1. Introduction
RE is a crucial subtask in the field of information extraction. It can be divided into sentence-level extraction and document-level extraction according to the length of the input text. Previous work [
1,
2] mainly focused on predicting the relation between entities in the same sentence and could not handle cross-sentence extraction. The authors of [
3] found that as many as 40.7% of the relational facts in the long corpus can only be extracted by combining the semantics of multiple sentences based on the statistics of the Wikipedia document corpus. Document-level corpus usually has a larger input length and a more complex structure, which poses great challenges to the information extraction capabilities of existing sentence-level models. Recently, many studies [
3,
4] have extended sentence-level RE to the document-level.
Many studies have adopted graph neural networks and used structure-dependent, heuristic, or structured attention mechanisms for relational reasoning [
5,
6,
7,
8,
9]. The document graph they constructed can connect entities at a longer distance, which makes up for the shortcomings of the RNN-based encoder. With the introduction of the transformer model [
10], studies have found that this model structure can implicitly capture long-distance dependencies [
11,
12]. Therefore, many studies have abandoned the graph neural network and used the pre-trained language model BERT [
13] for relational reasoning and achieved good results.
However, previous research focuses on integrating global contextual information to enhance entity representation while ignoring the impact of genuinely critical local information on relation classification. As shown in
Figure 1, we take the corpus mentioned in [
14] as an example. When classifying the relation between “John Stanistreet” and “Bendigo” in the text, we mark their cross-attention in the pre-training model on the corresponding words. The correct classification relation of this entity pair should be
place of birth and
place of death. However, by observing the visualization results, we found that the pre-training model focuses on some entity nouns and punctuation marks that are unrelated to the classification [
11]. The “born in” and “died in”, which are really helpful for the relation classification, were given little attention by the model. In addition, processing too much global context feature information may dilute the feature information provided by keywords, which will interfere and confuse the final classification task.
Based on the above observations, this paper proposes a keyword feature capture method based on the Self-Attention mechanism and uses the SAM module for recording context features in ConvLSTM [
15]. By searching for the keyword embeddings with high cross-attention of entities, the local feature information that is helpful for relation classification is recorded to enhance the performance of downstream classification tasks. The contributions of this article are as follows:
We present a BERT-LSTM-based model in the field of document RE that creatively uses the attention of subject-object entities to match the word embeddings that determine their relation;
An improved ConvLSTM model is introduced to make it suitable for document sequence extraction. We build the model’s attention relation from scratch and enable it to extract useful contextual keyword features;
Compared with state-of-the-art models, our model has achieved advanced performance on the three benchmark datasets, proving the effectiveness of using keywords for RE.
The rest of the article is organized as follows:
Section 2 will describe the previous related work and the foundation of our work.
Section 3 will explain how we decompose the RE task and present the overall structure of our method and the processing flow of each part. In
Section 4, we report the experimental performance of our model and give a detailed analysis of the experimental results to demonstrate the effectiveness of the method.
Section 5 summarizes the work with the limitations and future directions.
2. Related Work
Graph-based models and transformer-based models are the most common approaches for document-level RE. Graph-based methods are now widely adopted in RE because of their intuitiveness and effectiveness in relational reasoning. To cope with the challenge brought by document RE, the authors of [
6] proposed an edge-oriented document-level RE graph neural model (EoG). The authors of [
16] proposed a graphically enhanced dual attention network (GEDA) for attentional supervision from additional evidence to construct complex interactions between sentences and potential relational instances. The authors of [
17] proposed a Dual-tier Heterogeneous Graph (DHG) to model the structural information of documents and perform relational reasoning across sentences. The authors of [
18] proposed an encoder-classifier reconstructor model (HeterGSAN) that reconstructs the paths and puts more attention on related entity pairs instead of negative samples. In general, graph-based methods are popular in current applications and can overcome the problems caused by long-distance dependencies. However, the type of nodes and edges used in the graph-based approach requires delicate manual design, which is not considered elegant, and it is a common problem of the graph-based method on non-graph data.
