
Probabilistic Models for Competence Assessment in Education


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Related Work
1.2. Bayesian Networks
1.3. Representation
- The vertices represent the random variables that we model.
- For each vertex , there is a conditional probability distribution .
- Given a node X in a Bayesian network, its parent nodes are the set of nodes with a direct edge towards X.
- Given a node X in a Bayesian network, its children nodes are the set of nodes with an incoming edge from X.
- Given a node X in a Bayesian network, its ancestors are given by the set of all variables from which we can reach X through a directed, arbitrarily long path.
- Given the set of all the variables modeled in a Bayesian network, , an ancestral ordering of the variables is followed when traversing the network; if every time we reach a variable X, we have already visited its ancestors.
- Given a node X in a Bayesian network, its Markov blanket is given by its parents, its children, and the parents of its children.
1.4. Flow of Probabilistic Influence
- If W is an intermediate node and all the edges go in the same direction (Figure 3), then an update in X will be reflected in Y if and only if W is not an observed variable, and vice versa: an update in Y will be reflected in X if and only if W is not an observed variable.
- The same applies if W is a parent of two children X and Y (Figure 4). Again, there will be a flow of probabilistic influence from X to Y if and only if W is not observed.
- Finally, if X and Y are parents of W (v-structure, Figure 5), then the situation reverses, and there is a flow of probabilistic influence from X to Y if and only if W is observed.
- Let be a DAG.
- Let be a trail in .
- A trail is active given a set of observed variables W if
- Whenever there is a v-structure , or one of its descendants is in W.
- no other node along the trail is in W.
2. Materials and Methods
3. Results
3.1. Probabilistic Models of Peer Assessment
3.1.1. Personalized Automated Assessments
Model
Direct Trust
Indirect Trust
Incremental Updates
- Initially, the default direct trust distribution between any two peers i and j is the one describing ignorance (i.e., the flat equiprobable distribution ). When j evaluates an object that was already assessed by i, is updated as follows:
- Let for be the probability distribution of the assessment difference between i and j. The new assessment must be reflected in a change in the probability distribution. In particular, is increased a fraction of the probability of X not being equal to x:For instance, if the probability of x is 0.6 and is 0.1, then the new probability of x becomes . As in the example, the value of must be closer to 0 than to 1, for considerable changes can only be the result of information learned from the accumulation of many assessments.
- The resulting is then normalized by computing the distribution that respects the new computed value and has a minimal relative entropy with the previous probability distributions:where is a probability value in the original distribution, is a probability value in the potential new distribution , and specifies the constraint that needs to be satisfied by the resulting distribution.These direct trust distributions between peers are stored in a matrix .
- To encode the decrease in the integrity of information with time (information decays with time, I may be sure today about your high competence playing chess, but maybe in five years time I will be no longer sure if our interactions stop. You might have lost your abilities during that period), the direct trust distributions in are decayed towards a decay limit distribution after a certain grace period. In our case, the limit distribution is the flat equiprobable . When a new evaluation updates a direct trust distribution , is first decayed before it is modified.
- The indirect trust distributions between and each peer are stored in a distributions vector .Initially, contains the probability distributions describing ignorance . When matrix is updated, is also updated as a product of its former version times matrix :
- If a direct trust distribution exists between and j, the indirect trust distribution is overwritten with after the update of the indirect trust distributions.
3.1.2. Tuned Models of Peer Assessment in MOOCs
- The assignment’s true score, . In the case of the implementation presented here, this is the teacher’s grade.
- The grader’s bias, . This bias reflects a grader’s tendency to either inflate or deflate their assessment by a certain number of percentage points. The lower these biases, the more accurate the grades will be.
- The grader’s reliability, , reflecting how close on average a grader’s peer assessments tend to land near the corresponding assignment’s true score after having corrected for bias. In this context, reliability is a synonym for precision or inverse variance of a normal distribution. Notice that the reliability of every grader is fixed to be the same value.
