
Generating Activity-Based Mobility Plans from Trip-Based Models and Mobility Surveys



Abstract
1. Introduction
- An assessment of state-of-the-art mobility modeling;
- The identification of a research gap spanning between easy-to-implement, macroscopic trip-based models and complex, behavioral activity-based models;
- An approach to efficiently generate activity-based mobility plans from existing trip-based models and mobility surveys;
- Its application to the city of Munich;
- An overview and validation of the obtained results.
2. The Related Literature and Problem Statement
2.1. The Related Literature
2.1.1. Trip-Based Mobility Models
2.1.2. Activity-Based Mobility Models
2.1.3. Hybrid Mobility Models
2.2. Problem Statement
3. Materials and Methods
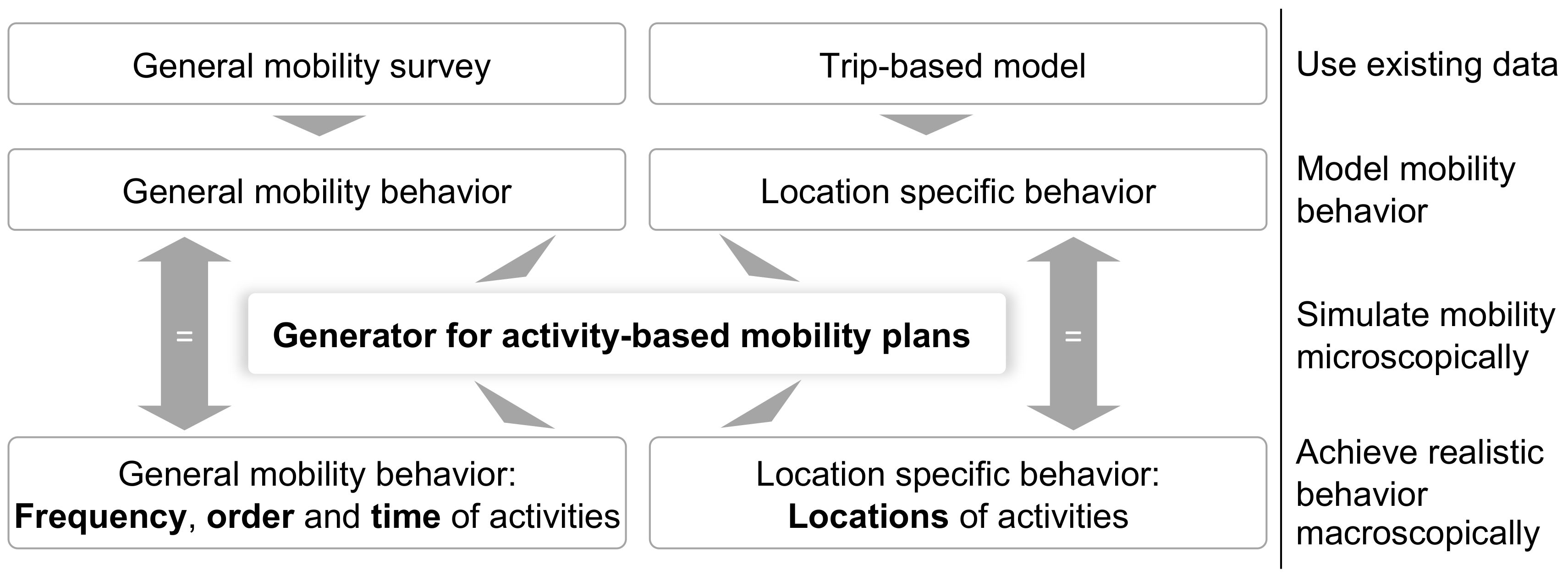
3.1. Requirements, Metrics, and Scope of Application
3.1.1. Output Requirements
- Req: generate microscopically consistent and feasible activity-based mobility plans;
- Req: achieve realistic macroscopic mobility behavior with regard to the order, frequency, location, time, and duration of activities as well as the induced travel distances;
- Req: differentiate by sociodemographic groups.
3.1.2. Data Requirements
- Req: already exists (i.e., not specifically created);
- Req: contains sociodemographic characteristics;
- Req: contains all microscopic and microscopic traits of the mobility behavior to be reflected.
3.1.3. Scope of Application
- Lim: trips by car;
- Lim: one homogeneous spatiotemporal environment.
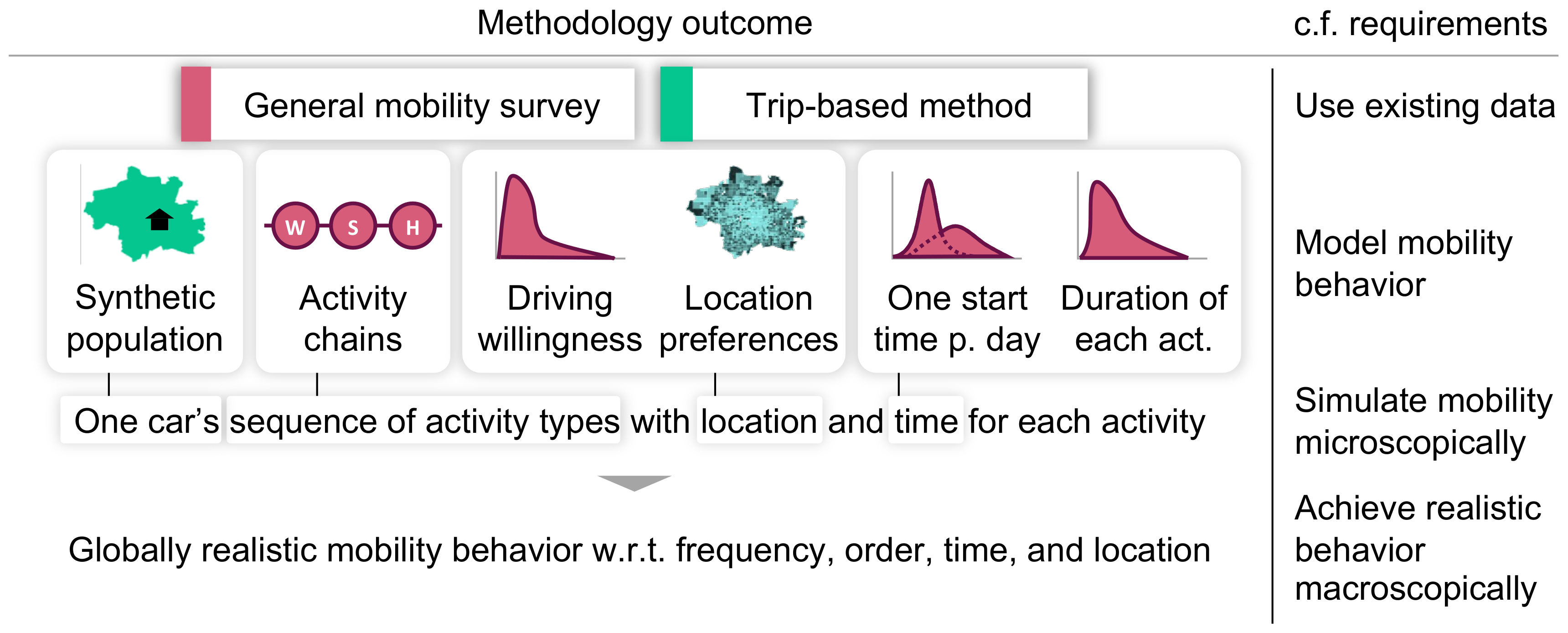
3.2. Input Data
3.3. Approach
3.3.1. Initialize the Population
- A car’s home location;
- The driver’s static activities, such as work and education. When performed, they were always assumed to be at the same place and at the same time of day;
- The driver’s work status.
