
Automatic Classification of Synthetic Voices for Voice Banking Using Objective Measures



Abstract
1. Introduction
2. Voice Banking and Personalized Synthetic Voices
3. Objective Measures Overview
3.1. STOI and ESTOI
3.2. SIIB
3.3. NISQA-TTS
4. Proposed Methodology
4.1. STOI-ESTOI
4.2. SIIB
4.3. NISQA
5. Experiments
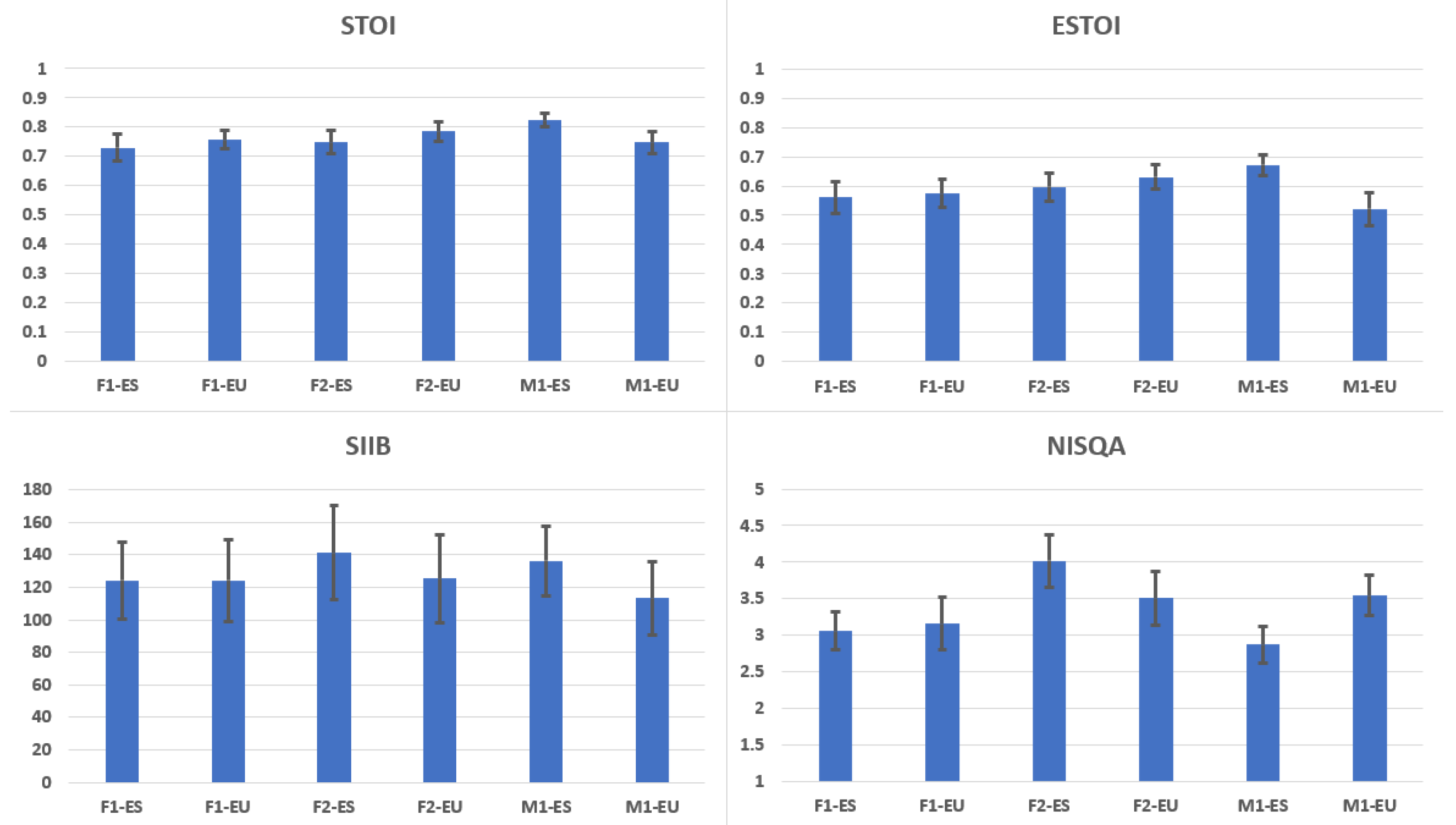
5.1. Evaluation of Standard HTS Voices
5.2. Objective Evaluation of the Donors’ Voices
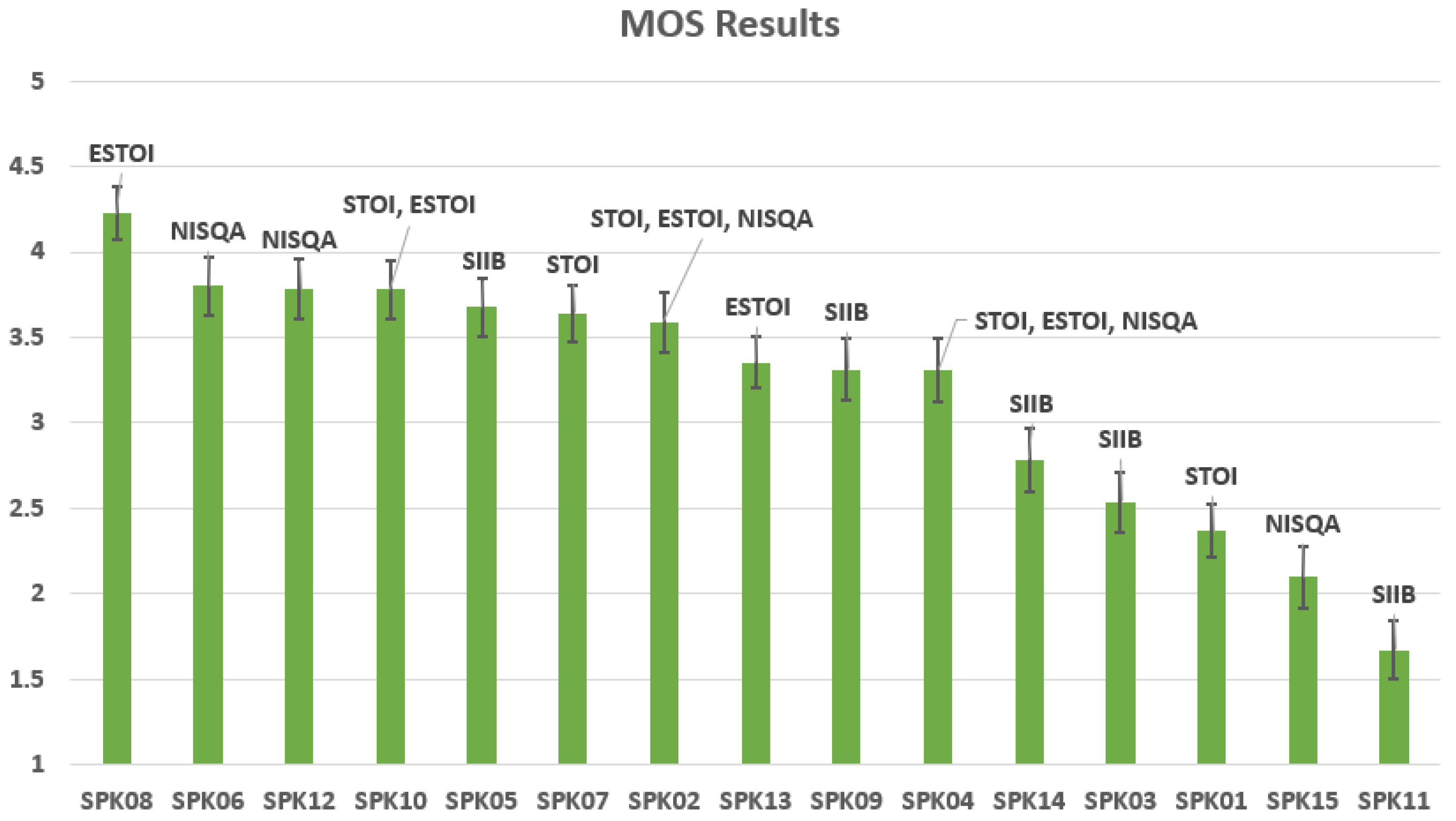
5.3. MOS Evaluation
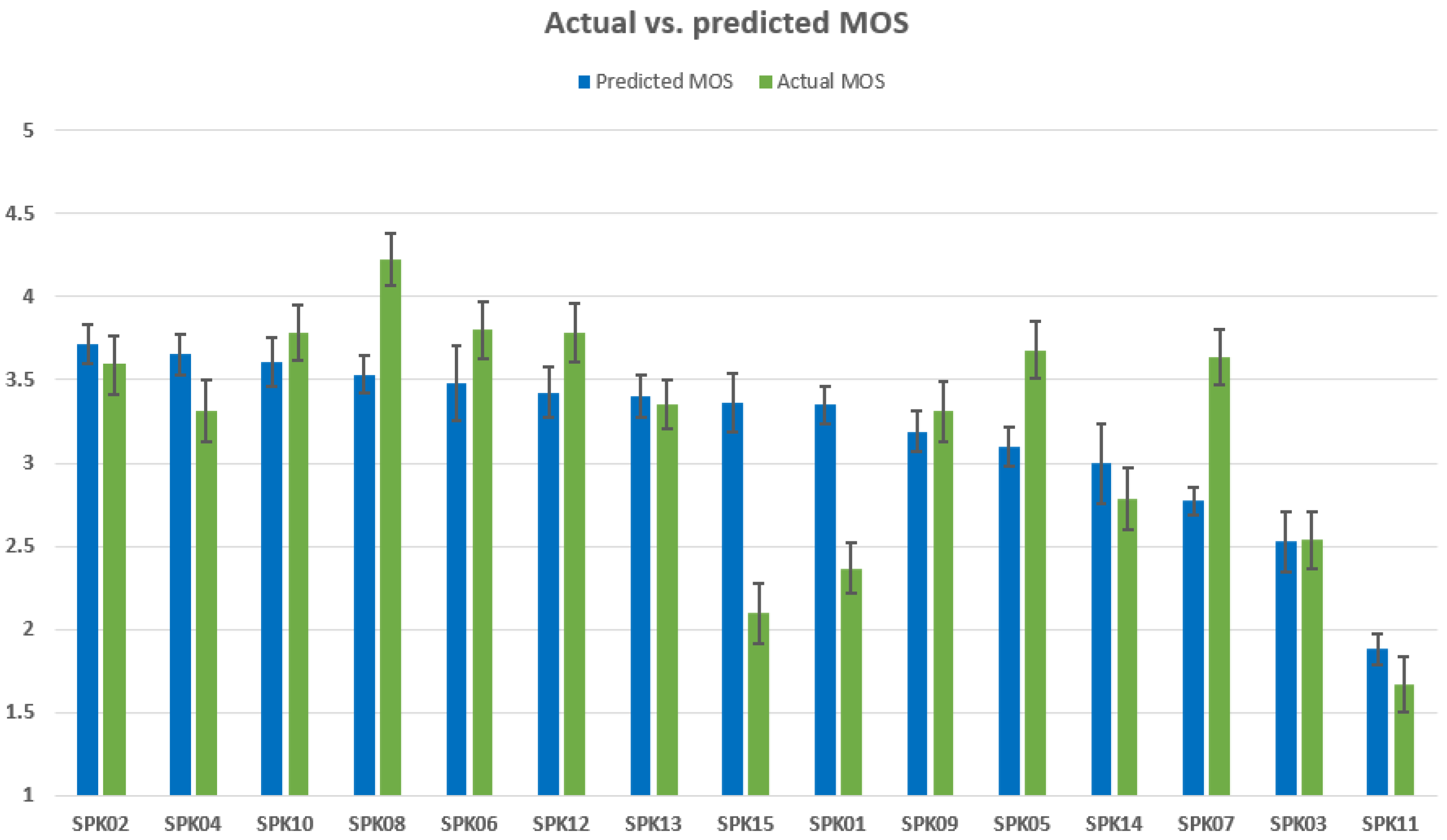
5.4. MOS Prediction
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lavan, N.; Mileva, M.; McGettigan, C. How does familiarity with a voice affect trait judgements? Br. J. Psychol. 2021, 112, 282–300. [Google Scholar] [CrossRef] [PubMed]
- Pucher, M.; Zillinger, B.; Toman, M.; Schabus, D.; Valentini-Botinhao, C.; Yamagishi, J.; Schmid, E.; Woltron, T. Influence of speaker familiarity on blind and visually impaired children’s and young adults’ perception of synthetic voices. Comput. Speech Lang. 2017, 46, 179–195. [Google Scholar] [CrossRef]