Partially Known Parameters
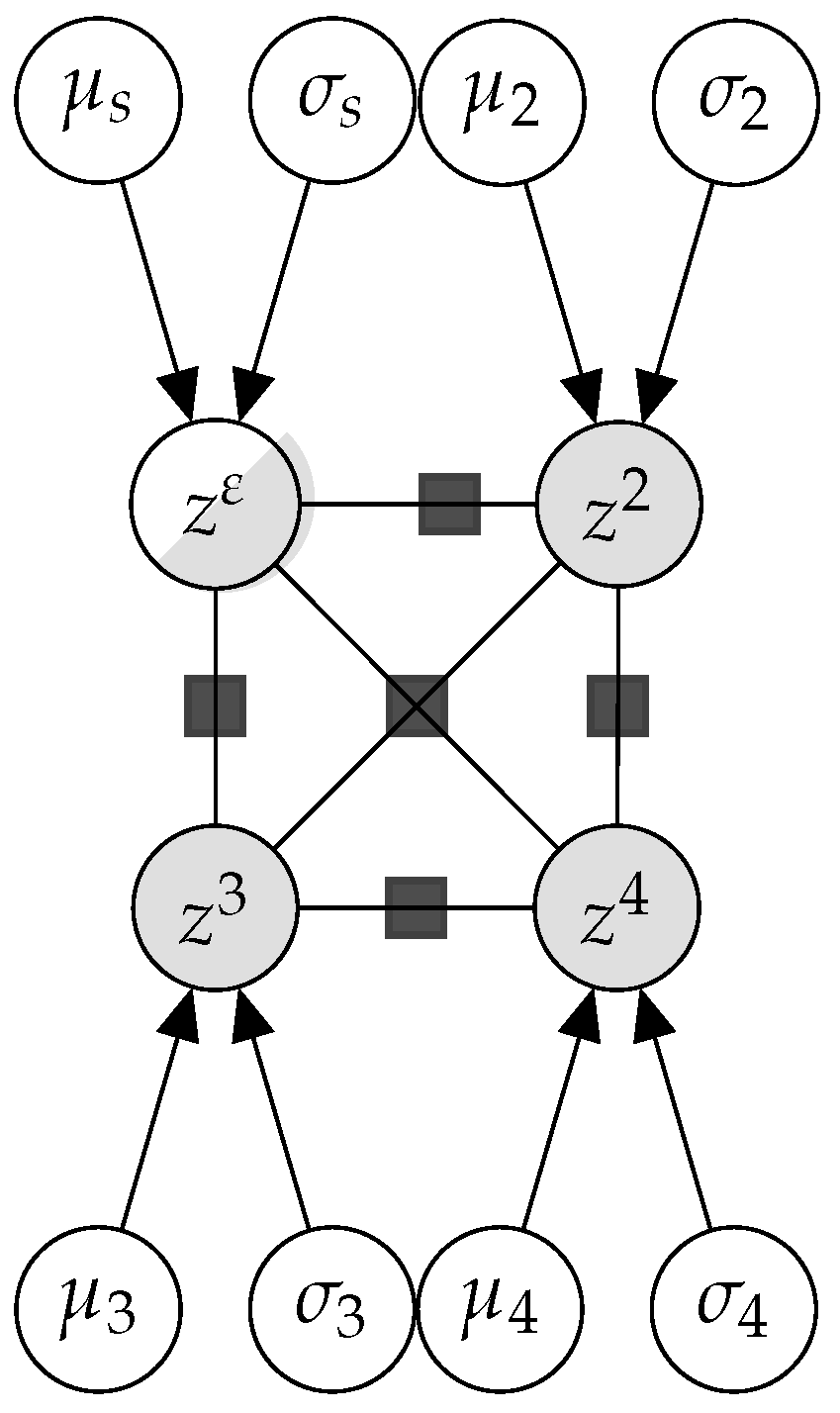
3.1.3. PG-Bivariate: A Bayesian Model of Grading Similarity
- The location vector, is composed of each of the peers’ location parameters separately.
- The covariance matrix contains the individual variances in its diagonal. The off-diagonal components codify the correlations between and when grading.
