
Multi-UAV Conflict Resolution with Graph Convolutional Reinforcement Learning



Abstract
1. Introduction
- RQ1 Can multi-UAV conflicts be solved by modeling conflict resolution as a MARL problem?
- RQ2 Do the agents learn any strategies in the conflict resolution process?
2. Related Work
3. Theoretical Background
3.1. Reinforcement Learning
- S is the state space,
- A is the action space,
- is the transition function which is a set of conditional probabilities between states,
- is the reward function
3.2. Multiagent Reinforcement Learning
3.3. Graph Convolutional Reinforcement Learning
4. Experimental Setup
4.1. Compound Conflicts
4.2. Traffic as a Graph
4.3. Training Environment
4.3.1. State Space
4.3.2. Action Space
4.3.3. Reward Function
4.4. Simulation Environment
4.5. Data Generation
| Algorithm 1 Data Generation Algorithm |
|
5. Simulation Results
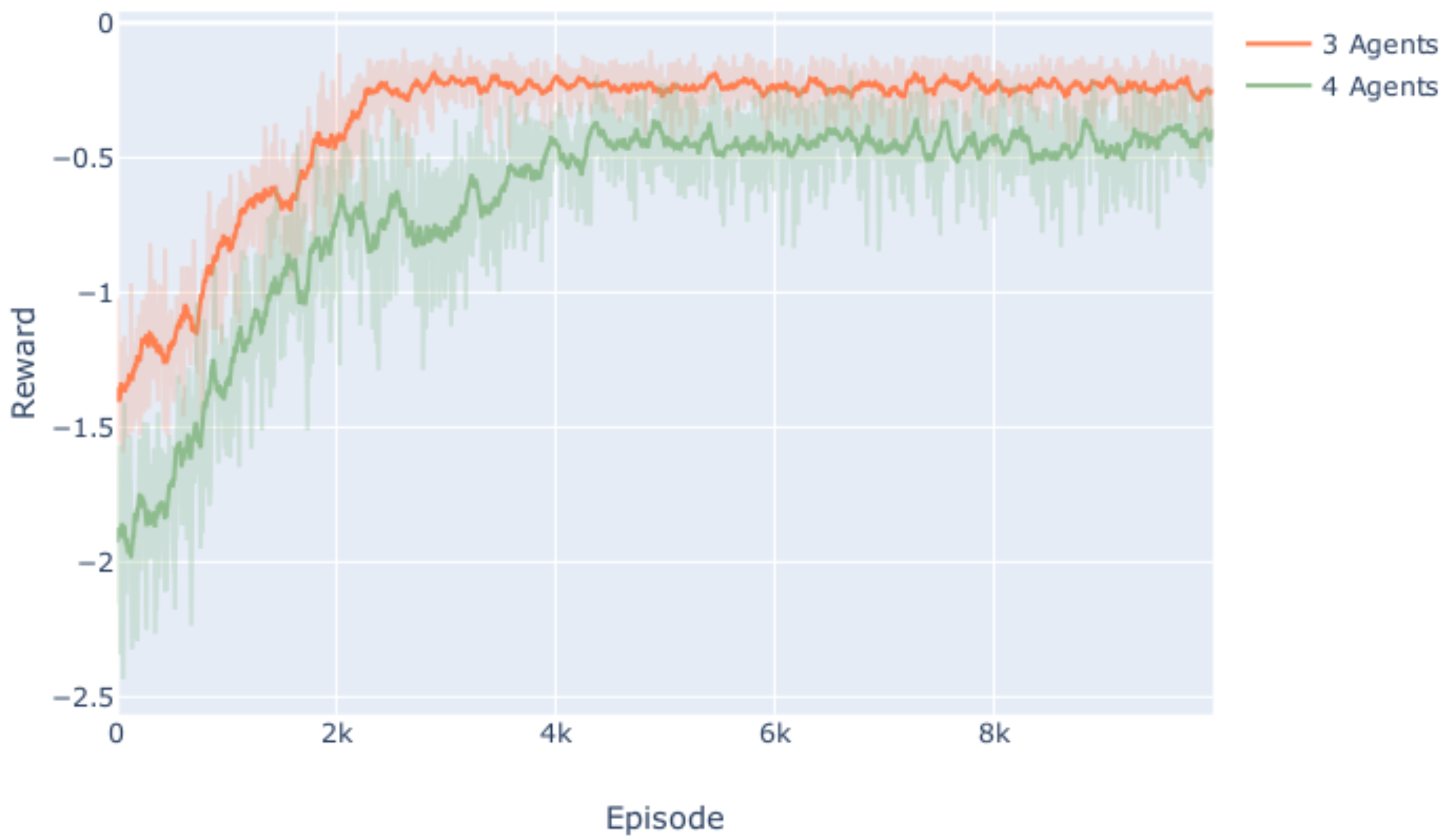
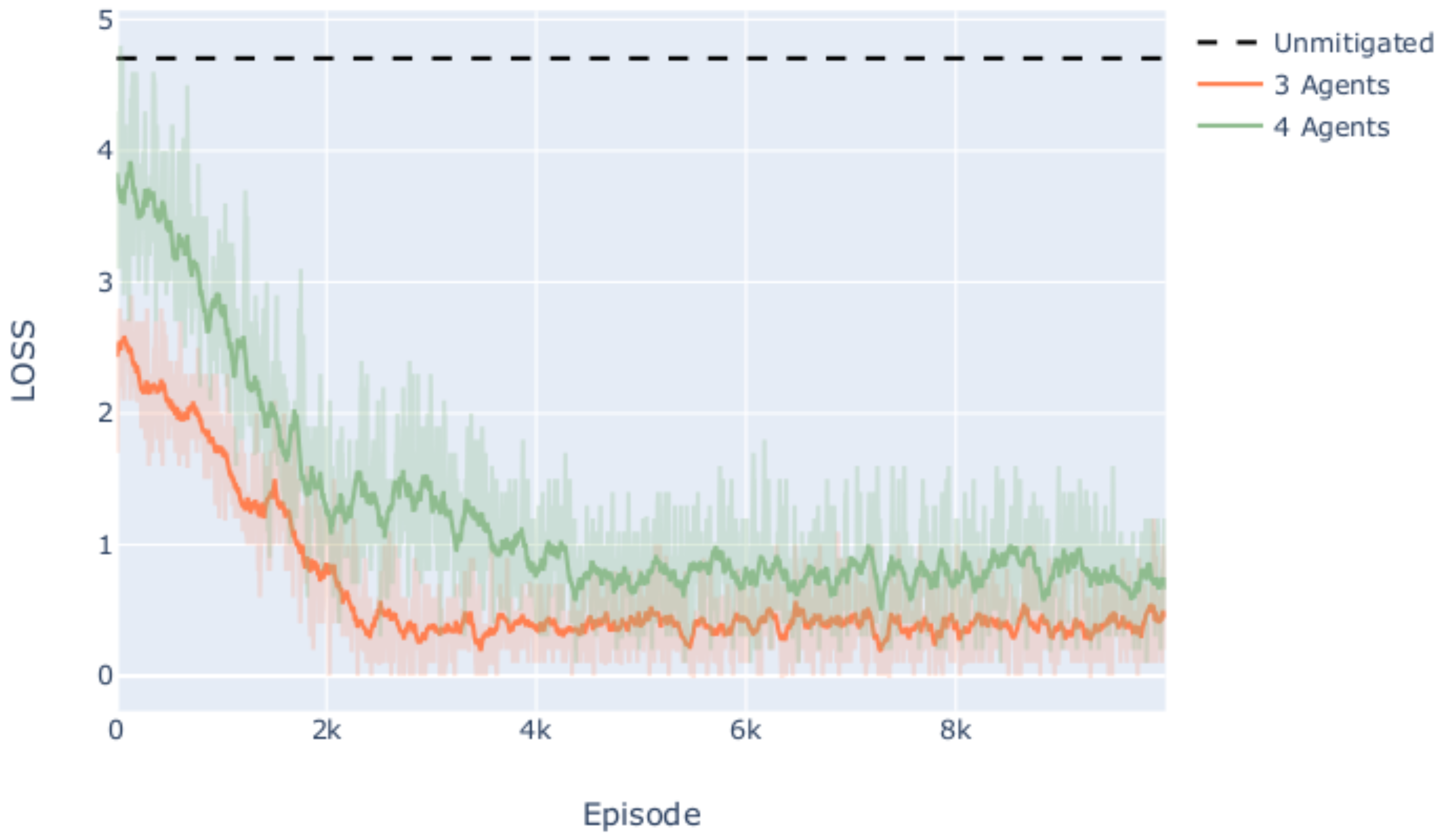
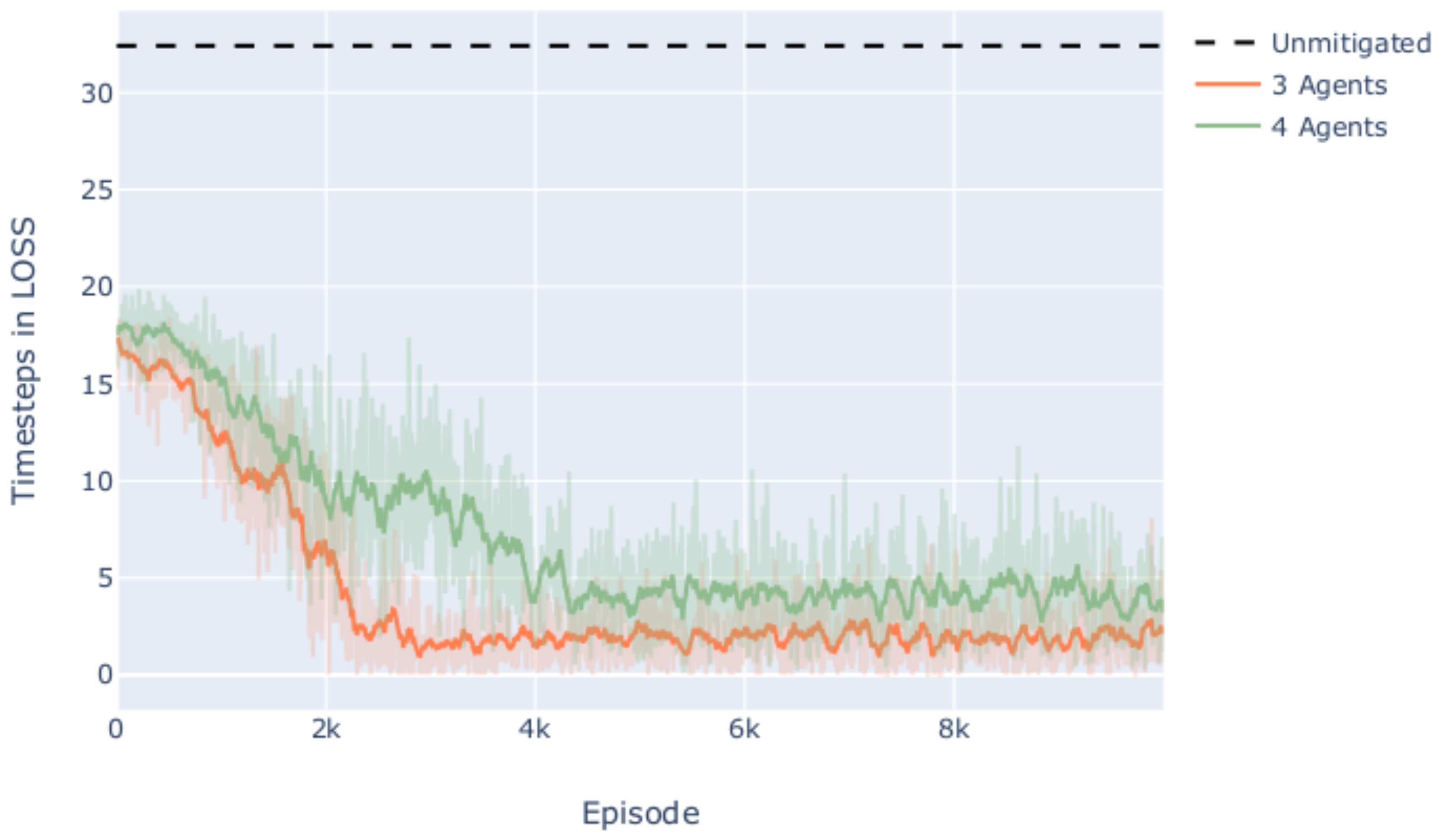
5.1. Conflict Resolution Performance
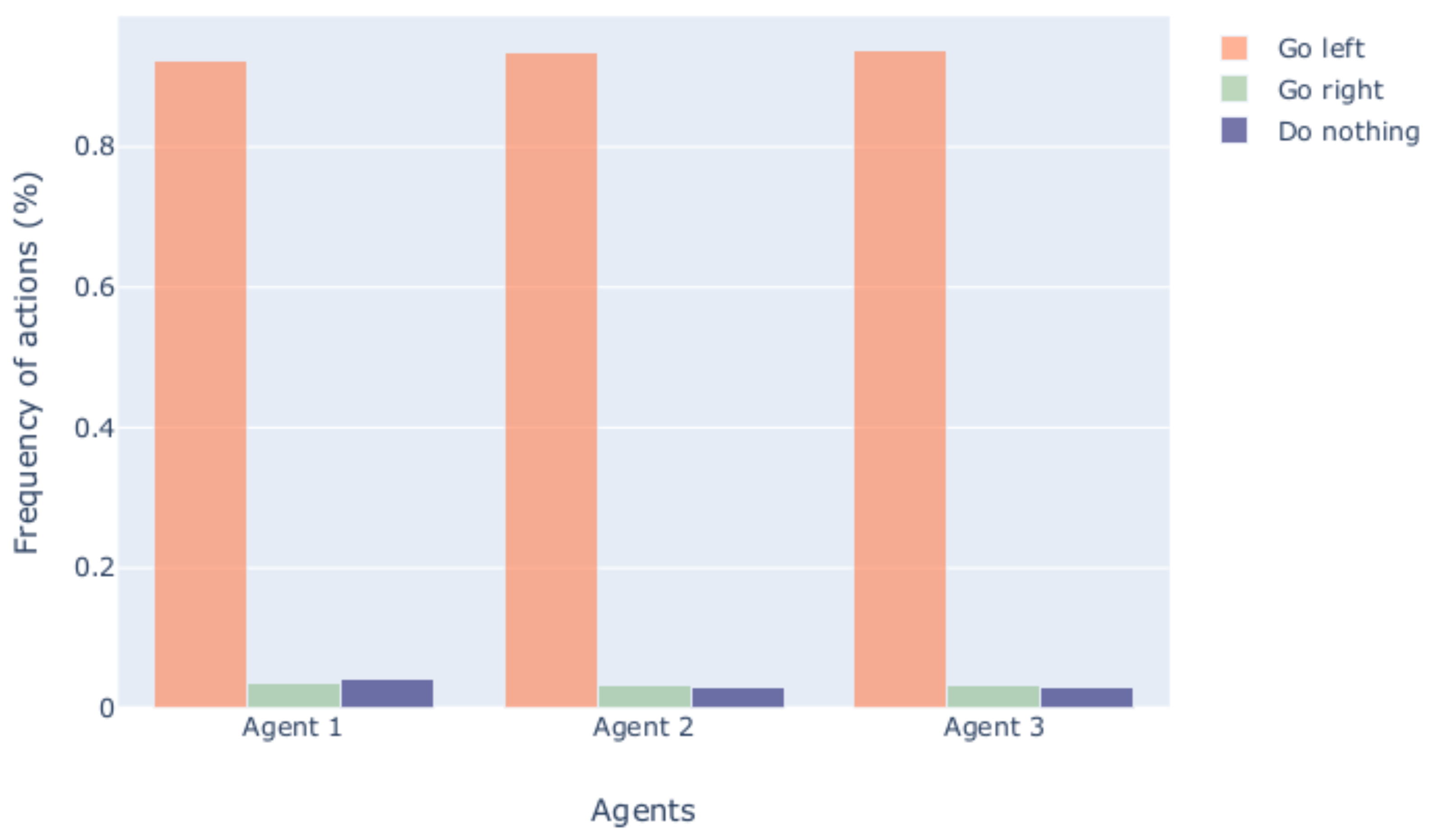
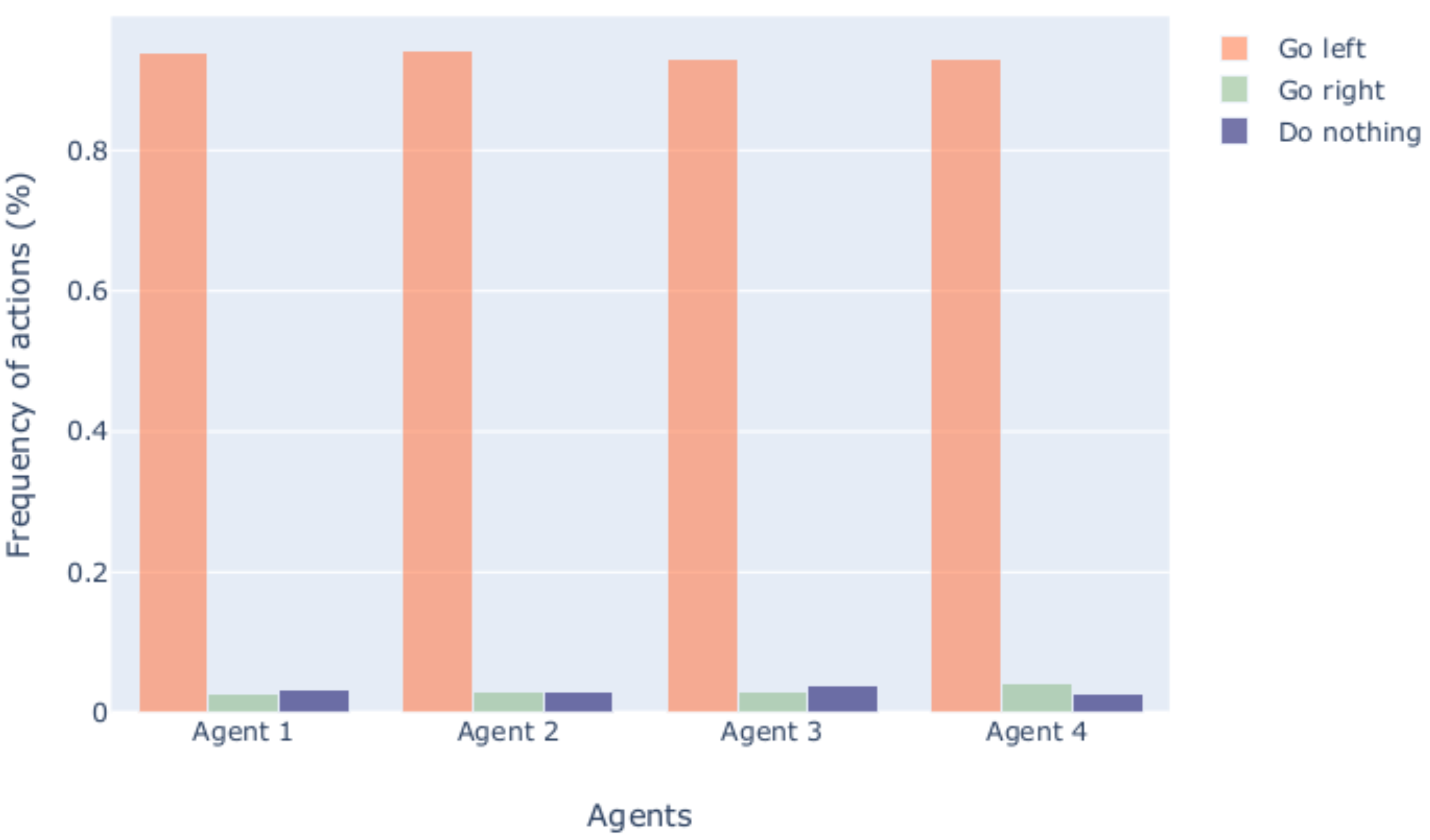
5.2. Agent Behavior
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- SESAR JU. European Drones Outlook Study; Single European Sky ATM Research; SESAR JU: Brussels, Belgium, 2016; p. 93. [Google Scholar]
- Barrado, C.; Boyero, M.; Brucculeri, L.; Ferrara, G.; Hately, A.; Hullah, P.; Martin-Marrero, D.; Pastor, E.; Rushton, A.P.; Volkert, A. U-space concept of operations: A key enabler for opening airspace to emerging low-altitude operations. Aerospace 2020, 7, 24. [Google Scholar] [CrossRef]
