1. Introduction
Clinical decision support systems (CDSSs) can assist healthcare practitioners in various decisions and patient care tasks [
1], and are expected to be especially helpful in low-resource settings. With the substantial progress artificial intelligence (AI) has made in the medical field towards clinical application [
2], much research has been done on the development of AI/machine learning-based CDSSs to support decision-making in many aspects, such as identifying prescriptions with a high risk of medication error [
3], diagnosing breast cancer [
4] and predicting its recurrence [
5], recommending treatment and predicting prognosis in patients with hepatocellular carcinoma [
6], predicting patient quality of life in amyotrophic lateral sclerosis [
7], automating sleep spindle detection [
8], etc. AI/machine learning-based CDSSs are able to process large-scale and complex data and generalize patterns from historical data to predict the outcomes of new and unseen data, having great potential to improve healthcare delivery.
With the advancements in machine and deep learning techniques, several reviews have identified that, among numerous studies on the application of AI/machine learning towards clinical decision support, artificial neural networks (ANNs) or support vector machines (SVMs) are the most common algorithms used in various medical domains [
9,
10,
11]. The algorithmic complexity of these algorithms often yields high performance; however, the issues associated with them are that they are black-boxes and their system reasoning is difficult to understand by healthcare practitioners. This lack of explainability poses a barrier to the use of AI/machine learning-based CDSSs. A model by Caruana et al. [
12] suggested patients with asthma had lower risks of dying from pneumonia, but this was because these patients tended to be admitted in the Intensive Care Unit (ICU) and receive aggressive care. This showed that a machine learning-based system can reflect true patterns in the training data, but still be problematic if trusted blindly in clinical practice. Incorporating explainable AI (XAI) in CDSSs could help prevent such mistakes being made, increase trustworthiness and acceptability of these systems and their potential to be adopted in clinical practice [
13]. Moreover, the World Health Organization AI Guidelines for Health endorsed ensuring explainability as a principle for the appropriate use of AI for health [
14].
A literature review on XAI in CDSSs identified a distinct lack of application of XAI in AI/machine learning-based CDSSs and a lack of user studies for XAI-enabled CDSSs [
13]. Nevertheless, the limited number of user studies has shown the importance of XAI in CDSSs. A user study by Panigutti et al. [
15] showed that an explanation leads to greater advice-taking and implicit trust of a CDSS, and healthcare providers preferred it when an explanation was presented. This is consistent with Antoniadi et al. [
16], who found that healthcare professionals preferred an explanation if given the option. Schoonderwoerd et al. [
17] and Hwang et al. [
18] also discovered that clinicians need explanations of CDSS outputs. Furthermore, Bussone et al. [
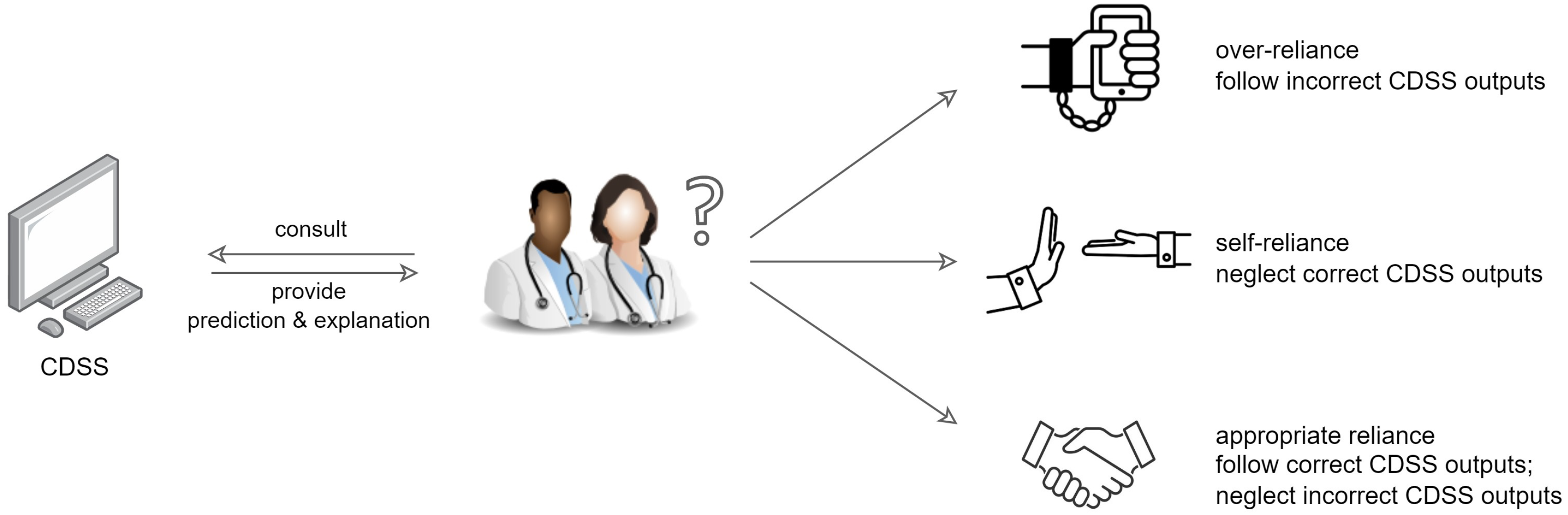
19] found that providing a comprehensive list of facts of patients to explain why the CDSS provided the outputs had a positive impact on healthcare professionals’ trust and reliance, but led to over-reliance, whereas a selective one resulted in self-reliance. As shown in
Figure 1, over-reliance refers to healthcare practitioners putting too much trust on the CDSS, even following the incorrect outputs, which may lead to the misuse of CDSS; self-reliance means healthcare practitioners neglect the correct outputs, which may result in CDSS disuse [
20]. Appropriate reliance on a CDSS should be promoted, where healthcare practitioners follow the correct outputs but reject incorrect ones.
Aside from the limited amount of user studies in general, there is a lack of comparison of different types of XAI methods with healthcare practitioners in CDSSs. According to Wang et al. [
21], the effects of explanations are largely different for decision-making tasks where people have different levels of domain expertise, and also the effects of different established XAI methods differ. To date, it is still unclear which XAI method works best for a CDSS, and what the underlying factors affecting a method’s effectiveness are. The effectiveness of a method comes not only from user preference or understanding, but also from guiding the user towards a correct decision. Therefore, there is a need for investigating appropriate advice-taking from a CDSS with both correct and incorrect predictions, as suggested by Panigutti et al. [
15].
