
Improving Entity Linking by Introducing Knowledge Graph Structure Information

 ,
, 
Abstract
:1. Introduction
2. Background and Related Work
2.1. Problem Definition
2.2. Entity Linking
2.3. Knowledge Graph Embedding
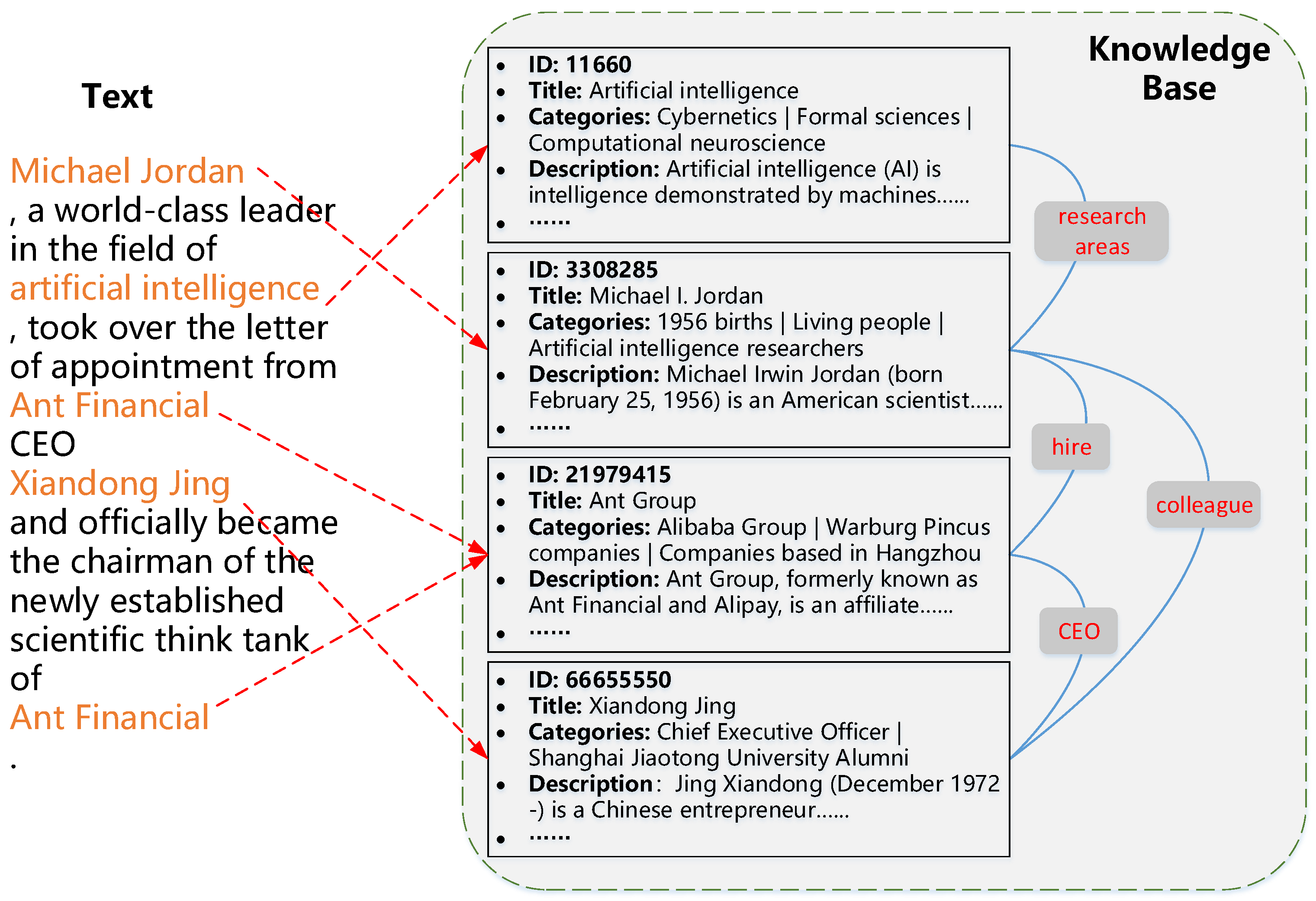
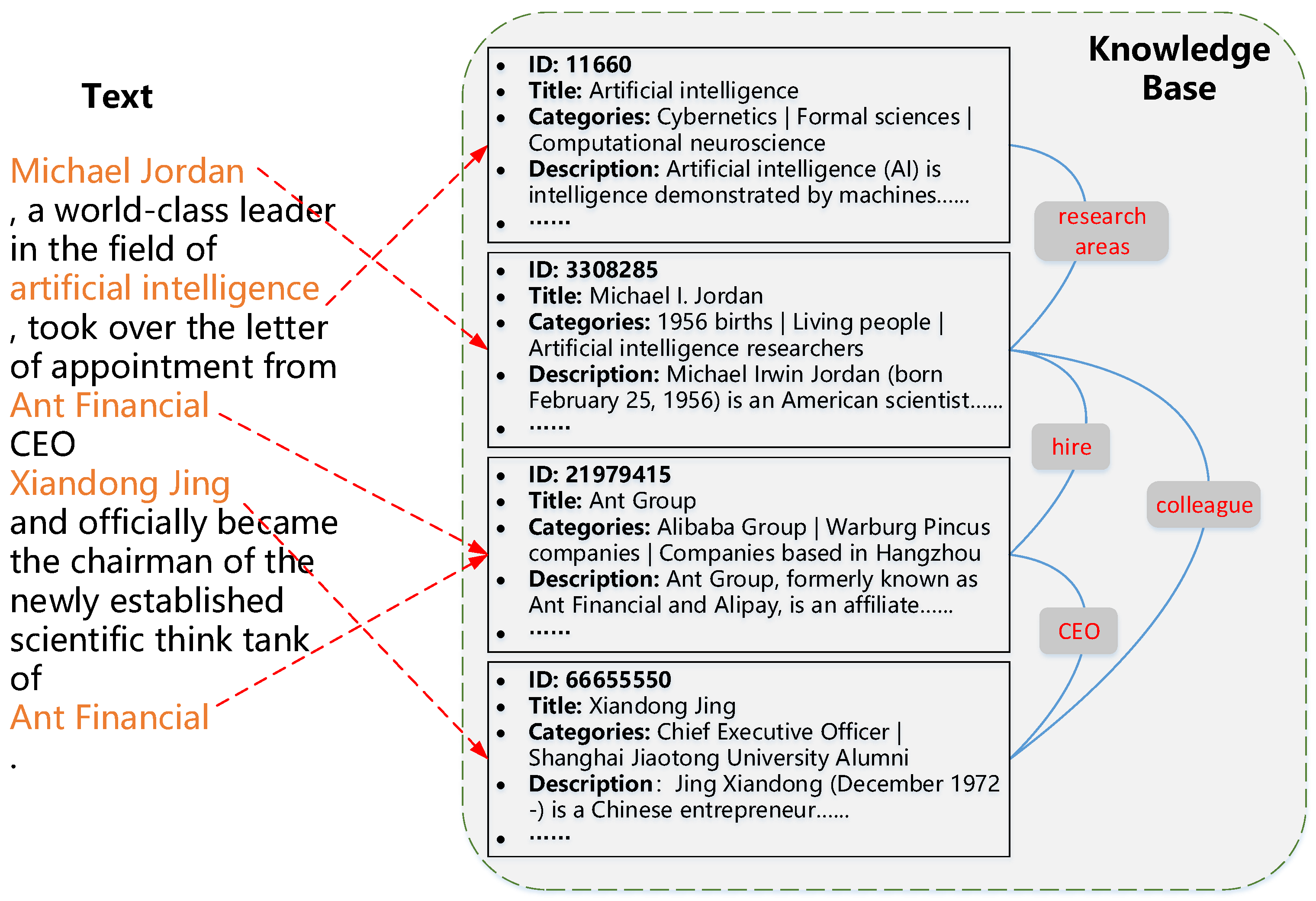
3. Learning Entity Embeddings KGEmbs
