
A Two-Phase Evolutionary Method to Train RBF Networks




Abstract
:1. Introduction
- The input layer, where the problem is presented in the form of patterns to the neural network.
- The processing layer, where a computation is performed using the Gaussian processing units . These units can have many forms in the relevant literature but the most used form is the Gaussian function expressed as:The value depends only on the distance of vector from some other vector , which typically is called centroid.
- The output layer where the output of every function is multiplied by a corresponding weight value .
2. Method Description
2.1. Bound Location Phase
- Setm = 0
- Set
- Fordo
- (a)
- Fordo
- i.
- Set = , =
- ii.
- Set
- (b)
- EndFor
- (c)
- Set,
- (d)
- Set
- EndFor
| Algorithm 1: The k-means algorithm. |
|
2.2. Main Algorithm
- Initialization Step
- (a)
- Read the train set with m patterns of d dimension.
- (b)
- Setk the number of nodes for the RBF network.
- (c)
- Estimate the vectors using the procedure of Section 2.1.
- (d)
- Initialize a genetic population of random chromosomes inside .
- (e)
- Set the selection rate , the mutation rate , and the maximum number of generations.
- Evaluation StepFor every chromosome g calculate the fitness using the procedure defined in Section 2.3.
- Genetic operations stepDuring this step three genetic operations are performed: selection, crossover and mutation.
- (a)
- Selection procedure. Firstly, the chromosomes are sorted with relevance to their corresponding fitness value. The best are transferred without change to the next generation and the remaining ones are substituted by offspring created through the crossover procedure. In the crossover procedure, the mating parent are selected using a tournament selection for every parent. The tournament selection is as follows:
- Select a set of chromosomes from the population.
- Return the chromosome with the best fitness value in that subset.
- (b)
- Crossover procedure. For every pair of selected parents create two new offspring and :with a random number and [37]. This crossover scheme will be able to better explore the search space of the train error.
- (c)
- Mutation procedure. For every element of each chromosome, create a random number . If , then change that element randomly. The mutation is performed in a way similar to other approaches of genetic algorithms [38] and it is described in Section 2.5.
- (d)
- Replace the worst chromosomes in the population with the generated offsprings.
- Termination Check Step
- (a)
- Set
- (b)
- Terminate if the termination criteria of Section 2.4 are satisfied, else Goto Evaluation Step.
2.3. Fitness Evaluation
- Decode the chromosome g to the parts (centers and variances) of the RBF network as defined by the layout of Table 1.
- Calculate the output vectors by solving the induced system of equations:
- (a)
- Set the matrix of k weights, and .
- (b)
- Solve:The matrix is the pseudo-inverse of , with
- Set
2.4. Stopping Rule
2.5. Mutation Procedure
3. Experiments
3.1. Experimental Setup
3.2. Experimental Datasets
- UCI dataset repository, https://archive.ics.uci.edu/ml/index.php (accessed on 18 January 2021)
- Keel repository, https://sci2s.ugr.es/keel/datasets.php (accessed on 18 January 2021) [41].
- The Alcohol dataset, which is related to alcohol consumption [42].
- The Appendicitis dataset, proposed in [43].
- The Australian dataset [44], which refers to credit card applications.
- The Balance dataset [45], which is used to predict psychological states.
- The Dermatology dataset [48], which is used for differential diagnosis of erythematosquamous diseases.
- The Hayes roth dataset [51].
- The Heart dataset [52], used to detect heart disease.
- The HouseVotes dataset [53], which is about votes in the U.S. House of Representatives.
- The Liverdisorder dataset [56], used to detect liver disorders in people using blood analysis.
- The Mammographic dataset [57], used to identify the severity of a mammographic mass lesions.
- The Parkinson dataset, which is composed of a range of biomedical voice measurements from 31 people, 23 with Parkinson’s disease (PD) [58].
- The Pima dataset [59], used to detect the presence of diabetes.
- The Popfailures dataset [60], related to climate model simulation crashes.
- The Regions2 dataset, which was created from liver biopsy images of patients with hepatitis C [61].
- The Ring dataset [62], a 20-dimension problem with two classes, where each class is drawn from a multivariate normal distribution.
- The Saheart dataset [63], used to detect heart disease.
- The Segment dataset [64], which contains patterns from a database of seven outdoor images (classes).
- The Sonar dataset [65]. The task is to discriminate between sonar signals bounced off a metal cylinder.
- The Spiral dataset, which is an artificial dataset containing 1000 two-dimensional examples that belong to two classes.
- The Tae dataset [66], which concerns evaluations of teaching performance.
- The Thyroid dataset, which concerns thyroid disease records [67].
- The Wdbc dataset [68], which contains data from breast tumors.
