1. Introduction
Smart meter data have already proved their importance for different players in the electricity sector. On the one hand, the transmission and distribution operators may have access to individual load profiles, allowing the estimation of future load demand for different areas. They provide the physical balance between supply and demand (at real time), and the opportunity to adjust the grid operation to minimize power losses, voltage drops (or other power quality events), thus increasing the grid resilience and reducing costs. For suppliers, it is also valuable to know in detail how the clients are effectively using this resource, estimating the expected accumulated electricity volume for their customer portfolio (at different hourly periods) when buying in the electricity market. Suppliers may also propose different commercial options (such as contracted power, the choice between flat/time of use/ or dynamic rates or even the counting cycles programmed in the meters) according to each consumer profile, launching fair rates, obtaining a distinct and valuable position as electricity retailers. Even end-users also take advantage of getting access to their own consumption, which should be viewed as a trigger to make demand more flexible, as this detailed information may undoubtedly increase awareness (when there are untypical consumptions, since alarmistic solutions are becoming popular). Furthermore, with the increasing and desired investment in renewable sources, traditional consumers are becoming prosumers and this phenomenon is expected to increase the interest of residential consumers (but not restricted to this sector) to rethink consumption behaviour, trying to match consumption with the available electricity from self-generation. The consequences are less dependence on electricity provided by the grid, with the inherent savings in energy bills and the reduction in greenhouse gas (GHG) emissions.
Through a comprehensive analysis of works developed in this domain, it becomes clear that several authors have made use of machine learning applications to estimate hourly electricity consumptions for the day-ahead, not only at a considerable aggregation level, but at a single household as well. Some references still use traditional statistical methods, such as Linear [
1] or Polynomial Regression, Autoregressive Integrated Moving Average—ARIMA models [
2,
3,
4] or some variants (such as incremental ARIMA or involving a prior stage of signal pre-processing) to enhance their performance. In [
5], a model based on Conditional Kernel Density Estimation is compared with machine learning models. Despite the interest associated with these simple approaches, there are some drawbacks often referred to, such as the effect of multicollinearity among the input variables being used [
6], and the models tend to become hostage and sensitive to the data quality, which is quite difficult to preserve in this kind of data series [
7].
Machine learning algorithms tend to be transversal to a major part of the analysed references. In this domain, Artificial Neural Networks (ANN) are, by far, the most used algorithms [
8]. This popular approach is a data-driven method [
9] that does not need to be explicitly programmed [
10]. ANN are often pointed out by their ability to learn and to identify hidden trends, thereby finding the intrinsic trends in time series [
11]. Their ability to generalize even in the presence of incomplete and noisy data (common in residential smart meter data) [
10] and their non-parametric distinction (they do not require prior assumptions about the data distribution) make them good approximators capable to model any continuous function at any desired accuracy. Some drawbacks associated with the use of ANNs in forecasting applications are the risk of getting underfitted (as it can get stuck on a local optimal solution) or overfitted models (if the training process is not interrupted through a proper cross-validation strategy) [
12]. Thus, the practical difficulty is to accurately find the weights associated with each connection along the training process [
11]. Another disadvantage of their use is the lack of explanatory variables, making them lose interpretability and explainability (also known as the black-box problem) [
10]. In [
9], it is mentioned that shallow ANN architectures may assume that inputs/outputs are independent of each other, even when dealing with sequential data. To overcome that fact, recent research is adopting novel methodologies based on deep learning. Recurrent Neural Networks (RNN) are one of the alternatives more adapted to time series data, using feedback connections among the nodes to remember the values from the previous time steps [
9]. Nevertheless, long sequences may cause serious problems that may be overcome by using Long Short-term memory networks (LSTM), a variant of RNN. LSTM use internal memories to store information and are faster to converge. Even with this apparent research potential, some authors [
13] have concluded that LSTM have limited improvements in accuracy when applied to residential smart meter data, are quite more complicated and more time-consuming, and are not feasible for daily use in practice. Ref. [
14] have tested Convolutional Neural Networks, LSTM and Bidirectional LSTM, being identified as challenging when tested alone, and the resulting training times are inconsistent due to various customer load profiles and different factors such as dataset sizes, number of features and prediction model parameters. Ref. [
15] also compared deep learning approaches with more usual models (Linear Regression, Random Forest (RF), K-Nearest Neighbours and Support Vector Regression (SVR)). Ref. [
16] also compared LSTM models with ANN, SVR and RF applied to a dataset involving Irish homes and businesses and assumed that error bars have less variance in MAPE metrics in more “old-fashioned” models (ANN, SVR and RF), while in LSTM approaches MAPE vary by up to 11% in the five models run. Ref. [
17] also concluded that Convolutional Neural Networks present some difficulties to predict spikes, as they exploit the temporal stationarity of load time series.
In the subset of machine learning, other popular methods have been applied in the last few years, such as Support Vector Machines, Decision Trees and Random Forests [
1,
12,
18,
19]. These approaches are also quite common to be proposed or to be used as benchmarks in comparative analysis. Support Vector Machines are based on a structural risk minimization principle, rather than an empirical risk minimization principle that characterizes ANN models [
5,
9,
11]. Their use is based on kernels, leading to the absence of local minima. They allow a considerable control of the process (acting on the tolerance margin or on the support vectors), being less dependent on the dimensionality of the feature space. The major challenge is the inherent combinatorial effort to fine tune the hyperparameters (error margin, penalty factor and kernel constant). Some authors propose metaheuristics to guide this search, while others explore simpler approaches such as a grid search technique [
5]. Decision Trees are interesting for use when time series with missing values are presented, as they can handle numerical data and categorical information [
19], which makes them very attractive models for various applications. Random Forest is an extension of Decision Trees, as it uses multiple models to improve its performance, rather than using a single tree model [
19]. Random Forest runs efficiently on large amounts of data, tends to provide high accuracy [
18] and has low sensitivity to parameter values, as it has an inherent internal cross-validation [
12]. The most interesting advantage is a suitable variable importance measure. The drawback often pointed out is the hard task to find an optimal architecture and parameter tuning [
9,
12,
18] (predefining the total number of trees, the maximum number of variables for decision splits or the minimum number of records for leaf nodes).
The use of ensemble methods is being substantially considered in the bibliography. Ref. [
20] propose the combination of ANN with RF models, ref. [
21] combines RF with Linear Regression and ref. [
18] propose a hybrid method combining Random Forest and Multilayer Perceptron. An ensemble method combining several single models including Auto-regressive, Multilayer Perceptron, Extreme Learning Machine, Radial Basis Function and Echo-State Network is proposed by [
7]. Refs. [
14,
15] combine different approaches involving deep learning. Despite the generic trend to improve forecasting accuracy, hybrid methods are considerably more time-consuming (when scalability has a key role) and lacks for interpretability and explainability.
Regarding error metrics, it is quite controversial to compare different works, as the datasets are obtained in different parts of the world (as access to smart meter data is becoming a reality in several developed countries) and the consumption patterns and volumes can be quite distinct. Ref. [
11] describes Mean Squared Errors from 0.1 to 0.13 kWh
2 for different hours being predicted and an accuracy from 52% to 70% (assuming a tolerance error within 10%). Ref. [
21] reveal a Root Mean Squared Error of about 0.704 kW when predicting active power for the day-ahead with 15 min resolution. Ref. [
14] shows Mean Absolute Percentage errors varying from 55.8% to 36.75% with the proposed hybrid model. Ref. [
7] noted a reduction from 15.7% to 13.54% in the Mean Absolute Percentage Error metric when applying their proposed ensemble method. Ref. [
22] proposes a federated learning algorithm with recurrent neural networks conducted with residential consumers, leading to a MAPE of about 17%.
