
Position Detection of Doors and Windows Based on DSPP-YOLO

Abstract
1. Introduction
- (1)
- We propose the DSPP-YOLO algorithm to detect doors and windows in an unknown environment and optimize the SLAM algorithm to realize the classification of an unknown environment.
- (2)
- We add down the sampled layer to deepen the Darknet53 network structure to enhance the learning of target semantic features and integrate the YOLOV3 network framework with the idea of DenseNet and spatial pooling pyramids to achieve optimization.
- (3)
- We use K-means++ clustering method to generate anchor boxes to improve the training accuracy. After training, according to the experimental results of the improved network, we can know that the detection accuracy of doors is improved by 3.3%, the detection accuracy of windows is improved by 8.8%, and the average accuracy of various types is improved by 6.05%.
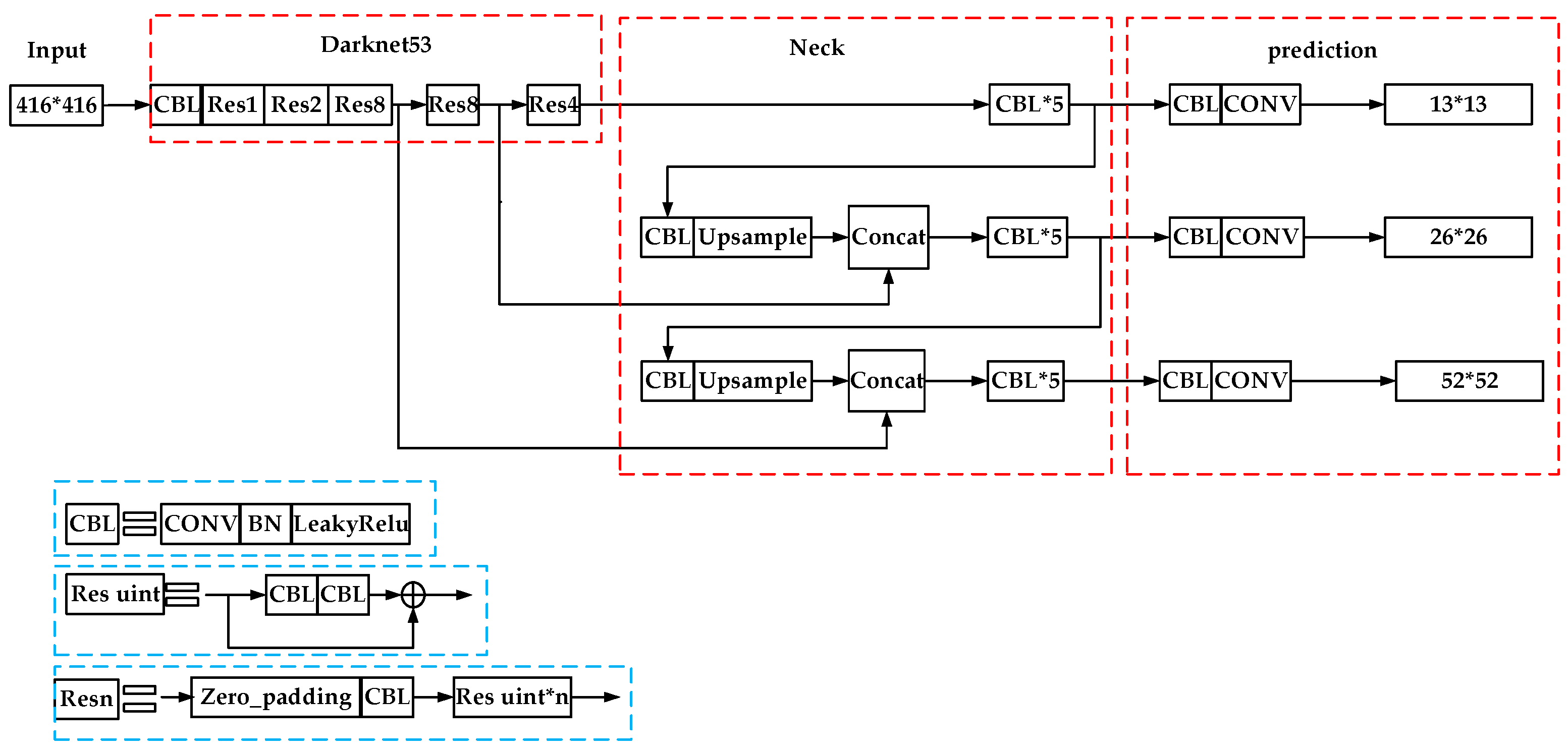
2. The Algorithm Principle of Yolov3
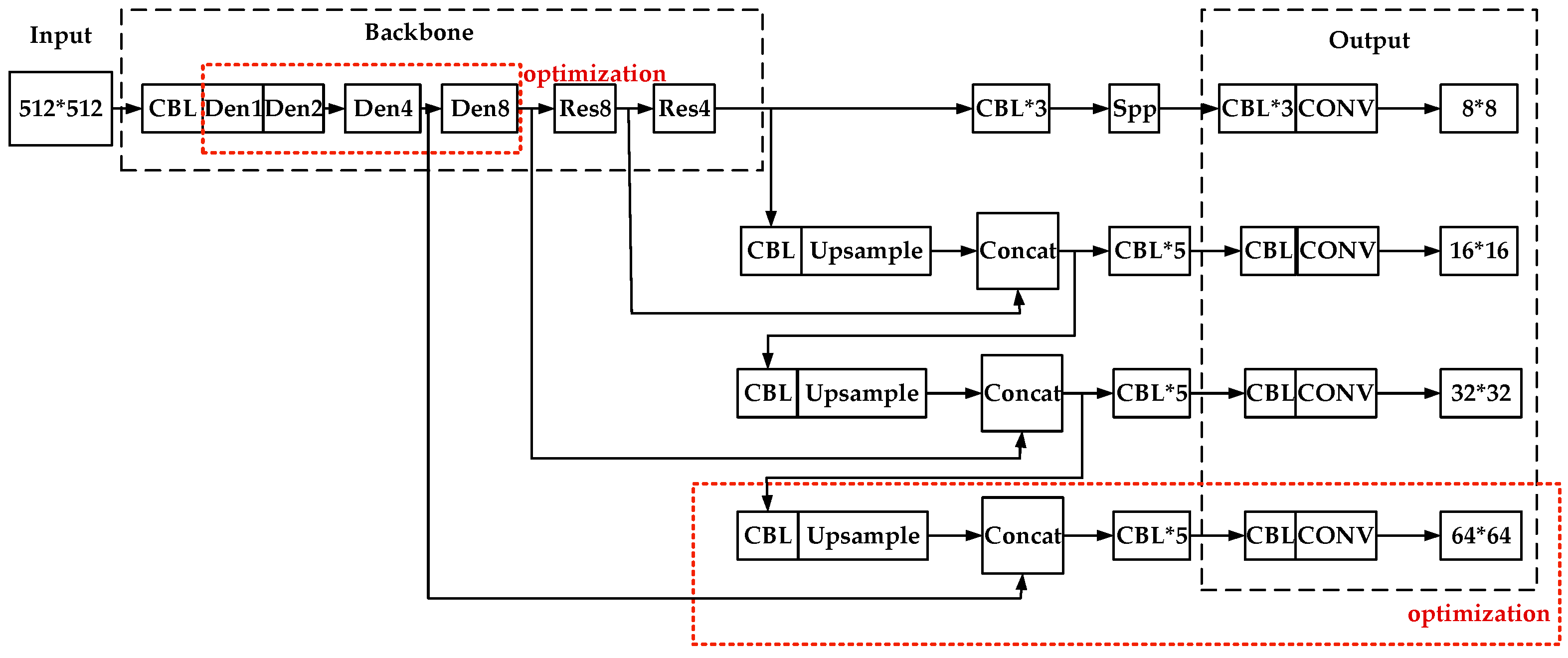
3. DSPP-YOLO
3.1. The Algorithm Design
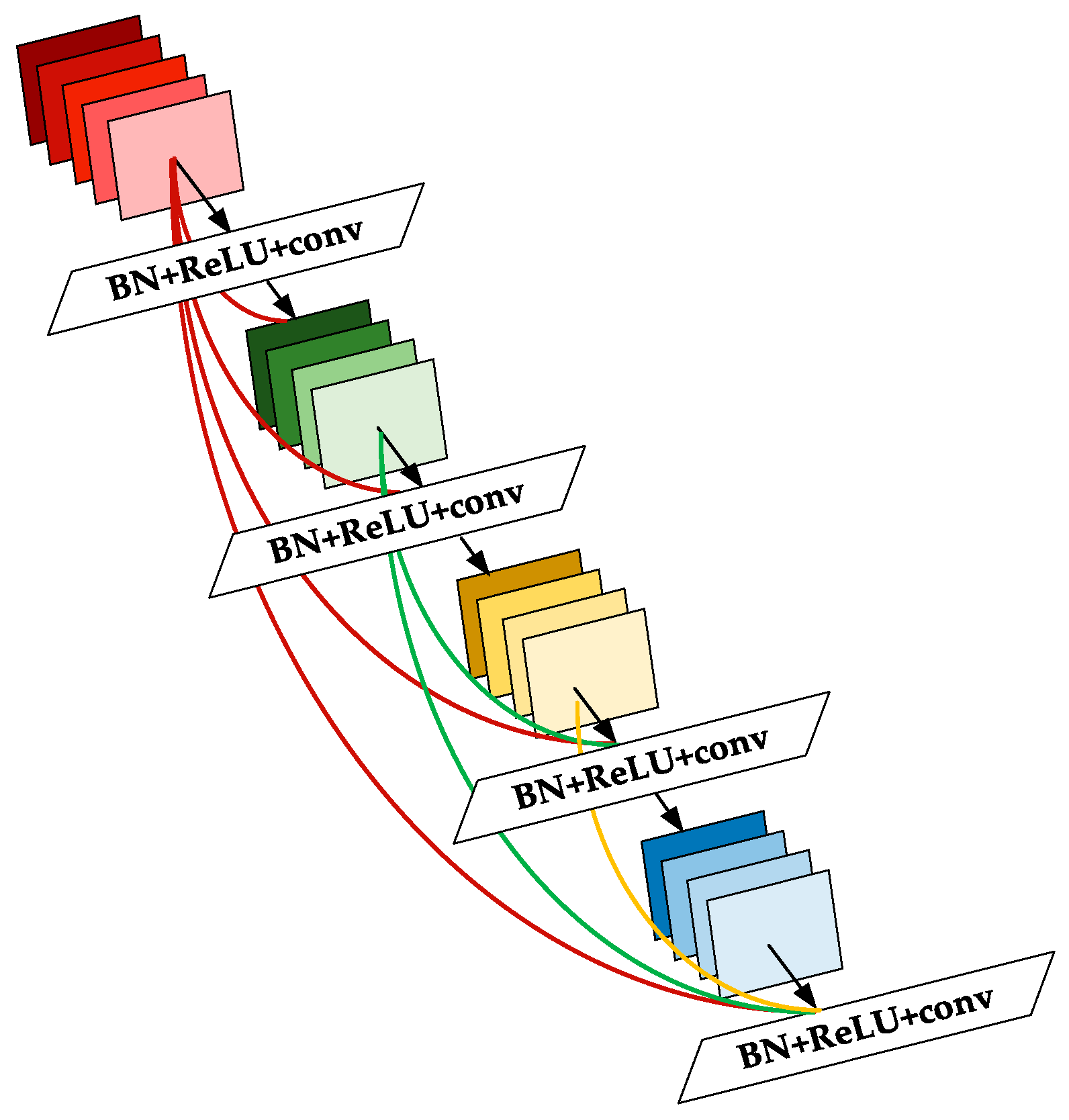
3.2. Improvement of Darknet53
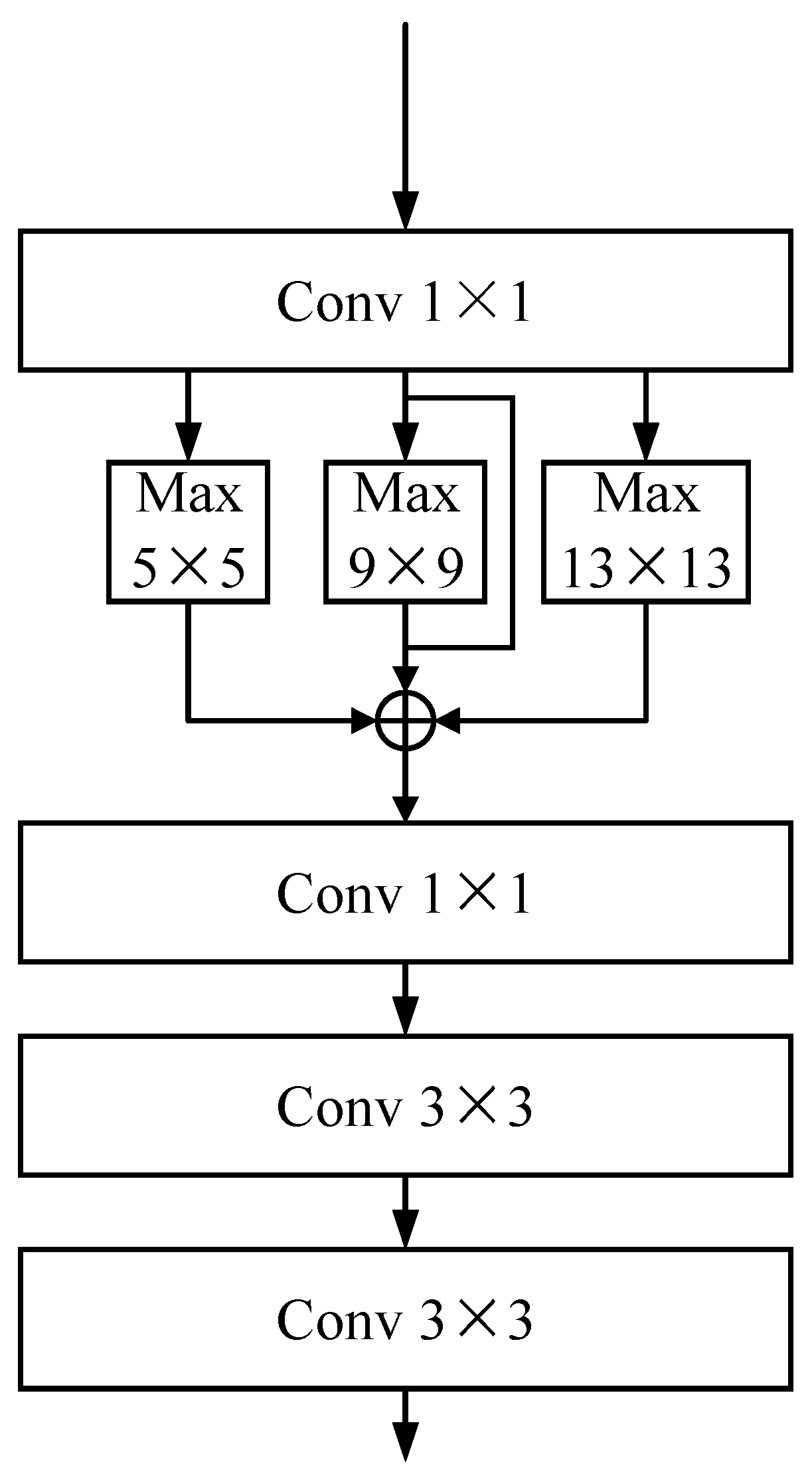
3.3. SPP Module
3.4. K-Means++ Algorithm
- (1)
- A random sample is selected as the initial cluster center in the dataset ;
