
Code Smell Detection Using Ensemble Machine Learning Algorithms



Abstract
1. Introduction
1.1. Motivation
1.2. Contributions
1.3. Research Questions
- RQ1.
- Which ensemble and deep learning algorithm is better/best for detecting the code smells?
- RQ2.
- Does a set of metrics chosen by the Chi-square FSA improve the performance of code smell detection?
- RQ3.
- Does the SMOTE class balancing technique improve the performance of code smell detection?
2. Literature Review
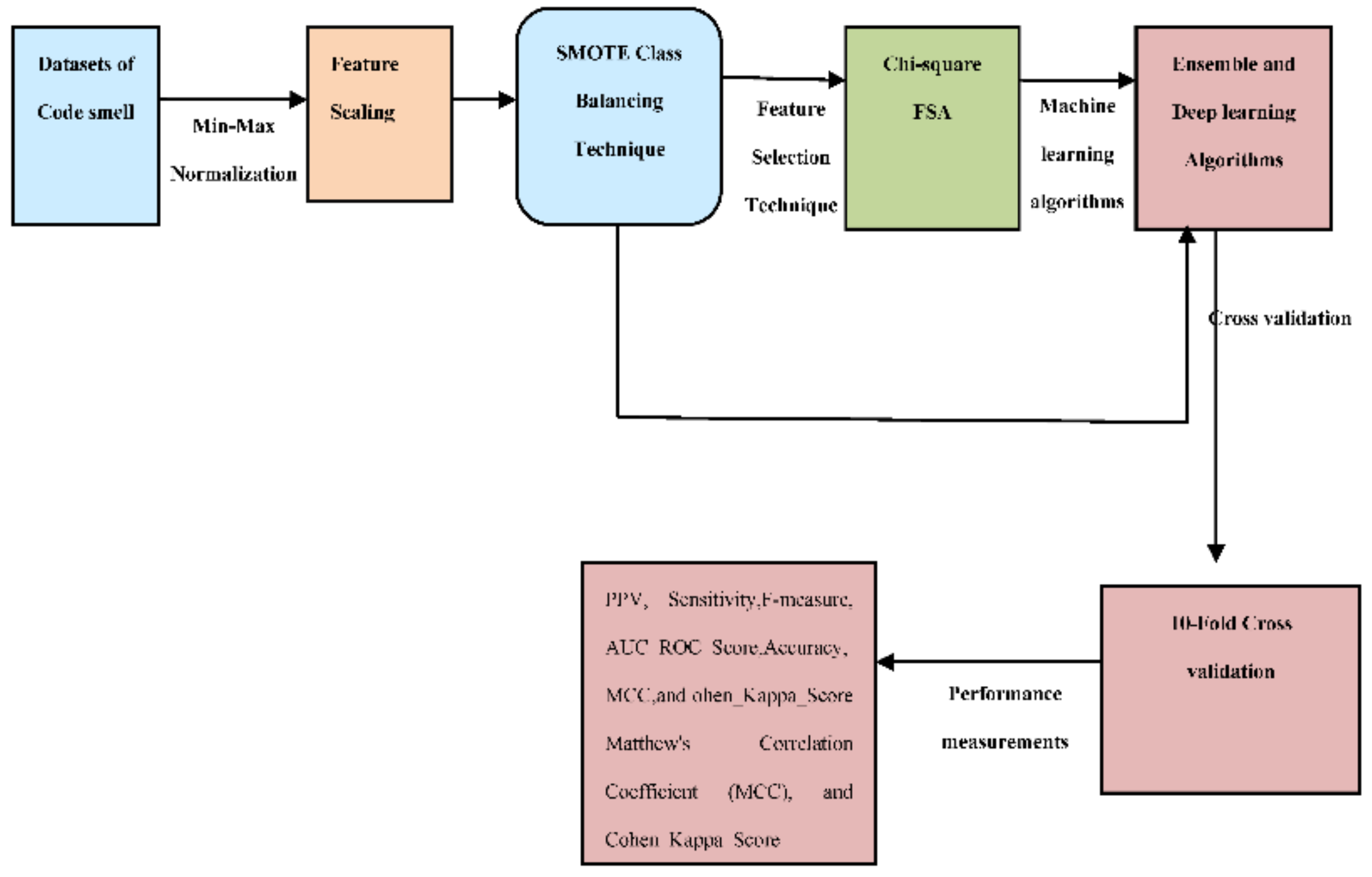
3. Proposed Research Framework
3.1. Dataset Choice and Illustration
3.2. Dataset Normalization
3.3. Class Balancing Technique
