
Multi-Scale Features for Transformer Model to Improve the Performance of Sound Event Detection

Abstract
:1. Introduction
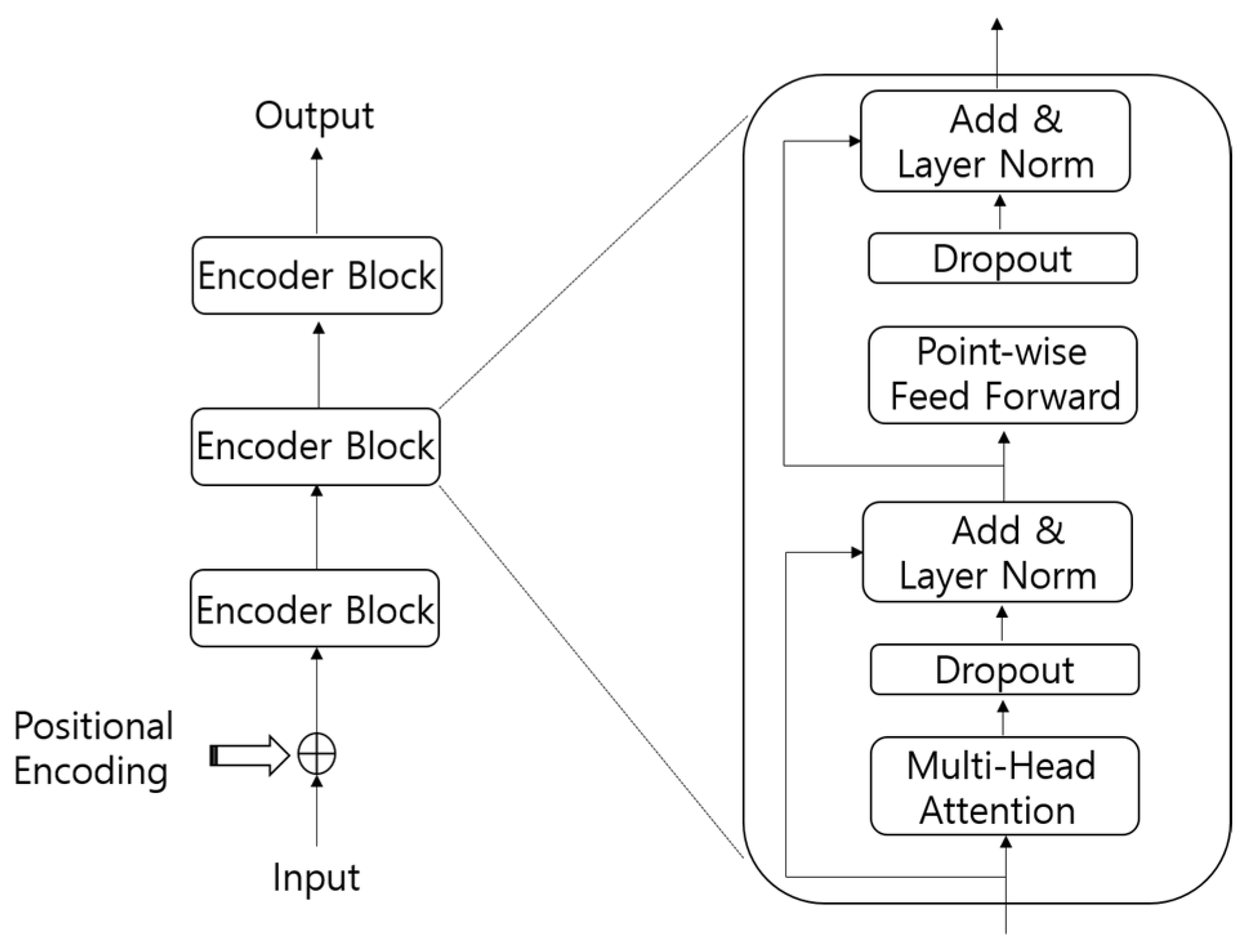
2. Transformer Encoder
2.1. Positional Encoding
2.2. Multi-Head Attention
2.3. Position-Wise Feed-Forward Networks
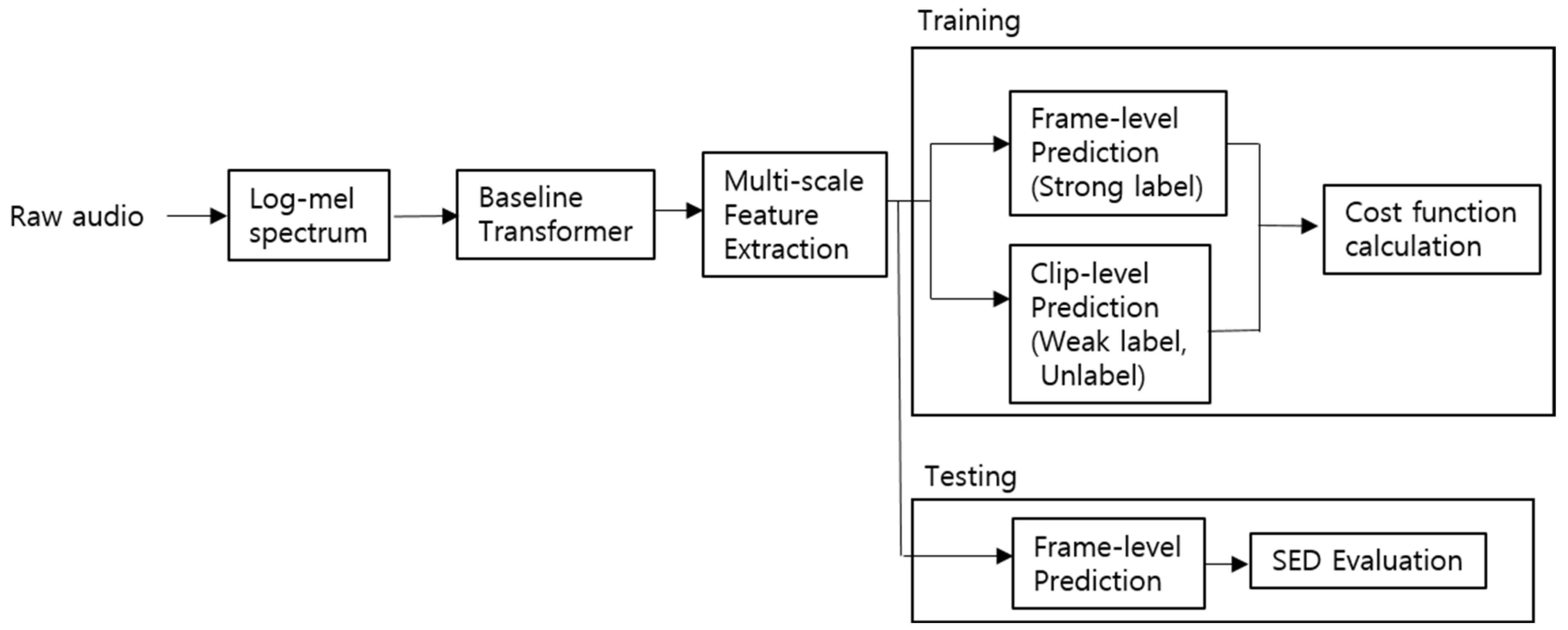
3. Proposed Network Architecture
3.1. Proposed Transformer Network Model
3.2. Mean-Teacher Model
4. Experimental Results
4.1. Experimental Condition
4.2. Evaluation Metrics
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Turpault, N.; Serizel, R.; Shah, A.; Salamon, J. Sound event detection in domestic environments with weakly labeled data and soundscape synthesis. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events, New York, NY, USA, 25–26 October 2019; pp. 253–257. [Google Scholar]
- Nandwana, M.K.; Ziaei, A.; Hansen, J. Robust unsupervised detection of human screams in noisy acoustic environments. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Brisbane, Australia, 19–24 April 2015; pp. 161–165. [Google Scholar]
- Crocco, M.; Cristani, M.; Trucco, A.; Murino, V.M. Audio surveillance: A systematic review. ACM Comput. Surv. 2016, 48, 1–46. [Google Scholar] [CrossRef]
- Salamon, J.; Bello, J.P. Feature learning with deep scattering for urban sound analysis. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 724–728. [Google Scholar]
- Ntalampiras, S.; Potamitis, I.; Fakotakise, N. On acoustic surveillance of hazardous situations. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 165–168. [Google Scholar]
- Wang, Y.; Neves, L.; Metze, F. Audio-based multimedia event detection using deep recurrent neural networks. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2742–2746. [Google Scholar]
- Dekkers, G.; Vuegen, L.; Waterschoot, T.; Vanrumste, B.; Karsmakers, P. DCASE 2018 Challenge—Task 5: Monitoring of domestic activities based on multi-channel acoustics. arXiv 2018, arXiv:1807.11246. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural Networks. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Cho, K.; Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Cakir, E.; Parascandolo, G.; Heittola, T.; Huttunen, H.; Virtanen, T. Convolutional recurrent neural networks for polyphonic sound event detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1291–1303. [Google Scholar] [CrossRef] [Green Version]
