
A Study on the Channel Expansion VAE for Content-Based Image Retrieval

Abstract
:1. Introduction
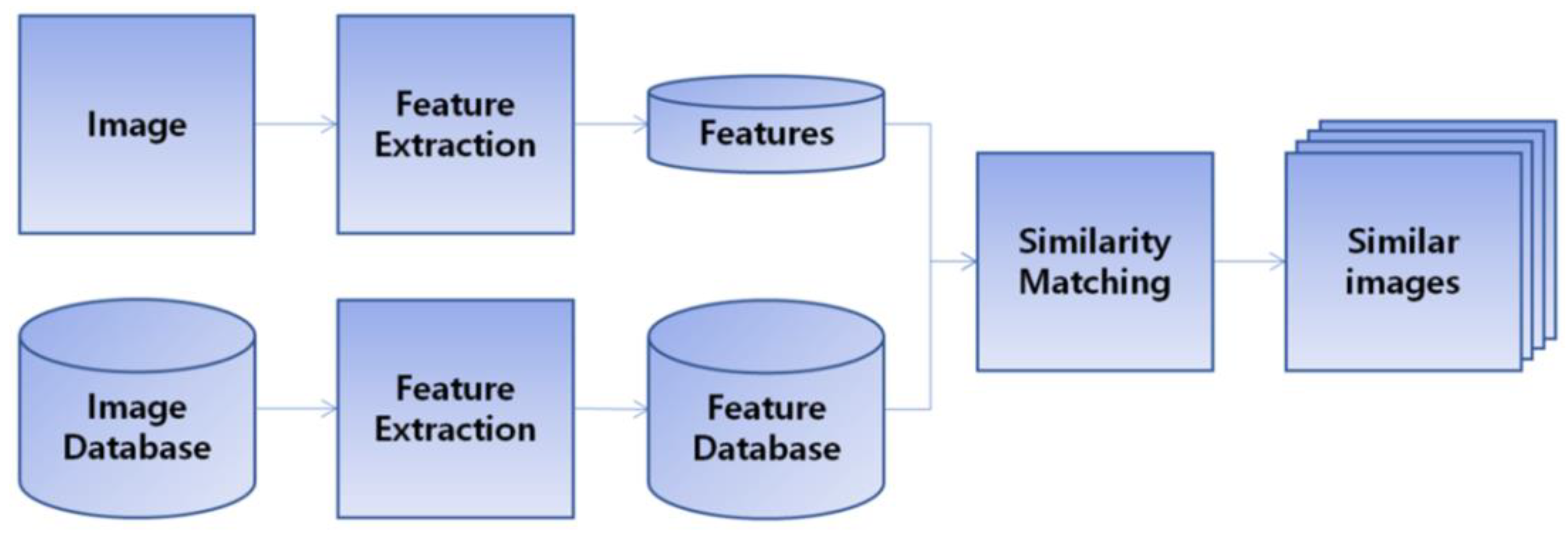
2. Related Work
3. Method
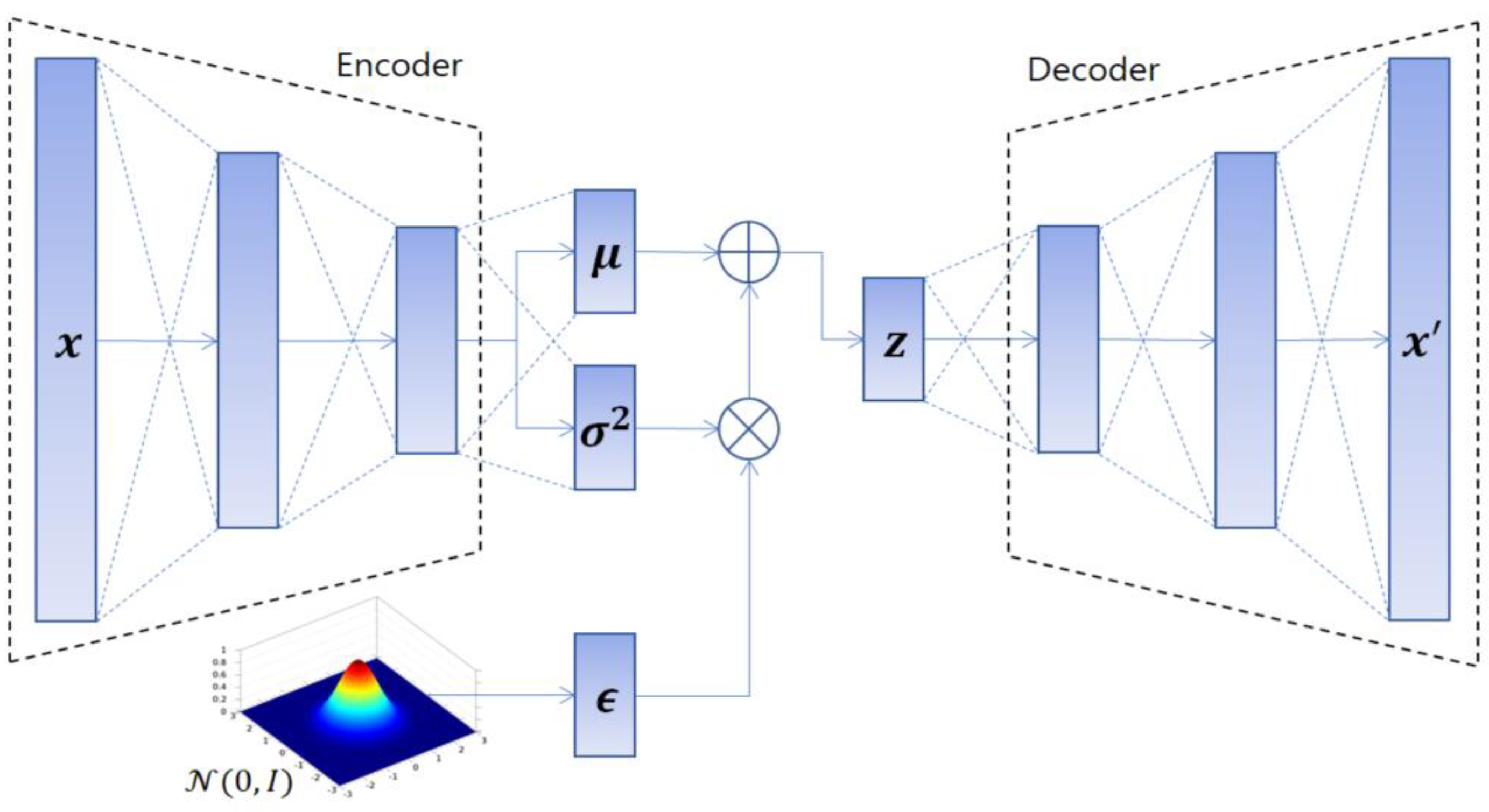
3.1. Variational Auto-Encoder
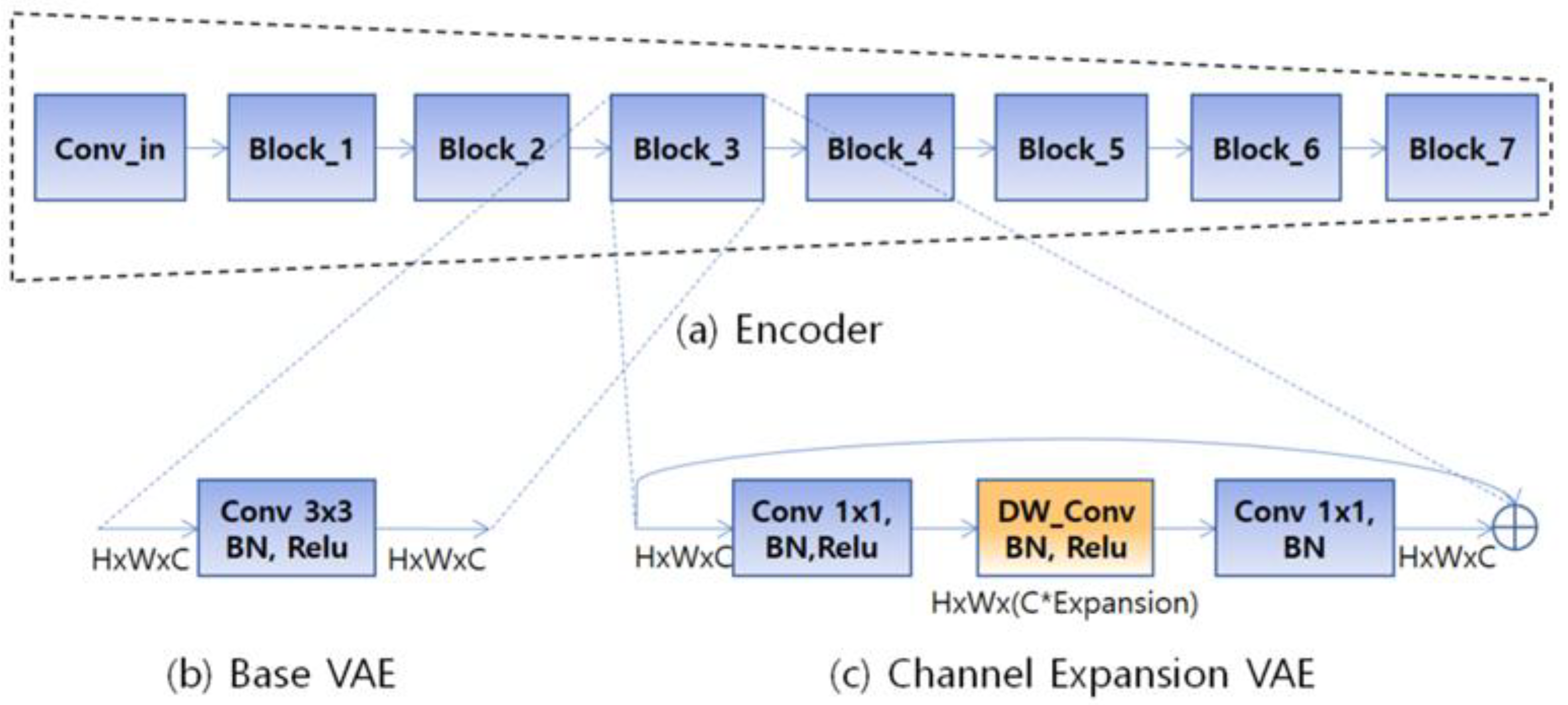
3.2. Channel Expansion
4. Experiment
4.1. Dataset
4.1.1. Oxford Flowers 102 Dataset
4.1.2. MNIST Dataset
4.2. Experiment
4.2.1. Setting
4.2.2. Channel Expansion Effect on complex dataset
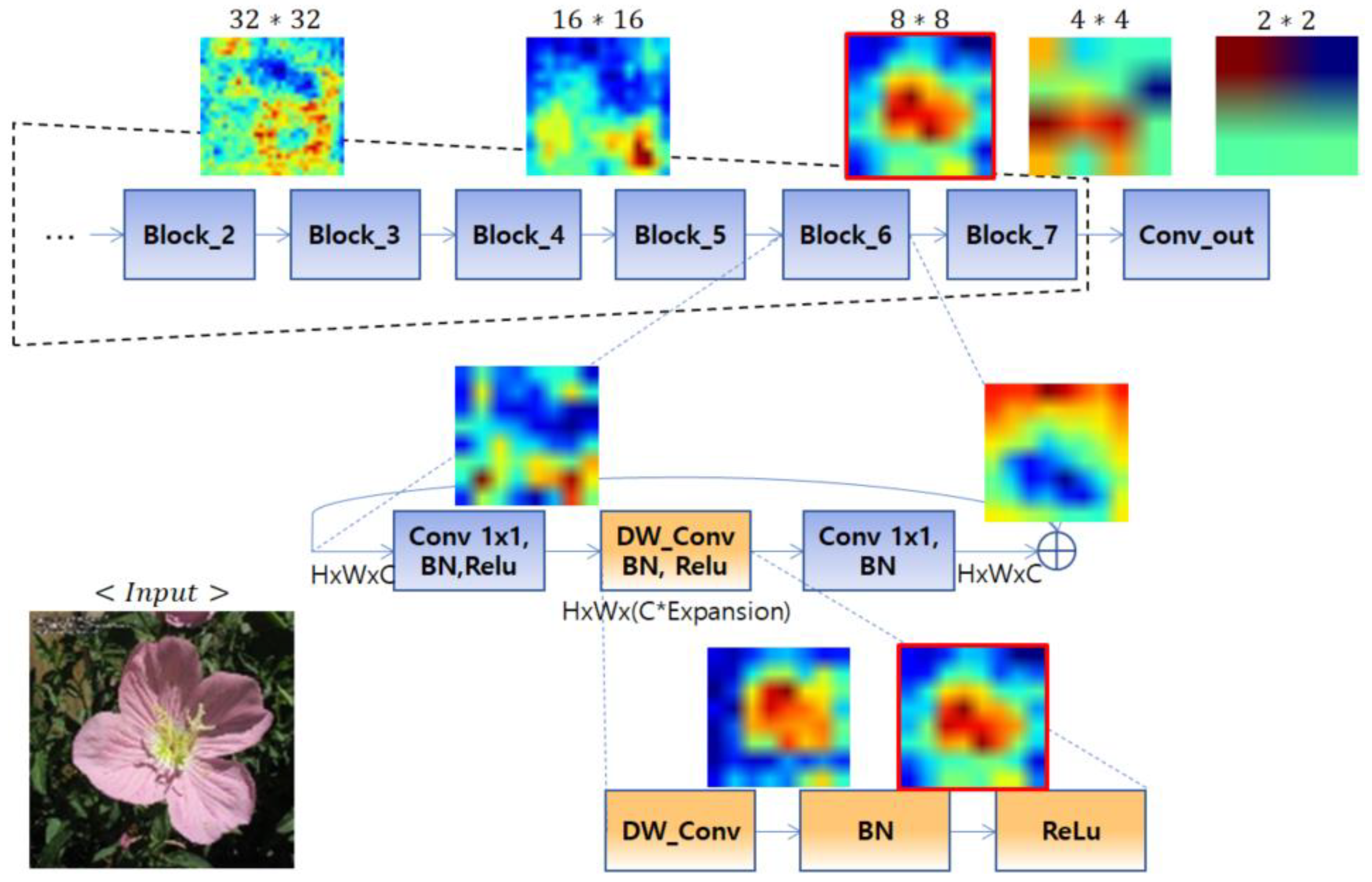
4.2.3. Regional Masking Effect
4.2.4. Compression performance
4.2.5. Comparison to Unsupervised IR Models
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dongyuan, L.; Xiaojun, B. Criminal Investigation Image Retrieval Based on Deep Learning. In Proceedings of the 2020 International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 25–27 September 2020. [Google Scholar]
- Kazuma, K.; Ryuichiro, H.; Yusuke, K.; Tatsuya, H.; Ryuji, H. Decomposing Normal and Abnormal Features of Medical Image for Content-based Image Retrieval. arXiv 2020, arXiv:2011.0622474. [Google Scholar]
- Subhankar, R.; Enver, S.; Begun, D.; Nicu, S. Metric-Learning based Deep Hashing Network for Content Based Retrieval of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 226–230. [Google Scholar]
