
Comparisons Where It Matters: Using Layer-Wise Regularization to Improve Federated Learning on Heterogeneous Data


Abstract
1. Introduction
- We improve performances in heterogeneous settings. By building on the most up-to-date understanding of neural networks, we apply layer-wise regularization to only important layers.
- We improve the efficiency and scalability of regularization. By regularizing only important layers, we exclusively show training times that are comparable to FedAvg.
2. Related Works
Layers in Neural Networks
3. FedCKA
3.1. Regularizing Naturally Similar Layers
3.2. Federated Learning with Non-IID Data
3.3. Measuring Layer-Wise Similarity
3.4. Modifications to FedAvg
| Algorithm 1: FedCKA |
Input: number of communication rounds R, number of clients C, number of local epochs E, loss weighting variable , learning rate Output: The trained model w
|
4. Experimental Results and Discussion
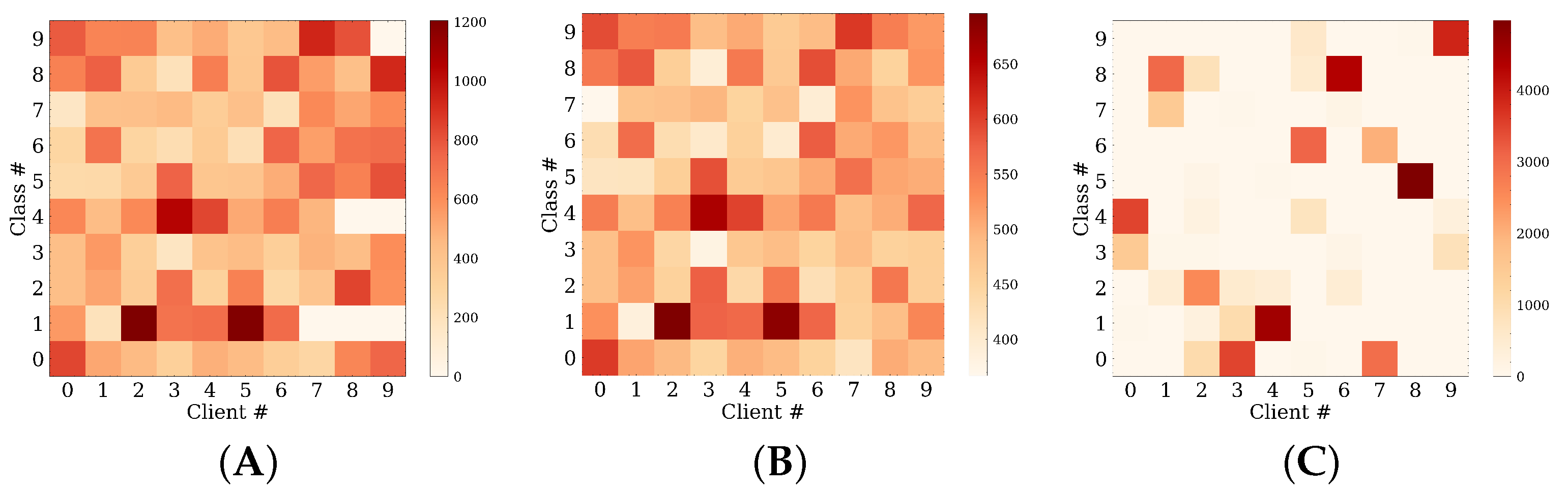
4.1. Experiment Setup
4.2. Accuracy
4.3. Communication Rounds and Local Epochs
4.4. Regularizing Only Important Layers
4.5. Using the Best Similarity Metric
4.6. Efficiency and Scalability
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FL | Federated Learning |
| IID | Independent and Identically Distributed |
| CKA | Centered Kernel Alignment |
References
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Sejnowski, T.J. (Ed.) The Deep Learning Revolution; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Verbraeken, J.; Wolting, M.; Katzy, J.; Kloppenburg, J.; Verbelen, T.; Rellermeyer, J.S. A Survey on Distributed Machine Learning. arXiv 2019, arXiv:1912.09789. [Google Scholar] [CrossRef]
- Samarakoon, S.; Bennis, M.; Saad, W.; Debbah, M. Distributed Federated Learning for Ultra-Reliable Low-Latency Vehicular Communications. IEEE Trans. Commun. 2020, 68, 1146–1159. [Google Scholar] [CrossRef]
- Yang, K.; Jiang, T.; Shi, Y.; Ding, Z. Federated Learning via Over-the-Air Computation. IEEE Trans. Wirel. Commun. 2020, 19, 2022–2035. [Google Scholar] [CrossRef]
- Brisimi, T.S.; Chen, R.; Mela, T.; Olshevsky, A.; Paschalidis, I.C.; Shi, W. Federated learning of predictive models from federated Electronic Health Records. Int. J. Med. Inform. 2018, 112, 59–67. [Google Scholar] [CrossRef] [PubMed]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. arXiv 2021, arXiv:1912.04977. [Google Scholar]
- Hsu, T.M.H.; Qi, H.; Brown, M. Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification. arXiv 2019, arXiv:1909.06335. [Google Scholar]
- Kornblith, S.; Norouzi, M.; Lee, H.; Hinton, G. Similarity of Neural Network Representations Revisited. In Proceedings of the 36th International Conference on Machine Learning, Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 3519–3529. [Google Scholar]
- Zhang, C.; Bengio, S.; Singer, Y. Are All Layers Created Equal? In Proceedings of the ICML 2019 Workshop on Identifying and Understanding Deep Learning Phenomena, Long Beach, CA, USA, 15 June 2019. [Google Scholar]
- Zhang, L.; Shen, L.; Ding, L.; Tao, D.; Duan, L.Y. Fine-tuning global model via data-free knowledge distillation for non-iid federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 10174–10183. [Google Scholar]
- Shen, Y.; Zhou, Y.; Yu, L. CD2-pFed: Cyclic Distillation-guided Channel Decoupling for Model Personalization in Federated Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 10041–10050. [Google Scholar]