One of the main categories of XAI methods is the granularity of explanations; this is, whether an explanation discloses the overall model behavior (global explanation), or provides information about a suggestion regarding a specific patient (local explanation). Since the majority of developers of XAI-enabled CDSSs has focused on providing local explanations [
13], we focused on two common and intuitive XAI methods that provide local explanations, namely explanation by feature contribution and explanation by example. We aimed to explore and compare the impact of these XAI methods on the advice-taking of healthcare practitioners in an explainable CDSS using both correctly and incorrectly predicted cases, as well as to explore healthcare practitioners’ preference through a user study. The CDSS we used is a machine learning-based CDSS developed for the prediction of gestational diabetes mellitus (GDM) [
22]. We ask the following research questions (RQs):
Does an explainable CDSS have any impact on healthcare practitioners’ decision-making?
Which XAI method leads to overall higher advice-taking for both correctly and incorrectly predicted cases? Is it associated with healthcare practitioners’ clinical expertise?
Do these XAI methods lead to appropriate advice-taking, over-reliance or self-reliance? Are they associated with healthcare practitioners’ clinical expertise?
Which XAI method or combination do healthcare practitioners prefer in a CDSS?
Is the advice-taking from an explainable CDSS associated with healthcare practitioners’ expertise, prior experience of CDSS, their attitude towards the use of CDSS, etc.?
2. Materials and Methods
In this section, we describe the recruitment of participants, the CDSS and two XAI methods used in the survey, the decision-making task, experimental design and data collection process.
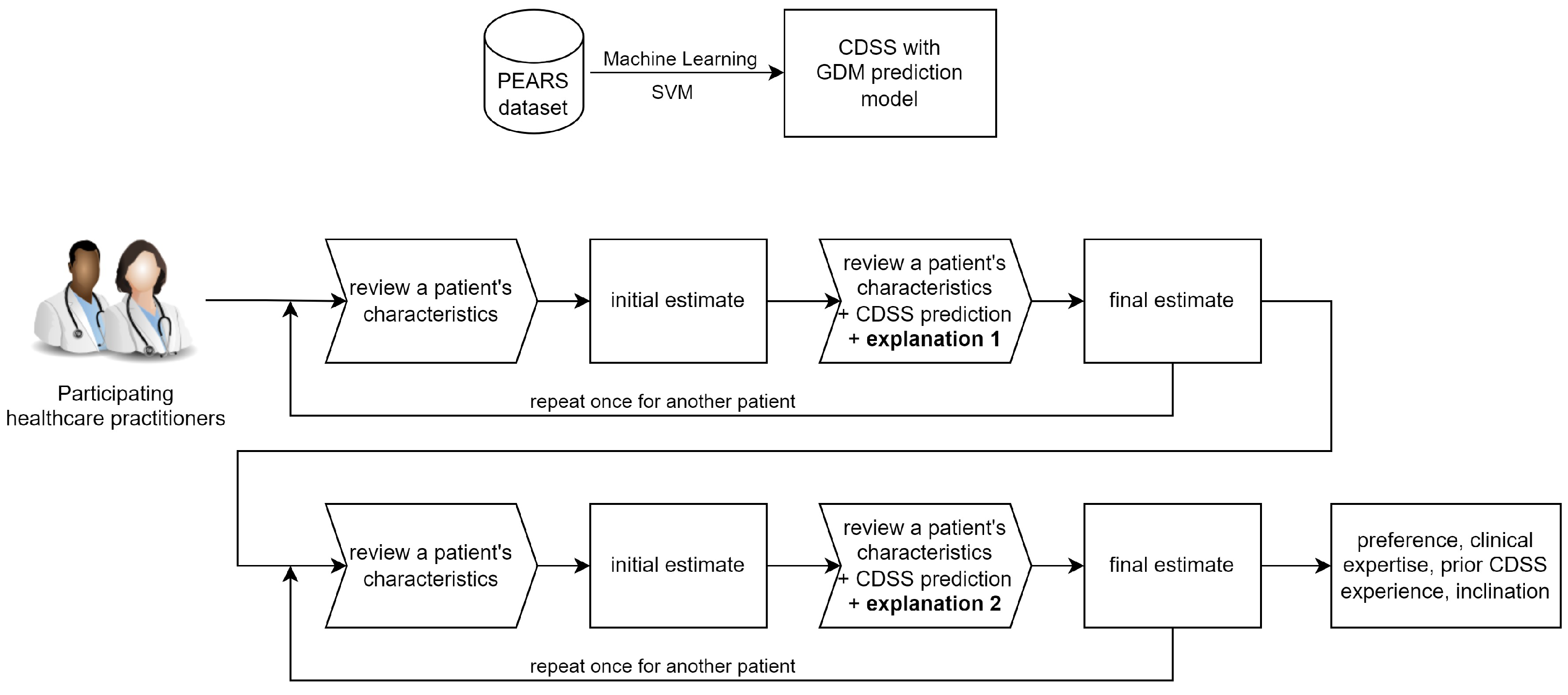
Figure 2 shows the workflow overview of this study.
2.1. Participants Recruitment
We ran an online survey using an anonymous Google form with healthcare practitioners caring for pregnant women who have or may develop GDM, including obstetricians, midwives, general practitioners (GPs), and dietitians. The survey was sent to healthcare practitioners in Ireland via an email invite to complete the survey. Ethical approval for this study was granted by University College Dublin Human Research Ethics Committee (LS-E-22-02-Mooney) on 6 January 2022. Written informed consent was obtained from all participants.
2.2. CDSS for the Prediction of GDM
To evaluate the impact of explanations on participants’ advice-taking from a CDSS, we used our machine learning-based CDSS developed to predict the risk of GDM in women with overweight and obesity [
22]. The CDSS consists of three different models that can predict GDM in theoretical, normal antenatal visit and remote settings. In this study, we used the model for a normal antenatal visit setting, due to the ease of use of the model in clinical practice. The model was developed based on a population from the Pregnancy Exercise and Nutrition Research Study (PEARS) dataset [
23]. The majority of this population are white Irish women. Only descriptive features available in clinical routine were included for this model. After appropriate data preparation, synthetic minority oversampling technique and feature selection, the model was trained using SVM, a black-box machine learning method, in Python 3.8.8 using scikit-learn 0.24.2 (see [
22] for more details). The model can predict GDM risk based on five features available at the first antenatal visit in Ireland: pregnant women’s family history of diabetes mellitus, age, body weight, serum white cell count and gestational age at the first antenatal visit. At a threshold of 0.5, it classifies pregnant women into those at low/high risk of developing GDM.