- Urszula, M.; Halina, K. Deep Learning: A New Era in Bridging the Semantic Gap. In Bridging the Semantic Gap in Image and Video Analysis; Springer: Berlin/Heidelberg, Germany, 2018; pp. 123–159. [Google Scholar]
- Ali, S.R.; Hossein, A.; Josephine, S.; Stefan, C. CNN Features off-the-shelf: An Astounding Baseline for Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR-W), Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar]
- Jeff, D.; Yangqung, J.; Oriol, V.; Judy, H.; Ning, Z.; Eric, T.; Trevor, D. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. PMLR 2014, 32, 647–655. [Google Scholar]
- Artem, B.; Anton, S.; Alexandr, C.; Victor, L. Neural Codes for Image Retrieval. Eur. Conf. Comput. Vis. 2014, 8689, 586–599. [Google Scholar]
- Artem, B.Y.; Victor, L. Aggregating Local Deep Features for Image Retrieval. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1269–1277. [Google Scholar]
- Yannis, K.; Clayton, M.; Simon, O. Cross-Dimensional Weighting for Aggregated Deep Convolutional Features. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2016; Volume 9913, pp. 685–701. [Google Scholar]
- Xiu-Shen, W.; Jian-Hao, L.; Jianxin, W.; Zhi-Hua, Z. Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval. IEEE Trans. Image Process. 2017, 26, 1868–1881. [Google Scholar]
- Jian, X.; Cunzhao, S.; Chengzuo, Q.; Chunheng, W.; Baihua, X. Unsupervised Part-based Weighting Aggregation of Deep Convolutional Features for Image Retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2017; Volume 8689, pp. 586–599. [Google Scholar]
