1. Introduction
With the rapid development of the Internet and the rise of communication platforms such as social media, online forums and e-commerce platforms, NLP technology plays a key role in the processing, understanding, and applications of text in the face of many unstructured text datasets generated on the Internet. Text sentiment analysis [
1] refers to analyzing, processing, and extracting subjective texts with emotional color by using NLP and text mining techniques. Sentiment analysis is one of the important basic research tasks, which plays an important role in computer automatic processing and the understanding of natural languages.
In recent years, more and more research institutions and scholars have paid attention to sentiment analysis. In SIGIR, ACL, WWW, CIKM, WSDM, and other famous international conferences, research results from this issue emerge one after another. Traditional text sentiment analysis methods mainly include sentiment lexis-based and supervised machine learning based methods, which have good performance in processing small-data text sentiment analysis tasks and have higher interpretability. However, traditional methods mainly have a problem with the sparsity of text representation and weak generalization ability.
Felipe [
2] proposed a method to train incremental word sentiment classifiers from time-varying distributed word vectors to automatically extract constantly updated sentiment words from a Twitter stream, resulting in a time-varying sentiment dictionary based on incremental word vectors. However, this method relies too much on the creation of an emotion dictionary. There is no context to this method, and the portability of the emotion dictionary is poor.
Ahmad [
3] proposed an optimized sentiment analysis framework OSAF based on SVM, which uses SVM grid searches technology and 10K cross verification. Mathapati [
4] proposed a sentiment analysis method based on emoticons and discussed the role of emoticons in sentiment analysis. Compared with the construction of emotion dictionary, the emotion classification method based on machine learning has some progress, but it still needs to mark the text features manually. Secondly, machine learning relies on a large amount of data, and such methods often cannot fully use contextual information in sentiment analysis, which affects the accuracy of the results.
Deep learning is the application of a multi-layer neural network of learning, which solves a lot of problems that are difficult to be solved by machine learning in the past. At present, deep learning models include CNN,
RNN,
LSTM [
5], Transformer,
BiLSTM [
6], GRU [
7], and attention mechanism. Rehman [
8] proposed a hybrid model using
LSTM and deep CNN models, which also used dropout technology, normalization, and correction linear elements to improve accuracy.
Xu [
9] proposed the
DomBERT model by combining ELMo [
10] and
BERT [
11], which showed excellent performance in aspect based sentiment analysis. As an application of transfer learning, a pretraining model can transfer knowledge learned from the open domain to downstream task to improve a low-resource task, which is also very beneficial for low-resource language processing.
Wu [
12] proposes two variants of context-guided BERT (CG-Bert) that learn to allocate Attention in different contexts. This modified Quasi-attention CG-Bert model can learn combinatorial Attention that supports subtractive Attention. Mao [
13] proposed a complete solution for ABSA and constructed two machine reading comprehension (MRC) problems and solved all subtasks by jointly training two bert-MRC models with shared parameters. Li [
14] proposed a new direction-based sentiment analysis method, GBCN, which uses a gating mechanism with an up-down file aspect embedding to enhance and control the BERT representation of aspect-oriented sentiment analysis.
For the sentiment analysis model based on a deep neural network, excellent results have been achieved in many sentiment analysis tasks, but its success depends heavily on large-scale training data with tags. For some widely used languages, the acquisition of manually tagged data may be relatively easy, so deep learning-based models succeed in sentiment analysis in these languages.
In the research community, using high-quality manual tagging, we have proposed sentiment analysis task training data in some languages with a large numbers of speakers, such as English. Using these high-quality annotation data, based on the cross-language transfer method, we can build sentiment analysis models for the Uyghur language with little or no annotation data. Therefore, although deep learning has gained preliminary application in NLP, it is still rarely used in the Uyghur language. This paper uses a pre-training model to automatically learn Uyghur language features and explores its feasibility in Uyghur sentiment analysis.
What causes the unique characteristics of Uyghur texts? There are a lot of parallel words in the Uyghur text, so there are ambiguities [
15]. The reason for this phenomenon is that it belongs to the Turkic language family of the Altai language family, which is an agglutinative language with complex morphological changes. The modern Uyghur language is based on the Arabic alphabet and has similar pronunciation and borrows many Arabic words, which are formed by combining affixes and stems. For example, Uyghur names lack a unified writing style, with some names being written in multiple ways. Therefore, its adhesion leads to data bias and results in data sparsity. This creates many unregistered people, institutions, and place names, leading to sparse data. Therefore, new ideas and methods are needed to further improve the accuracy of Uyghur sentiment analysis.
