1. Introduction
Steel production is the foundation of industrial countries, being widely used in aerospace, the automobile industry, national defense equipment, and other fields, so its production quality is of great significance to product safety [
1]. In recent years, the requirements for the quality of steel in industrial production have become higher and higher. In addition to meeting the required performance criteria, it must also have a good appearance, that is, a superior surface quality. In the process of steel production, due to environmental factors, raw material composition, inadequate process technology, etc., it is often accompanied by the appearance of surface defects. These defects will have a negative impact on the wear resistance, corrosion resistance, fatigue strength, etc. of the steel, so the identification of defects on the steel surface is extremely important.
Currently, defect detection methods are divided into two main categories: traditional machine vision detection and deep learning detection. Based on the use of a traditional machine vision algorithm to extract the changed features, we can use support vector machine (SVM) [
2], Random Forest [
3], and other classifiers for classification. However, due to the lack of obvious rules for the distribution of defects on the steel image, it is difficult to extract the features, which leads to difficulty in using the recognition algorithm and low recognition accuracy. Deep learning detection is an algorithm for the classification of steel surface defect images based on a convolutional neural network [
4], which can use the image as the direct input of the network to automatically extract features. Compared with traditional methods, it has higher accuracy and faster speed, as well as stronger adaptability. In actual production scenarios, the abovementioned defect detection procedures are usually deployed to detect steel products and classify them according to their performance.
2. Related Work
At the end of the 20th century, a relatively mature steel defect detection technology based on feature engineering and statistical information was developed [
5]. Guo et al. [
6] proposed an automatic detection algorithm based on principal component analysis (PCA). Luo [
7] proposed a defect detection algorithm based on hybrid support vector machine–quantum particle swarm optimization (SVM-QPSO) to judge whether a defect exists or not. However, when factors such as the types of steel plates produced, lighting conditions, and other factors change, the feature extractor must be modified or redesigned, otherwise the performance of the algorithm will decline rapidly. Therefore, this type of scheme often requires experts to design a specific feature extractor for each defect, which leads to high labor costs and low efficiency. In summary, it is urgent to propose a new defect detection scheme with higher flexibility and reliability.
With the rapid development and wide application of deep learning, new ideas have been brought to defect detection in industry. This method no longer relies on cumbersome feature engineering; moreover, the robustness to environmental changes has also been greatly improved. Apart from that, it also has the advantage of rapid deployment. Ferguson et al. [
8] showed the influence of defect detection of casting using a varied feature extractor, such as Visual Geometry Group (VGG-16) and Residual Network (ResNet-101). Xu et al. [
9] used feature cascade in VGG-16 to achieve better performance in defect detection. However, these methods are not real-time, and so cannot meet the balance between the speed and accuracy of defect detection. Therefore, when deep learning is applied to the field of defect detection, there are still two challenges:
The features of the defects are similar to the background, and different types of defects have a similar appearance;
There are insufficient training samples.
