
Making Sense of Language Signals for Monitoring Radicalization

 ,
,  ,
,  ,
,  ,
,  , , and
, , and 
Abstract
:1. Introduction
- RQ1
- What are the main linguistic signals that reveal radicalization factors?
- RQ2
- How can we computationally operate radicalization factors to monitor radicalization?
- RQ3
- How can semantic technology provide fine-grained query capabilities to social scientists to get insights from radicalization processes?
2. From Radicalization Drivers to Radicalization Signals
3. Semantic Modeling
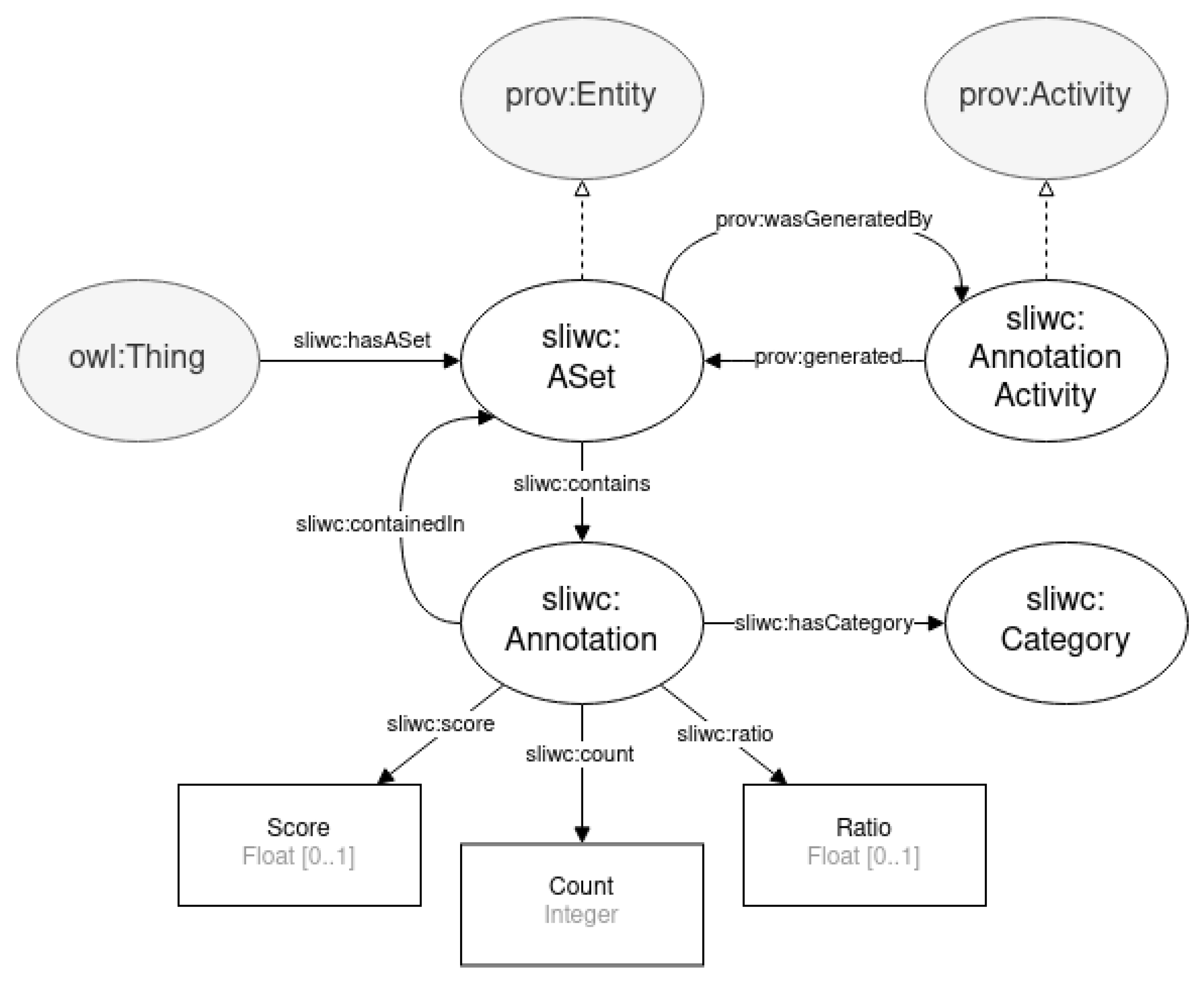
- Semantic LIWC (SLIWC) vocabulary [50] is a semantic taxonomy and vocabulary for annotations using the LIWC dictionary.
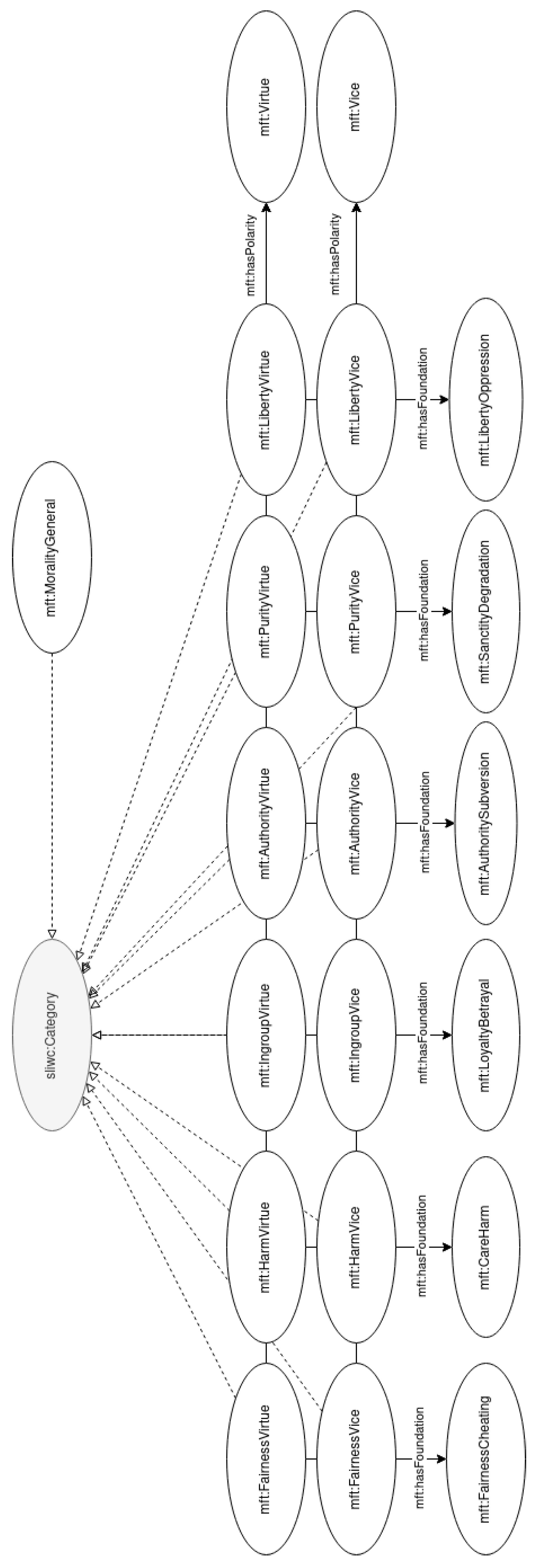
- MFT vocabulary [51], a vocabulary to model annotations in accordance with the MFT.
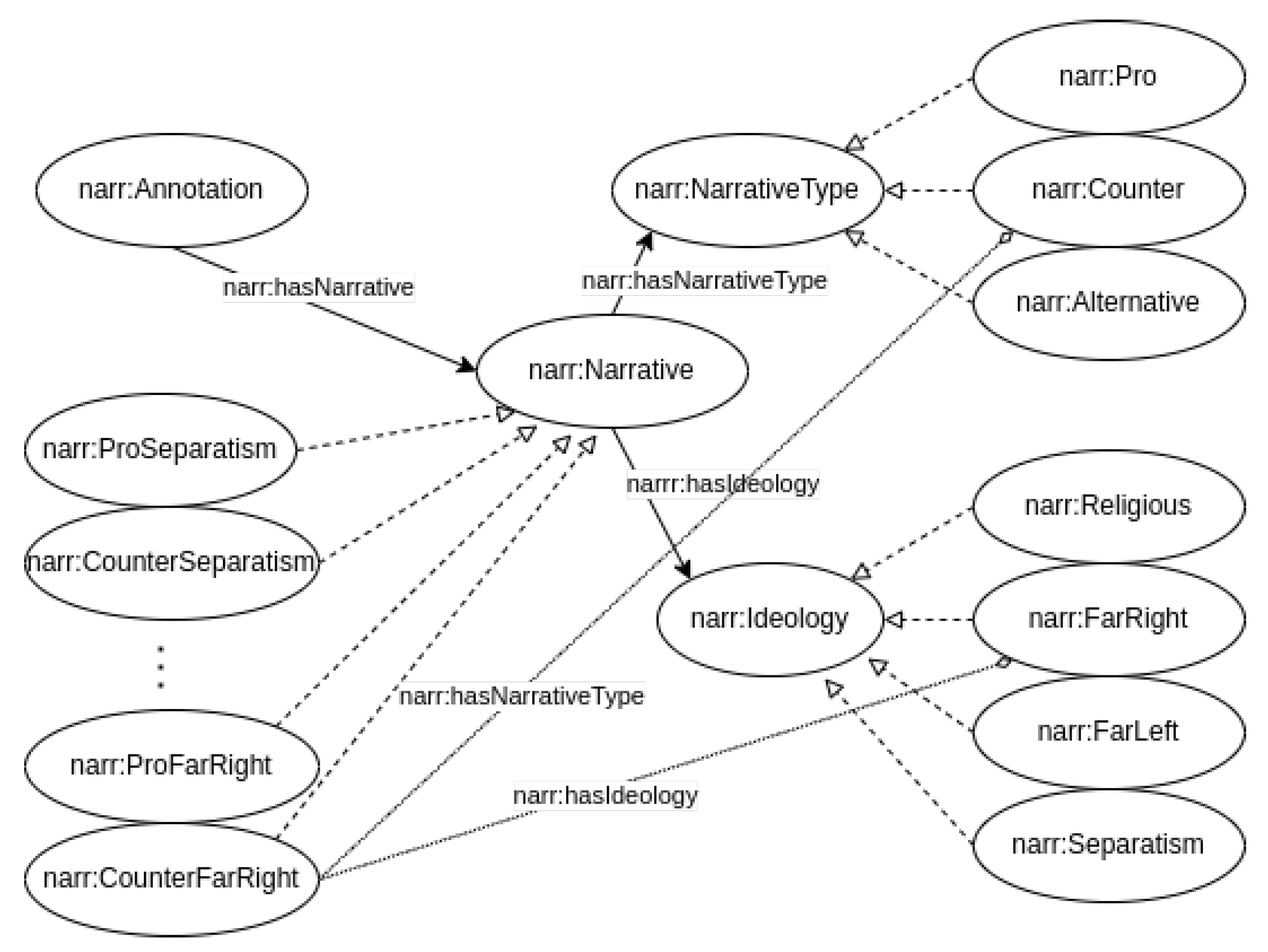
- Narrative vocabulary [52] contains the concepts necessary to annotate NIF or SIOC elements with a narrative component.
