
Malware Detection Issues, Challenges, and Future Directions: A Survey


 , ,
, ,
Abstract
1. Introduction
1.1. Paper Contribution
- (i)
- The association between the analysis approaches and the user data is highlighted.
- (ii)
- A detailed taxonomy that discusses the different types of malware signature and behaviour and distinguishes between manual and automated rules for malware detection is introduced, along with associating each subcategory detection approach with the data types used.
- (iii)
- This survey provides a taxonomy of feature extraction and representation methods based on the techniques used to extract and represent the features.
- (iv)
- A comprehensive understanding of the concepts for both data collection (analysis approaches) and feature extraction processes is presented in this review.
- (v)
- The open issues and the future directions of the research community are introduced in this review.
1.2. Paper Organization
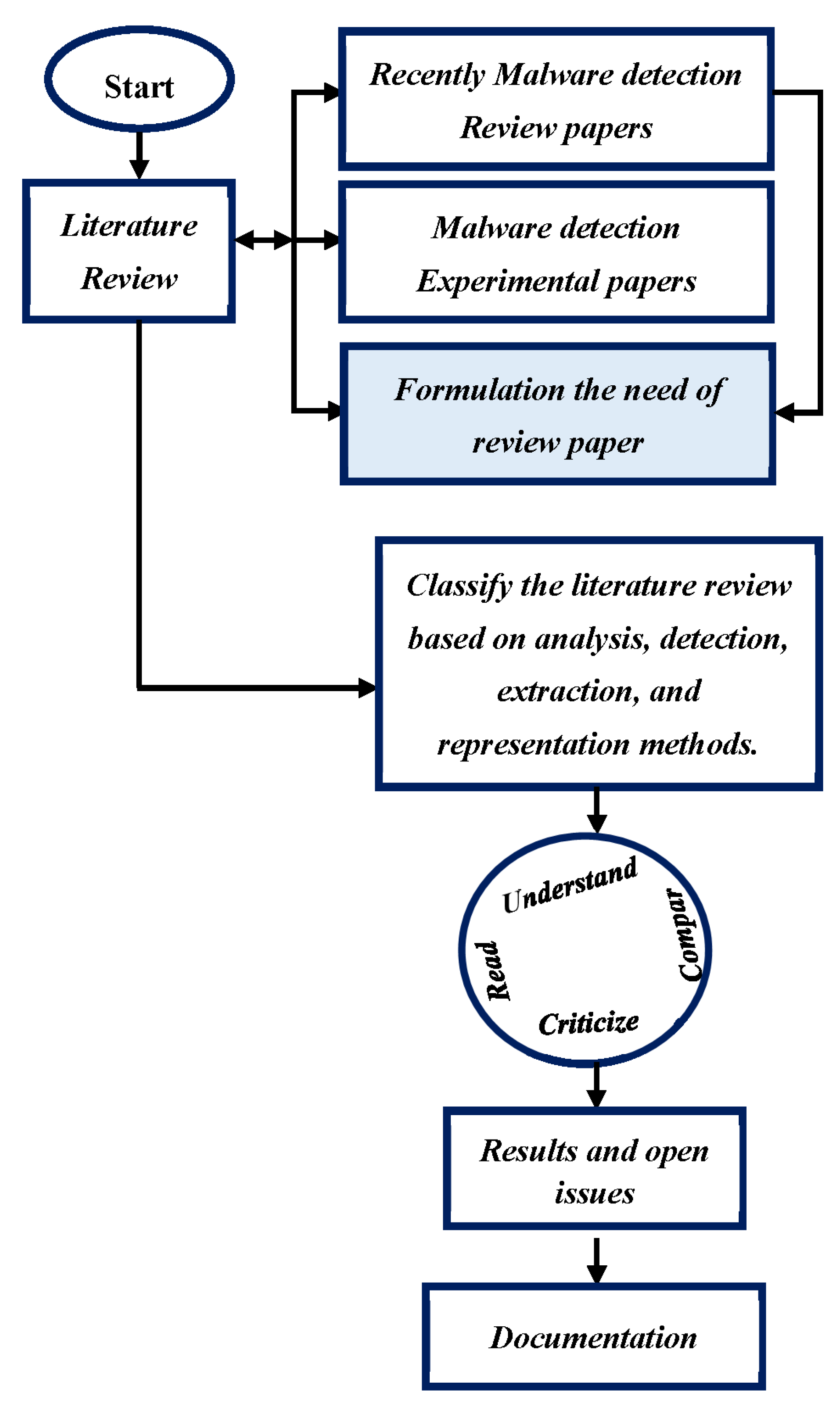
2. Research Methodology
3. Related Work
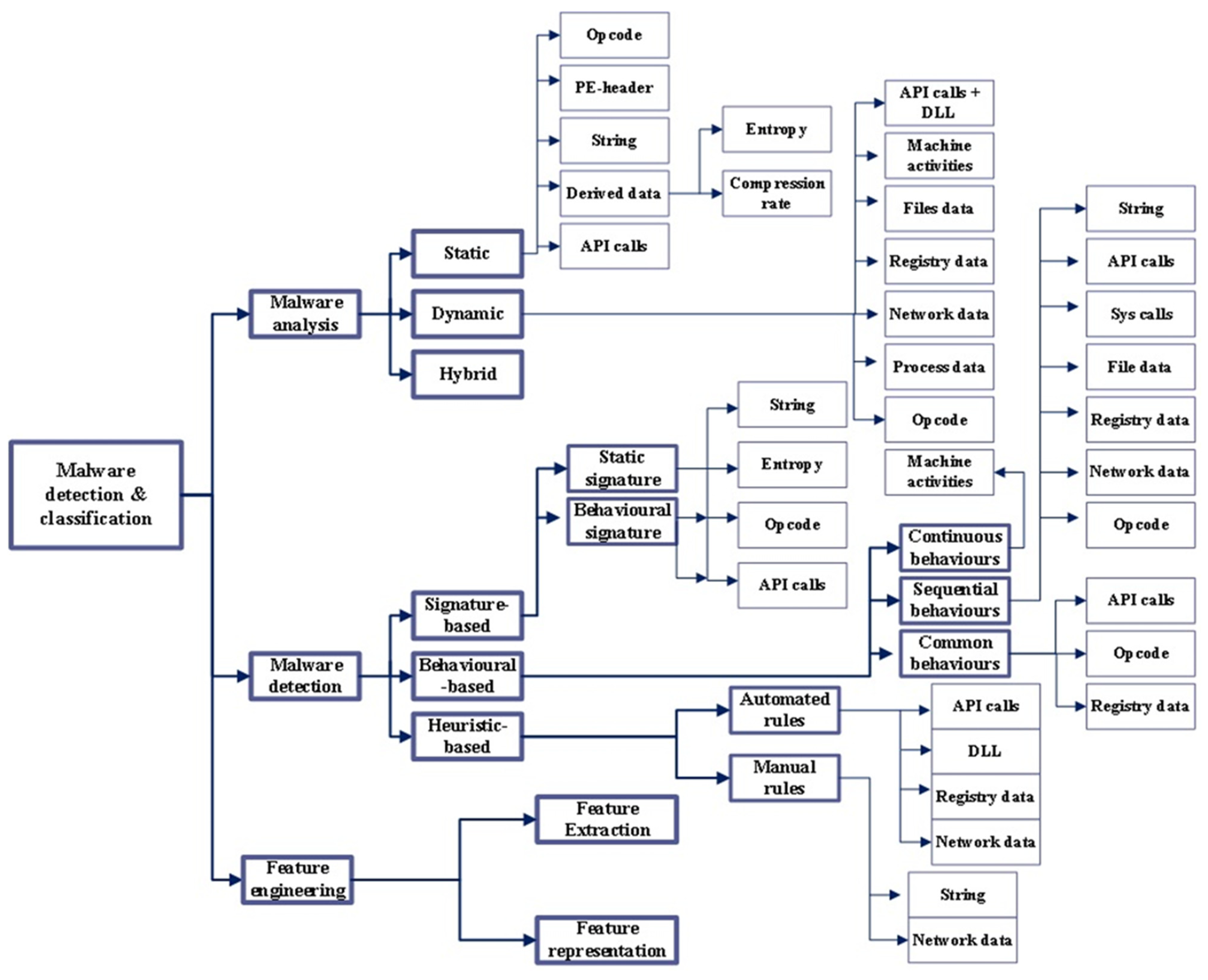
4. The Taxonomy of Malware Analysis and Detection Approaches
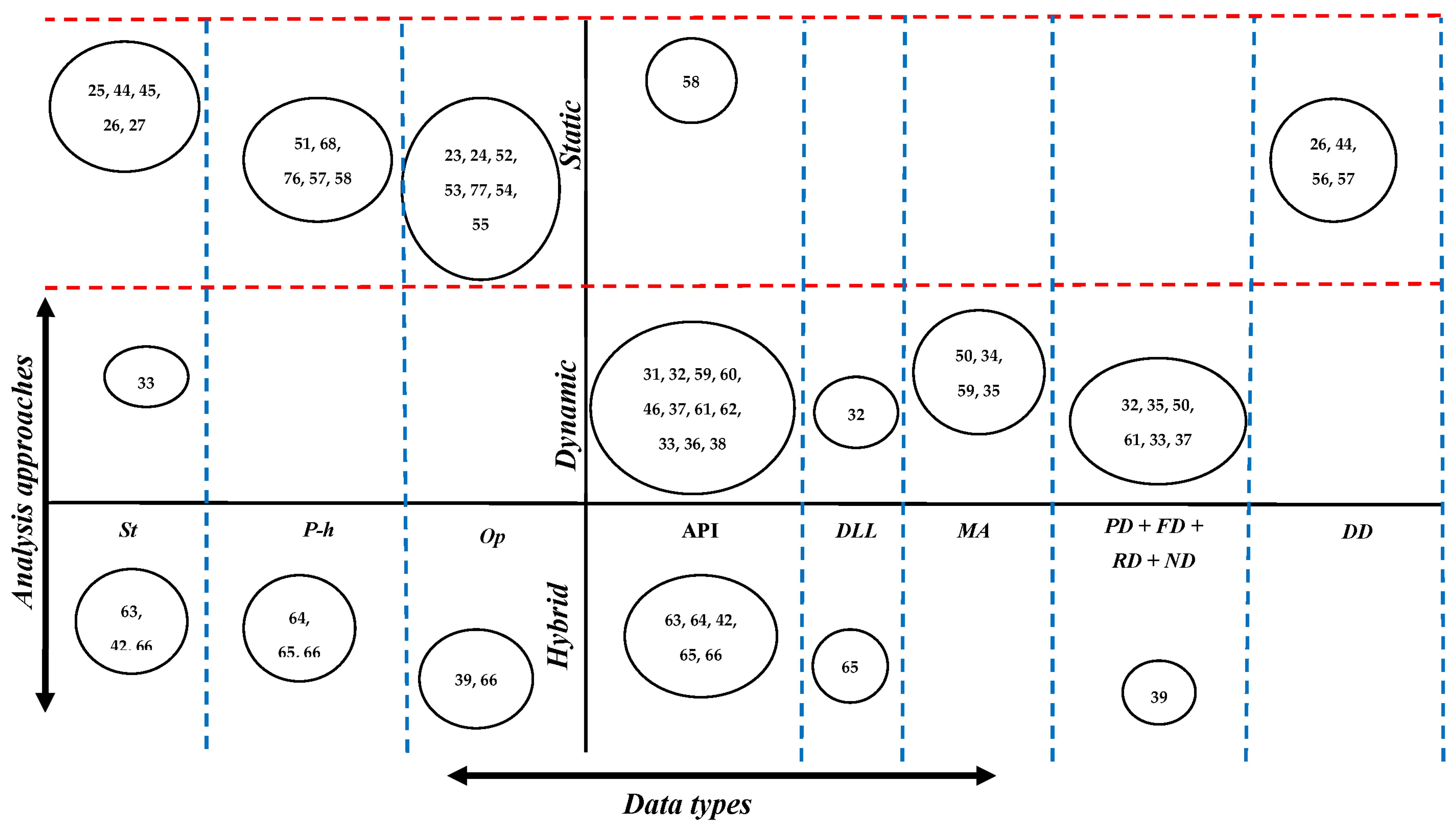
4.1. Malware Analysis Approaches and Data Types
4.1.1. Static Analysis
4.1.2. Dynamic Analysis
4.1.3. Hybrid Analysis
4.1.4. Malware Analysis and Data Types Discussion
4.2. Malware Detection Approaches
4.2.1. Signature-Based

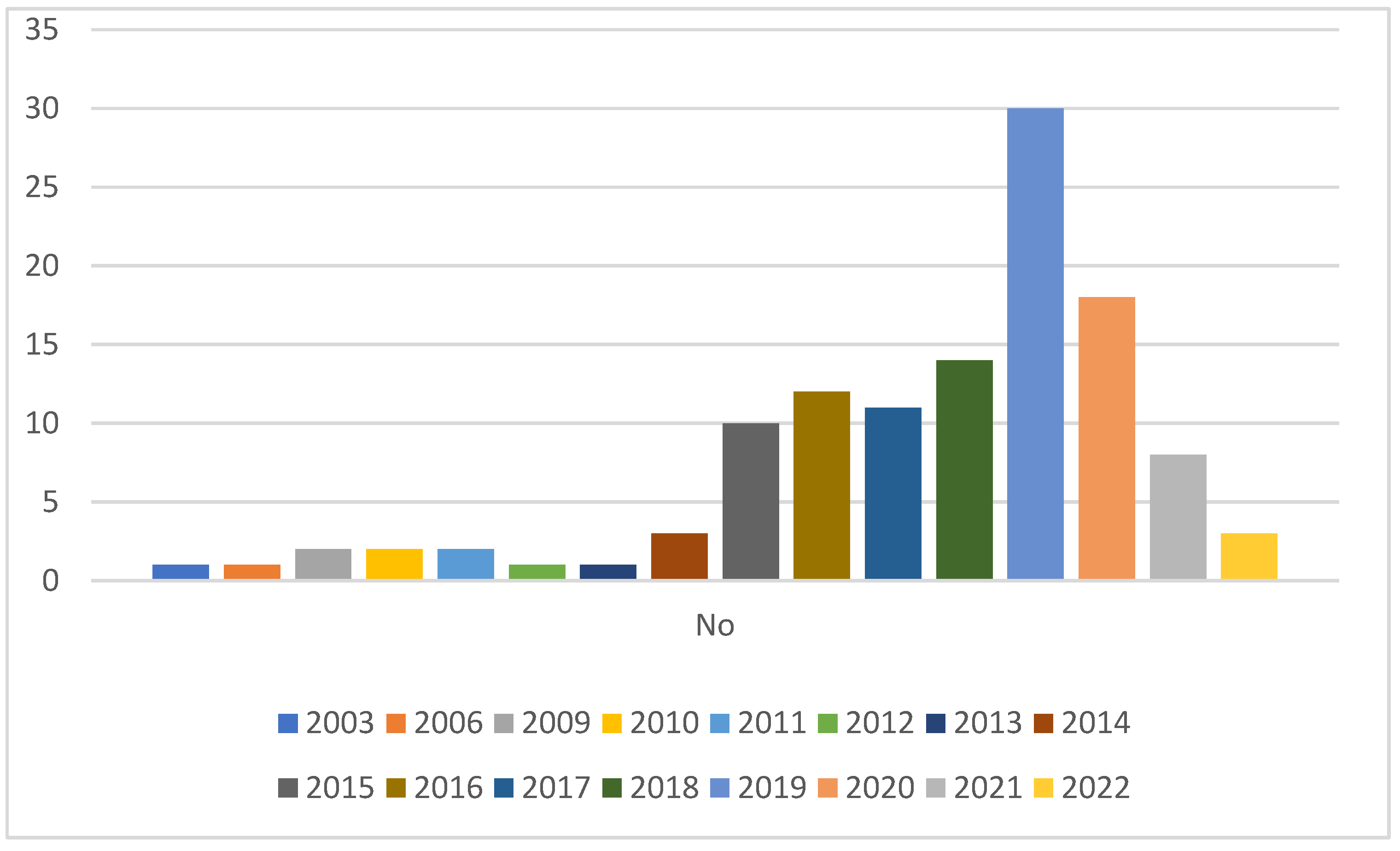{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Date | String | PE-Header | Opcode | API Calls | DLL | Machine Activities | Process Data | File Data | Registry Data | Network Data | Derived Data | Accuracy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Entropy | Compression | |||||||||||||
| Static Analysis | ||||||||||||||
| [38] | 2015 | ✓ | 98.60% | |||||||||||
| [31] | 2015 | ✓ | 99.97% | |||||||||||
| [64] | 2016 | ✓ | 99.00% | |||||||||||
