1. Introduction
With the penetration of the internet into various fields and industries and the growing scale of users, the scale of information carried by the internet is increasing, and the content is more heterogeneous and diverse, presenting challenges for people to access information rapidly and effectively. The arrival of the era of big data has changed this status quo, which is characterized by scale, diversity, rapidity, and authenticity. Big data technology provides the possibility of large-scale knowledge acquisition. In such a background, knowledge engineering (the technology of obtaining knowledge and information with high efficiency and large capacity by using modern scientific and technological means) has ushered in new development opportunities. Especially after Google announced the knowledge graph project in 2012 to enhance its search engine performance, knowledge engineering has entered a brand-new stage led by knowledge graph technology, that is, the knowledge engineering stage in the big data era. Knowledge graphs based on big data have rapidly gained significant attention from academia, industry, and government departments and the knowledge graph slowly extends from search engines to the question and answering system.
Large-scale knowledge bases (KB) have emerged over recent years, such as DBpedia [
1], Freebase [
2], Yago [
3], and the Chinese knowledge base published by the NLPCC-ICCPOL-2016 Knowledge Base Question Answering (KBQA) evaluation task [
4], KBQA tasks are gradually becoming a hot spot in the area of natural language processing. Knowledge graphs are a special type of semantic network, which represents entities in the objective world and their relationships in graphic forms. Generally, virtual knowledge exists in the form of triples, such as <entity, predicate, target value>, which can help organize, manage, and comprehend the vast amount of information available online. Most of the knowledge on the web is unstructured or semi-structured, organized in a way that is suitable for people to read and understand but not computer-friendly [
5]. Knowledge graphs are helpful in constructing heterogeneous knowledge in the domain and establishing inter-knowledge associations. Google, Facebook, and Baidu have developed some knowledge graphs, and demonstrated their value in many ways. KBQA [
6] utilizes knowledge graphs as one of the sources of knowledge to understand the questions using natural language input from users and identify the entities and predicates to find the corresponding target values as answers.
Existing mainstream approaches to Chinese Knowledge Base Question Answering (CKBQA) usually split the question and answering task into two subtasks: entity linking and predicate matching. Regarding the entity linking module, Wang et al. [
7] used convolutional neural networks(CNN) and Gate Recurrent Unit(GRU) models to obtain semantic representations of questions. Xie et al. [
8] used CNN to develop Named Entity Recognition (NER) and Bidirectional Long Short-Term Memory (BiLSTM) and CNN to implement predicate mapping. Yang et al. [
9] reported their progress in NER by extracting various features, using Gradient Boosting Decision Tree (GBDT) model exploration, and using Naive Bayes Support Vector Machine (NBSVM) and CNN support to design predicate mapping. Lai et al. [
10] generated candidate entities through an alias dictionary, constructed artificial rules for entity disambiguation, and calculated cosine similarity based on word vectors to score predicates. With the appearance of the pre-trained language model Bidirectional Encoder Representation from Transformers(BERT), Liu et al. [
11] finely tuned the model on the basis of the BERT pre-training task for different subtasks in the CKBQA process and obtained good results on the open-domain Chinese knowledge-based question-answering task. However, the aforementioned methods suffer from two disadvantages: firstly, while previous language knowledge can be incorporated into hand-crafted templates, template design can consume a large amount of computational time. At the same time, manual templates tend to have large granularity and are prone to exceptions, which limits the model of ability for generalization. Secondly, the performances of conventional methods are low on the Chinese dataset. Compared with the NER task for English, NER for Chinese is more difficult because Chinese sentences cannot be spatially segmented as naturally as English, and the presence of a large number of indistinguishable entities, as well as the presentation differences between Chinese questions and basic knowledge, which makes it difficult for general models to learn text features adequately. For Chinese NER, the common practice is to use the Chinese Word Segmentation (CWS) tool for segmentation before applying word order tokens. However, the noise present in the CWS tool itself can significantly affect the performance of NER models.
For the purpose of this work, we focus on the CKBQA task via the designed CWS and BERT models in order to address the difficulties such as the insufficient association between entities and predicates. To achieve the final answer selection, we link the score of entities and predicates, determining the query path and retrieve a definitive answer. The key contributions of this paper are as follows:
1. An NER transfer learning model is presented. By fusing CWS in the NER task, the accuracy of candidate entities is improved without introducing too much noise. We also use a pre-trained BERT model combined with CNN and Softmax models for entity disambiguation and predicate mapping in which richer contextual information can be learned. The model makes full use of the problem encoding and candidate information features extracted by the BERT model and has strong generalization for application in multi-domain knowledge bases.
2. The results of the experiments suggested that we have developed a satisfactory question answering system for the Chinese dataset. The current method achieves better on the NLPCC-ICCPOL 2016 KBQA dataset. It can generate more accurate and relevant answers due to the transfer learning and BERT’s powerful feature extraction capability.
The remainder of this work is organized as follows:
Section 2 describes the background of the question-answering system, KBQA, and NER.
Section 3 introduces the related technologies. The model, results, and discussion proposed by us will be presented in
Section 4,
Section 5 and
Section 6.
Section 7 provides a conclusion.
2. Background
2.1. Question Answering System
As a critical field in artificial intelligence [
12], intelligent question and answer is an essential branch of natural language processing, usually in a question-and-answer human-computer interaction to locate the user’s desired knowledge and provide personalized information services. Unlike search engines, it allows computers to answer users’ questions automatically in a precise natural language format. The history of intelligent question and answering dates back to 1950, when Alan Turing, the father of computer science, came up with the Turing Test to determine if it possible for a computer might think accurately and correctly, thus opening the chapter on natural language human-computer interaction. Around the 1960s, the first question-and-answering systems were introduced, and Green et al. designed a Baseball program that could answer questions about baseball games in plain English. In 1966, Weizen-Baum designed and implemented ELIZA Chatbot [
13], which can process simple problem statements. In 1971, another early chatbot [
14] was developed by Kenneth Colby, a psychiatrist at Stanford University, and named “Parry”. These question-answering systems based on rule matching could not be widely applied due to lacking data resources at that time.
