Abstract
Within the context of the Competence Centre for the Conservation of Cultural Heritage (4CH) project, the design and deployment of a platform-as-a-service cloud infrastructure for the first European competence centre of cultural heritage (CH) has begun, and some web services have been integrated into the platform. The first integrated service is the INFN-CHNet web application for FAIR storage of scientific analysis on CH: THESPIAN-Mask. It is based on CIDOC-CRM-compatible ontology and CRMhs, describing the scientific metadata. To ease the process of metadata generation and data injection, another web service has been developed: THESPIAN-NER. It is a tool based on a deep neural network for named entity recognition (NER), enabling users to upload their Italian-written report files and obtain labelled entities. Those entities are used as keywords either to serve as (semi)automatically custom queries for the database, or to fill (part of) the metadata form as a descriptor for the file to be uploaded. The services have been made freely available in the 4CH PaaS cloud platform.
1. Introduction
In the last decade, the evolution of information and communication technologies (ICTs), in particular cloud-related technologies and solutions, has enabled the possibility of defining standard methods to find, access, reuse, and integrate community-related data, especially via a web-based platform.
At the same time, in particular within the scientific community, the need for a rationalised organisation of digitalised data (and metadata) via standard methods and tools [1,2], has emerged.
In particular, the definition of the so-called findable, accessible, interoperable, reusable (FAIR) data principles [3], and their adoption in the European Open Science Cloud initiative [4], became an important activity devoted to identifying proven methods for making digital research objects more FAIR.
In this context, the Competence Centre for the Conservation of Cultural Heritage (4CH) European project [5] (the ancestor of this platform was devised and developed in the context of the European projects ARIADNEplus [6,7] and EOSC-Pillar [8]), and has the aim of setting up the methodological, procedural, and organizational framework of a competence centre—an infrastructure dedicated to knowledge organization and transfer through means such as training, standardization, and interdisciplinary collaboration.
In this respect, part of the activities are devoted to define and improve the tools for heritage science processing, integration, and analysis (THESPIAN) suite, a set of web services aimed at offering multiple microservices to the researchers of the Cultural Heritage Network (CHNet) of Istituto Nazionale di Fisica Nucleare (INFN), for storing their raw data by following the FAIR principles for establishing integration and interoperability among shared information.
In this paper, we describe the design, development, and deployment of a cloud-native web service, offered on the aforementioned THESPIAN platform, called THESPIAN-NER. Based on a deep neural network for natural language processing (NLP), it has been integrated within the 4CH cloud infrastructure. The goal of such research activity was focused on helping researchers to compile, archive, and query their research dataset items in the INFN-CHNet database via a web application offered as a software-as-a-service (SaaS) cloud suite.
The structure of the paper is as follows. In Section 2, the previous and related works on the THESPIAN suite and its related services are described. In Section 3, the design, development, and training of the NLP models adopted for the semantic classification is reported. In Section 4, the THESPIAN-NER web application design and related user experience is presented. In Section 5, the organisation of the 4CH infrastructure and the THESPIAN integration as a platform-as-a-service (PaaS) is highlighted. Final comments and a discussion are reported in Section 6.
2. Origin of the Work: A Cloud-Based Services for Cultural Heritage Science
As already pointed out, one of the main goals of the 4CH project is to design, devise, and deploy the CC cloud platform, which will host 4CH partners’ big data services (such as THESPIAN), as well as a cultural heritage knowledge base, with a focus on the most advanced 3D and semantic technologies for monuments and sites, with the goal of building their digital heritage twins.
The purpose of the THESPIAN suite is to create a web ecosystem for storage, retrieval, and analysis of scientific data coming from physical analysis on cultural heritage, and their metadata, modelled according to the state-of-the-art ontologies and standards, making them interoperable with other services according to the FAIR principles for data [3].
In this respect, THESPIAN is aimed at offering a suite of cloud-oriented services to store, access, and analyse data in the field of cultural heritage. The data storage is making use of metadata, based on a shared ontology, following the guidelines of the FAIR program established within the context of the European science cloud (EOSC).
The implementation of such FAIR data principles are materialized in the THESPIAN-Mask [9,10] web service hosted in the CHNet cloud environment. THESPIAN-Mask consists of a web application for assisted metadata generation and a service for persistent storage of scientific data and their metadata. The tool relies on a metadata model based on CRMhs, an extension of the CIDOC-CRM ontology [11], designed by INFN and VAST-LAB PIN for modelling the complex entities typical of heritage science [9]. To ease and standardise the metadata filling procedure, a set of tools based on open-source third-party application program interfaces (APIs) have been used and integrated into the service (see Figure 1 for more details). As an example of API, GEOdata URIs can be filled by a map tool offered by using OpenStreetMap [12], where users may either search for a location by manually inserting the latitude (or the longitude), or by clicking the point on the map, or by querying the GeoNames database to find the wanted location.

Figure 1.
View of the THESPIAN-Mask page devoted to the insertion of a new metadata record. The buttons for accessing third-party APIs are shown.
From the technical perspective, THESPIAN-Mask is composed of the following components.
- 1.
- First, we have the front-end, hosting an endpoint furnishing the HTML, CSS, and JavaScript (JS) bundle to be rendered in the client browser.
- 2.
- Secondly, we have the back end, offering a set of representational state transfer (REST)-ful APIs contactable via HTTP/2 protocol, for metadata/data upload and retrieval, and offering a set of tools, based on third-party APIs for metadata standardisation.
- 3.
- Lastly, we have MongoDB, a No-SQL database for storing the metadata entries.
A visual representation of the service is available in Figure 2. To ensure file persistency, the back end and DB use persistent (virtual) volumes that are not mutually accessed for security reasons.