Many researchers have also proposed the transformer-based approach. The transformer’s multi-headed attention component can divide semantic features into multiple subspaces, allowing the model to learn richer contextual features from the text. The authors of [
19] observed an unbalanced relation distribution on the DocRED dataset. They proposed a two-step RE mode, separating relation recognition and classification, which can avoid the influence of a large number of negative samples in the dataset. The authors of [
20] proposed a hierarchical inference network reasoning network (HIN) for document-level reasoning. It uses a hierarchical reasoning method to aggregate the reasoning information at the entity level, sentence level, and document level. The authors of [
21] proposed CorefBERT, which aims to capture co-referential information in the text. They incorporated entity-pair matching, mention-entity matching, and mention-mention matching into the pre-trained model to enhance the representation of the relational extraction model. The authors of [
14] proposed a model based on entity-enhanced embedding and adaptive threshold loss function. They used the attention matrix output by the pre-training model BERT to calculate the cross-attention between entities and introduced a threshold class to calculate the loss of positive and negative samples, respectively, which allowed their model to achieve SOTA results on multiple datasets. We can summarize the predecessors’ work into two aspects:
How to construct potentially useful information for determining the existence of relations from a large amount of textual data;
How to overcome the uneven distribution of relations in the dataset and the negative impact of a large number of negative samples on the model.
In addition, there have been research attempts to extract relations based on keywords in the field of professional documents. The authors of [
22] used a domain keyword collection mechanism to guide the model to focus on the semantic interaction between biological entities linked by keywords by manipulating the attention mask, which improved the F1 value by 5.6% on the Biocreative V Chemical Disease Relation (CDR) dataset. The authors of [
23] used the BiLSTM neural network and attention mechanism to extract time and sentence-level important information. They selected each sentence’s critical feature layer under the pooling layer’s action, which has also achieved advanced results in the field of patent document RE. In general, they constructed keyword-attentive models and made them more sensitive to specific words in the specialized domains. However, this approach cannot be generalized to open domains because it is not possible to enumerate all keywords in open domains.
The authors of [
24] used a SALSTM model that can mine and capture remote dependencies in the spatiotemporal sequence prediction task in the field of computer vision and achieved the most advanced results on multiple tasks such as precipitation prediction. Similar to precipitation prediction, the RE task is also a sequence feature extraction and prediction task. Inspired by this, we propose a SAM-LSTM model that can be used to process document sequences, integrates a self-attention memory module and trains a new attention layer from scratch. See the next section for specific methods.
3. Methodology
The structure and processing flow of the method proposed in this paper are shown in
Figure 2. The word embedding output by the pre-training model is the original input of the SAM-LSTM model, and the Self-Attention mechanism lets the model learn to find the critical feature information. The weighted feature after attention screening is combined with entity mentions and input to the fully connected layer for the final classification.
3.1. Encoder
We model the document-level RE task: with a document
d,
is the set of all entities it contained. The aim is to find out the existing relationship from the pre-specified relationship set
(NA stands for no relation) for every pair of entity pairs
in the set. An entity
can be mentioned multiple times in the document as
. If the entity pair
contains relation, then this relation is expressed through one of their mentions. The RE model needs to classify the relation between all entities in document
d. In order to further improve the task performance, we adopt the BERT pre-training model and integrate the following technologies to build the entire model. We can think of a document as a sequence of words
. We add the “*” symbol before and after the entity mention to mark the position of the entity. Then, we enter the document into the pre-training model BERT to obtain the word embedding sequence
H of the entire document:
For some documents whose length exceeds 512, we utilize dynamic windows to encode the entire document, and average the embedding of overlapping marks in different windows to get its final representation. Multiple mentions of an entity may produce different word embeddings, which is not conducive to further classification processing. As a result, logsumexp pooling [
25] is used in this paper. The embedding of the entity is obtained using the following formula for multiple mentions.
This pooling operation is similar to max pooling, but it can better accumulate the mentioned information, and it also shows better performance than average pooling in the experiment.