As deep learning and natural language processing technology rapidly advances, the question-answering system gradually transitions from early rule matching to retrieval matching [
15]. The core idea is to extract the core words in natural language questions, search for the relevant answers in documents or web pages according to the core words and return the corresponding answers using the correlation sorting algorithm. Ma et al. [
16] proposed the pseudo-correlation feedback algorithm based on the method of automatic document retrieval, which used the context information in the document to retrieve the most similar answers. The retrieval matching approach achieved good results when it was first proposed. However, as the number of data increased and the diversity of user questions emerged, the quality of answers extracted from documents or web pages by this approach varied, profoundly affecting system response time and the accuracy. Until the concept of knowledge graph was proposed, the KBQA is significantly improved in quality and has realized the form of extracting questions and answers from documents. At present, KBQA has received more and more attention from researchers, and it has become a topic of intense interest in the natural language field [
17].
2.2. Knowledge Graphs and Knowledge Bases
In 2012, Google originally put forward the concept of the knowledge graph and applied it to enhance the capabilities of conventional search engines. In the real world, the knowledge graph presents structural knowledge as triples (entity-relations-entity or concept-attribute-value), forming a multilateral relationship network. Its essence is a semantic network that can reveal the entities’ relationships. According to different knowledge coverage fields, the knowledge spectrum can be divided into broad domain knowledge spectrum (e.g., Wikidata [
18], DBpedia, CN-DBpedia [
19], Freebase, etc.) and specific domain knowledge spectrum (e.g., Ali Commodity Atlas [
20], Meituan Gourmet Atlas [
21], AMiner [
22]). Traditional knowledge graph construction methods include entity recognition [
23], entity disambiguation [
24], relationship extraction [
25] and knowledge storage, etc.
With the emergence and rapid development of deep learning, the knowledge graph has gradually changed from “symbol” connection to “vector” representation. The model of TransE is suggested by Boards et al, in which the entities and relationships are embedded into the semantic space of a low-dimensional vector, and the relation vector is considered to be a translation of the head entity vector into the tail entity vector. TransR/CTransR proposed by Lin et al. [
26] sets a unique relation matrix space M for each relation and incorporates entities and relations into vector semantic space via M matrix for translation calculation. The knowledge graph construction method based on knowledge representation learning fundamentally solves the long tail effect brought by the traditional method and greatly improves the usability of the knowledge graph.
2.3. KBQA
A crucial question related to KBQA is how to translate natural language problems into formal language that can be understood by the computer and obtain the answer to the problem through query and reasoning within the constructed KB. Therefore, KBQA mainly includes Semantic Parsing-based (SP-based) methods and Information Retrieval-based (IR-based) Methods.
The SP-based methods analyzes components of natural language questions, converts the query into logical expressions, and then converts the query into a knowledge graph query to get the answers. Hao et al. [
27] parsed natural utterances into subgraphs of knowledge graph to achieve complex question answering, and the model was found practical; Meng et al. [
28] designed a semantic query expansion method to solve the problem of difficulty in obtaining ideal answers from data sources, which expanded query terms in question triples from three semantic perspectives and achieved multi-semantic expansion of the question triples. This method can more clearly convert natural language problem statements into logical expressions. However, the method requires many manually defined logical expression rules, which perform well in specific domains but are not generalizable when dealing with large-scale knowledge graphs. In other words, this method is suitable in specific domains but cannot transform undefined rules when dealing with large-scale knowledge graphs.
The IR-based methods extract critical information from the question and use that to qualify the knowledge of the knowledge base and then retrieve the answer. Qiu et al. [
29] suggested a Stepwise Reasoning Network (SRN) model on the basis of intensive learning. The SRN model formalizes the problems as sequential strategy ones and an attention mechanism is adopted to obtain exclusive information within the problem, which significantly enhances the effectiveness of question and answering based on information retrieval methods; Xu et al. [
30] argued that KG lacks context to provide a more precise conceptual understanding, although it contains rich structural information. For this reason, they designed a model that uses external entity descriptions for knowledge understanding to assist in completing knowledge question and answering. This approach achieves optimal results on the Common-sense QA dataset and obtains the best results in the non-generative model of OpenBookQA.
2.4. NER
NER is the identification of named entities with particular meanings in text and classifying them into predefined entity types, such as person name, place name, institution name, time, currency, etc. Named entities usually contain rich semantics and are closely related to the critical information in the data. The NER task can resolve issues on information explosion in text data online, and obtain critical information effectively. Moreover, NER is commonly used in different areas, such as relationship extraction, machine translation, and knowledge graph construction.
Chinese-oriented NER started later. One has immediately noticed that Chinese is quite different from West Germanic languages such as English due to its language characteristics. Hence, NER in the Chinese field mainly has the following three particularities. (1) Chinese NER should solve the difficulty in boundary ambiguities. It is because Chinese unit vocabulary boundaries lack clear separators such as spaces in English text and have no apparent morphological transformation features. (2) Chinese NER must be combined with CWS and grammatical analysis, only which can correctly classify named entities and improve the performance of NER. (3) Context may have significant influence on NER tasks. In Chinese text, there may exist complex sentences, flexible expressions, and many omissions. The exact words in different fields have different meanings, and there may be multiple expressions for the same semantics, which can only be clarified by the context. In addition, the internet has developed so rapidly, and the greater personalization and randomization of text descriptions in online texts, makes identifying entities more difficult.
Nowadays, mainstream NER methods have three categories, including rule- and dictionary-based methods, statistical machine learning-based methods, and deep learning-based methods. This paper mainly studies the methods based on deep learning. The typical representative of Transformer-based methods is the pre-trained model BERT model. Souza1 et al. [
31] put forward a BERT-CRF(Conditional Random Field) model for the NER task, combining BERT’s transfer capability with the structured CRF prediction. Li et al. [
32] addressed the lack of large-scale labelled clinical data by pre-training the BERT model on unlabeled Chinese clinical electronic medical record text, thereby leveraging unlabeled domain-specific knowledge. Wu et al. [
33], who follows the work by Li et al., proposed a model based on Roberta and character root features, using Roberta to learn medical features, and using Bi-LSTM to extract character features. Yao et al. [
34] designed a model using Albert-AttBiLSTM-CRF and migration learning for fine-grained entity recognition text. In this model, A more lightweight pre-training model ALBERT was adopted to embed words in the original data Bi-LSTM was employed to extract the features of words with embedding and obtain contextual information, and a decoding layer using CRF was utilized for label decoding.
4. Method
The purpose of this section is to demonstrate the overall structure of BAT-KBQA framework and the details of component modules. We begin by explaining general design of our framework and then describe the details of the essential components.
