
Applying Deep Learning to Construct a Defect Detection System for Ceramic Substrates


Abstract
:1. Introduction
1.1. Research Motives
1.2. Research Purpose
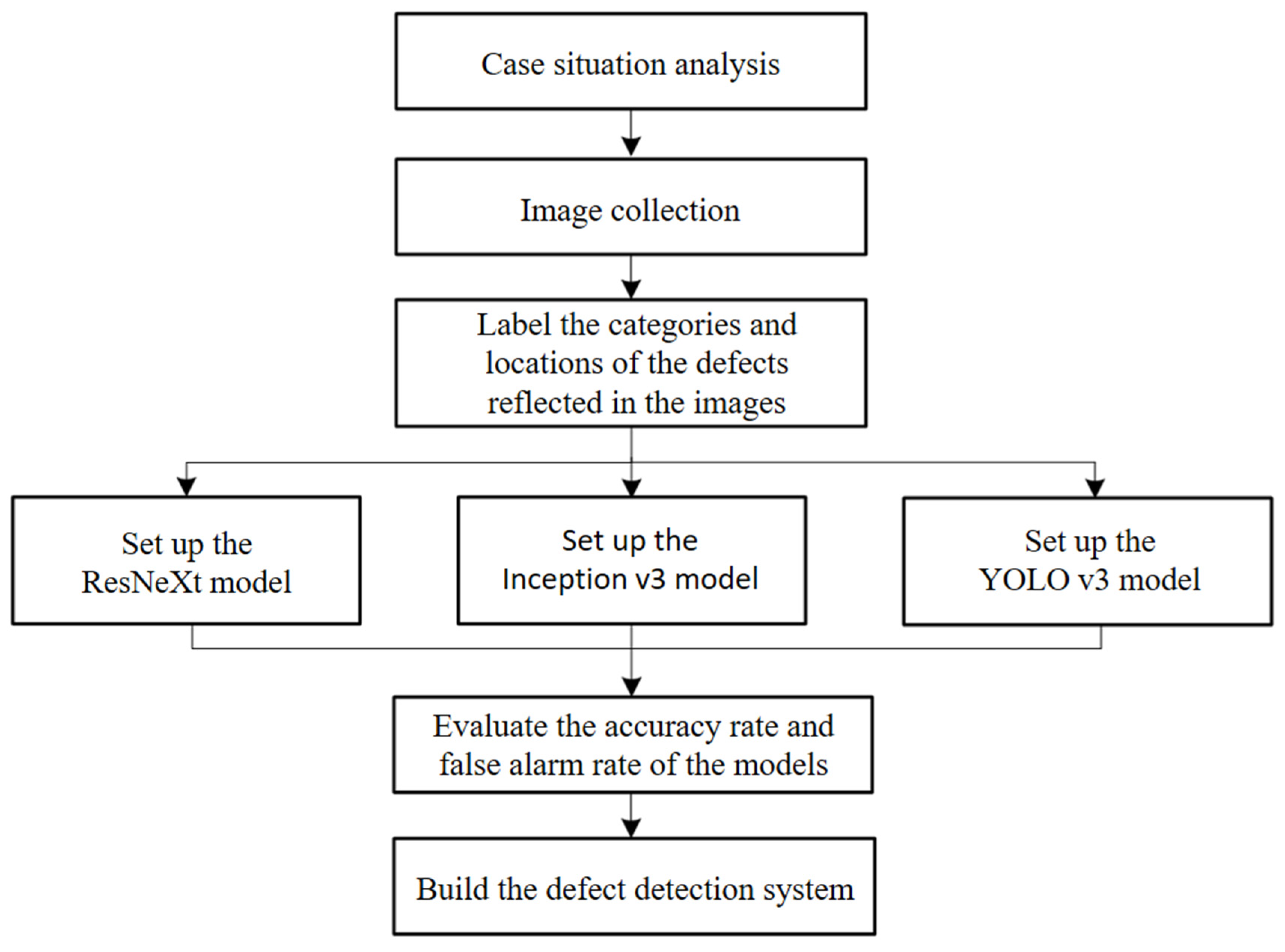
1.3. Research Process
2. Materials and Methods
2.1. Case Situation Analysis
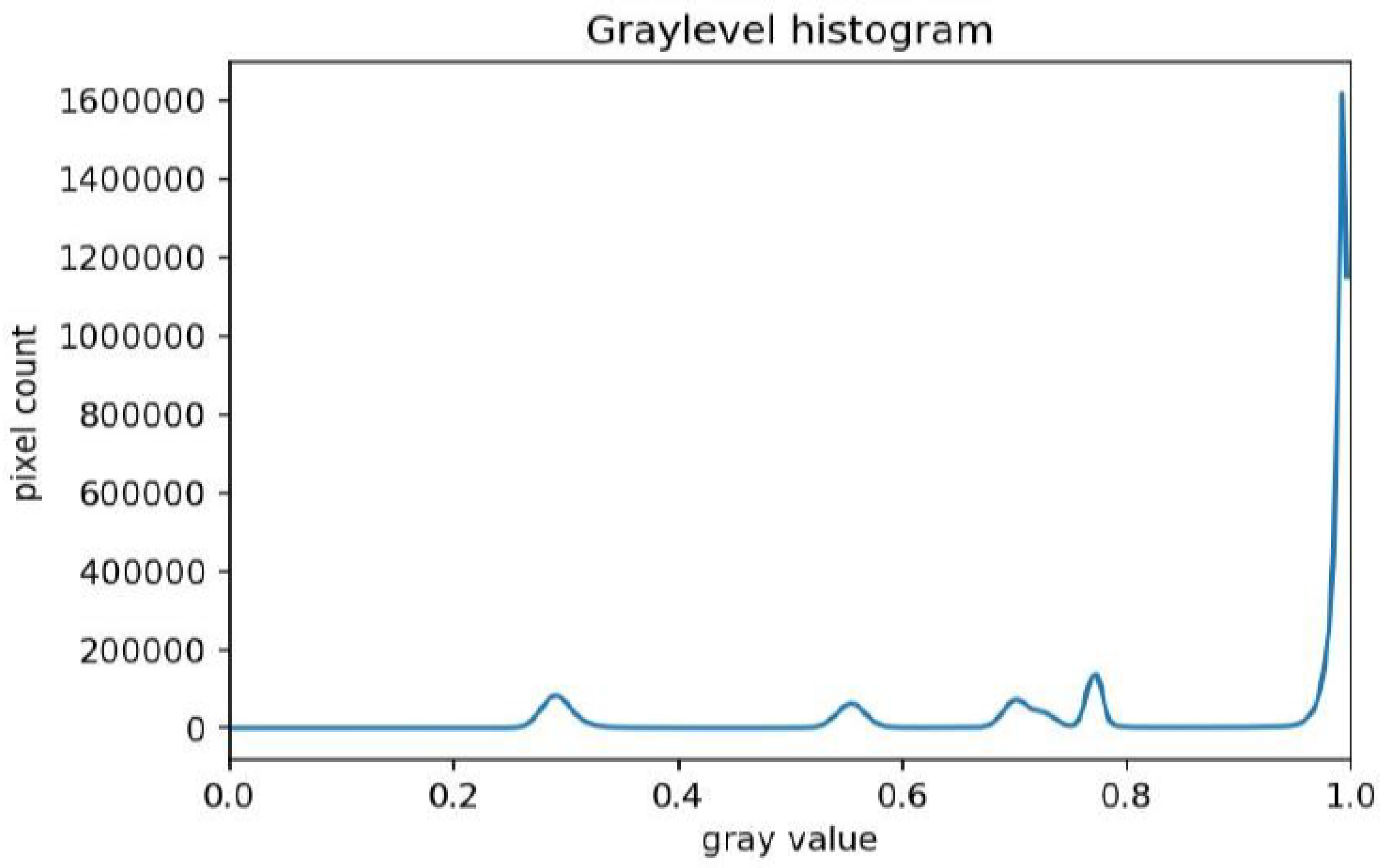
- A pixel turns on, if its gray level is >0.8.
- A pixel turns off, if its gray level is ≤0.8.
2.1.1. Image Collection
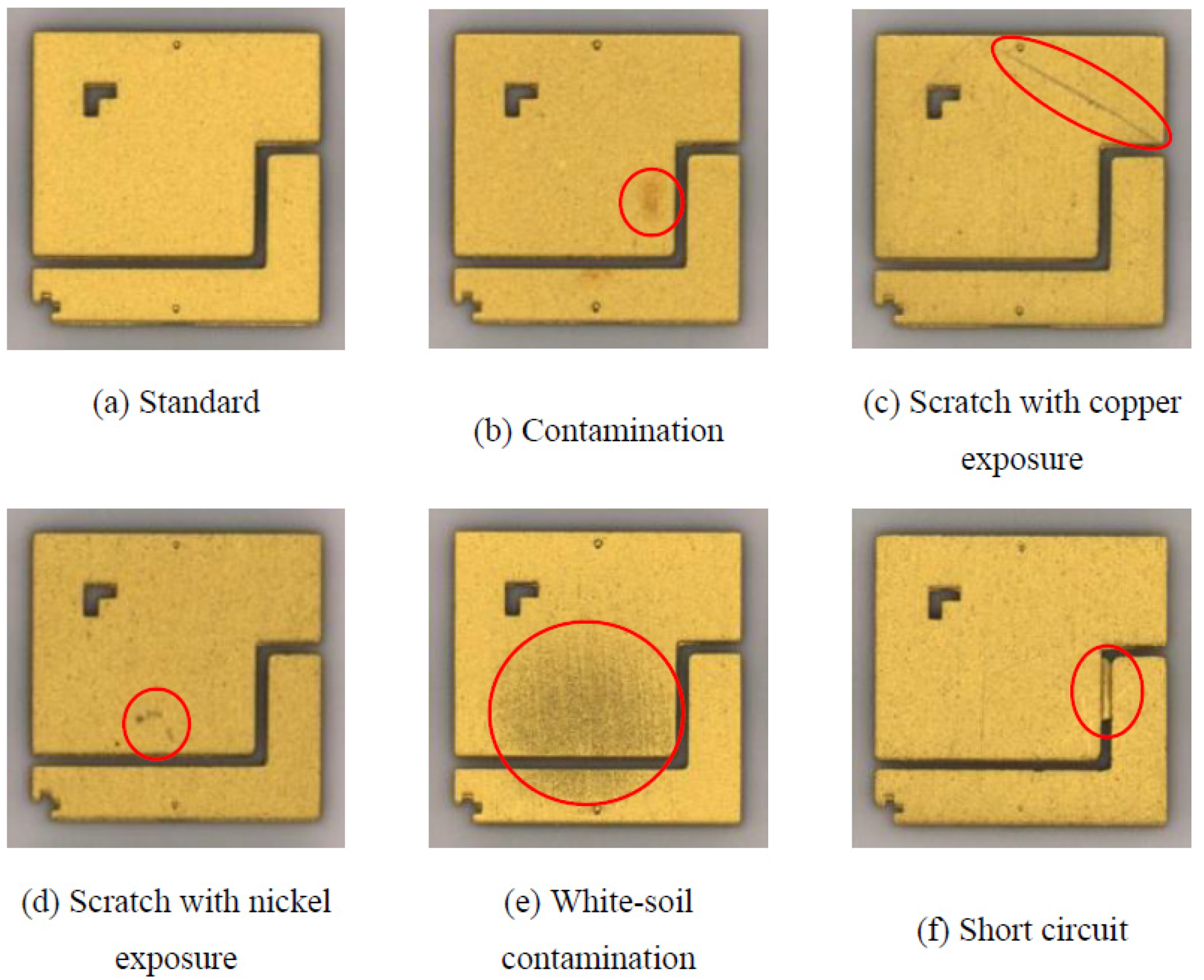
