
Semantic Metadata Annotation Services in the Biomedical Domain—A Literature Review


Abstract
:1. Introduction
- Formulates requirements for tools supporting retrospective semantic annotation/enrichment of (meta)data, questionnaires and data dictionaries derived from epidemiological studies, public health and clinical trials (Section 2);
- Reports a systematic literature search to find available techniques, technologies and tools to support users in retrospective semantic annotation (Section 3);
- Gives an overview of the existing metadata annotation services we could identify (Section 4.1);
- Evaluates the existing metadata annotation services against the set of requirements we formulated (Section 4.2).
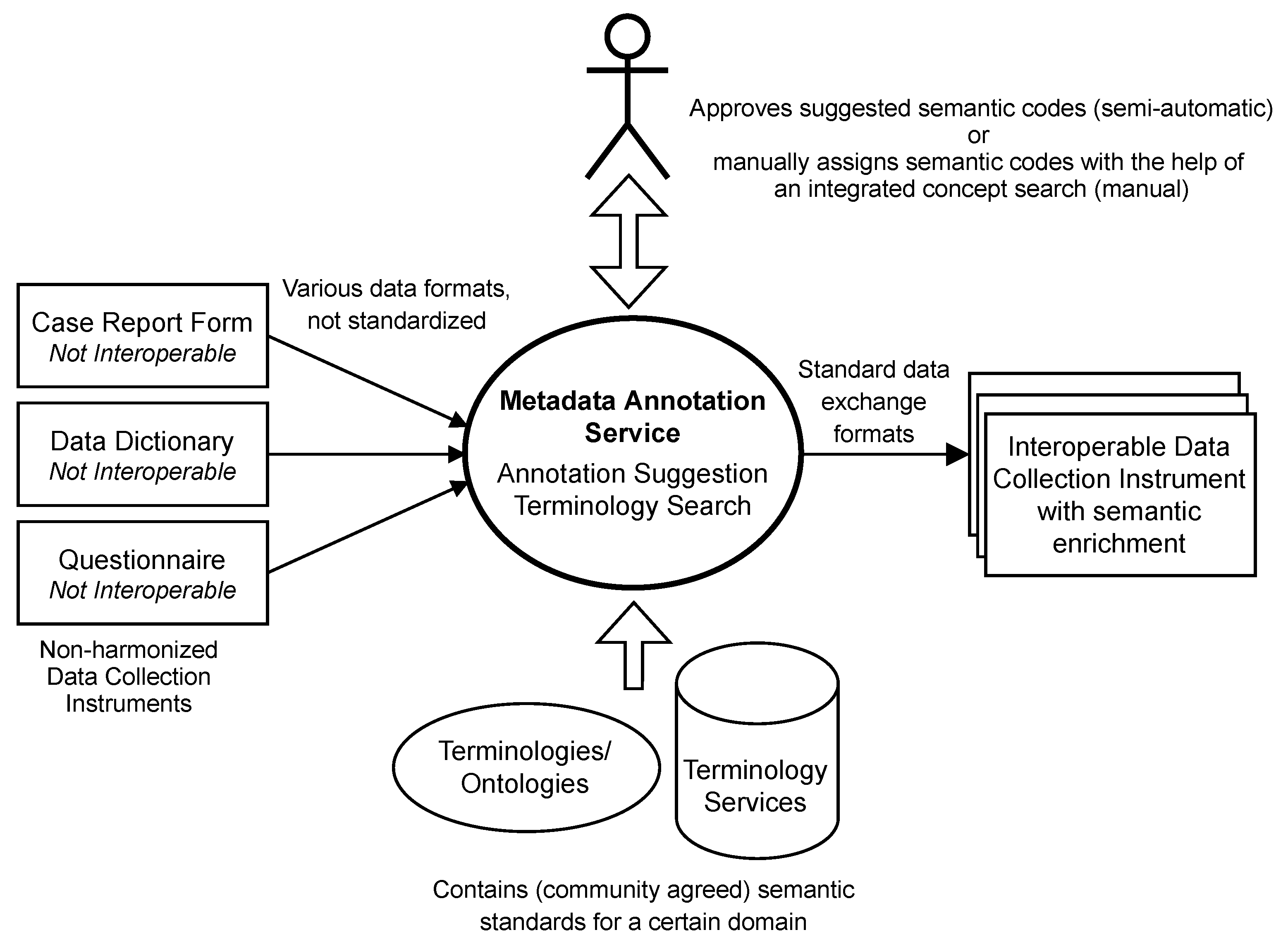
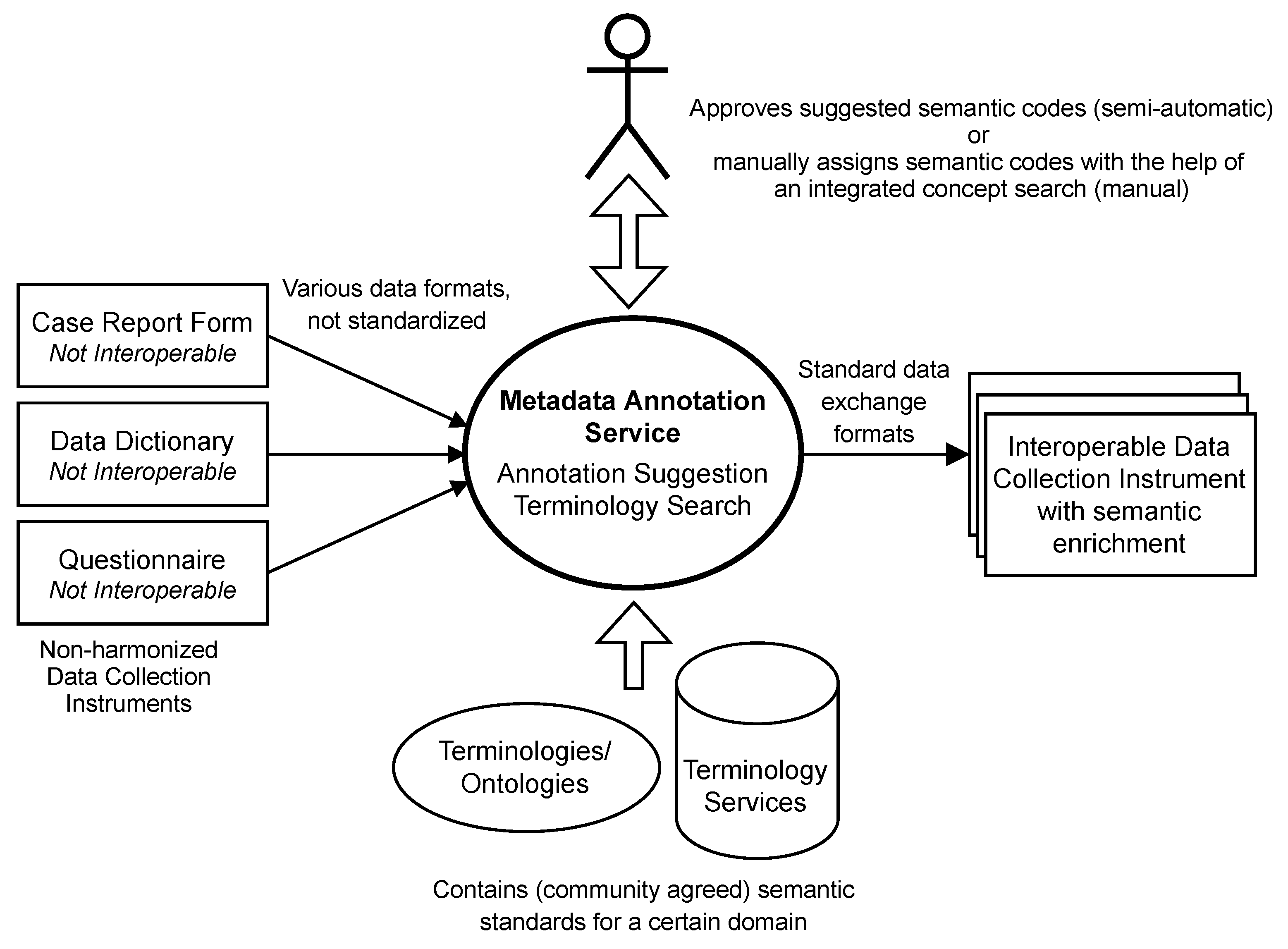
2. Definition and Requirements of a Semantic Metadata Annotation Service
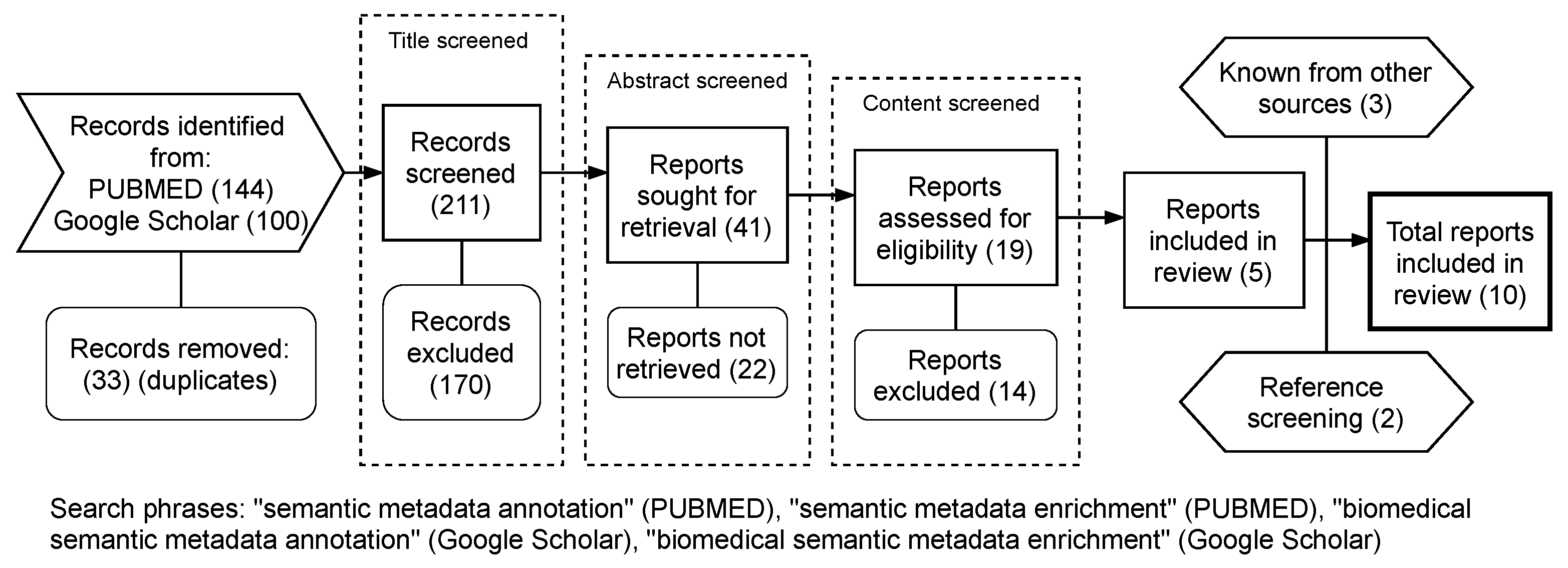
3. Methods—Systematic Literature Review
Categorization of Reviewed Articles
4. Results
4.1. Existing Semantic Metadata Annotation Services
- ODMedit
- Rightfield
- Swate
- OntoMaton
- eleMAP
- CEDAR Workbench
- Semantic Annotation Prototype of Wiktorin
- Metadata-Enricher
- SAP
- D2Refine
4.2. Requirements Revisited
4.2.1. Requirement 1: Open Accessible and Open Code
4.2.2. Requirement 2: Support for Common Data Formats
4.2.3. Requirements 3 and 4: FAIR Terminologies and Interfaces for Terminology Service Integration
4.2.4. Requirement 5: Terminology Search
4.2.5. Requirement 6: Annotation Suggestion
4.2.6. Requirement 7: Terminology Upload
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Andrew Cooper. REDCap Documentation. Available online: https://docs.redcap.qmul.ac.uk/code-list/ontologies/ (accessed on 29 December 2021).