Industrial defects rarely occur, but are various, and in most cases their appearances are not very different. Therefore, training on this kind of small sample dataset with large feature similarity can easily cause overfitting problems. What is more, its generalization ability is weak and difficult to apply in practice. Consequently, while considering real-time performance, how to further improve the accuracy of defect detection from the perspective of the model is still a problem of practical significance.
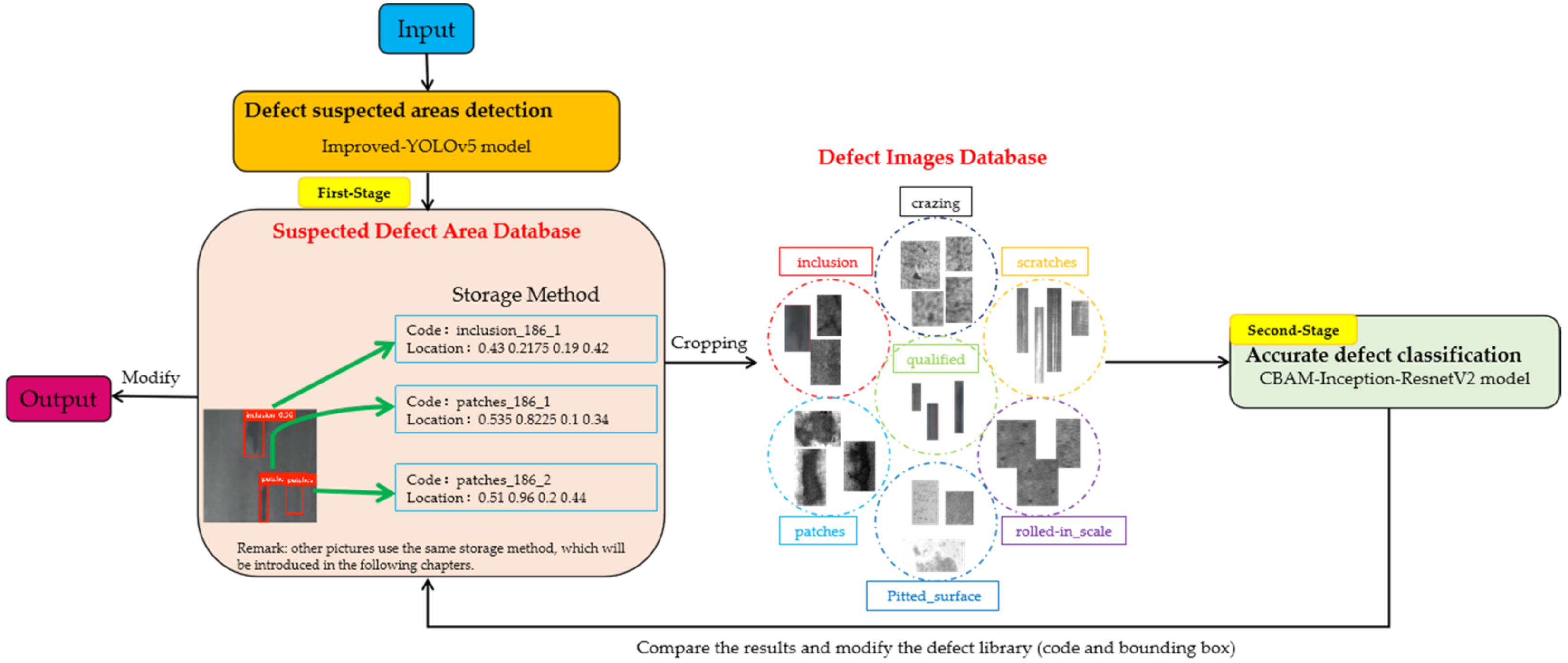
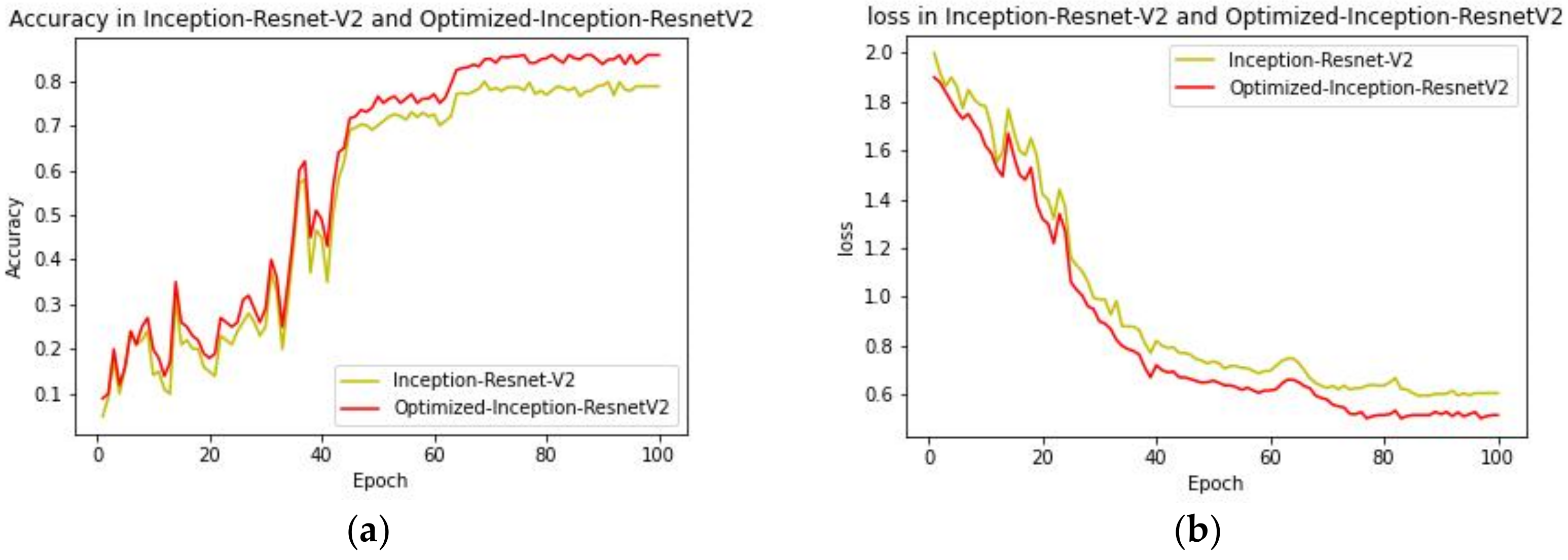
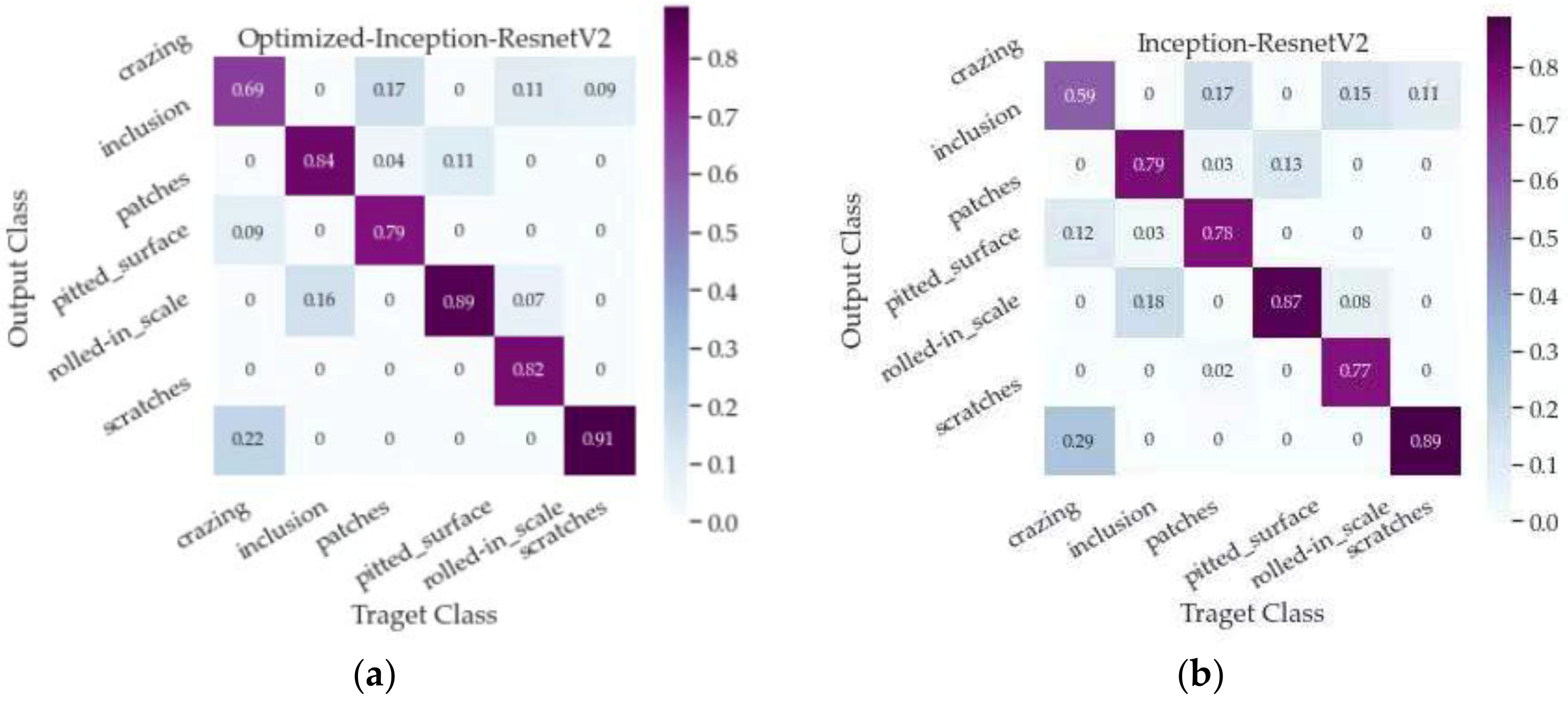
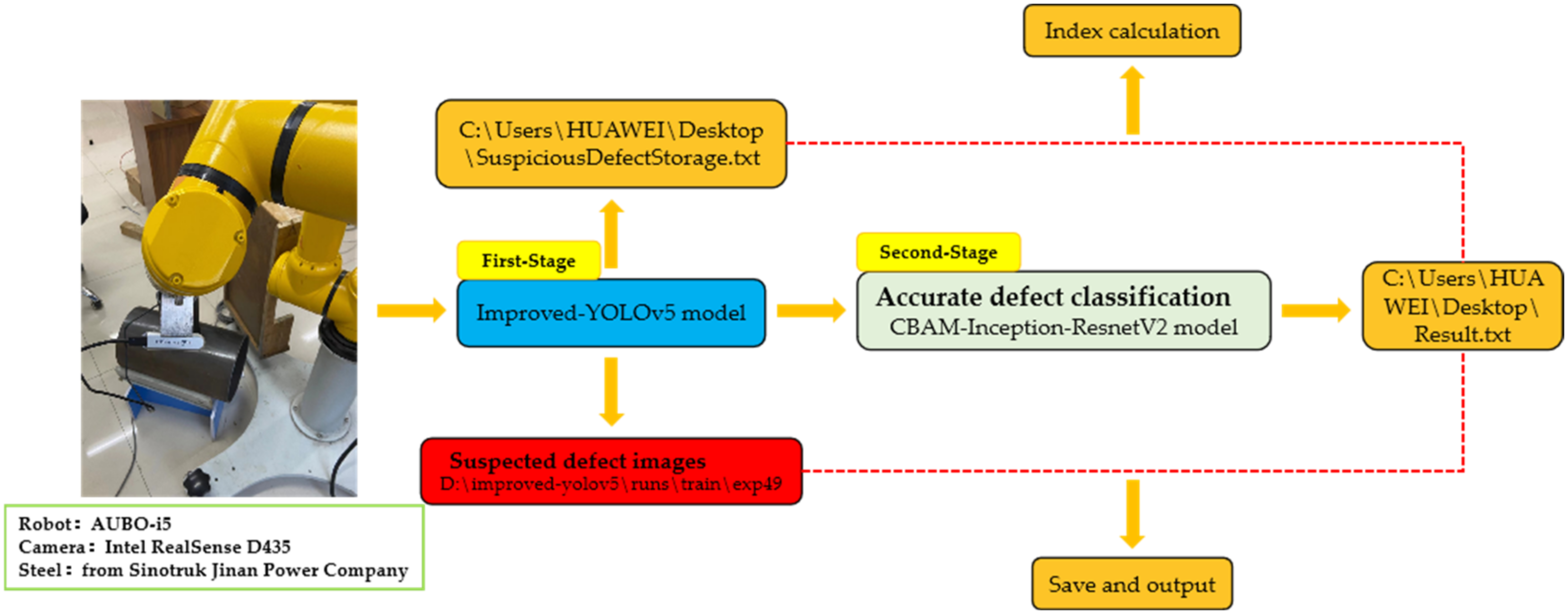
In response to the above problems, a two-stage defect detection framework based on Improved-YOLOv5 and Optimized-Inception-ResnetV2 is proposed. It completes detection and classification tasks through two specific models. The steps are shown in
Figure 1.
Step 1: First-stage recognition: obtain suspected defect areas on the surface of the steel through the trained Improved-YOLOv5 module. The precise positioning of the defect area on the steel surface is completed.
Step 2: Crop the suspected defect areas and map them to the uniform size. Each image may have one or more suspected area data groups, which are stored in the defect images database.
Step 3: Second-stage recognition: use the Optimized-Inception-ResnetV2 module, obtained through transfer learning, to provide image recognition services, perform secondary recognition of these suspected area groups, and obtain the final result, which is used as the final judgment result of the suspected defect area.
Step 4: Compare the detection result in the suspected defect area database with the result after the secondary recognition. If the two are the same, directly output the results in the suspected defect area database; if the results are different, modify the results stored in the database and output them.
If a single model is used for the target detection, it is necessary to find regions of interest (ROIs) in an entire image, which can be complicated by useless background information. The precise location of the defect area through the first-stage recognition reduces the interference of more background information on the defect features, so the second-stage recognition results are more accurate and the performance of the model is better. Accurate recognition after defect target positioning not only realizes the two-stage recognition of insignificant defects, but also solves the problem of similar features between defects to a certain extent, which makes the results more credible. At the same time, in order to more effectively locate the insignificant minor defects with high similarity on the steel surface, this paper improves YOLOv5 detection methods from three aspects. Firstly, improve the feature extraction capability of the backbone network, and further optimize the feature scales of the feature fusion layer and multiscale detection layer. In order to better extract defect features and achieve accurate classification, we integrated the convolutional block attention module (CBAM) attention mechanism module with the Inception-ResnetV2 model, which can independently learn the weights of different channels to enhance attention to the key channel domain. We further optimized the loss function of the benchmark model, adding L1 and L2 regularization to reduce the variance and reduce the occurrence of overfitting.
3. Improved-YOLOv5: Suspected Defect Area Detection
3.1. The YOLOv5 Model
YOLO is a target detection algorithm based on regression. After inputting the images or video into the deep network, YOLO completes the prediction of the classification and location information of the objects according to the calculation of the loss function, so it makes the target detection problem transform into a regression problem solution [
10].
