
Mask-Aware Semi-Supervised Object Detection in Floor Plans

 ,
,  ,
,  ,
, 
Abstract
1. Introduction
2. Related Work
2.1. Object Detection and Its Applications
2.2. Semi-Supervised Learning
2.3. Floor-Plan Analysis
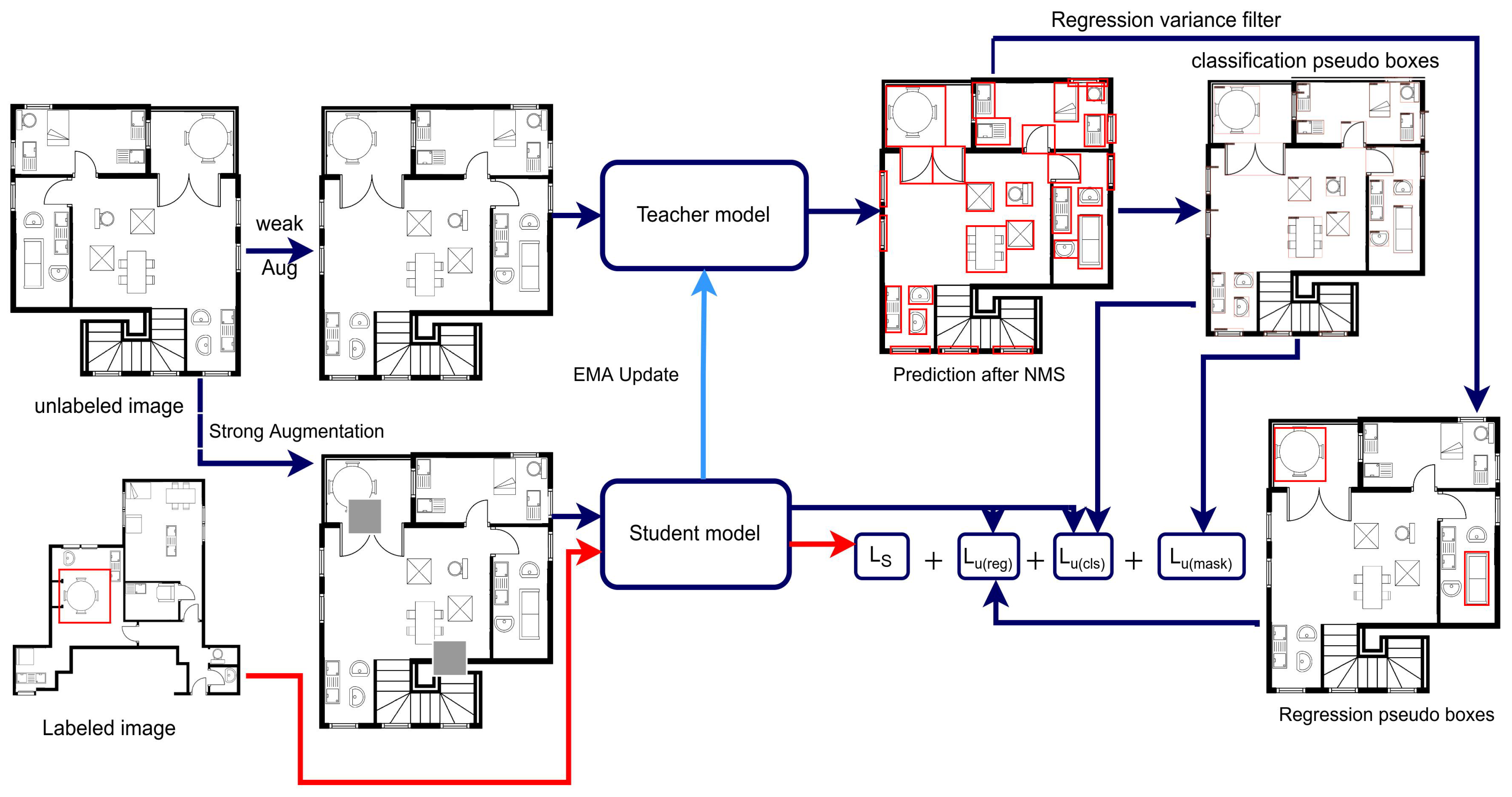
3. Method
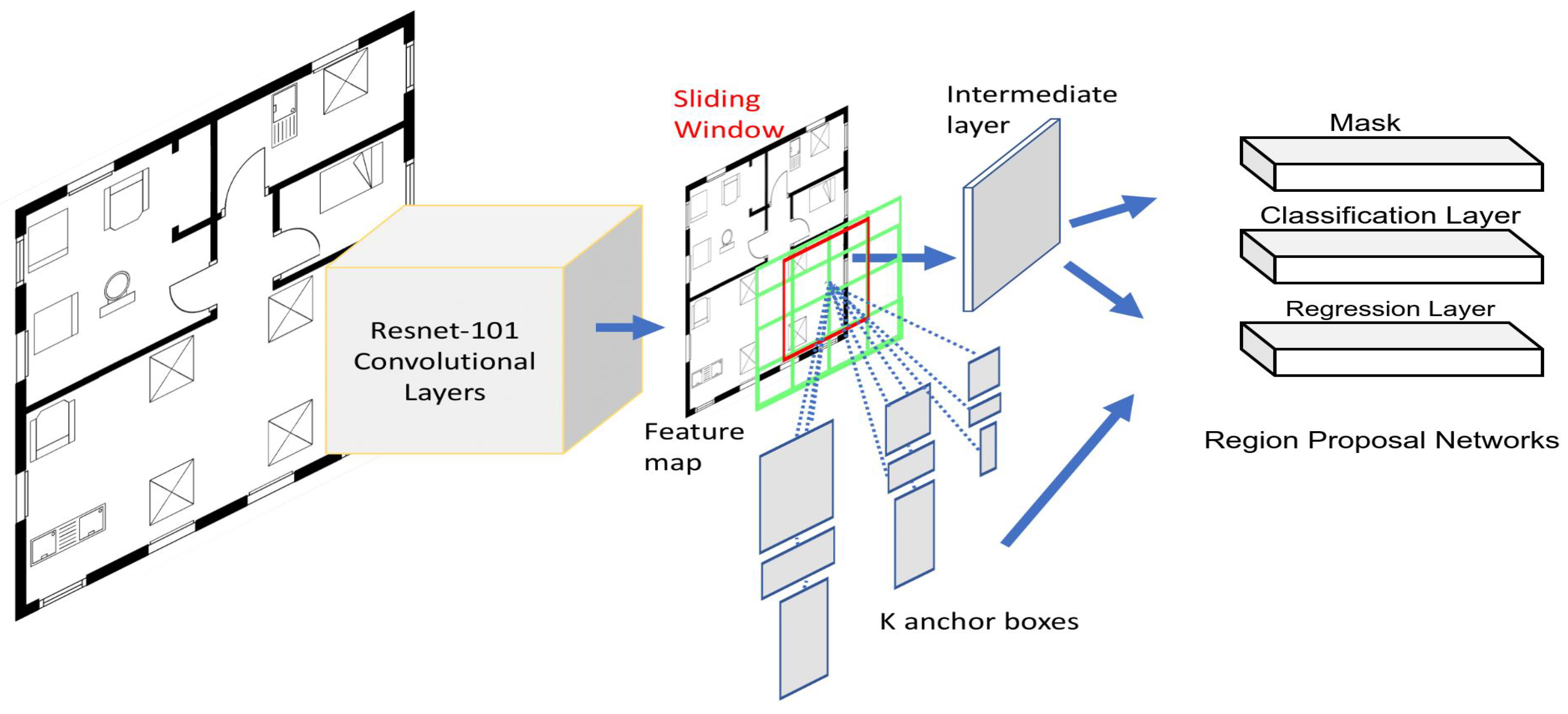
3.1. Mask R-CNN
3.2. Backbone Network
3.3. Semi-Supervised Model
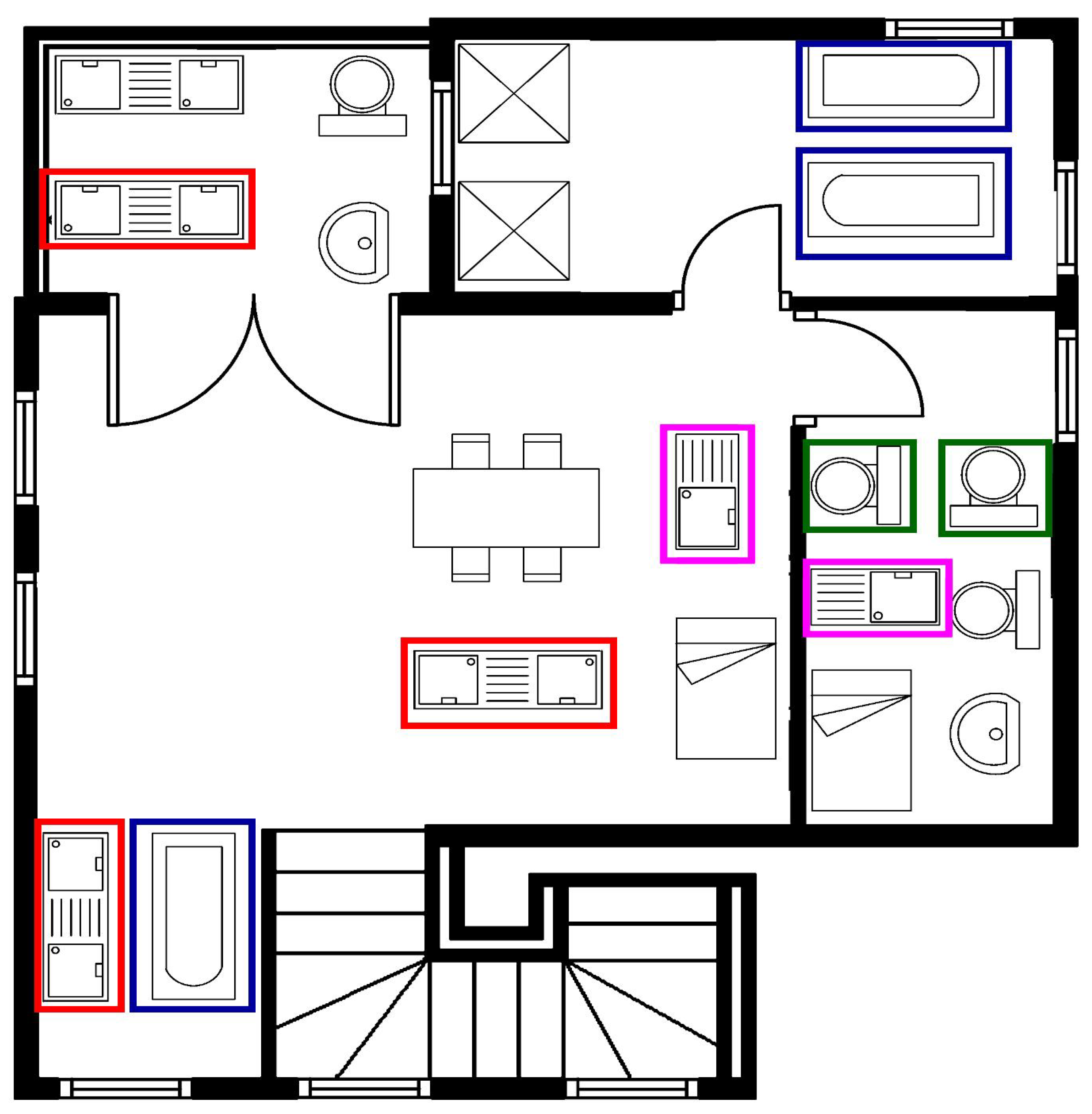
4. Dataset
5. Experiments
5.1. Implementation Details
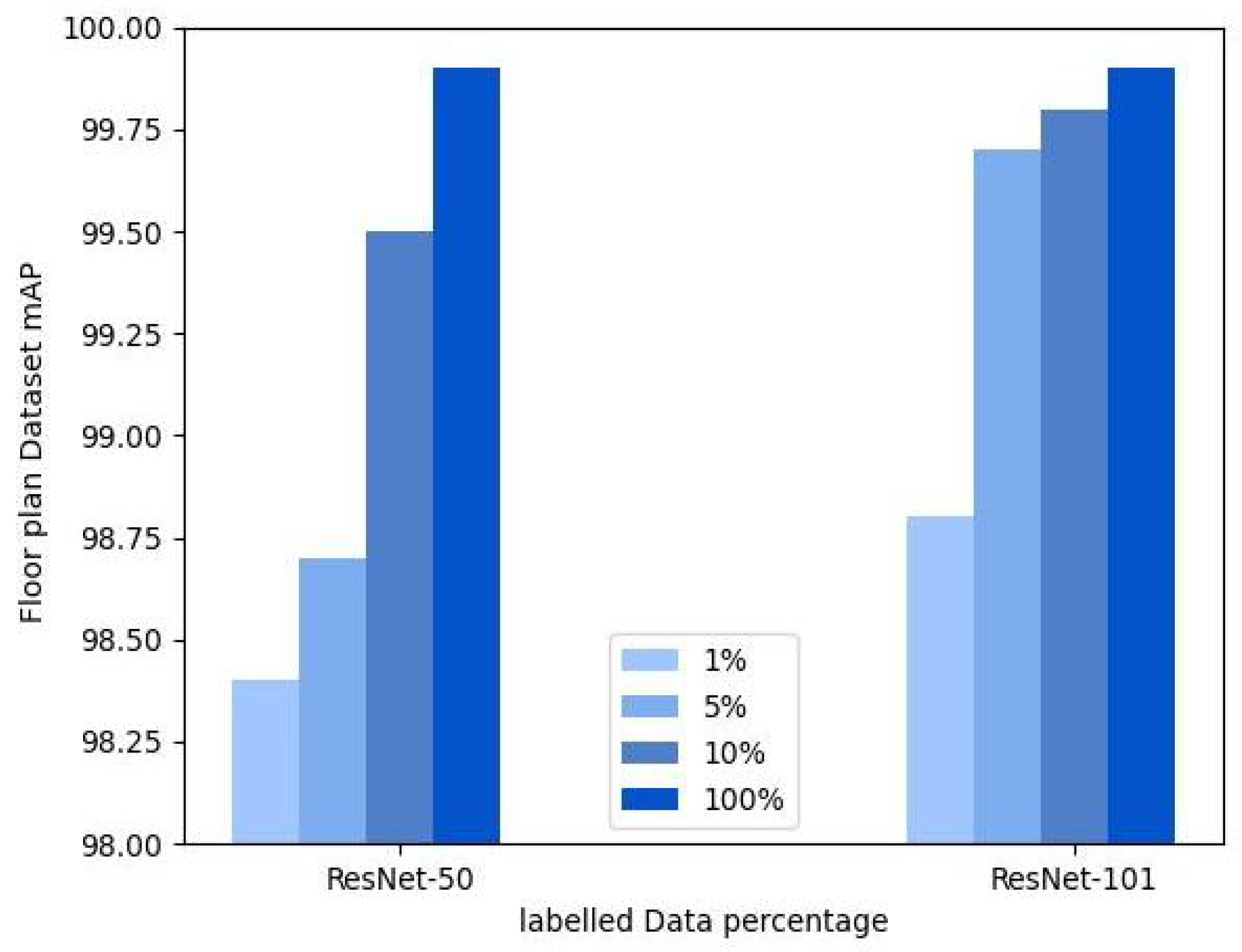
5.1.1. Partially Labeled Data
5.1.2. Fully Labeled Data
6. Evaluation Criteria
6.1. Intersection over Union
6.2. Average Precision
6.3. Mean Average Precision
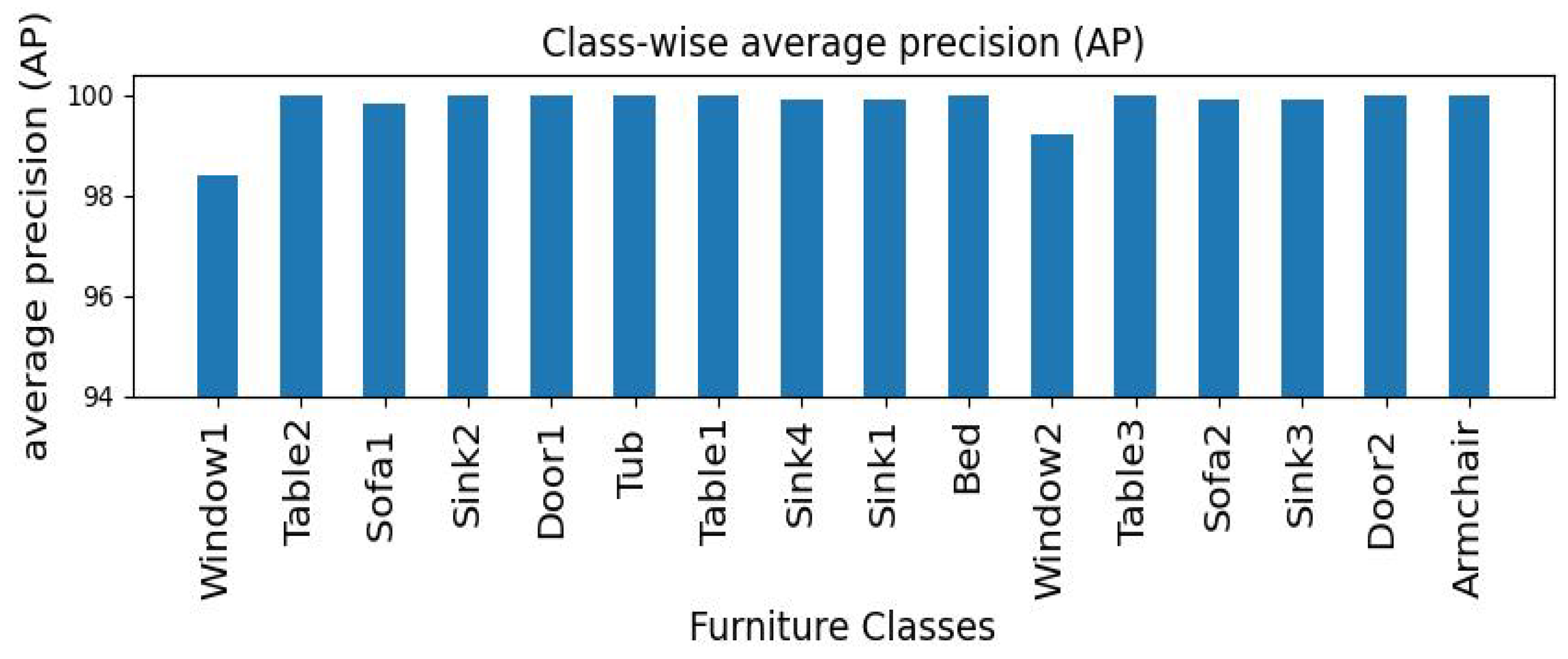
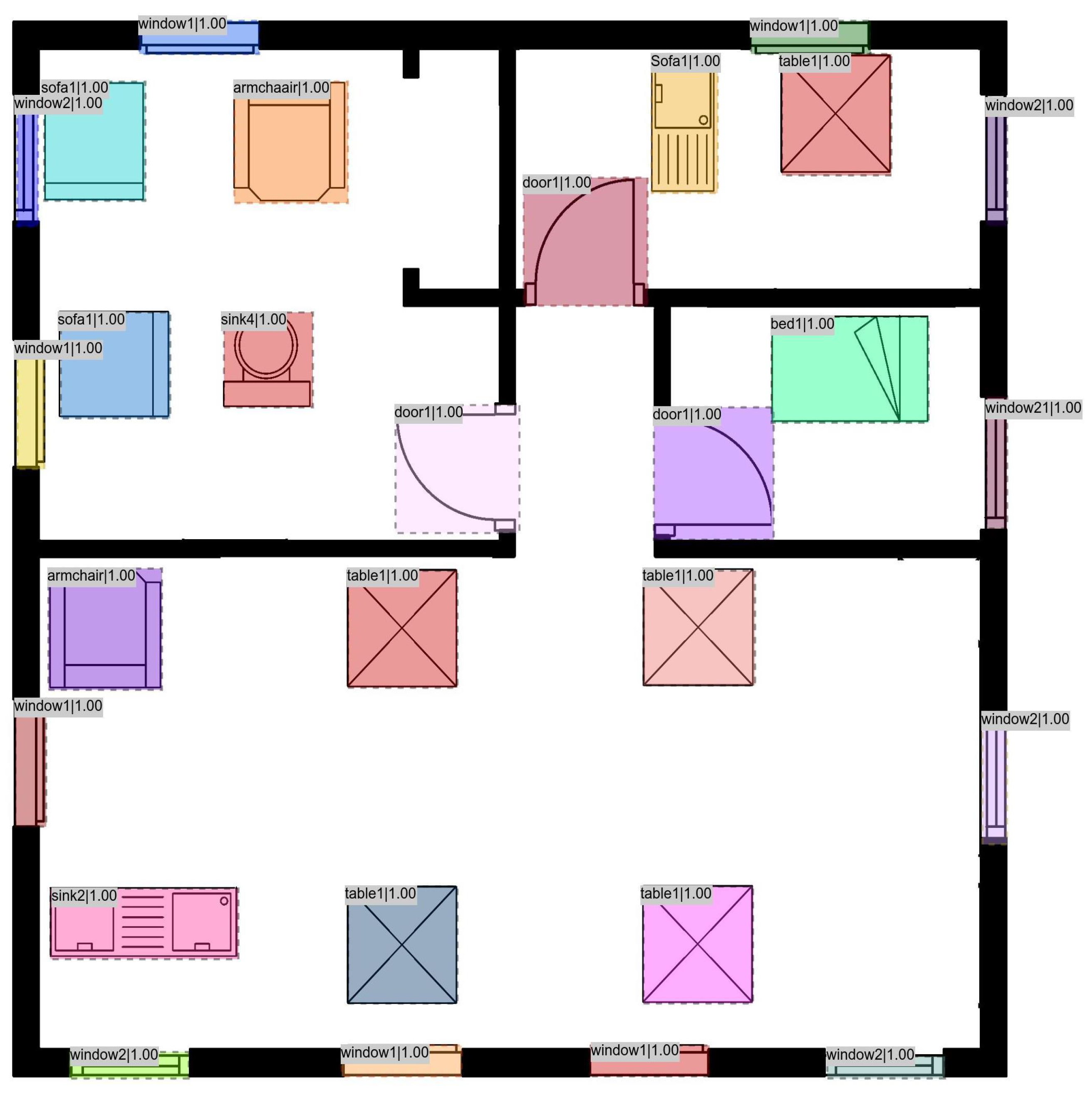
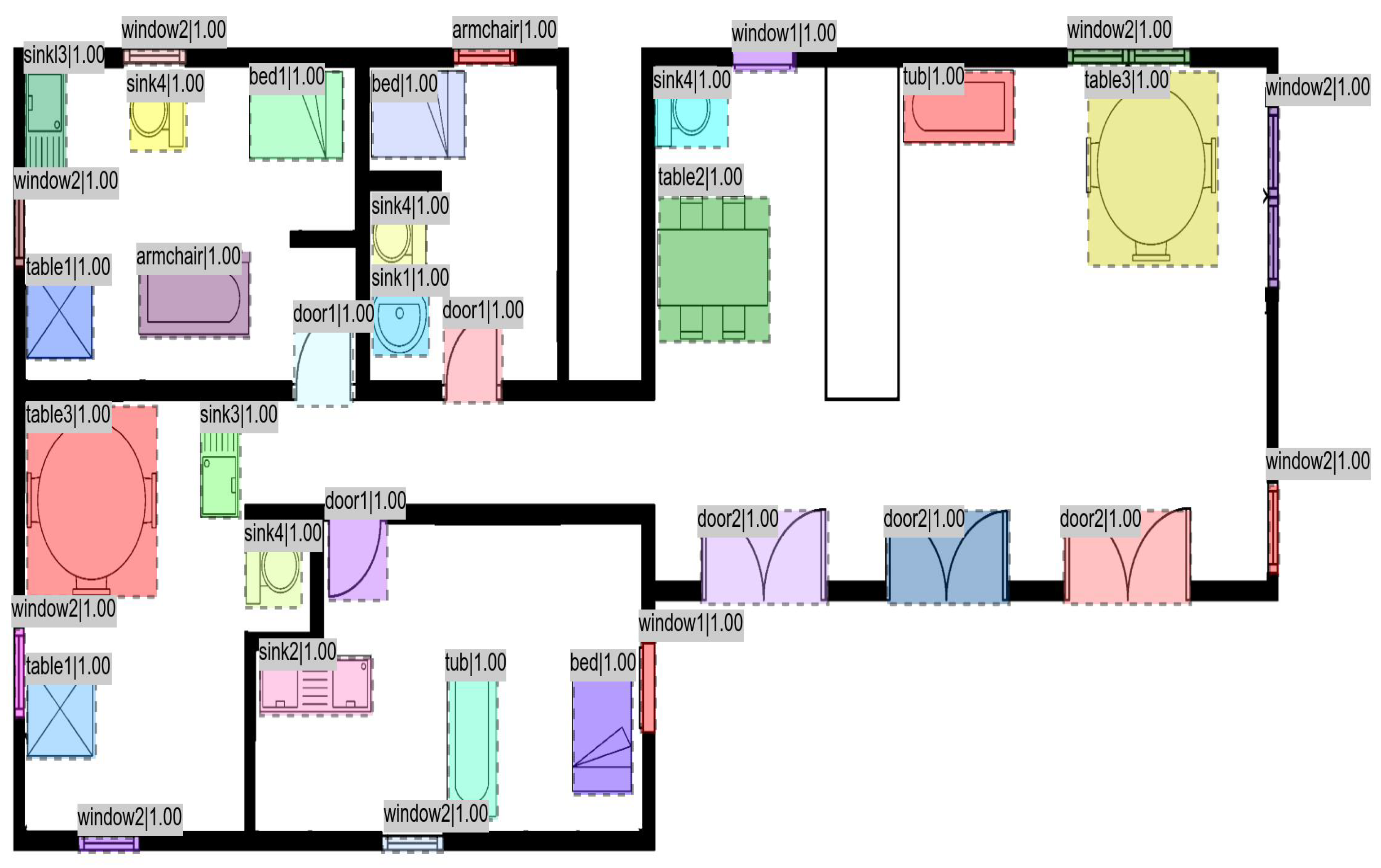
7. Results and Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Berthelot, D.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Sohn, K.; Zhang, H.; Raffel, C. ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring. arXiv 2019, arXiv:1911.09785. [Google Scholar]
- Sohn, K.; Berthelot, D.; Li, C.; Zhang, Z.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Zhang, H.; Raffel, C. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Simard, P.; Steinkraus, D.; Platt, J. Best practices for convolutional neural networks applied to visual document analysis. In Proceedings of the Seventh International Conference on Document Analysis and Recognition, Edinburgh, Scotland, 3–6 August 2003; pp. 958–963. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Xie, Q.; Hovy, E.H.; Luong, M.; Le, Q.V. Self-training with Noisy Student improves ImageNet classification. arXiv 2019, arXiv:1911.04252. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2017, arXiv:1703.10593. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.; Isola, P.; Saenko, K.; Efros, A.A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. arXiv 2017, arXiv:1711.03213. [Google Scholar]