2.3. Explanation by Feature Contribution
To explain the effect of each feature on a certain prediction by our SVM model, we used Shapley additive explanations (SHAP) [
24], a post hoc XAI method based on game theory that can explain the output of any machine learning model. It was applied to improve explainability in the context of machine learning-based CDSSs [
16,
25], and it has been shown to generate reliable explanations for our CDSS [
22].
We provided bar plots of SHAP values which showed the contribution of each feature to a prediction. A red bar suggests the feature increases the predicted GDM risk, whereas a blue bar suggests the feature decreases the risk. The length of the bar indicates the magnitude of the contribution. We also provided some textual explanations of which features increase or decrease the GDM risk.
Figure 3 shows the CDSS prediction and explanation by feature contribution for one of the exemplar cases presented in the Google form survey.
2.4. Explanation by Example
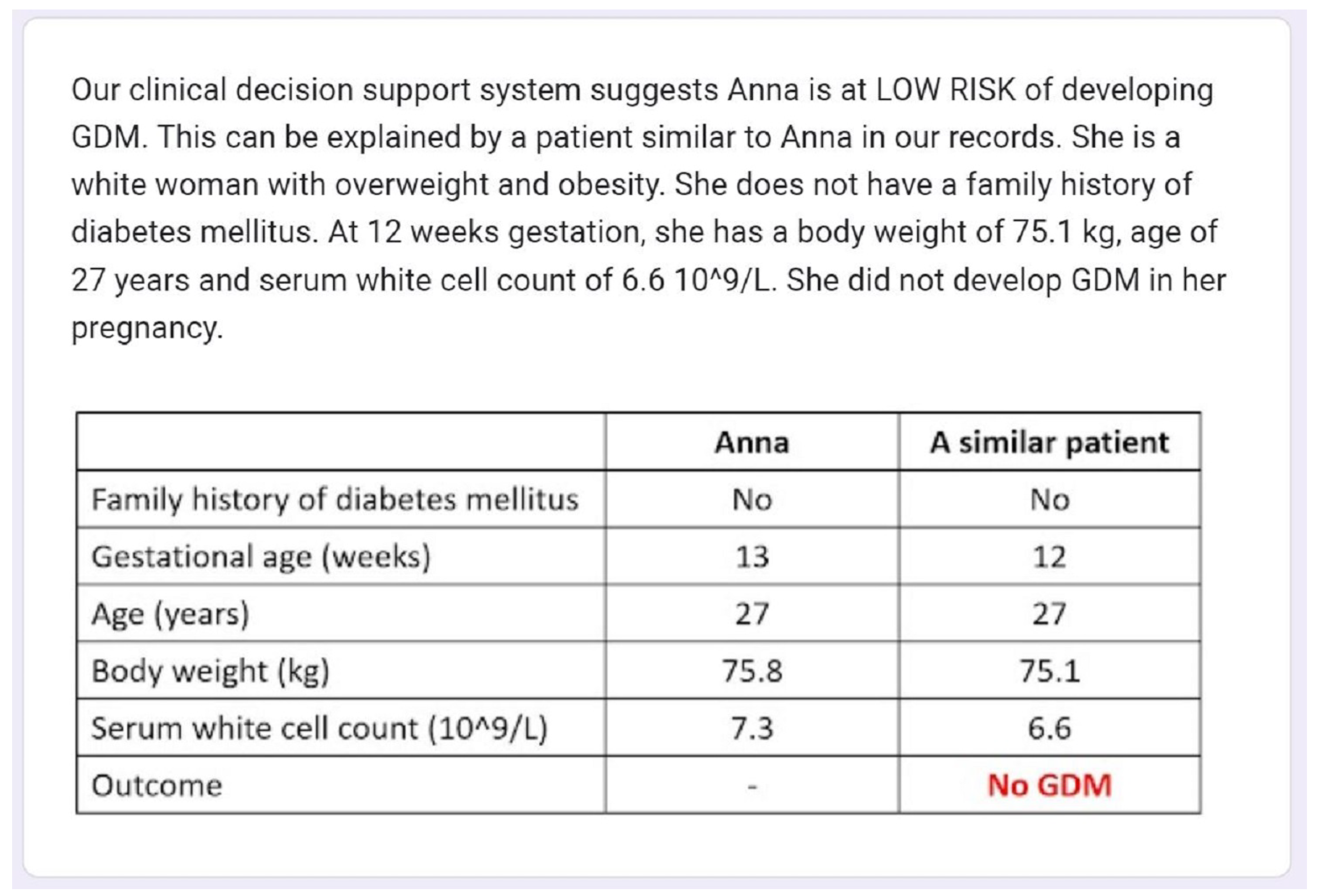
For each case, we also used the most similar case from the training set that has the same outcome as the prediction of the original case as an example-based explanation. The most similar case selected is the nearest neighbor using standard Euclidean distance. The maternal characteristics of the most similar case are presented both in text and in a table against the original case.
Figure 4 shows the CDSS prediction and explanation by example for one of the exemplar cases presented in the Google form survey.
2.5. Decision-Making Task
The decision-making task is the prediction of GDM risk in women with body mass index (BMI) > 25 kg/m2, on the scale of 0–100%. Participants were first presented with the patient’s five maternal characteristics at the first antenatal visit (family history of diabetes mellitus, age, body weight, serum white cell count, gestational age) only and were asked to make an initial estimate of this patient’s GDM risk based on their experience and expertise. Then they were presented with the risk category (i.e., high risk or low risk) predicted by our CDSS and an explanation, along with maternal characteristics, and were asked to make a second and final estimate.
2.6. Experimental Design and Data Collection
We adopted a within-subject design in this study. Each participant was asked to perform the decision-making task twice for each case, both before and after the CDSS prediction and explanation were presented, as described in
Section 2.5. Four different, yet comparable cases were selected for the survey; these cases emanated from the independent test set in the development of the CDSS (see [
22]). These four cases were women with BMI 25–39.9 kg/m
2 recruited at the National Maternity Hospital in Dublin, Ireland between 2013 and 2016 in the PEARS study [
23]. Two of them were correctly predicted by our CDSS and two were incorrectly predicted, for the purpose of identifying any self-reliance or over-reliance on the CDSS. These cases were confirmed to be analogous by a qualified obstetrician, and were grouped in pairs.
