
Sentence Boundary Extraction from Scientific Literature of Electric Double Layer Capacitor Domain: Tools and Techniques

 ,
,  ,
,  , , and
, , and 
Abstract
:1. Introduction
- Recommend a better Python package for extracting text from PDF files;
- Recommend a better NLP framework for sentence boundary detection;
- Determine the most effective technique by comparing the performance of the techniques used in terms of runtime and memory consumption.
2. Background Study
- Is the extracted textual content in a complete sentence form?
- Is a single sentence treated as multiple sentences?
3. Methods
3.1. Overview of the Employed Techniques
3.1.1. Core Python Packages
Pypdf2
| Algorithm 1 Text extraction using Pypdf2 tool |
Input: pdf file Output: text file
|
Pdfminer.six
| Algorithm 2 Text extraction using Pdfminer.six tool |
Input: pdf file Output: text file
|
Pymupdf
| Algorithm 3 Text extraction using the Pymupdf tool |
Input: pdf file Output: text file
|
Pdftotext
| Algorithm 4 Text extraction using Pdftotext tool |
Input: pdf file Output: text file
|
3.1.2. External Services with Python Wrapper
Tika
| Algorithm 5 Text extraction using Tika tool |
Input: pdf file Output: text file
|
Grobid
| Algorithm 6 Text extraction using Grobid tool |
Input: pdf file Output: text file
|
3.1.3. NLP Packages
NLTK
Gensim
Spacy
3.2. Experimental Procedure
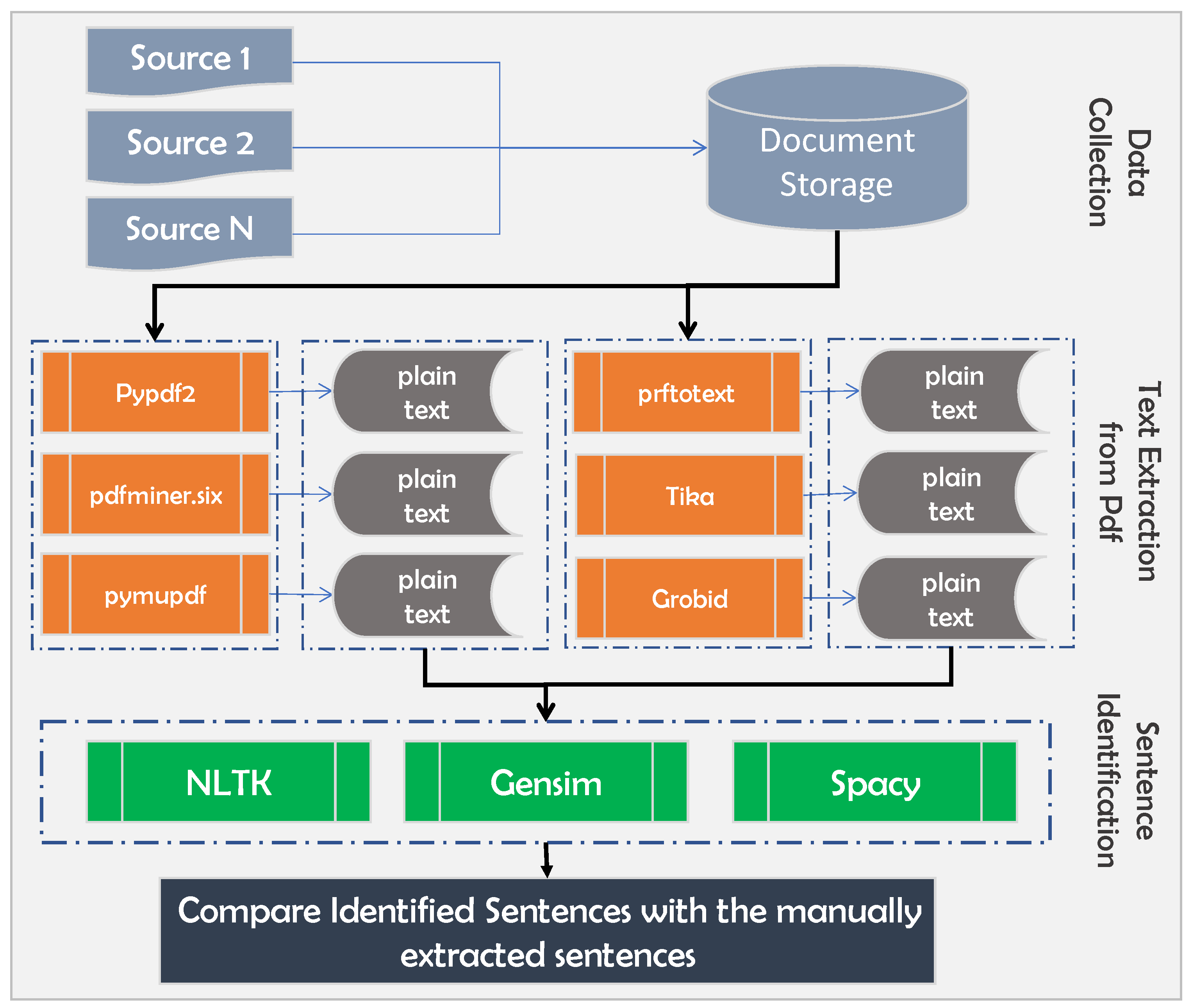
3.2.1. Data Collection
3.2.2. Text Extraction from PDF Documents
3.2.3. Sentence Boundary Examination from Extracted Text
3.3. Experimental Setup