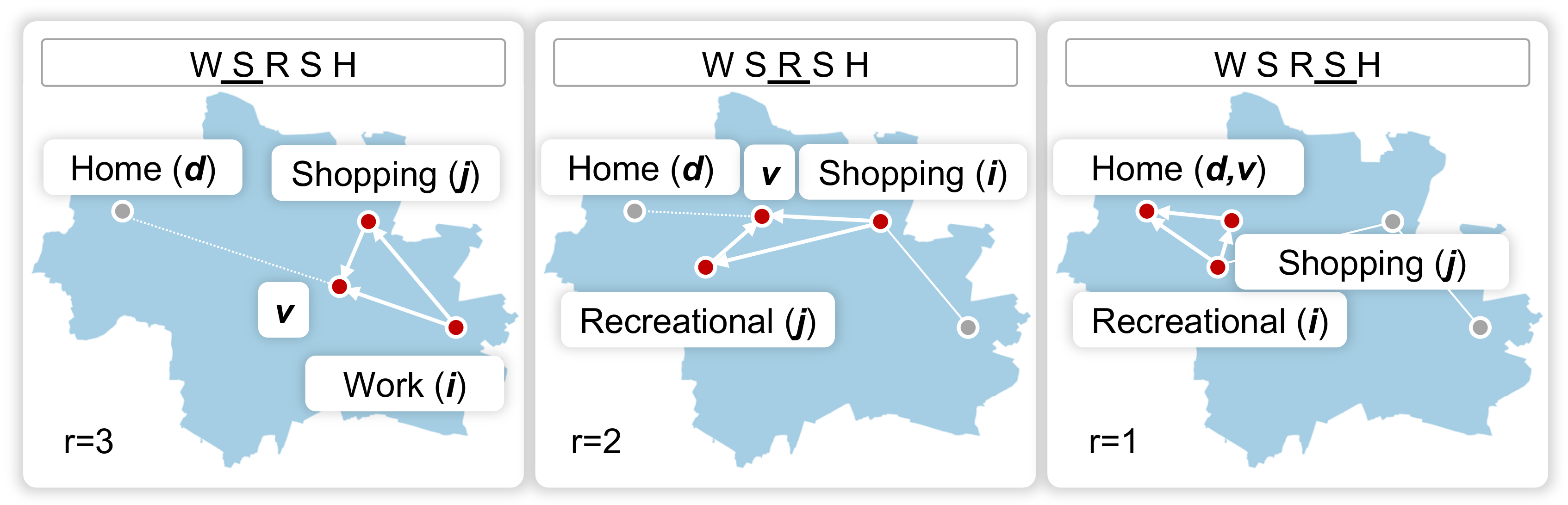
3.3.2. Derive the Activity Chains
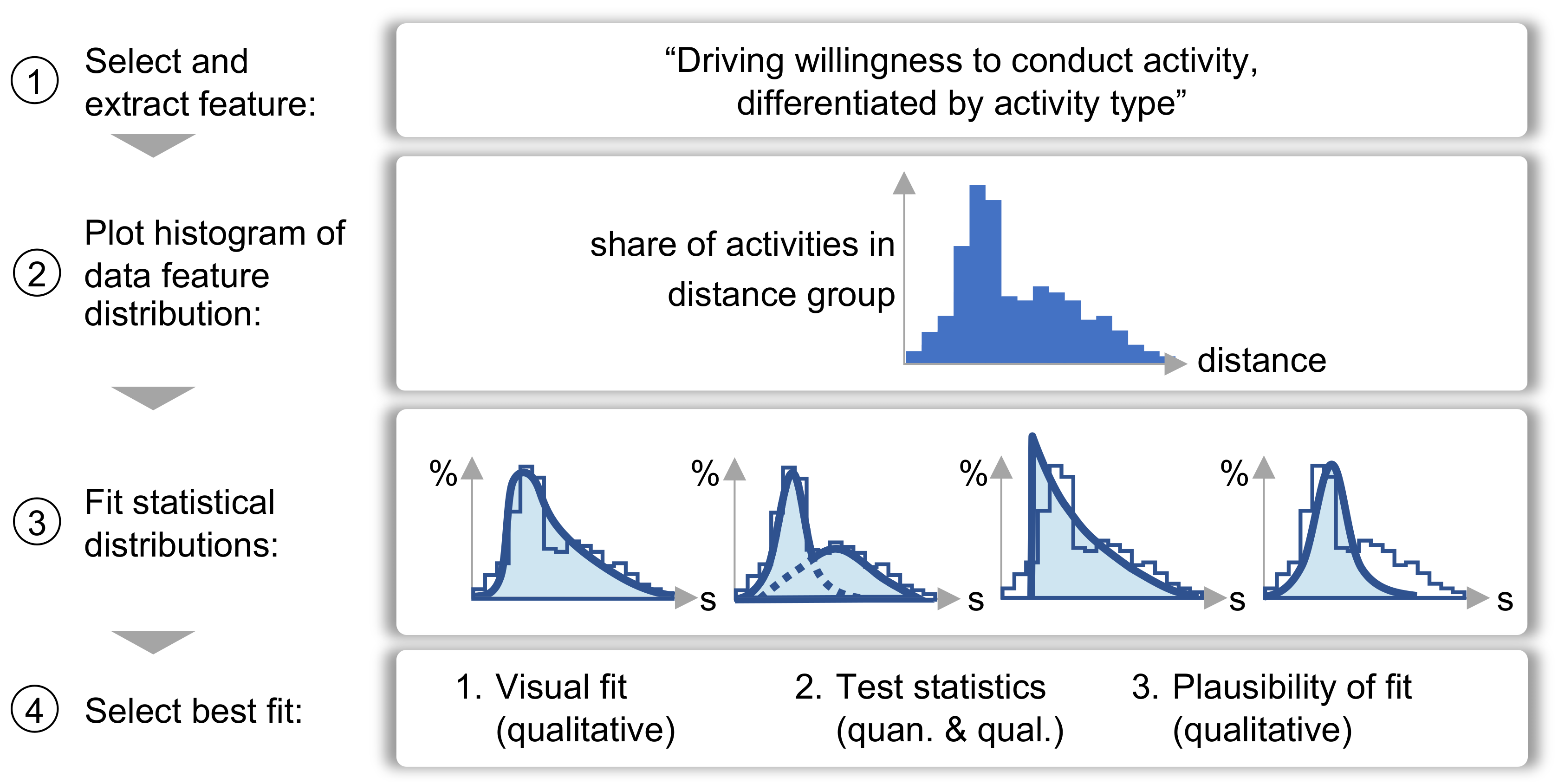
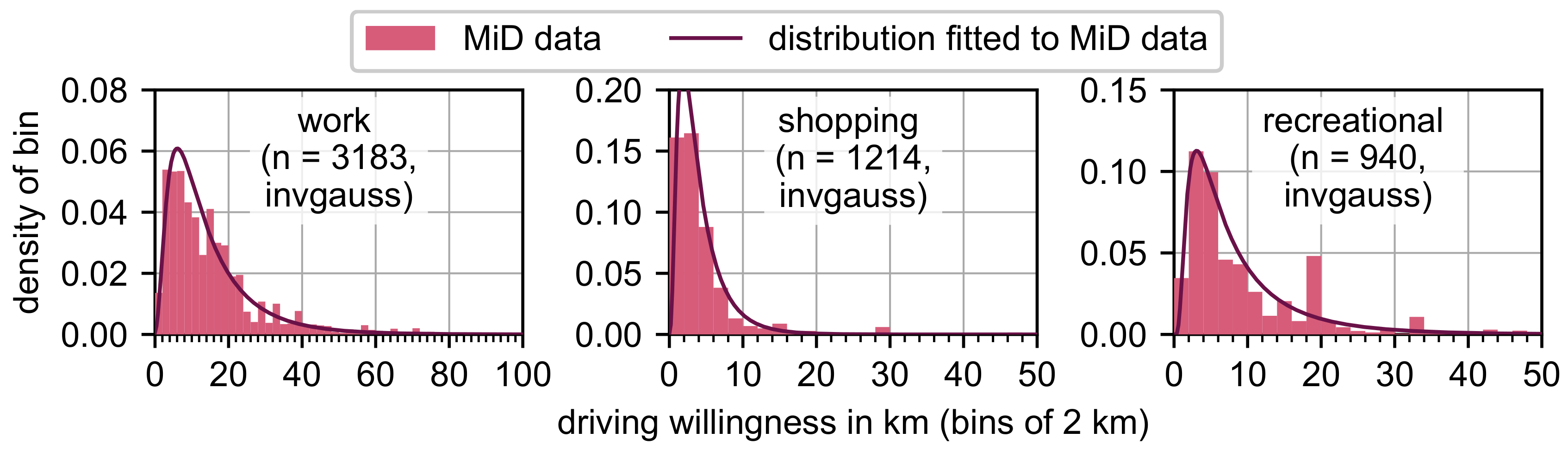
3.3.3. Assign Activity Locations
- Qualitative evaluation of the visual fit of the fitted distribution and a histogram of the analyzed feature, especially around the extreme values;
- Quantitative (Kolmogorov–Smirnov test and Anderson–Darling test) and qualitative (QQ-plot) evaluation of statistical tests;
- Qualitative plausibility check of whether the fitted distribution could be explained by real-life behavior, especially regarding overfitting.
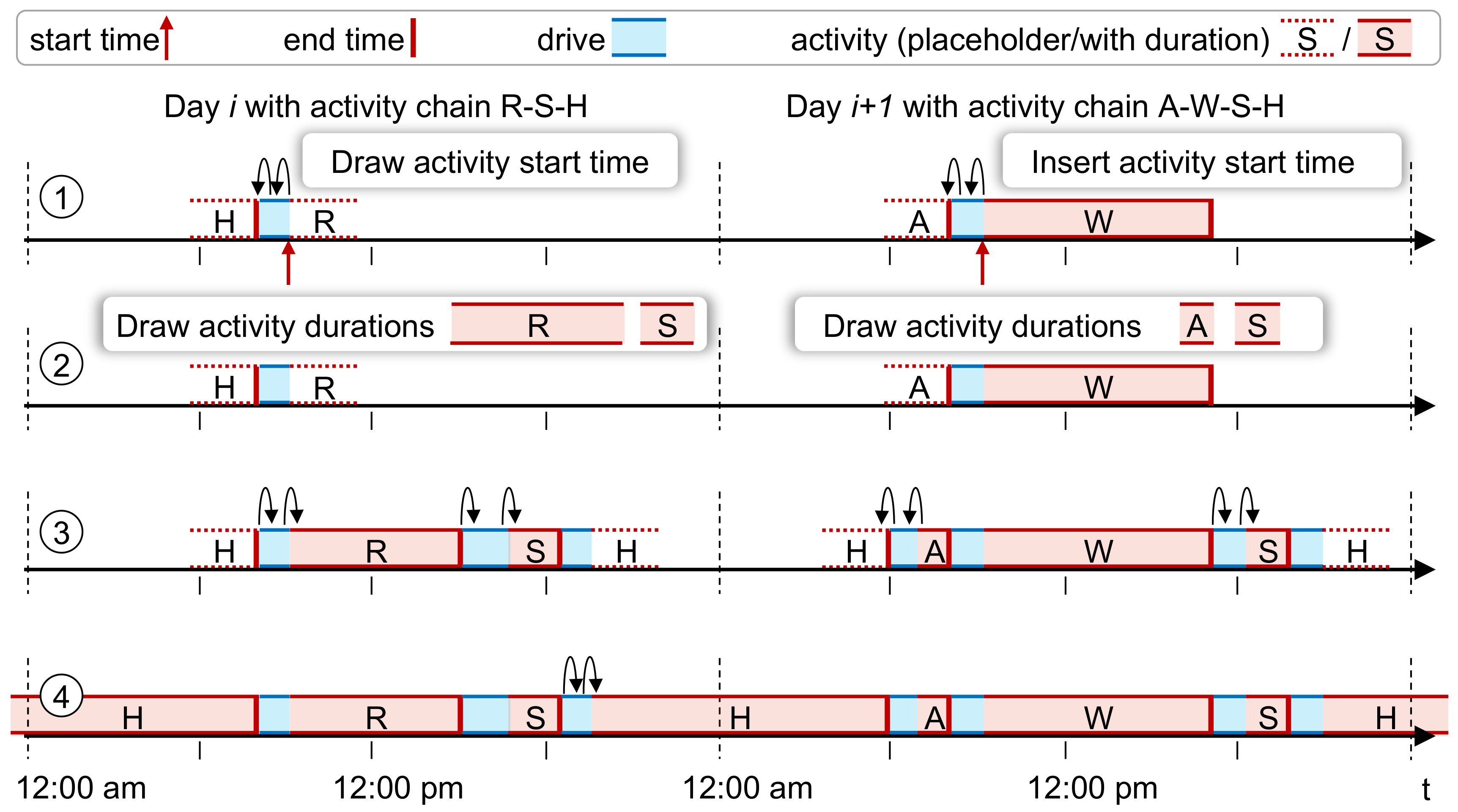
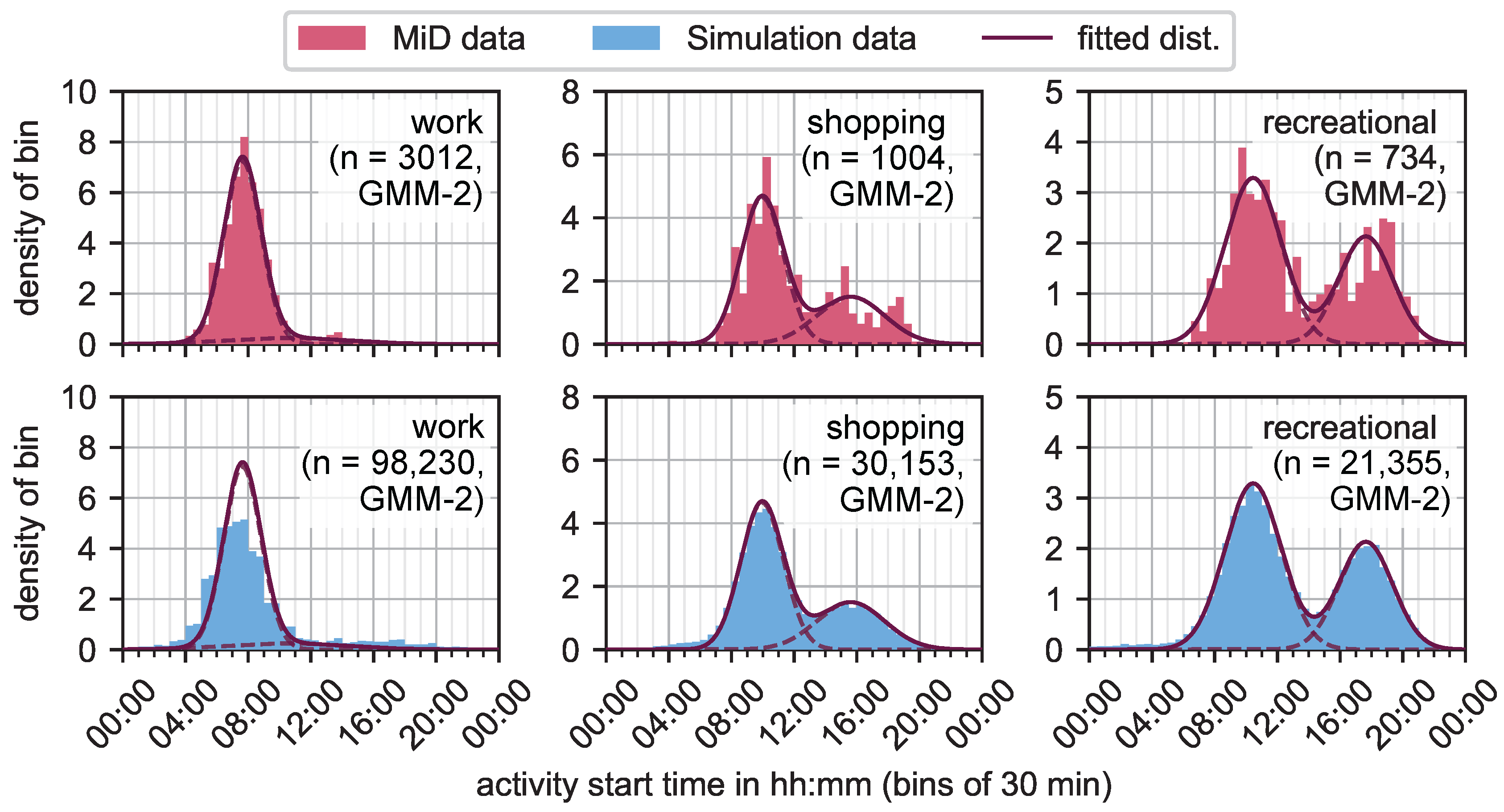
3.3.4. Determine the Times and Durations of the Activities
- Step 1: Determining One Anchor Time per Day
- Step 2: Drawing the Activity Durations
- Steps 3 & 4: Calculating the Activity End Times for All Activities and Calculating the Day’s Last Activity’s Duration
4. Results and Validation
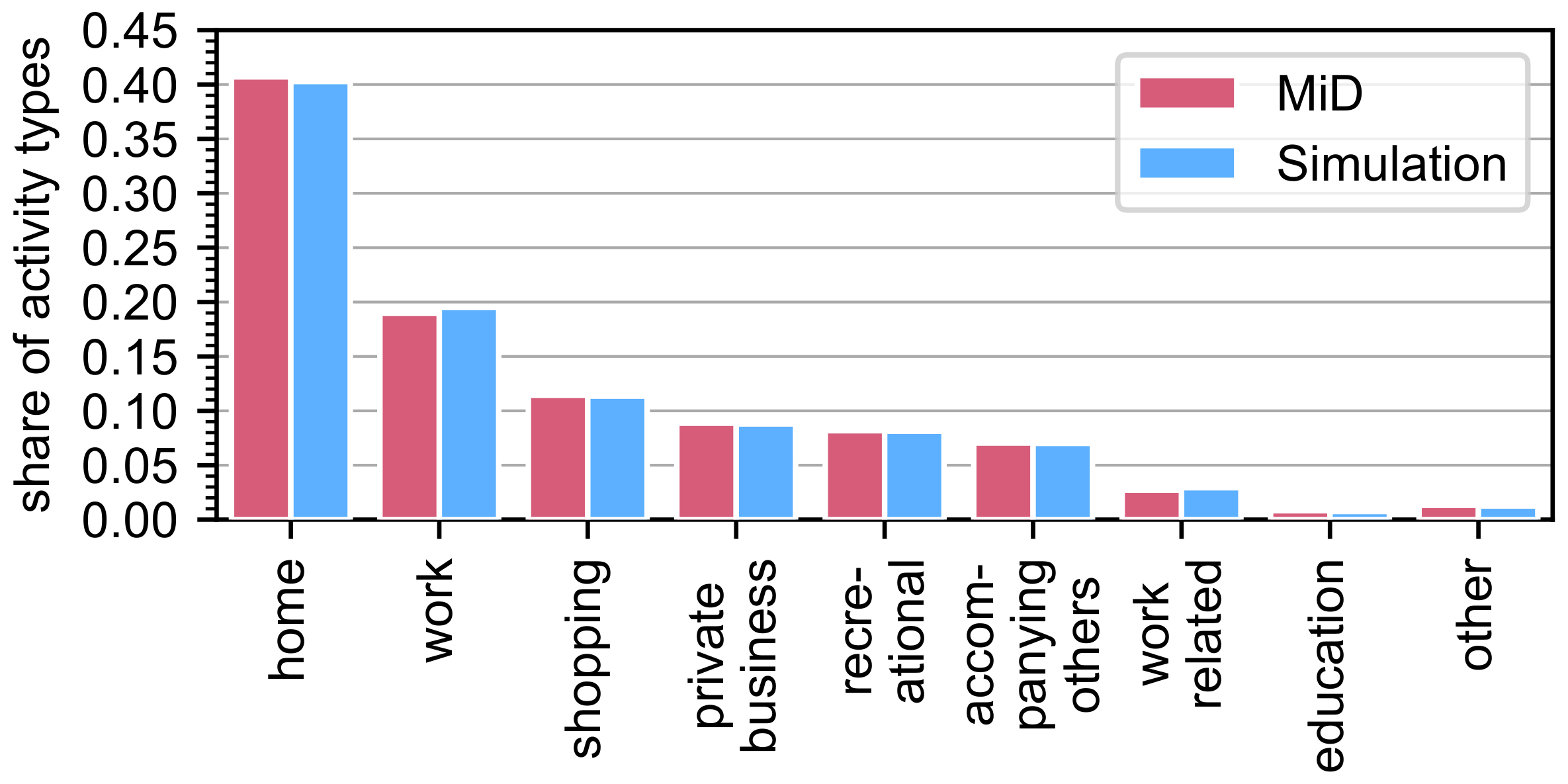
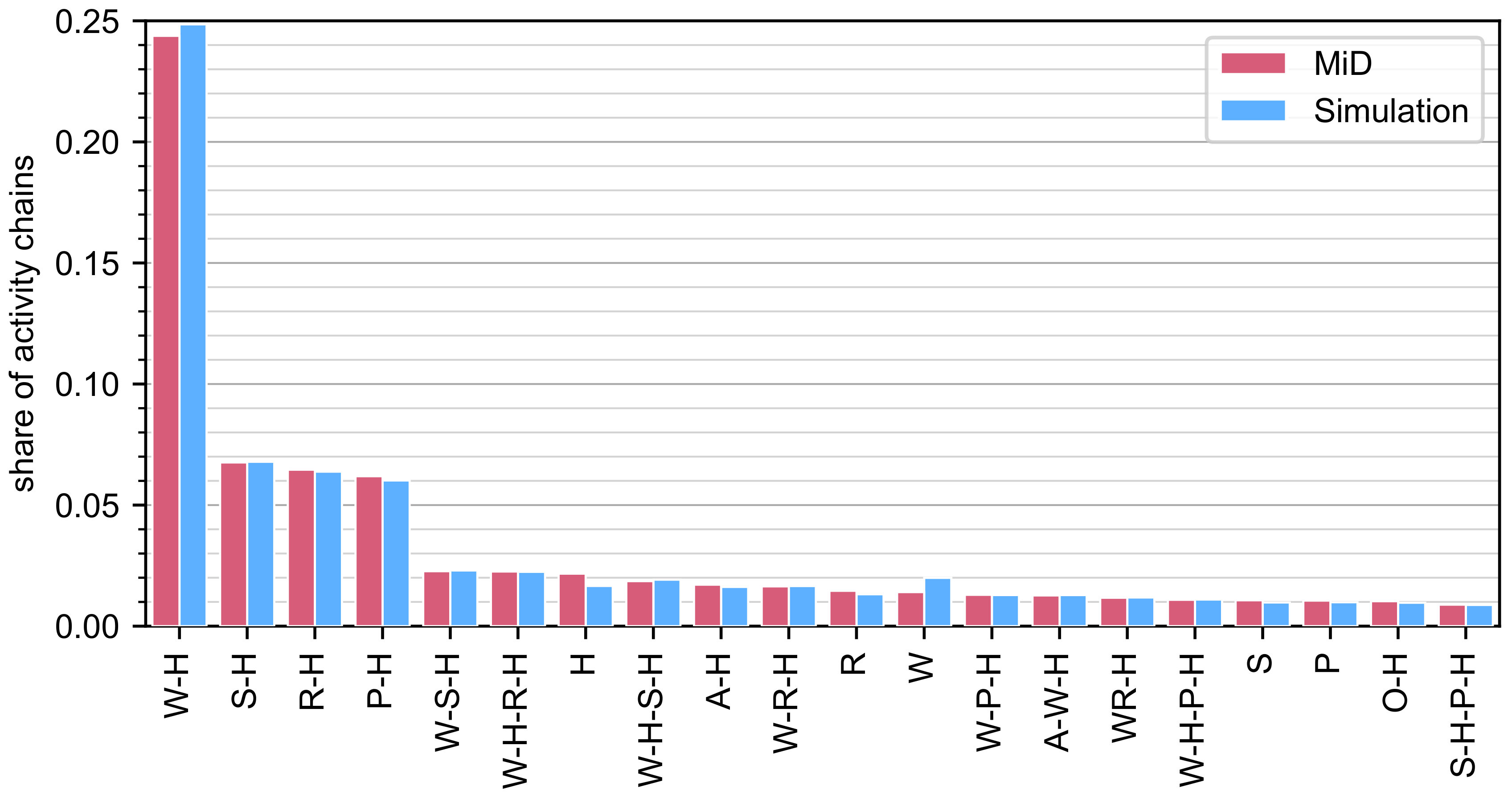
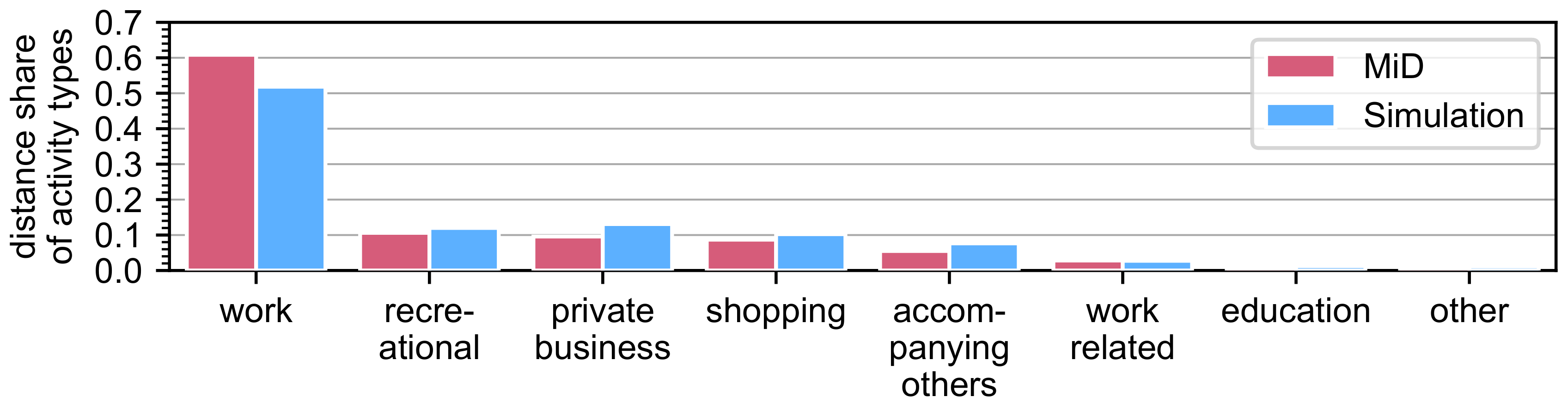
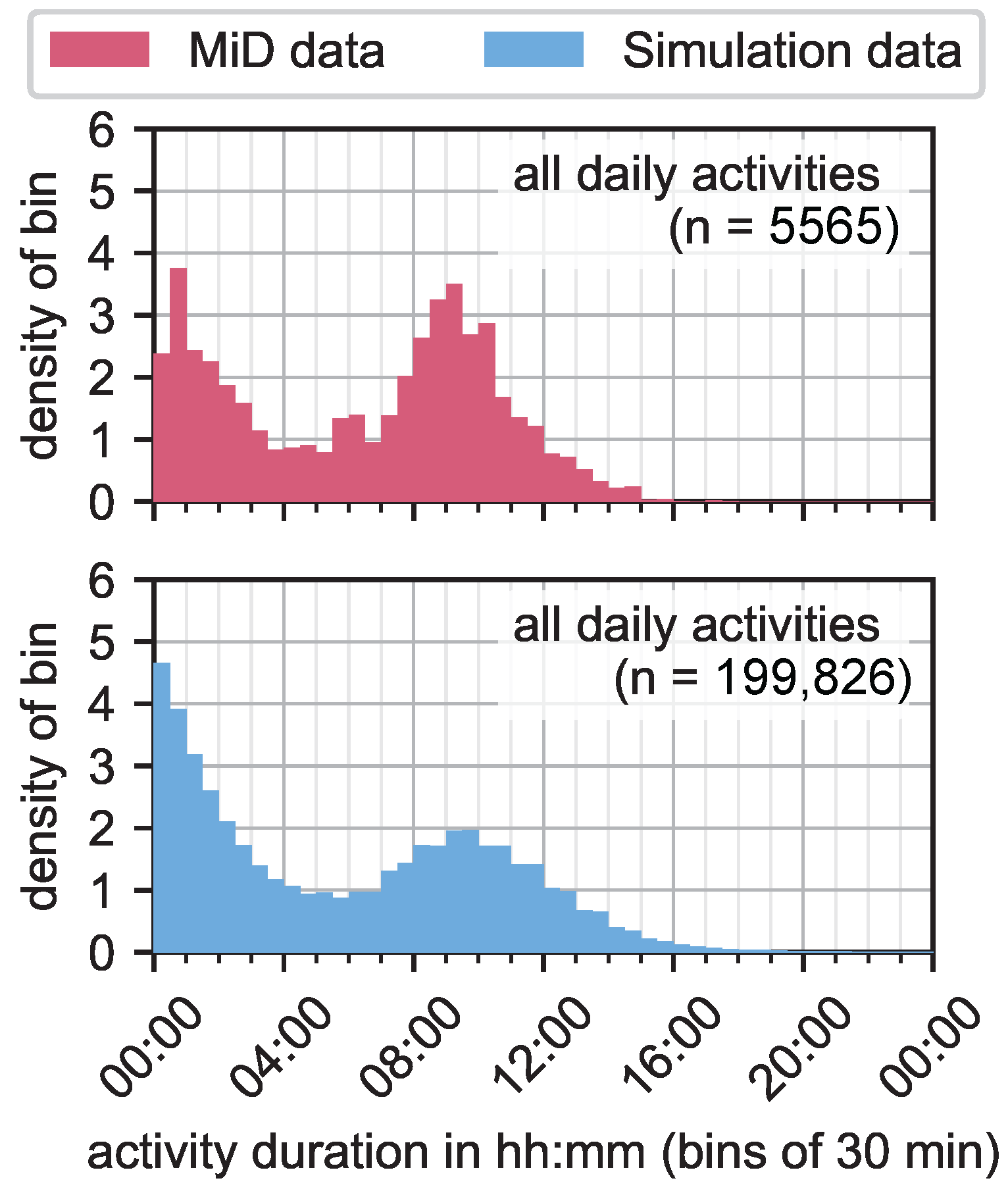
4.1. General Mobility Behavior
4.2. Spatiotemporal Mobility Behavior
5. Discussion
5.1. Requirement Fulfillment
5.2. Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CDF | cumulative distribution function |
| GPS | global positioning system |
| MATSim | Multi-Agent Transport Simulation |
| MITO | Microsimulation Transport Orchestrator |
| MID | Mobilität in Deutschland |
| probability density function | |
| QQ-plot | quantile–quantile plot |
| SMAPE | symmetric mean absolute percentage error |
| SUMO | Simulation of Urban Mobility |
| TAZ | TAZ |
References
- Horni, A.; Nagel, K.; Axhausen, K.W. The Multi-Agent Transport Simulation MATSim; Ubiquity Press: London, UK, 2016. [Google Scholar] [CrossRef]
- Lopez, P.A.; Behrisch, M.; Bieker-Walz, L.; Erdmann, J.; Flötteröd, Y.P.; Hilbrich, R.; Lücken, L.; Rummel, J.; Wagner, P.; Wiessner, E. Microscopic Traffic Simulation using SUMO. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2575–2582. [Google Scholar] [CrossRef]
