
From Word Embeddings to Pre-Trained Language Models: A State-of-the-Art Walkthrough


Abstract
:1. Introduction
2. Language Models and Word Embeddings
3. SOTA Pre-Trained Language Models (PLMs)
3.1. List of Recent Pretrained Language Models
3.2. Summary and Comparison
4. PLMs Applications, Parameters, Objectives, and Compression Methods
4.1. PLMs Applications
- Fine-tuning: involves performing general-purpose pre-training with a large unlabeled corpus, then adding an extra layer(s) for the specific task and further training the model using a task-specific annotated dataset, starting from the pretrained back-bone weights. PLMs are now being used to solve a wide range of NLP tasks (e.g., sentiment analysis, textual entailment, question answering, common sense reasoning, translation, summarization, named entity recognition [8,24,25,26], stance detection [76], semantic keyphrase extraction [77], etc.);
- Prompt-based learning: reducing an NLP challenge to a task comparable to the PLM’s pre-training objective (e.g., word prediction, textual entailment, classification, etc.). Few-shot/one-shot/zero-shot approaches can be achieved with prompting since they can better utilize the knowledge stored in PLMs [78,79];
4.2. PLMs Parameters
4.3. Compression Methods
5. Challenges, and Future Directions
5.1. More Data, More Parameters
5.2. Others Compression Alternatives
5.3. New Architectures of PLMs
5.4. Responsible Compute and GreenAI
6. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Harris, Z. Distributional structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Curran Associates, Inc.: Red Hook, NY, USA, 2013. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP2014), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Levy, O.; Goldberg, Y. Neural Word Embedding as Implicit Matrix Factorization. In Advances in Neural Information Processing Systems 27, Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; MIT Press: Cambridge, MA, USA, 2014; pp. 2177–2185. [Google Scholar]
- Liu, Q.; Huang, H.; Gao, Y.; Wei, X.; Tian, Y.; Liu, L. Task-oriented Word Embedding for Text Classification. In Proceedings of the 27th International Conference on Computational Linguistics (COLING), Santa Fe, NM, USA, 20–26 August 2018. [Google Scholar]
- Doan, T.M. Learning Word Embeddings. Ph.D. Thesis, University Jean Monnet, Saint-Etienne, France, 2018. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, X.; He, P.; Chen, W.; Gao, J. Multi-Task Deep Neural Networks for Natural Language Understanding. arXiv 2019, arXiv:1901.11504. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Black, S.; Biderman, S.; Hallahan, E.; Anthony, Q.; Gao, L.; Golding, L.; He, H.; Leahy, C.; McDonell, K.; Phang, J.; et al. GPT-NeoX-20B: An Open-Source Autoregressive Language Model. arXiv 2022, arXiv:2204.06745. [Google Scholar]
- Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Deerwester, S.; Harshman, R. Using Latent Semantic Analysis to Improve Access to Textual Information. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Washington, DC, USA, 15–19 May 1988; pp. 281–285. [Google Scholar]
- Deerwester, S.; Dumais, S.; Furnas, G.; Landauer, T.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- van der Maaten, L.J.P.; Hinton, G.E. Visualizing High-Dimensional Data Using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Bengio, Y.; Lauzon, V.; Ducharme, R. Experiments on the application of IOHMMs to model financial returns series. IEEE Trans. Neural Netw. 2001, 12, 113–123. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning. In Proceedings of the 25th International Conference on Machine Learning (ICML ’08), Helsinki, Finland, 5–9 July 2008; ACM: New York, NY, USA, 2008; pp. 160–167. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Short Papers. Association for Computational Linguistics: Valencia, Spain, 2017; Volume 2, pp. 427–431. [Google Scholar]
- McCann, B.; Bradbury, J.; Xiong, C.; Socher, R. Learned in Translation: Contextualized Word Vectors. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Akbik, A.; Blythe, D.; Vollgraf, R. Contextual String Embeddings for Sequence Labeling. In Proceedings of the 27th International Conference on Computational Linguistics (COLING), Santa Fe, NM, USA, 20–26 August 2018. [Google Scholar]
- Heinzerling, B.; Strube, M. BPEmb: Tokenization-free Pre-trained Subword Embeddings in 275 Languages. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; European Language Resources Association (ELRA): Miyazaki, Japan, 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL 2018), New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. OpenAI. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 18 April 2022).
