
A Study on High-Speed Outlier Detection Method of Network Abnormal Behavior Data Using Heterogeneous Multiple Classifiers



Abstract
:1. Introduction
2. Related Work
2.1. Machine Learning Based Anomaly Detection and Data Noise Reduction for Network Traffic Dataset
2.2. Noise Reduction Methods for Anomaly Detection
2.2.1. Decision Tree
2.2.2. Random Forest
2.2.3. Support Vector Machine
2.2.4. Naive Bayes Classifier
2.2.5. K-Nearest Neighbors Classifier
2.2.6. Logistic Regression
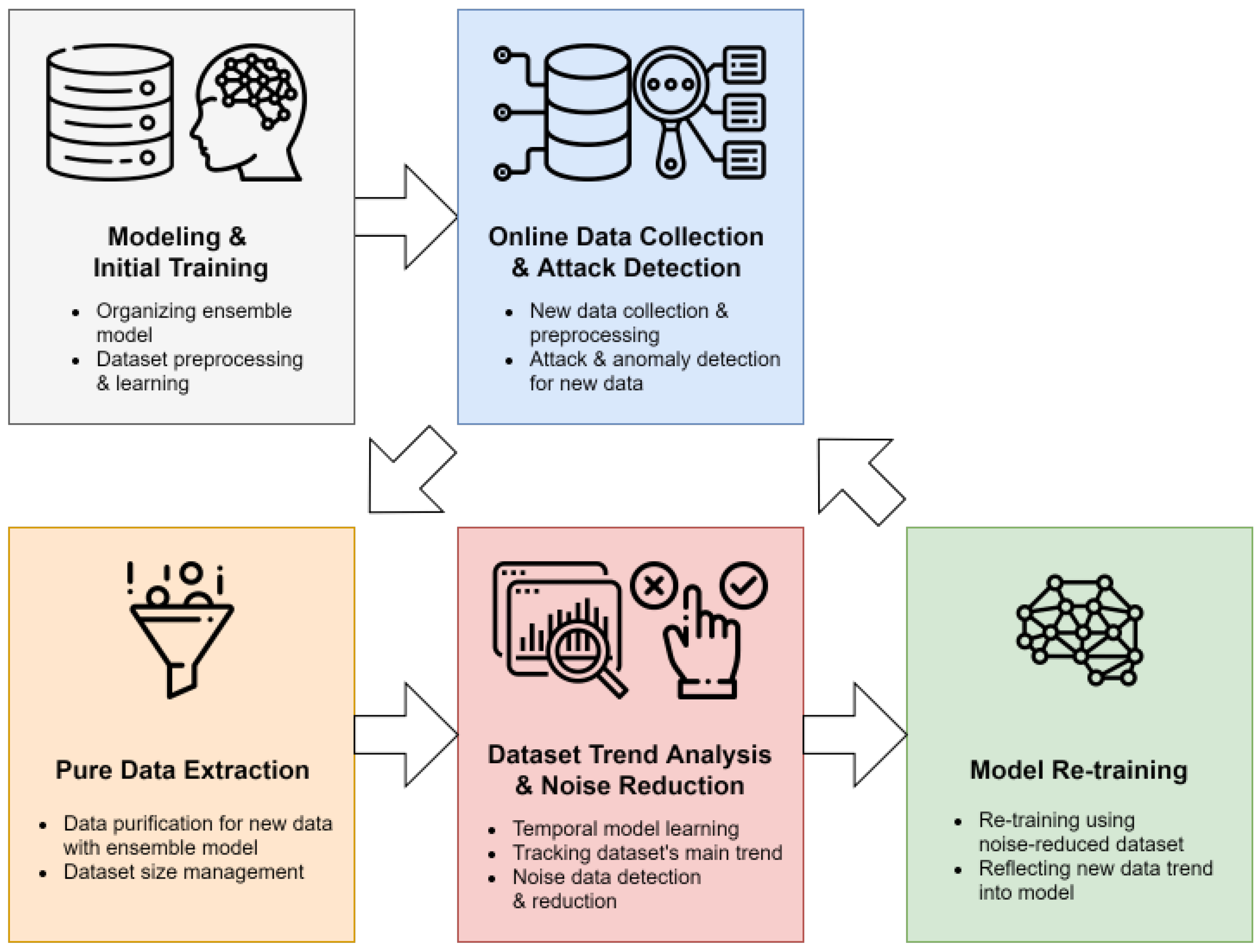
3. High Speed Outlier Detection of Network Abnormal Behavior
3.1. General Training Detection Phase
3.1.1. Modeling and Initial Training
3.1.2. Online Data Collection and Attack Detection Using Ensemble Model
3.2. Dataset Purification Model Re-Training
3.2.1. Pure Data Extraction
3.2.2. Dataset Trend Analysis and Noise Reduction
3.2.3. Model Retraining
4. Implementation
4.1. Model for Dataset Noise Reduction and Purification
4.2. Dataset Purification
| Algorithm 1: Data Purification Mechanism. |
| Input: previous training dataset T |
| newly observed data N |
| ensemble model E |
| unanimity threshold u |
| purity threshold p |
| Output: purified new training dataset P |
| 1 for each do |
| 2 preds = prediction(E, x) |
| 3 for each preds do |
