The first-generation individuals are usually generated by evenly occupying the whole design space, in order to capture more information of the feasible domain and procure a relatively good solution at the initial design stage. To achieve this goal, we can use stratified sampling approaches, such as Latin hypercube sampling or low-discrepancy sampling strategies, such as Sobol’s sequence.
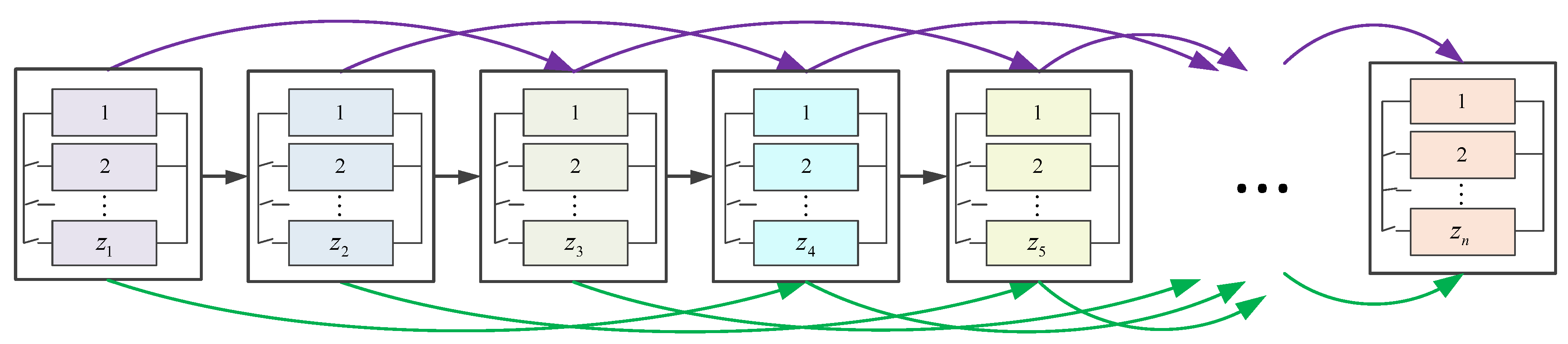
Then, we process the initial population, and the given constraints are utilized to filter out infeasible individuals while retain feasible ones. The current optimal solution is updated as the feasible individual with minimum objective function value. After that, a new-generation population should be produced with the intention of improving the solution. Before this, a criterion, dubbed the fitness, is usually used to evaluate existing feasible individuals, so as to determine the informative parent individuals (i.e., superior individuals) for the next generation. These superior individuals may be directly inherited by the offspring or act as guidelines to produce better offspring. Then, we process the new population with the same strategy of processing the previous population, in order to further refine the solution. This process is proceeded iteratively until the termination criterion or the limited maximum iteration number () is achieved.
From the above analyses, it is seen that step 5 is at the core of the whole optimization approach, i.e., the way to produce the next-generation population is the key ingredient of the optimization algorithm. The quality of the offspring severely affects the quality of the final solution and the convergence speed of the algorithm. Generally, we hope that the new population has the following peculiarities: (i) falling within the feasible region as far as possible; (ii) mining the information of the feasible domain as much as possible; and (iii) possessing better fitness than their parents. These are the directions of the proposed approach to improve the efficacy of population-based approaches. Obviously, for the desired feature #i, we need to resort to constraint functions (, because they decide whether an individual is feasible. For feature #ii, new individuals tend to be produced as evenly as possible in the feasible area, in order to fully mine the information of the feasible domain and escape local optima. As for #iii, we turn to current feasible individuals for help, striving to make new individuals better than their parents. In order to produce better offspring, the first idea that comes to mind is to straightforwardly generate new individuals in terms of the given proposal (or target) distribution. As such, the problem is transformed into how to establish a suitable proposal distribution to generate excellent offspring.
Motivated by these facts, we propose a new way to produce the offspring by drawing upon the principle of IS and SVM. The merits of the proposed algorithm can be explained from two perspectives. From the sampling perspective, the proposed algorithm helps to overcome sample degeneracy and keep the diversity of individuals, and ensures that each individual is informative. From the optimization perspective, the proposed algorithm brings more exploration to the neighborhood of good candidate solutions. It pays equal attention to possible solution spaces, rather than focusing only on elite parents, in order to perfectly avoid local optima. This advantage is very important for the problem of multiple discrete feasible regions, especially when the importance of each feasible region is close.