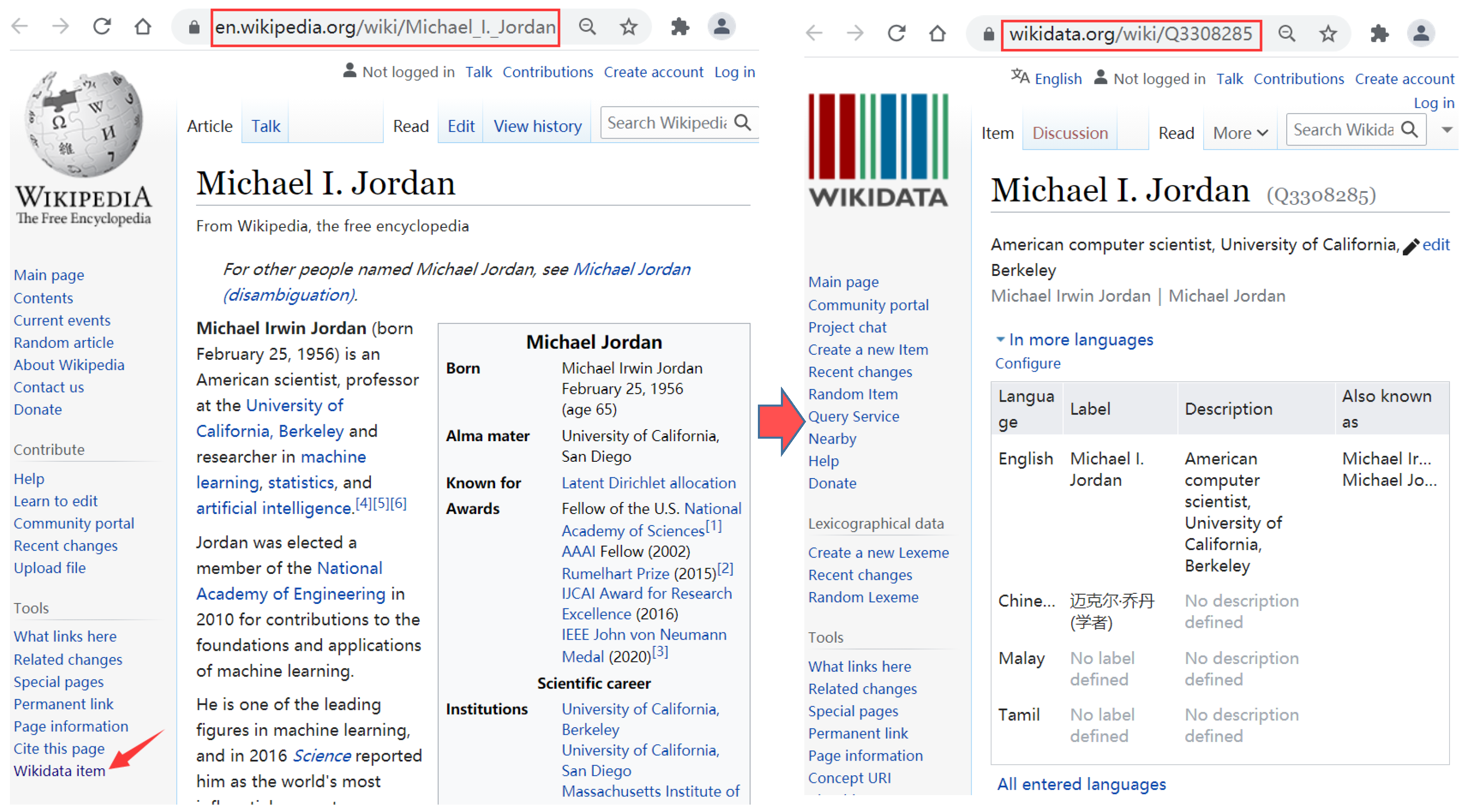
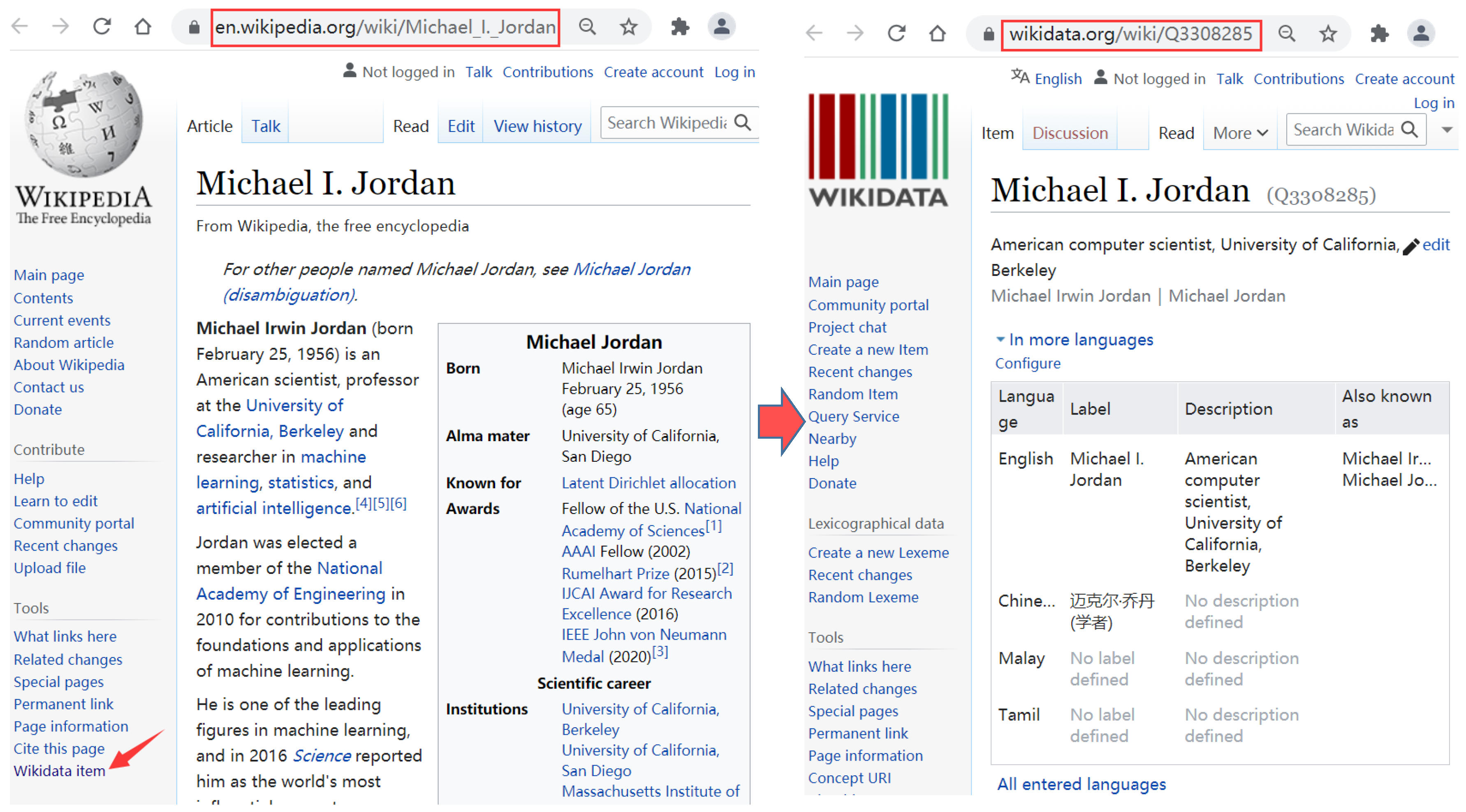
3.1. Wikipedia–Wikidata Mappings
3.2. Triple Knowledge
3.3. Entity and Relation Embeddings
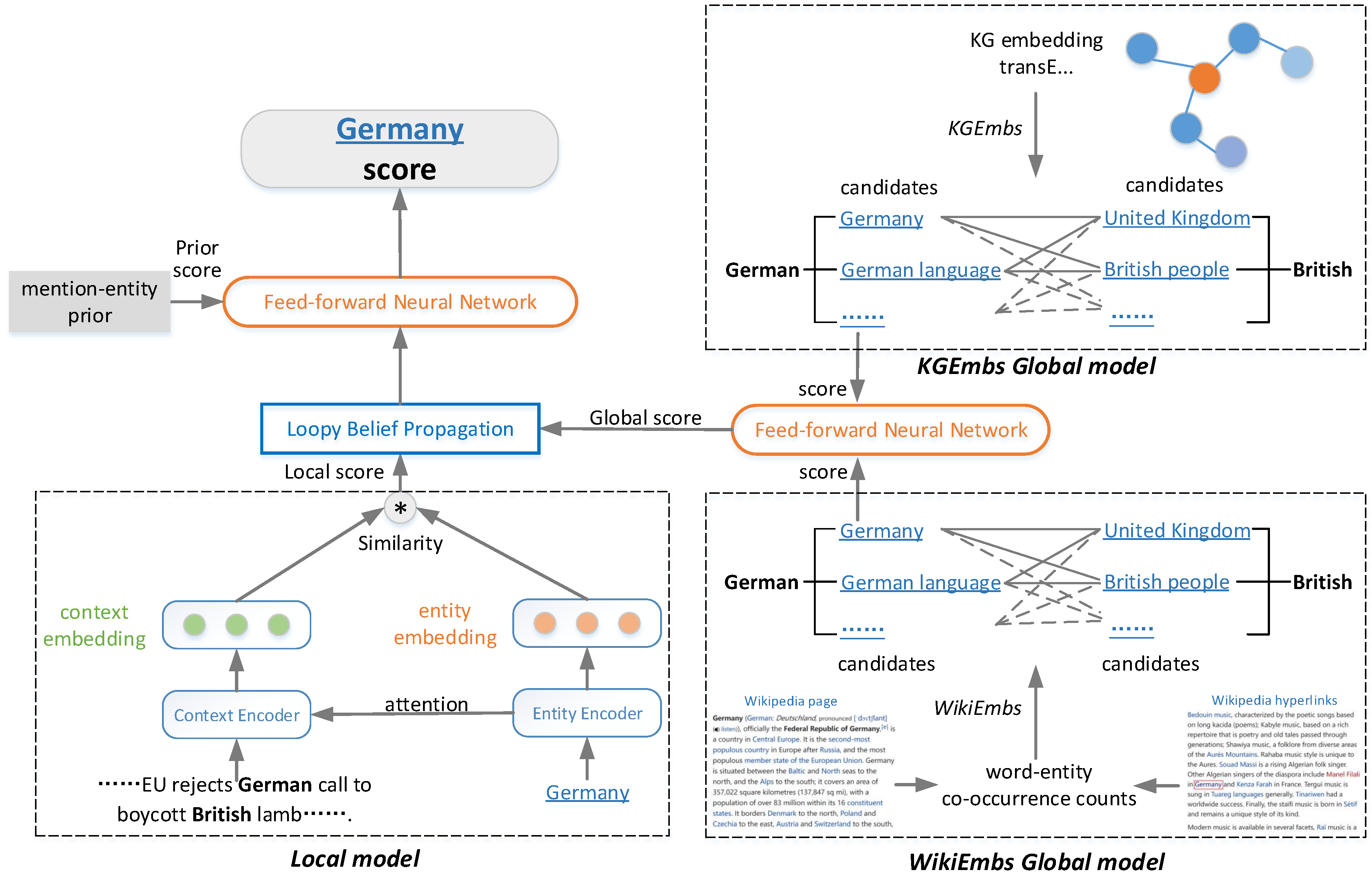
4. Model
4.1. Local Model
4.2. Global Model
4.3. Model Training
5. Experiments
5.1. Datasets
