
Pre-Inpainting Convolutional Skip Triple Attention Segmentation Network for AGV Lane Detection in Overexposure Environment


Abstract
:1. Introduction
- An AGV lane extraction method combining image inpainting and image segmentation network is proposed to improve the accuracy of AGV lane segmentation in overexposure conditions;
- The network parameters of MAE are optimized, reduced, and verified by experiments. On the premise of ensuring the repair quality, the inference speed of MAE model is improved;
- A convolutional skip triple attention network (CSTA) is designed. It meets the requirements of segmentation accuracy and segmentation speed at the same time. A lightweight backbone network is designed to improve the segmentation speed, and the triple attention module is designed to improve the segmentation accuracy.
2. Related Works
2.1. Image Inpainting
2.2. Lane Detection
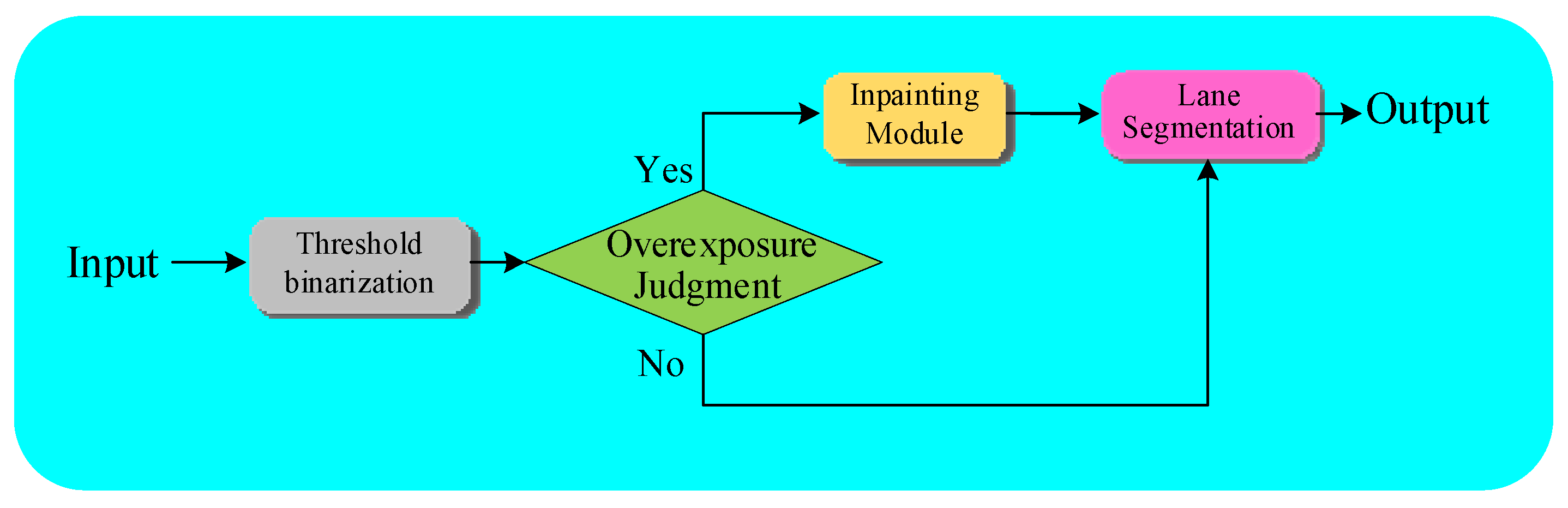
3. Methods
3.1. Data Preprocessing
3.2. Image Inpainting Module
3.3. CSTA Network Structure
4. Experiments and Results
4.1. Dataset Construction
4.2. Loss Function
4.3. Experiment Result
- (1)
- Pixel Accuracy (PA) is used to evaluate the ratio of correctly predicted pixels to the total number of pixels, which can be expressed as:
- (2)
- Since the boundaries of overexposed images are blurred after inpainting, F1-score is used to evaluate the quality of segmentation boundaries. F1-score refers to the average evaluation of Precision and Recall. The formula can be expressed as:
- (3)
- Intersection over Union (IoU) is used to evaluate whether the lane region can be accurately segmented by the network. That is, the intersection ratio of the predicted samples and the actual samples, which can be expressed as:
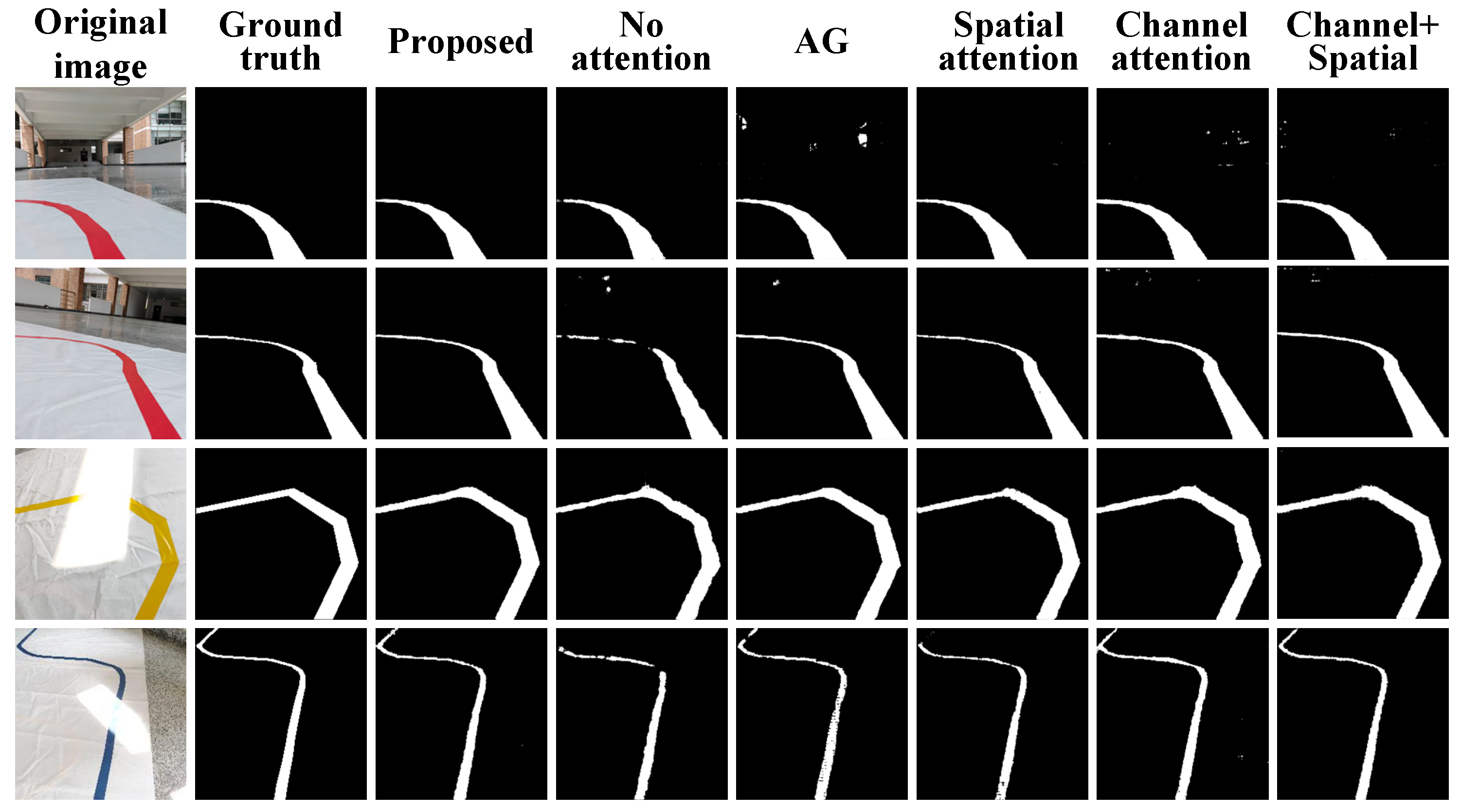
4.4. Ablation Experiment
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Javed, M.A.; Muram, F.U.; Punnekkat, S.; Hansson, H. Safe and secure platooning of Automated Guided Vehicles in Industry 4.0. J. Syst. Archit. 2021, 121, 102309. [Google Scholar] [CrossRef]
- Liu, J.; Liu, Z.; Zhang, H.; Yuan, H.; Manokaran, K.B.; Maheshwari, M. Multi-sensor information fusion for IoT in automated guided vehicle in smart city. Soft Comput. 2021, 25, 12017–12029. [Google Scholar] [CrossRef]
- Reis WP, N.; Couto, G.E.; Junior, O.M. Automated guided vehicles position control: A systematic literature review. J. Intell. Manuf. 2022, 1–63. [Google Scholar] [CrossRef]
- Zhou, S.; Cheng, G.; Meng, Q.; Lin, H.; Du, Z.; Wang, F. Development of multi-sensor information fusion and AGV navigation system. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 2043–2046. [Google Scholar]
- Liu, S.; Xiong, M.; Zhong, W.; Xiong, H. Towards Industrial Scenario Lane Detection: Vision-Based AGV Navigation Methods. In Proceedings of the IEEE International Conference on Mechatronics and Automation (ICMA), Beijing, China, 13–16 October 2020; pp. 1101–1106. [Google Scholar]
