1. Introduction
Customers are considered significant entities for any company in an industry full of vibrant and challenging businesses. In a competitive industry, when customers have multiple service providers to choose from, they may quickly switch services or even suppliers [
1]. This switch (customer churn) may be caused by unhappiness, rising costs, poor quality, a lack of features, or privacy issues [
2]. Several companies across different sectors, including banking services, airline services, and telecommunications, are directly affected by customer churning [
3,
4,
5,
6]. These companies increasingly focus on creating and sustaining long-term connections with their current customers. This tendency has been observed in the telecommunications sector.
Inarguably, continuous expansion and advancement in the telecommunications sector significantly boosted the range of companies in the sector, increasing competition [
7]. In other words, the telecommunications sector is experiencing significant customer churn due to tough competition, crowded markets, a dynamic environment, and the introduction of new and tempting packages. In this rapidly changing sector, it has become necessary to optimize earnings regularly, for which numerous tactics, such as bringing in new customers, up-selling current customers, and extending the retention time of existing customers, have been advocated. However, as has been observed from existing studies and reports, obtaining new customers might be more costly for businesses than retaining current customers. Predicting the probability of customer churning is fundamental to finding remedies to this issue [
8,
9,
10]. A major key purpose of Customer Churn Prediction (CCP) is to aid the creation of strategies for retaining customers that increase business revenue and industrial recognition. Nonetheless, companies in the Telecommunications sector now hold a wealth of information about their clients, such as call logs (domestic and international), short messages, voicemail messages, profiles, financial information, and other important details. This information is strategic and crucial for predicting which customers are at the point of churning. Companies must accurately predict the customer’s behavior before it happens [
11,
12].
There are two approaches to managing customer churn: (1) reactively and (2) proactively. In the reactive mode, the organization anticipates the consumer to terminate before offering enticing retention incentives. However, under the proactive method, the probability of churn is foreseen, and appropriate incentives are presented to consumers. Described in another way, the proactive approach is regarded as a binary classification problem wherein churners and non-churners are differentiated [
1,
13].
Several approaches, including rule-based and machine learning (ML)-based solutions, have been developed to address CCP. However, the lack of scalability and robustness of rule-based CCP models is a significant disadvantage [
14,
15]. In the case of the ML-based models in CCP, several methods have been developed with relative success. This is due to the disproportionate structure of churn datasets which has a derogatory effect on the effectiveness of typical ML approaches in CCP [
16,
17]. That is, it is critical to utilize clean and well-structured datasets in CCP as the performance of ML techniques is heavily reliant on the dataset’s characteristics. In other words, the frequency of class labels in a dataset is crucial for developing effective ML models. In practice, the distribution of class labels is uneven and, in several instances, significantly biased. This intrinsic inclination is referred to as the class imbalance problem [
18,
19].
The class imbalance issue happens when there is a significant disparity in the class labels (Majority and Minority). The inadequately distributed class labels make ML model generation difficult and, in most cases, inaccurate [
20,
21]. Consequently, CCP exhibits the class imbalance problem since there are more instances of non-churners (majority) than churners (minority). It is imperative to develop effective ML-based CCP models to accommodate the class imbalance problem [
15,
17].
This study pays close attention to class imbalance while developing ML-based CCP models with high prediction performance. Intelligent decision forest (DF) models such as Logistic Model Tree (LMT), Random Forest (RF), Functional Tree (FT), and enhanced variations of LMT, RF, and FT based on weighted soft voting and stacking ensembles are utilized for CCP. DF models generate extremely efficient decision trees (DTs) utilizing the prowess of all attributes in a dataset based on the diversity of tree models and predictive performance. This characteristic of DF is contrary to conventional DTs that utilize only a portion of the attributes [
22]. LMT as a DF method combines logistic regression (LR), and DT induction approaches into a distinct model component. The crux of LMT is introducing an LR function at the leaf nodes by gradually improving superior leaf nodes on the tree. Similarly, FT results from the functional induction of multivariate DTs and discriminant functions. That is, FT uses positive induction to hybridize a DT with a linear function, creating a DT with multivariate decision nodes and leaf nodes that employ discriminant functions to make predictions. Also, RF as a DF model is the collection of unrelated trees working together as a group (forest). RF creates subsets of data attributes that are used to create trees and then subsequently merged.
Furthermore, enhanced DF models based on weighted soft voting and stacking ensemble techniques are proposed. In this context, the weighted soft voting ensemble considers the probability value of each DF model in predicting the appropriate class label, while the stacking ensemble method takes advantage of the efficacy of multiple DF models. Our choice of weighted soft voting and stacking ensemble methods over other ensemble methods (hard voting, multischeme, dagging, bagging, and boosting) is based on their ability to handle uncertainty in the generated probability point and final decision process. These ensemble methods are suggested to augment the prediction performances of DF models to generate robust and generalizable CCP models. In addition, the synthetic minority over-sampling technique (SMOTE) is deployed as a viable solution to resolve the latent class imbalance problem in customer churn datasets.
The primary goal of this study is to investigate the effectiveness of DF models (LMT, RF, FT, and their enhanced ensemble variants) for CCP with the occurrence of the class imbalance problem.
The following is a summary of the primary accomplishment of this study:
To empirically examine the effectiveness of DF models (LMT, RF, FT) on both balanced and imbalanced CCP datasets.
To develop enhanced ensemble variants of DF models (LMT, RF, FT) based on weighted soft voting and stacking ensemble methods.
To empirically evaluate and compare DF models (LMT, RF, FT) and their enhanced ensemble variants with existing CCP models.
Additionally, the following research questions (RQs) are being addressed in this study:
How efficient are the investigated DF models (LMT, FT, and RF) in CCP compared with prominent ML classifiers?
How efficient are the DF models’ enhanced ensemble variations in CCP?
How do the suggested DF models and their ensemble variations compare to existing state-of-the-art CCP solutions?
The rest of the paper is structured as follows.
Section 2 provides an in-depth examination of current CCP solutions.
Section 3 describes the experimental framework and focuses on the proposed solutions.
Section 4 discusses the research observations in depth, and
Section 5 ends the study.
2. Related Works
This section investigates and examines existing CCP solutions that employ different ML-based algorithms.
CCP solutions based on ML algorithms have received much attention in the literature. Several studies in this field have employed baseline ML classifiers for CCP. Brandusoiu and Toderean [
23] implemented a support vector machine (SVM) utilizing four distinct kernel functions (Linear Kernel, Polynomial Kernel, Radial Basis Function (RBF) Kernel, and Sigmoid Kernel) for CCP. Findings from their results showed that SVM based on the Polynomial kernel had the best prediction performance. However, only one SVM and its variants were considered. The effectiveness of the implemented SVMs was not examined with other baseline ML methods. In another similar study, Hossain and Miah [
24] investigated the suitability of SVM for CCP but on a private dataset. Although more kernel functions were investigated in this case, SVM based on linear kernel had the best performance. Also, Mohammad, et al. [
25] explored the deployment of an Artificial Neural Network (ANN), LR, and RF for CCP. They reported that LR had superior performance compared to ANN and RF. Kirui, et al. [
26] deployed Bayesian-based models for CCP. Specifically, Naïve Bayes (NB) and Bayesian Network (BN) were used for CCP. New features were generated based on call details, and customer profiles were used to train NB and BN. From the experimental results, the performance of NB and BN were superior when compared with Decision Tree (DT). Also, Abbasimehr, et al. [
27] compared the performance of ANFIS as a Neuro-Fuzzy classifier with DT and RIPPER for CCP. The experimental results revealed that the performance of ANFIS was comparable to that of DT and RIPPER and produced fewer rules. Despite the successes of baseline ML classifiers, the problem of parameter tuning and optimization (SVM, LR, ANN, BN) is a major drawback.
To enhance the performances of baseline ML models in CCP, some studies introduced feature selection (FS) processes to select relevant features for CCP. Arowolo, Abdulsalam, Saheed and Afolayan [
2] combined the RelieFf FS method with Classification and Regression Trees (CART) and ANN for CCP. Zhang, et al. [
28] used features selected by the Affinity Propagation (AP) method on RF for CCP. Lalwani, Mishra, Chadha and Sethi [
1], in their study, deployed a gravitational search algorithm for the FS method and subsequently trained some baseline classifiers such as LR, SVM, DT, and NB for CCP. Also, Brânduşoiu, Toderean and Beleiu [
8] applied Principal Component Analysis (PCA) for dimensionality reduction with SVM, BN and ANN. It was observed that the deployed PCA positively enhanced the prediction performances of the experimented models. However, selecting an appropriate FS method for CCP could lead to another problem such as a filter rank selection problem. In addition, some of the applied FS methods such as PCA tend to give the features another representation which is often not appropriate.