5.2. Candidate Entity Generation
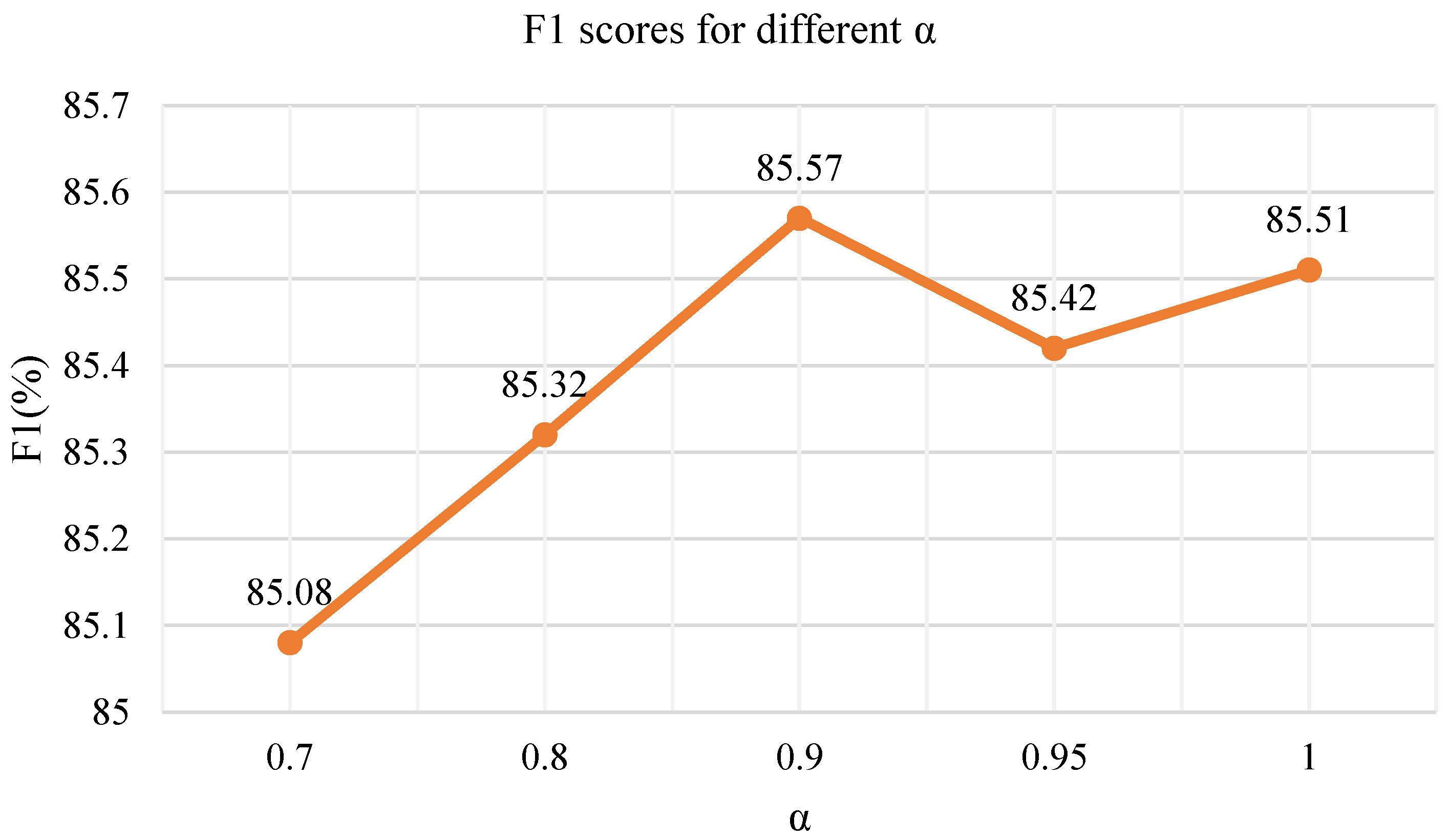
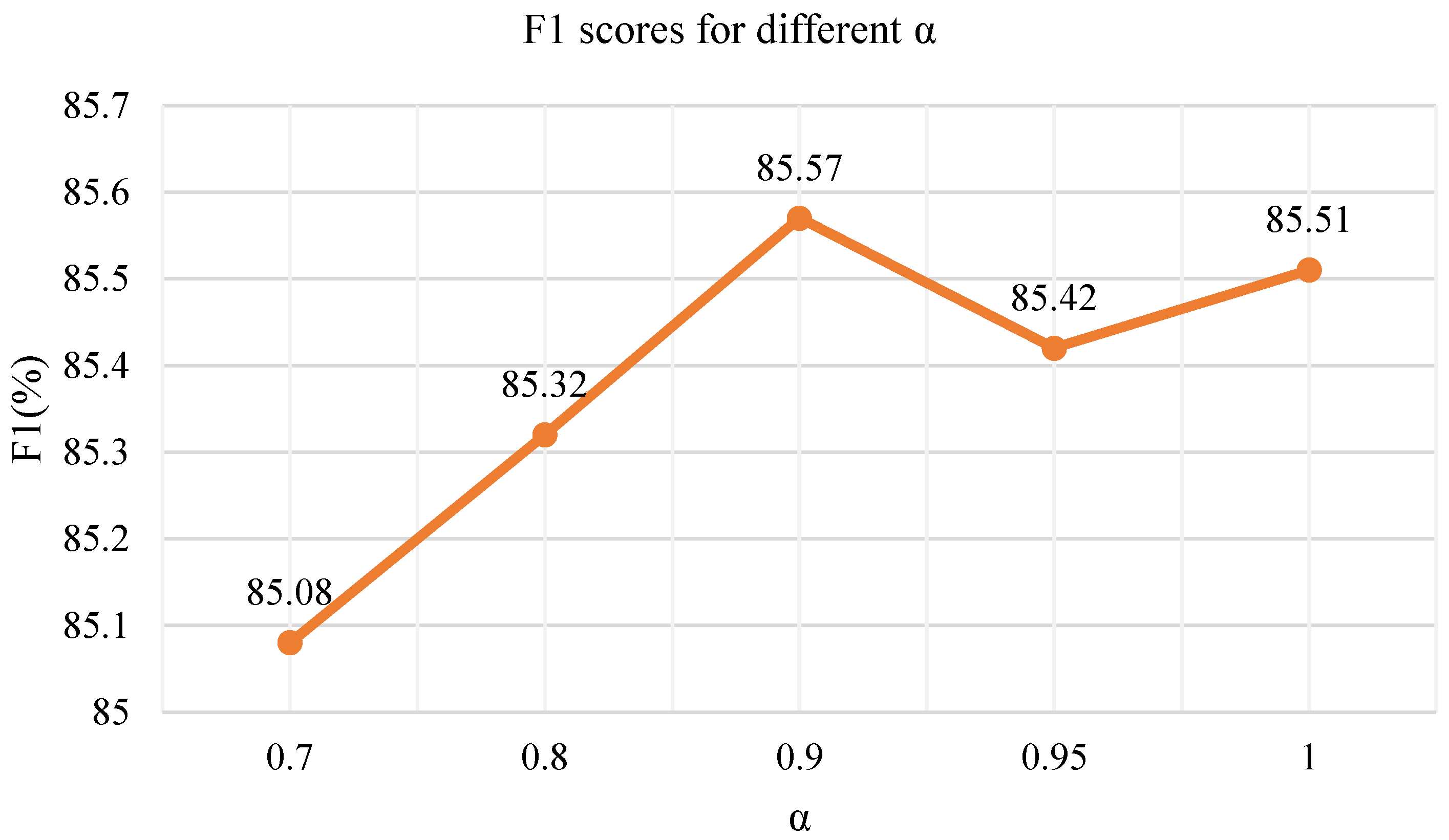
5.3. Hyper-Parameter Setting
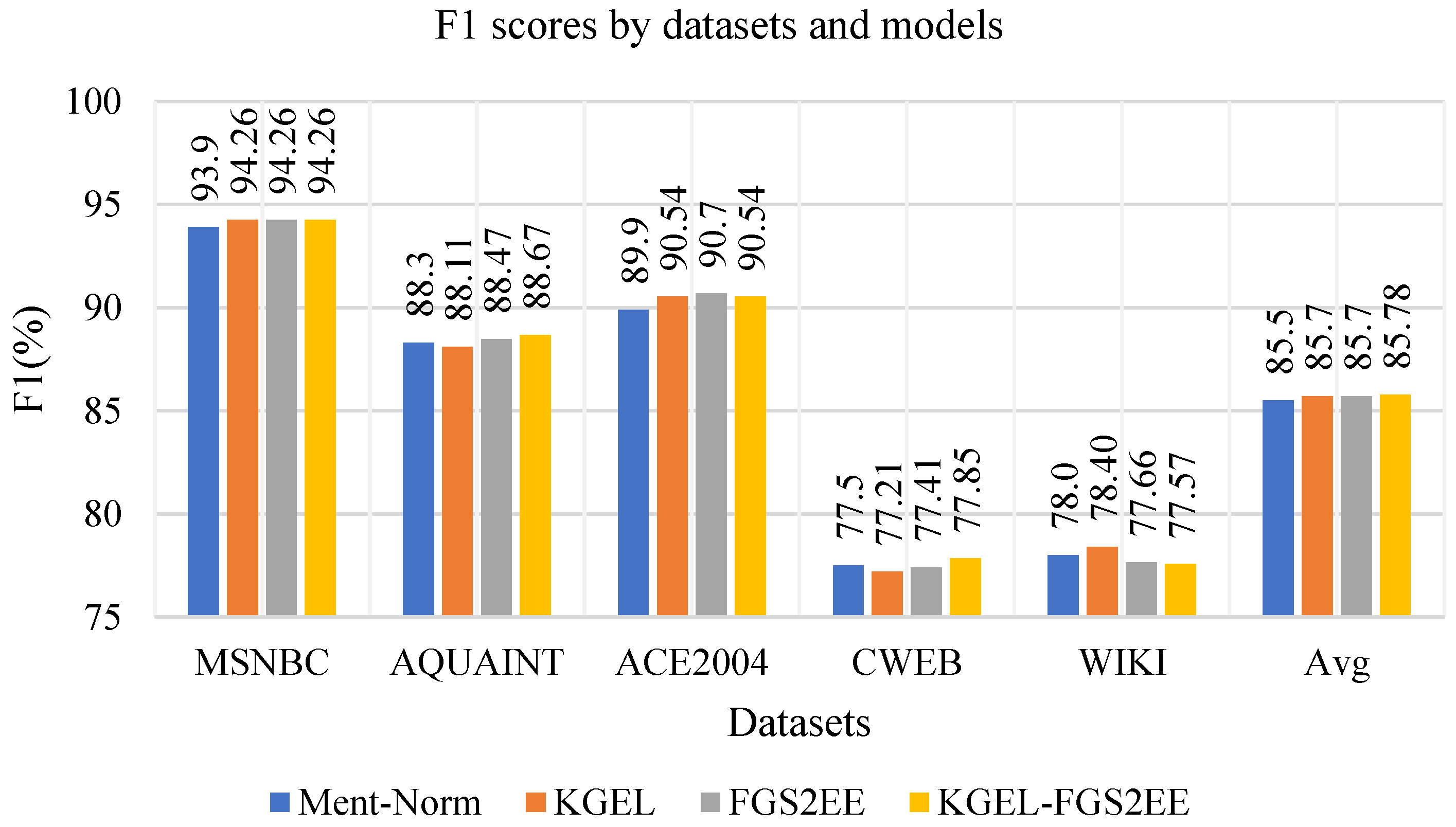
5.4. Main Results
- AIDA [48] combines the previous methods into a comprehensive framework that contains three measures: the prior probability of an entity being mentioned, the similarity between the context of mention and the candidate entity, and the consistency among candidate entities for all mentions. It constructs a weighted graph whose nodes are mentions and candidate entities and calculates a dense subgraph to obtain an approximately optimal mention-entity mapping.