2.1.2. Image Labeling
- Contamination: Contamination was mostly due to foreign matter from the surrounding environment attaching to the products or sticky dark yellow stains in irregular shapes (Figure 4b).
- White-soil contamination: Stains in larger areas, irregular shapes, and relatively dark colors (Figure 4e).
- Short circuit: Two electrodes linked by foreign matter (Figure 4f).
2.2. Training of the ResNeXt and Inception v3 Classification Model
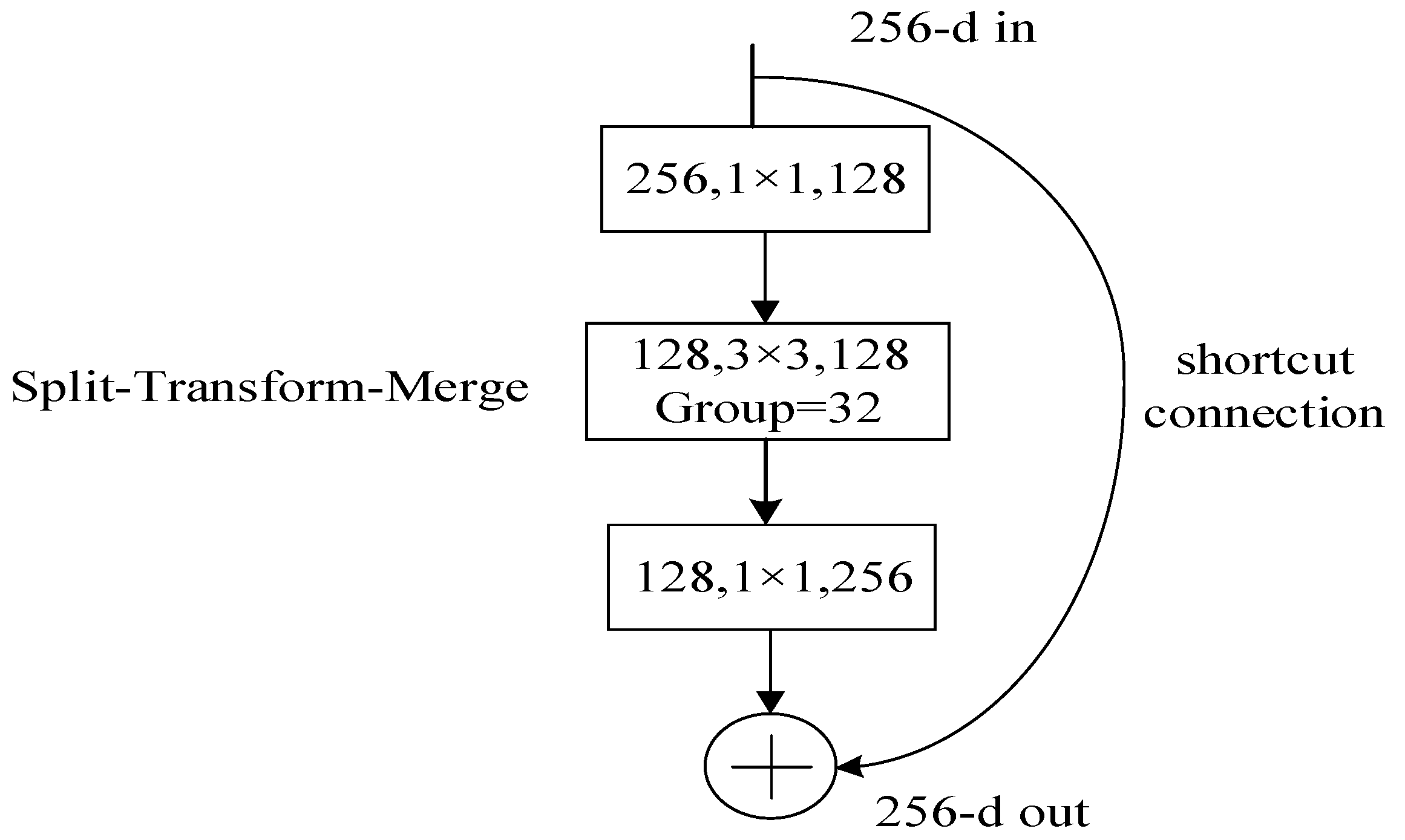
2.2.1. ResNeXt Networking Structure
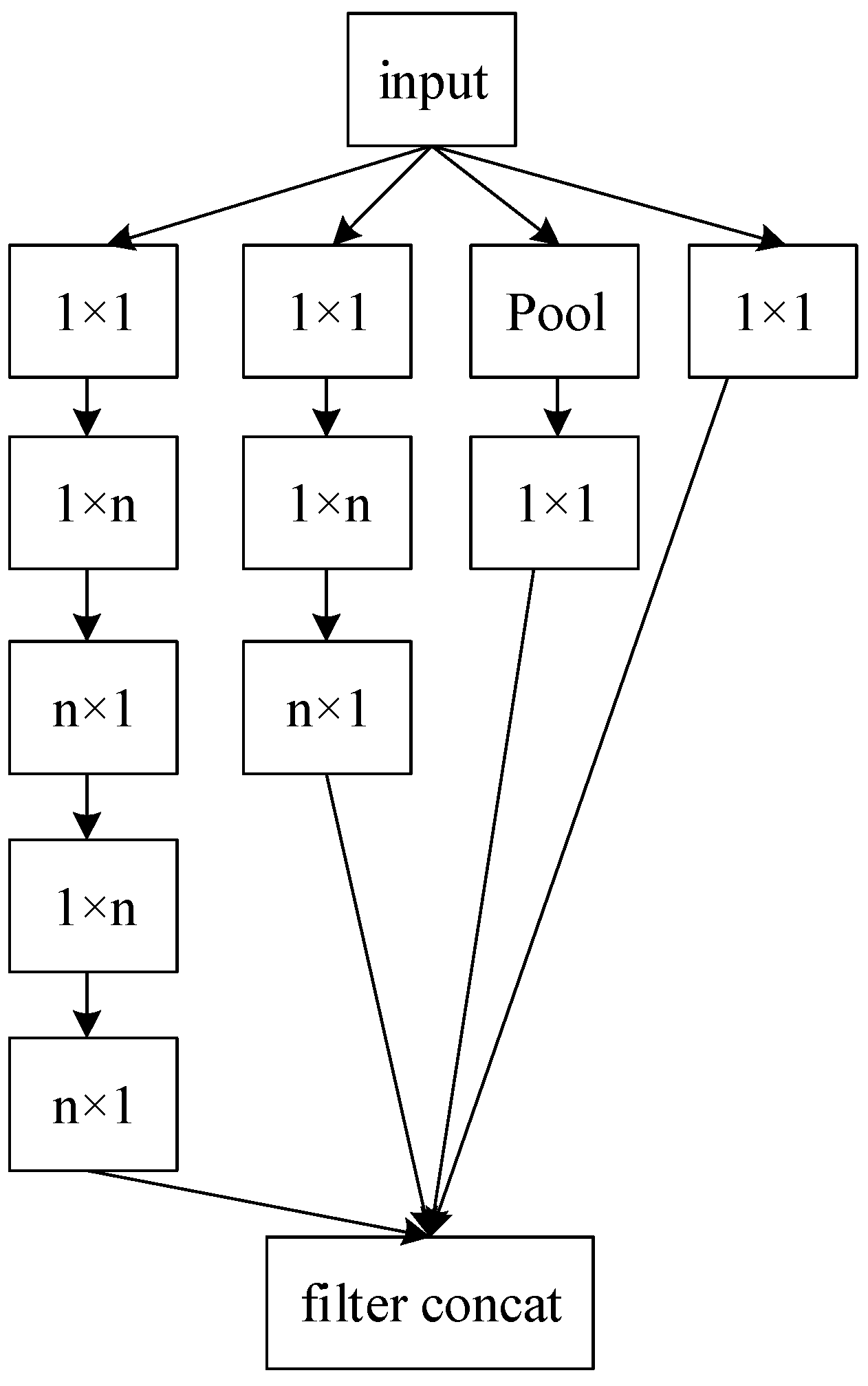
2.2.2. Network Structure of Inception v3
2.2.3. Model Training
- input the image;
- extract the features of the images through the networks and produce a feature map;
- use SoftMax classification software to transfer the features of the images into probability vectors for k dimension, use elements to express the probability of each class with a range of 0–1 and a sum of 1, and then calculate the probability of the image being in a certain class Equation (2);
- use Equation (3) to calculate the softmax loss value and then illustrate the prediction errors in the image classification (the deviation degree of the prediction value from the actual value), which should decrease with the training progression;
- trigger the termination condition (when the largest number of iterations have been reached) to complete the model training.
