1. Introduction
1.1. Background
Artificial intelligence for autonomous ships (unmanned surface vehicles (USVs) and autonomous surface vehicles (ASVs)) has been extensively investigated in the private sector (including bathymetric measurements, subsea pipelines management, marine geography surveys, and safety management) and the military sector (including patrol, security, intrusion detection, blockage, and defense). Artificial intelligence has proven its benefits in solving control issues related to the operation of ships under an unstable natural environment, reducing risk, and enhancing efficiency under collaborative or competitive conditions with other ships in the real ocean [
1,
2,
3,
4,
5,
6].
Operating autonomous ships is more difficult than self-driving cars because it is difficult to obtain explicit decision-making data from the environment. Self-driving cars learn the driving rules from definite environmental data, such as lanes and traffic lights. Dynamic obstacles around self-driving cars are considered when making decisions regarding the actions to be taken. However, in the case of an autonomous ship, it is difficult to obtain data regarding rules from the environment, and the rules must therefore be learned from the vessels sailing around them. Therefore, a learning environment that considers the ships operated by humans is required, and not only ship control but also human rule learning is required [
7,
8,
9].
In board games such as chess, human-level odds of winning have been achieved under the rules set by humans, and real-time video games such as Atari have achieved high scores through human-level control [
10,
11]. In Starcraft (a real-time strategy game), multiple agents can be controlled at the same time to outperform human players [
12], while in Minecraft (a role-playing video game), tiering problems are solved based on decision-making. This hints at the possibility of solving problems similar to a human [
13]. In this way, the reinforcement learning algorithm can establish not only the rules of the game but also the controls, strategies, and rules to solve problems like humans [
12,
13]. However, there are several factors, such as the natural environment and harbor entry/departure rules that have been defined for each harbor in the self-driving vessel’s learning, and this learning must be learned through surrounding vessels. This makes it difficult to establish an environment capable of learning human-level rules through learning [
14].
1.2. Challenges
In this study, an autonomous vessel moving to its destination was considered, taking into account the topographical features of the marine environment; the vessel follows the navigation rules in a human-like manner. Each harbor has a different marine traffic environment, which is defined by humans, and there are rules with regard to other ships the vessel encounters. These rules are not provided as signs or traffic lights in marine environments or ports. The typical method is to observe the behavior of other ships, learn the rules, set sail with nearby ships, or wait until all the ships have arrived [
15]. However, this process is time-consuming, and the simulation is expensive to implement if all these environments have been considered. In addition, it is difficult to build an environment by considering all the cases [
16,
17,
18]. Furthermore, previous learning experiences can be forgotten depending on the order of learning (catastrophic forgetting), and new environments can be learned [
19,
20]. The following is a summary of the issues to be considered relating to the learning environment, method, and the structure of the RL algorithm to learn for the application of RL algorithms to autonomous ships.
The first is the data of the RL algorithm, which is insufficient to learn the rules defined by humans and make decisions. The sailing environment to the destination considers the topographical features and the natural environment. Surrounding vessels, which have rules embedded in them, should respond to an autonomous learning ship. These vessels present a variety of vessel types and behaviors.
Second, learning a human rule requires a systematic learning method. Random learning can provide a wide range of experiences by providing different states, but the rules are hard to learn. Therefore, the learning environment must have rules and should be consistent.
The last issue is the complexity of decision-making for autonomous ships to operate. Autonomous ships shall plan a destination at the human level, decide the direction and speed by considering obstacle avoidance, sliding of the water surface, and control of the postures depending on the features of the vehicle itself to achieve the given missions. The more data provided, the larger the state space becomes. The decision-making space is also expanded depending on the number of actions. Substantial learning time may be required, or obscure results may be acquired because the learning results are not collected.
To solve these problems, previous studies have presented an environment that includes various partner ships for ship avoidance and route planning [
21,
22]. Simulation with other ships (including strategies) can make autonomous ships learn human-defined navigation rules in the environment. Through this research, we expect to not only learn a solution to solve the aforementioned problems but also learn human-defined navigation rules at the human level [
23,
24,
25]. Autonomous cars and robots have developed separate training platforms for continuously acquiring data and training in a given environment to solve learning environment problems, or the implemented simulation using OpenAI’s GYM based on open sources provides a relative vehicle environment [
26,
27,
28].
1.3. Approaches
This study solves three issues for autonomous ships to learn by implementing a sustainable intelligent learning framework.
First, this study proposes an approach to learn human-defined navigation rules by defining the operation cases of neighboring ships based on Case-Based RL. Various data are generated through autonomy compliance with human-defined navigation rules considering the neighboring ships.
Second, curriculum learning methods are applied to prevent catastrophic forgetting, from losing previous learning experience, and to reduce the learning time through systematic learning. The learning process is established for the autonomous ship to learn complicated problems with varying degrees of difficulty. One such method, Self-Play, induces sufficient learning experience with fewer data, making autonomous and neighboring ships with diverse purposes and compensations to learn competitively.
Third, the decision fields are divided and stratified to solve the complex problems involving the autonomous ship, and the algorithm structure is generalized. The layers are classified into the mission layer, sailing layer, and control layer. The layers are also further interconnected by target values, state data, assessment, and compensation per layer for auto-supervised learning. More definite learning results can be acquired per layer by stratifying the state-action space depending on the decision-making space.
1.4. Contributions
The training framework proposed in this study is different from those proposed in previous studies.
(1) The learning environment is intellectualized by applying case-based RL, which can include human-defined navigation rules for environments. This intellectual learning environment can solve the problem of insufficient environmental data in the marine environment using neighboring intellectual ships with rules and has expandability applicable to various ranges of simulators.
(2) The problems that the autonomous ship needs to solve are clarified, and the learning time can be saved because the global and local curricula are presented depending on the degree of difficulty. The learning results are enhanced with fewer data owing to self-play curriculum learning. Self-play curriculum learning facilitates a quick response to changes in marine traffic policies in a harbor and changes in the marine environment.
(3) The decision-making spaces of autonomous ships are simplified and clarified through hierarchical classification. The target value, state data, assessment, and compensation standards are automatically established for the supervised interlayer learning structure.
The stratified RL algorithm and intellectual learning framework can consistently cope with the changes in the marine space, where the RL algorithm is examined and operated. The change in ship control approaches through the development of shipbuilding technologies.
3. Intelligent Learning Framework for Autonomous Ships
This study proposes an approach to create an intelligent environment for autonomous ships to achieve human-level learning through an RL algorithm. Autonomically reacting against obstacles and expressing human-defined navigation rules are provided for neighboring ships, accounting for the majority of learning decision-making of autonomous ships by applying case-based RL to make them include human knowledge. The experiment defined the human experience in operating ships in the ocean as the case and adopted a curriculum learning approach that could adjust the degrees of difficulties based on complicated marine traffic conditions. Considering these learning environments, the autonomous ship learned various issues occurring in the ocean through self-play and neighboring ships based on human-defined navigation rules. The RL algorithm of autonomous ships hierarchically separated per decision field learns through the interaction among the mission, navigation, control fields, and environment. Moreover, the upper layer allowed the lower layer to learn through the interlayer teach-student curriculum learning approach.
This study adopts the multi-agent posthumous credit assignment based on counterfactual multi-agent policy gradients (COMA) as the RL algorithm applied to an autonomous ship [
58]. Autonomous ships and neighbor ships are operated by the same RL algorithm through ILFAS’s Self-Play curriculum learning. Recently, research is considering applying multi-agent RL to autonomous ships. This is to perform missions stably through one or more autonomous ships and to perform complex missions through the cooperation of autonomous ships. The ILFAS prepared enables multi-agent-based autonomous ships to be trained according to this research flow [
59,
60]. Multi-Agent RL is based on Actor-Critic, and when applied to a single autonomous ship, it behaves the same as a general single-agent. Because autonomous control is limited to the issues of a single ship, it is explained based on proximal policy optimization, whereas the RL algorithm is used for a single agent [
61]. The same RL algorithm used for an autonomous ship was also adopted to express diverse vessels operating in the environment. This paper explains the algorithm based on COMA and compares and evaluates the learning method for neighboring ships considering the performance of ILFAS.
