
MDA: An Intelligent Medical Data Augmentation Scheme Based on Medical Knowledge Graph for Chinese Medical Tasks

Abstract
1. Introduction
- We propose a medical data augmentation (MDA) method, which can effectively remedy the problem of semantic stability in the Chinese medical field;
- We experiment on NLP with two tasks: Named entity recognition (NER) and relational classification (RC). The MDA outperforms the traditional text data augmentation in terms of F1-score, and the MDA can increase the diversity of the augmented data;
2. Related Works
3. Our Proposed MDA
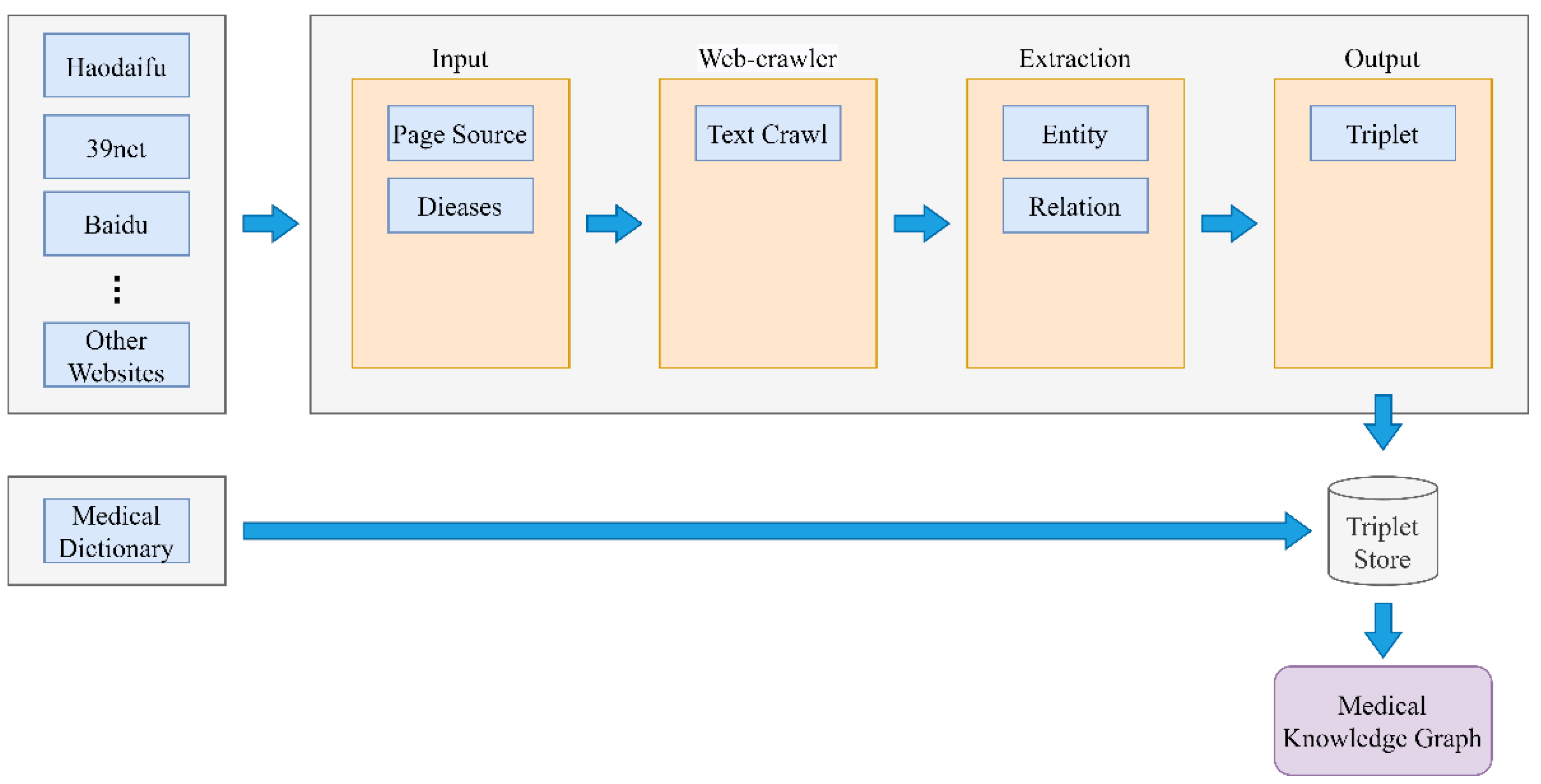
3.1. Medical Knowledge Graph Module
3.2. Medical Text Data Augmentation Module
| Algorithm 1: The Algorithm of the MDA |
| Input: Original dataset Sori, medical knowledge graph G; |
| Output: Augmented dataset Saug, the probability of change α; |
|
4. Performance Analysis
4.1. Data Augmentation Process
4.2. Datasets
- CCKS2019 is a dataset for the Chinese electronic medical record NER task of the 13th China Conference on Knowledge Graph and Semantic Computing which aims to provide a platform for researchers and application developers to test technologies, algorithms, and systems, and it consists of 1379 medical records that include six categories of entities, namely anatomy, disease, imaging examination, laboratory examination, drug, and operation. During the fine-tuning process, CCKS2019 is divided into a training dataset and a testing dataset in a certain proportion;
- CHIP2020 is a Chinese medical dataset for the RC task of the 6th China Health Information Processing Conference which is an annual conference on biological information processing and data mining, which contains 43 categories of pre-specified relations, 17,000 Chinese medical sentences, and 50,000 triplets. Moreover, the dataset consists of 518 pediatric diseases and 109 common diseases. In addition, the CHIP2020 includes more than ten categories of entity, such as symptoms, imaging examination, etc. Moreover, to enhance the normalization of the dataset, the CHIP2020 is divided into a training set and a testing set in the official method;
- BITEmrNER is a Chinese medical dataset for the NER task collected by the BIT laboratory, and it consists of 1200 electronic medical records with cerebrovascular disease from the First Hospital of Zhejiang Province and the Fourth Affiliated Hospital Zhejiang University of Medicine. Furthermore, the BitEmrNER consists of the medical description text data and label data, where the text data include the history of present illness and past medical history, and the label data include different categories of entities. In this study, we randomly select 900 samples from the BITEmrNER to augment the training set;
