
HDL-ODPRs: A Hybrid Deep Learning Technique Based Optimal Duplication Detection for Pull-Requests in Open-Source Repositories

Abstract
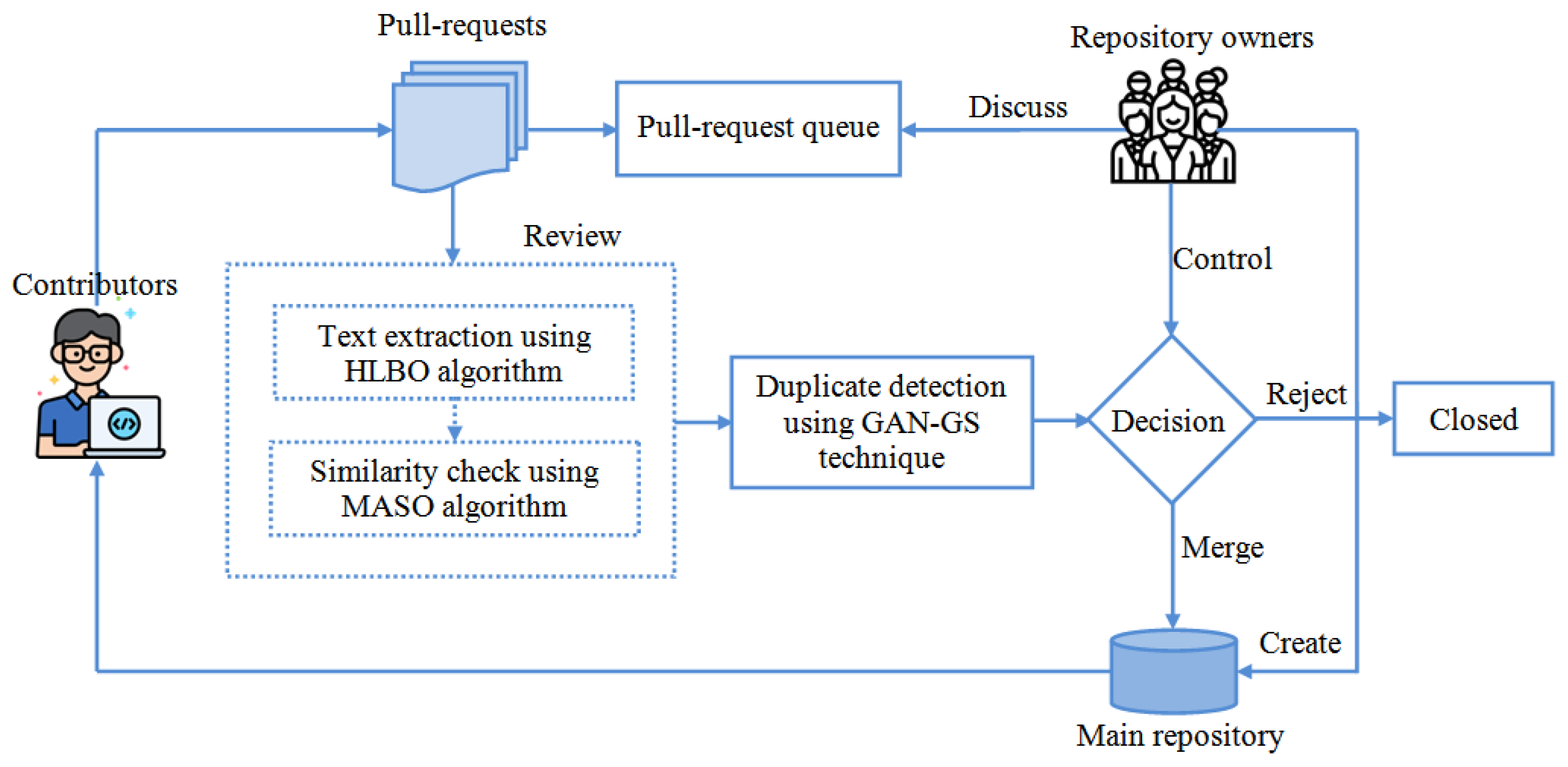
1. Introduction
- A hybrid leader-based optimization (HLBO) algorithm is used to extract textual data from pull requests, which ensures the detection accuracy.