- Zakharov, S.; Kehl, W.; Ilic, S. DeceptionNet: Network-Driven Domain Randomization. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 532–541. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mané, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies From Data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 113–123. [Google Scholar] [CrossRef]
- Zoph, B.; Cubuk, E.D.; Ghiasi, G.; Lin, T.; Shlens, J.; Le, Q.V. Learning Data Augmentation Strategies for Object Detection. arXiv 2019, arXiv:1906.11172. [Google Scholar]
- Gimenez, L.; Hippolyte, J.L.; Robert, S.; Suard, F.; Zreik, K. Review: Reconstruction of 3D building information models from 2D scanned plans. J. Build. Eng. 2015, 2, 24–35. [Google Scholar] [CrossRef]
- Ahmed, S.; Liwicki, M.; Weber, M.; Dengel, A. Automatic Room Detection and Room Labeling from Architectural Floor Plans. In Proceedings of the 2012 10th IAPR International Workshop on Document Analysis Systems, Gold Coast, QLD, Australia, 27–29 March 2012; pp. 339–343. [Google Scholar] [CrossRef]
- Sohn, K.; Zhang, Z.; Li, C.; Zhang, H.; Lee, C.; Pfister, T. A Simple Semi-Supervised Learning Framework for Object Detection. arXiv 2020, arXiv:2005.04757. [Google Scholar]
- Zoph, B.; Ghiasi, G.; Lin, T.; Cui, Y.; Liu, H.; Cubuk, E.D.; Le, Q.V. Rethinking Pre-training and Self-training. arXiv 2020, arXiv:2006.06882. [Google Scholar]
- Gurkan, H.; de Véricourt, F. Contracting, Pricing, and Data Collection Under the AI Flywheel Effect; Working Paper; ESMT: Berlin, Germany, 2022. [Google Scholar] [CrossRef]
