
A Review of Cell Operation Algorithm for 3D NAND Flash Memory



Abstract
:1. Introduction
2. Program Algorithm
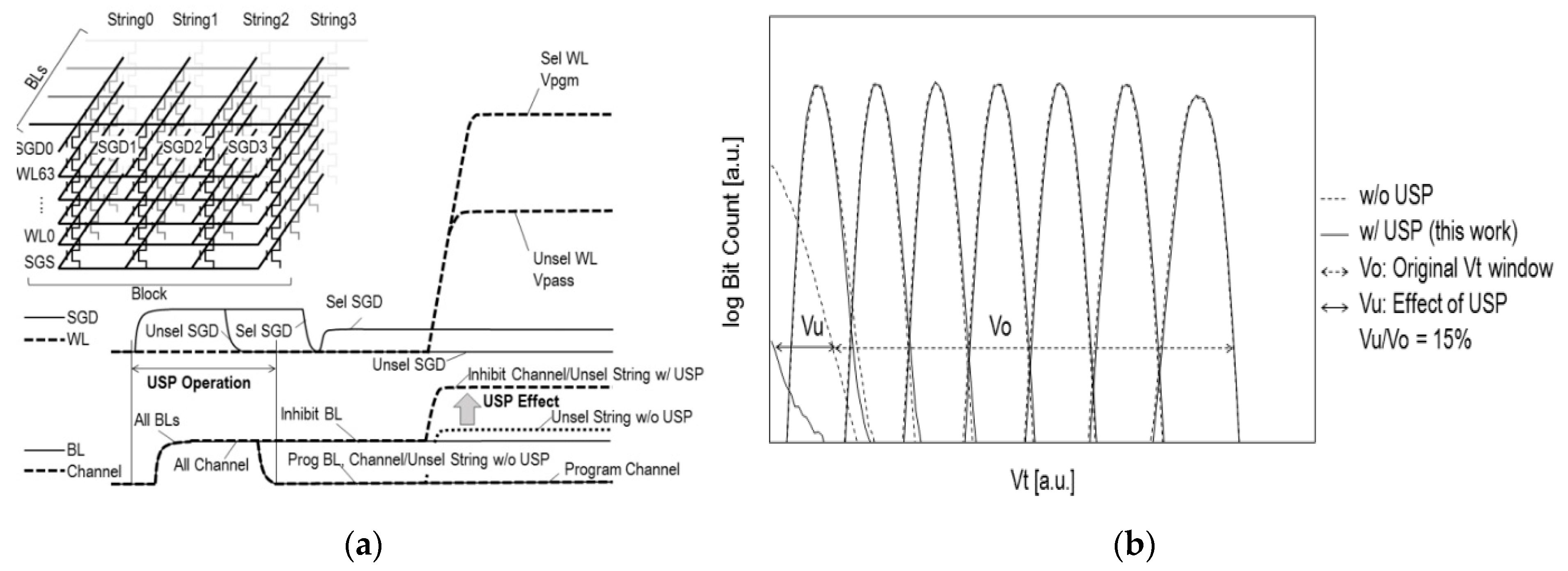
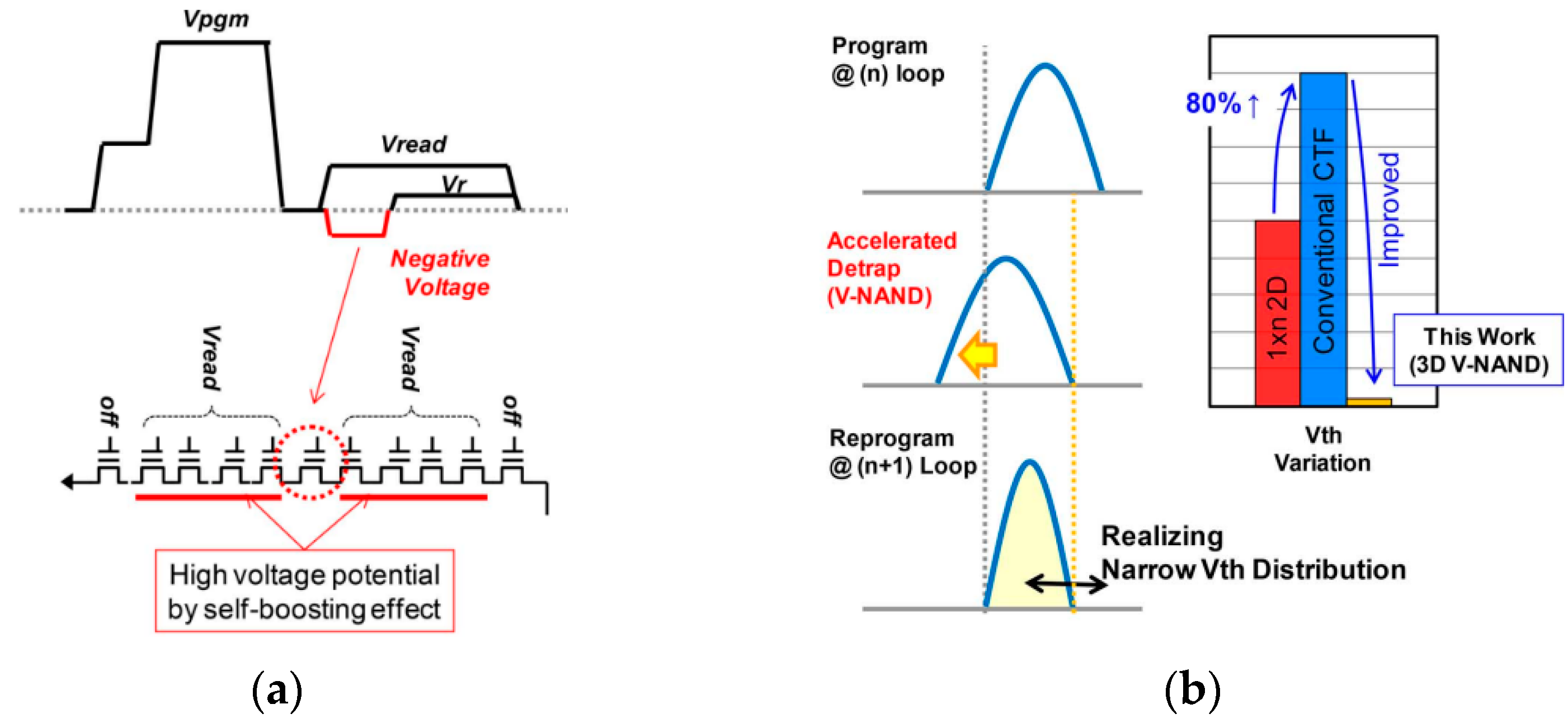
2.1. Improvement of the Program Disturb
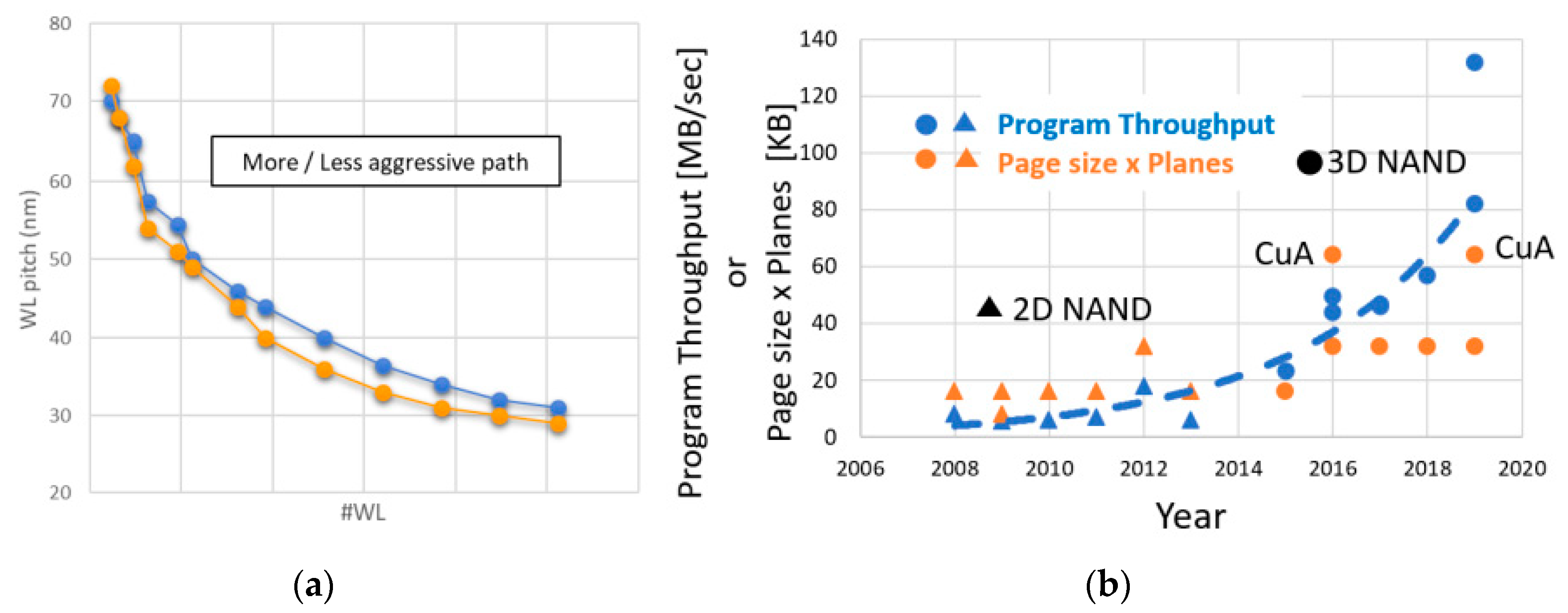
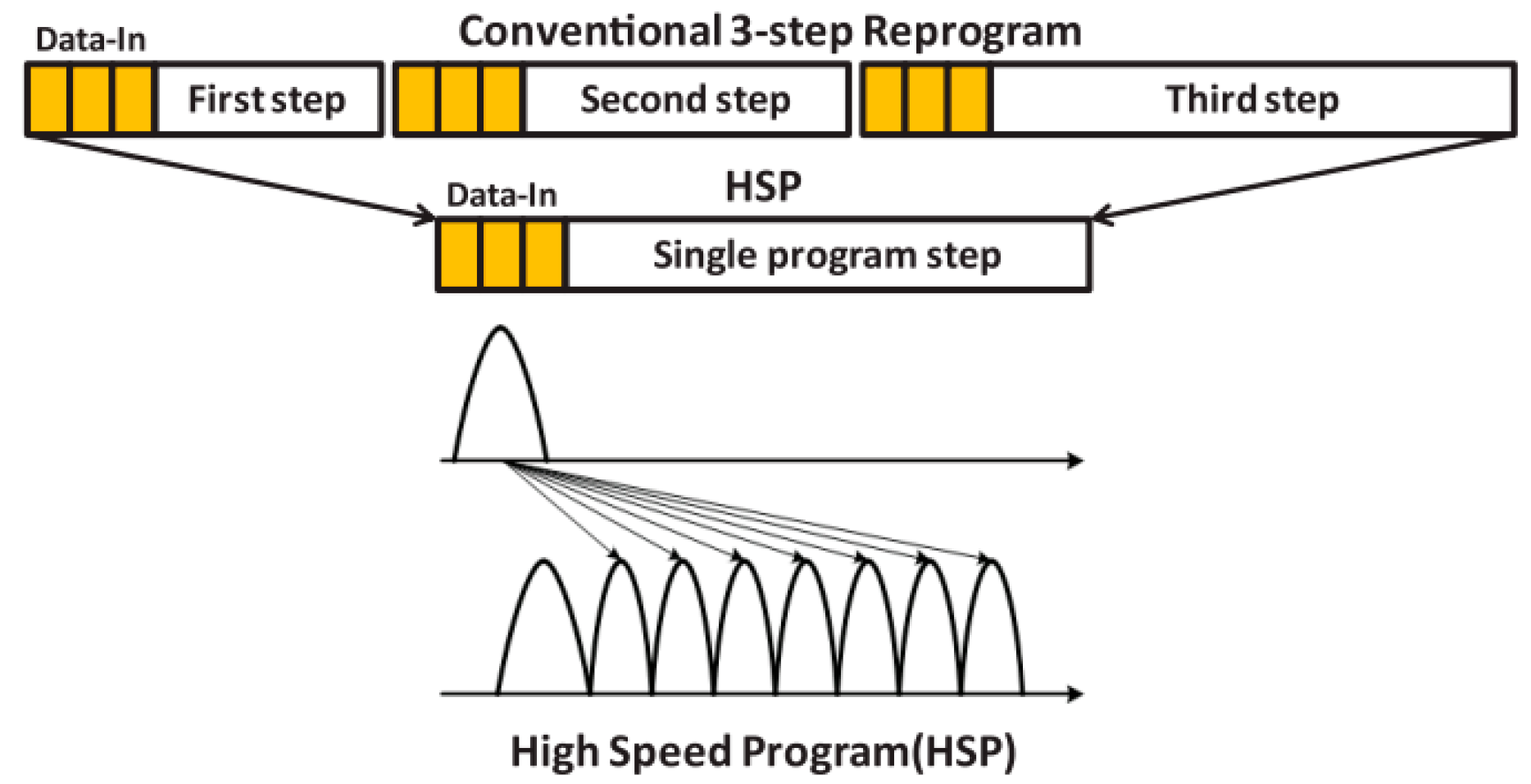
2.2. Improvement of Program Performance
2.3. Cell Variation Improvement
3. Read Algorithm
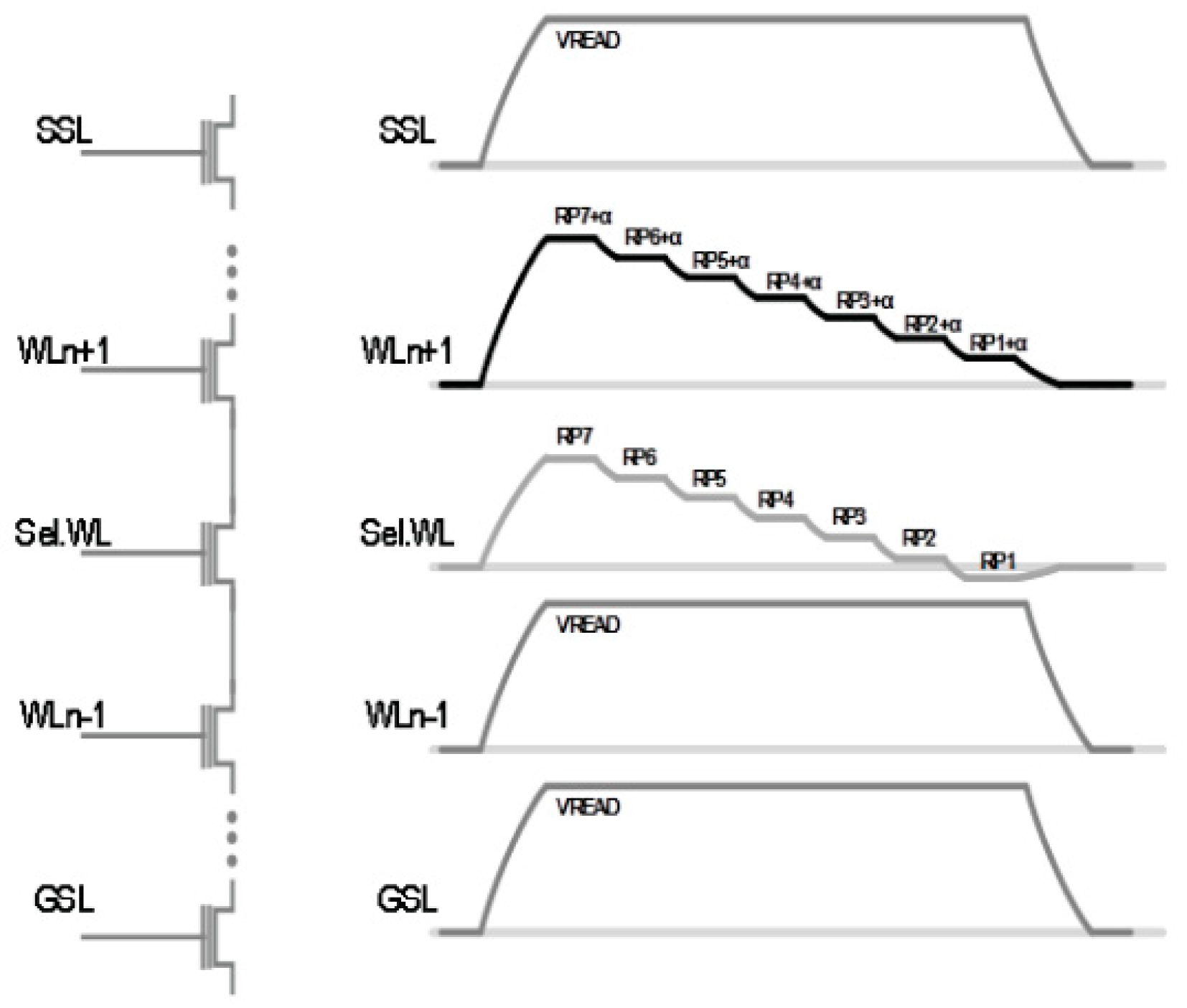
3.1. Improvement of Read Disturbance
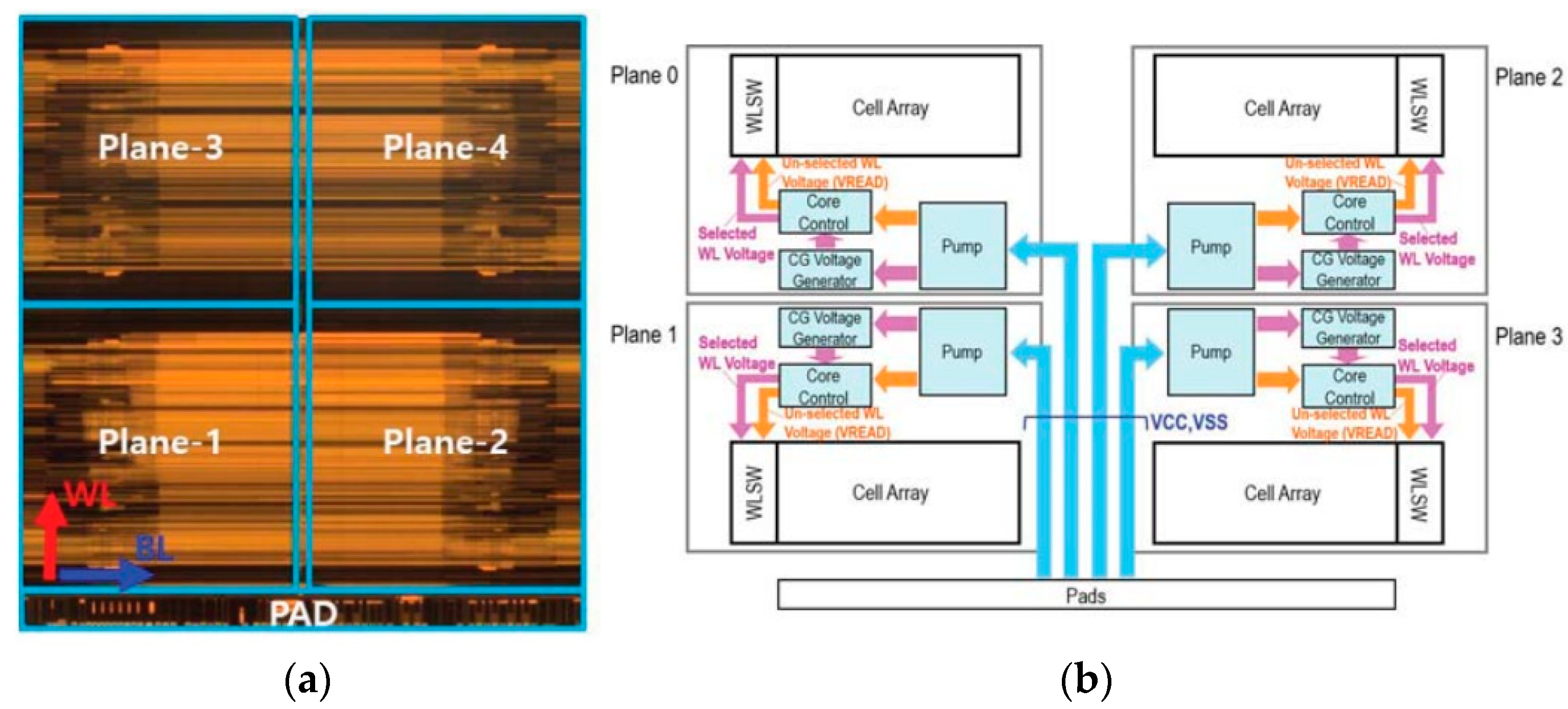
3.2. Improvement of Read Performance
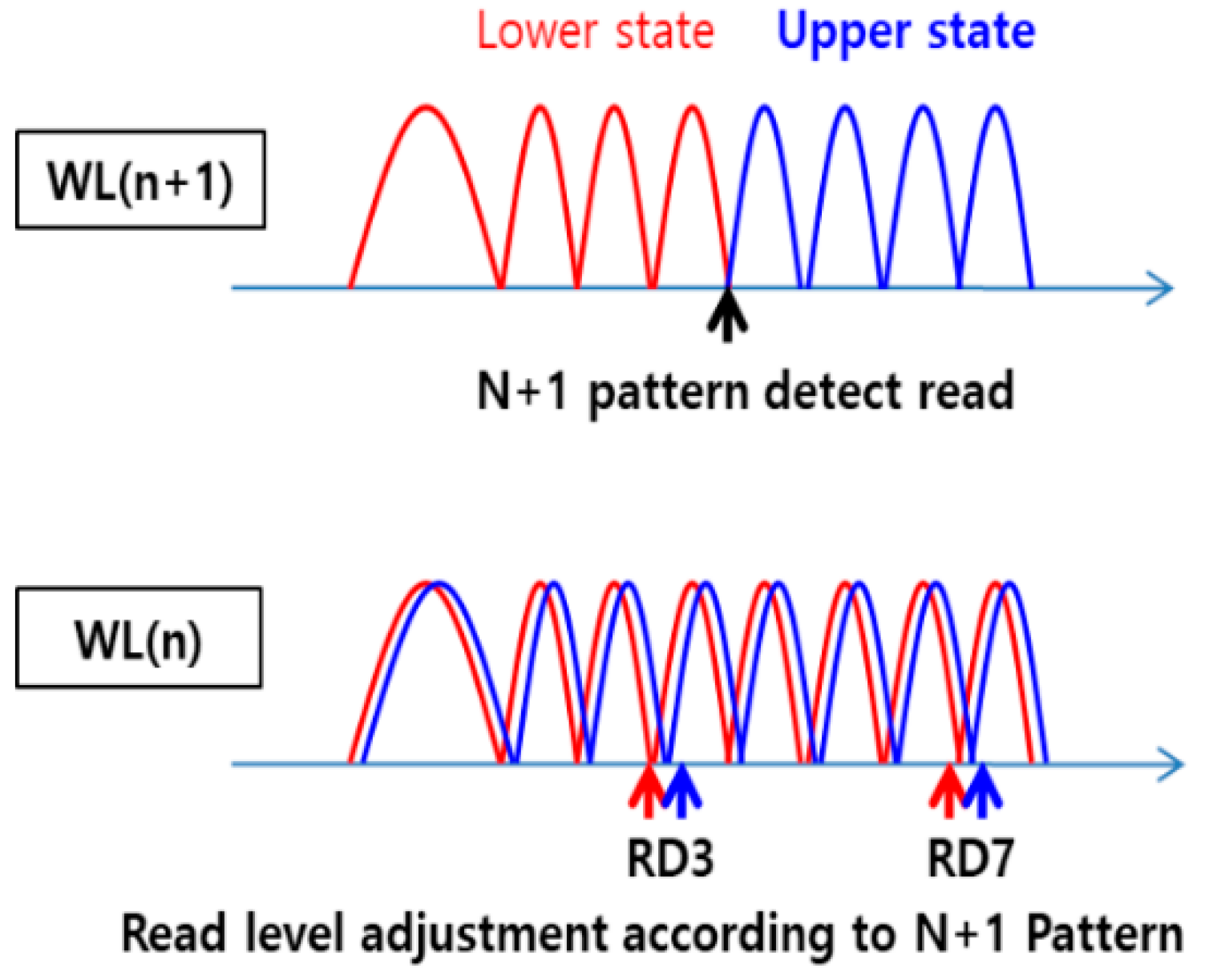
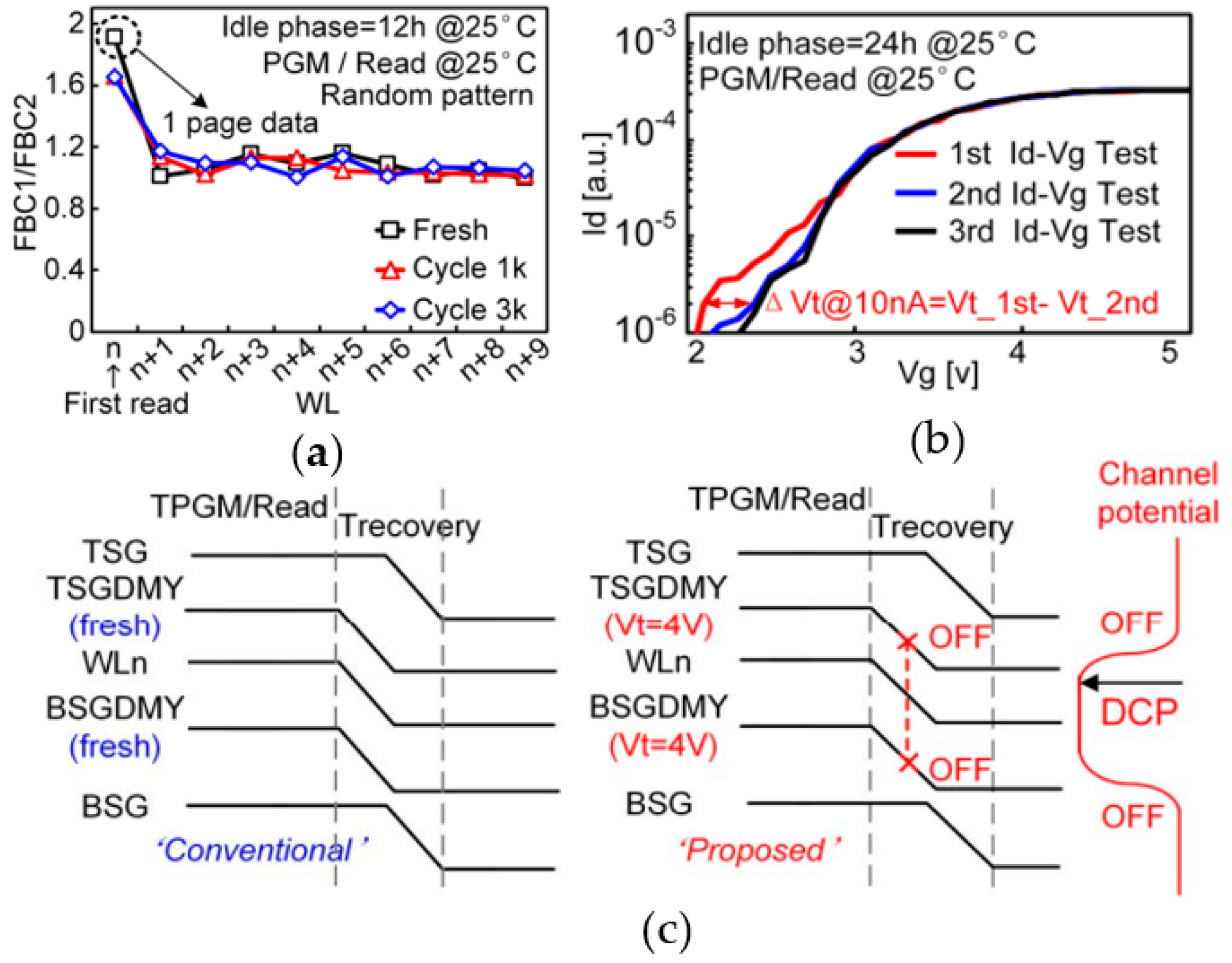
3.3. Read Failure Improvement
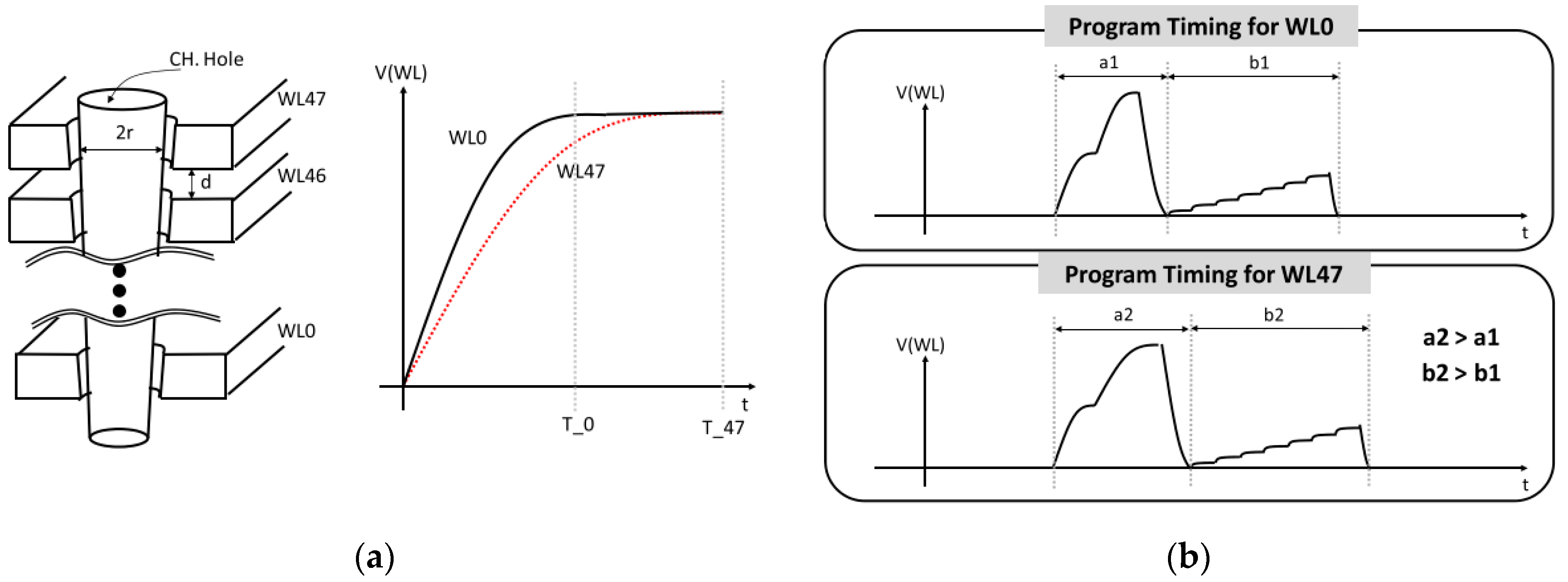
3.3.1. The WL Pitch Scaling
3.3.2. Poly-Silicon Channel Effect
4. Erase Algorithm
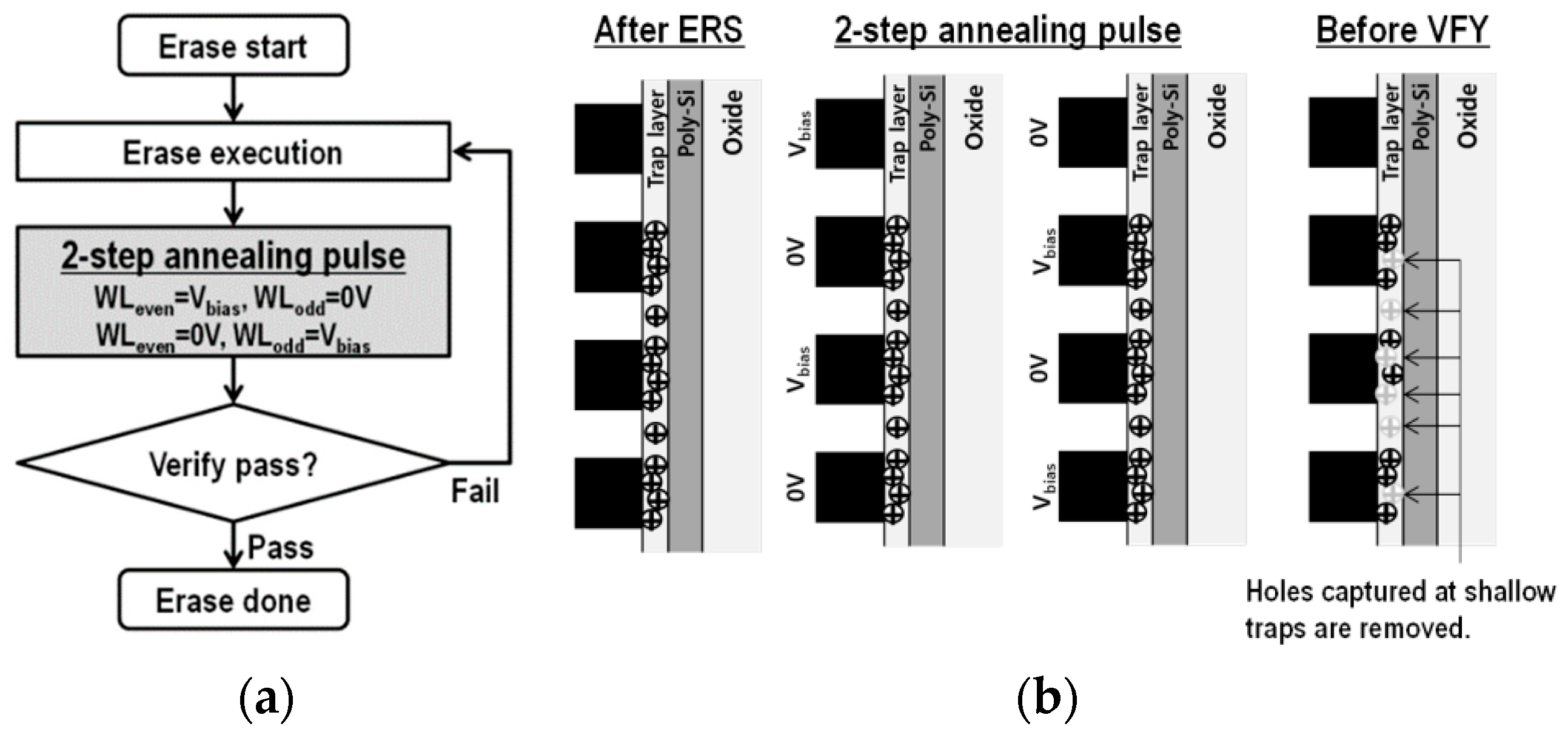
4.1. Improving the Effect of Lateral Migration
4.2. Reliability Improvement
4.3. Cell Variation Improvement
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Park, Y.; Lee, J.; Cho, S.S.; Jin, G.; Jung, E. Scaling and reliability of NAND flash devices. In Proceedings of the 2014 IEEE International Reliability Physics Symposium, Waikoloa, HI, USA, 1–4 June 2014; pp. 2E. 1.1–2E. 1.4. [Google Scholar]