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [Green Version]
- iAS interActive Systems GmbH. SecuTrial. Available online: https://www.secutrial.com/en/ (accessed on 29 December 2021).
- Harris, P.A.; Taylor, R.; Thielke, R.; Payne, J.; Gonzalez, N.; Conde, J.G. Research electronic data capture (REDCap)—A metadata-driven methodology and workflow process for providing translational research informatics support. J. Biomed. Inform. 2009, 42, 377–381. [Google Scholar] [CrossRef] [Green Version]
- EHDEN. European Health Data Evidence Network–ehden.eu. Available online: https://www.ehden.eu/ (accessed on 29 December 2021).
- Maelstrom Research. Available online: https://www.maelstrom-research.org/ (accessed on 29 December 2021).
- Bergeron, J.; Doiron, D.; Marcon, Y.; Ferretti, V.; Fortier, I. Fostering population-based cohort data discovery: The Maelstrom Research cataloguing toolkit. PLoS ONE 2018, 13, e0200926. [Google Scholar] [CrossRef] [PubMed]
- Fortier, I.; Raina, P.; Van den Heuvel, E.; Griffith, L.; Craig, C.; Saliba, M.; Doiron, D.; Knoppers, B.; Ferretti, V.; Granda, P.; et al. Maelstrom Research guidelines for rigorous retrospective data harmonization. Int. J. Epidemiol. 2016, 46, dyw075. [Google Scholar] [CrossRef] [Green Version]
- Doiron, D.; Marcon, Y.; Fortier, I.; Burton, P.; Ferretti, V. Software Application Profile: Opal and Mica: Open-source software solutions for epidemiological data management, harmonization and dissemination. Int. J. Epidemiol. 2017, 46, 1372–1378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nationale Forschungsdateninfrastruktur (NFDI) e.V. NFDI. Available online: https://www.nfdi.de/ (accessed on 29 December 2021).
- Mario Vivone. NFDI4Health. Available online: https://www.nfdi4health.de/en/ (accessed on 29 December 2021).
- Fluck, J.; Lindstädt, B.; Ahrens, W.; Beyan, O.; Buchner, B.; Darms, J.; Depping, R.; Dierkes, J.; Neuhausen, H.; Müller, W.; et al. NFDI4Health—Nationale Forschungsdateninfrastruktur für personenbezogene Gesundheitsdaten. Bausteine Forsch. 2021, 2, 72–85. [Google Scholar] [CrossRef]
- (PDF) HL7 FHIR: An Agile and RESTful Approach to Healthcare Information Exchange. Available online: https://ieeexplore.ieee.org/document/6627810 (accessed on 29 December 2021).
