
Underwater Accompanying Robot Based on SSDLite Gesture Recognition



Abstract
:1. Introduction
2. Related Work
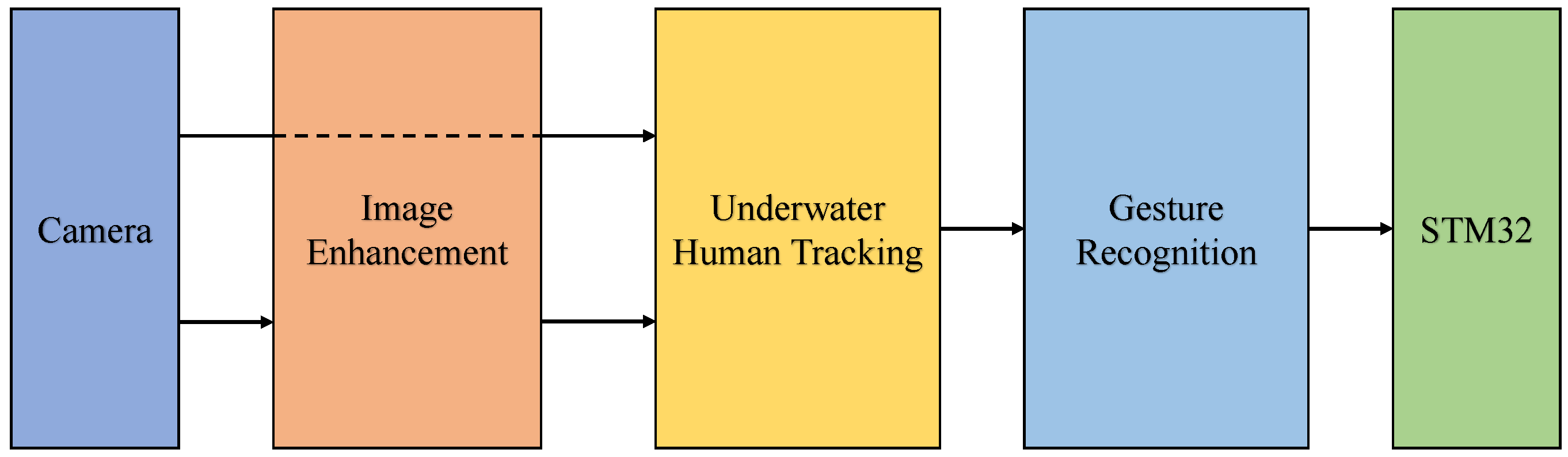
3. Framework and Methodology
3.1. Image Enhancement
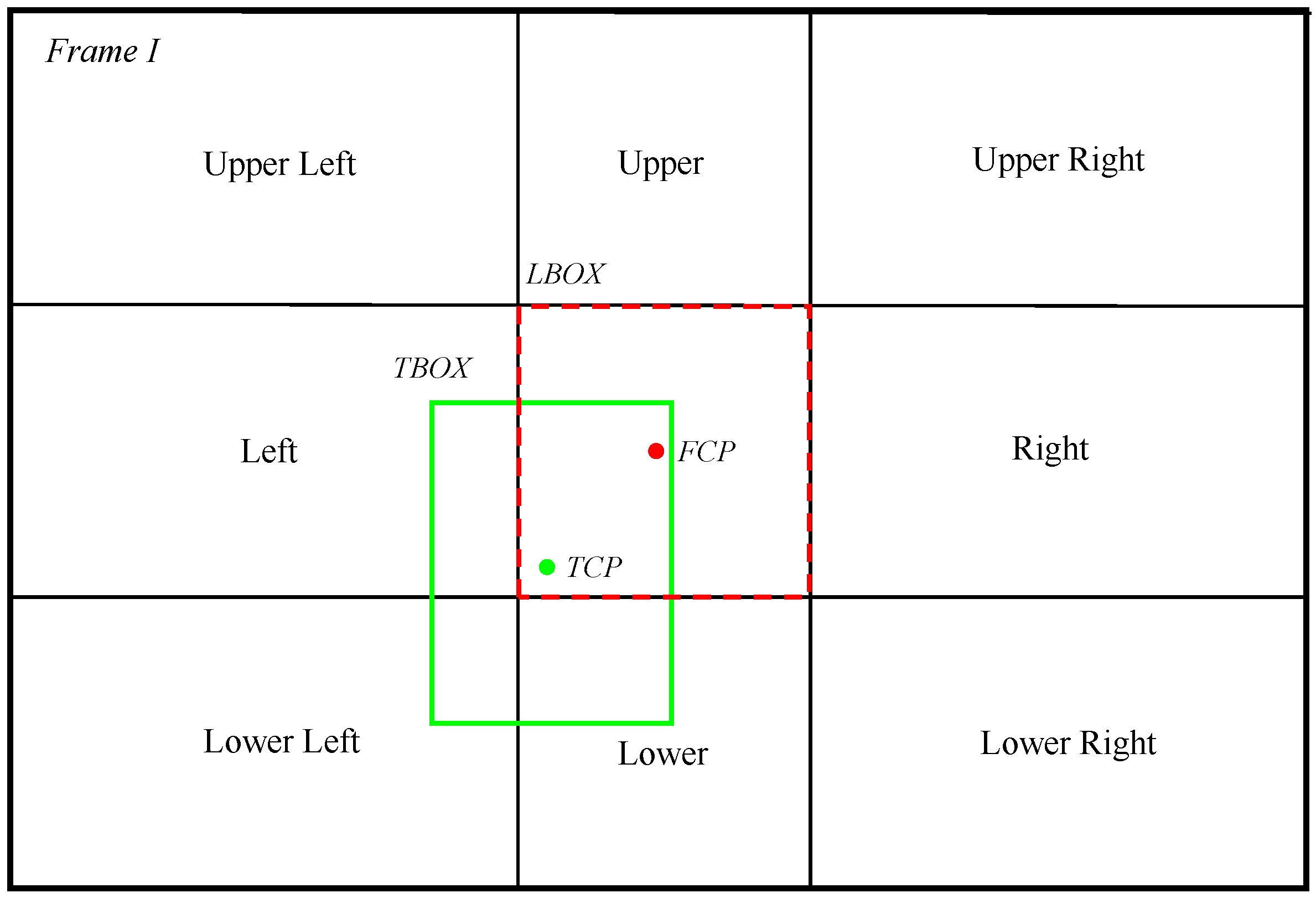
3.2. Underwater Human Tracking
| Algorithm 1: Underwater human tracking algorithm |
|
3.3. Gesture Recognition
4. Algorithm and System Experiment
4.1. Datasets
4.2. Performance Evaluation
4.2.1. Image Enhancement Performance
4.2.2. Recognition Performance
4.2.3. Comparison of Performance before and after Human Tracking
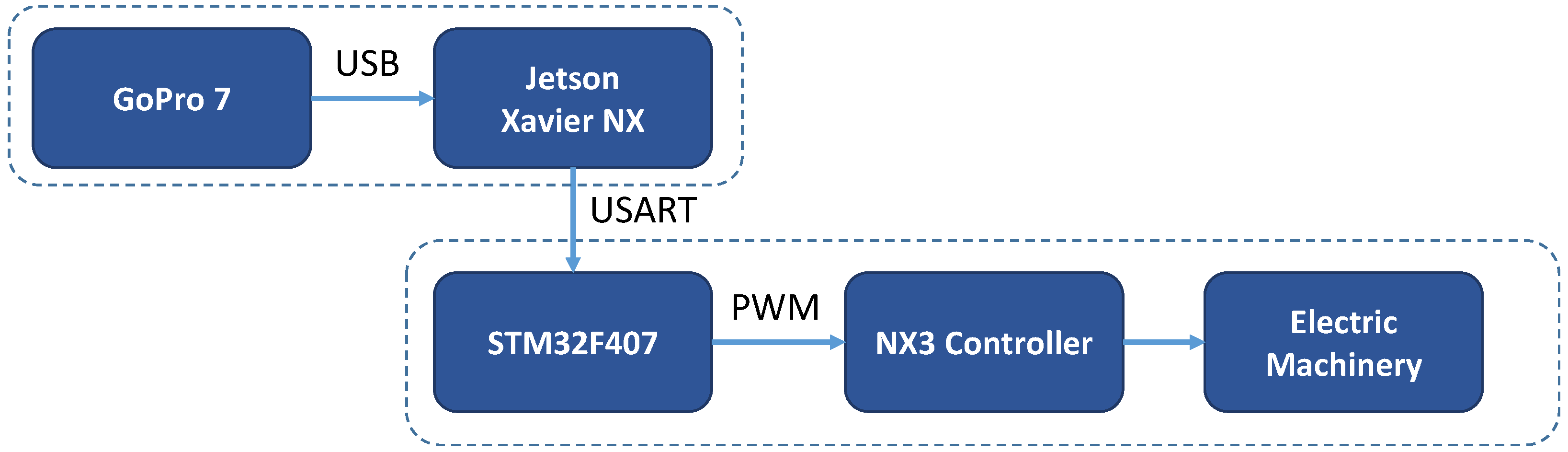
4.3. System Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- An, E.; Dhanak, M.R.; Shay, L.K.; Smith, S.; Van Leer, J. Coastal oceanography using a small AUV. J. Atmos. Ocean. Technol. 2001, 18, 215–234. [Google Scholar] [CrossRef]
- Pazmiño, R.S.; Cena, C.E.G.; Arocha, C.A.; Santonja, R.A. Experiences and results from designing and developing a 6 DoF underwater parallel robot. Robot. Auton. Syst. 2011, 59, 101–112. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, J.; Chemori, A.; Xiang, X. Virtual submerged floating operational system for robotic manipulation. Complexity 2018, 2018, 9528313. [Google Scholar] [CrossRef]
- Shojaei, K.; Dolatshahi, M. Line-of-sight target tracking control of underactuated autonomous underwater vehicles. Ocean Eng. 2017, 133, 244–252. [Google Scholar] [CrossRef]
- Ridao, P.; Carreras, M.; Ribas, D.; Sanz, P.J.; Oliver, G. Intervention AUVs: The next challenge. Annu. Rev. Control 2015, 40, 227–241. [Google Scholar] [CrossRef]
- Zhang, H.; Yuan, F.; Chen, J.; He, X.; Zhu, Y. Gesture-Based Autonomous Diving Buddy for Underwater Photography. In International Conference on Image and Graphics; Springer: Cham, Switzerland, 2021; pp. 195–206. [Google Scholar]
- Ura, T. Observation of deep seafloor by autonomous underwater vehicle. Indian J. Geo-Mar. Sci. 2013, 42, 1028–1033. [Google Scholar]
