
Goal-Conditioned Reinforcement Learning within a Human-Robot Disassembly Environment

 , ,
, ,  ,
,  , and
, and
Abstract
:1. Introduction
- A goal-conditioned RL approach that considers co-worker safety through real-time collision avoidance during the performance of non-monotonic disassembly tasks.
- Improved agent generalization capabilities to extract parts of different frictions, tolerances, and orientations, and despite noisy image captures.
- A new scalable multi-control framework for direct transfer of RL policies between robots and their control in reality independent of other software libraries.

2. Related Works
2.1. Contact-Rich Manipulation Tasks: Assembly and Disassembly
2.2. Path Planning and Collision Avoidance
3. Method
3.1. Markov Decision Process
3.1.1. State Space
3.1.2. Action Space
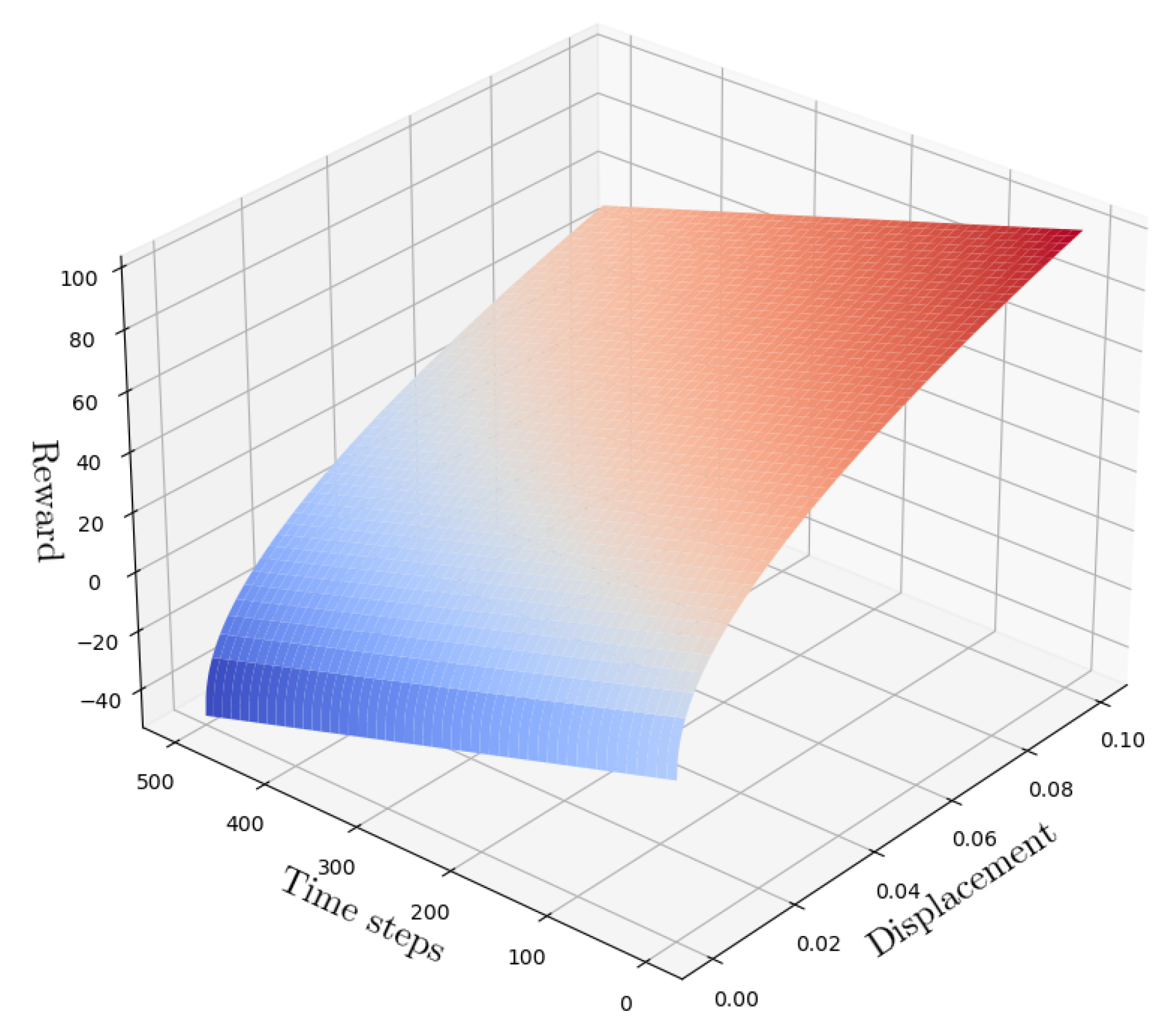
3.1.3. Reward Function
3.2. Reinforcement Learning Agents
4. Experiments and Results
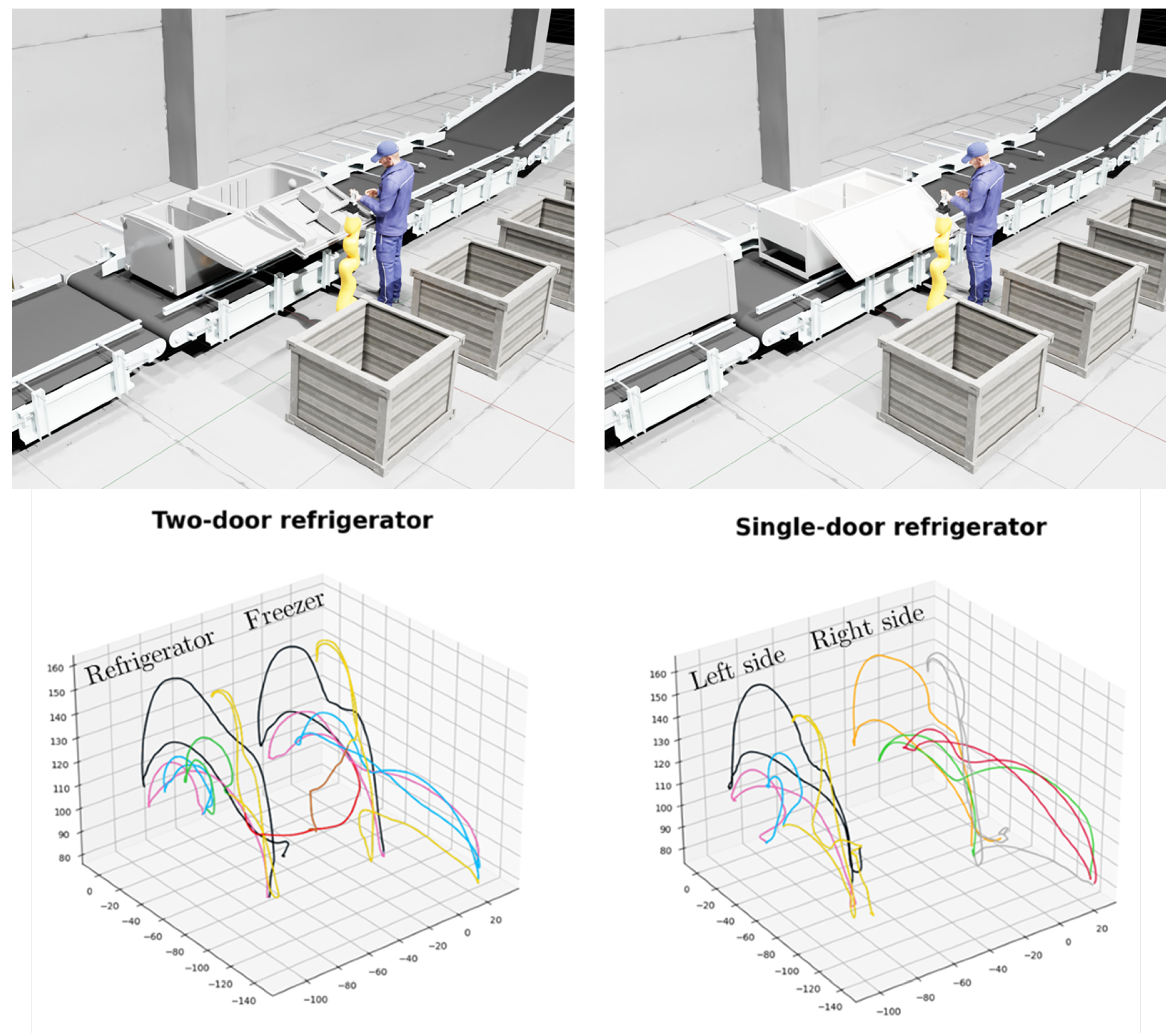
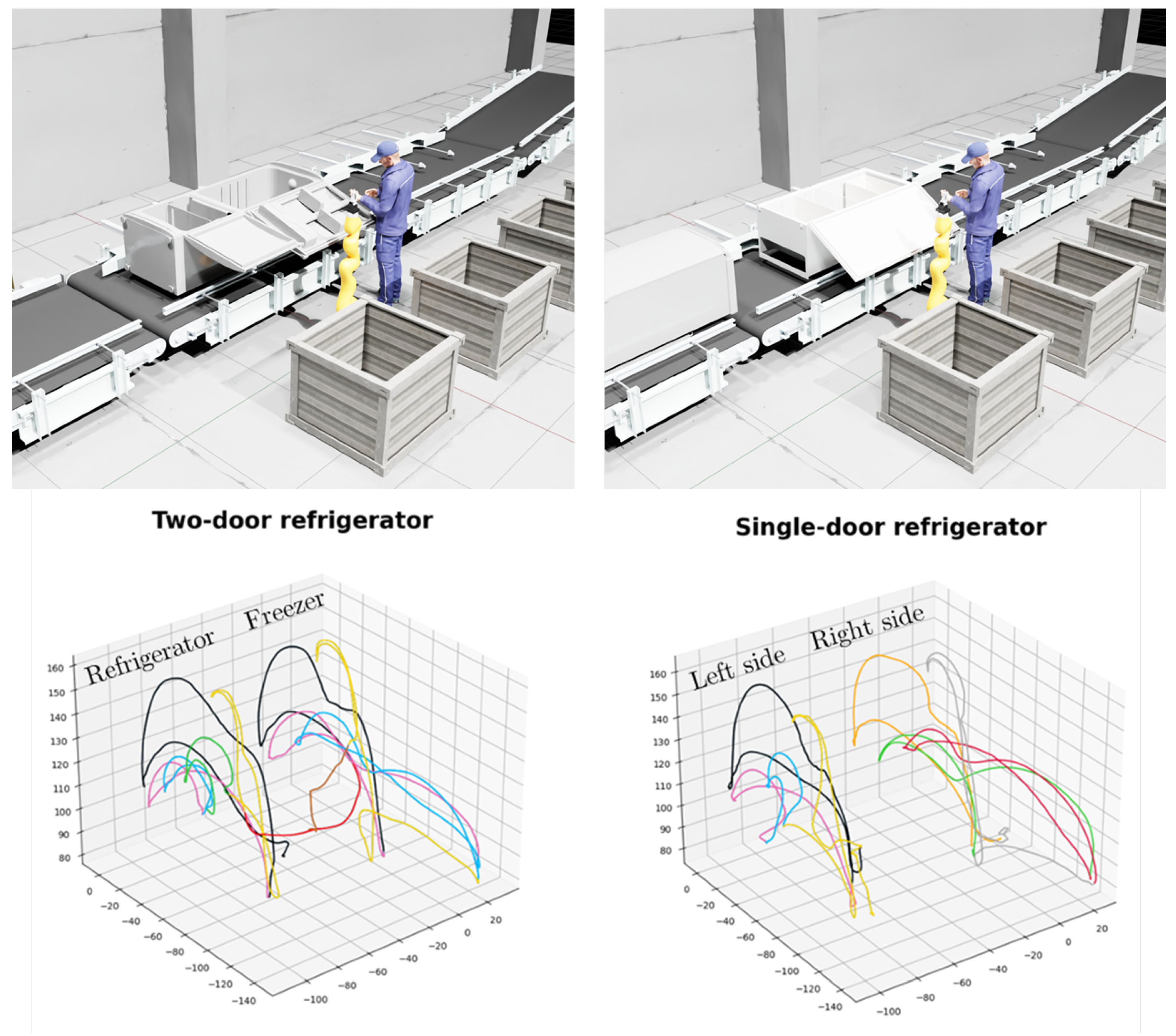
4.1. Task Description
4.2. Agent Training