- Adler, T.; Ben-Akiva, M. A theoretical and empirical model of trip chaining behavior. Transp. Res. Part B 1979, 13, 243–257. [Google Scholar] [CrossRef]
- Bowman, J.L.; Ben-akiva, M. Activity based travel forecasting. In Proceedings of the Conference of Activity Based Travel Forecasting (Transcript of a Tutorial on Activity Based Travel Forecasting), New Orleans, LA, USA, 2–5 June 1996; Travel Model Improvement Program, US Department of Transportation and Environmental Protection: Washington, DC, USA, 1996; pp. 1–32. [Google Scholar]
- Moeckel, R.; Kuehnel, N.; Llorca, C.; Moreno, A.T.; Rayaprolu, H. Agent-Based Simulation to Improve Policy Sensitivity of Trip-Based Models. J. Adv. Transp. 2020, 2020, 1902162. [Google Scholar] [CrossRef]
- Moeckel, R.; Huntsinger, L.; Donnelly, R. From Macro to Microscopic Trip Generation: Representing Heterogeneous Travel Behavior. Open Transp. J. 2017, 11, 31–43. [Google Scholar] [CrossRef][Green Version]
- Donnelly, R.; Erhardt, G.D.; Moeckel, R.; Davidson, W. NCHRP Synthesis 406: Advanced Practices in Travel Forecasting, 1st ed.; Transportation Research Board of the National Academies: Washington, DC, USA, 2010; pp. 1–90. [Google Scholar]
- Hess, A.; Hummel, K.A.; Gansterer, W.N. Data-driven human mobility modeling: A survey and engineering guidance for mobile networking. ACM Comput. Surv. 2015, 48, 1–39. [Google Scholar] [CrossRef]
- Barbosa, H.; Barthelemy, M.; Ghoshal, G.; James, C.R.; Lenormand, M.; Louail, T.; Menezes, R.; Ramasco, J.J.; Simini, F.; Tomasini, M. Human mobility: Models and applications. Phys. Rep. 2018, 734, 1–74. [Google Scholar] [CrossRef]
- González, M.C.; Hidalgo, C.A.; Barabási, A.L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef]
- Yin, M.; Sheehan, M.; Feygin, S.; Paiement, J.F.; Pozdnoukhov, A. A Generative Model of Urban Activities from Cellular Data. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1682–1696. [Google Scholar] [CrossRef]
- Song, C.; Koren, T.; Wang, P.; Barabási, A.L. Modelling the scaling properties of human mobility. Nat. Phys. 2010, 6, 818–823. [Google Scholar] [CrossRef]
- Wu, L.; Zhi, Y.; Sui, Z.; Liu, Y. Intra-urban human mobility and activity transition: Evidence from social media check-in data. PLoS ONE 2014, 9, e97010. [Google Scholar] [CrossRef]
