


Applying BERT for Early-Stage Recognition of Persistence in Chat-Based Social Engineering Attacks




Abstract
Featured Application
Abstract
1. Introduction
2. Background
2.1. Natural Language Processing
- Semantic Textual Similarity (STS) [5,6] is the semantic task of inferring the relation between different text data units. It is usually measured as a numerical score in the range of [0, 1] and quantifies the semantic similarity between different text data units. In earlier days, techniques such as Bag of Words (BoW) and Term Frequency-Inverse Document Frequency (TF-IDF) were used to represent text as vectors to aid the calculation of semantic similarity. These techniques were designed to identify if two text units contained the same words or a similar group of characters. However, sentences can have different meanings while containing the exact, same words or can contain different words while representing semantically similar concepts.
- Natural Language Inference, sometimes also called Textual Entailment [7,8,9], is the classification task of determining, given a text premise and a text hypothesis, whether the hypothesis is entailed by, contradictory to, or independent of the premise. The most popular categories used for textual entailment relationships are entailment, contradiction, and neutral.
- Paraphrase Recognition [10] can be described as another text classification task that determines whether two text data units have a similar meaning (or not) in a specific context.
2.2. Neural Networks
- pre-training, where the model learns a general-purpose representation of inputs, and
- adaptation, where the input representation is transferred to a downstream task. The adaptation has two main paradigms:
- a.
- Feature extraction, where the model’s weights remain unchanged and are used as features in a downstream task.
- b.
- Fine-tuning, where (some of) the model’s weights are unfrozen and fine-tuned for the new downstream task.
3. Related Work
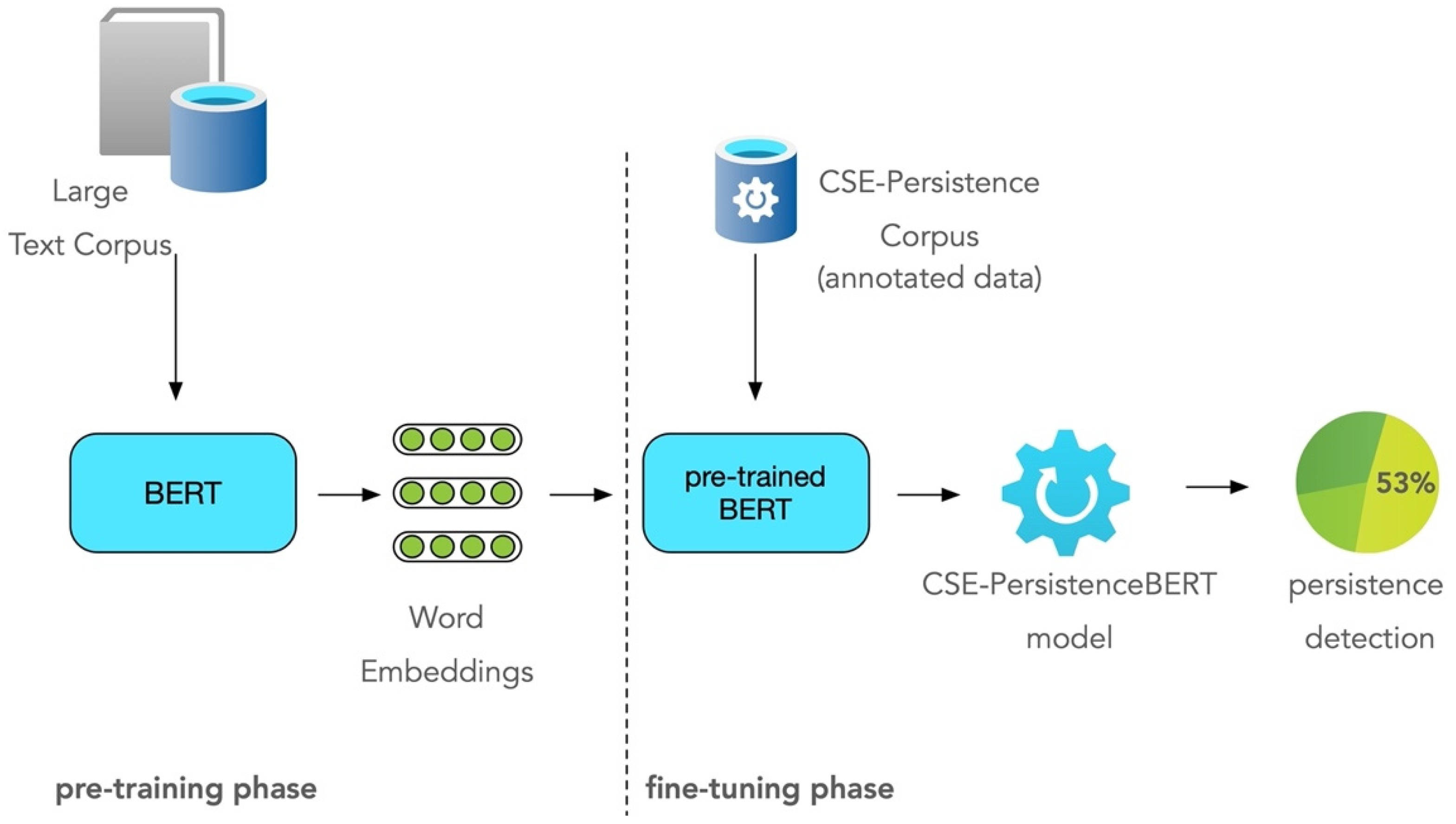
4. The Proposed Approach
4.1. The CSE-Persistence Corpus
- Identical (I): The two sentences are semantically close and share a common term targeting the same leaf entity in the CSE Ontology (e.g., USB_Stick in Figure 1).