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- MacCartney, B. Understanding natural language understanding. In Proceedings of the ACM SIGAI Bay Area Chapter Inaugural Meeting, San Mateo, CA, USA, 16 July 2014. [Google Scholar]
- Miah, M.; Sulaiman, J.; Sarwar, T.B.; Zamli, K.Z.; Jose, R. Study of Keyword Extraction Techniques for Electric Double-Layer Capacitor Domain Using Text Similarity Indexes: An Experimental Analysis. Complexity 2021, 2021, 8192320. [Google Scholar] [CrossRef]
- Max Ved. NLP vs. NLU: From Understanding a Language to Its Processing—Data Science Central. 2021. Available online: http://bit.do/nlp-vs-nlu (accessed on 24 November 2021).
- Jose, R.; Ramakrishna, S. Materials 4.0: Materials big data enabled materials discovery. Appl. Mater. Today 2018, 10, 127–132. [Google Scholar] [CrossRef]
- Kim, E.; Huang, K.; Saunders, A.; McCallum, A.; Ceder, G.; Olivetti, E. Materials Synthesis Insights from Scientific Literature via Text Extraction and Machine Learning. Chem. Mater. 2017, 29, 9436–9444. [Google Scholar] [CrossRef] [Green Version]
- Swain, M.C.; Cole, J.M. ChemDataExtractor: A Toolkit for Automated Extraction of Chemical Information from the Scientific Literature. J. Chem. Inf. Model. 2016, 56, 1894–1904. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Honnibal, M.; Montani, I. spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing. Appear 2017, 7, 411–420. [Google Scholar]
- Pierre Carbonnelle. PYPL PopularitY of Programming Language Index. 2021. Available online: https://pypl.github.io/PYPL.html (accessed on 14 July 2021).