- A multi-objective alpine skiing optimization (MASO) algorithm is used to compute the similarities between pull requests.
- A generative adversarial network (GAN) is merged with the global search (GS) algorithm to compute the duplicate contributions in pull requests.
- Finally, our proposed model is validated against the public standard benchmark datasets such as DupPR-basic and DupPR-complementary data [21].
2. Related Work
3. Problem Methodology and System Design
3.1. Problem Methodology
- To introduce optimal duplicate pull requests detection method to automatically detect duplicates to improve the accuracy.
- To propose optimization algorithm to extract textual data from pull requests in OSS repositories.
- To develop hybrid deep learning techniques for the similarity computation (textual, file-change, and code-change similarities) to further enhance the duplicate detection accuracy.
3.2. System Design
4. Proposed Methodology
4.1. Textual Data Extraction from Pull Requests
| Algorithm 1. Extraction of Textual Information HLBO | |
| 1. | Initialize the random population |
| 2. | Adjust n and s. |
| 3. | |
| 4. | If j = 0 and i = 1 |
| 5. | |
| 6 | |
| 7. | |
| 8. | Update the final values |
| 9. | End else |
| 10. | End |
4.2. Compute Similarities
| Algorithm 2. Alpine Skiing Optimization | |
| time values | |
| 1. | Begin; |
| 2. | For all mesh nodes in the 0-th row |
| 3. | For all j in [0..C) Do |
| 4. | For all mesh nodes in the 1-th row |
| 5. | End for |
| 6 | |
| 7. | |
| 8. | |
| 9. | |
| 10. | Update the final values |
| 11. | End |
4.3. Pull Requests’ Duplicate Detection
| Algorithm 3. Pull-Request Duplicate Detection Using GAN-GS | |
| , parameters | |
| 1. | Initialize the random population |
| 2. | Train the discriminator and generator by the loss function |
| 3. | |
| 4. | If j = 0 and i = 1 |
| 5. | |
| 6 | |
| 7. | |
| 8. | Update the final values |
| 9. | |
| 10. | End |
5. Results and Evaluation
5.1. Dataset Descriptions
5.1.1. DupPR-Basic Dataset
5.1.2. DupPR-Complementary Data
5.2. Comparative Analysis
5.2.1. Performance Comparison with DupPR-Basic Dataset
5.2.2. Performance Comparison with DupPR-Complementary Data
6. Conclusions and Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dinh-Trong, T.T.; Bieman, J.M. The FreeBSD project: A replication case study of open source development. IEEE Trans. Softw. Eng. 2005, 31, 481–494. [Google Scholar] [CrossRef]
- Williams, C.C.; Hollingsworth, J.K. Automatic mining of source code repositories to improve bug finding techniques. IEEE Trans. Softw. Eng. 2005, 31, 466–480. [Google Scholar] [CrossRef]
- Swedlow, J.R.; Kankaanpää, P.; Sarkans, U.; Goscinski, W.; Galloway, G.; Malacrida, L.; Sullivan, R.P.; Härtel, S.; Brown, C.M.; Wood, C.; et al. A global view of standards for open image data formats and repositories. Nat. Methods 2021, 18, 1440–1446. [Google Scholar] [CrossRef] [PubMed]
- Curry, P.A.; Moosdorf, N. An open source web application for distributed geospatial data exploration. Sci. Data 2019, 6, 1–7. [Google Scholar] [CrossRef]
- Ali, N.; Guéhéneuc, Y.G.; Antoniol, G. Trustrace: Mining software repositories to improve the accuracy of requirement traceability links. IEEE Trans. Softw. Eng. 2012, 39, 725–741. [Google Scholar] [CrossRef]