3.1. Semantic Vocabulary for LIWC (SLIWC)
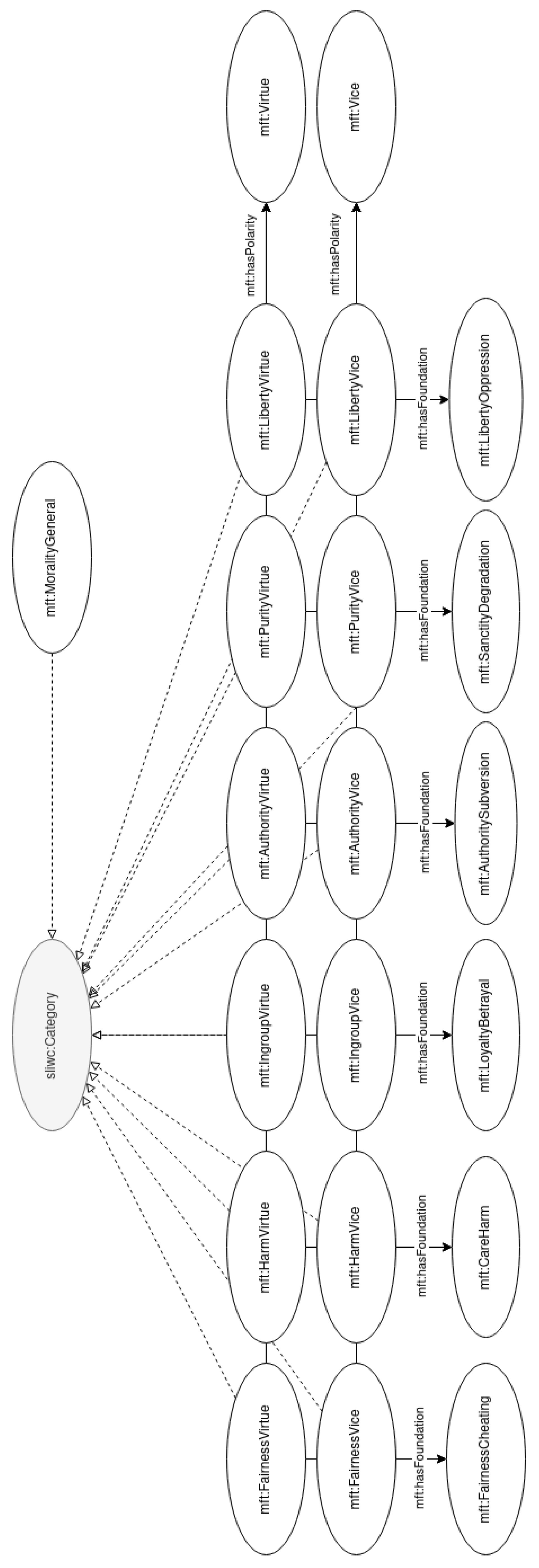
3.2. Vocabulary for the Moral Foundation Theory (MFT)
- Fairness, equality, or reciprocity/cheating: notions of rights and justice.
- Care/harm: compassion, protection of community members.
- Loyalty or ingroup/betrayal: respect for the norms of the group, patriotism, and sacrifice for the group.
- Authority or respect/subversion: obedience to authority figures and hierarchical structures.