4.1. Overall Architecture
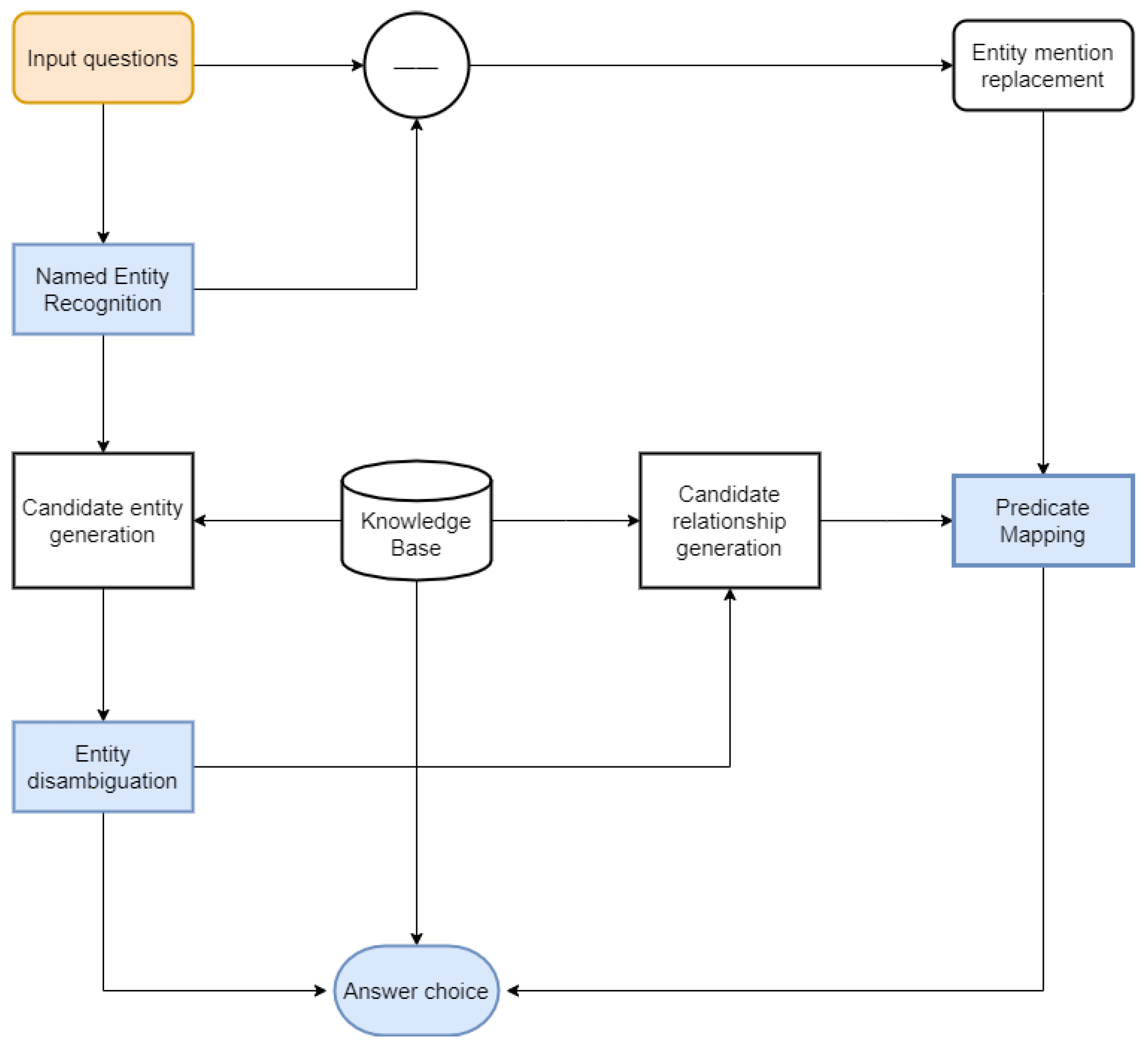
Figure 6 shows the overall flow of the KBQA system. The three core modules are entity linking (consisting of named entity identification and entity disambiguation), predicate mapping, and answer selection in the system. The objective of the entity linking step is to discover the name of entity posed in the query, while the predicate mapping step aims to find the relevant attributes asked in the question, and the answer selection is a combination of these two steps to reach an accurate answer. We use the example of “Who is the author of Journey to the West” to describe the flow of our system. Firstly, the NER model identifies the key entity “Journey to the West” from the question (in Chinese); combined with the knowledge base, we can generate a collection of candidate entities related to “Journey to the West”, and the entity disambiguation model scores the candidate entities. The highest scoring candidate entity “Journey to the West (novel)” is adopted as the question of subject entity; combining the subject entity and the knowledge base, the predicates of the subject entity are used as a candidate predicate set. The named entity is then replaced with the question sentence of the uniform identifier “entity” and the candidate predicate is fed into the predicate matching model, obtaining the predicate “author” with the highest score; finally, the answer selection module combines the entity and the predicate and queries the knowledge base to arrive at the final answer. The modules will be described in subsequent sections with more details.
4.2. Model for Entity Linking
Entity linking refers to the task, which links the expression in the text to the corresponding entity in the knowledge base to conduct entity disambiguation and assist humans and computers to understand the text’s particular meaning. For example, in the text “Do you know who is the author of the book ‘Journey to the West?’”, there is “Journey to the West (TV drama)”, “Journey to the West (novel)”, and “Journey to the West (game)” to express the corresponding entity of “Journey to the West” in the knowledge database. In our example, it links the expression “Journey to the West” to “Journey to the West (novel)” in the knowledge base to eliminate the ambiguity caused by other meanings. So, entity linking is the essential part of knowledge graph construction. The entity linkage model is divided into NER and entity disambiguation.