3.1. Importance Sampling for Optimal Proposal Distribution
Let
be the prior joint PDF of variables
, and
be the PDF of the needed proposal distribution. Then, for any integrable function
, its integration with respect to
equals:
Taking advantage of the instrumental PDF
, (10) can be equivalently expressed as:
If we draw
independent and identically distributed (i.i.d.) samples
from
and set their weights
according to:
Then, in view of (11), the estimate of
is:
This instrumental PDF
is also referred to as the IS PDF corresponding to
. A most direct IS PDF
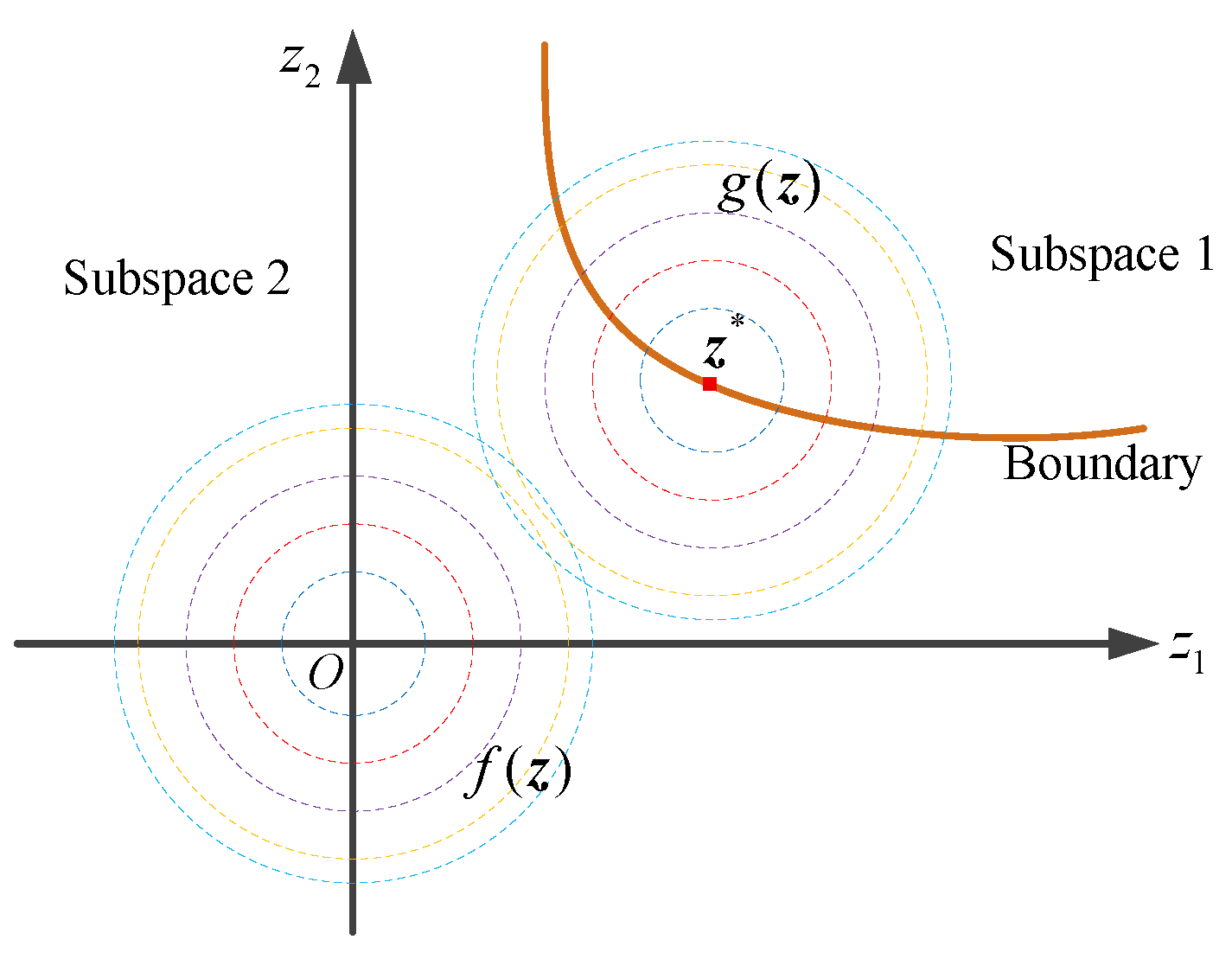
is to transfer the sampling center from the mean point to an informative point, as shown in
Figure 3. In
Figure 3, it is a 2D case in the standard normal space. The dashed lines stand for the iso-probability density lines of
or
. The mean point of
is the origin, and the sampling center of
is
. Now, suppose that subspace 1 is the region of interest (e.g., feasible domain), while subspace 2 is a region of no concern (e.g., infeasible domain). There is a boundary separating these two spaces. The purpose of sampling is to place samples in subspace 1 as much as possible. Obviously,
cannot complete this goal, but
can. This IS PDF is easy to understand, but its defects are evident. If a problem has multiple informative points and the importance of each informative point is close, this IS will be trapped into local optima, but for a practical problem, we cannot know whether it has multiple informative points in advance. For the investigated problem, the informative point can be viewed as a local optimal solution. Thus, we need to explore a more suitable IS strategy that globally explores the interested domain.
It is seen that the expectation of estimate
is:
Since
are i.i.d. samples from
, (14) can be further transformed into:
This indicates that (13) is an unbiased approximation of
.
Then, the variance of estimate
is:
In the same vein, due to
are i.i.d. samples from
,
can be converted into:
Because the variance of samples converges to that of the population in the sense of probability, we can obtain:
Substituting (18) for (17),
can be approximated by:
Reducing the variance
to 0, we can obtain:
where
is the optimal choice of
, i.e., optimal IS PDF.
This optimal IS PDF no longer provides the maximum priority for a certain point, but assigns priority depending on the contribution of the point itself to the solution. Its advantages are escaping from local optima and avoiding searching for the important point of constructing IS PDF.
