1. Introduction
Comprehensive information about the environment is one of the important properties of advanced driver-assistance system (ADAS). In order to thoroughly understand the road scenes, it is necessary to detect all the relevant surrounding objects with a sufficient range of view. During the last few years, deep-learning based methods show the most promising performance with the development of open-source frameworks [
1,
2,
3,
4,
5]. This approach requires a relatively large computational resource, but modern hardware can easily be adapted to real-time detection.
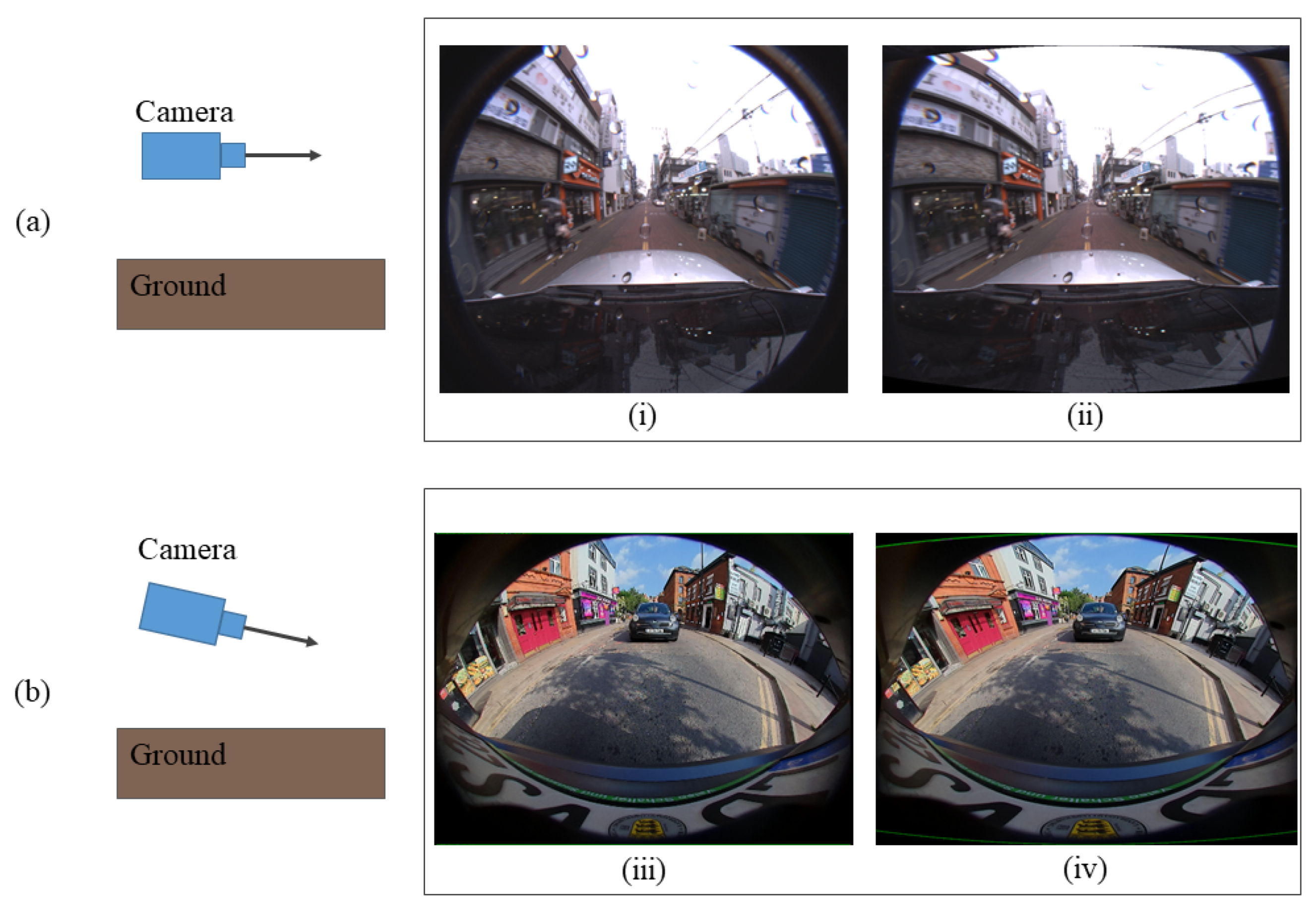
One of the core features in systems-on-board autonomous vehicles is perception. A combination of sensors, such as cameras, radar, lidar, and GPU, are used to collect the data around the environment and extract the relevant information in the perception stage. In a low-cost sensor setup, 2D cameras with a large field of view (FOV) can efficiently cover a large area around the vehicle and ensure the safety of the autonomous driving. Especially, the fisheye camera can obtain visual information with a more than 180° field of view, thus the fisheye camera is widely used in ground, aerial, and underwater autonomous robot as well as surveillance [
6,
7,
8].