- Prevot, T.; Rios, J.; Kopardekar, P.; Robinson, J.E., III; Johnson, M.; Jung, J. UAS Traffic Management (UTM) Concept of Operations to Safely Enable Low Altitude Flight Operations. In Proceedings of the 16th AIAA Aviation Technology, Integration, and Operations Conference, Washington, DC, USA, 13–17 June 2016; pp. 1–16. [Google Scholar] [CrossRef]
- Zhang, J. UOMS in China. In Proceedings of the EU-China APP Drone Workshop, Shenzhen, China, 6–8 June 2018; pp. 6–8. [Google Scholar]
- UTM—A Common Framework with Core Principles for Global Harmonization. Available online: https://www.icao.int/safety/UA/Documents/UTM%20Framework%20Edition%203.pdf (accessed on 11 October 2021).
- NASA Conflict Management Model. Available online: https://www.nasa.gov/sites/default/files/atoms/files/2020-johnson-nasa-faa.pdf (accessed on 11 October 2021).
- Radanovic, M.; Omeri, M.; Piera, M.A. Test analysis of a scalable UAV conflict management framework. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2019, 233, 6076–6088. [Google Scholar] [CrossRef]
- Consiglio, M.; Muñoz, C.; Hagen, G.; Narkawicz, A.; Balachandran, S. ICAROUS: Integrated configurable algorithms for reliable operations of unmanned systems. In Proceedings of the 2016 IEEE/AIAA 35th Digital Avionics Systems Conference (DASC), Sacramento, CA, USA, 25–29 September 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Johnson, S.C.; Petzen, A.N.; Tokotch, D.S. Johnson_DetectAndAvoid Aviation 2017 Handout. 