- Noulas, A.; Scellato, S.; Lambiotte, R.; Pontil, M.; Mascolo, C. A tale of many cities: Universal patterns in human urban mobility. PLoS ONE 2012, 7, e37027. [Google Scholar] [CrossRef]
- Bindschaedler, V.; Shokri, R. Synthesizing Plausible Privacy-Preserving Location Traces. In Proceedings of the 2016 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 546–563. [Google Scholar] [CrossRef]
- Nobis, C.; Köhler, K. Mobilität in Deutschland—MiD Nutzerhandbuch; Technical Report; Infas Institut für Angewandte Sozialwissenschaft GmbH: Bonn, Germany, 2018. [Google Scholar]
- Schneider, C.M.; Rudloff, C.; Bauer, D.; González, M.C. Daily travel behavior: Lessons from a week-long survey for the extraction of human mobility motifs related information. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013. [Google Scholar] [CrossRef]
- Raux, C.; Ma, T.Y.; Cornelis, E. Variability in daily activity-travel patterns: The case of a one-week travel diary. Eur. Transp. Res. Rev. 2016, 8, 26. [Google Scholar] [CrossRef]
- Shi, C.; Li, Q.; Lu, S.; Yang, X. Modeling the distribution of human mobility metrics with online car-hailing data-an empirical study in Xi’an, China. ISPRS Int. J. Geo-Inf. 2021, 10, 268. [Google Scholar] [CrossRef]
- Plötz, P.; Jakobsson, N.; Sprei, F. On the distribution of individual daily driving distances. Transp. Res. Part B Methodol. 2017, 101, 213–227. [Google Scholar] [CrossRef]
- Alessandretti, L.; Sapiezynski, P.; Lehmann, S.; Baronchelli, A. Multi-scale spatio-temporal analysis of human mobility. PLoS ONE 2017, 12, e0171686. [Google Scholar] [CrossRef]
- Bazzani, A.; Giorgini, B.; Rambaldi, S.; Gallotti, R.; Giovannini, L. Statistical laws in urban mobility from microscopic GPS data in the area of Florence. J. Stat. Mech. Theory Exp. 2010, 2010, P05001. [Google Scholar] [CrossRef]
- Jiang, S.; Guan, W.; Zhang, W.; Chen, X.; Yang, L. Human mobility in space from three modes of public transportation. Phys. A Stat. Mech. Its Appl. 2017, 483, 227–238. [Google Scholar] [CrossRef]
- Pappalardo, L.; Simini, F.; Rinzivillo, S.; Pedreschi, D.; Giannotti, F.; Barabási, A.L. Returners and explorers dichotomy in human mobility. Nat. Commun. 2015, 6, 8166. [Google Scholar] [CrossRef]