4.2.1. Hyperparameters Selection
4.2.2. Training
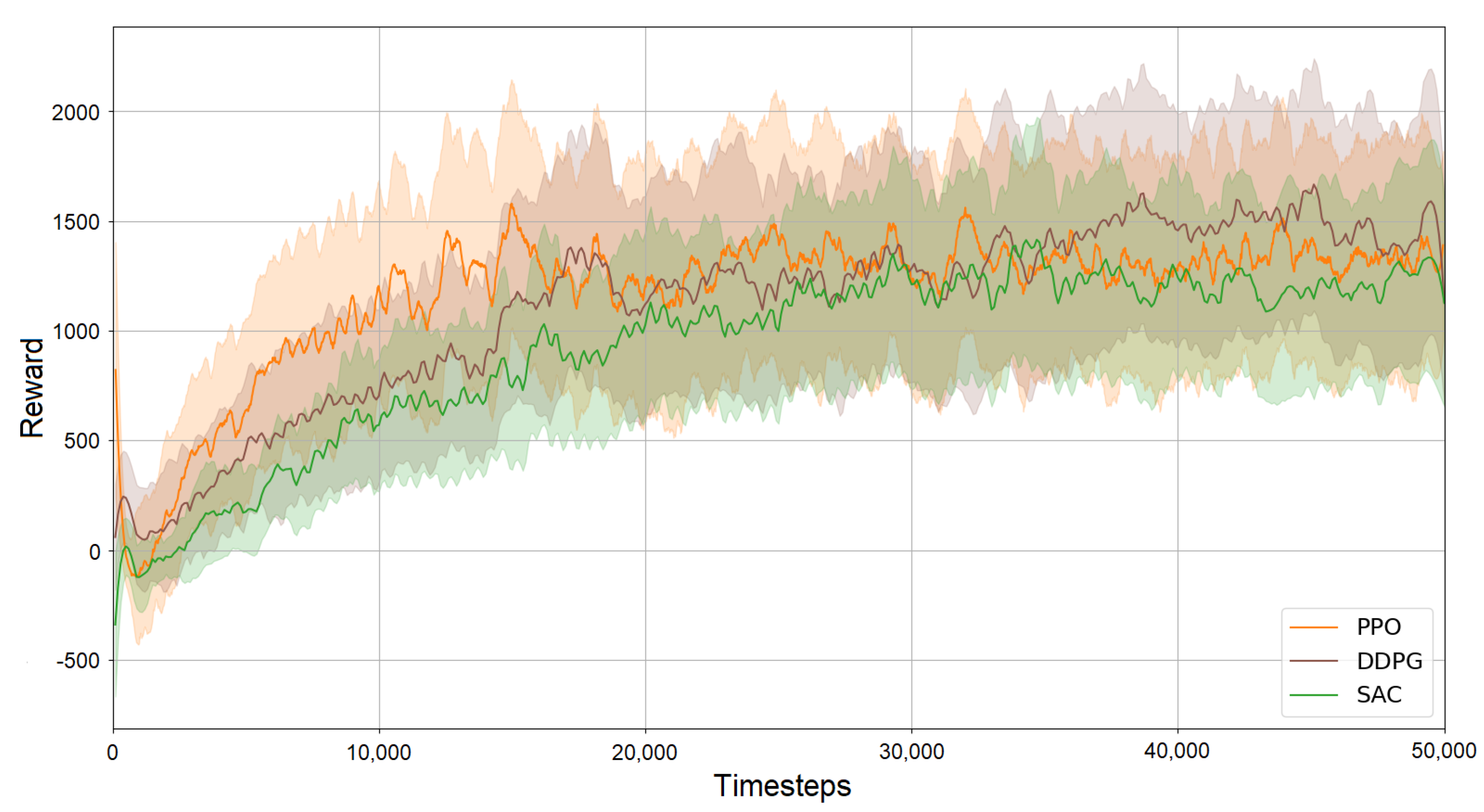
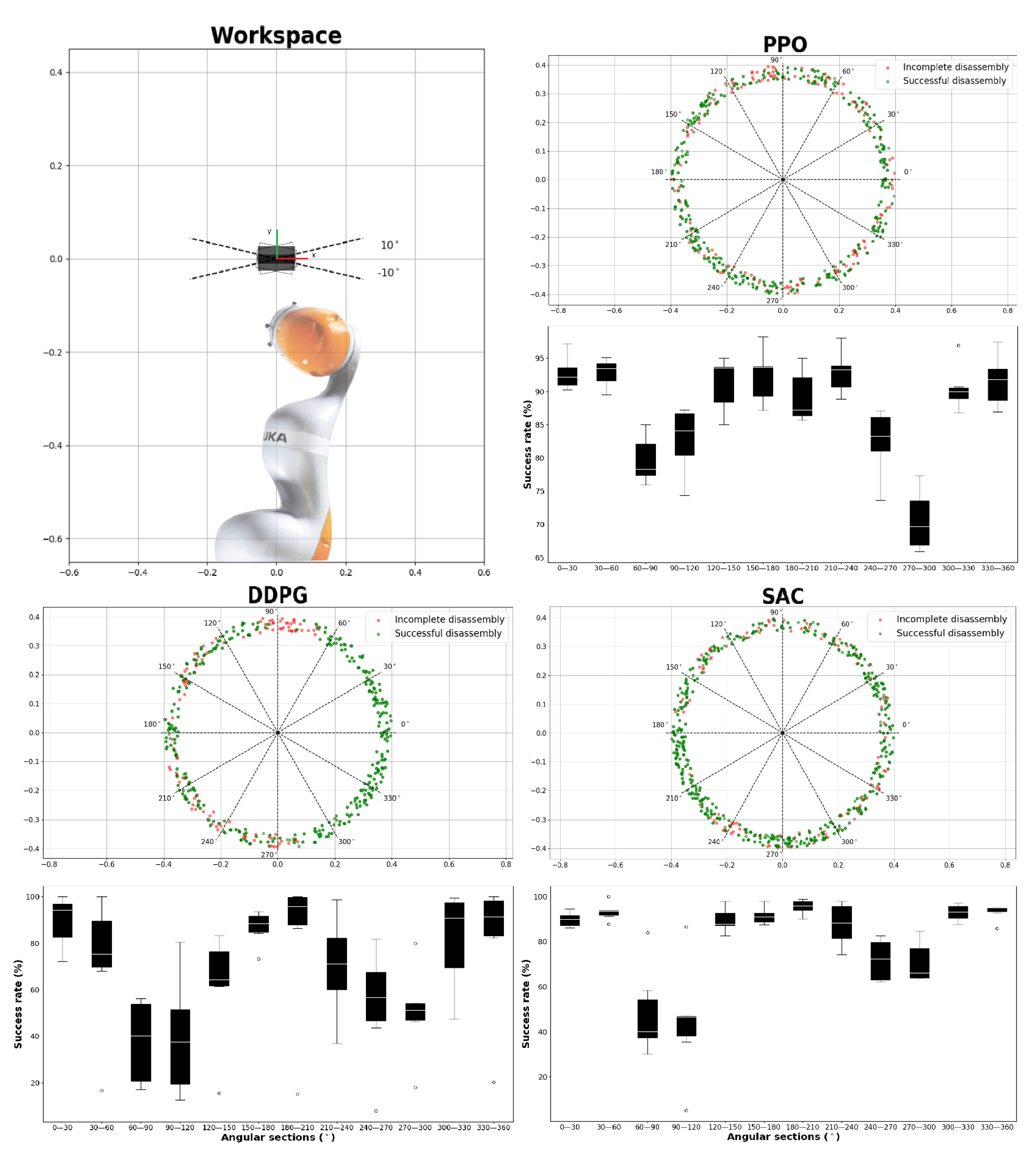
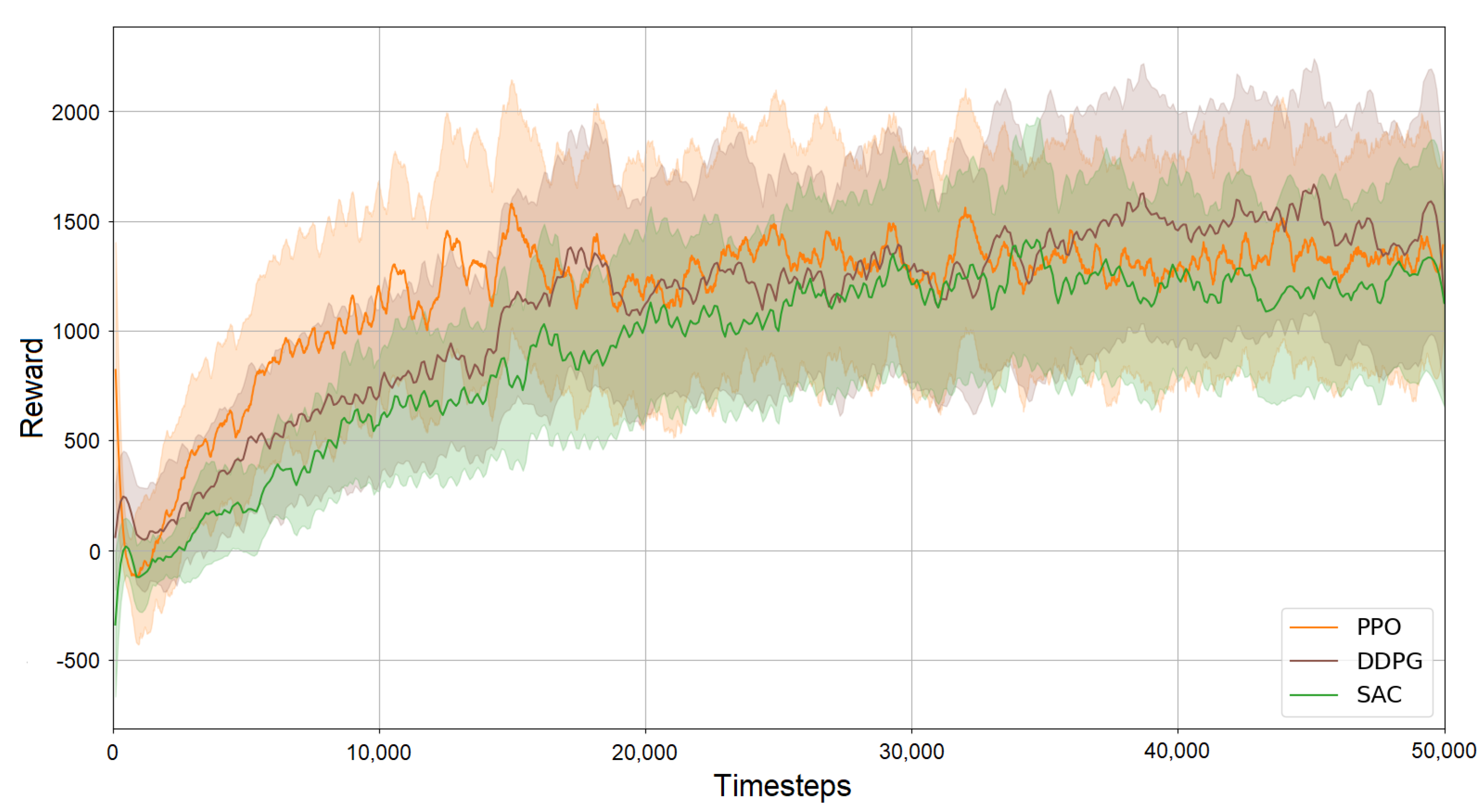
4.3. Simulation Results
- A refrigerator with two doors, one being the refrigerator and the other the freezer, where the co-worker would open one door, remove drawers and shelves from inside, put them aside, close the door and do the same with the second door.
- A second refrigerator with a single door on which the co-worker could work either to the robot’s left or right (Figure 5).
4.4. Experiments on the Real System
4.4.1. Simulation to Reality Deployment
4.4.2. Policy Transferability
4.4.3. Baseline Comparison
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| APF | Artificial Potential Field |
| DDPG | Deep Deterministic Policy Gradient |
| EoL | End-of-Life |
| HRI | Human-Robot Interaction |
| MDP | Markov Decision Process |
| ML | Machine Learning |
| PPO | Proximal Policy Optimization |
| RL | Reinforcement Learning |
| ROS | Robot Operating System |
| RRT | Rapid-exploring Random Trees |
| SAC | Soft Actor-Critic |
| TD3 | Twin Delayed DDPG |
| WEEE | Waste Electrical and Electronic Equipment |
References
- Waste from Electrical and Electronic Equipment (WEEE). Available online: https://ec.europa.eu/environment/topics/waste-and-recycling/waste-electrical-and-electronic-equipment-weee_en (accessed on 7 August 2022).
- Global Forum Tokyo Issues Paper 30-5-2014.pdf. Available online: https://www.oecd.org/environment/waste/Global%20Forum%20Tokyo%20Issues%20Paper%2030-5-2014.pdf (accessed on 7 August 2022).