| 4 if sum(y) then |
| 5 store y in U |
| 6 end if |
| 7 end |
| 8 end |
| 9 |
| 10 l = length(N) |
| 11 model_training() |
| 12 for each do |
| 13 preds = prediction(E, ) |
| 14 for each preds do |
| 15 if sum(y) then |
| 16 store y in P |
| 17 end if |
| 18 end |
| 19 end |
| 20 return P |
5. Experiments and Assumptions on Abnormal Behavior Detection and Noise Removal Performance
5.1. Dataset and Environments
5.2. Training and Test Dataset
5.3. Parameters Used in Ensemble Model for Attack Detection and Noise Reduction
5.3.1. Decision Tree
5.3.2. Random Forest
5.3.3. SVM
5.3.4. Naive-Bayes
5.3.5. K-NN
5.3.6. Logistic Regression
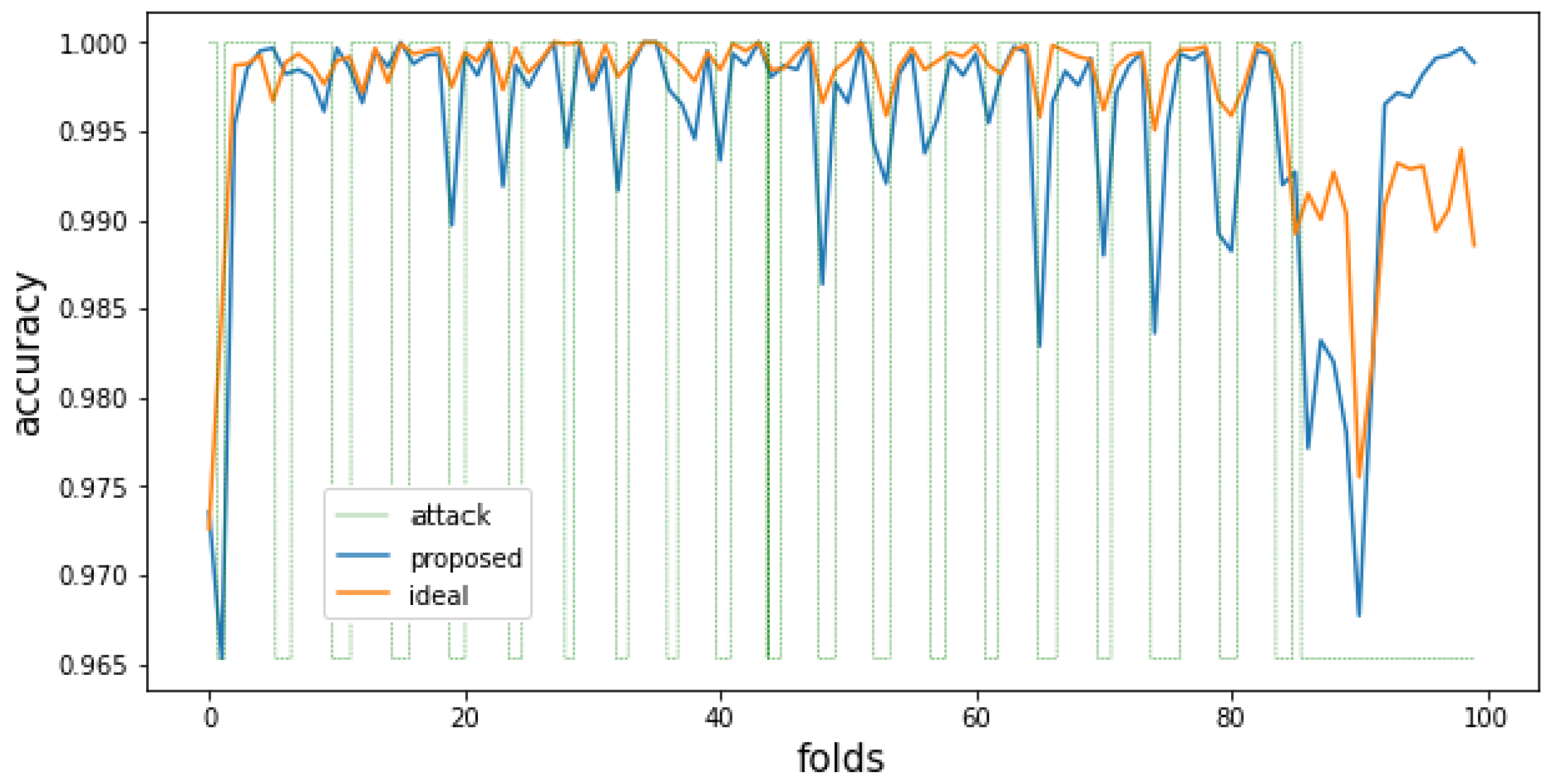
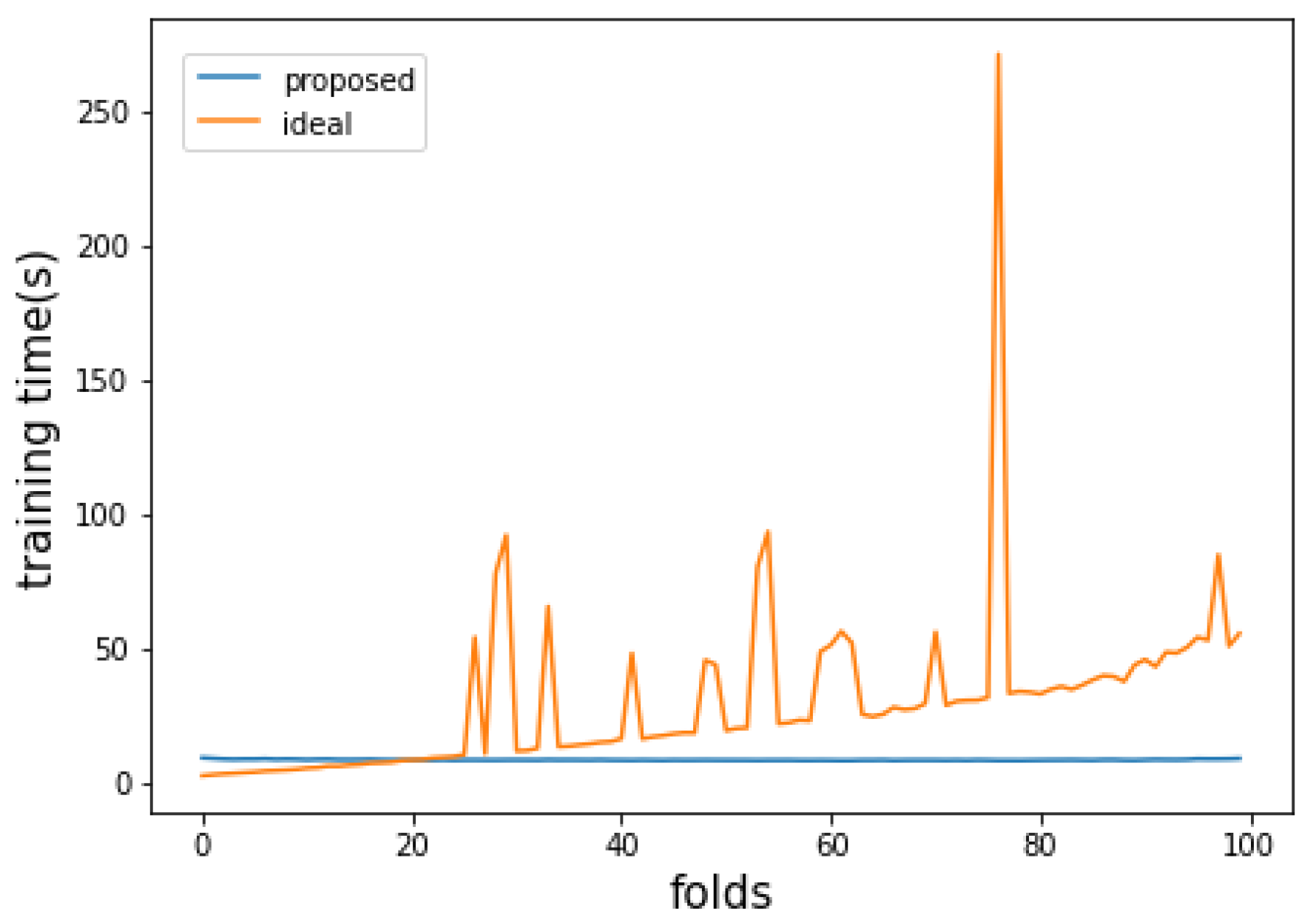
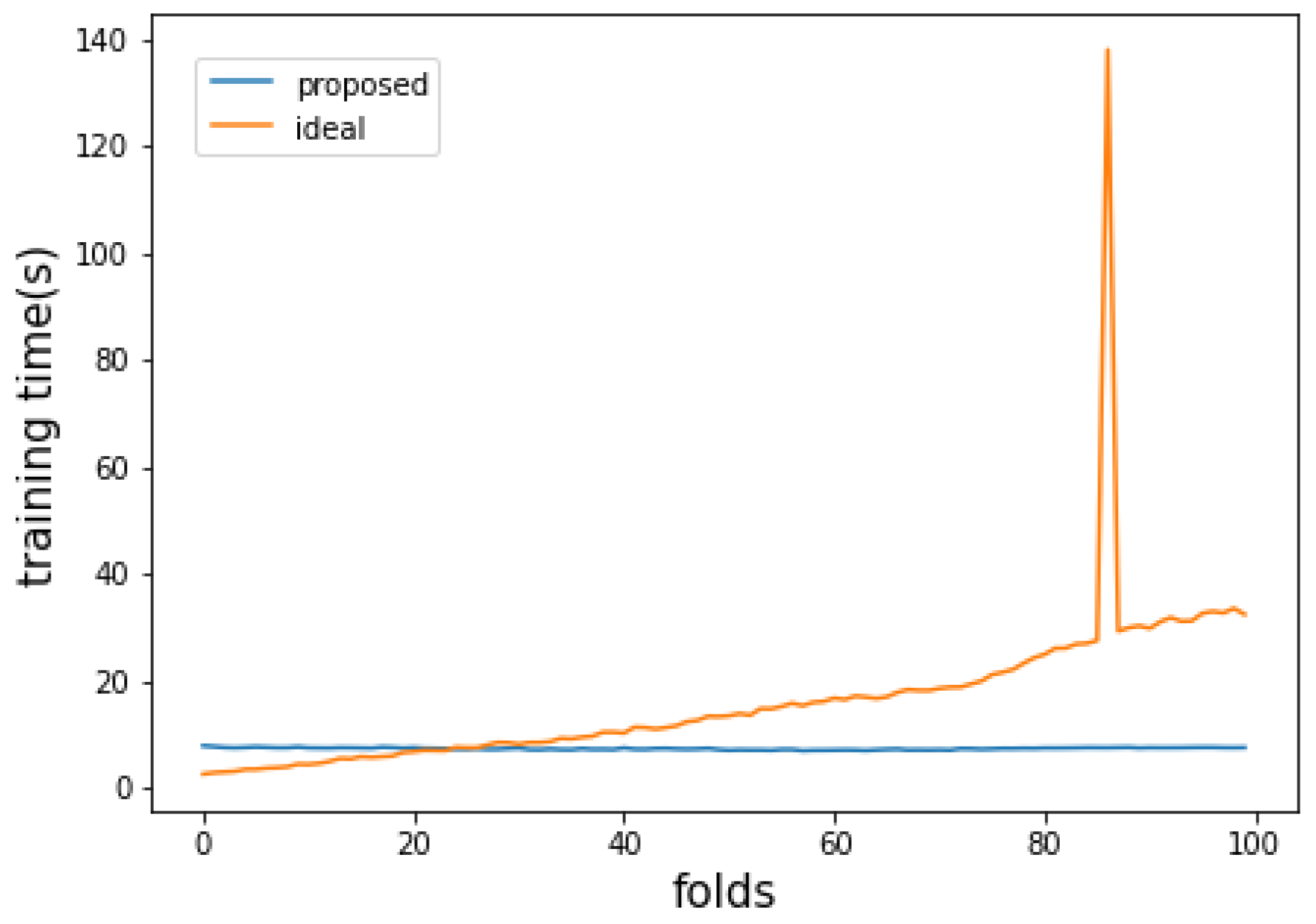
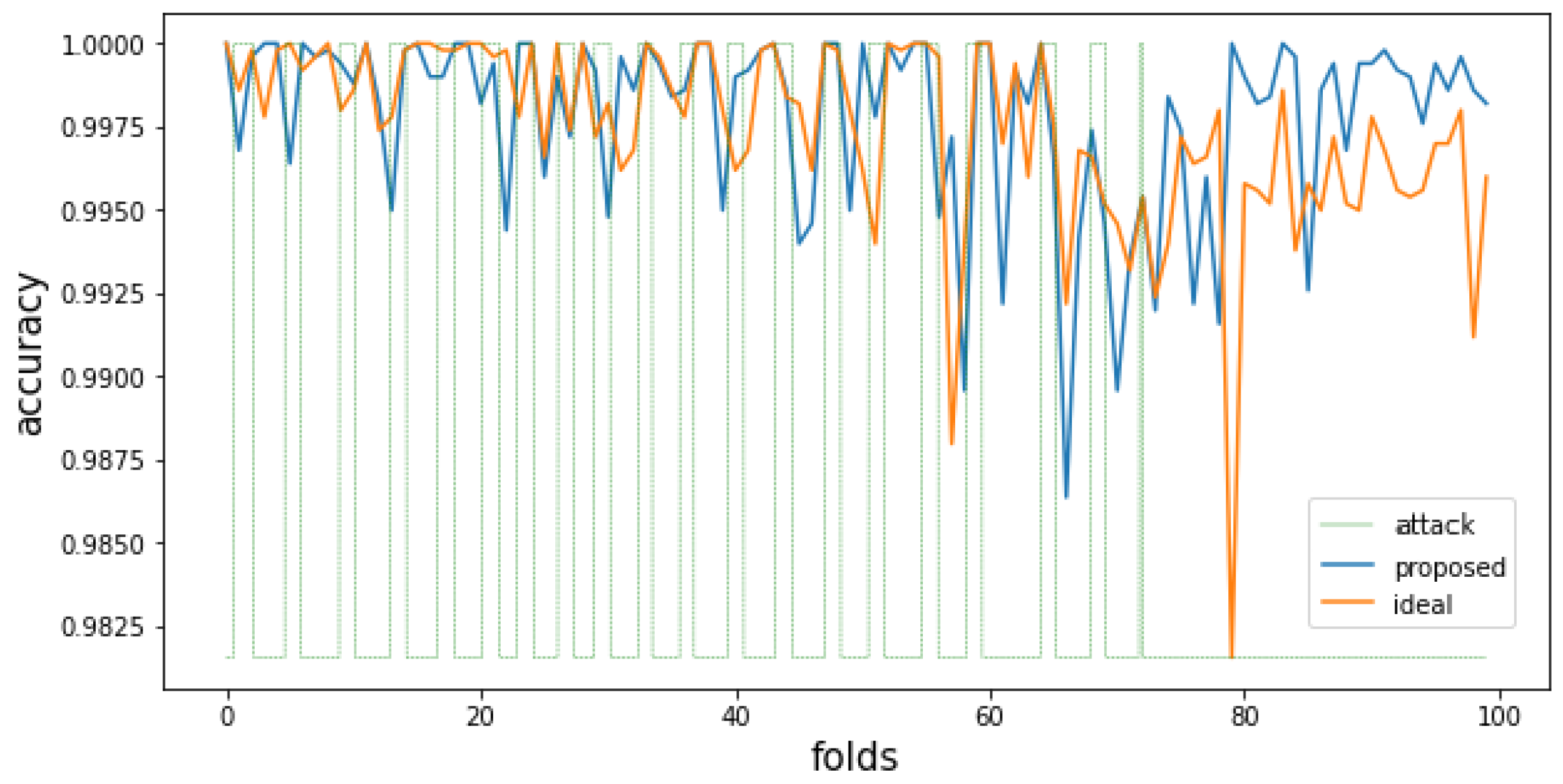
5.4. Evaluation of Attack Detection Performance and Ability to Trend Reflection
5.5. Discussion and Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ICS | Industrial Control System |
| IoT | Internet of Things |
| IT | Information Technology |
| CIC-IDS | Canadian Institute for Cybersecurity-Intrusion Detection System |
| SVM | Support Vector Machine |
| K-NN | K-Nearest Neighbors |
References