| [35] | 2018 | ✓ | ✓ | NA | ||||||||||
| [39] | 2017 | ✓ | 96.09% | |||||||||||
| [65] | 2017 | ✓ | 98.90% | |||||||||||
| [61] | 2017 | ✓ | 81.07% | |||||||||||
| [41] | 2018 | ✓ | NA | |||||||||||
| [32] | 2019 | ✓ | 99.80% | |||||||||||
| [33] | 2019 | ✓ | 87.50% | |||||||||||
| [42] | 2019 | ✓ | 97.87% | |||||||||||
| [66] | 2020 | ✓ | NA | |||||||||||
| [67] | 2019 | ✓ | 91.43% | |||||||||||
| [34] | 2016 | ✓ | ✓ | 89.44% | ||||||||||
| [36] | 2019 | ✓ | NA | |||||||||||
| [37] | 2019 | ✓ | ✓ | NA | ||||||||||
| [40] | 2020 | ✓ | ✓ | ✓ | NA | |||||||||
| [68] | 2016 | ✓ | ✓ | 98.17% | ||||||||||
| Dynamic analysis | ||||||||||||||
| [43] | 2015 | ✓ | 97.8% | |||||||||||
| [44] | 2016 | ✓ | 97.19% | |||||||||||
| [15] | 2016 | ✓ | 98.92% | |||||||||||
| [45] | 2016 | ✓ | ✓ | ✓ | 96.00% | |||||||||
| [52] | 2016 | ✓ | ✓ | NA | ||||||||||
| [69] | 2017 | ✓ | 98.54% | |||||||||||
| [47] | 2018 | ✓ | ✓ | NA | ||||||||||
| [49] | 2019 | ✓ | 92.00% | |||||||||||
| [54] | 2019 | ✓ | ✓ | 97.22% | ||||||||||
| [48] | 2019 | ✓ | 94.89% | |||||||||||
| [46] | 2020 | ✓ | 97.28% | |||||||||||
| [53] | 2019 | ✓ | ✓ | 75.01% | ||||||||||
| [70] | 2020 | ✓ | 98.43% | |||||||||||
| [51] | 2020 | ✓ | ✓ | ✓ | ✓ | ✓ | 99.54% | |||||||
| [71] | 2017 | ✓ | NA | |||||||||||
| Hybrid analysis | ||||||||||||||
| [72] | 2014 | ✓ | ✓ | 98.71% | ||||||||||
| [55] | 2016 | ✓ | ✓ | 99.99% | ||||||||||
| [73] | 2019 | ✓ | ✓ | 99.70% | ||||||||||
| [58] | 2021 | ✓ | ✓ | 94.70% | ||||||||||
| [74] | 2020 | ✓ | ✓ | ✓ | 93.92% | |||||||||
| [75] | 2020 | ✓ | ✓ | ✓ | ✓ | 96.30% | ||||||||
4.2.2. Behavioral-Based
4.2.3. Heuristic-Based
4.2.4. Malware Detection Discussion
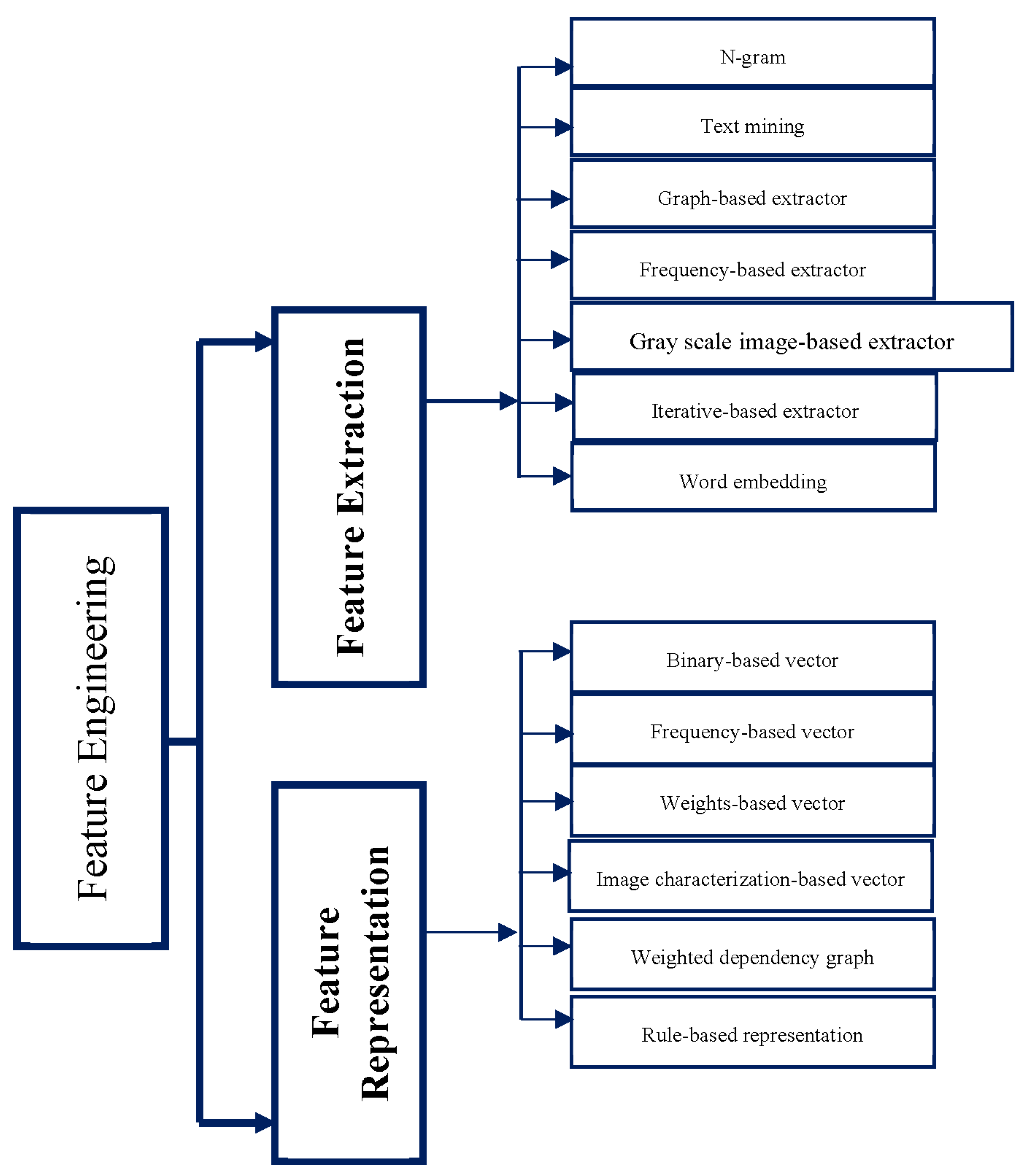
5. The Taxonomy of Feature Extraction and Representation Methods
5.1. Feature Extraction Methods
5.1.1. N-Gram