- Kononova, O.; Huo, H.; He, T.; Rong, Z.; Botari, T.; Sun, W.; Tshitoyan, V.; Ceder, G. Text-Mined Dataset of Inorganic Materials Synthesis Recipes. Sci. Data 2019, 6, 203. [Google Scholar] [CrossRef] [PubMed]
- Friedrich, A.; Heike, A.; Federico, T.; Johannes, H.; Renou, B.; Anika, M.; Lukas, L. The SOFC-exp corpus and neural approaches to information extraction in the materials science domain. arXiv 2020, arXiv:2006.03039. [Google Scholar]
- Hiszpanski, A.M.; Gallagher, B.; Chellappan, K.; Li, P.; Liu, S.; Kim, H.; Han, J.; Kailkhura, B.; Buttler, D.J.; Han, T.Y.J. Nanomaterial Synthesis Insights from Machine Learning of Scientific Articles by Extracting, Structuring, and Visualizing Knowledge. J. Chem. Inf. Model. 2020, 60, 2876–2887. [Google Scholar] [CrossRef] [PubMed]
- Kuniyoshi, F.; Kohei, M.; Jun, O.; Makoto, M. Annotating and extracting synthesis process of all-solid-state batteries from scientific literature. arXiv 2020, arXiv:2002.07339. [Google Scholar]
- Sarwar, T.B.; Noor, N.M.; Miah, M.S.U.; Rashid, M.; Al Farid, F.; Husen, M.N. Recommending Research Articles: A Multi-Level Chronological Learning-Based Approach Using Unsupervised Keyphrase Extraction and Lexical Similarity Calculation. IEEE Access 2021, 9, 160797–160811. [Google Scholar] [CrossRef]
- Miah, M.S.U.; Sulaiman, J.; Azad, S.; Zamli, K.Z.; Jose, R. Comparison of document similarity algorithms in extracting document keywords from an academic paper. In Proceedings of the 2021 International Conference on Software Engineering & Computer Systems and 4th International Conference on Computational Science and Information Management (ICSECS-ICOCSIM), Pekan, Malaysia, 24–26 August 2021; pp. 631–636. [Google Scholar]
- Nadkarni, P.M.; Ohno-Machado, L.; Chapman, W.W. Natural language processing: An introduction. J. Am. Med. Inform. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miah, M.S.U.; Tahsin, M.S.; Azad, S.; Rabby, G.; Islam, M.S.; Uddin, S.; Masuduzzaman, M. A Geofencing-based Recent Trends Identification from Twitter Data. In IOP Conference Series: Materials Science and Engineering; Institute of Physics Publishing: Bristol, UK, 2020; Volume 769, p. 012008. [Google Scholar]
- Sarwar, T.B.; Noor, N.M. An experimental comparison of unsupervised keyphrase extraction techniques for extracting significant information from scientific research articles. In Proceedings of the 2021 International Conference on Software Engineering & Computer Systems and 4th International Conference on Computational Science and Information Management (ICSECS-ICOCSIM), Pekan, Malaysia, 24–26 August 2021; pp. 130–135. [Google Scholar]
- Miah, M.S.U.; Bhowmik, A.; Anannya, R.T. Location, context and device aware framework (LCDF): A unified framework for mobile data management. In Proceedings of the International Conference on Computing Advancements, Dhaka, Bangladesh, 10–12 January 2020; ACM International Conference Proceeding Series. Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar]
- Michaud, A.; Oliver, A.; Trevor A., C.; Graham, N.; Severine, G. Integrating automatic transcription into the language documentation workflow: Experiments with Na data and the Persephone toolkit. Lang. Doc. Conserv. 2018, 12, 393–429. [Google Scholar]
- Friedrich, F.; Mendling, J.; Puhlmann, F. Process model generation from natural language text. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2011; Volume 6741, pp. 482–496. [Google Scholar]
- Bast, H.; Korzen, C. A Benchmark and Evaluation for Text Extraction from PDF. In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries, Toronto, ON, Canada, 19–23 June 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017. [Google Scholar]
- Taskaya, B. Reiz: Structural Source Code Search. J. Open Source Softw. 2021, 6, 3296. [Google Scholar] [CrossRef]
- Taskaya, B. Top PyPI Packages: A Monthly Dump of the 5000 Most-Downloaded Packages from PyPI. 2021. Available online: https://hugovk.github.io/top-pypi-packages/ (accessed on 24 November 2021).
- Azimjonov, J.; Alikhanov, J. Rule Based Metadata Extraction Framework from Academic Articles. arXiv 2018, arXiv:1807.09009. [Google Scholar]
- Nasar, Z.; Jaffry, S.W.; Malik, M.K. Information Extraction from Scientific Articles: A Survey; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; Volume 117. [Google Scholar]
- Wang, Z.; Liu, J.C. PDF2LaTeX: A Deep Learning System to Convert Mathematical Documents from PDF to LaTeX. In Proceedings of the ACM Symposium on Document Engineering, DocEng 2020, San Jose, CA, USA, 29 September–1 October 2020. [Google Scholar]
- Nadiah, A.; Rahman, C.A.; Abdullah, H.; Zainuddin, S.; Jaludin, A. The Comparisons of Ocr Tools: A Conversion Case in the Malaysian Hansard Corpus Development. Malays. J. Comput. 2019, 4, 335–348. [Google Scholar]
- Duretec, K.; Rauber, A.; Becker, C. A Text Extraction Software Benchmark Based on a Synthesized Dataset. In Proceedings of the 2017 ACM/IEEE Joint Conference on Digital Libraries (JCDL), Toronto, ON, Canada, 19–23 June 2017; pp. 1–10. [Google Scholar] [CrossRef]
- McKie, J.X. PyMuPDF 1.19.4 Performance Evaluation. 2021. Available online: https://pymupdf.readthedocs.io/en/latest/app2.html (accessed on 22 October 2021).