- Cakir, E.; Heittola, T.; Huttunen, H.; Virtanen, T. Polyphonic sound event detection using multilabel deep neural networks. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–7. [Google Scholar]
- McLoughlin, I.; Zhang, H.; Xie, Z.; Song, Y.; Xiao, W. Robust sound event classification using deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 540–552. [Google Scholar] [CrossRef] [Green Version]
- Nordby, J.; Nemazi, F.; Rieber, D. Automatic detection of noise events at shooting range using machine Learning. In Proceedings of the 7th International Congress on Sound and Vibration (ICSV27), Prague, Czech Republic, 11–16 July 2021. [Google Scholar]
- Chen, Y.; Jin, H. Rare sound event detection using deep learning and data augmentation. In Proceedings of the International Conference on Spoken Language Processing (Interspeech), Graz, Austria, 15–19 September 2019; pp. 619–623. [Google Scholar]
- Dhakal, P.; Damacharla, P.; Javaid, A.; Devabhaktuni, V. Detection and identification of background sounds to improvise voice interface in critical environments. In Proceedings of the IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Louisville, KY, USA, 6–8 December 2018; pp. 78–83. [Google Scholar]
- Mesaros, A.; Heittola, T.; Virtanen, T. TUT database for acoustic scene classification and sound event detection. In Proceedings of the 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016; pp. 1128–1131. [Google Scholar]
- Lu, R.; Duan, Z.; Zhang, C. Multi-scale recurrent neural networks for sound event detection. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 May 2018; pp. 131–135. [Google Scholar]
- Lee, J.; Nam, J. Multi-level and multi-scale feature aggregation using pre-defined convolutional neural networks for music auto-tagging. IEEE Signal Process. Lett. 2017, 24, 1208–1212. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Xianyu, H.; Tian, J.; Chen, W.; Meng, F.; Xu, M.; Cai, L. A deep bidirectional long short-term memory based multi-scale approach for music dynamic emotion prediction. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 544–548. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Koh, C.-Y.; Chen, Y.-S.; Liu, Y.-W.; Bai, M.-R. Sound event detection by consistency training and pseudo-labeling with feature-pyramid convolutional recurrent neural networks. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events DCASE 2020, Tokyo, Japan, 2–4 November 2020. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.-C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented Transformer for speech recognition. In Proceedings of the International Conference on Spoken Language Processing (Interspeech 2020), Shanghai, China, 25–29 October 2020; pp. 5036–5040. [Google Scholar]
- Miyazaki, K.; Komatsu, T.; Hayashi, T.; Watanabe, S.; Toda, T.; Takeda, K. Weakly-supervised sound event detection with self-attention. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 66–70. [Google Scholar]
- Miyazaki, K.; Komatsu, T.; Hayashi, T.; Watanabe, S.; Toda, T.; Takeda, K. Conformer-based sound event detection with semi-supervised learning and data augmentation. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events DCASE 2020, Tokyo, Japan, 2–4 November 2020. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30, 1195–1204. [Google Scholar]
- JiaKai, L. Mean teacher convolution system for DCASE 2018 task 4. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events DCASE 2018, Surrey, UK, 19–20 November 2018. [Google Scholar]
- Gemmeke, J.; Ellis, D.; Feedman, D.; Jasen, A.; Lawrence, W.; Moore, R.; Plakal, M.; Ritter, M. Audio set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar]
- Fonseca, E.; Pons, J.; Favory, X.; Font, F.; Bogdanov, D.; Ferraro, A.; Oramas, S.; Porter, A.; Serra, X. Freesound datasets: A platform for the creation of open audio datasets. In Proceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR), Suzhou, China, 23–27 October 2017; pp. 486–493. [Google Scholar]
- Dekkers, G.; Lauwereins, S.; Thoen, B.; Adhana, M.; Brouckxon, H.; Bergh, B.; Waterschoot, T.; Vanrumste, B.; Verhelst, M.; Karsmakers, P. The SINS database for detection of daily activities in a home environment using an acoustic sensor network. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017 Workshop (DCASE2017), München, Germany, 16–17 November 2017; pp. 32–36. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Mesaros, A.; Heittola, T.; Virtanen, T. Metrics for polyphonic sound event detection. Appl. Sci. 2016, 6, 162. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Validation Set | Evaluation Set | |||