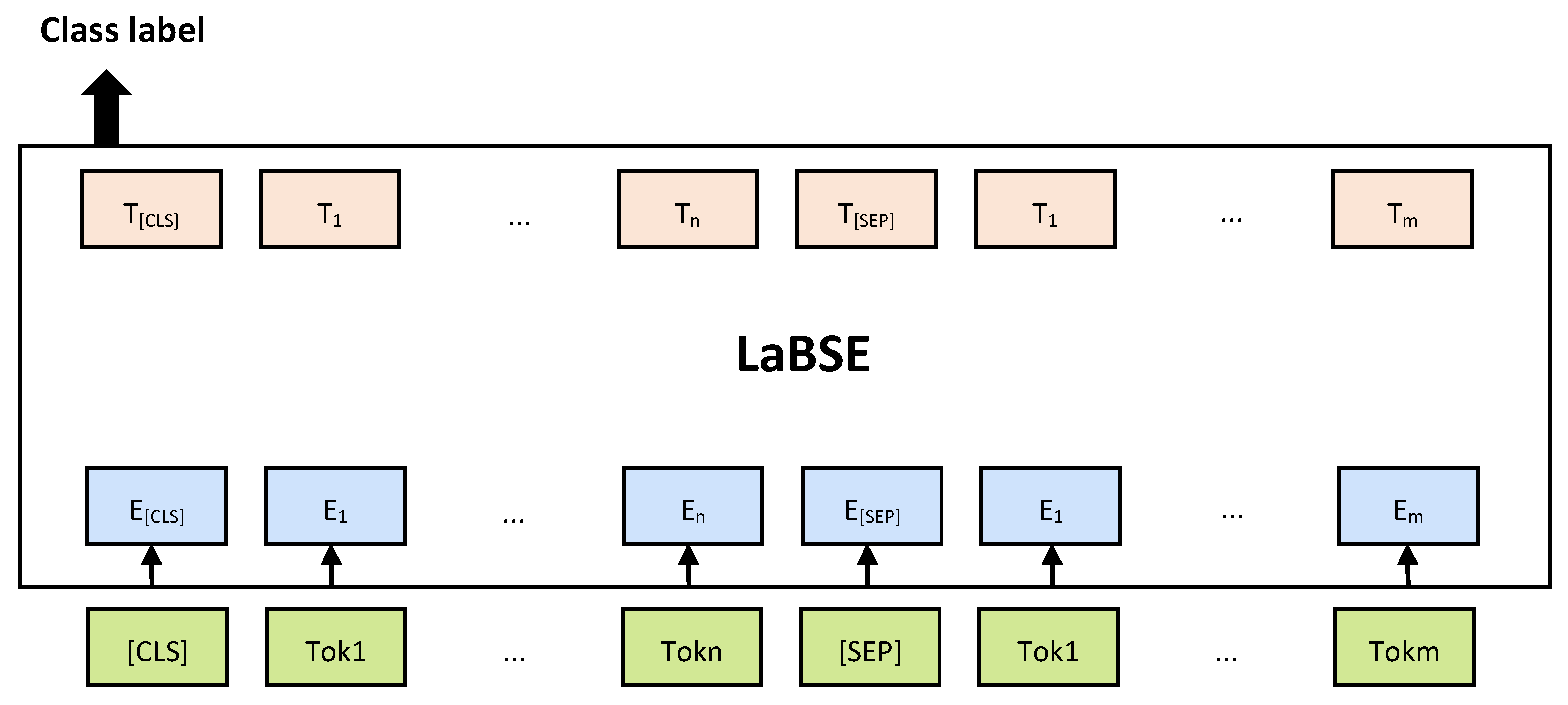
In this paper, the pre-training model was used to share the vocabulary layer, and they implemented the data augmentation strategy on the dataset. Thus, the generalization ability of the model was improved effectively. As depicted in
Figure 1, we propose a low-resource language model with the
BiLSTM layer that can address these issues:
AB-LaBSE. First, we propose data augmentation by
AEDA [
16] and using the shared vocabulary characteristics of the pre-training model
LaBSE [
17] to fine-tune the cross-lingual pre-training model, which is combined with deep learning
BiLSTM model.
We used LaBSE to pre-train a language model on a large cross-lingual corpus.We introduce an LSTM (Long- and short-term memory neural network) that selects relevant semantic and syntactic information from the pre-trained low-resource language model. To evaluate our model, we collected and annotated two datasets for Uyghur sentiment analysis. Respectively, these are hotel review dichotomies and five categories of emotion datasets. The experimental results show that AB-LaBSE can significantly improve the performance with a few labeled examples.
As a combined method, our contributions are as follows:
We constructed two sentiment analysis datasets, one of which was about two categories of hotel review sentiment analysis, and the other was a dataset containing five categories of emotion analysis, including happiness, surprise, sadness, anger, and neutral. We also completed the annotation of Uyghur datasets with the help of Uyghur language experts. They divided each of the language datasets for 80% training, 10% validation, and 10% testing.
We propose a fine-tuning strategy for Uyghur agglutinative languages—a data augmentation method, based on the feature that a cross-language pre-training model shares a vocabulary layer. They base it on the pre-training model for the Uyghur language, and at present, there is little research on the Uyghur language using a pre-training model.
We propose a method to add BiLSTM layers, in which our datasets from outputs that have been pre-trained across languages are associated with BiLSTM layers for better learning context features. In this task, the method can better select relevant semantic and feature information from the pre-trained language model. This method can improve the performance of downstream tasks effectively by taking advantage of the characteristics of context association of cohesive languages.
2. Related Works
Sentiment analysis has a wide range of applications, which are an important task in NLP. We summarized the related works on three topics: (1) data augmentation; (2) cross-lingual pre-trained language models; and (3) BiLSTM.
Data augmentation. Data augmentation is a class of methods used for synthesizing new data from existing data. It has played an important role in the experiment. We find that the larger the scale and the higher the quality, the better the generalization ability of the model. Data augmentation solves the problem of data accuracy by using original documents to generate similar examples, solving the problem of insufficient data effectively. It is an effective method used to expand the sizes of the data samples. In recent years, more and more people are creating data augmentation techniques in research. According to the diversity of generated samples, methods of data augmentation are divided into the following three categories: (1) Paraphrasing; (2) Noising; (3) Sampling.
Paraphrasing is used to make some changes to the words, phrases, and sentence structure in the sentence, keeping the original meaning. This method can make use of dictionaries, knowledge maps, semantic vectors,
BERT [
11] models, rules, Machine Translation, etc. It can randomly replace non-stop words with synonyms. For example, back translation [
18] can change the syntactic structure and retain semantic information, and it can often increase the diversity of textual data. However, the data generated by the back-translation method depends on the quality of the translation, and most of the translation results are not very accurate.