3.4. Feature Selection Approach (FSA)
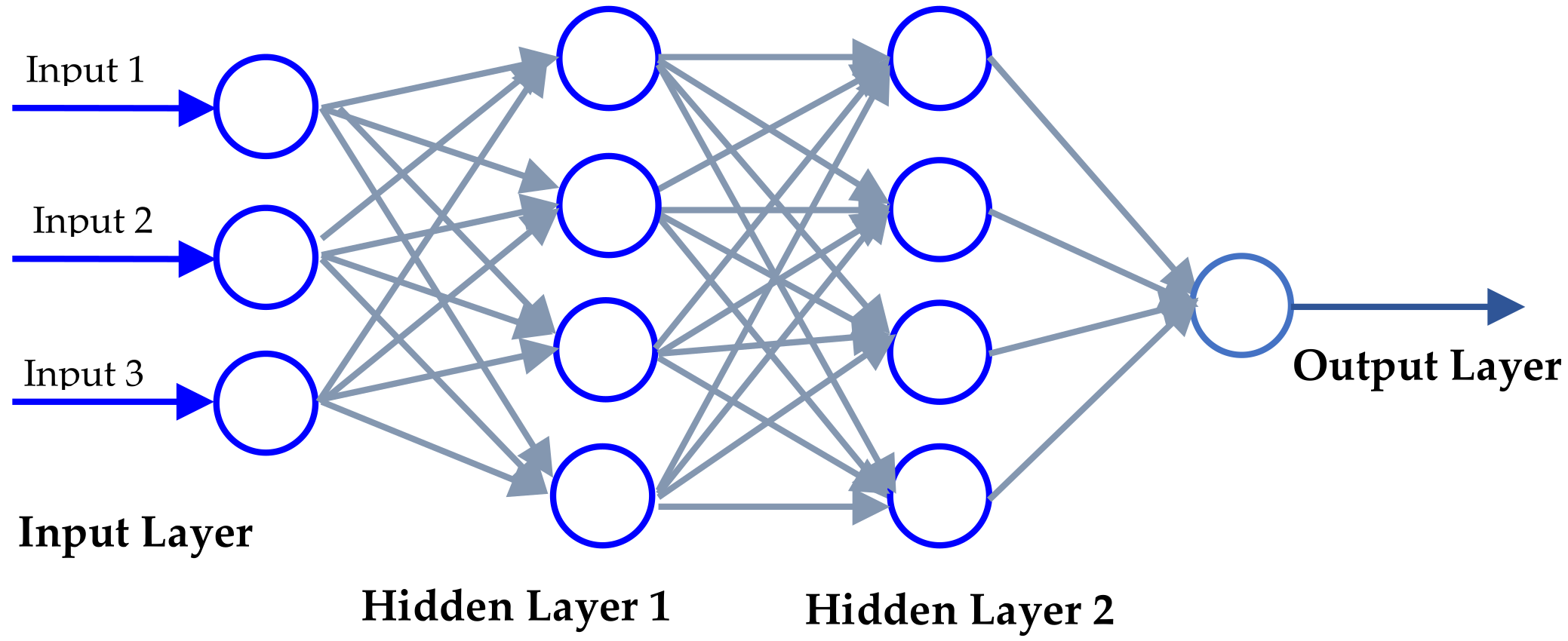
3.5. Proposed Ensemble and Deep Learning Algorithms
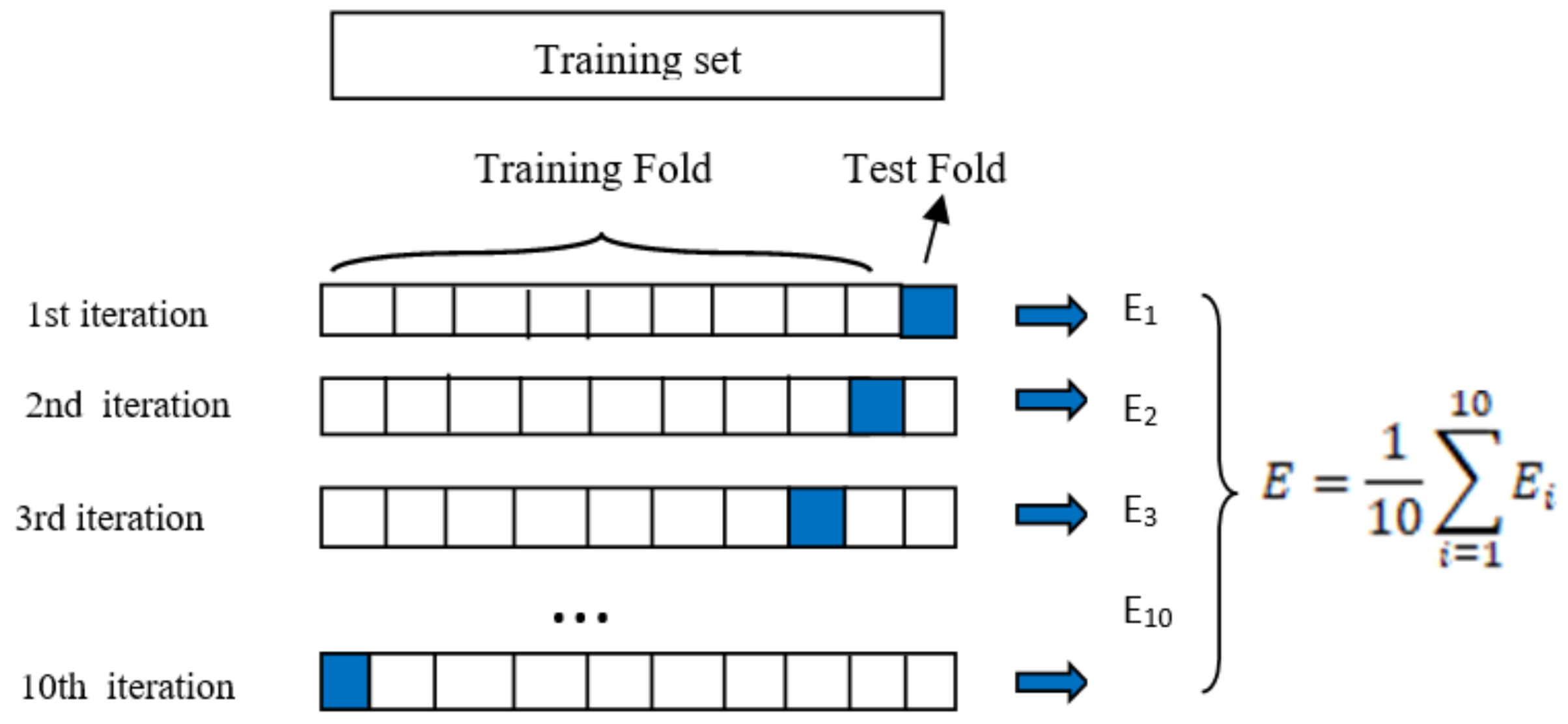
3.6. Evaluation Methodology
3.7. Key Measurements of Performance
- TP represents the outputs (occurrences) where the algorithm accurately expects the positive class.
- TN represents the outputs (occurrences) where the algorithm accurately expects the negative class.
- FP represents the outputs (occurrences) where the algorithm inaccurately expects the positive class.
- FN represents the outputs (occurrences) where the algorithm inaccurately expects the negative class.