- Similar (S): The two sentences are semantically related and share a common intent, which translates into a higher-level entity in the CSE ontology, targeting a different leaf entity (e.g., hardware as the higher-level entity and CD as the leaf entity in Figure 1).
- Different (D): The two sentences are not semantically related, and they do not share a common higher-level or leaf entity.
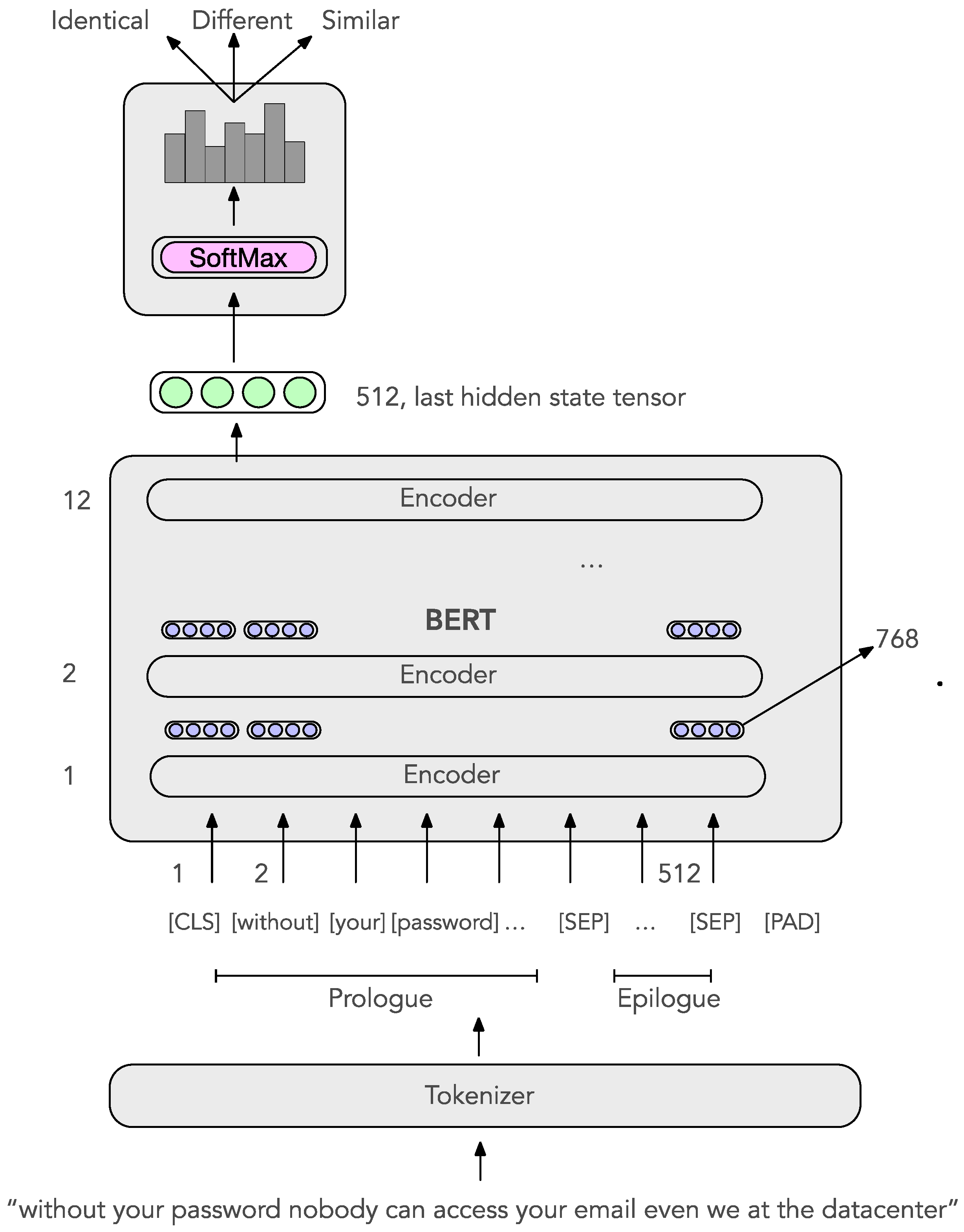
- The first sentence is referred to as the Prologue in the sense that the social engineering attacker uses it to introduce her intention to the play.
