1. Introduction
Coastal storms and hazard events are often analyzed to address dangers faced by coastal communities around the world. Many potential threats to communities residing in coastal areas are captured with a comprehensive plan for risk analysis. In 2018, a preliminary risk analysis estimated almost
$17 billion in damages across the state of North Carolina in the wake of Hurricane Florence [
1]. As a result, accurate and efficient evaluations of damage from coastal hazards such as hurricanes are necessary to provide data for addressing post-disaster relief efforts. Damage assessment is a primary tool for understanding the levels of damage to coastal populations in the aftermath of a hazard event. Knowledge of damage is further applied to models for risk assessment to mitigate damage from future hazards [
2].
Efficient relief plans and proper allocation of relief funding to the affected areas are impractical without accurate data. Traditionally, post-disaster data have been collected through methods involving individuals or teams making initial observations and assessments of damage. These people capture photographs of the damage in door-to-door assessments or windshield surveys (e.g., [
3,
4]). Remote validations are a supplemental tool used during the damage assessment process which increases the swiftness of the manual evaluations. These desktop assessments replace onsite validations when the risk for preliminary damage assessment staff is high and images of the damaged area are readily available [
4]. However, these validations still rely on humans to identify damaged structures and verify damage assessments making them prone to a significant level of inaccuracy.
In a myriad of classification tasks, artificial neural network technology has proven to be significantly more efficient in performing the same work as a human to a higher level of accuracy. Machine learning techniques possess particular advantages over humans in tasks that incorporate a large data set from multiple events of highly similar situations [
2]. Hurricanes provide a multitude of events for data collection that can be used by artificial neural network models to perform damage assessment. There are usually two types of data capturing hurricane damage to buildings. The first type is satellite imagery (e.g., [
5,
6]), and the other type is ground-level images/photos (e.g., [
7]) taken by drones or other similar ways. Both data types have been used for damage assessment. For example, Weber and Kané [
8] used the Mask R-CNN [
9] to predict both building locations and damage level based on pre-disaster and post-disaster images of xBD database [
6]. Furthermore, Hao et al. [
10] developed a multi-class deep learning model with an attention mechanism to assess damage levels of buildings given a pair of satellite images depicting a scene before and after a disaster using the xView2 dataset [
11]. Cheng et al. [
12] developed a stacked convolutional neural network architecture to train on an in-house visual dataset from Hurricane Dorian that was collected using an unmanned aerial vehicle. An effective hurricane damage assessment model should train on both aerial and ground-level image data to increase adaptability for emergency damage assessment of a future coastal hazard.
Social media has been explored as a primary source of data for hurricane damage assessment because of the swift integrability these platforms provide to automated damage assessments (e.g., [
13,
14,
15]). Hao and Wang [
16] used five machine learning classifiers that take social networking platform images and output the damage types and severity levels presented in images. Leveraging social media platforms to train damage assessment models has shown success with rapid operation capabilities.
The transfer learning approach to developing artificial neural network models for hurricane damage assessment has also been recently explored. Most of these studies focus on using transfer learning on pre-trained convolutional neural network (CNN) models with aerial images of hurricane damage to buildings (e.g., [
17,
18,
19,
20]). Liao et al. [
21] uses transfer learning on two well-established CNNs, AlexNet and VGGNet, to create classification models for the two-dimensional orthomosaic images gathered from unpiloted aerial systems. These and other similar studies limit the source of the training dataset, making the classification models useful only for functional datasets comprised of aerial images taken by satellite or drone. Our work incorporates both aerial and ground-level images for hurricane damage classification and detection of damaged buildings to create a more operational damage assessment framework to apply to future coastal hazards.
Incorporating transfer learning for building damage assessment is affected by the transferability of the learned features and information from the source domain to the target domain used for testing the model. Domain adaption when using transfer learning arises when there are discrepancies among images in the source domain and between the source and target domains (e.g., [
22,
23]). These discrepancies are a result of how remote sensing captures images with varying sensors, locations, times, and perspectives. This issue with domain invariance extends to the transferability of information derived from different coastal hazards. A CNN-based model was shown to reach high classification performance when training on the same damage type for different disasters [
24]. The source and target domains in our study do not present any major discrepancies. Rather, our damage classification and damage detection models focus on a single coastal hazard that causes multiple types of damage to enhance the efficacy of damage assessment.