| Reference | Feature Engineering | Model Type | Technique | Model Mode | Detection Approach | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Feature Extraction | Feature Representation | Binary-Class | Multi-Class | General | Specific | Signature-Based | Behavioral-Based | Heuristic-Based | ||
| [43] | Text mining | Weight-based vector | ✓ | ✓ | ✓ | |||||
| [72] | Frequency-based extractor, N-gram | Binary-based vector | ✓ | SVM | ✓ | ✓ | ||||
| [45] | Frequency-based extractor | Binary-based vector | ✓ | SVM | ✓ | ✓ | ||||
| [34] | Frequency-based extractor | Weight-based vector | ✓ | AMA | ✓ | ✓ | ||||
| [39] | Graph-based extractor | Weight-based vector | K-NN, SVM | |||||||
| [35] | Frequency-based extractor | Frequency-based vector | ✓ | RF | ✓ | ✓ | ||||
| [83] | N-gram | Binary-based vector | ✓ | K-NN | ✓ | ✓ | ||||
| [80] | Graph-based extractor | Weighted dependency graph | ✓ | ✓ | ✓ | |||||
| [84] | Iterative-based extractor | Weight-based vector | ✓ | J48, K-NN | ✓ | ✓ | ||||
| [54] | Text mining | Rule-based representation | ✓ | ✓ | ✓ | |||||
| [63] | Frequency-based extractor | Binary-based vector | ✓ | SVM | ✓ | ✓ | ||||
| [75] | N-gram, Frequency-based extractor, Gray-scale image-based extractor | Image characterization-based vector | ✓ | ✓ | XGBoost | ✓ | ✓ | |||
| [74] | N-gram | Weight-based vector | ✓ | RF | ✓ | ✓ | ||||
| [85] | Word embedding | Weight-based vector | ✓ | MC | ✓ | ✓ | ||||
| [50] | N-gram | Frequency-based vector | ✓ | SVM | ✓ | ✓ | ||||
| [10] | Graph-based extractor | Binary-based vector | HLES-MMI | ✓ | ✓ | |||||
| [81] | N-gram | Weight-based vector | ✓ | ✓ | ✓ | |||||
| [70] | N-gram | Binary-based vector | ✓ | LR | ✓ | ✓ | ||||
| [86] | Gray-scale image-based extractor | Image characterization-based vector | ✓ | SVM, CNN | ✓ | ✓ | ||||
| [40] | N-gram, Frequency-based extractor | Frequency-based vector, Weight vector | ✓ | XGBoost | ✓ | ✓ | ||||
| [87] | N-gram, Frequency-based extractor | Frequency-based vector | ✓ | CNN, BPNN | ✓ | ✓ | ||||