Different research has been applied in this domain, highlighting the importance of finding suitable forecasting models to be applied at household consumption level. Due to the inherent randomness and noise associated with residential consumption profiles, this task is often considered more challenging than forecasting at a level with more consumption aggregation (such as that of a public substation or even a national transmission grid).
The main contributions of this study can be summarized as follows:
- -
A comparison among different forecasting approaches: different alternatives were chosen to allow accurate predictions, also being interpretable models, providing feasible training times and easy to replicate.
- -
A comparison between different alternatives not applied to a single consumer with specific characteristics, but for a larger number of consumers to allow a fair and extended comparison of created models: load patterns available in the used dataset are diverse; thus, scalability and flexibility are providential tools for the proposed forecasting methods.
- -
A detailed analysis of the created forecasting models, allowing the interpretation of the different feature contributions and a comparison of the training times.
The article is organized as follows:
Section 2 describes the used dataset for this study and presents some background related to the used methods and the strategies adopted when applying them in this study, and the list of features considered is also introduced.
Section 3 is initiated with the description of the adopted error metrics, followed by the main results presentation, providing a detailed comparison among the proposed methods and allowing a comprehensive analysis of the main influential features in each case. Finally, in
Section 4, the main conclusions are drawn, revealing the potential amongst the forecasting models tested and highlighting a comparative analysis of these selected models. In this section, some topics are proposed for further research.
3. Results
This section is divided into three different subsections. The first one describes the error metrics used, while the second one is dedicated to the comparison among the three different forecasting models based on machine learning and comparing them with the Naïve model. At the end, the third subsection analyses and evaluates the effect of different features in each model, the training times associated with the different implementations and some relevant information regarding the derived ANN architectures.
3.1. Error Metrics Description
For our study, initial analysis on each method were based on the Mean Absolute Error (
MAE) and on the Mean Squared Error (
MSE). This is given as the simple formula:
N being the number of forecasted values. Since each model was tested separately before the comparison with another one, it was required to have a benchmark method to help grasp the quality of the performance. This also allowed to establish a scaling for the computed errors, avoiding having an error metric expressed in absolute values [
5]. The most common error measure in forecasting is the Mean Absolute Percentage Error (MAPE), where the error is expressed as a percentage of the observed value, but this measurement is known to have undesired effects, such as non-symmetry and being affected by null values presented in the data series. Thus, new metrics, called the Mean Absolute Scaled Error (
