
Neuro-Symbolic Word Embedding Using Textual and Knowledge Graph Information


Abstract
1. Introduction
- The proposed model sequentially trains on the symbolic information of the textual and external knowledge graphs to construct meaningful word embeddings.
- The proposed word embeddings (https://drive.google.com/file/d/1XXPYj47onzAx–DVvsIgib0HxzGd7wBR/view?usp=sharing, accessed on 21 August 2022) outperform those of previous methods on word embedding benchmarks.
2. Related Works
- Word Embedding
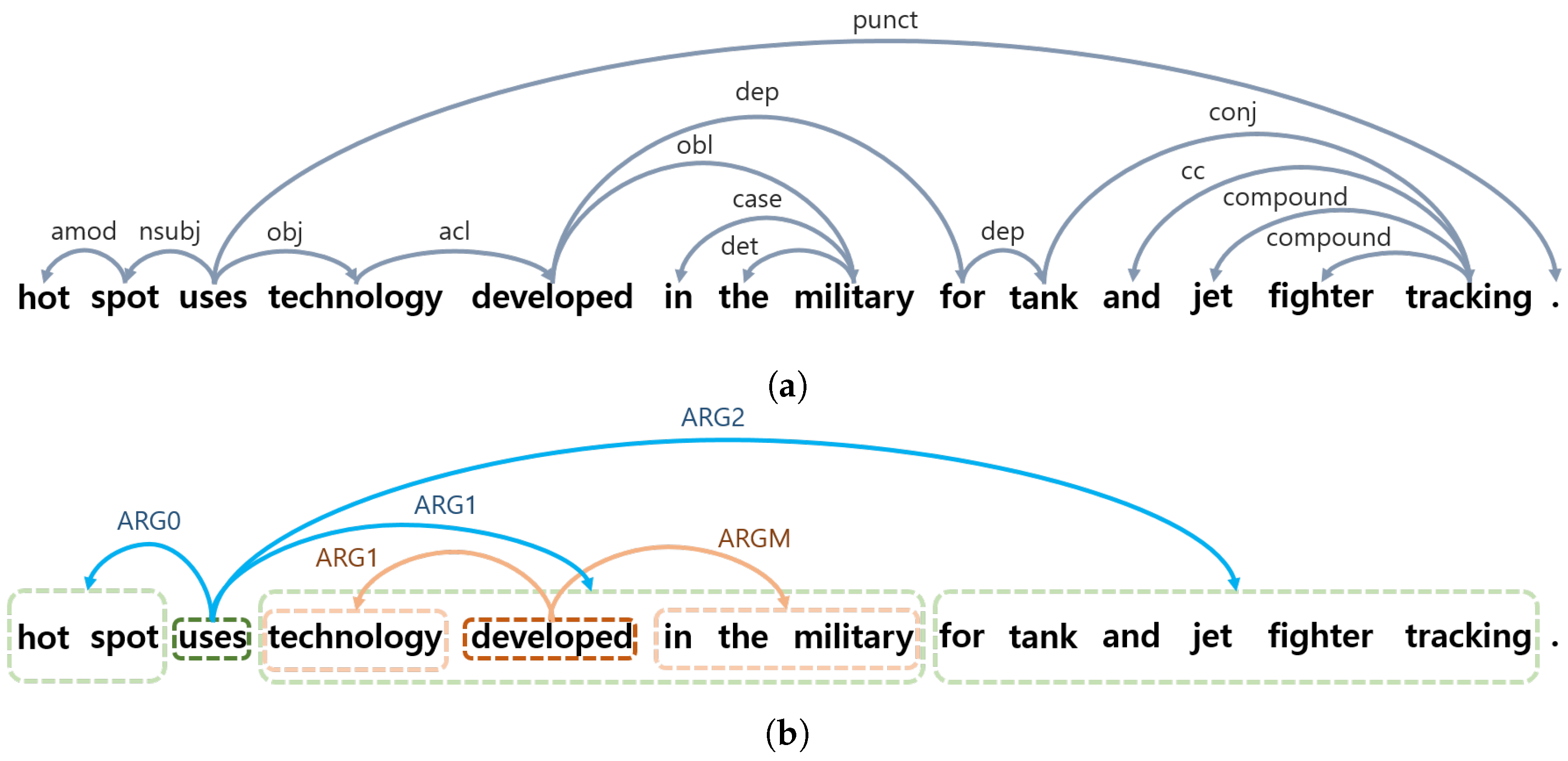
- Semantic Role Labeling (SRL)
- Dependence Parsing (DP)
- ConceptNet
3. Proposed Method
- TG-GCN
- CN-GCN
- Output Layer
4. Experimental Results and Analysis
4.1. Experimental Setup
4.1.1. Word Embedding Benchmarks
Word Similarity
Word Analogy
4.1.2. Extrinsic Tasks
Word Sense Disambiguation (WSD)
SQuAD 1.1
Part-of-Speech (POS) Tagging
Named Entity Recognition (NER)
4.2. Analysis of Word Embedding Benchmarks
4.2.1. Baseline
Skip-Gram (SG)
Continuous-Bag-of-Word (CBOW)
GloVe
FastText
Deps
SynGCN
SemGCN
BERT
4.3. Analysis
4.4. Analysis of Extrinsic Tasks
4.4.1. Baselines
ELMo
GAS
BiDAF
Baseline of POS and NER
4.5. Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Marcinkiewicz, M.A. Building a large annotated corpus of English: The Penn Treebank. In Using Large Corpora; MIT Press: Cambridge, MA, USA, 1994; p. 273. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of The Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–25 June 2014; pp. 55–60. [Google Scholar]
- Shi, P.; Lin, J. Simple bert models for relation extraction and semantic role labeling. arXiv 2019, arXiv:1904.05255. [Google Scholar]
- Luo, F.; Liu, T.; Xia, Q.; Chang, B.; Sui, Z. Incorporating Glosses into Neural Word Sense Disambiguation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2473–2482. [Google Scholar]
- Lee, K.; He, L.; Zettlemoyer, L. Higher-Order Coreference Resolution with Coarse-to-Fine Inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 687–692. [Google Scholar]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional attention flow for machine comprehension. arXiv 2016, arXiv:1611.01603. [Google Scholar]
- Levy, O.; Goldberg, Y. Dependency-based word embeddings. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 302–308. [Google Scholar]
- Vashishth, S.; Bhandari, M.; Yadav, P.; Rai, P.; Bhattacharyya, C.; Talukdar, P. Incorporating Syntactic and Semantic Information in Word Embeddings using Graph Convolutional Networks. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3308–3318. [Google Scholar]
- Palmer, M.; Gildea, D.; Xue, N. Semantic role labeling. Synth. Lect. Hum. Lang. Technol. 2010, 3, 1–103. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Speer, R.; Chin, J.; Havasi, C. Conceptnet 5.5: An open multilingual graph of general knowledge. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Meyer, C.M.; Gurevych, I. Wiktionary: A New Rival for Expert-Built Lexicons? Exploring the Possibilities of Collaborative Lexicography; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data. In The Semantic Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- Kübler, S.; McDonald, R.; Nivre, J. Dependency parsing. Synth. Lect. Hum. Lang. Technol. 2009, 1, 1–127. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Sang, E.F.T.K.; De Meulder, F. Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. Development 1837, 922, 1341. [Google Scholar]