| [88] | Word embedding | Weight-based vector | ✓ | RNN | ✓ | ✓ | ||||
| [89] | Frequency-based extractor | Weight-based vector | ✓ | CS | ✓ | ✓ | ||||
| [90] | Frequency-based extractor | Binary-based vector | ✓ | SVM | ✓ | ✓ | ||||
| [91] | Graph-based extractor | Weighted dependency graph | ✓ | ✓ | ✓ | ✓ | ||||
| [76] | Frequency-based extractor | Rule-based representation | ✓ | ✓ | ✓ | ✓ | ||||
| [92] | Frequency-based extractor | Weight-based vector | ✓ | JSD | ✓ | ✓ | ||||
| [93] | Gray-scale image-based extractor | Image characterization-based vector | ✓ | CNN | ✓ | ✓ | ||||
| [94] | Gray-scale image-based extractor | Image characterization-based vector | ✓ | SVM | ✓ | ✓ | ||||
5.1.2. Text Mining
5.1.3. Graph-Based Extractor
5.1.4. Frequency-Based Extractor
5.1.5. Word Embedding
5.1.6. Iterative-Based Extractor
5.1.7. Gray Scale Image-Based Extractor
5.1.8. Discussion of Feature Extraction Methods
5.2. Feature Representation Methods
5.2.1. Binary-Based Vector
5.2.2. Frequency-Based Vector
5.2.3. Weight-Based Vector
5.2.4. Image Characterization-Based Vector
5.2.5. Weighted Dependency Graph
5.2.6. Rule-Based Representation
5.2.7. Discussion of Feature Representation Methods
6. Open Issues
6.1. Obfuscation Techniques
6.2. Evasion Techniques
6.3. Zero-Day Malware
6.4. Redundancy and Irrelevant Behaviours
6.5. False Positive/Negative Rate
6.6. Incremental Learning
7. Future Directions
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Caviglione, L.; Choras, M.; Corona, I.; Janicki, A.; Mazurczyk, W.; Pawlicki, M.; Wasielewska, K. Tight Arms Race: Overview of Current Malware Threats and Trends in Their Detection. IEEE Access 2021, 9, 5371–5396. [Google Scholar] [CrossRef]
- Morgan, S. Cybercrime Damages $6 Trillion by 2021. 2017. Available online: https://cybersecurityventures.com/hackerpocalypse-cybercrime-report-2016/ (accessed on 15 July 2021).