- The second sentence is referred to as the Epilogue in the sense that it concludes the play and informs us how the story ends.
4.2. The Training Process
4.3. The CSE-PersistenceBERT Model
5. Implementation
5.1. CSE-Persistence Corpus
5.2. CSE-PersistenceBERT
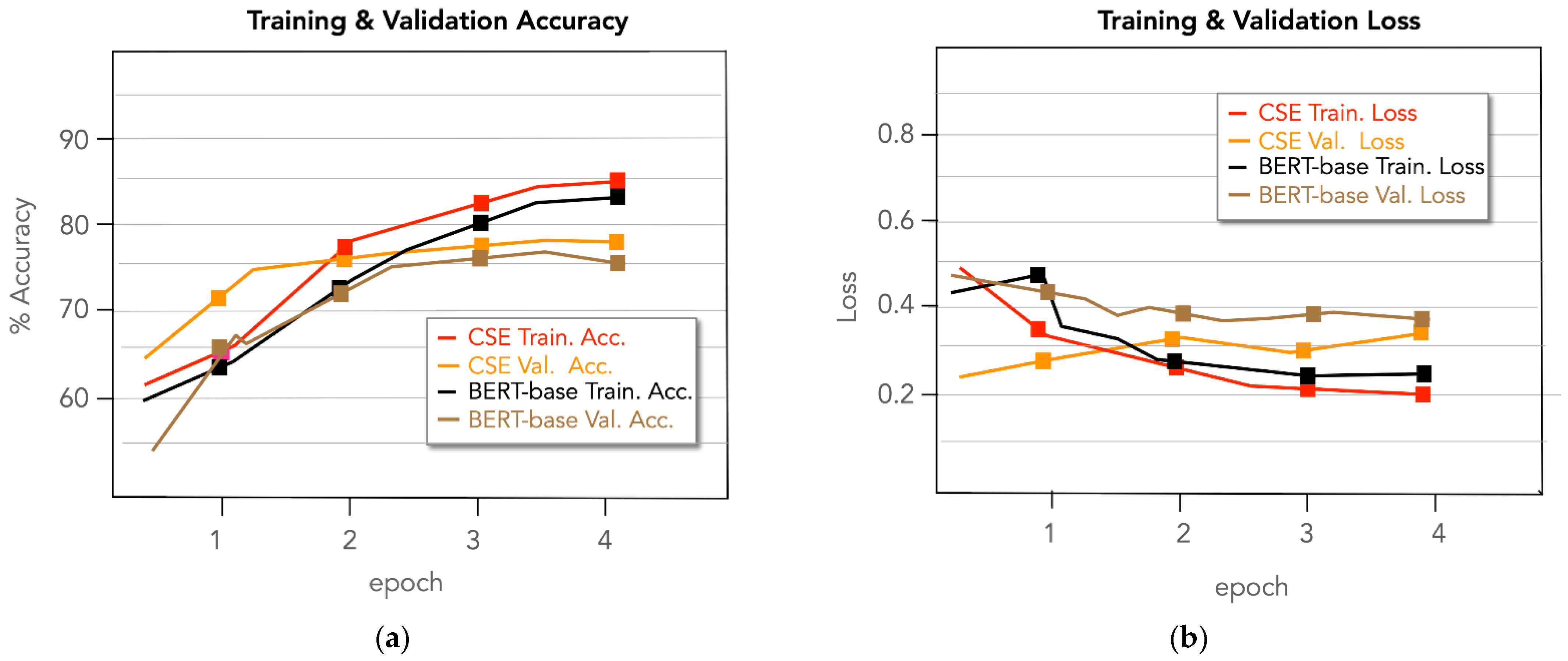
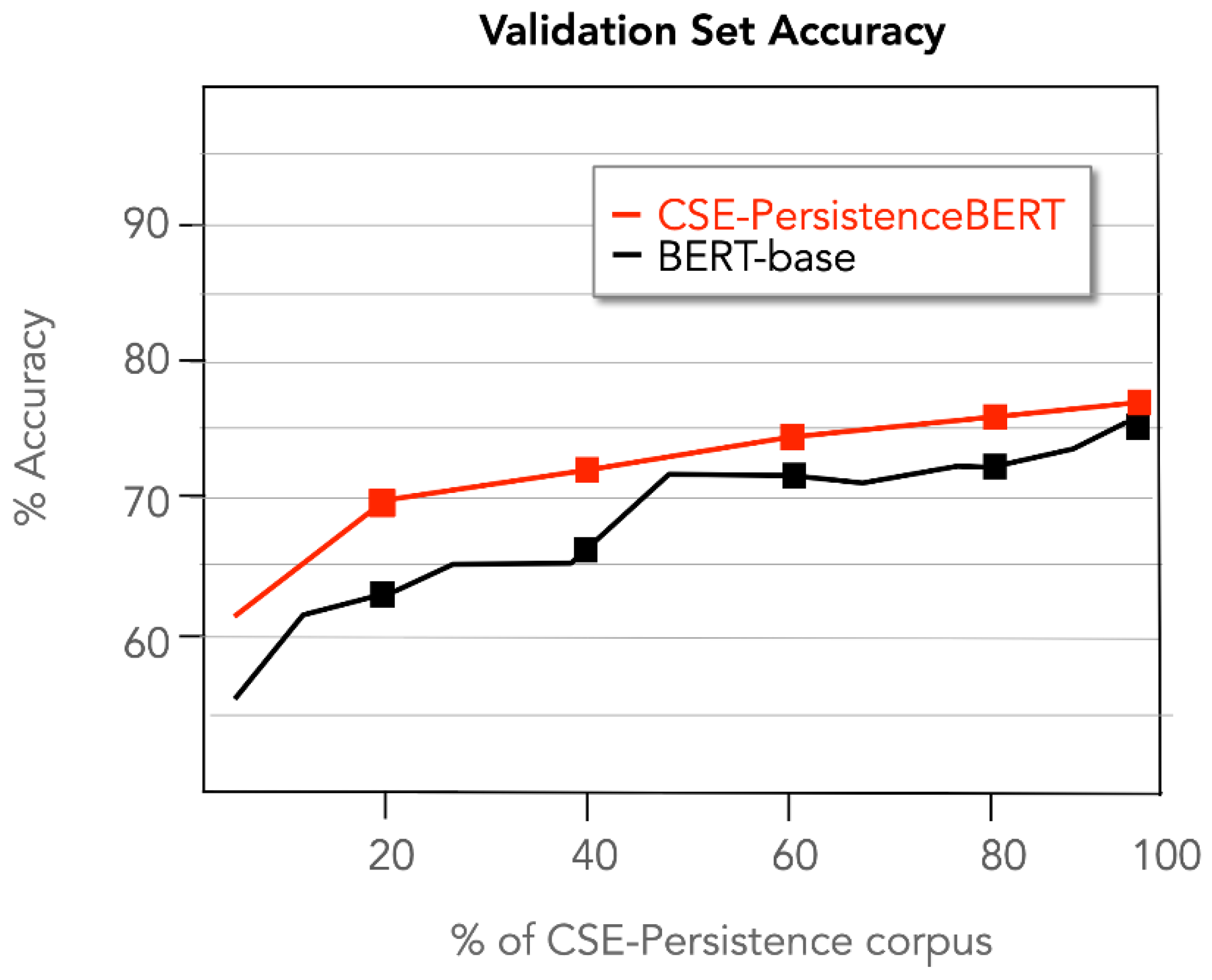
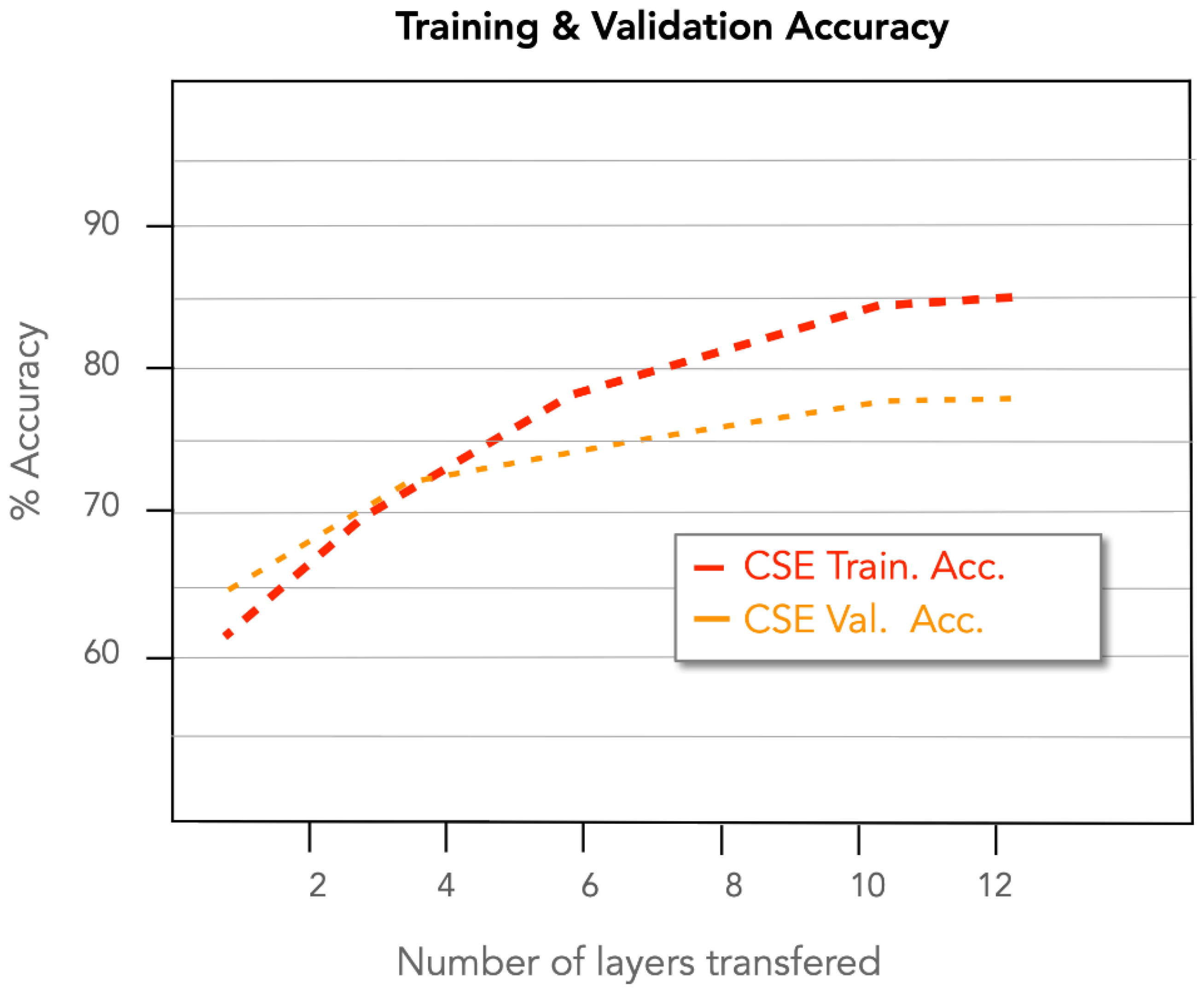
6. Evaluation
- True Positives (TP): Sentence pairs where the true tag is positive and whose category is correctly predicted to be positive.
- False Positives (FP): Sentence pairs where the true tag is negative and whose category is incorrectly predicted to be positive.
- True Negatives (TN): Sentence pairs where the true tag is negative and whose category is correctly predicted to be negative.
- False Negatives (FN): Sentence pairs where the true tag is positive and whose class is incorrectly predicted to be negative.
7. Discussion
- Less development and training time compared to an RNN model approach that is trained from scratch. The model weights are pre-trained, encoding valuable information trained on extensive corpora.
- Less training data as we only need to fine-tune the pre-trained model for a specific downstream task.
- Increased accuracy on the downstream task after fine-tuning for a few epochs (e.g., 2–4).