3.1. Architecture
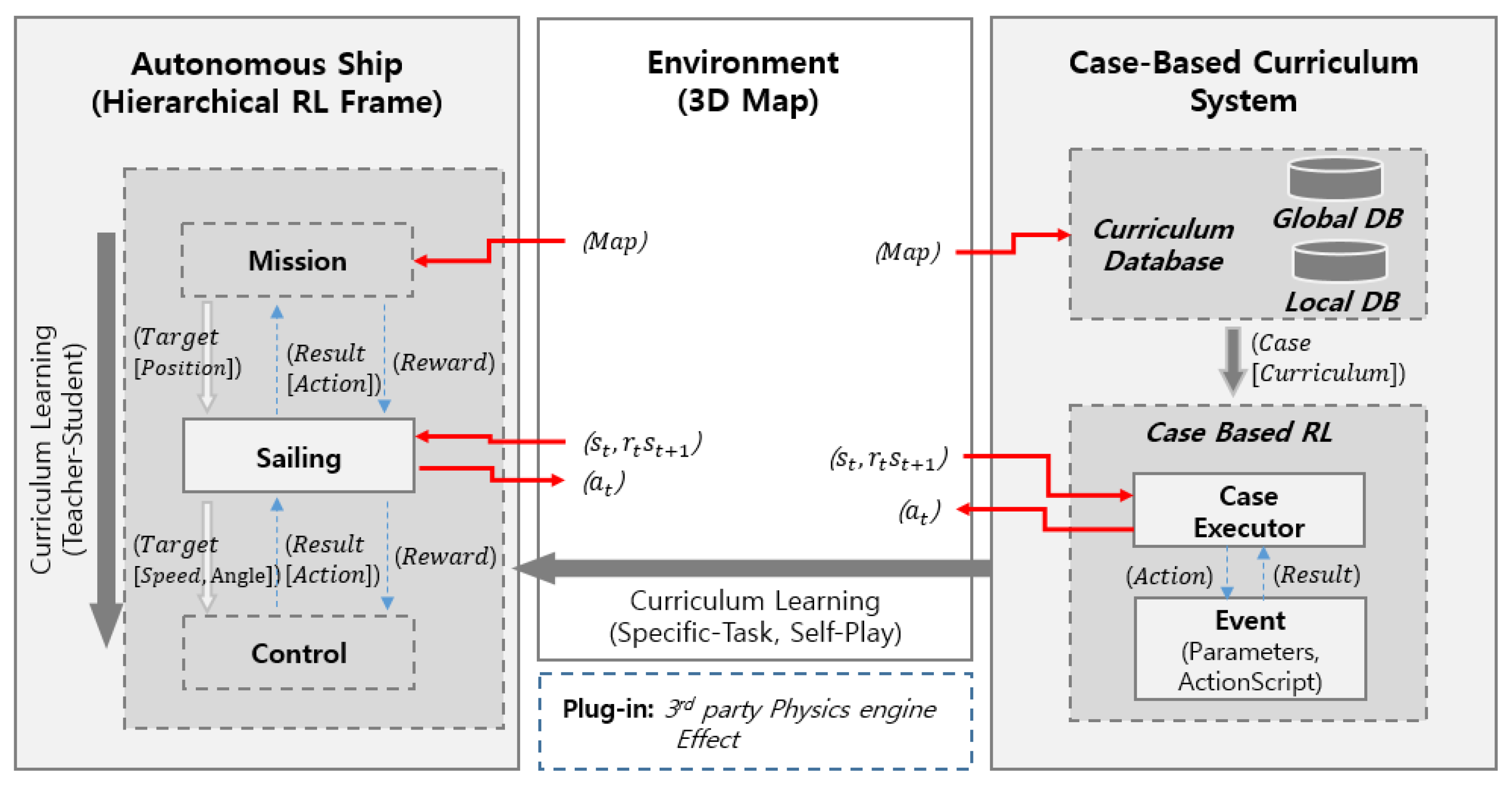
The learning framework (ILFAS) proposed in this study comprises three types: hierarchical RL frame to be applied to autonomous ships, case-based curriculum system-induced learning of autonomous ships, and environment used in the learning. The physical environment was created in three dimensions (3D) with a fixed height for the LiDAR simulation using unity. Moreover, the basic physics model for the acceleration of ship weight and surface sliding in the ocean was adopted.
The elements are explained from left to right in
Figure 1 to facilitate the understanding of the learning frame.
The hierarchical learning structure comprises the autonomous mission (
), which reduces the learning complexity of the autonomous ship to learn, autonomous sailing (
), and autonomous control (
) to make decisions and operate various vessels. Considering
in
Figure 1, the autonomous ship was learned through transfer learning using a case-based curriculum system, and
was learned through supervised learning based on
. After
Sailing was learned,
at which the autonomous ship should move to
Control could be presented. Therefore, the expected action value
a (the direction and speed) by
Sailing could also be predicted.
Sailing’s action value
and current state
are the
Target and
State values of
Control, which were provided along with environmental data, such as wind. Through
Control’s action in the learning process, the autonomous ship operated in the environment. The operation result of the autonomous ship was obtained as
of
Sailing, and
Control learns by returning the difference from the expected action value to
Control as reward
.
is environment data through
and environment plug-in learning become the state and target value of
. The state was transferred to
, the autonomous control, considering learning on
, and the actions from
are evaluated and learned by the autonomous ship.
is a general RL field related to space planning. For example, the marine space was divided based on the supervision scope of autonomous ships for ocean surveillance. The division of the marine space and movement location in sequence was determined for collecting marine data. A destination was delivered to
through the spatial data input from the environment, and the learning results of
were evaluated based on the successful arrival to the destination.
A case-based curriculum system configured the curriculum with the degrees of difficulty and space by defining cases of neighboring ships to be operated in the ocean. The curriculum was classified into the global curriculum that learns the entire given space and the local curriculum based on the sequence of time and space. The curriculum was provided in the environment in real-time. The cases stated in the curriculum were provided based on the decision-making order of neighboring ships. Moreover, the RL algorithm implementing the cases already learned the movement between waypoints.
3.2. Hierarchical RL Frame
This study hierarchically configured the RL of an autonomous ship to enable its operation in reality. The correlation between separate layers was explained using and as examples. RL based on a multi-agent algorithm was applied to for learning autonomous navigation, including path finding, collision avoidance, and human-defined navigation rules considering the operation of other ships. learned the actions to control the ship based on the environment transferred from . This process is consistent with the control methods and types of ships. The RL algorithm can be applied to existing ship and posture controls.
The state input and action output of
are explained.
observed in the autonomous ship for the decision-making of
is defined in Formula (1).
is the ship state;
is transferred from the environment, and it includes the data from the natural environment simulator. The absolute coordinates and relative directions of destination
were calculated. The LiDAR of
is the distance between the static obstacles, such as an embankment. The data were acquired through the short-range obstacle detection in the environment and dynamic obstacles (the neighboring ships operating around).
The action
was discretely declared to learn
. The maximum scope that can be changed at a time using Formula (2) limits the scope of one output action, such as
. The scope to be changed at a time varies based on the vessel type. The scope is the criteria for evaluation and compensation of the actions of
.
, the single-layer LiDAR inputs the obstacle detection data around the autonomous ships, and other sensors can be added when required. The relative location value of the autonomous ship was calculated using the obstacle and destination data, such as the real environment. The network of autonomous ship layers for path finding is defined, as shown in Formula (3). Considering the reward on
, when the autonomous ship successfully arrives at the destination provided in the mission, the goal and collision are one and 0.001, respectively. The depreciation rate (
) is 0.0001. The state value is received from the environment. The
network is shown in Formula (3):
After learning, the layer is ready to perform supervised learning for .
The observation value of
is the state value of
and is defined, as shown in Formula (4).
is the present state value, including the gradient of a ship.
is selectively applied based on the natural environment simulation, such as a plug-in. This value is the vector value of the wind direction and tide. Its relative value to an autonomous ship is calculated as shown in Formula (4):
, the natural environment, was provided through
, and the network is shown in Formula (5). The action
determined in
is defined as the target value
of
. If
, then the value zero (“0”) is transferred. The target value of
is given as
, which is the action to be taken by
. The action
of
, the autonomous control, is retransferred to
was implemented and received
from the environment to calculate the compensation reward as expressed below:
The reward of is in Formula (5) and was calculated as the difference between the action to take in the given state and the state after applying the action from . The action of the value expected by was taken considering the natural environment in and learning was performed in the layer to maximize the reward. Accordingly, the tilt and rollover state of a ship based on the control method of a ship and the physical features of a hull was acquired from the environment in .