- Berman, D.S.; Buczak, A.L.; Chavis, J.S.; Corbett, C.L. A survey of deep learning methods for cyber security. Information 2019, 10, 122. [Google Scholar] [CrossRef] [Green Version]
- Chaabouni, N.; Mosbah, M.; Zemmari, A.; Sauvignac, C.; Faruki, P. Network intrusion detection for IoT security based on learning techniques. IEEE Commun. Surv. Tutor. 2019, 21, 2671–2701. [Google Scholar] [CrossRef]
- Lu, Y.; Da Xu, L. Internet of Things (IoT) cybersecurity research: A review of current research topics. IEEE Internet Things J. 2018, 6, 2103–2115. [Google Scholar] [CrossRef]
- Tomić, I.; McCann, J.A. A survey of potential security issues in existing wireless sensor network protocols. IEEE Internet Things J. 2017, 4, 1910–1923. [Google Scholar] [CrossRef]
- Gong, S.; Cho, J.; Lee, C. A reliability comparison method for OSINT validity analysis. IEEE Trans. Ind. Inform. 2018, 14, 5428–5435. [Google Scholar] [CrossRef]
- Coulter, R.; Han, Q.L.; Pan, L.; Zhang, J.; Xiang, Y. Data-driven cyber security in perspective—Intelligent traffic analysis. IEEE Trans. Cybern. 2019, 50, 3081–3093. [Google Scholar] [CrossRef] [PubMed]
- Xiong, X.L.; Yang, L.; Zhao, G.S. Effectiveness evaluation model of moving target defense based on system attack surface. IEEE Access 2019, 7, 9998–10014. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Soman, K.; Poornachandran, P. Evaluation of recurrent neural network and its variants for intrusion detection system (IDS). Int. J. Inf. Syst. Model. Des. (IJISMD) 2017, 8, 43–63. [Google Scholar] [CrossRef]