- Hume, S.; Aerts, J.; Sarnikar, S.; Huser, V. Current applications and future directions for the CDISC Operational Data Model standard: A methodological review. J. Biomed. Inform. 2016, 60, 352–362. [Google Scholar] [CrossRef]
- Hussain, S.M.; Kanakam, P. SPARQL for Semantic Information Retrieval from RDF Knowledge Base. Int. J. Eng. Trends Technol. 2016, 41, 351–354. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Rashid, S.M.; McCusker, J.P.; Pinheiro, P.; Bax, M.P.; Santos, H.; Stingone, J.A.; Das, A.K.; McGuinness, D.L. The Semantic Data Dictionary - An Approach for Describing and Annotating Data. Data Intell. 2020, 2, 443–486. [Google Scholar] [CrossRef] [PubMed]
- Tchechmedjiev, A.; Abdaoui, A.; Emonet, V.; Zevio, S.; Jonquet, C. SIFR annotator: Ontology-based semantic annotation of French biomedical text and clinical notes. BMC Bioinform. 2018, 19, 405. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Galeota, E.; Pelizzola, M. Ontology-based annotations and semantic relations in large-scale (epi)genomics data. Brief Bioinform. 2017, 18, 403–412. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pathak, J.; Wang, J.; Kashyap, S.; Basford, M.; Li, R.; Masys, D.R.; Chute, C.G. Mapping clinical phenotype data elements to standardized metadata repositories and controlled terminologies: The eMERGE Network experience. J. Am. Med. Inf. Assoc. 2011, 18, 376–386. [Google Scholar] [CrossRef] [Green Version]
- Maguire, E.; González-Beltrán, A.; Whetzel, P.L.; Sansone, S.A.; Rocca-Serra, P. OntoMaton: A Bioportal powered ontology widget for Google Spreadsheets. Bioinformatics 2013, 29, 525–527. [Google Scholar] [CrossRef]
- Wiktorin, T. Semantische Annotation im Gesundheitswesen—Prototypische Entwicklung und Evaluation eines Kollaborativen Werkzeugs zur Semantischen Annotation Medizinischer Daten. Master’s Thesis, Hochschule Bonn-Rhein-Sieg, University of Applied Sciences, University Hospital Bonn (UKB), Bonn, Germany, 2021. [Google Scholar]
- DataPLANT. Swate. 2020-04-29T12:57:50Z. 2021. Available online: https://github.com/nfdi4plants/Swate (accessed on 22 October 2021).
- Sharma, D.K.; Solbrig, H.R.; Prud’hommeaux, E.; Lee, K.; Pathak, J.; Jiang, G. D2Refine: A Platform for Clinical Research Study Data Element Harmonization and Standardization. AMIA Summits Transl. Sci. Proc. 2017, 2017, 259–267. [Google Scholar] [PubMed]
- Quiñones, M.; Liou, D.T.; Shyu, C.; Kim, W.; Vujkovic-Cvijin, I.; Belkaid, Y.; Hurt, D.E. METAGENOTE: A simplified web platform for metadata annotation of genomic samples and streamlined submission to NCBI’s sequence read archive. BMC Bioinform. 2020, 21, 378. [Google Scholar] [CrossRef]
- Kim, H.H.; Park, Y.R.; Lee, K.H.; Song, Y.S.; Kim, J.H. Clinical MetaData ontology: A simple classification scheme for data elements of clinical data based on semantics. BMC Med. Inform. Decis. Mak. 2019, 19, 166. [Google Scholar] [CrossRef]
- Ganzinger, M.; Knaup, P. Semantic prerequisites for data sharing in a biomedical research network. Stud. Health Technol. Inf. 2013, 192, 938. [Google Scholar]
- Noy, N.; Shah, N.; Dai, B.; Dorf, M.; Griffith, N.; Jonquet, C.; Montegut, M.; Rubin, D.; Youn, C.; Musen, M. BioPortal: A Web Repository for Biomedical Ontologies and Data Resources Semantic Web Conference (ISWC2008). 2008. Available online: http://ceur-ws.org/Vol-401/iswc2008pd_submission_25.pdf (accessed on 7 September 2021).