- The EEG dataset from [71], which consists of five sets (denoted as Z, O, N, F and S), each containing 100 single-channel EEG segments each lasting 23.6 s. With different combinations of these sets the produced datasets are Z_F_S, ZO_NF_S, ZONF_S.
- The Zoo dataset [72], where the task is to classify animals in seven predefined classes.
- The Abalone dataset [73], which can be used to obtain a model to predict the age of abalone from physical measurements.
- The Airfoil dataset, which is used by NASA for a series of aerodynamic and acoustic tests [74].
- The Anacalt dataset [75], which contains information about the decisions taken by a supreme court.
- The BK dataset [76], used to estimate the points in a basketball game.
- The BL dataset, which can be downloaded from StatLib and contains data from an experiment on the effects of machine adjustments on the time it takes to count bolts.
- The Concrete dataset, used to measure the concrete compressive strength [77].
- The Housing dataset, taken from the StatLib library, which is maintained at Carnegie Mellon University, and described in [78].
- The Laser dataset, used in laser experiments. It has been obtained from the Santa Fe Time Series Competition Data repository.
- The MB dataset, available from Smoothing Methods in Statistics [77].
- The NT dataset, which contains data from [79] that examined whether the true mean body temperature is 98.6 F.
- The Quake dataset, whose objective is to approximate the strength of a earthquake. It has been obtained from the Bilkent University Function Approximation Repository.
3.3. Experimental Results
4. Conclusions
- Using parallel methods for the k-means clustering phase of the method.
- Dynamic selection of k in k-means algorithm.
- More advanced stopping rules for the genetic algorithm.
- Replacing the genetic algorithm with other optimization methods such as particle swarm optimization, ant colony optimization, etc.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Park, J.; Sandberg, I.W. Universal Approximation Using Radial-Basis-Function Networks. Neural Comput. 1991, 3, 246–257. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural networks and their applications. Rev. Sci. Instrum. 1994, 65, 1803–1832. [Google Scholar] [CrossRef] [Green Version]
- Teng, P. Machine-learning quantum mechanics: Solving quantum mechanics problems using radial basis function networks. Phys. Rev. E 2018, 98, 033305. [Google Scholar] [CrossRef] [Green Version]
- Jovanović, R.; Sretenovic, A. Ensemble of radial basis neural networks with K-means clustering for heating energy consumption prediction. FME Trans. 2017, 45, 51–57. [Google Scholar] [CrossRef] [Green Version]
- Alexandridis, A.; Chondrodima, E.; Efthimiou, E.; Papadakis, G.; Vallianatos, F.; Triantis, D. Large Earthquake Occurrence Estimation Based on Radial Basis Function Neural Networks. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5443–5453. [Google Scholar] [CrossRef]
- Gorbachenko, V.I.; Zhukov, M.V. Solving boundary value problems of mathematical physics using radial basis function networks. Comput. Math. Math. Phys. 2017, 57, 145–155. [Google Scholar] [CrossRef]