- Purity or sanctity/degradation: promotion of sacred values, chastity, control of one’s desires.
- Liberty/oppression: feelings of reactance and resentment people feel toward those who dominate them and restrict their liberty.
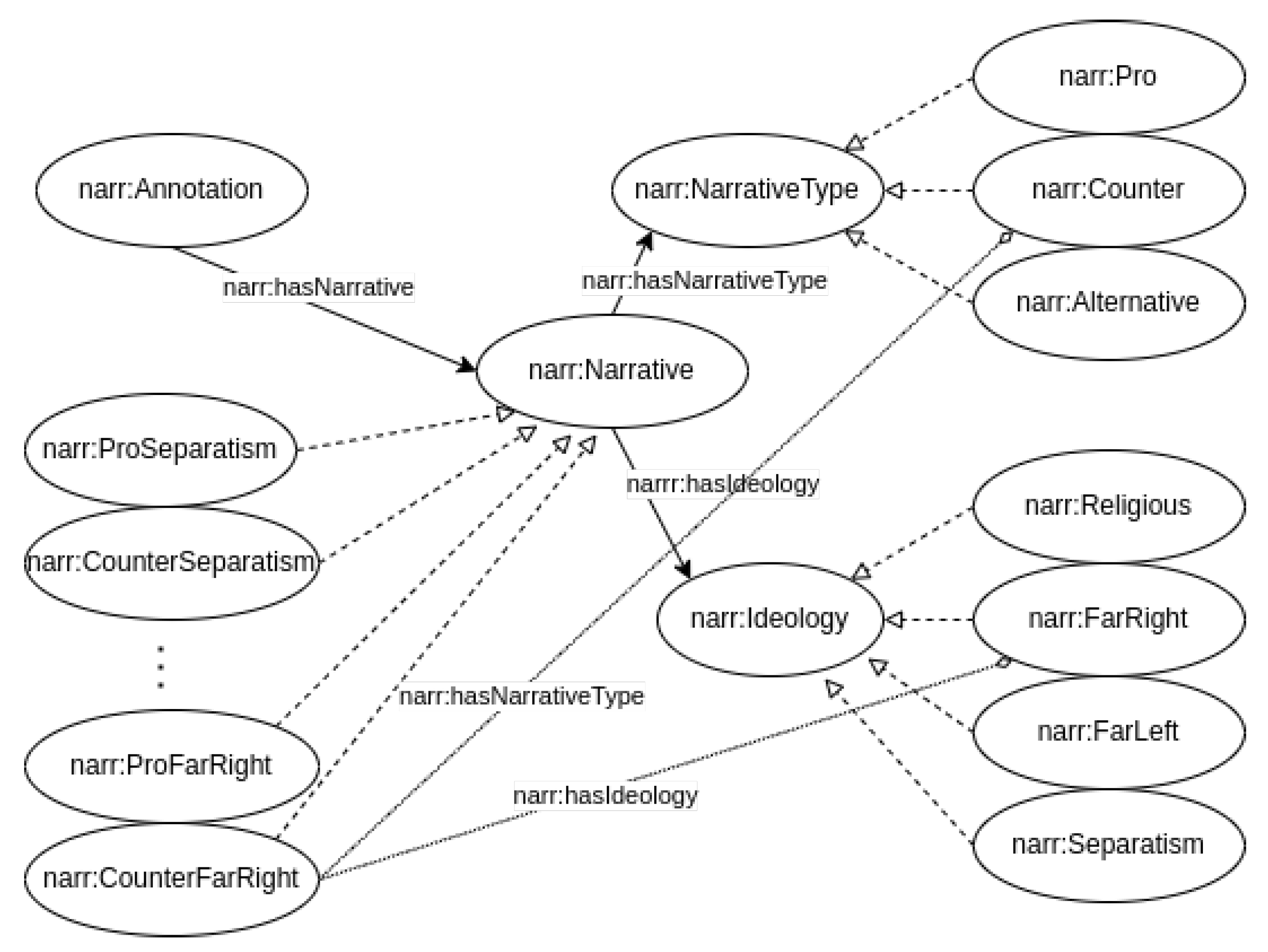
3.3. Vocabulary for Narrative
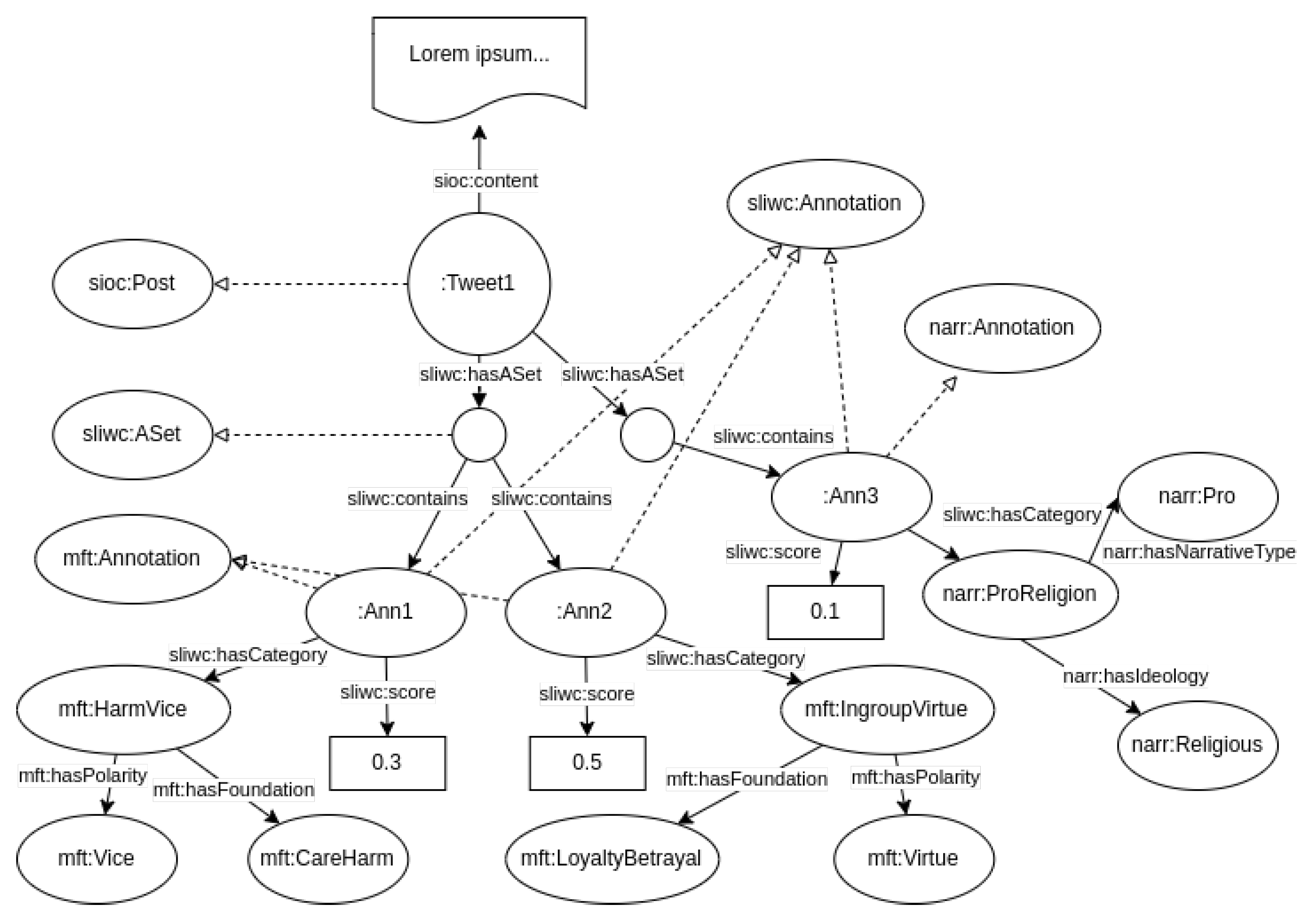
3.4. Examples of Semantic Annotation