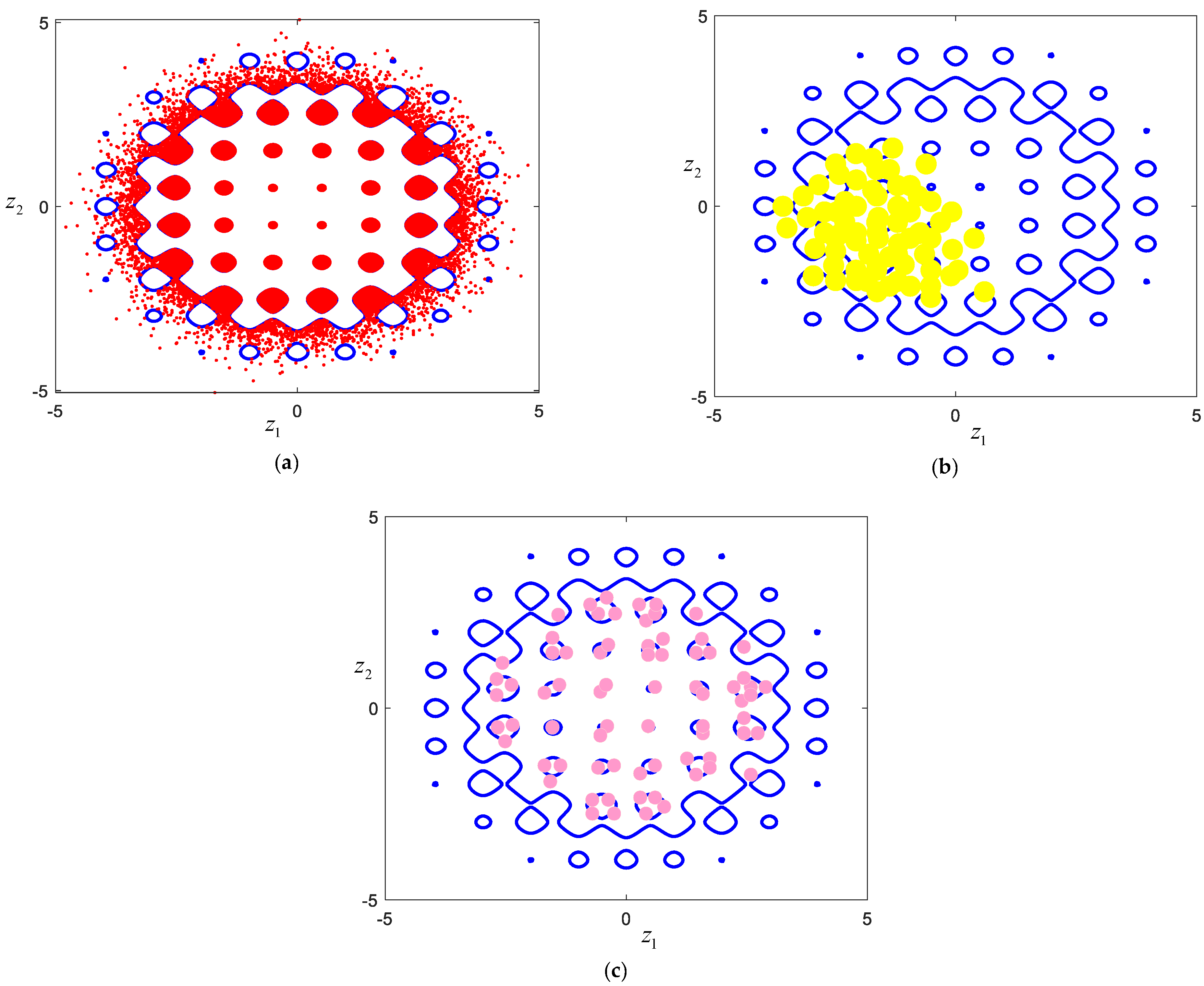
Figure 4a shows a 2D problem with multiple important points (regions), and the shaded area represents the region of interest. It is seen that this example possesses discrete interested domains that look like a chessboard. If we use the IS shown in
Figure 3 to sample for the interested domains, a possible result is shown in
Figure 4b. It can be observed that a vast majority of samples are concentrated in a local area. If the best solution is in this local area, this case can happen to get the global optimum. However, if the global optimum is far away from this region, it is obvious that this case is caught in the local optimum.
Figure 4c presents the sampling result obtained by the optimal IS PDF
. Compared with
Figure 4b, the generated samples cover multiple regions of interest. Therefore, it explores feasible regions more fully, and the possibility of obtaining the global optimal solution is obviously larger.
Now, recall that our purpose is to produce new individuals within the feasible domain that have better fitness than their parents. Let be an indicator function such that if belongs to the feasible domain, otherwise. Furthermore, let be the indicator function such that if , otherwise. is a constant that is related to the fitness. For two feasible individuals, and , if , we say that the fitness of is better than that of . Feasible individuals that satisfy are referred to as superior individuals, and those with are inferior individuals.
After that, we clarify the specific form of
as:
Here,
stands for an indicator function so that
if
is a feasible point with objective function value smaller than
, and
otherwise.
Using (21), the optimal proposal distribution (20) can be further expressed as:
Sampling from
theoretically can obtain the optimal desired offspring. However, this optimal IS PDF
is not available in practice, because we do not have any information of the feasible domain in advance. That is,
is unknown and should be explored. Meanwhile, we need to determine the threshold value
, in order to determine
. Hence, we can only integrate the current available information to establish an asymptotical alternative to the optimal IS PDF
, in order to generate offspring according to the proposal distribution. Obviously, the current information we have is that from parent populations. The indicator function
is unknown, but we can construct an alternative model
for it by leveraging the available information of the feasible/infeasible domains. In the same vein, the alternative model
for
can be also established through the data set including superior individuals (with
) and inferior individuals (
). Then, an asymptotical model
for
is constructed as follows:
where
is also referred to as the quasi-optimal IS PDF.
The remaining issue is how to construct the alternative models and . To construct the alternative model for , we utilize the existing feasible and infeasible individuals as the training data set. Meanwhile, the alternative model for is constructed by using two sets of feasible individuals: the one set contains feasible individual with objective function value larger than (inferior individuals), and the other set has feasible individual with objective function value smaller than (superior individuals). The alternative models are constructed by SVM using data sets, since these two tasks are binary-classification problems and SVM is good at handling such problems. In the following section, we first showcase a brief review of SVM. Then, the concrete procedures for constructing the alternative models and via SVM are presented.