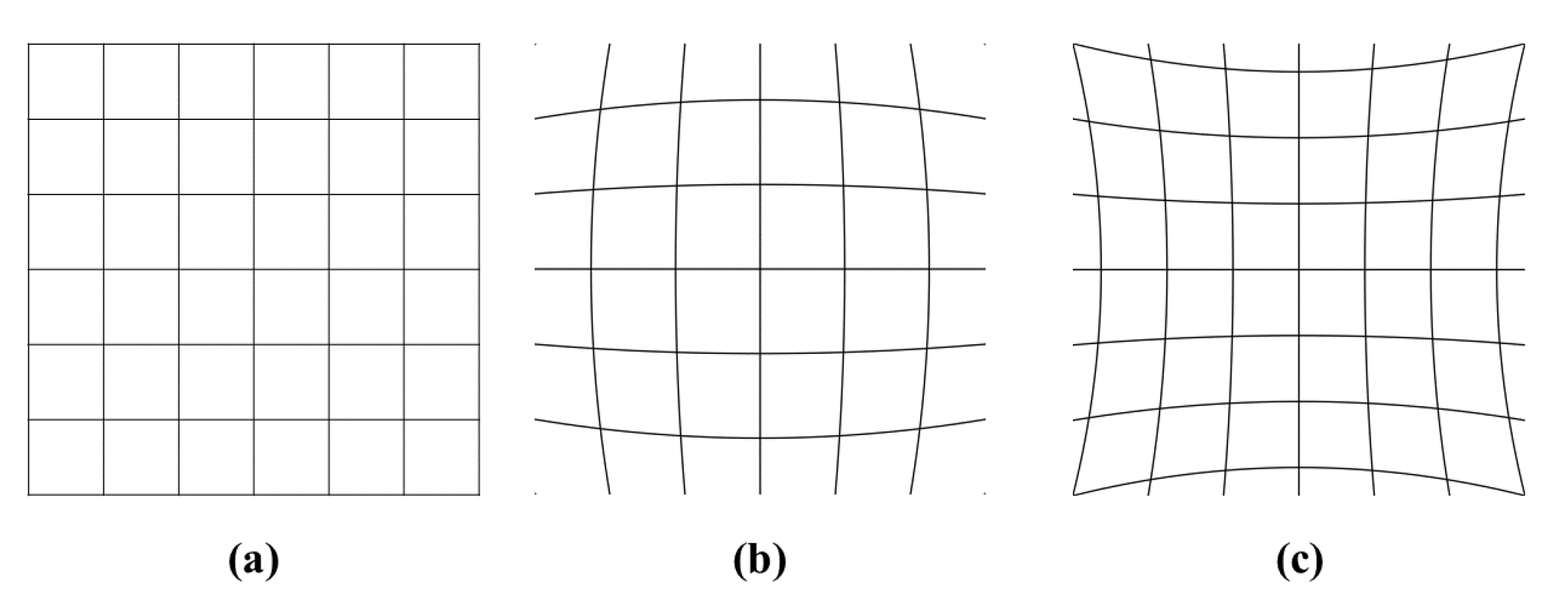
However, this advantage comes at the cost of strong radial distortion. The resulting issues, such as curving and diagonal tilting of objects are increasingly severe towards the edges of the fisheye image. Therefore, the shapes of the objects in the same category are less conformal to each other in different images and the target bounding box contains more unnecessary background. Another notable feature of the fisheye camera is that both relative size and distance are exaggerated. The ultra-wide angle lens shows nearby objects appear much larger, while objects located far away or in the boundary appear much smaller than the lens of perspective cameras. Consequently, the already poor performance of object detectors for small or tiny objects is further degraded.