MASE) and the Mean Squared Scaled Error (
MSSE), are then introduced and computed as:
MASE and MSSE above 1 means that the model being considered performed worse than the Naïve approach.
3.2. Forecasting Models Comparison
As mentioned earlier, for each one of the 71 consumers, the three different approaches (MARS, RF and ANN) were evaluated and compared with the
Naïve model. All the following presented results are related with the test sample. Attending to the
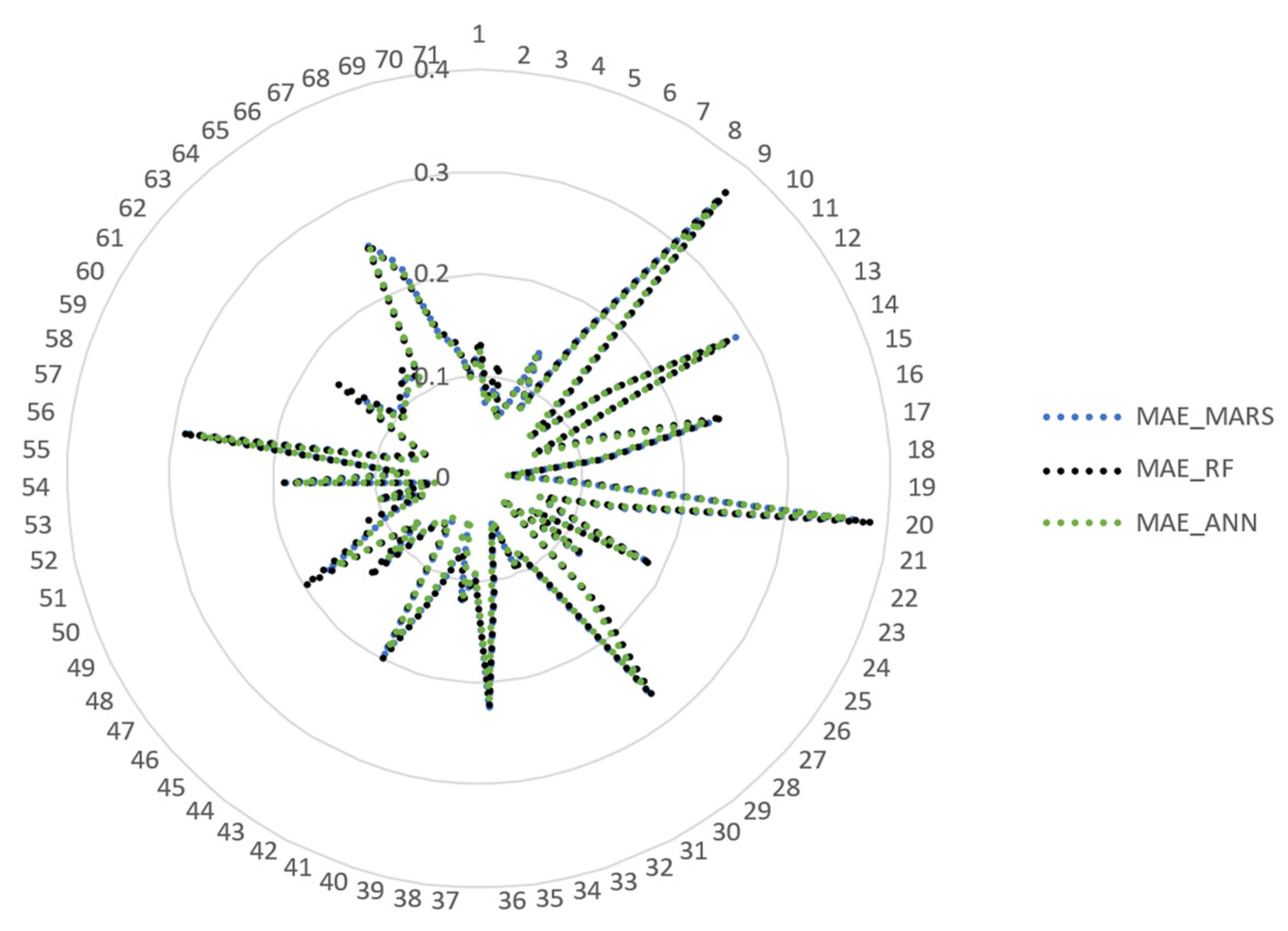
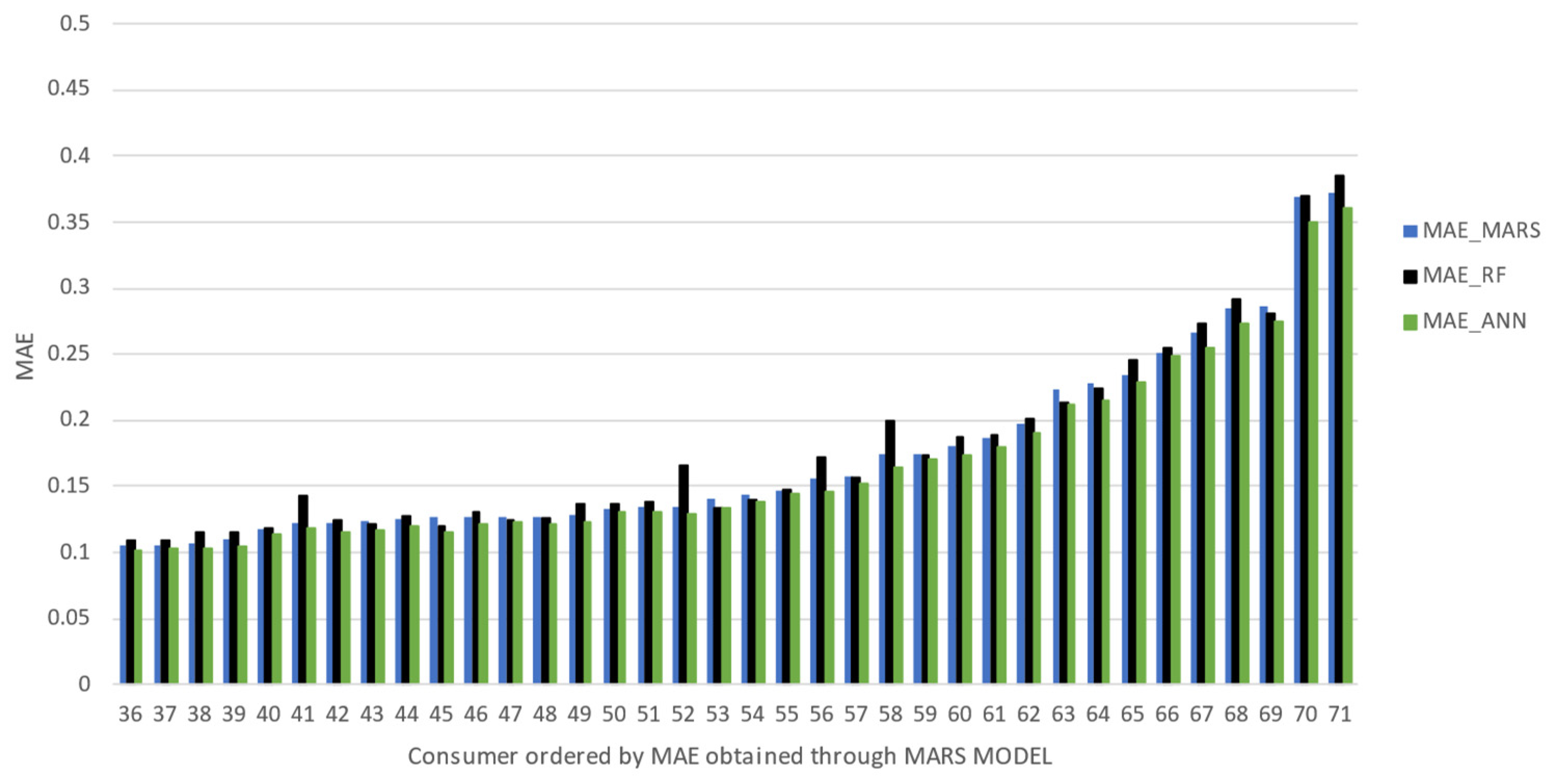
MAE metric, it can be stated that ANNs were the most accurate approach for 68 consumers and RF reveals the best performance for the remaining three consumers. In this case, despite MARS models showing similar forecasting performances compared with the concurrent ones, this approach was never the best one. With respect to the
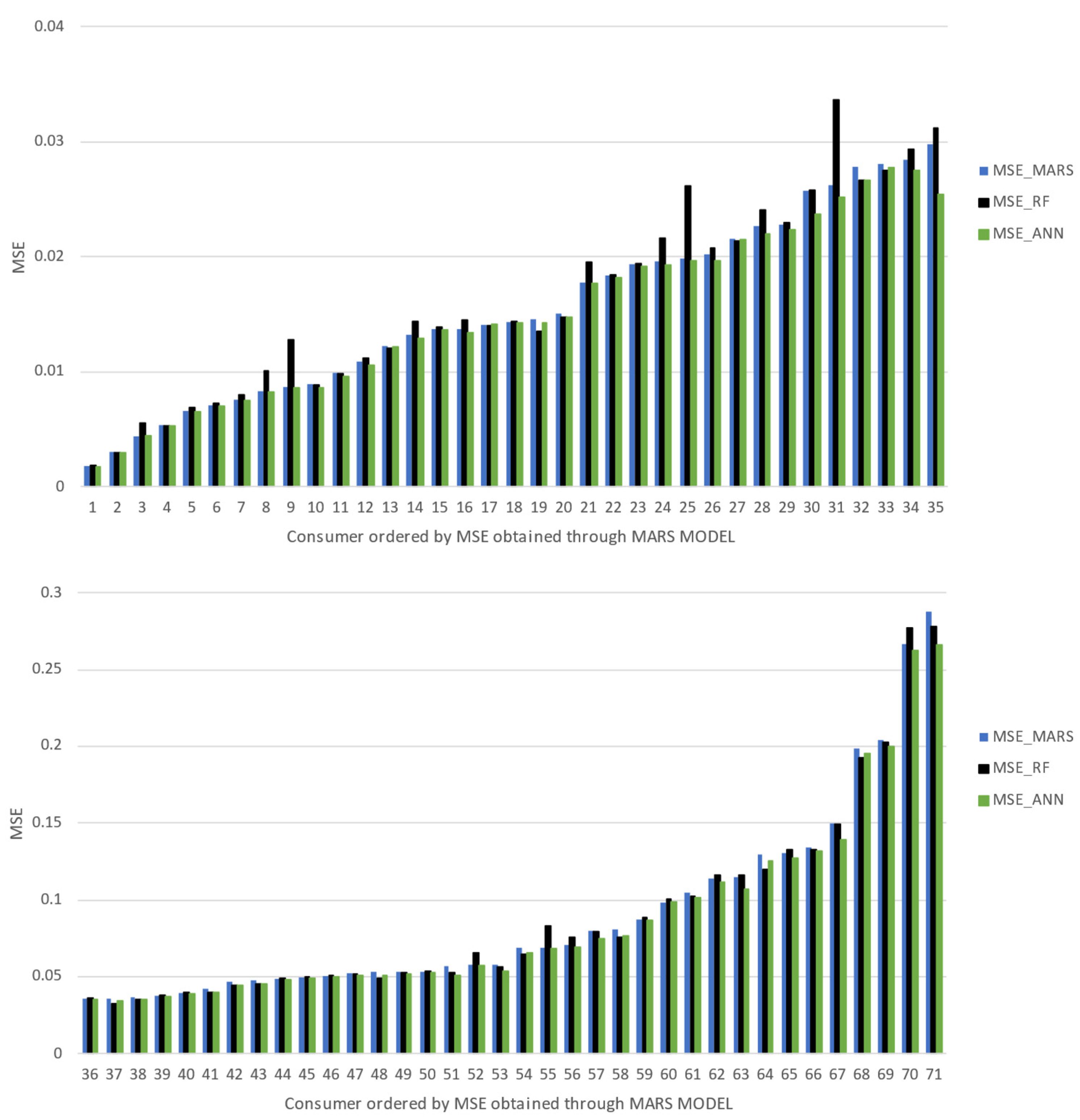
MSE metric, ANN was the most accurate approach for 54 consumers, and RF was the most accurate for 16 consumers and the remaining consumer was better forecasted using the MARS model. The differences in the absolute error metrics are not so significant (as can be visualized in
Figure 4 and
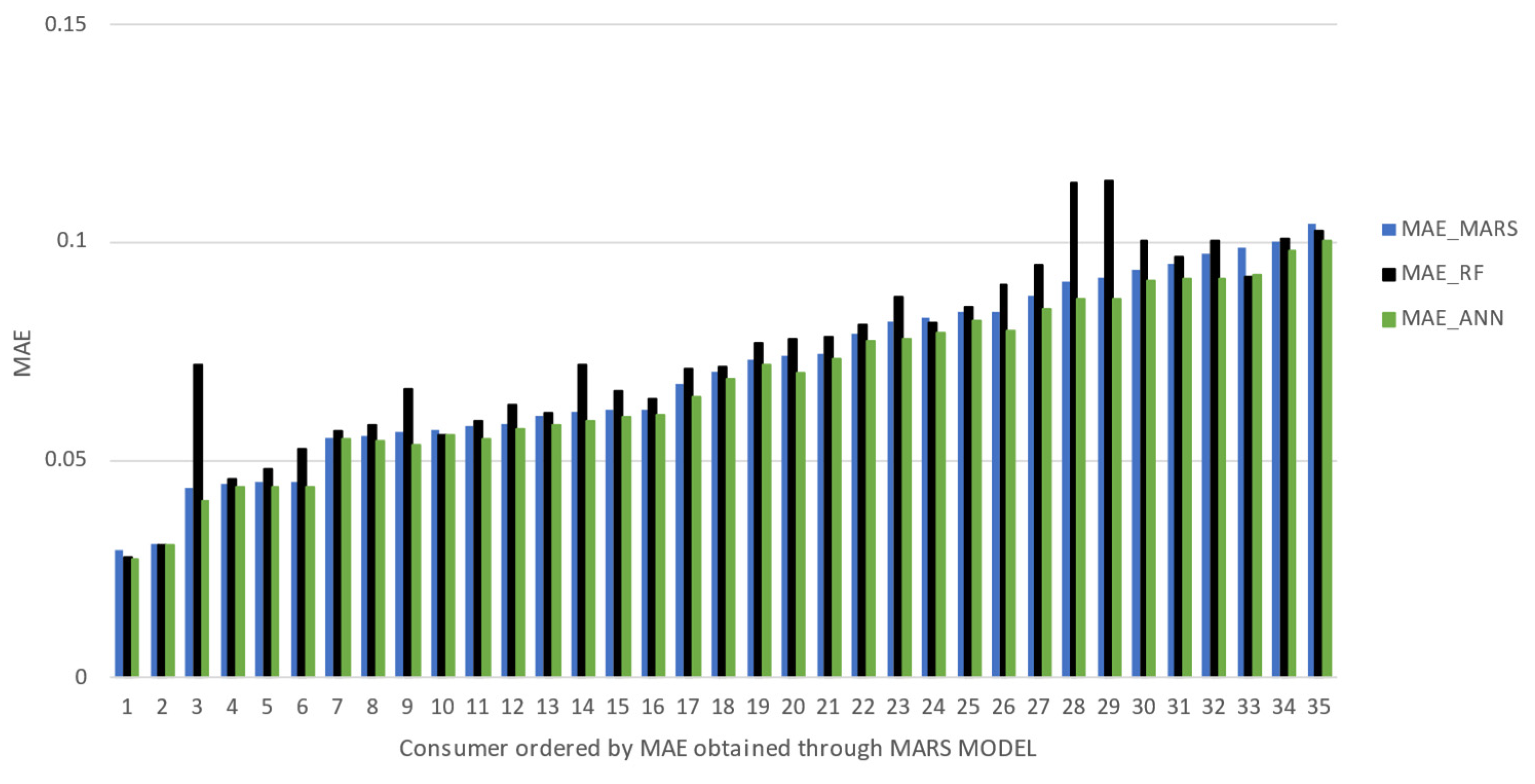
Figure 5); it is possible to infer that none of the different forecasting approaches applied somehow compromise an expected accuracy range. The radar charts allow a holistic view of the error analysis, with no prior logical order of the different consumers and highlighting the different forecasting methods. However, to allow a clearer analysis, bar charts were also used with an ascending trend of error metrics
MAE and