4. The Outcome of Proposed Algorithms
4.1. PerformanceComparisonbetweenFive Ensemble and Two Deep Learning Methods
4.2. Effect of Subset of Features Selected by Chi-Square FSA on Model Accuracy
4.3. Effect of Class Balancing Technique (SMOTE) on Model Accuracy
5. Discussion
5.1. Result Comparison of Our Approach with Others’ Correlated Work
5.2. Analysis of Our Work
5.3. Result and All Model Comparison of Our Approach with Other Correlated Works
5.4. Statistical Analysis
5.5. Threats to Validity
6. Conclusions and Future Scope
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Algorithms | DC | GC | FE | LM |
|---|---|---|---|---|
| AdaBoost | LOCNAMM_type, LOC_type, WMCNAMM_type, WMC_type, RFC_type, NOMNAMM_package, WOC_type, CFNAMM_type, ATFD_type | LOC_type, LOCNAMM_type, WMCNAMM_type, WMC_type, NOMNAMM_package, RFC_type, CFNAMM_type, ATFD_type, NOMNAMM_type, NOM_type, FANOUT_type, CBO_type | LOC_method, NOAV_method, CYCLO_method, ATFD_method, ATFD_type, CINT_method, NOLV_method, CFNAMM_method, FDP_method, FANOUT_method, CBO_type, Method | LOC_method, CYCLO_method, NOAV_method, NOLV_method, CINT_method, ATFD_type, CFNAMM_method, ATFD_method, FANOUT_method, ATLD_method, MAXNESTING_method, Method |
| Bagging | ||||
| Max voting | ||||
| Gradient Boosting | ||||
| XGBoost | ||||
| ANN | ||||
| CNN |
| Quality Dimension | Metric Label | Metric Name | Granularity |
|---|---|---|---|
| Size | LOC_type | Lines of Code | Project, Package, Class, Method |
| Size | LOCNAMM_type | Lines of Code Without Accessor or Mutator Methods | Class |
| Complexity | WMCNAMM_type | Weighted Methods Count of Not Accessor or Mutator Methods | Class |
| Complexity | WMC_type | Weighted Methods Count | Class |
| Size | NOMNAMM_package | Number of Not Accessor or Mutator Methods | Project, Package, Class |
| Coupling | RFC_type | Response for a Class | Class |
| Coupling | CFNAMM_type | Called Foreign Not Accessor or Mutator Methods | Class, Method |
| Coupling | ATFD_type | Access to Foreign Data | Method |
| Coupling | FANOUT_type | - | Class, Method |
| Size | NOMNAMM_type | Number of Not Accessor or Mutator Methods | Class |
| Size | NOM_type | Number of Methods | Project, Package, Class |
| Coupling | CBO_type | Coupling Between Objects Classes | Class |
| - | WOC_type | - | Class |
| Complexity | NOAV_method | Number of Accessed Variables | Method |
| Complexity | CYCLO_method | Cyclomatic Complexity | Method |
| Coupling | CINT_method | Coupling Intensity | Method |
| Size | MAXNESTING_method | Maximum Nesting Level | Method |
References
- Palomba, F.; Bavota, G.; Penta, M.D.; Oliveto, R.; Poshyvanyk, D.; de Lucia, A. Mining Version Histories for Detecting Code Smells. IEEE Trans. Softw. Eng. 2015, 41, 4062–4089. [Google Scholar] [CrossRef]
- Wikipedia Contributors. Code Smell. 20 October 2021. Available online: https://en.wikipedia.org/w/index.php?title=Code_smell&oldid=1050826229 (accessed on 16 November 2021).
- Kessentini, W.; Kessentini, M.; Sahraoui, H.; Bechikh, S.; Ouni, A. A cooperative parallel search-based software engineering approach for code-smells detection. IEEE Trans. Softw. Eng. 2014, 40, 841–861. [Google Scholar] [CrossRef]
- Fontana, F.A.; Braione, P.; Zanoni, M. Automatic detection of bad smells in code: An experimental assessment. J. Object Technol. 2012, 11, 5. [Google Scholar]
- Dewangan, S.; Rao, R.S. Code Smell Detection Using Classification Approaches. In Intelligent Systems; Udgata, S.K., Sethi, S., Gao, X.Z., Eds.; Lecture Notes in Networks and Systems; Springer: Singapore, 2022; Volume 431. [Google Scholar] [CrossRef]
- Rasool, G.; Arshad, Z. A review of code smell mining techniques. J. Softw. Evol. Process 2015, 27, 867–895. [Google Scholar] [CrossRef]
- Fontana, F.A.; Mäntylä, M.V.; Zanoni, M.; Marino, A. Comparing and experimenting machine learning techniques for code smell detection. Empir. Softw. Eng. 2016, 21, 1143–1191. [Google Scholar] [CrossRef]
- Lehman, M.M. Programs, life cycles, and laws of software evolution. Proc. IEEE 1980, 68, 1060–1076. [Google Scholar] [CrossRef]
- Wiegers, K. , Beatty, J. Software Requirements; Pearson Education: London, UK, 2013. [Google Scholar]
- Chung, L.; do Prado Leite, J.C.S. On Non-Functional Requirements in Software Engineering. In Conceptual Modeling: Foundations and Applications-Essays in Honor of John Mylopoulos; Borgida, A.T., Chaudhri, V., Giorgini, P., Yu, E., Eds.; Springer: Singapore, 2009; pp. 363–379. [Google Scholar]
- Fowler, M.; Beck, K.; Brant, J.; Opdyke, W.; Roberts, D. Refactoring: Improving the Design of Existing Code, 1st ed.; Addison-Wesley Professional: Boston, MA, USA, 1999. [Google Scholar]
- Yamashita, A.; Moonen, L. Do Code Smells Reflect Important Maintainability aspects? In Proceedings of the 28th IEEE International Conference Software Maintenance, Trento, Italy, 23 September 2012; pp. 306–315. [Google Scholar]
- Sjøberg, D.I.K.; Yamashita, A.; Anda, B.C.D.; Mockus, A.; Dyb, A.T. Quantifying the effect of code smells on maintenance effort. IEEE Trans. Softw. Eng. 2013, 39, 1144–1156. [Google Scholar] [CrossRef]
- Sahin, D.; Kessentini, M.; Bechikh, S.; Ded, K. Code-smells detection as a bi-level problem. ACM Trans. Softw. Eng. Methodol. 2014, 24, 6. [Google Scholar] [CrossRef]
- Olbrich, S.M.; Cruzes, D.S.; Sjoøberg, D.I.K. Are all Code Smells Harmful? A study of God Classes and Brain Classes in the evolution of Three open-Source Systems. In Proceedings of the 26th IEEE International Conference Software Maintenance, Timisoara, Romania, 12–18 September 2010. [Google Scholar]
- Khomh, F.; Penta, D.M.; Gueheneuc, Y.G. An Exploratory Study of the Impact of Code Smells on Software Change Proneness. In Proceedings of the 16th Working Conference on Reverse Engineering, Lille, France, 13–16 October 2009; pp. 75–84. [Google Scholar]
- Deligiannis, I.; Stamelos, I.; Angelis, L.; Roumeliotis, M.; Shepperd, M. A controlled experiment investigation of an object-oriented design heuristic for maintainability. J. Syst. Softw. 2004, 72, 129–143. [Google Scholar] [CrossRef]
- Li, W.; Shatnawi, R. An empirical study of the bad smells and class error probability in the post-release object-oriented system evolution. J. Syst. Softw. 2007, 80, 1120–1128. [Google Scholar] [CrossRef]