- GLOW is a global entity disambiguation system proposed by [49], which formulates the entity disambiguation task as an optimization problem with local and global variants.
- RI [50] combines statistical methods to perform richer relational analysis on the text. It proposes a modular formulation that includes the entity-relation inference problem. It also proves that the recognition of relations in the text is not only helpful for candidate entities, but also the subsequent ranking stage.
- PBoH [51] uses a graphical model to perform global entity disambiguation. It simultaneously disambiguates mentions in a document by using the co-occurrence probability between entities in the document and the local context information of the mentions. It uses LBP to perform approximate inference.
- Deep-ED [6] introduces an attention mechanism into the local model, and the context words of mentions are hard pruned. Its global model is a fully-connected pairwise conditional random field. Because the problem is NP-hard, it uses LBP to iteratively propagate entity scores to reduce complexity.
- Ment-Norm [7] models the latent relations between mentions and adds them to the global model in the form of features. There are two options for normalization, where it is normalization over mentions.
- DCA-SL [9] regards entity linking as a sequence decision task and uses the previous decision as dynamic contexts to improve the later decisions. It explores supervised learning strategies for learning the DCA model.
- DCA-RL [9] involves the use of reinforcement-learning strategies to learn the DCA model.
5.5. Ablation Study
- KGEL is our proposed method, which includes three modules: Local model, WikiEmbs Global model, and KGEmbs Global model.
- -KGEmbs represents the results on each dataset after removing the KGEmbs global model.
- -WikiEmbs represents the experimental results after removing the WikiEmbs global model.
- -local-WikiEmbs is the result of removing the Local model and WikiEmbs Global model at the same time.
5.6. Other Ways of Using KG Structure
- Ment-Norm is the model of Le and Titov [7] and also our basic model.
- KGEL is our main model; that is, the entity and relation embeddings obtained by the knowledge graph embedding method are used in the global model of entity linking.
- Related-Fixed refers to the method of using related entities mentioned in this section, in which the parameter is fixed at 0.9.
- Related-Vari means that the parameter is variable; that is, it changes during training.
- Based on Related-Vari, Related-Vari-diff makes the in the global model and the local model different.
- Related-nn indicates the use of a neural network to fuse and .
5.7. Better Baseline
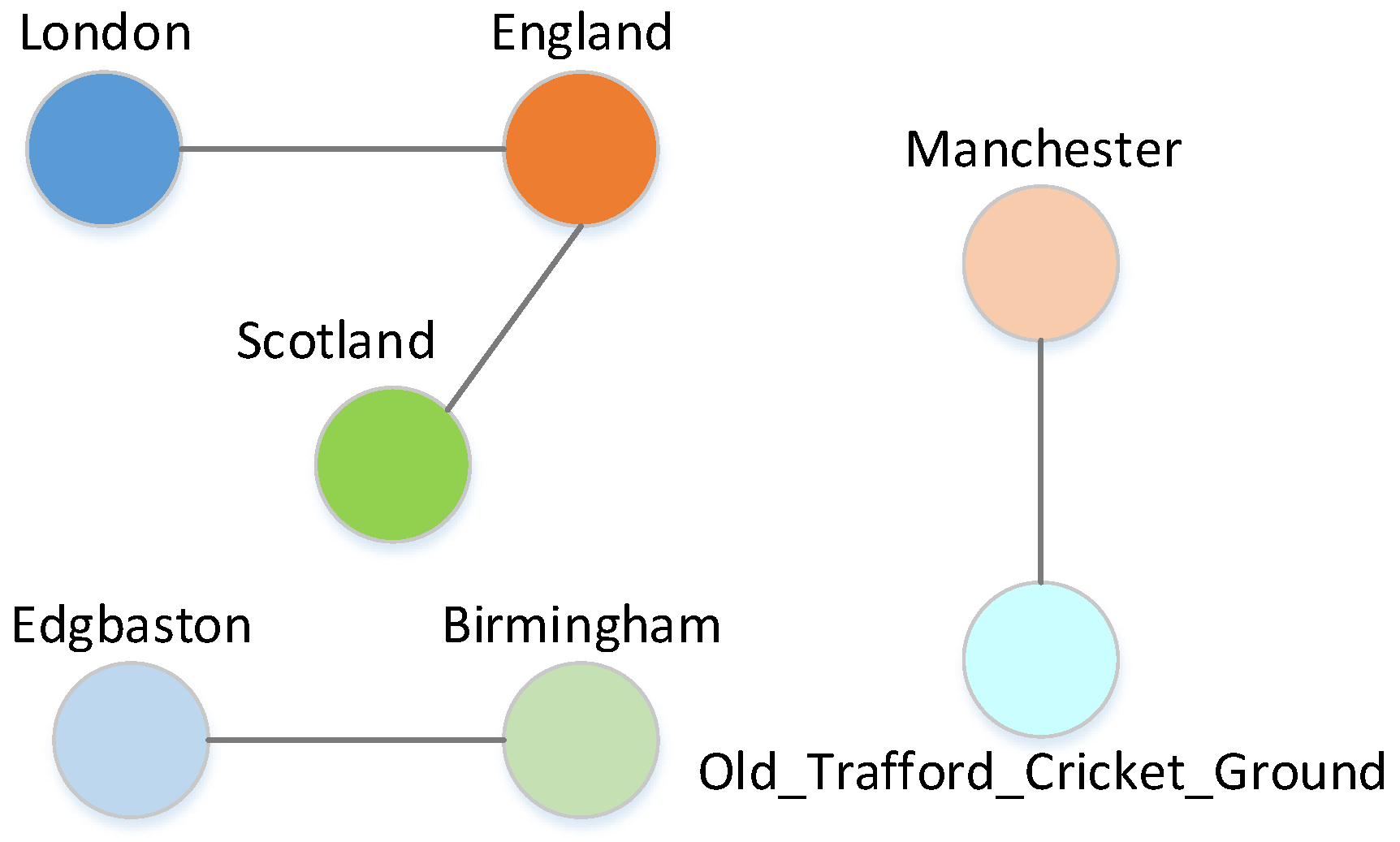
5.8. Case Study
5.9. Execution Times of the Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1250. [Google Scholar]
- Fabian, M.; Gjergji, K.; Gerhard, W. Yago: A core of semantic knowledge unifying wordnet and wikipedia. In Proceedings of the 16th International World Wide Web Conference, WWW, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Yih, S.W.t.; Chang, M.W.; He, X.; Gao, J. Semantic parsing via staged query graph generation: Question answering with knowledge base. In Proceedings of the Joint Conference of the 53rd Annual Meeting of the ACL and the 7th International Joint Conference on Natural Language Processing of the AFNLP, Beijing, China, 26–31 July 2015. [Google Scholar]
- Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; Weld, D.S. Knowledge-based weak supervision for information extraction of overlapping relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 541–550. [Google Scholar]
- Michelson, M.; Macskassy, S.A. Discovering users’ topics of interest on twitter: A first look. In Proceedings of the Fourth Workshop on Analytics for Noisy Unstructured Text Data, Toronto, ON, Canada, 26 October 2010; pp. 73–80. [Google Scholar]
- Ganea, O.E.; Hofmann, T. Deep joint entity disambiguation with local neural attention. arXiv 2017, arXiv:1704.04920. [Google Scholar]
- Le, P.; Titov, I. Improving entity linking by modeling latent relations between mentions. arXiv 2018, arXiv:1804.10637. [Google Scholar]
- Hou, F.; Wang, R.; He, J.; Zhou, Y. Improving entity linking through semantic reinforced entity embeddings. arXiv 2021, arXiv:2106.08495. [Google Scholar]