Contrary to the hierarchical structure connected to learning in previous studies, and separately generated actions and had independent learning structures. The actions of were applied to the environment without any modifications, and learning was preceded. When navigation to a destination went on smoothly after the learning completion of , the teach-student curriculum method implementing the learning of was applied.
3.3. Case-Based Curriculum System
The operation case of neighboring ships in the simulation comprises the following:
An event defined in this case is the detailed information to be implemented toward the final goal. The case consists of the waypoint coordinates based on the time schedule and states the detailed actions toward a destination or after movement, as described in Formula (7):
Action is defined as or and configured as [Stay, Cycle, etc.] and [Speed, Random, etc.]. Speed and Random were applied to ship control on the way to . Random noise was added to the action to propose the speed or unstable track. It considers a ship that is difficult to sail straight, such as a yacht. Stays and cycles are executed at . A ship stays on the ocean at a destination for a designated time or sails in a circle within 10 m of a destination. Action can be added depending on the purpose of the training. RL with neighboring ships transfers the ship control authority to action in the action script per event or uses it as the reference value for navigation. Single or multiple cases can be applied simultaneously, and the number of ships to arrange was designated. Therefore, the condition needs to be satisfied. Cases were defined by a human operator considering the number of ships, coordinates, and actions to be executed. Each data point was saved in a case-based system database. Cases included human-defined navigation rules and could record and define the ship operation state in harbors and coasts.
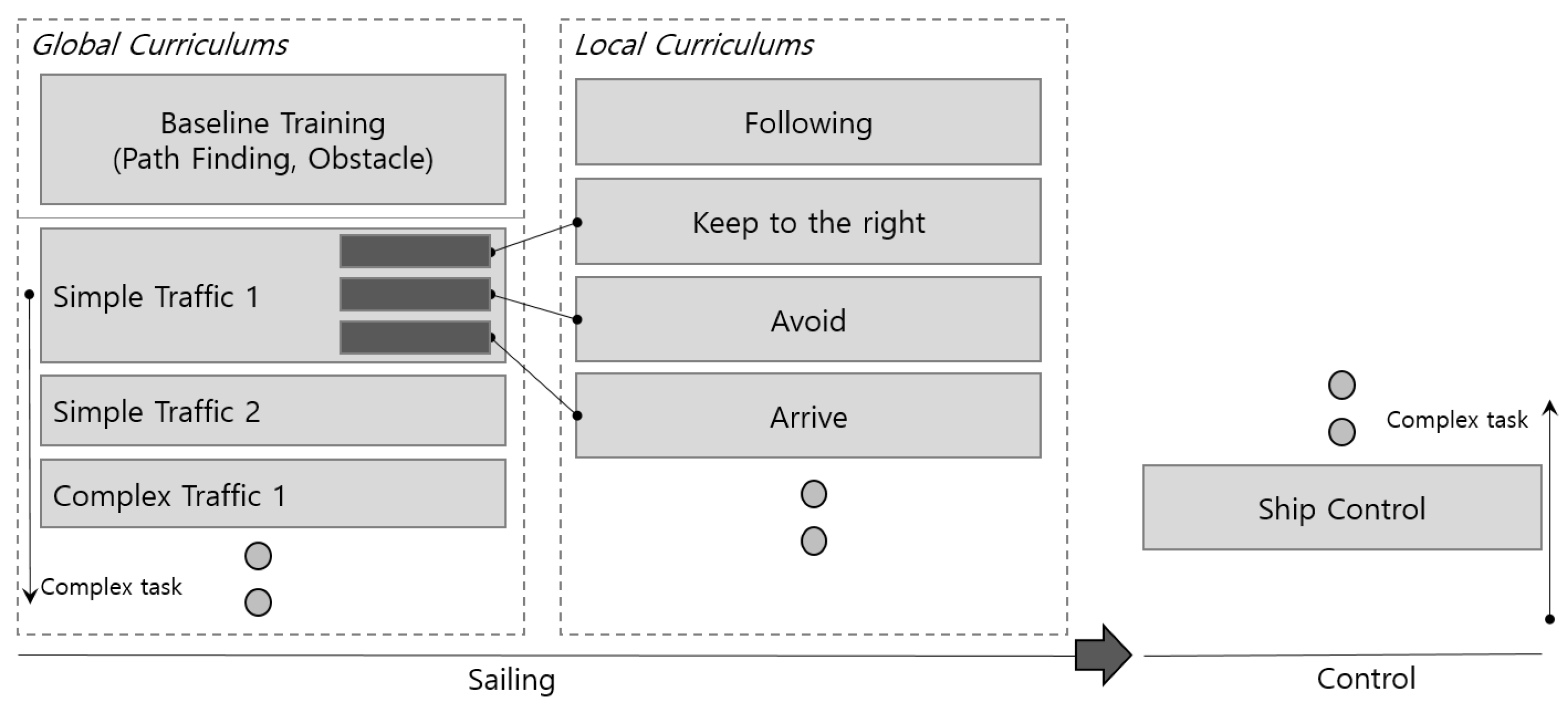
This study classifies the spaces for implementing the curriculum based on defined cases, as shown below.
Definition (8) includes path finding and fixed obstacle avoidance as the global content for the autonomous ship to learn. The experiment selected the harbor with busy marine traffic, and the curriculum started with learning to verify the route from the anchorage harbor to coastal waters. Considering this learning process, random waypoints in coastal waters were provided for departure. The autonomous ship learned considering the harbors with fixed obstacles and other obstacles in the coastal waters for departure and arrival.
Definition (9) is the intensive learning content in the local space based on the navigation time schedule for autonomous ships and is provided sequentially. The autonomous ship stands by for the port entry of neighboring ships or remains right in the waterway depending on the complexity of the marine traffic environment configured with neighboring ships in the harbor. It comprises the movement to a final destination to avoid moving fishing boats in coastal waters (Angler’s boats frequently move around, marine sports zones are small, and fast boats move around). The inward voyage was implemented in reverse order.
The curriculum learning was implemented from obstacles with a low degree of difficulty in finding a destination. This process aims to avoid static obstacles in the environment without dynamic obstacles to those with a higher degree of difficulty consisting of a busy marine traffic environment because the number and actions of neighboring ships are increased. Because the degree of difficulty got higher, the teach-student method was additionally implemented after the completion of learning for of the autonomous ship. The degree of difficulty in the controlling of increased as the environment became more complicated.
The RL algorithm applied to the cases was implemented in a given environment with waypoints and destinations transferred from the case-based curriculum system. The busy marine traffic environment was created as the neighboring ships operated by the multi-agent RL algorithm to avoid collisions. Various types of cases were implemented simultaneously, as demonstrated below:
The RL algorithm implementing cases is almost the same as the algorithm applied to an autonomous ship. The observation value
is shown in Formula (10). The subsequent waypoint was received through the case-based curriculum system sequentially for
G. On arrival at the final
G, the case ends. The action
is shown in Formula (11):
Although the same RL algorithm was applied, the agents could learn strategies through the self-reply curriculum learning with different goals and rewards and learn human-defined navigation rules through the learning process. When the diversity and number of learned autonomous ships increased, the RL algorithm for neighboring ships applied to the case-based curriculum could be used for additional learning. Self-play curriculum learning demonstrates good learning results through relatively continuous learning.
3.4. ILFAS Training
Although the types of RL algorithms have been continuously developed, they should prevent local optimization and maximization of rewards. Other researchers frequently use separately designed reward functions to achieve the above goals quickly. However, this study aims to train an RL algorithm designed to provide generally delayed and immediate rewards.
The subsequent algorithm is the policy-based multi-agent RL COMA algorithm. The following formula demonstrates the policy gradient with the Q function as the advantage using the actor–critic. The actor updates policies and the critic evaluates them in this configuration. Policies are updated simultaneously, and rewards are maximized as expressed below:
The RL applied to multiple ships updated
, the actor part taking log using Formula (9), and critic
comprising the Q function. Policies and rewards were each updated as critics in Formula (12), as shown in Formula (13), and approximated to
:
The actor and critic performed transfer learning by learning the environment changed based on Formulas (14) and (15).