- Cannarile, A.; Dentamaro, V.; Galantucci, S.; Iannacone, A.; Impedovo, D.; Pirlo, G. Comparing Deep Learning and Shallow Learning Techniques for API Calls Malware Prediction: A Study. Appl. Sci. 2022, 12, 1645. [Google Scholar] [CrossRef]
- Villalba, L.J.G.; Orozco, A.L.S.; Vivar, A.L.; Vega, E.A.A.; Kim, T.-H. Ransomware Automatic Data Acquisition Tool. IEEE Access 2018, 6, 55043–55051. [Google Scholar] [CrossRef]
- Urooj, U.; Al-Rimy, B.A.S.; Zainal, A.; Ghaleb, F.A.; Rassam, M.A. Ransomware Detection Using the Dynamic Analysis and Machine Learning: A Survey and Research Directions. Appl. Sci. 2022, 12, 172. [Google Scholar] [CrossRef]
- Hansen, S.S.; Larsen, T.M.T.; Stevanovic, M.; Pedersen, J.M. An approach for detection and family classification of malware based on behavioral analysis. In Proceedings of the 2016 International Conference on Computing, Networking and Communications (ICNC), Kauai, HI, USA, 15–18 February 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Vignau, B.; Khoury, R.; Halle, S. 10 Years of IoT Malware: A Feature-Based Taxonomy. In Proceedings of the 2019 IEEE 19th International Conference on Software Quality, Reliability and Security Companion (QRS-C), Sofia, Bulgaria, 22–26 July 2019; pp. 458–465. [Google Scholar] [CrossRef]
- Asam, M.; Hussain, S.J.; Mohatram, M.; Khan, S.H.; Jamal, T.; Zafar, A.; Khan, A.; Ali, M.U.; Zahoora, U. Detection of exceptional malware variants using deep boosted feature spaces and machine learning. Appl. Sci. 2021, 11, 10464. [Google Scholar] [CrossRef]
- Sahay, S.K.; Sharma, A.; Rathore, H. Evolution of Malware and Its Detection Techniques. In Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; Volume 933, pp. 139–150. [Google Scholar]
- Kakisim, A.G.; Nar, M.; Sogukpinar, I. Metamorphic malware identification using engine-specific patterns based on co-opcode graphs. Comput. Stand. Interfaces 2019, 71, 103443. [Google Scholar] [CrossRef]
- Sihwail, R.; Omar, K.; Ariffin, K.A.Z. A Survey on Malware Analysis Techniques: Static, Dynamic, Hybrid and Memory Analysis. Int. J. Adv. Sci. Eng. Inf. Technol. 2018, 8, 1662. [Google Scholar] [CrossRef]
- Vidal, J.M.; Orozco, A.L.S.; Villalba, L.J.G. Alert correlation framework for malware detection by anomaly-based packet payload analysis. J. Netw. Comput. Appl. 2017, 97, 11–22. [Google Scholar] [CrossRef]
- Saxena, S.; Mancoridis, S. Malware Detection using Behavioral Whitelisting of Computer Systems. In Proceedings of the 2019 IEEE International Symposium on Technologies for Homeland Security (HST), Greater Boston, MA, USA, 5–6 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Gajrani, J.; Sarswat, J.; Tripathi, M.; Laxmi, V.; Gaur, M.S.; Conti, M. A robust dynamic analysis system preventing SandBox detection by android malware. In Proceedings of the ACM International Conference Proceeding Series, Sochi, Russian, 8–10 September 2015. [Google Scholar] [CrossRef]
- Banin, S.; Shalaginov, A.; Franke, K. Memory access patterns for malware detection. Nor. Inf. 2016, 96, 107. [Google Scholar]
- Aslan, O.; Samet, R. A Comprehensive Review on Malware Detection Approaches. IEEE Access 2020, 8, 6249–6271. [Google Scholar] [CrossRef]
- AAbusitta, A.; Li, M.Q.; Fung, B.C. Malware classification and composition analysis: A survey of recent developments. J. Inf. Secur. Appl. 2021, 59, 102828. [Google Scholar] [CrossRef]
- Deylami, H.M.; Muniyandi, R.C.; Ardekani, I.T.; Sarrafzadeh, A. Taxonomy of malware detection techniques: A systematic literature review. In Proceedings of the 2016 14th Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, 12–14 December 2016; pp. 629–636. [Google Scholar] [CrossRef]
- Tahir, R. A Study on Malware and Malware Detection Techniques. Int. J. Educ. Manag. Eng. 2018, 8, 20–30. [Google Scholar] [CrossRef]
- Gibert, D.; Mateu, C.; Planes, J. The rise of machine learning for detection and classification of malware: Research developments, trends and challenges. J. Netw. Comput. Appl. 2020, 153, 102526. [Google Scholar] [CrossRef]
- Alsmadi, T.; Alqudah, N. A Survey on malware detection techniques. In Proceedings of the 2021 International Conference on Information Technology (ICIT), Amman, Jordan, 14–15 July 2021; IEEE: New York, NY, USA, 2021; pp. 371–376. [Google Scholar] [CrossRef]
- Panchariya, H.; Bharkad, S. Comparative Analysis of Feature Extraction Methods of Malware Detection. IOSR J. Comput. Eng. 2014, 16, 49–54. [Google Scholar] [CrossRef]
- El Merabet, H.; Hajraoui, A. A Survey of Malware Detection Techniques based on Machine Learning. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 366–373. [Google Scholar] [CrossRef]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. 2017, 50, 1–45. [Google Scholar] [CrossRef]
- Oyama, Y. Trends of anti-analysis operations of malwares observed in API call logs. J. Comput. Virol. Hacking Tech. 2018, 14, 69–85. [Google Scholar] [CrossRef]
- Sicato, J.C.S.; Sharma, P.K.; Loia, V.; Park, J.H. Vpnfilter malware analysis on cyber threat in smart home network. Appl. Sci. 2019, 9, 2763. [Google Scholar] [CrossRef]
- Chakkaravarthy, S.S.; Sangeetha, D.; Vaidehi, V. A Survey on malware analysis and mitigation techniques. Comput. Sci. Rev. 2019, 32, 1–23. [Google Scholar] [CrossRef]
- Souri, A.; Hosseini, R. A state-of-the-art survey of malware detection approaches using data mining techniques. Hum.-Cent. Comput. Inf. Sci. 2018, 8, 3. [Google Scholar] [CrossRef]
- Balkrishna, S.; Me, K.; Pratishthan, V.; Shital, M.; Kuber, B. A Survey on Data Mining Methods for Malware Detection. Int. J. Eng. Res. Gen. Sci. 2014, 2, 672–675. [Google Scholar]
- Naz, S.; Singh, D.K. Review of Machine Learning Methods for Windows Malware Detection. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zakeri, M.; Daneshgar, F.F.; Abbaspour, M. A static heuristic approach to detecting malware targets. Secur. Commun. Netw. 2015, 8, 30. [Google Scholar] [CrossRef]
- Zelinka, I.; Amer, E. An Ensemble-Based Malware Detection Model Using Minimum Feature Set. Mendel 2019, 25, 1–10. [Google Scholar] [CrossRef]
- Denzer, T.; Shalaginov, A.; Dyrkolbotn, G.O. Intelligent Windows Malware Type Detection based on Multiple Sources of Dynamic Characteristics. Nis. J. 2019, 12, 20. [Google Scholar]
- PSeshagiri, P.; Vazhayil, A.; Sriram, P. AMA: Static Code Analysis of Web Page for the Detection of Malicious Scripts. Procedia Comput. Sci. 2016, 93, 768–773. [Google Scholar] [CrossRef]
- Wael, D.; Sayed, S.G.; AbdelBaki, N. Enhanced Approach to Detect Malicious VBScript Files Based on Data Mining Techniques. Procedia Comput. Sci. 2018, 141, 552–558. [Google Scholar] [CrossRef]