Some current studies focused on the use of deep learning (DL) approaches like Deep Neural Network (DNN), Stacked Auto-Encoders (SAE), Recurrent Neural Network (RNN), Deep Belief Network (DBN), and Convolution Neural Network [
4,
9,
15,
29,
30,
31,
32]. Wael Fujo, Subramanian and Ahmad Khder [
15] developed a Deep-BP-ANN method for CCP. In the proposed method, two FS methods (Lasso Regularization (Lasso) and Variance Thresholding methods) select relevant and irredundant features. Thereafter, the Random Over-Sampling method is deployed to address the class imbalance problem. Deep-BP-ANN is developed based on diverse hyperparameter methods such as Early Stopping (ES), Model Checkpoint (MC), and Activity Regularization (AR) techniques. Observation from their results showed the increased effectiveness of Deep-BP-ANN over existing methods such as LR, NB, k Nearest Neighbour (kNN), ANN, CNN, and Lion Fuzzy Neural Network (LFNN) based on its selection of optimum features, epochs, and the number of neurons. Karanovic, Popovac, Sladojevic, Arsenovic and Stefanovic [
29] highlighted the suitability of CNN for CCP. The suggested CNN had an accuracy of 98% over Multi-Layer Perceptron (MLP). A similar finding was reported by Agrawal, et al. [
33] when they deployed CNN for CCP. Also, Cao, Liu, Chen and Zhu [
9] utilized SAE for features extraction and LR for CCP. Specifically, SAE is pretrained with its parameters tuned based on Backward Propagation (BP), and then the extracted features are classified by LR. It was observed that the suggested method had a comparable CCP performance. However, there is still room for improvement, particularly in parameter settings. Despite studies indicating that DL approaches are gaining attention and, in some situations, outperforming standard ML methods, the concerns of the system (hardware) reliability and hyper-parameter tweaking are some of its significant constraints.
In addition, substantial initiatives have been proposed to boost the efficacy of the baseline ML classifiers via ensemble techniques. Shabankareh, et al. [
34] proposed stacked ensemble methods using DT, chi-square automatic interaction detection (CHAID), MLP, and kNN with SVM in pairs. The experimental results indicated that the suggested stack ensembles are superior in performance to the individual DT, CHAID, MLP, kNN, and SVM. Mishra and Reddy [
10] compared the performance of selected ensemble methods with baseline classifiers such as SVM, NB, DT, and ANN. Their findings supported the ensemble methods over selected classifiers in terms of performance. Xu, et al. [
35] deployed stacking and voting ensemble methods on CCP. Initially, a feature grouping operation based on an equidistant measure was deployed by the authors to extend the sample space and reveal hidden data details. The suggested ensemble method was based on DT, LR, and NB. Reports from their study further support the effectiveness of ensemble methods over single classifiers in CCP. Saghir, et al. [
36] implemented ensemble-based NN approaches for CCP. The Bagging, Adaboost, and Majority Voting ensemble methods were developed based on MLP, ANN, and CNN. As observed in their results, in most cases the ensemble-based NN methods are superior to their counterparts. Although the effectiveness of the proposed methods was not correlated with conventional ML methods, the ensemble-based NN approach performed relatively well. In another context, Bilal, et al. [
37] successfully combined clustering algorithms and classification algorithms for CCP. Specifically, four different clustering methods, k-means, x-means, k-medoids, and random clustering, were combined with seven classifiers (kNN, DT, Gradient Boosted Tree (GBT), RF, MLP, NB, and kernel-based NB) based on boosting, bagging, stacking and majority voting. Aside from the ensemble methods being superior, it was also observed that the classification algorithms were better than the clustering algorithms even though the clustering techniques do not have to train any model. Nonetheless, although ensemble approaches have been proposed to accommodate imbalanced datasets, they are not considered a feasible solution to the class imbalance problem.
Summarily, numerous CCP models and methods have been suggested, ranging from conventional baseline ML models to advanced methods based on DL, ensemble, and neuro-fuzzy approaches (See
Table 1). However, developing new methodologies for CCP is an ongoing research project due to its significance in business research and development, particularly in customer relationship management (CRM). In addition, reports from previous studies have indicated that the class imbalance problem can affect the efficacy of ML-based CCP solutions. Hence, this research presents DF models and their ensemble-based variants for CCP.
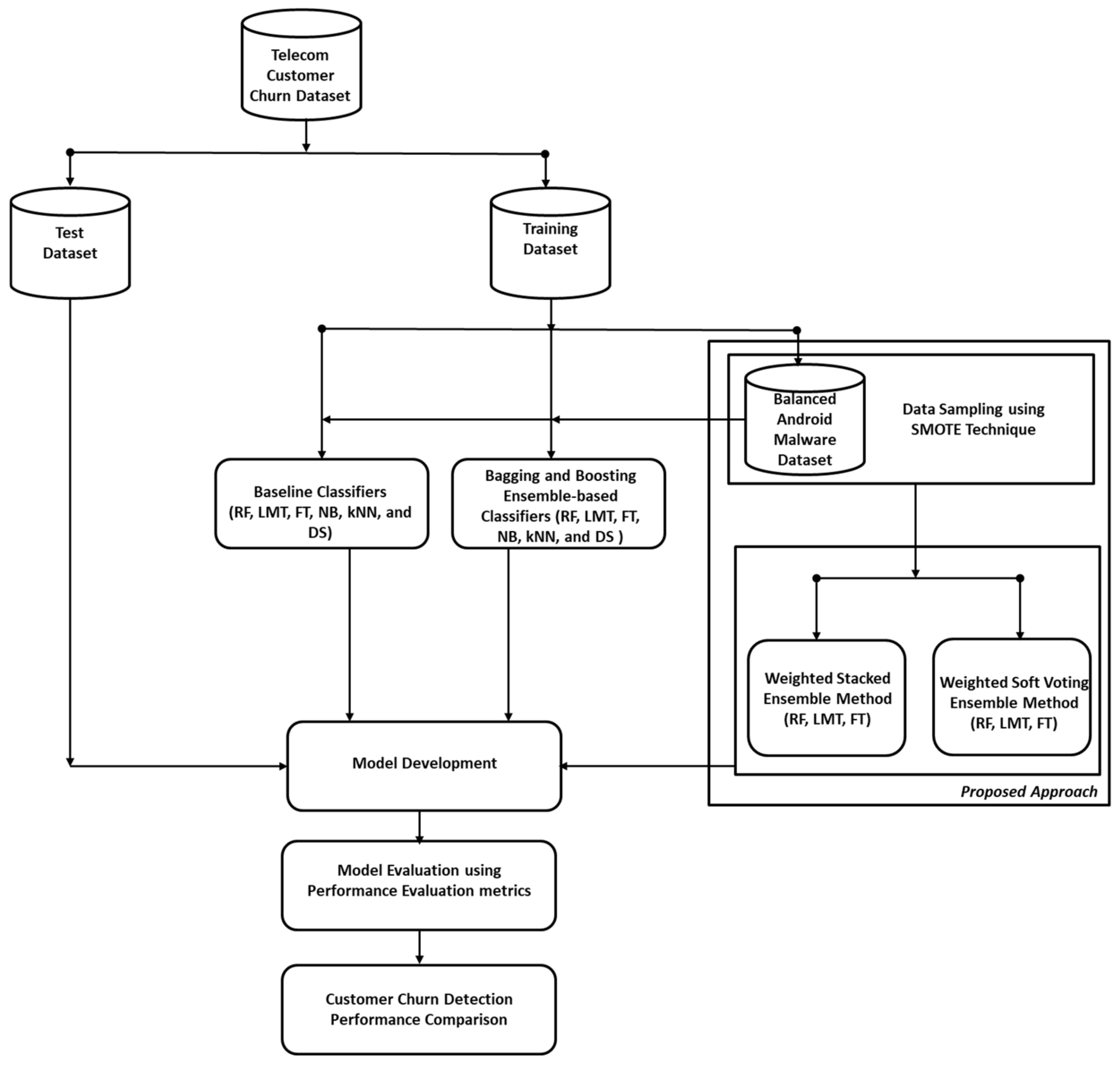
4. Results and Discussion
In this section, results and findings obtained from the experimental procedure shown in
Section 3.3 are presented and analyzed. The effectiveness of the CCP models will be discussed based on their respective prediction performances with or without the class imbalance problem. That is, the efficacies of the CCP models studied on both original and balanced (SMOTE) CCP datasets will be investigated.
Table 3 and
Table 4 present the comparison of CCP performances of DF models (LMT, FT, and RF) against ML classifiers (NB, kNN, and DS) on the original Datasets 1 and 2. The selected ML classifiers were chosen based on their prediction performances in ML tasks and distinct computational properties. In addition,
Table 5 and
Table 6 show the CCP performance of the DF models with the ML classifiers on SMOTE-balanced Dataset 1 and Dataset 2. The data sampling method (SMOTE) was deployed to address the inherent class imbalance problem in CCP datasets. In addition, the deployment of balanced datasets on the CCP models will indicate the impact of data sampling on CCP models. To develop effective CCP models, enhanced ensemble variants of the DT models (WSVEDFM and WSEDFM) were deployed on the original and balanced versions of Dataset 1 and Dataset 2. Specifically,
Table 7,
Table 8,
Table 9 and
Table 10 present the CCP performances of each of the DF models and their enhanced ensemble variants on the original and balanced studied customer churn datasets respectively. This analysis will show how the different DF models can work with imbalanced and balanced datasets. For a fair comparison, the CCP performances of DF models are further compared with renowned ensemble methods such as Bagging and Boosting. Finally, the CCP performances of the high-performing DF models are contrasted with current state-of-the-art CCP models. Consequently, the experimental results are aided by graphical representations to demonstrate the relevance of the observed experimental findings.