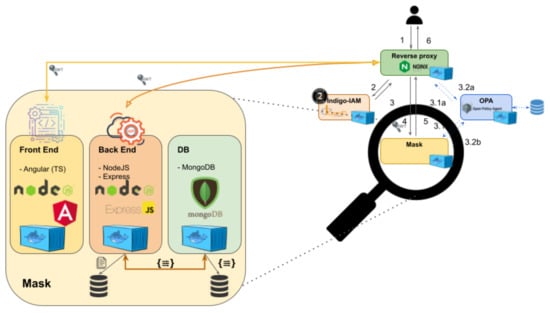
Figure 2.
Visual representation of the three services forming the THESPIAN-Mask web application.
The connections between the front end and back end are mediated by the authentication/authorization reverse proxy service; only authenticated and authorized users can access those services. The DB can only be contacted by the back end and is shielded from outside. The requests formulated by the front end used the HTTP/2 protocol and are sent to the back end via reverse proxy through an authenticated and authorized connection. The back end contacts the third-party APIs, get the replies and, again through the reverse proxy, replies to the front end.
THESPIAN-NER
To navigate the scientific database created by THESPIAN-Mask, and to ease the burden of metadata generation, the THESPIAN-NER web service has been designed and implemented. Based on the natural language processing (NLP) model for automatic named entity recognition (NER), (for some references about the application of named entity recognition in cultural heritage applications, see [13,14,15,16], and references therein), THESPIAN-NER allows users to (semi)automatically
- 1.
- generate custom THESPIAN-Mask queries; and
- 2.
- fill in THESPIAN-Mask metadata fields.
Both tasks are performed by using named entities inferred by the NLP model within written documents or reports (only available in the Italian language at present).
The NLP and NER models are capable of automatically annotating either archaeological documents and/or scientific reports by identifying and labelling relevant semantic entities. Those labels are in correspondence with CRMhs ontology (classes, properties), as well as metadata fields. For the time being, THESPIAN-NER is only available in the Italian language, as data mainly come from Italian collaborations and institutions working in the filed of cultural heritage. The adoption of English as well as other languages is foreseen in the near future.
The machine learning models implemented and used in the THESPIAN-NER application are trained neural networks: ArcheoNER, for processing archaeological texts, and hsNER, for scientific reports of analysis on cultural heritage. These models were built by using the open-source Python package spaCy [17,18,19,20] and fine tuned by using transfer learning to classify named entities with the aforementioned custom labels.
THESPIAN-NER offers the possibility of either generating queries on the CHNet database in a (semi)automatic way, or fill-in metadata fields. At the time of writing, only Italian written documents and reports, related to archaeological and heritage scientific topics, can be used for the analysis. This limitation is due to the fact that, at the moment, THESPIAN-NER is adopted by Italian researchers who use the tool to compose queries and metadata forms starting from their Italian written documents and reports. Future work is planned to extend NER models to other languages and, in this way, to engage the service adoption also to other scientific communities.
Furthermore, the semiautomatic query and metadata generation process, made compliant with FAIR principles, is performed though a user-friendly web graphical interface.
3. The Natural Language Processing Models
Two different architectural NLP models have been used for the present work: a convolutional neural network (CNN)-based model [18], and a transformer model [19].
To have the model infer named entities, and label them with our custom labels, we applied transfer learning to train these models and, in the end, fine tune the training.
As already mentioned, the spaCy library has been adopted because it offers pretrained, Italian-based models for both CNN and transformer. In particular, for the CNN model the it_core_news_lg has been used for training (originally trained on the Italian Stanford Dependency Treebank annotated according to the UD annotation [21,22]). The original output NER labels were Organisation (ORG), Miscellanea (MISC), Location (LOC) and Person (PER).
The pipeline for the model is tok2vec, morphologizer, tagger, parser, attribute_ruler, lemmatizer, ner; it has 500 k keys, 500 k unique vectors as word vectors, embedded in a 300-dimensional vector space.
On the other hand, the transformer model has been tested with a different pipeline: transformer, ner (for more details see Figure 3).
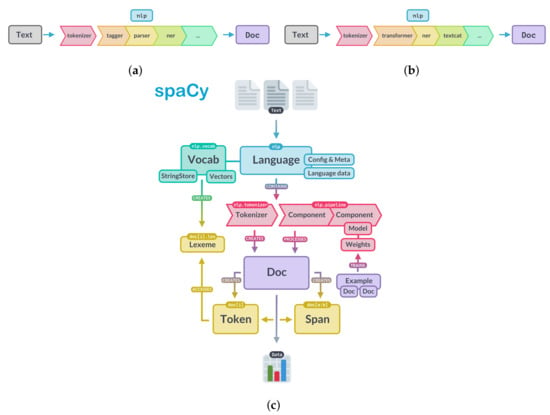
Figure 3.
Visual schema for the spaCy models. From [19]. (a) spaCy CNN model pipeline. (b) spaCy transformer model pipeline. (c) Generic spaCy architecture.
On top of each model, spaCy has its own Italian-language tokenizer.
We thus trained both architectures and compared their scores. Finally, the most performing one has been used.
3.1. Training Datasets
Both models, CNN and transformer, have been trained with two different datasets:
- 1.
- a set of Italian archaeological written documents, most of them publications in scientific journals; and
- 2.
- a set of Italian internal scientific reports, produced during the last 15 years at INFN-LABEC in Florence (Laboratorio di tecniche nucleari applicate all’Ambiente e ai BEni Culturali, or the Laboratory of Nuclear Techniques for Environment and Cultural Heritage) [23].
Both corpus were annotated by using the open-source program INCEpTION [24].
We will thus name ArcheoNER the model trained on the first dataset, and hsNER the model trained on the second.
The ArcheoNER dataset consists of i) 92 Italian-written archaeological documents containing 5230 entities, ii) nine entity labels, chosen for their relevance in the archaeological sector and according to their compatibility with top-level classes of the CRMhs ontology. The labels are name, three-letter label, and HEX code for HTML rendering. By using the open-source add-on library Displacy, it is possible to render the annotated text as HTML, where named entities are highlighted by using a hexadecimal (HEX) colour. Such a HEX colour is employed in the web application as a visual aid to users, in order to visually discriminate entities among NER labels.