2017. Available online: https://nari.arc.nasa.gov/sites/default/files/Johnson_DetectAndAvoid%20Aviation%202017%20Handout.pdf (accessed on 11 October 2021).
- Manfredi, G.; Jestin, Y. Are You Clear About ” Well Clear ”? In Proceedings of the 2018 International Conference on Unmanned Aircraft Systems (ICUAS), Dallas, TX, USA, 12–15 June 2018; pp. 599–605. [Google Scholar]
- Cook, B.; Arnett, T.; Cohen, K. A Fuzzy Logic Approach for Separation Assurance and Collision Avoidance for Unmanned Aerial Systems. In Modern Fuzzy Control Systems and Its Applications; InTech: Rijeka, Croatia, 2017; pp. 1–32. [Google Scholar] [CrossRef]
- Consiglio, M.; Duffy, B.; Balachandran, S.; Glaab, L.; Muñoz, C. Sense and avoid characterization of the independent configurable architecture for reliable operations of unmanned systems. In Proceedings of the 13th USA/Europe Air Traffic Management Research and Development Seminar 2019, Vienna, Austria, 17–21 June 2019. [Google Scholar]
- Muñoz, C.A.; Dutle, A.; Narkawicz, A.; Upchurch, J. Unmanned aircraft systems in the national airspace system: A formal methods perspective. ACM SIGLOG News 2016, 3, 67–76. [Google Scholar] [CrossRef]
- Weinert, A.; Campbell, S.; Vela, A.; Schuldt, D.; Kurucar, J. Well-clear recommendation for small unmanned aircraft systems based on unmitigated collision risk. J. Air Transp. 2018, 26, 113–122. [Google Scholar] [CrossRef]