Due to the unique feature of the strong radial distortion, object detection in the fisheye image must solve the two problems:
To solve these problems, many investigations have been introduced and they are categorized in the following two main approaches:
The first approach is using the original image. Instead of fisheye image rectification or undistortion, they investigate distortion-invariant or rotation-invariant neural networks. SphereNet [
9] suggests a distortion-invariant neural network for the omnidirectional images, adapting the sampling grid locations of a convolutional kernel. The SphereNet kernel uses the projection of the spherical camera model to the tangent plane on the sphere, yielding filter outputs which are invariant to latitudinal rotations.
Alternatively, a rotation-invariant model which predicts object orientations is proposed by [
10,
11]. In [
10], the original fisheye image is used without undistortion to avoid the bottleneck in achieving real-time recognition performance. The road object such as vehicle and pedestrian are rotated in the boundary of the original fisheye image, thus the authors proposes a rotation invariant deep neural network. In contrast, a rotation sensitive neural network is proposed in [
11] to detect objects in the original fisheye image. The bounding box is rotated to fit the orientation of the detecting object. However, these two investigations detect road or indoor objects which size is normal compared with the image size. In their test images, the sizes of the bounding boxes of pedestrian, vehicle, and computer monitor are generally large compared with the image size.
In [
12], the original fisheye image is trained without any lens parameters or calibration patterns. Instead, the authors propose a contour-based object detector to cope with the distortion of the fisheye image. A ’distortion shape matching’ strategy is proposed to train the contour information of objects using a fisheye image detection network. A small object detection method in the fisheye image is proposed in [
13]. The authors propose a concatenated feature pyramid, which is a variant of the Feature Pyramid Network (FPN), to find very small road objects in a fisheye image. They add an additional concatenation network to the original FPN in YOLOv3 to increase the small object detection performance.
The second approach is based on the rectification or undistortion of the original fisheye image. The generative-adversarial network is adapted to rectify the fisheye image in [
14,
15]. However, these studies require complex computations, hindering the real-time performance that are required from one-stage object detectors. The cylindrical projection model is also used to rectify the fisheye image and to find the 3D objects in the road scene [
16]. The authors propose that training the rectilinear images is better than using the original fisheye image for detecting the 3D road objects. The authors use their own fisheye image database for performance comparison. The images are captured by using a side view camera, thus the number of road objects is smaller than that in the standard benchmark.
As described above, recent investigations on the fisheye image object detection mostly utilize the original image rather than using rectification or undistortion method. This is due to the strong radial distortion of the fisheye image. Some investigations utilize the conventional cylindrical or spherical rectification; however, the rectified images still contain object size variation due to barrel or pincushion distortions.