3.2. SVM for Alternative Model
Given a binary-classification problem, let
be the set of labeled training data, where
is the
ith training sample,
is the label of
, and
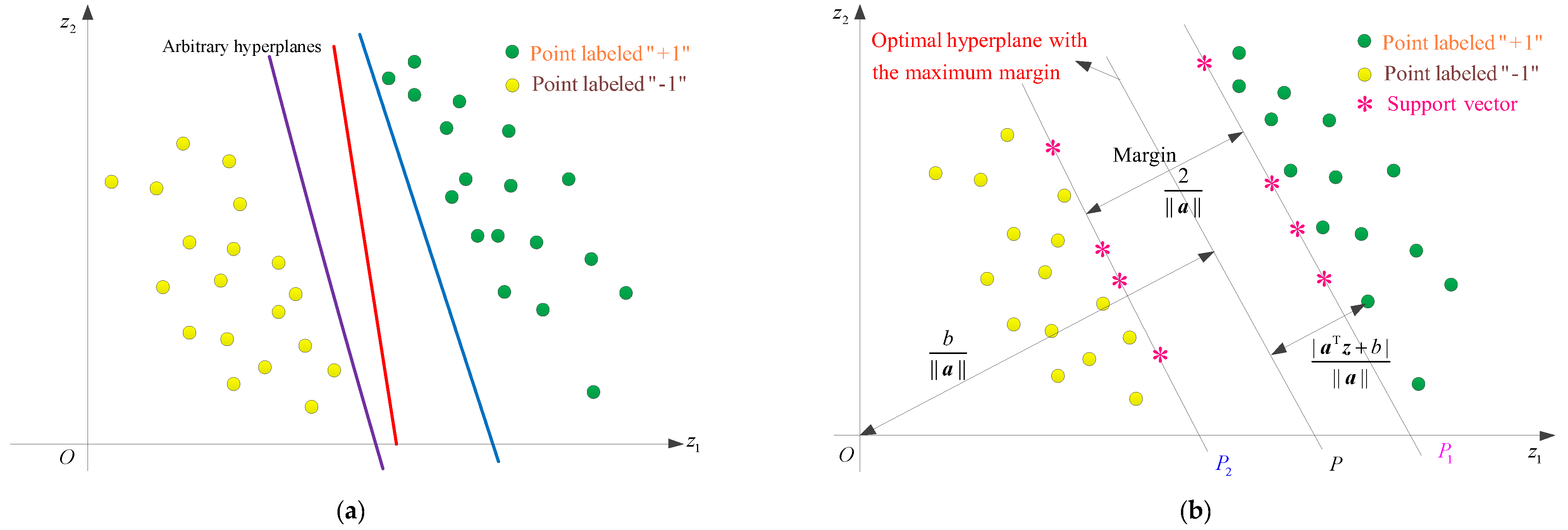
is the number of training samples. SVM aims to search for an optimal decision hyperplane for which all points labeled “−1” are located on one side and all points labeled “+1” on the other side [
24]. As shown in
Figure 5,
Figure 5a shows arbitrary hyperplanes that can distinguish two types of samples, while
Figure 5b represents the optimal classification hyperplane.
A possible hyperplane that divides a sample space into two types of subspaces is:
where the weight vector
is perpendicular to the hyperplane, and
b is a scalar parameter that represents the bias.
To determine
and
b, so as to orientate the hyperplane to be as far as possible from the closest samples, two hyperplanes (
and
) parallel to decision boundary
are as follows:
There are no points between
and
. The shortest distance from the decision boundary (
) to
is
, thus the margin between
and
is
. All training points
should satisfy
. Therefore, determining the optimal hyperplane
with maximum margin is equivalently reduced to finding
and
that give the maximum margin, as follows:
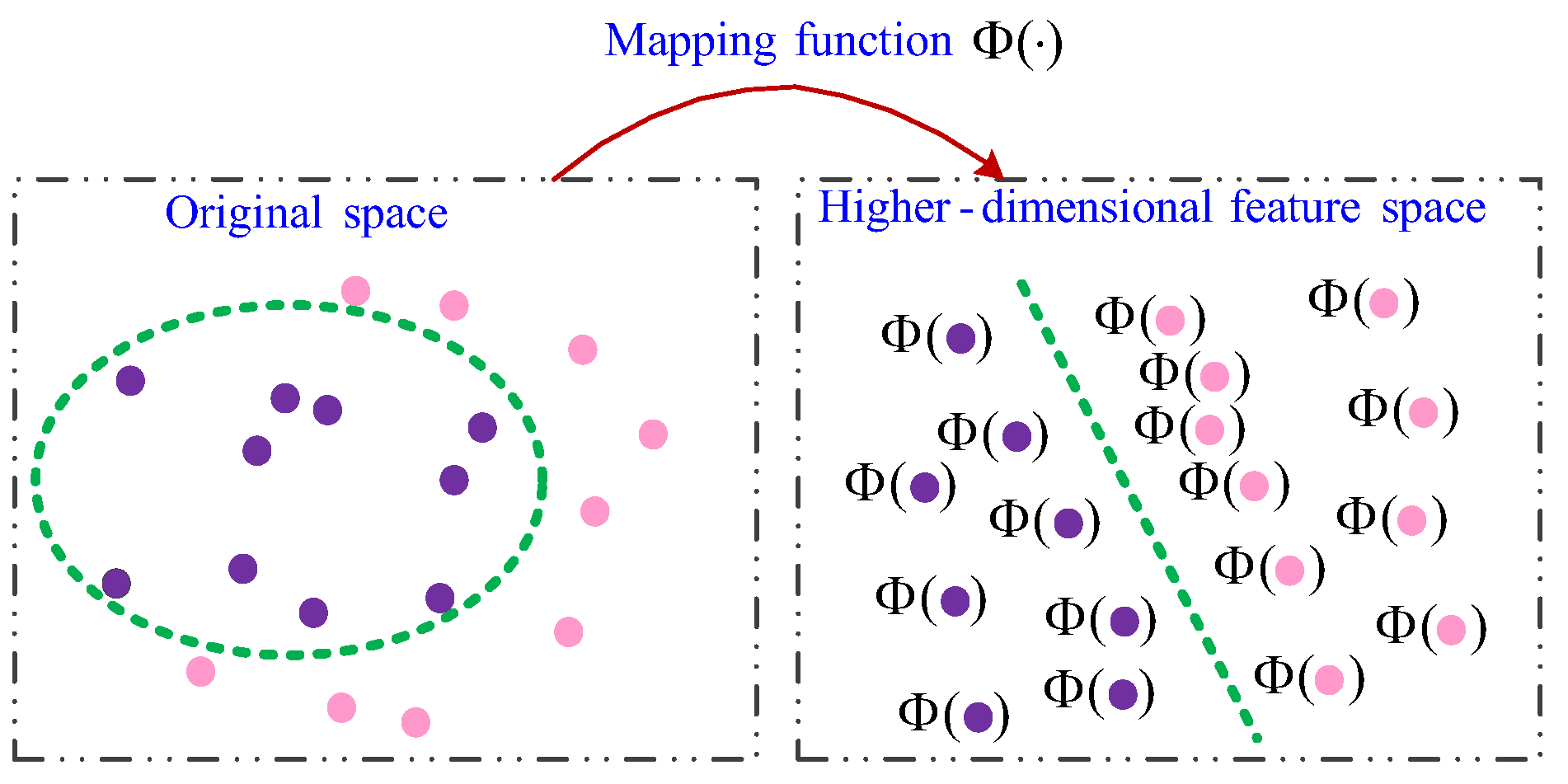
For the nonlinearly separable samples, SVM first maps the data into a higher-dimensional feature space where the points are linearly separable, as shown in
Figure 6.