- Nishida, Y.; Nagahashi, K.; Sato, T.; Bodenmann, A.; Thornton, B.; Asada, A.; Ura, T. Development of an autonomous underwater vehicle for survey of cobalt-rich manganese crust. In Proceedings of the OCEANS 2015-MTS/IEEE, Washington, DC, USA, 19–22 October 2015; pp. 1–5. [Google Scholar]
- Nakatani, T.; Ura, T.; Ito, Y.; Kojima, J.; Tamura, K.; Sakamaki, T.; Nose, Y. AUV “TUNA-SAND” and its Exploration of hydrothermal vents at Kagoshima Bay. In Proceedings of the OCEANS 2008-MTS/IEEE Kobe Techno-Ocean, Kobe, Japan, 8–11 April 2008; pp. 1–5. [Google Scholar]
- Kilfoyle, D.; Baggeroer, A. The state of the art in underwater acoustic telemetry. IEEE J. Ocean Eng. 2000, 25, 4–27. [Google Scholar] [CrossRef]
- Chiarella, D.; Bibuli, M.; Bruzzone, G.; Caccia, M.; Ranieri, A.; Zereik, E.; Marconi, L.; Cutugno, P. Gesture-based language for diver-robot underwater interaction. In Proceedings of the Oceans 2015—Genova, Genova, Italy, 18–21 May 2015; pp. 1–9. [Google Scholar]
- Mišković, N.; Bibuli, M.; Birk, A.; Caccia, M.; Egi, M.; Grammer, K.; Marroni, A.; Neasham, J.; Pascoal, A.; Vasilijević, A.; et al. Caddy—cognitive autonomous diving buddy: Two years of underwater human-robot interaction. Mar. Technol. Soc. J. 2016, 50, 54–66. [Google Scholar] [CrossRef]
- Gustin, F.; Rendulic, I.; Miskovic, N.; Vukic, Z. Hand gesture recognition from multibeam sonar imagery. IFAC-PapersOnLine 2016, 49, 470–475. [Google Scholar] [CrossRef]
- Buelow, H.; Birk, A. Gesture-recognition as basis for a Human Robot Interface (HRI) on a AUV. In Proceedings of the OCEANS’11 MTS/IEEE KONA, Waikoloa, HI, USA, 19–22 September 2011. [Google Scholar]
- Gordon, H.R. Can the Lambert-Beer law be applied to the diffuse attenuation coefficient of ocean water? Limnol. Oceanogr. 1989, 34, 1389–1409. [Google Scholar] [CrossRef]
- Hsu, R.C.; Su, P.C.; Hsu, J.L.; Wang, C.Y. Real-Time Interaction System of Human-Robot with Hand Gestures. In Proceedings of the 2020 IEEE Eurasia Conference on IOT, Communication and Engineering (ECICE), Yunlin, Taiwan, 23–25 October 2020; pp. 396–398. [Google Scholar]