- Howard, J.; Ruder, S. Fine-tuned Language Models for Text Classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Dai, A.M.; Le, Q.V. Semi-supervised Sequence Learning. arXiv 2015, arXiv:1511.01432. [Google Scholar]
- Peters, M.; Ammar, W.; Bhagavatula, C.; Power, R. Semi-supervised sequence tagging with bidirectional language models. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL 2017), Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Long Papers. Association for Computational Linguistics: Melbourne, Australia, 2018; Volume 1, pp. 328–339. [Google Scholar] [CrossRef]
- Zhu, Y.; Kiros, R.; Zemel, R.S.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.G.; Le, Q.V.; Salakhutdinov, R. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Chen, X.; Zhang, H.; Tian, X.; Zhu, D.; Tian, H.; Wu, H. ERNIE: Enhanced Representation through Knowledge Integration. arXiv 2019, arXiv:1904.09223. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.G.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lample, G.; Conneau, A. Cross-lingual Language Model Pretraining. arXiv 2019, arXiv:1901.07291. [Google Scholar]
- Keskar, N.S.; McCann, B.; Varshney, L.R.; Xiong, C.; Socher, R. CTRL: A Conditional Transformer Language Model for Controllable Generation. arXiv 2019, arXiv:1909.05858. [Google Scholar]
- Shoeybi, M.; Patwary, M.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv 2019, arXiv:1909.08053. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Bucilua Cristian, C.; Caruana, R.; Niculescu-Mizil, A. Model Compression. In KDD ’06, Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 535–541. [Google Scholar] [CrossRef]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. TinyBERT: Distilling BERT for Natural Language Understanding. arXiv 2019, arXiv:1909.10351. [Google Scholar]
- Zhao, S.; Gupta, R.; Song, Y.; Zhou, D. Extreme language model compression with optimal subwords and shared projections. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Sun, Z.; Yu, H.; Song, X.; Liu, R.; Yang, Y.; Zhou, D. Mobilebert: Task-agnostic compression of bert for resource limited devices. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2158–2170. [Google Scholar]
- Tsai, H.; Riesa, J.; Johnson, M.; Arivazhagan, N.; Li, X.; Archer, A. Small and practical BERT models for sequence labeling. arXiv 2019, arXiv:1909.00100. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P.J. PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization. Proc. Mach. Learn. Res. 2019, 119, 11328–11339. [Google Scholar]