- Xu, M.; Zhang, Z.; Hu, H.; Wang, J.; Wang, L.; Wei, F.; Bai, X.; Liu, Z. End-to-End Semi-Supervised Object Detection with Soft Teacher. arXiv 2021, arXiv:2106.09018. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- Mishra, S.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Towards Robust Object Detection in Floor Plan Images: A Data Augmentation Approach. Appl. Sci. 2021, 11, 11174. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Exploiting Concepts of Instance Segmentation to Boost Detection in Challenging Environments. Sensors 2022, 22, 3703. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Fan, X.; Ai, G.; Song, J.; Qin, Y.; Wu, J. Accurate Face Detection for High Performance. arXiv 2019, arXiv:1905.01585. [Google Scholar]
- Khan, A.H.; Munir, M.; van Elst, L.; Dengel, A. F2DNet: Fast Focal Detection Network for Pedestrian Detection. arXiv 2022, arXiv:2203.02331. [Google Scholar]
- Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Cascade Network with Deformable Composite Backbone for Formula Detection in Scanned Document Images. Appl. Sci. 2021, 11, 7610. [Google Scholar] [CrossRef]
- Nazir, D.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. HybridTabNet: Towards Better Table Detection in Scanned Document Images. Appl. Sci. 2021, 11, 8396. [Google Scholar] [CrossRef]
- Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. CasTabDetectoRS: Cascade Network for Table Detection in Document Images with Recursive Feature Pyramid and Switchable Atrous Convolution. J. Imaging 2021, 7, 214. [Google Scholar] [CrossRef]
- Naik, S.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Investigating Attention Mechanism for Page Object Detection in Document Images. Appl. Sci. 2022, 12, 7486. [Google Scholar] [CrossRef]
- Bachman, P.; Alsharif, O.; Precup, D. Learning with Pseudo-Ensembles. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar] [CrossRef]