4.1. CCP Performance Comparison of the DF Models and ML Classifiers
In this section, the CCP performance of LMT, FT, and RF as DF models are compared with the ML classifiers on original and SMOTE-balanced Dataset 1 and Dataset 2 as outlined in
Section 3.3 (Phase 1).
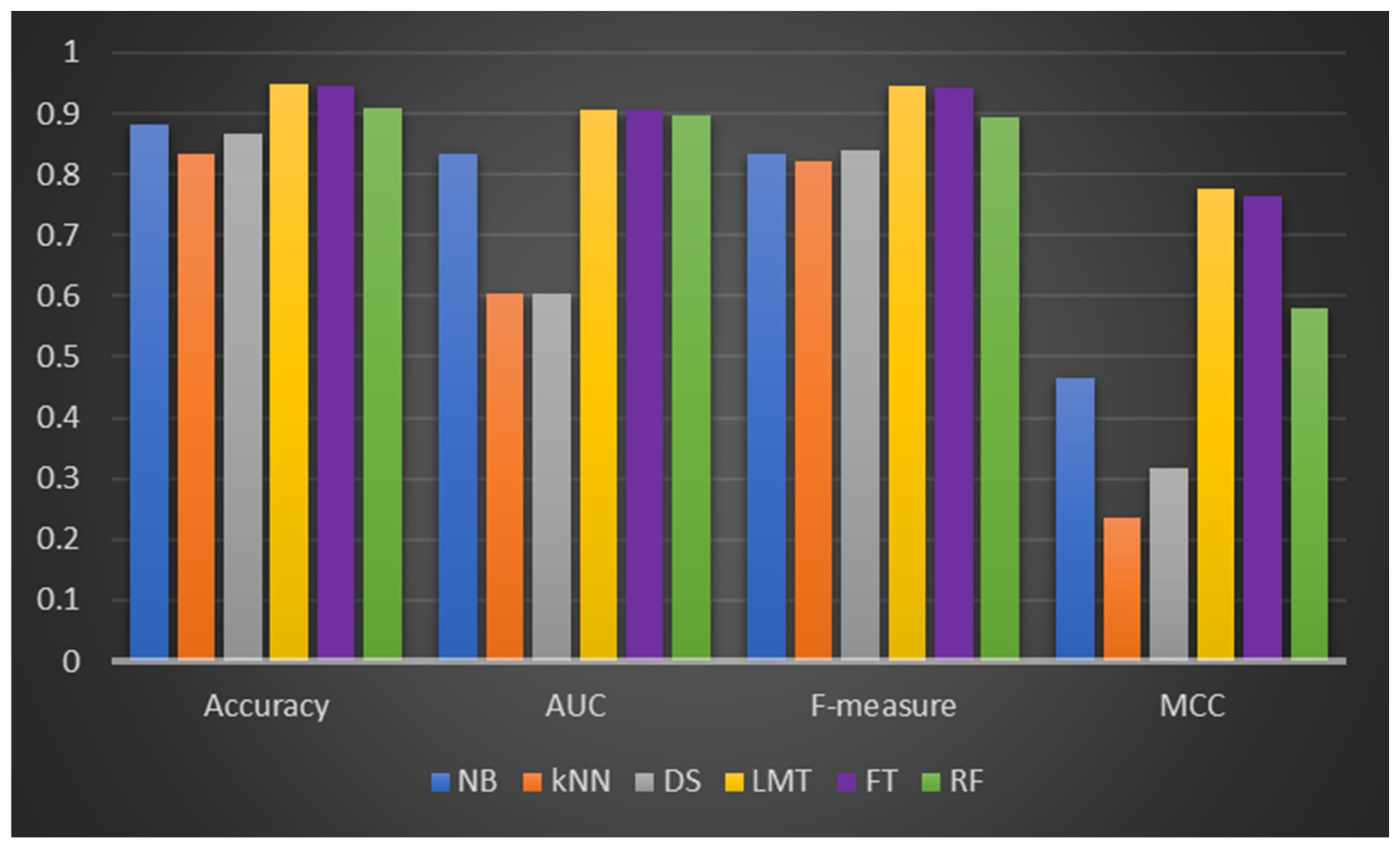
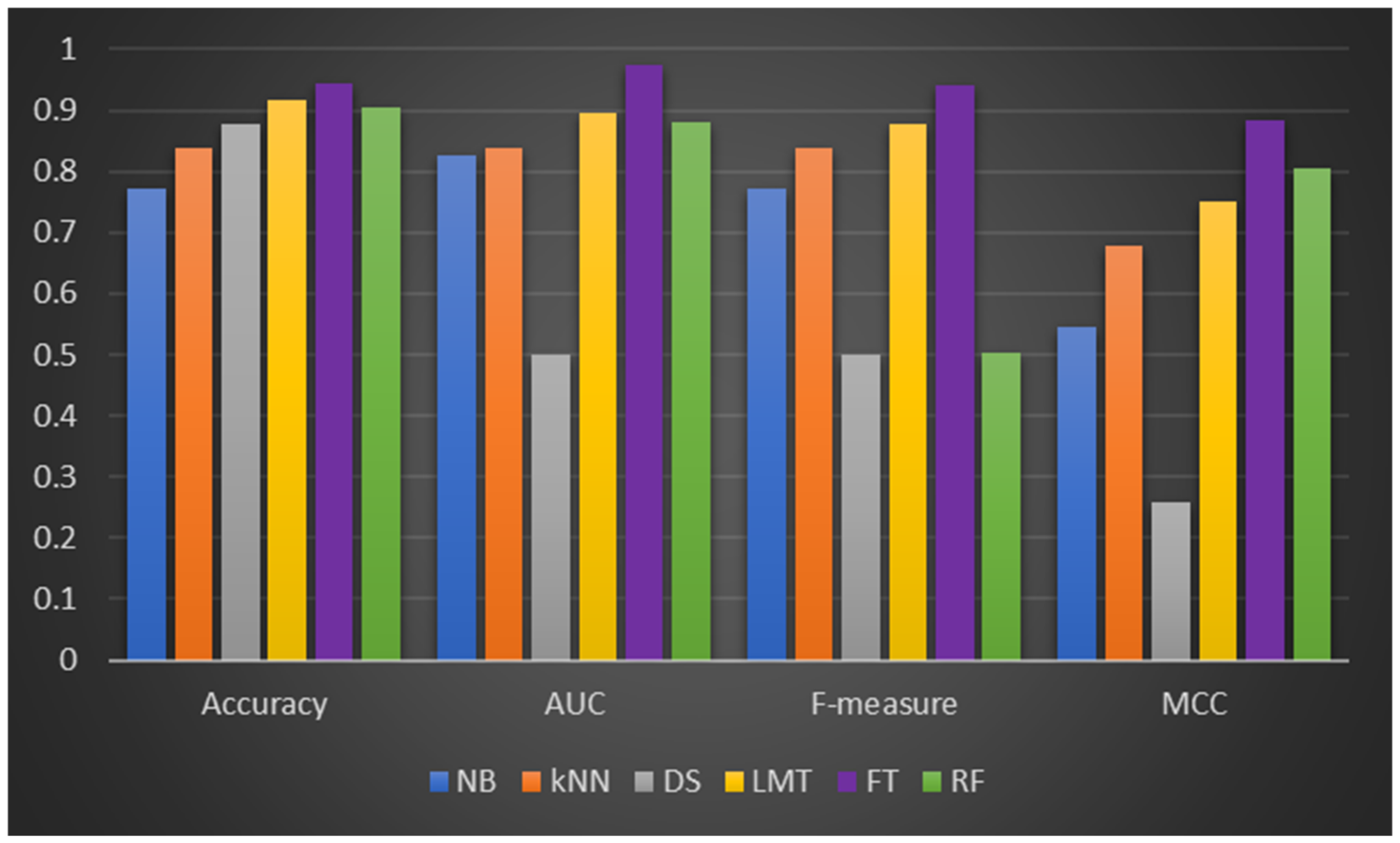
Table 3 illustrates the CCP performances of LMT, FT, and RF and the selected ML classifiers (NB, kNN, and DS) on Dataset 1 (Kaggle Dataset). It can be observed that the DF models were superior in prediction performances when compared to the experimented ML classifiers based on the studied performance metrics. Concerning accuracy values, LMT recorded the highest of 94.75% amongst the DF models, followed by FT and RF, respectively. As for the ML classifiers, NB performed best with 88.24% prediction accuracy. However, LMT, FT, and RF had +7.38, +7.0, and +3.09% accuracy increments compared to NB. The LMT, FT, and RF’s superior prediction accuracy values over NB, kNN, and DS, even on an imbalanced Dataset 1, highlights their resilience and usefulness for CCP. A similar occurrence can be observed regarding AUC values as the duo of LMT and FT both had the highest AUC values of 0.905 while RF had 0.896. The AUC values of these DF models were superior to that of NB (0.834), kNN (0.603), and DS (0.603). Also, the DF models obtained a strong ratio of sensitivity and recall, with LMT and FT having f-measure values of 0.945 and 00942, respectively. It is worth noting that the ML classifiers also had comparable f-measures, but they were still lower than those of the DF models. This observation confirms the performance stability of the DF models in CCP compared to experimented ML classifiers. In the case of the MCC values, the performances of the DF models are notably comparable, as LMT (0.777) was slightly better than FT (0.763). The other ML classifier had lower MCC values which indicate no conformity between the predicted and observed values.