- Fiorini, L.; Loizzo FG, C.; Sorrentino, A.; Kim, J.; Rovini, E.; Di Nuovo, A.; Cavallo, F. Daily gesture recognition during human-robot interaction combining vision and wearable systems. IEEE Sens. J. 2021, 21, 23568–23577. [Google Scholar] [CrossRef]
- Rautaray, S.S.; Agrawal, A. Vision Based Hand Gesture Recognition for Human Computer Interaction: A Survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- Chiarella, D.; Bibuli, M.; Bruzzone, G.; Caccia, M.; Ranieri, A.; Zereik, E.; Marconi, L.; Cutugno, P. A Novel Gesture-Based Language for Underwater Human—Robot Interaction. J. Mar. Sci. Eng. 2018, 6, 91. [Google Scholar] [CrossRef]
- Xu, P. Gesture-based Human-robot Interaction for Field Programmable Autonomous Underwater Robots. arXiv 2017, arXiv:1709.08945. [Google Scholar]
- Jiang, Y.; Zhao, M.; Wang, C.; Wei, F.; Wang, K.; Qi, H. Diver’s hand gesture recognition and segmentation for human–robot interaction on AUV. Signal Image Video Process. 2021, 15, 1899–1906. [Google Scholar] [CrossRef]
- Jiang, Y.; Peng, X.; Xue, M.; Wang, C.; Qi, H. An underwater human–robot interaction using hand gestures for fuzzy control. Int. J. Fuzzy Syst. 2021, 23, 1879–1889. [Google Scholar] [CrossRef]
- Cooper, N.; Lindsey, E.; Chapman, R.; Biaz, S. GPU Based Monocular Vision for Obstacle Detection; Techinical Report; Auburn University: Auburn, AL, USA, 2017. [Google Scholar]
- Shustanov, A.; Yakimov, P. A method for traffic sign recognition with CNN using GPU. In Proceedings of the 14th International Joint Conference on e-Business and Telecommunications–ICETE 2017, Madrid, Spain, 24–26 July 2017; Volume 5, pp. 42–47. [Google Scholar]
- Otterness, N.; Yang, M.; Rust, S.; Park, E.; Anderson, J.H.; Smith, F.D.; Berg, A.; Wang, S. An Evaluation of the NVIDIA TX1 for Supporting Real-time Computer-Vision Workloads. In Proceedings of the 2017 IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Pittsburgh, PA, USA, 18–21 April 2017; pp. 355–365. [Google Scholar]
