

Effectiveness of Machine Learning in Assessing the Diagnostic Quality of Bitewing Radiographs

 , and
, and
Abstract
Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Design
2.2. Data Collection
2.3. Data Preprocessing and Entry
- Radiographic ID: Each BW image was renamed with ten digits. The last seven digits referred to the patient’s file number on the R4 Clinical+ software, while the first three numbers represented the BW radiograph number for each specific patient.
- Acquisition date: the date when the BW radiograph was taken in MM/DD/YYYY format.
- Machine type: the type of machine used to acquire the BW radiographs, either sensor or digitalized plates.
- Radiograph view side: which side of the dentition was included in the BW radiograph (right or left).
- Score: the scoring system for each proximal surface and contact area between two teeth was established based on tooth structure, amount of contact overlap, and the field of the taken radiograph. The scores ranged from 0 to 11.
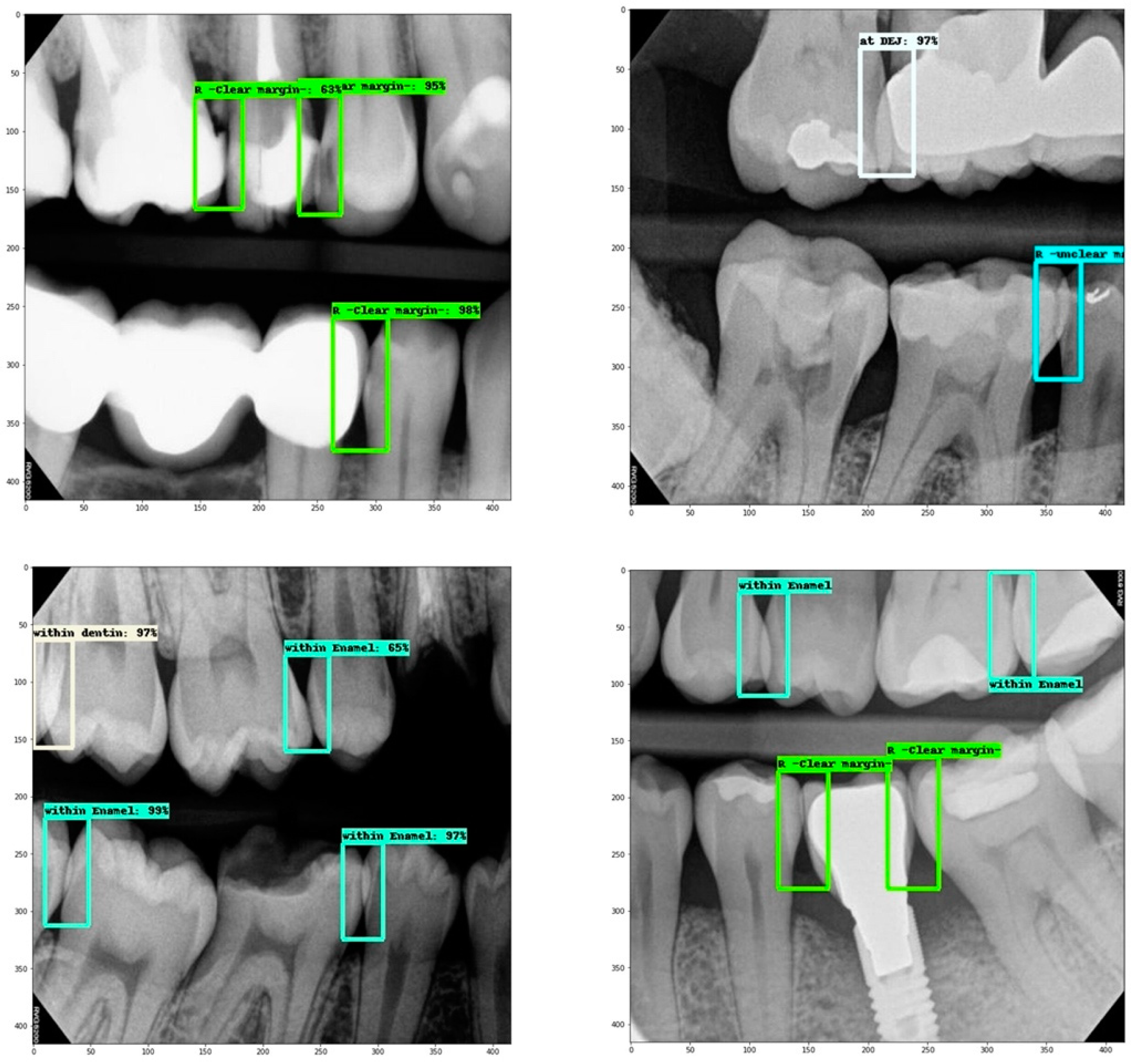
2.4. Dataset
- Overlap within enamel.
