
Online Kanji Characters Based Writer Identification Using Sequential Forward Floating Selection and Support Vector Machine



Abstract
1. Introduction
2. Related Work
3. Materials and Methods
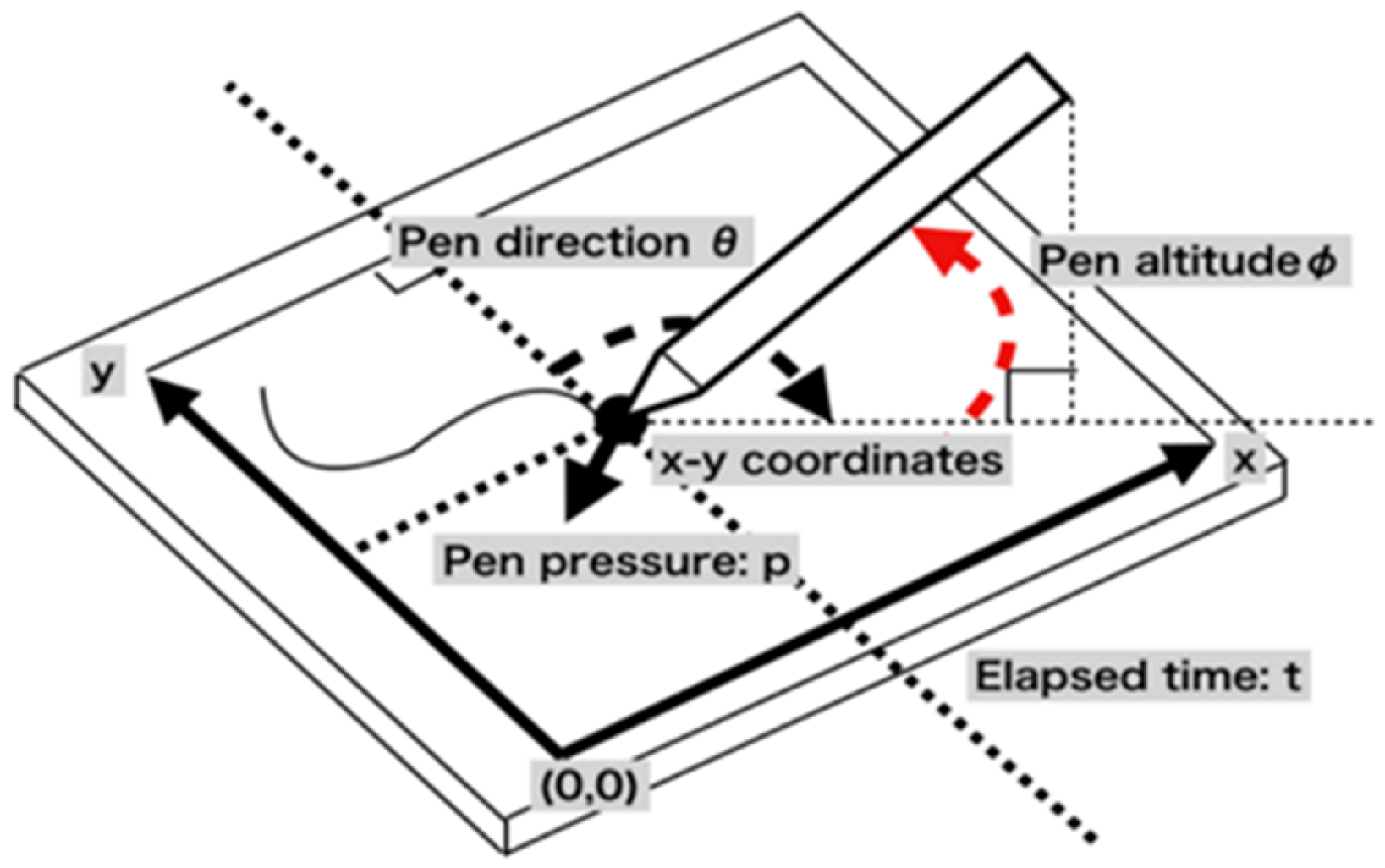
3.1. Device for Data Collection
3.2. Dataset Preparation
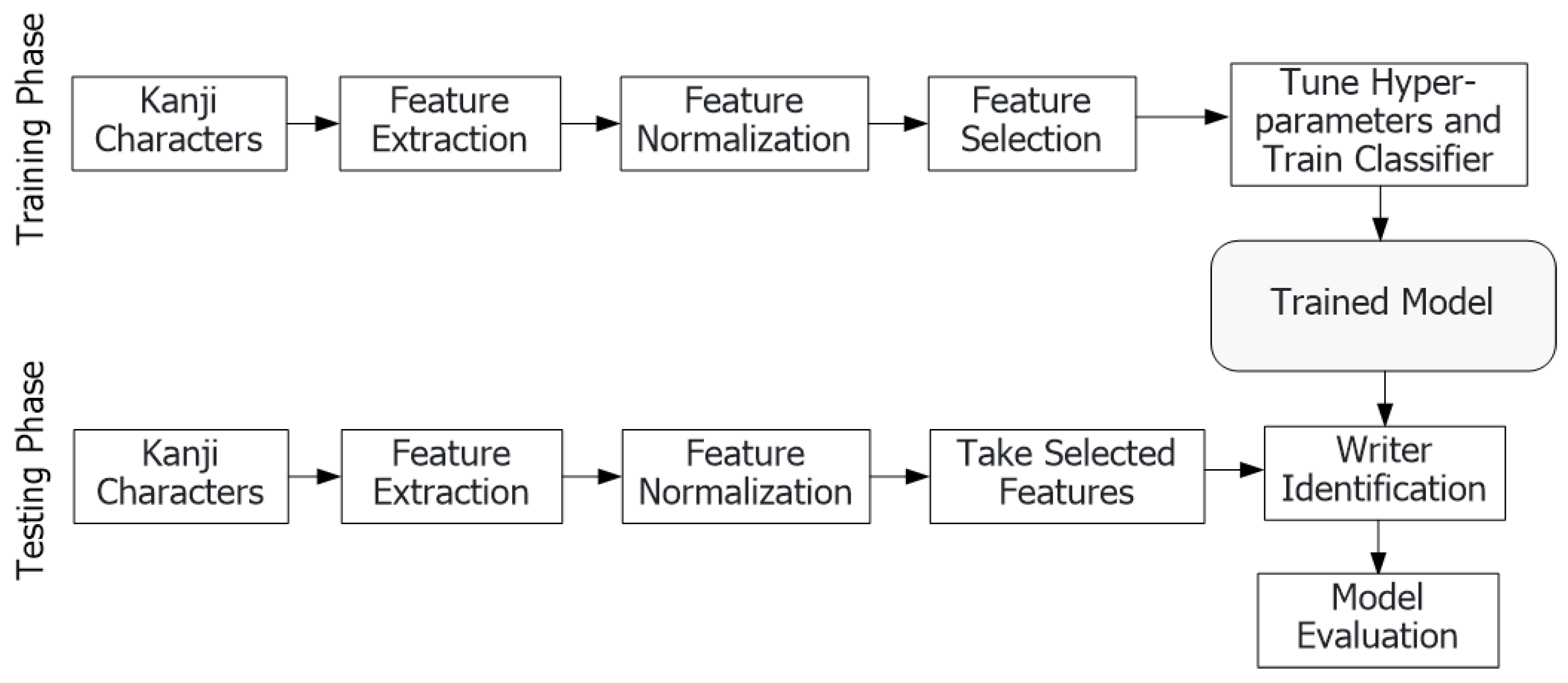
3.3. Proposed Methodology
3.4. Feature Extraction
3.5. Feature Normalization
3.6. Feature Selection
- Input:
- Output:, where
- Initialize:
- Step 1:
- = argmax , where is an evaluation index and is the feature with the highest evaluation when it is chosen.
- Step 2:
- = argmax , where andis the feature with the best performance when the feature is deleted.IfGo to Step 1.
