
Integroly: Automatic Knowledge Graph Population from Social Big Data in the Political Marketing Domain



Abstract
Featured Application
Abstract
1. Introduction
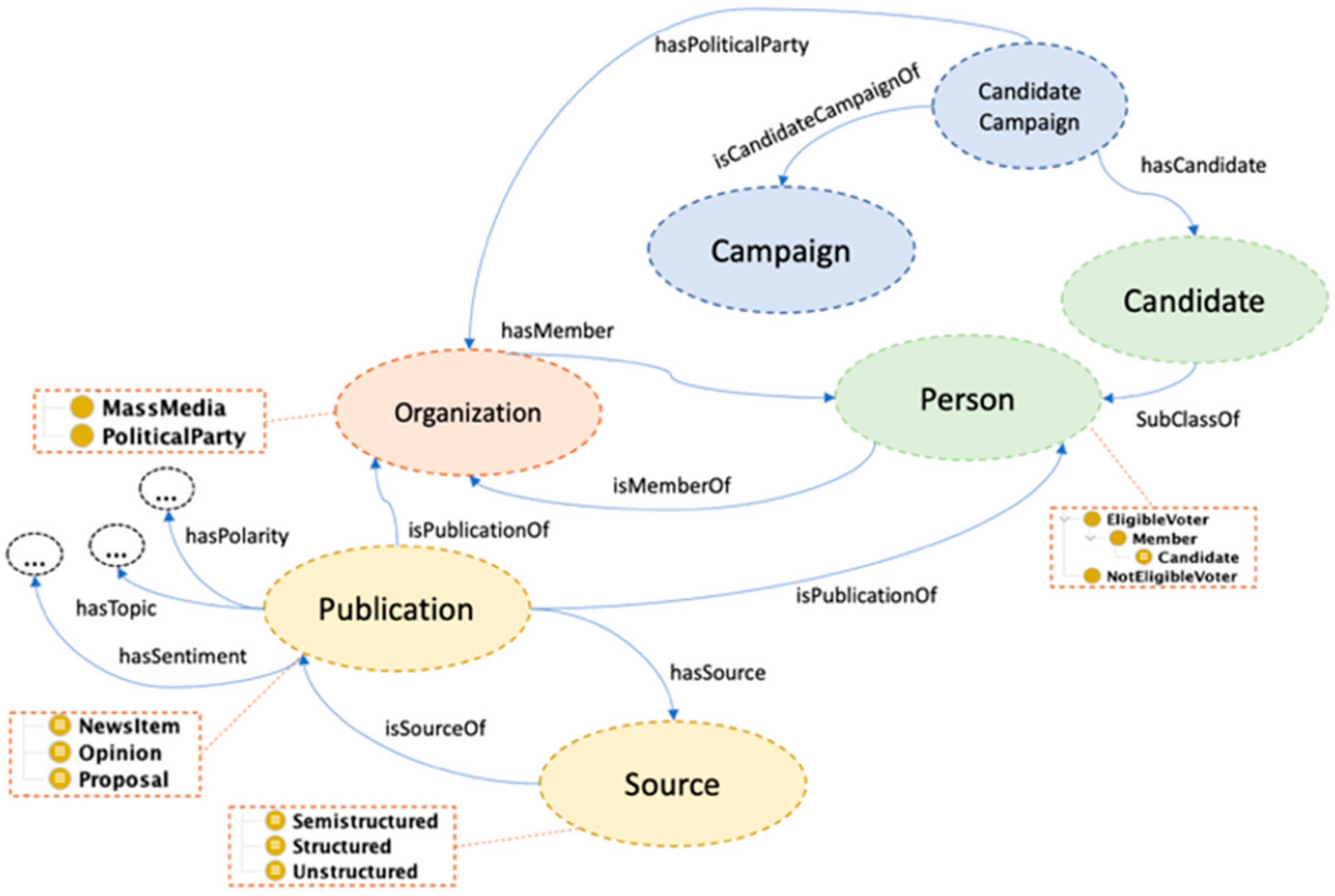
- We present the Political Marketing Ontology (PMont), a shareable conceptual model involving the most relevant elements in the political marketing domain, including three main operative knowledge items from political campaigns: candidate, electorate, and media. The ontology is an evolution of our previous work [20].
- Different unstructured, semi-structured, and structured data sources are exploited to populate the knowledge base by using a variety of information extraction techniques. New data sources can be added seamlessly.
- Data enrichment and analysis in semantic and linguistic levels for Spanish texts through NLP and ML techniques contributed to the validation and classification of the opinions, proposals, and news media publications.
- We propose an automatic KG population framework that homogenizes, collects, and relates the data of political marketing concepts with the possibility of inferring new knowledge for decision making.
- As a result of the work, a validated and populated KG for political marketing purposes was obtained.
