
Credibility Analysis on Twitter Considering Topic Detection

 ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
2. Related Work
3. Topic Detection Methods
3.1. Clustering Models
- Initialization: Select k random points as representative centroids.
- Repeat until convergence:
- −
- Assign each data point to the cluster of the nearest centroid.
- −
- Recompute each cluster centroid as the average of the assigned points.
3.2. Matrix Factorization Model
3.2.1. Latent Semantic Indexing
3.2.2. Non-Negative Matrix Factorization (NMF)
3.3. Probabilistic Model
4. Comparative Evaluation of Topic Detection Algorithms
4.1. The Dataset Description
4.2. Preprocessing
- Tokenization: the text is split at each blank character to create a list of single tokens (stand-alone words, numbers, signs, or a concatenated string such as a URL).
- Remove mentions or usernames from tweets that begin with ’@’ symbol and are followed by text (e.g., @jimcramer, @apple).
- Removing special characters: the characters, such as %, *, !, [, ), are removed to preserve the focus on words in every tweet.
- Removing Web URLs: URLs are not considered in our topic modeling approach because they contain unspecific and hardly interpretable information.
- Removing numbers: numbers are not considered because they generally do not contain semantically viable information for our purposes.
- Removing hashtags (e.g., #AAPL, #AppleSnob), emojis, symbols, and emoticons.
- Removing frequent words and stopwords that would not provide specific semantics. These are commonly words that do not carry distinct semantic meaning, e.g., the, an, and, what.
4.3. Processing
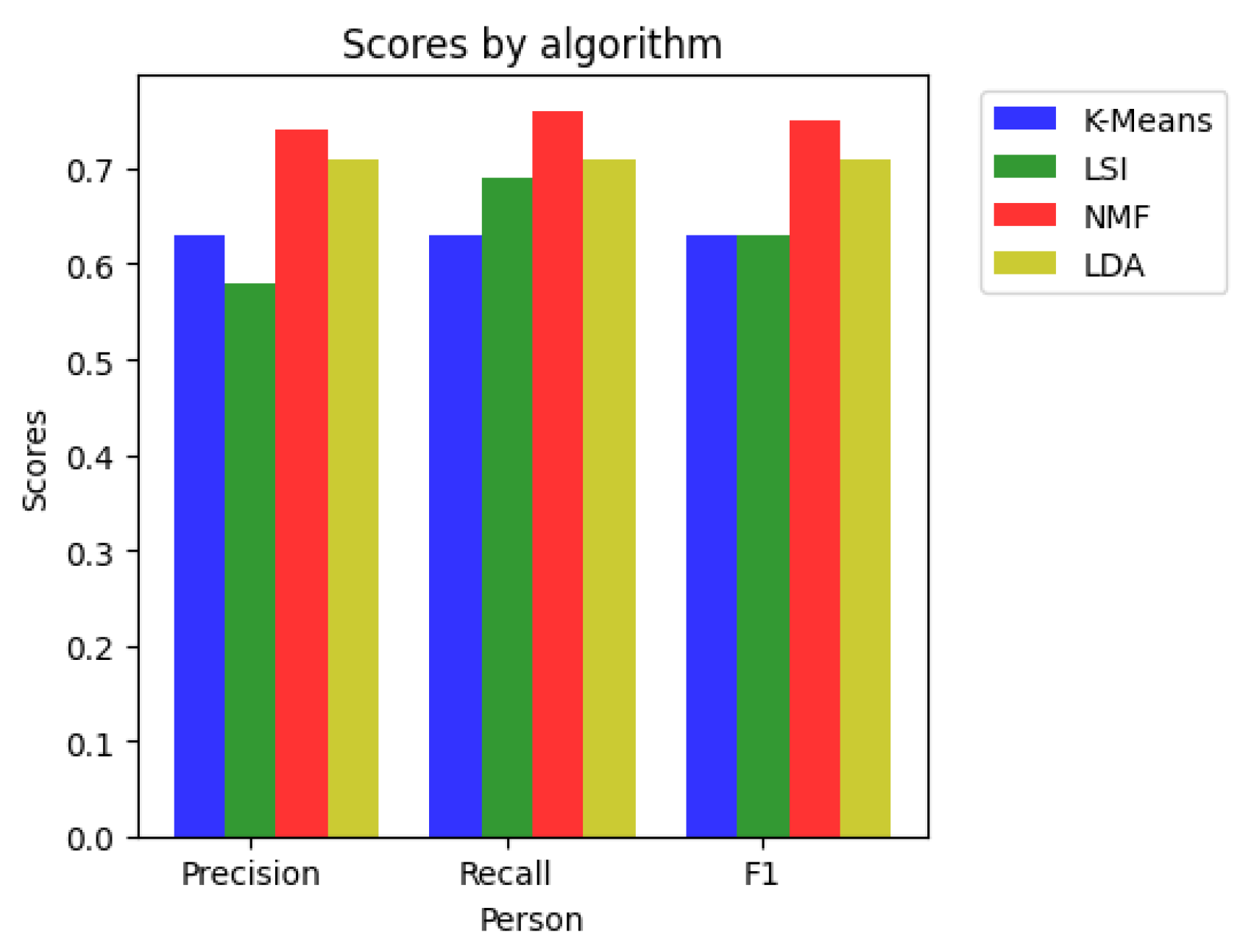
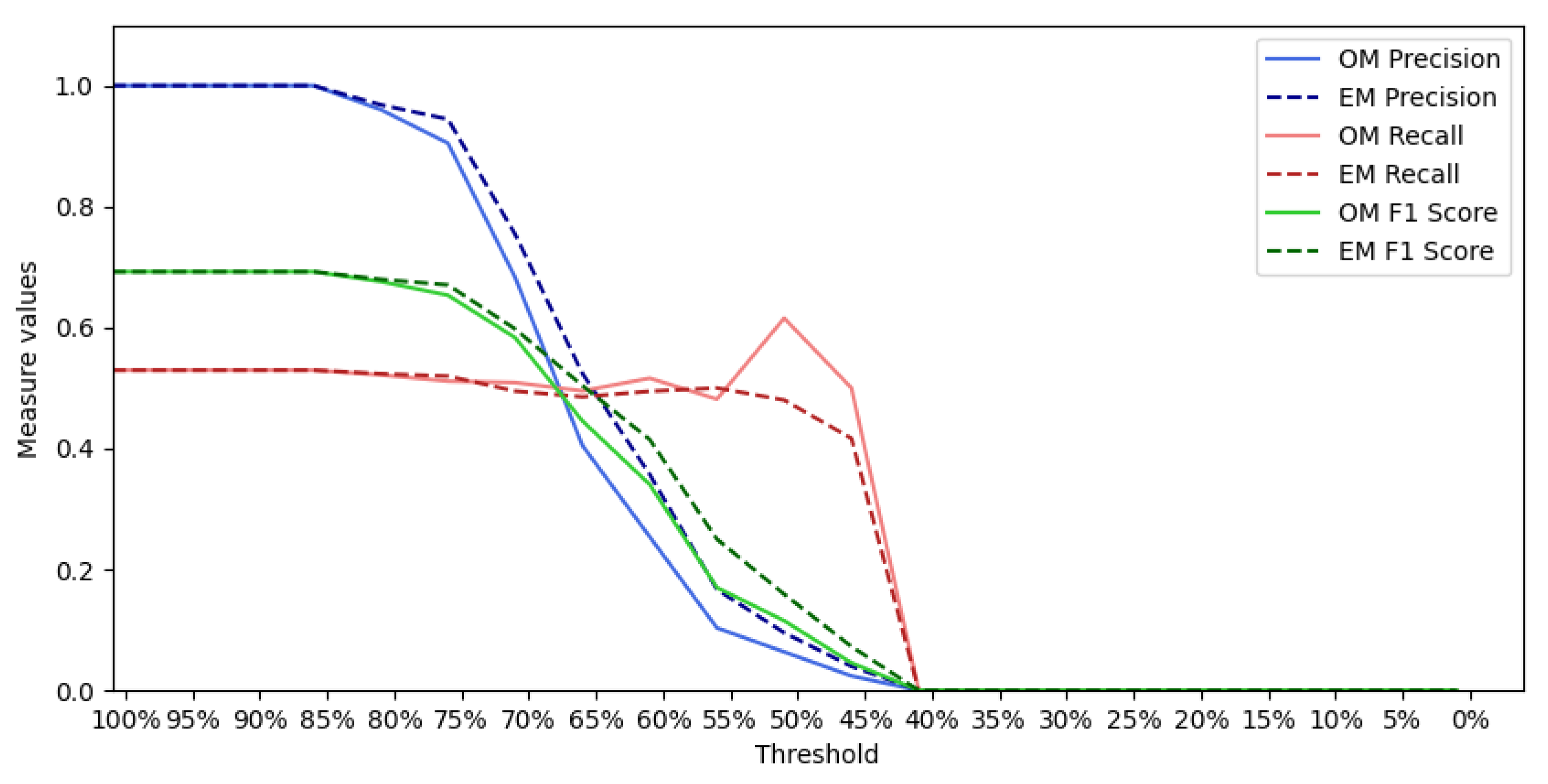
4.4. Evaluation Metrics for the Models
- Precision: The precision is the ratio , where is the number of true positives and the number of false positives. The precision is intuitively the ability of the classifier to not label a negative sample as positive.