- Ling, Y.T.; Sani, N.F.M.; Abdullah, M.T.; Hamid, N.A.W.A. Nonnegative matrix factorization and metamorphic malware detection. J. Comput. Virol. Hacking Tech. 2019, 15, 195–208. [Google Scholar] [CrossRef]
- Kumar, A.; Kuppusamy, K.; Aghila, G. A learning model to detect maliciousness of portable executable using integrated feature set. J. King Saud Univ.-Comput. Inf. Sci. 2019, 31, 252–265. [Google Scholar] [CrossRef]
- Khodamoradi, P.; Fazlali, M.; Mardukhi, F.; Nosrati, M. Heuristic metamorphic malware detection based on statistics of assembly instructions using classification algorithms. In Proceedings of the 2015 18th CSI International Symposium on Computer Architecture and Digital Systems (CADS), Tehran, Iran, 7–8 October 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Hashemi, H.; Azmoodeh, A.; Hamzeh, A.; Hashemi, S. Graph embedding as a new approach for unknown malware detection. J. Comput. Virol. Hacking Tech. 2017, 13, 153–166. [Google Scholar] [CrossRef]
- Euh, S.; Lee, H.; Kim, D.; Hwang, D. Comparative Analysis of Low-Dimensional Features and Tree-Based Ensembles for Malware Detection Systems. IEEE Access 2020, 8, 76796–76808. [Google Scholar] [CrossRef]
- Khalilian, A.; Nourazar, A.; Vahidi-Asl, M.; Haghighi, H. G3MD: Mining frequent opcode sub-graphs for metamorphic malware detection of existing families. Expert Syst. Appl. 2018, 112, 15–33. [Google Scholar] [CrossRef]
- Lu, R. Malware Detection with LSTM using Opcode Language. arXiv 2019, arXiv:1906.04593. [Google Scholar]
- Choudhary, S.; Vidyarthi, M.D. A Simple Method for Detection of Metamorphic Malware using Dynamic Analysis and Text Mining. Procedia Comput. Sci. 2015, 54, 265–270. [Google Scholar] [CrossRef]
- Galal, H.S.; Mahdy, Y.B.; Atiea, M.A. Behavior-based features model for malware detection. J. Comput. Virol. Hacking Tech. 2016, 12, 59–67. [Google Scholar] [CrossRef]
- Mosli, R.; Li, R.; Yuan, B.; Pan, Y. Automated malware detection using artifacts in forensic memory images. In Proceedings of the 2016 IEEE Symposium on Technologies for Homeland Security (HST), Waltham, MA, USA, 10–12 May 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Hwang, J.; Kim, J.; Lee, S.; Kim, K. Two-Stage Ransomware Detection Using Dynamic Analysis and Machine Learning Techniques. Wirel. Pers. Commun. 2020, 112, 2597–2609. [Google Scholar] [CrossRef]
- Jerlin, M.A.; Marimuthu, K. A New Malware Detection System Using Machine Learning Techniques for API Call Sequences. J. Appl. Secur. Res. 2018, 13, 45–62. [Google Scholar] [CrossRef]
- Kim, H.; Kim, J.; Kim, Y.; Kim, I.; Kim, K.J.; Kim, H. Improvement of malware detection and classification using API call sequence alignment and visualization. Cluster Comput. 2019, 22, 921–929. [Google Scholar] [CrossRef]
- Fasano, F.; Martinelli, F.; Mercaldo, F.; Santone, A. Energy Consumption Metrics for Mobile Device Dynamic Malware Detection. Procedia Comput. Sci. 2019, 159, 1045–1052. [Google Scholar] [CrossRef]
- Ahmed, Y.A.; Koçer, B.; Huda, S.; Al-Rimy, B.A.S.; Hassan, M.M. A system call refinement-based enhanced Minimum Redundancy Maximum Relevance method for ransomware early detection. J. Netw. Comput. Appl. 2020, 167, 102753. [Google Scholar] [CrossRef]
- Singh, J.; Singh, J. Detection of malicious software by analyzing the behavioral artifacts using machine learning algorithms. Inf. Softw. Technol. 2020, 121, 106273. [Google Scholar] [CrossRef]
- Norouzi, M.; Souri, A.; Zamini, M.S. A Data Mining Classification Approach for Behavioral Malware Detection. J. Comput. Netw. Commun. 2016, 2016, 1–9. [Google Scholar] [CrossRef]
- Arabo, A.; Dijoux, R.; Poulain, T.; Chevalier, G. Detecting Ransomware Using Process Behavior Analysis. Procedia Comput. Sci. 2020, 168, 289–296. [Google Scholar] [CrossRef]
- Belaoued, M.; Boukellal, A.; Koalal, M.A.; Derhab, A.; Mazouzi, S.; Khan, F.A. Combined dynamic multi-feature and rule-based behavior for accurate malware detection. Int. J. Distrib. Sens. Netw. 2019, 15, 155014771988990. [Google Scholar] [CrossRef]
- Fraley, J.B.; Figueroa, M. Polymorphic malware detection using topological feature extraction with data mining. In Proceedings of the SoutheastCon 2016, Norfolk, VA, USA, 30 March–3 April 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Ndibanje, B.; Kim, K.H.; Kang, Y.J.; Kim, H.H.; Kim, T.Y.; Lee, H.J. Cross-Method-Based Analysis and Classification of Malicious Behavior by API Calls Extraction. Appl. Sci. 2019, 9, 239. [Google Scholar] [CrossRef]
- Zhong, W.; Gu, F. A multi-level deep learning system for malware detection. Expert Syst. Appl. 2019, 133, 151–162. [Google Scholar] [CrossRef]
- Huang, X.; Ma, L.; Yang, W.; Zhong, Y. A Method for Windows Malware Detection Based on Deep Learning. J. Signal Process. Syst. 2021, 93, 265–273. [Google Scholar] [CrossRef]
- Damodaran, A.; Di Troia, F.; Visaggio, C.A.; Austin, T.; Stamp, M. A comparison of static, dynamic, and hybrid analysis for malware detection. J. Comput. Virol. Hacking Tech. 2017, 13, 1–12. [Google Scholar] [CrossRef]
- Wael, D.; Shosha, A.; Sayed, S.G. Malicious VBScript detection algorithm based on data-mining techniques. In Proceedings of the 2017 International Conference on Advanced Control. Circuits Systems (ACCS) Systems & 2017 International Conference on New Paradigms in Electronics & Information Technology (PEIT), Alexandria, Egypt, 5–8 November 2017; pp. 112–116. [Google Scholar] [CrossRef]
- Fuyong, Z.; Tiezhu, Z. Malware Detection and Classification Based on N-Grams Attribute Similarity. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; pp. 793–796. [Google Scholar] [CrossRef]
- Ki, Y.; Kim, E.; Kim, H.K. A Novel Approach to Detect Malware Based on API Call Sequence Analysis. Int. J. Distrib. Sens. Netw. 2015, 11, 659101. [Google Scholar] [CrossRef]
- Sihwail, R.; Omar, K.; Ariffin, K.A.Z.; Al Afghani, S. Malware Detection Approach Based on Artifacts in Memory Image and Dynamic Analysis. Appl. Sci. 2019, 9, 3680. [Google Scholar] [CrossRef]
- Kumar, R.; Vaishakh, A.R.E. Detection of Obfuscation in Java Malware. Procedia Comput. Sci. 2015, 78, 521–529. [Google Scholar] [CrossRef]
- Liu, L.; Wang, B.; Yu, B.; Zhong, Q. Automatic malware classification and new malware detection using machine learning. Front. Inf. Technol. Electron. Eng. 2017, 18, 1336–1347. [Google Scholar] [CrossRef]
- Li, X.; Qiu, K.; Qian, C.; Zhao, G. An Adversarial Machine Learning Method Based on OpCode N-grams Feature in Malware Detection. In Proceedings of the 2020 IEEE Fifth International Conference on Data Science in Cyberspace (DSC), Hong Kong, China, 27–30 July 2020; pp. 380–387. [Google Scholar] [CrossRef]