- Wang, Y.P.; Dang, J.W.; Li, Q.; Li, S. Multimodal medical image fusion using fuzzy radial basis function neural networks. In Proceedings of the 2007 International Conference on Wavelet Analysis and Pattern Recognition, Ningbo, China, 9–12 July 2017; pp. 778–782. [Google Scholar]
- Mehrabi, S.; Maghsoudloo, M.; Arabalibeik, H.; Noormand, R.; Nozari, Y. Congestive heart failure, Chronic obstructive pulmonary disease, Clinical decision support system, Multilayer perceptron neural network and radial basis function neural network. Expert Syst. Appl. 2009, 36, 6956–6959. [Google Scholar] [CrossRef]
- Veezhinathan, M.; Ramakrishnan, S. Detection of Obstructive Respiratory Abnormality Using Flow–Volume Spirometry and Radial Basis Function Neural Networks. J. Med. Syst. 2007, 31, 461. [Google Scholar] [CrossRef]
- Mai-Duy, N.; Tran-Cong, T. Numerical solution of differential equations using multiquadric radial basis function networks. Neural Netw. 2001, 14, 185–199. [Google Scholar] [CrossRef] [Green Version]
- Mai-Duy, N. Solving high order ordinary differential equations with radial basis function networks. Int. J. Numer. Meth. Eng. 2005, 62, 824–852. [Google Scholar] [CrossRef] [Green Version]
- Wan, C.; Harrington, P.d.B. Self-Configuring Radial Basis Function Neural Networks for Chemical Pattern Recognition. J. Chem. Inf. Comput. Sci. 1999, 39, 1049–1056. [Google Scholar] [CrossRef]
- Yao, X.; Zhang, X.; Zhang, R.; Liu, M.; Hu, Z.; Fan, B. Prediction of enthalpy of alkanes by the use of radial basis function neural networks. Comput. Chem. 2001, 25, 475–482. [Google Scholar] [CrossRef]
- Shahsavand, A.; Ahmadpour, A. Application of optimal RBF neural networks for optimization and characterization of porous materials. Comput. Chem. Eng. 2005, 29, 2134–2143. [Google Scholar] [CrossRef]
- Momoh, J.A.; Reddy, S.S. Combined Economic and Emission Dispatch using Radial Basis Function. In Proceedings of the 2014 IEEE PES General Meeting|Conference & Exposition, National Harbor, MD, USA, 27–31 July 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Guo, J.-J.; Luh, P.B. Selecting input factors for clusters of Gaussian radial basis function networks to improve market clearing price prediction. IEEE Trans. Power Syst. 2003, 18, 665–672. [Google Scholar]
- Falat, L.; Stanikova, Z.; Durisova, M.; Holkova, B.; Potkanova, T. Application of Neural Network Models in Modelling Economic Time Series with Non-constant Volatility. Procedia Econ. Financ. 2015, 34, 600–607. [Google Scholar] [CrossRef] [Green Version]
- Laoudias, C.; Kemppi, P.; Panayiotou, C.G. Localization Using Radial Basis Function Networks and Signal Strength Fingerprints in WLAN. In Proceedings of the GLOBECOM 2009—2009 IEEE Global Telecommunications Conference, Honolulu, HI, USA, 30 November–4 December 2009; pp. 1–6. [Google Scholar]
- Chen, S.; Mulgrew, B.; Grant, P.M. A clustering technique for digital communications channel equalization using radial basis function networks. IEEE Trans. Neural Netw. 1993, 4, 570–590. [Google Scholar] [CrossRef] [Green Version]