- McLain, T.W.; Duffield, M.O. A Well Clear Recommendation for Small UAS in High-Density, ADS-B-Enabled Airspace. In Proceedings of the AIAA Information Systems-AIAA Infotech @ Aerospace, Grapevine, TX, USA, 9–13 January 2017. [Google Scholar]
- Modi, H.C.; Ishihara, A.K.; Jung, J.; Nikaido, B.E.; D’souza, S.N.; Hasseeb, H.; Johnson, M. Applying Required Navigation Performance Concept for Traffic Management of Small Unmanned Aircraft Systems. In Proceedings of the 30th Congress of the International Council of the Aeronautical Sciences, Daejeon, Korea, 25–30 September 2016. [Google Scholar]
- Jiang, J.; Dun, C.; Huang, T.; Lu, Z. Graph convolutional reinforcement learning. arXiv 2018, arXiv:1810.09202. [Google Scholar]
- Skowron, M.; Chmielowiec, W.; Glowacka, K.; Krupa, M.; Srebro, A. Sense and avoid for small unmanned aircraft systems: Research on methods and best practices. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2019, 233, 6044–6062. [Google Scholar] [CrossRef]
- Kuchar, J.K.; Yang, L.C. A review of conflict detection and resolution modeling methods. IEEE Trans. Intell. Transp. Syst. 2000, 1, 179–189. [Google Scholar] [CrossRef]
- Ribeiro, M.; Ellerbroek, J.; Hoekstra, J. Review of conflict resolution methods for manned and unmanned aviation. Aerospace 2020, 7, 79. [Google Scholar] [CrossRef]
- Bertram, J.; Wei, P. Distributed computational guidance for high-density urban air mobility with cooperative and non-cooperative collision avoidance. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; p. 1371. [Google Scholar]