Figure 2 illustrates a graphical depiction of the CCP of the experimented models.
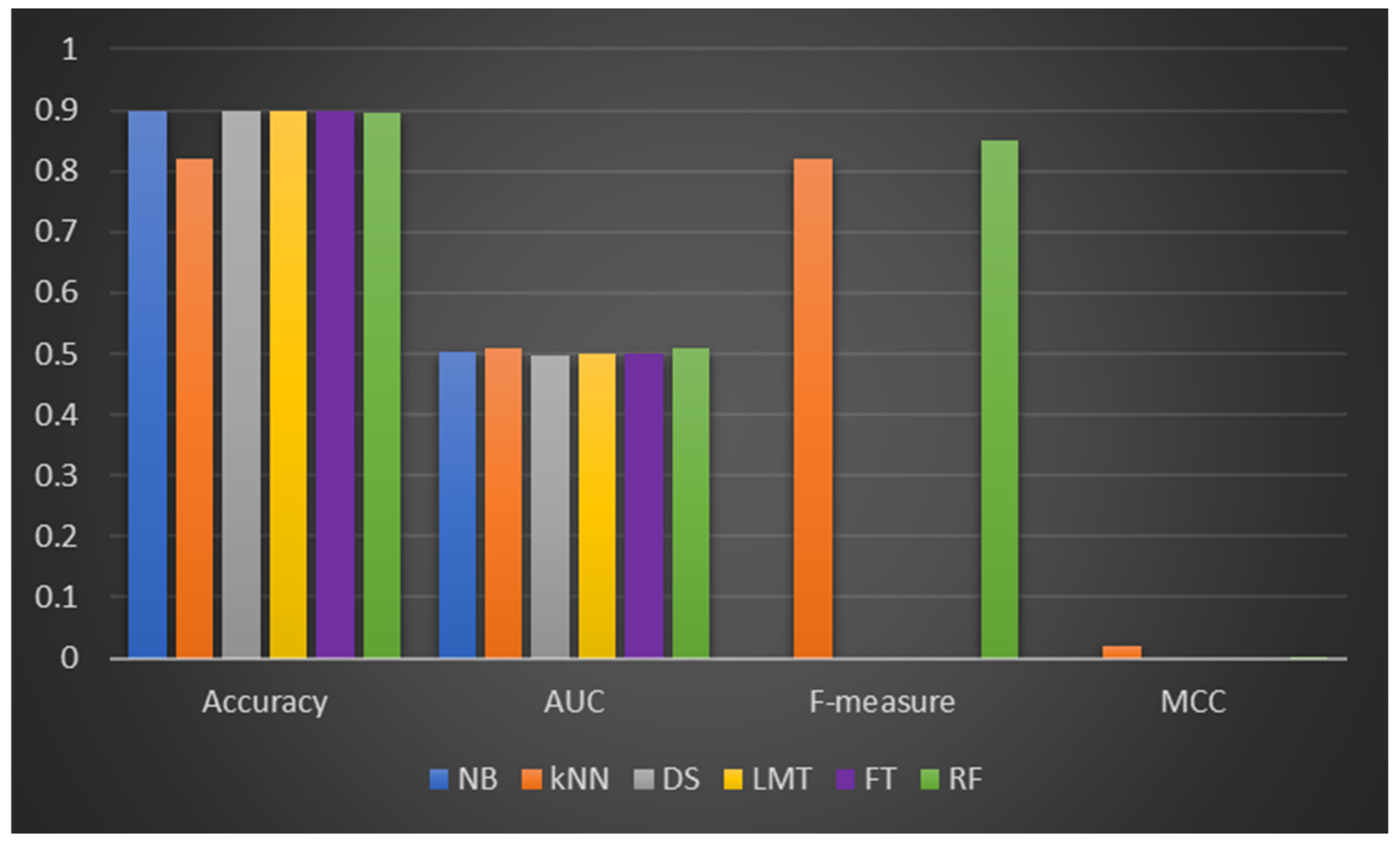
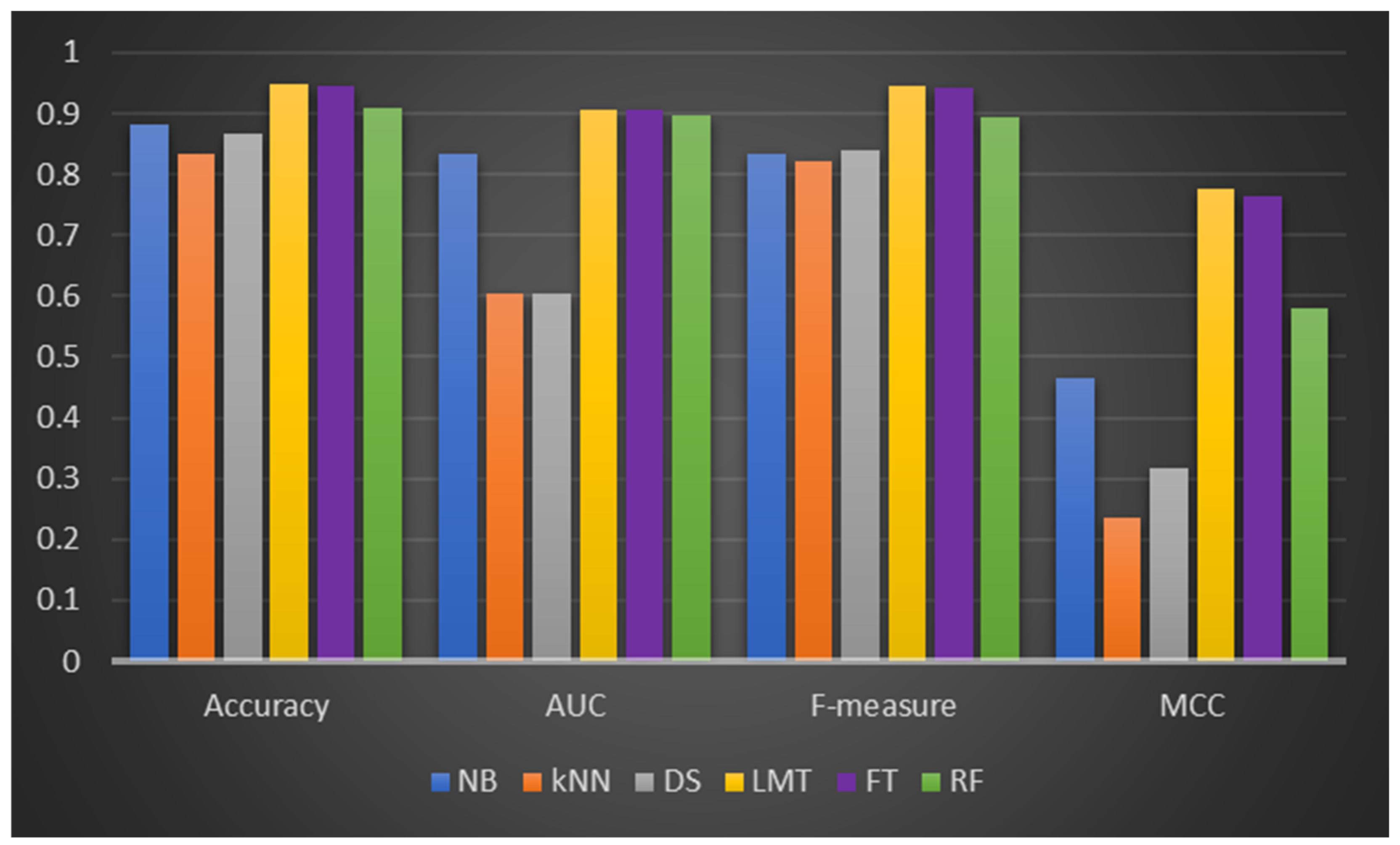
From Dataset 2 (presented in
Table 4), the DF models had comparable performance to the ML classifiers in terms of accuracy, AUC, f-measure, and MCC values. It was also discovered that the DF model experimental results on Dataset 2 are somewhat lower than those of Dataset 1. LMT, FT, and NB had similar prediction accuracy values (89.86%), and their respective AUC values are average (LMT: 0.5, FT: 0.5, NB: 0.503). Also, it can be observed that the f-measure and MCC values of some of the implemented models (NB, DS, LMT, and FT) are missing, and some models recorded poor performance based on f-measure and MCC values. This observation can be attributed to the nature and data quality of Dataset 2. That is, the presence of class imbalance (as indicated in
Table 2) (IR of 8.86) had a derogatory effect on the implemented DF and ML models.