| Listing 1. Example of a tweet annotation. |
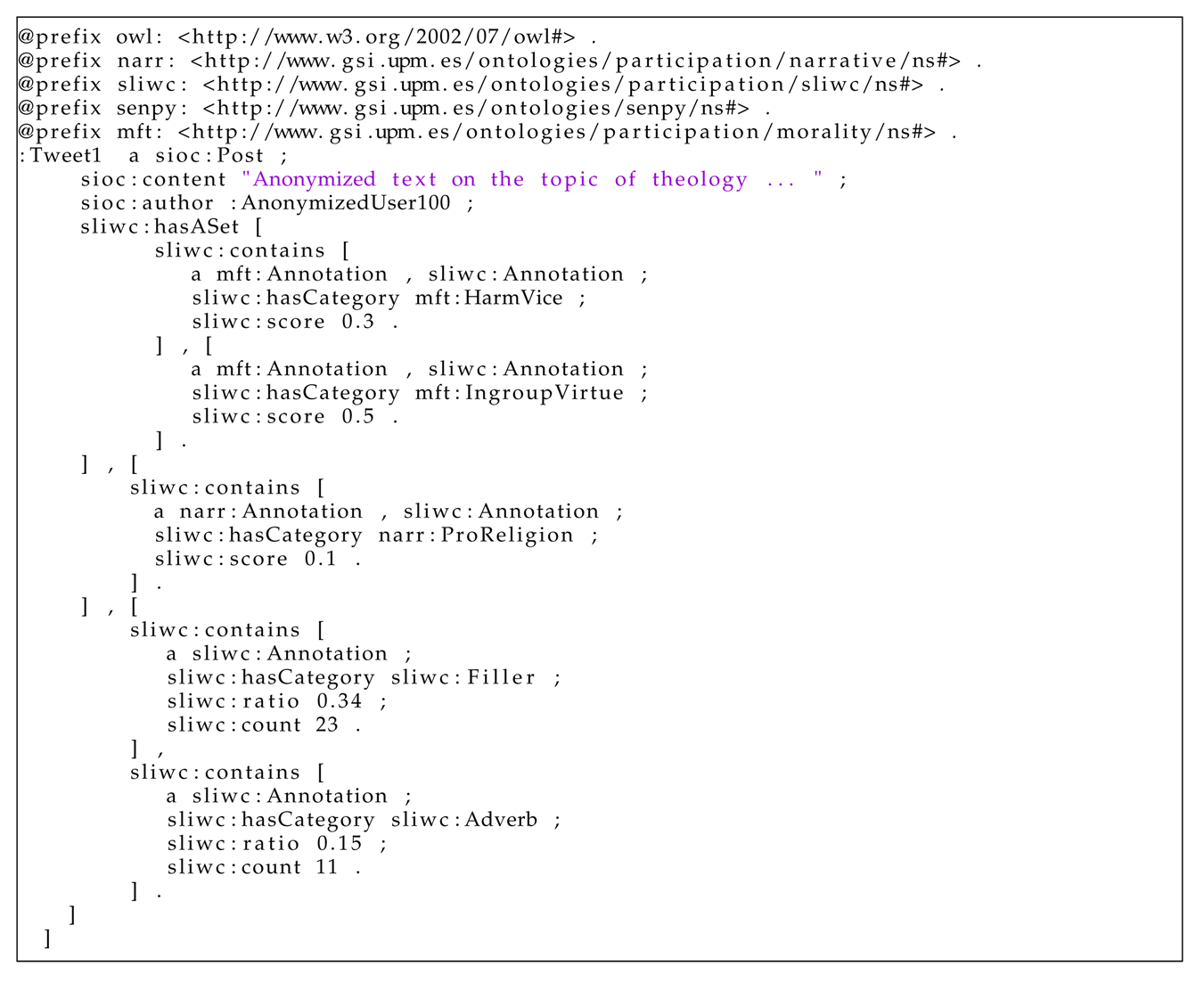 |
| Listing 2. Annotation of lexical entry. |
 |
4. Methods
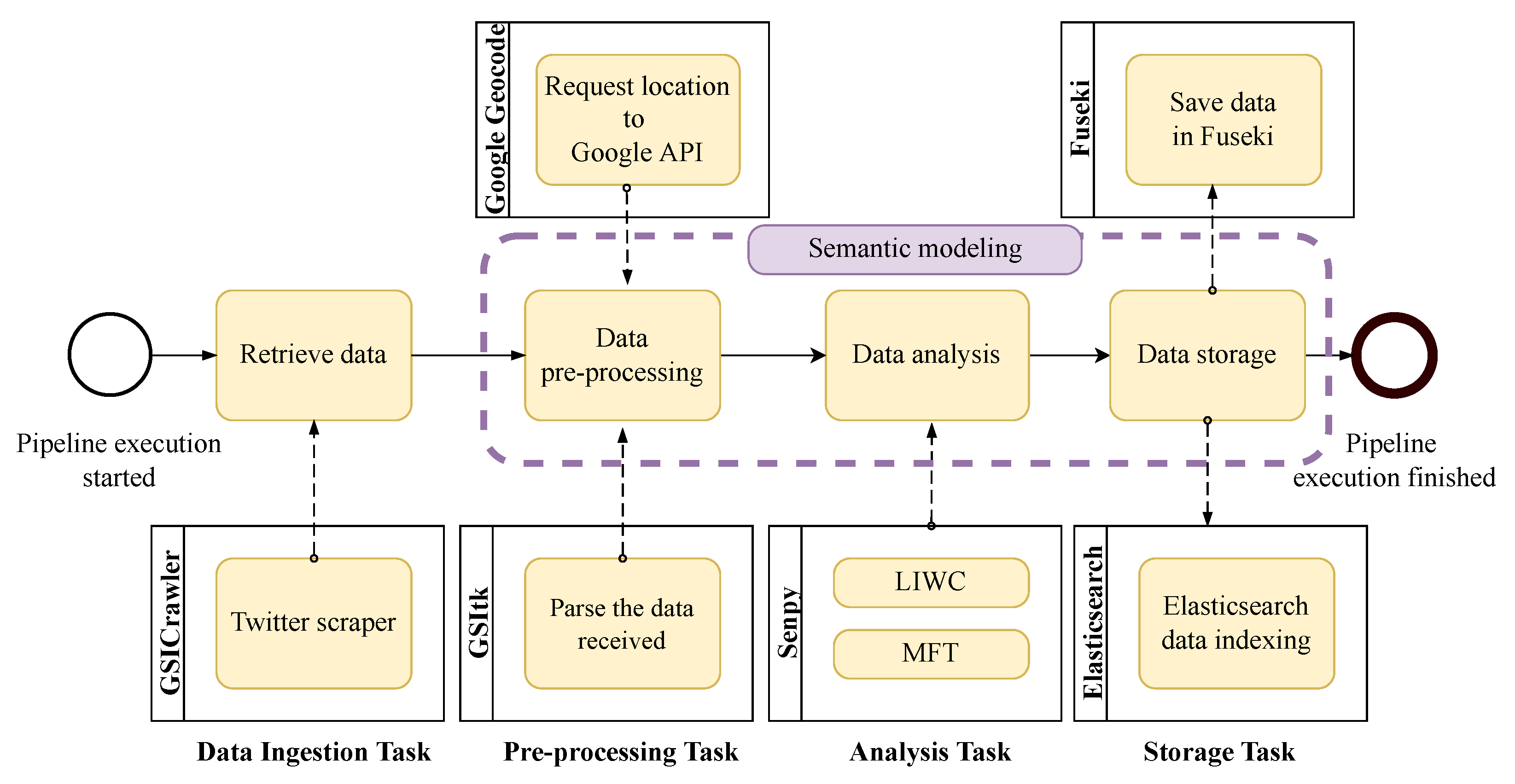
4.1. Software Architecture and Components
4.2. Data Source Selection
4.3. Linguistic Processing
4.4. Dashboard
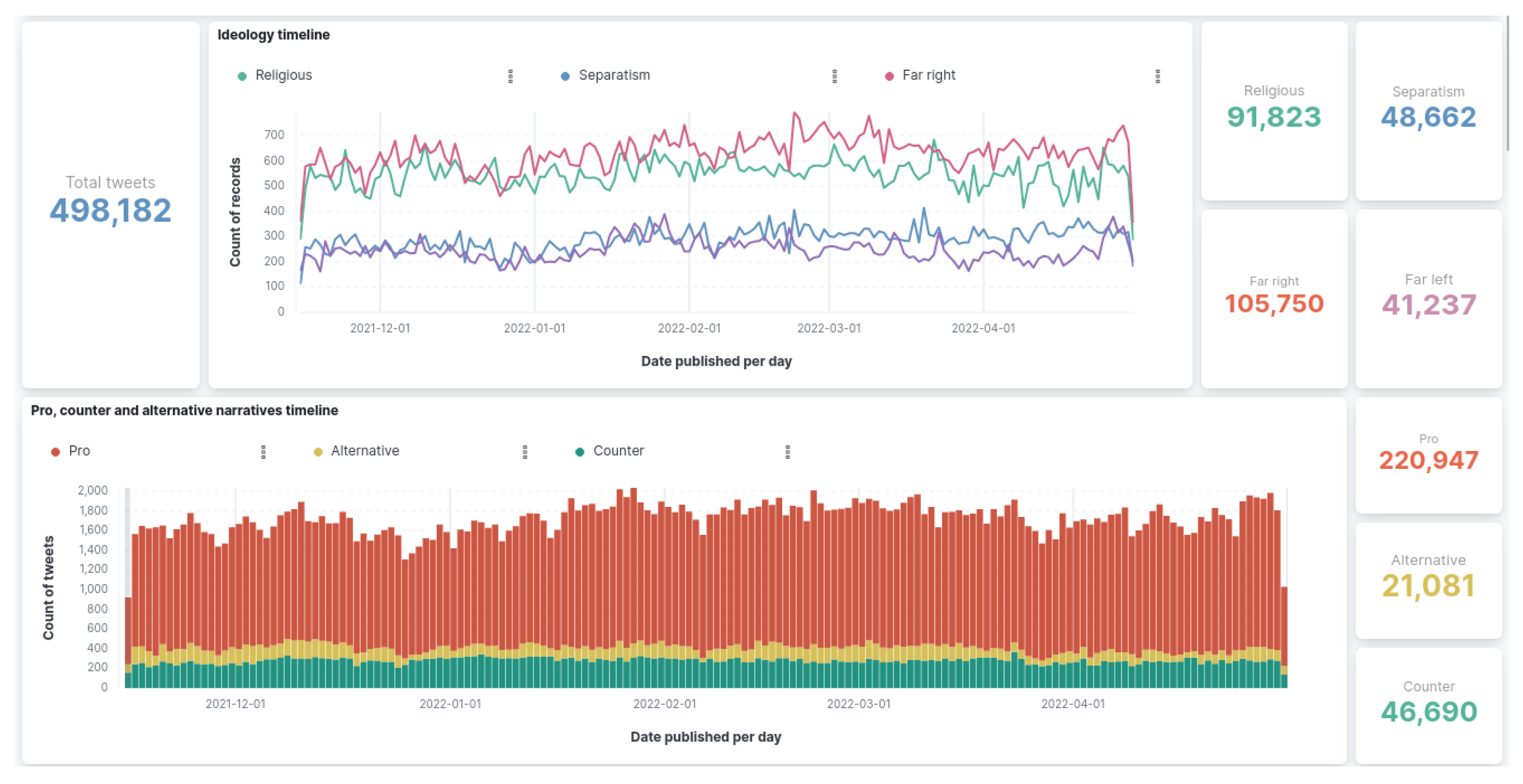
5. Results and Evaluation
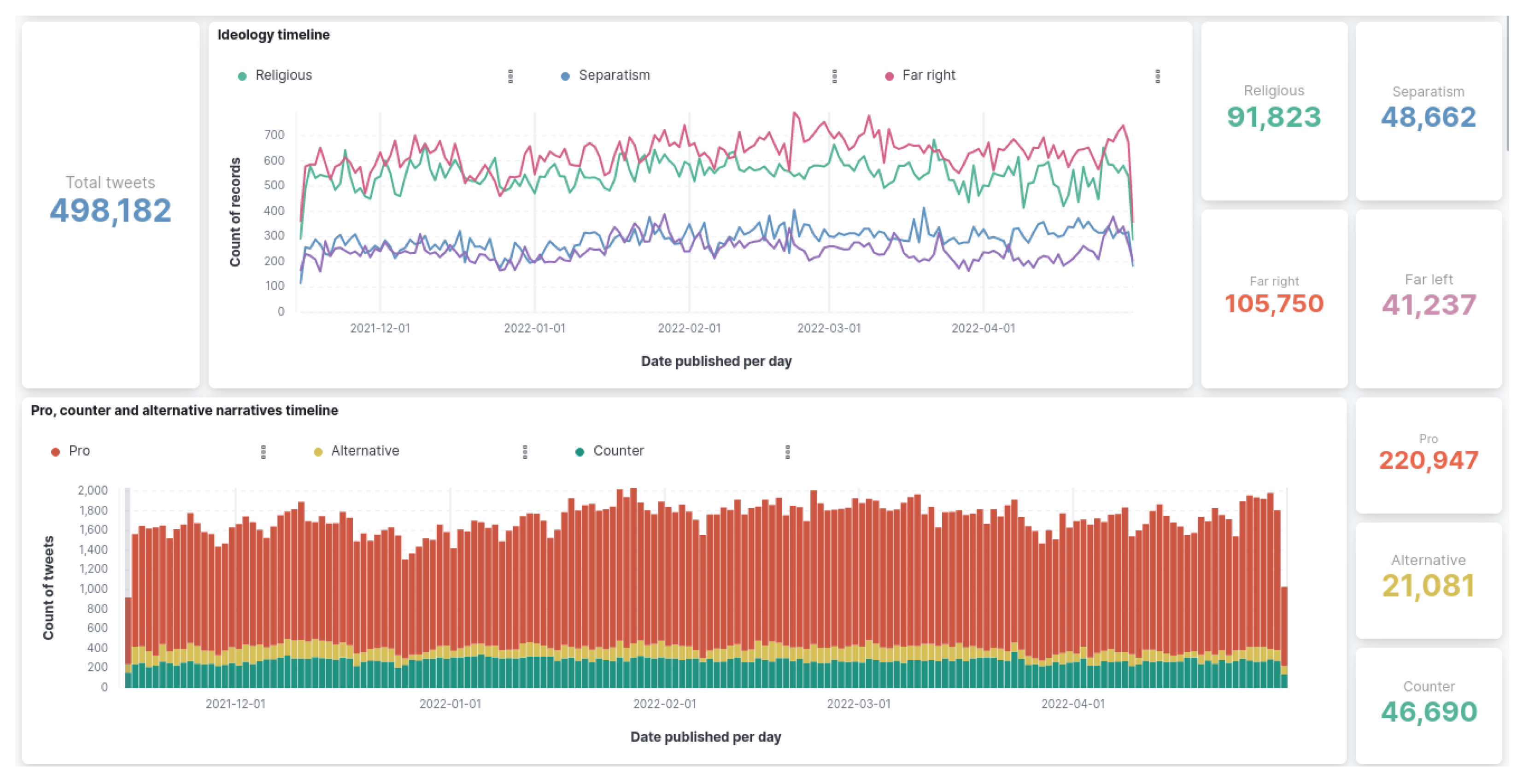
5.1. Analysis of Results
5.2. Evaluation
- 1.