- Yoon, T.; Shin, S.; Hwang, S.J.; Yang, E. Fedmix: Approximation of mixup under mean augmented federated learning. arXiv 2021, arXiv:2107.00233. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated Learning with Matched Averaging. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Li, X.; JIANG, M.; Zhang, X.; Kamp, M.; Dou, Q. FedBN: Federated Learning on Non-IID Features via Local Batch Normalization. In Proceedings of the International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated Optimization in Heterogeneous Networks. arXiv 2020, arXiv:1812.06127. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. SCAFFOLD: Stochastic Controlled Averaging for Federated Learning. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; Volume 119, pp. 5132–5143. [Google Scholar]
- Li, Q.; He, B.; Song, D. Model-Contrastive Federated Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), Nashville, TN, USA, 20–25 June 2021; pp. 10713–10722. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.bibsonomy.org/bibtex/cc2d42f2b7ef6a4e76e47d1a50c8cd86 (accessed on 27 September 2022).
- Li, F.F.; Karpathy, A.; Johnson, J. Tiny ImageNet. 2014. Available online: https://www.kaggle.com/c/tiny-imagenet (accessed on 27 September 2022).
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Ensemble Distillation for Robust Model Fusion in Federated Learning. arXiv 2021, arXiv:2006.07242. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR 2021), Vienna, Austria, 4 May 2021. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | CIFAR-10 | CIFAR-100 | Tiny ImageNet |
|---|---|---|---|
| FedAvg | 64.37% | 37.41% | 19.49% |
| FedProx | 64.58% | 37.81% | 20.93% |
| SCAFFOLD | 64.33% | 39.16% | 21.18% |
| MOON | 65.25% | 38.37% | 21.29% |
| FedCKA | 67.86% | 40.07% | 21.46% |
| Method | = 5.0 | = 1.0 | = 0.1 |
|---|---|---|---|
| FedAvg | 64.37% | 62.49% | 50.43% |
| FedProx | 64.58% | 62.51% | 51.07% |
| SCAFFOLD | 64.33% | 63.31% | 40.53% |
| MOON | 65.25% | 62.60% | 51.63% |
| FedCKA | 67.86% | 66.19% | 52.35% |
| Similarity Metric | Accuracy | Training Duration (s) |
|---|---|---|
| None (FedAvg) | 64.37% | 54.82 |
| Frobenius Norm | 65.54% | 64.73 |
| Vectorized Cosine | 66.67% | 65.75 |
| Kernel CKA | 67.93% | 122.41 |
| Linear CKA | 67.86% | 104.17 |
| Method | 7 Layers | Time Extended | 50 Layers | Time Extended |
|---|---|---|---|---|
| FedAvg | 54.82 | - | 638.79 | - |
| SCAFFOLD | 57.19 | 2.37 | 967.04 | 328.25 |
| FedProx | 57.20 | 2.38 | 862.12 | 223.33 |
| MOON | 97.58 | 42.76 | 1689.28 | 1050.49 |
| FedCKA | 104.17 | 49.35 | 750.97 | 112.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, H.M.; Kim, M.H.; Chung, T.-M. Comparisons Where It Matters: Using Layer-Wise Regularization to Improve Federated Learning on Heterogeneous Data. Appl. Sci. 2022, 12, 9943. https://doi.org/10.3390/app12199943
Son HM, Kim MH, Chung T-M. Comparisons Where It Matters: Using Layer-Wise Regularization to Improve Federated Learning on Heterogeneous Data. Applied Sciences. 2022; 12(19):9943. https://doi.org/10.3390/app12199943
Chicago/Turabian StyleSon, Ha Min, Moon Hyun Kim, and Tai-Myoung Chung. 2022. "Comparisons Where It Matters: Using Layer-Wise Regularization to Improve Federated Learning on Heterogeneous Data" Applied Sciences 12, no. 19: 9943. https://doi.org/10.3390/app12199943
APA StyleSon, H. M., Kim, M. H., & Chung, T.-M. (2022). Comparisons Where It Matters: Using Layer-Wise Regularization to Improve Federated Learning on Heterogeneous Data. Applied Sciences, 12(19), 9943. https://doi.org/10.3390/app12199943