MSE, using the MARS model as a reference in the ranking. The bar charts shown in
Figure 6 and
Figure 7, due to the high number of consumers being involved, were split into two different graphs.
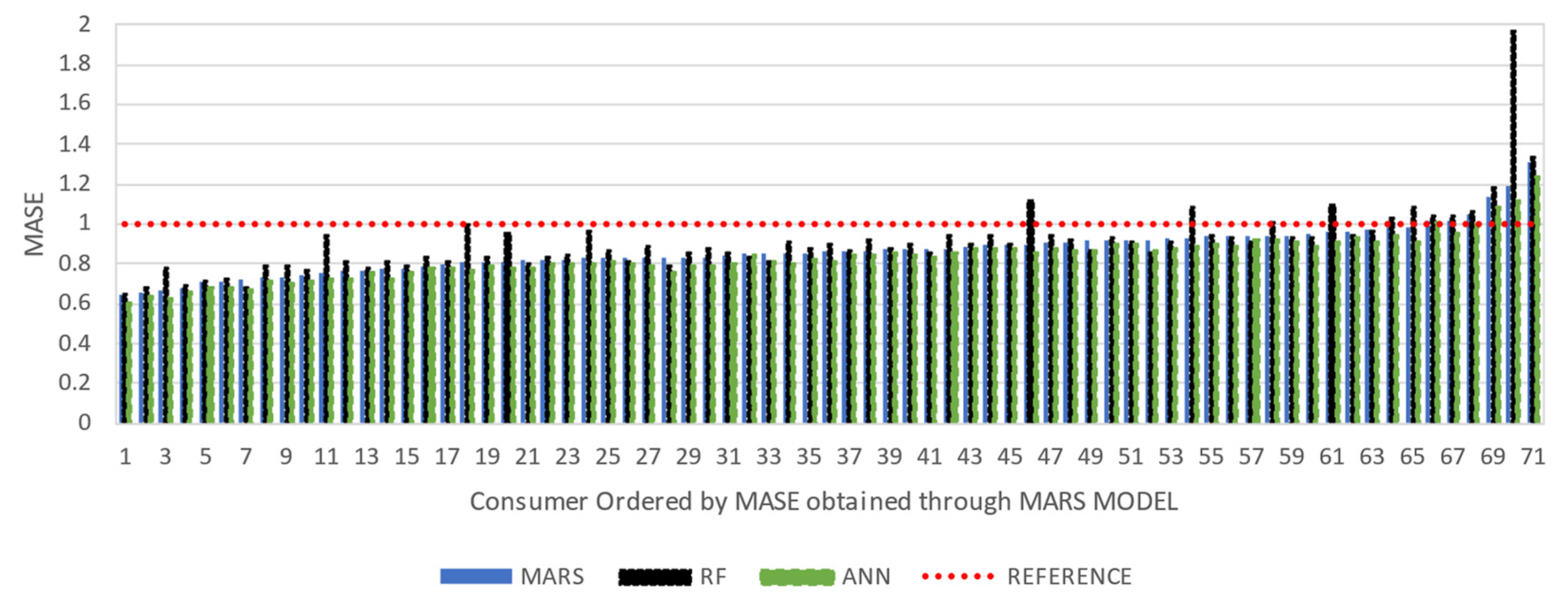
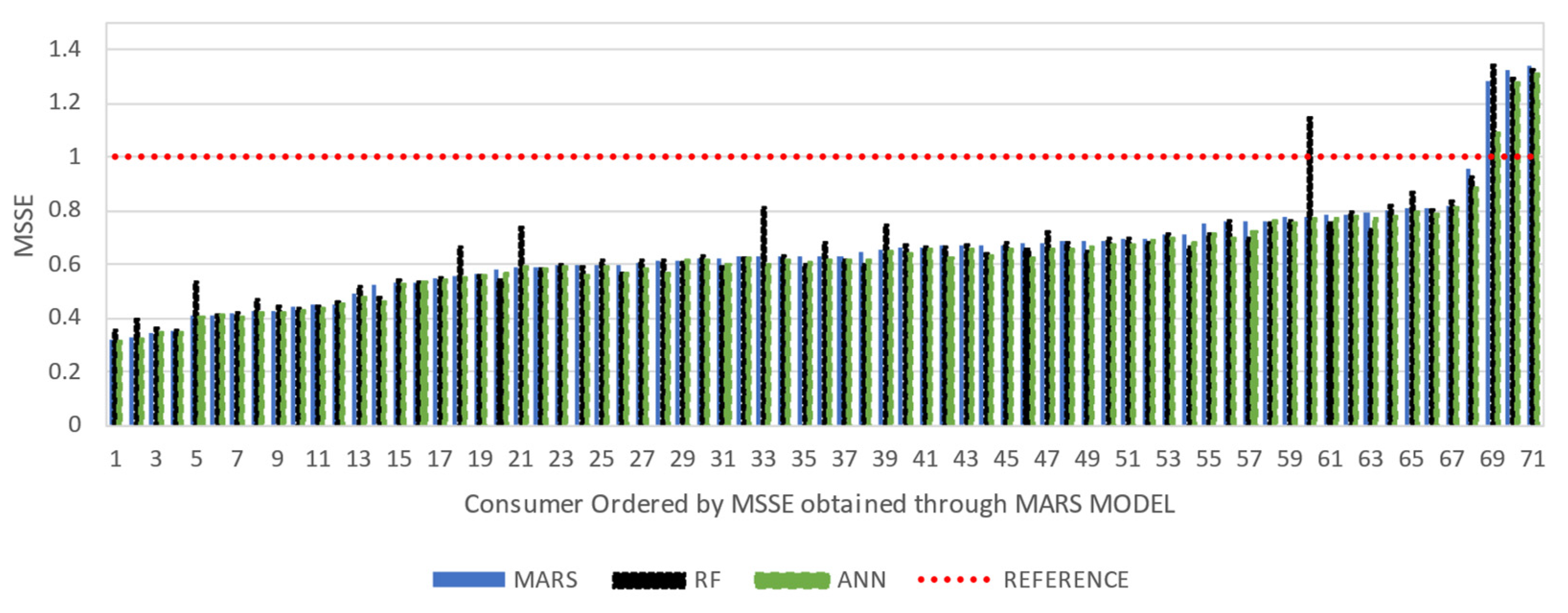
As mentioned earlier, scaled error metrics were also applied using the
Naïve model as baseline. A more detailed comparison of different applied models is possible, as shown in
Figure 8 and
Figure 9. As it is perceived, apart from some residual number of consumers, the forecasting methodologies are more precise than the
Naïve model as expected (
MASE values are below the unitary value, highlighted as Reference in the chart). For most of the tested consumers, ANN is the most accurate model, but with no significant differences among the approaches. With this
MASE analysis, it can be concluded that RF models reveal some weaknesses when applied to some specific consumers. These low performances identified are often related with cases of overfitting, as will be further discussed.
Regarding MSSE analysis, it can be pointed out that for almost all consumers, the three proposed approaches considerably reduce the error metrics identified in the Naïve model (MSSE typically below 0.8).
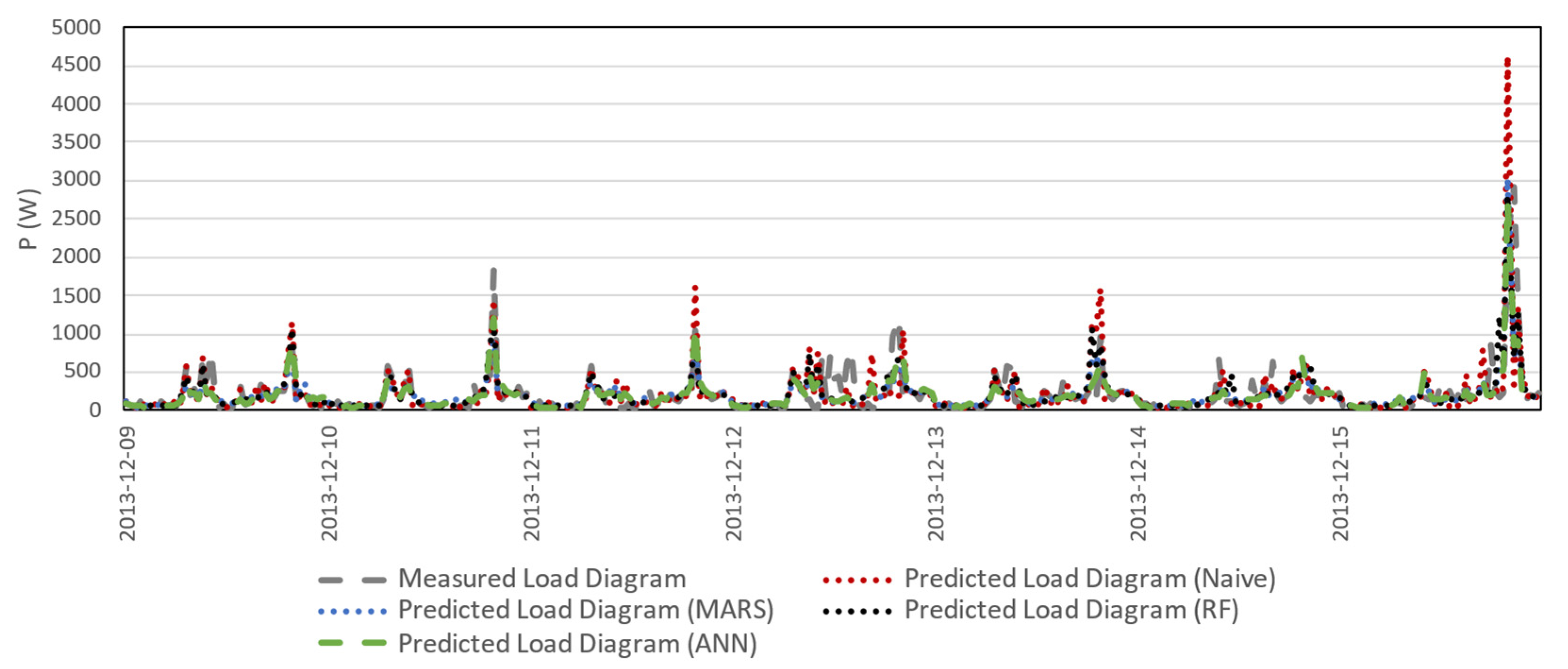
With the perspective of conveying the challenge associated with domestic load forecasting,
Figure 10 and
Figure 11 present measured weekly load diagrams during the test period and the short-term predictions (day-ahead forecasting) available by using the proposed methodologies. It must be stressed that the electricity consumption records available in the time series were converted to active power to build up these load profiles.