Noising is used to increase some discrete or continuous noises while keeping the label unchanged, which has little impact on semantics. People are immune to noise when reading text, such as words out of order and typos [
19]. Based on this idea, some noise can be added to the data to improve the robustness of the model. Since there are few synonyms in Uyghur language, replacing synonyms does not produce positive meaning. The method of data augmentation with noise is simple to use, but it will affect the sentence structure and semantics, with limited diversity, and mainly improve the robustness [
20].
Sampling aims to select new samples based on the current data distribution, which will generate more diverse data. Sampling aims to select new samples based on the current data distribution, which will generate more diverse data [
21]. Sampling refers to sampling new samples from the data distribution. Different from general paraphrasing, sampling is more task-dependent and needs to increase more diversity while ensuring data reliability. Rules, Seq2Seq Models, Language Models, and Self-training are usually used in experiments to increase data diversity.
Above all, the method of data augmentation can be used as a powerful tool to solve the problems of data imbalance and missing data quickly when we train the NLP model.
Research on sentiment analysis in machine learning. Firstly, we will analyze the research of sentiment analysis function in machine learning. Kim [
22] proposed the use of a convolutional neural network, CNN, to complete sentiment analysis and problem classification, which achieved good results. Li [
23] proposed to use undersampling and dynamically generating random subspace strategies to solve the problem of unbalanced datasets in sentiment analysis.
After the above analysis, we can conclude that it proved these methods to be simple and effective in sentiment analysis task, but there are some limitations: Without a large amount of manual annotation data, traditional machine learning methods will not perform well. The method, based on a shallow neural network, relies on grammatical features and word order features and has difficulties grasping the deep semantic information. We have paid little attention to the low-resource Uyghur language.
Convolutional neural network in deep learning has achieved good results, but it did not consider the potential theme of the text. Dwivedi [
24] proposed a rule model based on the Restricted RBM (Restred Bolzmann Machine) to analyze the sentiment analysis of sentences. Can [
25] proposes a limited data model based on the
RNN framework and a language with the largest dataset, and applies it to languages with limited resources, which has a better effect on the sentiment analysis of small languages. Based on
LSTM, Wang [
26] proposed a memory network classification of long-term and short-term aspect-oriented emotion based on attention. Chen [
27] proposed a new sentiment analysis scheme based on the data of Twitter and Weibo, embedding the attention-based short and long-term memory network to analyze the emotional factors of facial expressions, and training a sentiment classifier. Sangeetha [
28] proposed
LSTM with multi-layer fusion to process sentiment analysis. This method uses a multi-layer attention mechanism to process sentence input sequence in parallel and uses different pruning ratios to improve accuracy. Then, multi-layer information is fused, and it fed the results to the
LSTM layer as the input.
The Cross-lingual Pre-trained Language Model. In recent years, studies have shown that the generative training of natural language understanding proposed in monolingual languages such as English is very effective. Therefore, more and more people focus on the cross-language field with low resources. The researchers start from the
ELMo [
10] model, which uses BiLM (bidirectional language model) to pre-train the vector representation of words, which can dynamically generate the vector representation of words according to the training set. Sun [
29] proposed an aspect based sentiment analysis, fine-tuning
BERT’s pre-training model and getting new and good results on the SentiHood and SemEVAL-2014 Task 4 datasets. Yin [
30] proposed Senci-Bert (Senti-bert), a variant of
BERT, in which SentiBERT’s method has more advantages than the baseline in capturing negative and contrastive relationships and constructing combinatorial models.
3. Methodology
In this section, we will explain our approach. We divide our training into four stages. We first performed data enhancement on the unbalanced characteristics of our sentiment analysis dataset. Secondly, the language model is pre-trained on a large-scale cross-language text corpus. In addition, the BiLSTM layer is added to the output results of the pre-trained model. Finally, we use the dropout layer and a full connection to get the final sentiment analysis prediction.
3.1. Data Augmentation
In data augmentation, because the application of machine learning for textual research is still a highly active section, especially with the small amount of initial annotation data in research experiments, we need data augmentation to improve the data diversity of experimental datasets. After we use data enhancement in our model research, the number of datasets is improved, noise is added to the experimental data, the generalization ability of the model is improved, and the robustness of the model is improved. We used the latest
AEDA [
13] technology, which is a data enhancement technique that is easier to implement than the
EDA [
31] approach, which we compared with our results. In addition, only the insertion of punctuation marks for the original data sequence information modification is not obvious. It also preserves the order of the words while maintaining their position in the sentence lead, creating performance. In addition, deletion in
EDA can lead to information loss and thus mislead the network, whereas
AEDA preserves all input information.
In this paper, based on the cross-language characteristics of the
LaBSE [
14] model, we use
AEDA to expand the training data and to improve the ability of the model, aiming at the characteristics of Uyghur language with low resource stickiness. The word stem, through which words are made and connected by multiple suffixes, represented the content of this language. We first select the position where we want to insert the symbol. In order to ensure the correct insertion mark position, there are inserts, but not too many inserts to cause noise. Too much noise will have a negative effect on the model. Insertion positions in the sequence are determined by randomly specifying numbers between 1 and 1/3 of the sequence. To summarize, we use the shared lexical layer of the pre-trained model for each selected location, from “.”, “;”, “?”, “:”, “!”, “,“, and one punctuation mark is chosen at random. We show the specific augmentation in
Section 4.1.