Partially Known Parameters
3.2. Experiments
3.2.1. Experiments on Bayesian Networks
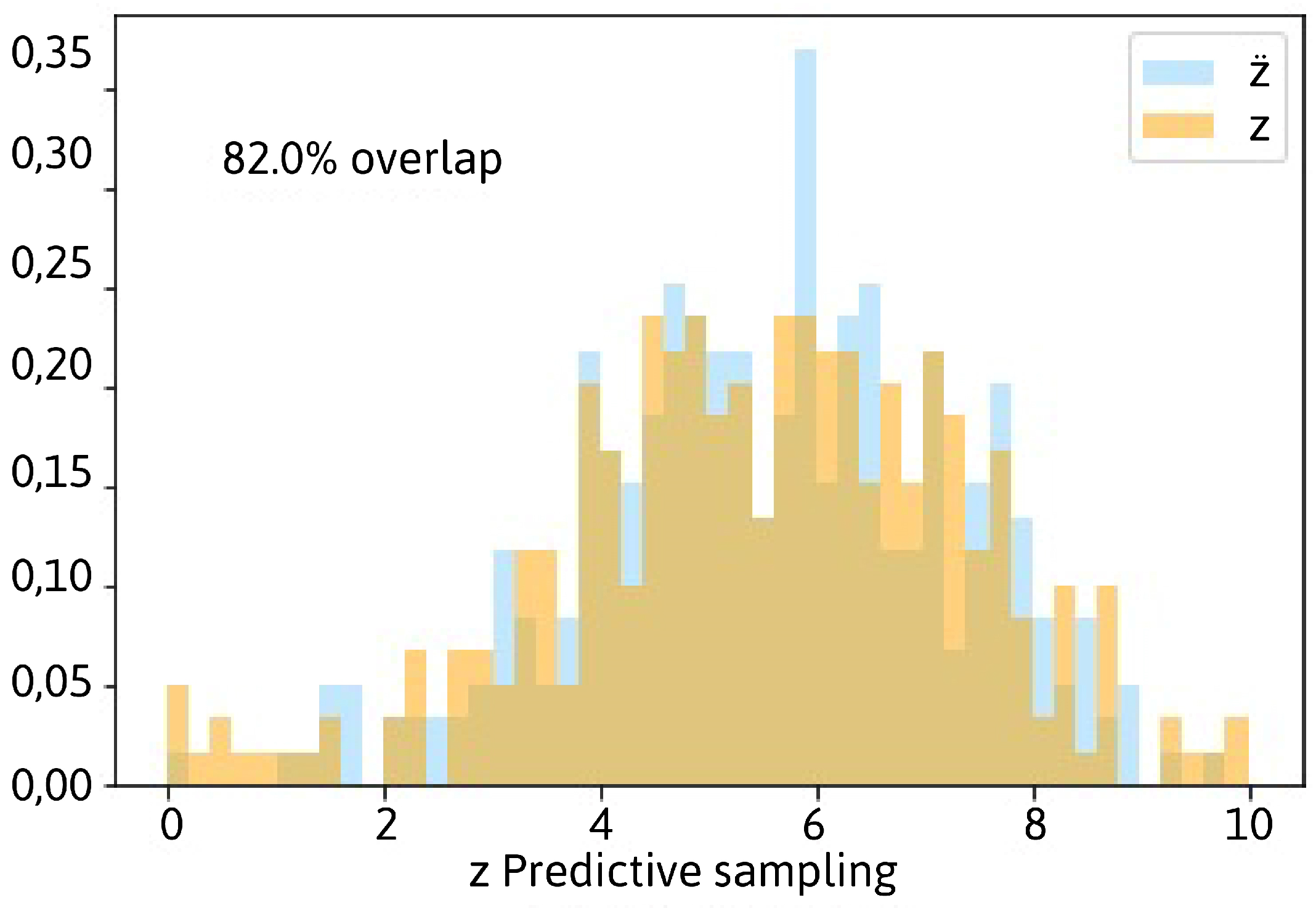
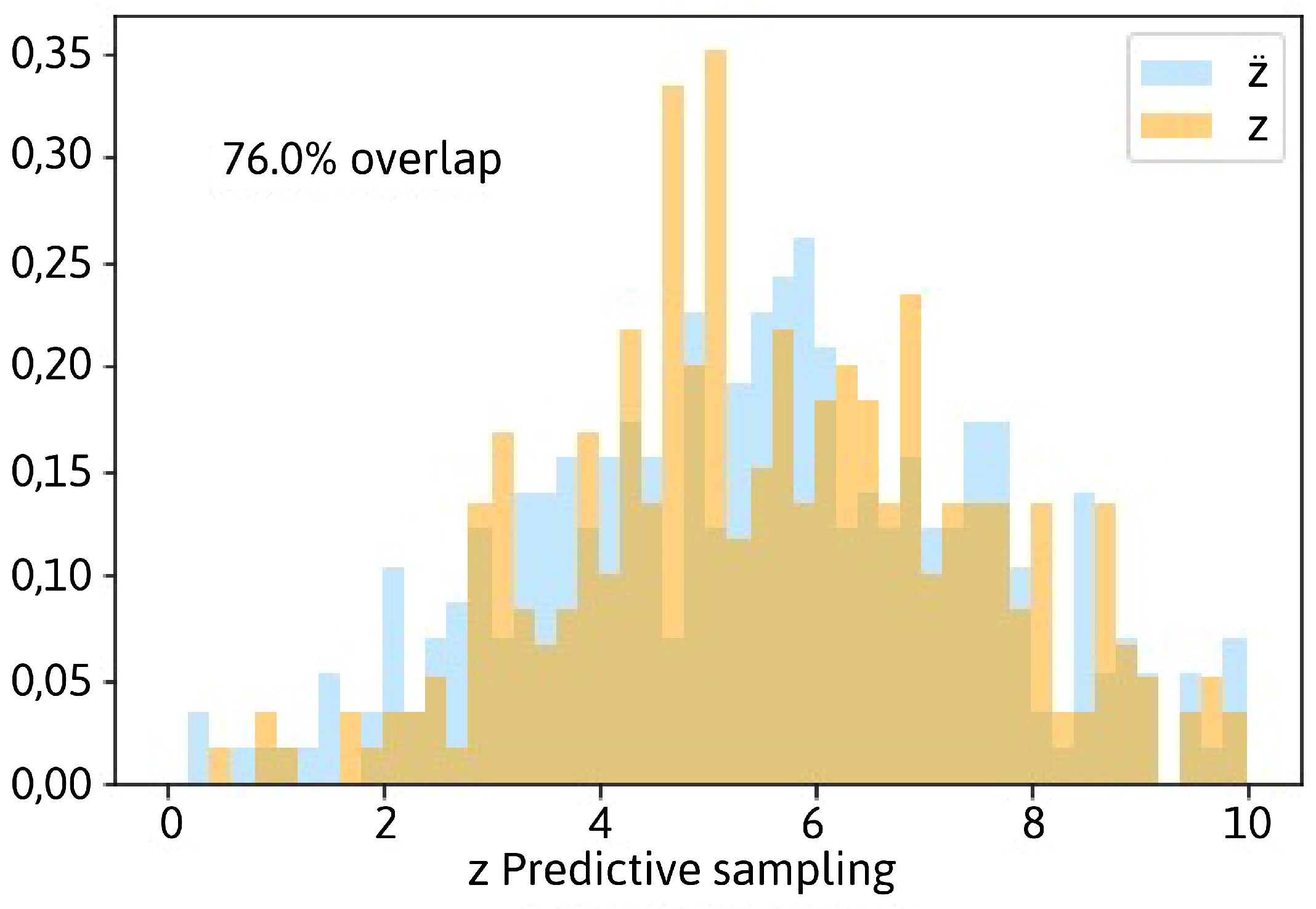
Posterior Predictive Sampling
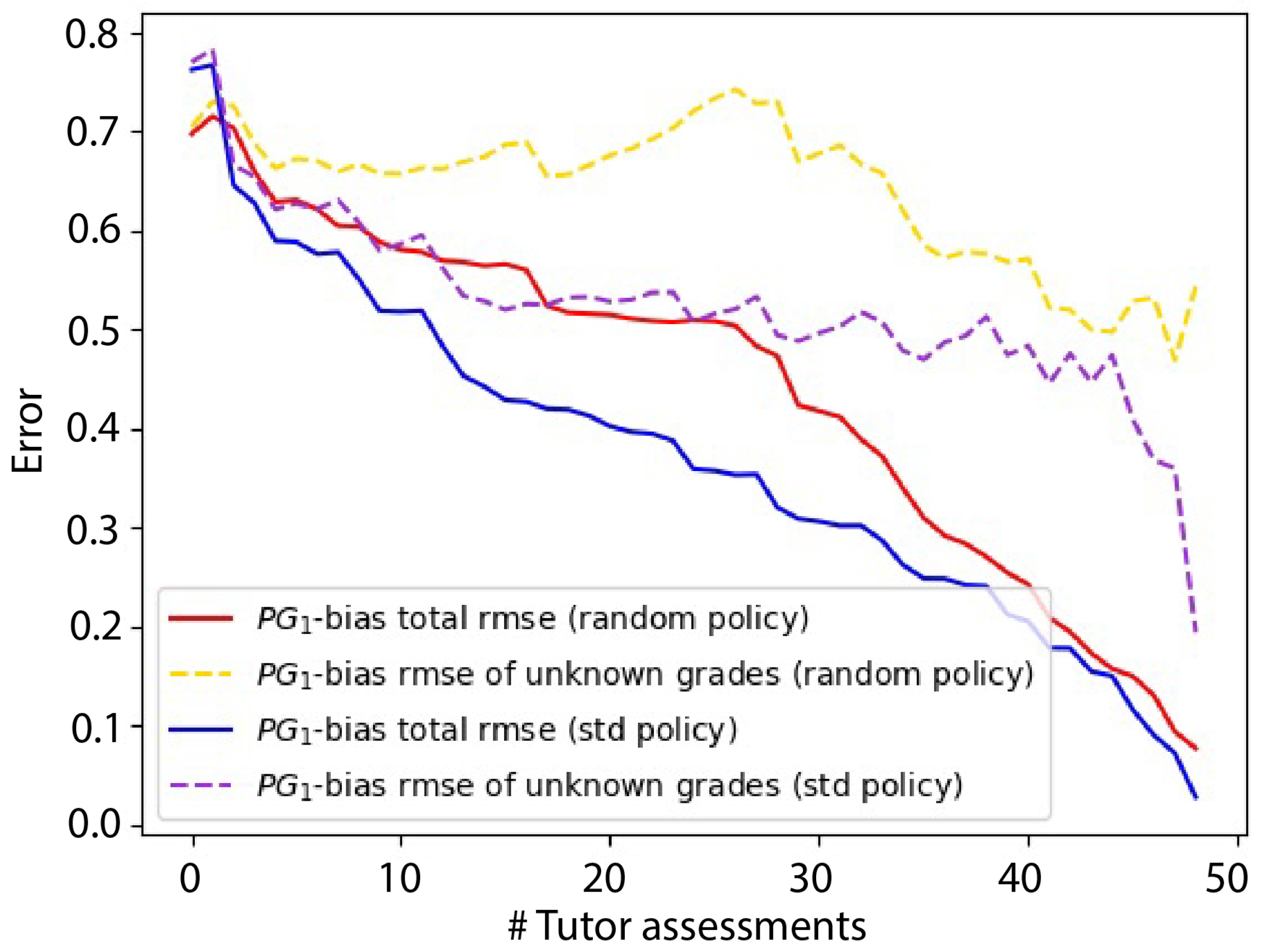
Studying the Error Evolution
- Random choice (baseline): The next observed ground truth is chosen randomly.
- Total decreasing policy: At each iteration, we picked and observed the true grade (i.e., the teacher’s grade) of that student whose assessment was introducing the highest root mean squared error.
- The red line shows the evolution of the estimations’ as we introduce new ground truths following a random policy.
- The yellow, discontinuous line shows the evolution of the estimations’ without considering the known ground truths to correct for overly optimistic low error values. Additionally, in this case, a random policy for ground truth injection is followed.
- The blue line shows the evolution of the estimations’ as we introduce new ground truths following an decreasing policy.
- The violet, discontinuous line shows the same information as the yellow line for the case of the decreasing policy.