- BITEmrRC is a Chinese medical dataset for the RC task collected by BIT laboratory, and it consists of electronic medical records with cerebrovascular disease from the First Hospital of Zhejiang Province and the Fourth Affiliated Hospital Zhejiang University of Medicine. In addition, the BITEmrRC contains more than 40 categories of pre-specified relations, 2400 Chinese medical sentences, and more than 8000 triplets. In this study, the BITEmrNER randomly selected 1600 samples from the BITEmrNER to augment the training set.
4.3. Results and Discussion
4.3.1. NER Task Evaluation
4.3.2. RC Task Evaluation
4.3.3. Ablation Experiments
4.3.4. Case Study
4.4. Engineering Applications
5. Conclusions and Our Future
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, W.; Qian, T.; Lyu, C.; Zhang, J.; Jin, G.; Li, Y.; Xu, Y. A multitask learning approach for named entity recognition by exploiting sentence-level semantics globally. Electronics 2022, 11, 3048. [Google Scholar] [CrossRef]
- Hu, W.; He, L.; Ma, H.; Wang, K.; Xiao, J. Kgner: Improving chinese named entity recognition by bert infused with the knowledge graph. Appl. Sci. 2022, 12, 7702. [Google Scholar] [CrossRef]
- Liu, J.W.B.; Su, S. The effect of data augmentation methods on pedestrian object detection. Electronics 2022, 11, 3185. [Google Scholar] [CrossRef]
- Vu, D.T.; Yu, G.; Lee, C.; Kim, J. Text data augmentation for the korean language. Appl. Sci. 2022, 12, 3425. [Google Scholar] [CrossRef]
- Bayer, M.; Kaufhold, M.-A.; Reuter, C. A survey on data augmentation for text classification. ACM Comput. Surv. 2022. [Google Scholar] [CrossRef]
- Kumar, P.; Kumar, R.; Srivastava, G.; Gupta, G.P.; Tripathi, R.; Gadekallu, T.R.; Xiong, N.N. Ppsf: A privacy-preserving and secure framework using blockchain-based machine-learning for iot-driven smart cities. IEEE Trans. Netw. Sci. Eng. 2021, 8, 2326–2341. [Google Scholar] [CrossRef]
- Fu, A.; Zhang, X.; Xiong, N.; Gao, Y.; Wang, H.; Zhang, J. Vfl: A verifiable federated learning with privacy-preserving for big data in industrial iot. IEEE Trans. Ind. Inform. 2020, 18, 3316–3326. [Google Scholar] [CrossRef]
- Gao, Y.; Xiang, X.; Xiong, N.; Huang, B.; Lee, H.J.; Alrifai, R.; Jiang, X.; Fang, Z. Human action monitoring for healthcare based on deep learning. IEEE Access 2018, 6, 52277–52285. [Google Scholar] [CrossRef]
- Lejeune, G.; Brixtel, R.; Doucet, A.; Lucas, N. Multilingual event extraction for epidemic detection. Artif. Intell. Med. 2015, 65, 131–143. [Google Scholar] [CrossRef]
- Mounsey, A.; Khan, A.; Sharma, S. Deep and transfer learning approaches for pedestrian identification and classification in autonomous vehicles. Electronics 2021, 10, 3159. [Google Scholar] [CrossRef]