- Kitaev, N.; Kaiser, L.; Levskaya, A. Reformer: The Efficient Transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; Chang, M. REALM: Retrieval-Augmented Language Model Pre-Training. arXiv 2020, arXiv:2002.08909. [Google Scholar]
- Rosset, C. Turing-NLG: A 17-Billion-Parameter Language Model by Microsoft. Microsoft Blog. 2020. Available online: https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/ (accessed on 19 April 2022).
- Clark, K.; Luong, M.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Herzig, J.; Nowak, P.K.; Müller, T.; Piccinno, F.; Eisenschlos, J.M. TAPAS: Weakly Supervised Table Parsing via Pre-training. arXiv 2020, arXiv:2004.02349. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T. MPNet: Masked and Permuted Pre-training for Language Understanding. Adv. Neural Inf. Process. Syst. 2020, 33, 16857–16867. [Google Scholar]
- Lewis, P.S.H.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. DeBERTa: Decoding-enhanced BERT with Disentangled Attention. arXiv 2020, arXiv:2006.03654. [Google Scholar]
- Lewis, M.; Ghazvininejad, M.; Ghosh, G.; Aghajanyan, A.; Wang, S.I.; Zettlemoyer, L. Pre-training via Paraphrasing. Adv. Neural Inf. Process. Syst. 2020, 33, 18470–18481. [Google Scholar]
- Lepikhin, D.; Lee, H.; Xu, Y.; Chen, D.; Firat, O.; Huang, Y.; Krikun, M.; Shazeer, N.; Chen, Z. {GS}hard: Scaling Giant Models with Conditional Computation and Automatic Sharding. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A massively multilingual pre-trained text-to-text transformer. arXiv 2020, arXiv:2010.11934. [Google Scholar]
- Wang, X.; Gao, T.; Zhu, Z.; Liu, Z.; Li, J.; Tang, J. KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation. Trans. Assoc. Comput. Linguist. 2021, 9, 176–194. [Google Scholar] [CrossRef]
- Chi, Z.; Huang, S.; Dong, L.; Ma, S.; Singhal, S.; Bajaj, P.; Song, X.; Wei, F. XLM-E: Cross-lingual Language Model Pre-training via ELECTRA. arXiv 2021, arXiv:2106.16138. [Google Scholar]
- Smith, S.; Patwary, M.; Norick, B.; LeGresley, P.; Rajbhandari, S.; Casper, J.; Liu, Z.; Prabhumoye, S.; Zerveas, G.; Korthikanti, V.; et al. Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model. arXiv 2022, arXiv:2201.11990. [Google Scholar]