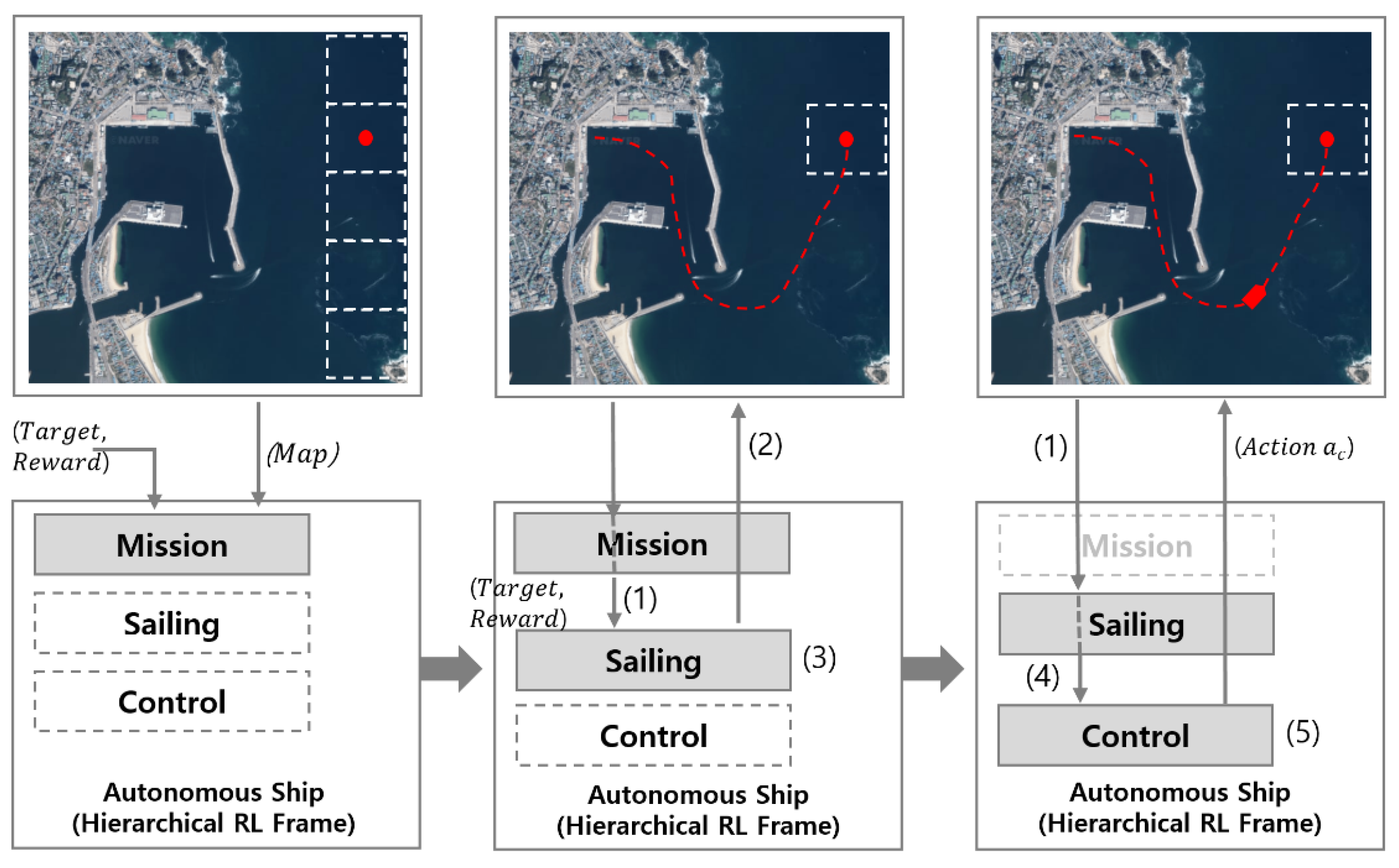
This study configured the curriculum, and Definitions (8) and (9) are explained in detail as follows:
Global Curriculum = [Find entire route], [avoid fixed obstacles], [case: avoid dynamic obstacles], etc.
Local Curriculum = [Stand by at dock area], [passing method in waterways], [avoid water recreation zone in coastal waters], etc.
The local curriculum in learning solves more difficult issues, although the global curriculum environment continuously exists. Regarding the RL of autonomous ships interacting with dynamic obstacles, path planning for autonomous navigation is learned in the global curriculum, and the navigation rules by collision avoidance are learned in the local curriculum. When
learning is completed, as shown in
Figure 2 and
Figure 3,
learning starts. The following example illustrates a curriculum configured for autonomous ships.
Transfer learning is based on baseline training, including pathfinding without obstacles. After learning was completed, learning was adjusted through
, as shown in Formula (16). Adjustment applies the probability rate
.
After the policies were adjusted through transfer learning, as shown in Formula (16), the reward trajectory was generated by with , which consists of . After global learning, a new environment with time and space was presented to the autonomous ship through the local curriculum. Therefore, was scattered and diffused when learning fails. To prevent the previous learning experience from being lost (catastrophic forgetting), the previous cases learned should be provided together as the degree of difficulty increases.
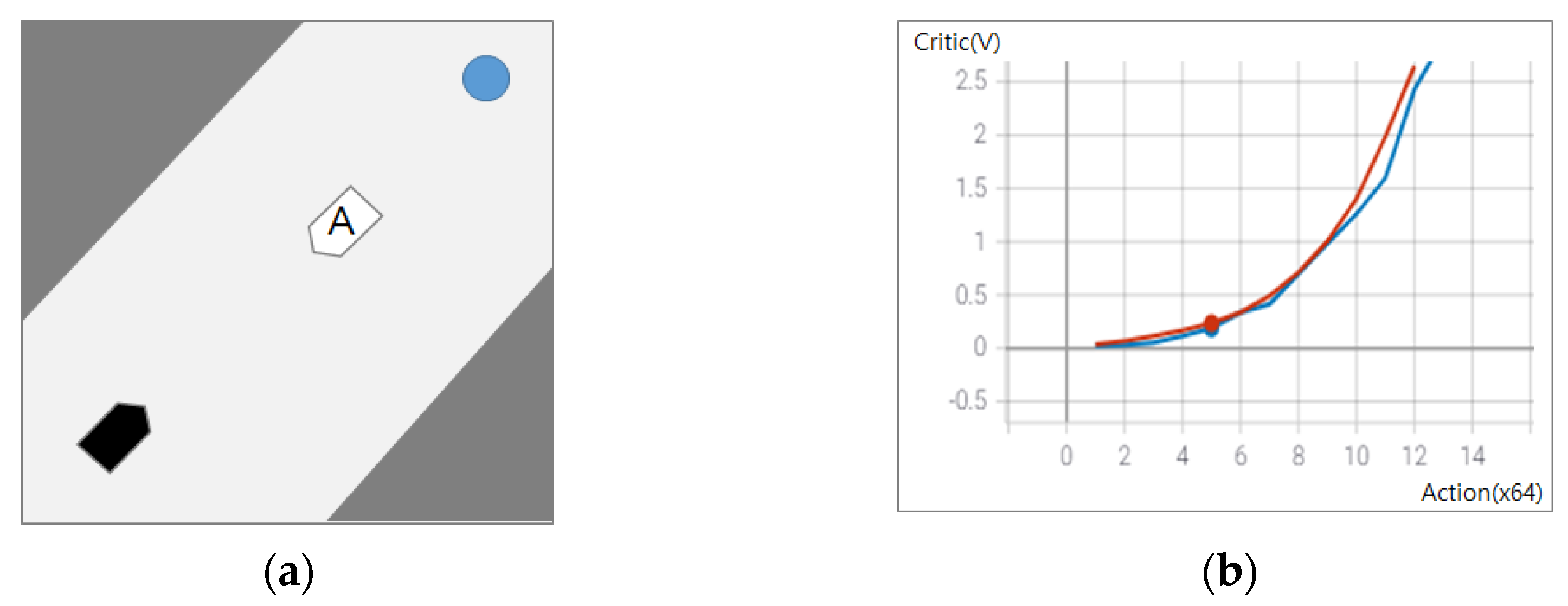
Considering the simple experiment below, we examined the implementation of transfer learning in an autonomous ship.
The experiment above explains the adjustment without catastrophic forgetting through curriculum learning and how to save learning time. The experiment proposes a new curriculum that makes the autonomous ship (black) learn basic pathfinding, and obstacle avoidance in a given space (harbor map) avoids the new ship (A) when encountering. Considering the global environment given in the global curriculum, the graph in
Figure 4b shows the values before (blue) and after (red) learning.