- Jiang, H.; Yang, Y.; Shi, M. Chemometrics in Tandem with Hyperspectral Imaging for Detecting Authentication of Raw and Cooked Mutton Rolls. Foods 2021, 10, 2127. [Google Scholar] [CrossRef]
- Li, X.; Jiang, H.; Jiang, X.; Shi, M. Identification of Geographical Origin of Chinese Chestnuts Using Hyperspectral Imaging with 1D-CNN Algorithm. Agriculture 2021, 11, 1274. [Google Scholar] [CrossRef]
- Fath, A.H.; Madanifar, F.; Abbasi, M. Implementation of multilayer perceptron (MLP) and radial basis function (RBF) neural networks to predict solution gas-oil ratio of crude oil systems. Petroleum 2020, 6, 80–91. [Google Scholar] [CrossRef]
- Deng, Y.; Zhou, X.; Shen, J.; Xiao, G.; Hong, H.; Lin, H.; Wu, F.; Liao, B.Q. New methods based on back propagation (BP) and radial basis function (RBF) artificial neural networks (ANNs) for predicting the occurrence of haloketones in tap water. Sci. Total Environ. 2021, 772, 145534. [Google Scholar] [CrossRef]
- Aqdam, H.R.; Ettefagh, M.M.; Hassannejad, R. Health monitoring of mooring lines in floating structures using artificial neural networks. Ocean Eng. 2018, 164, 284–297. [Google Scholar] [CrossRef]
- Arenas, M.G.; Parras-Gutierrez, E.; Rivas, V.M.; Castillo, P.A.; del Jesus, M.J.; Merelo, J.J. Parallelizing the Design of Radial Basis Function Neural Networks by Means of Evolutionary Meta-algorithms. In Proceedings of the Bio-Inspired Systems: Computational and Ambient Intelligence, IWANN 2009, Salamanca, Spain, 10–12 June 2009; Cabestany, J., Sandoval, F., Prieto, A., Corchado, J.M., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2009; Volume 5517. [Google Scholar]
- Brandstetter, A.; Artusi, A. Radial Basis Function Networks GPU-Based Implementation. IEEE Trans. Neural Netw. 2008, 19, 2150–2154. [Google Scholar] [CrossRef] [Green Version]
- Kuncheva, L.I. Initializing of an RBF network by a genetic algorithm. Neurocomputing 1997, 14, 273–288. [Google Scholar] [CrossRef]
- Kubat, M. Decision trees can initialize radial-basis function networks. IEEE Trans. Neural Netw. 1998, 9, 813–821. [Google Scholar] [CrossRef]
- Franco, D.G.B.; Steiner, M.T.A. New Strategies for Initialization and Training of Radial Basis Function Neural Networks. IEEE Lat. Am. Trans. 2017, 15, 1182–1188. [Google Scholar] [CrossRef]
- Ricci, E.; Perfetti, R. Improved pruning strategy for radial basis function networks with dynamic decay adjustment. Neurocomputing 2006, 69, 1728–1732. [Google Scholar] [CrossRef]
- Bortman, M.; Aladjem, M. A Growing and Pruning Method for Radial Basis Function Networks. IEEE Trans. Neural Netw. 2009, 20, 1039–1045. [Google Scholar] [CrossRef]
- Huang, G.-B.; Saratchandran, P.; Sundararajan, N. A generalized growing and pruning RBF (GGAP-RBF) neural network for function approximation. IEEE Trans. Neural Netw. 2005, 16, 57–67. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.Y.; Qin, Z.; Jia, J. A PSO-Based Subtractive Clustering Technique for Designing RBF Neural Networks. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), Hong Kong, 1–6 June 2008; pp. 2047–2052. [Google Scholar]