- Sanh, V.; Webson, A.; Raffel, C.; Bach, S.H.; Sutawika, L.; Alyafeai, Z.; Chaffin, A.; Stiegler, A.; Scao, T.L.; Raja, A.; et al. Multitask Prompted Training Enables Zero-Shot Task Generalization. arXiv 2021, arXiv:2110.08207. [Google Scholar]
- Edalati, A.; Tahaei, M.S.; Rashid, A.; Nia, V.P.; Clark, J.J.; Rezagholizadeh, M. Kronecker Decomposition for GPT Compression. arXiv 2021, arXiv:2110.08152. [Google Scholar]
- Du, N.; Huang, Y.; Dai, A.M.; Tong, S.; Lepikhin, D.; Xu, Y.; Krikun, M.; Zhou, Y.; Yu, A.W.; Firat, O.; et al. GLaM: Efficient Scaling of Language Models with Mixture-of-Experts. arXiv 2021, arXiv:2112.06905. [Google Scholar]
- Rae, J.W.; Borgeaud, S.; Cai, T.; Millican, K.; Hoffmann, J.; Song, H.F.; Aslanides, J.; Henderson, S.; Ring, R.; Young, S.; et al. Scaling Language Models: Methods, Analysis & Insights from Training Gopher. arXiv 2021, arXiv:2112.11446. [Google Scholar]
- Lin, X.V.; Mihaylov, T.; Artetxe, M.; Wang, T.; Chen, S.; Simig, D.; Ott, M.; Goyal, N.; Bhosale, S.; Du, J.; et al. Few-shot Learning with Multilingual Language Models. arXiv 2021, arXiv:2112.10668. [Google Scholar]
- Thoppilan, R.; Freitas, D.D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. LaMDA: Language Models for Dialog Applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- Gao, L.; Biderman, S.; Black, S.; Golding, L.; Hoppe, T.; Foster, C.; Phang, J.; He, H.; Thite, A.; Nabeshima, N.; et al. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv 2021, arXiv:2101.00027. [Google Scholar]
- Hoffmann, J.; Borgeaud, S.; Mensch, A.; Buchatskaya, E.; Cai, T.; Rutherford, E.; Casas, D.d.L.; Hendricks, L.A.; Welbl, J.; Clark, A.; et al. Training Compute-Optimal Large Language Models. arXiv 2022, arXiv:2203.15556. [Google Scholar] [CrossRef]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling Language Modeling with Pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar] [CrossRef]
- Barham, P.; Chowdhery, A.; Dean, J.; Ghemawat, S.; Hand, S.; Hurt, D.; Isard, M.; Lim, H.; Pang, R.; Roy, S.; et al. Pathways: Asynchronous Distributed Dataflow for ML. Proc. Mach. Learn. Syst. 2022, 4, 430–449. [Google Scholar] [CrossRef]
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X.V.; et al. OPT: Open Pre-trained Transformer Language Models. arXiv 2022, arXiv:2205.01068. [Google Scholar] [CrossRef]