The values are the same as the number of control signal commands from the autonomous ship and the number of steps to a destination and reward values. Autonomous navigation to a destination can be performed based on previous learning experiences on obstacle avoidance even before additional learning. However, the present location includes non-smooth reward values and unnecessary controls in the new environment. The autonomous ship can obtain more rewards with fewer commands through transfer learning, avoiding other vessels encountered through an additional learning of 2000 steps.
4. Experiment
The computer simulation was experimented in a virtual environment built up with a real harbor in Korea. The experiment compared random autonomous ship learning in an environment to neighboring ships sailing around, using the general RL method and autonomous ship learning by the ILFAS for two hierarchical RL algorithms. The word “Random” means random scenarios that make much experience of RL algorithm through enough exploration and exploitation. In this experiment, we compared our results to random scenarios because they can address against any status. Moreover, the stability of ship control was compared based on the success rate of autonomous navigation to a destination and the actions performed during autonomous navigation in the new environment. Finally, the experience examined whether an autonomous ship could learn human-defined navigation rules.
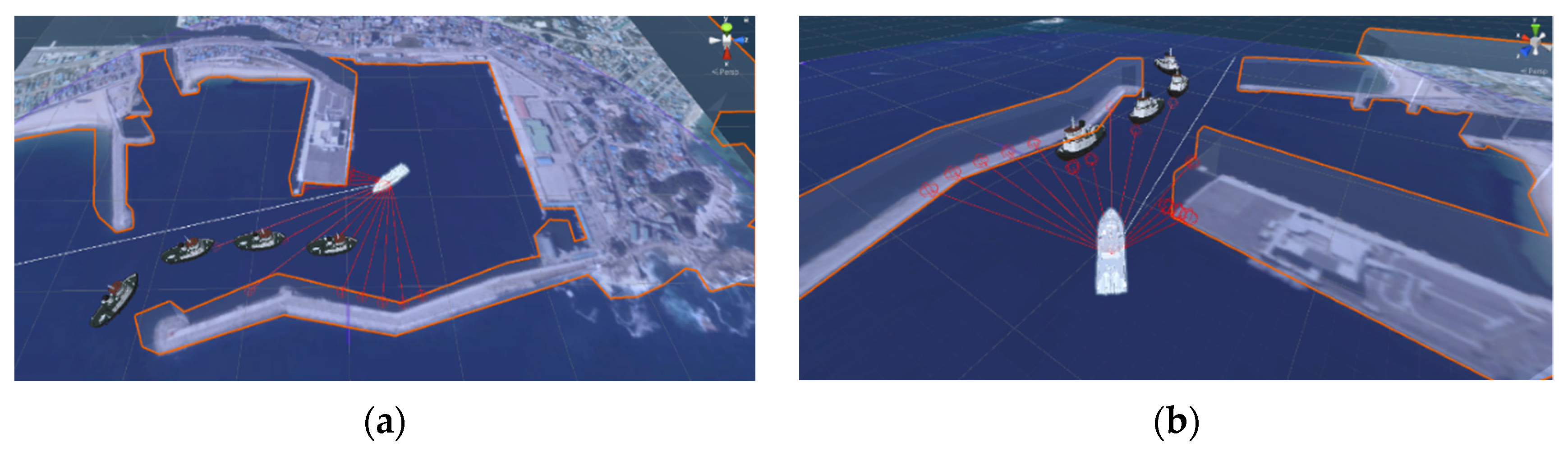
The 3D environment was implemented by adding the height on which the LiDAR simulator could detect the structures in the harbor in unity as like
Figure 5. A 3D ship model was used in the experiment. The ship size was enlarged by three times for the safety distance between ships and the data simplification of LiDAR. The penalty was immediately provided, and the scenario ended after the collision with obstacles, including neighboring ships.
4.1. Training: Baseline Training(Path Finding)
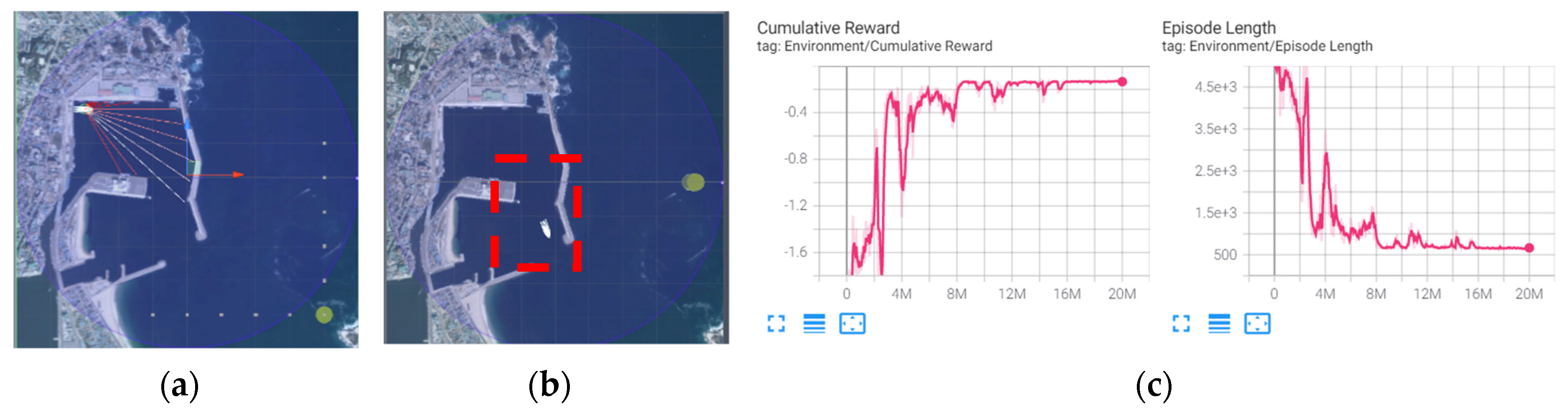
Basic learning on the global space is implemented through the curriculum, setting a random destination in the coastal waters and departing from the harbor. The training result is shown in
Figure 6.
The autonomous ship has additional learning on the avoidance of dynamic obstacles using different learning methods to compare the learned weight. General RL in an environment with random neighboring ships sailing around and RL training with two types of inward ship cases using ILFAS was compared. The learning time was measured until the autonomous ship arrived at a destination 100 consecutive times to avoid neighboring ships. The reward is high when the optimized navigation gets to the destination without collision. Episode Length is the number of actions and is equal to steps. A low value of Episode Length means that the goal has been arrived at with an optimized number of actions.
4.2. Training: Learning Avoidance of Dynamic Obstacles (ILFAS vs. Random)
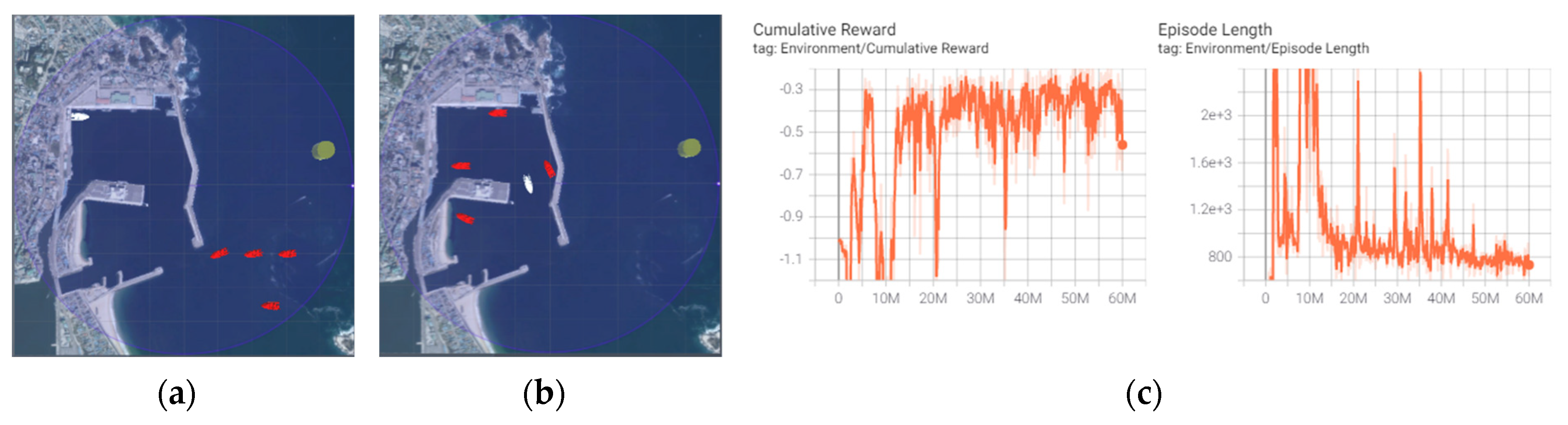
Considering the random RL, four random inward neighboring ships were generated in international waters. The autonomous ship aimed to sail to a randomly generated destination to avoid the neighboring ships from using various routes. The autonomous ship started to converge at 25 million steps and was finally stabilized at 50 million steps. Learning was implemented until the autonomous ship arrived at a destination 100 consecutive times in 100 attempts. The average step length (
H) per episode was 810 (no. of learning episodes = total number of learning steps/average number of scenario-ending steps). The training result is shown in
Figure 7.
