
Method for 2D-3D Registration under Inverse Depth and Structural Semantic Constraints for Digital Twin City


Abstract
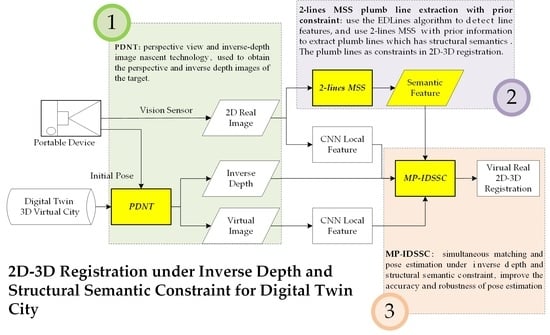
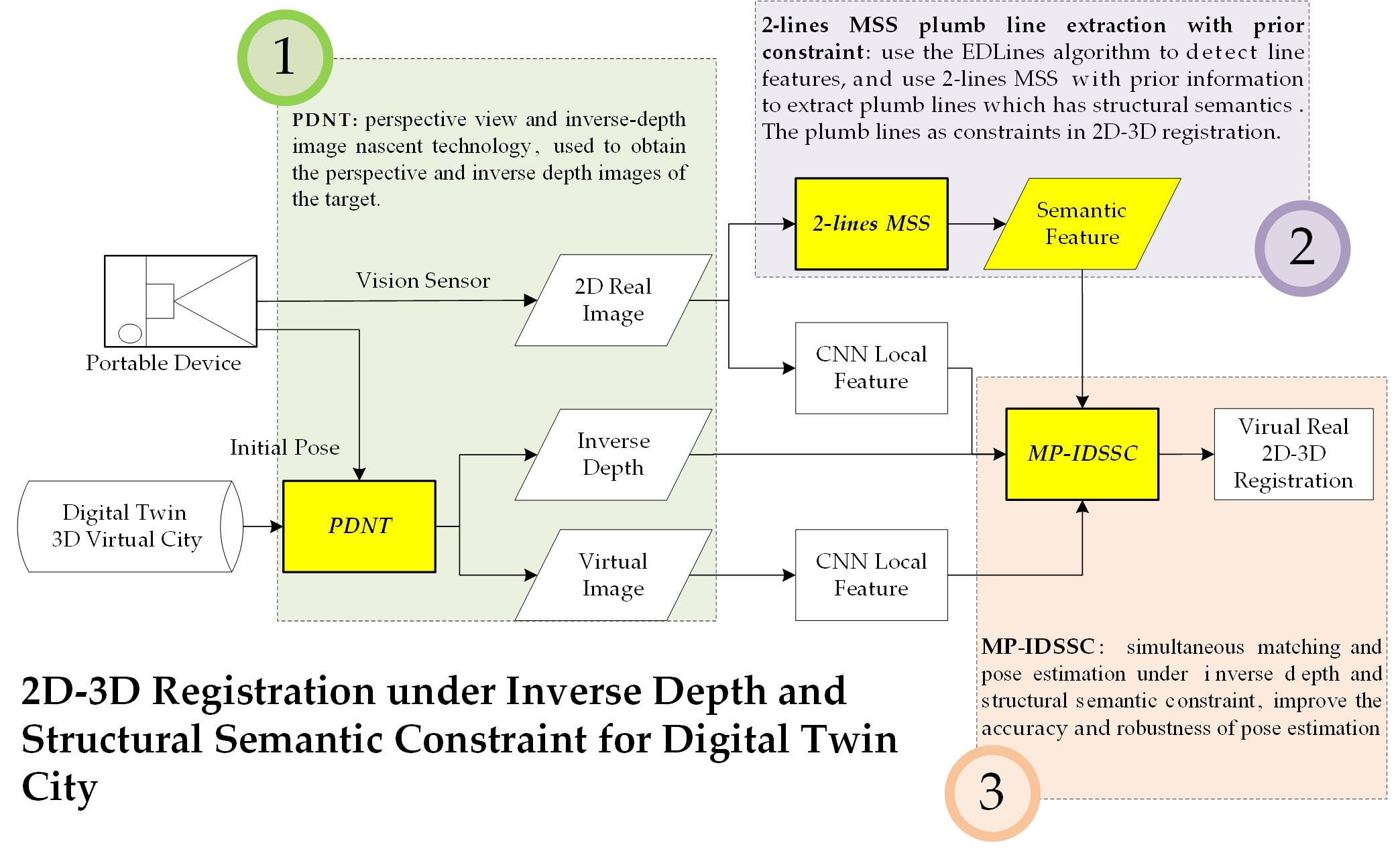
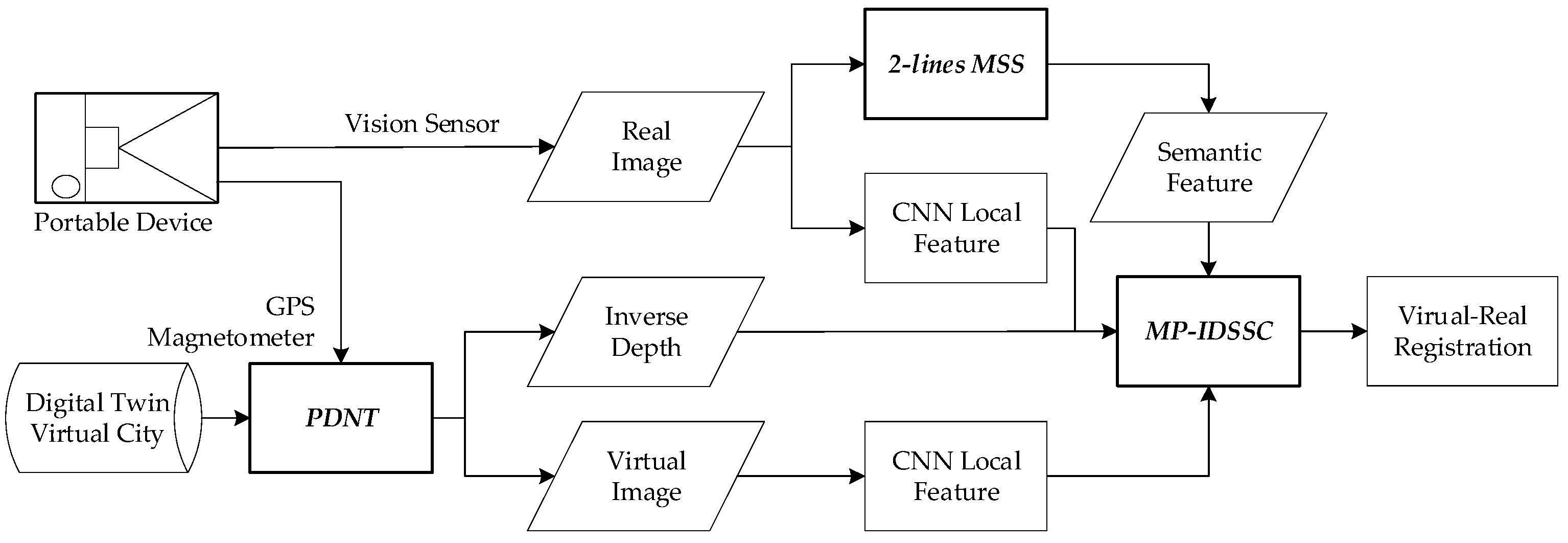
:
1. Introduction
- We developed a 2D-3D registration method with constraints of structural semantics and inverse depth coordinates, which effectively solves the problem of the large error caused by the uneven distribution of feature points in the vertical direction and achieves high-accuracy registration of monocular images in the digital twin scene.
- The proposed method seamlessly integrates with existing digital twin platforms. This method utilizes PDNT technology, which can be directly implemented using the basic functions of digital twin applications.
2. Related Works
2.1. Pose Estimation
2.2. Object Positioning
3. Materials and Methods
3.1. PDNT: Perspective View and Inverse-Depth Image Nascent Technology
3.2. Structural Semantic Feature Extraction
3.2.1. EDLines Line Feature Detection
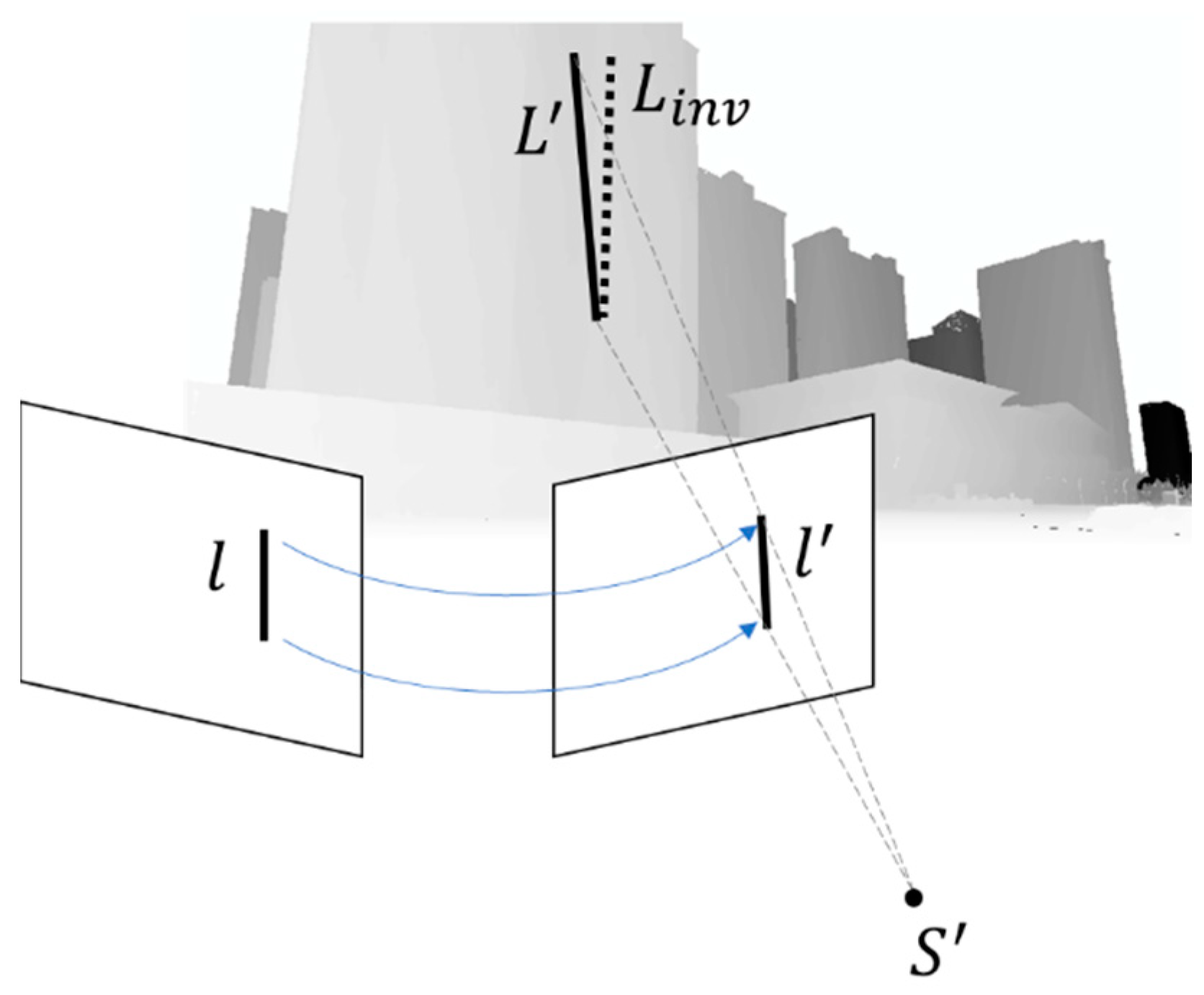
3.2.2. Two-Line MSS Plumb LINE Extraction with Prior Constraint
3.3. MP-IDSSC: Matching and Pose Estimation under Inverse Depth and Structural Semantic Constraints
3.3.1. Cross-Validation of Dynamic Adaptive Threshold
3.3.2. Fast P5P Method
3.3.3. Error Function Combined with Structural Semantic Constraint
4. Results and Discussion
4.1. Experiment of 2D-3D Registration
4.1.1. Experimental Environment
4.1.2. PDNT Experiment
4.1.3. Structural Semantic Feature Extraction Experiment
4.1.4. MP-IDSSC Experiment
- Evaluation Metrics
- 2.
- Results Analysis
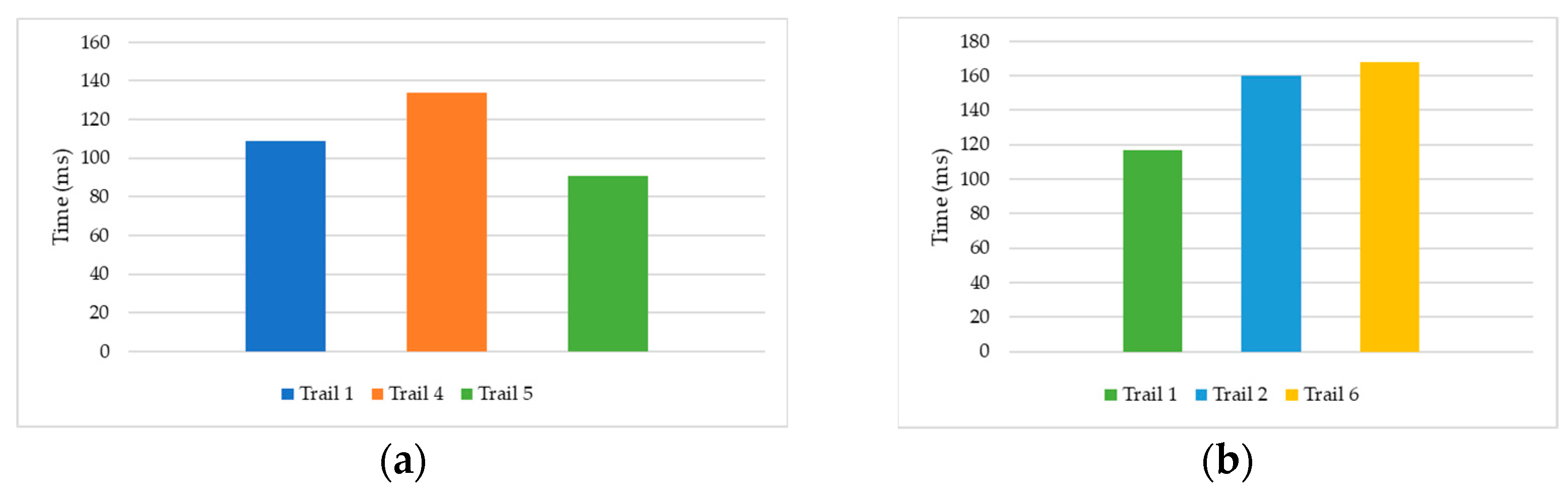
4.1.5. Time Efficiency Analysis Experiment
4.2. Application Experiment of Multi-Object Positioning for Monocular Image