3.2. Cross-Language Model Pre-Training
Researchers at Google have developed a multilingual
BERT Embedding model called language-agnostic
BERT Sentence Embedding(
LaBSE), which generates language-agnostic cross-language Sentence Embedding for 109 languages on a single model. In simple terms,
LaBSE combines MLM and TLM pre-training on a 12-layer Transformer that contains 500,000 tokens with translation sorting tasks performed using bidirectional biencoders. In this paper, we utilized
LaBSE to model the conditional probability.
LaBSE uses the parallel text or dual text to process all languages through byte pair encoding (BPE) [
32]. LaBSE’s research shows that this model is effective even in low-resource languages where no data is available during training. The model of the
LaBSE is shown in
Figure 2.
Shared contents include the same alphabet or the same anchor tokens, such as digits or proper nouns. This method of sharing dictionaries can improve the alignment of languages in the embedded space. We learn the BPE splits on the concatenation of sentences sampled randomly from the monolingual corpora. We sample sentences according to a multinomial distribution with probabilities. Additionally, sentences are sampled according to a probable multinomial distribution , where:
LaBSE adopted the strategy of in-batch negative sampling by training bidirectional dual Encoders with additive margin softmax loss:
The embedding space similarity of x and y is given by . In addition, , the loss attempts to rank , the true translation of , over all alternatives in the same batch even when is discounted by margin m.
Notice that
is symmetric and depends on whether the softmax is over the source or the target. To bi-directional ranking, the final loss function sums the source to target,
, and target to source,
, losses:
LaBSE adapted multilingual BERT and combined masked language model (MLM) and translation language model (TLM) pretraining with a translation ranking task using bi-directional dual encoders. This distributed sampling method prevents words in low-resource languages from being split at the character level. In particular, it increases the number of tokens associated with low-resource languages and eases the bias toward high-resource languages.
In the pre-training and parameter sharing stage of the model, for an L layer transformer encoder, LaBSE used a three-stage progressive stacking algorithm to train, which first learns a layers model, then layers, and finally all L layers. The parameters of the model will be copied to the subsequent training through the learning operation in the early stage.
3.3. BiLSTM
The
BiLSTM model was proposed by Grave by combining the bidirectional
RNN models
BRNN and
LSTM [
5] unit and verified its effectiveness in speech recognition tasks. The core idea of the
BiLSTM [
6] model is that the current input is related to the sequence before and after, and the realization is to input the data sequence into the model from two directions, respectively, and save the data information in two directions, namely the historical information and the future information, through the hidden layer. The recurrent neural network
RNN is good at capturing long dependent sequence relations. Some outputs of neurons can be transmitted to neurons again as inputs, and the previous information can be effectively utilized. However, in the process of training, the constant multiplication of the function derivative will lead to the problem of “gradient disappearance” and “gradient explosion”.
LSTM cleverly introduces a “gate” mechanism to solve this problem.
LSTM is composed of a series of repeated timing modules, each of which contains three gates and a memory cell, namely, the forgetting gate, input gate, and output gate. The forgetting gate determines what information the cell will discard, reads
and
, and outputs a value between 0 and 1 to each in cell state
.
The input gate determines what information is stored in the cell state, and there are two parts to this. First, a sigmoid neural network layer determines what values will be updated, called the “input gate layer.” Then, a tanh layer creates a new candidate vector
, which is added to the state.
When the unit information is updated, the old state is multiplied by
, irrelevant information is discarded, and
is added to form A new candidate value.
The output gate determines which part of the cell state will be output by running a sigmoid layer, and then processes the cell state through the tanh function to get a value between −1 and 1, which is multiplied by the output of the sigmoid gate, and finally outputs only part of the determined output.
where:
represents the activation function.
represents the neural network layer of sigmoid.
is the unit state input at time of
t.
,
and
are the settlement results of forgetting gate, input gate and output gate, respectively.
,
,
and
respectively represent the weight of forgotten gate, input gate, output gate, and the updated weight.
,
,
and
are the corresponding offset quantities.
In the process of text classification,
BiLSTM is used to make full use of the context information of text, which is to combine the two
LSTM models with opposite sequences. That is, add a layer of reverse
LSTM layer to the original forward
LSTM network layer and combine them, so the output can be expressed as:
for BiLSTM model outputs the text feature vector. Where is the output of the forward LSTM and is the output of the reverse LSTM.
In this experiment, we added a dropout layer to prevent the model from overfitting. At each iteration, neurons are randomly output to zero at the specified ratio. In the experiment, the output of
BiLSTM is denoted as
, and
stands for the ratio of the dropout layer.
Finally, the linear layer performs a linear transformation of the output of dropout, where
A is the weights and
b is the bias.
4. Experiments
4.1. Datasets
For our experiments, we made use of a low-resource language dataset—Uyghur. The experiment of a corpus containing Uyghur sentiment analysis from public comments on the hotel’s website (
https://www.dianping.com/) (accessed on 23 November 2021) grab the comment text (datasets) and a crawl Tianshan net and Xinhua Uyghur channel sentiment analysis of the dataset, under the guidance of Uyghur experts, to complete the corpus tagging work. The hotel evaluation data includes 2011 data of positive and negative emotions, and the emotional analysis includes five emotions, such as happy, surprised, sad, angry, and neutral, with 10,000 data. We divided our data into 80% training, 10% validation, and 10% test sets.
In this experiment, the data size of the training set before and after data augmentation is shown in
Table 1.
The details of the two datasets are shown in the
Figure 5. We illustrated with detailed examples of data.