- Karande, H.; Walambe, R.; Benjamin, V.; Kotecha, K.; Raghu, T.S. Stance Detection with BERT Embeddings for Credibility Analysis of Information on Social Media. PeerJ Comput. Sci. 2021, 7, e467. [Google Scholar] [CrossRef]
- Devika, R.; Vairavasundaram, S.; Mahenthar, C.S.J.; Varadarajan, V.; Kotecha, K. A Deep Learning Model Based on BERT and Sentence Transformer for Semantic Keyphrase Extraction on Big Social Data. IEEE Access 2021, 9, 165252–165261. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, Y.; Hao, C.; Qiu, H. NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task-Next Sentence Prediction. arXiv 2021, arXiv:2109.03564. [Google Scholar]
- Xu, H.; Chen, Y.; Du, Y.; Shao, N.; Wang, Y.; Li, H.; Yang, Z. ZeroPrompt: Scaling Prompt-Based Pretraining to 1000 Tasks Improves Zero-Shot Generalization. arXiv 2022, arXiv:2201.06910. [Google Scholar]
- Frankle, J.; Carbin, M. The Lottery Ticket Hypothesis: Training Pruned Neural Networks. arXiv 2018, arXiv:1803.03635. [Google Scholar]
- Liu, D.; Cheng, P.; Dong, Z.; He, X.; Pan, W.; Ming, Z. A General Knowledge Distillation Framework for Counterfactual Recommendation via Uniform Data. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 25–30 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 831–840. [Google Scholar]
- Ding, F.; Luo, F.; Hu, H.; Yang, Y. Multi-level Knowledge Distillation. arXiv 2020, arXiv:2012.00573. [Google Scholar]
- Sun, S.; Cheng, Y.; Gan, Z.; Liu, J. Patient Knowledge Distillation for BERT Model Compression. arXiv 2019, arXiv:1908.09355. [Google Scholar]
- Wang, T.; Zhu, J.; Torralba, A.; Efros, A.A. Dataset Distillation. arXiv 2018, arXiv:1811.10959. [Google Scholar]
- Chumachenko, A.; Gavrilov, D.; Balagansky, N.; Kalaidin, P. Weight squeezing: Reparameterization for extreme compression and fast inference. arXiv 2020, arXiv:2010.06993. [Google Scholar]
- Ganesh, P.; Chen, Y.; Lou, X.; Khan, M.A.; Yang, Y.; Sajjad, H.; Nakov, P.; Chen, D.; Winslett, M. Compressing Large-Scale Transformer-Based Models: A Case Study on BERT. Trans. Assoc. Comput. Linguist. 2021, 9, 1061–1080. [Google Scholar] [CrossRef]
- Gupta, M.; Agrawal, P. Compression of Deep Learning Models for Text: A Survey. ACM Trans. Knowl. Discov. Data (TKDD) 2020, 16, 1–55. [Google Scholar] [CrossRef]
- Schwartz, R.; Dodge, J.; Smith, N.A.; Etzioni, O. Green AI. Commun. ACM 2020, 63, 54–63. [Google Scholar] [CrossRef]