- Filip, R.; Giorgos, T.; Ondrej, C. Fine-tuning CNN Image Retrieval with No Human Annotation. IEEE Trans. Patter Anal. Mach. Intell. 2019, 41, 1655–1668. [Google Scholar]
- Giorgos, T.; Ronan, S.; Herve, J. Particular Object Retrieval with Integral Max-pooling of CNN Activations. In Proceedings of the ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Heejae, J.; Byungsoo, K.; Youngjoon, K.; Insick, K.; Jongtack, K. Combination of Multiple Global Descriptors for Image Retrieval. arXiv 2020, arXiv:1903.10663. [Google Scholar]
- Giorgos, T.; Tomas, J.; Ondrej, C. Learning and Aggregating Deep Local Descriptors for Instance-Level Recognition. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2020; pp. 460–477. [Google Scholar]
- Ian, J.G.; Jean, P.; Mehdi, M.; Bing, X.; David, W.; Sherjil, O.; Aaron, C.; Yoshua, B. Generative Adversarial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS), Montreal, Canada, 8–13 December 2014; Volume 2, pp. 2672–2680. [Google Scholar]
- Diederik, P.K.; Max, W. Auto-encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Ling, H.; Cong, B.; Yijuan, L.; Shengyong, C.; Qi, T. Adversarial Learning for Content-based Image Retrieval. In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019. [Google Scholar]