There are several challenges in the area of building damage assessment using artificial neural network models. First, machine learning training requires a considerable amount of input data in order to sufficiently assess the damage or classify the damage levels from images (e.g., [
5,
6]). Second, in-house machine learning model development requires a significant amount of effort to achieve high accuracy. This study focuses on the building damages due to hurricanes in the U.S. southeast area, and we improve the efficiency of assessing hurricane damage to buildings by applying neural network models for damage classification and object detection. We address the first challenge by developing our in-house building damage dataset using internet search engines, and we address the second challenge by utilizing the advanced artificial intelligence models for computer vision, MobileNet [
25], ResNet [
26], and EfficientNet [
27], through transfer learning.
This paper is organized as follows:
Section 2 presents the development of our in-house building damage images including data collection, data statistics, and data pre-processing.
Section 3 reviews the background of three artificial intelligence models that were used as the base of transfer learning for building damage assessment and explains the transfer learning workflow for both damage classification and damage detection.
Section 4 presents the training metrics, the damage classification results, and the damage detection results, further discussing the transfer learning results among three models. Finally, the conclusion and significance of this study are stated in
Section 5.
2. Building Damage Dataset
This section first presents the development of our in-house building damage image dataset. Then, we explain the data statistics for damage classification and damage detection.
2.1. Data Collection and Preparation
This study primarily focuses on the hurricane damage to buildings in the U.S. southeast region. We sourced the data from an internet search specifying criteria for photos related to hurricane damage, and a few thousand images taken from hurricane damage in Florida, Georgia, North Carolina, and South Carolina were prepared for a preliminary data cleanup. Each image in our in-house dataset was further examined for types of buildings and structures contained in the images to ensure they were characteristic of the U.S. east coast region.
The raw dataset was further processed for two tasks: damage classification and damaged object detection. For the first task, we examined the data to be used in the classification model and identified potential classes for image categorization. This step involved the additional cleanup and removal of remaining images that were duplicates or would not be a candidate for one of the image classes. For the second task, we also examined individual images to be used in the object detection model and removed those that did not capture a damaged structure. After final examination of both versions of the data, the images were ready for pre-processing before inputting them into the neural network models using transfer learning.