- Mario, L.; Yao, K.; Breitinger, C.; Beel, J.; Gipp, B. Evaluation of header metadata extraction approaches and tools for scientific PDF documents. In Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries, Indianapolis, IN, USA, 22–26 July 2013; pp. 385–386. [Google Scholar]
- Patrice Lopez. GROBID. 2021. Available online: https://github.com/kermitt2/grobid (accessed on 22 October 2021).
- Palmer, J.A. Pdftotext · PyPI. 2017. Available online: https://pypi.org/project/pdftotext/ (accessed on 20 October 2021).
- Singh, M.; Barua, B.; Palod, P.; Garg, M.; Satapathy, S.; Bushi, S.; Ayush, K.; Rohith, K.S.; Gamidi, T.; Goyal, P. OCR++: A Robust Framework for Information Extraction from Scholarly Articles. arXiv 2016, arXiv:1609.06423. [Google Scholar]
- George, S. Sentence boundary detection in legal text. In Proceedings of the Natural Legal Language Processing Workshop, Minneapolis, MN, USA, 7 June 2019; pp. 31–38. [Google Scholar]
- Thiengburanathum, P. A Comparison of Thai Sentence Boundary Detection Approaches Using Online Product Review Data. In Proceedings of the International Conference on Network-Based Information Systems, Victoria, BC, Canada, 31 August–2 September 2020; Springer: Cham, Switzerland, 2020; pp. 405–412. [Google Scholar]
- Tshitoyan, V.; Dagdelen, J.; Weston, L.; Dunn, A.; Rong, Z.; Kononova, O.; Persson, K.A.; Ceder, G.; Jain, A. Unsupervised word embeddings capture latent knowledge from materials science literature. Nature 2019, 571, 95–98. Available online: http://dx.doi.org/10.1038/s41586-019-1335-8 (accessed on 19 September 2021). [CrossRef] [PubMed] [Green Version]
- Guha, S.; Mullick, A.; Agrawal, J.; Ram, S.; Ghui, S.; Lee, S.C.; Bhattacharjee, S.; Goyal, P. MatScIE: An automated tool for the generation of databases of methods and parameters used in the computational materials science literature. Comput. Mater. Sci. 2021, 192, 110325. [Google Scholar] [CrossRef]
- Olivetti, E.A.; Cole, J.M.; Kim, E.; Kononova, O.; Ceder, G.; Han, T.Y.J.; Hiszpanski, A.M. Data-driven materials research enabled by natural language processing and information extraction. Appl. Phys. Rev. 2020, 7, 04131. [Google Scholar] [CrossRef]
- Phaseit Inc.; Fenniak, M. PyPDF2 Documentation—PyPDF2 1.26.0 Documentation. 2016. Available online: https://pythonhosted.org/PyPDF2/ (accessed on 29 November 2021).
- Marsman, P.; Shinyama, Y.; Guglielmetti, P. Pdfminer.six 20201018 Documentation. 2019. Available online: https://pdfminersix.readthedocs.io/en/latest/ (accessed on 27 November 2021).
- McKie, J.X. PyMuPDF Documentation—PyMuPDF 1.18.15 Documentation. 2015. Available online: https://pymupdf.readthedocs.io/en/latest/ (accessed on 27 November 2021).
- Fenniak, M. pyPdf. 2021. Available online: http://pybrary.net/pyPdf/ (accessed on 29 November 2021).
- Shinyama, Y. Pdfminer. 2021. Available online: https://github.com/euske/pdfminer (accessed on 28 November 2021).