- Hunt, A.J.; Black, A.W. Unit selection in a concatenative speech synthesis system using a large speech database. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings, Atlanta, GA, USA, 9 May 1996; Volume 1, pp. 373–376. [Google Scholar]
- Zen, H.; Tokuda, K.; Black, A. Statistical parametric speech synthesis. Speech Commun. 2009, 51, 1039–1064. [Google Scholar] [CrossRef]
- Pollet, V.; Breen, A. Synthesis by generation and concatenation of multiform segments. In Proceedings of the Ninth Annual Conference of the International Speech Communication Association, Brisbane, Australia, 22–26 September 2008. [Google Scholar]
- Dudley, H. Remaking speech. J. Acoust. Soc. Am. 1939, 11, 169–177. [Google Scholar] [CrossRef]
- Kawahara, H.; Masuda-Katsuse, I.; De Cheveigne, A. Restructuring speech representations using a pitch-adaptive time–frequency smoothing and an instantaneous-frequency-based F0 extraction: Possible role of a repetitive structure in sounds. Speech Commun. 1999, 27, 187–207. [Google Scholar] [CrossRef]
- Morise, M.; Yokomori, F.; Ozawa, K. WORLD: A vocoder-based high-quality speech synthesis system for real-time applications. IEICE Trans. Inf. Syst. 2016, 99, 1877–1884. [Google Scholar] [CrossRef]