3.2. Context Feature Extraction
Since the data volume remains large after one document word embedding, this paper performs contextual feature processing based on the ConvLSTM model [
15]. This model replaces the input-to-state, state-to-state fully connected operations of ordinary LSTM with convolutional operations, which can establish temporal relations as LSTM and carve local spatial features as CNN. It also enhances feature extraction while reducing the amount of operations. As shown in
Figure 3,
is the vector in the word embedding sequence,
is the state corresponding to cell at step
i,
is the current input feature,
is the sequence information accumulated by cell at step
i.
This model sequentially processes the word embedding sequence , controls the cell state by the operations of forgetting gate, input gate and output gate. Meanwhile, the SAM module is used to calculate the attention values with entity embeddings and for the memory and hidden state . Using this attention value to weight the current input features and the features stored in the memory module, we finally output the and update the .
3.3. Self-Attention Memory
It has been shown previously that obtaining the attentional relations from the pre-trained model may not yield good results for downstream relational classification tasks. We train a new attentional layer from scratch compared to the previous work [
14] which directly uses the multiheaded attention of BERT to process the full-text context. In this paper, a novel SAM module is proposed for capturing key features of full-text, while a memory unit
is used to store contextual sequence information with a global sensory field.
The main idea of the module processing is to use entity pairs to match the word embeddings of interest in the input sequence. Following ConvLSTM processing, the attention matrix of the entity pairs and features is generated, and the parts with greater attention are weighted and updated to be stored in the memory unit. This ensures that the model is able to store the key features of the entity’s dependency on the relation even after traversing the entire sequence of contexts.
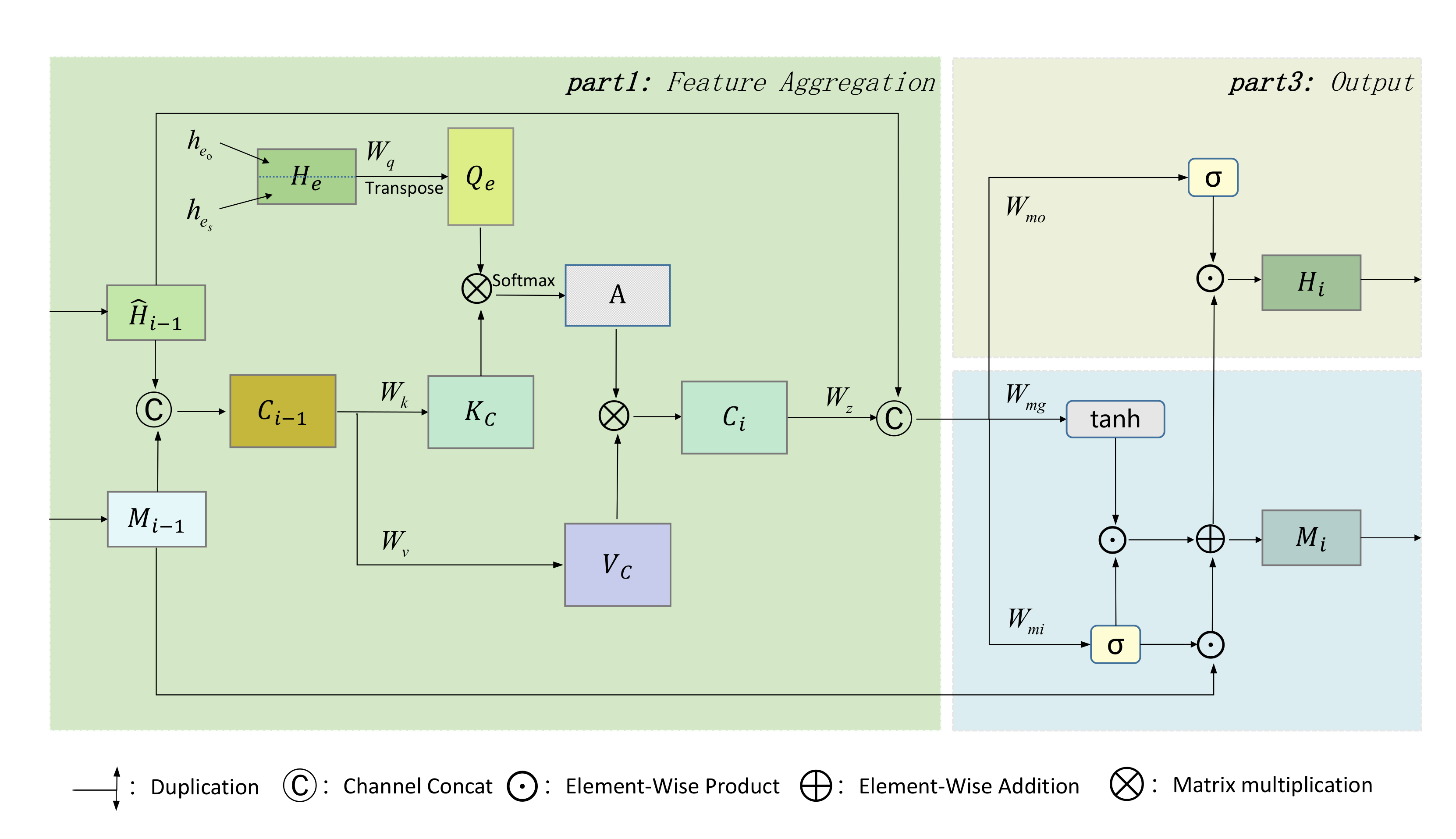
The detailed structure of the SAM module is shown in
Figure 4, where
is the current hidden feature being processed by ConvLSTM, and
is the memory accumulated since the previous step.
is the entity pair matrix, which is connected by the subject-object entity embedding
and
. The module can be divided into three parts: self-attentive feature aggregation, memory update, and output.
3.3.1. Feature Aggregation
To match the contexts of interest for entity pairs, we first splice
and
into the aggregation matrix
, and then perform a self-attentive operation on the entity pair matrix
with the aggregation matrix
. First, we calculate the value matrix
corresponding to
and the key matrix
. Then, we calculate the query matrix corresponding to
, where
,
,
are the weight parameters of the 1 × 1 convolution kernel. The product of the matrices is then used to compute the attention matrix
of the entity pair for the aggregated feature:
The
in
represents the subject’s attention to the
feature vector in
,
represents the object’s attention to the
feature vector in