- Shinyama, Y.; Guglielmetti, P.; Marsman, P. Converting a PDF File to Text—Pdfminer.six. 2019. Available online: https://pdfminersix.readthedocs.io/en/latest/topic/converting_pdf_to_text.html (accessed on 28 November 2021).
- Artifex Sofware Inc. MuPDF. 2020. Available online: https://www.mupdf.com/ (accessed on 30 November 2021).
- Kristian Høgsberg. Poppler. 2021. Available online: https://poppler.freedesktop.org/ (accessed on 30 November 2021).
- Glyph & Cog LLC. xpdf. 2021. Available online: http://www.xpdfreader.com/contact.html (accessed on 30 November 2021).
- Apache Software Foundation. Apache Tika—Getting Started with Apache Tika. 2021. Available online: https://tika.apache.org/1.27/gettingstarted.html (accessed on 1 December 2021).
- NLTK. NLTK Corpora. 2021. Available online: http://www.nltk.org/nltk_data/ (accessed on 15 August 2021).
- Bird, S.; Loper, E.; Klein, E. Natural Language Processing with Python; O’Reilly Media Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; European Language Resources Association: Paris, France, 2010; pp. 45–50. Available online: http://is.muni.cz/publication/884893/en (accessed on 4 September 2021).
- Prabhakaran, S. Gensim Tutorial—A Complete Beginners Guide. 2018. Available online: https://www.machinelearningplus.com/nlp/gensim-tutorial/ (accessed on 1 December 2021).
- Explosion. Sentencizer. 2021. Available online: https://spacy.io/api/sentencizer (accessed on 1 December 2021).
- NLTK Project. 2021. Natural Language Toolkit—NLTK 3.6.2 Documentation. Available online: http://www.nltk.org/ (accessed on 3 December 2021).