- Vongbunyong, S.; Chen, W.H. Disassembly automation. In Disassembly Automation; Springer: Berlin/Heidelberg, Germany, 2015; pp. 25–54. [Google Scholar]
- Hjorth, S.; Chrysostomou, D. Human–robot collaboration in industrial environments: A literature review on non-destructive disassembly. Robot. Comput.-Integr. Manuf. 2022, 73, 102208. [Google Scholar] [CrossRef]
- Shailaja, K.; Seetharamulu, B.; Jabbar, M. Machine learning in healthcare: A review. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; pp. 910–914. [Google Scholar]
- Bachute, M.R.; Subhedar, J.M. Autonomous driving architectures: Insights of machine learning and deep learning algorithms. Mach. Learn. Appl. 2021, 6, 100164. [Google Scholar] [CrossRef]
- Wang, W.; Siau, K. Artificial intelligence, machine learning, automation, robotics, future of work and future of humanity: A review and research agenda. J. Database Manag. 2019, 30, 61–79. [Google Scholar] [CrossRef]
- Jurgenson, T.; Avner, O.; Groshev, E.; Tamar, A. Sub-Goal Trees a Framework for Goal-Based Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Online, 13–18 July 2020; pp. 5020–5030. [Google Scholar]
- Yang, X.; Ji, Z.; Wu, J.; Lai, Y.-K.; Wei, C.; Liu, G.; Setchi, R. Hierarchical Reinforcement Learning With Universal Policies for Multistep Robotic Manipulation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4727–4741. [Google Scholar] [CrossRef]
- Liu, M.; Zhu, M.; Zhang, W. Goal-conditioned reinforcement learning: Problems and solutions. arXiv 2022, arXiv:2201.08299. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Pieter Abbeel, O.; Zaremba, W. Hindsight experience replay. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Zhang, H.; Wang, F.; Wang, J.; Cui, B. Robot grasping method optimization using improved deep deterministic policy gradient algorithm of deep reinforcement learning. Rev. Sci. Instrum. 2021, 92, 025114. [Google Scholar] [CrossRef]
- Vulin, N.; Christen, S.; Stevšić, S.; Hilliges, O. Improved learning of robot manipulation tasks via tactile intrinsic motivation. IEEE Robot. Autom. Lett. 2021, 6, 2194–2201. [Google Scholar] [CrossRef]
- Kim, Y.L.; Ahn, K.H.; Song, J.B. Reinforcement learning based on movement primitives for contact tasks. Robot.-Comput.-Integr. Manuf. 2020, 62, 101863. [Google Scholar] [CrossRef]
- Luo, J.; Solowjow, E.; Wen, C.; Ojea, J.A.; Agogino, A.M.; Tamar, A.; Abbeel, P. Reinforcement learning on variable impedance controller for high-precision robotic assembly. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QB, Canada, 20–25 May 2019; pp. 3080–3087. [Google Scholar]
- Li, X.; Xiao, J.; Zhao, W.; Liu, H.; Wang, G. Multiple peg-in-hole compliant assembly based on a learning-accelerated deep deterministic policy gradient strategy. Ind. Robot. Int. J. Robot. Res. Appl. 2021, 49, 54–64. [Google Scholar] [CrossRef]
- Ennen, P.; Bresenitz, P.; Vossen, R.; Hees, F. Learning robust manipulation skills with guided policy search via generative motor reflexes. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QB, Canda, 20–25 May 2019; pp. 7851–7857. [Google Scholar]
- Fan, Y.; Luo, J.; Tomizuka, M. A learning framework for high precision industrial assembly. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QB, Canda, 20–25 May 2019; pp. 811–817. [Google Scholar]
- Khader, S.A.; Yin, H.; Falco, P.; Kragic, D. Stability-guaranteed reinforcement learning for contact-rich manipulation. IEEE Robot. Autom. Lett. 2020, 6, 1–8. [Google Scholar] [CrossRef]
- Khader, S.A.; Yin, H.; Falco, P.; Kragic, D. Learning deep energy shaping policies for stability-guaranteed manipulation. IEEE Robot. Autom. Lett. 2021, 6, 8583–8590. [Google Scholar] [CrossRef]
- Ren, T.; Dong, Y.; Wu, D.; Chen, K. Learning-based variable compliance control for robotic assembly. J. Mech. Robot. 2018, 10, 061008. [Google Scholar] [CrossRef]
- Wang, Y.; Beltran-Hernandez, C.C.; Wan, W.; Harada, K. Hybrid Trajectory and Force Learning of Complex Assembly Tasks: A Combined Learning Framework. IEEE Access 2021, 9, 60175–60186. [Google Scholar] [CrossRef]
- Zhao, T.Z.; Luo, J.; Sushkov, O.; Pevceviciute, R.; Heess, N.; Scholz, J.; Schaal, S.; Levine, S. Offline meta-reinforcement learning for industrial insertion. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 6386–6393. [Google Scholar]
- Beltran-Hernandez, C.C.; Petit, D.; Ramirez-Alpizar, I.G.; Harada, K. Variable compliance control for robotic peg-in-hole assembly: A deep-reinforcement-learning approach. Appl. Sci. 2020, 10, 6923. [Google Scholar] [CrossRef]
- Kristensen, C.B.; Sørensen, F.A.; Nielsen, H.B.; Andersen, M.S.; Bendtsen, S.P.; Bøgh, S. Towards a robot simulation framework for e-waste disassembly using reinforcement learning. Procedia Manuf. 2019, 38, 225–232. [Google Scholar] [CrossRef]
- Simonič, M.; Žlajpah, L.; Ude, A.; Nemec, B. Autonomous Learning of Assembly Tasks from the Corresponding Disassembly Tasks. In Proceedings of the 2019 IEEE-RAS 19th International Conference on Humanoid Robots (Humanoids), Toronto, ON, Canada, 15–17 October 2019; pp. 230–236. [Google Scholar]
- Herold, R.; Wang, Y.; Pham, D.; Huang, J.; Ji, C.; Su, S. Using active adjustment and compliance in robotic disassembly. In Industry 4.0–Shaping The Future of The Digital World; CRC Press: Boca Raton, FL, USA, 2020; pp. 101–105. [Google Scholar]
- Serrano-Muñoz, A.; Arana-Arexolaleiba, N.; Chrysostomou, D.; Bøgh, S. Learning and generalising object extraction skill for contact-rich disassembly tasks: An introductory study. Int. J. Adv. Manuf. Technol. 2021, 1–13. [Google Scholar] [CrossRef]