- Recall: The recall is the ratio , where is the number of true positives and the number of false negatives. The recall is intuitively the ability of the classifier to find all the positive samples.
- F1-score: The F1 score can be interpreted as a weighted harmonic mean of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0. F1 score is defined as .
5. An Extended Credibility Model Proposal: Adding Topic Measure
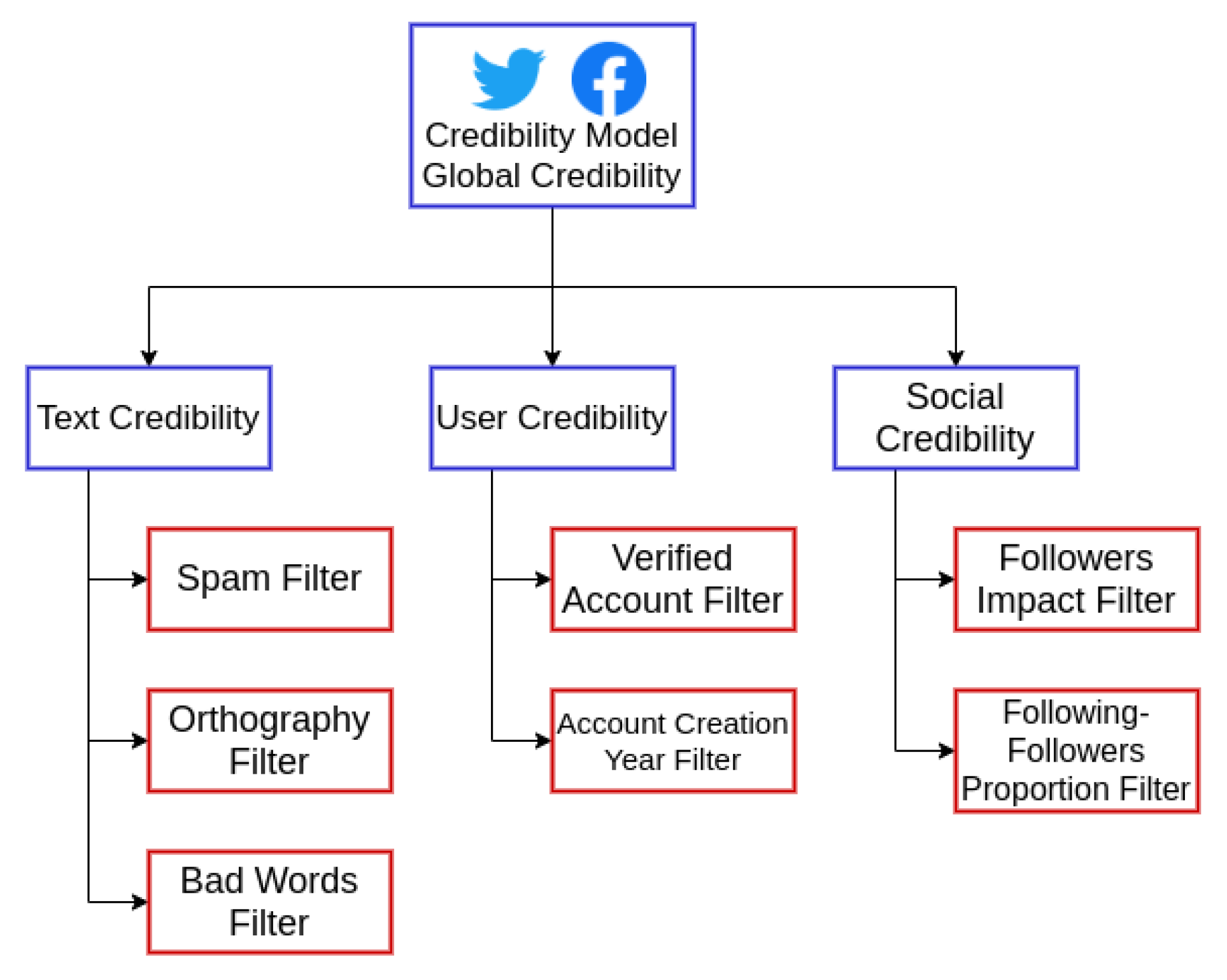
5.1. Original Credibility Model
5.1.1. Text Credibility
- isSpam(p.text) is a SPAM detector that determines the probability of p.text being spam;
- measures the bad words proportion against the number of words in a text;
- measures the misspelling errors proportion ;
- , and represent user-defined parameters to indicate the weights that the user gives to each filter, such that .
5.1.2. User Credibility
- is a function that returns 50 if the user is verified and 0 otherwise;
- measures the time since the user’s account was created, with a value between 0 and 50, increasing with the longevity of the account, such as=where
- −
- ;
- −
- ;
- −
- is the year in which the targeted social platform was created (e.g., 2006 for Twitter).
5.1.3. Social Credibility
- measures the impact on the number of followers;
- measures the proportion between the number of followers and followings of the user.
- is a user-defined parameter.
5.1.4. Credibility Level
- , , and are user-defined parameters to indicate the weights that the user gives to Text Credibility, User Credibility, and Social Credibility, respectively, such that ; by default, they are around 33%;
- , , and represent the credibility measure related to the text, the user, and the social impact of p, respectively.
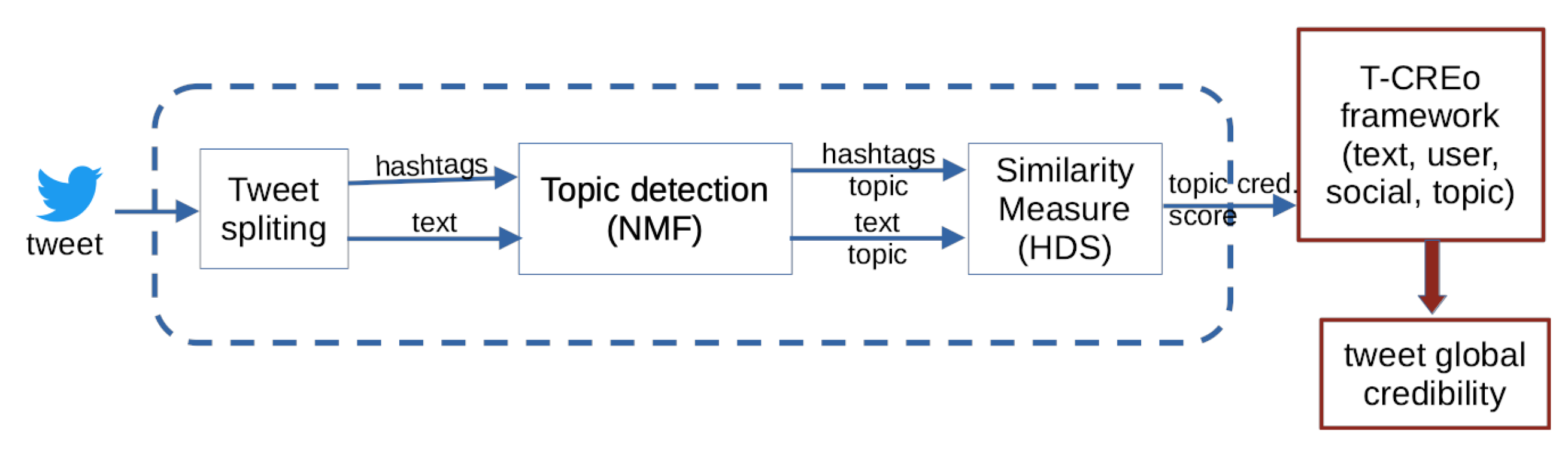
5.2. Extended Credibility Model with Topic Credibility
- P = probability distribution for the cleaned text;
- Q = probability distribution for the hashtag.