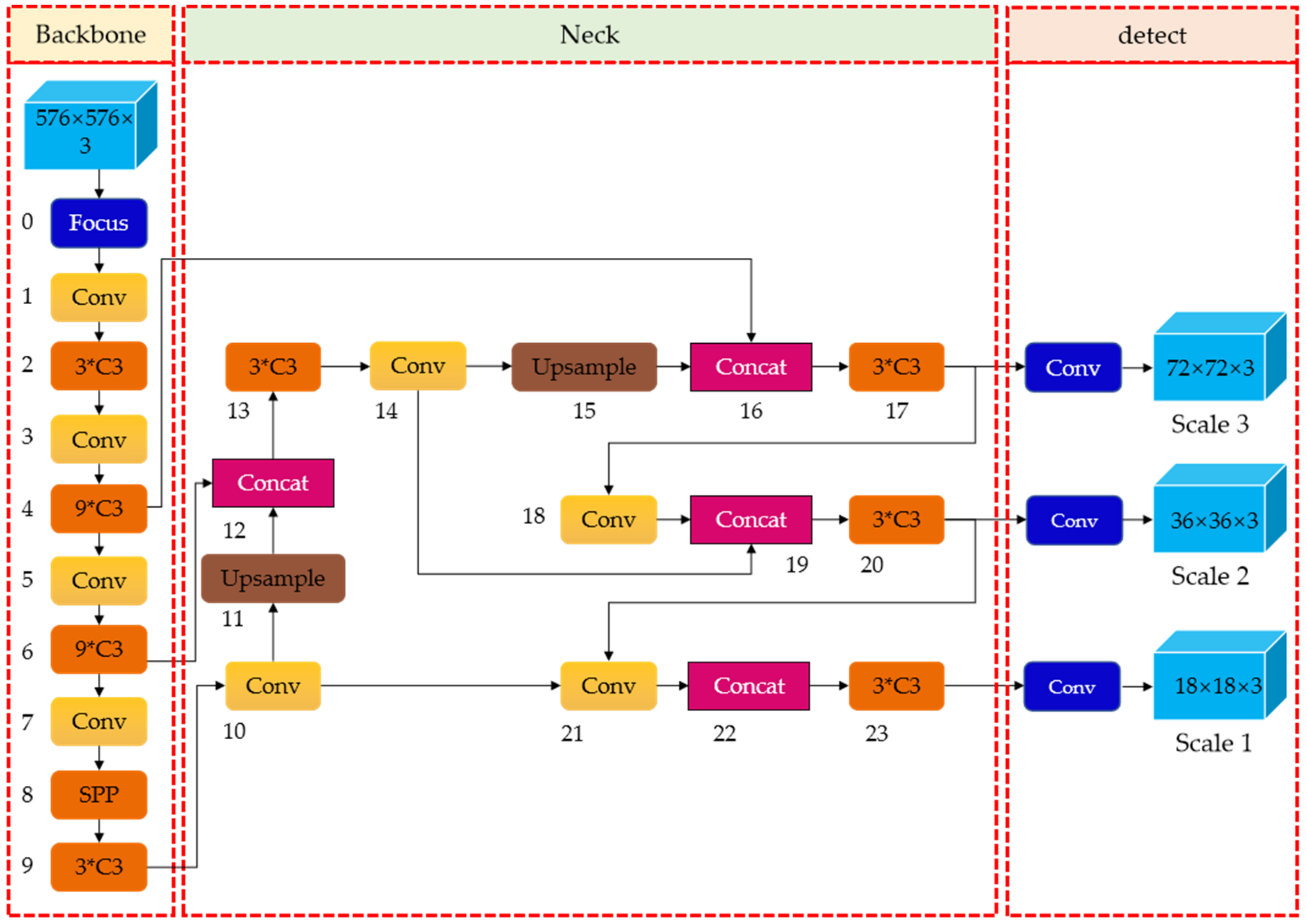
YOLOv5 [
11] is based on the YOLO detection architecture and uses the excellent algorithm optimization strategy in the field of convolutional neural networks in recent years, such as auto learning bounding box anchors, mosaic data augmentation, the cross-stage partial network, and so on; they are responsible for different functions in different locations of the YOLOv5 architecture. In the architecture, YOLOv5 consists of four main parts: input, backbone, neck, and output. The input terminal mainly contains the preprocessing of the data, including mosaic data augmentation [
12] and adaptive image filling. In order to adapt to different datasets, YOLOv5 integrates adaptive anchor frame calculation on the input, so that it can automatically set the initial anchor frame size when the dataset changes. The backbone network mainly uses a cross-stage partial network (CSP) [
13] and spatial pyramid pooling (SPP) [
14] to extract feature maps of different sizes from the input image by multiple convolution and pooling. BottleneckCSP is used to reduce the amount of calculation and increase the speed of inference, while the SPP structure realizes the feature extraction from different scales for the same feature map, and can generate three-scale feature maps, which helps improve the detection accuracy. In the neck network, the feature pyramid structures of FPN and PAN are used. The FPN [
15] structure conveys strong semantic features from the top feature maps into the lower feature maps. At the same time, the PAN [
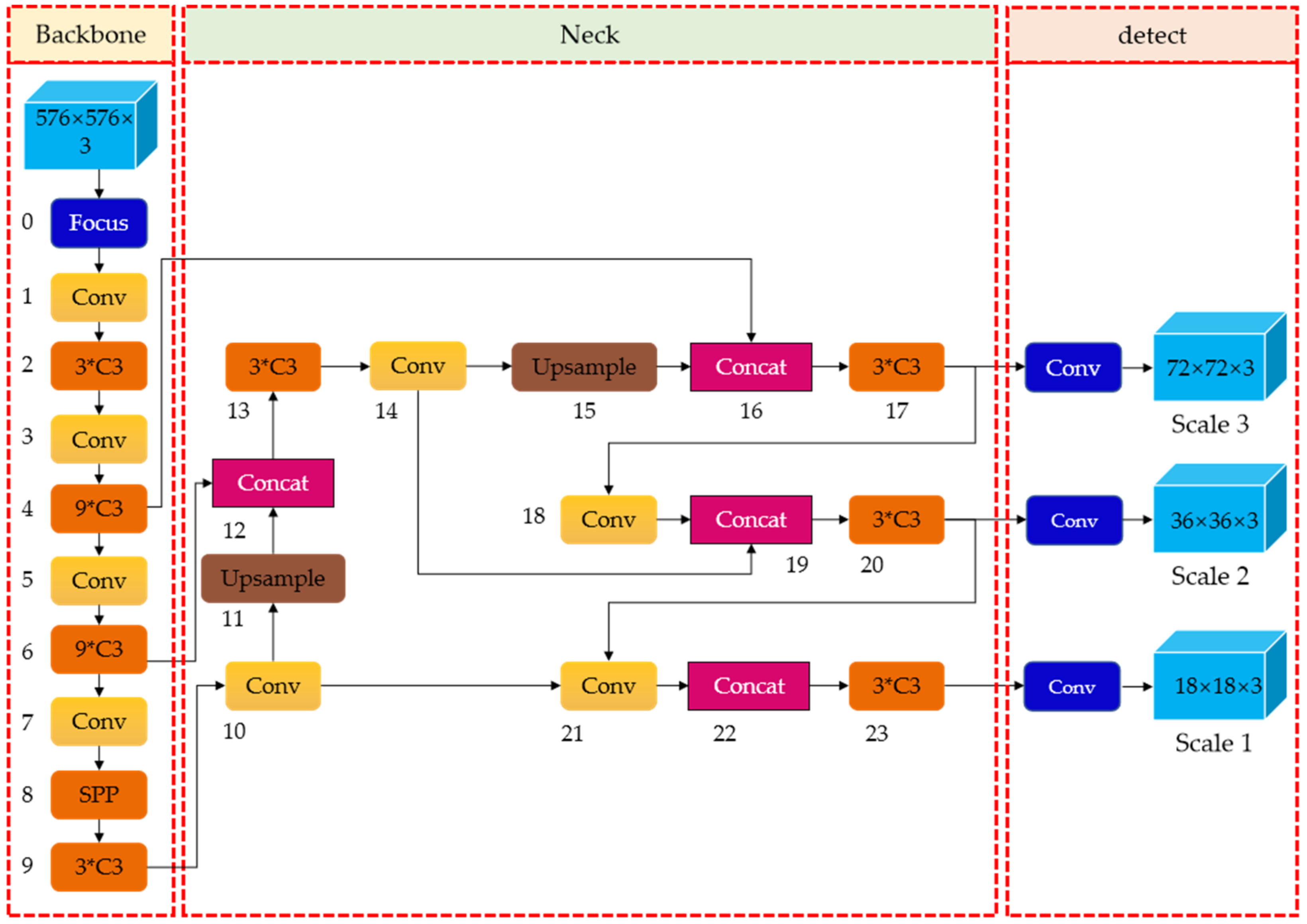
16] structure conveys strong localization features from lower feature maps into higher feature maps. These two structures jointly strengthen the feature extracted from different network layers in Backbone fusion, which further improves the detection capability. As a final detection step, the head output is mainly used to predict targets of different sizes on feature maps. The YOLOv5 consists of four architectures, named YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. The main difference between them lies in the number of feature extraction modules and convolution kernels at specific locations on the network. The network structure of YOLOv5 is shown in
Figure 2.
The defects on the steel surface are irregular in shape, random in location, and different in size; moreover, there are often a large number of targets with smaller scales. Under these circumstances, the original YOLOv5 model cannot fully meet the detection requirements, and there are situations such as low detection accuracy and missed detection. Therefore, this paper improves the original YOLOv5 network model. Firstly, we modified the backbone network, embedded an attention mechanism module to strengthen more important information, and reduced the interference of irrelevant information so as to improve the feature extraction ability of the model and improve the accuracy of defect detection. According to the distinguishing feature of small defect targets in steel, we further optimized the feature scales of the feature fusion layer and multiscale detection layer, so that the detection model could better adapt to the target detection of small defects, which improves the defect detection performance.
3.2. Improved Backbone
The backbone network of YOLOv5 is a convolutional neural network that extracts feature maps of different sizes from the input image by Focus slice, BottleneckCSP, and SPP modules [
17]. The feature extraction capability of the backbone network directly affects the detection performance of the entire model.
For a deep convolutional neural network, the overall structure is an inverted pyramid, and the size of the feature map is scaled with the entire network structure—that is, the deeper the network, the smaller the feature map. Therefore, for small targets in the image, their feature information may be assimilated by the feature information around the area due to the pooling and downsampling operation, then disappear. As for defects on the surface of the steel, it is often insignificant relative to the entire surface. If large-scale downsampling is performed, it will cause the loss of its own semantic information, and may lead to missed detection.