- Tian, Y.; Tan, H.; Lin, G. Statistical properties analysis of file modification in open-source software repositories. In Proceedings of the International Conference on Geoinformatics and Data Analysis, Prague, Czech Republic, 20–22 April 2018; pp. 62–66. [Google Scholar]
- Lowndes, J.S.S.; Best, B.D.; Scarborough, C.; Afflerbach, J.C.; Frazier, M.R.; O’Hara, C.C.; Jiang, N.; Halpern, B.S. Our path to better science in less time using open data science tools. Nat. Ecol. Evol. 2017, 1, 1–7. [Google Scholar]
- Padhye, R.; Mani, S.; Sinha, V.S. A study of external community contribution to open-source projects on GitHub. In Proceedings of the 11th Working Conference on Mining Software Repositories, Hyderabad, India, 31 May–1 June 2014; pp. 332–335. [Google Scholar]
- Gousios, G.; Vasilescu, B.; Serebrenik, A.; Zaidman, A. Lean GHTorrent: GitHub data on demand. In Proceedings of the 11th Working Conference on Mining Software Repositories, Hyderabad, India, 31 May–1 June 2014; pp. 384–387. [Google Scholar]
- Rahman, M.M.; Roy, C.K. An insight into the pull requests of github. In Proceedings of the 11th Working Conference on Mining Software Repositories, Hyderabad, India, 31 May–1 June 2014; pp. 364–367. [Google Scholar]
- Van Der Veen, E.; Gousios, G.; Zaidman, A. Automatically prioritizing pull requests. In Proceedings of the 2015 IEEE/ACM 12th Working Conference on Mining Software Repositories, Florence, Italy, 16–17 May 2015; pp. 357–361. [Google Scholar]
- Zampetti, F.; Ponzanelli, L.; Bavota, G.; Mocci, A.; Di Penta, M.; Lanza, M. How developers document pull requests with external references. In Proceedings of the 2017 IEEE/ACM 25th International Conference on Program Comprehension (ICPC), Buenos Aires, Argentina, 22–23 May 2017; pp. 23–33. [Google Scholar]
- Jiang, J.; Lo, D.; Ma, X.; Feng, F.; Zhang, L. Understanding inactive yet available assignees in GitHub. Inf. Softw. Technol. 2017, 91, 44–55. [Google Scholar] [CrossRef]
- Franco-Bedoya, O.; Ameller, D.; Costal, D.; Franch, X. Open source software ecosystems: A Systematic mapping. Inf. Softw. Technol. 2017, 91, 160–185. [Google Scholar] [CrossRef]
- Dias, L.F.; Steinmacher, I.; Pinto, G. Who drives company-owned OSS projects: Internal or external members? J. Braz. Comput. Soc. 2018, 24, 16. [Google Scholar] [CrossRef]
- Jiang, J.; Lo, D.; He, J.; Xia, X.; Kochhar, P.S.; Zhang, L. Why and how developers fork what from whom in GitHub. Empir. Softw. Eng. 2017, 22, 547–578. [Google Scholar] [CrossRef]
- Pinto, G.; Steinmacher, I.; Dias, L.F.; Gerosa, M. On the challenges of open-sourcing proprietary software projects. Empir. Softw. Eng. 2018, 23, 3221–3247. [Google Scholar] [CrossRef]
- Jarczyk, O.; Jaroszewicz, S.; Wierzbicki, A.; Pawlak, K.; Jankowski-Lorek, M. Surgical teams on GitHub: Modeling performance of GitHub project development processes. Inf. Softw. Technol. 2018, 100, 32–46. [Google Scholar] [CrossRef]
- Li, Z.X.; Yu, Y.; Yin, G.; Wang, T.; Wang, H.M. What are they talking about? Analyzing code reviews in pull-based development model. J. Comput. Sci. Technol. 2017, 32, 1060–1075. [Google Scholar] [CrossRef]
