
Real-Time Foreign Object and Production Status Detection of Tobacco Cabinets Based on Deep Learning


Abstract
1. Introduction
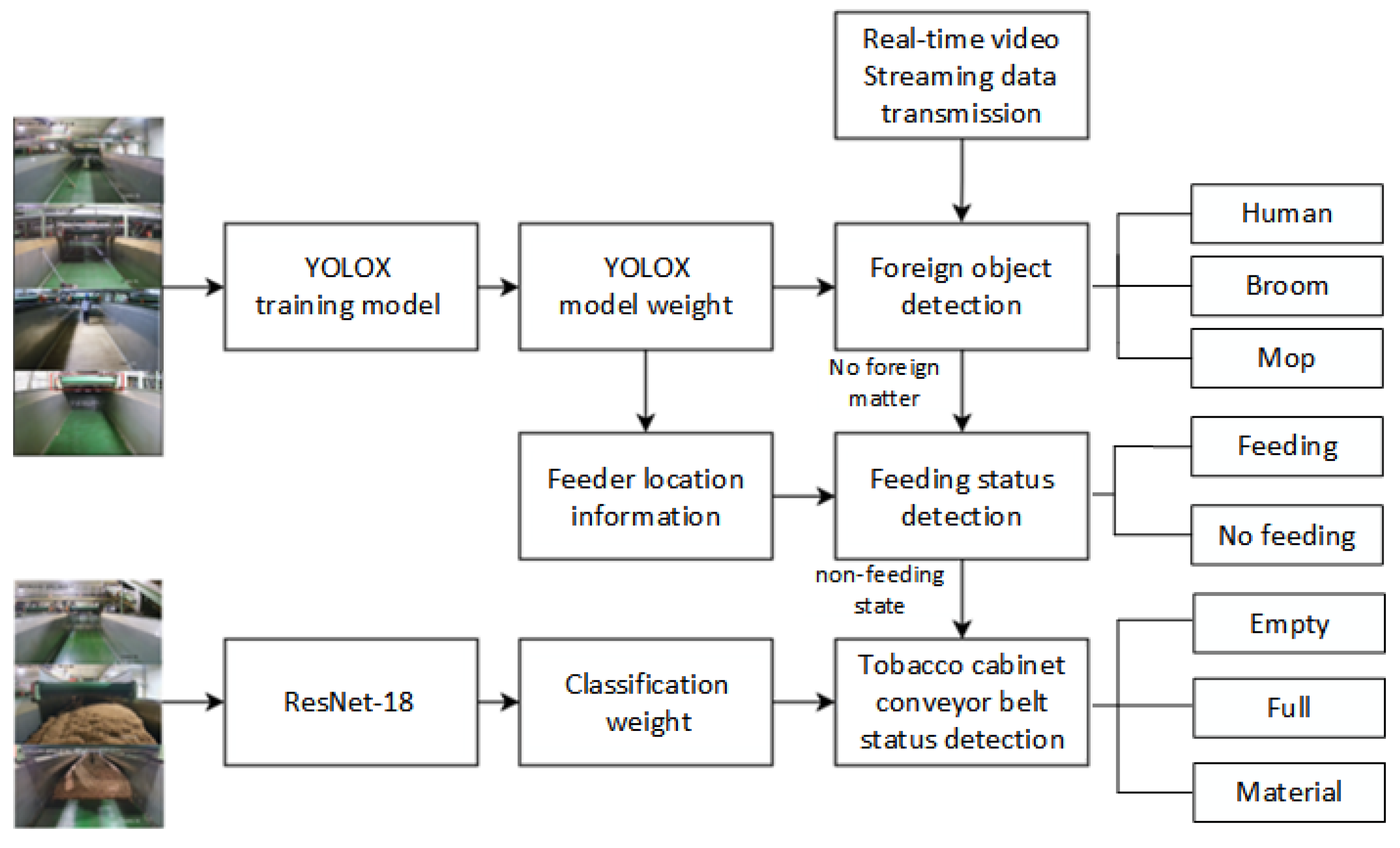
2. Materials and Methods
2.1. Acquiring the Detection Data of the Tobacco Cabinet