- Côté, R.G.; Jones, P.; Apweiler, R.; Hermjakob, H. The Ontology Lookup Service, a lightweight cross-platform tool for controlled vocabulary queries. BMC Bioinform. 2006, 7, 97. [Google Scholar] [CrossRef] [Green Version]
- Shah, N.H.; Bhatia, N.; Jonquet, C.; Rubin, D.; Chiang, A.P.; Musen, M.A. Comparison of concept recognizers for building the Open Biomedical Annotator. BMC Bioinform. 2009, 10 (Suppl. 9), S14. [Google Scholar] [CrossRef] [Green Version]
- Hanisch, D.; Fundel-Clemens, K.; Mevissen, H.T.; Zimmer, R.; Fluck, J. ProMiner: Rule-based Protein and Gene Entity Recognition. BMC Bioinform. 2005, 6 (Suppl. 1), S14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dugas, M.; Meidt, A.; Neuhaus, P.; Storck, M.; Varghese, J. ODMedit: Uniform semantic annotation for data integration in medicine based on a public metadata repository. BMC Med. Res. Methodol. 2016, 16, 65. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hegselmann, S.; Storck, M.; Geßner, S.; Neuhaus, P.; Varghese, J.; Dugas, M. A Web Service to Suggest Semantic Codes Based on the MDM-Portal. Stud. Health Technol. Inf. 2018, 253, 35–39. [Google Scholar]
- Microsoft. Microsoft Excel Spreadsheet Software | Microsoft 365. Available online: https://www.microsoft.com/en-us/microsoft-365/excel (accessed on 29 December 2021).
- Wolstencroft, K.; Owen, S.; Horridge, M.; Krebs, O.; Mueller, W.; Snoep, J.L.; du Preez, F.; Goble, C. RightField: Embedding ontology annotation in spreadsheets. Bioinformatics 2011, 27, 2021–2022. [Google Scholar] [CrossRef] [PubMed]
- Vandenbussche, P.Y.; Atemezing, G.; Poveda-Villalón, M.; Vatant, B. Linked Open Vocabularies (LOV): A gateway to reusable semantic vocabularies on the Web. Semant. Web. 2017, 8, 437–452. [Google Scholar] [CrossRef] [Green Version]
- Google. Google Sheets: Free Online Spreadsheet Editor. Available online: https://www.google.com/sheets/about/ (accessed on 29 December 2021).
- Musen, M.A.; Bean, C.A.; Cheung, K.H.; Dumontier, M.; Durante, K.A.; Gevaert, O.; Gonzalez-Beltran, A.; Khatri, P.; Kleinstein, S.H.; O’Connor, M.J.; et al. The center for expanded data annotation and retrieval. J. Am. Med. Inf. Assoc. 2015, 22, 1148–1152. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gonçalves, R.; O’Connor, M.; Martínez-Romero, M.; Egyedi, A.L.; Willrett, D.; Graybeal, J.; Musen, M. The CEDAR Workbench: An Ontology-Assisted Environment for Authoring Metadata that Describe Scientific Experiments. In International Semantic Web Conference; Springer: Cham, Switzerland, 2017; Volume 10588, pp. 103–110. [Google Scholar] [CrossRef]
- Bernasconi, A.; Canakoglu, A.; Colombo, A.; Ceri, S. Ontology-Driven Metadata Enrichment for Genomic Datasets; SWAT4LS. 2018. Available online: https://re.public.polimi.it/retrieve/handle/11311/1076522/341973/SWAT4HCLS2018_camera-ready.pdf (accessed on 29 December 2021).
- Ceri, S. Data-Driven Genomic Computing: Making Sense of Signals from the Genome; DAMDID/RCDL: 2017. Available online: http://ceur-ws.org/Vol-2022/paper01.pdf (accessed on 29 December 2021).
- Shankar, R.; Martínez-Romero, M.; O’Connor, M.; Graybeal, J.; Khatri, P.; Musen, M. SAP—A CEDAR-Based Pipeline for Semantic Annotation of Biomedical Metadata. 2016. Available online: https://figshare.com/articles/poster/SAP_a_CEDAR-based_pipeline_for_semantic_annotation_of_biomedical_metadata/4244465 (accessed on 29 December 2021). [CrossRef]
- OpenRefine. 2021-12-14T12:57:50Z. Available online: https://openrefine.org/index.html (accessed on 29 December 2021).