- Ullah, I.; Liu, K.; Yamamoto, T.; Zahid, M.; Jamal, A. Prediction of electric vehicle charging duration time using ensemble machine learning algorithm and Shapley additive explanations. Int. J. Energy Res. 2022, 46, 15211–15230. [Google Scholar] [CrossRef]
- Ullah, I.; Liu, K.; Yamamoto, T.; Al Mamlook, R.E.; Jamal, A. A comparative performance of machine learning algorithm to predict electric vehicles energy consumption: A path towards sustainability. Energy Environ. 2021, 0958305X211044998. [Google Scholar] [CrossRef]
- Ullah, I.; Liu, K.; Yamamoto, T.; Shafiullah, M.; Jamal, A. Grey wolf optimizer-based machine learning algorithm to predict electric vehicle charging duration time. Transp. Lett. 2022, 1–18. [Google Scholar] [CrossRef]
- Sarker, I.H. Deep learning: A comprehensive overview on techniques, taxonomy, applications and research directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef] [PubMed]
- Tang, J.; Li, S.; Liu, P. A review of lane detection methods based on deep learning. Pattern Recognit. 2021, 111, 107623. [Google Scholar] [CrossRef]
- Ghosh, S.; Das, N.; Das, I.; Maulik, U. Understanding deep learning techniques for image segmentation. ACM Comput. Surv. (CSUR) 2019, 52, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Mu, C.; Ma, X. Lane detection based on object segmentation and piecewise fitting. TELKOMNIKA Indones. J. Electr. Eng. 2014, 12, 3491–3500. [Google Scholar] [CrossRef]
- Haque, M.R.; Islam, M.M.; Alam, K.S.; Iqbal, H. A computer vision based lane detection approach. Int. J. Image Graph. Signal Process. 2019, 10, 27. [Google Scholar] [CrossRef] [Green Version]
- Mukhopadhyay, P.; Chaudhuri, B.B. A survey of Hough Transform. Pattern Recognit. 2015, 48, 993–1010. [Google Scholar] [CrossRef]
- Huang, Q.; Liu, J. Practical limitations of lane detection algorithm based on Hough transform in challenging scenarios. Int. J. Adv. Robot. Syst. 2021, 18, 17298814211008752. [Google Scholar] [CrossRef]
- Zhang, H.; Liang, J.; Jiang, H.; Cai, Y.; Xu, X. Lane line recognition based on improved 2D-gamma function and variable threshold Canny algorithm under complex environment. Meas. Control 2020, 53, 1694–1708. [Google Scholar] [CrossRef]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. Erfnet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2017, 19, 263–272. [Google Scholar] [CrossRef]
- Peng, J.; Liu, Y.; Tang, S.; Hao, Y.; Chu, L.; Chen, G.; Wu, Z.; Chen, Z.; Yu, Z.; Du, Y.; et al. PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model. arXiv 2022, arXiv:2204.02681. [Google Scholar]
- Song, Q.; Li, J.; Li, C.; Guo, H.; Huang, R. Fully attentional network for semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 28 February–1 March 2022; Volume 36, pp. 2280–2288. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Zhang, H.; Xu, L.; Liang, J.; Sun, X. Research on Guide Line Identification and Lateral Motion Control of AGV in Complex Environments. Machines 2022, 10, 121. [Google Scholar] [CrossRef]