For the comparison of the two types of explanations, one group of correct and incorrect cases were explained by feature contribution, and the other group by example, randomly assigned for each participant. The order of the correctly and incorrectly predicted cases in each group was also randomized in order to prevent order effect. Due to time restrictions, we did not ask participants to interact with the CDSS prototype directly. We presented the cases, predictions of our CDSS and explanations in text and figures in the Google form.
To measure the impact of CDSS predictions and explanations on participants’ GDM risk estimation, we used the weight of advice (WOA) as a dependent variable. WOA is defined as:
. It measures the percentage shift in judgment after advice, and it quantifies how much the participants follow the advice they receive. It was employed in several advice-taking studies [
26,
27], and it was previously used to measure healthcare providers’ advice-taking from an AI-based CDSS [
15]. In this study, the initial and final estimates are participants’ estimation of the GDM risk before and after the CDSS prediction and explanation, on the scale of 0–100%. The CDSS gives binary classification, predicting whether a case is at low risk or high risk of GDM. Therefore, the advice is either 0% or 100%. WOA ranges from 0 to 1, where 1 means a participant follow the prediction of our CDSS completely and 0 means the participant does not take any advice from our CDSS.
At the end of the survey, participants were asked which explanation or combination they preferred. They were asked to leave any comments (optional). They were also asked about their clinical expertise (type of healthcare practitioner, years of experience), their prior experience of CDSS, and their inclination towards CDSS use (11-point Likert scale, from 0 = “Not at all inclined” to 10 = “Extremely inclined”).
The survey (see
Form S1) was adapted from what was described in [
15] with changes, and was carefully designed in consultation with computer science experts and qualified healthcare practitioners. All names in the survey are pseudonyms. The survey was tested by qualified obstetricians before dissemination.
3. Results
A total of 26 healthcare practitioners completed this survey. We discarded one response from a GP who made an initial estimate of 0 for a case, which led to an undefined WOA value (). Responses from 25 participants were retained for analysis: 19 (76%) obstetricians, two (8%) midwives, and four (16%) dietitians. The average years of clinical experience was 11.68 years (standard deviation = 7.010), ranging from 3 to 34 years. The majority of participants (20, 80%) had no prior experience using a CDSS or any similar computer system, whereas five (20%, all obstetricians) did. In general, participants were inclined to use a CDSS (11-point Likert scale mean = 6.24, standard deviation = 2.538). Most participants (19, 76%) showed high inclination (11-point Likert scale > 5) towards the use of CDSSs. Only a small proportion (6, 24%) were not inclined (11-point Likert scale < 5) to CDSS use. None gave a neutral answer (11-point Likert scale = 5).
All data analysis was performed in R version 3.6.3.
3.1. RQ1: Impact on Decision-Making
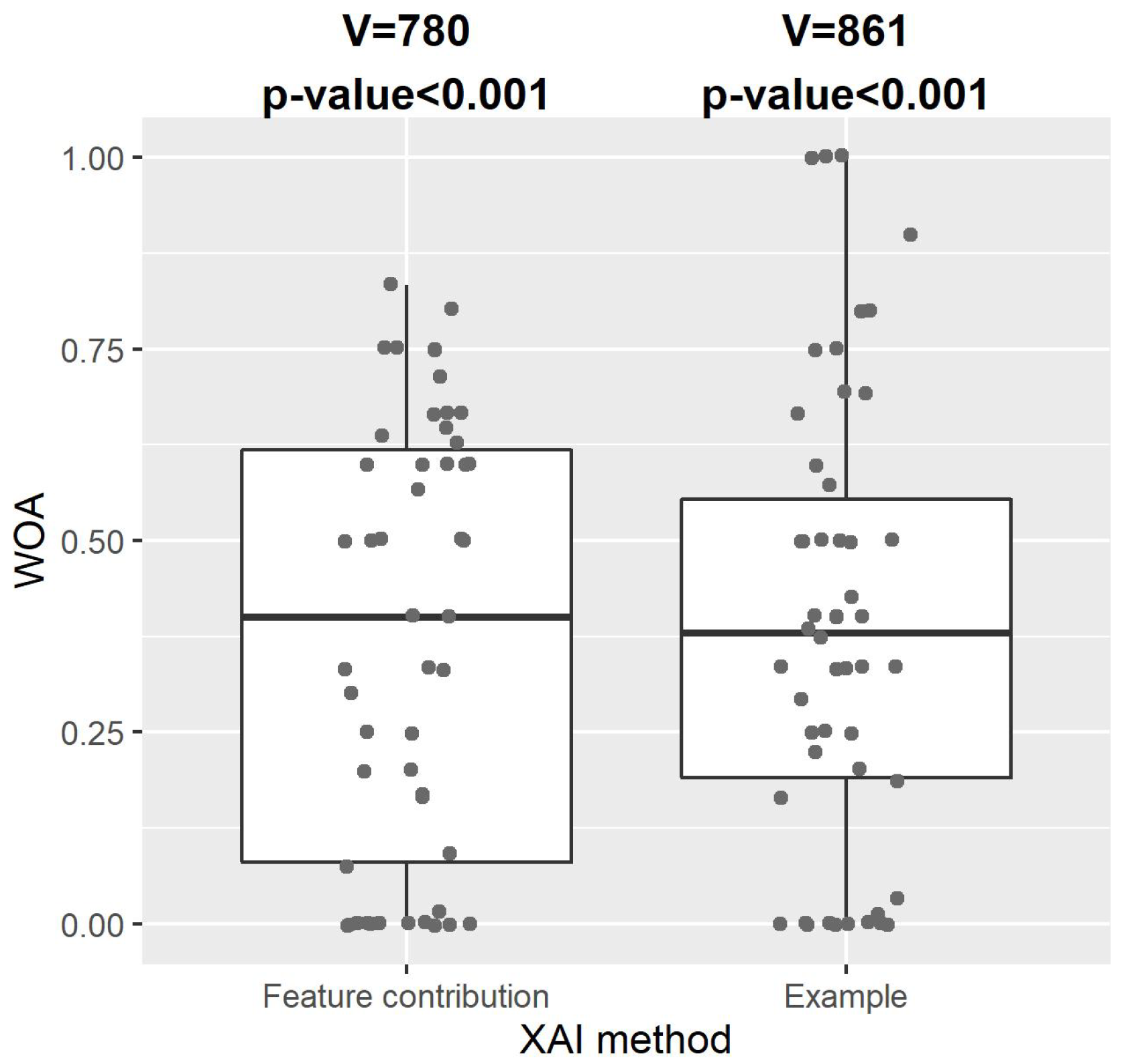
Figure 5 shows the distribution of WOA of our CDSS with explanation by feature contribution or example. One-sample one-sided Wilcoxon signed-rank tests indicated that WOA for both XAI methods were significantly greater than zero (explanation by feature contribution: V = 780,
p-value < 0.001; explanation by example: V = 861,
p-value < 0.001). This showed that the participating healthcare practitioners took a substantial amount of advice from our CDSS with either type of explanation, and that our explainable CDSS with either type of explanation had a significant impact on healthcare practitioners’ decision-making.