3.7. Classification Using SVM
4. Results and Discussion
4.1. Selected Features Using SFFS
4.2. Text-Dependent
4.3. Text-Independent
4.4. Comparison of Our Proposed Identification System and Similar Existing Studies
5. Conclusions and Future Work Direction
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shin, J.; Hasan, M.A.M.; Maniruzzaman, M.; Megumi, A.; Suzuki, A.; Yasumura, A. Online Handwriting Based Adult and Child Classification using Machine Learning Techniques. In Proceedings of the 2022 IEEE 5th Eurasian Conference on Educational Innovation (ECEI), Taipei, Taiwan, 10–12 February 2022; pp. 201–204. [Google Scholar]
- Shin, J.; Maniruzzaman, M.; Uchida, Y.; Hasan, M.; Mehedi, A.; Megumi, A.; Suzuki, A.; Yasumura, A. Important features selection and classification of adult and child from handwriting using machine learning methods. Appl. Sci. 2022, 12, 5256. [Google Scholar] [CrossRef]
- Huang, X.; Xiang, Y.; Chonka, A.; Zhou, J.; Deng, R.H. A generic framework for three-factor authentication: Preserving security and privacy in distributed systems. IEEE Trans. Parallel Distrib. Syst. 2010, 22, 1390–1397. [Google Scholar] [CrossRef]
- Abdi, M.N.; Khemakhem, M. Off-Line Text-Independent Arabic Writer Identification using Contour-Based Features. Int. J. Signal Image Process. 2010, 1, 4–11. [Google Scholar]
- Adak, C.; Chaudhuri, B.B. Writer identification from offline isolated Bangla characters and numerals. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 486–490. [Google Scholar]
- Rehman, A.; Naz, S.; Razzak, M.I.; Hameed, I.A. Automatic visual features for writer identification: A deep learning approach. IEEE Access 2019, 7, 17149–17157. [Google Scholar] [CrossRef]
- Shin, J.; Liu, Z.; Kim, C.M.; Mun, H.J. Writer identification using intra-stroke and inter-stroke information for security enhancements in P2P systems. Peer-Netw. Appl. 2018, 11, 1166–1175. [Google Scholar] [CrossRef]
- Tan, G.X.; Viard-Gaudin, C.; Kot, A.C. Automatic writer identification framework for online handwritten documents using character prototypes. Pattern Recognit. 2009, 42, 3313–3323. [Google Scholar] [CrossRef]
- Nakamura, Y.; Kidode, M. Individuality analysis of online kanji handwriting. In Proceedings of the Eighth International Conference on Document Analysis and Recognition (ICDAR’05), Seoul, Korea, 29 August–1 September 2005; pp. 620–624. [Google Scholar]
- Nasuno, R.; Arai, S. Writer identification for offline japanese handwritten character using convolutional neural network. In Proceedings of the 5th IIAE International Conference on Intelligent Systems and Image Processing, Hawaii, HI, USA, 7–12 September 2017; pp. 94–97. [Google Scholar]
- Soma, A.; Mizutani, K.; Arai, M. Writer identification for offline handwritten Kanji characters using multiple features. Int. J. Inf. Electron. Eng. 2014, 4, 331–336. [Google Scholar] [CrossRef]
- Grębowiec, M.; Protasiewicz, J. A neural framework for online recognition of handwritten kanji characters. In Proceedings of the 2018 Federated Conference on Computer Science and Information Systems (FedCSIS), Poznan, Poland, 9–12 September 2018; pp. 479–483. [Google Scholar]