- Borkar, A.; Donode, A.; Kumari, A. A survey on Intrusion Detection System (IDS) and Internal Intrusion Detection and protection system (IIDPS). In Proceedings of the 2017 International conference on inventive computing and informatics (ICICI), Coimbatore, India, 23–24 November 2017; pp. 949–953. [Google Scholar]
- Gopalakrishnan, T.; Ruby, D.; Al-Turjman, F.; Gupta, D.; Pustokhina, I.V.; Pustokhin, D.A.; Shankar, K. Deep learning enabled data offloading with cyber attack detection model in mobile edge computing systems. IEEE Access 2020, 8, 185938–185949. [Google Scholar] [CrossRef]
- Patel, A.; Roy, S.; Baldi, S. Wide-Area Damping Control Resilience towards Cyber-Attacks: A Dynamic Loop Approach. IEEE Trans. Smart Grid 2021, 12, 3438–3447. [Google Scholar] [CrossRef]
- Nilă, C.; Apostol, I.; Patriciu, V. Machine learning approach to quick incident response. In Proceedings of the 2020 13th International Conference on Communications (COMM), Bucharest, Romania, 18–20 June 2020; pp. 291–296. [Google Scholar]
- Cybenko, G.; Raz, G.M. Large-scale analogue measurements and analysis for cyber-security. In Data Science For Cyber-Security; World Scientific: Singapore, 2019; pp. 227–250. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 2018, 1, 108–116. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. A detailed analysis of the cicids2017 data set. In International Conference on Information Systems Security and Privacy; Springer: Berlin/Heidelberg, Germany, 2018; pp. 172–188. Available online: https://www.unb.ca/cic/datasets/ids-2017.html (accessed on 1 December 2021).
- Anderson, B.; McGrew, D. Machine learning for encrypted malware traffic classification: Accounting for noisy labels and non-stationarity. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, USA, 13–17 August 2017; pp. 1723–1732. [Google Scholar]
- Yu, Y.; Bian, N. An intrusion detection method using few-shot learning. IEEE Access 2020, 8, 49730–49740. [Google Scholar] [CrossRef]
- Ahmed, S.; Lee, Y.; Hyun, S.H.; Koo, I. Mitigating the impacts of covert cyber attacks in smart grids via reconstruction of measurement data utilizing deep denoising autoencoders. Energies 2019, 12, 3091. [Google Scholar] [CrossRef] [Green Version]
- Al-Abassi, A.; Karimipour, H.; Dehghantanha, A.; Parizi, R.M. An ensemble deep learning-based cyber-attack detection in industrial control system. IEEE Access 2020, 8, 83965–83973. [Google Scholar] [CrossRef]