- Yang, X.; Wei, P. Scalable multiagent computational guidance with separation assurance for autonomous urban air mobility. J. Guid. Control Dyn. 2020, 43, 1473–1486. [Google Scholar] [CrossRef]
- Hu, J.; Yang, X.; Wang, W.; Wei, P.; Ying, L.; Liu, Y. UAS Conflict Resolution in Continuous Action Space Using Deep Reinforcement Learning. In Proceedings of the AIAA Aviation 2020 Forum, Virtual Event, 15–19 June 2020; p. 2909. [Google Scholar]
- Ribeiro, M.; Ellerbroek, J.; Hoekstra, J. Determining Optimal Conflict Avoidance Manoeuvres At High Densities With Reinforcement Learning. In Proceedings of the 10th SESAR Innovation Days, Virtual Event, 7–10 December 2020. [Google Scholar]
- Isufaj, R.; Aranega Sebastia, D.; Piera, M.A. Towards Conflict Resolution with Deep Multi-Agent Reinforcement Learning. In Proceedings of the 14th USA/Europe Air Traffic Management Research and Development Seminar (ATM2021), New Orleans, LA, USA, 20–24 September 2021. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. arXiv 2017, arXiv:1706.02275. [Google Scholar]
- Pham, D.T.; Tran, N.P.; Alam, S.; Duong, V.; Delahaye, D. A machine learning approach for conflict resolution in dense traffic scenarios with uncertainties. In Proceedings of the ATM Seminar 2019, 13th USA/Europe ATM R&D Seminar, Vienna, Austria, 7–21 June 2019. [Google Scholar]