- Kim, H.; Ahn, S.-J.; Shin, Y.G.; Lee, K.; Jung, E. Evolution of NAND Flash Memory: From 2D to 3D as a Storage Market Leader. In Proceedings of the 2017 IEEE International Memory Workshop (IMW), Monterey, CA, USA, 14–17 May 2017. [Google Scholar]
- Yosuke, K.; Masaru, K.; Masaru, K.; Ryota, K.; Yoshiaki, F.; Hiroyasu, T.; Yuzo, N.; Megumi, I.; Hideaki, A.; Akihiro, N. Disturbless flash memory due to high boost efficiency on BiCS structure and optimal memory film stack for ultra high density storage device. In Proceedings of the 2008 IEEE International Electron Devices Meeting, San Francisco, CA, USA, 15 December 2008. [Google Scholar]
- Lee, J.; Jang, J.; Lim, J.; Shin, Y.G.; Lee, K.; Jung, E. A new ruler on the storage market: 3D-NAND flash for high-density memory and its technology evolutions and challenges on the future. In Proceedings of the 2016 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 3–7 December 2016. [Google Scholar]
- Kang, J.-K.; Lee, J.; Yim, Y.; Park, S.; Kim, H.S.; Cho, E.S.; Kim, T.; Lee, J.H.; Kim, J.; Lee, R.; et al. Highly Reliable Cell Characteristics with CSOB(Channel-hole Sidewall ONO Butting) Scheme for 7th Generation 3D-NAND. In Proceedings of the 2021 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 11 December 2021. [Google Scholar]