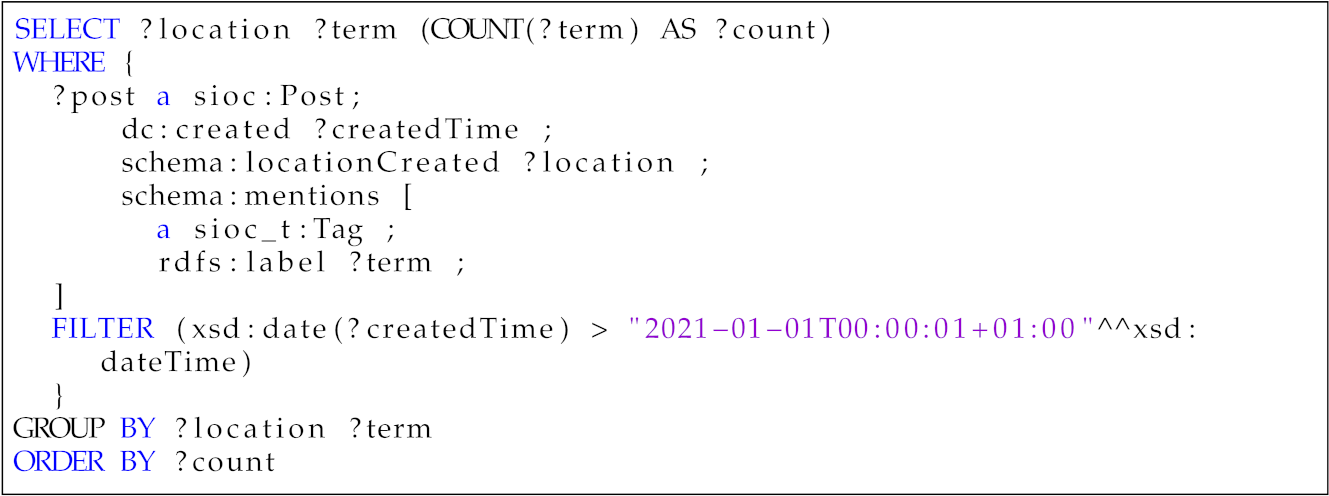
- Which is the most popular term in two different moments in time? A relevant insight into a community is the topics its addresses. Generally, online discussions can vary between different topics over time. This question was designed to uncover temporal trends of the topics discussed in the data. Moreover, we could also be interested in monitoring the temporal evolution of certain topics.Table 4. Competency question—Q1.
SPARQL Query Results Which is the most popular term in two different moments in time?
![Applsci 12 08413 i003]()
?createdDate ?term ?count 26-02-2022 Ukraine 23,010 03-02-2022 USA 19,926 - 2.
- Which are the leading core drivers in a given area? Core drivers are psychological traits that the proposed system can extract from the analyzed text. Since we studied geolocated content, it was possible to study specific areas and how they address personal and ingroup narratives. The study of how a community expresses its core drives can aid in describing the said community.Table 5. Competency question—Q2.
Which are the leading personal concerns in a given area?
![Applsci 12 08413 i004]()
?location ?term ?count Berlin, Germany Risk 8923 Hamburg, Germany Achievement 7332 Washington, DC Affiliation 2349 - 3.
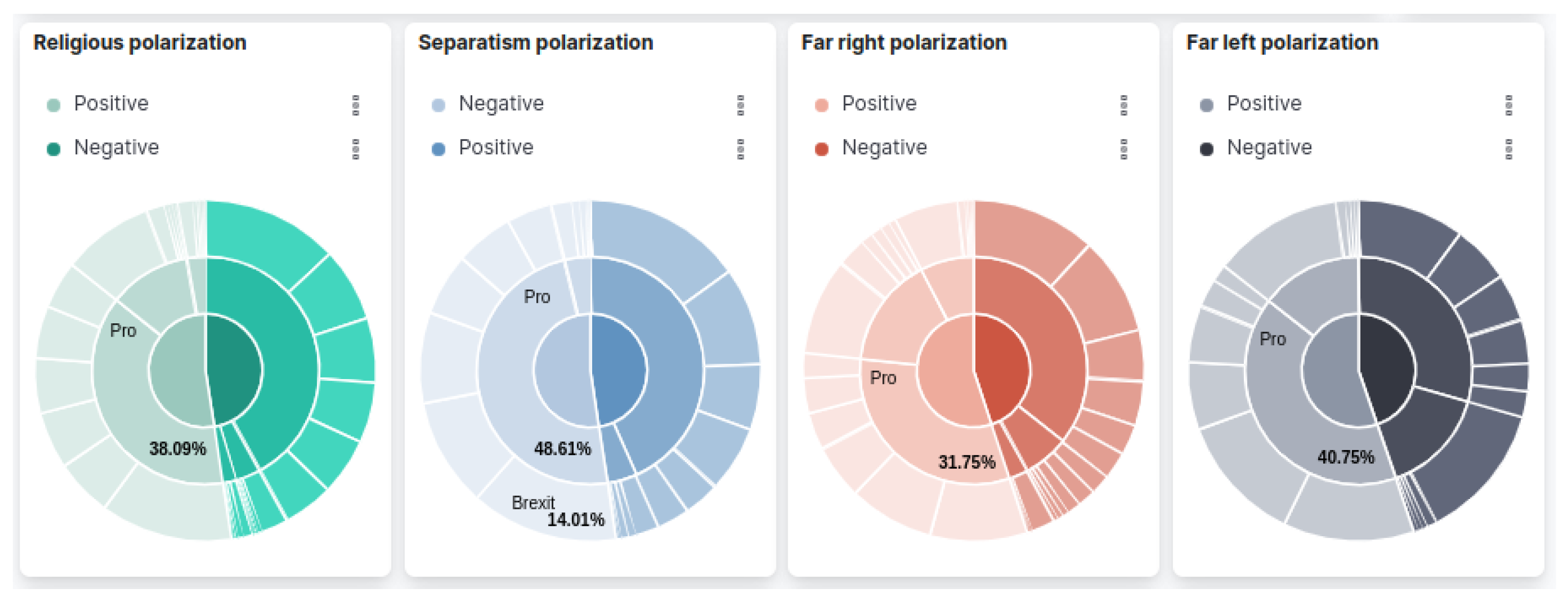
- Which is the ideology with a higher percentage of polarized content? Polarization in extremist or propagandistic content is a common trait. Thus, it is an interesting characteristic to study. This question is oriented to characterizing the language of each ideology, profiling the percentage of negative polarization overall.Table 6. Competency question—Q3.
Which is the ideology with a higher percentage of polarized content?
![Applsci 12 08413 i005]()
?ideology ?ratio Separatism 0.5232 Religious 0.4745 Far-left 0.4476 Far-right 0.4463 - 4.
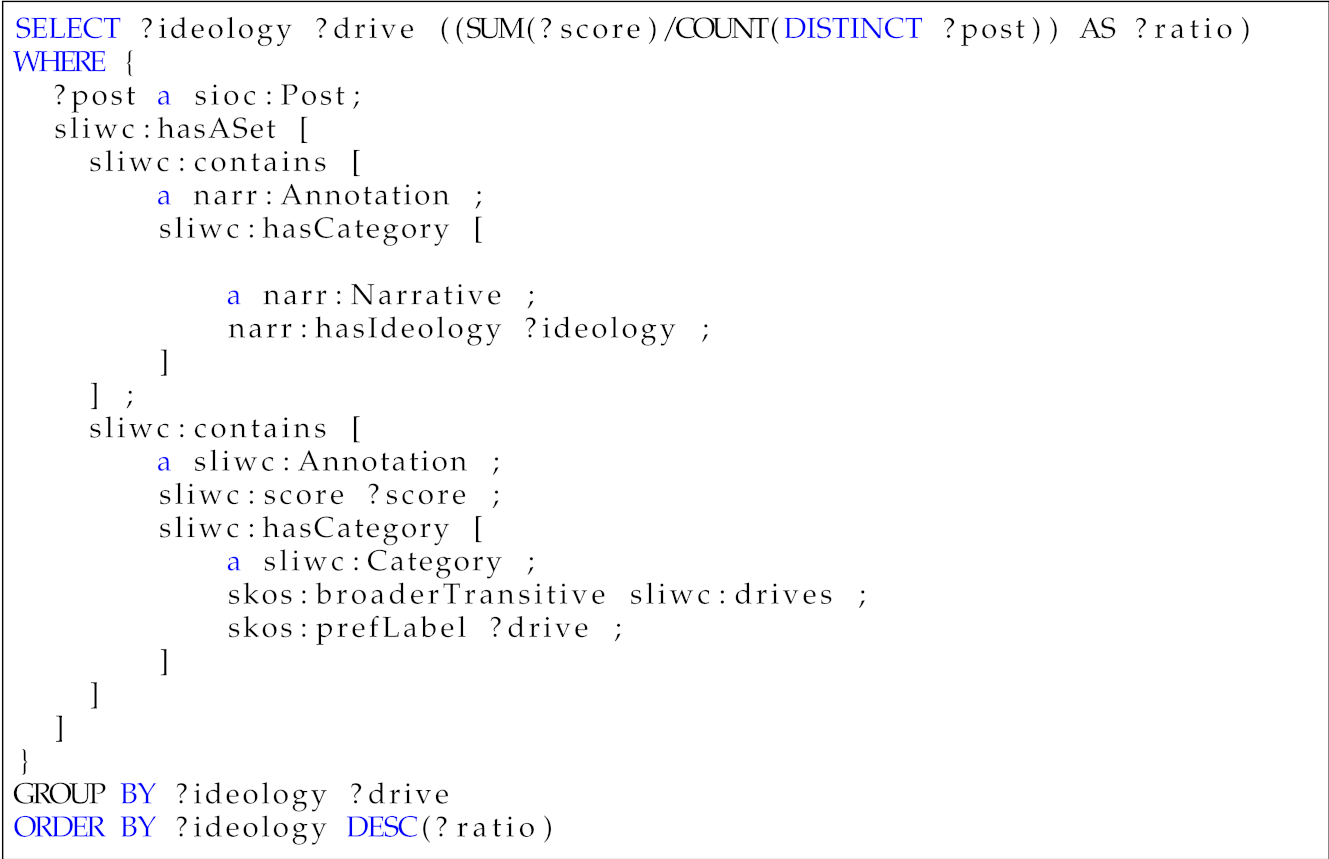
- Which core drive is the most prevalent in each ideology? As mentioned, core drives are an effective way of profiling language use. This question was aimed at profiling the most important core drivers among the different ideologies considered. This offers an insight into the motivation of the language used in the messages of each ideology.Table 7. Competency question—Q4.