- Perez-Castillo, R.; Piattini, M. Analyzing the harmful effect of god class refactoring on power consumption. IEEE Softw. 2014, 31, 48–54. [Google Scholar] [CrossRef]
- Guggulothu, T.; Moiz, S.A. Code smell detection using multi-label classification approach. Softw. Qual. J. 2020, 28, 1063–1086. [Google Scholar] [CrossRef]
- Lewowski, T.; Madeyski, L. How far are we from reproducible research on code smell detection? A systematic literature review. Inf. Softw. Technol. 2022, 144, 106783. [Google Scholar] [CrossRef]
- Alazba, A.; Aljamaan, H.I. Code smell detection using feature selection and stacking ensemble: An empirical investigation. Inf. Softw. Technol. 2021, 138, 106648. [Google Scholar] [CrossRef]
- Dewangan, S.; Rao, R.S.; Mishra, A.; Gupta, M. A Novel Approach for Code Smell Detection: An Empirical Study. IEEE Access 2021, 9, 162869–162883. [Google Scholar] [CrossRef]
- Sharma, T.; Efstathiou, V.; Louridas, P.; Spinellis, D. Code smell detection by deep direct-learning and transfer-learning. J. Syst. Softw. 2021, 176, 110936. [Google Scholar] [CrossRef]
- Mhawish, M.Y.; Gupta, M. Predicting code smells and analysis of predictions: Using machine learning techniques and software metrics. J. Comput. Sci. Technol. 2020, 35, 1428–1445. [Google Scholar] [CrossRef]
- Mhawish, M.Y.; Gupta, M. Generating Code-Smell Prediction Rules Using Decision Tree Algorithm and Software Metrics. Int. J. Comput. Sci. Eng. 2019, 7, 41–48. [Google Scholar] [CrossRef]
- Pushpalatha, M.N.; Mrunalini, M. Predicting the Severity of Closed Source Bug Reports Using Ensemble Methods. In Smart Intelligent Computing and Applications. Smart Innovation, Systems and Technologies; Satapathy, S., Bhateja, V., Das, S., Eds.; Springer: Singapore, 2019; Volume 105. [Google Scholar] [CrossRef]
- Pandey, S.K.; Tripathi, A.K. An Empirical Study towards dealing with Noise and Class Imbalance issues in Software Defect Prediction. Soft Comput. 2021, 25, 13465–13492. [Google Scholar] [CrossRef]
- Boutaib, S.; Bechikh, S.; Palomba, F.; Elarbi, M.; Makhlouf, M.; Said, L.B. Code smell detection and identification in imbalanced environments. Expert Syst. Appl. 2021, 166, 114076. [Google Scholar] [CrossRef]
- Fontana, F.A.; Zanoni, M. Code smell severity classification using machine learning techniques. Knowl. Based Syst. 2017, 128, 43–58. [Google Scholar] [CrossRef]
- Baarah, A.; Aloqaily, A.; Salah, Z.; Mannam, Z.; Sallam, M. Machine Learning Approaches for Predicting the Severity Level of Software Bug Reports in Closed Source Projects. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 285–294. [Google Scholar] [CrossRef]
- Pushpalatha, M.N.; Mrunalini, M. Predicting the severity of open source bug reports using unsupervised and supervised techniques. Int. J. Open Source Softw. Process. 2019, 10, 676–692. [Google Scholar] [CrossRef]
- Kaur, I.; Kaur, A. A Novel Four-Way Approach Designed with Ensemble Feature Selection for Code Smell Detection. IEEE Access 2021, 9, 8695–8707. [Google Scholar] [CrossRef]
- Draz, M.M.; Farhan, M.S.; Abdulkader, S.N.; Gafar, M.G. Code smell detection using whale optimization algorithm. Comput. Mater. Contin. 2021, 68, 1919–1935. [Google Scholar] [CrossRef]
- Gupta, H.; Kulkarni, T.G.; Kumar, L.; Neti, L.B.M.; Krishna, A. An Empirical Study on Predictability of Software Code Smell Using Deep Learning Models; Springer: Cham, Switzerland, 2021. [Google Scholar] [CrossRef]
- Di Nucci, D.; Palomba, F.; Tamburri, D.A.; Serebrenik, A.; de Lucia, A. Detecting Code Smells using Machine Learning Techniques: Are We There Yet? In Proceedings of the 2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER), Campobasso, Italy, 20–23 March 2018. [CrossRef]
- Yadav, P.S.; Dewangan, S.; Rao, R.S. Extraction of Prediction Rules of Code Smell using Decision Tree Algorithm. In Proceedings of the 2021 10th International Conference on Internet of Everything, Microwave Engineering, Communication and Networks (IEMECON), Jaipur, India, 1–2 December 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Pecorelli, F.; Palomba, F.; di Nucci, D.; de Lucia, A. Comparing Heuristic and Machine Learning Approaches for Metric-Based Code Smell Detection. In Proceedings of the 2019 IEEE/ACM 27th International Conference on Program Comprehension (ICPC), Montreal, QC, Canada, 25–26 May 2019; pp. 93–104. [Google Scholar] [CrossRef]
- Alkharabsheh, K.; Crespo, Y.; Manso, E.; Taboada, J.A. Software Design Smell Detection: A systematic mapping study. Softw. Qual. J. 2019, 27, 1069–1148. [Google Scholar] [CrossRef]
- Alkharabsheh, K.; Crespo, Y.; Fernández-Delgado, M.; Viqueira, J.R.; Taboada, A.J. Exploratory study of the impact of project domain and size category on the detection of the God class design smell. Softw. Qual. J. 2021, 29, 197–237. [Google Scholar] [CrossRef]
- Mansoor, U.; Kessentini, M.; Maxim, B.R.; Deb, K. Multi-objective code-smells detection using good and bad design examples. Softw. Qual. J. 2017, 25, 529–552. [Google Scholar] [CrossRef]
- Tempero, E.; Anslow, C.; Dietrich, J.; Han, T.; Li, J.; Lumpe, M.; Melton, H.; Noble, J. The Qualitas Corpus: A Curated Collection of Java Code for Empirical Studies. In Proceedings of the 17th Asia Pacific Software Engenering Conference, Sydney, Australia, 30 November–3 December 2010; pp. 336–345. [Google Scholar]
- Marinescu, C.; Marinescu, R.; Mihancea, P.; Ratiu, D.; Wettel, R. iPlasma: An Integrated Platform for Quality Assessment of Object-Oriented Design. In Proceedings of the 21st IEEE International Conference on Software Maintenance (ICSM 2005), Budapest, Hungary, 29 September 2005; pp. 77–80. [Google Scholar]
- Nongpong, K. Integrating “Code Smells” Detection with Refactoring Tool Support. Ph.D. Thesis, University of Wisconsin Milwaukee, Milwaukee, WI, USA, 2012. [Google Scholar]
- Marinescu, R. Measurement and Quality in Object-Oriented Design. Ph.D. Thesis, Department of Computer Science, “Polytechnic” University of Timisoara, Timisoara, Romania, 2002. [Google Scholar]
- Peshawa, J.; Muhammad, A.; Rezhna, H.F. Data Normalization and Standardization: A Technical Report. Mach. Learn. Tech. Rep. 2014, 1, 1–6. [Google Scholar]
- Boosting in Machine Learning | Boosting and AdaBoost. Available online: https://www.geeksforgeeks.org/boosting-in-machine-learning-boosting-and-adaboost/ (accessed on 26 November 2021).
