
Rwin-FPN++: Rwin Transformer with Feature Pyramid Network for Dense Scene Text Spotting

Abstract
:Featured Application
Abstract
1. Introduction
- (1)
- We improve the Swin Transformer network [13] to the Rwin Transformer network. Compared with the shifted windows-based Transformer (Swin Transformer), the rotated windows-based Transformer (Rwin Transformer) can achieve better rotational invariance of the self-attention mechanism. For the task of scene text detection, because there are a large number of rotated and distorted texts, we modified the Swin Transformer by adding a rotating window self-attention mechanism. Thus our network can enhance the attention to rotated and distorted scene text.
- (2)
- We combine the Rwin Transformer with the feature pyramid network to detect and recognize dense scene text. The Rwin Transformer is used to enhance the rotational invariance of the self-attention mechanism. The feature pyramid network is adopted to extract local low-level visual cues of scene text.
- (3)
- A dense scene text dataset was constructed to evaluate the performance of our Rwin-FPN++ network. The 620 pictures of this dataset were taken from the wiring of the terminal block of the substation panel cabinet. Text instances in these pictures are very dense, with horizontal, multi-oriented, and curved shapes. This dataset can be downloaded from https://github.com/cbzeng110/-DenseTextDetection (accessed on 10 February 2022).
- (4)
- The experiments show that our Rwin-FPN++ network can achieve an F-measure of 79% on our dense scene text. Compared with previous approaches, our method outperforms all other methods in F-measure by at least 2.8% and achieves state-of-the-art spotting performances.
2. Related Work
3. Proposed Method
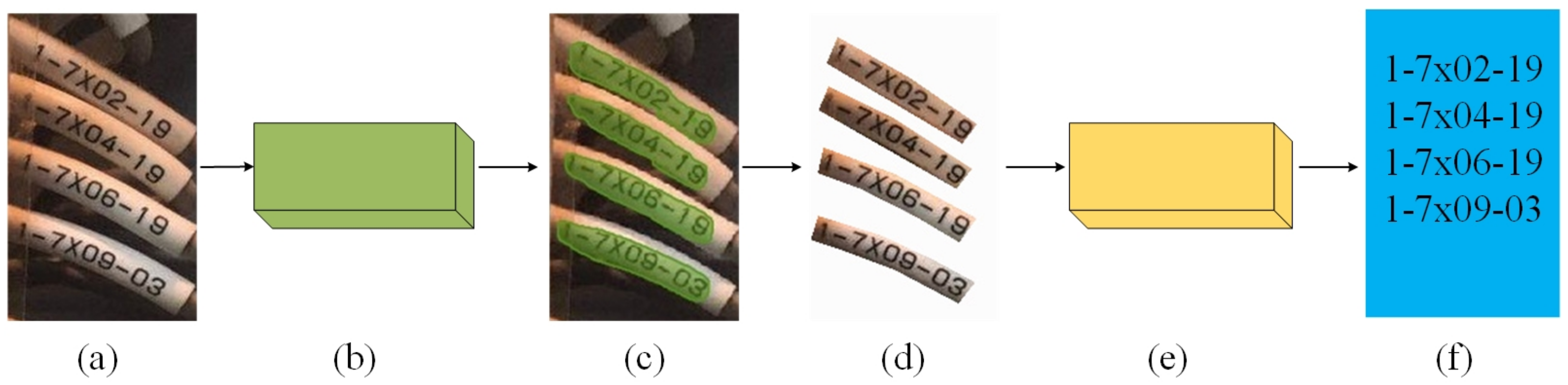
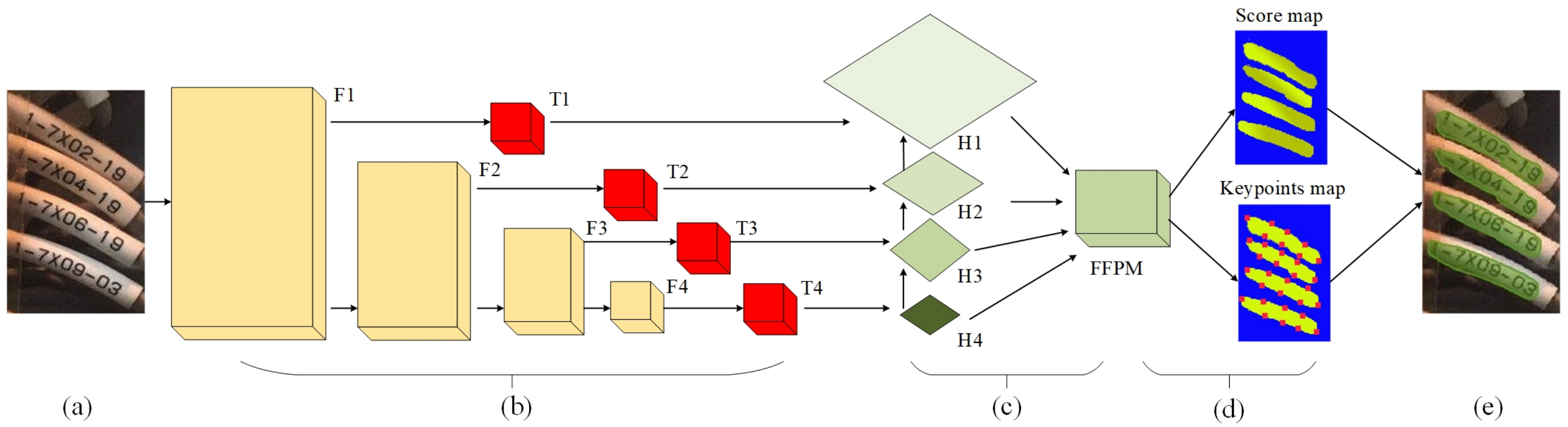
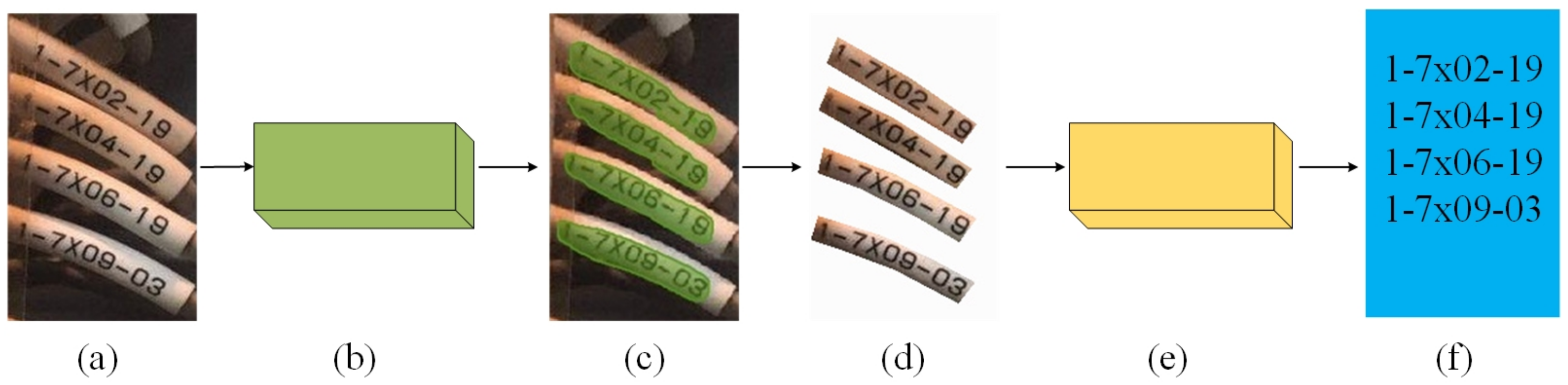
3.1. Overall Architecture
3.2. Text Detection
3.2.1. Rwin Transformer
3.2.2. Network Design
3.2.3. Detection Loss Function
3.3. Text Recognition
4. Experiment