Which core drive is the most prevalent in each ideology?
![Applsci 12 08413 i006]()
?ideology ?drive ?ratio Religious Affiliation 0.35 Separatism Achievement 0.35 Far right Power 0.32 Far left Power 0.33



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| DCMI | Dublin Core Metadata Initiative |
| FBI | Federal Bureau of Investigation |
| ISIS | Islamic State of Iraq and Syria |
| JSON | JavaScript Object Notation |
| JSON-LD | JavaScript Object Notation (JSON) for Linked Data |
| LIWC | Linguistic Inquiry and Word Count |
| MFD | Moral Foundations Dictionary |
| NBDRA | NIST Big Data Reference Architecture |
| NGO | Non-governmental organization |
| MFD | Moral Foundations Dictionary |
| MFT | Moral Foundations Theory |
| NIF | NLP Interchange Format |
| NLP | Natural Language Processing |
| RDF | Resource Description Framework |
| RDFS | Resource Description Framework Schema |
| SENPY | The Senpy Ontology |
| SIOC | Semantically-Interlinked Online Communities |
| SKOS | Simple Knowledge Organization System |
| SLIWC | Semantic LIWC |
| SPARQL | SPARQL Protocol and RDF Query Language |
| TF-IDF | term frequency-inverse document frequency |
| USSS | United States Secret Service |
References
- Vidino, L. Countering Radicalization in America Lessons from Europe; Technical report; US Institute of Peace: Washington, DC, USA, 2010. [Google Scholar]
- H2020 PARTICIPATION Project. Available online: https://participation-in.eu/ (accessed on 13 July 2022).
- Poggi, I.; D’Errico, F. Social signals: A psychological perspective. In Computer Analysis of Human Behavior; Springer: London, UK, 2011; pp. 185–225. [Google Scholar]
- Sánchez-Rada, J.F.; Iglesias, C.A. Social context in sentiment analysis: Formal definition, overview of current trends and framework for comparison. Inf. Fusion 2019, 52, 344–356. [Google Scholar] [CrossRef]
- Correa, D.; Sureka, A. Solutions to detect and analyze online radicalization: A survey. arXiv 2013, arXiv:1301.4916. [Google Scholar]
- Fernandez, M.; Asif, M.; Alani, H. Understanding the Roots of Radicalisation on Twitter. In Proceedings of the 10th ACM Conference on Web Science (WebSci ’18), Amsterdam, The Netherlands, 27–30 May 2018; ACM: New York, NY, USA, 2018; pp. 1–10. [Google Scholar]
- Saif, H.; Dickinson, T.; Kastler, L.; Fernandez, M.; Alani, H. A semantic graph-based approach for radicalisation detection on social media. In Proceedings of the European Semantic Web Conference, Portorož, Slovenia, 28 May–1 June 2017; Springer: Cham, Switzerland, 2017; pp. 571–587. [Google Scholar]
- Nouh, M.; Nurse, J.R.; Goldsmith, M. Understanding the radical mind: Identifying signals to detect extremist content on twitter. In Proceedings of the 2019 IEEE International Conference on Intelligence and Security Informatics (ISI), Shenzhen, China, 1–3 July 2019; pp. 98–103. [Google Scholar]
- Tausczik, Y.R.; Pennebaker, J.W. The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Araque, O.; Iglesias, C.A. An approach for radicalization detection based on emotion signals and semantic similarity. IEEE Access 2020, 8, 17877–17891. [Google Scholar] [CrossRef]
- Van Brunt, B.; Murphy, A.; Zedginidze, A. An exploration of the risk, protective, and mobilization factors related to violent extremism in college populations. Violence Gend. 2017, 4, 81–101. [Google Scholar] [CrossRef]
- Rose, M. Mass Shooters and Murderers: Motives and Paths; NetCE: Mount Laurel, NJ, USA, 2019. [Google Scholar]
- Simons, A.; Meloy, J.R. Foundations of threat assessment and management. In Handbook of Behavioral Criminology; Springer: Cham, Switzerland, 2017; pp. 627–644. [Google Scholar]
- Meloy, J.R. Identifying warning behaviors of the individual terrorist. FBI Law Enforc. Bull. 2016, 85, 1–9. [Google Scholar]
- Hamlett, L.E. Common Psycholinguistic Themes in Mass Murderer Manifestos. Ph.D. Thesis, Walden University, Minneapolis, MN, USA, 2017. [Google Scholar]
- Knoll, J.L. The “pseudocommando” mass murderer: Part II, the language of revenge. J. Am. Acad. Psychiatry Law Online 2010, 38, 263–272. [Google Scholar]
- Cohen, K.; Johansson, F.; Kaati, L.; Mork, J.C. Detecting linguistic markers for radical violence in social media. Terror. Political Violence 2014, 26, 246–256. [Google Scholar] [CrossRef]
- Grover, T.; Mark, G. Detecting potential warning behaviors of ideological radicalization in an alt-right subreddit. In Proceedings of the International AAAI Conference on Web and Social Media, Münich, Germany, 11–14 June 2019; Volume 13, pp. 193–204. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Nakayama, H. Hatesonar. Hate Speech Detection Library for Python. 2020. Available online: https://pypi.org/project/hatesonar/ (accessed on 13 July 2021).
- Torregrosa, J.; Panizo-Lledot, Á.; Bello-Orgaz, G.; Camacho, D. Analyzing the relationship between relevance and extremist discourse in an alt-right network on Twitter. Soc. Netw. Anal. Min. 2020, 10, 68. [Google Scholar] [CrossRef]
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8. [Google Scholar]
- Smith, L.G.; Wakeford, L.; Cribbin, T.F.; Barnett, J.; Hou, W.K. Detecting psychological change through mobilizing interactions and changes in extremist linguistic style. Comput. Hum. Behav. 2020, 108, 106298. [Google Scholar] [CrossRef]
- Graham, J.; Haidt, J.; Nosek, B.A. Liberals and conservatives rely on different sets of moral foundations. J. Personal. Soc. Psychol. 2009, 96, 1029. [Google Scholar] [CrossRef] [PubMed]
- Torregrosa, J.; Thorburn, J.; Lara-Cabrera, R.; Camacho, D.; Trujillo, H.M. Linguistic analysis of pro-isis users on twitter. Behav. Sci. Terror. Political Aggress. 2020, 12, 171–185. [Google Scholar] [CrossRef]
- Alizadeh, M.; Weber, I.; Cioffi-Revilla, C.; Fortunato, S.; Macy, M. Psychology and morality of political extremists: Evidence from Twitter language analysis of alt-right and Antifa. EPJ Data Sci. 2019, 8, 17. [Google Scholar] [CrossRef]
- Lara-Cabrera, R.; Pardo, A.G.; Benouaret, K.; Faci, N.; Benslimane, D.; Camacho, D. Measuring the radicalisation risk in social networks. IEEE Access 2017, 5, 10892–10900. [Google Scholar] [CrossRef]
- Van der Vegt, I.; Mozes, M.; Kleinberg, B.; Gill, P. The Grievance Dictionary: Understanding threatening language use. Behav. Res. Methods 2021, 53, 2105–2119. [Google Scholar] [CrossRef]
- Pais, S.; Tanoli, I.; Albardeiro, M.; Cordeiro, J. A Lexicon Based Approach to Detect Extreme Sentiments. In Proceedings of the ICIMP 2020, the Fifteenth International Conference on Internet Monitoring and Protection; Pais, S., Tanoli, I.K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; pp. 1–6. [Google Scholar]
- Baccianella, S.; Esuli, A.; Sebastiani, F. Sentiwordnet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the Lrec, Valletta, Malta, 17–23 May 2010; Volume 10, pp. 2200–2204. [Google Scholar]
- Cambria, E.; Li, Y.; Xing, F.Z.; Poria, S.; Kwok, K. SenticNet 6: Ensemble application of symbolic and subsymbolic AI for sentiment analysis. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Galway, Ireland, 19–23 October 2020; pp. 105–114. [Google Scholar]
- Artificial Intelligence Lab, Management Information Systems Department, University of Arizona. Ansar1 Forum Dataset. Dataset of the Dark Web Project on the Study of International Jihadi Social Media and Movement. 2010. Available online: https://www.azsecure-data.org/dark-web-forums.html (accessed on 13 July 2021).