2.2. Methods
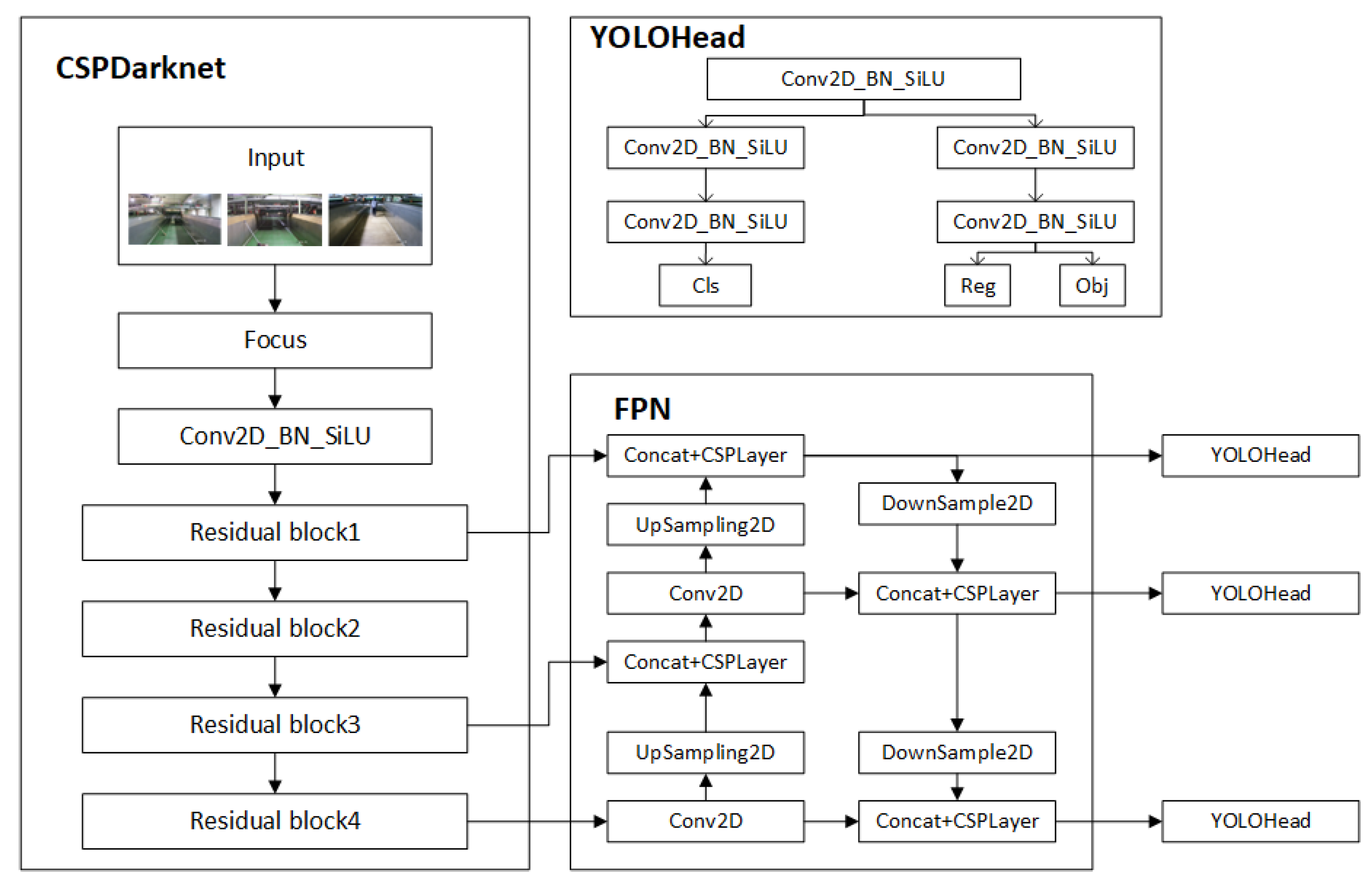
2.2.1. Foreign Object Detection of Tobacco Cabinet Based on YOLOX
- A.
- Backbone Network CSPDarknet
- B.
- Building FPN Feature Pyramid for Enhanced Feature Extraction
- C.