4.2.1. Named Entity Recognition
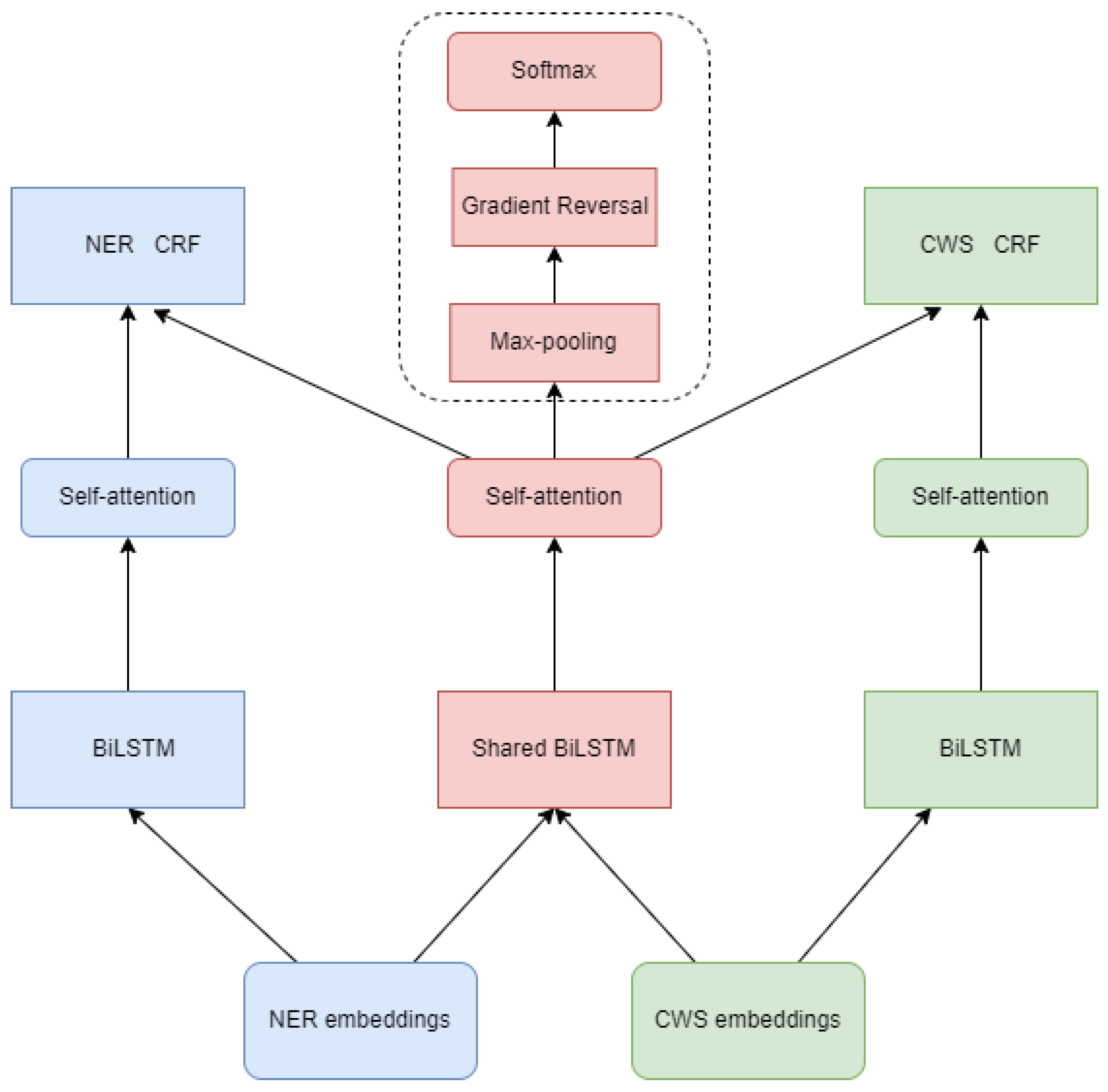
The goal of NER is to recognize named entities in text and assign them to the corresponding entity types. It is important since the semantic expression of Chinese corpus is sparse, many similar entities are difficult to be distinguished, and differences exist in the presentation of Chinese interrogative sentences and fundamental knowledge. Hence, it is difficult for general models to learn text features thoroughly, which makes it challenging to enhance the accuracy of entity linking. Here we suggest an adversarial transfer learning NER model. Our model incorporates adversarial transfer learning and the CWS task [
45] to solve these problems and introduces two major innovations, that is, applying CWS tasks brings shared information without introducing new noise and adding a self-attentive mechanism in the middle of the BiLSTM and CRF layers. The model tentatively learns word boundary information shared by the task from the CWS task, then filters particular information of CWS and unambiguously captures long range dependencies between two arbitrary characters in one sentence finally.
Figure 7 presents the architecture of this model. The model is composed of five elements: embedding layer, shared-private feature extractor, self-attention, task-specific CRF, and task discriminator. Each portion of the model would be given a detailed elaboration in subsequent sections.
First, the NER model is adopted to distinguish the topic entity in the question as the starting point for semantic parsing of the question, e.g., “Journey to the West?” in “Who is the author of Journey to the West?” is the reference form of the subject entity of the question. NER can be regarded as a sequence annotation task, in which the common tagging system “BIO” is used. Here “B” indicates the starting position of the entity mentioned, “I” indicates the middle or end positions of entity mentions, and “O” denotes that the character is not an entity mention. The position corresponding to the “Journey to the West” in the question is labelled as “B I I I”, and the other non-entity mentions are labelled as “O”. In this paper, the NER and CWS task datasets are labelled separately and embedded into the model for training.
The embedding layer and other neural network models have similarities. Pre-trained embedding dictionaries are loaded to map discrete NER and CWS characters into distributed embedding vectors.