- Verdecchia, R.; Cruz, L.; Sallou, J.; Lin, M.; Wickenden, J.; Hotellier, E. Data-Centric Green AI: An Exploratory Empirical Study. arXiv 2022, arXiv:2204.02766. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Deep Learning in NLP. arXiv 2019, arXiv:1906.02243. [Google Scholar]
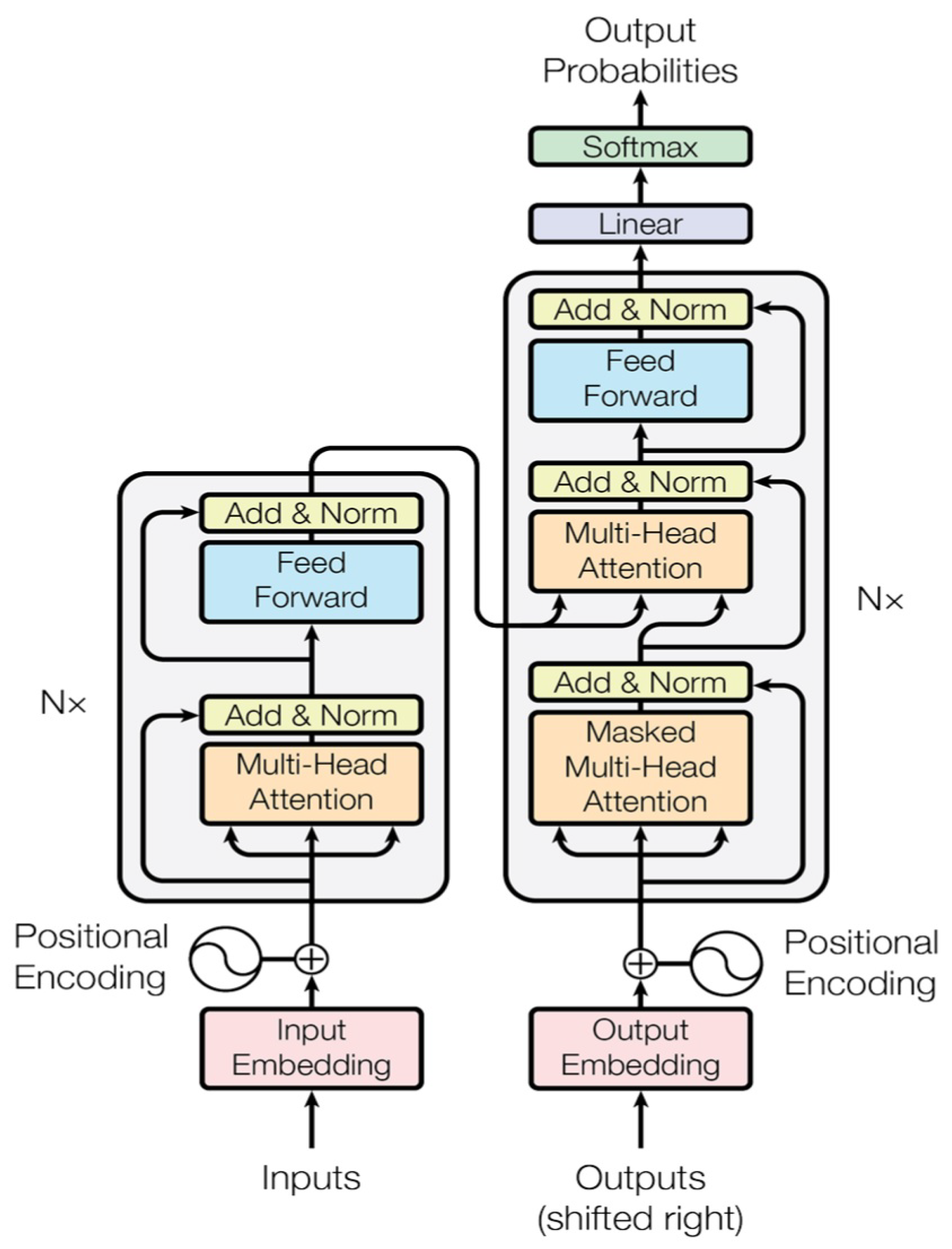

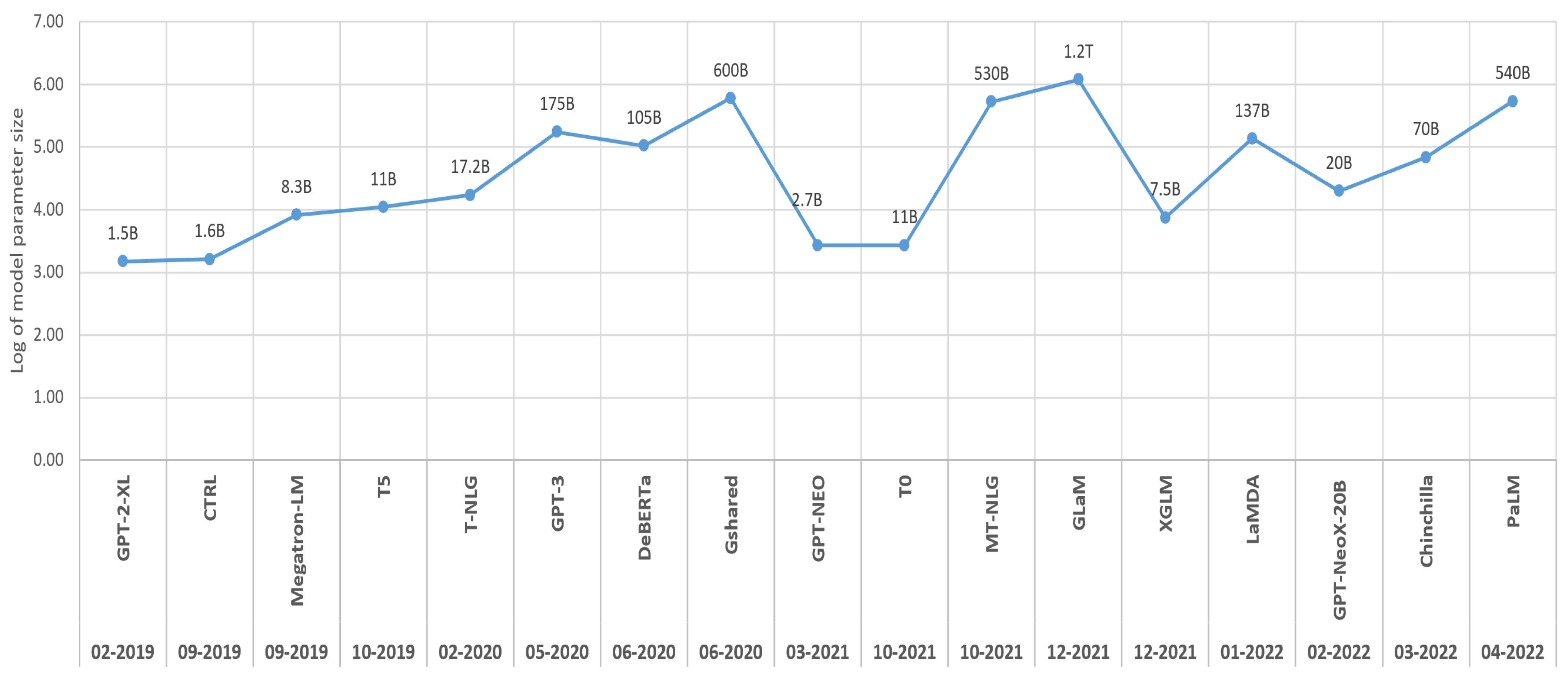

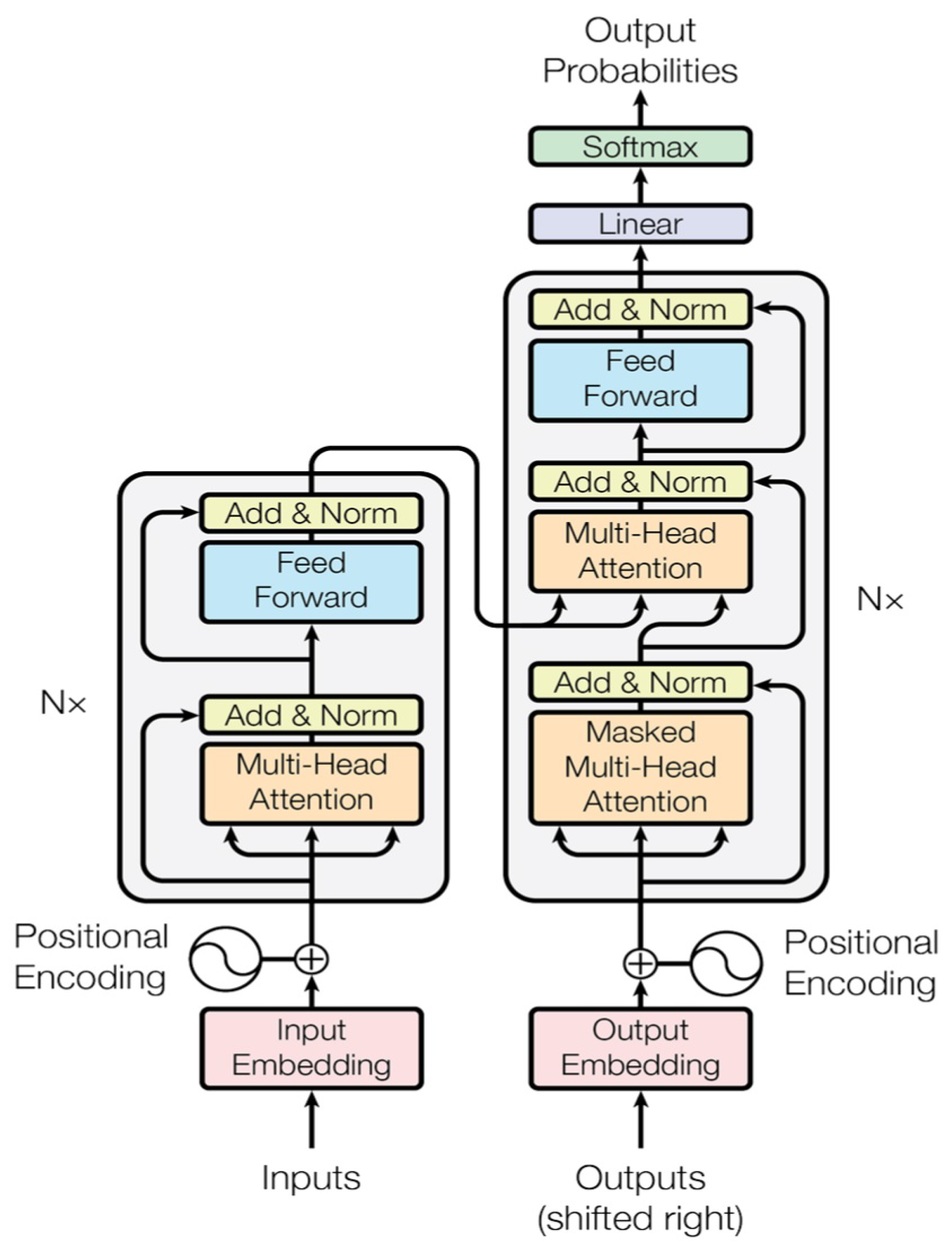{kind=link}
{kind=link}
{kind=link}
| Model | Layers | Attention Heads | CE Dimension | Parameters |
|---|---|---|---|---|
| GPT | 12 | 12 | 768 | 117M |
| BERT-Large | 24 | 16 | 1024 | 340M |
| GPT-2-1.5B | 48 | 12 | 1600 | 1.5B |
| RoBERTa | 24 | 16 | 1024 | 355M |
| DistilBERT-Base | 6 | 12 | 768 | 66M |
| ALBERT-Base | 12 | 12 | 768 | 12M |
| ALBERT-Large | 24 | 16 | 1024 | 18M |
| XLNet | 24 | 16 | 1024 | 340M |
| ELECTRA | 24 | 16 | 1024 | 335M |
| Megatron-LM | 72 | 32 | 3072 | 8.3B |
| T5-11B | 24 | 128 | 1024 | 11B |
| CTRL | 48 | 16 | 1280 | 1.63B |
| Longformer-Large | 24 | 16 | 1024 | 435M |
| Pegasus | 16 | 16 | 1024 | 568M |
| Turing-NLG | 78 | 28 | 4256 | 17.2B |
| OPT-125M | 12 | 12 | 768 | 125M |
| OPT-175B | 96 | 96 | 12,288 | 175B |
| Name | Lab | Param. | Dataset Sources | Data Size |
|---|---|---|---|---|
| Megatron MT-NLG | NVIDIA and Microsoft | 530B | The Pile v1 + more: OpenWebText2 (Reddit links) Stack Exchange and PubMed Abstracts Wikipedia and Books3 Gutenberg (PG-19) and BookCorpus2 NIH ExPorter Pile-CC ArXiv, GitHub Common Crawl 2020 and2021 + RealNews (120 GB). + CC-Stories (31 GB). | >825 GB |
| GPT-2 | Open AI | 1.5B | WebText (40 GB) | 40 GB |
| BERT | 345M |
BooksCorpus [4] 800M words Wikipedia 2500M English Wikipedia (12 GB) + BookCorpus (4 GB). | 16 GB | |
| Megatron-11B | FAIR | 11B |
English Wikipedia (12 GB) + BookCorpus (4 GB) + CC-News(76 GB). + OpenWebText/Reddit upvoted (38 GB). + Stories CC (31 GB). | 161 GB |
| RoBERTa.-Base | Facebook AI and Univ. of Wash. | 125M |
English Wikipedia (12 GB) + BookCorpus (4 GB) + CC-News (76 GB). + OpenWebText/Reddit (38 GB). + Stories CC (31 GB). | 161 GB |
| Megatron-LM | NVIDIA | 8.3B |
Wikipedia and OpenWebText RealNews + CC-Stories. | 174 GB |
| Fairseq. | Meta AI | 13B |
English Wikipedia (12 GB) + BookCorpus (4 GB) + CC-News (76 GB). + OpenWebText/Reddit upvoted (38 GB). + Stories, 1M story documents from the CC (31 GB). + English CC100 (292 GB). | 453 GB |
| GPT-3 | Open-AI | 175B |