Artefact (ART, #6196A4), Site (SIT, #D4AE60), Person (PER, #BF98D0), Time span (TSP, #61A46A), Activity (ACT, #D12153), Organisation (ORG, #B86F9A), Place (LOC, #EDE89B), Period (PRD, #ABEF70), Biological remains (BIO, #89CBCA)
The hsNER dataset consists of 43 Italian-written scientific reports (provided by LABEC) containing 5676 entities. In this case, 14 labels have been chosen for relevance and their compatibility with the CRMhs ontology, extending the previous as follows.
Artefact (ART, #6196A4), Person (PER, #BF98D0), Time span (TSP, #61A46A), Activity (ACT, #D12153), Organisation (ORG, #B86F9A), Place (LOC, #EDE89B), Natural object (BIO, #89CBCA), Sample (SAM, #8E44AD), Analysis (ANL, #909497), Material (MAT, #F8C471), Method (MET, #A2D9CE), Device (DEV, #FADBD8), Software (SOF, #E67E22), Result (RES, #58D68D).
The scientific reports adopted for the present study refer to analysis carried out at the LABEC laboratory, the INFN-CHNet node based in Florence (Italy). The analysis reported are either X-ray fluorescence (XRF) imaging of pictorial artworks and radiocarbon dating of various samples, of either natural objects or artefacts.
The labels defined for ArcheoNER and hsNER have been chosen by taking into account their relevance in respect to the topic addressed (either archaeological or heritage-scientific) and by considering their relationship with the THESPIAN-Mask JSON/XML entries and the relative CRMhs ontology (classes, properties).
From a certain perspective, hsNER extends ArcheoNER, by adding scientifically relevant entity labels, but it does not contain only archaeologically based labels, such as PRD and SIT (see Table 1). Due to the nature of the hsNER dataset, it could have been difficult to fine tune the training on those entities with it. For this reason, we are planning to increase the dataset by providing those labels too.

Table 1.
List of entity labels (by alphabetical order) for ArcheoNER and hsNER datasets. The three-letter abbreviation is described in the text. The last column reports the THESPIAN-Mask JSON keys associated with the NER Label. The BIO and NAT checkbox appears in yellow when they refer to the same label.
One of the major issues faced in the creation of the training dataset, for both ArcheoNER and hsNER, is its construction with the right amount and quality of data. In this respect, the Italian-written documents have been chosen carefully by imposing a strong constraint on their nature. Because the service is used by researchers to (semi)automatically create queries and fill in metadata forms related to their research analysis reports, the training dataset shall share a statistical similarity with those documents. This fact, even if does not constitute an issue, strongly limits the pace at which the dataset size can be increased, thus impacting the precision reachable by the two models. Indeed, as we will remark later in the paper, any sufficiently trained model will allow the creation of a working AI-powered query generator web service.
3.2. Model Training and Evaluation
The original spaCy models are trained to recognise four NER labels: Organisation (ORG), Miscellanea (MISC), Location (LOC) and Person (PER). Starting from there, we removed the output layer, inserted our ad hoc output layer and fine tuned the model, either for the archaeological (i.e. ArcheoNER model) or the scientific (i.e. hsNER) dataset.
We used precision (P), recall (R) and F-score (F) as scores, defined by the usual formulae:
where are the true positive counts, are false positive counts, and are false negative counts.
The results of the training and are reported in Table 2 for the ArcheoNER models, and in Table 3 for the hsNER models.
Table 2.
Comparison of the results of the two ArcheoNER models.
Table 3.
Comparison of the results of the two hsNER models.
Discussion on the Training Results
As a first result, as shown in Table 2 and Table 3, the transformer model performances are similar to those of the CNN model, furnishing little (for hsNER) to no (for ArcheoNER) improvement (see Table 2 and Table 3).
Moreover, hsNER achieves better results if compared with ArcheoNER, even if hsNER may be prone to overfitting, because it has been trained with the LABEC scientific reports. This is probably due to a limited statistical pool of entries in the dataset to be labelled. On the other side, ArcheoNER seems to present lower learning scores. This can be due to the fact that it has been trained on a dataset that was more statistically sparse, suggesting the need for a normalization and expansion of the training dataset.
Nevertheless, the result is not daunting. As previously stated in Section 3.1, in fact, both the models can be used to build a web service for (semi)automatic query generation. Indeed, both hsNER and ArcheoNER models are capable of correctly identifying the most relevant nominal entities present in the text, which are usually used to either construct the {key: value} query or to fill in the relevant metadata fields.
It should be made clear that an improvement on the models is planned for the future, either by increasing the dataset both in terms of size and quality of the data. Such action, in fact, will be translated into an improvement in the efficiency of the whole model and the related web service, up-to-date made available as a PaaS service in the 4CH Cloud infrastructure.
4. The Web Service Description: THESPIAN-NER
As visually depicted in Figure 4, THESPIAN-NER comprises a front end and a back end, and it is integrated within the 4CH cloud platform.
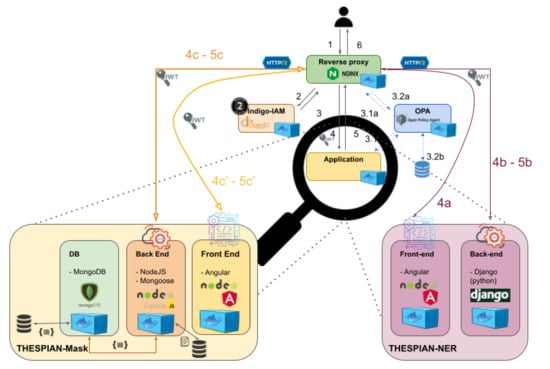
Figure 4.
Visual schema on how the THESPIAN–NER service operates.
The user can access the front end, which is in the form of a web page, where he/she can insert the Italian-written document to be used. The document can be inserted either by typing (or copying and pasting it) into the appropriate input section, or uploading it as a .txt or .pdf file (see Figure 5 for more details).