- Esmaeili, A.; Mozayani, N. Adjusting the parameters of radial basis function networks using Particle Swarm Optimization. In Proceedings of the 2009 IEEE International Conference on Computational Intelligence for Measurement Systems and Applications, Hong Kong, 11–13 May 2009; pp. 179–181. [Google Scholar]
- O’Hora, B.; Perera, J.; Brabazon, A. Designing Radial Basis Function Networks for Classification Using Differential Evolution. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, USA, 16–21 July 2006; pp. 2932–2937. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Davis Davis, CA, USA, 27 December 1965–7 January 1966; Volume 1, pp. 281–297. [Google Scholar]
- Kaelo, P.; Ali, M.M. Integrated crossover rules in real coded genetic algorithms. Eur. J. Oper. 2007, 176, 60–76. [Google Scholar] [CrossRef]
- Tsoulos, I.G. Modifications of real code genetic algorithm for global optimization. Appl. Math. Comput. 2008, 203, 598–607. [Google Scholar] [CrossRef]
- Sanderson, C.; Curtin, R. Armadillo: A template-based C++ library for linear algebra. J. Open Source Softw. 2016, 1, 26. [Google Scholar] [CrossRef]
- Chandra, R.; Dagum, L.; Kohr, D.; Maydan, D.; McDonald, J.; Menon, R. Parallel Programming in OpenMP; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001. [Google Scholar]
- Alcalá-Fdez, J.; Fernandez, A.; Luengo, J.; Derrac, J.; García, S.; Sánchez, L.; Herrera, F. KEEL Data-Mining Software Tool: Data Set Repository, Integration of Algorithms and Experimental Analysis Framework. J. Mult.-Valued Log. Soft Comput. 2011, 17, 255–287. [Google Scholar]
- Tzimourta, K.D.; Tsoulos, I.; Bilero, T.; Tzallas, A.T.; Tsipouras, M.G.; Giannakeas, N. Direct Assessment of Alcohol Consumption in Mental State Using Brain Computer Interfaces and Grammatical Evolution. Inventions 2018, 3, 51. [Google Scholar] [CrossRef] [Green Version]
- Weiss, S.M.; Kulikowski, C.A. Computer Systems That Learn: Classification and Prediction Methods from Statistics, Neural Nets, Machine Learning, and Expert Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1991. [Google Scholar]
- Quinlan, J.R. Simplifying Decision Trees. Int. Man–Mach. Stud. 1987, 27, 221–234. [Google Scholar] [CrossRef] [Green Version]
- Shultz, T.; Mareschal, D.; Schmidt, W. Modeling Cognitive Development on Balance Scale Phenomena. Mach. Learn. 1994, 16, 59–88. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.H.; Jiang, Y. NeC4.5: Neural ensemble based C4.5. IEEE Trans. Knowl. Data Eng. 2004, 16, 770–773. [Google Scholar] [CrossRef]
- Setiono, R.; Leow, W.K. FERNN: An Algorithm for Fast Extraction of Rules from Neural Networks. Appl. Intell. 2000, 12, 15–25. [Google Scholar] [CrossRef]
- Demiroz, G.; Govenir, H.A.; Ilter, N. Learning Differential Diagnosis of Eryhemato-Squamous Diseases using Voting Feature Intervals. Artif. Intell. Med. 1998, 13, 147–165. [Google Scholar]
- Valentini, G.; Masulli, F. NEURObjects: An object-oriented library for neural network development. Neurocomputing 2002, 48, 623–646. [Google Scholar] [CrossRef] [Green Version]