Wikipedia Books and Journals Common Crawl (filtered) WebText2 and Others. | 45 TB |
| OPT-175 | Meta AI | 175B |
BookCorpus and CC-Stories ThePile: + Pile-CC + USPTO + OpenWebText2 + Project Gutenberg + OpenSubtitles + Wikipedia + DMMathematics + HackerNews– Pushshift.io Reddit dataset + CCNewsV2 CommonCrawl News dataset | 800 GB |
| Year | Resource (PLMs) | Team | Architecture | Parameters |
|---|---|---|---|---|
| Mar-2018 | ELMO | AI2 | Bi-directional LM | 94M |
| Jun-2018 | GPT | OpenAI | Transformer Dec. | 117M |
| Oct-2018 | BERT-base | Transformer Enc. | 110M | |
| Oct-2018 | BERT-large | Transformer Enc. | 340M | |
| Jan-2019 | Transformer-XL | Google AI | Transformer | 257M |
| Jan-2019 | XLM | Facebook AI | Transformer | 570M |
| Feb-2019 | GPT-2-large | OpenAI | Transformer Dec. | 774M |
| Feb-2019 | GPT-2-medium | OpenAI | Transformer Dec. | 345M |
| Feb-2019 | GPT-2-small | OpenAI | Transformer Dec. | 124M |
| Feb-2019 | GPT-2-XL | OpenAI | Transformer Dec. | 1.5B |
| May-2019 | UNILM | Microsoft | Transformer Enc. | 340M |
| May-2019 | MASS | Microsoft Research Asia | Transformer | 120M |
| Jun-2019 | XLNET | Google Brain and CMU | Transformer Enc. | 340M |
| Jul-2019 | ERNIE 2.0 | Baidu | Transformer Enc. | 114M |
| Jul-2019 | RoBERTa (base) | Facebook AI | Transformer Enc. | 109M |
| Jul-2019 | RoBERTa (large) | Facebook AI | Transformer Enc. | 355M |
| Sep-2019 | ALBERT-B | Google and Toyota | Transformer Enc. | 12M |
| Sep-2019 | ALBERT-L | Google and Toyota | Transformer Enc. | 18M |
| Sep-2019 | CTRL | SalesForce | Transformer | 1.63B |
| Sep-2019 | Megatron-LM | Nvidia | Seq2Seq | 8.3B |
| Sep-2019 | TinyBERT | Huawei | Transformer Enc. | 14.5M |
| Oct-2019 | BART | Transformer | 460M | |
| Oct-2019 | DistilBERT | HuggingFace | Transformer Enc. | 66M |
| Oct-2019 | DistilGPT2 | HuggingFace | Transformer Dec. | 82M |
| Oct-2019 | T5 | Transformer | 11B | |
| Nov-2019 | XLM-R (base) | Facebook AI | Transformer | 270M |
| Nov-2019 | XLM-R (large) | Facebook AI | Transformer | 550M |
| Jan-2020 | Reformer | Google research | Transformer | 149M |
| Fev-2020 | MT-DNN | Microsoft | Transformer | 330M |
| Feb-2020 | T-NLG | Microsoft | Transformer | 17.2B |
| Mar-2020 | ELECTRA | Google Brain | Transformer Enc. | 335M |
| Apr-2020 | Longformer (base) | AllenAI | Transformer Enc. | 149M |
| Apr-2020 | Longformer (large) | AllenAI | Transformer Enc. | 435M |