The randomness in resulting active power series is clear and some abrupt changes (sudden peak values or unexpected low values) in active power load are in some cases difficult to predict with the different methodologies. The two presented consumers were chosen due to considerably different consumption volumes as well as load patterns.
3.3. In-Depth Analysis of the Trained Models
With the MARS, RF and ANN models already trained and providing the most accurate predictions for each consumer, it becomes relevant to proceed to a zoom-in look, with the intention of evaluating features’ relevance, training times and also, for the case of ANNs, the networks’ dimension.
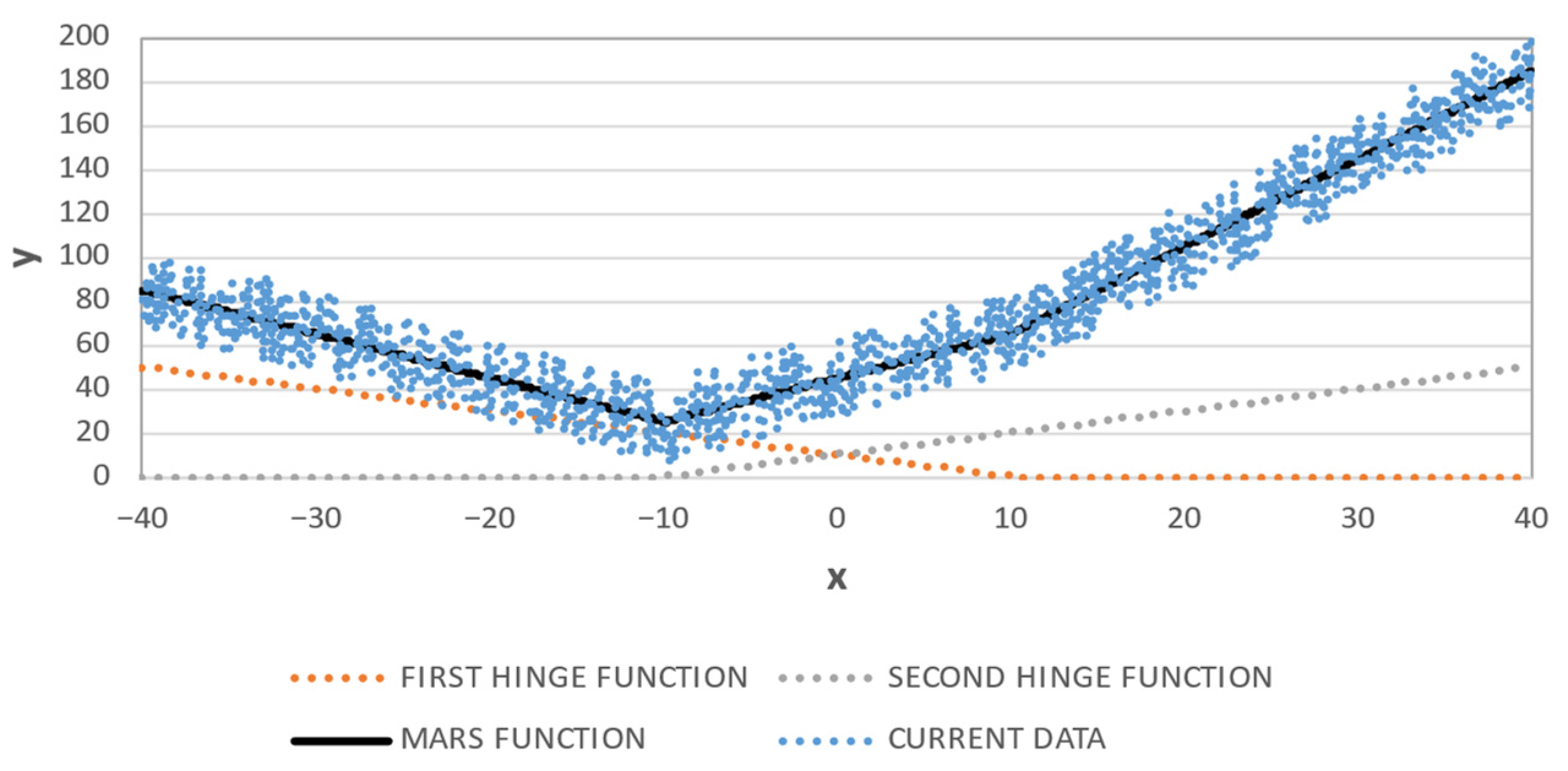
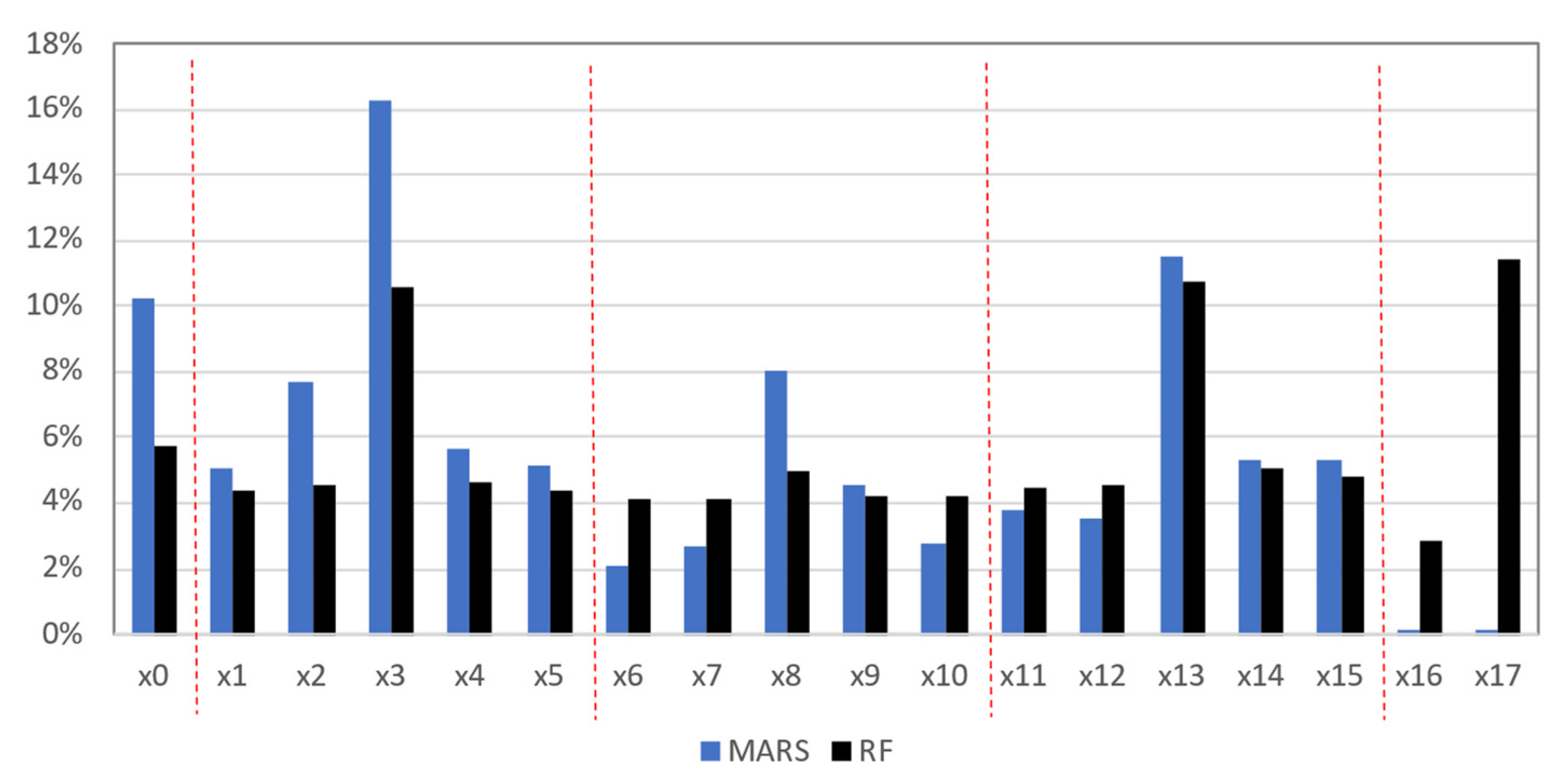
To evaluate features’ relevance in MARS models, the dependence of each model on the different features was identified and, for the different hinge functions and eventual linear dependences of single features, an average of absolute coefficient values was computed. After aggregating the effect verified for the studied consumers, normalised averages (sum of values equal to 1) are presented in
Figure 12. The labels are related with the used features (from x
0 to x
17) already presented in
Table 2. It can be noted that the features x
0, x
3, x
8, and x
13 tend to be the most influential in MARS models.