- Yu, Y.; Yin, G.; Wang, T.; Yang, C.; Wang, H. Determinants of pull-based development in the context of continuous integration. Sci. China Inf. Sci. 2016, 59, 080104. [Google Scholar] [CrossRef]
- Li, Z.; Yin, G.; Yu, Y.; Wang, T.; Wang, H. Detecting duplicate pull-requests in github. In Proceedings of the 9th Asia-Pacific Symposium on Internetware, Shanghai China, 23 September 2017; pp. 1–6. [Google Scholar]
- Yang, C.; Zhang, X.H.; Zeng, L.B.; Fan, Q.; Wang, T.; Yu, Y.; Yin, G.; Wang, H.M. RevRec: A two-layer reviewer recommendation algorithm in pull-based development model. J. Cent. South Univ. 2018, 25, 1129–1143. [Google Scholar] [CrossRef]
- Hu, D.; Zhang, Y.; Chang, J.; Yin, G.; Yu, Y.; Wang, T. Multi-reviewing pull-requests: An exploratory study on GitHub OSS projects. Inf. Softw. Technol. 2019, 115, 1–4. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, Y.; Wang, T.; Wang, H. iLinker: A novel approach for issue knowledge acquisition in GitHub projects. World Wide Web 2020, 23, 1589–1619. [Google Scholar] [CrossRef]
- Yang, C.; Fan, Q.; Wang, T.; Yin, G.; Zhang, X.H.; Yu, Y.; Wang, H.M. RepoLike: Amulti-feature-based personalized recommendation approach for open-source repositories. Front. Inf. Technol. Electron. Eng. 2019, 20, 222–237. [Google Scholar] [CrossRef]
- Nguyen, P.T.; Di Rocco, J.; Rubei, R.; Di Ruscio, D. An automated approach to assess the similarity of GitHub repositories. Softw. Qual. J. 2020, 28, 595–631. [Google Scholar] [CrossRef]
- Yang, W.; Pan, M.; Zhou, Y.; Huang, Z. Developer portraying: A quick approach to understanding developers on OSS platforms. Inf. Softw. Technol. 2020, 125, 106336. [Google Scholar] [CrossRef]
- Jiang, J.; Zheng, J.T.; Yang, Y.; Zhang, L. CTCPPre: A prediction method for accepted pull requests in GitHub. J. Cent. South Univ. 2020, 27, 449–468. [Google Scholar] [CrossRef]
- Eluri, V.K.; Mazzuchi, T.A.; Sarkani, S. Predicting long-time contributors for GitHub projects using machine learning. Inf. Softw. Technol. 2021, 138, 106616. [Google Scholar] [CrossRef]
- Jiang, J.; Zheng, J.; Yang, Y.; Zhang, L.; Luo, J. Predicting accepted pull requests in GitHub. Sci. China Inf. Sci. 2021, 64, 179105. [Google Scholar] [CrossRef]
- Golzadeh, M.; Decan, A.; Legay, D.; Mens, T. A ground-truth dataset and classification model for detecting bots in GitHub issue and PR comments. J. Syst. Softw. 2021, 175, 110911. [Google Scholar] [CrossRef]
- Li, Z.X.; Yu, Y.; Wang, T.; Yin, G.; Mao, X.J.; Wang, H.M. Detecting duplicate contributions in pull-based model combining textual and change similarities. J. Comput. Sci. Technol. 2021, 36, 191–206. [Google Scholar] [CrossRef]
- Li, Z.; Yu, Y.; Zhou, M.; Wang, T.; Yin, G.; Lan, L.; Wang, H. Redundancy, context, and preference: An empirical study of duplicate pull requests in OSS projects. IEEE Trans. Softw. Eng. 2020, 48, 1309–1335. [Google Scholar] [CrossRef]


{kind=link}
| Refs. | Year | Methodology | ML/DL Technique | OSS Repositories | Remarks | Research Gap |
|---|---|---|---|---|---|---|
| [22] | 2018 | Code review, pull-request prediction | SVM classifier | GitHub: Ruby on Rails and Angular.js. | Detection accuracy | Process for real-world issues may take a long time |