- Asai, M.; Tang, Z. Discrete word embedding for logical natural language understanding. arXiv 2020, arXiv:2008.11649. [Google Scholar]
- Funkner, A.A.; Zhurman, D.A.; Kovalchuk, S.V. Extraction of temporal structures for clinical events in unlabeled free-text electronic health records in russian. In Applying the FAIR Principles to Accelerate Health Research in Europe in the Post COVID-19 Era; IOS Press: Amsterdam, The Netherlands, 2021; pp. 55–56. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Cheng, H.; Xie, Z.; Shi, Y.; Xiong, N. Multi-step data prediction in wireless sensor networks based on one-dimensional cnn and bidirectional lstm. IEEE Access 2019, 7, 117883–117896. [Google Scholar] [CrossRef]
- Wu, X.; Lv, S.; Zang, L.; Han, J.; Hu, S. Conditional bert contextual augmentation. In Proceedings of the International Conference on Computational Science, Faro, Portugal, 12–14 June 2019; Springer: Berlin/Heidelberg, Germany; pp. 84–95. [Google Scholar]
- Li, B.; Hou, Y.; Che, W. Data augmentation approaches in natural language processing: A survey. AI Open 2022, 3, 71–90. [Google Scholar] [CrossRef]
- Daval-Frerot, G.; Weis, Y. Wmd at semeval-2020 tasks 7 and 11: Assessing humor and propaganda using unsupervised data augmentation. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 12–13 December 2020; pp. 1865–1874. [Google Scholar]
- Coulombe, C. Text data augmentation made simple by leveraging nlp cloud apis. arXiv 2018, arXiv:1812.04718. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. Adv. Neural Inf. Process. Syst. 2020, 33, 6256–6268. [Google Scholar]
- Zhang, Y.; Ge, T.; Sun, X. Parallel data augmentation for formality style transfer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3221–3228. [Google Scholar]
- Digamberrao, K.S.; Prasad, R.S. Author identification on literature in different languages: A systematic survey. In Proceedings of the 2018 International Conference on Advances in Communication and Computing Technology (ICACCT), Kochi, India, 13–15 September 2018; IEEE: Piscataway, NJ, USA; pp. 174–181. [Google Scholar]
- Perevalov, A.; Both, A. Augmentation-based answer type classification of the smart dataset. In Proceedings of the SMART@ ISWC, Online, 5 November 2020; pp. 1–9. [Google Scholar]
- Bornea, M.; Pan, L.; Rosenthal, S.; Florian, R.; Sil, A. Multilingual transfer learning for qa using translation as data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 12583–12591. [Google Scholar]
- Wang, W.Y.; Yang, D. That’s so annoying!!!: A lexical and frame-semantic embedding based data augmentation approach to automatic categorization of annoying behaviors using# petpeeve tweets. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2557–2563. [Google Scholar]