- Denoeux, T. A neural network classifier based on Dempster-Shafer theory. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2000, 30, 131–150. [Google Scholar] [CrossRef] [Green Version]
- Hayes-Roth, B.; Hayes-Roth, F. Concept learning and the recognition and classification of exemplars. J. Verbal Learn. Verbal Behav. 1977, 16, 321–338. [Google Scholar] [CrossRef]
- Kononenko, I.; Šimec, E.; Robnik-Šikonja, M. Overcoming the Myopia of Inductive Learning Algorithms with RELIEFF. Appl. Intell. 1997, 7, 39–55. [Google Scholar] [CrossRef]
- French, R.M.; Chater, N. Using noise to compute error surfaces in connectionist networks: A novel means of reducing catastrophic forgetting. Neural Comput. 2002, 14, 1755–1769. [Google Scholar] [CrossRef] [PubMed]
- Dy, J.G.; Brodley, C.E. Feature Selection for Unsupervised Learning. J. Mach. Learn. Res. 2004, 5, 845–889. [Google Scholar]
- Perantonis, S.J.; Virvilis, V. Input Feature Extraction for Multilayered Perceptrons Using Supervised Principal Component Analysis. Neural Process. Lett. 1999, 10, 243–252. [Google Scholar] [CrossRef]
- Garcke, J.; Griebel, M. Classification with sparse grids using simplicial basis functions. Intell. Data Anal. 2002, 6, 483–502. [Google Scholar] [CrossRef] [Green Version]
- Elter, M.; Schulz-Wendtland, R.; Wittenberg, T. The prediction of breast cancer biopsy outcomes using two CAD approaches that both emphasize an intelligible decision process. Med. Phys. 2007, 34, 4164–4172. [Google Scholar] [CrossRef]
- Little, M.A.; McSharry, P.E.; Hunter, E.J.; Spielman, J.; Ramig, L.O. Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. IEEE Trans. Biomed. Eng. 2009, 56, 1015. [Google Scholar] [CrossRef] [Green Version]
- Smith, J.W.; Everhart, J.E.; Dickson, W.C.; Knowler, W.C.; Johannes, R.S. Using the ADAP learning algorithm to forecast the onset of diabetes mellitus. In Proceedings of the Symposium on Computer Applications and Medical Care, Washington, DC, USA, 6–9 November 1988; pp. 261–265. [Google Scholar]
- Lucas, D.D.; Klein, R.; Tannahill, J.; Ivanova, D.; Brandon, S.; Domyancic, D.; Zhang, Y. Failure analysis of parameter-induced simulation crashes in climate models. Geosci. Model Dev. 2013, 6, 1157–1171. [Google Scholar] [CrossRef] [Green Version]
- Giannakeas, N.; Tsipouras, M.G.; Tzallas, A.T.; Kyriakidi, K.; Tsianou, Z.E.; Manousou, P.; Hall, A.; Karvounis, E.C.; Tsianos, V.; Tsianos, E. A clustering based method for collagen proportional area extraction in liver biopsy images. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Milan, Italy, 25–29 August 2015; pp. 3097–3100. [Google Scholar]
- Breiman, L. Bias, Variance and Arcing Classifiers; Tec. Report 460; Statistics Department, University of California: Berkeley, CA, USA, 1996. [Google Scholar]
- Hastie, T.; Tibshirani, R. Non-parametric logistic and proportional odds regression. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1987, 36, 260–276. [Google Scholar] [CrossRef]