- Cuttone, A.; Lehmann, S.; González, M.C. Understanding predictability and exploration in human mobility. EPJ Data Sci. 2018, 7, 1–17. [Google Scholar] [CrossRef]
- Barbosa, H.; de Lima-Neto, F.B.; Evsukoff, A.; Menezes, R. The effect of recency to human mobility. EPJ Data Sci. 2015, 4, 21. [Google Scholar] [CrossRef]
- König, A.; Grippenkoven, J. Travellers’ willingness to share rides in autonomous mobility on demand systems depending on travel distance and detour. Travel Behav. Soc. 2020, 21, 188–202. [Google Scholar] [CrossRef]
- Zhang, W.; He, R.; Xiao, Q.; Ma, C. Research on Strategy Control of Taxi Carpooling Detour Route under Uncertain Environment. Discret. Dyn. Nat. Soc. 2016, 2016, 4702360. [Google Scholar] [CrossRef]
- Beojone, C.V.; Geroliminis, N. A Path to Take Passengers from Single to Shared Rides: A Study on Ridesplitting; Urban Transport Systems Laboratory: Ecublens, Switzerland, 2020; pp. 1–10. [Google Scholar]
- Santi, P.; Resta, G.; Szell, M.; Sobolevsky, S.; Strogatz, S.H.; Ratti, C. Quantifying the benefits of vehicle pooling with shareability networks. Proc. Natl. Acad. Sci. USA 2014, 111, 13290–13294. [Google Scholar] [CrossRef] [PubMed]
- Alonso-Mora, J.; Samaranayake, S.; Wallar, A.; Frazzoli, E.; Rus, D. On-demand high-capacity ride-sharing via dynamic trip-vehicle assignment. Proc. Natl. Acad. Sci. USA 2017, 114, 462–467. [Google Scholar] [CrossRef] [PubMed]
- Schneider, U. User perceptions of the emerging hydrogen infrastructure for fuel cell electric vehicles. In Proceedings of the ECEEE Summer Study, Belambra Les Criques, Toulon/Hyeres, France, 29 May–3 June 2017; pp. 867–876. [Google Scholar]
- Schneider, F.; Daamen, W.; Hoogendoorn, S. Trip chaining of bicycle and car commuters: An empirical analysis of detours to secondary activities. Transp. A Transp. Sci. 2021, 2021, 1–24. [Google Scholar] [CrossRef]
- Meister, K.; Frick, M.; Axhausen, K.W. A GA-based household scheduler. Transportation 2005, 32, 473–494. [Google Scholar] [CrossRef]
- Hilgert, T.; Heilig, M.; Kagerbauer, M.; Vortisch, P. Modeling week activity schedules for travel demand models. Transp. Res. Rec. 2017, 2666, 69–77. [Google Scholar] [CrossRef]