- Overlap within a restoration (clear margin).
- Overlap at DEJ.
- Overlap within dentin.
- Overlap within a restoration (unclear margin).
2.5. Model Training
2.6. Model Assessment
2.7. Statistical Analysis
- Log loss: represents the summation of system errors.
- Recall: quantifies the number of correct positive predictions made from all positive predictions that could have been made.
- Precision: quantifies the number of correct positive predictions made by the model.
- F1 score: combines recall and precision into a single score by calculating the harmonic mean of precision and recall, which is the measure that is used to evaluate this model’s performance.
3. Results
3.1. Data Analysis
3.2. Machine Learning Performance Assessment
- “True positives (TP) of “X” are all X instances that are classified as X;
- “True negatives (TN) of “X” are all non-X instances that are not classified as X;
- “False positives (FP) of “X” are all non-X instances that are classified as X;
- “False negatives (FN) of “X” are all X instances that are not classified as X.
3.3. Web App
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Boeddinghaus, R.; Whyte, A. Trends in maxillofacial imaging. Clin. Radiol. 2018, 73, 4–18. [Google Scholar] [CrossRef] [PubMed]
- Jaju, P.P.; Jaju, S.P. Cone-beam computed tomography: Time to move from ALARA to ALADA. Imaging Sci. Dent. 2015, 45, 263–265. [Google Scholar] [CrossRef] [PubMed]
- Yeung, A.W.; Wong, N.S. Reject Rates of Radiographic Images in Dentomaxillofacial Radiology: A Literature Review. Int. J. Environ. Res. Public Health 2021, 18, 8076. [Google Scholar] [CrossRef]
- White, S.C.; Pharoah, M.J. Intraoral projections. In Oral Radiology–Principles and Interpretation, 7th ed.; Elsevier Mosby: Philadelphia, PA, USA, 2014; pp. 91–130. [Google Scholar]
- Khanagar, S.B.; Al-Ehaideb, A.; Maganur, P.C.; Vishwanathaiah, S.; Patil, S.; Baeshen, H.A.; Sarode, S.C.; Bhandi, S. Developments, application, and performance of artificial intelligence in dentistry–A systematic review. J. Dent. Sci. 2021, 16, 508–522. [Google Scholar] [CrossRef] [PubMed]
- Rajaraman, V. JohnMcCarthy—Father of artificial intelligence. Resonance 2014, 19, 198–207. [Google Scholar] [CrossRef]
- Yaji, A.; Prasad, S.; Pai, A. Artificial intelligence in dento-maxillofacial radiology. Acta Sci. Dent. Sci. 2019, 3, 116–121. [Google Scholar]
- Heidari, A.; Jafari Navimipour, N.; Unal, M.; Toumaj, S. Machine learning applications for COVID-19 outbreak management. Neural Comput. Appl. 2022, 10, 15313–15348. [Google Scholar] [CrossRef]