- Lowell, D.; Howard, B.; Lipton, Z.C.; Wallace, B.C. Unsupervised data augmentation with naive augmentation and without unlabeled data. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 4992–5001. [Google Scholar]
- Hou, Y.; Liu, Y.; Che, W.; Liu, T. Sequence-to-sequence data augmentation for dialogue language understanding. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1234–1245. [Google Scholar]
- Li, K.; Chen, C.; Quan, X.; Ling, Q.; Song, Y. Conditional augmentation for aspect term extraction via masked sequence-to-sequence generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7056–7066. [Google Scholar]
- Liu, D.; Gong, Y.; Fu, J.; Yan, Y.; Chen, J.; Lv, J.; Duan, N.; Zhou, M. Tell me how to ask again: Question data augmentation with controllable rewriting in continuous space. In Proceedings of the EMNLP (1), Online, 16–20 November 2020. [Google Scholar]
- Wu, C.; Ju, B.; Wu, Y.; Lin, X.; Xiong, N.; Xu, G.; Li, H.; Liang, X. Uav autonomous target search based on deep reinforcement learning in complex disaster scene. IEEE Access 2019, 7, 117227–117245. [Google Scholar] [CrossRef]
- Yan, G.; Li, Y.; Zhang, S.; Chen, Z. Data augmentation for deep learning of judgment documents. In Proceedings of the International Conference on Intelligent Science and Big Data Engineering, Nanjing, China, 17–20 October 2019; Springer: Berlin/Heidelberg, Germany; pp. 232–242. [Google Scholar]
- Longpre, S.; Wang, Y.; DuBois, C. How effective is task-agnostic data augmentation for pretrained transformers? In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 4401–4411. [Google Scholar]
- Yu, S.; Yang, J.; Liu, D.; Li, R.; Zhang, Y.; Zhao, S. Hierarchical data augmentation and the application in text classification. IEEE Access 2019, 7, 185476–185485. [Google Scholar] [CrossRef]
- Xie, Z.; Wang, S.I.; Li, J.; Lévy, D.; Nie, A.; Jurafsky, D.; Ng, A.Y. Data noising as smoothing in neural network language models. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Guo, H.; Mao, Y.; Zhang, R. Augmenting data with mixup for sentence classification: An empirical study. arXiv 2019, arXiv:1905.08941. [Google Scholar]
- Cheng, Y.; Jiang, L.; Macherey, W.; Eisenstein, J. Advaug: Robust adversarial augmentation for neural machine translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5961–5970. [Google Scholar]
- Min, J.; McCoy, R.T.; Das, D.; Pitler, E.; Linzen, T. Syntactic data augmentation increases robustness to inference heuristics. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2339–2352. [Google Scholar]
- Kang, D.; Khot, T.; Sabharwal, A.; Hovy, E. Adventure: Adversarial training for textual entailment with knowledge-guided examples. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2418–2428. [Google Scholar]