Figure 3 depicts DF’s and the ML classifiers’ CPP performances.
Based on the relative prediction performances of the DF models, which may have been affected by the latent class imbalance problem, the IR values for Dataset 1 and Dataset 2 are 5.9 and 8.86, respectively (See
Table 2). Hence, this research work explored the prediction performances of the DF models and ML classifiers on balanced (SMOTE) CCP datasets. It is worth noting that the purpose of the SMOTE data sampling method is to eliminate the class imbalance issue as identified in Dataset 1 and Dataset 2 (See
Table 2). Besides, the choice of SMOTE technique is due to its reported effectiveness and frequent deployment in current research. Specifically,
Table 5 and
Table 6 show the experimental results of DF models and ML classifiers on the balanced (SMOTE) Dataset 1 and Dataset 2, respectively.
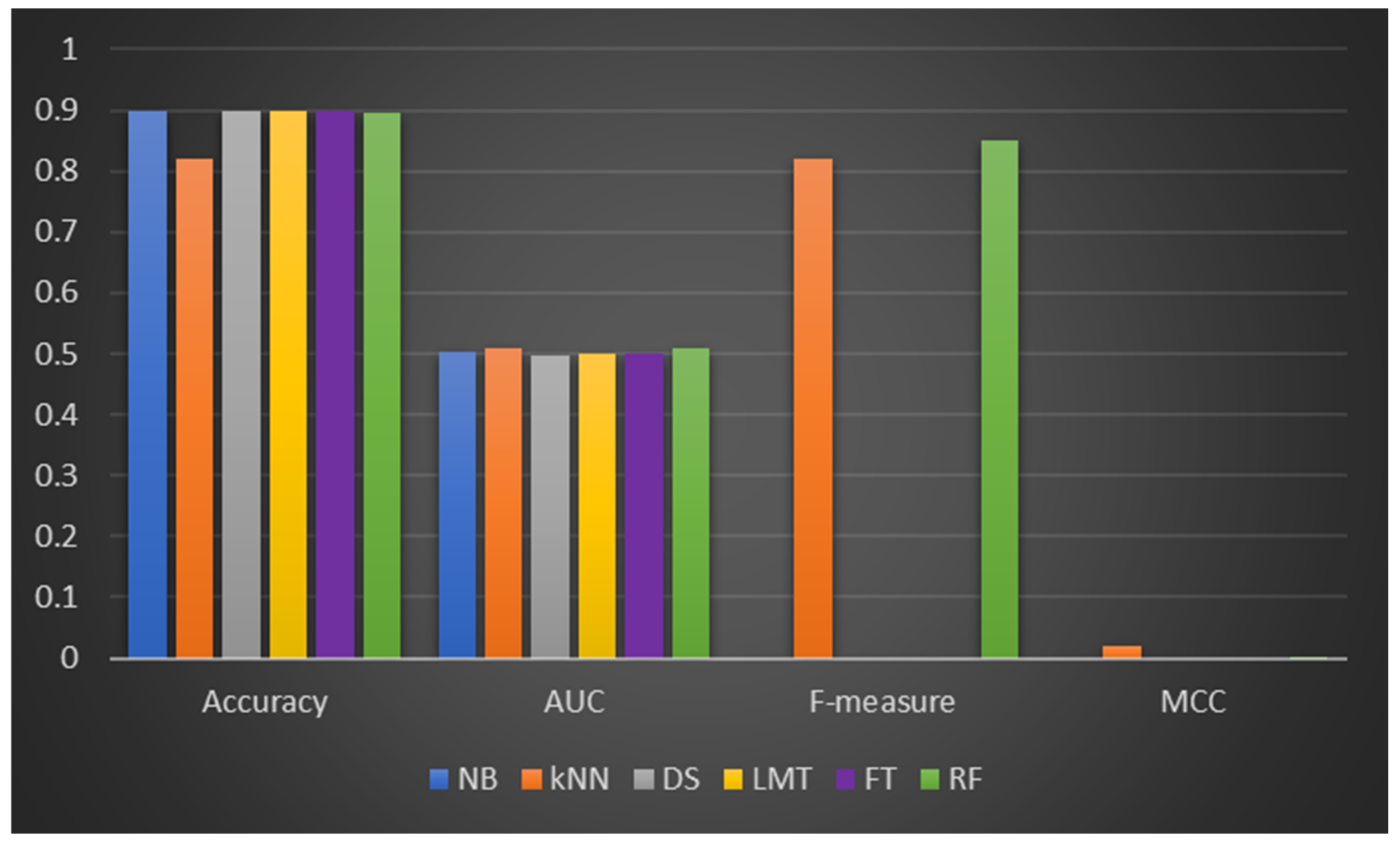
As seen in
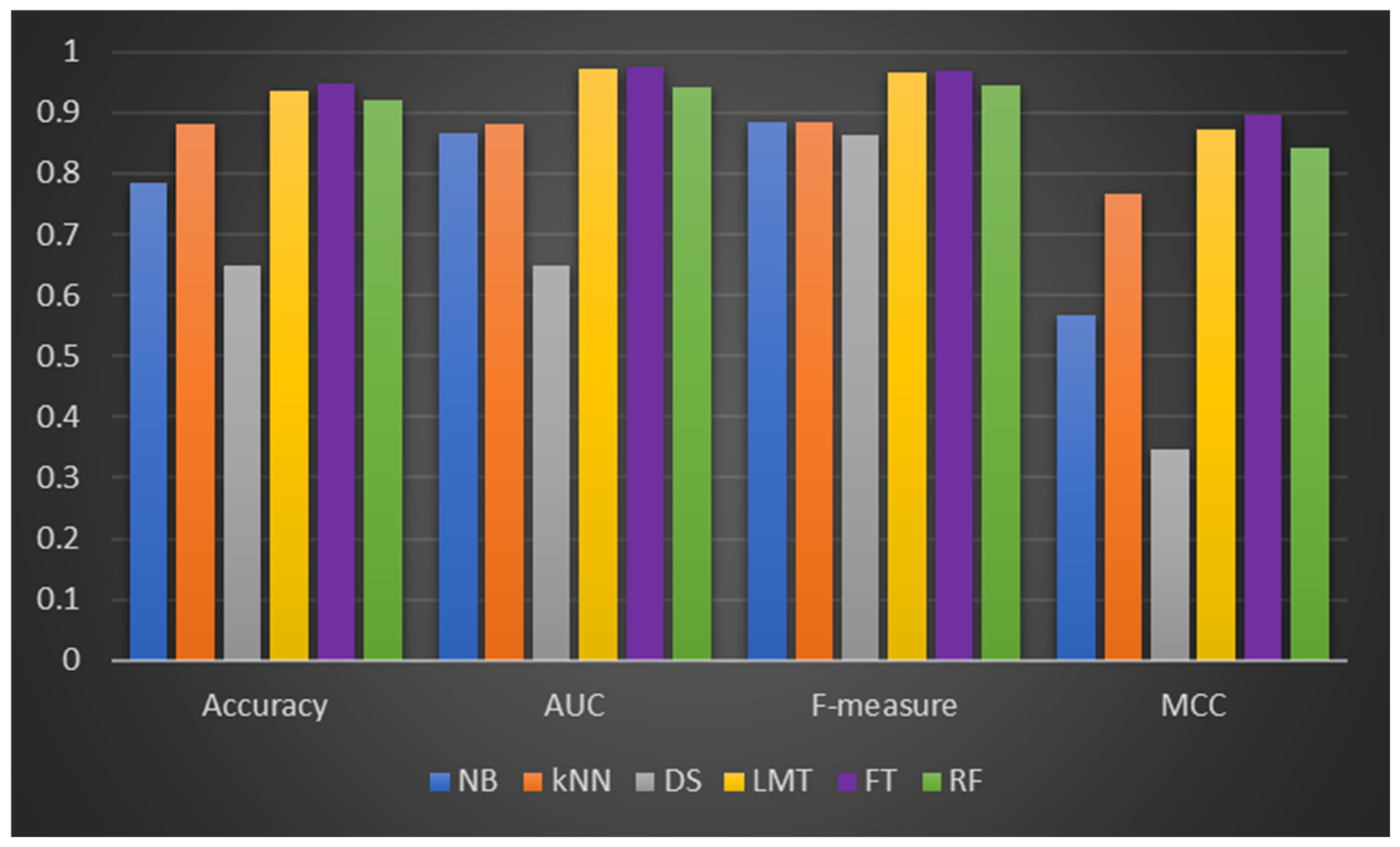
Table 5, the DF models (LMT, FT, and RF) are still superior to the ML classifiers (NB, kNN, and DS) on all performance parameters tested. FT and RF have a prediction accuracy of 94.83% and 92.14%, which are (+0.43%, +1.29%) better than FT and RF on original Dataset 1. Similar trends were observed in the performance of the DF models with AUC and MCC values. For instance, significant increments were observed in the AUC values of LMT (+7.3%), FT (+7.73%), and RF (+5.25%) on the balanced dataset compared with the original Dataset 1. Also, it was discovered that the ML classifiers had improved prediction performances based on AUC and MCC values. Specifically, the highest improvements in AUC values were attained by kNN (+46.1%) and DS (+7.79%). In addition, there was a notable increase in MCC value in NB (+21.9%), kNN (+223%), and DS (+9.15%). In terms of f-measure values, kNN (+7.55%) improved the most, followed by NB (+5.88%) and DS (+2.61%) in that order. However, in terms of the accuracy values, NB (−11.23%) and DS (−22.78%) had negative improvements, which may be due to the model overfitting observed in their respective CCP on the original dataset. This finding further affirms the importance of not using the accuracy value as the only performance metric since it does not represent the performance of an ML model adequately. On the SMOTE-balanced Dataset 1, the CCP performance of the DF models and the ML classifiers improved generally, but the DF models still achieved the highest overall performance. This finding could be related to deploying the data sampling (SMOTE) method to address the class imbalance issue in Dataset 1.