- Schneider, C.M.; Belik, V.; Couronné, T.; Smoreda, Z.; González, M.C. Unravelling daily human mobility motifs. J. R. Soc. Interface 2013, 10, 20130246. [Google Scholar] [CrossRef]
- Schlich, R.; Axhausen, K.W. Habitual travel behaviour: Evidence from a six-week travel diary. Transportation 2003, 30, 13–36. [Google Scholar] [CrossRef]
- Scherr, W.; Manser, P.; Joshi, C.; Frischknecht, N.; Métrailler, D. Towards agent-based travel demand simulation across all mobility choices—the role of balancing preferences and constraints. Eur. J. Transp. Infrastruct. Res. 2020, 20, 152–172. [Google Scholar] [CrossRef]
- Pas, E.I. Weekly travel-activity behavior. Transportation 1988, 15, 89–109. [Google Scholar] [CrossRef]
- Stopher, P.R.; Zhang, Y. Repetitiveness of daily travel. Transp. Res. Rec. 2011, 2230, 75–84. [Google Scholar] [CrossRef]
- Rasouli, S.; Timmermans, H. Activity-based models of travel demand: Promises, progress and prospects. Int. J. Urban Sci. 2014, 18, 31–60. [Google Scholar] [CrossRef]
- Feil, M. Choosing the Daily Schedule. Ph.D. Thesis, ETH Zurich, Zurich, Switzerland, 2010. [Google Scholar]
- Bowman, J.; Ben-Akiva, M. The Daily Activity Schedule Approach to Travel Demand Analysis. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1998. [Google Scholar]
- Bhat, C.R.; Guo, J.Y.; Srinivasan, S.; Sivakumar, A. Comprehensive econometric microsimulator for daily activity-travel patterns. Transp. Res. Rec. 2004, 1894, 57–66. [Google Scholar] [CrossRef]
- Ouyang, K.; Shokri, R.; Rosenblum, D.S.; Yang, W. A non-parametric generative model for human trajectories. IJCAI Int. Jt. Conf. Artif. Intell. 2018, 2018, 3812–3817. [Google Scholar] [CrossRef]
- Huang, D.; Song, X.; Fan, Z.; Jiang, R.; Shibasaki, R.; Zhang, Y.; Wang, H.; Kato, Y. A Variational Autoencoder Based Generative Model of Urban Human Mobility. In Proceedings of the 2nd International Conference on Multimedia Information Processing and Retrieval, MIPR 2019, San Jose, CA, USA, 28–30 March 2019; pp. 425–430. [Google Scholar] [CrossRef]