- Anaby-Tavor, A.; Carmeli, B.; Goldbraich, E.; Kantor, A.; Kour, G.; Shlomov, S.; Tepper, N.; Zwerdling, N. Do not have enough data? Deep learning to the rescue! In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 34, pp. 7383–7390. [Google Scholar]
- Quteineh, H.; Samothrakis, S.; Sutcliffe, R. Textual data augmentation for efficient active learning on tiny datasets. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA; pp. 7400–7410. [Google Scholar]
- Ng, N.; Cho, K.; Ghassemi, M. Ssmba: Self-supervised manifold based data augmentation for improving out-of-domain robustness. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, 16–20 November 2020; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA; pp. 1268–1283. [Google Scholar]
- Thakur, N.; Reimers, N.; Daxenberger, J.; Gurevych, I. Augmented sbert: Data augmentation method for improving bi-encoders for pairwise sentence scoring tasks. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 296–310. [Google Scholar]
- Yakunin, K.; Mukhamediev, R.I.; Zaitseva, E.; Levashenko, V.; Yelis, M.; Symagulov, A.; Kuchin, Y.; Muhamedijeva, E.; Aubakirov, M.; Gopejenko, V. Mass media as a mirror of the covid-19 pandemic. Computation 2021, 9, 140. [Google Scholar] [CrossRef]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. Dbpedia—A large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Wei, J.; Zou, K. Eda: Easy data augmentation techniques for boosting performance on text classification tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional lstm-crf models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Li, X.; Zhang, H.; Zhou, X. Chinese clinical named entity recognition with variant neural structures based on bert methods. J. Biomed. Inform. 2020, 107, 103422. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Huang, J.; Xu, C.; Zheng, H.; Zhang, L.; Wan, J. Research on named entity recognition of electronic medical records based on roberta and radical-level feature. Wirel. Commun. Mob. Comput. 2021, 2021, 2489754. [Google Scholar] [CrossRef]
- Bekoulis, G.; Deleu, J.; Demeester, T.; Develder, C. Joint entity recognition and relation extraction as a multi-head selection problem. Expert Syst. Appl. 2018, 114, 34–45. [Google Scholar] [CrossRef]
- Yu, B.; Zhang, Z.; Shu, X.; Wang, Y.; Liu, T.; Wang, B.; Li, S. Joint extraction of entities and relations based on a novel decomposition strategy. arXiv 2019, arXiv:1909.04273. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A novel cascade binary tagging framework for relational triple extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1476–1488. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Examples | |
|---|---|---|
| Original Data | Augmented Data | |