- Jiang, W.; Chen, Z.; Xiang, Y.; Shao, D.; Ma, L.; Zhang, J. SSEM: A novel self-adaptive stacking ensemble model for classification. IEEE Access 2019, 7, 120337–120349. [Google Scholar] [CrossRef]
- Nancy, P.; Muthurajkumar, S.; Ganapathy, S.; Kumar, S.S.; Selvi, M.; Arputharaj, K. Intrusion detection using dynamic feature selection and fuzzy temporal decision tree classification for wireless sensor networks. IET Commun. 2020, 14, 888–895. [Google Scholar] [CrossRef]
- Li, L.; Yu, Y.; Bai, S.; Cheng, J.; Chen, X. Towards effective network intrusion detection: A hybrid model integrating gini index and GBDT with PSO. J. Sens. 2018, 2018, 1578314. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, N.; Praça, I.; Maia, E.; Sousa, O. Intelligent cyber attack detection and classification for network-based intrusion detection systems. Appl. Sci. 2021, 11, 1674. [Google Scholar] [CrossRef]
- Ye, J.; Cheng, X.; Zhu, J.; Feng, L.; Song, L. A DDoS attack detection method based on SVM in software defined network. Secur. Commun. Netw. 2018, 2018, 9804061. [Google Scholar] [CrossRef]
- Sahoo, K.S.; Tripathy, B.K.; Naik, K.; Ramasubbareddy, S.; Balusamy, B.; Khari, M.; Burgos, D. An evolutionary SVM model for DDOS attack detection in software defined networks. IEEE Access 2020, 8, 132502–132513. [Google Scholar] [CrossRef]