- Goda, A. Recent Progress on 3D NAND Flash Technologies. Electronics 2021, 10, 3156. [Google Scholar] [CrossRef]
- Kim, S.S.; Yong, S.K.; Kim, W.; Kang, S.; Park, H.W.; Yoon, K.J.; Sheen, D.S.; Lee, S.; Hwang, C.S. Review of Semiconductor Flash Memory Devices for Material and Process Issues. Adv. Mater. 2022, 2200659. [Google Scholar] [CrossRef] [PubMed]
- Micheloni, R.; Crippa, L.; Zambelli, C.; Olivo, P. Architectural and Integration Options for 3D NAND Flash Memories. Computers 2017, 6, 27. [Google Scholar] [CrossRef] [Green Version]
- Lee, G.H.; Hwang, S.; Yu, J.; Kim, H. Architecture and process integration overview of 3D NAND flash technologies. Appl. Sci. 2021, 11, 6703. [Google Scholar] [CrossRef]
- Alsmeier, J.; Higashitani, M.; Paak, S.S.; Sivaram, S. Past and Future of 3D Flash. In Proceedings of the 2020 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 12–18 December 2020. [Google Scholar]
- Goda, A. 3-D NAND Technology Achievements and Future Scaling Perspectives. IEEE Trans. Electron Devices 2020, 67, 1373–1381. [Google Scholar] [CrossRef]