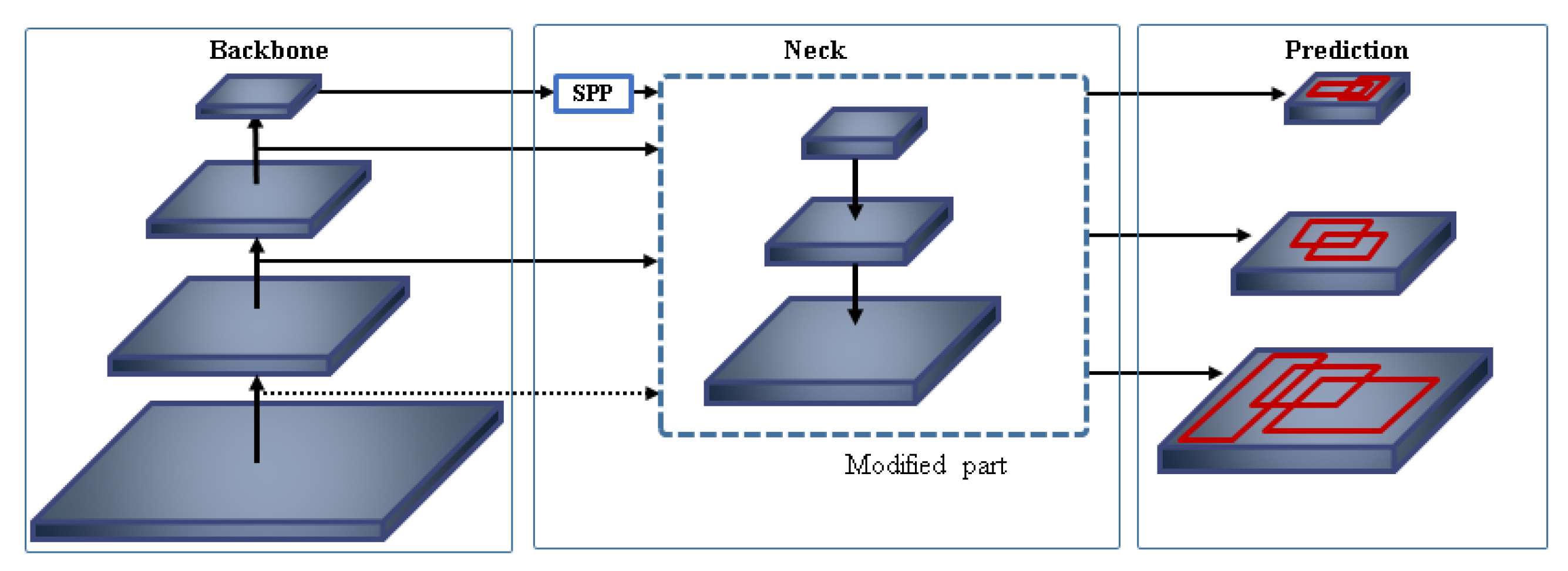
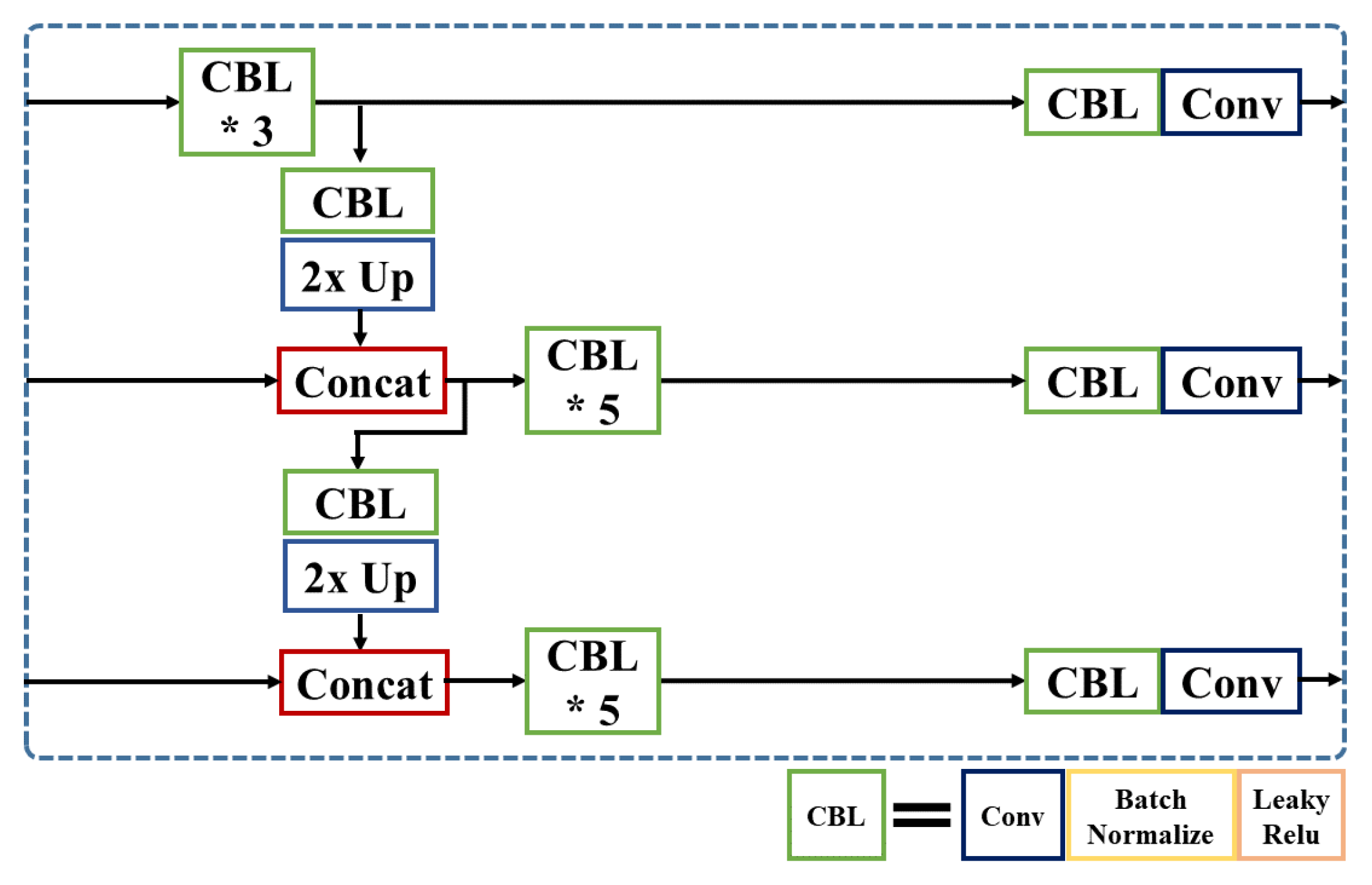
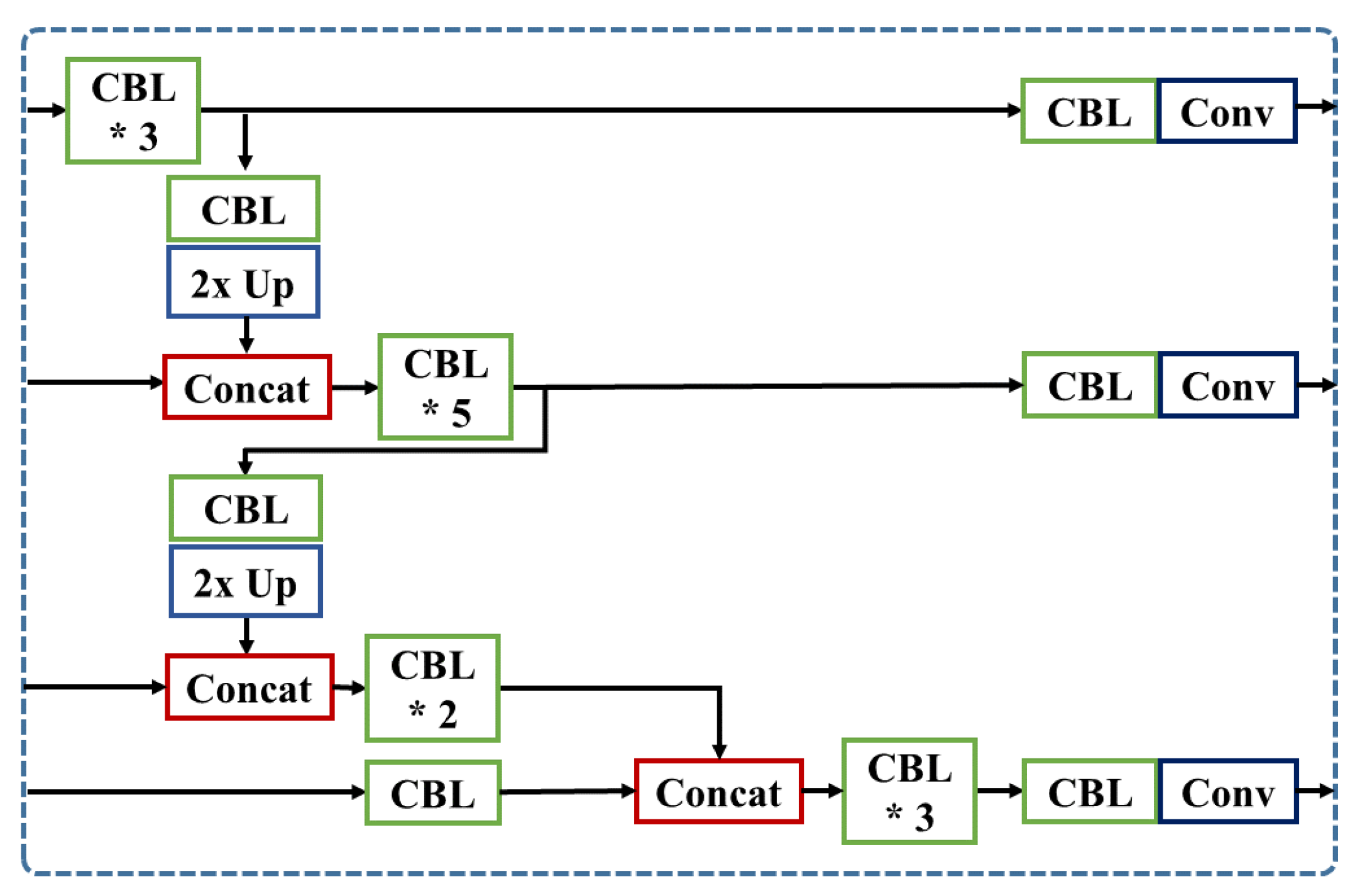
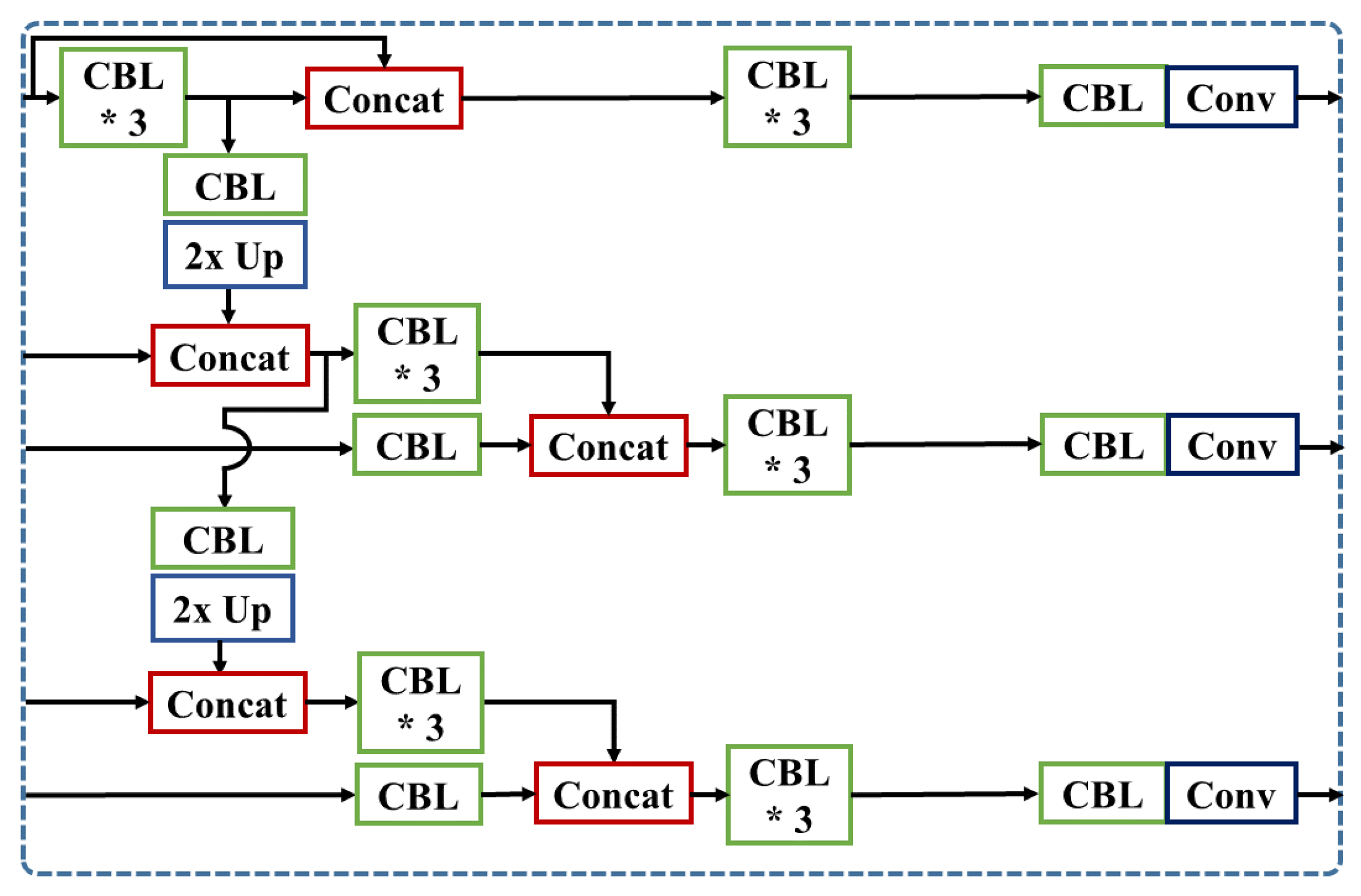
Therefore, in this paper, we first propose a new spherical-based projection in real-time speed to solve radial distortion and detect small objects with increased pixel information. Second, we propose a multi-level feature concatenation to a convolutional neural network, suggesting three types of concatenated YOLOv3 with Spatial Pyramid Pooling (SPP) module [
17,
18,
19,
20]. We evaluate our solution with several public datasets, as well as our new collection of images gathered with a 185° fisheye lens. The major contributions of this study are noted as follows.
Introduction of a new front-view fisheye dataset consisting of 5K bounding box annotations.
Proposal of an effective spherical projection model on fisheye images based on the size of objects in the dataset.