3.2. RQ2: Overall Advice-Taking
Table 1 shows the comparison between the WOA for these two XAI methods using paired-samples two-sided Wilcoxon signed-rank tests. We found no statistically significant difference between these methods in the advice-taking of all participating healthcare practitioners (V = 536.5,
p-value = 0.775). The rate of no advice-taking (WOA = 0) was 22% for explanation by feature contribution and 18% for explanation by example. A Fisher’s exact test showed no significant difference between these XAI methods (
p-value = 0.803). Additionally, there was no significant difference between these methods in any subgroups of participants grouped by their clinical expertise, including, the type of healthcare practitioners and years of experience (see
Table 1). Overall, we did not find significant differences in the impact of the two XAI methods on advice-taking of healthcare practitioners, regardless of their clinical expertise.
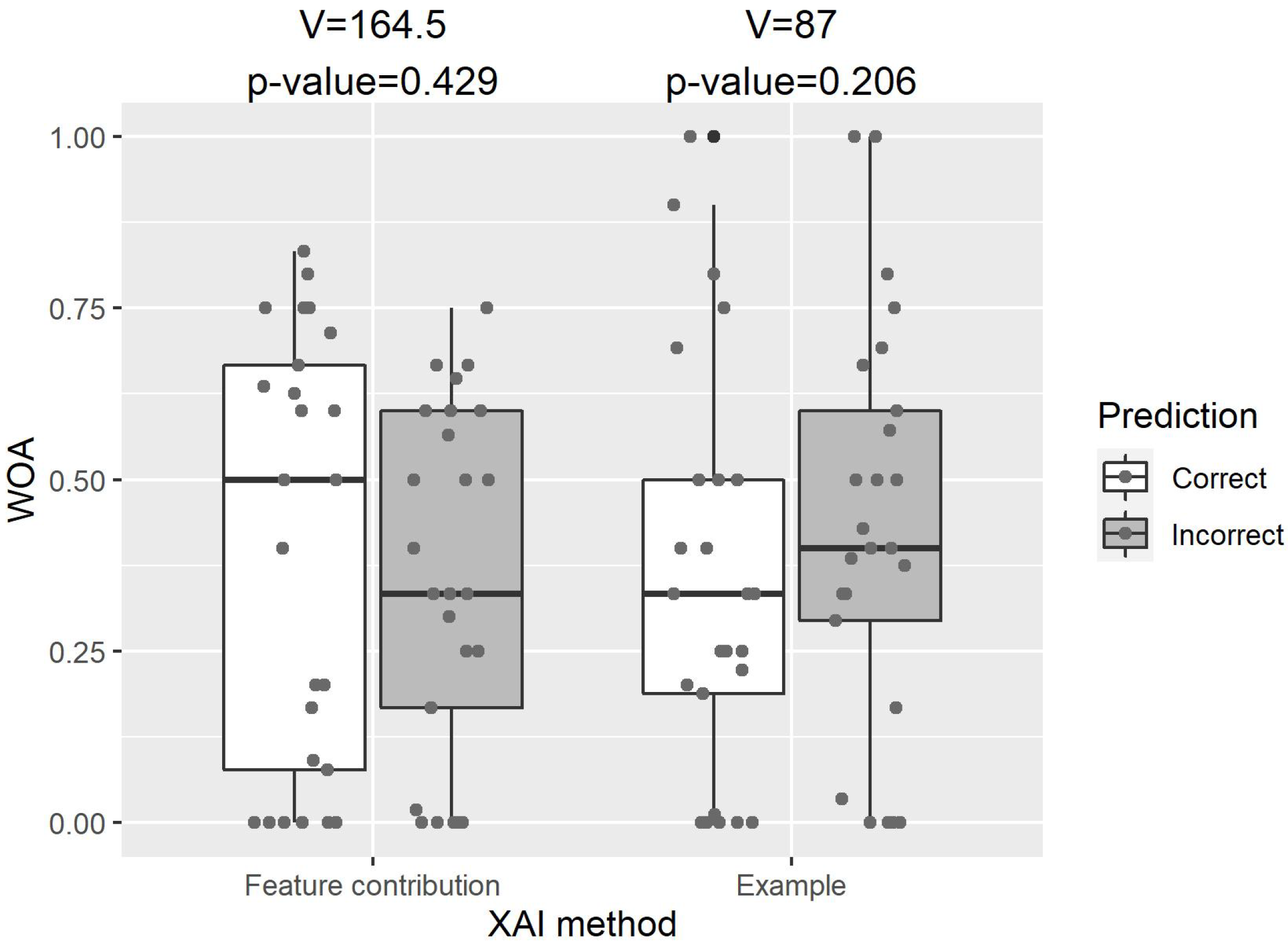
3.3. RQ3: Appropriate Advice-Taking, Over-Reliance or Self-Reliance
For both XAI methods, the paired-samples two-sided Wilcoxon signed-rank tests found no significant difference between the WOA for correct and incorrect cases predicted by our CDSS (explanation by feature contribution: V = 164.5,
p-value = 0.429; explanation by example: V = 87,
p-value = 0.206; see
Figure 6). Interestingly,
Figure 6 shows that for explanation by example, the WOA for the incorrect cases was higher than that for the correct cases, although this difference was not statistically significant. Additionally, we found no significant difference in the WOA between correct and incorrect cases among any subgroups of participants grouped by their clinical expertise, as shown in
Table 2. Regarding the rate of no advice-taking for all participants, Fisher’s exact tests showed no significant difference between these cases for both XAI methods (
p-value = 1 for both methods). Our results suggest that neither XAI method showed a sign of appropriate advice-taking when incorporated in our CDSS, and both methods may lead to over-reliance issues, regardless of the expertise of healthcare practitioners.