4.2. Baseline Models
In recent years, research on sentiment analysis has become more and more popular. We analyzed traditional machine learning methods and found them unsatisfactory. Therefore, we mainly used a cross-language pre-training model to compare the effects of this experiment.
Before us, only a few people have done Uyghur sentiment analysis on cross-language pre-training model. We compared our
AB-LaBSE model with several baseline models in different categories, including
mBERT [
33],
Sentence-bert [
34],
XLM-R [
35] and
XLM-align [
36], each of which is described below.
mBERT: Multilingual BERT is a transformer model pretrained on a large corpus of multilingual data in a self-supervised fashion, mBERT follows the same model architecture and training procedure as BERT, except that it is pre-trained on concatenated Wikipedia data of 104 languages. For tokenization, mBERT uses WordPiece embeddings with a 110,000-word shared vocabulary to facilitate embedding space alignment across different languages. This means it was pretrained on raw texts only, with no humans labeling them in any way (which is why it can use lots of publicly available data), instead of using an automatic process to generate inputs and labels from those texts.
Sentence-BERT: Sentence-BERT can be used to calculate sentence/text embedding for over 100 languages and is a deep learning model for state-of-the-art sentence, text, and image embedding. These embeddings can be compared with cosine similarity to find sentences with similar meanings, which can be used for semantic text similarity, semantic search, or free translation mining. The model makes sense for tasks such as clustering or semantic search, and is based on PyTorch and Transformer, providing a large collection of pre-trained models for a variety of tasks.
XLM-R: The
XLM-R uses filtered common-crawled data (more than 2 TB) to demonstrate that using a large-scale multi-language pretraining model can significantly improve the performance of cross-language migration tasks. The
XLM-R uses the XLM [
37] model in combination with Robert to significantly improve the performance of the pre-trained model.
XLM-align: The XLM-ALIGN cross-language model uses denoising word alignment as a new cross-language pre-training task, which improves cross-language portability across different datasets, especially for top-level tasks such as question answering and structured prediction.
4.3. Experiment Setting
In order to learn more about the Uyghur language, we use the