| [23] | 2019 | Multi-reviewing, pull-request prediction | Linear regression | Github REST API | Resolution latency | Not identifying and acquiring related issues |
| [24] | 2020 | Information retrieval, word and doc. embedding | Skip-gram model, PV-DBOW | GitHub:six projects (April 2018) | F-score, W-score and D-score | Affected by data dimensionality issues |
| [25] | 2019 | Recommendation process, pull-request prediction | Learning-to-rank (LTR) | GitHub: GHTorrent | Hit ratio, mean reciprocal rank | Different personality traits, educational backgrounds, and expertise levels |
| [26] | 2020 | Pull-request prediction | - | GitHub API: Java projects, DABLUE, CLAN | Success rate, Precision | Metadata is curated from different OSS forges |
| [27] | 2020 | Text, web data and code analysis | Portraitmodel | GitHub: TeslaZY | Precision | Not provide sufficient information |
| [28] | 2020 | CTCPPre, pull-request prediction | XGBoostclassifier | GitHub: 28 projects | Accuracy, precision, recall | Troublesome and time-consuming |
| [29] | 2021 | Pull-request prediction, LTC prediction | Naive Bayes, kNN, decision tree, and random forest | GitHub: REST API | Precision, recall, F1-score, MCC, and AUC | Not provide high detection rate |
| [30] | 2019 | Pull-request prediction | XGBoostclassifier | GitHub: 8 open source | Accuracy, precision | The complexity of modern distributed software development is rising |
| [31] | 2021 | Bot prediction, Pull-request prediction | Decision trees, Random forest, SVM, logistic regression, kNN | GitHub: ground truth dataset | Precision, recall and F1-score | Not taking into account the existence of bots, which lowers the detection’s precision |
| Attributes | Number of Pull-Requests | |
|---|---|---|
| Overall | Duplicate | |
| Number of pull-requests | 333,200 | 3619 |
| Number of contributors | 39,776 | 2589 |
| Number of reviewers | 24,071 | 2830 |
| Number of review comments | 2,191,836 | 39,945 |
| Number of checks | 364,646 | 4413 |
| Attributes | Number of Pull-Requests | |
|---|---|---|
| Overall | Duplicate | |
| Number of pull-requests | 1,144,251 | 3978 |
| Number of contributors | 29,978,291 | 2789 |
| Number of reviewers | 126,697 | 3145 |
| Number of review comments | 2,228,894 | 42,515 |
| Number of issues comments | 2,886,006 | 4878 |
| Repository Names | Pull-Requests | Performance Metrics (%) | ||||
|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F-Measure | SRE | ||
| angular/angular.js | 31 | 92.530 | 92.107 | 93.145 | 92.621 | 91.230 |
| facebook/react | 15 | 92.542 | 92.119 | 93.152 | 92.633 | 91.242 |
| twbs/bootstrap | 47 | 92.554 | 92.131 | 93.164 | 92.645 | 91.254 |
| symfony/symfony | 33 | 92.566 | 92.143 | 93.176 | 92.657 | 91.266 |
| rails/rails | 25 | 92.578 | 92.155 | 93.188 | 92.669 | 91.278 |
| joomla/joomla-cms | 19 | 92.590 | 92.167 | 93.200 | 92.681 | 91.290 |
| ansible/ansible | 18 | 92.602 | 92.179 | 93.212 | 92.693 | 91.302 |
| nodejs/node | 15 | 92.614 | 92.191 | 93.224 | 92.705 | 91.314 |
| cocos2d/cocos2d-x | 3 | 92.626 | 92.203 | 93.236 | 92.717 | 91.326 |