- Yang, X.; Gu, X.; Lin, S.; Tang, S.; Zhuang, Y.; Wu, F.; Chen, Z.; Hu, G.; Ren, X. Learning dynamic context augmentation for global entity linking. arXiv 2019, arXiv:1909.02117. [Google Scholar]
- Fang, W.; Zhang, J.; Wang, D.; Chen, Z.; Li, M. Entity disambiguation by knowledge and text jointly embedding. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 260–269. [Google Scholar]
- Luo, A.; Gao, S.; Xu, Y. Deep semantic match model for entity linking using knowledge graph and text. Procedia Comput. Sci. 2018, 129, 110–114. [Google Scholar] [CrossRef]
- Cetoli, A.; Akbari, M.; Bragaglia, S.; O’Harney, A.D.; Sloan, M. Named entity disambiguation using deep learning on graphs. arXiv 2018, arXiv:1810.09164. [Google Scholar]
- Mulang, I.O.; Singh, K.; Vyas, A.; Shekarpour, S.; Sakor, A.; Vidal, M.E.; Auer, S.; Lehmann, J. Context-aware entity linking with attentive neural networks on wikidata knowledge graph. arXiv 2019, arXiv:1912.06214. [Google Scholar]
- He, Z.; Liu, S.; Mu, L.; Ming, Z.; Wang, H. Learning Entity Representation for Entity Disambiguation. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Sofia, Bulgaria, 4–9 August 2013. [Google Scholar]
- Sun, Y.; Lin, L.; Tang, D.; Yang, N.; Ji, Z.; Wang, X. Modeling mention, context and entity with neural networks for entity disambiguation. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Francis-Landau, M.; Durrett, G.; Klein, D. Capturing semantic similarity for entity linking with convolutional neural networks. arXiv 2016, arXiv:1604.00734. [Google Scholar]
- Gupta, N.; Singh, S.; Roth, D. Entity linking via joint encoding of types, descriptions, and context. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2681–2690. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kolitsas, N.; Ganea, O.E.; Hofmann, T. End-to-end neural entity linking. arXiv 2018, arXiv:1808.07699. [Google Scholar]
- Eshel, Y.; Cohen, N.; Radinsky, K.; Markovitch, S.; Yamada, I.; Levy, O. Named entity disambiguation for noisy text. arXiv 2017, arXiv:1706.09147. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Guo, Z.; Barbosa, D. Robust named entity disambiguation with random walks. Semant. Web 2018, 9, 459–479. [Google Scholar] [CrossRef]
- Pershina, M.; He, Y.; Grishman, R. Personalized page rank for named entity disambiguation. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; 2015; pp. 238–243. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. 2001. Available online: https://repository.upenn.edu/cis_papers/159/?ref=https://githubhelp.com (accessed on 1 March 2022).
- Murphy, K.; Weiss, Y.; Jordan, M.I. Loopy belief propagation for approximate inference: An empirical study. arXiv 2013, arXiv:1301.6725. [Google Scholar]
- Fang, Z.; Cao, Y.; Li, Q.; Zhang, D.; Zhang, Z.; Liu, Y. Joint entity linking with deep reinforcement learning. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 438–447. [Google Scholar]
- Yamada, I.; Washio, K.; Shindo, H.; Matsumoto, Y. Global entity disambiguation with pretrained contextualized embeddings of words and entities. arXiv 2019, arXiv:1909.00426. [Google Scholar]
- Wu, J.; Zhang, R.; Mao, Y.; Guo, H.; Soflaei, M.; Huai, J. Dynamic graph convolutional networks for entity linking. In Proceedings of the Web Conference 2020, Ljubljana, Slovenia, 19–23 April 2020; pp. 1149–1159. [Google Scholar]
- Fang, Z.; Cao, Y.; Li, R.; Zhang, Z.; Liu, Y.; Wang, S. High quality candidate generation and sequential graph attention network for entity linking. In Proceedings of the Web Conference 2020, Ljubljana, Slovenia, 19–23 April 2020; pp. 640–650. [Google Scholar]
- Yamada, I.; Shindo, H.; Takeda, H.; Takefuji, Y. Joint learning of the embedding of words and entities for named entity disambiguation. arXiv 2016, arXiv:1601.01343. [Google Scholar]
- Yamada, I.; Shindo, H.; Takeda, H.; Takefuji, Y. Learning distributed representations of texts and entities from knowledge base. Trans. Assoc. Comput. Linguist. 2017, 5, 397–411. [Google Scholar] [CrossRef] [Green Version]
- Ling, J.; FitzGerald, N.; Shan, Z.; Soares, L.B.; Févry, T.; Weiss, D.; Kwiatkowski, T. Learning cross-context entity representations from text. arXiv 2020, arXiv:2001.03765. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; et al. Dbpedia–a large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A Three-Way Model for Collective Learning on Multi-Relational Data. 2011. Available online: https://openreview.net/forum?id=H14QEiZ_WS (accessed on 1 March 2022).