- Sara, T.F. Designing Variational Autoencoders for Image Retrieval; KTH EECS: Stockholm, Sweden, 2018. [Google Scholar]
- Yann, L.; Leon, B.; Yoshua, B.; Patrick, H. Gradient-based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar]
- James-Andrew, R.S. Exploiting Latent Codes: Interactive Fashion Product Generation, Similar Image Retrieval, and Cross-Category Recommendation using Variational Autoencoders. arXiv 2020, arXiv:2008.01053. [Google Scholar]
- Vaibhav, R.; Manideep, N.; Naresh, K.G.; Kaushika, T.; Swapnil, G. Auto-Encoders for Content-based Image Retrieval with its Implementation Using Handwritten Dataset. In Proceedings of the International Conference on Communication and Electronics Systems, Coimbatore, India, 10–12 June 2020. [Google Scholar]
- Manish, B.; Diane, O.; Juan, C.; Liping, Y.; Brendt, W. Diagram Image Retrieval using Sketch-based Deep Learning and Transfer Learning. In Proceedings of the IEEE Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Mingxing, T.; Bo, C.; Ruoming, P.; Vijay, V.; Mark, S.; Andrew, H.; Quoc, V.L. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Maria-Elena, N.; Andrew, Z. Automated Flower Classification over a Large Number of Classes. In Proceedings of the 2008 IEEE 6th Indian Conference on Computer Vision, Graphics & Image processing, Bhubaneswar, India, 16–19 December 2008; pp. 722–729. [Google Scholar]