Let
be the nonlinear mapping function, then (26) in the higher-dimensional feature space is:
Furthermore, SVM can be extended to allow for imperfect separation by penalizing the data falling between
and
. First, we introduce the nonnegative slack variables
so that:
Then, add a penalizing term to the objective function in (27), and the optimization problem in (27) is now formulated as:
where
is the penalty factor.
The Lagrangian function for (29) is:
where
and
are Lagrange multipliers satisfying
and
for
.
Then, the optimization problem (29) can be converted into:
The KKT conditions corresponding to (31) are as follows:
From conditions (35) and (36), it is seen that when
we can get
and
, thus
. Combining (32) we get
.
Taking (32)–(34) into (31), we can obtain:
Let be the kernel function. We do not need to know the explicit expression of the mapping function , as long as the kernel function is known.
For an arbitrary untrained point
, its label predicted by the trained SVM is:
where
is the symbolic function,
for
are
support vectors, and
is the sign of
.
represents the Lagrange multiplier corresponding to support vector
.
Remark 1. Only those samples that lie closest to the decision boundary satisfy , and these samples are referred to as the support vectors (just as the “*” points in Figure 5b). For the non-support vectors, their corresponding Lagrange multipliers equal zero. Remark 2. Parameter b can be solved by any support vector, but for accuracy, the estimate of b corresponding to each support vector is calculated, and their mean value is taken as the final estimate of b.
Remark 3. The soft penalty permits the misclassification. Increasing generates a stricter classification. If we reduce towards 0, it makes misclassification less important; if we increase to infinity, it means no misclassification is allowed.
Till now, we have expounded the basic idea of SVM. Hereinafter, the procedure of SVM for constructing the alternative models
and
are demonstrated, as shown in Algorithms 2 and 3, respectively.
| Algorithm 2 SVM for constructing the alternative model |
| 1. | Let be the set of feasible individuals, and be the collection of infeasible individuals. |
| 2. | The labels of individuals of are “+1,” while the labels of individuals of are “−1.” |
| 3. | Let , and is the set consisting of the labels of individuals in . |
| 4. | Construct the alternative model by using data set . |
| Algorithm 3 SVM for constructing the alternative model |
| 1. | Let be the set of feasible individuals, where is the size of . |
| 2. | Calculate objective function values . |
| 3. | Arrange these objective function values in descending order, i.e., . |
| 4. | Set a probability . |
| 5. | Let be the threshold that divides superior/inferior individuals. |
| 6. | Divide into two sets: a set with individuals whose objective function values are larger than λ, and the other set of individuals whose objective function values are smaller than λ. |
| 7. | The labels of individuals in are “−1,” and the labels of individuals in are “+1.” |
| 8. | Let be the set of labels of . |
| 9. | Establish the alternative model by using training sample set . |
It should be noted that in Algorithms 2 and 3, we use “−1” and “+1” to represent the symbols of the two types of samples, but in fact, when we code our algorithm, we use “0” instead of “−1” to label the unwanted point, or we can use transformations:
and
to make
and
can be utilized to construct the quasi-optimal IS PDF. This is also applicable for Algorithm 4.