- NMF is the topic detection algorithm;
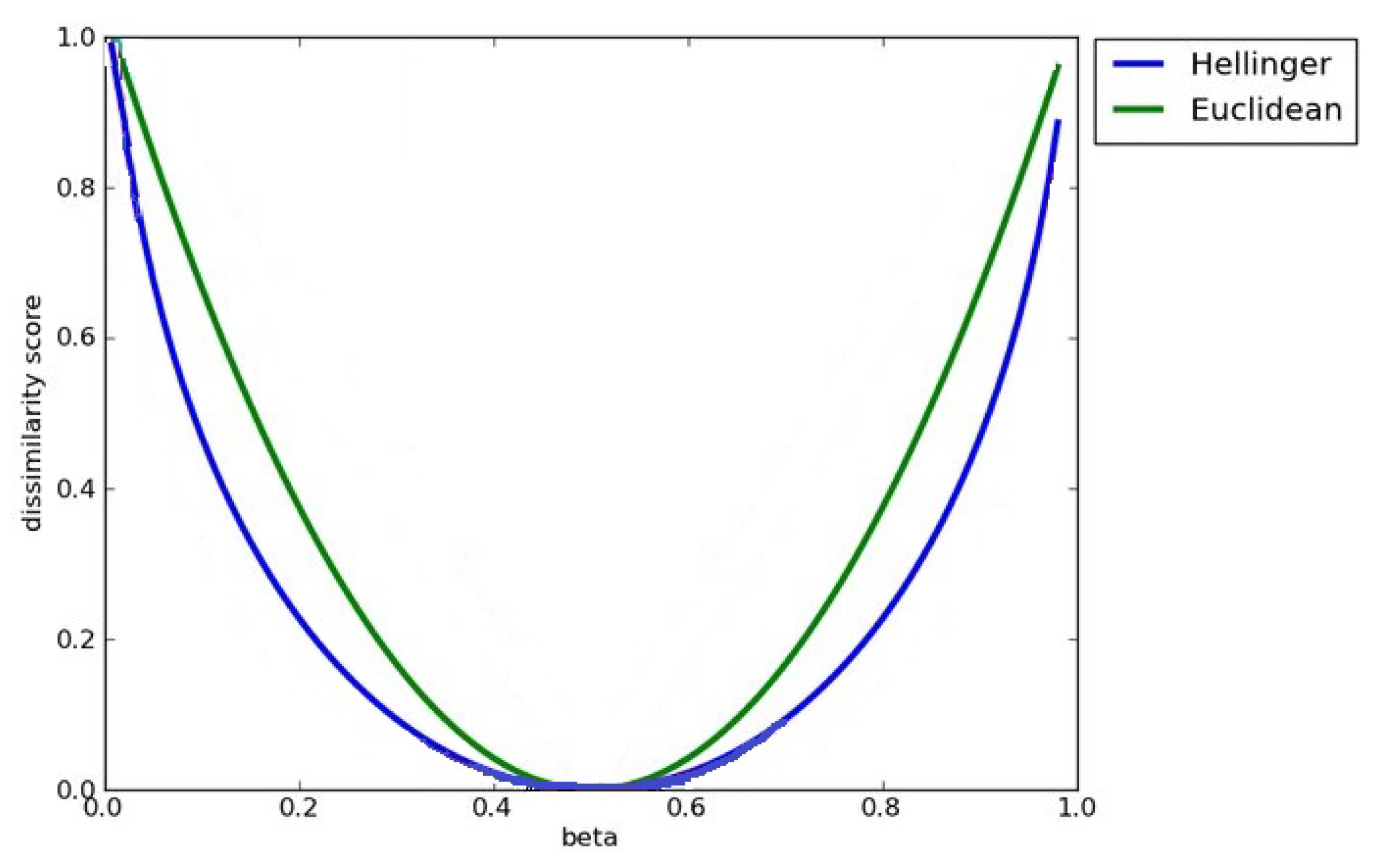
- HDS is the Hellinger distance between the topics of the tweet () and the topics of the ;
- n is the number of hashtags.
- , , , and are user-defined parameters to indicate the weights that the user gives to Text Credibility, User Credibility, Social Credibility, and Topic Credibility, respectively, such that ;
- , , and are user-defined parameters to indicate the weights that the user gives to Text Credibility, User Credibility, and Social Credibility, respectively, such that .
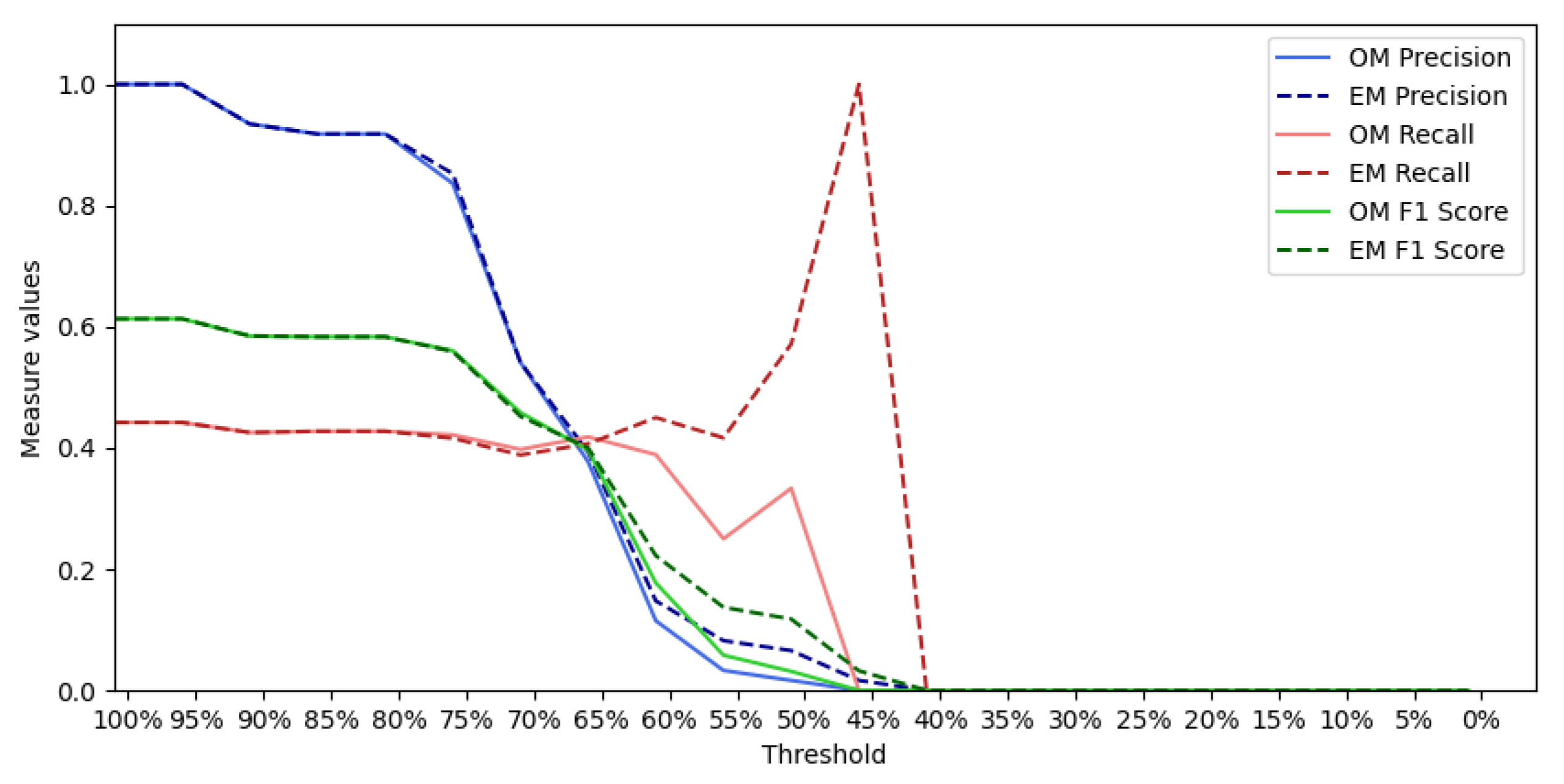
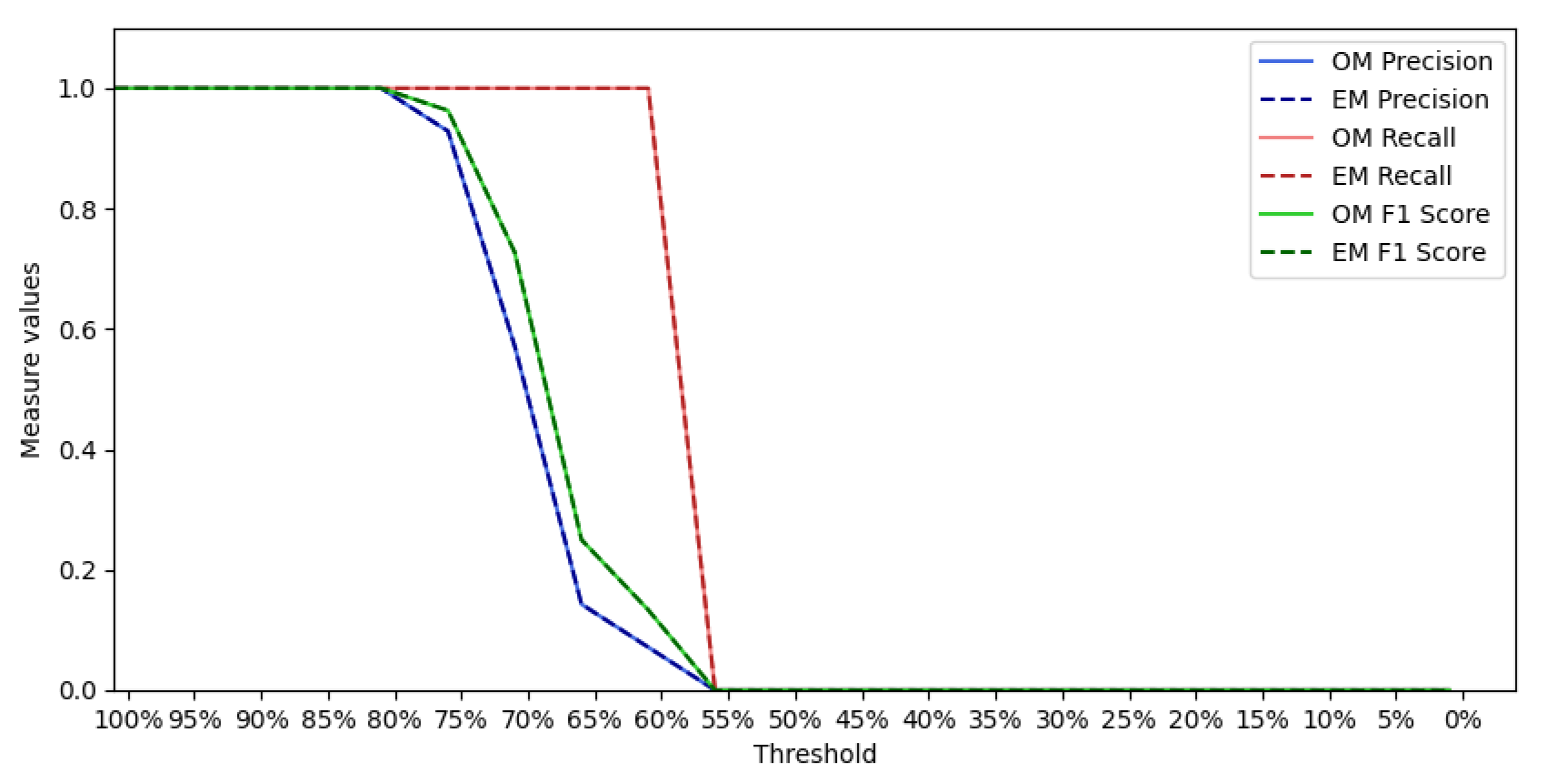
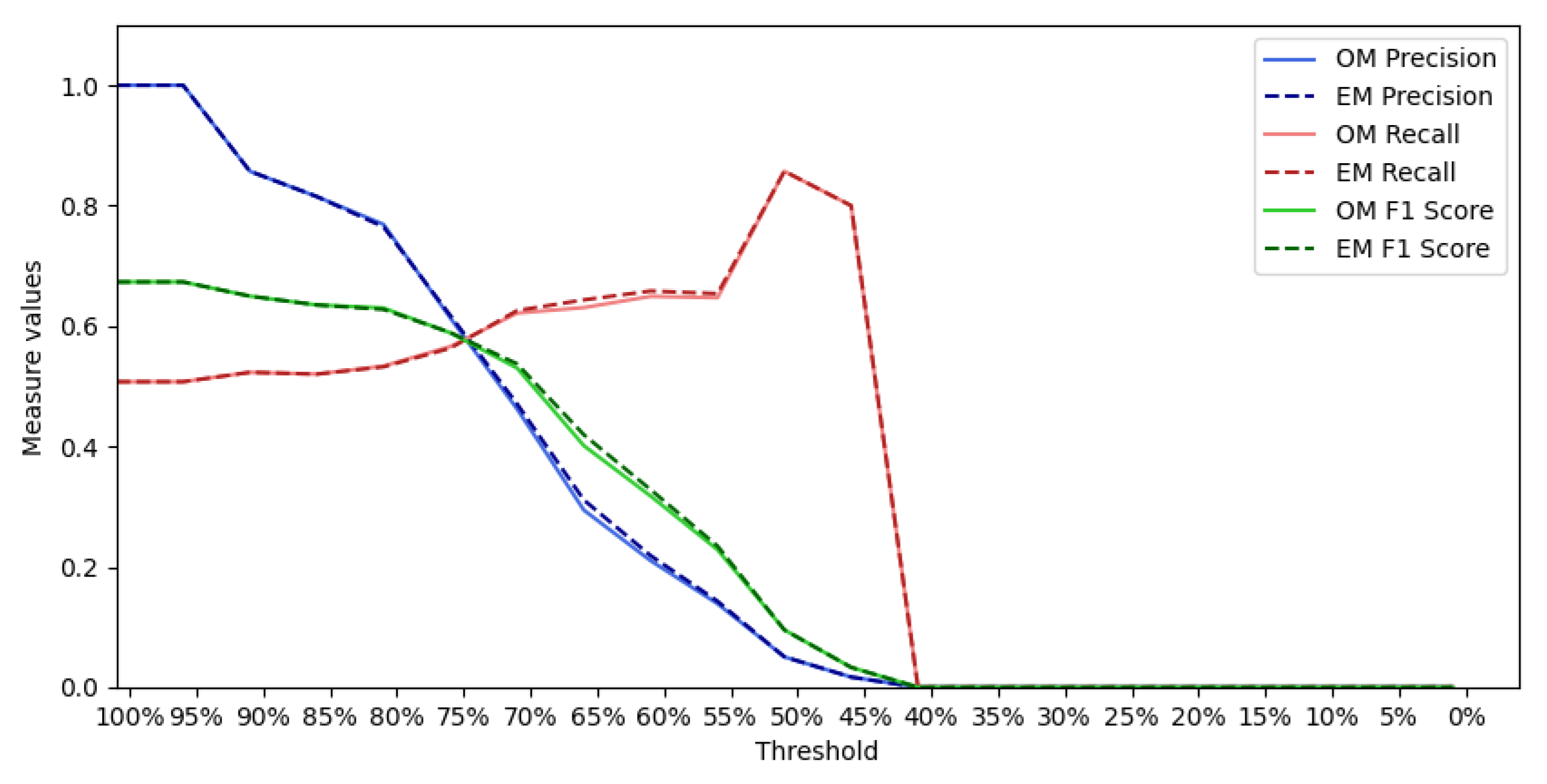
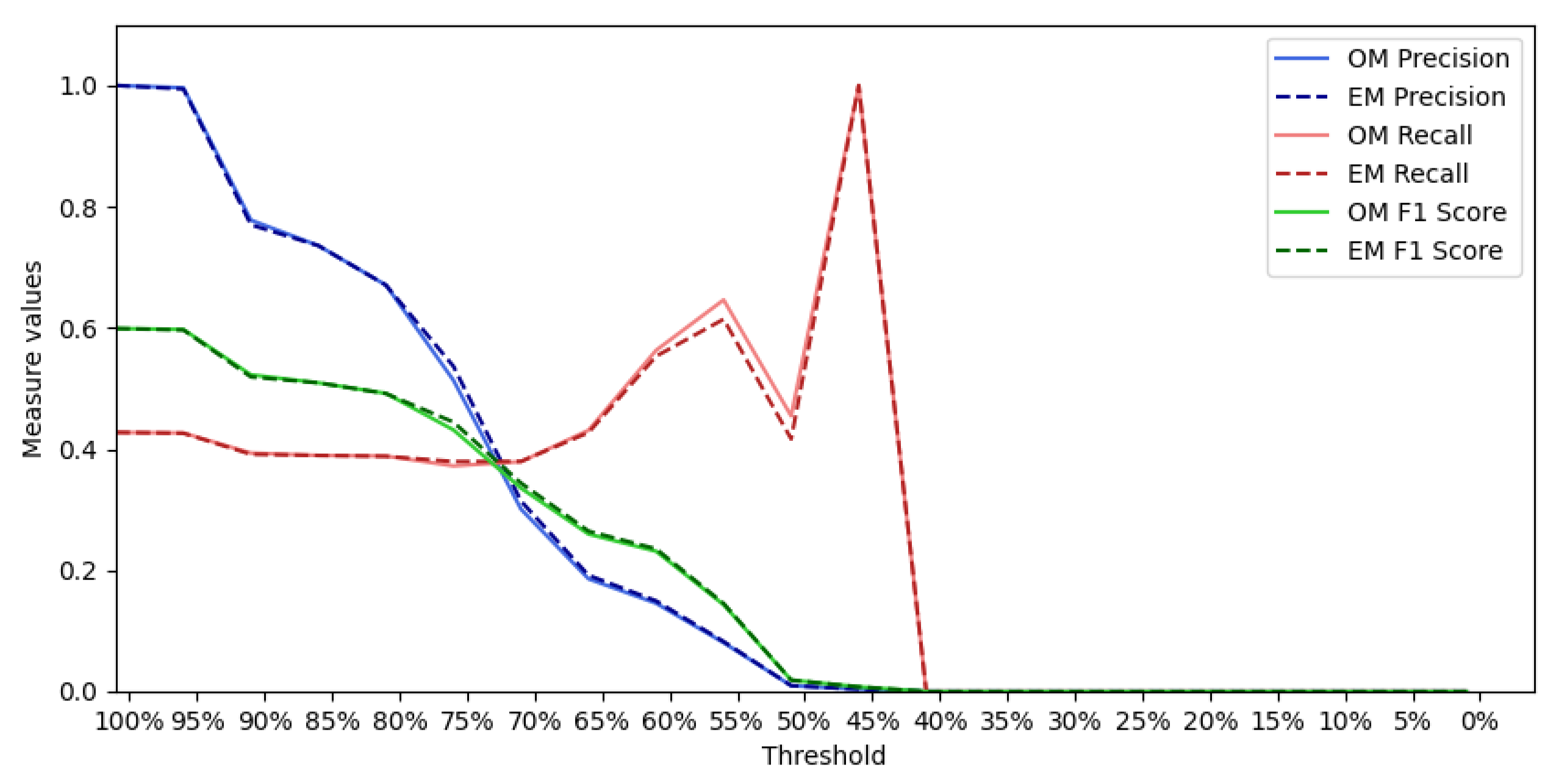
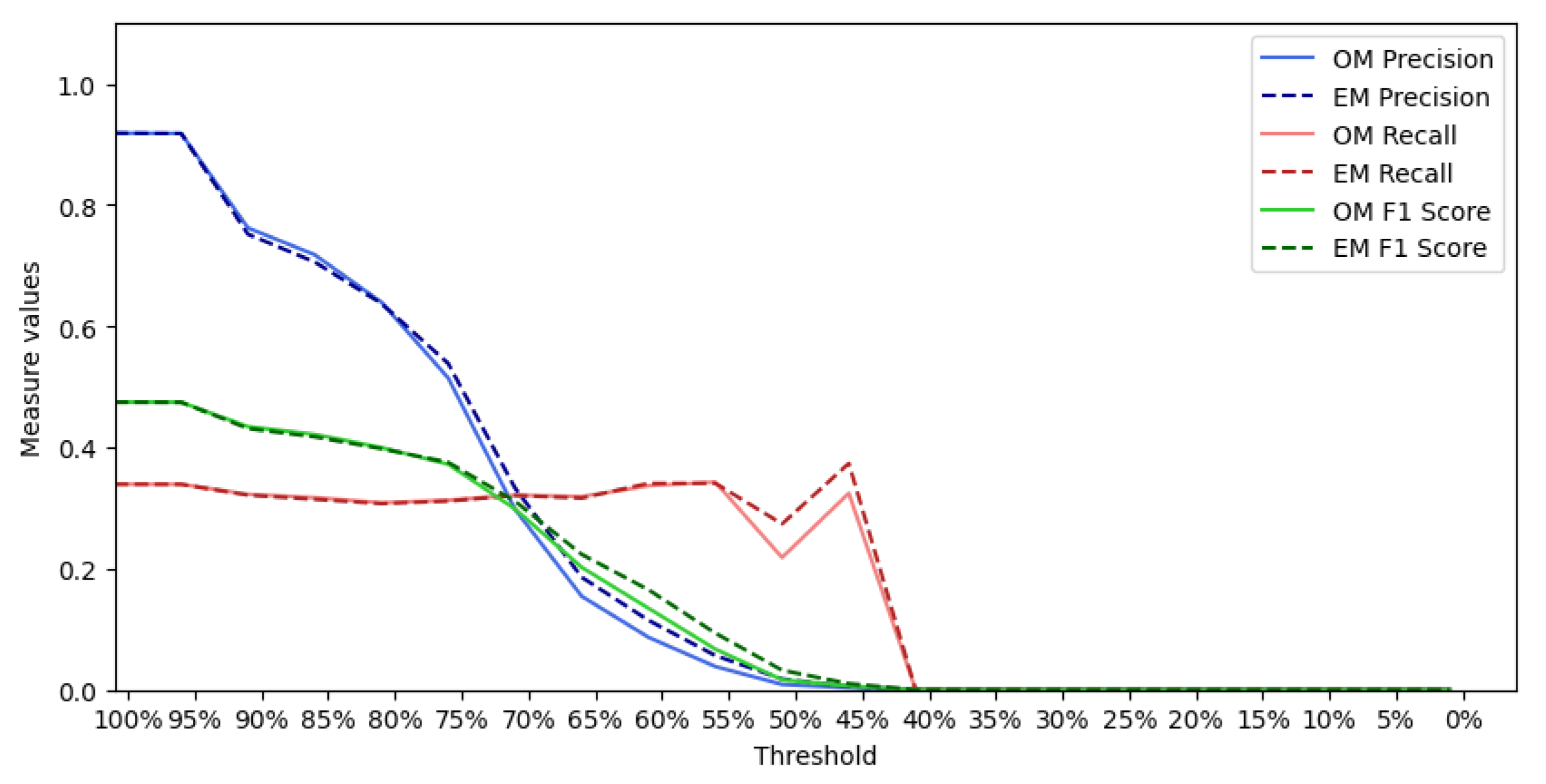
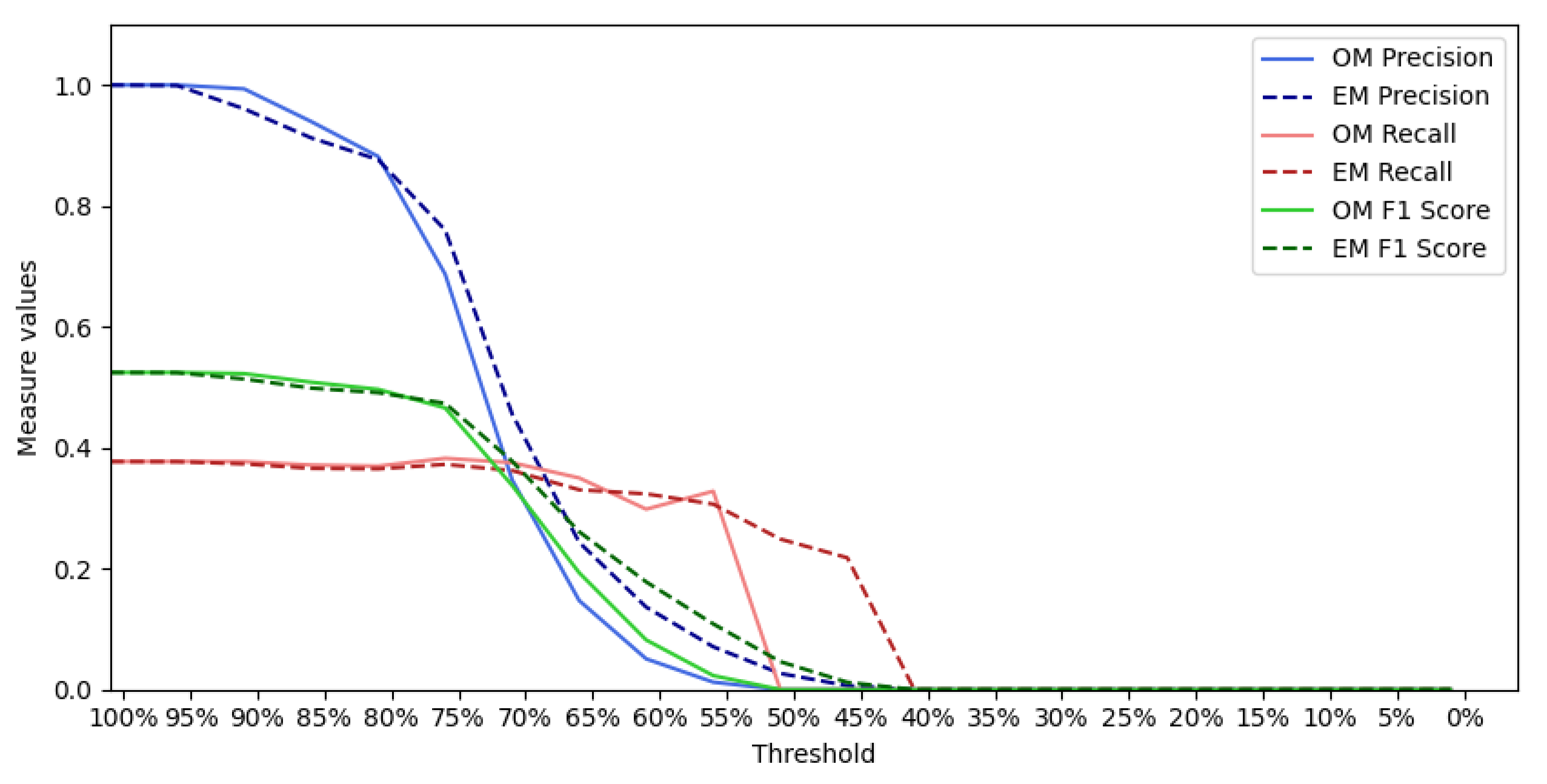
6. Qualitative and Quantitative Evaluation
6.1. Qualitative Analysis
6.2. Quantitative Analysis
6.2.1. Event “Putin Missing”
6.2.2. Event “Charlie Hebdo”
6.2.3. Event “Prince Toronto”
6.2.4. Event “Ottawa Shooting”
6.2.5. Event “Gurlitt”
6.2.6. Event “Ebola”
6.2.7. Event “Germanwings”
6.2.8. Event “Ferguson”
6.2.9. Event “Sydney Siege”
6.2.10. All Tweets from PHEME Dataset
6.2.11. All Tweets from PHEME Dataset with Hashtags
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aksoy, M.E. A Qualitative Study on the Reasons for Social Media Addiction. Eur. J. Educ. Res. 2018, 7, 861–865. [Google Scholar] [CrossRef]