| May-2020 | GPT-3 | OpenAI | Transformer Dec. | 175B |
| Jun-2020 | DeBERTa (base) | Microsoft | Transformer Dec. | 140M |
| Jun-2020 | DeBERTa (large) | Microsoft | Transformer Dec. | 400M |
| Jun-2020 | DeBERTa (xlarge) | Microsoft | Transformer Dec. | 750M |
| Jun-2020 | DeBERTa (xlarge-v2) | Microsoft | Transformer Dec. | 900M |
| Jun-2020 | DeBERTa (xxlarge-v2) | Microsoft | Transformer Dec. | 105B |
| Jun-2020 | MARGE | Facebook AI | Seq2Seq | 960M |
| Jun-2020 | GShared | Transformer | 600B | |
| Mar-2021 | GPT-NEO | EleutherAI | Transformer Dec. | 2.7B |
| Jun-2021 | XLM-E | Microsoft | Transformer | 279M |
| Oct-2021 | MT-NLG | Nvidia and Microsoft | Transformer | 530B |
| Oct-2021 | T0 | Researchers | Transformer | 11B |
| Dec-2021 | GLaM | Google AI | Transformer | 1.2 Trillion |
| Dec-2021 | Gopher | Google AI | Transformer | 280B |
| Dec-2021 | XGLM | Meta AI | Transformer | 7.5B |
| Jan-2022 | LaMDA | Transformer Dec. | 137B | |
| Feb-2022 | GPT-NeoX-20B | EleutherAI and CoreWeave | Transformer Dec. | 20B |
| Mar-2022 | Chinchilla | DeepMind | Transformer | 70B |
| Apr-2022 | PaLM | Google AI | Transformer | 540B |
| May-2022 | OPT | Meta AI | Transformer Dec | 175B |
| Model Comparison | Number of Parameters | Hardware | Training Time |
|---|---|---|---|
| ELMo | 94M | P100 × 3 | 14 days |
| BERT-Base | 110M | 8 × V100 | 12 days |
| BERT-Large | 340M | 64 TPU Chips | 4 days |
| RoBERTa-Large | 340M | 1024 × V100 | 1 day |
| DistlBERT-Base | 66M | 8 × V100 | 3.5 days |
| XLNET-Large | 340M | 512 TPU Chips | 2.5 days |
| GPT-2-Large | 570M | TPUv3 × 32 | 7 days |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mars, M. From Word Embeddings to Pre-Trained Language Models: A State-of-the-Art Walkthrough. Appl. Sci. 2022, 12, 8805. https://doi.org/10.3390/app12178805
Mars M. From Word Embeddings to Pre-Trained Language Models: A State-of-the-Art Walkthrough. Applied Sciences. 2022; 12(17):8805. https://doi.org/10.3390/app12178805
Chicago/Turabian StyleMars, Mourad. 2022. "From Word Embeddings to Pre-Trained Language Models: A State-of-the-Art Walkthrough" Applied Sciences 12, no. 17: 8805. https://doi.org/10.3390/app12178805
APA StyleMars, M. (2022). From Word Embeddings to Pre-Trained Language Models: A State-of-the-Art Walkthrough. Applied Sciences, 12(17), 8805. https://doi.org/10.3390/app12178805