- Zhang, H.; Xiao, X.; Mercaldo, F.; Ni, S.; Martinelli, F.; Sangaiah, A.K. Classification of ransomware families with machine learning based on N-gram of opcodes. Futur. Gener. Comput. Syst. 2019, 90, 211–221. [Google Scholar] [CrossRef]
- Belaoued, M.; Mazouzi, S. A chi-square-based decision for real-time malware detection using PE-file features. J. Inf. Process. Syst. 2016, 12, 644–660. [Google Scholar] [CrossRef]
- Burnap, P.; French, R.; Turner, F.; Jones, K. Malware classification using self organising feature maps and machine activity data. Comput. Secur. 2018, 73, 399–410. [Google Scholar] [CrossRef]
- Ali, M.; Shiaeles, S.; Bendiab, G.; Ghita, B. MALGRA: Machine Learning and N-Gram Malware Feature Extraction and Detection System. Electronics 2020, 9, 1777. [Google Scholar] [CrossRef]
- JVidal, M.; Orozco, A.L.S.; Villalba, L.J.G. Malware Detection in Mobile Devices by Analyzing Sequences of System Calls. Int. J. Comput. Electr. Autom. Control. Inf. Eng. 2017, 11, 588–592. [Google Scholar]
- Shijo, P.; Salim, A. Integrated Static and Dynamic Analysis for Malware Detection. Procedia Comput. Sci. 2015, 46, 804–811. [Google Scholar] [CrossRef]
- Darshan, S.L.S.; Jaidhar, C.D. Windows malware detection system based on LSVC recommended hybrid features. J. Comput. Virol. Hacking Tech. 2019, 15, 127–146. [Google Scholar] [CrossRef]
- Darshan, S.L.S.; Jaidhar, C.D. An empirical study to estimate the stability of random forest classifier on the hybrid features recommended by filter based feature selection technique. Int. J. Mach. Learn. Cybern. 2020, 11, 339–358. [Google Scholar] [CrossRef]
- Kang, J.; Won, Y. A study on variant malware detection techniques using static and dynamic features. J. Inf. Process. Syst. 2020, 16, 882–895. [Google Scholar] [CrossRef]
- Alieyan, K.; Almomani, A.; Anbar, M.; Alauthman, M.; Abdullah, R.; Gupta, B.B. DNS rule-based schema to botnet detection. Enterp. Inf. Syst. 2021, 15, 545–564. [Google Scholar] [CrossRef]
- Du, D.; Sun, Y.; Ma, Y.; Xiao, F. A Novel Approach to Detect Malware Variants Based on Classified Behaviors. IEEE Access 2019, 7, 81770–81782. [Google Scholar] [CrossRef]
- Catak, F.O.; Yazı, A.F.; Elezaj, O.; Ahmed, J. Deep learning based Sequential model for malware analysis using Windows exe API Calls. PeerJ Comput. Sci. 2020, 6, e285. [Google Scholar] [CrossRef] [PubMed]
- Shabtai, A.; Moskovitch, R.; Elovici, Y.; Glezer, C. Detection of malicious code by applying machine learning classifiers on static features: A state-of-the-art survey. Inf. Secur. Tech. Rep. 2009, 14, 16–29. [Google Scholar] [CrossRef]
- Ding, Y.; Xia, X.; Chen, S.; Li, Y. A malware detection method based on family behavior graph. Comput. Secur. 2018, 73, 73–86. [Google Scholar] [CrossRef]
- More, S.S.; Gaikwad, P.P. Trust-based Voting Method for Efficient Malware Detection. Procedia Comput. Sci. 2016, 79, 657–667. [Google Scholar] [CrossRef]
- Zhao, Y.; Bo, B.; Feng, Y.; Xu, C.; Yu, B. A Feature Extraction Method of Hybrid Gram for Malicious Behavior Based on Machine Learning. Secur. Commun. Netw. 2019, 2019, 1–8. [Google Scholar] [CrossRef]
- Banin, S.; Dyrkolbotn, G.O. Multinomial malware classification via low-level features. Digit. Investig. 2018, 26, S107–S117. [Google Scholar] [CrossRef]
- Daku, H.; Zavarsky, P.; Malik, Y. Behavioral-Based Classification and Identification of Ransomware Variants Using Machine Learning. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science And Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 1560–1564. [Google Scholar] [CrossRef]
- Amer, E.; Zelinka, I. A dynamic Windows malware detection and prediction method based on contextual understanding of API call sequence. Comput. Secur. 2020, 92, 101760. [Google Scholar] [CrossRef]
- Liu, X.; Lin, Y.; Li, H.; Zhang, J. A novel method for malware detection on ML-based visualization technique. Comput. Secur. 2020, 89, 101682. [Google Scholar] [CrossRef]
- Zhang, J.; Qin, Z.; Yin, H.; Ou, L.; Zhang, K. A feature-hybrid malware variants detection using CNN based opcode embedding and BPNN based API embedding. Comput. Secur. 2019, 84, 376–392. [Google Scholar] [CrossRef]
- Jha, S.; Prashar, D.; Long, H.V.; Taniar, D. Recurrent neural network for detecting malware. Comput. Secur. 2020, 99, 102037. [Google Scholar] [CrossRef]
- Santos, I.; Brezo, F.; Nieves, J.; Penya, Y.K.; Sanz, B.; Laorden, C.; Bringas, P.G. Idea: Opcode-sequence-based Malware Detection. In International Symposium on Engineering Secure Software and Systems; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Garg, V.; Yadav, R.K. Malware Detection based on API Calls Frequency. In Proceedings of the 2019 4th International Conference on Information Systems and Computer Networks (ISCON), Mathura, India, 21–22 November 2019; pp. 400–404. [Google Scholar] [CrossRef]
- Nikolopoulos, S.D.; Polenakis, I. A graph-based model for malware detection and classification using system-call groups. J. Comput. Virol. Hacking Tech. 2017, 13, 29–46. [Google Scholar] [CrossRef]
- Ghiasi, M.; Sami, A.; Salehi, Z. Dynamic VSA: A framework for malware detection based on register contents. Eng. Appl. Artif. Intell. 2015, 44, 111–122. [Google Scholar] [CrossRef]
- SJang, S.; Li, S.; Sung, Y. Generative adversarial network for global image-based local image to improve Malware classification using convolutional neural network. Appl. Sci. 2020, 10, 7585. [Google Scholar] [CrossRef]
- Nisa, M.; Shah, J.H.; Kanwal, S.; Raza, M.; Khan, M.A.; Damaševičius, R.; Blažauskas, T. Hybrid malware classification method using segmentation-based fractal texture analysis and deep convolution neural network features. Appl. Sci. 2020, 10, 4966. [Google Scholar] [CrossRef]
- Allen, F.E. Control flow analysis. ACM SIGPLAN Not. 1970, 5, 1–19. [Google Scholar] [CrossRef]
- Zhao, Z. A virus detection scheme based on features of Control Flow Graph. In Proceedings of the 2011 2nd International Conference on Artificial Intelligence, Management Science and Electronic Commerce, AIMSEC 2011—Proceedings, Zhengzhou, China, 8–10 August 2011; pp. 943–947. [Google Scholar] [CrossRef]
- Alami, N.; Meknassi, M.; En-Nahnahi, N. Enhancing unsupervised neural networks based text summarization with word embedding and ensemble learning. Expert Syst. Appl. 2019, 123, 195–211. [Google Scholar] [CrossRef]
- Amer, E.; El-Sappagh, S.; Hu, J. Contextual identification of windows malware through semantic interpretation of API call sequence. Appl. Sci. 2020, 10, 7673. [Google Scholar] [CrossRef]
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B.S. Malware images: Visualization and automatic classification. In Proceedings of the ACM International Conference Proceeding Series, Rourkela Odisha, India, 12–14 February 2011. [Google Scholar] [CrossRef]