One-sample one-sided Wilcoxon signed-rank tests showed that the WOA of our CDSS with either XAI method for the correctly predicted cases was significantly greater than zero (explanation by feature contribution: V = 190, p-value < 0.001; explanation by example: V = 210, p-value < 0.001), which did not suggest any overall self-reliance among the participants for the two XAI methods.
3.4. RQ4: Preferred XAI Method
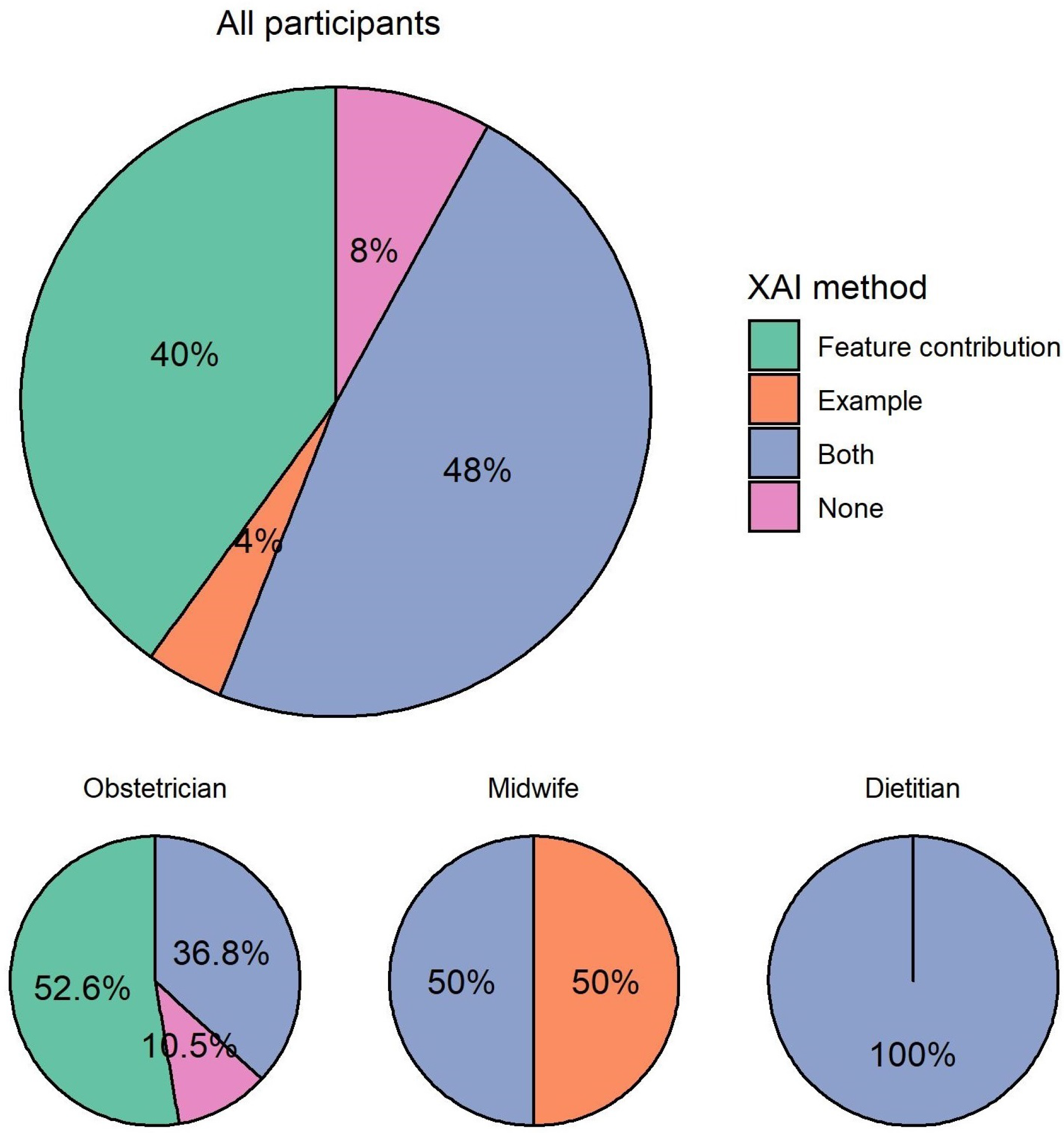
When asked which type of explanation they would prefer in a CDSS, almost half (12, 48%) of participants preferred to see both explanations, as shown in
Figure 7. For participants who preferred one over the other, there was a clear preference for explanation by feature contribution (10, 40%) over explanation by example (1, 4%). Only two (8%) participants preferred none of the explanations in a CDSS.
Among all participating obstetricians, more than half (10, 52.6%) preferred explanation by feature contribution. The rest preferred both explanations (7, 36.8%) or none of the explanations (2, 10.5%). Among the two participating midwives, one preferred explanation by example and one preferred both explanations. All participating dietitians preferred both explanations.
One participant justified the preference for explanation by feature contribution as one similar example only was not helpful, and suggested the use of a large group of similar examples:
“I don’t think comparing to one similar patient is helpful, this does not predict the risk to our patient. If comparing to other patients it should be a comparison to a large group of similar patients, not just one case. ” (Obstetrician)
One participant commented that they preferred to see both explanations in a CDSS for better clarity:
“visually clearer” (Dietitian)
3.5. RQ5: Factors Associated with Advice-Taking
Having identified no significant difference between the two XAI methods, we looked into factors that may affect healthcare practitioners’ overall advice-taking from an explainable CDSS.