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Meaning |
| BERT | Bidirectional Encoder Representations from Transformers |
| BoW | Bag-of-Words |
| CD | Compact Disk |
| CLS | Classification |
| CNN | Convolutional Neural Network |
| CSE | Chat-based Social Engineering |
| DVD | Digital Video Disk |
| GPT | Generative Pre-trained Transformer |
| HD | Hard Disk |
| ICT | Information and Communication Technology |
| IT | Information Technology |
| JSON | JavaScript Object Notation |
| LSTM | Long Short-Term Memory |
| NLP | Natural Language Processing |
| NLU | Natural Language Understanding |
| P4PIN | Paraphrase for Plagiarism Include Non-Plagiarism |
| PAD | Padding |
| PCA | Principal Components Analysis |
| RNN | Recurrent Neural Networks |
| SEP | Separator |
| SEQ2SEQ | Sequence to sequence |
| SME | Small-Medium Enterprise |
| SNLI | Stanford Natural Language Inference |
| STS | Semantic Textual Similarity |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| USB | Universal Serial Bus |
| WORD2VEC | Word to vector |
References
- Tsinganos, N.; Sakellariou, G.; Fouliras, P.; Mavridis, I. Towards an Automated Recognition System for Chat-based Social Engineering Attacks in Enterprise Environments. In Proceedings of the 13th International Conference on Availability, Reliability and Security, Hamburg, Germany, 27–30 August 2018. [Google Scholar] [CrossRef]
- Tsinganos, N.; Mavridis, I. Building and Evaluating an Annotated Corpus for Automated Recognition of Chat-Based Social Engineering Attacks. Appl. Sci. 2021, 11, 10871. [Google Scholar] [CrossRef]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar] [CrossRef]
- Chandrasekaran, D.; Mago, V. Evolution of Semantic Similarity—A Survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Agirre, E.; Diab, M.; Cer, D.; Gonzalez-Agirre, A. SemEval-2012 Task 6: A Pilot on Semantic Textual Similarity. In Proceedings of the First Joint Conference on Lexical and Computational Semantics—Volume 1: Proceedings of the Main Conference and the Shared Task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation, Montreal, QC, Canada, 7–8 June 2012; pp. 385–393. [Google Scholar]
- Manning, C.D. Local Textual Inference: It’s Hard to Circumscribe, But You Know It When You See It—And NLP Needs It. 2006. Available online: http://nlp.stanford.edu/~manning/papers/LocalTextualInference.pdf (accessed on 18 April 2022).
- Marelli, M.; Bentivogli, L.; Baroni, M.; Bernardi, R.; Menini, S.; Zamparelli, R. SemEval-2014 Task 1: Evaluation of Compositional Distributional Semantic Models on Full Sentences through Semantic Relatedness and Textual Entailment. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Dagan, I.; Glickman, O.; Magnini, B. The PASCAL Recognising Textual Entailment Challenge. In Machine Learning Challenges. Evaluating Predictive Uncertainty, Visual Object Classification, and Recognising Textual Entailment; Quiñonero-Candela, J., Dagan, I., Magnini, B., d’Alché-Buc, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3944, pp. 177–190. [Google Scholar] [CrossRef]
- Vrbanec, T.; Meštrović, A. Corpus-Based Paraphrase Detection Experiments and Review. Information 2020, 11, 241. [Google Scholar] [CrossRef]
- WordNet|A Lexical Database for English. Available online: https://wordnet.princeton.edu/ (accessed on 14 October 2021).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. Available online: http://arxiv.org/abs/1301.3781 (accessed on 3 March 2019).
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26–28 October 2014; pp. 1746–1751. [Google Scholar] [CrossRef]
- Mohamed, I.; Gomaa, W.; Abdalhakim, H. A Hybrid Model for Paraphrase Detection Combines pros of Text Similarity with Deep Learning. Int. J. Comput. Appl. 2019, 178, 18–23. [Google Scholar] [CrossRef]
- McCann, B.; Bradbury, J.; Xiong, C.; Socher, R. Learned in translation: Contextualized word vectors. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017; pp. 6297–6308. [Google Scholar]
- Singh, S.; Singh, S. Systematic review of spell-checkers for highly inflectional languages. Artif. Intell. Rev. 2020, 53, 4051–4092. [Google Scholar] [CrossRef]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Budzianowski, P.; Vulić, I. Hello, It’s GPT-2—How Can I Help You? Towards the Use of Pretrained Language Models for Task-Oriented Dialogue Systems. In Proceedings of the 3rd Workshop on Neural Generation and Translation, Hong Kong, China, 4 November 2019; pp. 15–22. [Google Scholar] [CrossRef]
- Ruder, S. Neural Transfer Learning for Natural Language Processing. Ph.D. Thesis, NUI Galway, Galway, Ireland, 2019. Available online: https://aran.library.nuigalway.ie/handle/10379/15463 (accessed on 23 November 2022).