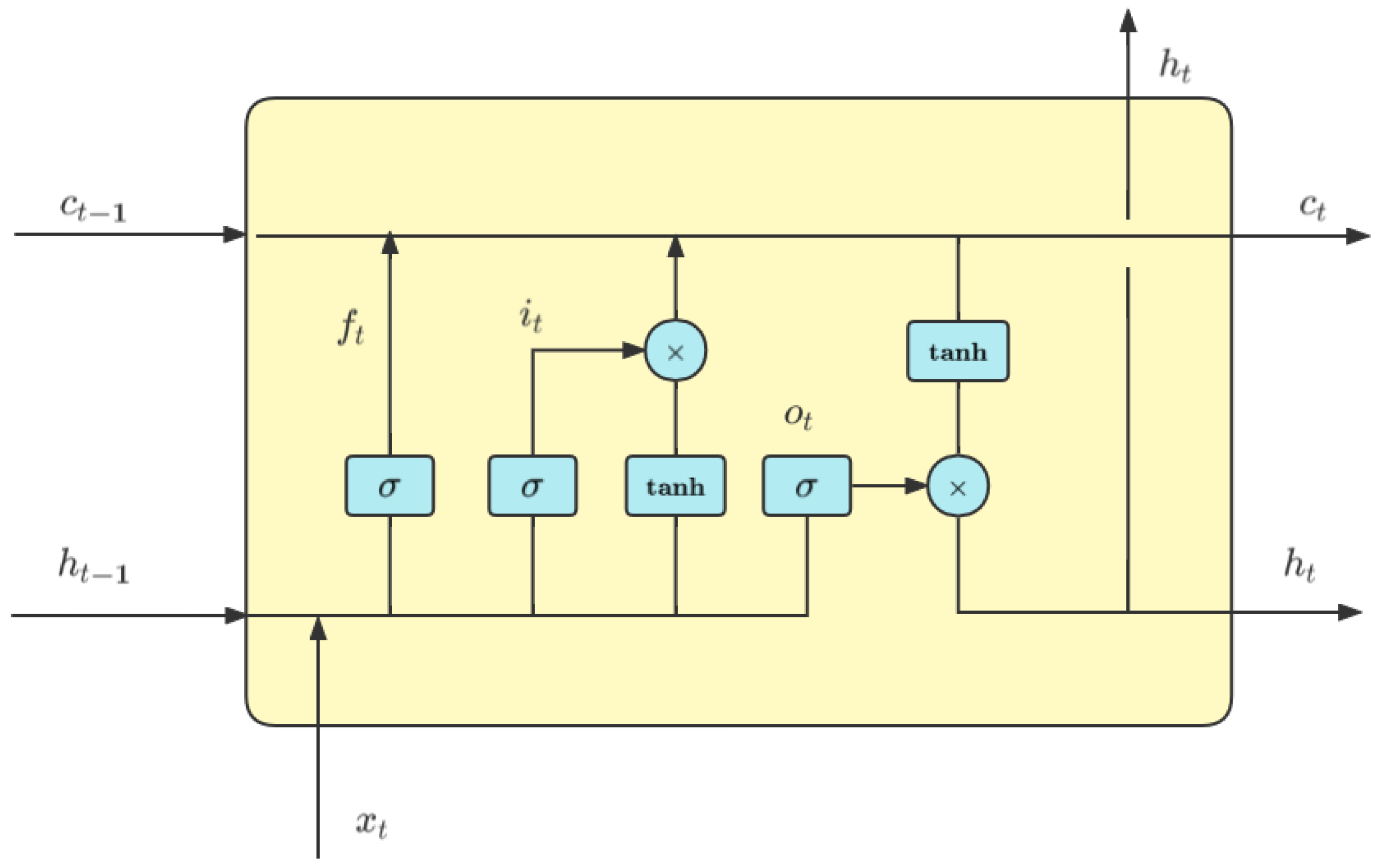
Long-term memory [
46] is a RNN’s variant and it can resolve the gradient disappearance and explosion problems by introducing gate mechanisms and memory units. The unidirectional LSTM utilizes only the past information but overlooks future information, so we use BiLSTM for feature extraction to fuse the information from two sides of the sequence. In our model, in addition to the two-end BiLSTM for extracting private features, we add a shared BiLSTM to extract the boundary information shared by the NER and CWS tasks. That is, for the dataset of task
m, the hidden states of the shared and private BiLSTM layers can be calculated as shown in the following.
where
is the shared BiLSTM parameter and
is the private BiLSTM parameters.
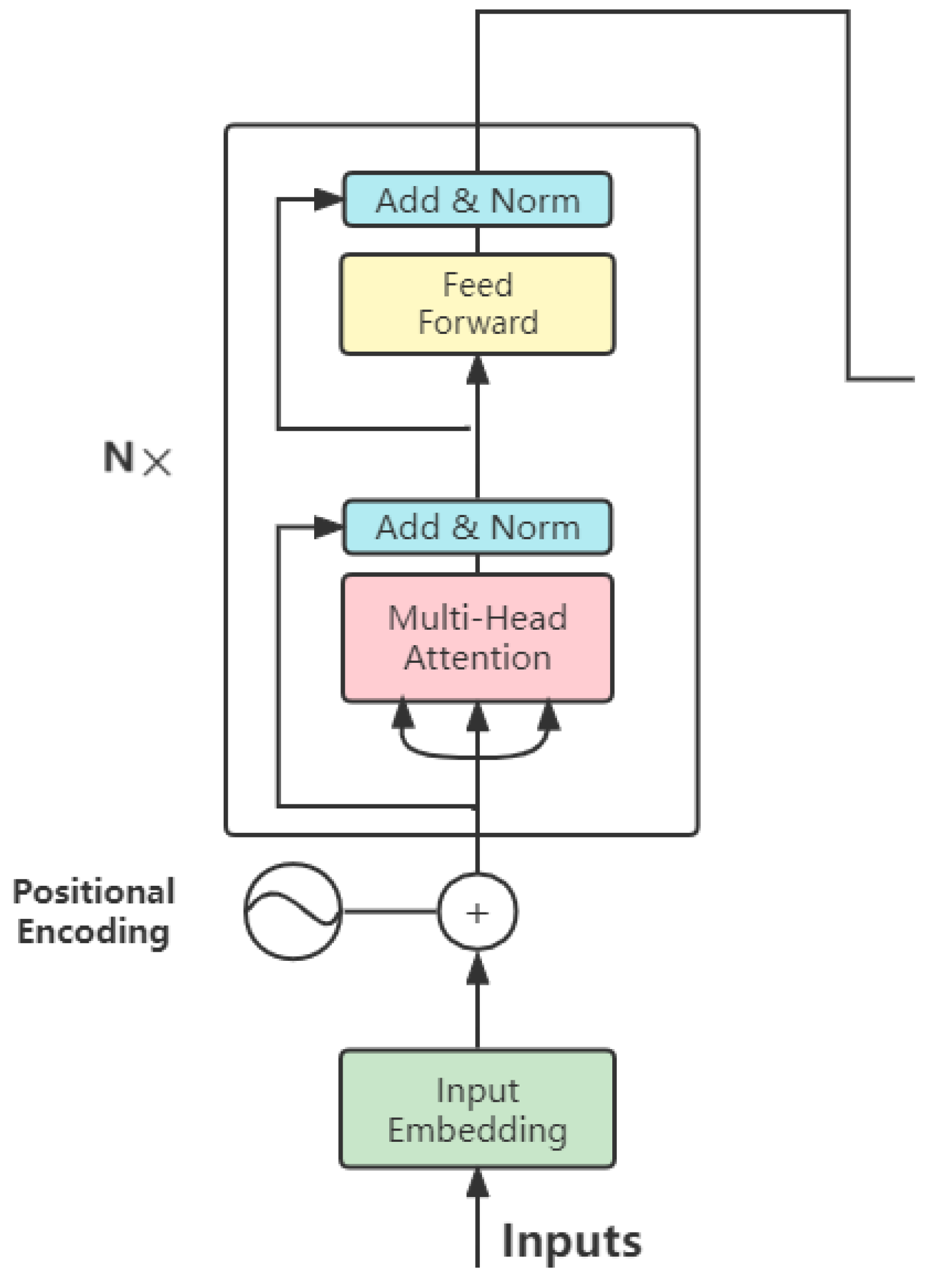
In the third step, we draw self-attention as applied to machine translation and semantic role labelling. After the feature extractor, we add a multi-headed attention mechanism [
40] in order to learn the dependencies between two arbitrary words in one sentence and seize the internal structural information of the sentence. The formula is as follows:
where
,
and
are query matrix, keys matrix and value matrix, respectively.