2.3. Training of the YOLO v3 Object Detection Model
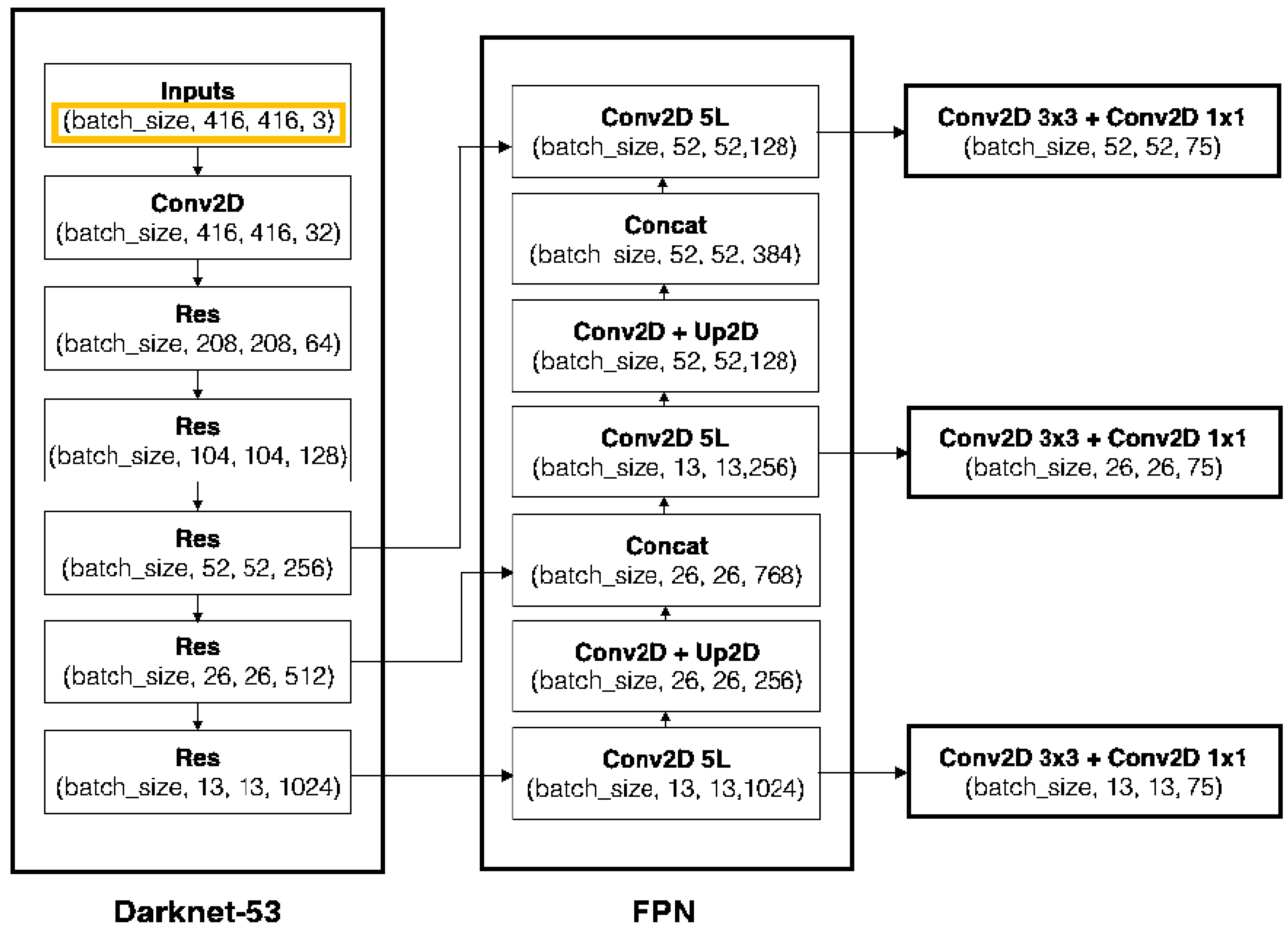
2.3.1. Network Structure
2.3.2. Model Training
2.4. Testing of the YOLO v3
2.4.1. Testing of the Trained Models
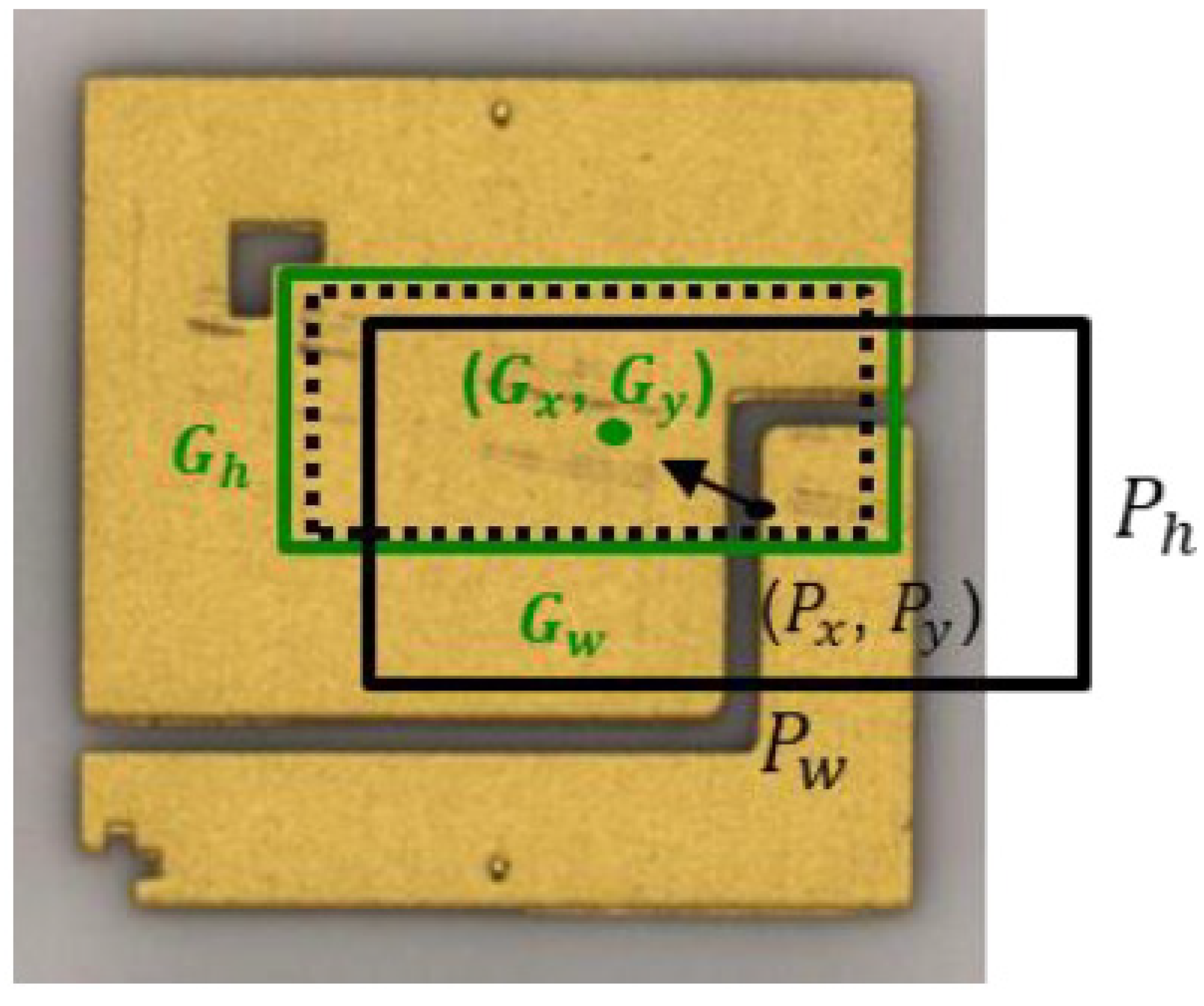
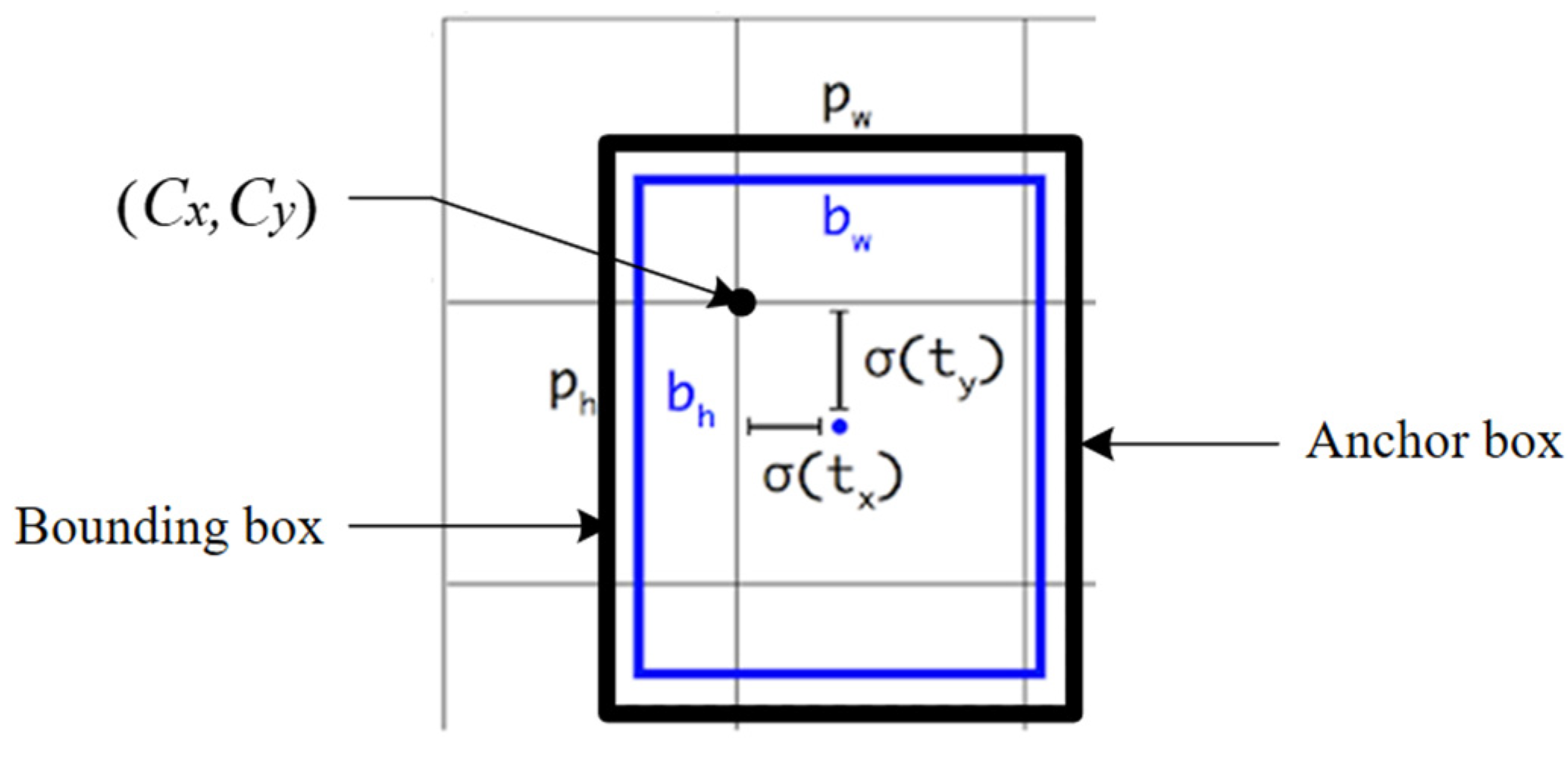
2.4.2. Bounding Box Prediction
3. Results
3.1. Model Comparison
3.2. Accuracy Rate and False Alarm Rate
4. Discussion
4.1. Application Effects and Applicable Scenarios
4.2. Effect Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hao, R.; Lu, B.; Cheng, Y.; Li, X.; Huang, B. A steel surface defect inspection approach towards smart industrial monitoring. J. Intell. Manuf. 2020, 32, 1833–1843. [Google Scholar] [CrossRef]
- Çelik, A.; Küçükmanisa, A.; Sümer, A.; Çelebi, A.; Urhan, O. A real-time defective pixel detection system for LCDs using deep learning-based object detectors. J. Intell. Manuf. 2020, 31, 1–10. [Google Scholar] [CrossRef]
- Tout, K.; Meguenani, A.; Urban, J.; Cudel, C. Automated vision system for magnetic particle inspection of crankshafts using convolutional neural networks. Int. J. Adv. Manuf. Technol. 2021, 112, 3307–3326. [Google Scholar] [CrossRef]
- Adibhatla, V.; Chih, H.; Hsu, C.; Cheng, J.; Abbod, M.; Shieh, J. Defect detection in printed circuit boards using you-only-look-once convolutional neural networks. Electronics 2020, 9, 1547. [Google Scholar] [CrossRef]
- Li, Y.; Kuo, P.; Guo, J. Automatic Industry PCB Board DIP Process Defect Detection System Based on Deep Ensemble Self-Adaption Method. IEEE Trans. Compon. Packag. Manuf. Technol. 2021, 11, 312–323. [Google Scholar] [CrossRef]