- O’Glasser, A.Y.; Jaffe, R.C.; Brooks, M. To Tweet or Not to Tweet, That Is the Question. Semin. Nephrol. 2020, 40, 249–263. [Google Scholar] [CrossRef]
- Yang, J.; Yu, M.; Qin, H.; Lu, M.; Yang, C. A Twitter Data Credibility Framework—Hurricane Harvey as a Use Case. ISPRS Int. J. Geo-Inf. 2019, 8, 111. [Google Scholar] [CrossRef]
- Cooper, G.P., Jr.; Yeager, V.; Burkle, F.M., Jr.; Subbarao, I. Twitter as a Potential Disaster Risk Reduction Tool. Part III: Evaluating Variables that Promoted Regional Twitter Use for At-risk Populations During the 2013 Hattiesburg F4 Tornado. PLoS Curr. 2022, 7. [Google Scholar] [CrossRef]
- Malik, A.; Heyman-Schrum, C.; Johri, A. Use of Twitter across educational settings: A review of the literature. Int. J. Educ. Technol. High. Educ. 2019, 16, 1–22. [Google Scholar] [CrossRef]
- Java, A.; Song, X.; Finin, T.; Tseng, B. Why We Twitter: Understanding Microblogging Usage and Communities. In Proceedings of the WebKDD/SNA-KDD ’07: Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 Workshop on Web Mining and Social Network Analysis, WebKDD/SNA-KDD ’07, San Jose, CA, USA, 12–15 August 2007; Association for Computing Machinery: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Antonakaki, D.; Fragopoulou, P.; Ioannidis, S. A survey of Twitter research: Data model, graph structure, sentiment analysis and attacks. Expert Syst. Appl. 2021, 164, 114006. [Google Scholar] [CrossRef]