d is the dimension of BiLSTM hidden layers. More information about self-attention mechanisms are detailed in [
40].
The next layer is the CRF [
47]. The CRF layer can add some constraints to the final predicted labels to ensure the reasonableness of the predicted labels. Because the labels are different, we create a unique CRF layer for each task separately. For each sentence of task m, the final representation is to concatenate the BiLSTM layer with the self-attention representation.The final decoding process uses the Viterbi algorithm.
As shown in the
Figure 7, the middle layer enters our task recognizer. We propose a task recognizer to determine from which task the sentences come. The following formula can signify the task recognizer:
where
denotes the parameters of task recognizer.
and
are trainable parameters.
m denotes the number of tasks. The middle layer is the shared features of CWS and NER tasks, to prevent task-specific features from being incorporated into the shared features. Inspired by adversarial networks, we introduce adversarial loss to train the shared BiLSTM, resulting in a task recognizer that cannot reliably identify the task from which the sentence comes. The following equation calculates the adversarial loss:
where
refers to the shared BiLSTM’s trainable parameters.
is the shared feature extractor.
is the number of training examples of task
m and
is the
i-th example. The shared BiLSTM develops a representation to deceive the task recognizer as part of a minimax optimization, while the task recognizer tries its best to accurately recognize the type of work. To tackle the minimal-extreme optimization problem, we add a gradient inversion layer below the Softmax layer. We reduce the task recognizer’s error during the training stage, and invert the gradient through the gradient inversion layer, which favors the shared feature extractor for studying the word boundary information shared by the task. The shared feature extractor and the task recognizer arrive at a point when the recognizer is unable to discriminate tasks based on the representations acquired from the shared feature extractor after training phrases.
In training, the following is the final loss function of our model:
where
denotes a hyper-parameter. Equation (
21) can be used to calculate
and
.
is a switching function determining which task the input is from. The formula is as follows:
where
is Chinese
training corpora and
is