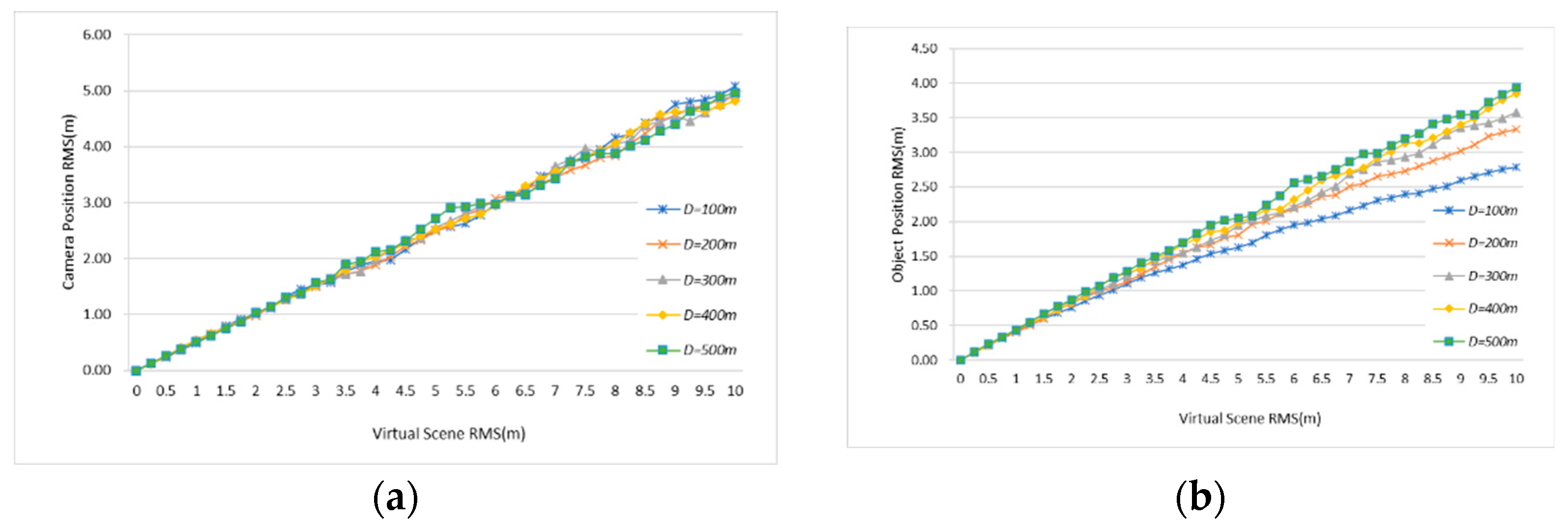
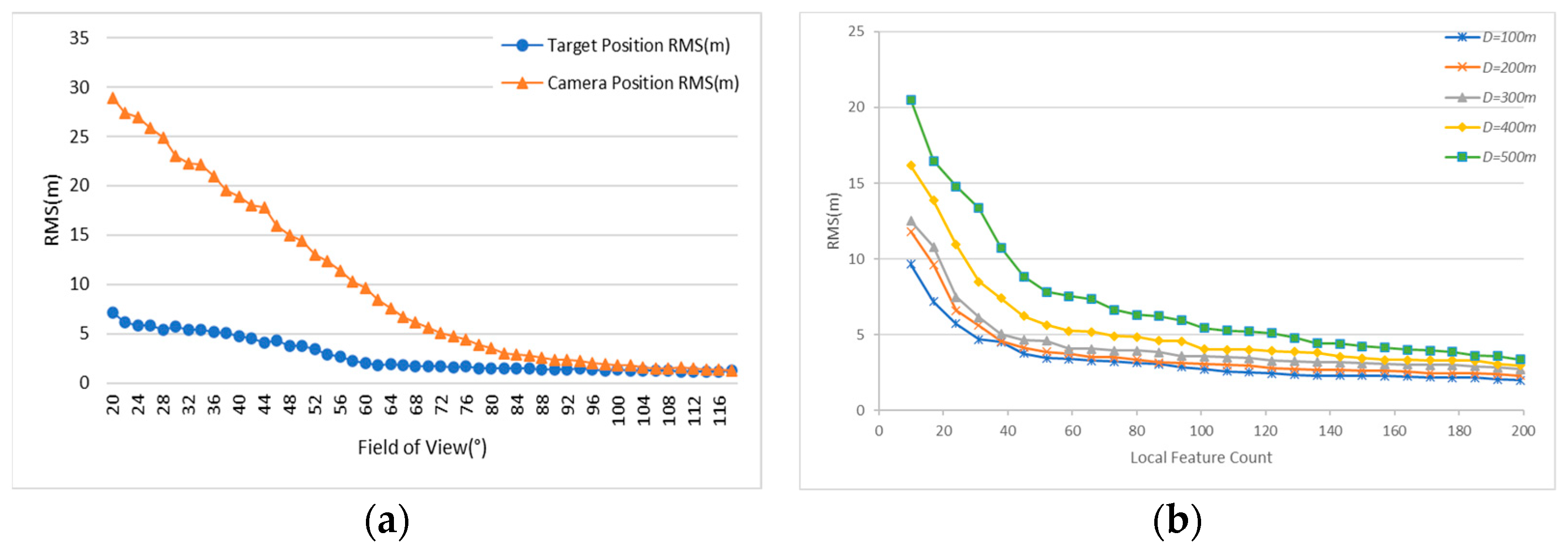
4.3. Simulation Experiments and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Deng, T.; Zhang, K.; Shen, Z.-J. A systematic review of a digital twin city: A new pattern of urban governance toward smart cities. J. Manag. Sci. Eng. 2021, 6, 125–134. [Google Scholar] [CrossRef]
- Gao, Z.; Song, Y.; Li, C.; Zeng, F.; Wang, P. Research on the Application of Rapid Surveying and Mapping for Large Scare Topographic Map by UAV Aerial Photography System. Remote Sens. 2017, 42, 121. [Google Scholar] [CrossRef]
- Billinghurst, M.; Clark, A.; Lee, G.J. A survey of augmented reality. Found. Trends Hum.-Comput. Interact. 2015, 8, 73–272. [Google Scholar] [CrossRef]
- Li, C.; Liu, Z.; Zhao, Z.; Dai, Z. A fast fusion method for multi-videos with three-dimensional GIS scenes. Multimed. Tools Appl. 2020, 80, 1671–1686. [Google Scholar] [CrossRef]
- Xu, Z.; Wang, G. Research on the Method of 3D Registration Technology. IOP Conf. Ser. Earth Environ. Sci. 2020, 440, 032139. [Google Scholar] [CrossRef]
- Coughlan, J.M.; Yuille, A.L. Manhattan World: Compass Direction From a Single Image by Bayesian Inference. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 941–947. [Google Scholar]
- Ma, W.; Xiong, H.; Dai, X.; Zheng, X.; Zhou, Y. An Indoor Scene Recognition-Based 3D Registration Mechanism for Real-Time. AR-GIS Vis. Mob. Appl. 2018, 7, 112. [Google Scholar]
- Li, J.; Wang, C.; Kang, X.; Zhao, Q. Camera localization for augmented reality and indoor positioning: A vision-based 3D feature database approach. Int. J. Digit. Earth 2019, 13, 727–741. [Google Scholar] [CrossRef]
- Wu, Y.; Che, W.; Huang, B.G.T. An Improved 3D Registration Method of Mobile Augmented Reality for Urban Built Environment. Int. J. Comput. Games Technol. 2021, 2021, 1–8. [Google Scholar] [CrossRef]