- Erro, D.; Sainz, I.; Navas, E.; Hernaez, I. Harmonics plus Noise Model based Vocoder for Statistical Parametric Speech Synthesis. IEEE J. Sel. Top. Signal Process. 2014, 8, 184–194. [Google Scholar] [CrossRef]
- Yamagishi, J.; Usabaev, B.; King, S.; Watts, O.; Dines, J.; Tian, J.; Guan, Y.; Hu, R.; Oura, K.; Wu, Y.J.; et al. Thousands of voices for HMM-based speech synthesis—Analysis and application of TTS systems built on various ASR corpora. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 984–1004. [Google Scholar] [CrossRef]
- Suni, A.; Raitio, T.; Vainio, M.; Alku, P. The GlottHMM speech synthesis entry for Blizzard Challenge 2010. In The Blizzard Challenge 2010 Workshop; Language Technologies Institute LTI: Pittsburgh, PA, USA, 2010; pp. 1–6. [Google Scholar]
- Ze, H.; Senior, A.; Schuster, M. Statistical parametric speech synthesis using deep neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7962–7966. [Google Scholar]
- Ling, Z.H.; Kang, S.Y.; Zen, H.; Senior, A.; Schuster, M.; Qian, X.J.; Meng, H.M.; Deng, L. Deep learning for acoustic modeling in parametric speech generation: A systematic review of existing techniques and future trends. IEEE Signal Process. Mag. 2015, 32, 35–52. [Google Scholar] [CrossRef]
- Arık, S.Ö.; Chrzanowski, M.; Coates, A.; Diamos, G.; Gibiansky, A.; Kang, Y.; Li, X.; Miller, J.; Ng, A.; Raiman, J.; et al. Deep voice: Real-time neural text-to-speech. In Proceedings of the International Conference on Machine Learning (PMLR), Sydney, NSW, Australia, 6–11 August 2017; pp. 195–204. [Google Scholar]
- Arik, S.; Diamos, G.; Gibiansky, A.; Miller, J.; Peng, K.; Ping, W.; Raiman, J.; Zhou, Y. Deep voice 2: Multi-speaker neural text-to-speech. arXiv 2017, arXiv:1705.08947. [Google Scholar]
- Ping, W.; Peng, K.; Gibiansky, A.; Arik, S.Ö.; Kannan, A.; Narang, S.; Raiman, J.; Miller, J. Deep Voice 3: 2000-Speaker Neural Text-to-Speech. 2017. arXiv 2017, arXiv:1710.07654. [Google Scholar]
- Sotelo, J.; Mehri, S.; Kumar, K.; Santos, J.F.; Kastner, K.; Courville, A.; Bengio, Y. Char2wav: End-to-End Speech Synthesis. 2017. Available online: https://mila.quebec/wp-content/uploads/2017/02/end-end-speech.pdf (accessed on 10 February 2022).