- Elkaseer, A.; Salama, M.; Ali, H.; Scholz, S. Approaches to a Practical Implementation of Industry 4.0. In Proceedings of the Eleventh International Conference on Advances in Computer-Human Interactions, Rome, Italy, 25–29 March 2018; pp. 141–146. [Google Scholar]
- Chang, W.J.; Chen, L.B.; Hsu, C.H.; Lin, C.P.; Yang, T.C. A Deep Learning-Based Intelligent Medicine Recognition System for Chronic Patients. IEEE Access 2019, 7, 44441–44458. [Google Scholar] [CrossRef]
- Sancho Aragón, J. Energy and Performance Modeling of NVIDIA Jetson TX1 Embedded GPU in Hyperspectral Image Classification Tasks for Cancer detection Using Machine Learning. Master’s Thesis, Escuela Técnica Superior de Ingeniería y Sistemas de Telecomunicación, Madrid, Spain, 2018. [Google Scholar]
- Tang, J.; Ren, Y.; Liu, S. Real-Time Robot Localization Vision and Speech Recognition on Nvidia Jetson TX1. arXiv 2017, arXiv:1705.10945. [Google Scholar]
- Wu, Y.; Gao, L.; Zhang, B.; Yang, B.; Chen, Z. Embedded GPU implementation of anomaly detection for hyperspectral images. High-Perform. Comput. Remote Sens. V 2015, 9646, 964608. [Google Scholar]
- Xing, H.; Guo, S.; Shi, L.; Hou, X.; Liu, Y.; Hu, Y.; Xia, D.; Li, Z. Quadrotor Vision-based Localization for Amphibious Robots in Amphibious Area. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; pp. 2469–2474. [Google Scholar]
- Jaffe, J.S. Computer modeling and the design of optimal underwater imaging systems. IEEE J. Ocean. Eng. 1990, 15, 101–111. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, arXiv:1708.0200228. [Google Scholar] [CrossRef] [PubMed]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In ECCV; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C.; Bekaert, P. Color balance and fusion for underwater image enhancement. IEEE Trans. Image Process. 2017, 27, 379–393. [Google Scholar] [CrossRef] [PubMed]
- Pan, P.; Yuan, F.; Cheng, E. Underwater image de-scattering and enhancing using dehaze net and HWD. J. Mar. Sci. Technol. 2018, 26, 531–540. [Google Scholar]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Lu, J.; Yuan, F.; Yang, W.; Cheng, E. An Imaging Information Estimation Network for Underwater Image Color Restoration. IEEE J. Ocean. Eng. 2021, 46, 1228–1239. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Actions | Take photo | Stop | Light up | Forward | Float up | Dive | Turn right | Turn left |