2.2. Data Statistics
The next step required dividing the dataset into a set for the classification model and a second set for the object detection model. The main difference among the two datasets was that the set applied to object detection required images only containing buildings, and the set applied to classification was independent from only using images containing buildings. Images contained in both sets of data are of varying pixel resolution and unaltered from the original source.
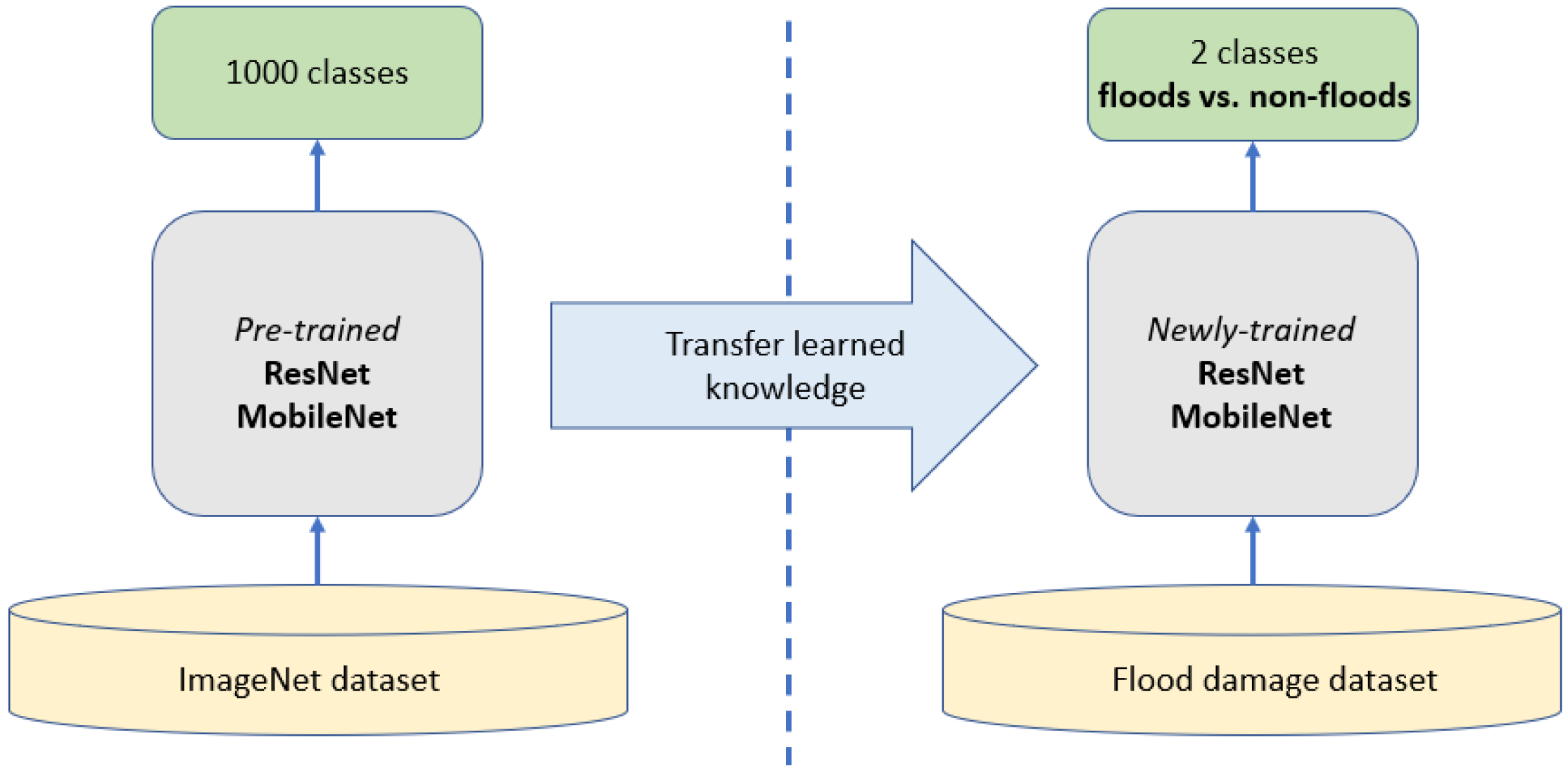
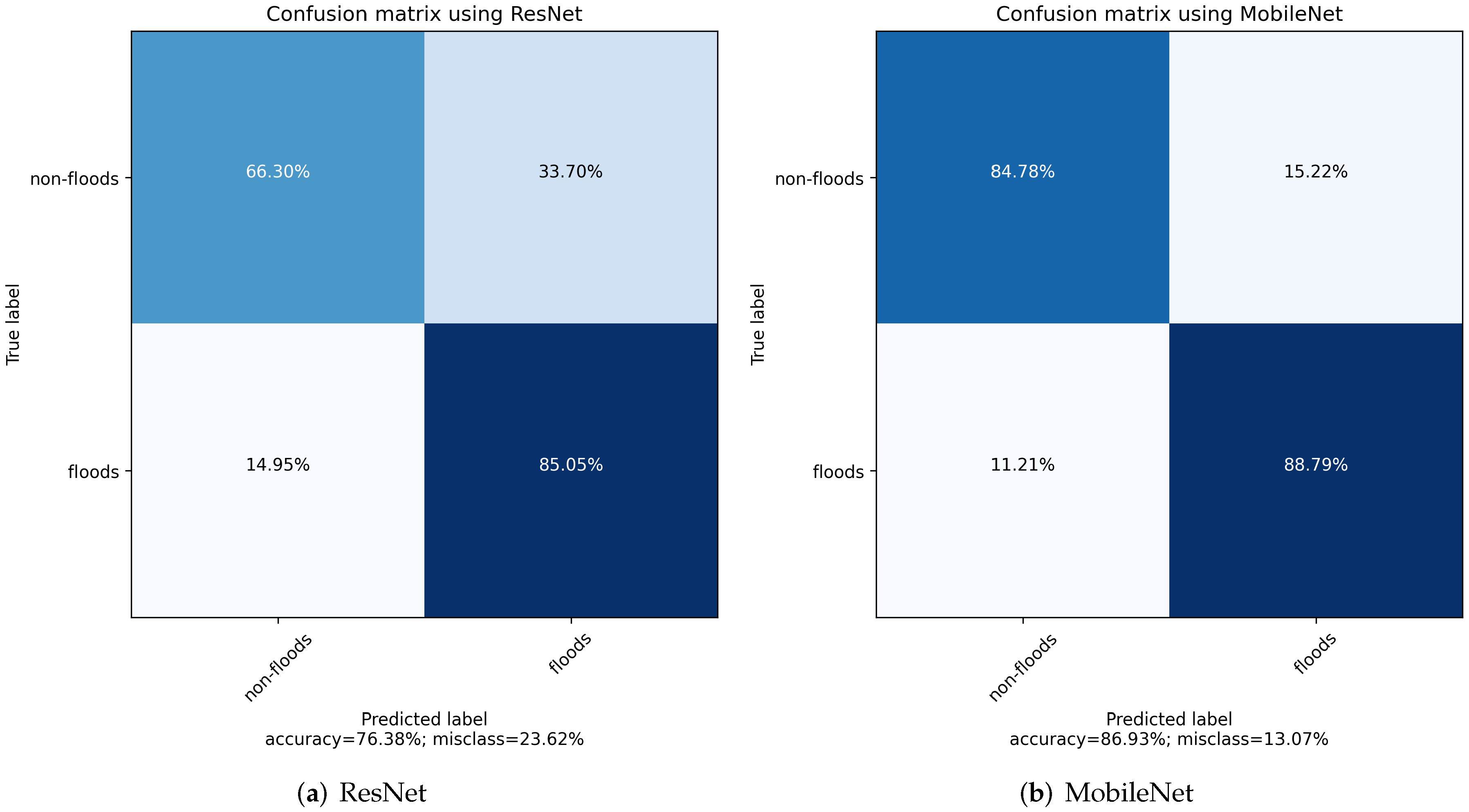
Historical hurricanes usually brought about significant flood damage due to storm surges and heavy precipitation. Thus, the damage classification research in this work aims to determine if there are floods in the image. To this purpose, we selected 1000 images from our dataset and divided them into two categories,
floods and
non-floods, as indicated in
Table 1. The motivation is to examine if neural network models can perform binary classification on our dataset. Flood damage is characterized by flood waters in the images, and it can occur in various ways. Typical
floods damages in our dataset include (1) flooded buildings, houses, and communities, (2) flooded streets, (3) flooded vehicles, and (4) flooded coastal areas. The