- Řehůřek, R. Documentation—Gensim. 2021. Available online: https://radimrehurek.com/gensim/auto_examples/index.html#documentation (accessed on 1 December 2021).
- Spacy.io. Install spaCy · spaCy Usage Documentation. 2021. Available online: https://spacy.io/usage (accessed on 3 December 2021).
- Python Software Foundation. Difflib-Helpers for Computing Deltas. 2021. Available online: https://docs.python.org/3/library/difflib.html (accessed on 4 December 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Package Name | Executable Script | Section-Wise Extraction | API Service | Web Service | Third Party Dependency |
|---|---|---|---|---|---|
| Pypdf2 | ✗ | ✗ | ✗ | ✗ | ✗ |
| Pymupdf | ✗ | ✗ | ✗ | ✗ | ✗ |
| Pdfminer.six | ✓ | ✗ | ✗ | ✗ | ✗ |
| Pdftotext | ✗ | ✗ | ✗ | ✗ | ✓ |
| Tika | ✓ | ✗ | ✗ | ✓ | ✗ |
| Grobid | ✓ | ✓ | ✓ | ✓ | ✗ |
| Document | Sentence Count |
|---|---|
| P1 | 143 |
| P2 | 119 |
| P3 | 119 |
| P4 | 350 |
| P5 | 178 |
| P6 | 81 |
| P7 | 121 |
| P8 | 153 |
| P9 | 141 |
| P10 | 86 |
| Package | Precision | Recall | F-1 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| NLTK | Spacy | Gensim | NLTK | Spacy | Gensim | NLTK | Spacy | Gensim | |
| Pypdf2 | 0.61 | 0.86 | 0.23 | 0.61 | 0.86 | 1.00 | 0.61 | 0.86 | 0.37 |
| Pymupdf | 0.63 | 0.70 | 0.18 | 1.00 | 1.00 | 1.00 | 0.75 | 0.82 | 0.30 |
| Pdfminer.six | 0.63 | 0.70 | 0.19 | 1.00 | 1.00 | 1.00 | 0.75 | 0.82 | 0.31 |
| Pdftotext | 0.62 | 0.69 | 0.27 | 1.00 | 1.00 | 1.00 | 0.74 | 0.81 | 0.42 |