- Samuel, J.; Garvey, M.; Kashyap, R. That Message Went Viral?! Exploratory Analytics and Sentiment Analysis into the Propagation of Tweets. arXiv 2020, arXiv:2004.09718. [Google Scholar] [CrossRef]
- Walck, P. Twitter: Social Communication in the Twitter Age. Int. J. Interact. Commun. Syst. Technol. 2013, 3, 66–69. [Google Scholar]
- Dongo, I.; Cadinale, Y.; Aguilera, A.; Martínez, F.; Quintero, Y.; Barrios, S. Web Scraping versus Twitter API: A Comparison for a Credibility Analysis. In Proceedings of the 22nd International Conference on Information Integration and Web-Based Applications & Services, iiWAS ’20, Chiang Mai, Thailand, 30 November–2 December 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 263–273. [Google Scholar] [CrossRef]
- Dongo, I.; Cardinale, Y.; Aguilera, A.; Martinez, F.; Quintero, Y.; Robayo, G.; Cabeza, D. A qualitative and quantitative comparison between Web scraping and API methods for Twitter credibility analysis. Int. J. Web Inf. Syst. 2021, 17, 580–606. [Google Scholar] [CrossRef]
- Hashemi, M. The Infrastructure Behind Twitter: Scale. 2017. Available online: https://blog.twitter.com/engineering/ (accessed on 15 July 2022).