- Heidari, A.; Toumaj, S.; Navimipour, N.J.; Unal, M. A privacy-aware method for COVID-19 detection in chest CT images using lightweight deep conventional neural network and blockchain. Comput. Biol. Med. 2022, 145, 105461. [Google Scholar] [CrossRef]
- Heidari, A.; Navimipour, N.J.; Unal, M.; Toumaj, S. The COVID-19 epidemic analysis and diagnosis using deep learning: A systematic literature review and future directions. Comput. Biol. Med. 2021, 14, 105141. [Google Scholar] [CrossRef]
- Pauwels, R. A brief introduction to concepts and applications of artificial intelligence in dental imaging. Oral Radiol. 2021, 37, 153–160. [Google Scholar] [CrossRef]
- Ekert, T.; Krois, J.; Meinhold, L.; Elhennawy, K.; Emara, R.; Golla, T.; Schwendicke, F. Deep learning for the radiographic detection of apical lesions. J. Endod. 2019, 45, 917–922. [Google Scholar] [CrossRef] [PubMed]
- Mohammad-Rahimi, H.; Motamedian, S.R.; Rohban, M.H.; Krois, J.; Uribe, S.; Nia, E.M.; Rokhshad, R.; Nadimi, M.; Schwendicke, F. Deep learning for caries detection: A systematic review: DL for Caries Detection. J. Dent. 2022, 30, 104115. [Google Scholar] [CrossRef]
- Karatas, O.; Cakir, N.N.; Ozsariyildiz, S.S.; Kis, H.C.; Demirbuga, S.; Gurgan, C.A. A deep learning approach to dental restoration classification from bitewing and periapical radiographs. Quintessence Int. 2021, 52, 568–574. [Google Scholar] [PubMed]
- Revilla-León, M.; Gómez-Polo, M.; Barmak, A.B.; Inam, W.; Kan, J.Y.; Kois, J.C.; Akal, O. Artificial intelligence models for diagnosing gingivitis and periodontal disease: A systematic review. J. Prosthet. Dent. 2022. online ahead of print. [Google Scholar] [CrossRef]
- Bayrakdar, I.S.; Orhan, K.; Akarsu, S.; Çelik, Ö.; Atasoy, S.; Pekince, A.; Yasa, Y.; Bilgir, E.; Sağlam, H.; Aslan, A.F.; et al. Deep-learning approach for caries detection and segmentation on dental bitewing radiographs. Oral Radiol. 2021, 22, 468–479. [Google Scholar] [CrossRef] [PubMed]
- Mertens, S.; Krois, J.; Cantu, A.G.; Arsiwala, L.T.; Schwendicke, F. Artificial intelligence for caries detection: Randomized trial. J. Dent. 2021, 115, 103849. [Google Scholar] [CrossRef] [PubMed]
- Devlin, H.; Williams, T.; Graham, J.; Ashley, M. The ADEPT study: A comparative study of dentists’ ability to detect enamel-only proximal caries in bitewing radiographs with and without the use of AssistDent artificial intelligence software. Br. Dent. J. 2021, 231, 481–485. [Google Scholar] [CrossRef]
- TensorFlow. Transfer Learning and Fine-Tuning|TensorFlow Core. 2021. Available online: https://www.tensorflow.org/ (accessed on 1 November 2021).
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Google Colab Notebook. Available online: https://colab.research.google.com (accessed on 1 November 2021).