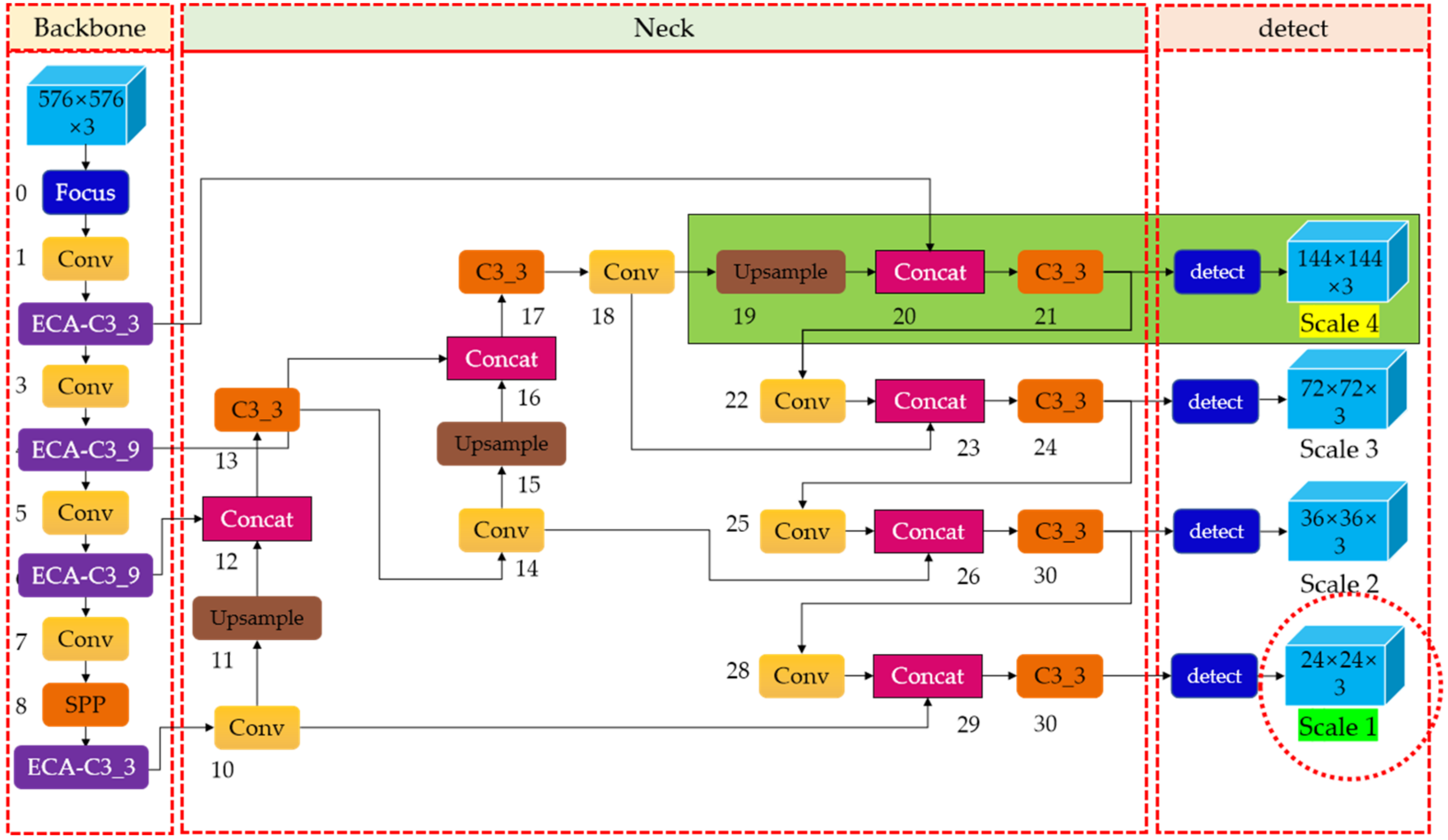
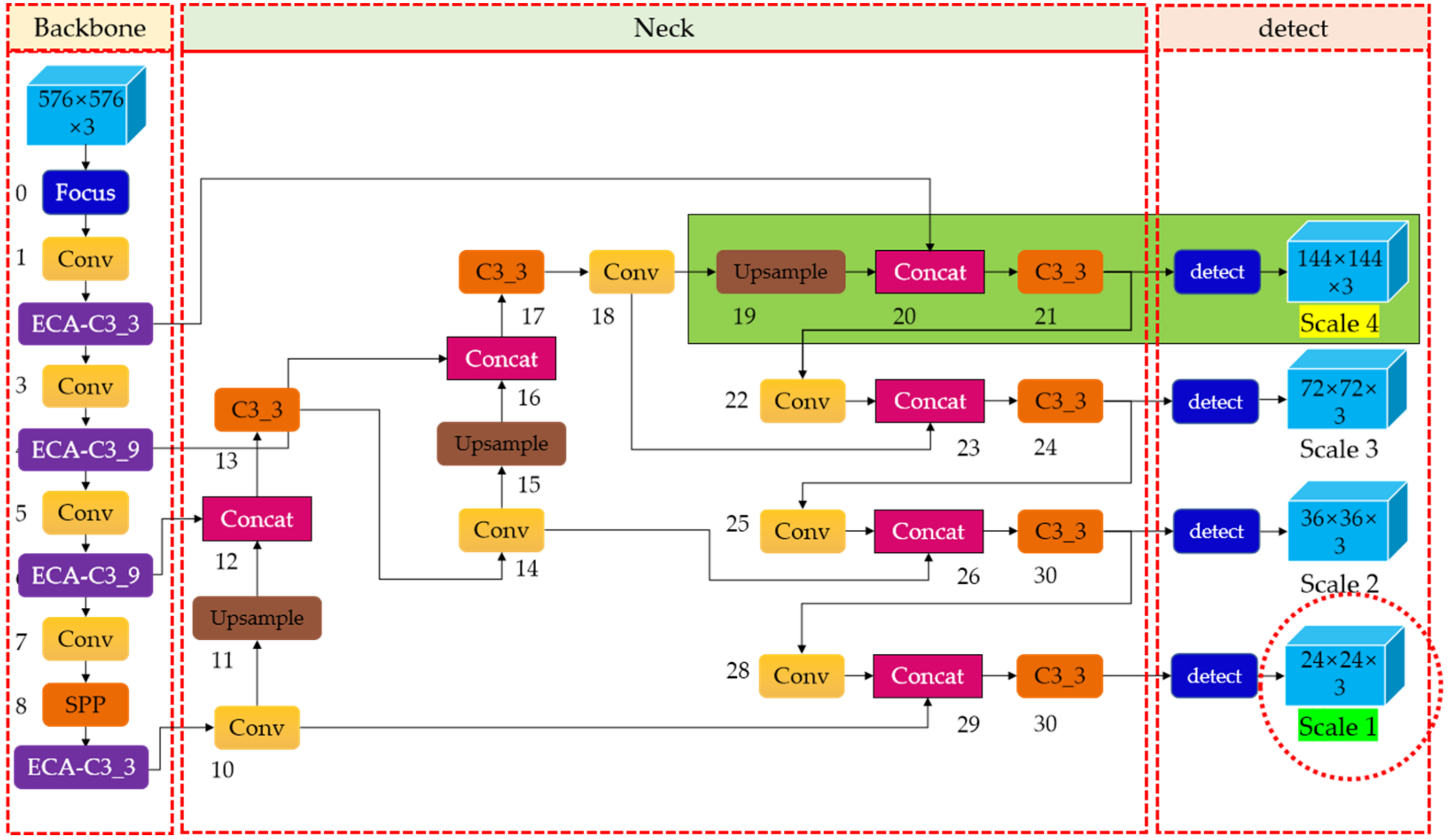
In order to avoid a substantial loss of defect semantic information and, improve the feature extraction capability of the backbone network for steel defects, we removed the Conv and C3 layer that obtained 1/32 scale feature information (refers to the size of feature maps generated is 18 × 18 pixels) in the original YOLOv5, and replaced it with a Conv and C3 layer that extracted feature information at a 1/24 scale (i.e., the size of feature maps generated is 24 × 24 pixels). With this modification, after the feature information generated by the shallow network was fused with the deep information, a 1/24-scale detection head (one level lower than the original YOLOv5, represented as Scale 1 with the green background, surrounded by a red circle) was formed to detect large-scale targets. We know that YOLOv5 generates feature maps of large, medium, and small scales, so in this way, the size of the large-scale feature map extracted by the model was reduced by one level, which reduced the interference of large-scale useless information, and improved the detection accuracy. The backbone network before and after modification are shown in
Figure 3.
3.3. The Attention Mechanism
The morphological features contained in feature maps of different scales, which are extracted by the backbone network, included not only foreground objects, but also background information. For small targets, the foreground information in the feature map is sparser. In order to help YOLOv5 ignore confusing information and focus on useful target objects, we embedded an efficient channel attention network (ECA-Net) [
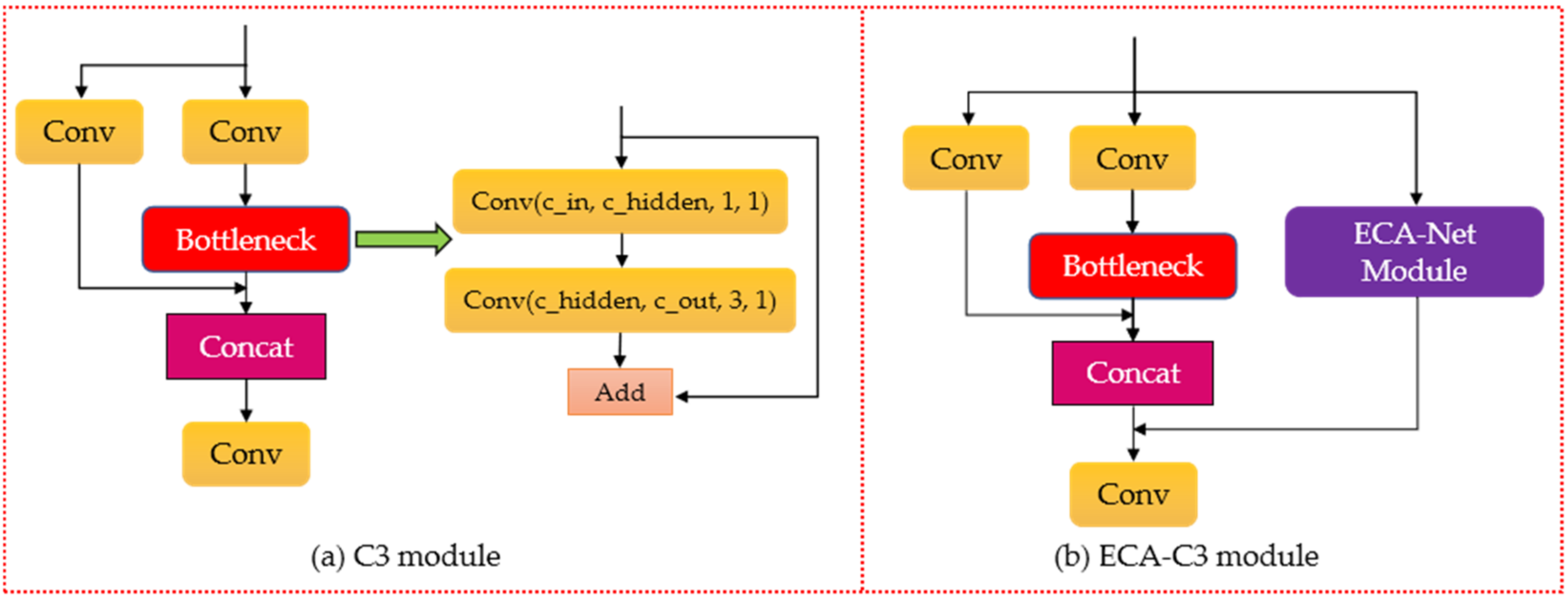
18] mechanism into the backbone network, connected it in parallel to the C3 module, and named it ECA-C3. Next, we replaced the C3 module in the original YOLOv5 backbone network with the ECA-C3 module.