- Fupei, W.; Xianmin, Z. Feature-Extraction-Based Inspection Algorithm for IC Solder Joints. IEEE Trans. Compon. Packag. Manuf. Technol. 2011, 1, 689–694. [Google Scholar] [CrossRef]
- Ye, Q.; Cai, N.; Li, J.; Li, F.; Wang, H.; Chen, X. IC Solder Joint Inspection Based on an Adaptive-Template Method. IEEE Trans. Compon. Packag. Manuf. Technol. 2018, 8, 1121–1127. [Google Scholar] [CrossRef]
- Tsai, D.M.; Huang, C.K. Defect Detection in Electronic Surfaces Using Template-Based Fourier Image Reconstruction. IEEE Trans. Compon. Packag. Manuf. Technol. 2019, 9, 163–172. [Google Scholar] [CrossRef]
- Cai, N.; Cen, G.; Wu, J.; Li, F.; Wang, H.; Chen, X. SMT solder joint inspection via a novel cascaded convolutional neural network. IEEE Trans. Compon. Packag. Manuf. Technol. 2018, 8, 670–677. [Google Scholar] [CrossRef]
- Ray, S.; Mukherjee, J. A hybrid approach for detection and classification of the defects on printed circuit board. Int. J. Comput. Appl. 2015, 121, 42–48. [Google Scholar] [CrossRef]
- Sanguannam, A.; Srinonchat, J. Analysis ball grid array defects by using new image technique. In Proceedings of the 2008 9th International Conference on Signal Processing, Beijing, China, 26–29 October 2008; IEEE: Piscatway, NJ, USA, 2008; pp. 785–788. [Google Scholar]
- Abdelhameed, M.; Awad, M.; Abd El-Aziz, H. A robust methodology for solder joints extraction. In Proceedings of the 2013 8th International Conference on Computer Engineering & Systems (ICCES), Cairo, Egypt, 26–27 November 2013; IEEE: Piscatway, NJ, USA, 2013; pp. 268–273. [Google Scholar]