2. Literature Review
2.1. Political Marketing
2.2. Ontology Instantiation: Populating Knowledge Graphs
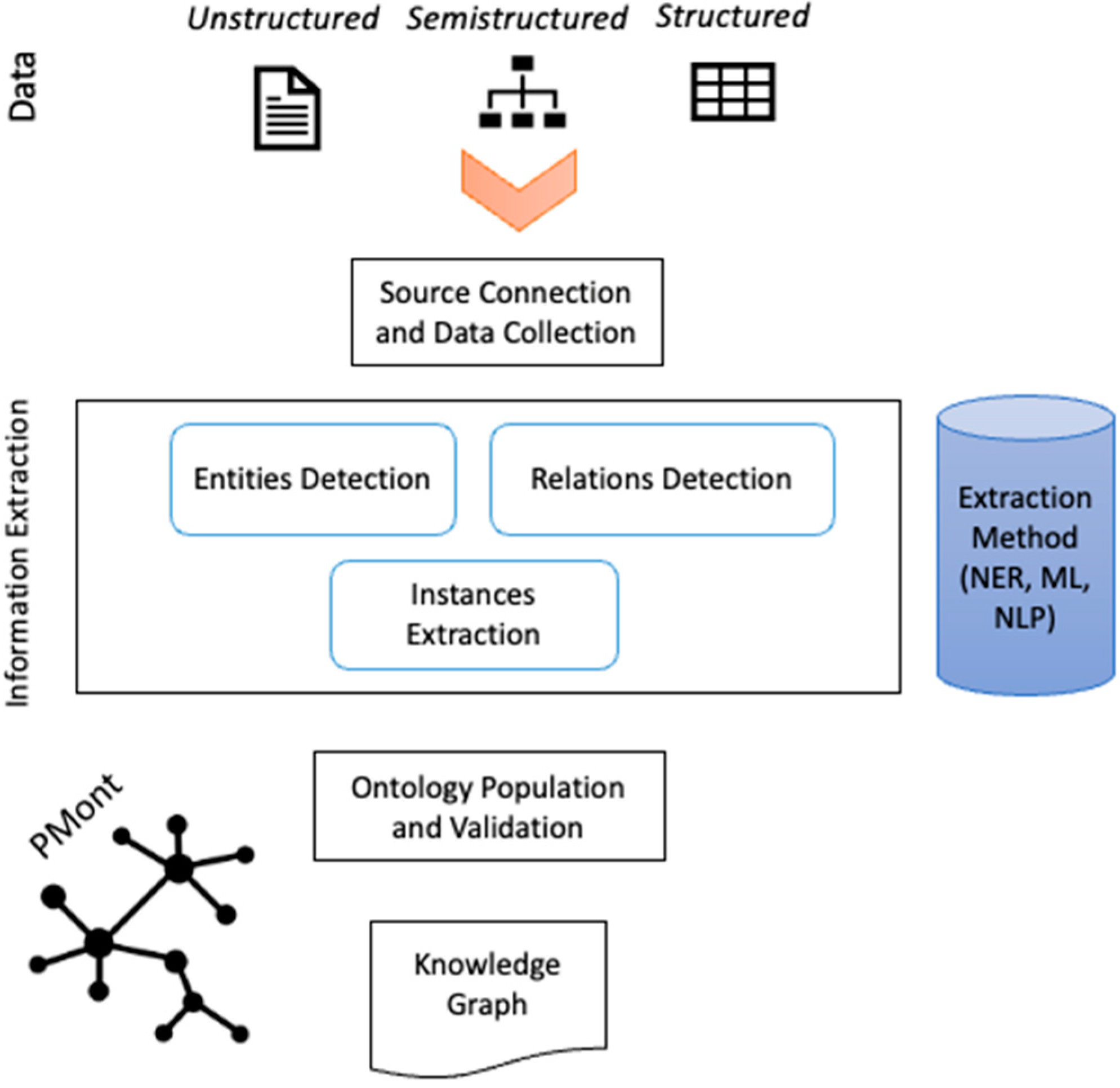
3. Integroly: A Framework for Political Marketing Knowledge Graph Enrichment
3.1. PMont: Political Marketing Ontology
- What does the electorate demand?
- What does public opinion say about the candidate (profile, proposals)?
- What does public opinion say about the political party to which the candidate belongs?
- What kind of message and political language should the candidate establish to positively impact citizenship?
- What kind of campaign proposals should be designed?
- What are the target groups of the electorate?
- In which group has greater acceptance?
- What comparative does the candidate have with his adversaries?
- In what mass media does the candidate have the greatest impact?
- Which mass media are partial (identify candidate/party of your liking) and which are impartial?