- Drchal, J.; Čertický, M.; Jakob, M. Data-driven activity scheduler for agent-based mobility models. Transp. Res. Part C Emerg. Technol. 2019, 98, 370–390. [Google Scholar] [CrossRef]
- Pappalardo, L.; Simini, F. Data-Driven Generation of Spatio-Temporal Routines in Human Mobility; Springer: Berlin/Heidelberg, Germany, 2018; Volume 32, pp. 787–829. [Google Scholar] [CrossRef]
- Pozdnoukhov, A. Travel Demand Nowcasting; Technical Report 19; Department of Transportation: Washington, DC, USA, 2018. [Google Scholar]
- Kulkarni, V.; Garbinato, B. Generating Synthetic Mobility Traffic Using RNNs. In Proceedings of the 1st Workshop on Artificial Intelligence and Deep Learning for Geographic Knowledge Discovery, Los Angeles Area, CA, USA, 7–10 November 2017; pp. 1–4. [Google Scholar]
- Davidson, W.; Donnelly, R.; Vovsha, P.; Freedman, J.; Ruegg, S.; Hicks, J.; Castiglione, J.; Picado, R. Synthesis of first practices and operational research approaches in activity-based travel demand modeling. Transp. Res. Part A Policy Pract. 2007, 41, 464–488. [Google Scholar] [CrossRef]
- Adenaw, L.; Lienkamp, M. Multi-criteria, co-evolutionary charging behavior: An agent-based simulation of urban electromobility. World Electr. Veh. J. 2021, 12, 18. [Google Scholar] [CrossRef]
- Graham, D.J.; Glaister, S. Road Traffic Demand Elasticity Estimates: A Review. Transp. Rev. 2004, 24, 261–274. [Google Scholar] [CrossRef]
- Libardo, A.; Nocera, S. Transportation elasticity for the analysis of Italian transportation demand on a regional scale. Traffic Eng. Control 2008, 49, 187–192. [Google Scholar]
- Wardman, M. Price Elasticities of Surface Travel Demand A Meta-analysis of UK Evidence. J. Transp. Econ. Policy JTEP 2014, 48, 367–384. [Google Scholar]
- Luo, F.; Cao, G.; Mulligan, K.; Li, X. Explore spatiotemporal and demographic characteristics of human mobility via Twitter: A case study of Chicago. Appl. Geogr. 2016, 70, 11–25. [Google Scholar] [CrossRef]
- Arentze, T.A.; Timmermans, H.J. A learning-based transportation oriented simulation system. Transp. Res. Part B Methodol. 2004, 38, 613–633. [Google Scholar] [CrossRef]
- Auld, J.; Mohammadian, A.K. Activity planning processes in the Agent-based Dynamic Activity Planning and Travel Scheduling (ADAPTS) model. Transp. Res. Part A Policy Pract. 2012, 46, 1386–1403. [Google Scholar] [CrossRef]