- Peters, M.E.; Ruder, S.; Smith, N.A. To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks. In Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019), Florence, Italy, 2 August 2019; pp. 7–14. [Google Scholar] [CrossRef]
- Wiggins, W.F.; Tejani, A.S. On the Opportunities and Risks of Foundation Models for Natural Language Processing in Radiology. Radiol. Artif. Intell. 2022, 4, e220119. [Google Scholar] [CrossRef]
- Church, K.W.; Chen, Z.; Ma, Y. Emerging trends: A gentle introduction to fine-tuning. Nat. Lang. Eng. 2021, 27, 763–778. [Google Scholar] [CrossRef]
- Gupta, A.; Agarwal, A.; Singh, P.; Rai, P. A deep generative framework for paraphrase generation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5149–5156. [Google Scholar]
- Thompson, V. Methods for Detecting Paraphrase Plagiarism. arXiv 2017, arXiv:1712.10309. Available online: http://arxiv.org/abs/1712.10309 (accessed on 27 April 2022).
- Ahmed, M.; Samee, M.R.; Mercer, R.E. Improving Tree-LSTM with Tree Attention. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019; pp. 247–254. [Google Scholar] [CrossRef]
- Benabbou, F.; El Mostafa, H. A System for Ideas Plagiarism Detection: State of art and proposed approach. Inf. Fusion 2020, 9. [Google Scholar] [CrossRef]
- Shuang, K.; Zhang, Z.; Loo, J.; Su, S. Convolution-deconvolution word embedding: An end-to-end multi-prototype fusion embedding method for natural language processing. Inf. Fusion 2020, 53, 112–122. [Google Scholar] [CrossRef]
- Kubal, D.R.; Nimkar, A.V. A survey on word embedding techniques and semantic similarity for paraphrase identification. Int. J. Comput. Syst. Eng. 2019, 5, 36–52. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Duong, P.H.; Cambria, E. Learning short-text semantic similarity with word embeddings and external knowledge sources. Knowl.-Based Syst. 2019, 182, 104842. [Google Scholar] [CrossRef]
- Agirre, E.; Banea, C.; Cardie, C.; Cer, D.; Diab, M.; Gonzalez-Agirre, A.; Guo, W.; Lopez-Gazpio, I.; Maritxalar, M.; Mihalcea, R.; et al. SemEval-2015 task 2: Semantic textual similarity, english, spanish and pilot on interpretability. In Proceedings of the 9th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2015, Denver, CO, USA, 4–5 June 2015; pp. 252–263. [Google Scholar] [CrossRef]
- Sánchez-Vega, J.F. Identificación de Plagio Parafraseado Incorporando Estructura, Sentido y Estilo de los Textos. Ph.D. Thesis, Instituto Nacional de Astrofísica, Optica y Electrónica, San Andrés Cholula, Mexico, 2016. [Google Scholar]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 632–642. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Transformers. Available online: https://huggingface.co/docs/transformers/index (accessed on 8 April 2022).
- Gardner, M.; Grus, J.; Neumann, M.; Tafjord, O.; Dasigi, P.; Liu, N.; Peters, M.; Schmitz, M.; Zettlemoyer, L. AllenNLP: A deep semantic natural language processing platform. arXiv 2018, arXiv:1803.07640. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 8–14 December 2019; Curran Associates Inc.: Vancouver, BC, Canada, 2019; pp. 8026–8037. [Google Scholar]
- Raval, S. Bert-as-Service. 2022. Available online: https://github.com/llSourcell/bert-as-service (accessed on 13 July 2022).