- Namboodiri, A.; Gupta, S. Text independent writer identification from online handwriting. In Proceedings of the Tenth International Workshop on Frontiers in Handwriting Recognition, La Baule, France, 23–26 October 2006; pp. 287–292. [Google Scholar]
- Li, B.; Sun, Z.; Tan, T. Hierarchical shape primitive features for online text-independent writer identification. In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 986–990. [Google Scholar]
- Wu, Y.; Lu, H.; Zhang, Z. Text-independent online writer identification using hidden markov models. IEICE Trans. Inf. Syst. 2017, 100, 332–339. [Google Scholar] [CrossRef]
- Khalid, S.; Naqvi, U.; Siddiqi, I. Framework for human identification through offline handwritten documents. In Proceedings of the 2015 International Conference on Computer, Communications, and Control Technology (I4CT), Kuching, Sarawak, Malaysia, 21–23 April 2015; pp. 54–58. [Google Scholar]
- Nguyen, H.T.; Nguyen, C.T.; Ino, T.; Indurkhya, B.; Nakagawa, M. Text-independent writer identification using convolutional neural network. Pattern Recognit. Lett. 2019, 121, 104–112. [Google Scholar] [CrossRef]
- 京相雅樹. その他の生体特徴による個人認証. 生体医工学 2006, 44, 47–53. [Google Scholar]
- Dargan, S.; Kumar, M.; Garg, A.; Thakur, K. Writer identification system for pre-segmented offline handwritten Devanagari characters using k-NN and SVM. Soft Comput. 2020, 24, 10111–10122. [Google Scholar] [CrossRef]
- Bensefia, A.; Djeddi, C. Feature’s Selection-Based Shape Complexity for Writer Identification Task. In Proceedings of the 2020 International Conference on Pattern Recognition and Intelligent Systems, Athens, Greece, 30 July–2 August 2020; pp. 1–6. [Google Scholar]
- Bulacu, M.; Schomaker, L. Text-independent writer identification and verification using textural and allographic features. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 701–717. [Google Scholar] [CrossRef] [PubMed]
- Saranya, K.; Vijaya, M. Text dependent writer identification using support vector machine. Int. J. Comput. Appl. 2013, 65, 1–6. [Google Scholar]
- Thendral, T.; Vijaya, M.; Karpagavalli, S. Analysis of Tamil character writings and identification of writer using Support Vector Machine. In Proceedings of the 2014 IEEE International Conference on Advanced Communications, Control and Computing Technologies, Ramanathapuram, India, 8–10 May 2014; pp. 1407–1411. [Google Scholar]
- Soma, A.; Arai, M. Writer identification for offline handwritten Kanji without using character recognition features. In Proceedings of the 2013 International Conference on Information Science and Technology Applications (ICISTA-2013), Macau, China, 17–19 June 2013; pp. 96–98. [Google Scholar]
- Semma, A.; Hannad, Y.; Siddiqi, I.; Djeddi, C.; El Kettani, M.E.Y. Writer identification using deep learning with fast keypoints and harris corner detector. Expert Syst. Appl. 2021, 184, 115473. [Google Scholar] [CrossRef]
- 青木隆浩. バイオメトリクス. 映像情報メディア学会誌 2016, 70, 307–312. [Google Scholar] [CrossRef][Green Version]
- Drotár, P.; Mekyska, J.; Rektorová, I.; Masarová, L.; Smékal, Z.; Faundez-Zanuy, M. Evaluation of handwriting kinematics and pressure for differential diagnosis of Parkinson’s disease. Artif. Intell. Med. 2016, 67, 39–46. [Google Scholar] [CrossRef]