Figure 4 depicts the performance of DF models and ML classifiers on CCP performance on the balanced Dataset 1.
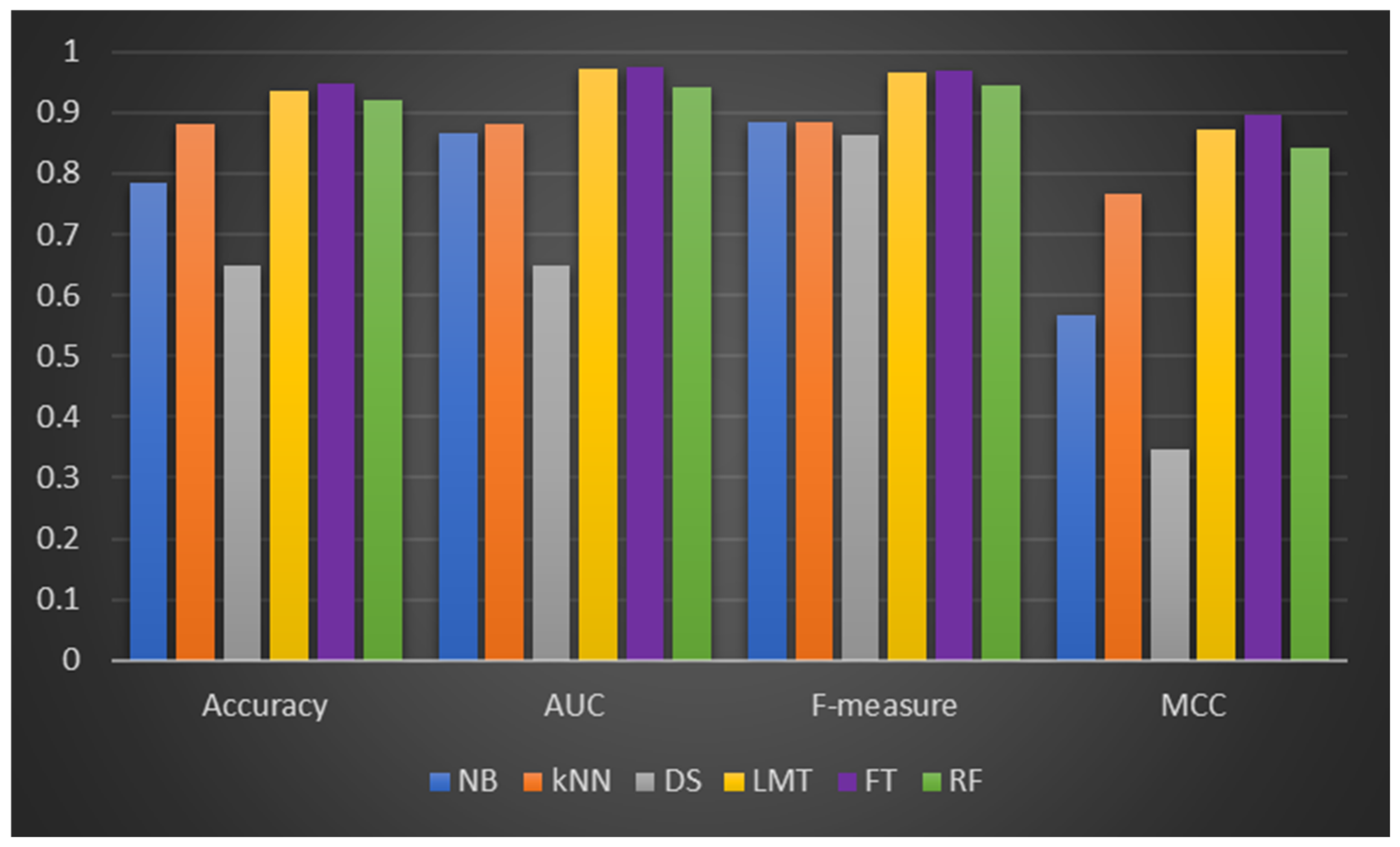
Additionally,
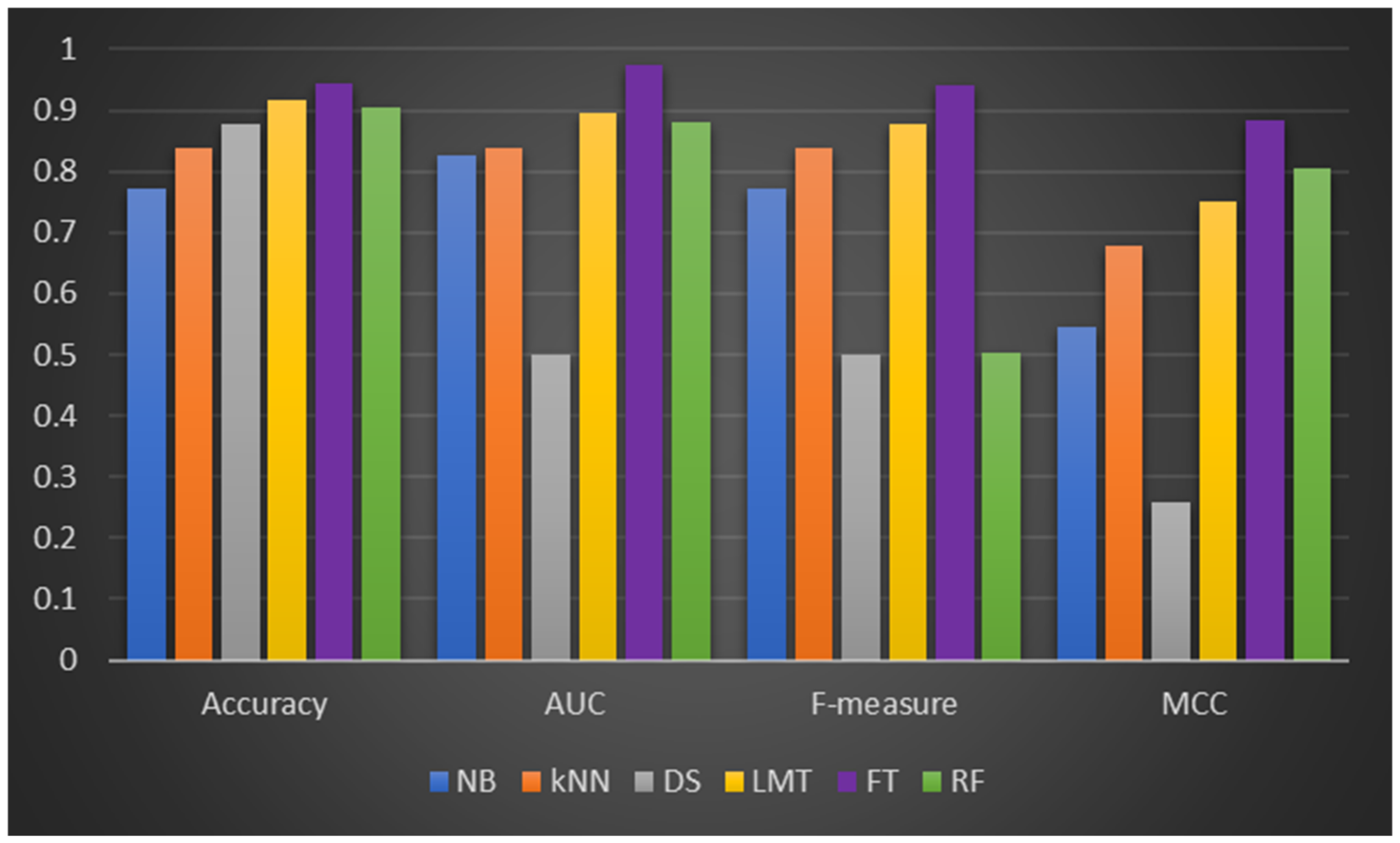
Table 6 displays the experimental results of the DF models and ML classifiers on balanced Dataset 2. The DF models still produced the best CCP performance based on all performance criteria analyzed. Balanced Dataset 1 showed a similar outcome to the experimental findings on balanced Dataset 2. That is, the DF models and the ML classifiers improved their CCP performance. As indicated in
Table 6, FT (+4.89%), LMT (+1.63%), and RF (+0.93%) outperformed their respective CCP capabilities on the original Dataset 2. In terms of AUC values, the DF models (LMT (+79.2%), FT (+94.6%), and RF (+73.23%)) all showed significant improvement. The analysis based on the f-measure metric yielded similar results. Except for RF, the f-measure values of LMT, FT, and the ML classifiers improved. In terms of the MCC measure, the DF models showed significant incremental improvements in their respective MCC values, which showed a strong relationship between the observed and predicted outcome. Other ML classifiers (NB, kNN, and DS) also showed comparable MCC values.