- Wang, Y.; Skerry-Ryan, R.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards end-to-end speech synthesis. arXiv 2017, arXiv:1703.10135. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4779–4783. [Google Scholar]
- Ping, W.; Peng, K.; Chen, J. Clarinet: Parallel wave generation in end-to-end text-to-speech. arXiv 2018, arXiv:1807.07281. [Google Scholar]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Griffin, D.; Lim, J. Signal estimation from modified short-time Fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- Toman, M.; Meltzner, G.S.; Patel, R. Data Requirements, Selection and Augmentation for DNN-based Speech Synthesis from Crowdsourced Data. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 2878–2882. [Google Scholar]
- Taigman, Y.; Wolf, L.; Polyak, A.; Nachmani, E. Voiceloop: Voice fitting and synthesis via a phonological loop. arXiv 2017, arXiv:1707.06588. [Google Scholar]
- Jia, Y.; Zhang, Y.; Weiss, R.J.; Wang, Q.; Shen, J.; Ren, F.; Chen, Z.; Nguyen, P.; Pang, R.; Moreno, I.L.; et al. Transfer learning from speaker verification to multispeaker text-to-speech synthesis. arXiv 2018, arXiv:1806.04558. [Google Scholar]
- Cooper, E.; Lai, C.I.; Yasuda, Y.; Fang, F.; Wang, X.; Chen, N.; Yamagishi, J. Zero-shot multi-speaker text-to-speech with state-of-the-art neural speaker embeddings. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6184–6188. [Google Scholar]
- Erro, D.; Hernáez, I.; Navas, E.; Alonso, A.; Arzelus, H.; Jauk, I.; Hy, N.Q.; Magariños, C.; Pérez-Ramón, R.; Sulír, M.; et al. ZureTTS: Online Platform for Obtaining Personalized Synthetic Voices. In Proceedings of the eNTERFACE’14, Bilbao, Spain, 9 June–5 July 2014. [Google Scholar]
- Laboratory, A.S.P. ZureTTS. Available online: https://aholab.ehu.eus/ahomytts/ (accessed on 10 February 2022).
- Alonso, A.; García, V.; Hernaez, I.; Navas, E.; Sanchez, J. Automatic Speaker Adaptation Assessment Based on Objective Measures for Voice Banking Donors. In Proceedings of the IBERSPEECH 2020, Valladolid, Spain, 24–26 March 2021; pp. 210–214. [Google Scholar]
- Model Talker. Available online: https://www.modeltalker.org/ (accessed on 10 February 2022).
- Speak Unique. Available online: https://www.speakunique.co.uk/ (accessed on 10 February 2022).
- VocalID. Available online: https://vocalid.ai/ (accessed on 10 February 2022).
- The Voice Keeper. Available online: https://thevoicekeeper.com/ (accessed on 10 February 2022).
- Acapela Group. Available online: http://www.acapela-group.com/solutions/my-own-voice/ (accessed on 10 February 2022).
- CereVoice. Available online: https://www.cereproc.com/en/products/cerevoiceme (accessed on 10 February 2022).