- Jiang, S.; Ferreira, J.; González, M.C. Clustering daily patterns of human activities in the city. Data Min. Knowl. Discov. 2012, 25, 478–510. [Google Scholar] [CrossRef]
- Hertkorn, G.; Wagner, P. The application of microscopic activity based travel demand modelling in large scale simulations. In Proceedings of the World Conference on Transport Research (WCTR), Istanbul, Turkey, 4–8 July 2004; pp. 1–10. [Google Scholar]
- Durchschnittsgeschwindigkeit in Europäischen Städten. Available online: https://de.statista.com (accessed on 17 August 2022).
- Schröder, D.; Gotzler, F. Comprehensive spatial and cost assessment of urban transport options in Munich. J. Urban Mobil. 2021, 1, 100007. [Google Scholar] [CrossRef]
- Eagle, N.; Pentland, A.S. Eigenbehaviors: Identifying structure in routine. Behav. Ecol. Sociobiol. 2009, 63, 1057–1066. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value | Parameter | Value |
|---|---|---|---|---|---|
| 50,000 | 7 d | 2 d | |||
| 0.59 | 0.4 | 0.05 | |||
| 0 | 1.5 | 32 |
| MID | Simulation | ||||
|---|---|---|---|---|---|
| End | Home | Elsewhere | End | Home | Elsewhere |
| Start | Start | ||||
| Home | 0.801 | 0.079 | Home | 0.811 | 0.089 |
| Elsewhere | 0.089 | 0.031 | Elsewhere | 0.072 | 0.028 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adenaw, L.; Bachmeier, Q. Generating Activity-Based Mobility Plans from Trip-Based Models and Mobility Surveys. Appl. Sci. 2022, 12, 8456. https://doi.org/10.3390/app12178456
Adenaw L, Bachmeier Q. Generating Activity-Based Mobility Plans from Trip-Based Models and Mobility Surveys. Applied Sciences. 2022; 12(17):8456. https://doi.org/10.3390/app12178456
Chicago/Turabian StyleAdenaw, Lennart, and Quirin Bachmeier. 2022. "Generating Activity-Based Mobility Plans from Trip-Based Models and Mobility Surveys" Applied Sciences 12, no. 17: 8456. https://doi.org/10.3390/app12178456
APA StyleAdenaw, L., & Bachmeier, Q. (2022). Generating Activity-Based Mobility Plans from Trip-Based Models and Mobility Surveys. Applied Sciences, 12(17), 8456. https://doi.org/10.3390/app12178456