- Zhixiang, C.; Jiwen, L.; Jianjiang, F.; Jie, Z. Nonlinear Discrete Hashing. IEEE Trans. Multimed. 2017, 19, 123–135. [Google Scholar]
- Cong, B.; Ling, H.; Xiang, P.; Jianwei, Z.; Shengyong, C. Optimization of Deep Convolutional Neural Network for Large Scale Image Retrieval. Neurocomputing 2018, 303, 60–67. [Google Scholar]
- Yunchao, G.; Svetlana, L.; Albert, G.; Florent, P. Iterative Quantization: A Procrustean Approach to Learning Binary Codes for Large-Scale Image Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2916–2929. [Google Scholar]
- Jae-Pil, H.; Youngwoon, L.; Junfeng, H.; Shih-Fu, C.; Sung-Eui, Y. Spherical Hashing: Binary Code Embedding with Hyper-spheres. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2304–2316. [Google Scholar]
- Jiwen, L.; Venice, E.L.; Jie, Z. Deep Hashing for Scalable Image Search. IEEE Trans. Image Process. 2017, 26, 2352–2367. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | Kernel Size | Output Size | Repeat |
|---|---|---|---|
| Conv_in | 3 × 3 | 64 × 64 × 32 | ×1 |
| Block_1 | 3 × 3 | 64 × 64 × 16 | ×1 |
| Block_2 | 5 × 5 | 32 × 32 × 40 | ×2 |
| Block_3 | 3 × 3 | 16 × 16 × 80 | ×3 |
| Block_4 | 5 × 5 | 16 × 16 × 112 | ×3 |
| Block_5 | 5 × 5 | 8 × 8 × 192 | ×4 |
| Block_6 | 3 × 3 | 4 × 4 × 320 | ×1 |
| Block_7 | 3 × 3 | 2 × 2 × 512 | ×1 |
| Layer_out | GMP||FCL | 512 | ×1 |