| Tika | 0.63 | 0.70 | 0.20 | 1.00 | 1.00 | 1.00 | 0.75 | 0.82 | 0.75 |
| Grobid | 0.88 | 0.91 | 0.86 | 0.93 | 0.96 | 0.94 | 0.90 | 0.93 | 0.89 |
| Document | Grobid | Pdfminer.six | Pdftotext | Pymupdf | Pypdf2 | Tika |
|---|---|---|---|---|---|---|
| P1 | 0.92 | 0.76 | 0.19 | 0.84 | 0.19 | 0.79 |
| P2 | 0.72 | 0.21 | 0.10 | 0.22 | 0.10 | 0.22 |
| P3 | 0.87 | 0.64 | 0.23 | 0.69 | 0.13 | 0.66 |
| P4 | 0.88 | 0.66 | 0.30 | 0.79 | 0.24 | 0.75 |
| P5 | 0.61 | 0.11 | 0.05 | 0.12 | 0.04 | 0.14 |
| P6 | 0.90 | 0.63 | 0.21 | 0.74 | 0.23 | 0.78 |
| P7 | 0.63 | 0.12 | 0.05 | 0.12 | 0.07 | 0.18 |
| P8 | 0.92 | 0.76 | 0.26 | 0.84 | 0.22 | 0.62 |
| P9 | 0.89 | 0.71 | 0.21 | 0.81 | 0.26 | 0.74 |
| P10 | 0.81 | 0.44 | 0.23 | 0.53 | 0.08 | 0.55 |
| Average score | 0.81 | 0.50 | 0.18 | 0.57 | 0.16 | 0.54 |
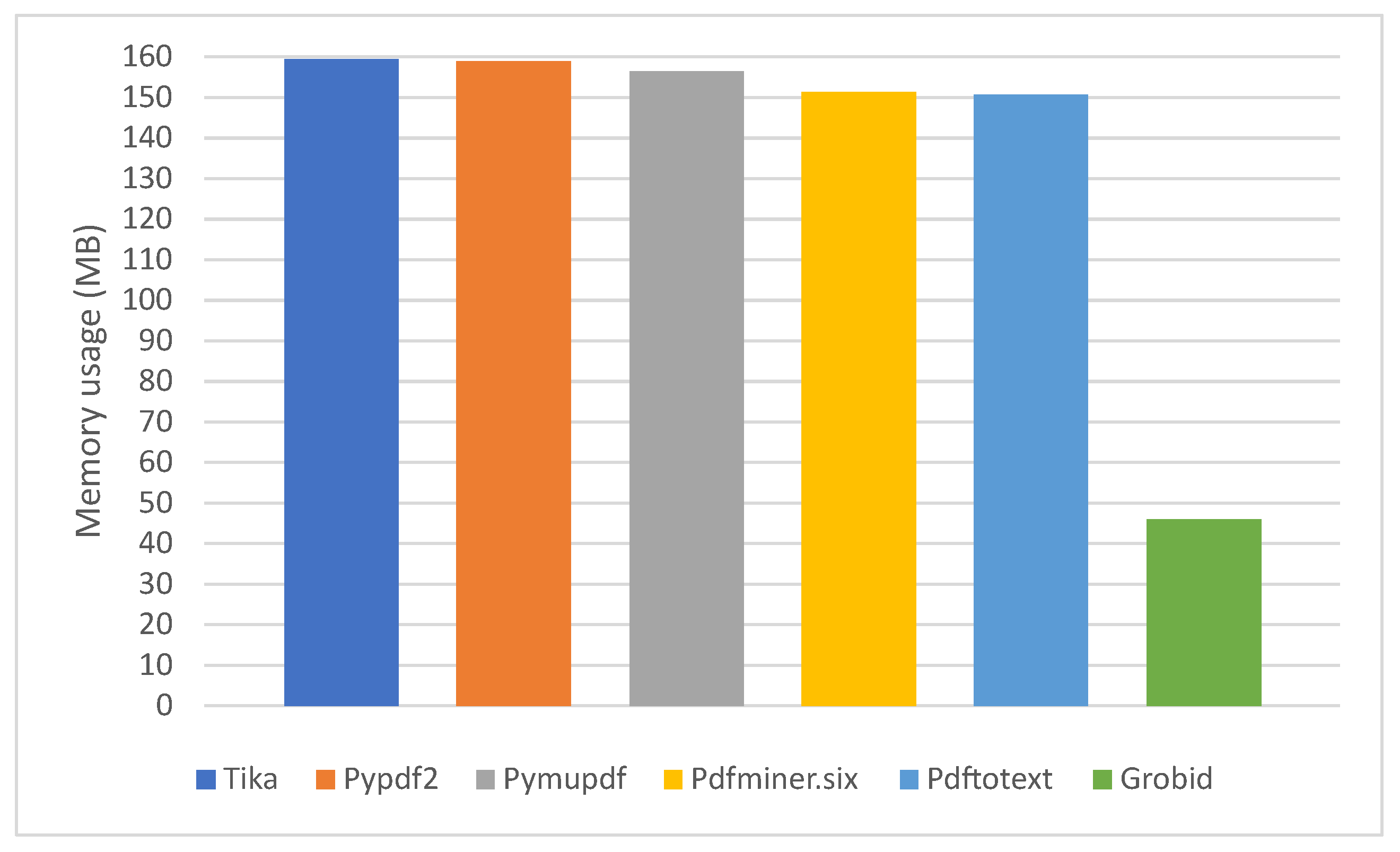
| Package | Memory Usage (MB) |
|---|---|
| Tika | 159.46 |
| Pypdf2 | 158.91 |
| Pymupdf | 156.37 |
| Pdfminer.six | 151.34 |
| Pdftotext | 150.75 |
| Grobid | 46.13 |
| Package | Runtime (Second) |
|---|---|
| Tika | 3.35 |
| Pypdf2 | 10.9 |
| Pymupdf | 1.23 |
| Pdfminer.six | 26.1 |
| Pdftotext | 1.96 |
| Grobid | 36.5 |
| Package | Memory Usage (MB) 10 Documents | Memory Usage (MB) 50 Documents | Memory Usage (MB) 100 Documents |
|---|---|---|---|
| Tika | 159.46 | 200.52 | 232.43 |
| Pypdf2 | 158.91 | 198.23 | 225.67 |
| Pymupdf | 156.37 | 200.01 | 220.45 |
| Pdfminer.six | 151.34 | 175.54 | 198.23 |
| Pdftotext | 150.75 | 180.07 | 222.97 |
| Grobid | 46.13 | 68.16 | 75.05 |
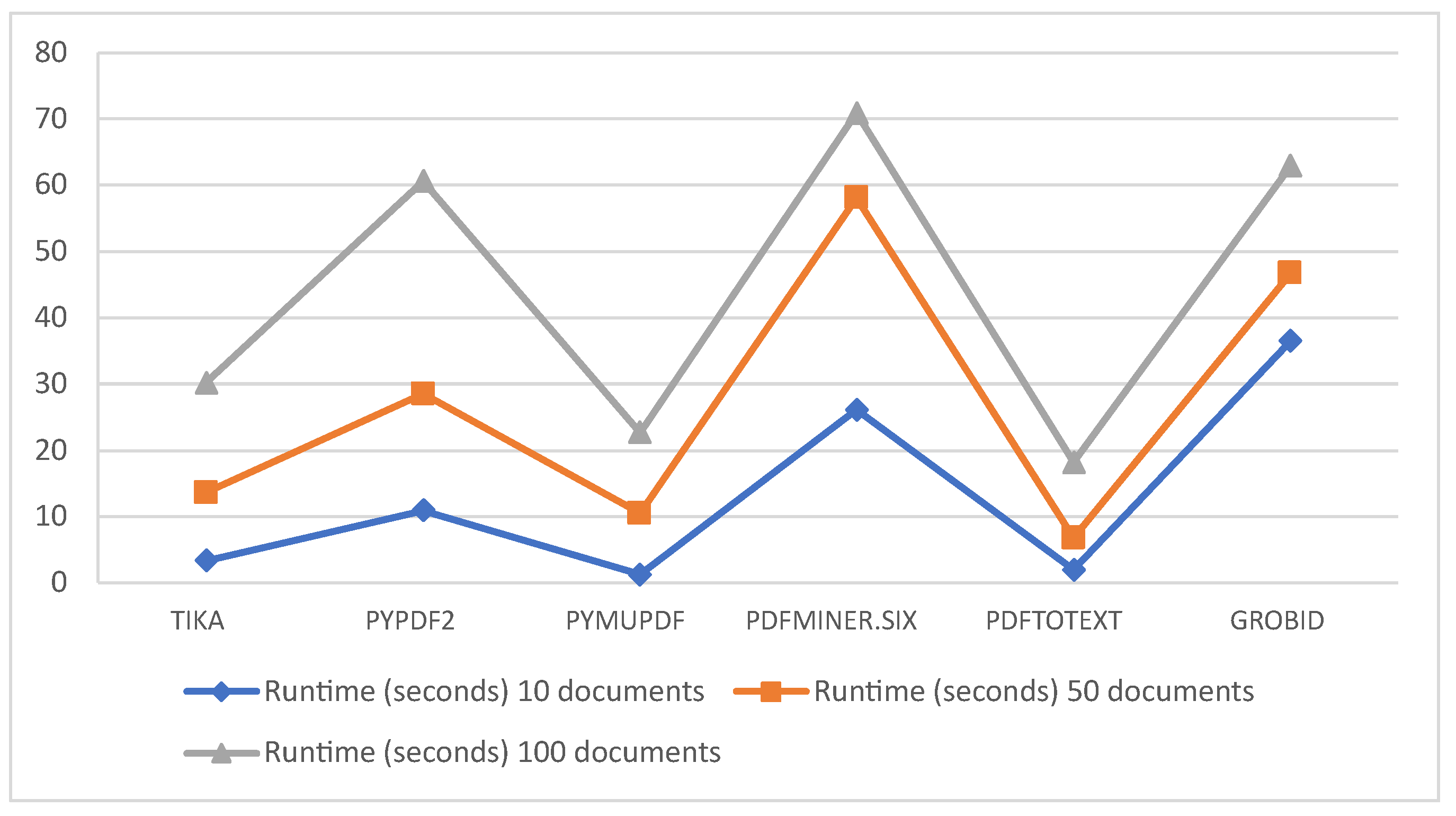