non-floods images are related to hurricane damage, but they do not include floods in them; these images needed to be characteristic of areas and buildings damaged from hurricanes because the purpose of our classification models is to exemplify their success learning from data that would be used for traditional hurricane damage assessment. Finally, the binary classification task does not require additional data processing other than sorting the images into two categories.
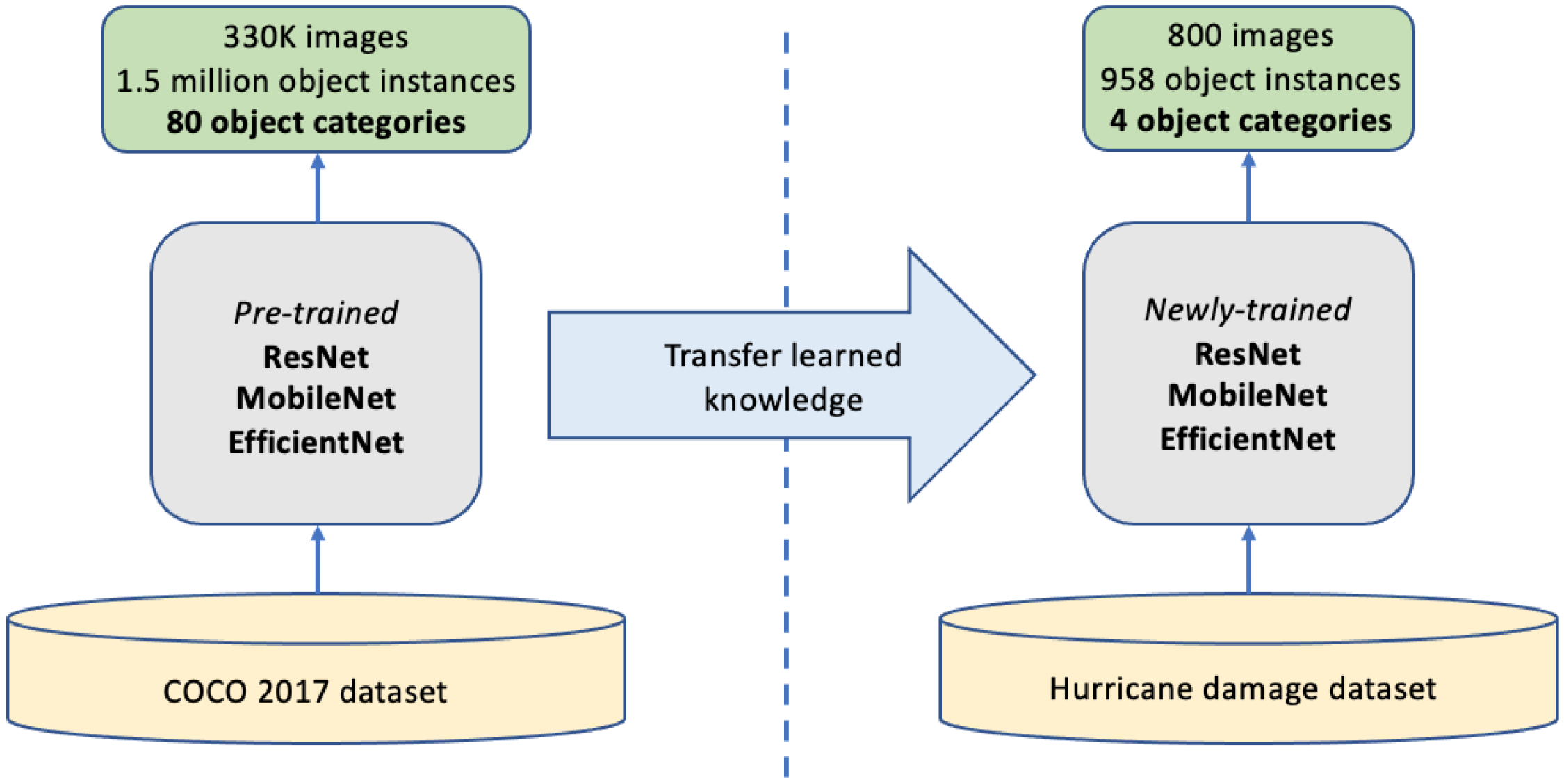
Unlike the data preparation for damage classification, machine learning object detection requires the preparation of labeled data, which guides the model to learn common features in a specific type of object. The pre-processing image labeling in this work was accomplished by using the open-source annotation tool, LabelImg [
28]. This tool allowed us to take an input image in our dataset and create bounding boxes around the areas of interest in the image corresponding to an annotation label. The position of the bounding box and the label were then exported for neural network model training. The object detection dataset consisted of 800 images that were annotated, and annotation labels are the damaged objects as listed in
Table 2. Four categories of objects were identified from our hurricane damage dataset, and the features associated with each of them are briefly explained below.
Damaged roof. The bounding box label highlights a roof that has the whole roof, some shingles, or parts of the roof damaged. The bounding box label typically encompasses the entire roof in the image; however, if the entire roof is not visible then the damaged area and any additional parts of the roof that are visible were included.