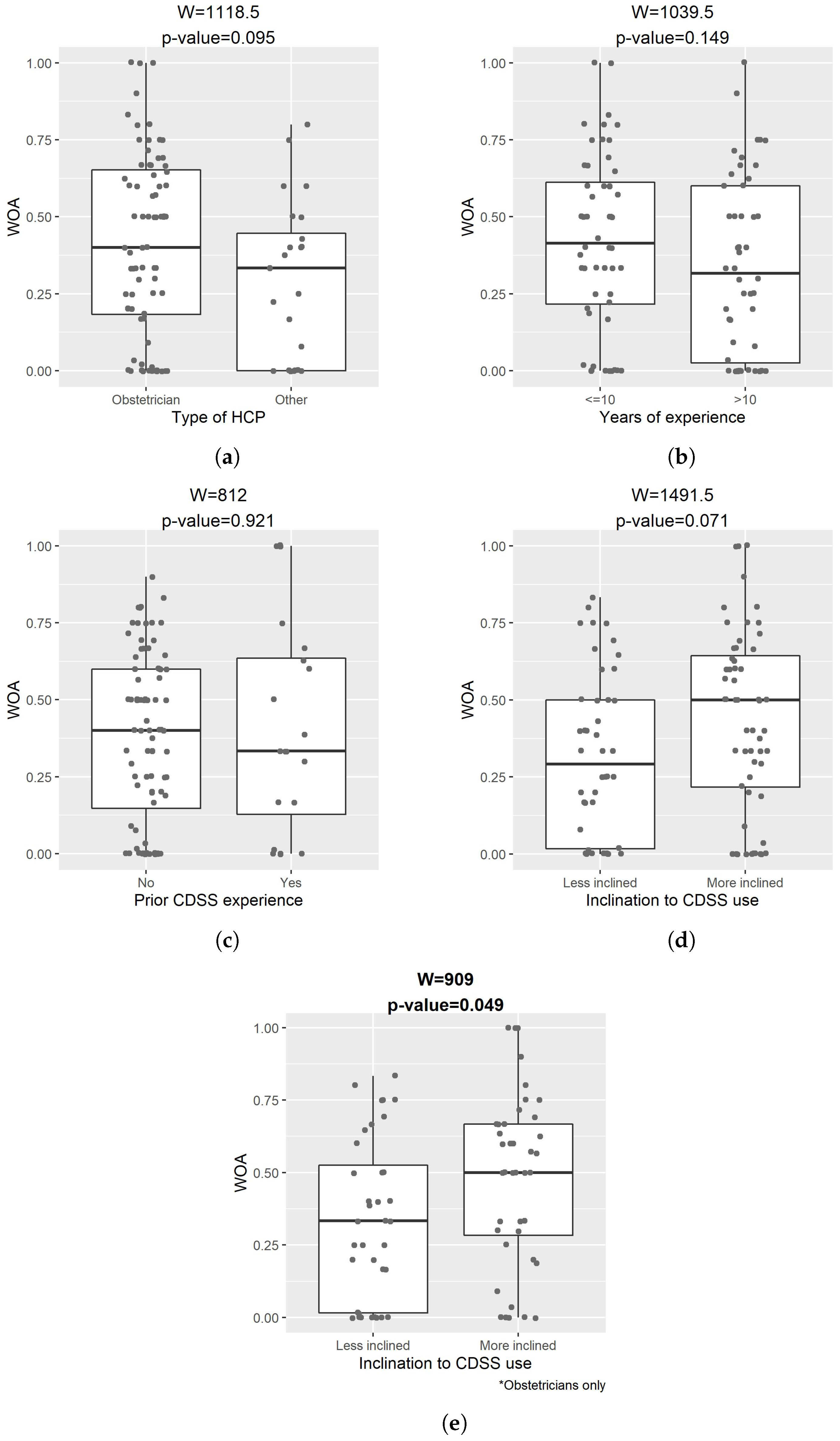
Figure 8 compares the WOA of our CDSS explained by either of the XAI methods between subgroups of participants. The two-sided Wilcoxon rank sum tests suggested that WOA did not have a significant difference by the type of healthcare practitioner, years of experience, or prior experience of CDSS. For some of the comparisons, this may be due to the small sample size.
Obstetricians who explicitly expressed higher inclination (11-point Likert scale ⩾ 7) towards the use of CDSS had significantly overall higher WOA than those that expressed lower inclination (11-point Likert scale < 7) (W = 909, p-value = 0.049). This indicated that the inclination towards CDSS use was an important factor for the advice-taking from an explainable CDSS among obstetricians. However, this did not apply to the entire cohort of participants, either because of differences in the advice-taking behavior between different types of healthcare practitioners or the limited sample size.
3.6. Others
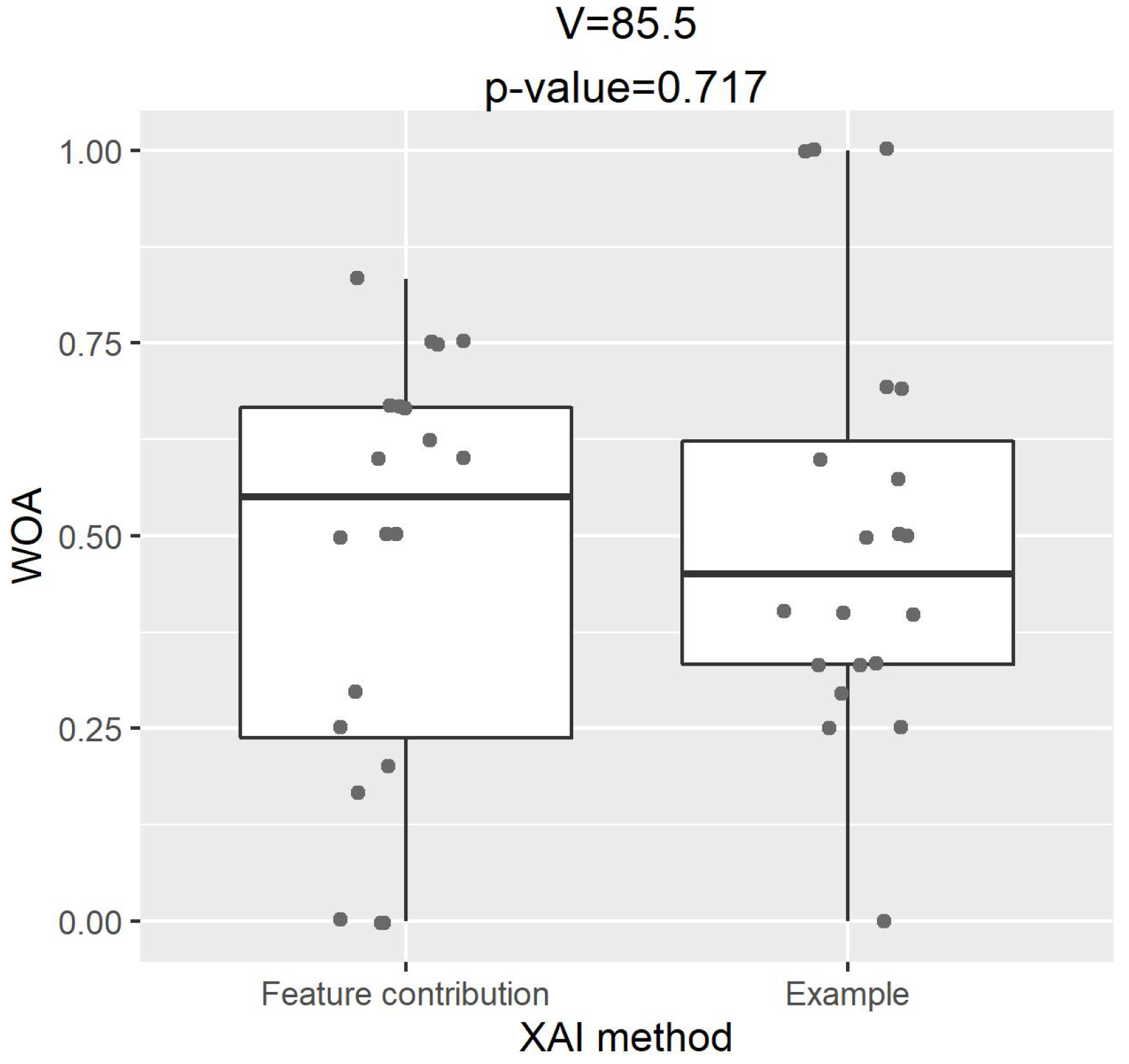
We investigated the association between healthcare practitioners’ preference for explanations and their advice-taking.