- Yue, L.; Li, H.; Zheng, X.J.S. Distorted Building Image Matching With Automatic Viewpoint Rectification and Fusion. Sensors 2019, 19, 5205. [Google Scholar] [CrossRef]
- Huang, W.; Sun, M.; Li, S. A 3D GIS-Based Interactive Registration Mechanism for Outdoor Augmented Reality System. Expert Syst. Appl. 2016, 55, 48–58. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-Net: A Trainable cnn for Joint Description and Detection of Local Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8092–8101. [Google Scholar]
- Li, J.; Hu, Q.; Ai, M. 4FP-Structure: A Robust Local Region Feature Descriptor. Photogramm. Eng. Remote Sens. 2017, 83, 813–826. [Google Scholar] [CrossRef]
- Liu, Z.; Marlet, R. Virtual Line Descriptor and Semi-local Matching Method for Reliable Feature Correspondence. In Proceedings of the Machine Vision Conference, Surrey, UK, 3–7 September 2012; Volume 2012, pp. 16.1–16.11. [Google Scholar]
- Chum, O.; Matas, J. Matching With PROSAC-Progressive Sample Consensus. In Proceedings of the Computer Vision and Pattern Recognition (CVPR05), San Diego, CA, USA, 20–26 June 2005; pp. 220–226. [Google Scholar]
- Sattler, T.; Leibe, B.; Kobbelt, L. SCRAMSAC: Improving RANSAC’s Efficiency With a Spatial Consistency Filter. In Proceedings of the International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2090–2097. [Google Scholar]
- Jiang, S.; Jiang, W. Reliable Image Matching via Photometric and Geometric Constraints Structured by Delaunay Triangulation. ISPRS J. Photogramm. Remote Sens. 2019, 153, 1–20. [Google Scholar] [CrossRef]
- Bian, J.; Lin, W.; Liu, Y.; Zhang, L.; Yeung, S.; Cheng, M.; Reid, I. GMS: Grid-Based Motion Statistics for Fast, Ultra-Robust Fea-ture Correspondence. Int. J. Comput. Vis. 2020, 128, 1580–1593. [Google Scholar] [CrossRef]