training corpora. In each iteration of the training phase, we sequentially select a task from
and obtain different training samples to update the parameters. We optimize the final loss function by utilizing the Adam algorithm. Since the convergence rates of the Chinese
task and the
task could be distinct, we duplicate the above iterations until early stopping based on the performance of the Chinese
task.
4.2.2. Model for Entity Disambiguation
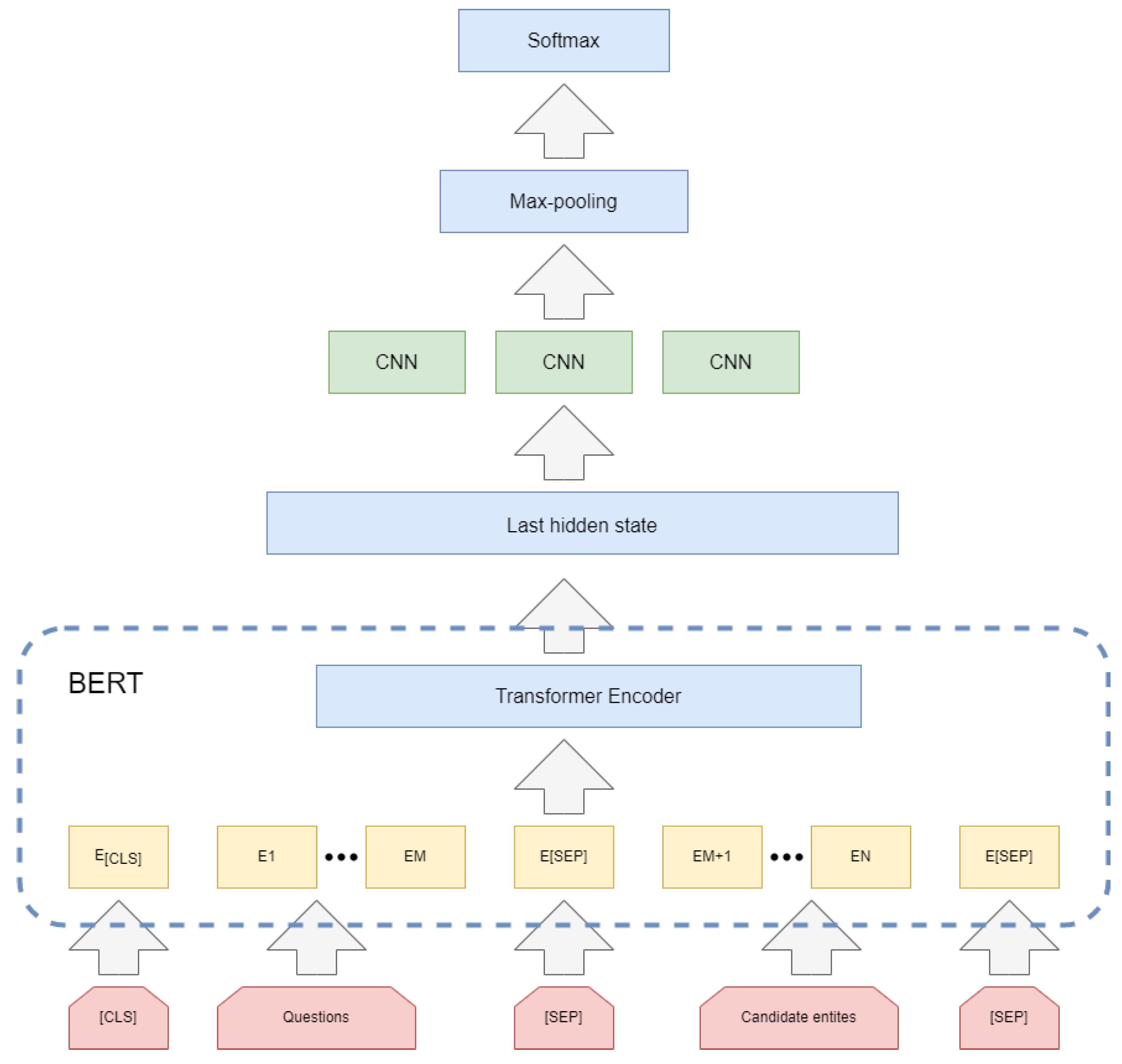
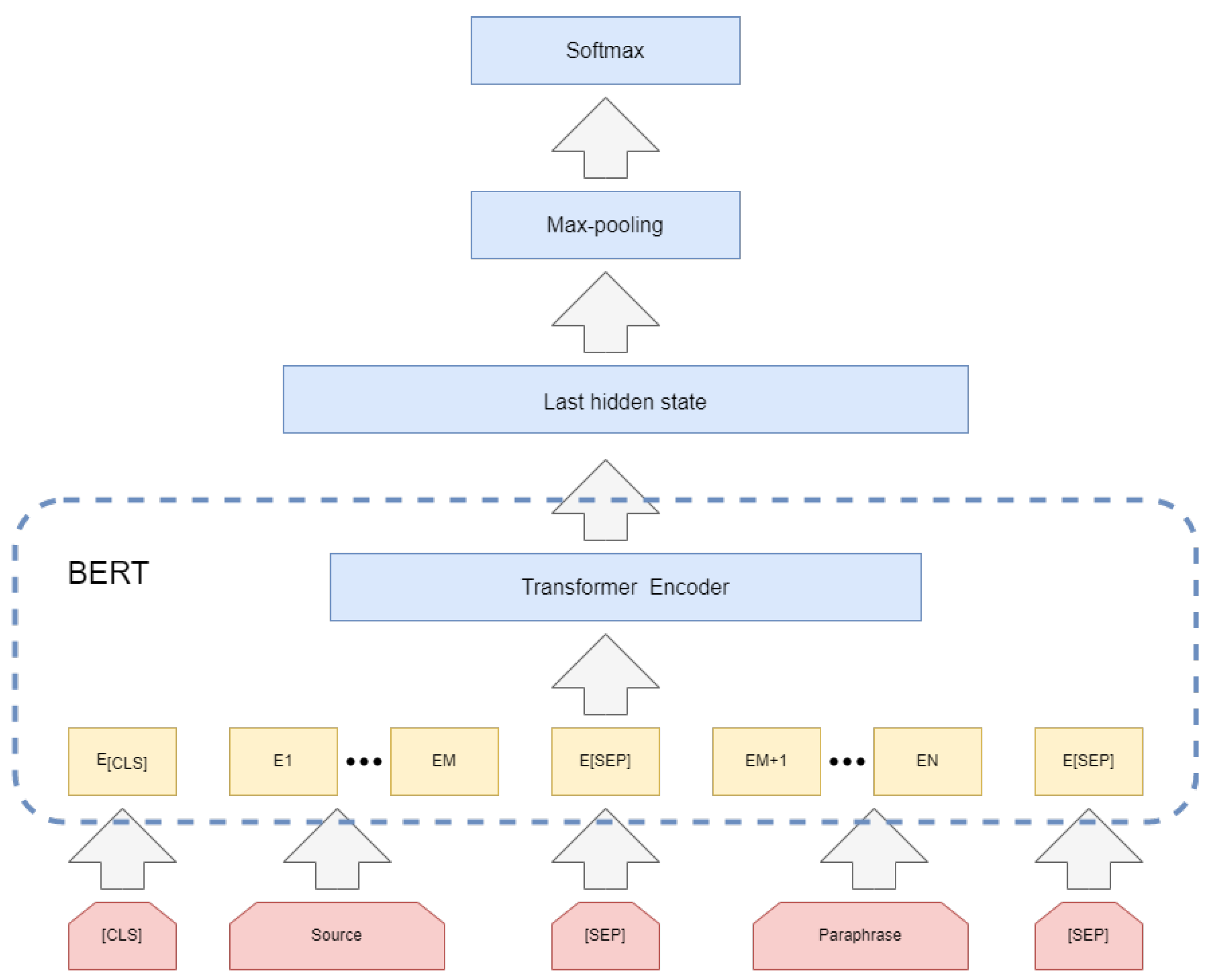
Next, since the entities mentioned in the natural language question may correspond to multiple entities saved in the knowledge base. After obtaining the entity identification of the subject entity in each question, it is essential to generate a set of candidate entities related to the entity mention from the knowledge base and disambiguate these candidate entity sets and to select the correct one. Accurately matching the subject entities asked in the question can also reduce the candidate set size for the next step of predicate matching and enhance the efficiency of the question answering system. We suggest a BERT-CNN model that introduces the predicate features of the entities once they are chained in order to boost the performance of the entity disambiguation task.
In the entity disambiguation part, to obtain the set of candidate entities close to the subject entities in the question, we firstly generate the set of candidate entities by mapping the entity mentions identified in the previous step to the mention2id library provided by the NLPCC- ICCPOL-2016KBQA evaluation. For entity mentions that could not be mapped, we relied on the knowledge base to retrieve entities with similar character as the candidate entity set. Then, we input the interrogative sentences and the set of candidate entities into the BERT-CNN [
35] model (as shown in
Figure 8). This task can be viewed as a binary task, with the output label 1 if the candidate entity is a subject entity in a labeled triplet and 0 otherwise. The input data are in the form of [CLS], problem character sequences, [SEP], candidate entities for concatenation with predicate features, [SEP]. Among them, the predicate feature is the chained relationship from candidate entities in the knowledge graph to the connected predicates, as shown in Formula (16), where
q represents the problem,
e represents the candidate entity, and
represents the chained relationship starting from
e.