- Palmer, M.; Fellbaum, C.; Cotton, S.; Delfs, L.; Dang, H.T. English tasks: All-words and verb lexical sample. In Proceedings of the International Workshop on Evaluating Word Sense Disambiguation Systems, Toulouse, France, 5–6 July 2001; pp. 21–24. [Google Scholar]
- Snyder, B.; Palmer, M. The English all-words task. In Proceedings of the Proceedings the International Workshop on the Evaluation of Systems for the Semantic Analysis of Text, Barcelona, Spain, 25–26 July 2004; pp. 41–43. [Google Scholar]
- Pradhan, S.; Loper, E.; Dligach, D.; Palmer, M. Semeval-2007 task-17: English lexical sample, srl and all words. In Proceedings of the International Workshop on Semantic Evaluations, Prague, Czech Republic, 23–24 June 2007; pp. 87–92. [Google Scholar]
- Navigli, R.; Jurgens, D.; Vannella, D. Semeval-2013 task 12: Multilingual word sense disambiguation. In Proceedings of the International Workshop on Semantic Evaluation, Atlanta, GA, USA, 14–15 June 2013; Volume 2, pp. 222–231. [Google Scholar]
- Moro, A.; Navigli, R. Semeval-2015 task 13: Multilingual all-words sense disambiguation and entity linking. In Proceedings of the International Workshop on Semantic Evaluation, Denver, CO, USA, 4–5 June 2015; pp. 288–297. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Komninos, A.; Manandhar, S. Dependency based embeddings for sentence classification tasks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1490–1500. [Google Scholar]
- Li, C.; Li, J.; Song, Y.; Lin, Z. Training and evaluating improved dependency-based word embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Marcheggiani, D.; Titov, I. Encoding Sentences with Graph Convolutional Networks for Semantic Role Labeling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1506–1515. [Google Scholar]
- Mikolov, T.; Yih, W.t.; Zweig, G. Linguistic regularities in continuous space word representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 746–751. [Google Scholar]
- Finkelstein, L.; Gabrilovich, E.; Matias, Y.; Rivlin, E.; Solan, Z.; Wolfman, G.; Ruppin, E. Placing search in context: The concept revisited. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 406–414. [Google Scholar]
- Kiela, D.; Hill, F.; Clark, S. Specializing Word Embeddings for Similarity or Relatedness. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, 17–21 September 2015; pp. 2044–2048. [Google Scholar]
- Luong, M.T.; Socher, R.; Manning, C.D. Better word representations with recursive neural networks for morphology. In Proceedings of the Seventeenth Conference On Computational Natural Language Learning, Sofia, Bulgaria, 8–9 August 2013; pp. 104–113. [Google Scholar]
- Bruni, E.; Boleda, G.; Baroni, M.; Tran, N.K. Distributional semantics in technicolor. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Stroudsburg, PA, USA, 8–14 July 2012; pp. 136–145. [Google Scholar]