- Pai, P.; Naidu, V.P.S. Target Geo-localization Based on Camera Vision Simulation of UAV. J. Opt. 2017, 46, 425–435. [Google Scholar] [CrossRef]
- Fu, Q.; Quan, Q.; Cai, K.-Y. Robust Pose Estimation for Multirotor UAVs Using Off-Board Monocular Vision. IEEE Trans. Ind. Electron. 2017, 64, 7942–79511. [Google Scholar] [CrossRef]
- Zhang, L.; Deng, F.; Chen, J.; Bi, Y.; Phang, S.K.; Chen, X.; Chen, B.M. Vision-Based Target Three-Dimensional Geolocation Using Unmanned Aerial Vehicles. IEEE Trans. Ind. Electron. 2018, 65, 8052–8061. [Google Scholar] [CrossRef]
- Roig, G.; Boix, X.; Shitrit, H.B.; Fua, P. Conditional Random Fields for Multi-camera Object Detection. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; Volume 2011, pp. 563–570. [Google Scholar]
- Shi, J.; Zou, D.; Bai, S.; Qian, Q.; Pang, L. Reconstruction of dense three-dimensional shapes for outdoor scenes from an image sequence. Opt. Eng. 2013, 52, 123104. [Google Scholar] [CrossRef]
- Sánchez, A.; Naranjo, J.M.; Jiménez, A.; González, A. Analysis of Uncertainty in a Middle-Cost Device for 3D Measurements in BIM Perspective. Sensors 2016, 16, 1557. [Google Scholar] [CrossRef]
- Ma, J.; Bajracharya, M.; Susca, S.; Matthies, L.; Malchano, M. Real-Time Pose Estimation of a Dynamic Quadruped in GPS-Denied Environments for 24-Hour Operation. Int. J. Robot. Res. 2016, 35, 631–653. [Google Scholar] [CrossRef]
- Tekaya, S.B. Distance Estimation Using Handheld Devices; Naval Postgraduate School: Monterey, CA, USA, 2013. [Google Scholar]
- Akinlar, C.; Topal, C. EDLines: A real-time line segment detector with a false detection control. Pattern Recognit. Lett. 2011, 32, 1633–1642. [Google Scholar] [CrossRef]