- Markatos, E.; Balzarotti, D.; Almgren, M.; Athanasopoulos, E.; Bos, H.; Cavallaro, L.; Ioannidis, S.; Lindorfer, M.; Maggi, F.; Minchev, Z.; et al. The Red Book; Chalmers Research: Gothenburg, Sweden, 2013. [Google Scholar]
- Abdullah-All-Tanvir; Mahir, E.M.; Akhter, S.; Huq, M.R. Detecting Fake News using Machine Learning and Deep Learning Algorithms. In Proceedings of the 2019 7th International Conference on Smart Computing & Communications (ICSCC), Sarawak, Malaysia, 28–30 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Hassan, E.A.; Meziane, F. A Survey on Automatic Fake News Identification Techniques for Online and Socially Produced Data. In Proceedings of the 2019 International Conference on Computer, Control, Electrical, and Electronics Engineering (ICCCEEE), Khartoum, Sudan, 21–23 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake News Detection on Social Media: A Data Mining Perspective. SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Wong, K.F. Detect Rumors on Twitter by Promoting Information Campaigns with Generative Adversarial Learning. In Proceedings of the WWW ’19: The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 3049–3055. [Google Scholar] [CrossRef]
- Shao, C.; Ciampaglia, G.L.; Flammini, A.; Menczer, F. Hoaxy: A Platform for Tracking Online Misinformation. In Proceedings of the 25th International Conference Companion on World Wide Web; International World Wide Web Conferences Steering Committee: Republic and Canton of Geneva, CHE, WWW ’16 Companion, Montreal, QC, Canada, 11–15 May 2016; pp. 745–750. [Google Scholar] [CrossRef]
- Brummette, J.; DiStaso, M.; Vafeiadis, M.; Messner, M. Read All About It: The Politicization of “Fake News” on Twitter. J. Mass Commun. Q. 2018, 95, 497–517. [Google Scholar] [CrossRef]
- Murayama, T.; Wakamiya, S.; Aramaki, E.; Kobayashi, R. Modeling the spread of fake news on Twitter. PLoS ONE 2021, 16, e0250419. [Google Scholar] [CrossRef]
- Mehrotra, R.; Sanner, S.; Buntine, W.; Xie, L. Improving LDA Topic Models for Microblogs via Tweet Pooling and Automatic Labeling. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 889–892. [Google Scholar] [CrossRef]
- Dongo, I.; Cardinale, Y.; Aguilera, A. Credibility Analysis for Available Information Sources on the Web: A Review and a Contribution. In Proceedings of the 2019 4th International Conference on System Reliability and Safety (ICSRS), Rome, Italy, 20–22 November 2019; pp. 116–125. [Google Scholar] [CrossRef]
- Al-Khalifa, H.; Al-Eidan, R. An experimental system for measuring the credibility of news content in Twitter. Intl. J. Web Inf. Syst. 2011, 7, 130–151. [Google Scholar] [CrossRef]
- Gupta, A.; Kumaraguru, P.; Castillo, C.; Meier, P. Tweetcred: Real-time credibility assessment of content on twitter. In Proceedings of the International Conference on Social Informatics, Barcelona, Spain, 11–13 November 2014; pp. 228–243. [Google Scholar]
- Liu, X.; Nourbakhsh, A.; Li, Q.; Fang, R.; Shah, S. Real-time rumor debunking on twitter. In Proceedings of the International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 1867–1870. [Google Scholar]
- AlRubaian, M.; Al-Qurishi, M.; Al-Rakhami, M.; Hassan, M.M.; Alamri, A. CredFinder: A real-time tweets credibility assessing system. In Proceedings of the International Conference on Advances in Social Networks Analysis and Mining, San Francisco, CA, USA, 18–21 August 2016; pp. 1406–1409. [Google Scholar]
- Namihira, Y.; Segawa, N.; Ikegami, Y.; Kawai, K.; Kawabe, T.; Tsuruta, S. High Precision Credibility Analysis of Information on Twitter. In Proceedings of the 2013 International Conference on Signal-Image Technology & Internet-Based Systems, Kyoto, Japan, 2–5 December 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 909–915. [Google Scholar] [CrossRef]
- Hamdi, T.; Slimi, H.; Bounhas, I.; Slimani, Y. A Hybrid Approach for Fake News Detection in Twitter Based on User Features and Graph Embedding. In Proceedings of the International Conference on Distributed Computing and Internet Technology, Bhubaneswar, India, 9–12 January 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 266–280. [Google Scholar]
- Tan, S. Spot the Lie: Detecting Untruthful Online Opinion on Twitter. Ph.D. Thesis, Department of Computing, Imperial College London, London, UK, 2017. [Google Scholar]
- Garcia, K.; Berton, L. Topic detection and sentiment analysis in Twitter content related to COVID-19 from Brazil and the USA. Appl. Soft Comput. 2021, 101, 107057. [Google Scholar] [CrossRef] [PubMed]
- Castillo, C.; Mendoza, M.; Poblete, B. Information credibility on twitter. In Proceedings of the International Conference on WWW, Hyderabad, India, 28 March–1 April 2011; pp. 675–684. [Google Scholar]
- Lorek, K.; Suehiro-Wiciński, J.; Jankowski-Lorek, M.; Gupta, A. Automated Credibility Assessment on Twitter. Comput. Sci. 2015, 16, 157. [Google Scholar] [CrossRef]
- Ibrahim, R.; Elbagoury, A.; Kamel, M.S.; Karray, F. Tools and approaches for topic detection from Twitter streams: Survey. Knowl. Inf. Syst. 2018, 54, 511–539. [Google Scholar] [CrossRef]
- Mottaghinia, Z.; Feizi-Derakhshi, M.R.; Farzinvash, L.; Salehpour, P. A review of approaches for topic detection in Twitter. J. Exp. Theor. Artif. Intell. 2021, 33, 747–773. [Google Scholar] [CrossRef]