- Wu, W.; Chen, C. A system for automated BGA inspection. In Proceedings of the IEEE Conference on Cybernetics and Intelligent Systems, Singapore, 1–3 December 2004; IEEE: Piscatway, NJ, USA, 2004; Volume 2, pp. 786–790. [Google Scholar]
- Gao, H.; Jin, W.; Yang, X.; Kaynak, O. A line-based-clustering approach for ball grid array component inspection in surface-mount technology. IEEE Trans. Ind. Electron. 2017, 64, 3030–3038. [Google Scholar] [CrossRef]
- Liao, J.Y. The demand for smart detection in the PCB industry is fermented. AOI identification is optimized by AI as a trend. Digitimes 2018.
- Aswini, E.; Divya, S.; Kardheepan, S.; Manikandan, T. Mathematical morphology and bottom-hat filtering approach for crack detection on relay surfaces. In Proceedings of the International Conference on Smart Structures and Systems—ICSSS’13, Chennai, India, 28–29 March 2013; pp. 108–113. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 2017, 21–26 July; pp. 7263–7271.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction Results | |||
|---|---|---|---|
| Defect Features Exist | Defect Features Does Not Exist | ||
| Actual Performance | Defect Features Exist | True Positive (TP) | False Negative (FN) |
| Defect Features Does Not Exist | False Positive (FP) | True Negative (TN) | |
| Predictions | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ResNeXt+YOLO v3 | Inception v3+YOLO v3 | YOLO v3 | ||||||||
| Contaminations | Scratches | Immaculate | Contaminations | Scratches | Immaculate | Contaminations | Scratches | Immaculate | ||