- Lu, X.; Yaoy, J.; Li, H.; Liu, Y.; Zhang, X. 2-Line Exhaustive Searching for Real-Time Vanishing Point Estimation in Manhattan World. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 31 March 2017; Volume 2017, pp. 345–353. [Google Scholar]
- Mukhopadhyay, P.; Chaudhuri, B.B. A survey of Hough Transform. Pattern Recognit. 2015, 48, 993–1010. [Google Scholar] [CrossRef]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A Line Segment Detector. Image Processing Line 2012, 2, 35–55. [Google Scholar] [CrossRef]
- Fotiou, I.A.; Rostalski, P.; Parrilo, P.A.; Morari, M. Parametric Optimization and Optimal Control Using Algebraic Geometry Methods. Int. J. Control 2006, 79, 1340–1358. [Google Scholar] [CrossRef]
- Sarlin, P.-E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning Feature Matching With Graph Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Deng, F.; Zhang, L.; Gao, F.; Qiu, H.; Gao, X.; Chen, J. Long-Range Binocular Vision Target Geolocation Using Handheld Electronic Devices in Outdoor Environment. IEEE Trans. Image Process. 2020, 29, 5531–5541. [Google Scholar] [CrossRef]
- Cai, Y.; Ding, Y.; Xiu, J.; Zhang, H.; Qiao, C.; Li, Q. Distortion Measurement and Geolocation Error Correction for High Altitude Oblique Imaging Using Airborne Cameras. J. Appl. Remote Sens. 2020, 14, 014510. [Google Scholar] [CrossRef]
- Qiao, C.; Ding, Y.; Xu, Y.; Xiu, J. Ground Target Geolocation Based on Digital Elevation Model for Airborne Wide-Area Reconnaissance System. J. Appl. Remote Sens. 2018, 12, 016004. [Google Scholar] [CrossRef]
- Collings, B.J.; Niederreiter, H. Random Number Generation and Quasi-Monte Carlo Methods. J. Am. Stat. Assoc. 1993, 88, 699. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | CamPOS | Actual | Error | |||
|---|---|---|---|---|---|---|