- Bagging in Machine Learning: Step to Perform and Its Advantages. Available online: https://www.simplilearn.com/tutorials/machine-learning-tutorial/bagging-in-machine-learning#what_is_bagging_in_machine_learning (accessed on 26 November 2021).
- ML | Voting Classifier using Sklearn. Available online: https://www.geeksforgeeks.org/ml-voting-classifier-using-sklearn/ (accessed on 26 November 2021).
- How the Gradient Boosting Algorithm Works? Available online: https://www.analyticsvidhya.com/blog/2021/04/how-the-gradient-boosting-algorithm-works/ (accessed on 26 November 2021).
- Grossi, E.; Buscema, M. Introduction to artificial neural networks. Eur. J. Gastroenterol. Hepatol. 2007, 19, 1046–1054. [Google Scholar] [CrossRef]
- upGrad. Neural Network: Architecture, Components & Top Algorithms. Available online: https://www.upgrad.com/blog/neural-network-architecture-components-algorithms/ (accessed on 4 September 2022).
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- K-Fold Cross-Validation. Available online: http://karlrosaen.com/ml/learning-log/2016-06-20/ (accessed on 4 September 2022).
- Machine Learning with Python. Available online: https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_algorithms_performance_metrics.html (accessed on 4 September 2022).
- Phi Coefficient. Available online: https://en.wikipedia.org/wiki/Phi_coefficient (accessed on 4 September 2022).
- Cohen’s Kappa. Available online: https://en.wikipedia.org/wiki/Cohen%27s_kappa (accessed on 4 September 2022).



| Author Name | Year | Proposed Model | Datasets | FSAs | Results |
|---|---|---|---|---|---|
| Dewangan et al. [5] | 2021 | Six MLTs | code smell datasets from Fontana et al. [7] | Chi-square and Wrapper based FSA | Logistic regression obtained 100% accuracy for the LM dataset. |
| Fontana et al. [7] | 2016 | 16 MLT | code smell datasets from Fontana et al. [7] | N/A | In the B-J48 Pruned for LM dataset, the accuracy was 99.10%. |
| Guggulothu et al. [20] | 2020 | Random Forest (RF), J48 Unpruned MLT, B-RF algorithms etc. | FE and LM with Multi-label approach from Fontana et al. [7] | N/A | In RF 95.9% accuracy for LM. In B-J48 Pruned 99.1%accuracy for FE |
| Mhawish et al. [25] | 2020 | MLTs | code smell datasets from Fontana et al. [7] (with original and refined datasets) | Genetic algorithm-based GA-CFS and GA-Naive Bayes FSA | 99.70% accuracy for DC dataset |
| Mohammad Y. Mhawish et al. [26] | 2019 | MLTs | code smell datasets from Fontana et al. [7] | Genetic algorithm-based GA-CFS and GA-Naive Bayes FSA | 98.38% accuracy for LM |
| M. N. Pushpalatha et al. [27] | 2019 | Ensemble algorithms | Bug severity reports for closed source datasets (NASA PITs Dataset taken from promise repository [30]) | Chi-square and Information gain | N/A |
| Fontana et al. [30] | 2017 | Multinomial classifier and regression method | Severity code smell datasets from Fontana et al. [30] | variance filter, correlation filter | In the B-J48 Pruned for FE dataset, the accuracy was 93%. |
| Aladdin et al. [31] | 2019 | Eight MLTs | Bug report dataset | N/A | 86.31% accuracy in Logistic regression decision tree |
| Pushpalatha et al. [32] | 2019 | Ensemble algorithms using supervised and unsupervised classification | Bug severity reports for closed source datasets | Information gain and Chi-square | 79.85% to 89.80% Varies accuracy for PitsC |
| I. Kaur et al. [33]. | 2021 | Ensemble algorithms | three open-source java datasets | Correlation FSA | N/A |
| M. M. Draz et al. [34]. | 2021 | Whale optimization algorithm | code smell datasets from M.M. Draz et al. [34] | N/A | The precision and recall were 94.24%, 93.4% respectively. |
| Gupta et al. [35] | 2021 | Deep learning | Eight code smell dataset from Gupta et al. [35] | Wilcoxon Sign Rank Test and Cross-Correlation analysis | 96.84% accuracy in SMOTE algorithm |
| Di Nucci et al. [36] | 2018 | MLTs | code smell datasets from Fontana et al. [7] | N/A | Approx 84.00% accuracy in RF and J48 for FE. |
| Yadav et al. [37] | 2021 | decision tree model with hyper parameter tuning | code smell datasets from Fontana et al. [7] | N/A | reached 97.62% in blob class and data class datasets. |
| F. Pecorelli et al. [38] | 2019 | MLTs | Five matrix-based code smell datasets from F. Pecorelli et al. [38] | N/A | DECOR typically obtained better performance than the ML baseline |