- Brittain, M.; Yang, X.; Wei, P. A deep multiagent reinforcement learning approach to autonomous separation assurance. arXiv 2020, arXiv:2003.08353. [Google Scholar]
- Dalmau, R.; Allard, E. Air Traffic Control Using Message Passing Neural Networks and Multi-Agent Reinforcement Learning. In Proceedings of the 10th SESAR Innovation Days, Virtual Event, 7–10 December 2020. [Google Scholar]
- Manfredi, G.; Jestin, Y. An introduction to ACAS Xu and the challenges ahead. In Proceedings of the 2016 IEEE/AIAA 35th Digital Avionics Systems Conference (DASC), Sacramento, CA, USA, 25–29 September 2016; pp. 1–9. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, MA, USA, 1998; Volume 135. [Google Scholar]
- Lee, J.B.; Rossi, R.A.; Kim, S.; Ahmed, N.K.; Koh, E. Attention models in graphs: A survey. ACM Trans. Knowl. Discov. Data (TKDD) 2019, 13, 1–25. [Google Scholar] [CrossRef]
- Hernandez-Leal, P.; Kartal, B.; Taylor, M.E. A survey and critique of multiagent deep reinforcement learning. Auton. Agents Multi-Agent Syst. 2019, 33, 750–797. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic programming and stochastic control processes. Inf. Control 1958, 1, 228–239. [Google Scholar] [CrossRef]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An introduction to deep reinforcement learning. arXiv 2018, arXiv:1811.12560. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Littman, M.L. Markov games as a framework for multiagent reinforcement learning. In Machine Learning Proceedings 1994, Proceedings of the Eleventh International Conference, Rutgers University, New Brunswick, NJ, USA, 10–13 July 1994; Elsevier: Amsterdam, The Netherlands, 1994; pp. 157–163. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1263–1272. [Google Scholar]