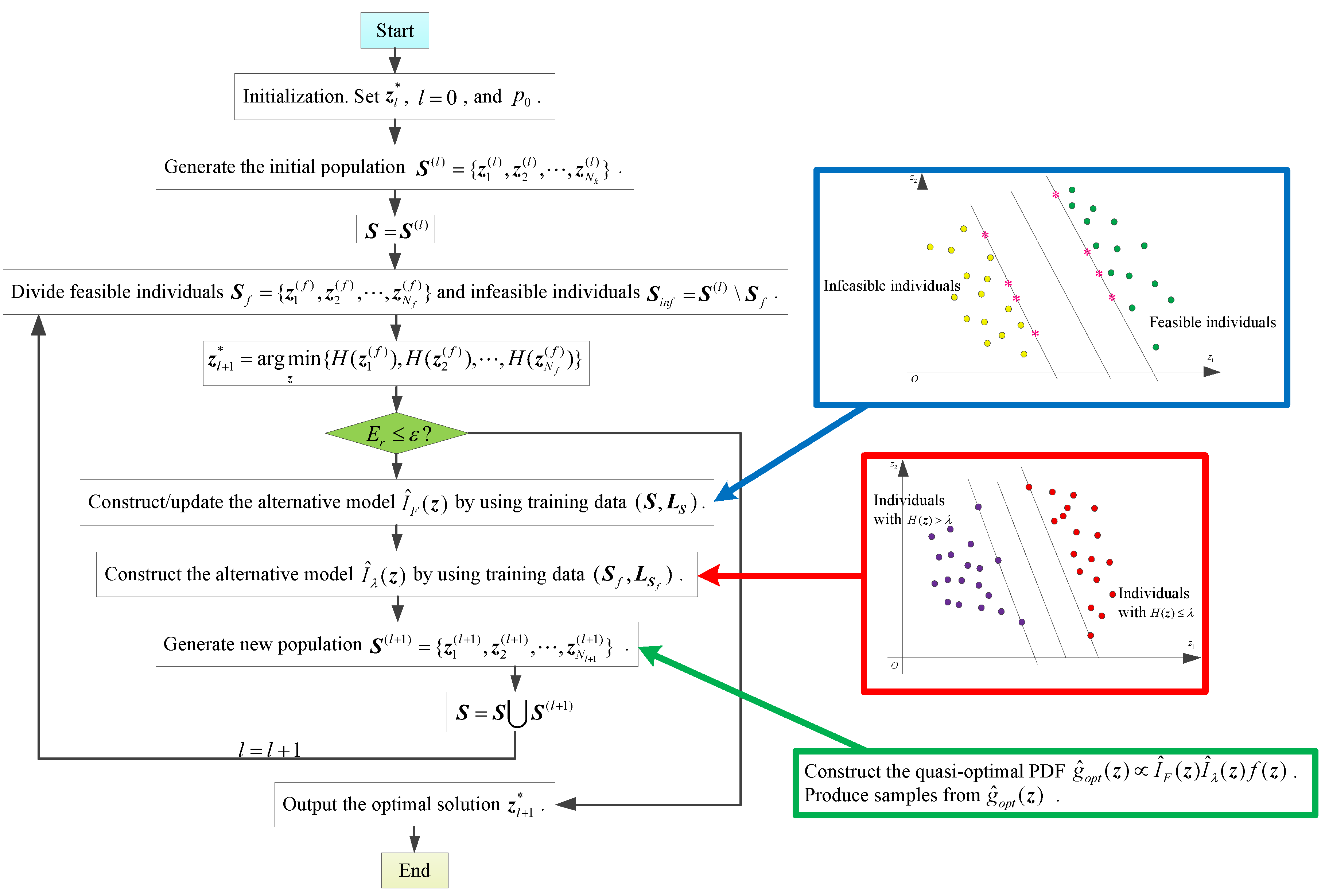
3.3. General Whole Algorithm of the Proposed Solution Procedure
In this section, the concrete solution procedure of the proposed approach for solving the optimization problem is demonstrated. The general whole algorithm of the proposed approach is Algorithm 4, and the corresponding flowchart is depicted in
Figure 7.
| Algorithm 4 The general process of the proposed optimization approach |
| 1. | Let be the initial solution of decision variables, and . |
| 2. | Set a value to . |
| 3. | Produce the first-generation population . |
| 4. | Let . |
| | For , do: |
| 5. | Evaluate whether the individuals in satisfy the given constraints. |
| 6. | Sift out the feasible individuals and infeasible individuals . |
| 7. | Update the current optimal solution as . |
| 8. | Calculate . |
| | If ( is a small real number) |
| | Break |
| |
End if |
| 9. | Construct/update the classifier dividing the feasible/infeasible domains via SVM. |
| | 9.1. Label “+1” to feasible individuals and “−1” to infeasible individuals, for individuals in . |
| | 9.2. Let be the set of labels of individuals in . |
| | 9.3. Construct/update by using . |
| 10. | Construct the classifier via SVM. |
| | 10.1. Rank the objective function values of in descending order, i.e., . |
| | 10.2. Let the th objective function value be the threshold, i.e., . |
| | 10.3. Divide as superior individuals with objective function values smaller than , and inferior individuals with objective function values larger than . |
| | 10.4. Label “+1” to individuals in and “−1” to individuals in . |
| | 10.5. Construct the classifier by using . |
| 11. | Produce the next-generation population . |
| | 11.1. Construct the quasi-optimal IS PDF . |
| | 11.2. Generate the next-generation population in terms of . |
| 12. | Let . |
| | End for |
| 13. | Output the optimal decision scheme . |
Some details of Algorithm 4 are as follows.
- (1)
The initial solution can be a feasible solution or an arbitrary point in the design domain. It does not affect the quality of the whole algorithm, since it is just used as an extra stopping condition. In addition, the maximum number of iterations could be conveniently set to .
- (2)
The preset probability divides feasible individuals into two groups: the group whose objective function value is smaller than , and the other group, whose objective function value is larger than . From the perspective of fitness, the former group of samples are excellent individuals with “high” fitness and should be retained to produce offspring. The latter group of samples do not adapt to the current environment and are inferior individuals that will be discarded. Of course, the choice of directly affects the convergence speed of the algorithm and whether the optimal solution can be found.
- (3)
In step 9, we construct the initial SVM model by using the initial information of the feasible/infeasible domains. Then, the SVM model will be updated by the expanded data set (see step 12). This adequately excavates the information of the design domain, and thus we can construct a more precise asymptotical boundary to separate the feasible domain from the infeasible domain.