Figure 4a,b show the architecture of the C3 module and ECA-C3 module, respectively.
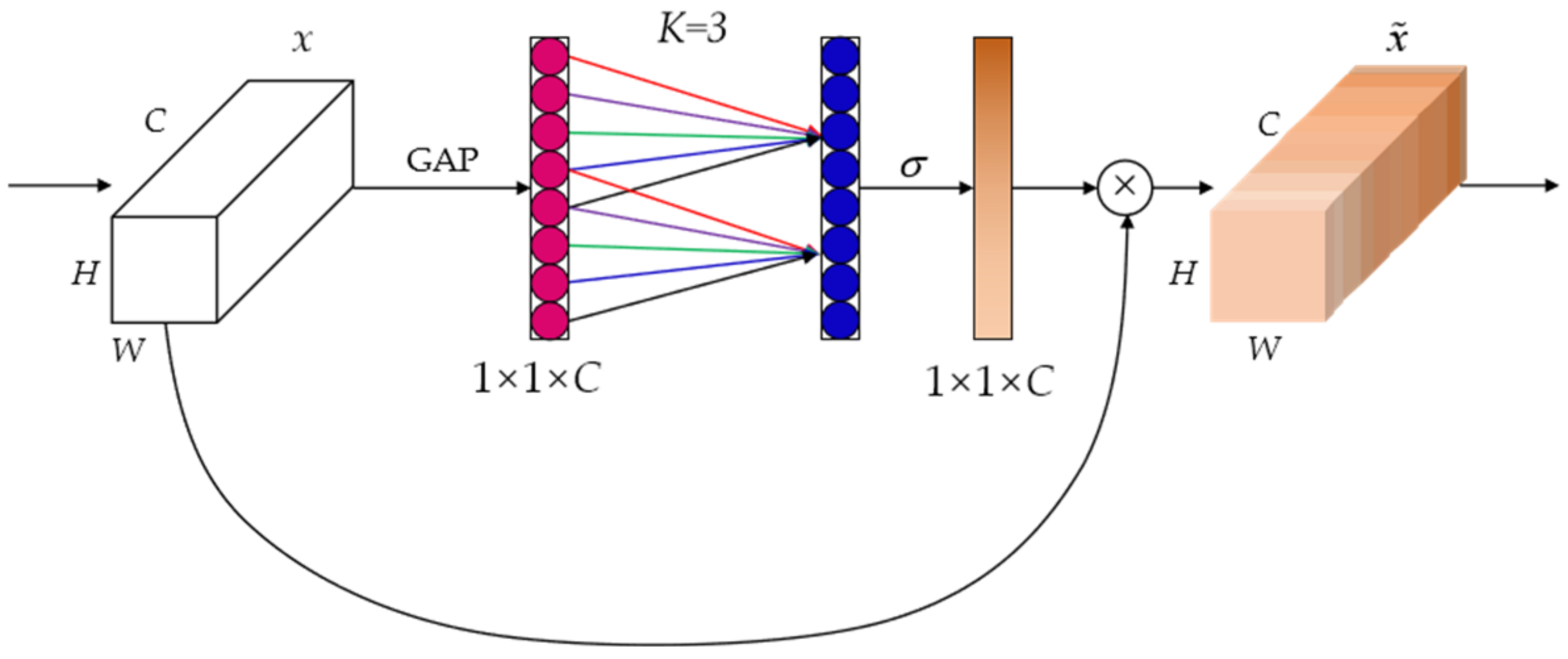
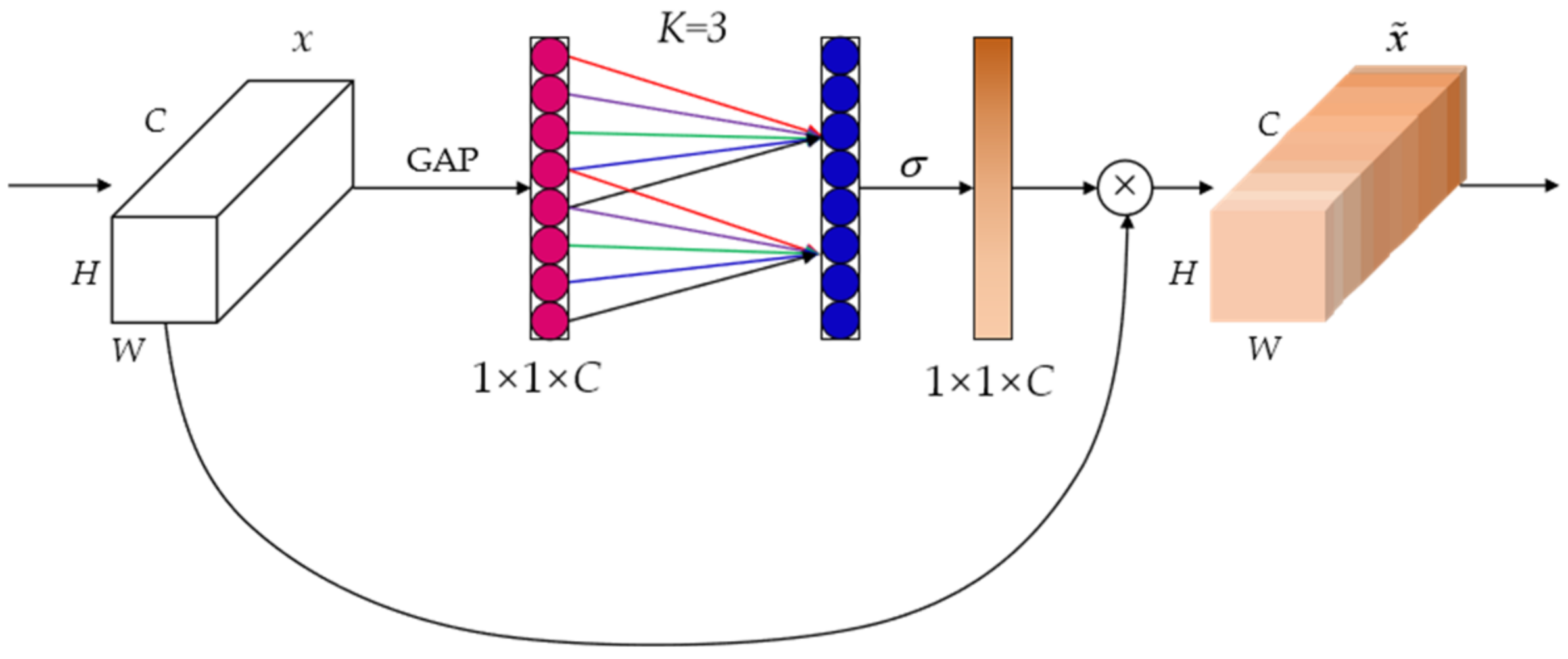
The efficient channel attention network (ECA-Net) is a local cross-channel interaction strategy without dimensionality reduction. At the same time, it can also adaptively select the size of the one-dimensional convolution kernel. The ECA module effectively captures information about cross-channel interactions and obtains a significant performance increase.
Figure 5 shows the structure diagram of the ECA module.
In order to make the neural network learn the attention weights of each channel adaptively, ECA-Net captures local cross-channel interaction information by considering each channel and its K neighbors. The convolutional kernel size K represents the coverage of local cross-channel interactions, i.e., how many neighbors of that channel are involved in the attention calculation. K is related to the channel dimension C, as long as the channel dimension C is given, the kernel size K will be adaptively determined as shown in Equation (1):
where C is the channel dimension,
denotes the nearest odd number of
;
is set to 2 and b to 1.
A one-dimensional convolution operation is performed on the obtained convolution kernel, and the sigmoid activation function is used to get the weights of each channel. The equation is as follows:
where
represents a one-dimensional convolution operation with a kernel of K,
is the sigmoid activation function, whose calculation formula is
,
y represents the different channels,
is the weights of each channel generated, and its dimension is 1 × 1 × C.
Finally, the generated attention weights and input feature maps are weighted and summed, so that the extracted features are more directional, which makes these features able to be more fully utilized. The weighting equation is as follows:
where
represents multiplying element by element, and
is the output result after passing the ECA module.
As we can see that the ECA attention module embedded in the backbone network is represented by the purple module in
Figure 6.
3.4. Increasing Scale of Model Prediction
As for steel defect detection, the difficulty is that the defect area is too small relative to the entire steel surface, which makes defect features not obvious when the images are not enlarged. In order to solve this problem, we made the following improvements to the architecture of the feature fusion layer and detection layer.
As seen in the previous section, in the target detection process, shallow features are conducive to the detection of small-scale targets, while deep features are more conducive to large-scale target detection. In the feature fusion layer and detection layer network, the feature pyramid network (FPN) and the pixel aggregation network (PAN) [
16] architectures are used to strengthen the feature fusion capability and transferability of positioning. Finally, there are three feature fusion layers that generate three scales of new feature maps with sizes of 72 × 72 × 255, 36 × 36 × 25, and 18 × 18 × 255; the three output detection layer scales corresponding to them are 1/8, 1/16, and 1/32, respectively, for the detection of small, medium, and large goals.
As shown in
Figure 6, we added the 1/4-scale detection layer marked with the green background to generate 144 × 144 feature maps to capture shallower feature information on the steel surface. This scale detection head is represented as Scale 4 with the yellow background in
Figure 6. The new fusion layer starts to strengthen the features from the second layer of the backbone network, which eliminates the shortcomings of the original YOLOv5 model that does not make full use of the shallow features. With this improvement, the features of the shallower network can be reused in the deeper network. Therefore, the newly added prediction head at the end of the network can generate low-level and high-resolution feature maps, which are more sensitive to small targets, thus improving small object detection.