- El-Shafai, W.; Almomani, I.; AlKhayer, A. Visualized malware multi-classification framework using fine-tuned cnn-based transfer learning models. Appl. Sci. 2021, 11, 6446. [Google Scholar] [CrossRef]
- Canfora, G.; Di Sorbo, A.; Mercaldo, F.; Visaggio, C.A. Obfuscation techniques against signature-based detection: A case study. In Proceedings of the 2015 Mobile Systems Technologies Workshop: Architecture, Technology Trends, and Memory Solutions, MST 2015, Milano, Italy, 22 May 2015; pp. 21–26. [Google Scholar] [CrossRef]
- Yewale, A.; Singh, M. Malware detection based on opcode frequency. In Proceedings of the 2016 International Conference on Advanced Communication Control and Computing Technologies (ICACCCT), Tamil Nadu, India, 25–27 May 2016; pp. 646–649. [Google Scholar] [CrossRef]
- Wuechner, T.; Cislak, A.; Ochoa, M.; Pretschner, A. Leveraging compression-based graph mining for behavior-based malware detection. IEEE Trans. Dependable Secur. Comput. 2019, 16, 99–112. [Google Scholar] [CrossRef]
- Mirzazadeh, R.; Moattar, M.H.; Jahan, M.V. Metamorphic Malware Detection Using Linear Discriminant Analysis and Graph Similarity Reza. In Proceedings of the 2015 5th International Conference on Computer and Knowledge Engineering (ICCKE), Iran, Islamic, 29–30 October 2015. [Google Scholar]
- Parmuval, P.; Hasan, M.; Patel, S. Malware Family Detection Approach using Image Processing Techniques: Visualization Technique. Int. J. Comput. Appl. Technol. Res. 2018, 7, 129–132. [Google Scholar] [CrossRef]
- You, I.; Yim, K. Malware Obfuscation Techniques: A Brief Survey. In Proceedings of the 2010 International Conference on Broadband, Wireless Computing, Communication and Applications, Fukuoka, Japan, 4–6 November 2010; pp. 297–300. [Google Scholar] [CrossRef]
- Vidal, J.M.; Castro, J.M.; Orozco, A.S.; Villalba, L.G. Evolutions of Evasion Techniques against network Intrusion Detection Systems. In Proceedings of the ICIT 2013 The 6th International conference on Information Technology, Amman, Jordan, 8 May 2013. [Google Scholar]
- Wong, W.; Stamp, M. Hunting for metamorphic engines. J. Comput. Virol. 2006, 2, 211–229. [Google Scholar] [CrossRef]
- Christodorescu, M.; Jha, S. Static analysis of executables to detect malicious patterns. In Proceedings of the 12th USENIX Security Symposium, Washington, DC, USA, 4–8 August 2003; pp. 169–186. [Google Scholar]
- Veerappan, C.S.; Keong, P.L.K.; Tang, Z.; Tan, F. Taxonomy on malware evasion countermeasures techniques. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018; pp. 558–563. [Google Scholar] [CrossRef]
- Kruegel, C. Evasive Malware Exposed and Deconstructed (Talk). In Proceedings of the RSA Conference, San Francisco, CA, USA, 20–24 April 2015; pp. 12–20. [Google Scholar]
- Venkatraman, S.; Alazab, M. Use of Data Visualisation for Zero-Day Malware Detection. Secur. Commun. Netw. 2018, 2018, 1728303. [Google Scholar] [CrossRef]
- Millar, S.; McLaughlin, N.; del Rincon, J.M.; Miller, P. Multi-view deep learning for zero-day Android malware detection. J. Inf. Secur. Appl. 2021, 58, 102718. [Google Scholar] [CrossRef]
- Yang, S.; Li, S.; Chen, W.; Liu, Y. A Real-Time and Adaptive-Learning Malware Detection Method Based on API-Pair Graph. IEEE Access 2020, 8, 208120–208135. [Google Scholar] [CrossRef]
- Letteri, I.; di Cecco, A.; della Penna, G. Dataset Optimization Strategies for MalwareTraffic Detection. arXiv 2020, arXiv:2009.11347. [Google Scholar]
- Parrales-Bravo, F.; Torres-Urresto, J.; Avila-Maldonado, D.; Barzola-Monteses, J. Relevant and Non-Redundant Feature Subset Selection Applied to the Detection of Malware in a Network. In Proceedings of the 2021 IEEE Fifth Ecuador Technical Chapters Meeting (ETCM), Cuenca, Ecuador, 12–15 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Yoo, S.; Kim, S.; Kim, S.; Kang, B.B. AI-HydRa: Advanced hybrid approach using random forest and deep learning for malware classification. Inf. Sci. 2021, 546, 420–435. [Google Scholar] [CrossRef]
- Gavrilut, D.; Benchea, R.; Vatamanu, C. Optimized Zero False Positives Perceptron Training for Malware Detection. In Proceedings of the 2012 14th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing, Timisoara, Romania, 26–29 September 2012; pp. 247–253. [Google Scholar] [CrossRef]
- Najari, S. Malware Detection Using Data Mining Techniques. Int. J. Intell. Inf. Syst. 2014, 3, 33. [Google Scholar] [CrossRef][Green Version]





| Review Paper | Date | Link Data Types to Analysis Approaches | Link Data Types to Detection Approaches | Detection Approaches in Deep Categories | Techniques-Based Extraction Methods | Representation Methods | Show the Border between Collection Data and Feature Extraction Phases |
|---|---|---|---|---|---|---|---|
| [19] | 2018 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 |
| [20] | 2020 | ✓ | 🗴 | 🗴 | ✓ | ✓ | ✓ |
| [21] | 2021 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 |
| [22] | 2014 | ✓ | 🗴 | 🗴 | ✓ | 🗴 | 🗴 |
| [23] | 2019 | 🗴 | 🗴 | 🗴 | ✓ | 🗴 | 🗴 |
| [16] | 2020 | ✓ | ✓ | 🗴 | ✓ | 🗴 | 🗴 |
| [17] | 2021 | ✓ | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 |
| [24] | 2017 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 |
| [1] | 2021 | 🗴 | ✓ | 🗴 | 🗴 | 🗴 | 🗴 |
| [9] | 2020 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 |
| [25] | 2018 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 |
| [26] | 2019 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 |
| [27] | 2019 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 |
| [28] | 2018 | 🗴 | ✓ | 🗴 | 🗴 | 🗴 | 🗴 |
| [29] | 2014 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 |
| This survey | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aboaoja, F.A.; Zainal, A.; Ghaleb, F.A.; Al-rimy, B.A.S.; Eisa, T.A.E.; Elnour, A.A.H. Malware Detection Issues, Challenges, and Future Directions: A Survey. Appl. Sci. 2022, 12, 8482. https://doi.org/10.3390/app12178482
Aboaoja FA, Zainal A, Ghaleb FA, Al-rimy BAS, Eisa TAE, Elnour AAH. Malware Detection Issues, Challenges, and Future Directions: A Survey. Applied Sciences. 2022; 12(17):8482. https://doi.org/10.3390/app12178482
Chicago/Turabian StyleAboaoja, Faitouri A., Anazida Zainal, Fuad A. Ghaleb, Bander Ali Saleh Al-rimy, Taiseer Abdalla Elfadil Eisa, and Asma Abbas Hassan Elnour. 2022. "Malware Detection Issues, Challenges, and Future Directions: A Survey" Applied Sciences 12, no. 17: 8482. https://doi.org/10.3390/app12178482
APA StyleAboaoja, F. A., Zainal, A., Ghaleb, F. A., Al-rimy, B. A. S., Eisa, T. A. E., & Elnour, A. A. H. (2022). Malware Detection Issues, Challenges, and Future Directions: A Survey. Applied Sciences, 12(17), 8482. https://doi.org/10.3390/app12178482