. To find the feature vector that both the subject/object entities are interested in, we calculate the cross-attention by multiplying the attention of both, and the normalized cross-attention weights are multiplied with the value matrix
to get the new aggregated feature
. Finally,
is stitched together with the current moment feature as the input for the next step:
3.3.2. Memory Update
In this paper, a gating mechanism similar to the GRU [
26] (Gate Recurrent Unit) model is used to update the memory adaptively. The input gating
and the fusion feature
are generated by aggregating the features
and the original input
. To reduce the parameters, it is straightforward to use
to represent the forgetting gate, and the specific update process is as follows. To reduce the number of parameters, we directly use
to represent the oblivion gate. The specific update process is as follows:
To further reduce the computational effort, this paper uses depthwise separable convolution [
27] instead of standard convolution operations. Compared with the original storage unit updated by ConvLSTM through convolutional operations, the memory module proposed in this paper is updated not only by convolutional operations but also by aggregating features
, which can capture the global dependencies of entities at all times. Therefore, we consider that the memory module can contain the international and contextual information filtered by the attention mechanism.
3.3.3. Output
The output of the module is the dot product of the output gate
and the updated memory
. The procedure is as follows:
3.4. Classification Module
The entity pair embedding
,
and the contextual key feature matrix
can be obtained through the above steps for the word embedding sequence. These entities are mapped to hidden states by feedforward networks, and then, we use bilinear functions and sigmoid activation functions to calculate the probability of the relation
r:
where
are the training parameters of the model,
is the probability of the existence of various relations between entity pairs predicted by the model. Previous work [
19] observed that the entity relation extraction dataset generally has an unbalanced relation distribution and most of the entity pairs are unrelated to each other. So, inspired by the idea that the target class score is greater than every non-target class in Circle Loss [
28], we introduce a balanced loss function training model. Initially, a loss function in the logsumexp form can be formulated as follows:
We also note that the RE task is essentially a multi-label classification task. Therefore, a threshold is needed to determine which classes need to be output. Instead of introducing an additional threshold class as in the previous work [
14], we directly use the score
of the unrelated class
as the threshold, and thus, the loss function can be further obtained as:
This loss expects all target class scores to be greater than each non-target class, and also expects all target class scores to be greater than the threshold and all non-target class scores to be less than the threshold . In this way, the model can automatically learn and determine the labels to be output: output the relation classes greater than the threshold as having a relation, and otherwise output no relation label .