Proposal and analysis of three feature concatenation methods to reduce small objects detection issues in real-time object detector.
Figure 1 shows some examples of object detection bounding boxes from several types of fisheye images. The size of bounding boxes is different according to the size of the detected objects. In the previous investigations, the detected objects are generally large in the image. Thus, the detection is relatively easier than small or tiny objects. In contrast, in this paper, we propose a deep neural network to detect not only regular but also small or tiny road objects. In one of our results in
Figure 1g, the bounding box size of the detected object is very tiny compared with the size of the rectified image. To achieve the best performance of tiny object detection, we propose a new spherical projection model and feature concatenation methods.
In
Section 2, we describe related works on commonly used fisheye camera projection models, fisheye lens dataset, and deep-learning-based object detection models.
Section 3 briefly describes the proposed projection algorithm, the details of the experimental setup, and concatenated model design. In
Section 4, we present the experiments and analysis of the results. Finally,
Section 5 and
Section 6 discuss the quantitative improvement of the proposed method based on the results of four datasets and conclude the paper.
6. Conclusions
This paper proposes a deep neural network for detecting small and tiny objects in fisheye images. Nowadays, the use of the fisheye image is increasing because of the unique advantage of obtaining ultra-wide field of views. However, object detection in the fisheye image suffer from too small object size, curving and tilting in the image boundary. In this paper, we propose to transform the original fisheye image to an effective spherical projection image using the expansion weight. Using two scale parameters, central or marginal areas of spherical images are expandable for reducing the effect of radial and overall size distortions to the objects.
Additionally, we propose three multi-level feature concatenation methods and analyze the effect of small object detection: SCat, LCat, SLCat. With short-skip concatenated layers and additional convolutions, the SCat achieves higher accuracy on complex urban scene datasets. From the LCat model, we have shown that the feature concatenation with a too shallow layer without sufficient convolution layers increases the difficulties to extract important features for the prediction layers. The SLCat network, combining short and long skip-layers, mostly presents better performance compared to the baseline model. Finally, we provide a fisheye dataset from one front view camera for autonomous driving with 2D bounding box annotation files, hoping the release of this dataset can help the development of fisheye lens related research.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}