| Alkharabsheh et al. [39] | 2019 | MLT (Systematic mapping study) | GC dataset Design Smell datasets | N/A | 99.82% of kappa in RF |
| Alkharabsheh et al. [40] | 2021 | Eight MLTs | GC datasets Design Smell GC datasets [40] | N/A | N/A |
| Mansoor et al. [41] | 2017 | MLTs | code smell datasets from Mansoor et al. [41] | N/A | Average 87.00% of precision and 92.00% of recall for five code smell datasets |
| Proposed approach | - | Five MLTs and two deep learning | code smell datasets Fontana et al. [7] | Chi-square | All five MLTs obtained 100% accuracy for the LM dataset. |
| Code Smells | Reference, Tool/Detection Rules |
|---|---|
| GC | iPlasma (GC, Brain Class), PMD [43] |
| DC | iPlasma, Fluid Tool [44], Anti-Pattern Scanner [15] |
| FE | iPlasma, Fluid Tool [44] |
| LM | iPlasma (Brain Method), PMD, Marinescu detection rule [45] |
| Code Smell Dataset | Samples | Selected Metrics |
|---|---|---|
| DC | 420 | 61 |
| GC | 420 | 61 |
| FE | 420 | 82 |
| LM | 420 | 82 |
| Dataset Used | Set of Metrics | Chi-Square FSA’s Extracted Metrics |
|---|---|---|
| DC | 09 | LOCNAMM_type, LOC_type, WMCNAMM_type, WMC_type, RFC_type, NOMNAMM_package, WOC_type, CFNAMM_type, ATFD_type |
| GC | 12 | LOC_type, LOCNAMM_type, WMCNAMM_type, WMC_type, NOMNAMM_package, RFC_type, CFNAMM_type, ATFD_type, NOMNAMM_type, NOM_type, FANOUT_type, CBO_type |
| FE | 12 | LOC_method, NOAV_method, CYCLO_method, ATFD_method, ATFD_type, CINT_method, NOLV_method, CFNAMM_method, FDP_method, FANOUT_method, CBO_type, Method |
| LM | 12 | LOC_method, CYCLO_method, NOAV_method, NOLV_method, CINT_method, ATFD_type, CFNAMM_method, ATFD_method, FANOUT_method, ATLD_method, MAXNESTING_method, Method |
| Datasets | PPV (%) | Sensitivity (%) | F-Measure (%) | AUC_ROC_Score (%) | Accuracy (%) | MCC (%) | Cohen_Kappa (%) |
|---|---|---|---|---|---|---|---|
| DC | 98 | 99 | 99 | 84.26 | 98.80 | 94.47 | 94.30 |
| GC | 97 | 97 | 97 | 87.97 | 97.62 | 91.92 | 91.89 |
| FE | 100 | 100 | 100 | 98.72 | 100 | 100 | 100 |
| LM | 100 | 100 | 100 | 98.98 | 100 | 100 | 100 |
| Datasets | PPV (%) | Sensitivity (%) | F-Measure (%) | AUC_ROC_Score (%) | Accuracy (%) | MCC (%) | Cohen_Kappa (%) |
|---|---|---|---|---|---|---|---|
| DC | 100 | 100 | 100 | 97.92 | 98.80 | 94.42 | 94.42 |
| GC | 100 | 100 | 100 | 98.92 | 97.62 | 97.55 | 97.51 |
| FE | 100 | 100 | 100 | 94.20 | 100 | 100 | 100 |
| LM | 100 | 100 | 100 | 88.80 | 99.94 | 100 | 100 |
| Datasets | PPV (%) | Sensitivity (%) | F-Measure (%) | AUC_ROC_Score (%) | Accuracy (%) | MCC (%) | Cohen_Kappa (%) |
|---|---|---|---|---|---|---|---|
| DC | 100 | 100 | 100 | 94.62 | 98.81 | 100 | 100 |
| GC | 98 | 97 | 98 | 85.24 | 97.62 | 88.97 | 88.37 |
| FE | 100 | 100 | 100 | 97.67 | 97.87 | 94.40 | 94.25 |
| LM | 100 | 100 | 100 | 97.62 | 97.92 | 80.95 | 80.95 |
| Datasets | PPV (%) | Sensitivity (%) | F-Measure (%) | AUC_ROC_Score (%) | Accuracy (%) | MCC (%) | Cohen_Kappa (%) |
|---|---|---|---|---|---|---|---|
| DC | 100 | 100 | 100 | 92.40 | 98.80 | 94.89 | 94.89 |
| GC | 99 | 99 | 99 | 91.84 | 97.62 | 92.66 | 92.62 |
| FE | 100 | 100 | 100 | 97.25 | 95.74 | 90.20 | 89.72 |
| LM | 100 | 100 | 100 | 95. 66 | 100 | 100 | 100 |
| Datasets | PPV (%) | Sensitivity (%) | F-Measure (%) | AUC_ROC_Score (%) | Accuracy (%) | MCC (%) | Cohen_Kappa (%) |
|---|---|---|---|---|---|---|---|
| DC | 100 | 100 | 100 | 92.54 | 99.80 | 100 | 100 |
| GC | 98 | 99 | 99 | 87.26 | 97.62 | 94.69 | 94.54 |
| FE | 100 | 100 | 100 | 93.40 | 100 | 92.36 | 92.07 |
| LM | 100 | 100 | 100 | 84.33 | 100 | 100 | 100 |
| Datasets | PPV (%) | Sensitivity (%) | F-Measure (%) | AUC_ROC_Score (%) | Accuracy (%) | MCC (%) | Cohen_Kappa (%) |
|---|---|---|---|---|---|---|---|
| DC | 96 | 96 | 96 | 93.64 | 97.82 | 95.52 | 95.12 |
| GC | 96 | 96 | 96 | 92.89 | 97.23 | 96.26 | 96.12 |
| FE | 98 | 98 | 98 | 97.28 | 97.98 | 99.12 | 99.08 |
| LM | 98 | 97 | 98 | 96.29 | 98.25 | 98.78 | 98.66 |
| Datasets | PPV (%) | Sensitivity (%) | F-Measure (%) | AUC_ROC_Score (%) | Accuracy (%) | MCC (%) | Cohen_Kappa (%) |
|---|---|---|---|---|---|---|---|
| DC | 98 | 99 | 98 | 93.64 | 97.82 | 95.52 | 95.12 |
| GC | 99 | 99 | 98 | 92.89 | 97.23 | 96.26 | 96.12 |
| FE | 100 | 99 | 100 | 99.12 | 99.08 | 99.12 | 99.08 |