| Package | Runtime (Seconds) 10 Documents | Runtime (Seconds) 50 Documents | Runtime (Seconds) 100 Documents |
|---|---|---|---|
| Tika | 3.35 | 13.6 | 30.16 |
| pypdf2 | 10.9 | 28.5 | 60.6 |
| pymupdf | 1.23 | 10.5 | 22.7 |
| pdfminer.six | 26.1 | 58.1 | 70.9 |
| pdftotext | 1.96 | 6.8 | 18.2 |
| grobid | 36.5 | 46.7 | 62.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miah, M.S.U.; Sulaiman, J.; Sarwar, T.B.; Naseer, A.; Ashraf, F.; Zamli, K.Z.; Jose, R. Sentence Boundary Extraction from Scientific Literature of Electric Double Layer Capacitor Domain: Tools and Techniques. Appl. Sci. 2022, 12, 1352. https://doi.org/10.3390/app12031352
Miah MSU, Sulaiman J, Sarwar TB, Naseer A, Ashraf F, Zamli KZ, Jose R. Sentence Boundary Extraction from Scientific Literature of Electric Double Layer Capacitor Domain: Tools and Techniques. Applied Sciences. 2022; 12(3):1352. https://doi.org/10.3390/app12031352
Chicago/Turabian StyleMiah, Md. Saef Ullah, Junaida Sulaiman, Talha Bin Sarwar, Ateeqa Naseer, Fasiha Ashraf, Kamal Zuhairi Zamli, and Rajan Jose. 2022. "Sentence Boundary Extraction from Scientific Literature of Electric Double Layer Capacitor Domain: Tools and Techniques" Applied Sciences 12, no. 3: 1352. https://doi.org/10.3390/app12031352
APA StyleMiah, M. S. U., Sulaiman, J., Sarwar, T. B., Naseer, A., Ashraf, F., Zamli, K. Z., & Jose, R. (2022). Sentence Boundary Extraction from Scientific Literature of Electric Double Layer Capacitor Domain: Tools and Techniques. Applied Sciences, 12(3), 1352. https://doi.org/10.3390/app12031352