- Jurgens, D.; Mohammad, S.; Turney, P.; Holyoak, K. Semeval-2012 task 2: Measuring degrees of relational similarity. In Proceedings of the SEM 2012: The First Joint Conference on Lexical and Computational Semantics–Volume 1: Proceedings of the Main Conference and the Shared Task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation (SemEval 2012), Stroudsburg, PA, USA, 7–8 June 2012; pp. 356–364. [Google Scholar]
- Raganato, A.; Camacho-Collados, J.; Navigli, R. Word sense disambiguation: A unified evaluation framework and empirical comparison. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, Valencia, Spain, 3–7 April 2017; pp. 99–110. [Google Scholar]



{kind=link}
{kind=link}
| Model | Word Similarity | Word Analogy | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| WS353 | WS353S | WS353R | SimLex999 | RW | MEN3K | Avg | MSR | SemEval12 | Avg | |
| SG | 61.0 | 68.9 | 53.7 | 34.9 | 34.5 | 67.0 | 53.3 | 30.6 | 20.5 | 25.6 |
| CBOW | 62.7 | 70.7 | 53.9 | 38.0 | 30.0 | 68.6 | 54.0 | 44.0 | 18.9 | 31.5 |
| GloVe | 54.2 | 64.3 | 50.2 | 31.6 | 29.9 | 68.3 | 49.8 | 61.4 | 16.9 | 39.2 |
| FastText | 68.3 | 74.6 | 61.6 | 38.2 | 37.3 | 74.8 | 59.1 | 53.2 | 19.5 | 36.4 |
| Deps | 60.6 | 73.1 | 46.8 | 39.6 | 33.0 | 60.5 | 52.3 | 40.3 | 22.9 | 31.6 |
| BERT-base | 51.8 | 60.1 | 37.3 | 48.1 | 26.7 | 42.8 | 44.5 | 52.7 | 20.8 | 36.8 |
| BERT-large | 57.8 | 65.8 | 46.4 | 47.5 | 27.6 | 51.8 | 49.5 | 57.6 | 20.7 | 39.2 |
| OurModel(CN-GCN) | 65.9 | 78.8 | 54.7 | 57.0 | 36.5 | 71.0 | 60.7 | 54.6 | 24.4 | 39.5 |
| Model | WS353 | MSR |
|---|---|---|
| SynGCN | 60.9 | 52.8 |
| SemGCN | 65.3 | 54.4 |
| TG-GCN | 62.7 | 54.0 |
| Our model (CN-GCN) | 65.9 | 54.6 |
| Model | Test Datasets | Concatenation of Test Datasets | |||
|---|---|---|---|---|---|
| SE2 | SE3 | SE13 | SE15 | All | |
| GAS (linear) with GloVe | 72.0 | 70.0 | 66.7 | 71.6 | 70.1 |
| GAS (concat) with GloVe | 72.1 | 70.2 | 67.0 | 71.8 | 70.3 |
| (linear) with GloVe | 72.4 | 70.1 | 67.1 | 72.1 | 70.4 |
| (concat) with GloVe | 72.2 | 70.5 | 67.2 | 72.6 | 70.6 |
| (concat) with CN-GCN | 75.6 | 73.5 | 71.4 | 73.5 | 71.0 |
| Model | EM-Dev (%) | F1-Dev (%) | EM-Test (%) | F1-Test (%) |
|---|---|---|---|---|
| BiDAF with GloVe | 62.0 | 73.5 | 65.1 | 75.3 |
| BiDAF with CN-GCN | 63.0 | 74.2 | 65.9 | 75.9 |
| Embedding | POS | NER |
|---|---|---|
| ELMo | 96.1 | 90.3 |
| w/ Concat SemGCN embedding | 96.2 | 90.9 |
| w/ Concat CN-GCN embedding | 97.0 | 91.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, D.; Lim, J.; Lim, H. Neuro-Symbolic Word Embedding Using Textual and Knowledge Graph Information. Appl. Sci. 2022, 12, 9424. https://doi.org/10.3390/app12199424
Oh D, Lim J, Lim H. Neuro-Symbolic Word Embedding Using Textual and Knowledge Graph Information. Applied Sciences. 2022; 12(19):9424. https://doi.org/10.3390/app12199424
Chicago/Turabian StyleOh, Dongsuk, Jungwoo Lim, and Heuiseok Lim. 2022. "Neuro-Symbolic Word Embedding Using Textual and Knowledge Graph Information" Applied Sciences 12, no. 19: 9424. https://doi.org/10.3390/app12199424
APA StyleOh, D., Lim, J., & Lim, H. (2022). Neuro-Symbolic Word Embedding Using Textual and Knowledge Graph Information. Applied Sciences, 12(19), 9424. https://doi.org/10.3390/app12199424