- Keon-Soo, S.; Eun-Seok, C.; Sung-Wook, J.; Se-Hoon, K.; Hyun-Seung, Y.; Kwang-Sun, J.; Han-Soo, J.; Jung-Seok, O.; Yoon-Soo, J.; Kyung-Jin, P.; et al. Inherent Issues and Challenges of Program Disturbance of 3D NAND Flash Cell. In Proceedings of the 2012 4th IEEE International Memory Workshop, Milan, Italy, 20–23 May 2012. [Google Scholar]
- Cho, J.; Kimpton, D.; Guichard, E. Optimization of select gate transistor in advanced 3D NAND memory cell. In Proceedings of the 2019 International Conference on Simulation of Semiconductor Processes and Devices (SISPAD), Udine, Italy, 4–6 September 2019. [Google Scholar]
- Kwon, D.W.; Kim, W.; Kim, D.-B.; Lee, S.-H.; Seo, J.Y.; Baek, M.-H.; Park, J.-H.; Choi, E.; Cho, G.S.; Park, S.-K.; et al. Analysis on Program Disturbance in Channel-Stacked NAND Flash Memory With Layer Selection by Multilevel Operation. IEEE Trans. Electron Devices 2016, 63, 1041–1046. [Google Scholar] [CrossRef]
- Seo, J.Y.; Kim, Y.; Park, B.-G. New program inhibition scheme for high boosting efficiency in three-dimensional NAND array. Jpn. J. Appl. Phys. 2014, 53, 070304. [Google Scholar] [CrossRef]
- Kang, M.; Kim, Y. Natural Local Self-Boosting Effect in 3D NAND Flash Memory. IEEE Electron Device Lett. 2017, 38, 1236–1239. [Google Scholar] [CrossRef]