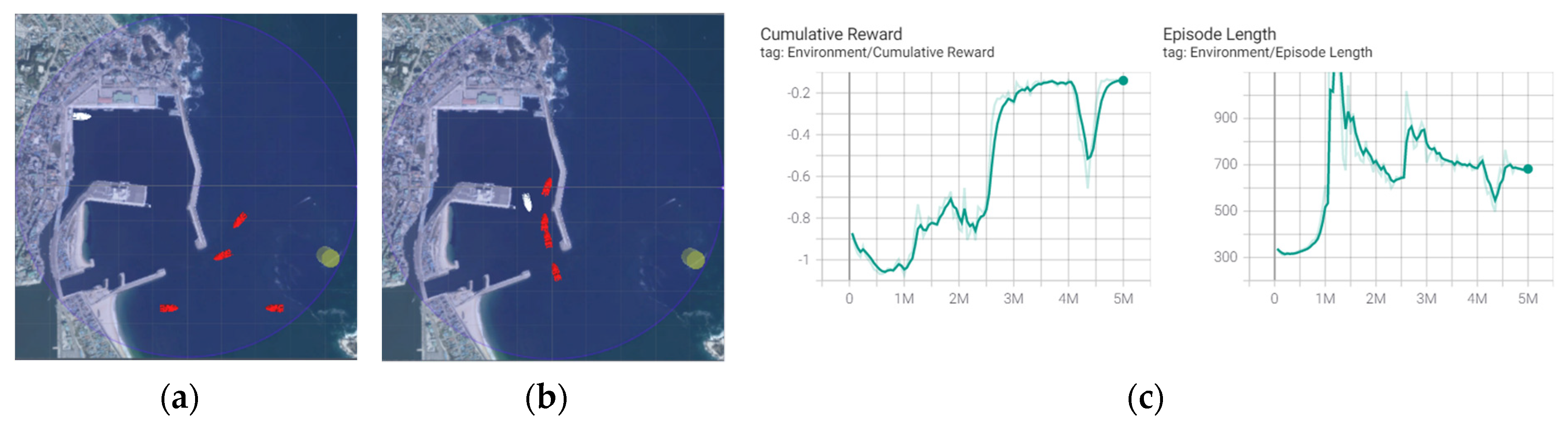
Regarding the ILFAS RL, the case-based curriculum system operates neighboring ships for human-defined general inward ships. The case is the inward ship curriculum for several ships that are generally observed in harbors. Although the neighboring ships avoid collisions when collisions are estimated in the simulation environment using the ILFAS, the episode ends when collision occurs. The autonomous ship started to converge at three million steps and was stabilized from five million steps. The experiment aimed to successfully arrive at a destination 100 times in 100 attempts. The average episode length was approximately 700. The training result is shown in
Figure 8.
Learning results: Although random RL had various kinds of experiences through random inward neighboring ships, it required 10 times more learning time than the ILFAS until the autonomous ship arrived at a destination 100 times in 100 attempts. The average episode length (the ship control signal) was 100 steps more than that of ILFAS.
V(s) in
Figure 9 demonstrates that
is stabilized as the autonomous navigation continues. Although the random RL showed new learning owing to catastrophic forgetting, RL by the ILFAS indicated that additional learning was performed based on the previous learning experience.
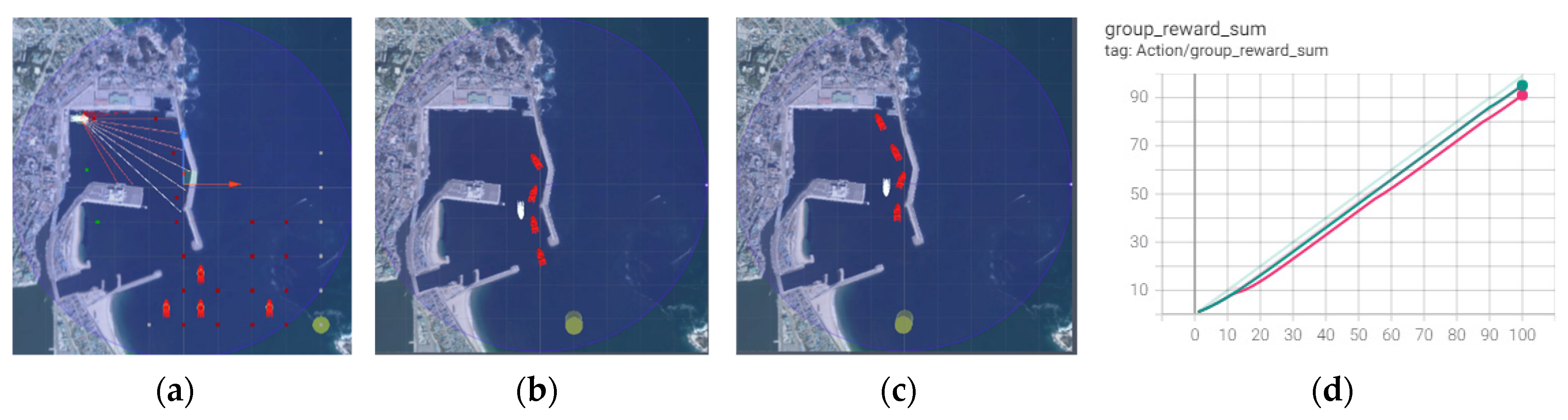
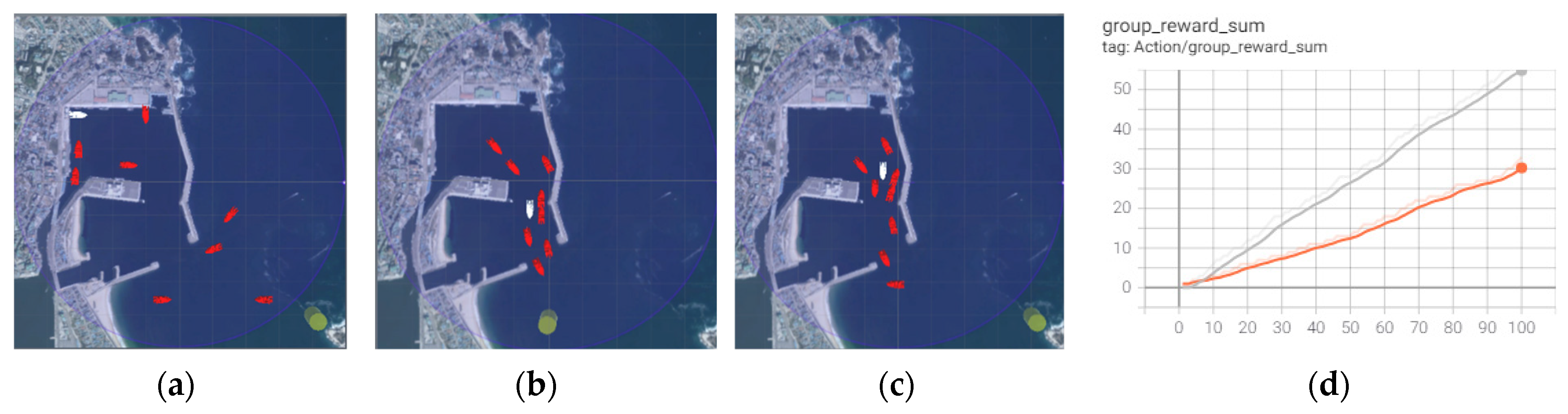
4.3. Experiment: Simple Traffic 1(Marine Traffic Environment for Inward Ships)
After learning the avoidance of dynamic obstacles, two RL algorithms were implemented and compared in the new environment. The new environment had neighboring ships following the right path to comply with human-defined navigation rules in the harbor that were not randomly created. The experiment result is shown in
Figure 10.