- (4)
The quasi-optimal IS PDF
is established by using the constructed SVM models
and
. Since the denominator
is a constant that does not affect the probability density, we can only utilize the numerator
to produce the offspring. Furthermore, since we only know the lower and upper bounds of decision variables
z, it is convenient to regard that the prior distribution of
is uniform. That is,
is a constant, so we can use
to produce new individuals. The modified Metropolis–Hastings sampler is applied to generate the quasi-optimal new individuals, and the thinning procedure is used to ensure these individuals are independent [
31].
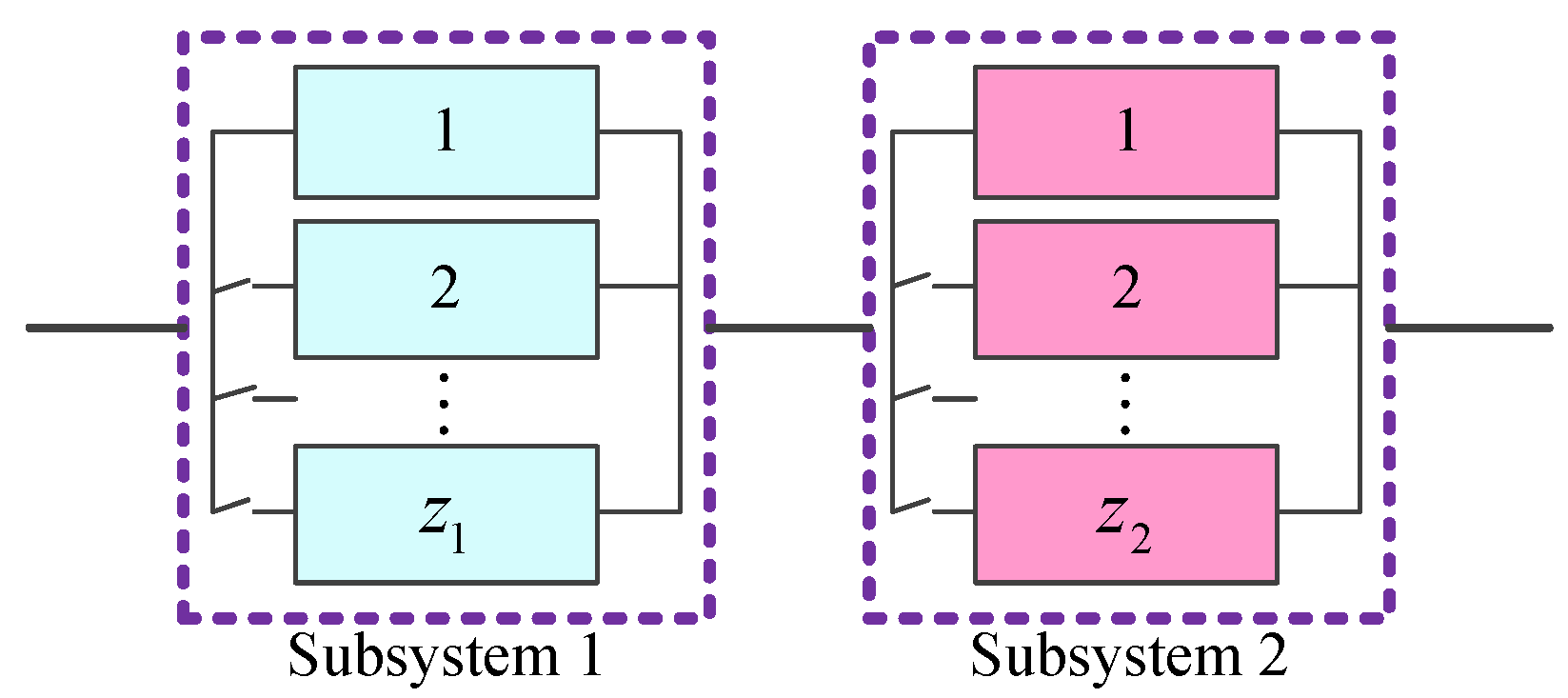
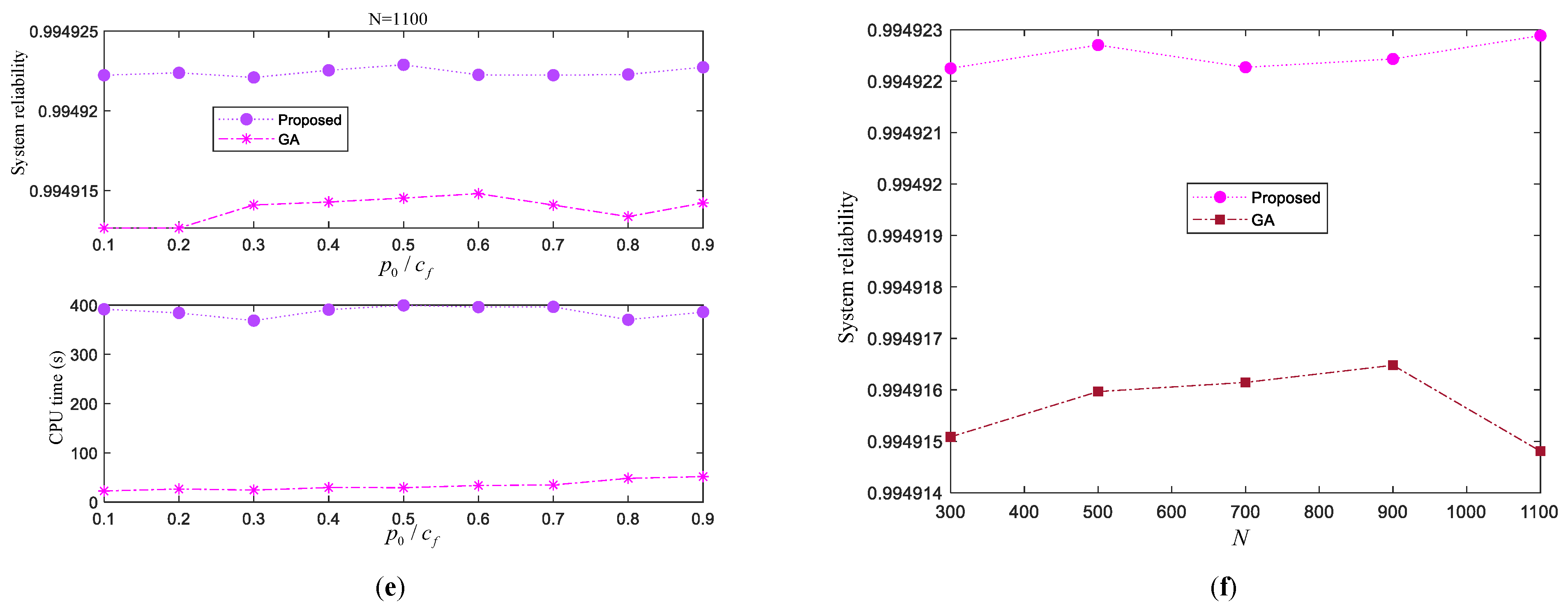
Example 2. Consider the case study in Example 1. Here, we setand, then the Lin/Con//:F system is reduced to a series system with two subsystems, as shown in Figure 8. For a subsystem, it involves an active-standby component andcold-standby redundant components. Meanwhile, the system reliability is reduced to:
where the redundancy level
is the decision vector. Suppose that the component reliabilities for subsystem 1 and subsystem 2 are 0.93 and 0.92, respectively. The reliability of each switch is 0.9998. In addition,
,
, and
.