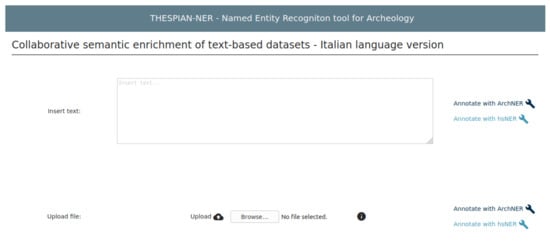
Figure 5.
The NER web page.
After the document to be uploaded has been chosen, the user can upload it by using the appropriate API (either ArcheoNER or hsNER). After that, the document is sent to the NER service back end and processed by using the selected best-trained model. As a response, the back end returns the document as HTML code and the list of annotated entities as an array. Thus, the annotated text is rendered on the web page, divided into sections for labels, and arranged by the number of occurrences of the designated entities that were recognised in the text.
Both the annotated text and the entity list are shown in two HTML divisions: the first is rendered as a text, where the named entities are highlighted with their HEX code colour and followed by the bold three-letter label acronym; the second is shown as a list of lists, i.e. the nominal entities are divided by labels, and ordered by their number in decreasing order (labels with more nominal entities appear on top). To the right of the labels’ names in Figure 6, the number of named entities found is reported.
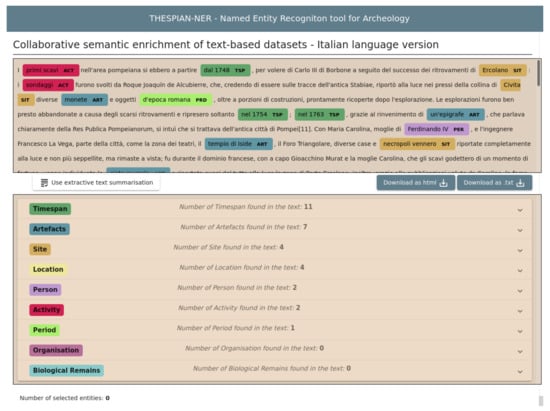
Figure 6.
The NER web page after the ArcheoNER analysis. It can be seen the labels ordered by the number of entities found. On the left, under the annotated text, it is possible to see the button to show the summarised text.
After that, users may inspect the named entities by clicking on the down arrow on the right, opening the second list, i.e. the list of the named entities with that certain label. Users may click on the check button available on the right of the named entity, to select it for further use.
After the named entities have been selected (from different labels and/or same label), by clicking on the appropriate button (see Figure 7) users may either
- 1.
- cast a query on the THESPIAN-Mask database;
- use a logic OR on the whole labels;
- use a stricter logic AND on the labels; or
- 2.
- generate a (semi)filled-in metadata mask and open it into the THESPIAN-Mask service.
4.1. (Semi)Automatic Query Creation
As stated before, users may select named entities to compose their queries by simply using the user interface (see Table 1 for a relation between CRMhs ontology (classes, properties) [25] and the NER labels (see Table 4 for their relation with the MongoDB JSON keys); they can either perform a logic OR or a logic AND on the labels. As an example, choosing the named entity ’Leonardo da Vinci’ from the Person (PER, #BF98D0) list, the user may cast the query on the database with the corresponding {key: value} of {studyObject.author: ’Leonardo da Vinci’}, as shown graphically in Table 5.
Table 4.
Map between CRMhs ontology classes and properties (C, P) and ArcheoNER labels.
Table 5.
Example of a match between the annotated entity and the relative MongoDB query.

Figure 7.
The NER web page after the ArcheoNER analysis. In the opened timespan section, the list of entities are shown. The button for the entity selection can be seen on the right of the entity’s name. At the bottom right, is possible to see the two buttons for querying the database, whereas on the opposite side it is possible to see the number of the chosen entities and the button to generate the prefilled metadata mask and open it in the THESPIAN-Mask web page.
The logic OR refers to the possibility of casting a query, searching for entries having at least one of the desired named entities. On the contrary, the logic AND query means that the metadata entry must have at least one of the selected named entities for each label (see Figure 8 for details).
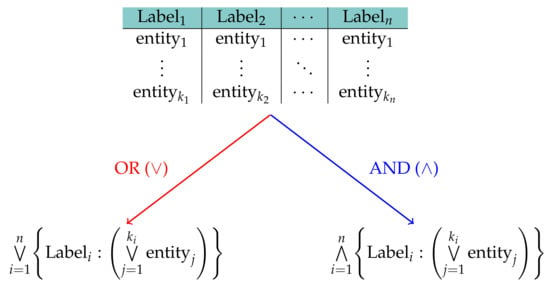
Figure 8.
Graphical representation of the AND and OR queries; from a set of selected entities, arranged by their label.
The JSON object for the MongoDB query is thus built by giving it the appropriate MongoDB dictionary, with the MongoDB "$in", "$all" keys (The "$all" operator selects the documents where the value of a field is an array that contains all the specified elements, whereas the "$in" operator selects the documents where the value of a field equals any value in the specified array).
When users click the relevant button (see Figure 7), an HTTP GET request is made to the THESPIAN-Mask back end. The request made uses the mongoose.js module to query the MongoDB database and retrieve records whose metadata entries match the composed query.
The entries are thus sent back as JSON objects and rendered on the page, where users may download them (as JSON or XML) or the associated files (usually raw or elaborated data coming from scientific analysis of cultural heritage). In the future, users may also be able to open the web-based analysis services offered in the cloud [10,26,27].
4.2. (Semi)Automatic Metadata Creation
Users can also use the labelled entities to build a prefilled metadata mask. By exploiting the relation between NER labels and mask keys, users can compose (at least part of) their metadata mask by selecting the wanted named entities, which will be used as a value for the key associated with their label (see Figure 9).

Figure 9.
Visual explanation of the flow from label/entity selection to key/value metadata creation.