- Miyato, T.; Maeda, S.I.; Koyama, M.; Ishii, S. Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1979–1993. [Google Scholar] [CrossRef] [PubMed]
- Sajjadi, M.; Javanmardi, M.; Tasdizen, T. Regularization with Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 1171–1179. [Google Scholar]
- Laine, S.; Aila, T. Temporal Ensembling for Semi-Supervised Learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Grandvalet, Y.; Bengio, Y. Semi-Supervised Learning by Entropy Minimization. In Proceedings of the 17th International Conference on Neural Information Processing Systems (NIPS’04); MIT Press: Cambridge, MA, USA, 2004; pp. 529–536. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised Data Augmentation for Consistency Training. In Proceedings of the Advances in Neural Information Processing Systems, Online Conference, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 6256–6268. [Google Scholar]
- Radosavovic, I.; Dollár, P.; Girshick, R.; Gkioxari, G.; He, K. Data Distillation: Towards Omni-Supervised Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4119–4128. [Google Scholar] [CrossRef]
- Jeong, J.; Lee, S.; Kim, J.; Kwak, N. Consistency-based Semi-supervised Learning for Object detection. In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Tang, P.; Ramaiah, C.; Xu, R.; Xiong, C. Proposal Learning for Semi-Supervised Object Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual Conference, 5–9 January 2021; pp. 2290–2300. [Google Scholar]
- Li, Y.; Huang, D.; Qin, D.; Wang, L.; Gong, B. Improving Object Detection with Selective Self-Supervised Self-Training. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIX. Springer: Berlin/Heidelberg, Germany, 2020; pp. 589–607. [Google Scholar] [CrossRef]