- Bonilla, M.; Pallottino, L.; Bicchi, A. Noninteracting constrained motion planning and control for robot manipulators. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4038–4043. [Google Scholar]
- Lin, H.C.; Liu, C.; Fan, Y.; Tomizuka, M. Real-time collision avoidance algorithm on industrial manipulators. In Proceedings of the 2017 IEEE Conference on Control Technology and Applications (CCTA), Mauna Lani, HI, USA, 27–30 August 2017; pp. 1294–1299. [Google Scholar]
- Chen, J.H.; Song, K.T. Collision-free motion planning for human-robot collaborative safety under cartesian constraint. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 4348–4354. [Google Scholar]
- Yasar, M.S.; Iqbal, T. A scalable approach to predict multi-agent motion for human-robot collaboration. IEEE Robot. Autom. Lett. 2021, 6, 1686–1693. [Google Scholar] [CrossRef]
- Buerkle, A.; Eaton, W.; Lohse, N.; Bamber, T.; Ferreira, P. EEG based arm movement intention recognition towards enhanced safety in symbiotic Human-Robot Collaboration. Robot.-Comput.-Integr. Manuf. 2021, 70, 102137. [Google Scholar] [CrossRef]
- Li, Q.; Nie, J.; Wang, H.; Lu, X.; Song, S. Manipulator Motion Planning based on Actor-Critic Reinforcement Learning. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 4248–4254. [Google Scholar]
- Prianto, E.; Kim, M.; Park, J.-H.; Bae, J.-H.; Kim, J.-S. Path planning for multi-arm manipulators using deep reinforcement learning: Soft actor–critic with hindsight experience replay. Sensors 2020, 20, 5911. [Google Scholar] [CrossRef]
- Zhou, D.; Jia, R.; Yao, H.; Xie, M. Robotic Arm Motion Planning Based on Residual Reinforcement Learning. In Proceedings of the 2021 13th International Conference on Computer and Automation Engineering (ICCAE), Melbourne, Australia, 20–22 March 2021; pp. 89–94. [Google Scholar]
- Zhou, D.; Jia, R.; Yao, H. Robotic Arm Motion Planning Based on Curriculum Reinforcement Learning. In Proceedings of the 2021 6th International Conference on Control and Robotics Engineering (ICCRE), Beijing, China, 16–18 April 2021; pp. 44–49. [Google Scholar]
- El-Shamouty, M.; Wu, X.; Yang, S.; Albus, M.; Huber, M.F. Towards safe human-robot collaboration using deep reinforcement learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 30–31 August 2020; pp. 4899–4905. [Google Scholar]
- Prianto, E.; Park, J.-H.; Bae, J.-H.; Kim, J.-S. Deep Reinforcement Learning-Based Path Planning for Multi-Arm Manipulators with Periodically Moving Obstacles. Appl. Sci. 2021, 11, 2587. [Google Scholar] [CrossRef]
- Sangiovanni, B.; Rendiniello, A.; Incremona, G.P.; Ferrara, A.; Piastra, M. Deep reinforcement learning for collision avoidance of robotic manipulators. In Proceedings of the 2018 European Control Conference (ECC), Limassol, Cyprus, 12–15 June 2018; pp. 2063–2068. [Google Scholar]
- Sangiovanni, B.; Incremona, G.P.; Piastra, M.; Ferrara, A. Self-configuring robot path planning with obstacle avoidance via deep reinforcement learning. IEEE Control. Syst. Lett. 2020, 5, 397–402. [Google Scholar] [CrossRef]
- Xiong, B.; Liu, Q.; Xu, W.; Yao, B.; Liu, Z.; Zhou, Z. Deep reinforcement learning-based safe interaction for industrial human-robot collaboration. In Proceedings of the 49th International Conference on Computers and Industrial Engineering, Beijing, China, 18–21 October 2019; Volume 49, pp. 1–13. [Google Scholar]
- Zhao, X.; Fan, T.; Li, Y.; Zheng, Y.; Pan, J. An Efficient and Responsive Robot Motion Controller for Safe Human-Robot Collaboration. IEEE Robot. Autom. Lett. 2021, 6, 6068–6075. [Google Scholar] [CrossRef]
- Yamada, J.; Lee, Y.; Salhotra, G.; Pertsch, K.; Pflueger, M.; Sukhatme, G.S.; Lim, J.J.; Englert, P. Motion planner augmented reinforcement learning for robot manipulation in obstructed environments. arXiv 2020, arXiv:2010.11940. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; Cambridge University Press: Cambridge, MA, USA, 2018; p. 1. [Google Scholar]
- Thomas, G.; Chien, M.; Tamar, A.; Ojea, J.A.; Abbeel, P. Learning robotic assembly from cad. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3524–3531. [Google Scholar]
- Spector, O.; Zacksenhouse, M. Deep reinforcement learning for contact-rich skills using compliant movement primitives. arXiv 2020, arXiv:2008.13223.s. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Serrano-Muñoz, A.; Arana-Arexolaleiba, N.; Chrysostomou, D.; Bøgh, S. skrl: Modular and Flexible Library for Reinforcement Learning. arXiv 2022, arXiv:2202.03825. [Google Scholar]
- Baklouti, S.; Gallot, G.; Viaud, J.; Subrin, K. On the Improvement of Ros-Based Control for Teleoperated Yaskawa Robots. Appl. Sci. 2021, 11, 7190. [Google Scholar] [CrossRef]
- Park, J.; Delgado, R.; Choi, B.W. Real-time characteristics of ROS 2.0 in multiagent robot systems: An empirical study. IEEE Access 2020, 8, 154637–154651. [Google Scholar] [CrossRef]
- Martín-Martín, R.; Lee, M.A.; Gardner, R.; Savarese, S.; Bohg, J.; Garg, A. Variable impedance control in end-effector space: An action space for reinforcement learning in contact-rich tasks. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 1010–1017. [Google Scholar]
- Garcıa, J.; Fernández, F. A Comprehensive Survey on Safe Reinforcement Learning. J. Mach. Learn. Res. 2015, 16, 1437–1480. [Google Scholar]
- Brunke, L.; Greeff, M.; Hall, A.W.; Yuan, Z.; Zhou, S.; Panerati, J.; Schoellig, A.P. Safe Learning in Robotics: From Learning-Based Control to Safe Reinforcement Learning. arXiv 2022, arXiv:abs/2108.06266. [Google Scholar]
- ISO/TS 15066; Robots and Robotic Devices—Collaborative Robots. International Organization for Standardization: Geneva, Switzerland, 2016.