- Kachavimath, A.V.; Nazare, S.V.; Akki, S.S. Distributed Denial of Service Attack Detection using Naïve Bayes and K-Nearest Neighbor for Network Forensics. In Proceedings of the 2020 2nd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bangalore, India, 5–7 March 2020; pp. 711–717. [Google Scholar]
- Tuan, T.A.; Long, H.V.; Son, L.H.; Kumar, R.; Priyadarshini, I.; Son, N.T.K. Performance evaluation of Botnet DDoS attack detection using machine learning. Evol. Intell. 2020, 13, 283–294. [Google Scholar] [CrossRef]
- Gu, P.; Khatoun, R.; Begriche, Y.; Serhrouchni, A. k-Nearest Neighbours classification based Sybil attack detection in Vehicular networks. In Proceedings of the 2017 Third International Conference on Mobile and Secure Services (MobiSecServ), Miami Beach, FL, USA, 11–12 February 2017; pp. 1–6. [Google Scholar]
- Besharati, E.; Naderan, M.; Namjoo, E. LR-HIDS: Logistic regression host-based intrusion detection system for cloud environments. J. Ambient Intell. Humaniz. Comput. 2019, 10, 3669–3692. [Google Scholar] [CrossRef]
- Iadarola, G.; Martinelli, F.; Mercaldo, F.; Santone, A. Towards an interpretable deep learning model for mobile malware detection and family identification. Comput. Secur. 2021, 105, 102198. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Quantity |
|---|---|
| Total Data | 225,711 |
| Normal data | 97,686 (43.28%) |
| Attack data | 128,025 (56.72%) |
| Filtered attack data | 25,605 |
| Features | 77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, J.; Gong, S.; Choi, K. A Study on High-Speed Outlier Detection Method of Network Abnormal Behavior Data Using Heterogeneous Multiple Classifiers. Appl. Sci. 2022, 12, 1011. https://doi.org/10.3390/app12031011
Cho J, Gong S, Choi K. A Study on High-Speed Outlier Detection Method of Network Abnormal Behavior Data Using Heterogeneous Multiple Classifiers. Applied Sciences. 2022; 12(3):1011. https://doi.org/10.3390/app12031011
Chicago/Turabian StyleCho, Jaeik, Seonghyeon Gong, and Ken Choi. 2022. "A Study on High-Speed Outlier Detection Method of Network Abnormal Behavior Data Using Heterogeneous Multiple Classifiers" Applied Sciences 12, no. 3: 1011. https://doi.org/10.3390/app12031011
APA StyleCho, J., Gong, S., & Choi, K. (2022). A Study on High-Speed Outlier Detection Method of Network Abnormal Behavior Data Using Heterogeneous Multiple Classifiers. Applied Sciences, 12(3), 1011. https://doi.org/10.3390/app12031011