- What part of the electorate has decided its vote (identify individual voters and their candidate/chosen political party) and what part of the electorate is undecided (identify individuals)?
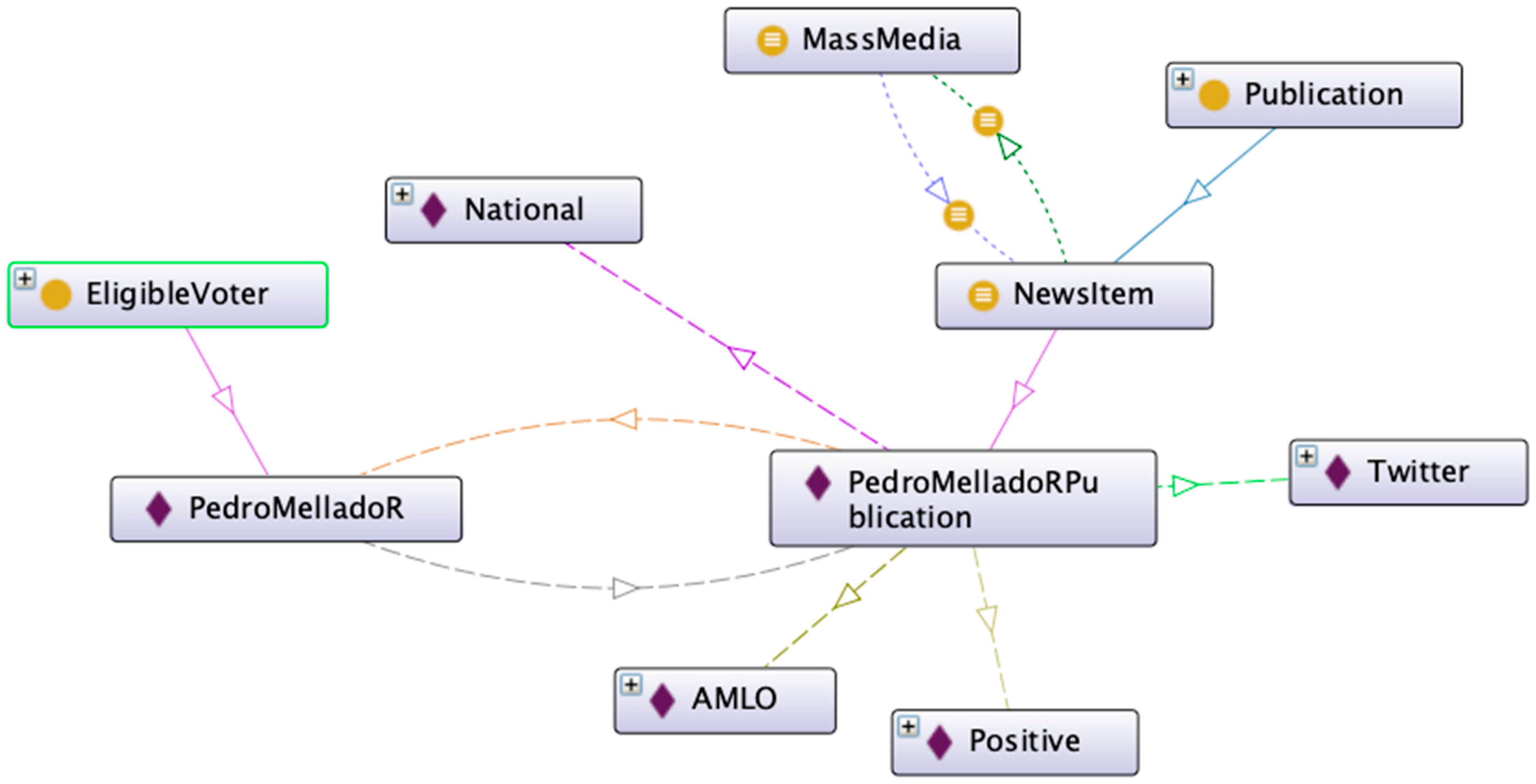
- Campaign: this class defines the dates of the campaign and political election. It is related to political parties and candidates.
- Candidate: it represents a person affiliated to a Political Party, with the intention of being elected to a public office.
- CandidateCampaign: this class is used to define ternary relationships between the classes Campaign, Candidate, and Political Party.
- Organization: it is a superclass containing two subclasses, namely, Mass Media and Political Party, with the purpose of defining structures and groups of people.
- Person: it is a superclass containing two subclasses, namely, EligibleVoter and NotEligibleVoter. EligibleVoter is the person who can vote for a candidate in a political election, while NotEligibleVoter cannot vote under the circumstances demanded by the law where the election is located (for example, minor).
- Publication: it represents different types of publications. In particular, three subclasses are considered, namely, NewsItem (news article created and shared by mass media), Proposal (a political proposal by a candidate), and Opinion (public opinion by a citizen shared on social media).