- Geifman, Y.; El-Yaniv, R. SelectiveNet: A Deep Neural Network with an Integrated Reject Option. arXiv 2019, arXiv:1901.09192. [Google Scholar]
- Wang, K.; Yan, X.; Zhang, D.; Zhang, L.; Lin, L. Towards Human-Machine Cooperation: Self-Supervised Sample Mining for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1605–1613. [Google Scholar] [CrossRef]
- Xie, Q.; Dai, Z.; Hovy, E.H.; Luong, M.; Le, Q.V. Unsupervised Data Augmentation. arXiv 2019, arXiv:1904.12848. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. RandAugment: Practical Data Augmentation with No Separate Search. arXiv 2019, arXiv:1909.13719. [Google Scholar]
- Ghorbel, A.; Lemaitre, A.; Anquetil, E.; Fleury, S.; Jamet, E. Interactive interpretation of structured documents: Application to the recognition of handwritten architectural plans. Pattern Recognit. 2015, 48, 2446–2458. [Google Scholar] [CrossRef]
- Macé, S.; Locteau, H.; Valveny, E.; Tabbone, S. A system to detect rooms in architectural floor plan images. In Proceedings of the DAS ’10, Boston, MA, USA, 9–11 June 2010. [Google Scholar]
- Lladós, J.; López-Krahe, J.; Martí, E. A System to Understand Hand-Drawn Floor Plans Using Subgraph Isomorphism and Hough Transform. Mach. Vis. Appl. 1997, 10, 150–158. [Google Scholar] [CrossRef]
- Eklund, A. Cascade Mask R-CNN and Keypoint Detection Used in Floorplan Parsing. Dissertation. 2020. Available online: https://www.mysciencework.com/publication/show/cascade-mask-rcnn-keypoint-detection-used-floorplan-parsing-907b4082 (accessed on 29 August 2022).
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef]
- Goyal, S.; Chattopadhyay, C.; Bhatnagar, G. Plan2Text: A framework for describing building floor plan images from first person perspective. In Proceedings of the 2018 IEEE 14th International Colloquium on Signal Processing Its Applications (CSPA), Penang, Malaysia, 9–10 March 2018; pp. 35–40. [Google Scholar] [CrossRef]