- Yamagishi, J.; Veaux, C.; King, S.; Renals, S. Speech synthesis technologies for individuals with vocal disabilities: Voice banking and reconstruction. Acoust. Sci. Technol. 2012, 33, 1–5. [Google Scholar] [CrossRef][Green Version]
- Creer, S.; Cunningham, S.; Green, P.; Yamagishi, J. Building personalised synthetic voices for individuals with severe speech impairment. Comput. Speech Lang. 2013, 27, 1178–1193. [Google Scholar] [CrossRef]
- Pierard, A.; Erro, D.; Hernaez, I.; Navas, E.; Dutoit, T. Surgery of speech synthesis models to overcome the scarcity of training data. In Proceedings of the International Conference on Advances in Speech and Language Technologies for Iberian Languages, Lisbon, Portugal, 23–25 November 2016; pp. 73–83. [Google Scholar]
- Yamagishi, J.; Nose, T.; Zen, H.; Ling, Z.H.; Toda, T.; Tokuda, K.; King, S.; Renals, S. Robust Speaker-Adaptive HMM-Based Text-to-Speech Synthesis. IEEE Trans. Audio, Speech Lang. Process. 2009, 17, 1208–1230. [Google Scholar] [CrossRef]
- Moreno Bilbao, M.A.; Poig, D.; Bonafonte Cávez, A.; Lleida, E.; Llisterri, J.; Mariño Acebal, J.B.; Nadeu Camprubí, C. Albayzin speech database: Design of the phonetic corpus. In Proceedings of the EUROSPEECH 1993: 3rd European Conference on Speech Communication and Technology, Berlin, Germany, 22–25 September 1993; pp. 175–178. [Google Scholar]
- Sainz, I.; Erro, D.; Navas, E.; Hernáez, I.; Sanchez, J.; Saratxaga, I.; Odriozola, I. Versatile Speech Databases for High Quality Synthesis for Basque. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 23–25 May 2012; pp. 3308–3312. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. A short-time objective intelligibility measure for time-frequency weighted noisy speech. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4214–4217. [Google Scholar]
- Jensen, J.; Taal, C.H. An algorithm for predicting the intelligibility of speech masked by modulated noise maskers. IEEE/ACM Trans. Audio Speech, Lang. Process. 2016, 24, 2009–2022. [Google Scholar] [CrossRef]
- Van Kuyk, S.; Kleijn, W.B.; Hendriks, R.C. An instrumental intelligibility metric based on information theory. IEEE Signal Process. Lett. 2017, 25, 115–119. [Google Scholar] [CrossRef]
- Mittag, G.; Möller, S. Deep Learning Based Assessment of Synthetic Speech Naturalness. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 1748–1752. [Google Scholar]
- Jørgensen, S.; Cubick, J.; Dau, T. Speech intelligibility evaluation for mobile phones. Acta Acust. United Acust. 2015, 101, 1016–1025. [Google Scholar] [CrossRef]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time—Frequency weighted noisy speech. IEEE Trans. Audio, Speech, Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Falk, T.H.; Parsa, V.; Santos, J.F.; Arehart, K.; Hazrati, O.; Huber, R.; Kates, J.M.; Scollie, S. Objective quality and intelligibility prediction for users of assistive listening devices: Advantages and limitations of existing tools. IEEE Signal Process. Mag. 2015, 32, 114–124. [Google Scholar] [CrossRef]
- Xia, R.; Li, J.; Akagi, M.; Yan, Y. Evaluation of objective intelligibility prediction measures for noise-reduced signals in mandarin. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4465–4468. [Google Scholar]
- Jensen, J.; Taal, C.H. Speech intelligibility prediction based on mutual information. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 430–440. [Google Scholar] [CrossRef]
- Schlittenlacher, J.; Baer, T. Text-to-speech for the hearing impaired. arXiv 2020, arXiv:2012.02174. [Google Scholar]
- Ayllón, D.; Sánchez-Hevia, H.A.; Figueroa, C.; Lanchantin, P. Investigating the Effects of Noisy and Reverberant Speech in Text-to-Speech Systems. In Proceedings of the INTERSPEECH 2019, Graz, Austria, 15–19 September 2019; pp. 1511–1515. [Google Scholar]
- Janbakhshi, P.; Kodrasi, I.; Bourlard, H. Pathological Speech Intelligibility Assessment Based on the Short-time Objective Intelligibility Measure. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6405–6409. [Google Scholar] [CrossRef]
- Mittag, G.; Möller, S. Non-intrusive speech quality assessment for super-wideband speech communication networks. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7125–7129. [Google Scholar]
- NISQA. Available online: https://github.com/gabrielmittag/NISQA (accessed on 10 February 2022).