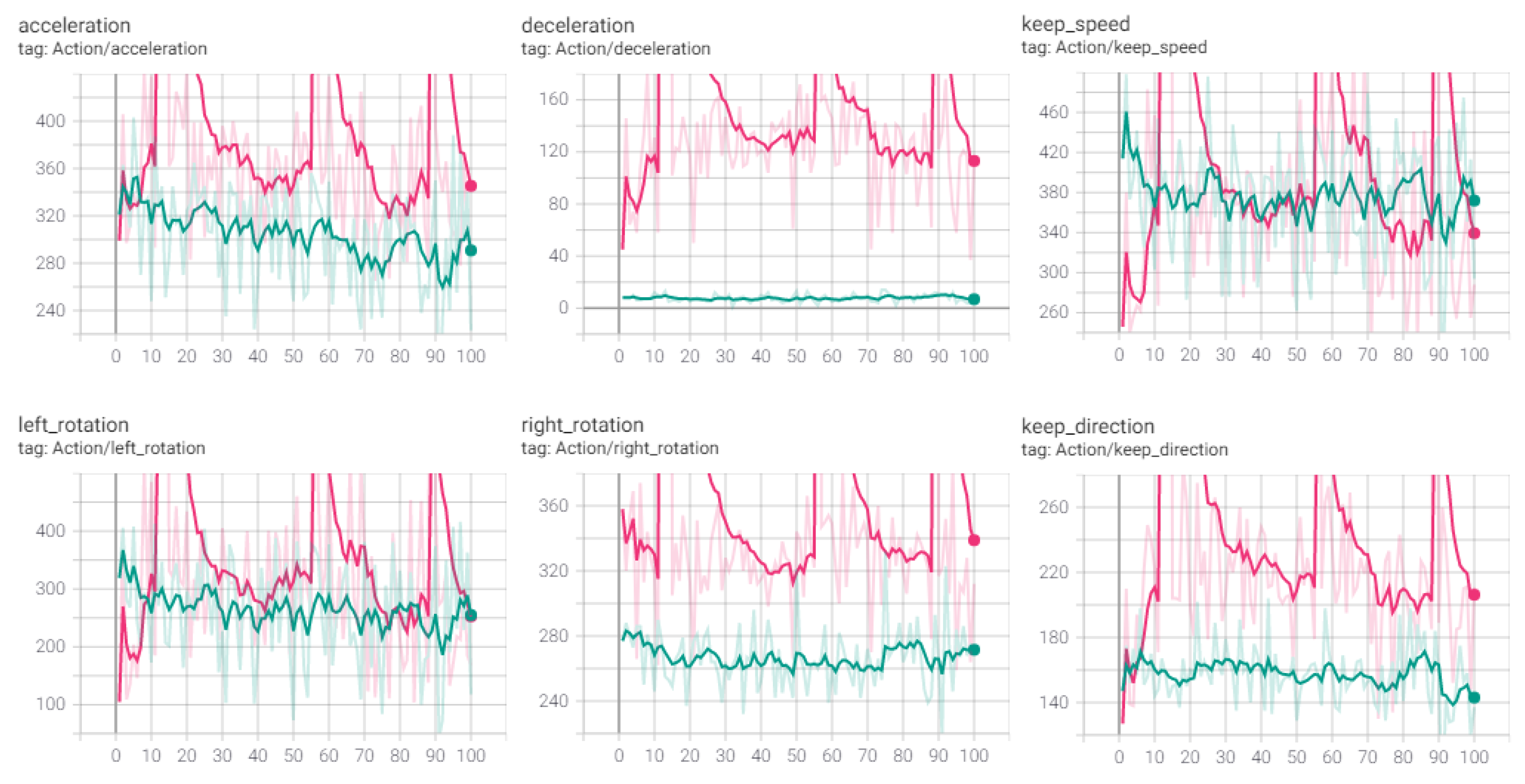
The learning results in
Section 4.2 were applied to this experiment. Although the successful arrival rates to a destination were similar (90% in 100 episodes), the ILFAS showed a slightly high success rate. The ILFAS learned the intrinsic motivation that the right path was safe; therefore, it avoided neighboring ships encountered. Random RL did not know the navigation rules of neighboring ships entering the harbor using the left path; hence, it selected the right path as the avoidance action. However, both learning methods showed significant differences in controlling autonomous ships. As shown in
Figure 11, the ILFAS is stable in controlling the ship; however, the control by the random RL fluctuates substantially.
4.4. Experiment: Simple Traffic 2(Marine Traffic Environment of Outward Ships)
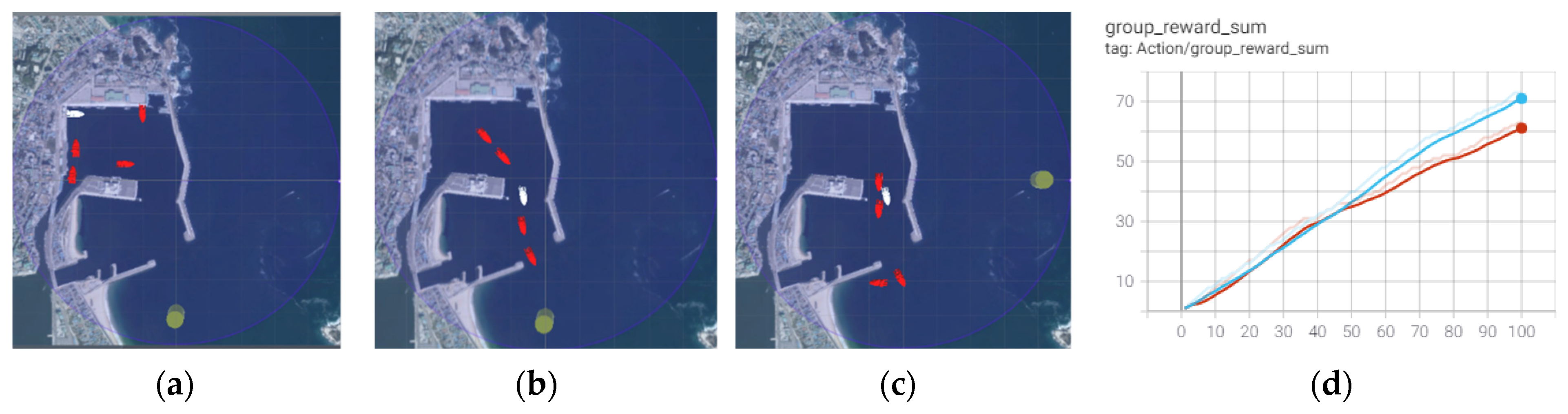
The experiment compared the operation of an autonomous ship to several outward ships without additional learning. In contrast to the experiment in
Section 4.3, four neighboring ships departed from the harbor, and two ships were artificially placed in front of those ships. There is a gap between neighboring ships #3 and #2, wide enough for one ship to enter. Two additional ships departed from the last ship. Moreover, the neighboring ships sped down to induce the autonomous ship to crash against other ships. To avoid collision with the neighboring ship in front, the autonomous ship sped down. This experiment aims to verify whether the autonomous ship can retain the learning experience of taking the right path as specified in the human-defined navigation rules, even without neighboring ships entering the harbor using the left path. The experiment result is shown in
Figure 12.
The learning results in
Section 4.1 (the learning results using the ILFAS and random RL) were applied to two inward cases without additional learning. Neither the ILFAS nor random RL did not learn this environment before. This experiment aimed to verify whether the autonomous ship could adapt to the marine traffic environment with neighboring ships departing from the harbor simultaneously.