Damaged wall. The labeling bounding box highlights a damaged building wall or windows within a wall. Damage to walls/windows could range from areas with minor disintegration of brick or glass structure to entire loss of the wall or window structure.
Flood damage. The bounding box label highlights flood waters in an image. The flood water can occur in various places as explained in the binary classification dataset. Due to this sporadic nature, in some images, multiple bounding box labels were used to encapsulate the entirety of the flood water.
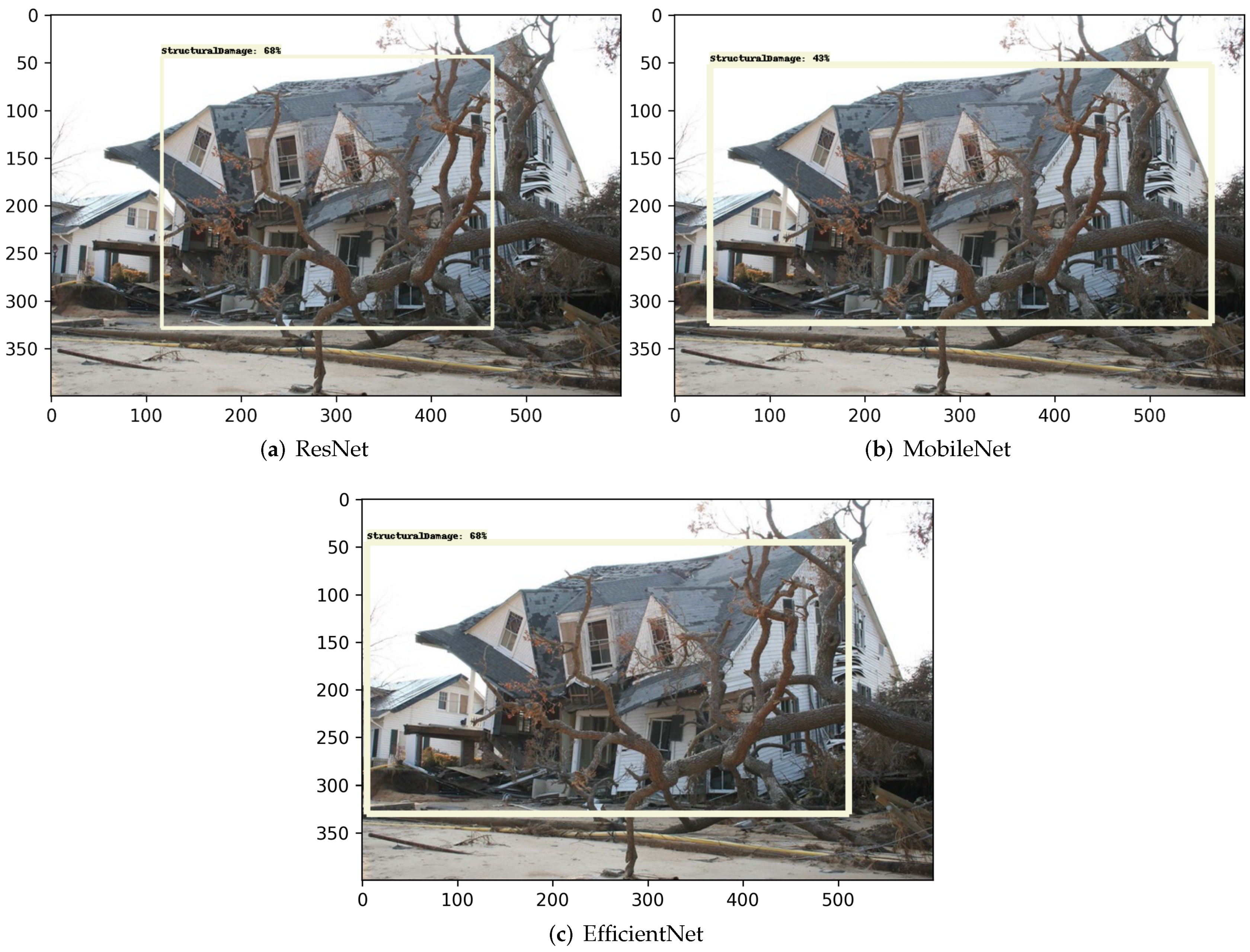
Structural damage. The bounding box label highlights a building suffering from structural damage, e.g., the disintegration of the roof and/or any floor(s) within the building, complete loss of multiple walls/structures, or the collapse of the whole building.
It should be pointed out that the total number of samples in
Table 2 is 958, which is greater than the total number of annotated images, i.e., 800. The difference is due to the fact that multiple objects were annotated/observed in a single image, resulting in a larger number of objects than the number of images.
5. Conclusions
This study has developed transfer-learning-based artificial intelligence models to assess building damages due to hurricanes in the U.S. southeast region. We developed our in-house building damage image dataset and subset it into (i) damage classification (i.e., floods vs. non-floods) and (ii) damaged object detection including damaged roof, damaged wall, flood damage, and structural damage. We developed