- Artificial Intelligence Lab, Management Information Systems Department, University of Arizona. Turn to Islam Forum Dataset. Dataset of the English Language Forum with the Goal of “Correcting the Common Misconceptions about Islam”. Radical Participants May Occasionally Display Their Support for Fundamentalist Militant Groups. 2013. Available online: https://www.azsecure-data.org/dark-web-forums.html (accessed on 13 July 2021).
- Wahyuningsih, T. Problems, Challenges, and Opportunities Visualization on Big Data. J. Appl. Data Sci. 2020, 1, 20–28. [Google Scholar] [CrossRef]
- Capozzi, A.T.; Lai, M.; Basile, V.; Poletto, F.; Sanguinetti, M.; Bosco, C.; Patti, V.; Ruffo, G.; Musto, C.; Polignano, M.; et al. “Contro L’Odio”: A Platform for Detecting, Monitoring and Visualizing Hate Speech against Immigrants in Italian Social Media. IJCoL Ital. J. Comput. Linguist. 2020, 6, 77–97. [Google Scholar] [CrossRef]
- Di Nicola, A.; Andreatta, D.; Martini, E.; Antonopoulos, G.; Baratto, G.; Bonino, S.; Bressan, S.; Burke, S.; Cesarotti, F.; Diba, P.; et al. HATEMETER: Hate Speech Tool for Monitoring, Analysing and Tackling Anti-Muslim Hatred Online. eCrime; Technical Report; Commissioning bodyEuropean Union’s Rights, Equality and Citizenship Programme: Trento, Italy, 2020. [Google Scholar]
- Laurent, M. Project Hatemeter: Helping NGOs and Social Science researchers to analyze and prevent anti-Muslim hate speech on social media. Procedia Comput. Sci. 2020, 176, 2143–2153. [Google Scholar] [CrossRef]
- H2020 Trivalent Project. Terrorism pReventIon Via rAdicaLisation countEr-NarraTive. Available online: http://trivalentproject.eu/ (accessed on 13 July 2022).
- Beheshti, A.; Moraveji-Hashemi, V.; Yakhchi, S.; Motahari-Nezhad, H.R.; Ghafari, S.M.; Yang, J. personality2vec: Enabling the analysis of behavioral disorders in social networks. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston TX, USA, 3–7 February 2020; pp. 825–828. [Google Scholar]
- Chiarcos, C.; McCrae, J.; Cimiano, P.; Fellbaum, C. Towards open data for linguistics: Linguistic linked data. In New Trends of Research in Ontologies and Lexical Resources; Springer: Berlin/Heidelberg, Germany, 2013; pp. 7–25. [Google Scholar]
- Sánchez-Rada, J.F.; Iglesias, C.A. Onyx: A Linked Data Approach to Emotion Representation. Inf. Process. Manag. 2016, 52, 99–114. [Google Scholar] [CrossRef]
- Auer, S.; Bryl, V.; Tramp, S. Linked Open Data–Creating Knowledge Out of Interlinked Data: Results of the LOD2 Project; Springer: Cham, Switzerland, 2014; Volume 8661. [Google Scholar]
- Buitelaar, P.; Wood, I.D.; Negi, S.; Arcan, M.; McCrae, J.P.; Abele, A.; Robin, C.; Andryushechkin, V.; Ziad, H.; Sagha, H.; et al. Mixedemotions: An open-source toolbox for multimodal emotion analysis. IEEE Trans. Multimed. 2018, 20, 2454–2465. [Google Scholar] [CrossRef]
- Breslin, J.G.; Decker, S.; Harth, A.; Bojars, U. SIOC: An approach to connect web-based communities. Int. J. Web Based Communities 2006, 2, 133–142. [Google Scholar] [CrossRef]
- Dublin Core Metadata Initiative. Dublin Core Metadata Element Set, Version 1.1; Technical report; Dublin Core Metadata Initiative: Silver Spring, MD, USA, 2012. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A Nucleus for a Web of Open Data. In The Semantic Web; Springer: Cham, Switzerland, 2007; pp. 722–735. [Google Scholar]
- Hellmann, S.; Lehmann, J.; Auer, S.; Brümmer, M. Integrating NLP Using Linked Data. In Proceedings of the International Semantic Web Conference, Sydney, Australia, 21–25 October 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 98–113. [Google Scholar]
- Westerski, A.; Iglesias, C.A.; Rico, F.T. Linked Opinions: Describing Sentiments on the Structured Web of Data. In Proceedings of the SDoW@ ISWC, Bonn, Germany, 23–27 October 2011. [Google Scholar]
- Barhamgi, M.; Masmoudi, A.; Lara-Cabrera, R.; Camacho, D. Social networks data analysis with semantics: Application to the radicalization problem. J. Ambient. Intell. Humaniz. Comput. 2018, 1–15. [Google Scholar] [CrossRef]
- SLIWC. Semantic LIWC vocabulary. Available online: https://www.gsi.upm.es/ontologies/participation/sliwc/ (accessed on 13 July 2022).
- Morality Vocabulary. Available online: https://www.gsi.upm.es/ontologies/participation/morality/ (accessed on 13 July 2022).
- Narrative Vocabulary. Available online: https://www.gsi.upm.es/ontologies/participation/narrative/ (accessed on 13 July 2022).
- Sánchez-Rada, J.F.; Araque, O.; Iglesias, C.A. Senpy: A Framework for Semantic Sentiment and Emotion Analysis Services. Knowl. Based Syst. 2020, 190, 105193. [Google Scholar] [CrossRef]
- Lebo, T.; Sahoo, S.; McGuinness, D.; Belhajjame, K.; Cheney, J.; Corsar, D.; Garijo, D.; Soiland-Reyes, S.; Zednik, S.; Zhao, J. PROV-O: The PROV Ontology; W3C Recommendation, World Wide Web Consortium: Cambridge, MA, USA, 2013. [Google Scholar]
- Pennebaker Conglomerates, I. Comparing LIWC2015 and LIWC2007. 2021. Available online: http://liwc.wpengine.com/compare-dictionaries/ (accessed on 7 October 2021).
- Miles, A.; Pérez-Agüera, J.R. Skos: Simple knowledge organisation for the web. Cat. Classif. Q. 2007, 43, 69–83. [Google Scholar] [CrossRef]
- Buckingham, L.; Alali, N. Extreme parallels: A corpus-driven analysis of ISIS and far-right discourse. Kōtuitui N. Z. J. Soc. Sci. Online 2020, 15, 310–331. [Google Scholar] [CrossRef]
- Strapparava, C.; Valitutti, A. WordNet-Affect: An Affective Extension of WordNet. Lrec 2004, 4, 40. [Google Scholar]
- Moral Foundations Dictionary. Available online: https://moralfoundations.org/other-materials/ (accessed on 13 July 2022).
- Haidt, J.; Graham, J. When morality opposes justice: Conservatives have moral intuitions that liberals may not recognize. Soc. Justice Res. 2007, 20, 98–116. [Google Scholar] [CrossRef]
- Fafalios, P.; Iosifidis, V.; Ntoutsi, E.; Dietze, S. TweetsKB: A Public and Large-Scale RDF Corpus of Annotated Tweets. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 3–7 June 2018; Springer: Cham, Switzerland, 2018; pp. 177–190. [Google Scholar]
- Buitelaar, P.; Cimiano, P.; McCrae, J.; Montiel-Ponsada, E.; Declerck, T. Ontology Lexicalisation: The lemon Perspective. In Proceedings of the Workshop Proceedings of the 9th International Conference on Terminology and Artificial Intelligence, Granada, Spain, 8–10 November 2011; INALCO: Paris, France, 2011; pp. 33–36. [Google Scholar]
- Chang, W.L.; Boyd, D.; Levin, O. NIST Big Data Interoperability Framework: Volume 6, Reference Architecture; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2018. [Google Scholar]
- World Wide Web Consortium. SPARQL 1.1 Overview; Technical Report; World Wide Web Consortium: Cambridge, MA, USA, 2013. [Google Scholar]
- White, T. Hadoop: The Definitive Guide; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Thusoo, A.; Sarma, J.S.; Jain, N.; Shao, Z.; Chakka, P.; Zhang, N.; Antony, S.; Liu, H.; Murthy, R. Hive-a petabyte scale data warehouse using hadoop. In Proceedings of the 2010 IEEE 26th International Conference on Data Engineering (ICDE 2010), Long Beach, CA, USA, 1–6 March 2010; pp. 996–1005. [Google Scholar]
- Spotify. Luigi. Available online: https://github.com/spotify/luigi (accessed on 11 May 2022).
- Sánchez-Rada, J.F.; Pascual, A.; Conde, E.; Iglesias, C.A. A Big Linked Data Toolkit for Social Media Analysis and Visualization Based on W3C Web Components. In Proceedings of the OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”, Valletta, Malta, 22–26 October 2018; Springer: Cham, Switzerland, 2018; pp. 498–515. [Google Scholar]
- Kouzis-Loukas, D. Learning Scrapy; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Poldi, F.; Twint Community. Twint. 2021. Available online: https://github.com/twintproject/twint (accessed on 13 July 2021).