- (2)
- Calculate the shortest distance between each sample and the current cluster center, and calculate the probability that each sample will be selected as the next cluster center, , and then get the next cluster center through the wheel method;
- (3)
- Repeat the previous step until a given number k of cluster centers are selected and stop the calculation.
3.5. Pseudocode
| Algorithm 1 The pseudocode of feature extraction |
| 1. For ; ; |
| 2. Read photos of doors and Windows |
| 3. Divide the picture into areas for use |
| 4. Search for areas with possible target centers |
| 5. Generate bounding boxes in possible regions |
| 6. Predict target width and height |
| 7. According to anchor boxes size and object size adjust bounding boxes size |
| 8. Predict the target category |
| 9. Calculate the confidence score of bounding boxes |
| 10. Output the center coordinates, width and height, and object category of the bounding box with the highest confidence |
| 11. end for |
| Algorithm 2 The pseudocode of training model. |
| Input: : set of training images |
| : the width of anchor boxes |
| : the height of anchor boxes |
| Output: : the target category |
| : coordinates of the center of the bounding boxes |
| : the width of the bounding boxes |
| : the height of the bounding boxes |
| 1. For to do: |
| 2. According to the feature extraction algorithm to extract the training picture: |
| 3. Calculate the error between the target center coordinates predicted by the model and the real training images |
| 4. Calculate the error between the width-height coordinates of the model predicted detection box and the real detection box |
| 5. Calculate the confidence errors of the objects in the predictive detection boxes of models |
| 6. Calculate the confidence errors of the objects is not found in the predictive detection boxes of models |
| 7. Calculate the error between the prediction categories and |
| 8. The training model adaptively adjusts learning according to the loss function |
| 9. Convergence of loss function |
| 10. Obtain the training model with the minimum loss function to achieve target detection |
4. Experimental Analysis
4.1. Experimental Data Set and Environment
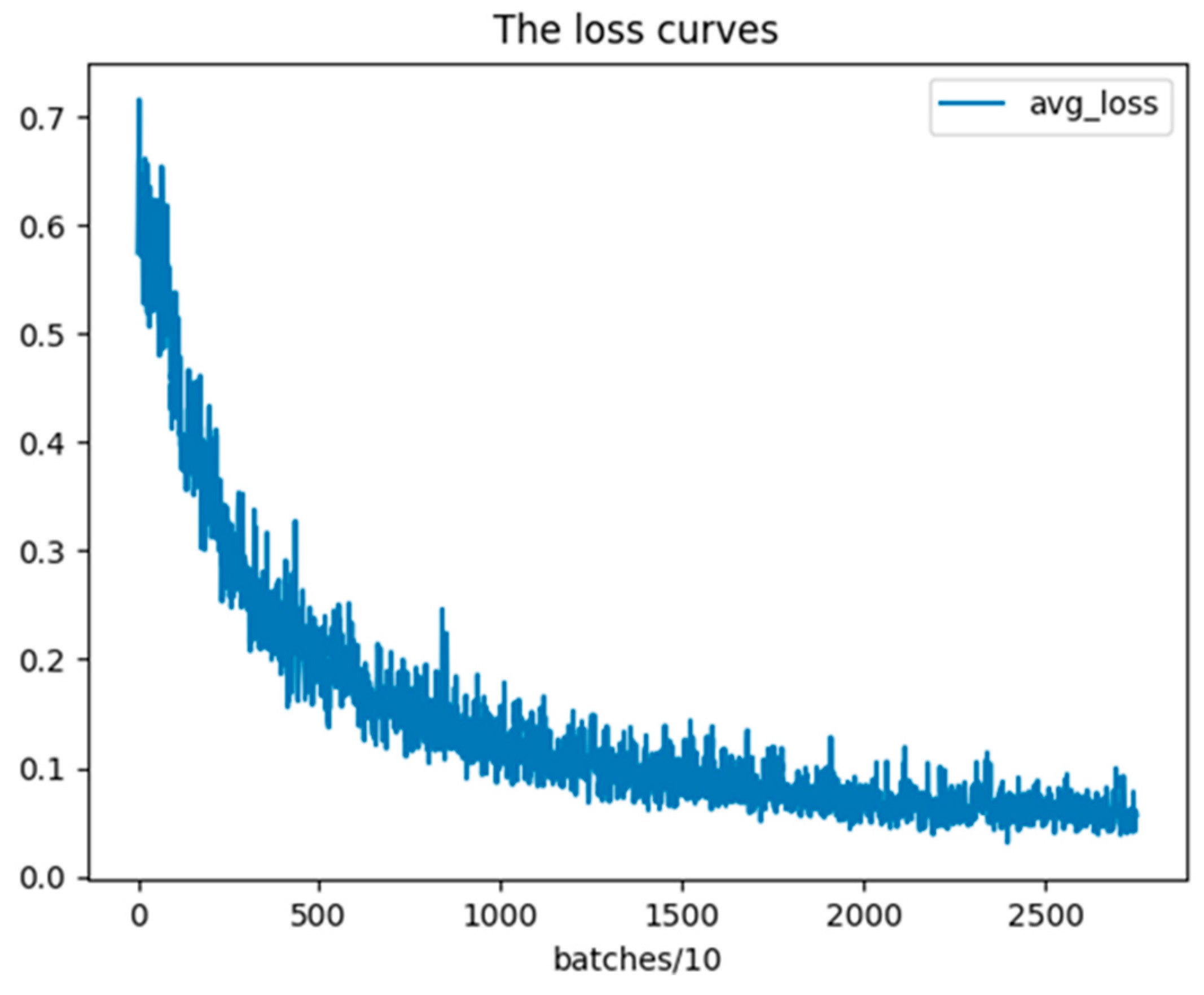
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
References
- Di, K.; Wan, W.; Zhao, H.; Liu, Z.; Wang, R.; Zhang, F. Progress and Applications of Visual SLAM. Acta Geod. Et Cartogr. Sin. 2018, 47, 770–779. [Google Scholar]