| SR | He was sick with heart disease | He was sick with pneumonia |
| RI | He was sick with heart disease | He was seriously sick with heart disease |
| RS | He was sick with heart disease | He was disease with heart sick |
| RD | He was sick with heart disease | |
| Methods | Examples | |||
|---|---|---|---|---|
| Original Data | Keywords | Medical Knowledge | Augmented Data | |
| MKB | Text: 脑出血患者出现头痛 (The patient with the cerebral hemorrhage had a headache) Label: 脑出血—症状—头痛 (‘cerebral hemorrhage’—‘symptoms’—‘headache’) | 脑出血 cerebral hemorrhage 头痛 headache | 脑出血-症状-头晕 (‘cerebral hemorrhage’—‘symptoms’—‘dizzy’) 脑出血—同义词—脑血管病等 (‘cerebral hemorrhage’—‘synonymy’—‘cerebrovascular disease’) | Text: 脑血管病患者出现头晕 (The patient with the cerebrovascular disease had a dizzy) Label: 脑血管病—症状—头晕 (‘cerebrovascular disease’—‘symptoms’—‘dizzy’) |
| WI | Text: 脑出血患者出现头痛 (The patient with the cerebral hemorrhage had a headache) Label: 脑出血—症状—头痛 (‘cerebral hemorrhage’—‘symptoms’—‘headache’) | 脑出血 cerebral hemorrhage 头痛 headache | 头痛—形容词—严重的 (‘headache’—‘adjectives’—‘severe’) 头痛—形容词—复杂的 (‘headache’—‘adjectives’—‘complex’) | Text: 脑出血患者出现严重头痛 (The patient with the cerebral hemorrhage had a severe headache) Label: 脑出血—症状—头痛 (‘cerebral hemorrhage’—‘symptoms’—‘headache’) |
| WS | Text: 脑出血患者出现头痛 (The patient with the cerebral hemorrhage had a headache) Label: 脑出血—症状—头痛 (‘cerebral hemorrhage’—‘symptoms’—‘headache’) | 脑出血 cerebral hemorrhage 头痛 headache | - | Text: 脑出血出现患者头疼 (The had with the cerebral hemorrhage patient a headache) Label: 脑出血—症状—头痛 (‘cerebral hemorrhage’—‘symptoms’—‘headache’) |
| WD | Text: 脑出血患者出现头痛 (The patient with the cerebral hemorrhage had a headache) Label: 脑出血—症状—头痛 (‘cerebral hemorrhage’—‘symptoms’—‘headache’) | 脑出血 cerebral hemorrhage 头痛 headache | - | Text: 脑出血 ( Label: 脑出血—症状—头痛 (‘cerebral hemorrhage’—‘symptoms’—‘headache’) |
| Statistics | CCKS2019 | CHIP2020 | BITEmrNER | BITEmrRC | ||||
|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | |
| Sentence | 1000 | 379 | 3585 | 900 | 300 | 1600 | 800 | |
| Task | NER | RC | NER | RC | ||||
| Categories | 6 | 43 | 6 | 40 | ||||
| Datasets | Text | Label |
|---|---|---|
| CCKS2019 | 患者4月余前因“下腹疼痛不适, 伴反酸、嗳气”在我院完善相关检查后确诊“胃体胃窦癌”。病人在全麻上行“远端胃大部分切除”’。在我院行SOX (奥沙利铂+替吉奥) 方案化疗。 (Before the end of 4 months, the patient was diagnosed as ‘gastric antrum cancer’ in our hospital due to ‘lower quadrant abdominal pain with acid regurgitation and belching’. The patient underwent ‘distal gastrectomy’ under general anesthesia. SOX (Oxaliplatin+ Tegafur) regimen chemotherapy was performed in our hospital.) | 腹-解剖部位, 胃体胃窦癌—疾病和诊断, 远端胃大部分切除—手术, 奥沙利铂—药物, 替吉奥—药物 (‘abdominal’—‘anatomic site’, ‘gastric antrum cancer’—‘diseases and diagnoses’, ‘lower quadrant abdominal pain with acid regurgitation and belching’—‘operation’, ‘Oxaliplatin’—‘drug’, ‘Tegafur’—‘drug’,) |
