Site Selection of a Convenience Store. Appl. Sci. 2022, 12, 3036. https://doi.org/10.3390/app12063036
Fu H-P, Yeh H-P, Chang T-H, Teng Y-H, Tsai C-C. Applying ANN and TM to Build a Prediction Model for the Site Selection of a Convenience Store. Applied Sciences. 2022; 12(6):3036. https://doi.org/10.3390/app12063036
Chicago/Turabian StyleFu, Hsin-Pin, Hsiao-Ping Yeh, Tein-Hsiang Chang, Ying-Hua Teng, and Cheng-Chang Tsai. 2022. "Applying ANN and TM to Build a Prediction Model for the Site Selection of a Convenience Store" Applied Sciences 12, no. 6: 3036. https://doi.org/10.3390/app12063036
APA StyleFu, H.-P., Yeh, H.-P., Chang, T.-H., Teng, Y.-H., & Tsai, C.-C. (2022). Applying ANN and TM to Build a Prediction Model for the Site Selection of a Convenience Store. Applied Sciences, 12(6), 3036. https://doi.org/10.3390/app12063036