- Diaz, M.; Moetesum, M.; Siddiqi, I.; Vessio, G. Sequence-based dynamic handwriting analysis for Parkinson’s disease detection with one-dimensional convolutions and BiGRUs. Expert Syst. Appl. 2021, 168, 114405. [Google Scholar] [CrossRef]
- Muramatsu, D.; Matsumoto, T. Effectiveness of pen pressure, azimuth, and altitude features for online signature verification. In International Conference on Biometrics; Springer: Berlin, Germany, 2007; pp. 503–512. [Google Scholar]
- Pudil, P.; Novovičová, J.; Kittler, J. Floating search methods in feature selection. Pattern Recognit. Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Raschka, S. MLxtend: Providing machine learning and data science utilities and extensions to Python’s scientific computing stack. J. Open Source Softw. 2018, 3, 638–640. [Google Scholar] [CrossRef]
- Jan, S.U.; Lee, Y.D.; Shin, J.; Koo, I. Sensor fault classification based on support vector machine and statistical time-domain features. IEEE Access 2017, 5, 8682–8690. [Google Scholar] [CrossRef]
- Hasan, M.A.M.; Nasser, M.; Pal, B.; Ahmad, S. Support vector machine and random forest modeling for intrusion detection system (IDS). J. Intell. Learn. Syst. Appl. 2014, 2014, 45–52. [Google Scholar] [CrossRef]
- Nelli, F. Machine Learning with scikit-learn. In Python Data Analytics; Springer: Berlin, Germany, 2018; pp. 313–347. [Google Scholar]
- Hsu, C.W.; Lin, C.J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]



{kind=link}
{kind=link}
| Authors | DT | SS | Methods | Language | Writers | ACC(%) |
|---|---|---|---|---|---|---|
| Nakamura et al. [9] | Online | 1230 | ANOVA | Kanji | 41 | 90.4 |
| Soma et al. [11] | Offline | 5000 | Majority Voting | Kanji | 100 | 99.0 |
| Namboodiri and Gupta [13] | Online | 400 | NN | English | 6 | 88.0 |
| Li et al. [14] | Online | 1500 | k-NN | English | 242 | 93.6 |
| Wu et al. [15] | Online | 1700 | HMM | English | 200 | 95.5 |
| Nguyen et al. [17] | Offline | 2965 | CNN | Kanji | 480 | 93.8 |
| Rehman et al. [6] | Online | 52,800 | P2P | Chinese | 48 | 99.0 |
| Abdi et al. [4] | Offline | 4800 | k-NN | Arabic | 82 | 90.2 |
| Nasuno and Arai [10] | offline | 50,000 | CNN | Japanese | 100 | 90.0 |
| SN | Features | Descriptions | Calculation Formula |
|---|---|---|---|
| 1 | Speed mean | Mean of speed. | |
| 2 | Speed std | Std of speed. | |
| 3 | Max speed | Maximum speed. | |
| 4 | First speed mean | Mean of the speed of the first 10% of the whole. | |
| 5 | First speed std | Std of the speed of the first 10% of the whole. | |
| 6 | Last speed mean | Mean speed of the last 10% of the whole. | |
| 7 | Last speed std | Std of the speed of the last 10% of the whole. | |
| 8 | Piv | Maximum speed recorded at any time. | |
| 9 | Accel. mean | Mean of accel. | |
| 10 | Accel. std | Std of accel. | |
| 11 | Max accel. | Maximum accel. | |
| 12 | First accel. mean | Mean of accel. of the first 10% of the whole. | |
| 13 | First accel. std | Std of accel. of the first 10% of the whole. | |
| 14 | Last accel. mean | Mean of accel. of the last 10% of the whole. | |
| 15 | Last accel. std | Std of accel. of the last 10% of the whole. | |
| 16 | Pia | Maximum accel. recorded at any point. | |