These are related with past record values verified 8 days ago, 7 days ago and 2 days ago at the same hourly period being predicted. The strategy of including “neighbouring” records (not at the similar hourly periods, but at hourly periods hp − 2, hp − 1, hp + 1 and hp + 2) to give the effect of trend when forecasting, denotes specific features (such as x2, x14 and x15) to be interesting.
In addition, the dependence on the cyclic variables (x16 and x17) seems to be low. With a more detailed analysis, it can be concluded that for the individual models created for each individual consumer, the contribution of these cyclic variables was imposing a linear dependence of these variables without the effect of hinge functions. As the input variables were not normalised, the ranges of these cyclic variables are considerably higher than the historical electricity consumption records (from x0 to x15); thus, the resulting coefficients are considerably lower, distorting the real effect of these variables.
Proceeding with the same analysis for the RF model and combining the RF features’ relevance for the different models (individual consumers) through an average results in the normalised relevance of each feature, also shown in
Figure 12.
It can be validated that the electricity consumption values identified at similar hourly periods 7 days before and 2 days before the day being predicted are the most relevant in the forecasting process. In this case, the cyclic variable associated with the hourly period is also valuable, as the regression trees often create a branch to determine the following sub-node according to this feature.
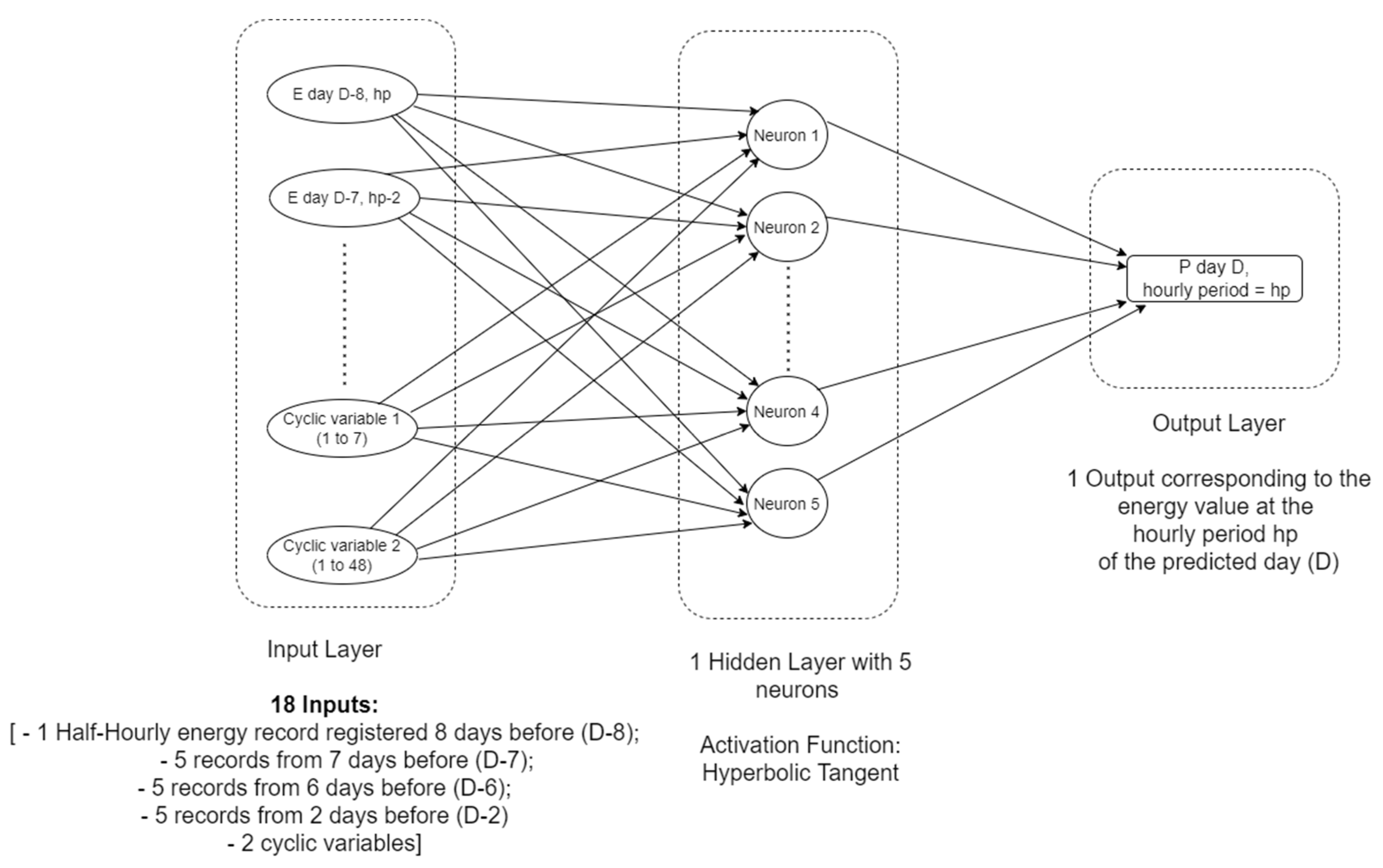
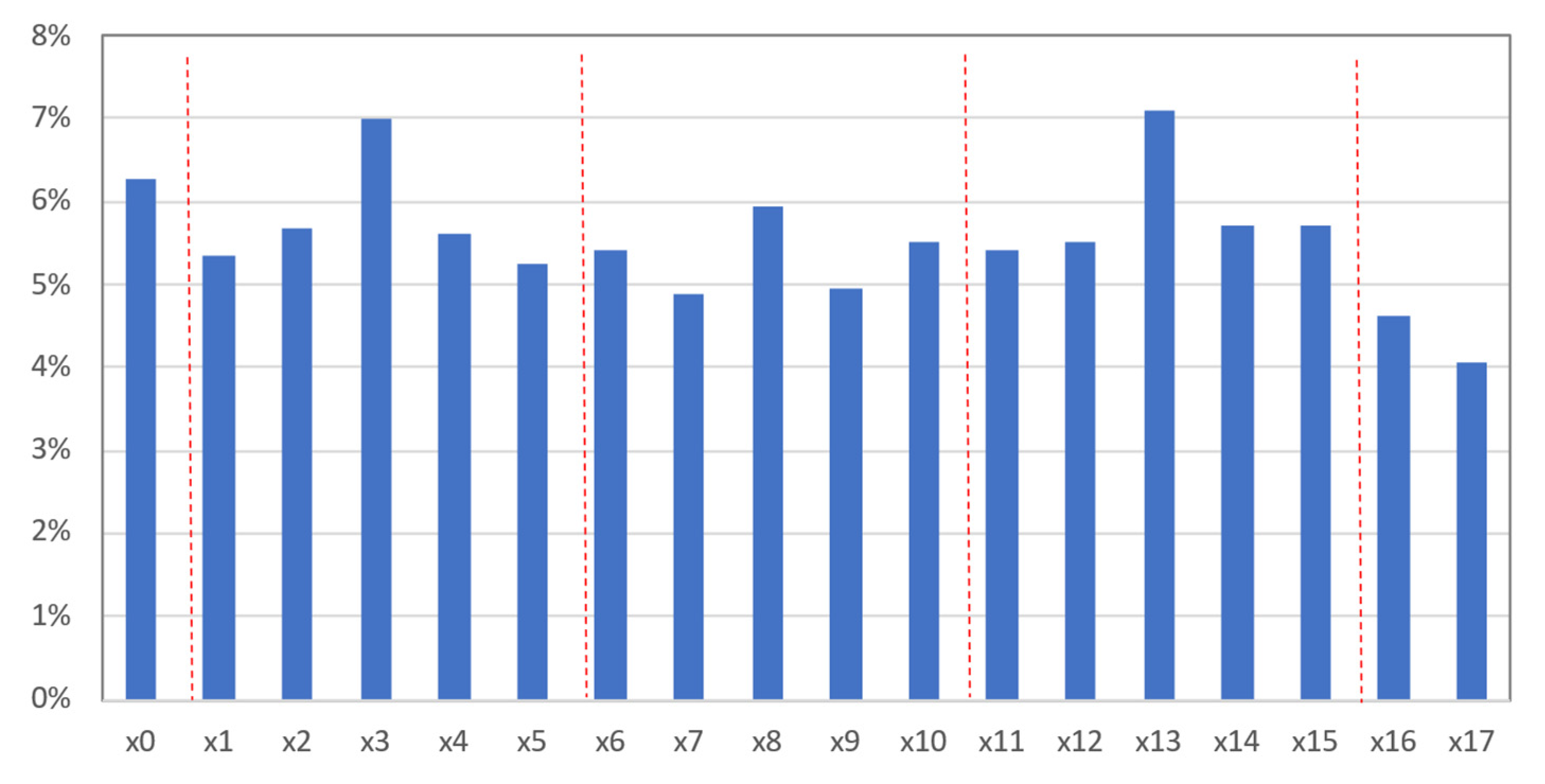
For the interpretation of relevant features in ANN models, after finding the best models, the weights obtained in the first layers (according to the connections between the different inputs and the different neurons assumed in each model) were analysed. For each ANN, an average of the absolute weights associated to each individual feature was assumed to characterise this corresponding feature. At the end, the relative importance of each feature was obtained by an average of its relative importance for the 71 consumers. The resulting normalised relevance for each individual feature is presented in
Figure 13.
Again, from the historical electricity consumption data, the electricity consumption records available at the similar hourly periods are the most important. In this case, the relative importance of adjacent hourly periods seems to be more relevant to pass to the ANN, to allow the perspective of transmitting the effect of trend. As before, the effect of day D-7 and day D-2 seems to be more important than that of day D-6. Finally, cyclic variables assume a relative importance in the context of ANN training. In this research, a straightforward analysis to the weights vector in the first layer was followed. Nevertheless, a sensitivity analysis could be followed, involving the concept of partial derivatives, to give a perspective on the local rate of change of the output with respect to an individual input holding the other inputs fixed [
27,
31]. As the neural network models evaluated use nonlinear activation functions between the different layers, a simple comparison of weights may not be reliable enough. In multilayer networks, a partial derivative has the same interpretation as a weight in a linear model, but instead of extending the analysis to the entire input space, it is only focused on the neighbourhood of the input point being considered.
During different experiments, processing times were recorded for each forecasting model and for each consumer analysed. The PC used during the tests was an Intel-core i7, 2.5 GHz with 12 GB of installed memory (RAM). Despite the available records of training times and simulation times (only during the prediction and not interfering in the modelling) for the training and test subsets, these two latest ones are so negligible that they are not here presented.