- Potter, B.J.; Shrout, M.K.; Harrell, J.C. Reproducibility of beam alignment using different bite-wing radiographic techniques. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. Endod. 1995, 79, 532–535. [Google Scholar] [CrossRef]
- Saghiri, M.A.; Garcia-Godoy, F.; Gutmann, J.L.; Lotfi, M.; Asgar, K. The reliability of artificial neural network in locating minor apical foramen: A cadaver study. J. Endod. 2012, 38, 1130–1134. [Google Scholar] [CrossRef]
- Devito, K.L.; de Souza Barbosa, F.; Felippe Filho, W.N. An artificial multilayer perceptron neural network for diagnosis of proximal dental caries. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2008, 106, 879–884. [Google Scholar] [CrossRef]
- Johari, M.; Esmaeili, F.; Andalib, A.; Garjani, S.; Saberkari, H. Detection of vertical root fractures in intact and endodontically treated premolar teeth by designing a probabilistic neural network: An ex vivo study. Dentomaxillofac. Radiol. 2017, 46, 20160107. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.H.; Kim, D.H.; Jeong, S.N.; Choi, S.H. Diagnosis and prediction of periodontally compromised teeth using a deep learning-based convolutional neural network algorithm. J. Periodontal. Implant. Sci. 2018, 48, 114–123. [Google Scholar] [CrossRef] [PubMed]
- Aubreville, M.; Knipfer, C.; Oetter, N.; Jaremenko, C.; Rodner, E.; Denzler, J.; Bohr, C.; Neumann, H.; Stelzle, F.; Maier, A. Automatic classification of cancerous tissue in laser endomicroscopy images of the oral cavity using deep learning. Sci. Rep. 2017, 7, 11979. [Google Scholar] [CrossRef] [PubMed]
- Yasa, Y.; Çelik, Ö.; Bayrakdar, I.S.; Pekince, A.; Orhan, K.; Akarsu, S.; Atasoy, S.; Bilgir, E.; Odabaş, A.; Aslan, A.F. An artificial intelligence proposal to automatic teeth detection and numbering in dental bite-wing radiographs. Acta Odontol. Scand. 2021, 79, 275–281. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Class | Contact Area Count (%) in the Whole Dataset | Contact Area Count (%) in the Training Set |
|---|---|---|
| Overlap within enamel | 1124 (57.6) | 555 (52.8) |
| Overlap within restoration (clear margins) | 352 (18.0) | 226 (21.5) |
| Overlap at DEJ | 162 (8.3) | 83 (7.9) |
| Overlap within dentin | 109 (5.6) | 64 (6.1) |
| Overlap within restoration (unclear margins) | 204 (10.5) | 123 (11.7) |
| Total | 1951 (100) | 1051 (100) |
| Overlap within Enamel | Overlap within Restoration (Clear Margin) | Overlap at DEJ | Overlap within Dentin | Overlap within Restoration (Unclear Margin) | |
|---|---|---|---|---|---|
| TP | 133 | 13 | 7 | 3 | 2 |
| FP | 16 | 0 | 5 | 2 | 0 |
| FN | 15 | 8 | 5 | 11 | 4 |
| Precision | 0.893 | (1no FP) | 0.583 | 0.600 | (1no FP) |
| Recall | 0.899 | 0.619 | 0.583 | 0.214 | 0.333 |
| F1 score | 0.896 | 0.764 | 0.583 | 0.316 | 0.499 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barayan, M.A.; Qawas, A.A.; Alghamdi, A.S.; Alkhallagi, T.S.; Al-Dabbagh, R.A.; Aldabbagh, G.A.; Linjawi, A.I. Effectiveness of Machine Learning in Assessing the Diagnostic Quality of Bitewing Radiographs. Appl. Sci. 2022, 12, 9588. https://doi.org/10.3390/app12199588
Barayan MA, Qawas AA, Alghamdi AS, Alkhallagi TS, Al-Dabbagh RA, Aldabbagh GA, Linjawi AI. Effectiveness of Machine Learning in Assessing the Diagnostic Quality of Bitewing Radiographs. Applied Sciences. 2022; 12(19):9588. https://doi.org/10.3390/app12199588
Chicago/Turabian StyleBarayan, Mohammed A., Arwa A. Qawas, Asma S. Alghamdi, Turki S. Alkhallagi, Raghad A. Al-Dabbagh, Ghadah A. Aldabbagh, and Amal I. Linjawi. 2022. "Effectiveness of Machine Learning in Assessing the Diagnostic Quality of Bitewing Radiographs" Applied Sciences 12, no. 19: 9588. https://doi.org/10.3390/app12199588
APA StyleBarayan, M. A., Qawas, A. A., Alghamdi, A. S., Alkhallagi, T. S., Al-Dabbagh, R. A., Aldabbagh, G. A., & Linjawi, A. I. (2022). Effectiveness of Machine Learning in Assessing the Diagnostic Quality of Bitewing Radiographs. Applied Sciences, 12(19), 9588. https://doi.org/10.3390/app12199588