transfer learning workflows that take advantage of feature extraction from three advanced neural network models in computer vision (i.e., EfficientNet, ResNet, and MobileNet) and successfully retrained these models for building damage assessment. Finally, we evaluated the classification and object detection performance among the different models. Our major findings and contributions include
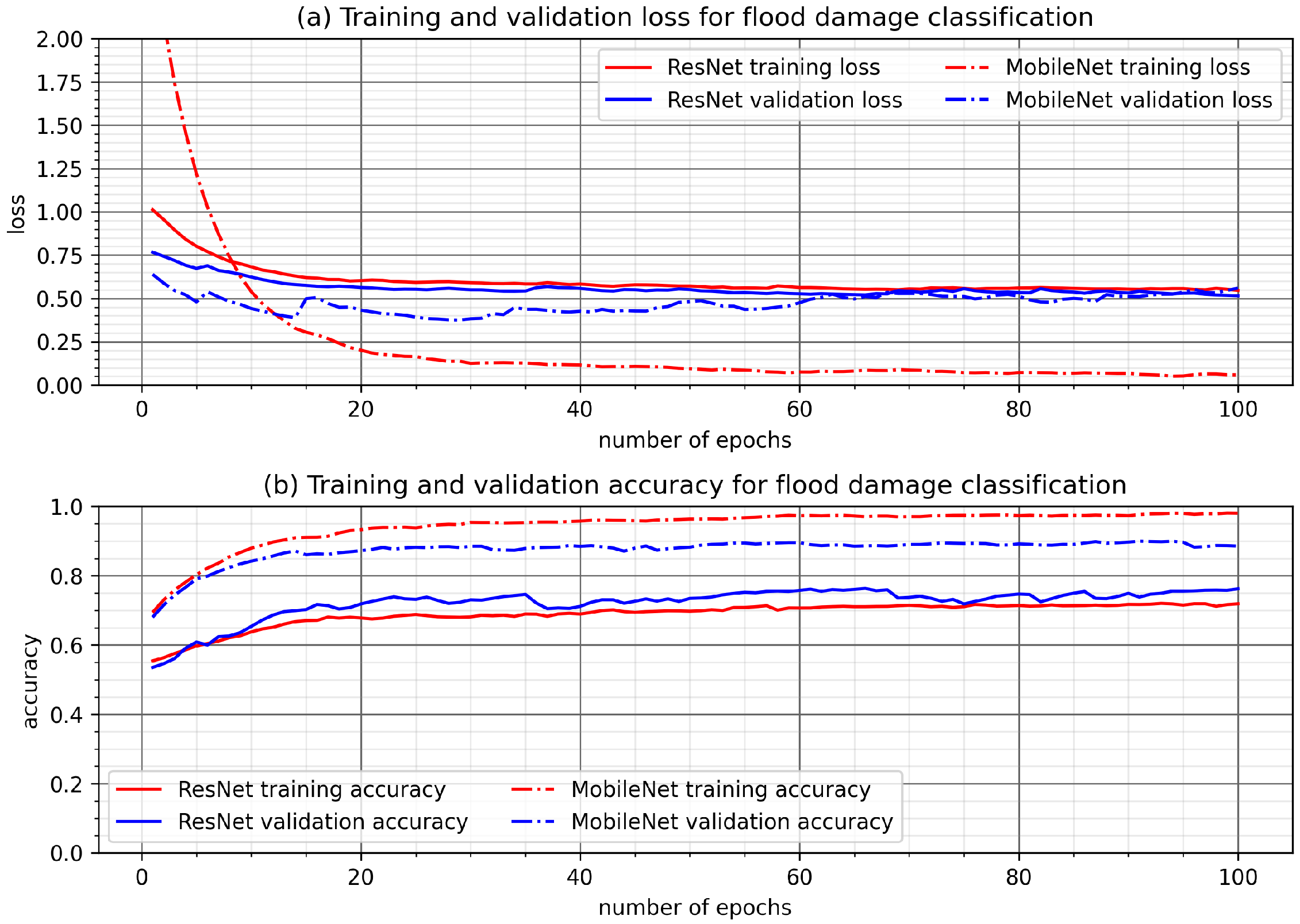
The transfer learning based flood damage classification models were developed using ResNet and MobileNet. A binary classification was carried out to detect floods and non-floods images. Several methods were used to evaluate the performance of the transfer learning models. The confusion matrix comparison showed both ResNet and MobileNet are able to correctly classify floods and non-floods with a relatively high accuracy. Specifically, the overall accuracy is about 76% using ResNet and 87% using MobileNet. Three metrics (precision, recall, and F1 score) were further calculated and compared between two models. The result obtained using MobileNet as the base model is consistently better than that using ResNet. For example, the F1 score, a harmonic mean of precision and recall, is about 0.88 using MobileNet. It is about 9% higher than the F1 score using ResNet (0.79). Overall, this study showed that hurricane flood damage to buildings can be correctly classified using artificial intelligence models developed using transfer learning techniques on the basis of advancing machine learning models in computer vision.