4. Experiment and Results
4.1. Dataset
We evaluated the proposed model on three popular document-level relationship extraction datasets (DocRED [
4], CDR [
29], and GDA [
30]), all of which involve challenging relational inference on multiple entities across multiple sentences. DocRED and CDR provide human-validated data. They use crowdsourcing to manually annotate all possible relationships in the documents, which ensures the quality of the data and better guides the deep learning model. In order to ensure the validity and generality of our approach, we have compared performance primarily on the human-validated part of the DocRED dataset. The statistical information for each dataset is shown in
Table 1.
DocRED is a large-scale dataset built with Wikipedia. It provides comprehensive manual annotation of entity mentions, entity types, relationship facts, and corresponding inference-supporting evidence. In addition, DocRED collects remotely supervised data, which uses a fine-tuned BERT model to identify entities and link them to Wikidata. 101,873 document instances are then scaled by obtaining relationship labels through remote monitoring.
CDR (Chemical-Disease Reactions dataset) is a biomedical dataset constructed with PubMed abstracts. It contains 1500 documents with human annotations, which are equally divided into a training set, a development set, and a test set. CDR is a binary classification task designed to identify induced relations from chemical entities to disease entities, and is of great importance for biomedical research.
GDA (Gene-Disease Associations dataset) is similar to the CDR and is also a binary relationship classification task for identifying interactions between gene and disease concepts but at a much larger scale. Constructed using the remotely supervised MEDLINE summarization technique, it contains 29,192 documents as training set and 1000 documents as a test set.
4.2. Experimental Settings
The experiments in this paper are based on Pytorch, using BERT-base and RoBERTa-large as Encoder on DocRED, and SciBERT-base as Encoder on CDR and GDA datasets. We use AdamW and set a warm-up learning rate of 6% to optimize the model. The detailed hyper-parameters settings are shown in
Table 2. The model is trained on an NVIDIA P100 16GB GPU. We measured RE performance by calculating precision, recall and F-measurement scores on the test set. By evaluating all false positives, false negatives, correct positives and correct negatives, we used the standard formula to calculate the F1-score as:
4.3. Results on the DocRED Dataset
We compared our model with graph neural models, including GEDA [
16], LSR [
7], GLRE [
9], GAIN [
8], HeterGSAN [
18]; and transformer-based models, including BERT [
19], BERT-TS [
19], HIN [
20], Coref [
21], ATLOP [
14]. We run five experiments with different random seeds and record the mean and standard deviation on the development set. The experimental results are shown in
Table 3, and the SAM-LSTM-BERTbase in this paper achieved the best-known results on the DocRED dataset. These models’ performance results are taken from their original articles.
4.4. Results on the Biomedical Datasets
In experiments on two biomedical datasets, we compared SAM-LSTM with many models, including EoG [
6], LSR [
7], DHG [
17], GLRE [
9], and ATLOP [
14]. We applied the SciBERTbase [
31] model pre-trained in the scientific publications corpus. The results are shown in
Table 4, where SAM-LSTM improved the F1 scores of GDA 0.8%. We also note that [
22] achieved better results than we did on the CDR dataset. We believe this is due to their use of a pre-trained biomedical language representation model and the injection of domain expertise in the RE process.
4.5. Ablation Study
A series of comparative experiments are conducted to validate the effectiveness of the components in this paper. This is shown in
Table 5.
w/o Memory means that the model only calculates self-attention with the current input each time and does not update memory; w/o Self-Attention means that the standard ConvLstm operation is used to replace the Self-Attention part of the model; w/o Balanced loss means that the loss function of the baseline is used. In addition, considering that the BERT model also comes with a multi-headed attention mechanism, we directly remove the LSTM layer and test the effect of the BERT+classifier.