Table 3 shows the resulting training times for the different forecasting models.
As can be seen, the most time-consuming is the Random Forest Regressor (RF model), and in some cases (individual consumers) this can be avoided as the models tend to be overfitted. The hyperparameters’ definition would be providential to circumvent this effect. ANN models tend to be rapidly trained; however, several tests were in fact considered, including several trials and different numbers of neurons, until the most accurate model was found. MARS models are a good compromise to have a straightforward and interpretable model, with low computational time to train (not depending on several trials, unless different hyperparameters—maximum number of hinge functions, the penalty parameter or the maximum number of interactions—are explored through a metaheuristic or a grid-search technique).
In
Figure 14, it is shown that almost 70% of the consumers tested were in fact modelled with an ANN with seven or more neurons. Despite this fact, error metrics found in ANNs with higher dimensions are not that much lower than the error metrics obtained with lower ANN dimensions. More than the ANN dimension, each energy behaviour idiosyncrasy and the quality of measured data are more influential on the forecasting accuracy, as the forecasting quality was revealed to be not so sensitive to the ANN architecture.
4. Conclusions
The developed research revealed many interesting and useful insights. On one hand, despite the ANN models being more accurate and more flexible to be adapted to different consumers’ patterns, it is clear that the three different forecasting approaches do not differ significantly in accuracy of estimating half-hourly electricity consumption records for the day-ahead, applied to different consumers. This implies that the quality of smart meter data used, the feature selection phase and each model’s parametrization may be quite more determining to enhance the forecasting action, rather than the chosen forecasting model itself. Regarding this, for the electricity supplier/distributor, the trade-off between the accuracy and the interpretability of each individual model must be considered. This conclusion is strengthened when a scale effect is involved, as several individual forecasting models should be trained and used for different end-users.
On the other hand, with a thorough analysis of the trained models, it was possible to identify some relevant features that are transversal to the different approaches (mainly the electricity consumption records measured at similar hourly periods 2 and 7 days before). The strategy of including previous electricity consumption records at hourly periods “adjacent” to the similar hourly periods seems to be more justified in the case of ANN and not so relevant to MARS or RF models. The effects of including cyclic variables to distinguish the consumption pattern specific to each day of the week or even to each hourly period tend to be notorious and should not be avoided. Some experiments were exploited without these cyclic variables, leading to an overall degradation in forecasting performances.
Further research should address the inclusion of exogenous variables in the models (including weather variables on a half-hourly basis or, at least, considering daily meteorological values associated with extreme conditions—e.g., minimum, and maximum values of temperature on a daily basis). To overcome the risk of overfitting in the RF model, different hyperparameters should be explored by eventually using a metaheuristic. Finally, rather than simply looking at the weights vector in the first ANN layer, a sensitivity analysis based on partial derivatives must be followed up to better evaluate features’ relevance in ANNs.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}