- Kim, H.J.; Hong, S.E.; Cha, K.J. seq2vec: Analyzing sequential data using multi-rank embedding vectors. Electron. Commer. Res. Appl. 2020, 43, 101003. [Google Scholar] [CrossRef]
- Phang, J.; Févry, T.; Bowman, S.R. Sentence Encoders on STILTs: Supplementary Training on Intermediate Labeled-data Tasks. arXiv 2019, arXiv:1811.01088. [Google Scholar]
- Huang, L.; Dou, Z.; Hu, Y.; Huang, R. Textual Analysis for Online Reviews: A Polymerization Topic Sentiment Model. IEEE Access 2019, 7, 91940–91945. [Google Scholar] [CrossRef]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; Long Papers. Volume 1, pp. 3816–3830. [Google Scholar] [CrossRef]
- Hu, Y.; Ding, J.; Dou, Z.; Chang, H. Short-Text Classification Detector: A Bert-Based Mental Approach. Comput. Intell. Neurosci. 2022, 2022, 8660828. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Fang, H.; Khabsa, M.; Mao, H.; Ma, H. Entailment as Few-Shot Learner. arXiv 2021, arXiv:2104.14690. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Prologue | Epilogue | Paraphrase Recognition Label |
|---|---|---|---|
| 1 | I have my resume on this USB key | Are you using a USB extension cord | identical |
| 2 | See, without your password, nobody can access your mail | As smart as they are, they didn’t the password | identical |
| 3 | When did you last change your password | I can cut some corners and save some time but I’ll need your username and password | identical |
| 4 | My network connection just went down like you said | I am just working on an audit | different |
| 5 | Hello how may I help you | Is there anything else I can help you with today | similar |
| 6 | It’s called Doctors Database and I believe that they are located in Denver Colorado | Hello John. This is Bill Jenkins from Doctor’s Database in Denver | identical |
| 7 | We’re trying to troubleshoot a computer networking problem | In the back of the computer can you recognize the network cable | identical |
| 8 | I am sorry for interrupting you, but I am experiencing a problem with my Charge 2 | When I tried to turn on the Charge 2 I saw that the battery was leaking | similar |
| 9 | I need that info to report back to my boss | My boss will probably fire me if I don’t have it for the morning | similar |
| 10 | The chief executive character is in a meeting with important clients and would like the password reset as his current email account | But we need the details or we can’t give you any information | different |
| Data set size | 16,900 sentences |
| Type of text units | Pairs of sentences |
| Source of judgment | Three judges |
| Training pairs | 13,520 |
| Development pairs | 1690 |
| Test pairs | 1690 |
| Identical sentences | 6484 |
| Similar sentences | 5023 |
| Different sentences | 5393 |
| Prologue | Epilogue | Annotators Labels | Paraphrase Recognition Label |
|---|---|---|---|
| Without your password, nobody can access your mail, even we at the data center | I can cut some corners to save some time, but I’ll need your username and password 1 | III | Identical 2 |
| Just double-click on the icon when it downloads | You must open the file when it’s done | SSS | Similar |
| Are you using a USB extension cord | Thanks for the quick replies | DDD | Different |
| Index | Sentence | Similarity |
|---|---|---|
| 1 | The chief executive character is in a meeting with important clients and would like the password reset as his current email account password no longer works | 0.7804 |
| 2 | And listen we just installed an update that allows people to change their passwords | 0.6937 |
| 3 | Now go ahead and type your password but don’t tell me what it is | 0.5255 |
| 4 | You should never tell anybody your password not even tech support | 0.3490 |
| 5 | In this case, would you like to reset your password | 0.3488 |
| Model | Training Accuracy (%) | Training Loss | Validation Accuracy (%) | Validation Loss |
|---|---|---|---|---|
| Baseline | 82.57 | 0.36 | 73.83 | 0.39 |
| BERT-base | 84.01 | 0.24 | 76.79 | 0.37 |
| CSE-PersistenceBERT | 84.96 | 0.21 | 78.03 | 0.36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsinganos, N.; Fouliras, P.; Mavridis, I. Applying BERT for Early-Stage Recognition of Persistence in Chat-Based Social Engineering Attacks. Appl. Sci. 2022, 12, 12353. https://doi.org/10.3390/app122312353
Tsinganos N, Fouliras P, Mavridis I. Applying BERT for Early-Stage Recognition of Persistence in Chat-Based Social Engineering Attacks. Applied Sciences. 2022; 12(23):12353. https://doi.org/10.3390/app122312353
Chicago/Turabian StyleTsinganos, Nikolaos, Panagiotis Fouliras, and Ioannis Mavridis. 2022. "Applying BERT for Early-Stage Recognition of Persistence in Chat-Based Social Engineering Attacks" Applied Sciences 12, no. 23: 12353. https://doi.org/10.3390/app122312353
APA StyleTsinganos, N., Fouliras, P., & Mavridis, I. (2022). Applying BERT for Early-Stage Recognition of Persistence in Chat-Based Social Engineering Attacks. Applied Sciences, 12(23), 12353. https://doi.org/10.3390/app122312353