| Actual | Contaminations | 95 | 1 | 2 | 95 | 1 | 2 | 95 | 1 | 2 |
| Scratches | 0 | 98 | 0 | 0 | 96 | 2 | 0 | 98 | 0 | |
| Immaculate | 0 | 0 | 200 | 1 | 0 | 199 | 8 | 4 | 188 | |
| ResNeXt+YOLO v3 | Inception v3+YOLO v3 | YOLO v3 | |
|---|---|---|---|
| Labeling Method | Name folders/ labeling Master | Name folders/ labeling Master | labeling Master |
| Building Method | More complicated | More complicated | Easier |
| Prediction Process | Two-stage | Two-stage | One-stage |
| Applicable Scenarios | Defects located in the center of the image | (i) Larger defects with consistent locations (ii) Defects located in the center of the image | (i) Distinct differences between standard and defect images (ii) Defects located in the center of the image |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, C.-Y.; Lin, I.-C.; Liu, Y.-L. Applying Deep Learning to Construct a Defect Detection System for Ceramic Substrates. Appl. Sci. 2022, 12, 2269. https://doi.org/10.3390/app12052269
Huang C-Y, Lin I-C, Liu Y-L. Applying Deep Learning to Construct a Defect Detection System for Ceramic Substrates. Applied Sciences. 2022; 12(5):2269. https://doi.org/10.3390/app12052269
Chicago/Turabian StyleHuang, Chien-Yi, I-Chen Lin, and Yuan-Lien Liu. 2022. "Applying Deep Learning to Construct a Defect Detection System for Ceramic Substrates" Applied Sciences 12, no. 5: 2269. https://doi.org/10.3390/app12052269
APA StyleHuang, C.-Y., Lin, I.-C., & Liu, Y.-L. (2022). Applying Deep Learning to Construct a Defect Detection System for Ceramic Substrates. Applied Sciences, 12(5), 2269. https://doi.org/10.3390/app12052269