| rust-lang/rust | 9 | 92.638 | 92.215 | 93.248 | 92.729 | 91.338 |
| ceph/ceph | 9 | 92.650 | 92.227 | 93.264 | 92.741 | 91.350 |
| zendframework/zf2 | 9 | 92.662 | 92.239 | 93.272 | 92.753 | 91.362 |
| django/django | 3 | 92.674 | 92.251 | 93.284 | 92.765 | 91.374 |
| pydata/pandas | 3 | 92.686 | 92.263 | 93.296 | 92.777 | 91.386 |
| elastic/elasticsearch | 6 | 92.698 | 92.275 | 93.308 | 92.789 | 91.398 |
| JuliaLang/julia | 3 | 92.710 | 92.287 | 93.324 | 92.801 | 91.410 |
| scikit-learn/scikit-learn | 3 | 92.722 | 92.299 | 93.332 | 92.813 | 91.422 |
| kubernetes/kubernetes | 13 | 92.734 | 92.311 | 93.344 | 92.825 | 91.434 |
| docker/docker | 7 | 92.746 | 92.323 | 93.356 | 92.837 | 91.446 |
| symfony/symfony-docs | 19 | 92.758 | 92.335 | 93.368 | 92.849 | 91.458 |
| Average | 92.644 | 92.221 | 93.254 | 92.734 | 91.344 | |
| Detection Techniques | Metrics (%) | ||||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F-Measure | SRE | |
| GDN-GS | 92.644 | 92.221 | 93.254 | 92.735 | 91.344 |
| PRs-text [21] | 87.414 | 86.991 | 88.024 | 87.505 | 86.114 |
| PRs-text-similarity [32] | 82.184 | 81.761 | 82.794 | 82.275 | 80.884 |
| PRs-Improved [33] | 76.954 | 76.531 | 77.564 | 77.045 | 75.654 |
| k-nearest neighbor | 66.494 | 66.071 | 67.104 | 66.585 | 65.194 |
| Random forest | 61.264 | 60.841 | 61.874 | 61.355 | 59.964 |
| Support vector machine | 71.724 | 71.301 | 72.334 | 71.815 | 70.424 |
| Hierarchical clustering | 56.034 | 55.611 | 56.644 | 56.125 | 54.734 |
| K-means clustering | 50.804 | 50.381 | 51.414 | 50.895 | 49.504 |
| Detection Techniques | Metrics (%) | ||||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F-Measure | SRE | |
| GDN-GS | 96.87 | 95.23 | 96.12 | 95.6729 | 93.56 |
| PRs-text [21] | 87.414 | 86.991 | 88.024 | 87.505 | 86.114 |
| PRs-text-similarity [32] | 82.184 | 81.761 | 82.794 | 82.275 | 80.884 |
| PRs-Improved [33] | 76.954 | 76.531 | 77.564 | 77.045 | 75.654 |
| Random forest | 61.264 | 60.841 | 61.874 | 61.355 | 59.964 |
| K-means clustering | 50.804 | 50.381 | 51.414 | 50.895 | 49.504 |
| Hierarchical clustering | 56.034 | 55.611 | 56.644 | 56.125 | 54.734 |
| Support vector machine | 71.724 | 71.301 | 72.334 | 71.815 | 70.424 |
| k-nearest neighbor | 66.494 | 66.071 | 67.104 | 66.585 | 65.194 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, S.S. HDL-ODPRs: A Hybrid Deep Learning Technique Based Optimal Duplication Detection for Pull-Requests in Open-Source Repositories. Appl. Sci. 2022, 12, 12594. https://doi.org/10.3390/app122412594
Alotaibi SS. HDL-ODPRs: A Hybrid Deep Learning Technique Based Optimal Duplication Detection for Pull-Requests in Open-Source Repositories. Applied Sciences. 2022; 12(24):12594. https://doi.org/10.3390/app122412594
Chicago/Turabian StyleAlotaibi, Saud S. 2022. "HDL-ODPRs: A Hybrid Deep Learning Technique Based Optimal Duplication Detection for Pull-Requests in Open-Source Repositories" Applied Sciences 12, no. 24: 12594. https://doi.org/10.3390/app122412594
APA StyleAlotaibi, S. S. (2022). HDL-ODPRs: A Hybrid Deep Learning Technique Based Optimal Duplication Detection for Pull-Requests in Open-Source Repositories. Applied Sciences, 12(24), 12594. https://doi.org/10.3390/app122412594