Figure 5 depicts the DF models and ML classifiers’ CCP performance on the balanced Dataset 2.
The following observations were noticed based on the preceding experimental results assessments on studied CCP datasets:
The DF models (LMT, FT, and RF) outperformed the ML classifiers (NB, kNN, and DS) in CCP. It is worth noting that the experiment ML classifiers were chosen based on their use and performance in current CCP studies and ML tasks.
The use of the SMOTE data sampling approach not only solved the class imbalance issue but also enhanced the CCP performances of the DF models and ML classifiers.
The DF models can predict customer churn effectively with or without a data sampling strategy.
These experimental findings verify and substantiate using DF models (LMT, FT, and RF) for CCP. DF models enhanced ensemble variants (WSVEDFM and WSEDFM), on the other hand, were created to improve the DF models CCP performance.
Section 4.2 presents and discusses the empirical assessment of experimental outcomes of WSVEDFM and WSEDFM methods.
4.2. CCP Performance Comparison of DF Models and Their Enhanced Ensemble Variants (WSVEDFM and WSEDFM)
This section compared the CCP performances of the DF models with their enhanced ensemble variants on the original and balanced CCP datasets. Specifically,
Table 7 and
Table 8 display the experimental results based on the original Dataset 1 and Dataset 2, while
Table 9 and
Table 10 show the results on balanced Dataset 1 and Dataset 2 as outlined in
Section 3.3 (Phase 2).
Table 7 and
Table 8 display the detection performances of LMT, FT, RF, WSVEDFM, and WSEDFM on original Dataset 1 and Dataset 2. On Dataset 1 (
Table 7), both WSVEDFM and WSEDFM outperformed the DF models. WSVEDFM recorded a prediction accuracy value of 95.81%, an AUC value of 0.951, an f-measure value of 0.958, and an MCC value of 0.879. Likewise, WSEDFM showed a similar prediction accuracy value of 95.53%, an AUC value of 0.948, an f-measure value of 0.955, and an MCC value of 0.865. Significantly, the AUC value of 0.951 and 0.948 achieved by WSVEDFM and WSEDFM, respectively, demonstrate the efficacy of the two models (WSVEDFM and WSEDFM) in distinguishing churners from non-churners with a high degree of certainty. Similarly, relatively high MCC values achieved by WSVEDFM (0.879) and WSEDFM (0.865) indicate a positive correlation between the observed and the predicted CCP outcome. Also, from the experimental results on Dataset 2 (
Table 8), WSVEDFM and WSEDFM were superior to the DF models on studied performance metrics. However, the performances of the models on Dataset 2 were not as effective as the performance on Dataset 1. This concern is due to the inherent data quality issues with Dataset 2. In addition, the CCP performance of LMT, FT, RF, WSVEDFM, and WSEDFM on balanced Dataset 1 and Dataset 2 were analyzed. This contraction is intended to determine the impact of deploying SMOTE data sampling method on the CCP performance of WSVEDFM and WSEDFM methods. That is, to investigate if the CCP performance of WSVEDFM and WSEDFM will be improved on balanced CCP datasets.
Table 9 and
Table 10 show the CCP performances of LMT, FT, RF, WSVEDFM, and WSEDFM on balanced Dataset 1 and Dataset 2.
On the balanced Dataset 1, WSVEDFM and WSEDFM outperformed LMT, FT, and RF, as shown in
Table 9. For instance, WSVEDFM and WSEDFM demonstrated significant increment in prediction accuracy values above LMT (+2.89%), FT (+1.56%) and RF (+4.53%) respectively. Furthermore, WSVEDFM (0.990) and WSEDFM (0.989) demonstrated +1.54% and +1.44% increment in AUC values over FT (0.975) which had the best AUC values from the DF models respectively. Also, there is a significant difference in the MCC values of the WSVEDFM and WSEDFM over the individual DF models. WSVEDFM (0.981) and WSEDFM (0.971) showed +11.1% and +9.97% increment in MCC values over FT (0.883) which also happened to have the best MCCC values from the DF models. A similar trend was also detected in experimental results from the balanced Dataset 2. As shown in
Table 10, WSVEDFM (96.57%) and WSEDFM (96.43%) recorded +2.45% and +2.30% increment in prediction accuracy values over FT (94.26%). Also, the AUC and MCC values of WSVEDFM (96.57%) and WSEDFM (96.43%) are superior to any DF models. Although amongst the DF models (LMT, FT, and RF), FT had the best CCP performance on both balanced Dataset 1 and Dataset 2; however, the DF models CCP performances are still outperformed by their enhanced ensemble variants (WSVEDFM and WSEDFM). Based on the results of the experimental tests reported here, it can be concluded that the upgraded variants (WSVEDFM and WSEDFM), particularly WSVEDFM, are more effective than any of the DF models (LMT, FT, and RF) in CCP tasks.
In addition, for more generalizable results and assessment, the CCP performances of WSVEDFM and WSEDFM methods are compared with prominent ensemble methods such as Bagging and Boosting. Bagging and Boosting ensemble methods have been reported to have a positive impact on its base model by amplifying prediction performance [
65,
66].
Section 4.3 presents a detailed analysis of the comparison of the proposed ensemble methods (WSVEDFM and WSEDFM) with Bagged and Boosted DF models on both original and balanced CCP datasets.
4.3. CCP Performance Comparison of Enhanced DFEnsemble Variants, Bagging and Boosting Ensemble Methods
In this section, further assessment and performance comparisons were conducted to validate the effectiveness of WSVEDFM and WSEDFM for CCP processes. Specifically, the proposed DF ensemble variants were compared with Bagged and Boosted DF models on both original and balanced (SMOTE) Dataset 1 and Dataset 2.
Table 11,
Table 12,
Table 13 and
Table 14 outline the CCP performance and comparison of WSVEDFM and WSEDFM with the Bagged DF and Boosted DF models on original and balanced CCP datasets.
As shown in
Table 10 and
Table 11, the Bagged and Boosted DF models had comparable performances as the WSVEDFM and WSEDFM on Dataset 1 and Dataset 2, respectively. In some cases, the differences in the prediction accuracy and f-measure values of the proposed DF ensemble variants and the Bagged and Boosted DF modes are insignificant. However, the WSVEDFM and WSEDFM are still superior in performance. For instance, WSVEDFM (0.951) and WSEDFM (0.948) had a +3.59% and +3.27% increment in AUC values over Bagged FT (0.918), which had the highest AUC value amongst the Bagged and Boosted DF models. A similar trend was observed with the MCC values with WSVEDFM (0.879) and WSEDFM (0.865), recording a +9.74% and +7.99% over Bagged FT (0.801). Contrary to the findings from
Table 11, the CCP performance of the studied models on Dataset 2, as shown in
Table 12, is relatively good. This could be related to the observed data quality problem (high IR) in Dataset 2. However, on a general note, the WSVEDFM and WSEDFM outperformed the Bagged and Boosted DF models, although the CCP performances of the Bagged DF models are better than the Boosted DF models. This finding can be due to the independent and parallel mode of model development in the Bagging method, which reduces variances amongst its base models and avoids model overfitting. In addition, the CCP performances of WSVEDFM and WSEDFM with Bagged and Boosted DF models on balanced Dataset 1 and Dataset 2 were compared.
Table 13 and
Table 14 display the CCP performances of WSVEDFM, WSEDFM, Bagged DF models, and Boosted DF models on balanced Dataset 1 and Dataset 2, respectively.