- Zhang, Y.; Jin, L.; Jiang, D.; Zou, X.; Zhao, Z.; Gao, J.; Zeng, M.; Zhou, W.; Tang, Z.; Huo, Z. Leakage characterization of top select transistor for program disturbance optimization in 3D NAND flash. Solid State Electron. 2018, 141, 18–22. [Google Scholar] [CrossRef]
- Han, S.; Jeong, Y.; Jhon, H.; Kang, M. Investigation of Inhibited Channel Potential of 3D NAND Flash Memory According to Word-Line Location. Electronics 2020, 9, 268. [Google Scholar] [CrossRef]
- Kim, Y.; Kang, M. Down-coupling phenomenon of floating channel in 3D NAND flash memory. IEEE Electron Device Lett. 2016, 37, 1566–1569. [Google Scholar] [CrossRef]
- Raghunathan, S. (Invited) 3D-NAND Reliability: Review of key mechanisms and mitigations. In Proceedings of the 2020 4th IEEE Electron Devices Technology & Manufacturing Conference (EDTM), Penang, Malaysia, 6–21 April 2020. [Google Scholar]
- Yamashita, R.; Magia, S.; Higuchi, T.; Yoneya, K.; Yamamura, T.; Mizukoshi, H.; Zaitsu, S.; Yamashita, M.; Toyama, S.; Kamae, N.; et al. 11.1 A 512Gb 3b/cell flash memory on 64-word-line-layer BiCS technology. In Proceedings of the 2017 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 5–9 February 2017.