- Alash, H.M.; Al-Sultany, G.A. Improve topic modeling algorithms based on Twitter hashtags. J. Phys. Conf. Ser. 2020, 1660, 012100. [Google Scholar] [CrossRef]
- Huang, J.; Thornton, K.; Efthimiadis, E. Conversational Tagging in Twitter. In Proceedings of the 21st Conference on Hypertext and Hypermedia (HT), Toronto, ON, Canada, 13–16 June 2020; pp. 173–178. [Google Scholar] [CrossRef]
- Godin, F.; Slavkovikj, V.; De Neve, W.; Schrauwen, B.; Van de Walle, R. Using topic models for Twitter hashtag recommendation. In Proceedings of the WWW ’13 Companion: Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 593–596. [Google Scholar] [CrossRef]
- Kou, F.F.; Du, J.P.; Yang, C.X.; Shi, Y.S.; Cui, W.Q.; Liang, M.Y.; Geng, Y. Hashtag Recommendation Based on Multi-Features of Microblogs. J. Comput. Sci. Tech. 2018, 33, 711–726. [Google Scholar] [CrossRef]
- Figueiredo, F.; Jorge, A. Identifying topic relevant hashtags in Twitter streams. Inform. Sci. 2019, 505, 65–83. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.; Dou, W.; Wang, X.; Akella, S. Tag-Latent Dirichlet Allocation: Understanding Hashtags and Their Relationships. In Proceedings of the WI-IAT ’13: 2013 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT)—Volume 01, Melbourne, Australia, 14–17 December 2020; IEEE Computer Society: Piscataway, NJ, USA, 2013; pp. 260–267. [Google Scholar] [CrossRef]
- Cardinale, Y.; Dongo, I.; Robayo, G.; Cabeza, D.; Aguilera, A.; Medina, S. T-CREo: A Twitter Credibility Analysis Framework. IEEE Access 2021, 9, 32498–32516. [Google Scholar] [CrossRef]
- Verasakulvong, E.; Vateekul, P.; Piyatumrong, A.; Sangkeettrakarn, C. Online Emerging Topic Detection on Twitter Using Random Forest with Stock Indicator Features. In Proceedings of the 2018 15th International Joint Conference on Computer Science and Software Engineering (JCSSE), Nakhonpathom, Thailand, 11–13 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Lee, K.; Palsetia, D.; Narayanan, R.; Patwary, M.d.M.A.; Agrawal, A.; Choudhary, A. Twitter Trending Topic Classification. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11 December 2011; pp. 251–258. [Google Scholar] [CrossRef]
- Zhang, C.; Lu, S.; Zhang, C.; Xiao, X.; Wang, Q.; Chen, G. A Novel Hot Topic Detection Framework With Integration of Image and Short Text Information From Twitter. IEEE Access 2018, 7, 9225–9231. [Google Scholar] [CrossRef]
- Choi, H.J.; Park, C.H. Emerging topic detection in twitter stream based on high utility pattern mining. Expert Syst. Appl. 2019, 115, 27–36. [Google Scholar] [CrossRef]
- Alrubaian, M.; Al-Qurishi, M.; Hassan, M.; Alamri, A. A Credibility Analysis System for Assessing Information on Twitter. IEEE Trans. Dependable Secur. Comput. 2016, 15, 661–674. [Google Scholar] [CrossRef]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1988. [Google Scholar] [CrossRef]
- Tehrani, A.F.; Ahrens, D. Modified sequential k-means clustering by utilizing response: A case study for fashion products. Expert Syst. 2017, 34, e12226. [Google Scholar] [CrossRef]
- Landauer, T.K.; Foltz, P.W.; Laham, D. An introduction to latent semantic analysis. Discourse Process. 1998, 25, 259–284. [Google Scholar] [CrossRef]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Hofmann, T. Probabilistic latent semantic indexing. In Proceedings of the SIGIR ’99: 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; Association for Computing Machinery: New York, NY, USA, 1999; pp. 50–57. [Google Scholar] [CrossRef]
- Golub, G.H.; Reinsch, C. Singular value decomposition and least squares solutions. Numer. Math. 1970, 14, 403–420. [Google Scholar] [CrossRef]
- Wang, Y.X.; Zhang, Y.J. Nonnegative Matrix Factorization: A Comprehensive Review. IEEE Trans. Knowl. Data Eng. 2012, 25, 1336–1353. [Google Scholar] [CrossRef]
- Saxena, A.; Mueller, C. Intelligent Intrusion Detection in Computer Networks using Swarm Intelligence. Int. J. Comput. Appl. 2018, 179, 1–9. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar] [CrossRef]
- Gimpel, K. Modeling Topics; Technical Report; Carnegie Melon University: Pittsburgh, PA, USA, 2006. [Google Scholar]
- Kalyanam, J.; Quezada, M.; Poblete, B.; Lanckriet, G. Prediction and Characterization of High-Activity Events in Social Media Triggered by Real-World News. PLoS ONE 2016, 11, e0166694. [Google Scholar] [CrossRef] [PubMed]
- Godbole, S.; Sarawagi, S. Discriminative Methods for Multi-labeled Classification. In Advances in Knowledge Discovery and Data Mining; Springer: Berlin, Germany, 2004; pp. 22–30. [Google Scholar] [CrossRef]
- Xin, E.Z.; Murthy, D.; Lakuduva, N.S.; Stephens, K.K. Assessing the Stability of Tweet Corpora for Hurricane Events Over Time: A Mixed Methods Approach. In Proceedings of the SMSociety ’19: 10th International Conference on Social Media and Society, Toronto, ON, Canada, 19–21 July 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 59–66. [Google Scholar] [CrossRef]
- González-Castro, V.; Alaiz-Rodríguez, R.; Alegre, E. Class distribution estimation based on the Hellinger distance. Inform. Sci. 2013, 218, 146–164. [Google Scholar] [CrossRef]
- Maiya, A.S.; Rolfe, R.M. Topic Similarity Networks: Visual Analytics for Large Document Sets. arXiv 2014, arXiv:1409.7591. [Google Scholar] [CrossRef]
- Dingemans, S. Application of Short Text Topic Modelling Techniques to Greta Thunberg Discussion on Twitter. Master’s Thesis, National College of Ireland, Dublin, Ireland, 2020. [Google Scholar]