- Zeng, Z.; Li, X.; Yu, Y.K.; Fu, C.W. Deep Floor Plan Recognition Using a Multi-Task Network With Room-Boundary-Guided Attention. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9095–9103. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Liu, C.; Wu, J.; Kohli, P.; Furukawa, Y. Raster-to-Vector: Revisiting Floorplan Transformation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2214–2222. [Google Scholar] [CrossRef]
- Yamasaki, T.; Zhang, J.; Takada, Y. Apartment Structure Estimation Using Fully Convolutional Networks and Graph Model. In Proceedings of the 2018 ACM Workshop on Multimedia for Real Estate Tech (RETech’18), Yokohama, Japan, 11 June 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Dodge, S.; Xu, J.; Stenger, B. Parsing floor plan images. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 358–361. [Google Scholar] [CrossRef]
- de las Heras, L.P.; Ahmed, S.; Liwicki, M.; Valveny, E.; Sánchez, G. Statistical segmentation and structural recognition for floor plan interpretation. Int. J. Doc. Anal. Recognit. (IJDAR) 2014, 17, 221–237. [Google Scholar] [CrossRef]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Tarvainen, A.; Valpola, H. Weight-averaged consistency targets improve semi-supervised deep learning results. arXiv 2017, arXiv:1703.01780. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-Based Object Detectors with Online Hard Example Mining. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Delalandre, M.; Valveny, E.; Pridmore, T.; Karatzas, D. Generation of Synthetic Documents for Performance Evaluation of Symbol Recognition & Spotting Systems. Int. J. Doc. Anal. Recognit. 2010, 13, 187–207. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Liu, Y.; Ma, C.; He, Z.; Kuo, C.; Chen, K.; Zhang, P.; Wu, B.; Kira, Z.; Vajda, P. Unbiased Teacher for Semi-Supervised Object Detection. arXiv 2021, arXiv:2102.09480. [Google Scholar]