LaBSE model, which uses 17 billion monolingual sentences and 6 billion pairs of bilingual sentences to train, using cosine distance to find the nearest neighbor translation for a given sentence. We ran these typical models on a 4386Tesla K80 gpu and built the experimental model using pytorch version 1.9.0. The parameters set in the experiment are shown in
Table 2.
4.4. Results and Analysis
In this experiment, we used the “strict” standard to evaluate the model’s results. In this experiment, P (precise rate), R (recall rate), and F (F1-Measure) value were used as evaluation indexes to evaluate the effectiveness of the experimental method. P refers to the ratio of the number of correctly classified comment texts to the total number of comment texts. R refers to the ratio of the number of correctly classified texts belonging to a certain emotional orientation to the number of truly emotional orientation comments in the review texts. F value is the harmonic average of precise and recall rate.
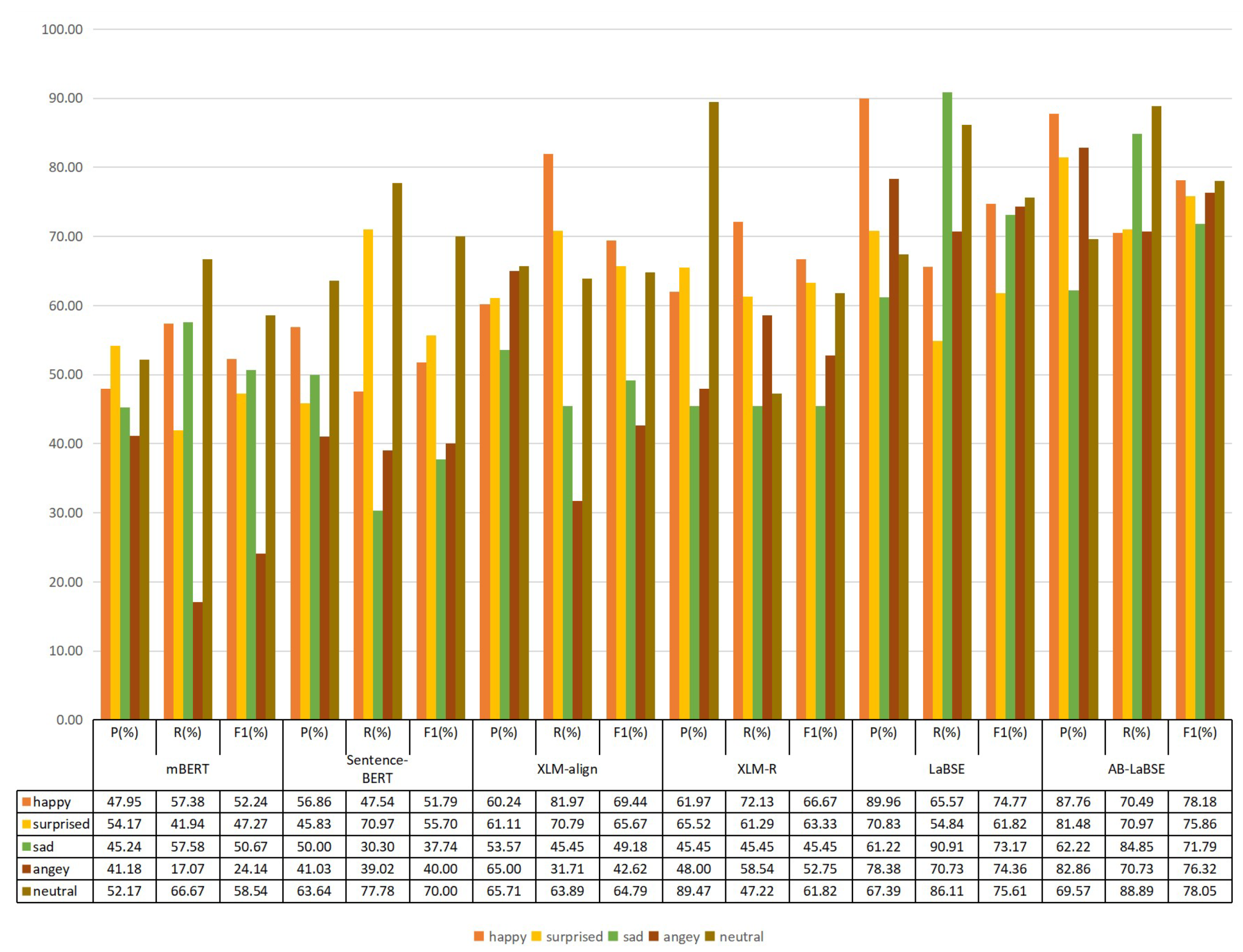
In this section, by comparing the accuracy and recall rates of these models, we can prove that the
AB-LaBSE model used in this paper has the best effect. As can be seen from
Table 3 and
Table 4, the
AB-LaBSE model proposed by us has significantly improved in the above three indicators, reaching the optimal value in the comparison model, and its F1 value is also the highest, so the performance of the model is the most stable. By comparing the
mBERT model and
Sentence-BERT model, the
mBERT model does not add Uyghur language data for training, so our five categorical emotion analysis dataset has a poor effect on this model. However, with the increase of data volume, The
mBERT model performs much better than the
Sentence-BERT model on the binary dataset of hotel reviews. It uses WordPiece embedding to promote the spatial alignment of embedding across languages. The
BERT model maps sentences to a vector space. This vector space is not suitable for cosine similarity, however, the
Sentence-BERT model overcomes this shortcoming, so in the case of a relatively small dataset, the effect of using the
Sentence-BERT pre-training model is better than
mBERT.
By comparing the data in
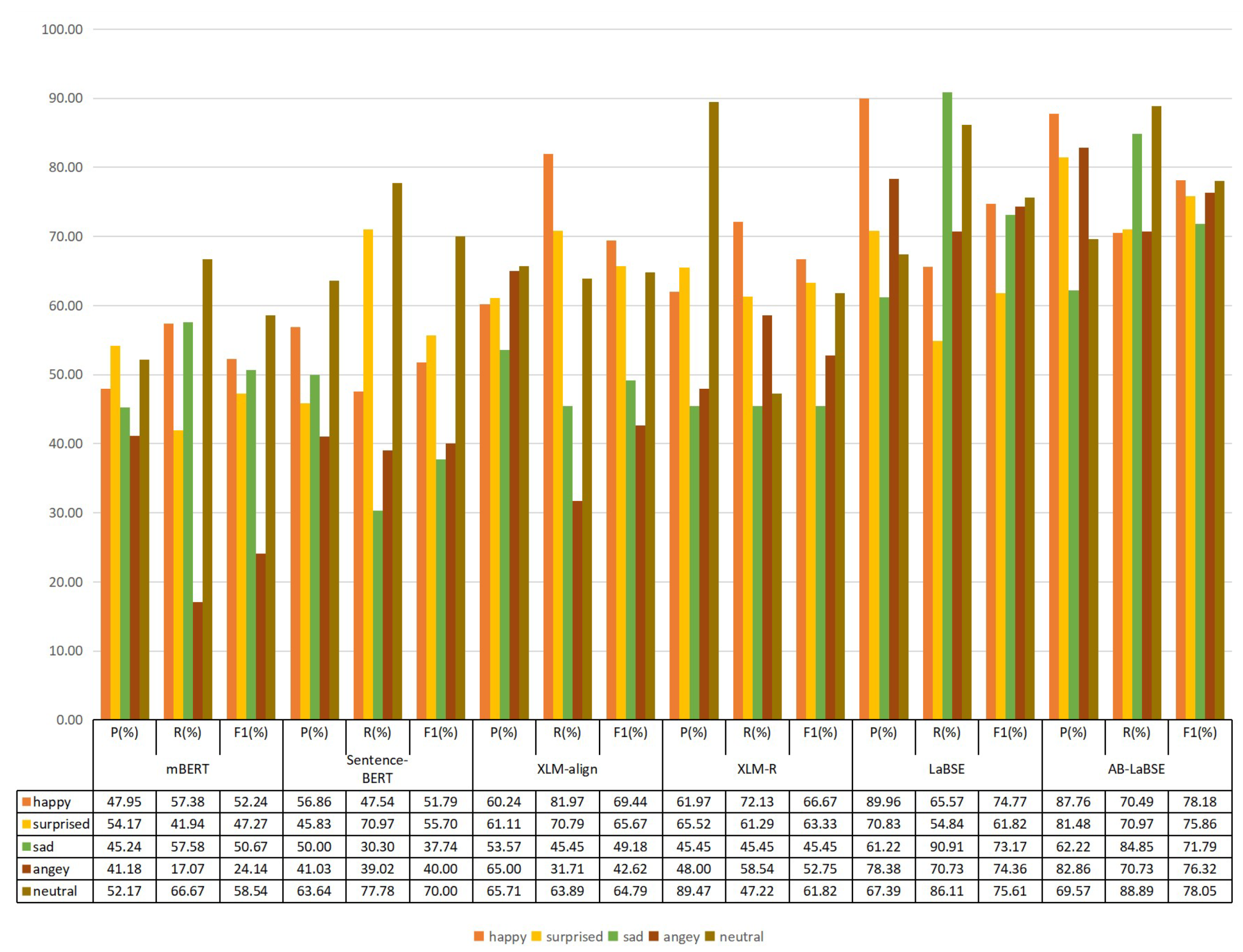
Figure 6 and
Figure 7, we can see that the recognition effect of
XLM class model is generally better than that of the
BERT class model. A large part of the reason is that the
XLM class model now uses a large shared statement block model to mark strings and adds the Uyghur language dataset to the model.