- Get Forecast Results with YOLO head
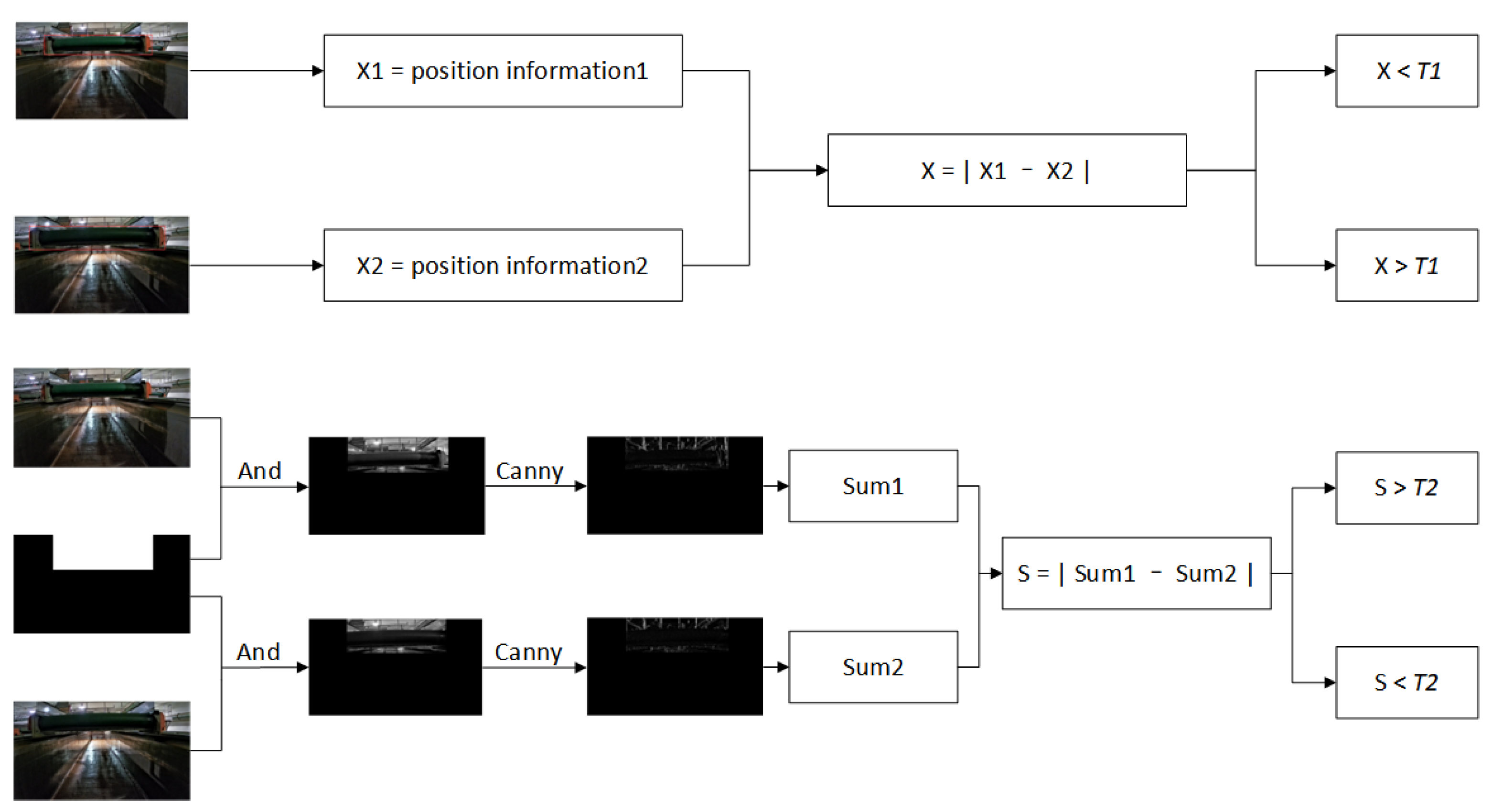
2.2.2. Check the Feeding Status
2.2.3. Tobacco Cabinet Conveyor Belt Status Detection
3. Results and Discussion
3.1. Analysis of Foreign Object State Detection Results
3.2. Analysis of the Test Results of the Feeding State
3.3. Analysis of the Test Results of the Production Status of the Tobacco Cabinet Conveyor Belt
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Glenn Jocher; Yolov5. 2021. Available online: https://github.com/ultralytics/yolov5 (accessed on 15 July 2021).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhang, Y.; Zhang, W.; Yu, J.; He, L.; Chen, J.; He, Y. Complete and accurate holly fruits counting using YOLOX object detection. Comput. Electron. Agric. 2022, 198, 107062. [Google Scholar] [CrossRef]
- Hu, X.; Liu, Y. Real-time detection of uneaten feed pellets in underwater images for aquaculture using an improved YOLO-V4 network. Comput. Electron. Agric. 2021, 185, 106135. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, W. Face mask wearing detection algorithm based on improved YOLO-v4. Sensors 2021, 21, 3263. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Jiachun, Z. Real-time face detection based on YOLO. In Proceedings of the 2018 1st IEEE International Conference on Knowledge Innovation and Invention (ICKII), Jeju, Korea, 23–27 July 2018; pp. 221–224. [Google Scholar] [CrossRef]
- El-Sawy, A.; El-Bakry, H.; Loey, M. CNN for handwritten arabic digits recognition based on LeNet-5. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, Cairo, Egypt, 24–26 November 2016; pp. 566–575. [Google Scholar]
- Zhang, C.W.; Yang, M.Y.; Zeng, H.J.; Wen, J.P. Pedestrian detection based on improved LeNet-5 convolutional neural network. J. Algorithms Comput. Technol. 2019, 13, 1748302619873601. [Google Scholar] [CrossRef]
- Li, T.; Jin, D.; Du, C. The image-based analysis and classification of urine sediments using a LeNet-5 neural network. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2020, 8, 109–114. [Google Scholar] [CrossRef]
- Ma, M.; Gao, Z.; Wu, J.; Chen, Y.; Zheng, X. A smile detection method based on improved LeNet-5 and support vector machine. In Proceedings of the 2018 IEEE Smartworld, Guangzhou, China, 8–12 October 2018; pp. 446–451. [Google Scholar] [CrossRef]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Facial landmark detection by deep multi-task learning. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 94–108. [Google Scholar]
- The MPLab GENKI Database, GENKI-4K Subset. Available online: http://mplab.ucsd.edu (accessed on 16 August 2021).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Mozaffari, M.H.; Lee, W.S. Semantic Segmentation with Peripheral Vision. In Proceedings of the International Symposium on Visual Computing, San Diego, CA, USA, 5–7 October 2020; pp. 421–429. [Google Scholar]
- Wang, J.; Zhang, X. A Method for Recognizing Cigarettes in Cigarette Cabinet Based on Deep. Learning. Patent CN201811100834.4, 15 February 2019. [Google Scholar]