- Zhang, Y.; Jin, L.; Zou, X.; Liu, H.; Zhang, A.; Huo, Z. A Novel Program Scheme for Program Disturbance Optimization in 3-D NAND Flash Memory. IEEE Electron Device Lett. 2018, 39, 959–962. [Google Scholar] [CrossRef]
- Wang, J.; Wang, M. Separation of the geometric current in charge pumping measurement of polycrystalline Si thin-film transistors. IEEE Trans. Electron Devices 2014, 61, 4113–4119. [Google Scholar] [CrossRef]
- Caillat, C.; Beaman, K.; Bicksler, A.; Camozzi, E.; Ghilardi, T.; Huang, G.; Liu, H.; Liu, Y.; Mao, D.; Mujumdar, S.; et al. 3DNAND GIDL-Assisted Body Biasing for Erase Enabling CMOS under Array (CUA) Architecture. In Proceedings of the 2017 IEEE International Memory Workshop (IMW), Monterey, CA, USA, 14–17 May 2017. [Google Scholar]
- Jeong, Y.; Ham, I.; Han, S.; Kang, M. Optimal dummy word line condition to suppress hot carrier injection phenomenon due to the natural local self-boosting effect in 3D NAND flash memory. Jpn. J. Appl. Phys. 2020, 59, SGGB17. [Google Scholar] [CrossRef]
- Chen, W.-C.; Lue, H.-T.; Hsieh, C.-C.; Wang, K.-C.; Lu, C.-Y. Performance enhancement of 3-D NAND flash featuring a two-step dummy wordline program waveform and pair-bitline program scheme. IEEE Trans. Electron Devices 2020, 67, 99–104. [Google Scholar] [CrossRef]
- Lin, W.-L.; Tsai, W.-J.; Cheng, C.C.; Lu, C.-C.; Ku, S.H.; Chang, Y.W.; Wu, G.-W.; Liu, L.; Hwang, S.W.; Lu, T.-C.; et al. Hot-Carrier Injection-Induced Disturb and Improvement Methods in 3D NAND Flash Memory. In Proceedings of the 2019 International Symposium on VLSI Technology, Systems and Application (VLSI-TSA), Hsinchu, Taiwan, 22–25 April 2019. [Google Scholar]
- Yoon, C.-W. The Fundamentals of NAND Flash Memory: Technology for tomorrow’s fourth industrial revolution. IEEE Solid-State Circuits Mag. 2022, 14, 56–65. [Google Scholar] [CrossRef]
- Chang, Y.-M.; Chang, Y.-H.; Kuo, T.-W.; Li, Y.-C.; Li, H.-P. Disturbance Relaxation for 3D Flash Memory. IEEE Trans. Comput. 2016, 65, 1467–1483. [Google Scholar] [CrossRef]
- Yuh, J.; Li, J.; Li, H.; Oyama, Y.; Hsu, C.; Anantula, P.; Jeong, S.; Amarnath, A.; Darne, S.; Bhatia, S.; et al. A 1-Tb 4b/Cell 4-Plane 162-Layer 3D Flash Memory With a 2.4-Gb/s I/O Speed Interface. In Proceedings of the 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 20–24 February 2022. [Google Scholar]
- Pekny, T.; Vu, L.; Tsai, J.; Srinivasan, D.; Yu, E.; Pabustan, J.; Xu, J.; Deshmukh, S.; Chan, K.-F.; Piccardi, M.; et al. A 1-Tb Density 4b/Cell 3D-NAND Flash on 176-Tier Technology with 4-Independent Planes for Read using CMOS-Under-the-Array. In Proceedings of the 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 20–24 February 2022. [Google Scholar]
- Kim, M.; Yun, S.W.; Park, J.; Park, H.K.; Lee, J.; Kim, Y.S.; Na, D.; Choi, S.; Song, Y.; Lee, J.; et al. A 1Tb 3b/Cell 8th-Generation 3D-NAND Flash Memory with 164 MB/s Write Throughput and a 2.4 Gb/s Interface. In Proceedings of the 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 20–24 February 2022. [Google Scholar]
- Shibata, N.; Maejima, H.; Isobe, K.; Iwasa, K.; Nakagawa, M.; Fujiu, M.; Shimizu, T.; Honma, M.; Hoshi, S.; Kawaai, T.; et al. A 70 nm 16 Gb 16-Level-Cell NAND flash Memory. IEEE J. Solid-State Circuits 2008, 43, 929–937. [Google Scholar] [CrossRef]
- Im, J.-W.; Jeong, W.-P.; Kim, D.-H.; Nam, S.-W.; Shim, D.-K.; Choi, M.-H.; Yoon, H.-J.; Kim, D.-H.; Kim, Y.-S.; Park, H.-W.; et al. 7.2 A 128Gb 3b/cell V-NAND flash memory with 1 Gb/s I/O rate. In Proceedings of the 2015 IEEE International Solid-State Circuits Conference-(ISSCC) Digest of Technical Papers, San Francisco, CA, USA, 22–26 February 2015. [Google Scholar]
- Jeong, W.; Im, J.-W.; Kim, D.-H.; Nam, S.-W.; Shim, D.-K.; Choi, M.-H.; Yoon, H.-J.; Kim, D.-H.; Kim, Y.-S.; Park, H.-W.; et al. A 128 Gb 3b/cell V-NAND Flash Memory With 1 Gb/s I/O Rate. IEEE J. Solid-State Circuits 2016, 51, 204–212. [Google Scholar] [CrossRef]
- Kim, D.-H.; Kim, H.; Yun, S.; Song, Y.; Kim, J.; Joe, S.-M.; Kang, K.-H.; Jang, J.; Yoon, H.-J.; Lee, K.; et al. 13.1 A 1Tb 4b/cell NAND Flash Memory with tPROG = 2 ms, tR = 110 µs and 1.2 Gb/s High-Speed IO Rate. In Proceedings of the 2020 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 16–20 February 2020. [Google Scholar]
- Lee, S.; Kim, C.; Kim, M.; Joe, S.-M.; Jang, J.; Kim, S.; Lee, K.; Kim, J.; Park, J.; Lee, H.-J.; et al. A 1Tb 4b/cell 64-stacked-WL 3D NAND flash memory with 12 MB/s program throughput. In Proceedings of the 2018 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 11–15 February 2018. [Google Scholar]
- Dong, G.; Xie, N.; Zhang, T. On the Use of Soft-Decision Error-Correction Codes in nand Flash Memory. IEEE Trans. Circuits Syst. I Regul. Pap. 2011, 58, 429–439. [Google Scholar] [CrossRef]
- Maejima, H.; Kanda, K.; Fujimura, S.; Takagiwa, T.; Ozawa, S.; Sato, J.; Shindo, Y.; Sato, M.; Kanagawa, N.; Musha, J.; et al. A 512Gb 3b/Cell 3D flash memory on a 96-word-line-layer technology. In Proceedings of the 2018 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 11–15 February 2018. [Google Scholar]
- Kim, C.; Kim, D.H.; Jeong, W.; Kim, H.J.; Park, I.H.; Park, H.W.; Lee, J.; Park, J.; Ahn, Y.L.; Lee, J.Y.; et al. A 512Gb 3b/cell 64-Stacked WL 3D V-NAND Flash Memory. IEEE J. Solid State Circuits 2017, 53, 124–133. [Google Scholar] [CrossRef]
- Kim, J.H.; Yim, Y.; Lim, J.; Kim, H.S.; Cho, E.S.; Yeo, C.; Lee, W.; You, B.; Lee, B.; Kang, M. Highly Manufacturable 7 th Generation 3D NAND Flash Memory with COP structure and Double Stack Process. In Proceedings of the 2021 Symposium on VLSI Technology, Hsinchu, Taiwan, 13–19 June 2021; pp. 1–2. [Google Scholar]
- Kang, D.; Jeong, W.; Kim, C.; Kim, D.-H.; Cho, Y.S.; Kang, K.-T.; Ryu, J.; Kang, K.-M.; Lee, S.; Kim, W.; et al. 256 Gb 3b/cell V-NAND flash memory with 48 stacked WL layers. In Proceedings of the 2016 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 31 January–4 February 2016. [Google Scholar]
- Sim, J.-M.; Kang, M.; Song, Y.-H. A Novel Program Operation Scheme With Negative Bias in 3-D NAND Flash Memory. IEEE Trans. Electron Devices 2021, 68, 6112–6117. [Google Scholar] [CrossRef]
- Kang, D.; Jeong, W.; Kim, C.; Kim, D.-H.; Cho, Y.S.; Kang, K.-T.; Ryu, J.; Kang, K.-M.; Lee, S.; Kim, W.; et al. 256 Gb 3 b/Cell V-nand Flash Memory With 48 Stacked WL Layers. IEEE J. Solid-State Circuits 2017, 52, 210–217. [Google Scholar] [CrossRef]