The result reveals that the performance of the model decreases after removing any of the components. The Memory module and Self-Attention have the greatest impact, bringing a decrease of 1.07% and 1.48% after removal. This indicates the effectiveness of the SAM-LSTM network for extracting document-level entity relations. In addition, the results of LSTM removal demonstrate that directly training the attentional relations of BERT to weight the contexts cannot achieve the desired results. We suggest that this may be due to the large parameters of the pre-trained model, and the training corpus within the dataset cannot support the model to shift its attention to keywords through learning rapidly.
4.6. Case Study
In order to further investigate the effectiveness of this model compared to the ATLOP model, we divided the dataset into different groups in terms of corpus length and tested the ATLOP model and our model on them separately.
From the results in
Figure 5, it can be seen that the SAM-LSTM model in this paper consistently outperforms the ATLOP model. It can also be seen that the performance of our model decreases more slowly when the text length rises. This indicates that the method in this paper can preserve the key feature information even in longer difficult cases through a powerful self-attentive mechanism, while being less affected by irrelevant information. We also note that the time consumption of our model does not increase significantly when faced with long difficult cases. This is mainly influenced by the length of the sequence due to the nature of the LSTM itself. However, the processing time of our method increased by a factor of 1.5 on average compared to ATLOP. We believe that this is mainly due to our strategy of successfully matching keywords for each pair of entities, which generates a relatively large amount of computation when there are more entities in the document.
In addition, to explore whether the models in this paper can actually capture key features, experiments are designed to compare the contextual feature extraction ability of the SAM-LSTM model with that of the ATLOP model. The analysis continues using the corpus mentioned in
Section 1. While classifying the relation between the two entities “John Stanistreet” and “Bendigo” in the text, the contextual features used by the two models for classification are first obtained. Then, the cosine similarity is computed between the two and the word embeddings of the manually selected keywords “born” and “died”.
The experimental results in
Table 6 show that the similarity of our model is up to 8.13% higher than that of ATLOP. This supports why our model performs better: ATLOP uses the attention relation of the pre-trained model to weight the average word embedding of the full text, so that the key features are diluted by the large number of irrelevant vectors within the document, which deviates from the features originally needed for the downstream classification task. In contrast, the self-attentive memory unit used in this paper can capture and record these features while processing full-text information, which can achieve more favorable results for classification.
To further validate the performance of our model in difficult cases, we chose a text containing distant relational dependencies as an example. As shown in
Figure 6, when our model classifies the relationship between “Tang Dynasty” and ’Chang’an’, it can be seen that the subject ’Tang Dynasty’ is separated from the object ’Chang’an’ by 13 sentences.
However, we can see from the similarity visualization that our model still accurately filters the keyword “capital” in 15 sentences and finally outputs features that are highly similar to it.
5. Conclusions
This paper proposes the SAM-LSTM model to reconstruct global entity dependencies to find the critical semantic features. We first illustrate that it is not appropriate to use the attention layer of the pre-trained model directly. Then, we construct the new keyword attention relation and extract contextual features via recording and updating memory. Finally, we use a multi-label classification loss function that can balance the categories. With the above techniques, we further improve the performance of the document-level RE task on a public dataset. This paper also designs experiments to demonstrate that the model in this paper can better capture local keyword information compared to the current state-of-the-art models. The approach of enhancing relation classification by capturing the keyword features of entity relation dependencies is effective. Since we have achieved advanced results on both open and specialized domains/datasets, we can say that the approach of this paper can be applied to the domains not exposed to the model. Without constructing keyword features for each specific domain, our model has strong applicability to the new domains. In the course of our experiments, we also found that processing the context for each entity pair is relatively time-consuming. We will explore a common keyword extraction method for documents in the future to speed up the computation of the model and allow all entity pairs to find the content of interest in a shared keyword pool.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}