- Zhou, J.M.; Zhou, Q.X.; Liu, Y.D.; Dong-Dong, X.U.; Feng, Z.Y. Application of infrared imaging techniques in automatic processing of agricultural products. Chin. Agric. Mech. 2010. Available online: http://en.cnki.com.cn/Article_en/CJFDTOTAL-GLJH201006020.htm (accessed on 16 August 2021).
- Zhou, R.Z.R.; Ye, M.Y.M.; Chen, H.C.H. Apple bruise detect with hyperspectral imaging technique. Chin. Opt. Lett. 2013, 12, S11101–S311103. [Google Scholar] [CrossRef]
- Liu, D.; Duan, S.; Zhang, L. A method for detecting tobacco foreign bodies based on support vector machines. Mech. Des. Manuf. Eng. 2012, 41, 55–58. [Google Scholar]
- Chao, M.; Kai, C.; Zhiwei, Z. Research on tobacco foreign object detection device based on machine vision. Trans. Inst. Meas. Control 2020, 42, 2857–2871. [Google Scholar] [CrossRef]
- Mozaffari, M.H.; Tay, L.L. Anomaly detection using 1D convolutional neural networks for surface enhanced raman scattering. In SPIE Future Sensing Technologies; SPIE—International Society for Optics and Photonics: Bellingham, WA, USA, 2020; pp. 162–168. Available online: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/11525/115250S/Anomaly-detection-using-1D-convolutional-neural-networks-for-surface-enhanced/10.1117/12.2576447.short (accessed on 16 August 2021.).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Platt, J. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines. 1998. Available online: https://www.microsoft.com/en-us/research/publication/sequential-minimal-optimization-a-fast-algorithm-for-training-support-vector-machines/ (accessed on 16 August 2021).
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://proceedings.neurips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html (accessed on 16 August 2021). [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy |
|---|---|
| Our method | 96.36% |
| The YOLOX position information | 94.55% |
| Method | Number of Data Sets | Accuracy |
|---|---|---|
| ResNet-18 | 717 | 95.30% |
| LeNet-5 | 717 | 91.67% |
| SVM | 717 | 73.51% |
| AlexNet | 717 | 85.16% |
| ResNet-101 | 717 | 79.55% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Zhao, J.; Yu, Z.; Xie, S.; Ji, X.; Wan, Z. Real-Time Foreign Object and Production Status Detection of Tobacco Cabinets Based on Deep Learning. Appl. Sci. 2022, 12, 10347. https://doi.org/10.3390/app122010347
Wang C, Zhao J, Yu Z, Xie S, Ji X, Wan Z. Real-Time Foreign Object and Production Status Detection of Tobacco Cabinets Based on Deep Learning. Applied Sciences. 2022; 12(20):10347. https://doi.org/10.3390/app122010347
Chicago/Turabian StyleWang, Chengyuan, Junli Zhao, Zengchen Yu, Shuxuan Xie, Xiaofei Ji, and Zhibo Wan. 2022. "Real-Time Foreign Object and Production Status Detection of Tobacco Cabinets Based on Deep Learning" Applied Sciences 12, no. 20: 10347. https://doi.org/10.3390/app122010347
APA StyleWang, C., Zhao, J., Yu, Z., Xie, S., Ji, X., & Wan, Z. (2022). Real-Time Foreign Object and Production Status Detection of Tobacco Cabinets Based on Deep Learning. Applied Sciences, 12(20), 10347. https://doi.org/10.3390/app122010347