- Zambaldi, V.; Raposo, D.; Santoro, A.; Bapst, V.; Li, Y.; Babuschkin, I.; Tuyls, K.; Reichert, D.; Lillicrap, T.; Lockhart, E.; et al. Relational deep reinforcement learning. arXiv 2018, arXiv:1806.01830. [Google Scholar]
- Koca, T.; Isufaj, R.; Piera, M.A. Strategies to Mitigate Tight Spatial Bounds Between Conflicts in Dense Traffic Situations. In Proceedings of the 9th SESAR Innovation Days, Athens, Greece, 2–5 December 2019. [Google Scholar]
- Hoekstra, J.M.; Ellerbroek, J. Bluesky ATC simulator project: An open data and open source approach. In Proceedings of the 7th International Conference on Research in Air Transportation, FAA/Eurocontrol USA/Europe, Philadelphia, PA, USA, 20–24 June 2016; Volume 131, p. 132. [Google Scholar]
- Shi, K.; Cai, K.; Liu, Z.; Yu, L. A Distributed Conflict Detection and Resolution Method for Unmanned Aircraft Systems Operation in Integrated Airspace. In Proceedings of the 2020 AIAA/IEEE 39th Digital Avionics Systems Conference (DASC), San Antonio, TX, USA, 11–15 October 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Mullins, M.; Holman, M.W.; Foerster, K.; Kaabouch, N.; Semke, W. Dynamic Separation Thresholds for a Small Airborne Sense and Avoid System. In Proceedings of the AIAA Infotech@Aerospace (I@A) Conference, Boston, MA, USA, 19–22 August 2013. [Google Scholar]