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 2071–2080. [Google Scholar]
- Bordes, A.; Glorot, X.; Weston, J.; Bengio, Y. A semantic matching energy function for learning with multi-relational data. Mach. Learn. 2014, 94, 233–259. [Google Scholar] [CrossRef] [Green Version]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 9. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Fan, M.; Zhou, Q.; Chang, E.; Zheng, F. Transition-based knowledge graph embedding with relational mapping properties. In Proceedings of the 28th Pacific Asia Conference on Language, Information and Computing, Phuket, Thailand, 12–14 December 2014; pp. 328–337. [Google Scholar]
- Zhang, Z.; Cai, J.; Zhang, Y.; Wang, J. Learning hierarchy-aware knowledge graph embeddings for link prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3065–3072. [Google Scholar]
- Chao, L.; He, J.; Wang, T.; Chu, W. PairRE: Knowledge graph embeddings via paired relation vectors. arXiv 2020, arXiv:2011.03798. [Google Scholar]
- Cao, Z.; Xu, Q.; Yang, Z.; Cao, X.; Huang, Q. Dual quaternion knowledge graph embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 6894–6902. [Google Scholar]
- Zhao, Y.; Zhou, H.; Xie, R.; Zhuang, F.; Li, Q.; Liu, J. Incorporating Global Information in Local Attention for Knowledge Representation Learning. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online Event, 1–6 August 2021; pp. 1341–1351. [Google Scholar]
- Hoffart, J.; Yosef, M.A.; Bordino, I.; Fürstenau, H.; Pinkal, M.; Spaniol, M.; Taneva, B.; Thater, S.; Weikum, G. Robust disambiguation of named entities in text. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Scotland, UK, 27–31 July 2011; pp. 782–792. [Google Scholar]
- Ratinov, L.; Roth, D.; Downey, D.; Anderson, M. Local and global algorithms for disambiguation to wikipedia. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 1375–1384. [Google Scholar]
- Cheng, X.; Roth, D. Relational inference for wikification. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, DC, USA, 18–21 October 2013; pp. 1787–1796. [Google Scholar]
- Ganea, O.E.; Ganea, M.; Lucchi, A.; Eickhoff, C.; Hofmann, T. Probabilistic bag-of-hyperlinks model for entity linking. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 927–938. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wikipedia–Wikidata Mappings | Triples | |||
|---|---|---|---|---|
| en.wikipedia.org/wiki/Universe | Q1 | Q1 | P2670 | Q523 |
| en.wikipedia.org/wiki/Star | Q523 | Q1 | P2184 | Q136407 |
| en.wikipedia.org/wiki/Big_Bang | Q323 | Q1 | P793 | Q323 |
| en.wikipedia.org/wiki/Happiness | Q8 | Q8 | P31 | Q331769 |
| en.wikipedia.org/wiki/Mood_(psychology) | Q331769 | Q8 | P31 | Q9415 |
| … | … | |||
| en.wikipedia.org/wiki/Toledo, _Minas_Gerais | Q22065023 | Q22065023 | P131 | Q39109 |
| en.wikipedia.org/wiki/Minas_Gerais | Q39109 | Q22065023 | P17 | Q155 |
| Dataset | Number Mentions | Number Docs | Mentions per Doc | Gold Recall |
|---|---|---|---|---|
| AIDA-train | 18,448 | 946 | 19.5 | - |
| AIDA-A | 4791 | 216 | 22.1 | 97.3 |
| AIDA-B | 4485 | 231 | 19.4 | 98.3 |
| MSNBC | 656 | 20 | 32.8 | 98.5 |
| AQUAINT | 727 | 50 | 14.5 | 94.2 |
| ACE2004 | 257 | 36 | 7.1 | 90.6 |