| 17 | Pressure mean | Mean of pen pressure. | |
| 18 | Pressure std | Std of pen pressure. | |
| 19 | Max pressure | Maximum of pen pressure. | |
| 20 | First pressure mean | Mean of pen pressure of the first 10% of the whole. | |
| 21 | First pressure std | Std of pen pressure of the first 10% of the whole. | |
| 22 | Last pressure mean | Mean of pen pressure of the last 10% of the whole. | |
| 23 | Last pressure std | The std of pen pressure of the last 10% of the whole. | |
| 24 | Azimuth mean | Mean of azimuth. | |
| 25 | Azimuth std | Std of azimuth. | |
| 26 | First azimuth mean | Mean of the azimuth of the first 10% of the whole. | |
| 27 | First azimuth std | Std of the azimuth of the first 10% of the whole. | |
| 28 | Last azimuth mean | Mean of the azimuth of the last 10% of the whole. | |
| 29 | Last azimuth std | Std of the azimuth of the last 10% of the whole. | |
| 30 | Altitude mean | Mean of altitude. | |
| 31 | Altitude std | Std of altitude. | |
| 32 | First altitude mean | Mean of the altitude of the first 10% of the whole. | |
| 33 | First altitude std | Std of the altitude of the first 10% of the whole. | |
| 34 | Last altitude mean | Mean of the altitude of the last 10% of the whole. | |
| 35 | Last altitude std | Std of the altitude of the last 10% of the whole. | |
| 36 | Positive pressure change mean | Mean of increase in pen pressure between two time points. | , where |
| 37 | Positive pressure changes std | Std of increase in pen pressure between two time points. | , where |
| 38 | Max positive pressure change | Maximum increase in pen pressure between two time points. | for |
| 39 | Negative pressure change mean | Mean decrease in pen pressure between two time points. | , where |
| 40 | Negative pressure changes std | Std of decrease in pen pressure between two time points. | , where |
| SN | Features | SN | Features | SN | Features |
|---|---|---|---|---|---|
| 1 | Accel. mean | 11 | Altitude mean | 21 | Altitude std |
| 2 | Azimuth mean | 12 | Azimuth std | 22 | Altitude mean first accel. mean |
| 3 | First azimuth mean | 13 | First pressure mean | 23 | First pressure std |
| 4 | First speed mean | 14 | First speed std | 24 | Last accel. mean |
| 5 | Last accel. std | 15 | Last altitude mean | 25 | Last azimuth mean |
| 6 | Last speed mean | 16 | Last pressure mean | 26 | Last pressure std |
| 7 | Last azimuth mean | 17 | Last speed std | 27 | Max accel. |
| 8 | Max pressure | 18 | Negative pressure change mean | 28 | Negative pressure changes std |
| 9 | Pressure mean | 19 | Positive pressure change mean | 29 | Positive pressure changes std |
| 10 | Pressure std | 20 | Speed mean | 30 | Speed std |
| SN | Kanji | ACC | SN | Kanji | ACC | SN | Kanji | ACC | SN | Kanji | ACC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 避 | 99.2 | 19 | 臓 | 97.4 | 37 | 衛 | 96.6 | 55 | 甘 | 95.9 |
| 2 | 担 | 98.6 | 20 | 岡 | 97.2 | 38 | 右 | 96.5 | 56 | 鯛 | 95.7 |
| 3 | 甫 | 98.6 | 21 | 湖 | 97.1 | 39 | 肇 | 96.5 | 57 | 憲 | 95.7 |
| 4 | 還 | 98.3 | 22 | 旬 | 97.1 | 40 | 委 | 96.3 | 58 | 響 | 95.4 |
| 5 | 虚 | 98.1 | 23 | 完 | 97.1 | 41 | 込 | 96.3 | 59 | 麗 | 95.4 |
| 6 | 鐵 | 98.1 | 24 | 崩 | 96.9 | 42 | 末 | 96.3 | 60 | 蹟 | 95.3 |