| Position (m) (X/Y/Z) | Orientation (°) (Y/P/R) | Position (m) (X/Y/Z) | Orientation (°) (Y/P/R) | Position(m) (X/Y/Z) | Orientation (°) (Y/P/R) | |
| P1 | −2093390.42 | 284.9 | −2093394.17 | 269.67 | 3.75 | 15.23 |
| 4806197.15 | −13.5 | 4806194.13 | −5.78 | 3.02 | −7.72 | |
| 3621100.70 | 360.0 | 3621107.46 | 353.68 | −6.76 | 6.32 | |
| P2 | −2093850.41 | 217.2 | −2093851.67 | 222.46 | 1.26 | −5.26 |
| 4806374.77 | 3.1 | 4806372.58 | 10.63 | 2.18 | −7.53 | |
| 3620496.15 | 359.0 | 3620501.33 | 1.39 | −5.18 | −2.39 | |
| Trial | Feature Extraction | Pose Estimation Method |
|---|---|---|
| Trial 1 | SuperPoint | IDSSC-MP |
| Trial 2 | D2-NET | IDSSC-MP |
| Trial 3 | SuperPoint | IDC |
| Trial 4 | SuperPoint | SuperGlue |
| Trial 5 | SuperPoint | GMS |
| Trial 6 | SIFT | Ransac |
| Trials | Image | NCM | RMSE | CP X/Y/Z(m) | CPE(m) | CO Y/P/R(°) | |
|---|---|---|---|---|---|---|---|
| Trial 1 | P1 | 332 | 0.60 | −2093392.02 | 2.15 | 270.81 | 19.89 |
| 4806196.97 | 2.83 | −7.39 | 28.18 | ||||
| 3621103.69 | 3.77 | 354.87 | 20.76 | ||||
| P2 | 373 | 0.59 | −2093851.7 | 0.44 | 221.33 | 19.63 | |
| 4806372.58 | 0.89 | 9.48 | 20.07 | ||||
| 3620501.74 | 1.18 | 0.70 | 12.13 | ||||
| Trial 2 | P1 | 223 | 1.83 | −2093390.58 | 3.59 | 271.37 | 29.67 |
| 4806196.99 | 2.85 | −7.78 | 34.99 | ||||
| 3621102.49 | 4.97 | 355.83 | 37.61 | ||||
| P2 | 273 | 1.66 | −2093851.79 | 0.56 | 221.29 | 20.42 | |
| 4806372.7 | 1.01 | 9.16 | 25.56 | ||||
| 3620501.78 | 1.60 | 0.73 | 11.51 | ||||
| Trial 3 | P1 | 173 | 0.86 | −2093392.05 | 2.18 | 271.31 | 28.53 |
| 4806197.18 | 3.05 | −10.02 | 74.00 | ||||
| 3621100.77 | 6.69 | 356.40 | 47.56 | ||||
| P2 | 219 | 0.67 | −2093851.84 | 0.61 | 221.28 | 20.68 | |
| 4806372.32 | 0.63 | 8.60 | 35.34 | ||||
| 3620501.88 | 2.23 | 0.81 | 10.03 | ||||