- McAuliffe, M.; Socolof, M.; Mihuc, S.; Wagner, M.; Sonderegger, M. Montreal Forced Aligner: Trainable text-speech alignment using Kaldi. In Proceedings of the INTERSPEECH 2017, Stockholm, Sweden, 20–24 August 2017; pp. 498–502. [Google Scholar]
- Tokuda, K.; Zen, H.; Yamagishi, J.; Black, A.; Masuko, T.; Sako, S.; Oura, K.; Hasimoto, K.; Sawada, K.; Yoshimura, T. The HMM-based speech synthesis system (HTS). Available online: http://hts.sp.nitech.ac.jp (accessed on 10 February 2022).
- Erro, D.; Hernaez, I.; Alonso, A.; García-Lorenzo, D.; Navas, E.; Ye, J.; Arzelus, H.; Jauk, I.; Hy, N.Q.; Magariños, C.; et al. Personalized synthetic voices for speaking impaired: Website and app. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Voice | Speaker | Language | Gender | # of Sentences |
|---|---|---|---|---|
| F1-ES | F1 | ES | F | 3994 |
| F1-EU | F1 | EU | F | 3797 |
| F2-ES | F2 | ES | F | 3712 |
| F2-EU | F2 | EU | F | 3831 |
| M1-ES | M1 | ES | M | 3995 |
| M1-EU | M1 | EU | M | 3799 |
| - | STOI | ESTOI | SIIB | NISQA |
|---|---|---|---|---|
| 1st | SPK01 | SPK02 | SPK03 | SPK04 |
| 2nd | SPK04 | SPK04 | SPK05 | SPK06 |
| 3rd | SPK07 | SPK08 | SPK09 | SPK02 |
| 4th | SPK02 | SPK10 | SPK11 | SPK12 |
| 5th | SPK10 | SPK13 | SPK14 | SPK15 |
| - | STOI | ESTOI | SIIB |
|---|---|---|---|
| ESTOI | 0.912 | - | - |
| SIIB | 0.363 | 0.292 | - |
| NISQA | 0.449 | 0.476 | 0.258 |
| STOI | ESTOI | NISQA | SIIB |
|---|---|---|---|
| 0.452 | 0.584 | 0.356 | −0.199 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alonso, A.; García, V.; Hernaez, I.; Navas, E.; Sanchez, J. Automatic Classification of Synthetic Voices for Voice Banking Using Objective Measures. Appl. Sci. 2022, 12, 2473. https://doi.org/10.3390/app12052473
Alonso A, García V, Hernaez I, Navas E, Sanchez J. Automatic Classification of Synthetic Voices for Voice Banking Using Objective Measures. Applied Sciences. 2022; 12(5):2473. https://doi.org/10.3390/app12052473
Chicago/Turabian StyleAlonso, Agustin, Víctor García, Inma Hernaez, Eva Navas, and Jon Sanchez. 2022. "Automatic Classification of Synthetic Voices for Voice Banking Using Objective Measures" Applied Sciences 12, no. 5: 2473. https://doi.org/10.3390/app12052473
APA StyleAlonso, A., García, V., Hernaez, I., Navas, E., & Sanchez, J. (2022). Automatic Classification of Synthetic Voices for Voice Banking Using Objective Measures. Applied Sciences, 12(5), 2473. https://doi.org/10.3390/app12052473