4.1. Training Set
4.2. Implementation Details
4.3. Evaluation Results
4.3.1. Evaluation of Detection Task
4.3.2. Evaluation of Spotting Task
5. Ablation Study
6. Conclusions
7. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DCNN | Deep Convolutional Neural Network(CNN) |
| Rwin | Rotated Windows-based Transformer |
| Swin | Shifted Windows-based Transformer |
| FPN | Feature Pyramid Network |
| Rwin-FPN++ | Rwin Transformer with FPN for Dense Scene Text Spotting |
References
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Reading text in the wild with convolutional neural networks. Int. J. Comput. Vis. (IJCV) 2016, 116, 1–20. [Google Scholar] [CrossRef]
- Borisyuk, F.; Gordo, A.; Sivakumar, V. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; ACM: New York, NY, USA, 2018. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Graves, A.; Fernndez, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the International Conference on Machine Learning (ICML), Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar]
- Liu, Y.; Shen, C.; Jin, L.; He, T.; Chen, P.; Liu, C.; Chen, H. ABCNet v2: Adaptive Bezier-Curve Network for Real-time End-to-end Text Spotting. IEEE Trans. Pattern Anal. Mach. Intell. arXiv 2021, arXiv:2105.03620. [Google Scholar] [CrossRef]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. EAST: An efficient and accurate scene text detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T.E. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape Robust Text Detection with Progressive Scale Expansion Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Liu, X.; Liang, D.; Yang, Z.; Lu, T.; Shen, C. PAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5349–5367. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X. Textboxes: A fast text detector with a single deep neural network. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Zhu, Y.; Chen, J.; Liang, L.; Kuang, Z.; Jin, L.; Zhang, W. Fourier contour embedding for arbitrary-shaped text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3123–3131. [Google Scholar]