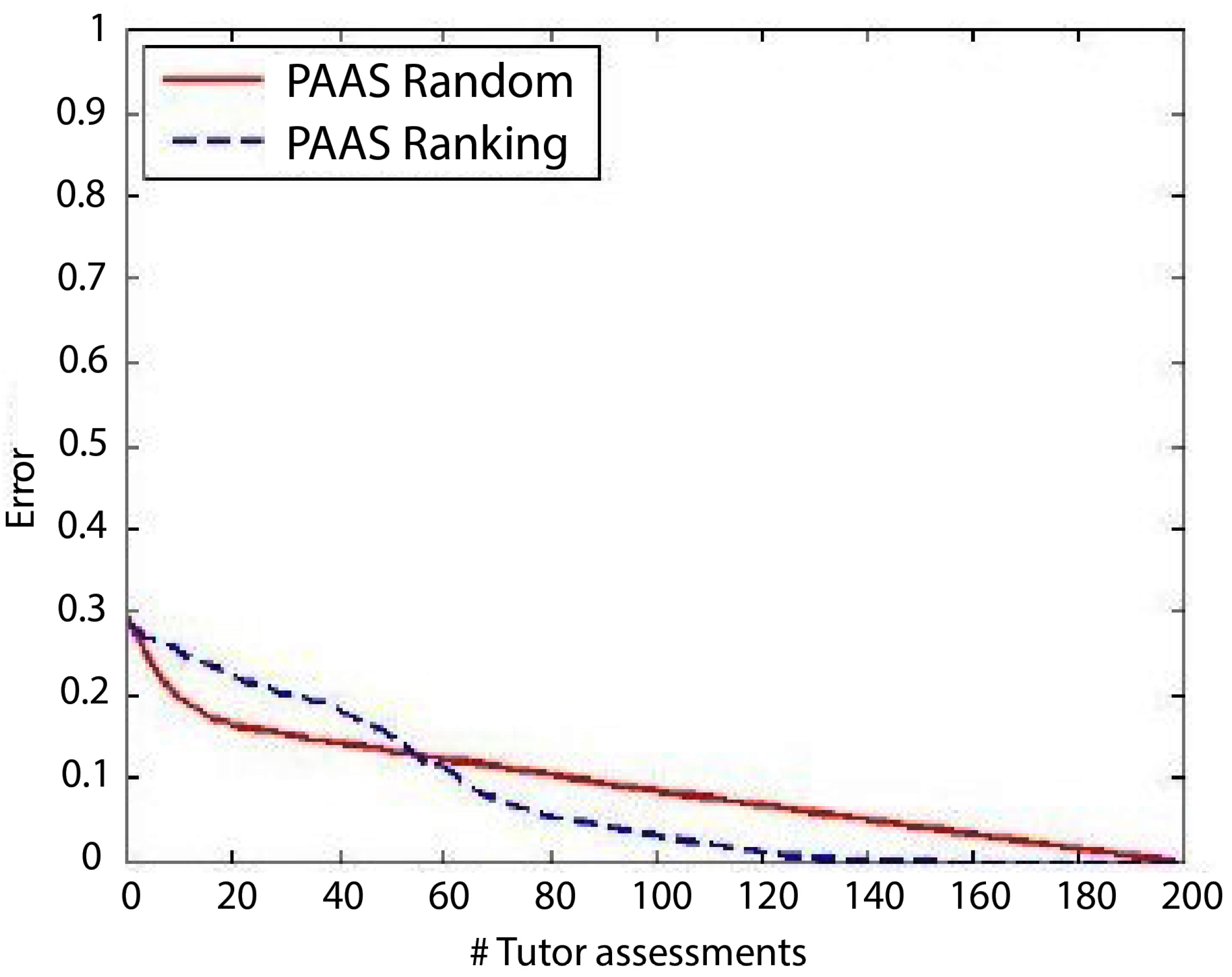
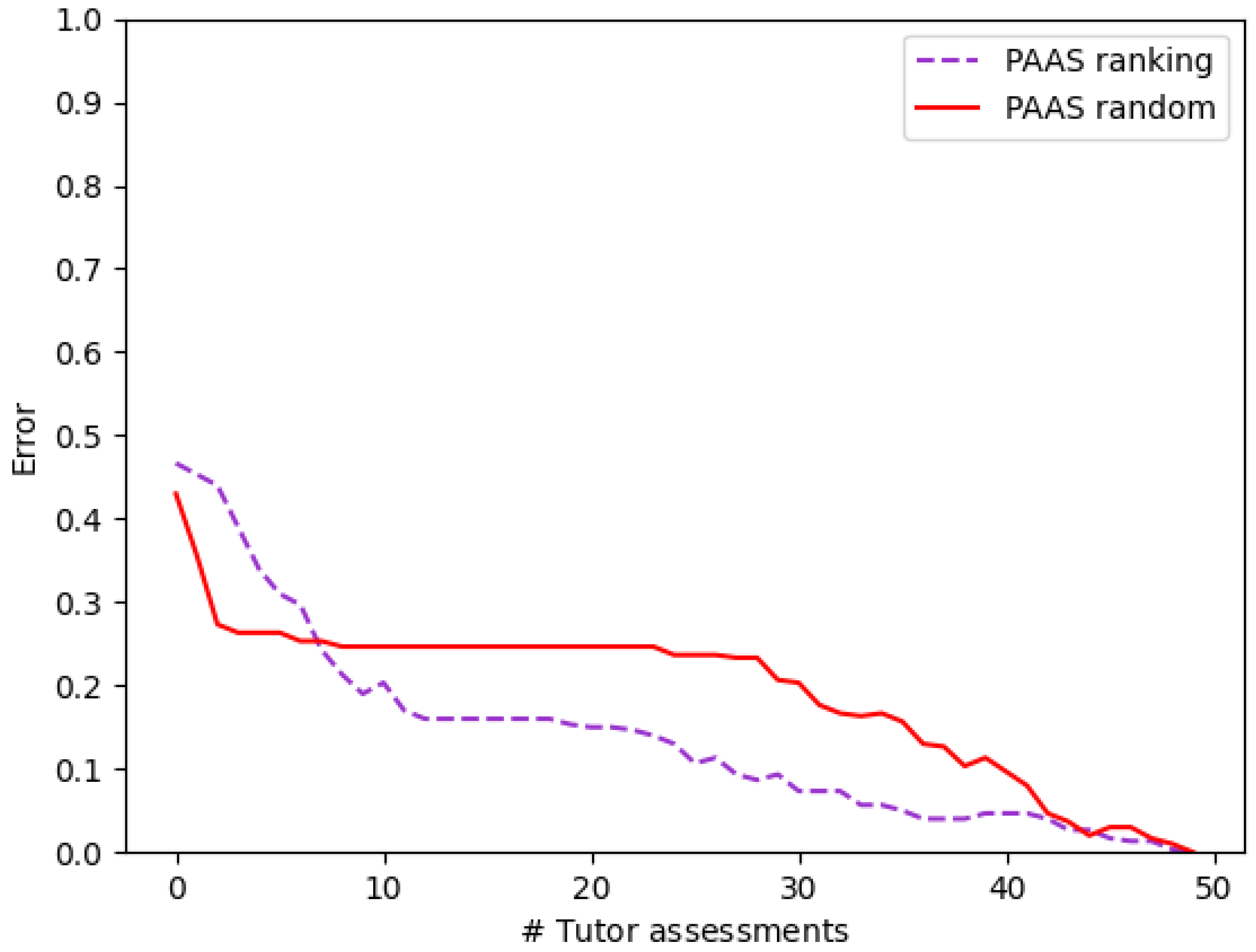
3.2.2. Experiments on PAAS
3.2.3. Comparison of the Three Models
4. Discussion
- The small number (5) of peers assessing each assignment.
- The fact that these graders are chosen randomly.