4. Optimized-Inception-ResnetV2: Accurate Defect Identification
After Improved-YOLOv5 model defect detection, we obtained images with bounding box and classes, and saved them in the suspected defect area database. Next, we cropped the suspected defect area surrounded by the bounding box. Then we obtained one or several groups of suspected defect area groups from each image after cropping. Furthermore, we numbered these suspected defect area groups, so as to directly locate the position of the suspected defect area in the original image during subsequent modification. The numbering method was composed of three parts: the type of the defect, the serial number of the original image, and the serial number of defects, such as patches_186_2. We used the Optimized-Inception-ResnetV2 model obtained by transfer learning to classify these suspected defect area groups, and regarded it as the final judgment result of the suspected defect area. Then we found the bounding box and class of the image in the corresponding suspected defect area database according to the number of each suspected defect area group, modified it in terms of the two-stage recognition comparison result for further industrial processing, and output the final result.
4.1. The Inception-ResnetV2 Model
The Inception-Resnet [
19] architecture, proposed by Szegedy, is a mixture of Inception and Resnet network backbone architectures. The Inception module is a network with good local topology, i.e., multiple convolution or pooling operations are performed on the input image in parallel. It does not restrict itself to a specific convolution kernel, but uses all convolution kernels of different sizes at the same time, and then merges all convolution output results to form a deeper feature map. Taking advantage of that can lead to better image representation [
12]. Resnet [
20] is a residual neural network architecture with a depth of 152 layers, proposed by Kaiming He in the ImageNet competition. He introduced a shortcut architecture in the neural network. Specifically, this means adding the input layer transfer and convolution results, which reduces the problems of a neural network such as the gradient dispersion caused by rather deep depth.
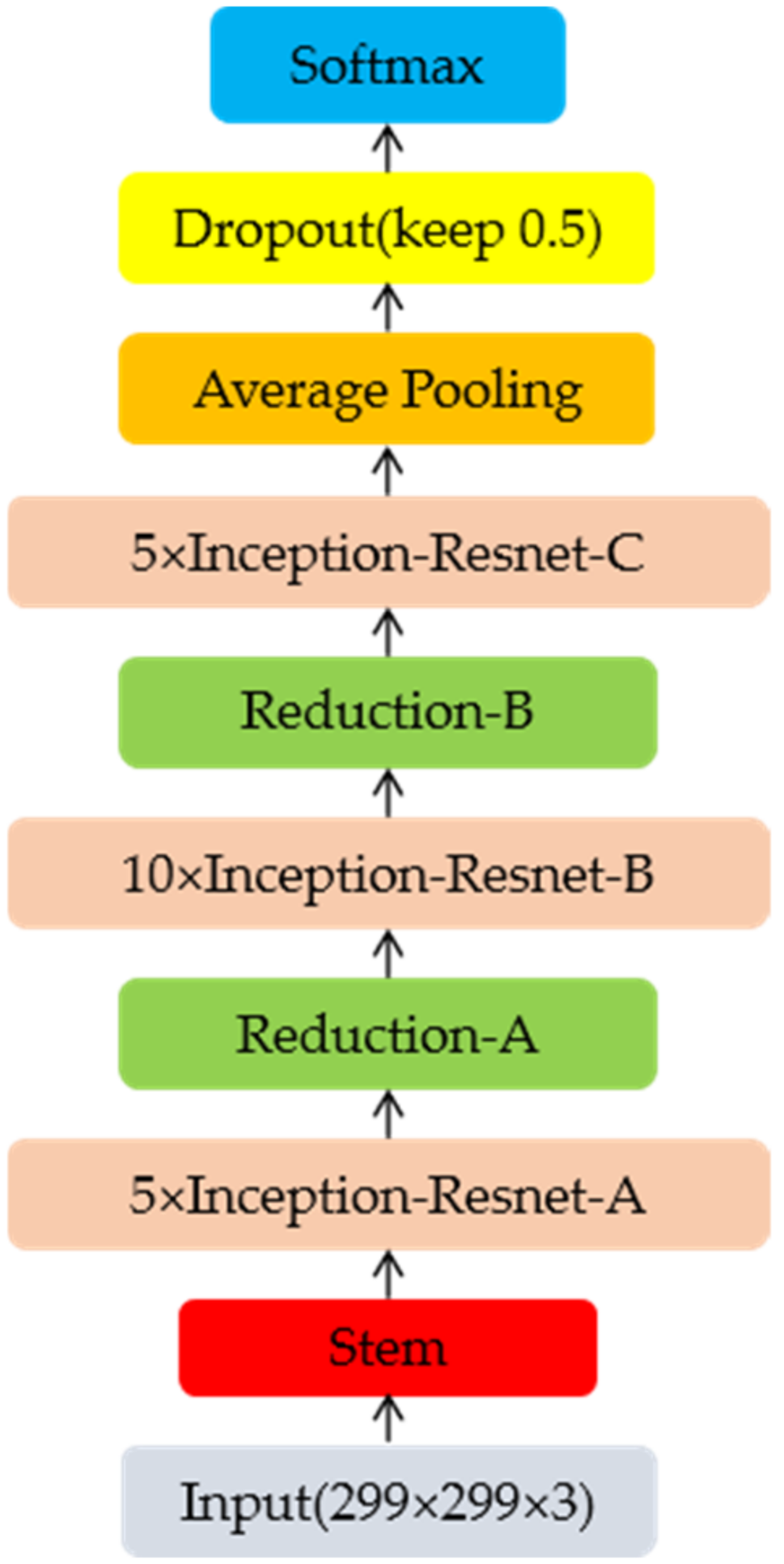
As shown in
Figure 7, the Inception-ResnetV2 network redefines the input image size to 299 × 299 × 3, so as to maximize the recognition ability of graphics. The Stem architecture adopts the parallel structure and decomposition idea in the InceptionV3 [
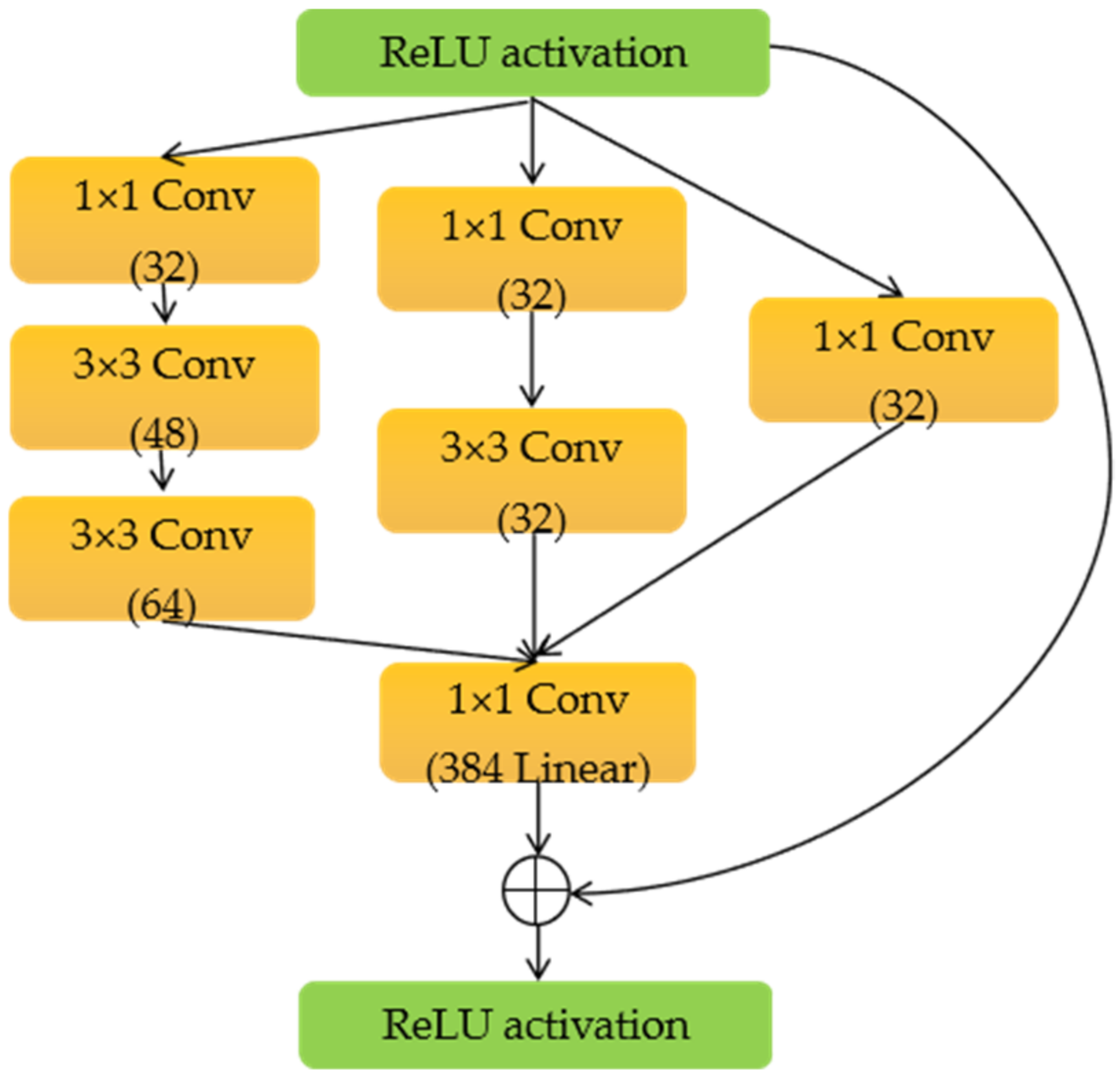
21] model, which can reduce the amount of calculation with little information loss. The 1 × 1 convolution kernel in the structure is used to reduce the dimensionality. Inception-Resnet-A, Inception-Resnet-B, and Inception-Resnet-C architectures adopt the Inception + residual network design, with deeper layers, more complex architecture, and more channels to obtain feature maps. The three architectures, Reduction-A, Reduction-B, and Reduction-C, are used to reduce the amount of calculation and the size of the feature map. The Inception-ResnetV2 model integrates the advantages of the Inception module and the residual network structure, which not only can increase the depth and width of the network but also avoid the disappearance of the gradients.