- Shibata, N.; Kanda, K.; Shimizu, T.; Nakai, J.; Nagao, O.; Kobayashi, N.; Miakashi, M.; Nagadomi, Y.; Nakano, T.; Kawabe, T.; et al. A 1.33Tb 4-bit/Cell 3D-Flash Memory on a 96-Word-Line-Layer Technology. IEEE J. Solid State Circuits 2019, 55, 178–188. [Google Scholar] [CrossRef]
- Park, J.-W.; Kim, D.; Ok, S.; Park, J.; Kwon, T.; Lee, H.; Lim, S.; Jung, S.-Y.; Choi, H.; Kang, T.; et al. 30.1 A 176-Stacked 512Gb 3b/Cell 3D-NAND Flash with 10.8Gb/mm2 Density with a Peripheral Circuit Under Cell Array Architecture. In Proceedings of the 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021. [Google Scholar]
- Tanaka, T.; Helm, M.; Vali, T.; Ghodsi, R.; Kawai, K.; Park, J.-K.; Yamada, S.; Pan, F.; Einaga, Y.; Ghalam, A.; et al. 7.7 A 768Gb 3b/cell 3D-floating-gate NAND flash memory. In Proceedings of the 2016 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 31 January–4 February 2016. [Google Scholar]
- Park, K.-T.; Nam, S.; Kim, D.; Kwak, P.; Lee, D.; Choi, Y.-H.; Choi, M.-H.; Kwak, D.-H.; Kim, D.-H.; Kim, M.-S.; et al. Three-Dimensional 128 Gb MLC Vertical nand Flash Memory With 24-WL Stacked Layers and 50 MB/s High-Speed Programming. IEEE J. Solid-State Circuits 2015, 50, 204–213. [Google Scholar] [CrossRef]
- Park, K.-T.; Han, J.-M.; Kim, D.; Nam, S.; Choi, K.; Kim, M.-S.; Kwak, P.; Lee, D.; Choi, Y.-H.; Kang, K.-M.; et al. 19.5 Three-dimensional 128Gb MLC vertical NAND Flash-memory with 24-WL stacked layers and 50 MB/s high-speed programming. In Proceedings of the 2014 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 9–13 February 2014. [Google Scholar]
- Kang, D.; Kim, M.; Jeon, S.C.; Jung, W.; Park, J.; Choo, G.; Shim, D.-K.; Kavala, A.; Kim, S.-B.; Kang, K.-M.; et al. 13.4 A 512Gb 3-bit/Cell 3D 6th-Generation V-NAND Flash Memory with 82 MB/s Write Throughput and 1.2 Gb/s Interface. In Proceedings of the 2019 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 17–21 February 2019. [Google Scholar]
- Chen, C.-P.; Lue, H.-T.; Hsieh, C.-C.; Chang, K.-P.; Hsieh, K.-Y.; Lu, C.-Y. Study of fast initial charge loss and it’s impact on the programmed states Vt distribution of charge-trapping NAND Flash. In Proceedings of the 2010 International Electron Devices Meeting, San Francisco, CA, USA, 6–8 December 2010; pp. 5.6.1–5.6.4. [Google Scholar]
- Ouyang, Y.; Xia, Z.; Yang, T.; Shi, D.; Zhou, W.; Huo, Z. Optimization of performance and reliability in 3D NAND flash memory. IEEE Electron Device Lett. 2020, 41, 840–843. [Google Scholar] [CrossRef]
- Maconi, A.; Arreghini, A.; Compagnoni, C.M.; Spinelli, A.; Van Houdt, J.; Lacaita, A.L. Comprehensive investigation of the impact of lateral charge migration on retention performance of planar and 3D SONOS devices. Solid State Electron. 2012, 74, 64–70. [Google Scholar] [CrossRef]
- Padovani, A.; Pesic, M.; Kumar, M.A.; Blomme, P.; Subirats, A.; Vadakupudhupalayam, S.; Baten, Z.; Larcher, L. Understanding and variability of lateral charge migration in 3D CT-NAND flash with and without band-gap engineered barriers. In Proceedings of the 2019 IEEE International Reliability Physics Symposium (IRPS), Monterey, CA, USA, 31 March–4 April 2019; pp. 1–8. [Google Scholar]
- Cheng, T.; Jia, J.; Jin, L.; Jia, X.; Xia, S.; Lu, J.; Li, K.; Luo, Z.; Li, D.; Liu, H.; et al. Investigation of Re-Program Scheme in Charge Trap-Based 3D NAND Flash Memory. IEEE J. Electron Devices Soc. 2021, 9, 640–644. [Google Scholar] [CrossRef]
- Du, Z.; Li, S.; Wang, Y.; Fu, X.; Liu, F.; Wang, Q.; Huo, Z. Adaptive Pulse Programming Scheme for Improving the Vth Distribution and Program Performance in 3D NAND Flash Memory. IEEE J. Electron Devices Soc. 2021, 9, 102–107. [Google Scholar] [CrossRef]
- Hsu, T.-H.; Lue, H.-T.; Lai, E.-K.; Hsieh, J.-Y.; Wang, S.-Y.; Yang, L.-W.; King, Y.-C.; Yang, T.; Chen, K.-C.; Hsieh, K.-Y. A high-speed BE-SONOS NAND flash utilizing the field-enhancement effect of FinFET. In Proceedings of the 2007 IEEE International Electron Devices Meeting, Washington, DC, USA, 6–8 December 2007; pp. 913–916. [Google Scholar]
- Kim, W.; Byeon, D.; Joe, S.-M.; Lee, J.; Song, J.H. Cell Operation Technologies to Overcome Scale-down Issues in 3D NAND Flash Memory. In Proceedings of the 2022 International Conference on Electronics, Information, and Communication (ICEIC), Jeju, Korea, 3–5 September 2022; pp. 298–299. [Google Scholar]
- Yi, S.-I.; Kim, J. Novel Program Scheme of Vertical NAND Flash Memory for Reduction of Z-Interference. Micromachines 2021, 12, 584. [Google Scholar] [CrossRef]
- Wang, Y.; Tan, J.; Mao, R.; Li, T. Temperature-Aware Persistent Data Management for LSM-Tree on 3-D NAND Flash Memory. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2020, 39, 4611–4622. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, J.; Chen, J.; Mao, R. PVSensing: A Process-Variation-Aware Space Allocation Strategy for 3D NAND Flash Memory. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2022, 41, 1302–1315. [Google Scholar] [CrossRef]
- Zhang, Y.; Jin, L.; Jiang, D.; Zou, X.; Liu, H.; Huo, Z. A Novel Read Scheme for Read Disturbance Suppression in 3D NAND Flash Memory. IEEE Electron Device Lett. 2017, 38, 1669–1672. [Google Scholar] [CrossRef]
- Cho, W.; Jung, J.; Kim, J.; Ham, J.; Lee, S.; Noh, Y.; Kim, D.; Lee, W.; Cho, K.; Kim, K.; et al. A 1-Tb, 4b/Cell, 176-Stacked-WL 3D-NAND Flash Memory with Improved Read Latency and a 14.8Gb/mm2 Density. In Proceedings of the 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 20–24 February 2022. [Google Scholar]
- Wang, H.-H.; Shieh, P.-S.; Huang, C.-T.; Tokami, K.; Kuo, R.; Chen, S.-H.; Wei, H.-C.; Pittikoun, S.; Aritome, S. A New Read-Disturb Failure Mechanism Caused by Boosting Hot-Carrier Injection Effect in MLC NAND Flash Memory. In Proceedings of the 2009 IEEE International Memory Workshop, Monterey, CA, USA, 10–14 May 2009. [Google Scholar]
- Choe, B.-I.; Lee, J.-K.; Park, B.-G.; Lee, J.-H. Suppression of Read Disturb Fail Caused by Boosting Hot Carrier Injection Effect for 3-D Stack NAND Flash Memories. IEEE Electron Device Lett. 2014, 35, 42–44. [Google Scholar] [CrossRef]
- Jo, H.; Shin, H. New Read Schemes to Reduce Read Disturbance Due to HCI in Full Boosting Channel 3-D NAND Flash Memories. In Proceedings of the 2021 Silicon Nanoelectronics Workshop (SNW), Honolulu, HI, USA, 13–14 June 2021; pp. 1–2. [Google Scholar]
- Kwon, D.W.; Kim, D.-B.; Lee, J.; Kim, S.; Lee, R.; Lee, J.-H.; Park, B.-G. Analysis on New Read Disturbance Induced by Hot Carrier Injections in 3-D Channel-Stacked NAND Flash Memory. IEEE Trans. Electron Devices 2019, 66, 3326–3330. [Google Scholar] [CrossRef]