| CWEB | 11,154 | 320 | 34.8 | 91.1 |
| WIKI | 6821 | 320 | 21.3 | 92.4 |
| Model | AIDA-B | MSNBC | AQUAINT | ACE2004 | CWEB | WIKI | Avg |
|---|---|---|---|---|---|---|---|
| AIDA | - | 79 | 56 | 80 | 58.6 | 63 | 67.32 |
| GLOW | - | 75 | 83 | 82 | 56.2 | 67.2 | 72.68 |
| RI | - | 90 | 90 | 86 | 67.5 | 73.4 | 81.38 |
| PBoH | 87.6 | 91 | 89.2 | 88.7 | - | - | - |
| Deep-ED | 92.22 | 93.7 | 88.5 | 88.5 | 77.9 | 77.5 | 85.22 |
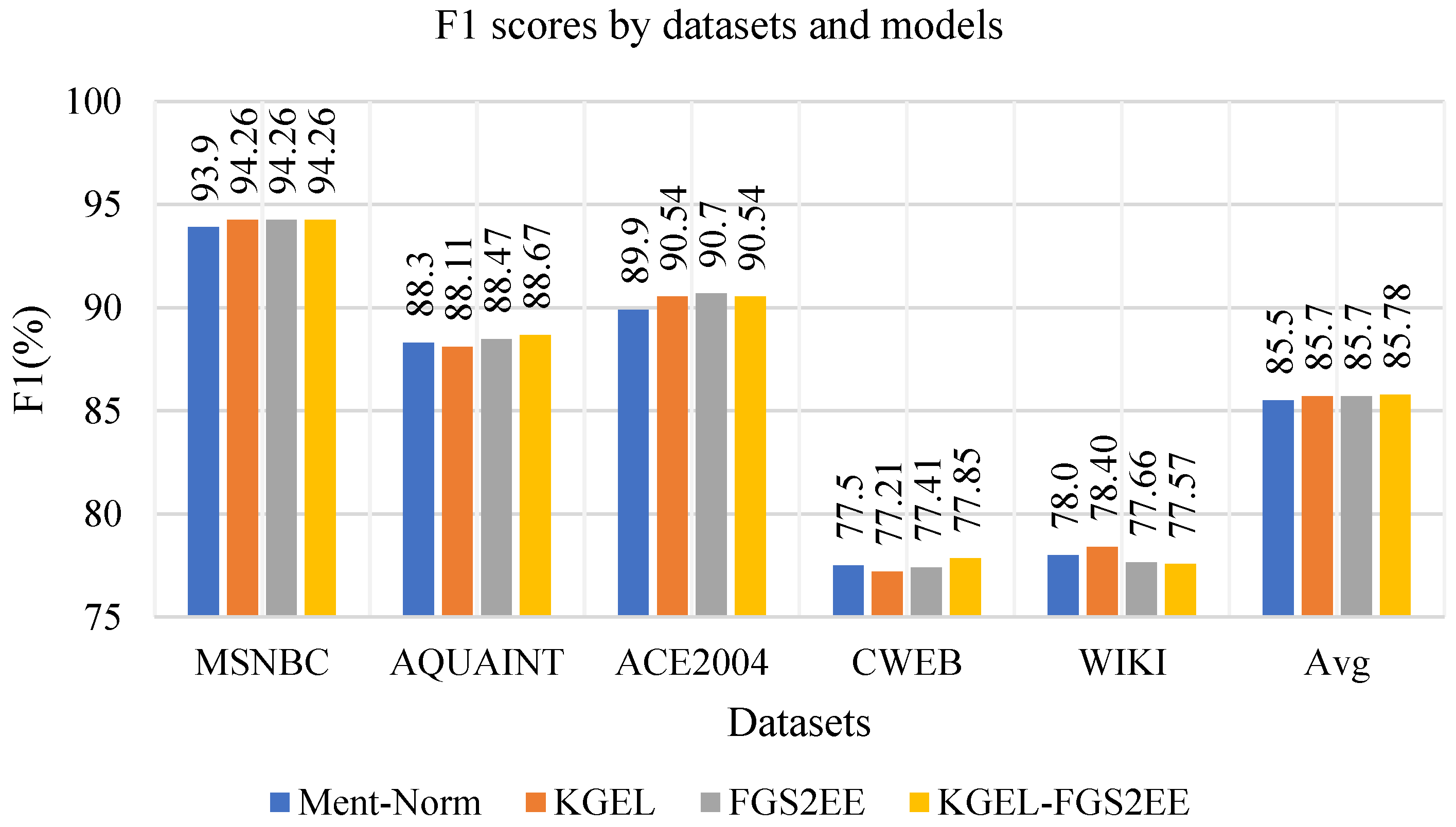
| Ment–Norm | 93.07 | 93.9 | 88.3 | 89.9 | 77.5 | 78 | 85.5 |
| DCA-SL | 94.64 | 94.57 | 87.38 | 89.44 | 73.47 | 78.16 | 84.6 |
| DCA-RL | 93.73 | 93.80 | 88.25 | 90.14 | 75.59 | 78.84 | 85.32 |
| KGEL(ours) | 93.47 | 94.26 | 88.11 | 90.54 | 77.21 | 78.40 | 85.7 |
| Model | AIDA-B | MSNBC | AQUAINT | ACE2004 | CWEB | WIKI | Avg |
|---|---|---|---|---|---|---|---|
| KGEL | 93.47 | 94.26 | 88.11 | 90.54 | 77.21 | 78.40 | 85.7 |
| - KGEmbs | 93.07 | 93.9 | 88.3 | 89.9 | 77.5 | 78.0 | 85.5 |
| - WikiEmbs | 87.16 | 92.12 | 81.54 | 87.73 | 72.84 | 68.96 | 80.64 |
| - local | 84.86 | 91.05 | 79.16 | 86.92 | 70 | 64.46 | 78.32 |
| - WikiEmbs |
| Model | MSNBC | AQUAINT | ACE2004 | CWEB | WIKI | Avg |
|---|---|---|---|---|---|---|
| Ment–Norm | 93.9 | 88.3 | 89.9 | 77.5 | 78.0 | 85.5 |
| KGEL | 94.26 | 88.11 | 90.54 | 77.21 | 78.40 | 85.7 |
| Related-Fixed | 94.26 | 88.39 | 89.74 | 77.41 | 78.06 | 85.57 |
| Related-Vari | 93.65 | 88.25 | 88.13 | 77.07 | 77.82 | 84.98 |
| Related-Vari-diff | 93.8 | 87.41 | 87.73 | 77.01 | 77.39 | 84.67 |
| Related-nn | 92.58 | 86.43 | 88.13 | 74.87 | 71.67 | 82.74 |
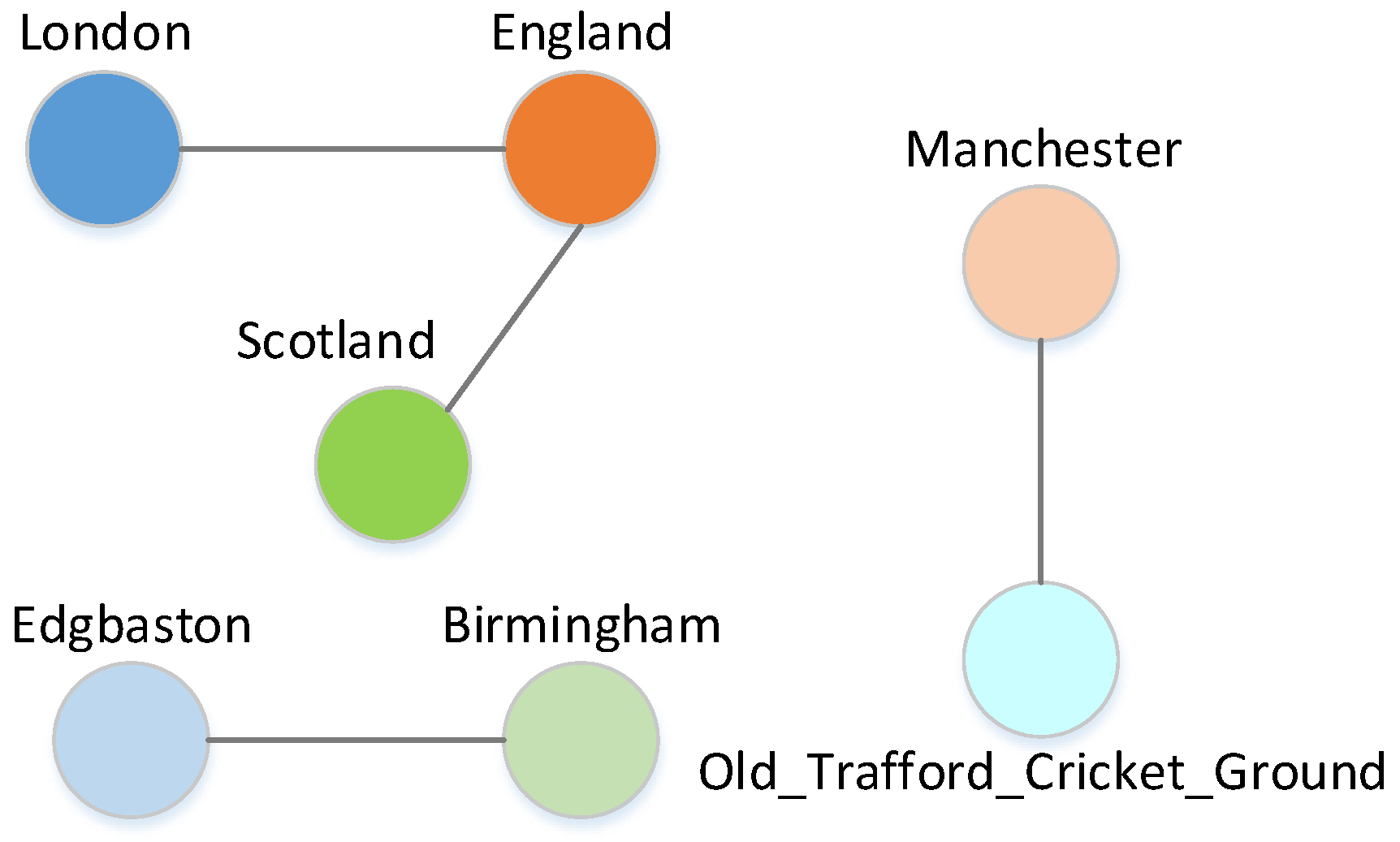
| Mention | Pred | Gold |
|---|---|---|
| …Arrive in London May 14… | London | London |
| …matches against English county sides… | England | England |
| …Counties and Scotland Tour itinerary… | Scotland_national_cricket_team | Scotland |
| …match (at Edgbaston,Birmingham)… | Edgbaston_Cricket_Ground | Edgbaston |
| …Edgbaston, Birmingham) June… | Birmingham | Birmingham |
| …international (at The Oval, London)… | The_Oval | The_Oval |
| …Sussex or Surrey (three days)… | Surrey_County_Cricket_Club | Surrey_County_Cricket_Club |
| Model | Train Time/Epoch | Inference Time |
|---|---|---|
| Ment-Norm | 23 s | 9 s |
| KGEL | 25 s | 10 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Li, F.; Li, S.; Li, X.; Liu, K.; Liu, Q.; Dong, P. Improving Entity Linking by Introducing Knowledge Graph Structure Information. Appl. Sci. 2022, 12, 2702. https://doi.org/10.3390/app12052702
Li Q, Li F, Li S, Li X, Liu K, Liu Q, Dong P. Improving Entity Linking by Introducing Knowledge Graph Structure Information. Applied Sciences. 2022; 12(5):2702. https://doi.org/10.3390/app12052702
Chicago/Turabian StyleLi, Qijia, Feng Li, Shuchao Li, Xiaoyu Li, Kang Liu, Qing Liu, and Pengcheng Dong. 2022. "Improving Entity Linking by Introducing Knowledge Graph Structure Information" Applied Sciences 12, no. 5: 2702. https://doi.org/10.3390/app12052702
APA StyleLi, Q., Li, F., Li, S., Li, X., Liu, K., Liu, Q., & Dong, P. (2022). Improving Entity Linking by Introducing Knowledge Graph Structure Information. Applied Sciences, 12(5), 2702. https://doi.org/10.3390/app12052702