- Araque, O.; Sánchez-Rada, J.F.; Iglesias, C.A. GSITK: A sentiment analysis framework for agile replication and development. SoftwareX 2022, 17, 100921. [Google Scholar] [CrossRef]
- Google Inc. Google Geocoding API. 2021. Available online: https://developers.google.com/maps/documentation/geocoding/overview (accessed on 15 July 2021).
- Burton, S.H.; Tanner, K.W.; Giraud-Carrier, C.G.; West, J.H.; Barnes, M.D. “Right Time, Right Place” Health Communication on Twitter: Value and Accuracy of Location Information. J. Med. Internet Res. 2012, 14, e156. [Google Scholar] [CrossRef] [PubMed]
- Gormley, C.; Tong, Z. Elasticsearch: The Definitive Guide: A Distributed Real-Time Search and Analytics Engine; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [Google Scholar]
- Kellogg, G.; Sporny, M.; Lanthaler, M. JSON-LD 1.1; W3C Community Specification, World Wide Web Consortium: Cambridge, MA, USA, 2019. [Google Scholar]
- Jena, A. Apache Jena Fuseki. In The Apache Software Foundation. 2014. Available online: https://jena.apache.org/documentation/fuseki2/ (accessed on 13 July 2021).
- Gupta, Y. Kibana Essentials; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Ranstorp, M.; Gustafsson, L.; Hyllengren, P.; Ahlin, F. Preventing and Countering Violent Extremism; Technical Report DRDC-RDDC-2017-C093; Swedish Defence University, Center for Asymmetric Threat Studies (CATS): Stockholm, Sweden, 2016. [Google Scholar]
- Network, R.A. Counter Narratives and Alternative Narratives. Ran Issue Paper. 2015. Available online: https://home-affairs.ec.europa.eu/system/files_en?file=2020-09/issue_paper_cn_oct2015_en.pdf (accessed on 13 July 2021).
- Upal, A. Alternative Narratives for Preventing the Radicalization of Muslim Youth. J. Deradicalization 2015, 1, 138–162. [Google Scholar]
- Wojcieszak, M. ‘Don’t talk to me’: Effects of ideologically homogeneous online groups and politically dissimilar offline ties on extremism. New Media Soc. 2010, 12, 637–655. [Google Scholar] [CrossRef]
- Twitter. Twitter Developer Platform. 2021. Available online: https://developer.twitter.com/en (accessed on 13 July 2021).
- Pennebaker, J.W. Using computer analyses to identify language style and aggressive intent: The secret life of function words. Dyn. Asymmetric Confl. 2011, 4, 92–102. [Google Scholar] [CrossRef]
- Tumasjan, A.; Sprenger, T.; Sandner, P.; Welpe, I. Predicting Elections with Twitter: What 140 Characters Reveal about Political Sentiment. In Proceedings of the International AAAI Conference on Web and Social Media, Washington, DC, USA, 23–26 May 2010; Volume 4. [Google Scholar]
- Hall, M.; Logan, M.; Ligon, G.S.; Derrick, D.C. Do machines replicate humans? Toward a unified understanding of radicalizing content on the open social web. Policy Internet 2020, 12, 109–138. [Google Scholar] [CrossRef]
- Haidt, J.; Joseph, C. Intuitive ethics: How innately prepared intuitions generate culturally variable virtues. Daedalus 2004, 133, 55–66. [Google Scholar] [CrossRef]
- Araque, O.; Gatti, L.; Kalimeri, K. MoralStrength: Exploiting a moral lexicon and embedding similarity for moral foundations prediction. Knowl. Based Syst. 2020, 191, 105184. [Google Scholar] [CrossRef]
- GSI-UPM. PARTICIPATION Dashboard. 2022. Available online: https://participation.gsi.upm.es/ (accessed on 7 July 2022).
- Grüninger, M.; Fox, M. Methodology for the Design and Evaluation of Ontologies. In Proceedings of the IJCAI’95, Workshop on Basic Ontological Issues in Knowledge Sharing, Montreal, QC, Canada, 13 April 1995. [Google Scholar]
- Menini, S.; Moretti, G.; Corazza, M.; Cabrio, E.; Tonelli, S.; Villata, S. A System to Monitor Cyberbullying based on Message Classification and Social Network Analysis. In Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 1–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 105–110. [Google Scholar] [CrossRef]
- Agarwal, S.; Sureka, A. Applying social media intelligence for predicting and identifying online radicalization and civil unrest oriented threats. arXiv 2015, arXiv:1511.06858. [Google Scholar]
- Kaur, A.; Saini, J.K.; Bansal, D. Detecting radical text over online media using deep learning. arXiv 2019, arXiv:1907.12368. [Google Scholar]
- Alvari, H.; Sarkar, S.; Shakarian, P. Detection of Violent Extremists in Social Media. In Proceedings of the 2019 2nd International Conference on Data Intelligence and Security (ICDIS), South Padre Island, TX, USA, 28–30 June 2019; pp. 43–47. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Jahan, M.S.; Oussalah, M. A systematic review of Hate Speech automatic detection using Natural Language Processing. arXiv 2021, arXiv:2106.00742. [Google Scholar]



| Type | Drivers & Factors | Signal | Data Resource | References |
|---|---|---|---|---|
| Micro | Warning behaviors | Linguistic markers, entity recognition, emotions, hate speech, offensive language | Violent term dictionary, lexical databases (e.g., WordNet), LIWC, HateSonar | Lone wolf [17] Far-right [18] |
| Micro | Identity crisis, grievance | Negative emotions | LIWC and MFT | Religious [23], Separatist [23] |
| Micro | Social psychological factors | Expression of linguistic dimensions (e.g., pronouns), personal concerns (e.g., death), cognitive processs (e.g., certainty), and affective processes (e.g., anger) | LIWC | Religious [25] |
| Micro | Emotional drivers | Extreme opinions | ExtremeSentiLex | Religious [29] |
| Micro | Frustration, introversion, discrimination, identity | Linguistic markers | - | Religious [27] |
| Micro | Grievance | Lingustic markers | Grievance dictionary | Lone wolf and others [28] |
| Micro | Psychological factors | Psychological indicators, Moral values | LIWC, MFT | Political [26] |
| Meso | Group membership | Use of jargon or vernacular | Daesh vernacular dictionary | Religious [23] |
| Meso | Group dynamics | Social context (sequential accounts, followers, followed) | Religious [23] |
| Religious | Far Right | Far Left | Separatism | |
|---|---|---|---|---|
| Pro | is | supremacy | socialism | indyref |
| iraq | invasion | cityworkers | Brexit | |
| islamicstate | GreatReplacement | Courage | Donbas | |
| alleyesonisis | defendEurope | antifa | VoteLeave | |
| syria | Qanon | commune | separatism | |
| khilafarestored | Pizzagate | Commune71 | PKK | |
| islam | nazism | ViveLaCommune | islamicstate | |
| muslims | incel | Marx | ||
| brotherhood | fascism | Revolution | ||
| Gamergate | ||||
| AfD | ||||
| MAGA | ||||
| antifeminist | ||||
| Counter | eurotopia | diversity | AntiAntifa | DogsAgainstBrexit |
| antiterrorism | stopHate | antisocialism | nationalidentity | |
| antiterror | antifascist | GoodNightLeftSide | Framing | |
| peace | nonazis | Remain | ||
| antiterrorist | FCKNZS | |||
| againstterrorism | noafd | |||
| stopterrorim | ||||
| notinmyname | ||||
| Alternative | notanotherbrother | hopenothate | WhitePrivilege | StrongerIn |
| wearethemany | LeaveNoOneBehind |
| Religious | Separatism | Far-Right | Far-Left | |
|---|---|---|---|---|
| Pro | 80,378 | 44,646 | 65,531 | 31,641 |
| Counter | 8721 | 4423 | 33,539 | 679 |
| Alternative | 3563 | 20 | 8188 | 9427 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Araque, Ó.; Sánchez-Rada, J.F.; Carrera, Á.; Iglesias, C.Á.; Tardío, J.; García-Grao, G.; Musolino, S.; Antonelli, F. Making Sense of Language Signals for Monitoring Radicalization. Appl. Sci. 2022, 12, 8413. https://doi.org/10.3390/app12178413
Araque Ó, Sánchez-Rada JF, Carrera Á, Iglesias CÁ, Tardío J, García-Grao G, Musolino S, Antonelli F. Making Sense of Language Signals for Monitoring Radicalization. Applied Sciences. 2022; 12(17):8413. https://doi.org/10.3390/app12178413
Chicago/Turabian StyleAraque, Óscar, J. Fernando Sánchez-Rada, Álvaro Carrera, Carlos Á. Iglesias, Jorge Tardío, Guillermo García-Grao, Santina Musolino, and Francesco Antonelli. 2022. "Making Sense of Language Signals for Monitoring Radicalization" Applied Sciences 12, no. 17: 8413. https://doi.org/10.3390/app12178413
APA StyleAraque, Ó., Sánchez-Rada, J. F., Carrera, Á., Iglesias, C. Á., Tardío, J., García-Grao, G., Musolino, S., & Antonelli, F. (2022). Making Sense of Language Signals for Monitoring Radicalization. Applied Sciences, 12(17), 8413. https://doi.org/10.3390/app12178413