| Model | Top_1 | Top_5 | Top_10 |
|---|---|---|---|
| VAE | 30.4% | 37.6% | 36.3% |
| CEVAE | 36.2% | 43.0% | 41.2% |
| Dimension | Descriptor | Inference Time (s) | ||
|---|---|---|---|---|
| GMP From Block_6 | GMP + AMP From Block_6 | Encoder Output | ||
| 2304 | - | 45.2% | - | 0.277 |
| 1152 | 45.3% | 45.2% | - | 0.106 |
| 512 | 45.1% | 45.3% | 43.0% | 0.067 |
| 256 | 44.9% | 44.8% | 43.0% | 0.060 |
| 128 | 44.3% | - | 43.0% | 0.057 |
| 62 | 43.5% | - | 42.2% | 0.055 |
| 32 | 41.8% | - | 40.0% | 0.053 |
| 16 | 39.5% | - | 33.9% | 0.051 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.; Lee, Y.; Ko, H.-H.; Kang, M. A Study on the Channel Expansion VAE for Content-Based Image Retrieval. Appl. Sci. 2022, 12, 9160. https://doi.org/10.3390/app12189160
Lee K, Lee Y, Ko H-H, Kang M. A Study on the Channel Expansion VAE for Content-Based Image Retrieval. Applied Sciences. 2022; 12(18):9160. https://doi.org/10.3390/app12189160
Chicago/Turabian StyleLee, Kyounghak, Yeonghun Lee, Hyung-Hwa Ko, and Minsoo Kang. 2022. "A Study on the Channel Expansion VAE for Content-Based Image Retrieval" Applied Sciences 12, no. 18: 9160. https://doi.org/10.3390/app12189160
APA StyleLee, K., Lee, Y., Ko, H.-H., & Kang, M. (2022). A Study on the Channel Expansion VAE for Content-Based Image Retrieval. Applied Sciences, 12(18), 9160. https://doi.org/10.3390/app12189160