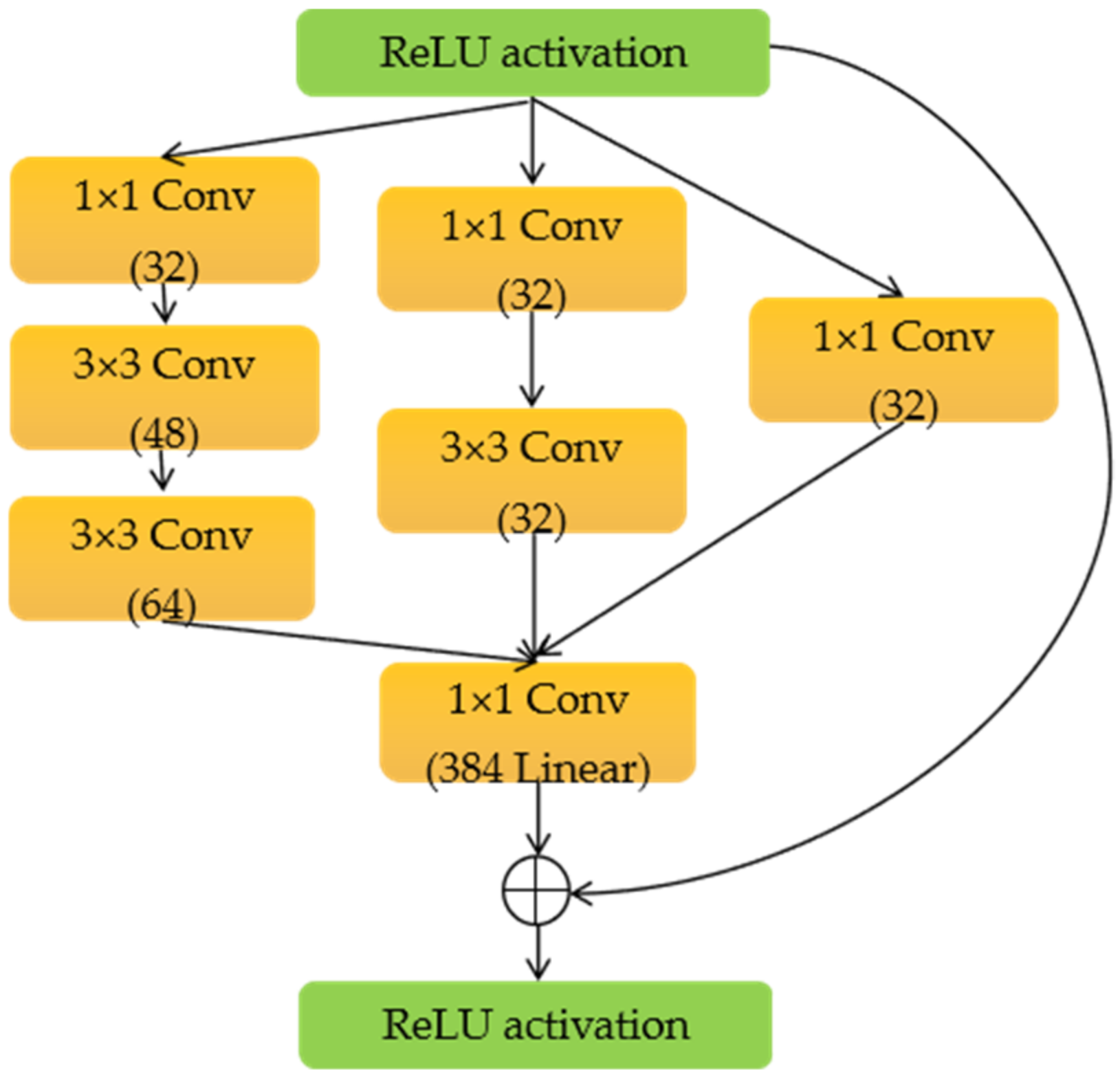
Figure 8 shows the architecture of Inception-Resnet-A; the others are similar.
4.2. The CBAM Attention Mechanism
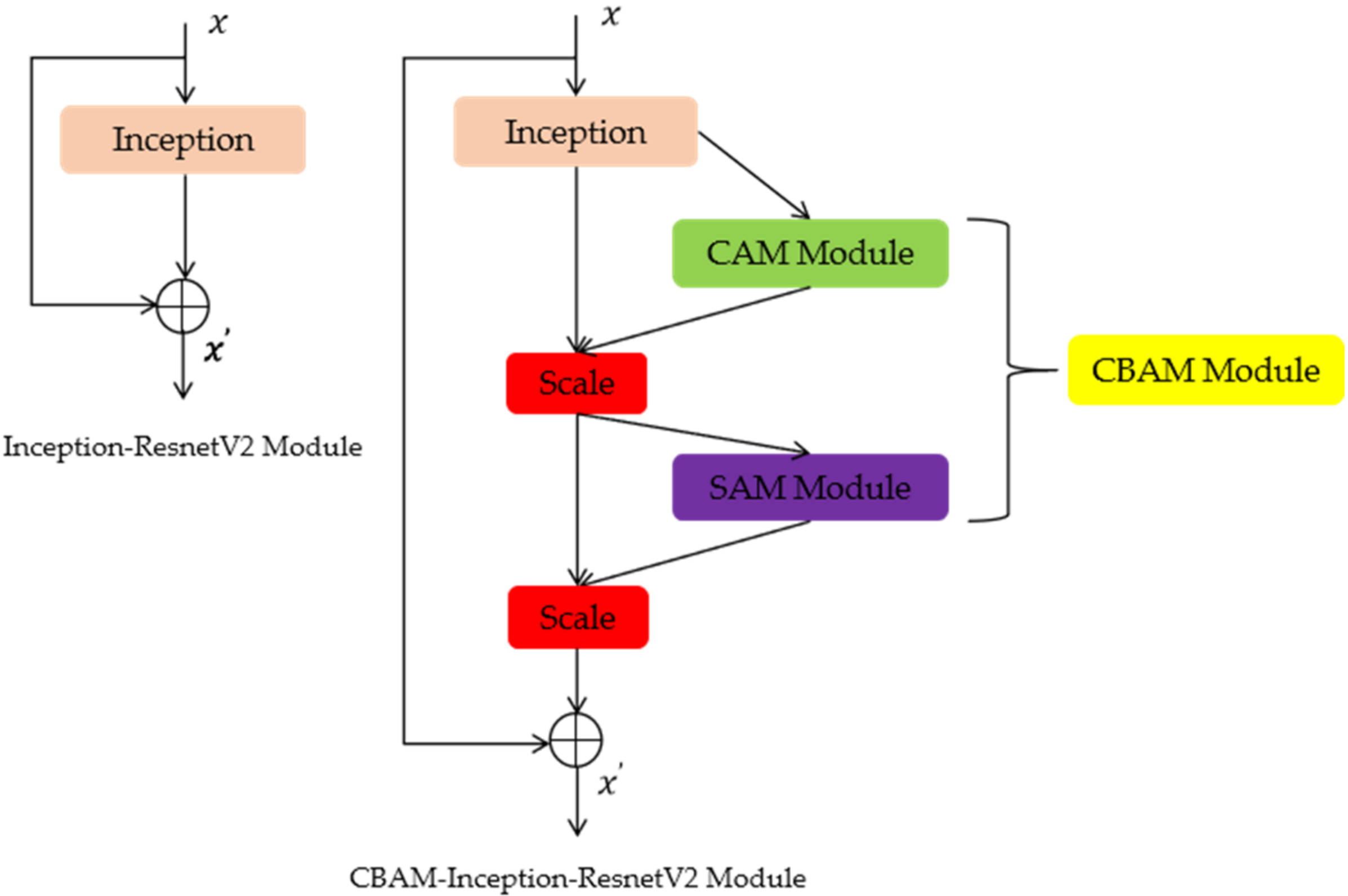
In order to save resources and obtain the most effective information quickly, the attention mechanism has become a very effective method to improve the feature extraction capabilities of neural networks. It can focus limited attention on key information and ignore other useless information automatically. In order to better extract defect features and achieve accurate classification, we embedded the convolutional block attention module (CBAM) mechanism [
22] module in Inception-Resnet-A, Inception-Resnet-B, and Inception-Resnet-C of the Inception-ResnetV2 network. The specific architecture is shown in
Figure 9.