The full flow, reported in Listing 1, comprises the following steps: (i) the basic JSON object is built, in analogy with the one built for the AND query (actually the custom function doing that is more or less the same, this.buildObjectForQuery , with the addJsonForDbFetch variable set to false); and (ii) the JSON object is refined to match the THESPIAN-Mask JSON object and then parsed to string by using the JavaScript/TypeScript built in JSON.stringify method.
Listing 1.
The construction of metadata.
Listing 1.
The construction of metadata.
 |
After that, a cookie, containing the JSON object, is created. Whenever a THESPIAN-Mask metadata mask page is initialised, a check on the presence of such a cookie is performed; if found, the appropriate form fields are filled.
Finally, such a page will be opene in a new browser tab. Because it triggers the ngOnInit Angular callback method, the aforementioned check is performed, thus filling the appropriate fields in the metadata mask.
5. Cloud-Oriented Services for the 4CH Framework
During the 4CH project activities, an important effort has been spent to design a proper architecture aimed at hosting all the elements needed to provide users with the capability of using different software services, made available via a platform in order to let them be able to use resource infrastructures in a seamless and transparent way. This has been made possible by adopting the current technology based on lightweight containers and related virtualization developments.
In particular, to host the 4CH services for cultural heritage, a cloud-based infrastructure has been implemented as a pilot infrastructure hosted on the OpenStack [28] cloud at CNAF, the national center of the Italian Institute for Nuclear Physics (INFN) dedicated to research and development on information and communication technologies. The adopted tools and solutions are aimed at providing distributed computing resources, network, and storage. Moreover, on top of the 4CH Platform, some ancillary services providing useful functionalities such as reverse proxy, image repository, monitoring, and authorization and authentication, already deployed, have been also considered and integrated together into the 4CH platform-as-a-service (PaaS; see Figure 10 for a visual description).
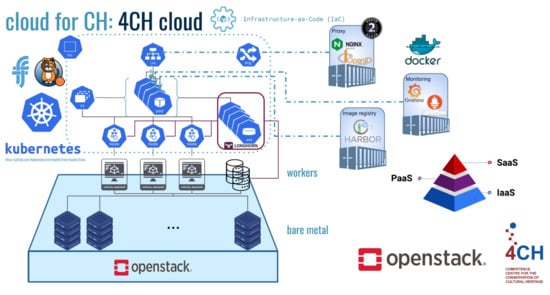
Figure 10.
Schema of the 4CH competence centre cloud PaaS, also showing the ancillary software services.
5.1. The 4CH Cloud Platform: Design and Approach
The development approach of the 4CH cloud platform adopted the infrastructure-as-code (IaC) approach, i.e. the process of managing and provisioning computing resources through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools. Following the IaC approach, the Kubernetes [29] solution has been adopted and implemented. Kubernetes is an open-source container orchestration system used to automate the management, scaling, and deployment of web services integrated into the cloud.
By defining a set of building blocks, Kubernetes can collectively provide mechanisms that deploy, maintain, and scale applications based on CPU, memory, or custom metrics. Thanks to its loosely coupled nature, Kubernetes is enough extensible to meet different workloads.
The Kubernetes cluster is composed of a master and several worker nodes suitable to host the 4CH services, as the THESPIAN SaaS platform, comprising THESPIAN-Mask, THESPIAN-NER, and THESPIAN-XRF [10]. To expose services and applications to the users, an ingress object has been also made available.
The platform was deployed by using the Rancher Kubernetes Engine (RKE).
As explained above, on top of the Kubernetes cluster some other components have been deployed to improve functionalities of the cluster: Canal for the network service and Longhorn for the storage service.
On top of the Kubernetes cluster, some components have been deployed to improve the cluster functionalities such as networking and storage.
Networking is provided by Canal [30] which is a combination of Calico [31] and Flannel [32]. Calico is open-source networking and network security solution for containers, virtual machines, and native host-based workloads. Flannel is a dedicated networking plugin for Kubernetes which provides an overlay network which allows communication between Kubernetes workloads. Moreover, Calico increases the network security by setting policies that control the communications within it.
On the other hand, storage services rely on Longhorn [33], an open-source software that implements distributed block storage by using containers and microservices. Longhorn creates a dedicated storage controller for each block device volume and synchronously replicates the volume across multiple replicas stored on multiple nodes. The storage controller and replicas are themselves orchestrated by using Kubernetes. Moreover, to increase availability, Longhorn creates replicas of each volume. Replicas contain a chain of snapshots of the volume, with each snapshot storing the change from a previous snapshot.
5.2. The 4CH Cloud Platform Ancillary Services
The 4CH platform comes with some services needed to maintain the functionalities of the platform itself. All the internal services, the so called ancillary services, hosted by the 4CH platform are provided as container and are orchestrated via Kubernetes.
Authentication/Authorisation Flow
The 4CH cloud platform relies on INDIGO-IAM service [34], which provides the authentication and authorization mechanisms by implementing (i) the OAuth2.0 standard authorisation framework with the OpenID Connect (OIDC) [35] layer, and (ii) the user-group model to manage the authorization procedure.
Moreover, the 4CH platform relies on a customized version of the Nginx-proxy. Nginx-proxy, in fact, not only acts as a reverse proxy that intercepts users’ requests and redirects them to the correct service, it also takes care also of the authentication mechanism provided via INDIGO-IAM.
Image Repository Service
To ease the deployment of web services in the 4CH PaaS, an image repository service based on Harbor [36] has been provided. Harbor is an open-source software aimed at storing the images related to the different services running in the platform for an easy redeployment and to have up-to-date images available.
Harbor has been integrated with INDIGO-IAM, so members of the project registered in INDIGO-IAM service can also be authenticated to push images to Harbor.
Monitoring Service
The 4CH Platform provides a monitoring service to check both the status of the platform and the status of the different applications running on top of it. In particular, Grafana [37] and Prometheus [38] have been deployed for such purposes.