- Dash, M.; Liu, H.; Scheuermann, P.; Tan, K.L. Fast hierarchical clustering and its validation. Data Knowl. Eng. 2003, 44, 109–138. [Google Scholar] [CrossRef]
- Gorman, R.P.; Sejnowski, T.J. Analysis of Hidden Units in a Layered Network Trained to Classify Sonar Targets. Neural Netw. 1988, 1, 75–89. [Google Scholar] [CrossRef]
- Lim, T.S.; Loh, W.Y. A Comparison of Prediction Accuracy, Complexity, and Training Time of Thirty-Three Old and New Classification Algorithms. Mach. Learn. 2000, 40, 203–228. [Google Scholar] [CrossRef]
- Quinlan, J.R.; Compton, P.J.; Horn, K.A.; Lazurus, L. Inductive knowledge acquisition: A case study. In Proceedings of the Second Australian Conference on Applications of Expert Systems, Sydney, Australia, 14–16 May 1986. [Google Scholar]
- Wolberg, W.H.; Mangasarian, O.L. Multisurface method of pattern separation for medical diagnosis applied to breast cytology. Proc. Natl. Acad. Sci. USA 1990, 87, 9193–9196. [Google Scholar] [CrossRef] [Green Version]
- Raymer, M.; Doom, T.E.; Kuhn, L.A.; Punch, W.F. Knowledge discovery in medical and biological datasets using a hybrid Bayes classifier/evolutionary algorithm. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2003, 33, 802–813. [Google Scholar] [CrossRef]
- Zhong, P.; Fukushima, M. Regularized nonsmooth Newton method for multi-class support vector machines. Optim. Methods Softw. 2007, 22, 225–236. [Google Scholar] [CrossRef]
- Andrzejak, R.G.; Lehnertz, K.; Mormann, F.; Rieke, C.; David, P.; Elger, C.E. Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: Dependence on recording region and brain state. Phys. Rev. E 2001, 64, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Koivisto, M.; Sood, K. Exact Bayesian Structure Discovery in Bayesian Networks. J. Mach. Learn. Res. 2004, 5, 549–573. [Google Scholar]
- Nash, W.J.; Sellers, T.L.; Talbot, S.R.; Cawthor, A.J.; Ford, W.B. The Population Biology of Abalone (_Haliotis_ species) in Tasmania. I. Blacklip Abalone (_H. rubra_) from the North Coast and Islands of Bass Strait; Technical Report No. 48; Sea Fisheries Division-Department of Primary Industry and Fisheries: Hobart, Australia, 1994; ISSN 1034-3288. [Google Scholar]
- Brooks, T.F.; Pope, D.S.; Marcolini, A.M. Airfoil Self-Noise and Prediction; Technical Report, NASA RP-1218; NASA: Hampton, VA, USA, 1989. [Google Scholar]
- Simonoff, J.S. Analyzing Categorical Data; Springer: New York, NY, USA, 2003. [Google Scholar]
- Simonoff, J.S. Smooting Methods in Statistics; Springer: New York, NY, USA, 1996. [Google Scholar]
- Yeh, I.C. Modeling of strength of high performance concrete using artificial neural networks. Cem. Concr. Res. 1998, 28, 1797–1808. [Google Scholar] [CrossRef]
- Harrison, D.; Rubinfeld, D.L. Hedonic prices and the demand for clean air. J. Environ. Econ. Manag. 1978, 5, 81–102. [Google Scholar] [CrossRef] [Green Version]
- Mackowiak, P.A.; Wasserman, S.S.; Levine, M.M. A critical appraisal of 98.6 degrees f, the upper limit of the normal body temperature, and other legacies of Carl Reinhold August Wunderlich. J. Am. Med. Assoc. 1992, 268, 1578–1580. [Google Scholar] [CrossRef]