- Silver, D.; Singh, S.; Precup, D.; Sutton, R.S. Reward is enough. Artif. Intell. 2021, 299, 103535. [Google Scholar] [CrossRef]
- Rao, A.; Plank, P.; Wild, A.; Mass, W. A Long Short-Term Memory for AI Applications in Spike-based Neuromorphic Hardware. Nat. Mach. Intell. 2022, 4, 467–479. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| 500 | |
| 50 | |
| 1000 | |
| 0.1 m | |
| 2 N | |
| 7.5° | |
| 0.2 m |
| Agent | Parameters | Value |
|---|---|---|
| PPO | Memory size | 16 |
| Rollouts | 16 | |
| Learning epochs | 8 | |
| Discount factor | 0.99 | |
| DDPG | Memory size | 50,000 |
| Batch size | 512 | |
| Discount factor | 0.99 | |
| Learning rate | ||
| Noise type | Ornstein-Uhlenbeck | |
| 0.15 | ||
| 0.2 | ||
| Base scale | 0.1 | |
| SAC | Memory size | 50,000 |
| Batch size | 512 | |
| Discount factor | 0.99 | |
| Learning rate | ||
| Initial entropy value | 0.2 |
| Robot | m Tolerance Parts Disassembly | |||||||||
| S 1 | D 2 | S | D | S | D | S | D | S | D | |
| KUKA LBR Iiwa | 20/20 (100%) | 17/20 (85%) | 20/20 (100%) | 19/20 (95%) | 20/20 (100%) | 19/20 (95%) | 20/20 (100%) | 18/20 (90%) | 20/20 (100%) | 17/20 (85%) |
| Franka Emika Panda | 17/20 (85%) | 18/20 (90%) | 20/20 (100%) | 19/20 (95%) | 20/20 (100%) | 20/20 (100%) | 18/20 (90%) | 18/20 (90%) | 19/20 (95%) | 17/20 (85%) |
| Robot | 5×m Tolerance Parts Disassembly | |||||||||
| S | D | S | D | S | D | S | D | S | D | |
| KUKA LBR Iiwa | 15/20 (75%) | 14/20 (70%) | 19/20 (95%) | 17/20 (85%) | 18/20 (90%) | 16/20 (80%) | 20/20 (100%) | 17/20 (85%) | 19/20 (95%) | 14/20 (70%) |
| Franka Emika Panda | 14/20 (70%) | 14/20 (70%) | 19/20 (95%) | 17/20 (85%) | 18/20 (90%) | 17/20 (85%) | 19/20 (95%) | 16/20 (80%) | 17/20 (85%) | 15/20 (75%) |
| Robot | 5×m Tolerance Parts Disassembly | |||||||||
| S | D | S | D | S | D | S | D | S | D | |
| KUKA LBR Iiwa | 15/20 (75%) | 15/20 (75%) | 20/20 (100%) | 17/20 (85%) | 19/20 (95%) | 14/20 (70%) | 20/20 (100%) | 17/20 (85%) | 20/20 (100%) | 13/20 (65%) |
| Franka Emika Panda | 14/20 (70%) | 14/20 (70%) | 18/20 (90%) | 16/20 (80%) | 18/20 (90%) | 17/20 (85%) | 20/20 (100%) | 15/20 (75%) | 19/20 (95%) | 14/20 (70%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elguea-Aguinaco, Í.; Serrano-Muñoz, A.; Chrysostomou, D.; Inziarte-Hidalgo, I.; Bøgh, S.; Arana-Arexolaleiba, N. Goal-Conditioned Reinforcement Learning within a Human-Robot Disassembly Environment. Appl. Sci. 2022, 12, 11610. https://doi.org/10.3390/app122211610
Elguea-Aguinaco Í, Serrano-Muñoz A, Chrysostomou D, Inziarte-Hidalgo I, Bøgh S, Arana-Arexolaleiba N. Goal-Conditioned Reinforcement Learning within a Human-Robot Disassembly Environment. Applied Sciences. 2022; 12(22):11610. https://doi.org/10.3390/app122211610
Chicago/Turabian StyleElguea-Aguinaco, Íñigo, Antonio Serrano-Muñoz, Dimitrios Chrysostomou, Ibai Inziarte-Hidalgo, Simon Bøgh, and Nestor Arana-Arexolaleiba. 2022. "Goal-Conditioned Reinforcement Learning within a Human-Robot Disassembly Environment" Applied Sciences 12, no. 22: 11610. https://doi.org/10.3390/app122211610
APA StyleElguea-Aguinaco, Í., Serrano-Muñoz, A., Chrysostomou, D., Inziarte-Hidalgo, I., Bøgh, S., & Arana-Arexolaleiba, N. (2022). Goal-Conditioned Reinforcement Learning within a Human-Robot Disassembly Environment. Applied Sciences, 12(22), 11610. https://doi.org/10.3390/app122211610