Grafana is a multiplatform open-source analytics and interactive visualization web application. It provides charts, graphs, and alerts for the web when connected to supported data sources. Prometheus is a free software application used for event monitoring and alerting. It records real-time metrics in a time series database built by using an HTTP pull model, with flexible queries and real-time alerting. Grafana provides a graphical dashboard where both capacities and usage of virtual resources and services are shown.
5.3. THESPIAN-NER Integration in the 4CH Cloud
THESPIAN-NER is a cloud-native web application; as previously described in Section 4, it comprises two services: a front End and a back End.
The front end, offering users the HTML, CSS, and JavaScript to be interpreted by the browser, is an Angular application [39]. It is containerised by using Docker [40] (and following the Docker best practices ( https://docs.docker.com/develop/develop-images/dockerfile_best-practices/, accessed on 14 October 2022) and the 4CH requirements, described in the deliverable D3.1). It is a horizontally scalable service because it only furnishes a copy of the bundled web page content to users’ browsers. It communicates to the back end solely through standard HTTP2 protocol communications, always passing through the 4CH Cloud reverse proxy, which enforces authentication and authorisation.
The back end is a Django-based [41] representational state transfer (REST) API [42], exposing two endpoints: one for ArcheoNER, and one for hsNER. It is containerised by using Docker. Both endpoints are hidden behind the 4CH platform NGINX [43] reverse proxy, which enforces an authorisation/authentication mechanism through an INDIGO-IAM OAuth2-based [44] service.
As visually explained in Figure 4, the NER service can also contact the exposed REST API endpoints of THESPIAN-Mask to fetch the database, again, by passing through the reverse proxy. The full flow of the user experience of the THESPIAN-NER application embedded in the 4CH cloud, from the technical perspective, is (see Figure 4 for the visual explanation of the numbers reported below).
- 1.
- Users access the reverse proxy which replies with the platform homepage.
- 2.
- Registered users can perform the authentication procedure; they are redirected to the INDIGO-IAM service.
- 3.
- The INDIGO-IAM service replies to authenticated users with their JSON Web Token (JWT) [45]. Few services may employ the Open Policy Agent (OPA) [46], but THESPIAN-NER does not use it.
- 4.
- Authenticated users can now access THESPIAN-NER.
- 4a.
- First, users reach NER service’s front end, which gives the the bundled HTML, CSS, and JS, forming the THESPIAN-NER web page. From THESPIAN-NER web page, users may contact the THESPIAN-NER back-end APIs (4b), the THESPIAN-NER back-end APIs (4c), and the THESPIAN-NER front end to get the web page (4c’), always through the reverse proxy.
- 4b.
- Users may send the text they want to elaborate, either to ArcheoNER API or hsNER API.
- 4c.
- Users may cast the (semi)automatically generated query by contacting the appropriate THESPIAN-Mask Back End API.
- 4c’.
- Users may contact the THESPIAN-Mask front-end endpoint, with the generated cookie containing the pre-filling information.
- 5.
- Upon success, the contacted API replies back with the appropriate response.
- 5b.
- The annotated text is sent back to users, together with a summarised text and a list of the labelled nominal entities found.
- 5c.
- The entries found after the query are returned as a JSON.
- 5c’.
- The prefilled page of the THESPIAN-Mask front-end application is opened.
6. Discussion
In the present work, THESPIAN-NER, a cloud-native web application for assisted, AI-powered metadata generation and custom query creation, has been presented and discussed. It is currently available to researches in the 4CH Cloud as a part of the INFN-CHNet SaaS cloud suite, embedded therein, as explained in the text.
The service’s two deep neural NLP networks, ArcheoNER and hsNER, have been presented in detail. These models were developed by customising the spaCy v3 models and were trained by using transfer learning on two ad hoc datasets to identify named entities having archaeological and/or scientific significance. The outcomes coming from the two models may not seem completely satisfactory at first glance, due to their relatively low scores, but they can be nevertheless considered adequate for the purpose of the development of the application itself. It is important to stress here that additional work is needed to improve the NER models, either by exploring different model architectures or by enlarging and diversifying the training datasets.
Nonetheless, these two models enabled us to create and deploy the online service THESPIAN-NER, deferring the task of optimising the model performances in favour of providing users with quick access to the cloud-native web application for either semiautomatically generating their custom queries or metadata form.
THESPIAN-NER, together with the aforementioned THESPIAN-Mask, THESPIAN-XRF, and THESPIAN-RadioCarbonApp, constitute the THESPIAN suite of applications that have been ported to a cloud-native environment. In such respect, the activities carried out to integrate the application in the 4CH cloud platform have been presented and discussed, together with the architectural design and definition of the related cloud platform.
To properly integrate web application in a cloud-oriented environment, as an added value, procedures have been presented and described with the aim to define real guidelines to be established within the 4CH community.
Author Contributions
In particular, the individual contribution is reported hereafter. Conceptualization, A.C.; Methodology, A.B.; Software, A.B., A.A. and L.C.; Formal analysis, A.B.; Data curation, A.F.; Writing—original draft, A.B. and A.A.; Writing—review & editing, F.G. and A.C.; Project administration, A.C. All authors have read and agreed to the published version of the manuscript.