| Trial 4 | P1 | 182 | 0.82 | −2093392.95 | 1.22 | 271.33 | 28.97 |
| 4806197.72 | 3.58 | −10.03 | 74.17 | ||||
| 3621100.53 | 6.93 | 356.38 | 47.21 | ||||
| P2 | 146 | 0.96 | −2093851.6 | 0.40 | 221.33 | 19.72 | |
| 4806372.82 | 1.13 | 8.455 | 37.96 | ||||
| 3620500.33 | 1.79 | 0.685 | 12.30 | ||||
| Trial 5 | P1 | 30 | 1.89 | −2093391.17 | 3.00 | 271.55 | 32.81 |
| 4806196.71 | 2.57 | −9.75 | 69.37 | ||||
| 3621098.40 | 9.06 | 356.13 | 42.84 | ||||
| P2 | 33 | 1.33 | −2093851.7 | 0.43 | 221.25 | 21.11 | |
| 4806373.89 | 2.20 | 8.34 | 39.88 | ||||
| 3620498.87 | 3.24 | 0.7 | 12.04 | ||||
| Trial 6 | P1 | 13 | 1.05 | −2093246.81 | 147.36 | 183.38 | 1506.04 |
| 4806182.10 | 12.03 | −34.71 | 504.92 | ||||
| 3621131.57 | 24.11 | 76.59 | 1447.05 | ||||
| P2 | 7 | 1.69 | −2093842.5 | 8.77 | 218.86 | 23.38 | |
| 4806368.51 | 3.17 | 17.66 | 162.83 | ||||
| 3620501.05 | 1.07 | 7.16 | 124.96 |
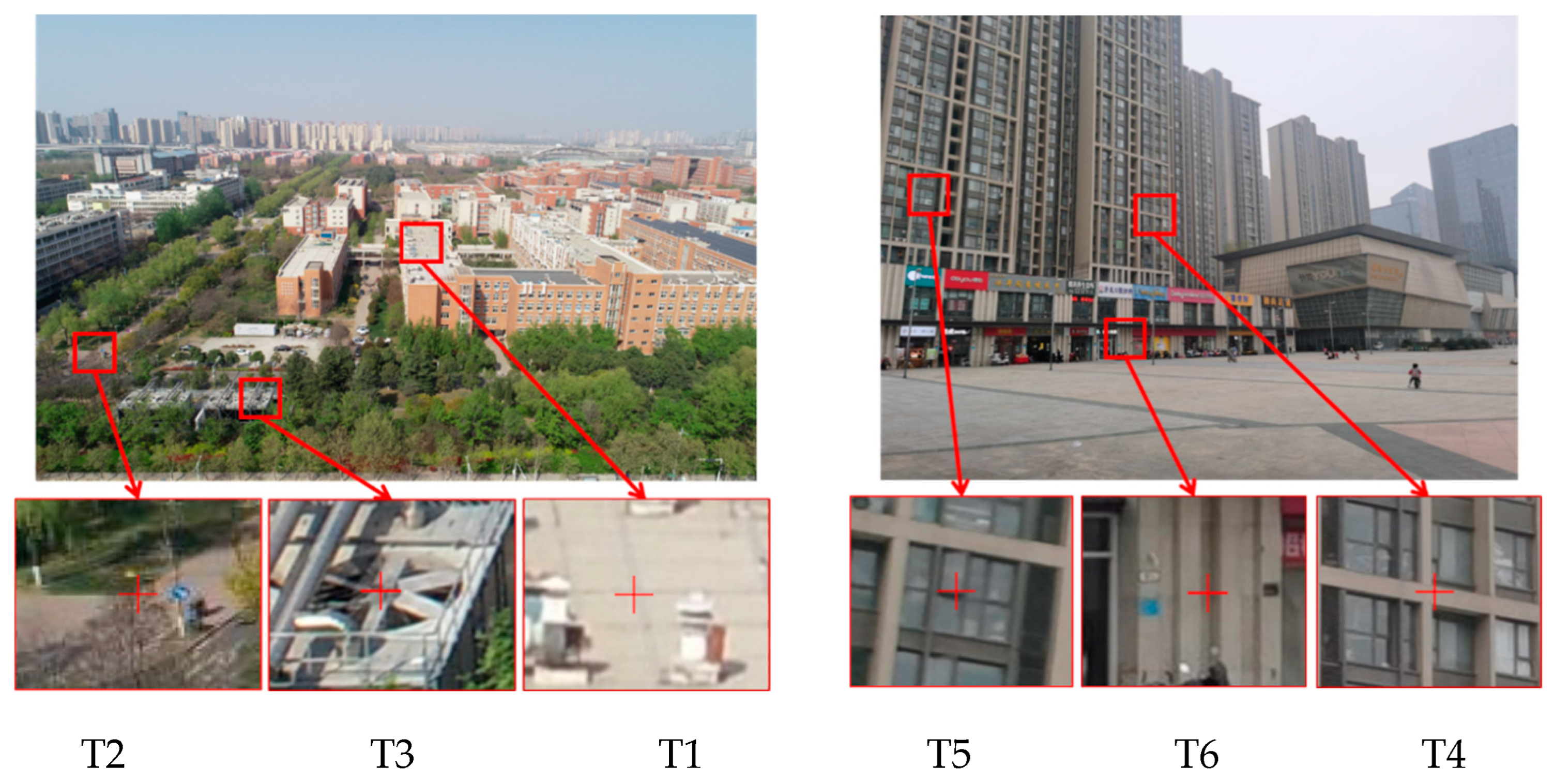
| T1 | T2 | T3 | T4 | T5 | T6 | |
|---|---|---|---|---|---|---|
| TD(m) | 225.08 | 172.25 | 119 | 103 | 82 | 64 |
| RD | (728,435) | (111,655) | (423,755) | (696,534) | (138,433) | (751,863) |
| BC | −2093175.39 | −2093268.12 | −2093291.67 | −2093828.59 | −2093861.08 | −2093831.16 |
| 4806240.40 | 4806242.66 | 4806203.83 | 4806463.96 | 4806437.85 | 4806415.05 | |
| 3621093.20 | 3621000.58 | 3621049.34 | 3620461.02 | 3620453.39 | 3620457.80 |
| Target | Index | Trial 1 | Trial 4 | Trial 5 |
|---|---|---|---|---|
| T1 | PE(m) | −0.31/−0.36/0.13 | −0.27/0.64/−0.41 | 0.18/−0.38/0.5 |
| APE(m) | 0.50 | 0.80 | 0.65 | |
| RPE | 0.25% | 0.39% | 0.32% | |
| T2 | PE(m) | −0.25/−0.32/0.31 | −0.98/0.88/−1.68 | −2.88/0.21/−2.06 |
| APE(m) | 0.68 | 2.13 | 3.54 | |
| RPE | 0.4% | 1.2% | 2.0% | |
| T3 | PE(m) | −1.52/0.19/−0.66 | −0.72/0.72/1.97 | −1.31/−1.64/1.56 |