XLM-aligin also introduces denoising Word alignment before cross-language training, which is better than the above two models. It can also be seen from the experimental results that the F1 of
XLM-R is higher than that of
XLM-aligin. In the two-category experiment, the F1 value of negative increased by 15.6%, and the F1 value of positive increased by 2.02%. This is because
XLM-R combines
XLM’s cross-language and Roberta’s improved optimization function and larger model parameter number, so as to improve the accuracy of recognition.
Its language processing for low-resource languages is also very good. We can see that the pre-training model has achieved the best results in the downstream tasks, and the F1 value has improved a lot.
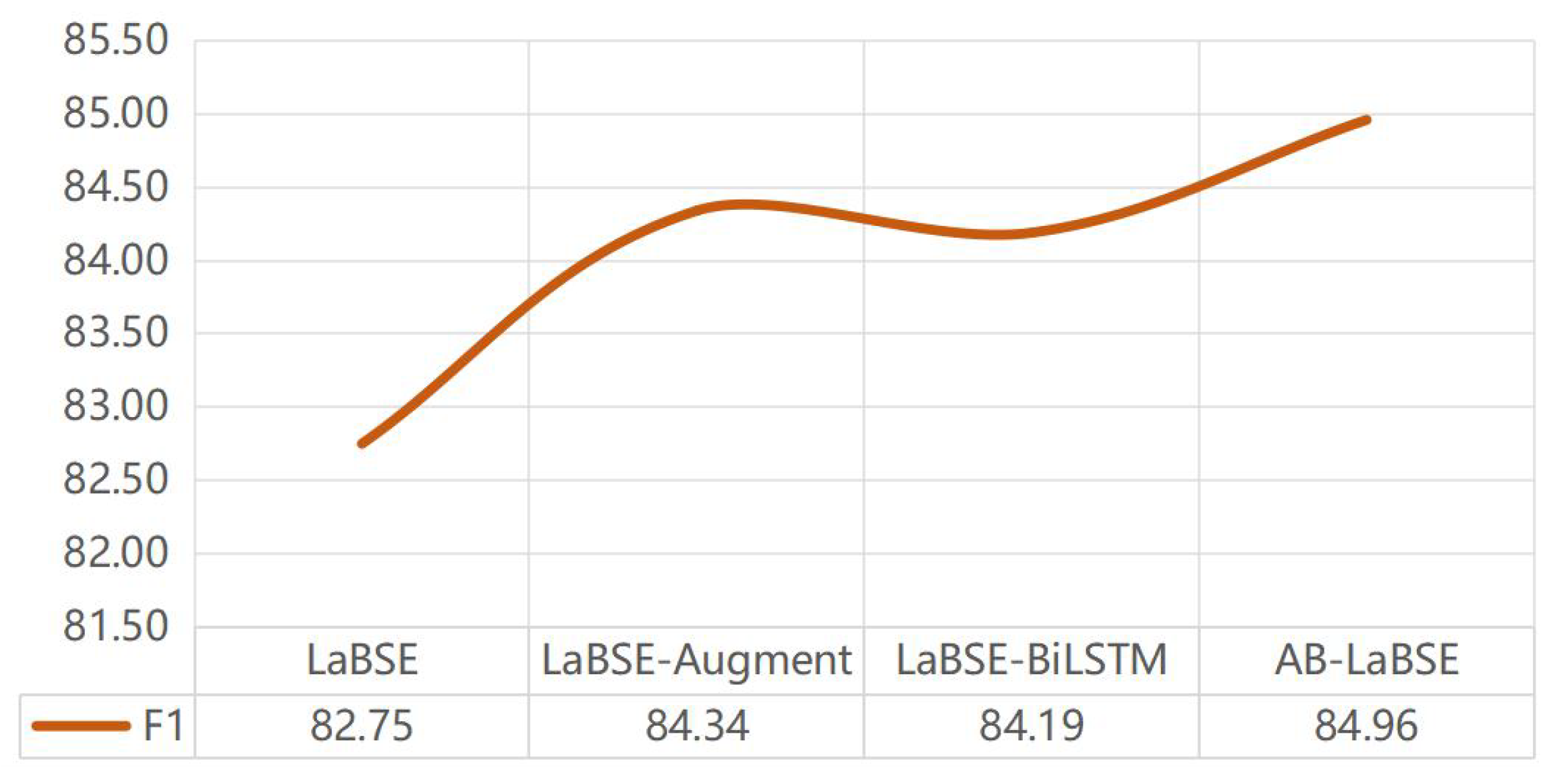
In order to further verify the influence of
BiLSTM on the effect of dichotomous datasets and five categorical datasets, two versions are used for comparison, as shown in
Table 5 and
Table 6, showing the scores of
LaBSE algorithm in the two datasets. In the sentiment analysis of hotel review dichotomous datasets, with the addition of
BiLSTM layer, the overall effect is getting better and better. The results showed that P, R, and F1 values were 76.78%, 77.19%, and 76.04%, respectively. In the emotion analysis of five categorical datasets, with the addition of
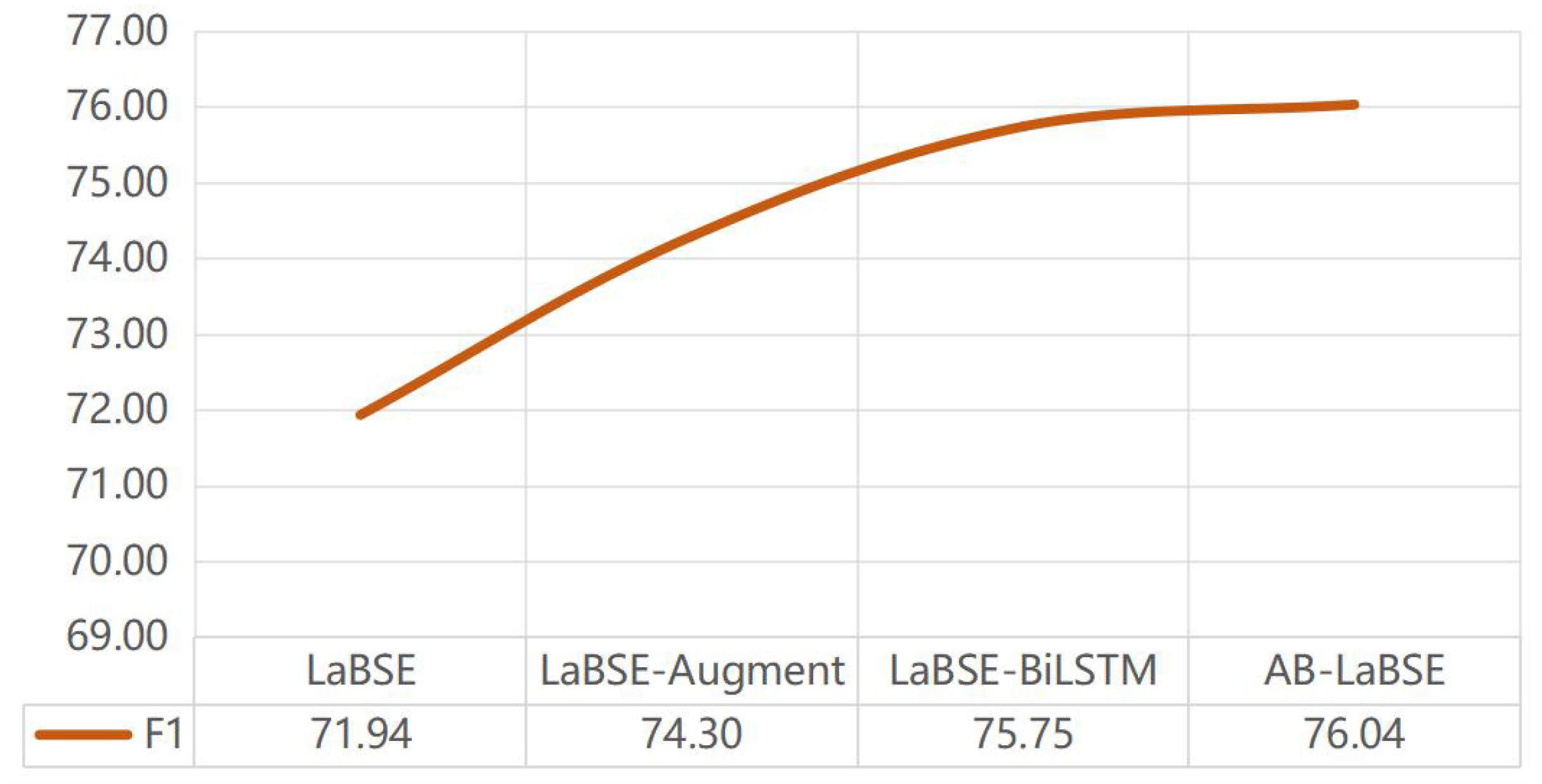
BiLSTM layer, the overall effect is getting better and better. The results showed that P, R, and F1 values were 85.66%, 84.34%, and 84.96%, respectively.
4.5. Ablation Study
In order to evaluate the role of key factors in the used methods, we used the