|---|---|---|---|---|---|
| Label Type | Weak | Strong | Unlabeled | Strong | Strong |
| No. of clips | 1578 | 2045 | 14,412 | 1168 | 692 |
| Properties | Real recording | Synthetic | Real recording | Real recording | Real recording |
| Clip length | 10 s | ||||
| Classes (10) | Speech, Dog, Cat, Alarm bell ring, Dishes, Frying, Blender, Running water, Vacuum cleaner, Electric shaver toothbrush | ||||
| Basic Transformer Model | Mean-Teacher Model | |
|---|---|---|
| # Training samples | 3623 (# weak = 1578, # strong = 2045) | 18,035 (# weak = 1578, # strong = 2045, # unlabeled = 14,412) |
| Batch size | 128 (weak = 64, strong = 64) | 128 (weak = 32, strong = 32, unlabeled = 64) |
| Batch iteration steps | 3100 | 30,000 |
| Optimizer | Adam (lr = 0.001, betas = 0.9, 0.98) | |
| Learning Rate Scheduling | StepLR (step size = 1033, gamma = 0.1) | StepLR (step size = 10,000, gamma = 0.1) |
| Ramp-up Length | - | 10,000 |
| Early-stopping Patience | 10 Epochs | |
| Validation Data | |||||
|---|---|---|---|---|---|
| Baseline Transformer | Multi-Scale Transformer | ||||
| F-Score (%) | ER | F-Score (%) | ER | ||
| w/o Post Processing | NEB = 1 | 25.36 | 2.37 | 27.30 | 2.44 |
| NEB = 2 | 28.77 | 2.31 | 28.20 | 2.33 | |
| NEB = 3 | 25.41 | 2.33 | 28.08 | 2.30 | |
| Average | 26.51 | 2.34 | 27.79 | 2.35 | |
| Relative Improvement | - | - | 4.8% | 0% | |
| w/ Post Processing | NEB = 1 | 35.44 | 1.32 | 37.12 | 1.26 |
| NEB = 2 | 38.14 | 1.30 | 37.91 | 1.27 | |
| NEB = 3 | 35.47 | 1.33 | 37.64 | 1.26 | |
| Average | 36.35 | 1.32 | 37.50 | 1.27 | |
| Relative Improvement | - | - | 3.2% | 6.2% | |
| Evaluation Data | |||||
|---|---|---|---|---|---|
| Baseline Transformer | Multi-Scale Transformer | ||||
| F-Score (%) | ER | F-Score (%) | ER | ||
| w/o Post Processing | NEB = 1 | 29.68 | 1.80 | 33.13 | 1.75 |
| NEB = 2 | 34.89 | 1.69 | 33.83 | 1.69 | |
| NEB = 3 | 29.29 | 1.76 | 35.81 | 1.61 | |
| Average | 31.29 | 1.75 | 34.26 | 1.68 | |
| Relative Improvement | - | - | 9.5% | 4% | |
| w/ Post Processing | NEB = 1 | 36.36 | 1.17 | 39.32 | 1.10 |
| NEB = 2 | 41.07 | 1.11 | 39.91 | 1.11 | |
| NEB = 3 | 36.52 | 1.17 | 40.88 | 1.08 | |
| Average | 37.98 | 1.15 | 40.03 | 1.10 | |
| Relative Improvement | - | - | 5.4% | 4.3% | |
| Validation Data | |||||
|---|---|---|---|---|---|