| LM | 100 | 100 | 99 | 99.29 | 99.26 | 98.78 | 98.66 |
| Algorithms | DC | GC | FE | LM | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F (%) | AUC (%) | A (%) | F (%) | AUC (%) | A (%) | F (%) | AUC (%) | A (%) | F (%) | AUC (%) | A (%) | |
| AdaBoost | 99.00 | 84.26 | 98.80 | 97.00 | 87.97 | 97.62 | 100 | 98.72 | 100 | 100 | 98.98 | 100 |
| Bagging | 100 | 97.92 | 98.80 | 100 | 98.92 | 97.62 | 100 | 94.20 | 100 | 100 | 88.80 | 99.94 |
| Max voting | 100 | 94.62 | 98.81 | 98.00 | 85.24 | 97.62 | 100 | 97.67 | 97.87 | 100 | 97.62 | 97.92 |
| Gradient Boosting | 100 | 92.40 | 98.80 | 99.00 | 91.84 | 97.62 | 100 | 97.25 | 95.74 | 100 | 95. 66 | 100 |
| XGBoost | 100 | 92.54 | 99.80 | 99.00 | 87.26 | 97.62 | 100 | 93.40 | 100 | 100 | 84.33 | 100 |
| ANN | 96.00 | 93.64 | 97.82 | 96.00 | 92.89 | 97.23 | 98.00 | 97.28 | 97.98 | 98.00 | 96.29 | 98.25 |
| CNN | 98.00 | 93.64 | 97.82 | 98.00 | 92.89 | 97.23 | 100 | 99.12 | 99.08 | 99.00 | 99.29 | 99.26 |
| MLT | Number of Selected Features | Accuracy for DC Dataset (%) | Accuracy for GC Dataset (%) | Accuracy for FE Dataset (%) | Accuracy for LM Dataset (%) |
|---|---|---|---|---|---|
| Adaboost algorithm | 8 | 96.43 | 95.23 | 100 | 100 |
| 9 | 97.61 | 97.62 | 100 | 100 | |
| 10 | 98.80 | 97.62 | 100 | 100 | |
| 11 | 98.80 | 97.62 | 97.87 | 97.91 | |
| 12 | 97.61 | 97.62 | 100 | 100 | |
| All features | 98.80 | 97.62 | 100 | 100 | |
| Bagging algorithm | 8 | 99.92 | 98.80 | 97.87 | 97.92 |
| 9 | 97.62 | 97.62 | 97.87 | 97.92 | |
| 10 | 98.80 | 97.62 | 100 | 99.94 | |
| 11 | 97.62 | 98.80 | 97.87 | 100 | |
| 12 | 97.62 | 99.24 | 100 | 100 | |
| All Features | 98.80 | 98.80 | 97.87 | 100 | |
| Max voting algorithm | 8 | 98.81 | 95.24 | 97.87 | 97.92 |
| 9 | 100 | 97.61 | 97.87 | 100 | |
| 10 | 98.81 | 97.62 | 97.87 | 97.92 | |
| 11 | 98.80 | 97.62 | 100 | 97.92 | |
| 12 | 98.80 | 96.42 | 91.45 | 97.92 | |
| All Features | 97.62 | 95.23 | 100 | 100 | |
| Gradient boosting algorithm | 8 | 99.96 | 98.80 | 100 | 100 |
| 9 | 98.80 | 96.43 | 100 | 100 | |
| 10 | 98.80 | 97.62 | 95.74 | 100 | |
| 11 | 99.28 | 98.80 | 95.74 | 100 | |
| 12 | 98.80 | 97.62 | 97.87 | 100 | |
| All features | 98.80 | 98.80 | 97.87 | 100 | |
| XGboost algorithm | 8 | 98.80 | 96.42 | 97.87 | 100 |
| 9 | 98.80 | 97.62 | 97.87 | 100 | |
| 10 | 99.80 | 97.62 | 100 | 100 | |
| 11 | 99.88 | 98.80 | 99.56 | 97.92 | |
| 12 | 99.26 | 97.62 | 97.87 | 97.92 | |
| All features | 98.80 | 97.62 | 97.87 | 97.92 | |
| ANN | 8 | 97.23 | 97.12 | 97.98 | 97.96 |
| 9 | 97.23 | 97.14 | 97.98 | 97.96 | |
| 10 | 97.82 | 97.23 | 97.98 | 98.25 | |
| 11 | 98.67 | 97.98 | 98.76 | 98.25 | |
| 12 | 98.62 | 97.23 | 98.98 | 99.02 | |
| All features | 99.12 | 97.56 | 98.76 | 98.25 | |
| CNN | 8 | 97.82 | 97.12 | 98.76 | 98.88 |
| 9 | 97.82 | 97.23 | 98.98 | 98.88 | |
| 10 | 97.82 | 97.23 | 99.08 | 99.26 | |
| 11 | 98.98 | 98.24 | 99.08 | 99.26 | |
| 12 | 99.26 | 98.24 | 99.56 | 99.36 | |
| All features | 99.16 | 98.78 | 99.36 | 99.26 |
| Algorithms | DC | GC | FE | LM | ||||
|---|---|---|---|---|---|---|---|---|
| Accuracy with Applied SMOTE | Accuracy without Applied SMOTE | Accuracy with Applied SMOTE | Accuracy without Applied SMOTE | Accuracy with Applied SMOTE | Accuracy without Applied SMOTE | Accuracy with Applied SMOTE | Accuracy without Applied SMOTE | |
| AdaBoost | 99.10 | 98.80 | 98.21 | 97.62 | 98.65 | 100 | 100 | 100 |
| Bagging | 99.11 | 99.92 | 98.21 | 99.24 | 100 | 100 | 100 | 100 |
| Max voting | 99.10 | 100 | 98.21 | 97.62 | 100 | 100 | 100 | 100 |
| Gradient Boosting | 100 | 99.96 | 99.10 | 98.80 | 100 | 100 | 100 | 100 |
| XGBoost | 100 | 99.88 | 97.32 | 98.80 | 98.64 | 100 | 100 | 100 |
| ANN | 99.12 | 98.67 | 98.37 | 97.98 | 99.06 | 98.98 | 99.00 | 99.02 |
| CNN | 99.26 | 99.26 | 98.78 | 98.78 | 99.24 | 99.56 | 99.67 | 99.36 |
| Year | Author Name | Datasets | |||||||
|---|---|---|---|---|---|---|---|---|---|
| DC | GC | FE | LM | ||||||
| Best Algorithm | Accuracy (%) | Best Algorithm | Accuracy (%) | Best Algorithm | Accuracy (%) | Best Algorithm | Accuracy (%) | ||
| 2016 | Fontana et al. [7] | B-J48 Pruned | 99.02 | Naive Bayes | 97.55 | B-JRip | 96.64 | B-J48 Pruned | 99.43 |
| 2018 | Nucci et al. [36] | RF and J48 | Approx 83 | J48 and RF | Approx 83 | J48 and RF | Approx 84 | J48 and RF | Approx 82 |