- The fact that the process is entirely anonymous concerning the students (the graders do not know who are they assessing, and the gradees do not know the identity of their graders).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| BN | Bayesian network |
| DAG | Directed acyclic graph |
| MOOC | Massive open online course |
| NLP | Natural language processing |
| PAAS | Personalized automated assessments |
| PGM | Probabilistic graphical model |
| RMSE | Root mean squared error |
References
- Schön, D.A. The Design Studio: An Exploration of Its Traditions and Potentials; International Specialized Book Service Incorporated: London, UK, 1985. [Google Scholar]
- Tinapple, D.; Olson, L.; Sadauskas, J. CritViz: Web-based software supporting peer critique in large creative classrooms. Bull. IEEE Tech. Comm. Learn. Technol. 2013, 15, 29. [Google Scholar]
- Kulkarni, C.; Wei, K.P.; Le, H.; Chia, D.; Papadopoulos, K.; Cheng, J.; Koller, D.; Klemmer, S.R. Peer and self assessment in massive online classes. ACM Trans. Comput.-Hum. Interact. (TOCHI) 2013, 20, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Piech, C.; Huang, J.; Chen, Z.; Do, C.; Ng, A.; Koller, D. Tuned models of peer assessment in MOOCs. arXiv 2013, arXiv:1307.2579. [Google Scholar]
- Sterbini, A.; Temperini, M. Correcting open-answer questionnaires through a Bayesian-network model of peer-based assessment. In Proceedings of the 2012 International Conference on Information Technology Based Higher Education and Training (ITHET), Istanbul, Turkey, 21–23 June 2012; pp. 1–6. [Google Scholar]
- Bachrach, Y.; Graepel, T.; Minka, T.; Guiver, J. How to grade a test without knowing the answers—A Bayesian graphical model for adaptive crowdsourcing and aptitude testing. arXiv 2012, arXiv:1206.6386. [Google Scholar]
- Mi, F.; Yeung, D.Y. Probabilistic graphical models for boosting cardinal and ordinal peer grading in MOOCs. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Gutierrez, P.; Osman, N.; Roig, C.; Sierra, C. Personalised Automated Assessments. In Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems, Singapore, 9–13 May 2016; Jonker, C.M., Marsella, S., Thangarajah, J., Tuyls, K., Eds.; ACM: New York, NY, USA, 2016; pp. 1115–1123. [Google Scholar]
- De Alfaro, L.; Shavlovsky, M. CrowdGrader: A tool for crowdsourcing the evaluation of homework assignments. In Proceedings of the 45th ACM Technical Symposium on Computer Science Education, Atlanta, GA, USA, 5–8 March 2014; pp. 415–420. [Google Scholar]
- Ashley, K.; Goldin, I. Toward ai-enhanced computer-supported peer review in legal education. In Legal Knowledge and Information Systems; IOS Press: Amsterdam, The Netherlands, 2011; pp. 3–12. [Google Scholar]
- Balfour, S.P. Assessing Writing in MOOCs: Automated Essay Scoring and Calibrated Peer ReviewTM. Res. Pract. Assess. 2013, 8, 40–48. [Google Scholar]
- Admiraal, W.; Huisman, B.; Pilli, O. Assessment in Massive Open Online Courses. Electron. J. E-Learn. 2015, 13, 207–216. [Google Scholar]
- The Earth Mover’s Distance (EMD); The Stanford University: Stanford, CA, USA, 1999.
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Stan Development Team. PyStan: The Python Interface to Stan. 2021. Available online: http://mc-stan.org/2 (accessed on 14 December 2021).








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
López de Aberasturi Gómez, A.; Sabater-Mir, J.; Sierra, C. Probabilistic Models for Competence Assessment in Education. Appl. Sci. 2022, 12, 2368. https://doi.org/10.3390/app12052368
López de Aberasturi Gómez A, Sabater-Mir J, Sierra C. Probabilistic Models for Competence Assessment in Education. Applied Sciences. 2022; 12(5):2368. https://doi.org/10.3390/app12052368
Chicago/Turabian StyleLópez de Aberasturi Gómez, Alejandra, Jordi Sabater-Mir, and Carles Sierra. 2022. "Probabilistic Models for Competence Assessment in Education" Applied Sciences 12, no. 5: 2368. https://doi.org/10.3390/app12052368
APA StyleLópez de Aberasturi Gómez, A., Sabater-Mir, J., & Sierra, C. (2022). Probabilistic Models for Competence Assessment in Education. Applied Sciences, 12(5), 2368. https://doi.org/10.3390/app12052368