| Baseline Mean-Teacher Model | Multi-Scale Mean-Teacher Model | ||||
| F-Score (%) | ER | F-Score (%) | ER | ||
| w/o Post Processing | NEB = 1 | 31.43 | 1.69 | 36.15 | 1.57 |
| NEB = 2 | 35.95 | 1.57 | 37.49 | 1.50 | |
| NEB = 3 | 33.58 | 1.56 | 37.54 | 1.46 | |
| Average | 33.65 | 1.61 | 37.06 | 1.51 | |
| Relative Improvement | - | - | 10.1% | 6.2% | |
| w/ Post Processing | NEB = 1 | 40.02 | 1.11 | 44.17 | 1.06 |
| NEB = 2 | 44.05 | 1.06 | 44.57 | 1.05 | |
| NEB = 3 | 41.75 | 1.09 | 44.66 | 1.04 | |
| Average | 41.94 | 1.09 | 44.46 | 1.05 | |
| Relative Improvement | - | - | 6% | 3.7% | |
| Evaluation Data | |||||
|---|---|---|---|---|---|
| Baseline Mean-Teacher Model | Multi-Scale Mean-Teacher Model | ||||
| F-Score (%) | ER | F-Score (%) | ER | ||
| w/o Post Processing | NEB = 1 | 35.80 | 1.36 | 42.21 | 1.24 |
| NEB = 2 | 42.46 | 1.23 | 42.46 | 1.20 | |
| NEB = 3 | 36.48 | 1.31 | 43.45 | 1.16 | |
| Average | 38.25 | 1.30 | 42.71 | 1.20 | |
| Relative Improvement | - | - | 11.6% | 7.7% | |
| w/ Post Processing | NEB = 1 | 40.37 | 1.02 | 46.20 | 0.95 |
| NEB = 2 | 45.82 | 0.96 | 46.10 | 0.96 | |
| NEB = 3 | 40.46 | 1.03 | 46.55 | 0.94 | |
| Average | 42.22 | 1.00 | 46.28 | 0.95 | |
| Relative Improvement | - | - | 9.6% | 5% | |
| DCASE 2019 Baseline [1] | Transformer Model in [25] | Proposed Multi-Scale Transformer | Proposed Multi-Scale Mean-Teacher Transformer | |
|---|---|---|---|---|
| w/o P.P | 23.61% | 21.31% | 27.79% | 37.06% |
| w/P.P | 30.61% | 34.28% | 37.50% | 44.46% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.-J.; Chung, Y.-J. Multi-Scale Features for Transformer Model to Improve the Performance of Sound Event Detection. Appl. Sci. 2022, 12, 2626. https://doi.org/10.3390/app12052626
Kim S-J, Chung Y-J. Multi-Scale Features for Transformer Model to Improve the Performance of Sound Event Detection. Applied Sciences. 2022; 12(5):2626. https://doi.org/10.3390/app12052626
Chicago/Turabian StyleKim, Soo-Jong, and Yong-Joo Chung. 2022. "Multi-Scale Features for Transformer Model to Improve the Performance of Sound Event Detection" Applied Sciences 12, no. 5: 2626. https://doi.org/10.3390/app12052626
APA StyleKim, S.-J., & Chung, Y.-J. (2022). Multi-Scale Features for Transformer Model to Improve the Performance of Sound Event Detection. Applied Sciences, 12(5), 2626. https://doi.org/10.3390/app12052626