Funding
The present work has been partially funded by the European Commission within the Framework Programme Horizon 2020 with the project 4CH (GA n.101004468—4CH). The work of AB was funded by the research grant titled “4CH operating platform and cultural heritage cloud” and funded by Project 4CH.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| INFN | Istituto Nazionale di Fisica Nucleare |
| CHNet | Cultural Heritage Network |
| CH | Cultural Heritage |
| FAIR | Findable, Accessible, Interoperable, Accessible |
| NLP | Natural Language Processing |
| NER | Named Entity Recognition |
| 4CH | Competence Centre for the Conservation of Cultural Heritage |
| CC | Competence Centre |
| EOSC | European Open Science Cloud |
| THESPIAN | Tools for HEritage Science Processing, Integration, and ANalysis |
| UX | User eXperience |
| IaaS | Infrastructure-as-a-Service |
| PaaS | Platform-as-a-Service |
| SaaS | Software-as-a-Service |
| IaC | Infrastructure-as-Code |
| ICT | Information and Communication Technology |
| JWT | JSON Web Token |
References
- Bechhofer, S.; De Roure, D.; Gamble, M.; Goble, C.; Buchan, I. Research Objects: Towards Exchange and Reuse of Digital Knowledge. Nat. Preced. 2010. [CrossRef]
- Roche, D.G.; Kruuk, L.E.; Lanfear, R.; Binning, S.A. Public data archiving in ecology and evolution: How well are we doing? PLoS Biol. 2015, 13, e1002295. [Google Scholar] [CrossRef] [PubMed]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed]
- Mons, B.; Neylon, C.; Velterop, J.; Dumontier, M.; da Silva Santos, L.O.B.; Wilkinson, M.D. Cloudy, increasingly FAIR; revisiting the FAIR Data guiding principles for the European Open Science Cloud. Inf. Serv. Use 2017, 37, 49–56. [Google Scholar] [CrossRef]
- The 4CH Project—Competence Centre for the Conservation of Cultural Heritage. Available online: https://www.4ch-project.eu/ (accessed on 14 October 2022).
- ARIADNEplus. Available online: https://ariadne-infrastructure.eu/ (accessed on 14 October 2022).
- Julian, R. D5.2 First Report on Data Infrastructure Update and Extension; Zenodo Digital Library, 2020. Available online: https://zenodo.org/record/4922749#.Y5wwsXbMJPZ (accessed on 1 October 2022). [CrossRef]
- European Open Science Cloud—Pillar. Available online: https://www.eosc-pillar.eu/ (accessed on 14 October 2022).
- Castelli, L.; Felicetti, A.; Proietti, F. Heritage Science and Cultural Heritage: Standards and tools for establishing cross-domain data interoperability. Int. J. Digit. Libr. 2019, 22, 279–287. [Google Scholar] [CrossRef]
- Bombini, A.; Castelli, L.; dell’Agnello, L.; Felicetti, A.; Giacomini, F.; Niccolucci, F.; Taccetti, F. CHNet cloud: An EOSC-based cloud for physical technologies applied to cultural heritages. In Proceedings of the Conferenza GARR 2021—Sostenibile/Digitale. Dati e Tecnologie per il Futuro, Online, 7–16 June 2021. [Google Scholar] [CrossRef]
- Bekiari, C.; Bruseker, G.; Doerr, M.; Oreand, C.E.; Stead, S.; Velios, A. CIDOC CRM; Version 7.1.1; Digital Library; International Committee for Documentation (CIDOC) of the International Council of Museums (ICOM): Paris, France, 2021. [Google Scholar] [CrossRef]
- OpenStreetMap Contributors. Planet Dump. 2017. Available online: https://www.openstreetmap.org (accessed on 14 October 2022).
- van Hooland, S.; De Wilde, M.; Verborgh, R.; Steiner, T.; Van de Walle, R. Exploring entity recognition and disambiguation for cultural heritage collections. Digit. Scholarsh. Humanit. 2013, 30, 262–279. [Google Scholar] [CrossRef]
- Mosallam, Y.; Abi-Haidar, A.; Ganascia, J.G. Unsupervised Named Entity Recognition and Disambiguation: An Application to Old French Journals. In Proceedings of the Advances in Data Mining. Applications and Theoretical Aspects, St. Petersburg, Russia, 16–20 July 2014; Perner, P., Ed.; Springer International Publishing: Cham, Switzerland, 2014; pp. 12–23. [Google Scholar] [CrossRef]
- van Dalen-Oskam, K.; de Does, J.; Marx, M.; Sijaranamual, I.; Depuydt, K.; Verheij, B.; Geirnaert, V. Named Entity Recognition and Resolution for Literary Studies. In Proceedings of the Computational Linguistics in the Netherlands Journal, Leiden, The Netherlands, 17 January 2014; Available online: https://hdl.handle.net/11245/1.504898 (accessed on 14 October 2022).
- Jain, N.; Krestel, R. Who is Mona L.? Identifying Mentions of Artworks in Historical Archives. In Proceedings of the Digital Libraries for Open Knowledge, Oslo, Norway, 9–12 September 2019; Doucet, A., Isaac, A., Golub, K., Aalberg, T., Jatowt, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 115–122. [Google Scholar] [CrossRef]
- Honnibal, M.; Johnson, M. An Improved Non-monotonic Transition System for Dependency Parsing. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 1373–1378. [Google Scholar]
- Honnibal, M.; Montani, I.; Honnibal, M.; Peters, H.; Landeghem, S.V.; Samsonov, M.; Geovedi, J.; Regan, J.; Orosz, G.; Kristiansen, S.L.; et al. Explosion/spaCy: V2.1.7: Improved Evaluation, Better Language Factories and Bug Fixes. Zenodo Digital Library. 2019. Available online: https://zenodo.org/record/3358113/export/hx#.Y5vH6X1BxPY (accessed on 5 October 2022). [CrossRef]
- Montani, I.; Honnibal, M.; Landeghem, S.V.; Boyd, A.; Peters, H.; McCann, P.O.; Samsonov, M.; Geovedi, J.; O’Regan, J.; Orosz, G.; et al. Explosion/spaCy: V3.1.4: Python 3.10 Wheels and Support for AppleOps; Zenodo Digital Library, 2021. Available online: https://zenodo.org/record/5617894#.Y5vICX1BxPY (accessed on 12 October 2022). [CrossRef]
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-Strength Natural Language Processing in Python; Zenodo Digital Library, 2020. Available online: https://zenodo.org/record/7437997#.Y5vIDX1BxPY (accessed on 6 October 2022). [CrossRef]