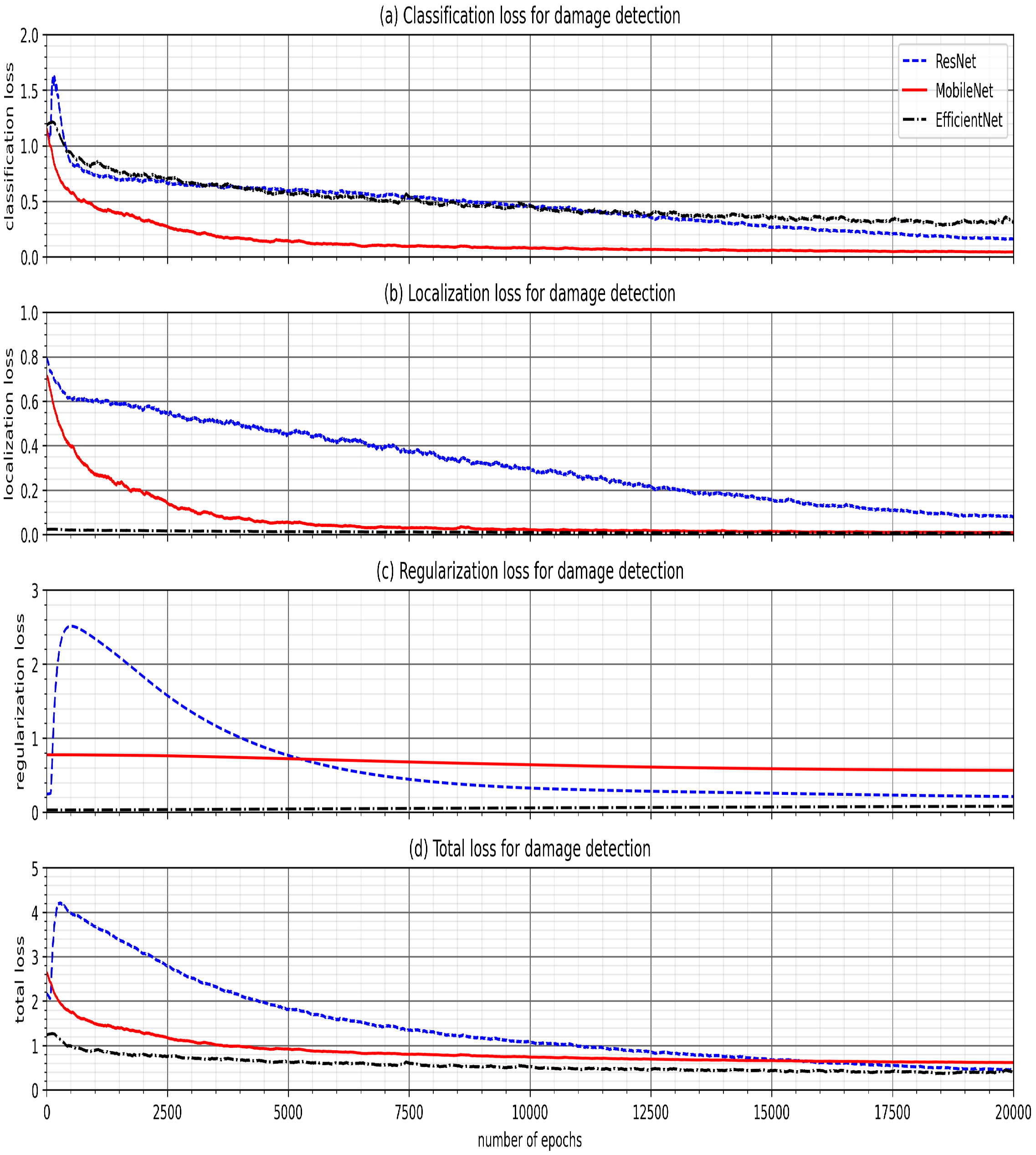
The transfer-learning-based damage detection models were developed using ResNet, MobileNet, and EfficientNet. Four damage types were captured in four object classes: damaged roof, damaged wall, flood damage, and structural damage. Two methods were primarily used to evaluate the performance of the transfer learning models for damage detection. The top three confidence scores and associated object class were tabulated for each model, showing that each model was capable of predicting the correct object class in the image; the MobileNet model consistently achieved the highest confidence score and proved to be the more accurate model in detecting hurricane damage. Then, the images of each type of damage were displayed with the top bounding box prediction for each model. Likewise, MobileNet consistently achieved the most accurate localizations of the detected damage in each image. Therefore, this study showed that various types of damage from hurricanes can be accurately detected using artificial intelligence models developed through transfer learning to further advance machine learning applications in computer vision.
From creating our in-house damage assessment framework, we were able to show that a significant level of accuracy for damage classification can be achieved using transfer learning techniques on a pre-trained neural network. Given the relatively small and broad range of images used for the input data set, our classification model displayed a high degree of versatility that could be used during a spectrum of hurricane and other coastal hazard events. The object detection results highlight the model’s ability to successfully identify damaged areas of buildings and structures from test data in a time span of seconds, which is necessary for more efficient damage assessment.
Our work can be improved with further research into applying transfer learning techniques to create classification and object detection models trained on post-disaster imagery. Using these machine learning models would significantly reduce the time required for damage assessment. Therefore, relief plans created in the wake of a future coastal hazard would save hours to days of time required to determine the total damage incurred. As a result, impacted coastal communities would be able to receive more reliable and prompt relief from direct implementation of artificial intelligence technology such as our classification and object detection models.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}