| 2020 | Mhawishet al. [25] | RF | 99.70 | GBT | 98.48 | Decision tree | 97.97 | RF | 95.97 |
| 2020 | Guggulothu et al. [20] | - | - | - | - | B-J48 Pruned | 99.10 | RF | 95.90 |
| 2021 | Alazba et al. [22] | Stack-LR | 98.92 | Stack-SVM | 97.00 | Stack-LR | 95.38 | Stack-SVM | 99.24 |
| 2021 | Dewangan et al. [23] | RF | 99.74 | RF | 98.21 | Decision tree | 98.60 | Logistic Regression | 100.00 |
| Proposed Approach | Max Voting | 100 | Bagging | 99.24 | All five methods | 100 | All Five Methods | 100 | |
| Author Name | Applied Algorithms | Datasets | ||||
|---|---|---|---|---|---|---|
| DC | GC | FE | LM | |||
| Applied FSA and Other Techniques | Accuracy (%) with Best Algorithm | Accuracy (%) with Best Algorithm | Accuracy (%) with Best Algorithm | Accuracy (%) with Best Algorithm | ||
| Fontana et al. [7] | B-J48 Pruned, B-J48 UnPruned, JRip Pruned, JRipUnPruned, RF, Naive Bayes, SMO LibSVM, B-Random Forest, B-JRip, J48 Reduced Error Pruning, B-J48 Reduced Error Pruning | - | 99.02% accuracy using B-J48 Pruned | 97.55% accuracy using Naive Bayes | 96.64% accuracy using B-JRip | 99.43% accuracy using B-J48 Pruned |
| Nucci et al. [36] | B J48 Pruned, B J48 Unpruned, J48 Reduced Error Pruning, B-J48 Reduced Error Pruning, B JRip, B-RF, B-Naive Bayes, B SMO RBF, B SMO Poly, B LibSVM C-SVC Linear, B LibSVM C-SVC Poly, B LibSVM C-SVC Radial, B LibSVM C-SVC Sigmoid, RF, Naive Bayes, SMO RBF, SMO Polynomial, LibSVM C-SVC Linear, LibSVM C-SVC Poly, LibSVM C-SVC Radial, LibSVM C-SVC Sigmoid | GainRatio FSA | Approx 83% accuracy using RF and J48 | Approx 83% accuracy using J4 and RF | Approx 84% accuracy using J48 and RF | Approx 82% accuracy using J48 and RF |
| Mhawishet al. [25] | Deep learning, DT, GBT, SVM, RF, MLP | Genetic Algorithm based FSA and Grid search-based parameter optimization technique | 99.70% accuracy using RF | 98.48% accuracy using GBT | 97.97% accuracy using DT | 95.97% accuracy using RF |
| Guggulothuet al. [20] | J48 Pruned, RF, B-J48 Pruned, B-J48 UnPruned, B-Random Forest | - | - | - | 99.10% accuracy using B-J48 Pruned | 95.90% accuracy using RF |
| Alazba et al. [22] | DT, SVM(Lin), SVM(Sig), SVM(Poly), SVM(RBF), NB(B), NB(M), NB(G), LR, MLP, SGD, GP, KNN, LDA, Stack-LR, Stack-DT, Stack-SVM | Gain FSA | 98.92% accuracy using Stack-LR | 97.00% accuracy using Stack-SVM | 95.38% accuracy using Stack-LR | 99.24% accuracy using Stack-SVM |
| Dewangan et al. [23] | Naive Bayes, KNN, DT, MLP, LR, RF | Chi-squared and Wrapper-based FSA, and Grid search parameter optimization | 99.74% accuracy using RF | 98.21% accuracy using RF | 98.60% accuracy using DT | 100% accuracy using LR |
| P.S. Yadav et al. [37] | decision tree model with hyper parameter tuning | Grid search parameter optimization | 97.62% accuracy using DT | 97.62% accuracy using DT | - | - |
| Proposed Approach | AdaBoost, Bagging, Max voting, GB, XGBoost, ANN, CNN | Chi-squared FSA, and SMOTE class balancing technique | 100% accuracy using Max voting | 99.24% accuracy using Bagging | 100% accuracy using all five ensemble methods | 100% accuracy using all five ensemble methods |
| Classifier | Data Class (%) | God Class (%) | Feature Envy (%) | Long Method (%) |
|---|---|---|---|---|
| AdaBoost | 98 | 97 | 97 | 97 |
| Bagging | 80 | 90 | 80 | 90 |
| Max voting | 97 | 98 | 98 | 99 |
| Gradient Boosting | 98 | 97 | 97 | 97 |
| XGBoost | 97 | 97 | 98 | 97 |
| ANN | 80 | 90 | 80 | 90 |
| CNN | 80 | 90 | 80 | 90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dewangan, S.; Rao, R.S.; Mishra, A.; Gupta, M. Code Smell Detection Using Ensemble Machine Learning Algorithms. Appl. Sci. 2022, 12, 10321. https://doi.org/10.3390/app122010321
Dewangan S, Rao RS, Mishra A, Gupta M. Code Smell Detection Using Ensemble Machine Learning Algorithms. Applied Sciences. 2022; 12(20):10321. https://doi.org/10.3390/app122010321
Chicago/Turabian StyleDewangan, Seema, Rajwant Singh Rao, Alok Mishra, and Manjari Gupta. 2022. "Code Smell Detection Using Ensemble Machine Learning Algorithms" Applied Sciences 12, no. 20: 10321. https://doi.org/10.3390/app122010321
APA StyleDewangan, S., Rao, R. S., Mishra, A., & Gupta, M. (2022). Code Smell Detection Using Ensemble Machine Learning Algorithms. Applied Sciences, 12(20), 10321. https://doi.org/10.3390/app122010321