The mathematical model of the optimization problem of this example under budget constraint is:
where
is the budget constraint.
For comparison, we first utilize GA to explore the optimal decision scheme of this optimization problem. The obtained optimal decision scheme is
, and the corresponding system reliability is
. The value of the constraint function is
, which indicates that the constraint is satisfied. Then, we implement the proposed approach to address this optimization problem. The initial solution is chosen as
. Through two iterations, the optimal solution obtained by the proposed approach is also
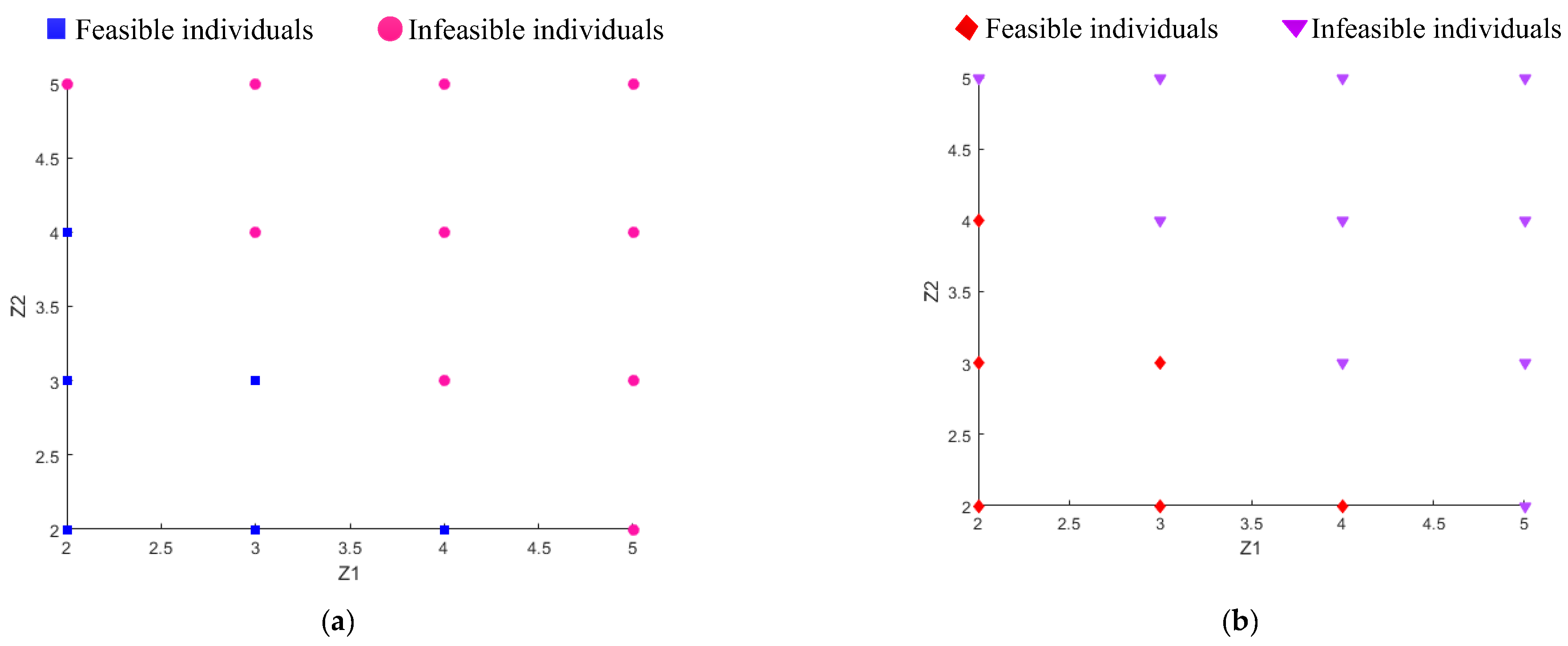
. This is consistent with that obtained by GA. To showcase the quality of the alternative model constructed by SVM, the feasible/infeasible candidates distinguished by SVM and the actual constraint function are shown in
Figure 9a and
Figure 9b, respectively. It is seen that the constructed alternative model is sufficiently accurate to separate feasible individuals from infeasible individuals.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}