- Mailman, M.D.; Feolo, M.; Jin, Y.; Kimura, M.; Tryka, K.; Bagoutdinov, R.; Hao, L.; Kiang, A.; Paschall, J.; Phan, L.; et al. The NCBI dbGaP database of genotypes and phenotypes. Nat. Genet. 2007, 39, 1181–1186. [Google Scholar] [CrossRef] [Green Version]
- Kirby, J.C.; Speltz, P.; Rasmussen, L.V.; Basford, M.; Gottesman, O.; Peissig, P.L.; Pacheco, J.A.; Tromp, G.; Pathak, J.; Carrell, D.S.; et al. PheKB: A catalog and workflow for creating electronic phenotype algorithms for transportability. J. Am. Med. Inf. Assoc. 2016, 23, 1046–1052. [Google Scholar] [CrossRef]
- TCGA Data Dictionary. 2021-12-14T12:57:50Z. Available online: https://www.cancer.gov/about-nci/organization/ccg/research/structural-genomics/tcga (accessed on 29 December 2021).
- U.S. National Institutes of Health and NIH. FormBuilder. 2020-04-29T12:57:50Z. Available online: https://formbuilder.nci.nih.gov/FormBuilder/formSearchAction.do (accessed on 29 December 2021).
- U.S. Department of Health and Human Services | National Institutes of Health | National Cancer Institute | USA.gov. LexEVS-EVS-LexEVS-NCI Wiki. Available online: https://wiki.nci.nih.gov/display/lexevs/lexevs (accessed on 29 December 2021).
- Needleman, S.B.; Wunsch, C.D. A general method applicable to the search for similarities in the amino acid sequence of two proteins. J. Mol. Biol. 1970, 48, 443–453. [Google Scholar] [CrossRef]
- Christen, V.; Groß, A.; Rahm, E. A Reuse-Based Annotation Approach for Medical Documents; Springer International Publishing: Cham, Switzerland, 2016; pp. 135–150. Available online: https://www.springerprofessional.de/en/a-reuse-based-annotation-approach-for-medical-documents/10816504 (accessed on 29 December 2021). [CrossRef]
- Jonquet, C.; Toulet, A.; Arnaud, E.; Aubin, S.; Dzalé Yeumo, E.; Emonet, V.; Graybeal, J.; Laporte, M.A.; Musen, M.A.; Pesce, V.; et al. AgroPortal: A vocabulary and ontology repository for agronomy. Comput. Electron. Agric. 2018, 144, 126–143. [Google Scholar] [CrossRef]
- SNOMED International. Snap2SNOMED. Available online: https://snap2snomed.app/ (accessed on 29 December 2021).
- European Food Safety Authority. Food Classification Standardization—The FoodEx2 System | EFSA. Available online: https://www.efsa.europa.eu/en/data/data-standardisation (accessed on 29 December 2021).
- SNOMED International. SNOMED. Available online: https://www.snomed.org/ (accessed on 29 December 2021).