- Zheng, J.; Zhang, Z. Research on AGV visual perception dynamic exposure algorithm based on gray entropy threshold difference value. In Proceedings of the 2022 4th International Conference on Advances in Computer Technology, Information Science and Communications (CTISC), Suzhou, China, 22–24 April 2022; pp. 1–6. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Yang, C.; Lu, X.; Lin, Z.; Shechtman, E.; Wang, O.; Li, H. High-resolution image inpainting using multi-scale neural patch synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6721–6729. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. (ToG) 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Yan, Z.; Li, X.; Li, M.; Zuo, W.; Shan, S. Shift-net: Image inpainting via deep feature rearrangement. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 1–17. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Shen, L.; Hong, R.; Zhang, H.; Zhang, H.; Wang, M. Single-shot semantic image inpainting with densely connected generative networks. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1861–1869. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.; Ebrahimi, M. Edgeconnect: Structure guided image inpainting using edge prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 16000–16009. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Wang, N.; Li, J.; Zhang, L.; Du, B. MUSICAL: Multi-Scale Image Contextual Attention Learning for Inpainting. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 3748–3754. [Google Scholar]
- Shi, Y.; Fan, Y.; Zhang, N. A generative image inpainting network based on the attention transfer network across layer mechanism. Optik 2021, 242, 167101. [Google Scholar]
- Wang, D.; Xie, C.; Liu, S.; Niu, Z.; Zuo, W. Image inpainting with edge-guided learnable bidirectional attention maps. arXiv 2021, arXiv:2104.12087. [Google Scholar]
- Yoo, S.; Lee, H.S.; Myeong, H.; Yun, S.; Park, H.; Cho, J.; Kim, D.H. End-to-end lane marker detection via row-wise classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 1006–1007. [Google Scholar]
- Qin, Z.; Wang, H.; Li, X. Ultra fast structure-aware deep lane detection. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; pp. 276–291. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; p. 32. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection cnns by self attention distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1013–1021. [Google Scholar]
- Xu, H.; Wang, S.; Cai, X.; Zhang, W.; Liang, X.; Li, Z. Curvelane-nas: Unifying lane-sensitive architecture search and adaptive point blending. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; pp. 689–704. [Google Scholar]
- Andreatos, A.; Leros, A. Contour Extraction Based on Adaptive Thresholding in Sonar Images. Information 2021, 12, 354. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Ajani, T.S.; Imoize, A.L.; Atayero, A.A. An overview of machine learning within embedded and mobile devices–optimizations and applications. Sensors 2021, 21, 4412. [Google Scholar] [CrossRef]