| 7 | 旭 | 98.0 | 25 | 車 | 96.9 | 43 | 凰 | 96.3 | 61 | 圏 | 95.1 |
| 8 | 魅 | 98.0 | 26 | 鞠 | 96.9 | 44 | 雪 | 96.2 | 62 | 藁 | 95.1 |
| 9 | 鳥 | 98.0 | 27 | 性 | 96.9 | 45 | 方 | 96.2 | 63 | 名 | 95.1 |
| 10 | 柿 | 97.8 | 28 | 釉 | 96.9 | 46 | 石 | 96.2 | 64 | 台 | 94.7 |
| 11 | 惹 | 97.7 | 29 | 亜 | 96.9 | 47 | 羊 | 96.2 | 65 | 四 | 94.5 |
| 12 | 讃 | 97.5 | 30 | 巣 | 96.9 | 48 | 曲 | 96.2 | 66 | 士 | 94.3 |
| 13 | 君 | 97.5 | 31 | 函 | 96.8 | 49 | 区 | 96.0 | 67 | 今 | 93.6 |
| 14 | 鋒 | 97.5 | 32 | 蘭 | 96.8 | 50 | 寵 | 96.0 | 68 | 升 | 93.1 |
| 15 | 策 | 97.4 | 33 | 忘 | 96.8 | 51 | 機 | 96.0 | 69 | 川 | 92.5 |
| 16 | 歯 | 97.4 | 34 | 渡 | 96.6 | 52 | 禾 | 96.0 | 70 | 上 | 92.5 |
| 17 | 武 | 97.4 | 35 | 憾 | 96.6 | 53 | 刊 | 95.9 | 71 | 入 | 91.2 |
| 18 | 費 | 97.4 | 36 | 滝 | 96.6 | 54 | 彌 | 95.9 | 72 | 人 | 84.2 |
| Kanji | ACC | Cost | Gama | Kernel |
|---|---|---|---|---|
| 避担 | 99.4 | 0.1 | 0.00001 | Linear |
| 避担甫 | 99.6 | 10 | 0.01 | RBF |
| 避担甫還 | 99.4 | 0.1 | 0.00001 | Linear |
| SN | Characters | SVM-WO-SFFS | SVM-W-SFFS |
|---|---|---|---|
| 1 | Top 5 | 96.2 | 99.0 |
| 2 | Top 10 | 96.5 | 97.7 |
| 3 | Top 15 | 96.0 | 97.0 |
| 4 | Top 20 | 96.2 | 97.4 |
| 5 | Top 25 | 95.6 | 97.1 |
| 6 | Top 30 | 96.1 | 96.7 |
| 7 | Top 35 | 95.6 | 96.9 |
| 8 | Top 40 | 95.5 | 96.9 |
| 9 | Top 45 | 95.5 | 96.3 |
| 10 | Top 50 | 95.3 | 96.1 |
| 11 | Top 55 | 94.7 | 95.9 |
| 12 | Top 60 | 94.8 | 95.6 |
| 13 | Top 65 | 94.2 | 95.3 |
| 14 | Top 70 | 94.1 | 95.0 |
| 15 | All 72 | 93.9 | 94.3 |
| Authors | Data Types | Study Types | Samples | Methods | Language | Characters | Writers | ACC (%) |
|---|---|---|---|---|---|---|---|---|
| Nakamura et al. [9] | Online | Text-independent | 1230 | Based on Distance | Kanji | 4 | 41 | 96.5 |
| Soma and Arai [24] | Offline | Text-dependent | 50,000 | Based on Distance | Kanji | 100 | 100 | 95.2 |
| Soma et al. [11] | Offline | Text-dependent | 50,000 | Majority Voting | Kanji | 100 | 100 | 99.0 |
| Nguyen et al. [17] | Offline | Text-independent | 2965 | CNN | Kanji | 100 | 400 | 93.8 |
| Our proposed | Online | Text-independent | 47,520 | SVM | Kanji | 72 | 33 | 99.0 |
| Text-dependent | 47,520 | SVM | Kanji | 72 | 33 | 99.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasan, M.A.M.; Shin, J.; Maniruzzaman, M. Online Kanji Characters Based Writer Identification Using Sequential Forward Floating Selection and Support Vector Machine. Appl. Sci. 2022, 12, 10249. https://doi.org/10.3390/app122010249
Hasan MAM, Shin J, Maniruzzaman M. Online Kanji Characters Based Writer Identification Using Sequential Forward Floating Selection and Support Vector Machine. Applied Sciences. 2022; 12(20):10249. https://doi.org/10.3390/app122010249
Chicago/Turabian StyleHasan, Md. Al Mehedi, Jungpil Shin, and Md. Maniruzzaman. 2022. "Online Kanji Characters Based Writer Identification Using Sequential Forward Floating Selection and Support Vector Machine" Applied Sciences 12, no. 20: 10249. https://doi.org/10.3390/app122010249
APA StyleHasan, M. A. M., Shin, J., & Maniruzzaman, M. (2022). Online Kanji Characters Based Writer Identification Using Sequential Forward Floating Selection and Support Vector Machine. Applied Sciences, 12(20), 10249. https://doi.org/10.3390/app122010249