- Hussain, I.; Park, S.J. Big-ECG: Cardiographic Predictive Cyber-Physical System for Stroke Management. IEEE Access 2021, 9, 123146–123164. [Google Scholar] [CrossRef]
- Hussain, I.; Park, S.J. HealthSOS: Real-Time Health Monitoring System for Stroke Prognostics. IEEE Access 2020, 8, 213574–213586. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| No. | Requirement | Description | Prioritization |
|---|---|---|---|
| 1 | Open accessible and/or Open Code | The software is available under an open-source license or the service is free to use | MUST |
| 2 | Support of common data formats | The software supports common and domain specific import and export data formats | MUST |
| 3 | FAIR Terminologies | Integrated terminologies comply with the FAIR principles | MUST |
| 4 | Terminology Search | The software provides a possibility to search for concepts/classes within integrated terminologies/ontologies | MUST |
| 5 | Annotation Suggestion | The software provides suggestions for semantic concept annotations for each data element (semi-autonomous process) | SHOULD |
| 6 | Interface to external terminology/ontology services | The software offers the possibility to connect to an external terminology/ontology/SPARQL service | SHOULD |
| 7 | Extension of Terminologies/Ontologies | The software allows one to extend the default set of integrated terminologies/ontologies | MAY |
| Service | Requirement 1: Open Accessible/Open Code | Requirement 2: Common Standard Formats, Import/Export | Requirement 3: FAIR Terminologies | Requirement 4: Terminology Search | Requirement 5: Annotation Suggestion | Requirement 6: Interface for Terminology Service Integration | Requirement 7: Terminology Upload |
|---|---|---|---|---|---|---|---|
| ODMedit [32] | Yes */No | ODM/ODM | MDM repository (consists of UMLS codes) | Yes (MDM repository) | Yes | No indication | No indication |
| Rightfield [35] | Yes/Yes | MS Excel/MS Excel, CSV, RDF | NCBO BioPortal, Local Files | Yes | No | No indication | Yes, import of local files |
| OntoMaton [21] | Yes/Yes | MS Excel, OpenDocument, PDF, HTML, CSV, TSV | NCBO Bioportal, Linked Open Vocabularies, EBI Ontology Lookup Service | Yes | No | No indication | No indication |
| eleMAP [20] | No/No indication | Unknown/MS Excel, XML | caDSR, NCI-T, SNOMED CT | Yes | Yes | No indication | No indication |
| CEDAR Workbench [38] | Yes */Yes | XML/JSON, JSON-LD, RDF | NCBO BioPortal | Yes | Yes | No indication | No |
| Prototype Wiktorin | No **/No | No indication | SNOMED CT, LOINC, ATC | Yes | Yes | No indication | No |
| SAP [42] | No **/No | Unknown | NCBO BioPortal | Unknown | Yes | No indication | No indication |
| Metadata-Enricher [40] | No ’/Yes | Unknown | OLS | Unknown | Yes | No indication | No indication |
| Swate [23] | Yes/Yes | MS Excel/MS Excel, CSV, RDF | Chemical Entities Of Biological Interest, Environment Ontology, Gene Ontology, PSI-MOD, Proteomics Standards Initiative Mass Spectrometry vocabularies, Ontology for Biomedical Investigations, Phenotype and Trait Ontology, nfdi4pso, Plant Experimental Conditions, Plant Ontology, Relation Ontology, Plant Trait Ontology | Yes | No | No indication | No, but concepts can be added to the Swate ontology |
| D2Refine [24] | Yes /Yes | CSV, TSV, HTML, Excel, ODF, XML, RDF, ADL2.0 (OpenEHR RM or OpenCIMI RM) | Common Terminology Services 2 (CTS2) | Yes | Yes | (CTS2)-compliant terminology services | Yes, CTS2 compliant terminology |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sasse, J.; Darms, J.; Fluck, J. Semantic Metadata Annotation Services in the Biomedical Domain—A Literature Review. Appl. Sci. 2022, 12, 796. https://doi.org/10.3390/app12020796
Sasse J, Darms J, Fluck J. Semantic Metadata Annotation Services in the Biomedical Domain—A Literature Review. Applied Sciences. 2022; 12(2):796. https://doi.org/10.3390/app12020796
Chicago/Turabian StyleSasse, Julia, Johannes Darms, and Juliane Fluck. 2022. "Semantic Metadata Annotation Services in the Biomedical Domain—A Literature Review" Applied Sciences 12, no. 2: 796. https://doi.org/10.3390/app12020796
APA StyleSasse, J., Darms, J., & Fluck, J. (2022). Semantic Metadata Annotation Services in the Biomedical Domain—A Literature Review. Applied Sciences, 12(2), 796. https://doi.org/10.3390/app12020796