- Chen, B.; Chen, W.; Yang, S.; Xuan, Y.; Song, J.; Xie, D.; Pu, S.; Song, M.; Zhuang, Y. Label Matching Semi-Supervised Object Detection. arXiv 2022, arXiv:2206.06608. [Google Scholar]
- Ziran, Z.; Marinai, S. Object Detection in Floor Plan Images. In Proceedings of the Artificial Neural Networks in Pattern Recognition, Siena, Italy, 19–21 September 2018; Pancioni, L., Schwenker, F., Trentin, E., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 383–394. [Google Scholar]
- GitHub, I. Open Source Survey. 2019. Available online: https://github.com/dwnsingh/Object-Detection-in-Floor-Plan-Images (accessed on 29 August 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detector | Backbone | 1% | 5% | 10% |
|---|---|---|---|---|
| Faster R-CNN | ResNet-50 | 98.1 | 98.5 | 99.2 |
| Faster R-CNN | ResNet-101 | 98.3 | 99.4 | 99.6 |
| Mask R-CNN | ResNet-50 | 98.27 ↓ 8.94 | 98.74 ↓ 16 | 99.5 ↓ 37.5 |
| Mask R-CNN | ResNet-101 | 98.8 ↓ 29.4 | 99.7 ↓ 50 | 99.8 ↓ 50 |
| N | mAP | mAP@0.5 | mAP@0.75 |
|---|---|---|---|
| 5 | 0.996 | 0.998 | 0.997 |
| 10 | 0.998 | 1.0 | 1.0 |
| 15 | 0.997 | 1.0 | 1.0 |
| Threshold | mAP | mAP@0.5 | mAP@0.75 |
|---|---|---|---|
| 0.04 | 0.998 | 0.998 | 1.0 |
| 0.03 | 0.997 | 1.0 | 1.0 |
| 0.02 | 0.998 | 1.0 | 1.0 |
| 0.01 | 0.992 | 1.0 | 1.0 |
| Method | Detector | 5% | 10% | |
|---|---|---|---|---|
| Supervised | Mask R-CNN | 92.26 ± 0.16 | 92.89 ± 0.15 | 93.16 ± 0.12 |
| STAC [13] | Faster R-CNN | 94.86 ± 0.12 (+2.6) | 95.43 ± 0.14 (+2.54) | 97.12 ± 0.15 (+3.96) |
| Unbiased Teacher [66] | Faster R-CNN | 96.12 ± 0.143 (+3.86) | 96.87 ± 0.15 (+3.98) | 97.18 ± 0.12 (+4.02) |