| Gestures examples |  |  |  |  |  |  |  |  |
| Method | PSNR | SSIM |
|---|---|---|
| Retinex-based | 14.6280 | 0.3658 |
| Multi-scale fusion | 12.1468 | 0.2349 |
| WaterGAN | 16.7906 | 0.3649 |
| Proposed | 24.0392 | 0.6609 |
| Method | Backbone | mAP | Speed | Model Size |
|---|---|---|---|---|
| YOLOv3 | DarkNet-53 | 0.940 | 7.8 fps | 117 MB |
| RefineDet | VGG-16 | 0.849 | 4.6 fps | 129 MB |
| RetinaNet | ResNet-50 | 0.861 | 3.5 fps | 138 MB |
| SSD | VGG-16 | 0.821 | 3.7 fps | 90.6 MB |
| SSDLite | MobileNetv3 | 0.882 | 17.2 fps | 14.0 MB |
| Backbone | mAP | Speed | Model Size |
|---|---|---|---|
| VGG-16 | 0.9998 | 10.8 fps | 94.1 MB |
| V2 | 0.9990 | 21.3 fps | 12.7 MB |
| V3-Small | 0.9994 | 23.5 fps | 5.71 MB |
| V3-Large | 0.9998 | 21.2 fps | 14.4 MB |
| Score Threshold | mAP (before Tracking) | mAP (after Tracking) | Improvement Rate |
|---|---|---|---|
| 0.5 | 0.527 | 0.735 | 39.5% |
| 0.6 | 0.491 | 0.735 | 49.7% |
| 0.7 | 0.418 | 0.720 | 72.2% |
| 0.8 | 0.364 | 0.671 | 84.3% |
| 0.9 | 0.327 | 0.670 | 104.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, T.; Zhu, Y.; Wu, K.; Yuan, F. Underwater Accompanying Robot Based on SSDLite Gesture Recognition. Appl. Sci. 2022, 12, 9131. https://doi.org/10.3390/app12189131
Liu T, Zhu Y, Wu K, Yuan F. Underwater Accompanying Robot Based on SSDLite Gesture Recognition. Applied Sciences. 2022; 12(18):9131. https://doi.org/10.3390/app12189131
Chicago/Turabian StyleLiu, Tingzhuang, Yi Zhu, Kefei Wu, and Fei Yuan. 2022. "Underwater Accompanying Robot Based on SSDLite Gesture Recognition" Applied Sciences 12, no. 18: 9131. https://doi.org/10.3390/app12189131
APA StyleLiu, T., Zhu, Y., Wu, K., & Yuan, F. (2022). Underwater Accompanying Robot Based on SSDLite Gesture Recognition. Applied Sciences, 12(18), 9131. https://doi.org/10.3390/app12189131