- Ding, S.; Xu, L.; Su, C.; Jin, F. An optimizing method of RBF neural network based on genetic algorithm. Neural Comput. Appl. 2012, 21, 333–336. [Google Scholar] [CrossRef]
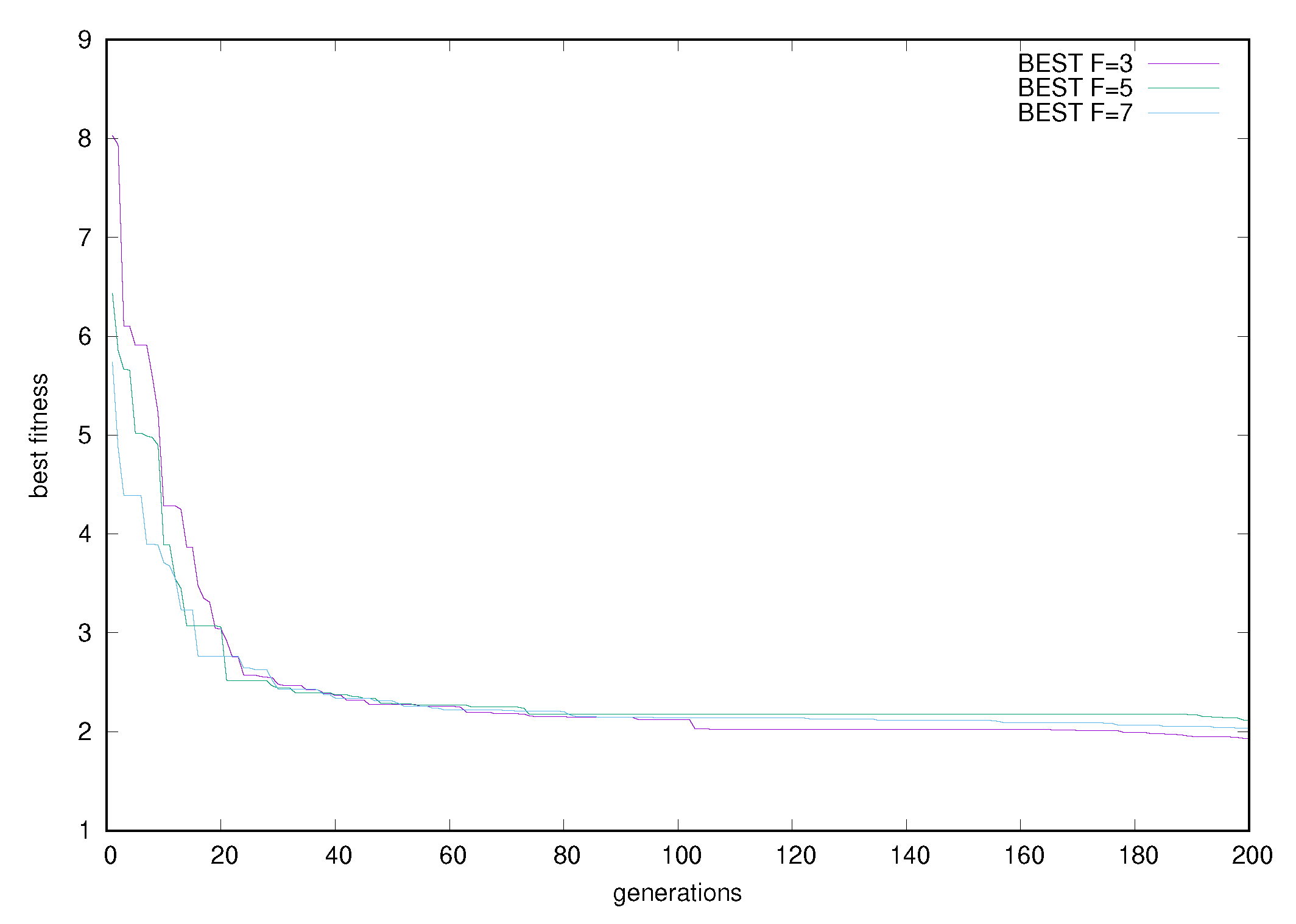

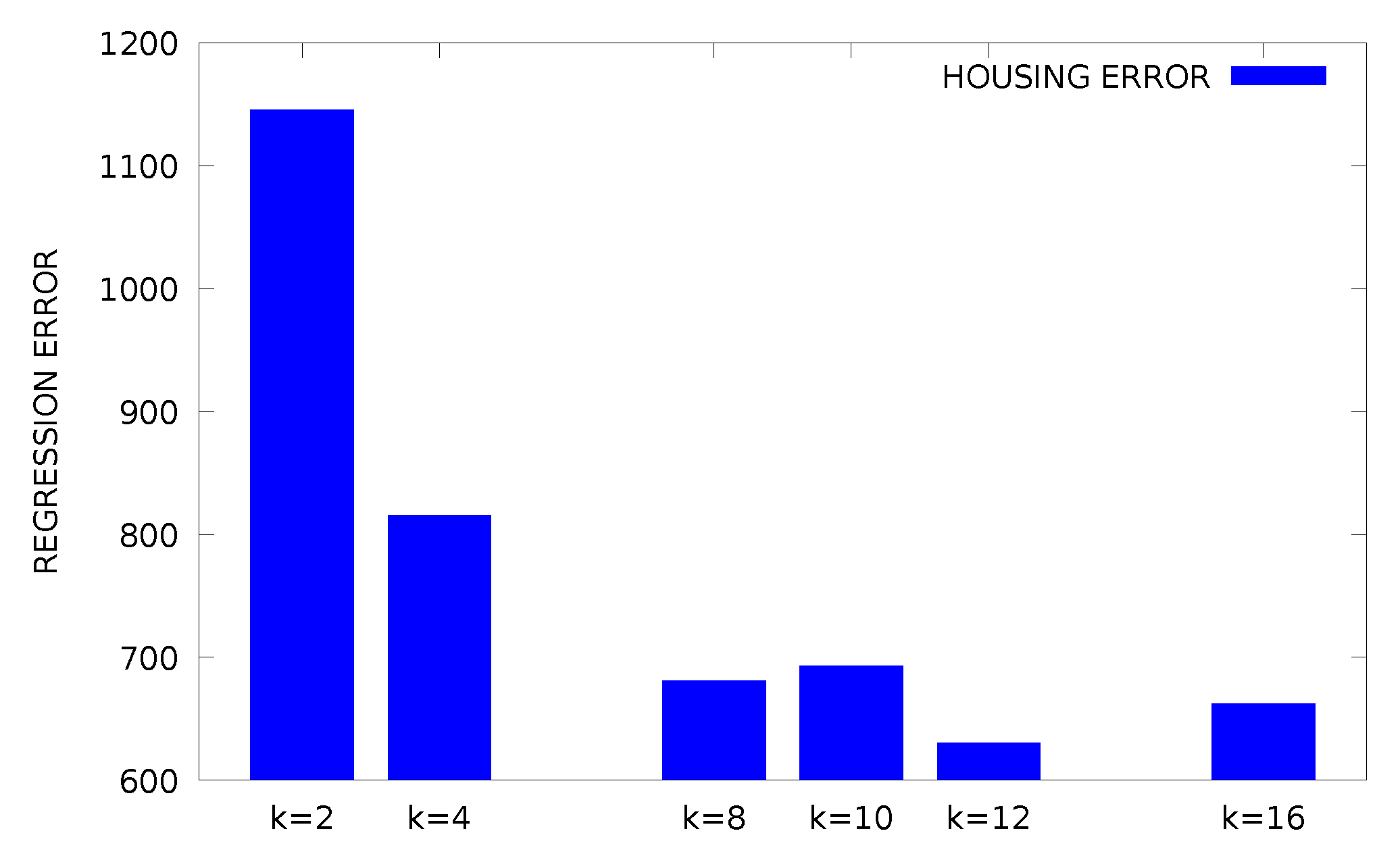


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| … | … | … | … |
| Parameter | Value |
|---|---|
| k | 10 |
| 200 | |
| 0.90 | |
| 0.05 | |
| F | 3.0 |
| 200 |
| Dataset | KRBF | GRBF | Proposed |
|---|---|---|---|
| Alcohol | 46.63% | 52.30% | 21.86% |
| Appendicitis | 12.23% | 16.83% | 16.03% |
| Australian | 34.89% | 41.79% | 22.97% |
| Balance | 33.42% | 38.02% | 12.88% |
| Cleveland | 67.10% | 67.47% | 51.75% |
| Dermatology | 62.34% | 61.46% | 37.37% |
| Glass | 50.16% | 61.30% | 49.16% |
| Hayes Roth | 64.36% | 63.46% | 35.26% |
| Heart | 31.20% | 28.44% | 17.80% |
| HouseVotes | 6.13% | 11.99% | 3.67% |
| Ionosphere | 16.22% | 19.83% | 10.33% |
| Liverdisorder | 30.84% | 36.97% | 28.73% |
| Mammographic | 21.38% | 30.41% | 17.25% |
| Parkinsons | 17.42% | 33.81% | 17.37% |
| Pima | 25.78% | 27.83% | 24.00% |
| Popfailures | 7.04% | 7.08% | 5.44% |
| Regions2 | 38.29% | 39.98% | 25.81% |
| Ring | 21.65% | 50.36% | 2.09% |
| Saheart | 32.19% | 33.90% | 29.38% |
| Segment | 59.68% | 54.25% | 39.44% |
| Sonar | 27.85% | 34.20% | 19.62% |
| Spiral | 44.87% | 50.02% | 18.98% |
| Tae | 60.07% | 61.78% | 52.44% |
| Thyroid | 10.52% | 8.53% | 7.12% |
| Wdbc | 7.27% | 8.82% | 5.29% |
| Wine | 31.41% | 31.47% | 8.67% |
| Z_F_S | 13.16% | 23.37% | 4.21% |
| ZO_NF_S | 9.02% | 22.18% | 4.17% |
| ZONF_S | 4.03% | 17.41% | 2.18% |
| ZOO | 21.93% | 33.50% | 9.00% |
| Dataset | KRBF | GRBF | Proposed |
|---|---|---|---|
| Abalone | 2559.48 | 4161.66 | 1960.22 |
| Airfoil | 5.49 | 18.15 | 0.58 |
| Anacalt | 11.628 | 5.58 | 0.003 |
| BK | 0.17 | 0.21 | 0.23 |
| BL | 0.05 | 0.019 | 0.0009 |
| Concrete | 1.15 | 1.50 | 0.52 |
| Housing | 2884.09 | 4784.50 | 693.22 |
| Laser | 2.35 | 6.94 | 1.04 |
| MB | 11.33 | 2.44 | 0.63 |
| NT | 72.14 | 0.22 | 0.09 |
| Quake | 15.36 | 171.43 | 7.86 |
| Dataset | Precision KRBF | Recall KRBF | Precision Proposed | Recall Proposed |
|---|---|---|---|---|
| Housevotes | 90.61% | 95.60% | 96.44% | 94.25% |
| Spiral | 55.53% | 55.93% | 82.93% | 84.66% |
| ZONF_S | 92.76% | 87.23% | 97.27% | 94.55% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsoulos, I.G.; Tzallas, A.; Karvounis, E. A Two-Phase Evolutionary Method to Train RBF Networks. Appl. Sci. 2022, 12, 2439. https://doi.org/10.3390/app12052439
Tsoulos IG, Tzallas A, Karvounis E. A Two-Phase Evolutionary Method to Train RBF Networks. Applied Sciences. 2022; 12(5):2439. https://doi.org/10.3390/app12052439
Chicago/Turabian StyleTsoulos, Ioannis G., Alexandros Tzallas, and Evangelos Karvounis. 2022. "A Two-Phase Evolutionary Method to Train RBF Networks" Applied Sciences 12, no. 5: 2439. https://doi.org/10.3390/app12052439
APA StyleTsoulos, I. G., Tzallas, A., & Karvounis, E. (2022). A Two-Phase Evolutionary Method to Train RBF Networks. Applied Sciences, 12(5), 2439. https://doi.org/10.3390/app12052439