| Label Match [67] | Faster R-CNN | 98.1 ± 0.12 (+6.01) | 98.54 ± 0.16 (+5.65) | 99.1 ± 0.12 (+5.94) |
| Mask-Aware (Our) | Faster R-CNN | 98.27 ± 0.20 (+6.01) | 99.74 ± 0.25 (+6.85) | 99.5 ± 0.15 (+6.43) |
| Mask-Aware (Our) | Mask R-CNN | 98.8 ± 0.10 (+6.54) | 99.7 ± 0.15 (+6.81) | 99.8 ± 0.10 (+6.64) |
| Method | Approach_Dataset | Detector | mAP |
|---|---|---|---|
| Ziran et al. [68] | supervised_d1 | Faster R-CNN | 0.31 |
| Ziran et al. [68] | supervised_d2 | Faster R-CNN | 0.39 |
| Singh et al. [69] | supervised_(SESYD+ROBIN) | Faster R-CNN | 0.756 |
| Singh et al. [69] | supervised_(SESYD+ROBIN) | YOLO | 0.857 |
| Mishra et al. [20] | supervised_SFPI | Cascade Mask R-CNN | 0.995 |
| Ours | semi-supervised_SFPI | Faster R-CNN | 0.996 |
| Ours | semi-supervised_SFPI | Mask R-CNN | 0.998 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shehzadi, T.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Mask-Aware Semi-Supervised Object Detection in Floor Plans. Appl. Sci. 2022, 12, 9398. https://doi.org/10.3390/app12199398
Shehzadi T, Hashmi KA, Pagani A, Liwicki M, Stricker D, Afzal MZ. Mask-Aware Semi-Supervised Object Detection in Floor Plans. Applied Sciences. 2022; 12(19):9398. https://doi.org/10.3390/app12199398
Chicago/Turabian StyleShehzadi, Tahira, Khurram Azeem Hashmi, Alain Pagani, Marcus Liwicki, Didier Stricker, and Muhammad Zeshan Afzal. 2022. "Mask-Aware Semi-Supervised Object Detection in Floor Plans" Applied Sciences 12, no. 19: 9398. https://doi.org/10.3390/app12199398
APA StyleShehzadi, T., Hashmi, K. A., Pagani, A., Liwicki, M., Stricker, D., & Afzal, M. Z. (2022). Mask-Aware Semi-Supervised Object Detection in Floor Plans. Applied Sciences, 12(19), 9398. https://doi.org/10.3390/app12199398