LaBSE pre-training model to train and test the hotel review binary and emotion analysis of five categories of Uyghur datasets for methods with and without data enhancement and methods with and without the
BilSTM layer, as shown in
Figure 8 and
Figure 9.
The effect of augmentation. For the binary dataset of hotel review, in the process of the experiment, we only performed data augmentation for the data items marked negative in view of the uneven distribution of training data in this dataset. Therefore, the performance of the negative F1 value attribute is improved by 3.1%, and the total F1 value is also improved by 1.59%. For the five categories of emotion analysis dataset, the data volume of this dataset is small. As a result, we performed random data augmentation on the data of the training set to improve the final performance. In
Figure 9, we can see the result after data augmentation, and the overall effect has been improved by 2.36%. Experimental results show that this method can improve the performance of tasks with low resource datasets and enable us to obtain more semantic vector representations of original texts using pre-training models.
The effect of BiLSTM. By comparing the F1 values of various methods, we analyzed the two datasets separately, in the two categories datasets, the result improved by 1.44% after adding the BiLSTM layer. In the five categories dataset, the result improved by 3.81% after adding the BiLSTM layer. The BiLSTM layer not only considers the forward text sequence information, but also considers the reverse text sequence information, mining the semantic relationship between texts at a deeper level, thus greatly improving the performance of our model.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}