- Hawking, S. Hellinger Distance—Encyclopedia of Mathematics; EMS: Berlin, Germany, 1988. [Google Scholar]
- Brandmaier, A. Permutation Distribution Clustering and Structural Equation Model Trees; Technical Report, Science and Technology Faculties; University of Saarland: Berlin, Germany, 2011. [Google Scholar]
- Lupa, J.C. Análisis de Credibilidad en la Red Social Twitter a través de su Actividad Social. Bachelor’s Thesis, Universidad Católica San Pablo, Arequipa, Peru, 2021. [Google Scholar]
- Mandical, R.R.; Mamatha, N.; Shivakumar, N.; Monica, R.; Krishna, A.N. Identification of Fake News Using Machine Learning. In Proceedings of the 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 2–4 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Aphiwongsophon, S.; Chongstitvatana, P. Detecting Fake News with Machine Learning Method. In Proceedings of the 2018 15th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Chiang Rai, Thailand, 18–21 July 2018; pp. 528–531. [Google Scholar] [CrossRef]
- Ahmed, A.A.A.; Aljabouh, A.; Donepudi, P.K.; Choi, M.S. Detecting Fake News Using Machine Learning: A Systematic Literature Review. arXiv 2021, arXiv:2102.04458. [Google Scholar]
- Zubiaga, A.; Zubiaga, A.; Hoi, G.W.S.; Liakata, M.; Procter, R. PHEME dataset of rumours and non-rumours. Figshare 2016. [Google Scholar] [CrossRef]
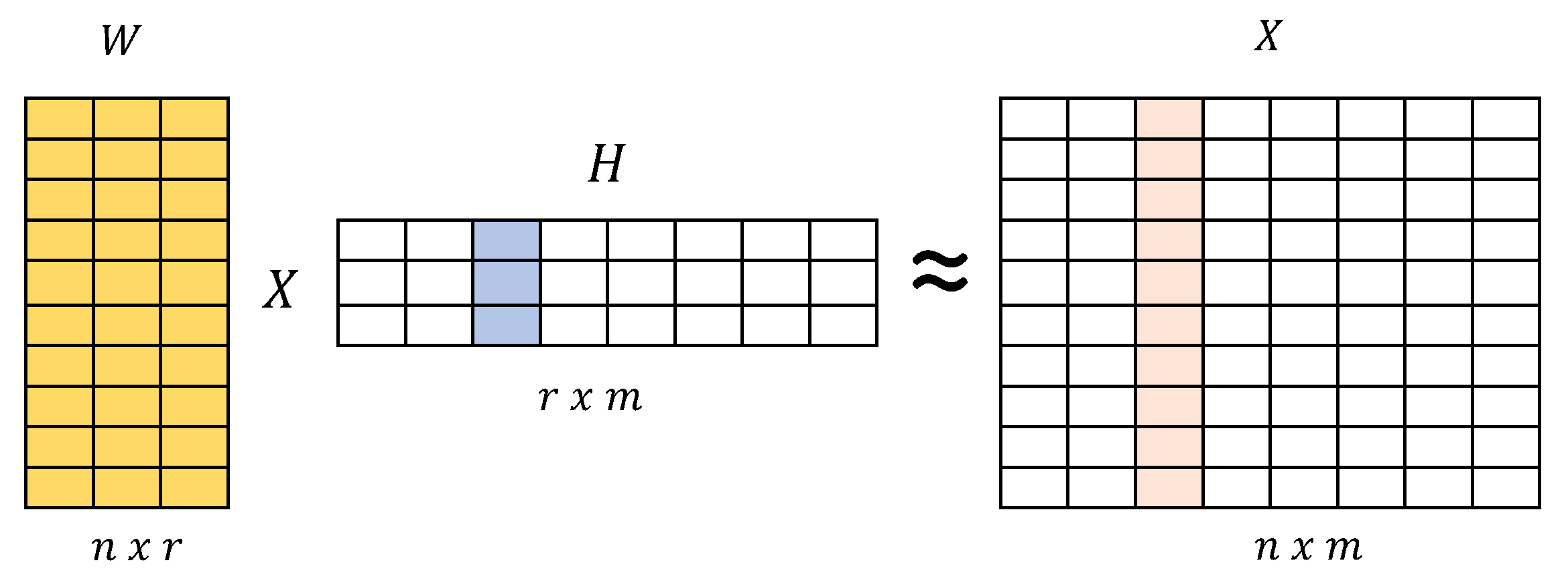








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tweet id | Topic id |
|---|---|
| xxxxxx69185540096 | 1 |
| xxxxxx462185543091 | 2 |
| xxxxxx365534545634 | 2 |
| xxxxxx435353345345 | 2 |
| xxxxxx534986734857 | 3 |
| xxxxxx837593759879 | 3 |
| Headline Text | Hashtags | Clean Tweet |
|---|---|---|
| #AAPL:The 10 best Steve Jobs emails ever…htt… | [#AAPL] | best steve job email ever |
| RT @JPDesloges: Why AAPL Stock Had a Mini-Flas… | [#aapl] | aapl stock mini flash crash today aapl |
| My cat only chews @apple cords. Such an #Apple… | [#AppleSnob] | cat chew cord |
| I agree with @jimcramer that the #IndividualIn… | [#IndividualInvestor, #Apple, #AAPL] | agre trade extend today pullback good see |
| Nobody expects the Spanish Inquisition #AAPL | [#AAPL] | nobodi expect spanish inquisit |
| Model | Parameters | Algorithms |
|---|---|---|
| LDA | n_components = 250,
max_iter = 100, learning_method = ’online’ | LatentDirichletAllocation.html |
| LSI | n_components = 250, n_iter = 100 | TruncatedSVD.html |
| NMF | n_components = 250 | NMF.html |
| KMEANS | n_clusters = 250 | KMeans.html |
| Metrics | K-Means | LSI | NMF | LDA |
|---|---|---|---|---|
| Precision | 0.63 | 0.58 | 0.74 | 0.71 |
| Recall | 0.63 | 0.69 | 0.76 | 0.71 |
| F1 Score | 0.63 | 0.63 | 0.75 | 0.71 |
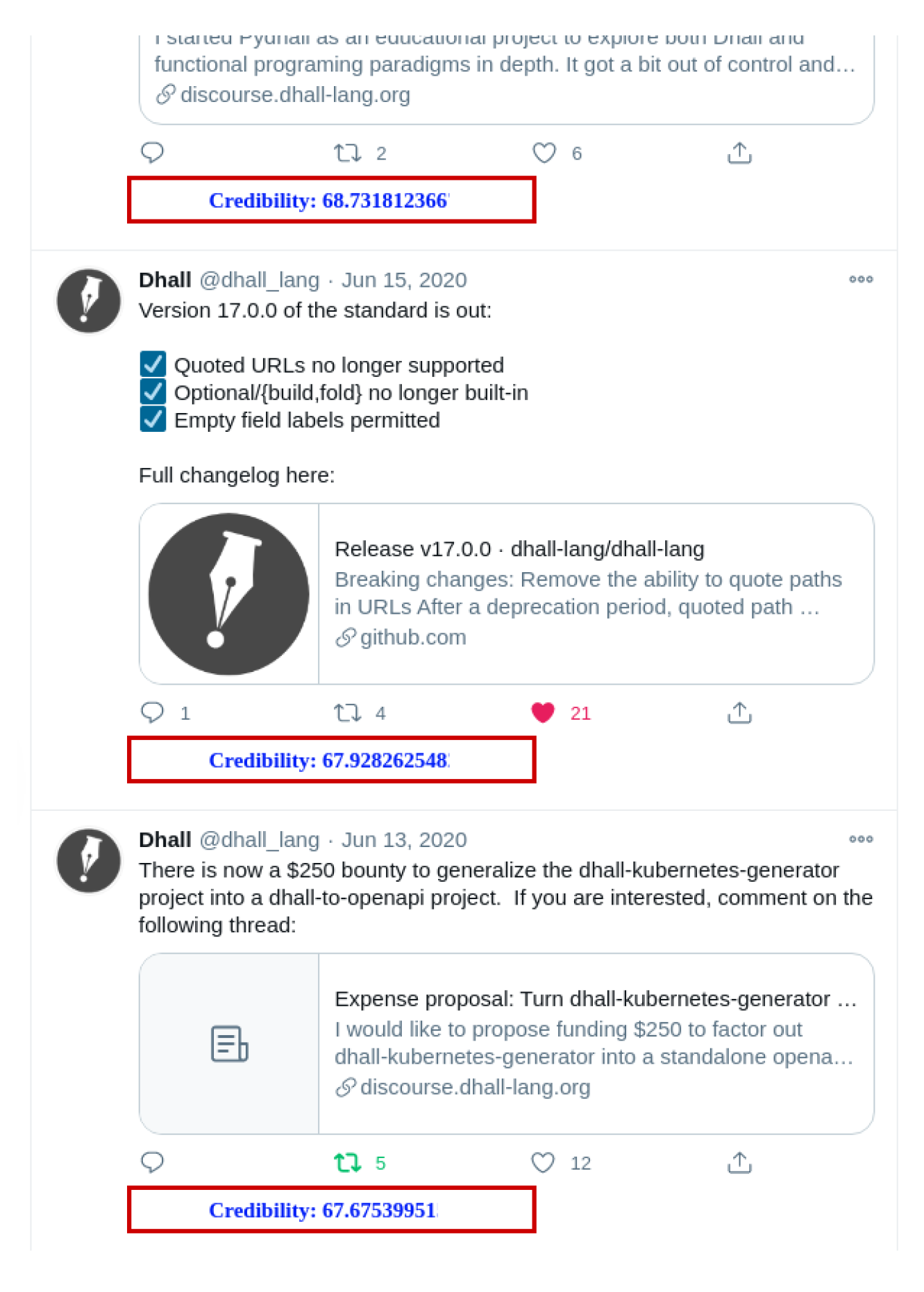
| N° | Tweet | Real or Fake | HDS Result | Original Model | Extended Model |
|---|---|---|---|---|---|
| 1 | Black teenage boys are not men. They are children. Stop referring to a 17 year old as a man. You are killing children. #ferguson | Real | 0.33 | 55.53 | 58.48 |
| 2 | #Putin is not the only thing missing....Look what is missing from the top of the #Kremlin today #putindead #Russia | Real | 0.24 | 60.78 | 64.36 |
| 3 | Tainted #Gurlitt collection should be sold with profits going to Jewish organizations. #WWII | Real | 0.04 | 63.05 | 71.08 |
| 4 | #BREAKING At least two killed in hostage drama east of Paris: source | Fake | 0.40 | 74.45 | 70.86 |
| 5 | Live Nation quashes #Prince rumour. The Purple One will not be playing at #Toronto’s Massey Hall. | Fake | 0.30 | 65.04 | 66.17 |
| 6 | #WATCH: An aviation expert says the #4U9525 distress call was circulated on Twitter within three minutes. | Fake | 0.28 | 74.70 | 73.83 |
| Tweet ID | Survey-Avg (%) | Original Credibility Model (%) | Extended Credibility Model (%) | # Hashtags |
|---|---|---|---|---|
| xxxxxx9982542508038 | 70 | 68.51 | 68.51 | 00 |
| xxxxxx6261988499456 | 45 | 44.16 | 44.16 | 00 |
| xxxxxx454692450304 | 70 | 76.52 | 76.52 | 00 |
| xxxxxx114923732992 | 15 | 49.74 | 49.74 | 00 |
| xxxxxx4739103236099 | 65 | 69.78 | 72.33 | 01 |
| xxxxxx4980596994048 | 30 | 28.99 | 28.99 | 00 |
| xxxxxx0877124628487 | 50 | 37.67 | 37.67 | 00 |
| xxxxxx6507817824261 | 45 | 27.86 | 27.86 | 00 |
| xxxxxx3352350662666 | 65 | 44.05 | 44.05 | 00 |
| xxxxxx6331631550472 | 40 | 38.69 | 38.69 | 00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernandez-Mendoza, M.; Aguilera, A.; Dongo, I.; Cornejo-Lupa, J.; Cardinale, Y. Credibility Analysis on Twitter Considering Topic Detection. Appl. Sci. 2022, 12, 9081. https://doi.org/10.3390/app12189081
Hernandez-Mendoza M, Aguilera A, Dongo I, Cornejo-Lupa J, Cardinale Y. Credibility Analysis on Twitter Considering Topic Detection. Applied Sciences. 2022; 12(18):9081. https://doi.org/10.3390/app12189081
Chicago/Turabian StyleHernandez-Mendoza, Maria, Ana Aguilera, Irvin Dongo, Jose Cornejo-Lupa, and Yudith Cardinale. 2022. "Credibility Analysis on Twitter Considering Topic Detection" Applied Sciences 12, no. 18: 9081. https://doi.org/10.3390/app12189081
APA StyleHernandez-Mendoza, M., Aguilera, A., Dongo, I., Cornejo-Lupa, J., & Cardinale, Y. (2022). Credibility Analysis on Twitter Considering Topic Detection. Applied Sciences, 12(18), 9081. https://doi.org/10.3390/app12189081