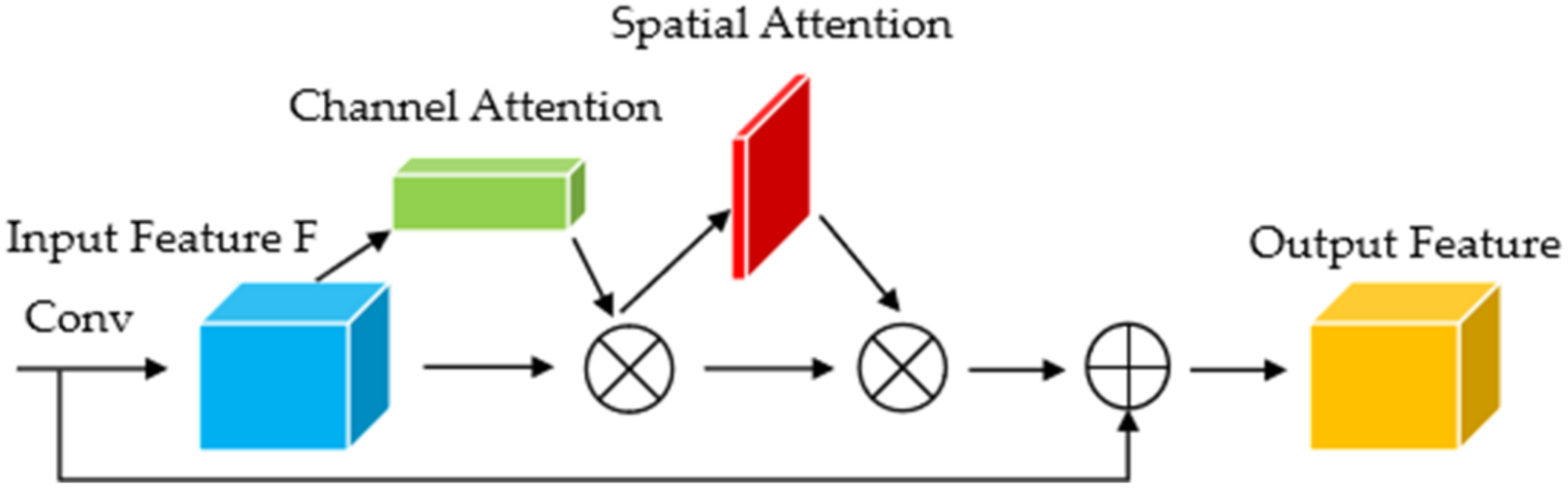
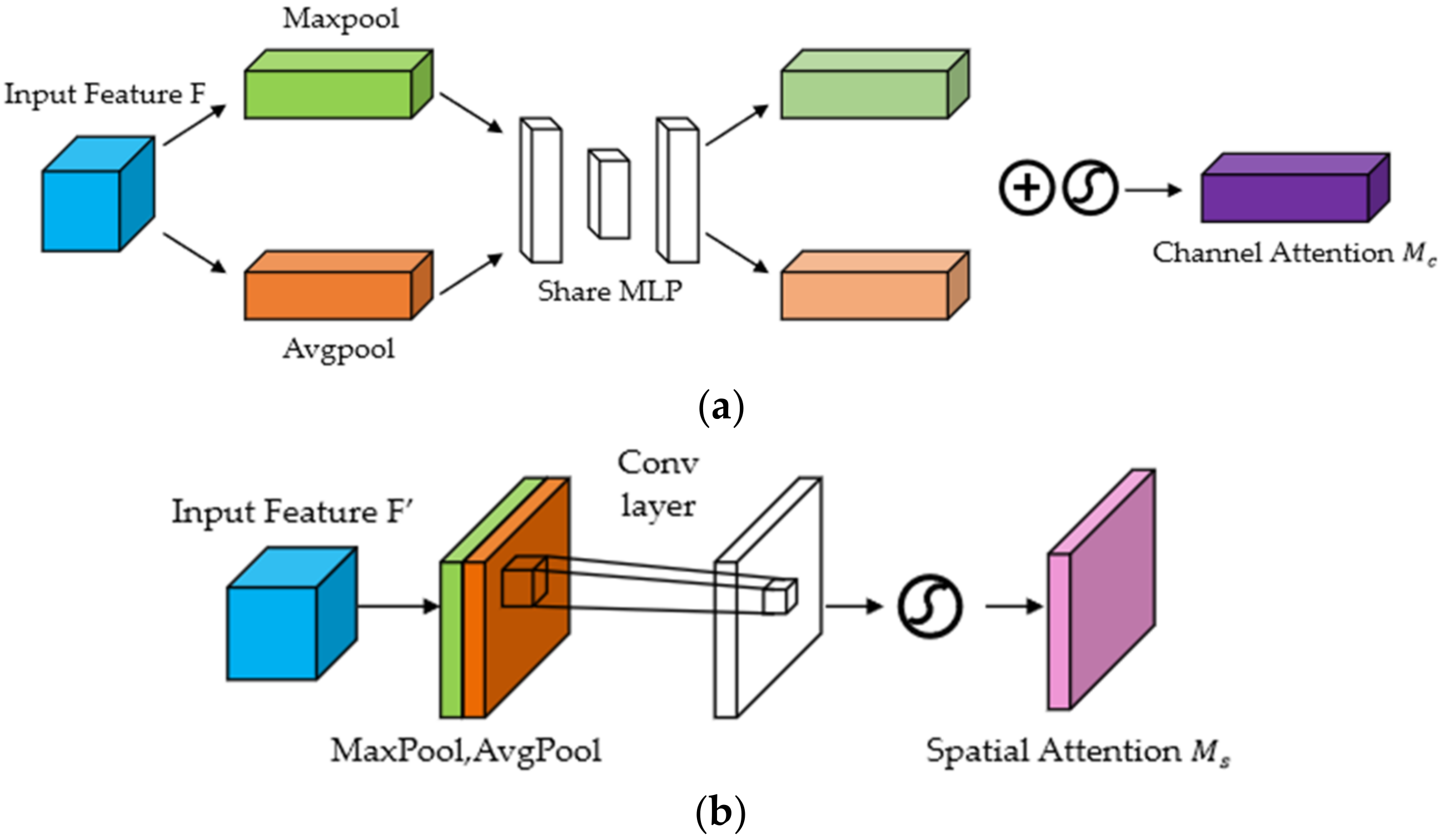
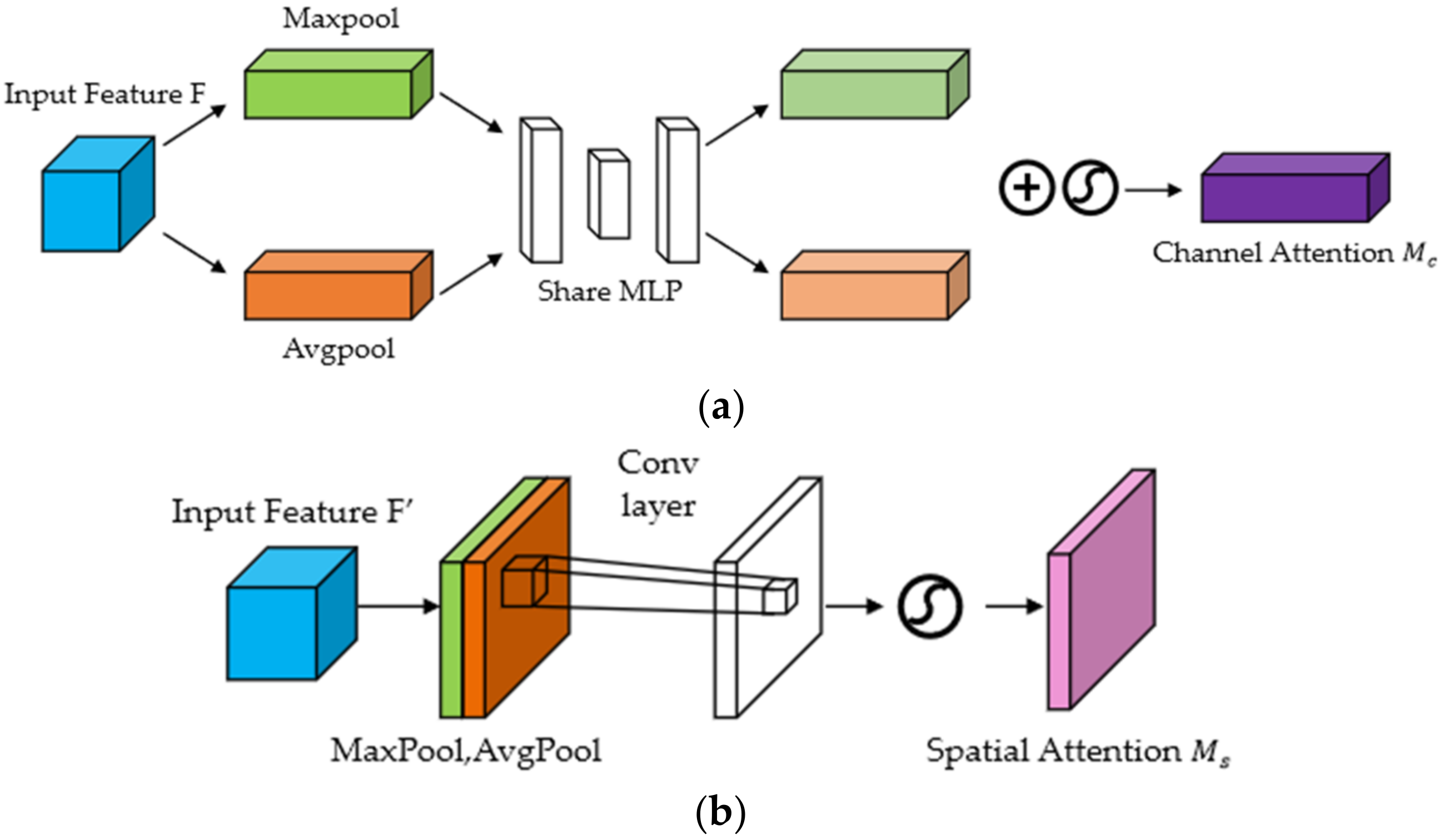
As shown in
Figure 10, CBAM contains two independent submodules, a Channel Attention Module (CAM) and a Spatial Attention Module (SAM). They perform channel and spatial attention, respectively, emphasize important features, and suppress general features, which achieves the purpose of improving the target detection effect. This not only saves parameters and computing power [
23], but also ensures that it can be integrated into the existing network architecture as a plug-and-play module.
Figure 11a shows the calculation process of CAM. For the input feature map, H, W, and C indicate the length, width, and number of channels, respectively. We can calculate the weight of each channel according to the following equation:
Each channel of the input feature map undergoes max pooling and average pooling at the same time, and then passes through a Multilayer Perceptron (MLP). Next, element-wise addition is performed on the feature vector output by the MLP, and finally, the sigmoid activation function is performed. Through this process, we can obtain the channel attention.
Figure 11b shows the calculation process of SAM. Taking the feature map output by the CAM module as the input, max pooling and average pooling are performed in sequence, and then a convolution operation is performed on the obtained intermediate vector. After taking the obtained convolution results to pass the sigmoid activation function
, we can obtain the spatial attention, as shown in Equation (5):
4.3. Optimization of Model Parameters
(1) In order to reduce the number of parameters of the model, we simplified the model, and reduced the number of Reduction-A, Reduction-B, and Reduction-C to three, five, and three. The last layer is the Softmax layer, but the output size depends on the specific problem. In this paper, there are six types of defects on the steel surface.
(2) We use the cross-entropy loss function [
24] as the cost function. However, it can be seen from the foregoing that the similarity of industrial defects is relatively high and the defects are often not obvious, so it is easy to cause overfitting during training. Therefore, we added L1 and L2 mixed regularization to the loss function to avoid this phenomenon and make the model more robust when it is used in an industrial environment.
The optimized loss function
is as follows:
where p represents the actual probability distribution of x, q represents the predicted probability distribution of x,
represents weights, and
represents the regularization parameter. The average of the cross entropy is calculated in the entire batch to get corss_loss, and then L1 and L2 mixed regularization is performed to reduce overfitting.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}