Figure 9 shows the comparison of WOA between two XAI methods for those who preferred an explanation by feature contribution only. A paired-samples two-sided Wilcoxon signed-rank test indicated that, although these healthcare practitioners had a clear preference for explanations, there was no significant difference in their actual advice-taking between the two XAI methods (V = 85.5,
p-value = 0.717).
In this study, we found that initial estimates of GDM risk can vary largely among the healthcare practitioners for the same case. For the four cases used in the survey, initial estimates of GDM risk ranged between 5–80%, 10–90%, 9–90% or 8–92%. This is potentially because there is no unified way to predict and quantify GDM risk on a scale of 0–100%.
We received a positive feedback on the clinical applicability of our CDSS for the prediction of GDM:
“… I can see its clinical applicability”. (Obstetrician)
However, some participants expressed concerns on our CDSS, including the input features it used, and the lack of universal definition and diagnostic criteria of GDM being a barrier to its clinical application:
“… Height matters. ” (Dietitian)
“… there is no internationally accepted definition of GDM and no accepted screening protocol … I think it is hard to understand the added clinical benefit of a risk prediction tool …”. (Obstetrician)
4. Discussion
Although explanations of CDSS outputs are deemed highly important for the appropriate use and acceptance of these systems, it is not yet clear what type of explanations can be more useful for their end-users. In the era of XAI, a variety of techniques to explain machine learning models are available, but little is known about their correlation with user-understanding [
13]. We conducted a user study with healthcare practitioners of pregnant women in Ireland to investigate and compare two different types of XAI methods based on the machine learning-based CDSS we developed to predict GDM among women with overweight and obesity.
Our results, primarily based on obstetricians, showed that a CDSS, explained by either feature contribution or example, can have a substantial impact on the decision-making of healthcare practitioners, demonstrating the effectiveness of our explainable CDSS. It has been argued in literature, that example-based methods such as k-nearest neighbors (KNN), are motivated by human-reasoning [
28,
29,
30,
31]; thus, they may be appropriate for machine learning models used in the medical domain, as they can explain the model’s reasoning by allowing the user to compare it to similar case(s) and also apply their expertise to assess the quality of the suggestion [
32]. In our work, we found no difference between the two XAI methods, explanation by feature contribution and explanation by example, regarding the advice-taking from a CDSS. Additionally, we found that both methods may lead to over-reliance issues, i.e., healthcare practitioners may be misled by an incorrect prediction of the CDSS. A previous study that compared rule-based and example-based explanations found that both types of explanations also led to over-reliance on the model’s predictions, although the participants in that study were not healthcare practitioners [
33].
Despite many participating healthcare practitioners preferring both types of explanation, we noticed a clear preference for explanation by feature contribution over explanation by example, while the preference for XAI methods differed according to the expertise of healthcare practitioners. More than half of the obstetricians preferred an explanation by feature contribution only, whereas all participating dietitians preferred to have both an explanation by feature contribution and by example. The vast majority of participants preferred to have at least one of the XAI methods in a CDSS; therefore, we suggest that CDSS developers should incorporate some XAI methods in AI-based CDSSs where possible. It might be helpful to include multiple options of explanations for healthcare practitioners with different clinical expertise and cognitive styles. Healthcare practitioners have personal preferences concerning the information that they provide in their diagnosis [
17], which would affect their preferred type of displayed information and explanation by a CDSS.
In addition, although most participating healthcare practitioners had no prior experience of using a CDSS, the majority were highly inclined to use a CDSS, indicating the potential for CDSS use in clinical settings. We identified the inclination towards CDSS use as an important factor that impacts the advice-taking among obstetricians. Computer-based training [
34], involving machine learning education and its application in medical schools [
35], may improve healthcare practitioners’ inclination towards technology use and may eventually enhance the adoption of machine learning-based systems in clinical practice. We did not find any association between the advice-taking of healthcare practitioners and their clinical expertise, years of experience or their prior experience of CDSS use.
One of the limitations of this study is the small sample size despite our best efforts for study participation. Our CDSS was developed mainly based on white Irish women, which limits our target participants to healthcare practitioners of pregnant women in Ireland only. In addition, an anecdotal feedback on our survey suggests that midwives and dietitians may be less comfortable with making decisions on GDM risk than obstetricians, which explains the limited number of responses from the former cohort. The decision-making task and features used in our CDSS were not exactly the same as those that healthcare practitioners normally perform or see in a clinical setting, which may have put some healthcare practitioners off. Another limitation of this study is that we did not provide any information on the accuracy of our CDSS, which might have impacted healthcare practitioners’ over-reliance on the system.
Future work could be conducted on the evaluation of CDSSs with other explanation methods, including example-based explanations with more than one example, with a focus on identifying the XAI methods that will lead to appropriate reliance on the system (i.e., users following correct suggestions and rejecting incorrect ones). User studies with other types of healthcare practitioners, preferably larger samples if possible, are necessary. Focus groups could also lead to the elicitation of further insights, knowledge, and opinions on the CDSS and its explanations.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}