- Dai, P.; Zhang, S.; Zhang, H.; Cao, X. Progressive contour regression for arbitrary-shape scene text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7393–7402. [Google Scholar]
- Tang, J.; Zhang, W.; Liu, H.; Yang, M.; Jiang, B.; Hu, G.; Bai, X. Few Could Be Better Than All: Feature Sampling and Grouping for Scene Text Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- Qiao, Z.; Zhou, Y.; Yang, D.; Zhou, Y.; Wang, W. Seed: Semantics enhanced encoder-decoder framework for scene text recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13528–13537. [Google Scholar]
- Aberdam, A.; Litman, R.; Tsiper, S.; Anschel, O.; Slossberg, R.; Mazor, S.; Manmatha, R.; Perona, P. Sequence-to-sequence contrastive learning for text recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15302–15312. [Google Scholar]
- Fang, S.; Xie, H.; Wang, Y.; Mao, Z.; Zhang, Y. Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7098–7107. [Google Scholar]
- Wang, P.; Zhang, C.; Qi, F.; Liu, S.; Zhang, X.; Lyu, P.; Shi, G. PGNet: Real-time Arbitrarily-Shaped Text Spotting with Point Gathering Network. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Online, 2–9 February 2021; pp. 2782–2790. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic data for text localisation in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2315–2324. [Google Scholar]
- Yuliang, L.; Lianwen, J.; Shuaitao, Z.; Sheng, Z. Detecting curve text in the wild: New dataset and new solution. arXiv 2017, arXiv:1712.02170. [Google Scholar]
- Ch’ng, C.K.; Chan, C.S.; Liu, C. Total-Text: Towards Orientation Robustness in Scene Text Detection. Int. J. Doc. Anal. Recognit. (IJDAR) 2020, 23, 31–52. [Google Scholar] [CrossRef]
- ICDAR. Competition on Multi-Lingual Scene Text Detection. 2017. Available online: http://rrc.cvc.uab.es/?ch=8&com=introduction (accessed on 15 September 2021).
- ICDAR. Robust Reading Challenge on Arbitrary-Shaped Text. 2019. Available online: http://rrc.cvc.uab.es/?ch=14 (accessed on 15 September 2021).