- Bosco, C.; Lenci, A.; Montemagni, S.; Simi, M. Universal Dependencies 2.9—Italian Corpus; LINDAT/CLARIAH-CZ Digital Library at the Institute of Formal and Applied Linguistics (ÚFAL), Faculty of Mathematics and Physics, Charles University: Prague, Czechia, 2021. [Google Scholar]
- Bosco, C.; Montemagni, S.; Simi, M. Converting Italian Treebanks: Towards an Italian Stanford Dependency Treebank. In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, Sofia, Bulgaria, 8–9 August 2013; Association for Computational Linguistics: Sofia, Bulgaria, 2013; pp. 61–69. [Google Scholar]
- Chiari, M.; Barone, S.; Bombini, A.; Calzolai, G.; Carraresi, L.; Castelli, L.; Czelusniak, C.; Fedi, M.E.; Gelli, N.; Giambi, F.; et al. LABEC, the INFN ion beam laboratory of nuclear techniques for environment and cultural heritage. Eur. Phys. J. Plus 2021, 136, 472. [Google Scholar] [CrossRef] [PubMed]
- Klie, J.C.; Bugert, M.; Boullosa, B.; de Castilho, R.E.; Gurevych, I. The INCEpTION Platform: Machine-Assisted and Knowledge-Oriented Interactive Annotation. In Proceedings of the 27th International Conference on Computational Linguistics: System Demonstrations. Association for Computational Linguistics, Santa Fé, Mexico, 20–26 August 2018; pp. 5–9. [Google Scholar]
- Niccolucci, F.; Felicetti, A. A CIDOC CRM-based Model for the Documentation of Heritage Sciences. In Proceedings of the 2018 3rd Digital Heritage International Congress (DigitalHERITAGE) held jointly with 2018 24th International Conference on Virtual Systems Multimedia (VSMM 2018), San Francisco, CA, USA, 26–30 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Bombini, A.; Anderlini, L.; dell’Agnello, L.; Giaocmini, F.; Ruberto, C.; Taccetti, F. The AIRES-CH Project: Artificial Intelligence for Digital REStoration of Cultural Heritages Using Nuclear Imaging and Multidimensional Adversarial Neural Networks. In Proceedings of the Image Analysis and Processing—ICIAP, Lecce, Italy, 23–27 May 2022; Sclaroff, S., Distante, C., Leo, M., Farinella, G.M., Tombari, F., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 685–700. [Google Scholar] [CrossRef]
- Bombini, A.; Anderlini, L.; dell’Agnello, L.; Giacomini, F.; Ruberto, C.; Taccetti, F. Hyperparameter Optimisation of Artificial Intelligence for Digital REStoration of Cultural Heritages (AIRES-CH) Models. In Proceedings of the Computational Science and Its Applications—ICCSA 2022 Workshops, Malaga, Spain, 4–7 July 2022; Gervasi, O., Murgante, B., Misra, S., Rocha, A.M.A.C., Garau, C., Eds.; Springer International Publishing: Cham, witzerland, 2022; pp. 91–106. [Google Scholar] [CrossRef]
- Rackspace Hosting; NASA; Open Infrastructure Foundation and Community. Openstack. Version: Yoga, 30-03-2022. Available online: https://www.openstack.org/ (accessed on 11 October 2022).
- Cloud Native Computing Foundation. Kubernetes. Version: 1.25.0, 23-08-2022. Available online: https://kubernetes.io/ (accessed on 11 October 2022).
- Installs Calico for Policy and Flannel (aka Canal) for Networking. Available online: https://projectcalico.docs.tigera.io/ (accessed on 11 October 2022).
- Project Calico. Version: 3.24.1, 26-08-2022. Available online: https://projectcalico.docs.tigera.io/ (accessed on 11 October 2022).
- Flannel. Available online: https://github.com/flannel-io/flannel (accessed on 11 October 2022).
- Cloud Native Computing Foundation. Longhorn. Version: 1.3.1, 11-08-2022. Available online: https://longhorn.io/ (accessed on 11 October 2022).
- Ceccanti, A.; Hardt, M.; Wegh, B.; Millar, A.; Caberletti, M.; Vianello, E.; Licehammer, S. The INDIGO-Datacloud Authentication and Authorization Infrastructure. J. Phys. Conf. Ser. 2017, 898, 102016. [Google Scholar] [CrossRef]
- OpenID Foundation. OpenID Connect. Version: 1.0, 04-02-2014. 2022. Available online: https://openid.net/ (accessed on 11 October 2022).
- Cloud Native Computing Foundation. Harbor. Version: 1.10.13, 26-08-2022. Available online: https://goharbor.io/ (accessed on 11 October 2022).
- Grafana Labs. Grafana. Version: 9.1.1, 23-08-2022. Available online: https://www.grafana.com/ (accessed on 11 October 2022).
- Cloud Native Computing Foundation. Prometheus. Version: 2.37.0, 14-07-2022. Available online: https://prometheus.io/ (accessed on 11 October 2022).
- Google. Angular. Version: 14.1.0, 20-07-2022. Available online: https://angular.io/ (accessed on 11 October 2022).
- Merkel, D. Docker: Lightweight linux containers for consistent development and deployment. Linux J. 2014, 2014, 2. Available online: https://www.docker.com/ (accessed on 14 October 2022).
- Django Software Foundation. Django. Version: 2.2, 2019-05-05. Available online: https://djangoproject.com (accessed on 11 October 2022).
- Fielding, R.T.; Taylor, R.N. Architectural Styles and the Design of Network-Based Software Architectures. PhD Thesis, University of California, San Diego, CA, USA, 2000. [Google Scholar]
- Igor Sysoevn. NGINX. Version: 1.23.1, 19-07-2022. Available online: https://nginx.org/ (accessed on 11 October 2022).
- Hardt, D. The OAuth 2.0 Authorization Framework. 1-10-2010. Available online: https://www.rfc-editor.org/rfc/rfc6749 (accessed on 11 October 2022).
- Jones, M.; Bradley, J.; Sakimura, N. JSON Web Token (JWT). RFC Editor, Digital library. [CrossRef]
- Cloud Native Computing Foundation. Open Policy Agent (OPA). Version: 0.43.0, 23-08-2022. Available online: https://www.openpolicyagent.org (accessed on 11 October 2022).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).