As shown in
Table 13 and
Table 14, it can be observed that there are significant improvements in the performances of the WSVEDFM and WSEDFM over the Bagged and Boosted DF models on the balanced Dataset 1 and Dataset 2. Specifically, from
Table 13, WSVEDFM and WSEDFM had a +0.36% increment in prediction accuracy values more than the best performer (Bagged FT) in this case. Also, a +2.29% and +2.94% increment in MCC values of WSVEDFM and WSEDFM over Bagged FT was observed. In the balanced Dataset 2 (See
Table 14), WSVEDFM and WSEDFM had a +7.23% and +7.07% increase in prediction accuracy value over BaggedRF. Based on MCC values, WSVEDFM and WSEDFM achieved +22.47% and +21.22% increment over Bagged RF. From the Bagged and Boosted DF models, BaggedRF had the best performance on balanced Dataset 2.
In summary, based on the observed experimental findings on the analyses of the experimental results of the WSVEDFM, WSEDFM, Bagged DF models, and Boosted DF models on the balanced Dataset 1 and Dataset 2, it is fair to assert that the enhanced DF ensemble variants are more suitable for CCP than the prominent Bagged and Boosted DF models. Nonetheless, the CCP performances of the DF models and their enhanced ensemble variants are compared with existing CCP models in
Section 4.4.
4.4. CCP Performance Comparison of DF Models and Their Enhanced Ensemble Variants with Existing CCP Methods
For comprehensiveness, the CCP performances of the LMT, FT, RF, WSVEDFM, and WSEDFM are compared to those of current CCP solutions.
Table 15 and
Table 16 show the CCP performance of proposed DF models and current CCP solutions on Dataset 1 and Dataset 2, respectively.
As presented in
Table 15, the CCP performance of the DF models and its enhanced ensemble variants are compared with that of Tavassoli and Koosha [
59], Ahmad, Jafar and Aljoumaa [
60], Jain, Khunteta and Shrivastav [
67], Saghir, Bibi, Bashir and Khan [
36], Jain, Khunteta and Srivastava [
68], Jeyakarthic and Venkatesh [
69], Praseeda and Shivakumar [
70], and Dalli [
71] on Dataset 1. These existing CCP models range from ensemble methods to sophisticated DL methods. For instance, Tavassoli and Koosha [
59] developed a hybrid ensemble (BNNGA) method for CCP, which had a prediction accuracy value of 86.81% and an f-measure value of 0.688. Similarly, Saghir, Bibi, Bashir and Khan [
36] deployed a Bagged MLP, while Jain, Khunteta and Srivastava [
68] used a LogitBoost approach for CCP. However, the CCP performances of the DF models and their enhanced ensemble variants are superior to these ensemble-based CCP models in most cases. Using another approach, Ahmad, Jafar and Aljoumaa [
60] combined Social Network Analysis (SNA) and XGBoost for CCP. The SNA was deployed to generate new features for the CCP. Also, Jain, Khunteta and Shrivastav [
67] enhanced CNN with a Variable Auto-Encoder (VAE). Although their AUC value of SNA+XGBoost is quite significant and the prediction accuracy and f-measure of CNN+VAE is above 90%, there CCP performance are still less than that of the proposed methods. Praseeda and Shivakumar [
70] used a probabilistic-based fuzzy local information c-means (PFLICM) for CCP. PFLICM is a clustering based approach and it had a prediction accuracy value of 95.41%. In addition, Dalli [
71] hyper-parameterized DL+RMSProp and Jeyakarthic and Venkatesh [
69] designed an adaptive Gain with Back Propagation Neural Networks (P-AGBPNN) for CCP process. These methods are based on enhanced DL techniques with comparable CCP performance. In summary, the proposed DF models and its enhanced ensemble variants are superior to examined existing CCP models with different computational processes on Dataset 1.
Furthermore,
Table 16 presents the CCP performance comparison of the DF models and their enhanced ensemble variants with CCP solutions of Tavassoli and Koosha [
59], Saghir, Bibi, Bashir and Khan [
36], Shaaban, Helmy, Khedr and Nasr [
62], and Bilal, Almazroi, Bashir, Khan and Almazroi [
37]. These existing CCP solutions were developed with Dataset 2 as utilized in this study. Specifically, Saghir, Bibi, Bashir and Khan [
36] deployed a Bagging ensemble approach for CCP with a prediction accuracy value of 80.80% and an f-measure value of 0.784. Also, Shaaban, Helmy, Khedr and Nasr [
62] used a parameterized SVM for CCP. The relatively low CCP performances of these methods, when compared with the proposed DF methods, could result from the failure to address the class imbalance problem in their respective studies. In addition, Bilal, Almazroi, Bashir, Khan and Almazroi [
37] combined clustering and classification methods for CCP. Specifically, Kmediod was combined with a gradient boosting technique (GBT), and the resulting model is evaluated using diverse ensemble techniques such as Bagging, Stacking, Voting, and Adaboost. While the CCP performance of their method was comparable to the proposed DF models, the high computational complexity of their methods is a concern. Regardless, the DF models and their enhanced ensemble variants are superior to the existing CCP models evaluated on Dataset 2.
4.5. Answers to Research Questions
Based on the investigations, the following findings were obtained to answer the RQs posed in the introduction section.
- RQ1:
How efficient are the investigated DF models (LMT, FT, and RF) in CCP as compared with prominent ML classifiers
The experimental findings showed that the investigated DF models (LMT, FT, and RF) outperformed the prominent ML classifiers in terms of CCP performance. This higher CCP performance was demonstrated on both Dataset 1 and Dataset 2.
- RQ2:
How efficient are the DF models’ enhanced ensemble variations in CCP?
The WSVEDFM and WSEDFM outperformed the individual DF models and the Bagged and Boosted individual DF models on both the original and balanced (SMOTE) CCP datasets. Furthermore, the SMOTE methodology we used addressed the intrinsic class imbalance issue seen in the CCP datasets and improved the CCP performances of the suggested DF models, notably the WSVEDFM and WSEDFM techniques.
- RQ3:
How do the suggested DF models and their ensemble variations compare to existing state-of-the-art CCP solutions?
Furthermore, observable findings indicated that the suggested DF models (LMT, FT, and RF) and enhanced ensemble variants (WSVEDFM and WSEDFM) outperformed current CCP solutions on the studied CCP datasets in most cases.
5. Threats to Validity
This section describes the validity threats faced during the experiment. According to Zhang, Moro and Ramos [
11], CCP is becoming increasingly relevant, and evaluating and limiting threats to the validity of experimental results is an important component of any empirical study.
External validity: The potential to generalize the experimental research is important to its validity. The kind and number of datasets utilized in the experimental phase may affect the generalizability of research findings in several ways. As a result, two major and frequently used CCP datasets with a diverse set of features (Kaggle (20) and UCI (18)) have been identified. These datasets are freely accessible to the public and are widely used for training and evaluating CCP methods. Furthermore, this study provided a complete analysis of the experimentation method, which might assist in the reproducibility and validity of its methodological approaches to diverse CCP datasets.
Internal validity: This concept highlights the significance and regularity of datasets, ML techniques, and empirical analysis. As such, notable ML approaches developed and used in previous research are used in this study. The ML techniques were selected for their merit (effectiveness) and diversity. In addition, to prevent unexpected errors in empirical findings, the investigated CCP models were systematically implemented (trained) on the chosen CCP datasets using the CV approach, and each experiment was repeated 10 times for thoroughness. However, future studies may examine other model assessment methodologies and tactics.
Construct validity: This issue is related to the choice of evaluation criteria used to evaluate the efficiency of CCP models that have been investigated. Accuracy, AUC, f-measure, and MCC were all used in this research work. These metrics offered a detailed and complete empirical analysis of the CCP models used in the experiment. Furthermore, the DF models we used for CCP were developed specifically to determine the churning process and status.
6. Conclusions and Future Works
In this research work, DF models and their enhanced ensemble variants were developed for customer churn prediction. Specifically, LMT, FT, RF, Weighted Soft Voting Ensemble Decision Forest Method (WSVEDFM), and Weighted Stacking Ensemble Decision Forest Method (WSEDFM) were developed and tested on original (imbalanced) and balanced (SMOTE) telecommunication customer churn datasets. Experiments were conducted to examine the efficacy and applicability of the suggested DF models. Empirical results showed that the DF models outperformed base-line ML classifiers such as NB, kNN, and DS on the imbalanced and balanced Kaggle and UCI telecommunication customer churn datasets. This discovery validates the applicability of DF models for CCP. Furthermore, the enhanced ensemble versions of the DF models (WSEDFM and WSVEDFM) beat Bagged and Boosted models on imbalanced and balanced datasets, indicating their usefulness in CCP. Furthermore, the suggested DF models (LMT, FT, RF, WSVEDFM, and WSEDFM) outperformed the best models in the literature on Kaggle and UCI telecommunication customer churn datasets. As a result, this research recommends deploying suggested DF models for CCP.
As a continuation of this research work, we intend to investigate the spotting and removal of outliers and extreme values, which could contribute to improved outcomes (CCP models). Also, the characteristics of projected customer churns were not explored in this research work, though they may be relevant to corporations deciding whether to retain certain churn customers. As a result, good churn clients may have a higher lifetime value. Nonetheless, we hope to address these critical concerns in future research work.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}