- Artieda, J.; Sebastian, J.M.; Campoy, P.; Correa, J.F.; Mondragon, I.F.; Martinez, C.; Olivares, M. Visual 3-D SLAM from UAVs. J. Intell. Robot. Syst. 2009, 55, 299–321. [Google Scholar] [CrossRef]
- Steder, B.; Grisetti, G.; Stachniss, C.; Burgard, W. Visual SLAM for Flying Vehicles. IEEE Trans. Robot. 2008, 24, 1088–1093. [Google Scholar] [CrossRef]
- Thrun, S.; Montemerlo, M.; Dahlkamp, H.; Stavens, D.; Aron, A.; Diebel, J.; Fong, P.; Gale, J.; Halpenny, M.; Hoffmann, G.; et al. Stanley: The robot that won the DARPA Grand Challenge. J. Field Robot. 2006, 23, 661–692. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Wu, X.; Song, X.; Gao, S.; Chen, C. Review of target detection algorithms based on deep learning. Transducer Microsyst. Technol. 2021, 40, 4. [Google Scholar]
- Hong-kun, C.; Hui-lan, L. Survey of Object Detection Based on Deep Learning. Acta Electonica Sin. 2020, 48, 1230–1239. [Google Scholar] [CrossRef]
- Uijlings, J.R.R.; Van De Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Carreira, J.; Sminchisescu, C. CPMC: Automatic Object Segmentation Using Constrained Parametric Min-Cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1312–1328. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- An, J.; Wang, Z. A Fast Iteration Algorithm Suitable for Incremental Learning for Training Support Vector Machine. Comput. Appl. 2003, 23, 12. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 15th IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems, NIPS 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Dai, J.F.; Li, Y.; He, K.M.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Khalid, M.; Baber, J.; Kasi, M.K.; Bakhtyar, M.; Devi, V.; Sheikh, N. Empirical Evaluation of Activation Functions in Deep Convolution Neural Network for Facial Expression Recognition. In Proceedings of the 43rd International Conference on Telecommunications and Signal Processing (TSP), Electr Network, Milan, Italy, 7–9 July 2020; pp. 204–207. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Forrest, I.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. DenseNet: Implementing Efficient ConvNet Descriptor Pyramids; Cornell University Library: Ithaca, NY, USA, 2014. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Map | ||||
|---|---|---|---|---|
| Receptive field | Big | Medium | Small | Smaller |
| Anchor box | ||||
| Hardware | Correlation Configuration |
|---|---|
| Central processing unit | Intel(R) Core(TM) i5-9300H CPU @ 2.40GHz |
| GPU | NVIDIA GTX 1080TI |
| GPU acceleration library | CUDA10.1, CuDNN7.6.5 |
| Operating system | Ubuntu16.04 |
| Deep Learning Framework | Darknet53 |
| AP (Average Precision) | mAP (Mean Average Precision) | Detection Time (136 Images) | ||
|---|---|---|---|---|
| YOLO | door | 7.7032 s | ||
| window | ||||
| YOLOV2 | door | 7.7124 s | ||
| window | ||||
| YOLOV3-Tiny | door | 5.34 s | ||
| window | 27.5% | |||
| YOLO-144884 | door | 8.0031 s | ||
| window | ||||
| YOLOV3 | door | 7.7007 s | ||
| window | ||||
| DSPP-YOLO | door | 7.906 s | ||
| window |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Li, J.; Jiang, Y.; Zeng, M.; Pang, M. Position Detection of Doors and Windows Based on DSPP-YOLO. Appl. Sci. 2022, 12, 10770. https://doi.org/10.3390/app122110770
Zhang T, Li J, Jiang Y, Zeng M, Pang M. Position Detection of Doors and Windows Based on DSPP-YOLO. Applied Sciences. 2022; 12(21):10770. https://doi.org/10.3390/app122110770
Chicago/Turabian StyleZhang, Tong, Jiaqi Li, Yilei Jiang, Mengqi Zeng, and Minghui Pang. 2022. "Position Detection of Doors and Windows Based on DSPP-YOLO" Applied Sciences 12, no. 21: 10770. https://doi.org/10.3390/app122110770
APA StyleZhang, T., Li, J., Jiang, Y., Zeng, M., & Pang, M. (2022). Position Detection of Doors and Windows Based on DSPP-YOLO. Applied Sciences, 12(21), 10770. https://doi.org/10.3390/app122110770