After BERT network coding, the hidden layer vectors of the last four encoder outputs are obtained, and the hidden layer outputs
H after addition. Formula (17) illustrates the features of the convolution layer
C:
where
is the sigmoid function, ⨂ is the convolution operation,
W is the weight in the convolution kernel, and
b is the bias.
H extract features through three convolution layers corresponding to stepsize 1, 3 and 5, respectively. Then the features feed into the highest pooling layer and the Softmax layer carries out classification after concatenation the three vectors, and the output label is 0 or 1. Formula (18) explains that the loss function is the cross-entropy loss function, which is minimized during training. In the prediction, the probability that the candidate entity is predicted as tag 1 is taken as the candidate entity’s score.
Figure 8.
Entity Disambiguation model.
Figure 8.
Entity Disambiguation model.
4.3. Model for Predicate Mapping
Due to the variety of natural language questions, different expressions may correspond to the same question intent, and the same subject entity may also generate different predicates, which poses a major challenge to the domain KBQA task. Such as matching between the question “Who wrote the Journey to the West” and “Author ”. The predicate matching model is suitable for matching the predicates in the question with the predicates in the knowledge base, understand the intent of question, and select the predicate that best matches the question. First, the entity disambiguation results can reduce the size of candidate predicates set, so we start from the sample of candidate entities acquired in the entity disambiguation task and retrieve the set of predicates of that entity in the knowledge base as candidate predicates set. Next, we notice that in answering the question “Who wrote the Journey to the West?”, the information of the candidate predicates can be enriched by adding the information of the first-degree chained predicates of the candidate answer entities retrieved by the candidate predicates. For example, “The candidate entities of Journey to the West include release date, director, author, etc.” are related to the candidate predicate “author”.
Therefore, this paper proposes a BERT-Softmax model [
11] (as shown in
Figure 9) for entity-predicate matching. We treat BERT-Softmax as a binary sequence classification problem, where the output label is 1 for candidate relation samples that accurately reflect the intent of question and 0 for those inaccurately reflecting the aim of question. The input data are composed of two portions: the question and predicate. The input data of the question part consist of [CLS], a sequence of question characters with the entity character replaced by the entity character, [SEP], the candidate relation, and [SEP], which is encoded by the BERT network to acquire the hidden vector of the last four encoder layers, stitched together and input to the Softmax layer for classification. The output label is 0 or 1. The loss function is also the cross-entropy loss function, which was minimized during training. In the prediction, the probability of predicting a candidate relationship as label 1 is used as the score of candidate relationship.
4.4. Answer Selection Module
The answer selection module is responsible for integrating the two processes that came before it. To get the best answer, when our entity can match the corresponding predicate, we calculate the score
of the candidate entity and the score
of the candidate predicate. The final score
S is obtained by weighting
and
. The formula is as follows.
where
is a hyperparameter. We choose the highest score as the best matching relationship and acquire the answer by querying the KB.
6. Discussion
Table 7 presented performance comparison between our method and other published methods. The systems of Lai et al. [
10], Xie et al. [
52], and Yang et al. [
9] are the top three for the NLPCC 2016 KBQA evaluation task, and they all combine neural networks and manually constructed rules to ensure the quality of question and answering. BB-KBQA [
11] fine-tunes the pre-training task based on BERT to achieve three subtasks of NER, entity disambiguation, and predicate mapping, but the performance on the first two subtasks is weaker than the model of this paper, resulting in a lower final performance than the KBQA in this paper. The results of experiments demonstrates that the BAT-KBQA can achieve an Averaged F1 value of 87.74%, which achieves the best results and improves the question answering system accuracy compared with other published methods.
Finally, we analyzed the effect of the CWS task of this work, and the results show that word boundary information from the CWS task is effective for the Chinese NER task. Particularly when various entities appear at the same time, our model can correctly classify the word in different scenarios. Then, the performance of the question-answering system is evaluated. The results are found accurate except for some triples and wrong answers. For example, for the question “Where did Jie Wang debut?” (in Chinese), corresponding to the knowledge triple <Jie Wang, debut place, Taiwan>, our system predicts the subject entity and predicate as <Jie Wang (male singer from Hong Kong and Taiwan), debut place>, indicating that the entity disambiguation module can correctly select the answer Jie Wang, who is a singer. For the question “Which factory built submarine type 212?” (in Chinese), the corresponding knowledge triple is <212 type submarine, built, Hathaway Shipyard (hdw)>, and the subject entity and predicate predicted by our system is <212 type submarine, manufacturing plant>, which shows that although the predicate chosen by the predicate matching module is different from the labeled predicate, the correct predicate is chosen by understanding the intention of the question, and the correct answer is finally found. In practice, the method employs some artificial rules because of the introduction of CWS task, which requires data annotation such as the NER task. Therefore, additional effort should be spent on annotation and the need for manual labeling data is sometimes tedious. However, labeling is relatively easy and within an acceptable range.
In summary, we can see that introduction of CWS in the NER task can enhance the accuracy of entity linking. In our work, entity disambiguation and predicate mapping combined with BERT pre-training exhibit better performance, and the entities also have a strong correlation with the predicates. Compared to other models that use more complex features and artificial rules, our KBQA system achieve better results with only neural network models and a small number of simple text features. Therefore, our system achieves sufficient accuracy and can effectively answer the questions asked by the users.
7. Conclusions
In this paper, by fusing CWS in the NER task, the accuracy of candidate entities is improved without introducing too much noise. A multi-channel entity disambiguation model is proposed to enhance the features of candidate entities to bridge the semantic gap between the question and the knowledge base. The model makes full use of the problem encoding and candidate information features extracted by the BERT model and has strong generalization for application in multi-domain knowledge bases. The current method is evaluated from experiments on the NLPCC-ICCPOL-2016KBQA Chinese open question and answering dataset, with an average F1 score of 87.74%.
The results of experiments indicate that we have developed a satisfactory question answering system for the Chinese dataset. Our method performs better on the NLPCC-ICCPOL 2016 KBQA dataset. The system we developed may fill the gap in the technical research of the tutor selection service system. Later, we will use the BAT-KBQA framework on the Chinese Academy of Sciences tutor dataset to develop a tutor KBQA for students, so that students can quickly select tutors.
In future work, different subtasks will be trained in combination, or more knowledge graph representation learning methods can be introduced to obtain richer features.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}