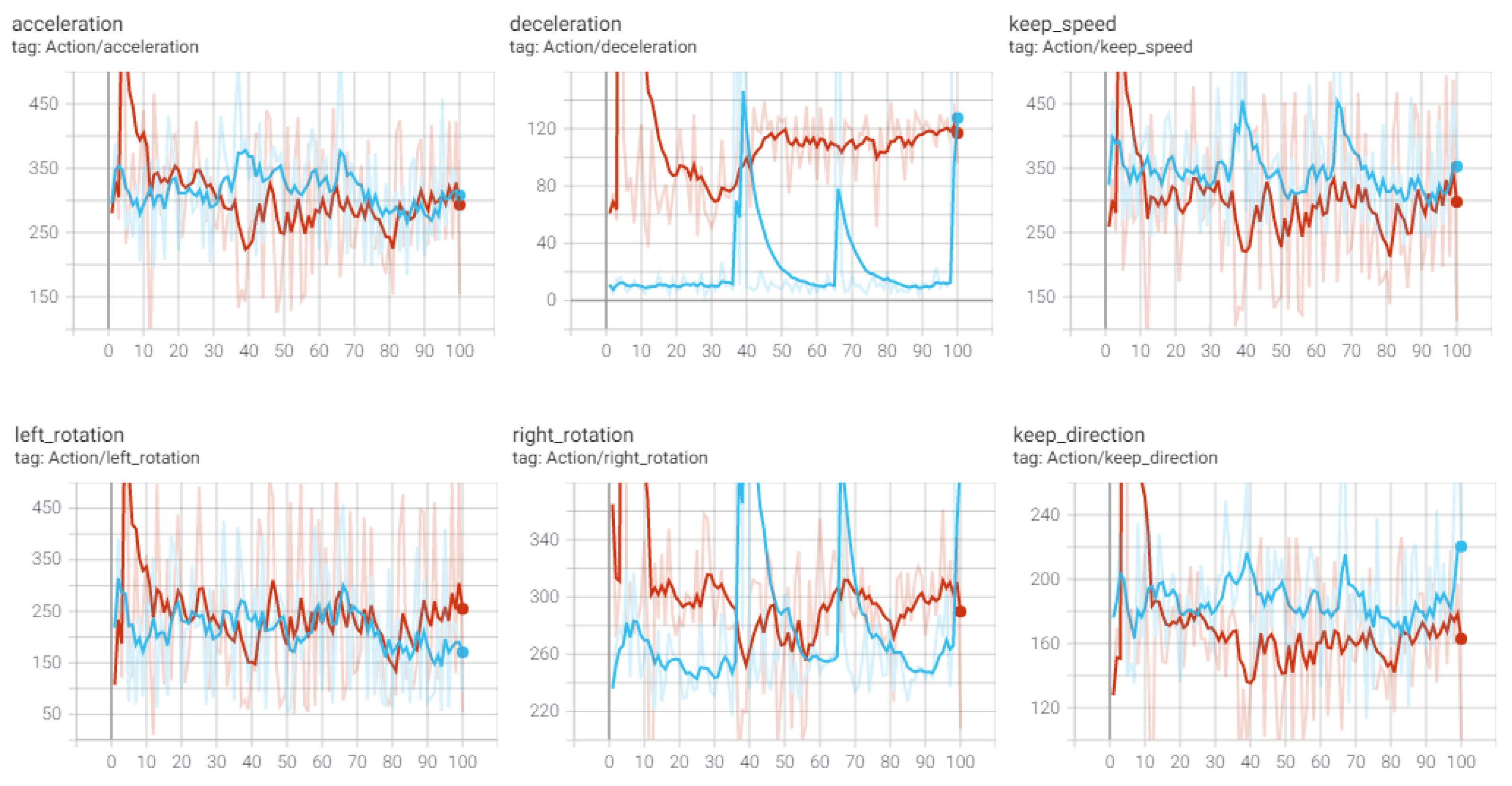
Although the ILFAS did not sufficiently learn how to respond to obstacles existing in front through learning with neighboring ships on the right path, its success rate to a destination was 10% higher than that of the random RL. The ILFAS complied with human-defined navigation rules, maintained the right path if possible, and did not surpass the neighboring ships in front. However, the random RL did not keep its position among the outward ships, stayed in the harbor, and departed later or departed using the empty space on the left. The graphs in
Figure 13 compare the number of controls. The ILFAS shows a better stability of control than the random RL with sufficient experience.
4.5. Experiment: Complex Traffic(Complicated Marine Traffic Environment with In-Ward/Outward Ships)
The busy harbor conditions were implemented by adding inward and outward ships to the environment in
Section 4.3. Considering a successful departure, the autonomous ship needs to properly control the speed between outward ships or depart from a harbor after entry into or departure from the harbor is completed. RL using ILFAS cannot learn how to wait. By contrast, the random RL did not learn the navigation rules through neighboring ships, and there was no space on the left path to get ahead of other ships in the busy marine traffic environment. The experiment result is shown in
Figure 14.
The ILFAS created busy marine traffic circumstances has a high degree of difficulty induced by the presence of inward and outward ships. The circumstances are the same for the curriculum with a high degree of difficulty and a total of eight neighboring ships because two cases are implemented simultaneously in the ILFAS. The autonomous ship could smoothly sail among outward ships while keeping it right as usual. In the experiment, although the autonomous ship by the ILFAS RL proceeded and showed expected actions, 30% of the episodes crashed against the ship in front, failing to control the speed.
The autonomous ship using the random RL learned only the path finding in the shortest time as random learning. The successful arrival rate to a destination was low because there was no space to get ahead to avoid inward ships on the left and outward ships slowly moving on the right front as compared to the experiment in
Section 4.3. The experiment indicated that it was difficult to induce an autonomous ship to learn human-defined navigation rules through unorganized random learning.
4.6. Learning and Experiment Results
Because RL algorithms cannot consider all situations, learning is sufficiently provided by adding noise to the environment created using random rules or a random environment in unmanned ships to avoid collision, such as in sensors and cameras [
32,
33]. However, it is difficult to solve the issues of autonomous ships using random learning in navigation if there are dynamic obstacles that occupy most of the area in the environment and certain rules. Furthermore, even when the rules to learn are included, it requires excessive time to learn certain rules using the random learning method.
This study demonstrates that when the autonomous ship learns autonomous navigation using the ILFAS in the space, unnecessary experience is eliminated and learning results are stabilized as compared to general random learning. Additional learning can be performed in a new environment based on previous experiences. Moreover, the learning time was reduced and definite learning results were acquired. Subsequently, the autonomous ship can learn human-defined navigation rules using the ILFAS. To generalize the learning methods and verify the learning results, the ILFAS demonstrated better results in the autonomous navigation field in the new environment and relatively stable results in the ship control field.
Additional learning related to the complex-traffic environment in
Section 4.5 was performed. Based on the successful arrival rate to waypoints, learning was completed only after approximately 3400 episodes. Furthermore, because intelligent neighboring ships sailed using a multi-agent RL algorithm, a slight difference was always generated in the gaps between ships and actions. The autonomous ship could obtain sufficient learning data from such changes and sailed to the right among outward ships or standby ships in a complicated marine traffic environment. Even when the autonomous ship waited in the harbor, neighboring ships sailed as a reaction against the autonomous ship. Thus, the autonomous ship can learn how to properly wait in the harbor for departure.
5. Conclusions
This study has attempted to solve learning environment issues when applying RL to autonomous ships. If the environment is not intelligent, even with such a great expert and distinguished algorithm, and if the autonomous ship has to adapt itself to the real environment, then it cannot help facing the limits in learning. Particularly, if the neighboring ships are not intelligent, then there is a limit to the research on intelligent autonomous ships. Moreover, it requires too much time and cost to find an expert or data to consider all the issues and to make the autonomous ship learn data.
Therefore, this study aims to implement an intelligent environment that enables autonomous ships to acquire sufficient experience using RL in the general marine environment and to learn the events that humans cannot estimate by themselves. Furthermore, this study proposes the ILFAS to investigate whether an autonomous ship can learn from general issues to inherent human norms that cannot be numerically presented. This paper presents one of the solutions to solve the insufficient environmental problem of RL and transfer human knowledge and experience to autonomous ships. It can reduce RL learning time and lower the cost of building a learning environment. In conclusion, we built an intelligent learning framework that can obtain the learning results expected by humans in a short time and at low cost. The learned hierarchical RLs of stratified autonomous ships can be reused. When autonomous ships with the same control type are applied to another environment, only the navigation part is relearned in the mission, navigation, and control layers, and other layers can be reused.
In the field of defense, you can build an example of your opponent’s naval infiltration strategy and tactics. The application of this environment to the civil sector could consider the delivery of emergency medical supplies. Similar to the experiment of this paper. However, we focused on learning the human-defined rule. Research should be conducted continuously to increase the effectiveness of autonomous ships in situations such as natural environments and bad weather on behalf of humans.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}