- Trovao, J.P. Digital transformation, systemic design, and automotive electronics [automotive electronics]. IEEE Veh. Technol. Mag. 2020, 15, 149–159. [Google Scholar] [CrossRef]
- Khochare, A.; Kesanapalli, S.A.; Bhope, R.; Simmhan, Y. Don’t Miss the Train: A Case for Systems Research into Training on the Edge. In Proceedings of the 2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Lyon, France, 30 May–3 June 2022; pp. 985–986. [Google Scholar]
- Sipola, T.; Alatalo, J.; Kokkonen, T.; Rantonen, M. Artificial Intelligence in the IoT Era: A Review of Edge AI Hardware and Software. In Proceedings of the 2022 31st Conference of Open Innovations Association (FRUCT), Helsinki, Finland, 27–29 April 2022; pp. 320–331. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | IoU | F1-Score | PA | fwt (ms) |
|---|---|---|---|---|
| ERFNet | 0.8009 | 0.8851 | 0.9795 | 19.5816 |
| CCNet | 0.7973 | 0.8814 | 0.9817 | 108.8108 |
| PP-LiteSeg | 0.9011 | 0.9474 | 0.9916 | 52.8683 |
| FLANet | 0.8967 | 0.9384 | 0.9907 | 39.2761 |
| Proposed | 0.9019 | 0.9461 | 0.9912 | 8.6956 |
| Method | IoU | F1-Score | PA | fwt (ms) |
|---|---|---|---|---|
| ERFNet | 0.7463 | 0.8452 | 0.9805 | 19.5031 |
| CCNet | 0.5646 | 0.7106 | 0.9674 | 108.3623 |
| PP-LiteSeg | 0.7052 | 0.8177 | 0.9803 | 53.0378 |
| FLANet | 0.7268 | 0.8334 | 0.9797 | 39.4803 |
| Proposed | 0.8355 | 0.9059 | 0.9889 | 18.5327 |
| Module Composition | Performance Evaluation Metrics | ||||
|---|---|---|---|---|---|
| AG | Spatial Attention | Channel Attention | IoU | F1-Score | PA |
| × | × | × | 0.7949 | 0.8806 | 0.9861 |
| √ | × | × | 0.8114 | 0.8905 | 0.9873 |
| × | √ | × | 0.8197 | 0.8954 | 0.9881 |
| × | × | √ | 0.8073 | 0.8881 | 0.9867 |
| × | √ | √ | 0.8001 | 0.8841 | 0.9858 |
| √ | √ | √ | 0.8293 | 0.9031 | 0.9885 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Yang, X.; Wu, L.; Hu, J.; Zou, B.; Zhang, Y.; Zhang, J. Pre-Inpainting Convolutional Skip Triple Attention Segmentation Network for AGV Lane Detection in Overexposure Environment. Appl. Sci. 2022, 12, 10675. https://doi.org/10.3390/app122010675
Yang Z, Yang X, Wu L, Hu J, Zou B, Zhang Y, Zhang J. Pre-Inpainting Convolutional Skip Triple Attention Segmentation Network for AGV Lane Detection in Overexposure Environment. Applied Sciences. 2022; 12(20):10675. https://doi.org/10.3390/app122010675
Chicago/Turabian StyleYang, Zongxin, Xu Yang, Long Wu, Jiemin Hu, Bo Zou, Yong Zhang, and Jianlong Zhang. 2022. "Pre-Inpainting Convolutional Skip Triple Attention Segmentation Network for AGV Lane Detection in Overexposure Environment" Applied Sciences 12, no. 20: 10675. https://doi.org/10.3390/app122010675
APA StyleYang, Z., Yang, X., Wu, L., Hu, J., Zou, B., Zhang, Y., & Zhang, J. (2022). Pre-Inpainting Convolutional Skip Triple Attention Segmentation Network for AGV Lane Detection in Overexposure Environment. Applied Sciences, 12(20), 10675. https://doi.org/10.3390/app122010675