- Wan, Q.; Ji, H.; Shen, L. Self-attention based Text Knowledge Mining for Text Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5983–5992. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Bagdanov, A.; Iwamura, M.; Shafait, F. ICDAR 2015 competition on robust reading. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015. [Google Scholar]
- Lyu, P.; Liao, M.; Yao, C.; Wu, W.; Bai, X. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X. Textboxes++: A single-shot oriented scene text detector. IEEE Trans. Image Process. 2018, 27, 3676–3690. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, M.; Pang, G.; Huang, J.; Hassner, T.; Bai, X. Mask textspotter v3: Segmentation proposal network for robust scene text spotting. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 706–722. [Google Scholar]
- Baek, Y.; Shin, S.; Baek, J.; Park, S.; Lee, J.; Nam, D.; Lee, H. Character region attention for text spotting. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 504–521. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision | Recall | F-Measure |
|---|---|---|---|
| EAST [6] | 53.2 | 48.5 | 50.7 |
| Textspotter [37] | 72.4 | 70.9 | 71.6 |
| Textboxes++ [38] | 73.2 | 71.9 | 72.6 |
| PSENet [8] | 73.7 | 70.1 | 71.8 |
| Pan++ [10] | 76.6 | 71.1 | 73.7 |
| ABCNet v2 [5] | 79.7 | 73.1 | 76.2 |
| Our approach | 82.2 | 76.1 | 79.0 |
| Method | Precision | Recall | F-Measure |
|---|---|---|---|
| East [6] | 50.0 | 36.2 | 42.0 |
| Textboxes++ [38] | 77.2 | 81.9 | 79.6 |
| PSENet [8] | 78.0 | 84.0 | 80.9 |
| Pan++ [10] | 81.0 | 89.3 | 85.0 |
| ABCNet v2 [5] | 84.1 | 90.2 | 87.0 |
| Our approach | 85.2 | 91.2 | 88.0 |
| Method | Precision | Recall | F-Measure |
|---|---|---|---|
| East [6] | 48.0 | 35.2 | 40.6 |
| Textboxes++ [38] | 74.1 | 80.5 | 77.2 |
| PSENet [8] | 76.0 | 82.2 | 78.9 |
| Pan++ [10] | 80.0 | 83.5 | 81.7 |
| ABCNet v2 [5] | 83.8 | 85.6 | 84.5 |
| Our approach | 83.1 | 88.5 | 85.7 |
| Method | None | S | W | G |
|---|---|---|---|---|
| Mask TextSpotter [39] | 70.5 | 82.2 | 81.0 | 69.0 |
| Textboxes++ [38] | 67.2 | 81.9 | 79.6 | 67.2 |
| Craft [40] | 68.0 | 82.1 | 80.9 | 68.0 |
| Pan++ [10] | 71.0 | 83.3 | 82.0 | 69.1 |
| ABCNet v2 [5] | 72.1 | 85.2 | 83.0 | 70.1 |
| Our approach | 75.2 | 88.5 | 85.1 | 73.2 |
| Method | Precision | Recall | F-Measure |
|---|---|---|---|
| without Transformer | 75.0 | 66.2 | 70.3 |
| Swin Transformer | 80.2 | 73.9 | 76.9 |
| Rwin Transformer | 82.2 | 76.1 | 79.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, C.; Liu, Y.; Song, C. Rwin-FPN++: Rwin Transformer with Feature Pyramid Network for Dense Scene Text Spotting. Appl. Sci. 2022, 12, 8488. https://doi.org/10.3390/app12178488
Zeng C, Liu Y, Song C. Rwin-FPN++: Rwin Transformer with Feature Pyramid Network for Dense Scene Text Spotting. Applied Sciences. 2022; 12(17):8488. https://doi.org/10.3390/app12178488
Chicago/Turabian StyleZeng, Chengbin, Yi Liu, and Chunli Song. 2022. "Rwin-FPN++: Rwin Transformer with Feature Pyramid Network for Dense Scene Text Spotting" Applied Sciences 12, no. 17: 8488. https://doi.org/10.3390/app12178488
APA StyleZeng, C., Liu, Y., & Song, C. (2022). Rwin-FPN++: Rwin Transformer with Feature Pyramid Network for Dense Scene Text Spotting. Applied Sciences, 12(17), 8488. https://doi.org/10.3390/app12178488