- Huh, H.; Cho, W.; Lee, J.; Noh, Y.; Park, Y.; Ok, S.; Kim, J.; Cho, K.; Lee, H.; Kim, G.; et al. 13.2 A 1Tb 4b/Cell 96-Stacked-WL 3D NAND Flash Memory with 30 MB/s Program Throughput Using Peripheral Circuit Under Memory Cell Array Technique. In Proceedings of the 2020 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 16–20 February 2020. [Google Scholar]
- Higuchi, T.; Kodama, T.; Kato, K.; Fukuda, R.; Tokiwa, N.; Abe, M.; Takagiwa, T.; Shimizu, Y.; Musha, J.; Sakurai, K.; et al. 30.4 A 1Tb 3b/Cell 3D-Flash Memory in a 170+ Word-Line-Layer Technology. In Proceedings of the 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021. [Google Scholar]
- Kim, M.; Jung, W.; Lee, H.-J.; Chung, E.-Y. A novel nand flash memory architecture for maximally exploiting plane-level parallelism. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 1957–1961. [Google Scholar] [CrossRef]
- Siau, C.; Kim, K.-H.; Lee, S.; Isobe, K.; Shibata, N.; Verma, K.; Ariki, T.; Li, J.; Yuh, J.; Amarnath, A.; et al. 13.5 A 512Gb 3-bit/Cell 3D Flash Memory on 128-Wordline-Layer with 132 MB/s Write Performance Featuring Circuit-Under-Array Technology. In Proceedings of the 2019 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 17–21 February 2019. [Google Scholar]
- Khakifirooz, A.; Balasubrahmanyam, S.; Fastow, R.; Gaewsky, K.H.; Ha, C.W.; Haque, R.; Jungroth, O.W.; Law, S.; Madraswala, A.S.; Ngo, B.; et al. 30.2 A 1Tb 4b/Cell 144-Tier Floating-Gate 3D-NAND Flash Memory with 40 MB/s Program Throughput and 13.8 Gb/mm2 Bit Density. In Proceedings of the 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021. [Google Scholar]
- Cai, Y.; Ghose, S.; Haratsch, E.F.; Luo, Y.; Mutlu, O. Error characterization, mitigation, and recovery in flash-memory-based solid-state drives. Proc. IEEE 2017, 105, 1666–1704. [Google Scholar] [CrossRef]
- Jo, H.; Ahn, S.; Shin, H. Investigation and Modeling of Z-Interference in Poly-Si Channel-Based 3-D NAND Flash Memories. IEEE Trans. Electron Devices 2022, 69, 543–548. [Google Scholar] [CrossRef]
- Liu, Y.-H.; Jiang, C.-M.; Chen, W.-C.; Wang, T.; Tsai, W.-J.; Lu, T.-C.; Chen, K.-C.; Lu, C.-Y. Electric Field Induced Nitride Trapped Charge Lateral Migration in a SONOS Flash Memory. IEEE Electron Device Lett. 2017, 38, 48–51. [Google Scholar] [CrossRef]
- Sim, J.-M.; Kang, M.; Song, Y.-H. A New Read Scheme for Alleviating Cell-to-Cell Interference in Scaled-Down 3D NAND Flash Memory. Electronics 2020, 9, 1775. [Google Scholar] [CrossRef]
- Resnati, D.; Goda, A.; Nicosia, G.; Miccoli, C.; Spinelli, A.S.; Monzio Compagnoni, C. Temperature Effects in NAND Flash Memories: A Comparison Between 2-D and 3-D Arrays. IEEE Electron Device Lett. 2017, 38, 461–464. [Google Scholar] [CrossRef]
- Choi, S.; Park, K.; Passerini, M.; Park, H.; Kim, D.; Kim, C.; Park, K.; Kim, J. A cell current compensation scheme for 3D NAND FLASH memory. In Proceedings of the 2015 IEEE Asian Solid-State Circuits Conference (A-SSCC), Xia’men, China, 9–11 November 2015. [Google Scholar]
- Rachidi, S.; Arreghini, A.; Verreck, D.; Donadio, G.L.; Banerjee, K.; Katcko, K.; Oniki, Y.; Van Den Bosch, G.; Rosmeulen, M. At the Extreme of 3D-NAND Scaling: 25 nm Z-Pitch with 10 nm Word Line Cells. In Proceedings of the 2022 IEEE International Memory Workshop (IMW), Dresden, DE, USA, 15–18 May 2022. [Google Scholar]
- Zhao, C.; Jin, L.; Li, D.; Xu, F.; Zou, X.; Zhang, Y.; Song, Y.; Wei, H.; Chen, Y.; Li, C.; et al. Investigation of Threshold Voltage Distribution Temperature Dependence in 3D NAND Flash. IEEE Electron Device Lett. 2019, 40, 204–207. [Google Scholar] [CrossRef]
- Lin, W.-L.; Tsai, W.-J.; Cheng, C.C.; Ku, S.H.; Liu, L.; Hwang, S.W.; Lu, T.-C.; Chen, K.-C.; Tseng, T.-Y.; Lu, C.-Y. Grain Boundary Trap-Induced Current Transient in a 3-D NAND Flash Cell String. IEEE Trans. Electron Devices 2019, 66, 1734–1740. [Google Scholar] [CrossRef]
- Tsai, W.-J.; Lin, W.L.; Cheng, C.C.; Ku, S.H.; Chou, Y.L.; Liu, L.; Hwang, S.W.; Lu, T.C.; Chen, K.C.; Wang, T.; et al. Polycrystalline-silicon channel trap induced transient read instability in a 3D NAND flash cell string. In Proceedings of the 2016 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 3–7 December 2016. [Google Scholar]
- Zambelli, C.; Micheloni, R.; Scommegna, S.; Olivo, P. First Evidence of Temporary Read Errors in TLC 3D-NAND Flash Memories Exiting From an Idle State. IEEE J. Electron Devices Soc. 2020, 8, 99–104. [Google Scholar] [CrossRef]
- Xia, S.; Jia, X.; Jin, L.; Luo, Z.; Song, Y.; Liu, C.; Xu, F.; Li, K.; Li, H.; Li, D.; et al. Analysis and Optimization of Temporary Read Errors in 3D NAND Flash Memories. IEEE Electron Device Lett. 2021, 42, 820–823. [Google Scholar] [CrossRef]
- Jia, X.; Jin, L.; Hou, W.; Wang, Z.; Jiang, S.; Li, K.; Huang, D.; Liu, H.; Wei, W.; Lu, J. Impact of cycling induced intercell trapped charge on retention charge loss in 3-D NAND flash memory. IEEE J. Electron Devices Soc. 2020, 8, 62–66. [Google Scholar] [CrossRef]
- Kim, S.; Shin, H. Analysis of the Effect of Residual Holes on Lateral Migration During the Retention Operation in 3-D NAND Flash Memory. IEEE Trans. Electron Devices 2021, 68, 6094–6099. [Google Scholar] [CrossRef]
- Yan, L.; Jin, L.; Zou, X.; Ai, D.; Li, D.; Zhang, A.; Wei, H.; Chen, Y.; Huo, Z. Investigation of Erase Cycling Induced TSG Vt Shift in 3D NAND Flash Memory. IEEE Electron Device Lett. 2019, 40, 21–23. [Google Scholar] [CrossRef]
- Park, J.K.; Moon, D.-I.; Choi, Y.-K.; Lee, S.-H.; Lee, K.-H.; Pyi, S.H.; Cho, B.J. Origin of transient Vth shift after erase and its impact on 2D/3D structure charge trap flash memory cell operations. In Proceedings of the 2012 International Electron Devices Meeting, San Francisco, CA, USA, 10–13 December 2012. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.K.; Kim, S.E. A Review of Cell Operation Algorithm for 3D NAND Flash Memory. Appl. Sci. 2022, 12, 10697. https://doi.org/10.3390/app122110697
Park JK, Kim SE. A Review of Cell Operation Algorithm for 3D NAND Flash Memory. Applied Sciences. 2022; 12(21):10697. https://doi.org/10.3390/app122110697
Chicago/Turabian StylePark, Jong Kyung, and Sarah Eunkyung Kim. 2022. "A Review of Cell Operation Algorithm for 3D NAND Flash Memory" Applied Sciences 12, no. 21: 10697. https://doi.org/10.3390/app122110697
APA StylePark, J. K., & Kim, S. E. (2022). A Review of Cell Operation Algorithm for 3D NAND Flash Memory. Applied Sciences, 12(21), 10697. https://doi.org/10.3390/app122110697