| CHIP2020 | 按病程发展及主要临床表现, 可分为急性、慢性及晚期血吸虫病。急性血吸虫病多见于夏秋季, 以小儿及青壮年为多。 (Schistosomiasis can be divided into acute, chronic and advanced schistosomiasis according to its course and main clinical manifestations. Acute schistosomiasis is more common in summer and autumn, especially in children and young adults.) | 血吸虫病—病理分型—急性血吸虫病, 急性血吸虫病—病理分型—吸虫病, 急性血吸虫病—多发群体—小儿及青壮年 (‘Schistosomiasis’—‘pathological classification’—‘acute schistosomiasis’, ‘acute schistosomiasis’—‘pathological classification’—‘fluke disease’, ‘acute schistosomiasis’—‘groups’—‘children and young adults’) |
| BITEmrNER | 脑出血患者出现头痛, 呕吐。患者查头颅CT左侧额颞顶部硬膜下出血。 (The patient with intracerebral hemorrhage had headache, vomiting. The patient was examined on head CT for subdural hemorrhage on the left frontotemporal parietal side.) | 脑出血—疾病, 头颅CT—影像学检查 (‘intracerebral hemorrhage’—‘disease’, ‘head CT’—‘imaging examination’) |
| BITEmrRC | 脑出血患者出现头痛, 呕吐。患者查头颅CT左侧额颞顶部硬膜下出血。 (The patient with intracerebral hemorrhage had headache, vomiting. The patient was examined on head CT for subdural hemorrhage on the left frontotemporal parietal side.) | 脑出血—临床表现—头痛, 脑出血—临床表现—呕吐, 脑出血—影像学检查—头颅CT (‘intracerebral hemorrhage’—‘clinical manifestation’—‘headache’, ‘intracerebral hemorrhage’—‘clinical manifestation’—‘vomiting’, ‘intracerebral hemorrhage’—‘imaging examination’—‘head CT’) |
| Models | CCKS2020 | BITEmrNER | ||||
|---|---|---|---|---|---|---|
| Original | EDA | MDA | Original | EDA | MDA | |
| BERT + CRF | 80.56 | 81.34 | 83.29 | 82.67 | 83.55 | 85.51 |
| BiLSTM + CRF | 81.00 | 82.04 | 83.45 | 83.35 | 84.22 | 85.88 |
| Ra-RC | 82.87 | 83.69 | 85.64 | 84.29 | 84.69 | 86.64 |
| Models | CHIP2020 | BITEmrRC | ||||
|---|---|---|---|---|---|---|
| Original | EDA | MDA | Original | EDA | MDA | |
| Multi-Head attention | 47.10 | 47.92 | 49.21 | 70.27 | 70.90 | 72.38 |
| ETL-Span | 49.46 | 60.17 | 51.38 | 71.8 | 72.62 | 74.33 |
| RoBERTa + CasRel | 58.27 | 59.11 | 60.18 | 86.01 | 86.45 | 89.37 |
| Methods | NER | RC |
|---|---|---|
| F1 | F1 | |
| Ours | 86.64 | 89.37 |
| -MKR | 84.48 | 87.01 |
| -WI | 85.83 | 88.49 |
| -WS | 86.07 | 88.74 |
| -WD | 86.11 | 88.71 |
| Text | Label |
|---|---|
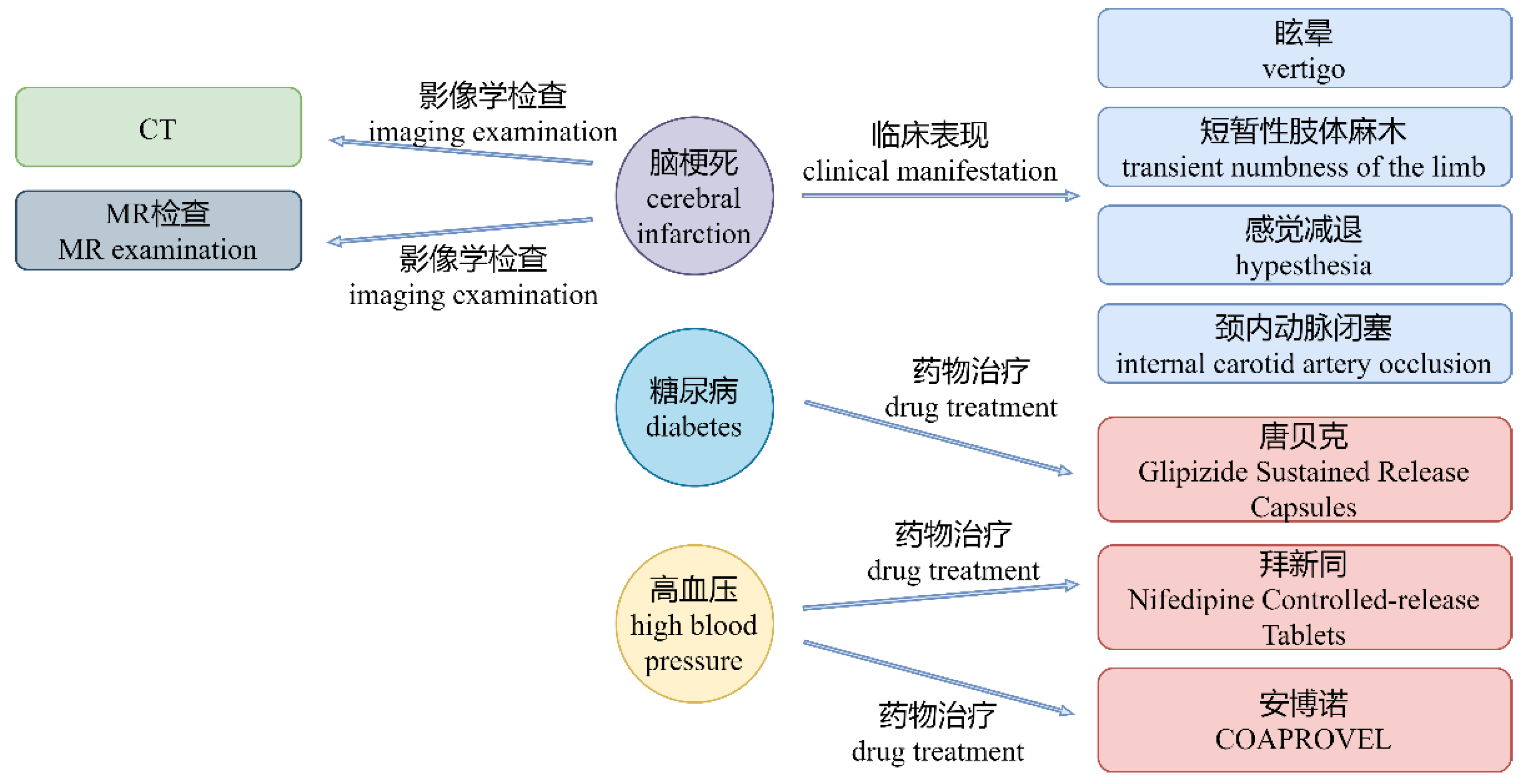
| 脑梗死患者出现左侧肢体麻木, 伴感觉减退, 伴眩晕, 短暂性肢体麻木, 颈内动脉闭塞。遂至我院门诊就诊, 查CT示桥脑梗死可能, 建议MR检查。右侧丘脑陈旧性梗死灶。高血压服用“拜新同, 安博诺”。糖尿病服用“唐贝克”。 (Patients with cerebral infarction developed left limb numbness, hypesthesia, transient numbness of the limb, vertigo, and internal carotid artery occlusion occurred. Then he went to the outpatient department of our hospital. CT examination showed possible pontine infarction, and MR examination was suggested. This is an old infarct in the right thalamus. High blood pressure takes ‘Nifedipine Controlled-release Tablets, COAPROVEL’. Diabetes takes ‘Glipizide Sustained Release Capsules’.) | 脑梗死—临床表现—眩晕, 脑梗死—临床表现—感觉减退, 脑梗死—临床表现—短暂性肢体麻木, 脑梗死—临床表现—颈内动脉闭塞, 脑梗死—影像学检查—CT, 脑梗死—影像学检查—MR检查, 糖尿病—药物治疗—唐贝克, 高血压—药物治疗—拜新同, 高血压—药物治疗—安博诺 (‘cerebral infarction’—‘clinical manifestation’—‘vertigo’, ‘cerebral infarction’—‘clinical manifestation’—‘hypesthesia’, ‘cerebral infarction’—‘clinical manifestation’—‘transient numbness of the limb’, ‘cerebral infarction’—‘clinical manifestation’—‘internal carotid artery occlusion’, ‘cerebral infarction’—‘imaging examination’—‘CT’, ‘cerebral infarction’—‘imaging examination’—‘MR examination’, ‘diabetes’—‘drug treatment’—‘Glipizide Sustained Release Capsules’, ‘high blood pressure’—‘drug treatment’—‘Nifedipine Controlled-release Tablets’, ‘high blood pressure’—‘drug treatment’—‘COAPROVEL’) |
| Text | Label |
|---|---|
| 脑梗死患者产生左侧肢体麻木, 伴视物模糊, 伴严重眩晕, 头昏, 神志不清。遂至我院 | 脑梗死—临床表现—眩晕, 脑梗死—临床表现—视物模糊, 脑梗死—临床表现—头昏, 脑梗死—临床表现—神志不清, 脑梗死—影像学检查—CT, 脑梗死—影像学检查—脑血管造影, 糖尿病—药物治疗—贝纳鲁肽, 高血压—药物治疗—拜新同, 高血压—药物治疗—安博诺 (‘cerebral infarction’—‘clinical manifestation’—‘vertigo’, ‘cerebral infarction’—‘clinical manifestation’—‘blurred vision’, ‘cerebral infarction’—‘clinical manifestation’—‘dizziness’, ‘cerebral infarction’—‘clinical manifestation’—‘confusion’, ‘cerebral infarction’—‘imaging examination’—‘CT’, ‘cerebral infarction’—‘imaging examination’—‘cerebral angiography’, ‘diabetes’—‘drug treatment’—‘Benaglutide Injection’, ‘high blood pressure’—‘drug treatment’—‘Nifedipine Controlled-release Tablets’, ‘high blood pressure’—‘drug treatment’—‘COAPROVEL’) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, B.; Zhang, L.; Huang, J.; Zheng, H.; Wan, J.; Zhang, L. MDA: An Intelligent Medical Data Augmentation Scheme Based on Medical Knowledge Graph for Chinese Medical Tasks. Appl. Sci. 2022, 12, 10655. https://doi.org/10.3390/app122010655
Shi B, Zhang L, Huang J, Zheng H, Wan J, Zhang L. MDA: An Intelligent Medical Data Augmentation Scheme Based on Medical Knowledge Graph for Chinese Medical Tasks. Applied Sciences. 2022; 12(20):10655. https://doi.org/10.3390/app122010655
Chicago/Turabian StyleShi, Binbin, Lijuan Zhang, Jie Huang, Huilin Zheng, Jian Wan, and Lei Zhang. 2022. "MDA: An Intelligent Medical Data Augmentation Scheme Based on Medical Knowledge Graph for Chinese Medical Tasks" Applied Sciences 12, no. 20: 10655. https://doi.org/10.3390/app122010655
APA StyleShi, B., Zhang, L., Huang, J., Zheng, H., Wan, J., & Zhang, L. (2022). MDA: An Intelligent Medical Data Augmentation Scheme Based on Medical Knowledge Graph for Chinese Medical Tasks. Applied Sciences, 12(20), 10655. https://doi.org/10.3390/app122010655