| APE(m) | 1.66 | 2.21 | 2.61 | |
| RPE | 1.5% | 1.90% | 2.37% | |
| PE(m) | 0.1/0.07/0.1 | 0.07/0.12/0.01 | 0.01/0.12/−0.05 | |
| T4 | APE(m) | 0.16 | 0.15 | 0.13 |
| RPE | 0.15% | 0.14% | 0.12% | |
| PE(m) | 0.27/0.12/0.11 | 0.21/0.14/0.05 | −0.32/0.22/0.02 | |
| T5 | APE(m) | 0.32 | 0.25 | 0.40 |
| RPE | 0.4% | 0.49% | 0.35% | |
| PE(m) | −0.05/1.54/−1.71 | −0.1/2.32/−2.39 | 1.01/2.27/−2.86 | |
| T6 | APE(m) | 2.30 | 3.33 | 3.79 |
| RPE | 3.5% | 5.2% | 5.9% |
| Data | Error Model | Unit |
|---|---|---|
| Camera Position Error | Normal Distribution | |
| Camera Orientation Error | Normal Distribution | |
| Pixel Measurement Error | Normal Distribution | |
| Feature Matching Error | Normal Distribution | / |
| Image Distortion Error | / | |
| Virtual Scene RMS Error | Normal Distribution | |
| Feature Count | / | / |
| Field of View | / | / |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, X.; Zhou, Y.; Shi, Q. Method for 2D-3D Registration under Inverse Depth and Structural Semantic Constraints for Digital Twin City. Appl. Sci. 2022, 12, 8543. https://doi.org/10.3390/app12178543
Hu X, Zhou Y, Shi Q. Method for 2D-3D Registration under Inverse Depth and Structural Semantic Constraints for Digital Twin City. Applied Sciences. 2022; 12(17):8543. https://doi.org/10.3390/app12178543
Chicago/Turabian StyleHu, Xiaofei, Yang Zhou, and Qunshan Shi. 2022. "Method for 2D-3D Registration under Inverse Depth and Structural Semantic Constraints for Digital Twin City" Applied Sciences 12, no. 17: 8543. https://doi.org/10.3390/app12178543
APA StyleHu, X., Zhou, Y., & Shi, Q. (2022). Method for 2D-3D Registration under Inverse Depth and Structural Semantic Constraints for Digital Twin City. Applied Sciences, 12(17), 8543. https://doi.org/10.3390/app12178543