- Ho, F.; Geraldes, R.; Alves Gonçalves, A.; Cavazza, M.; Prendinger, H. Improved Conflict Detection and Resolution for Service UAVs in Shared Airspace. IEEE Trans. Veh. Technol. 2018, 68, 1231–1242. [Google Scholar] [CrossRef]
- Johnson, S.C.; Petzen, A.N.; Tokotch, D.S. Exploration of Detect-and-Avoid and Well-Clear Requirements for Small UAS Maneuvering in an Urban Environment. In Proceedings of the 17th AIAA Aviation Technology, Integration, and Operations Conference, Denver, CO, USA, 5–9 June 2017. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 3 Agents | 4 Agents |
|---|---|
| 5650 | 4461 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Isufaj, R.; Omeri, M.; Piera, M.A. Multi-UAV Conflict Resolution with Graph Convolutional Reinforcement Learning. Appl. Sci. 2022, 12, 610. https://doi.org/10.3390/app12020610
Isufaj R, Omeri M, Piera MA. Multi-UAV Conflict Resolution with Graph Convolutional Reinforcement Learning. Applied Sciences. 2022; 12(2):610. https://doi.org/10.3390/app12020610
Chicago/Turabian StyleIsufaj, Ralvi, Marsel Omeri, and Miquel Angel Piera. 2022. "Multi-UAV Conflict Resolution with Graph Convolutional Reinforcement Learning" Applied Sciences 12, no. 2: 610. https://doi.org/10.3390/app12020610
APA StyleIsufaj, R., Omeri, M., & Piera, M. A. (2022). Multi-UAV Conflict Resolution with Graph Convolutional Reinforcement Learning. Applied Sciences, 12(2), 610. https://doi.org/10.3390/app12020610