- Source: it indicates the source of the publications. It is a superclass containing Structured, Semistructured, and Unstructured as subclasses.
3.2. Source Connection and Data Collection
3.3. Information Extraction
- For NER, we used the TextRazor API. This API works by leveraging a huge knowledge base of entities extracted from various web sources, including Wikipedia, DBPedia, and Wikidata. A matching engine is in charge of finding relationships between the text content and the possible entities grouped as dictionaries. Additionally, a statistics-based tagger is used to identify people, places, and companies among other concepts, and regular expressions are applied to spot the less ambiguous elements including email addresses and websites.
- As regards relation extraction, we produced linked data using the TextRazor API, first, disambiguating the terms and, second, linking the entities to canonical IDs in the linked web (Wikipedia, DBPedia, and Wikidata IDs). In this process, we converted raw text into a set of well-structured subject–predicate–object expressions that related entities, phrases, and concepts. The approach of linking entities to canonical IDs offers great accuracy and recall, providing the flexibility to an unlimited number of relationship types.
- As mentioned above, sentiment and polarity extraction are completed using the Stanford CoreNLP toolkit, an approach with a good understanding of the relevant metadata, deploying existing sentiment lexicons (including misspellings, morphological variants, slang, and social media markup) and the basic feature extraction (tokenization, stemming, POS-tagging). The whole features combination provided us with a robust tool for sentiment and polarity analysis.
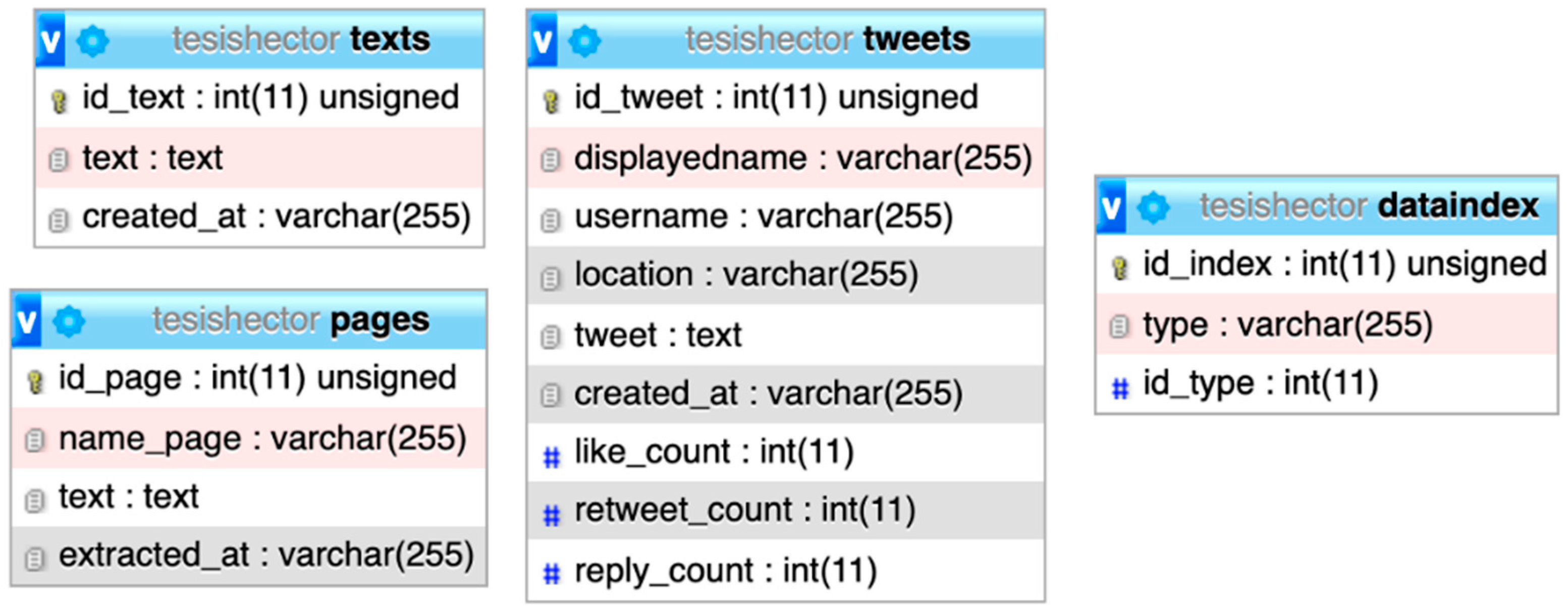
- The framework interface allows adding unstructured data (e.g., text) to the database, and then, extracting it with a query statement. The text below is a real record from the texts table in the database (an excerpt of the text in natural language written in Spanish gathered from a news website):
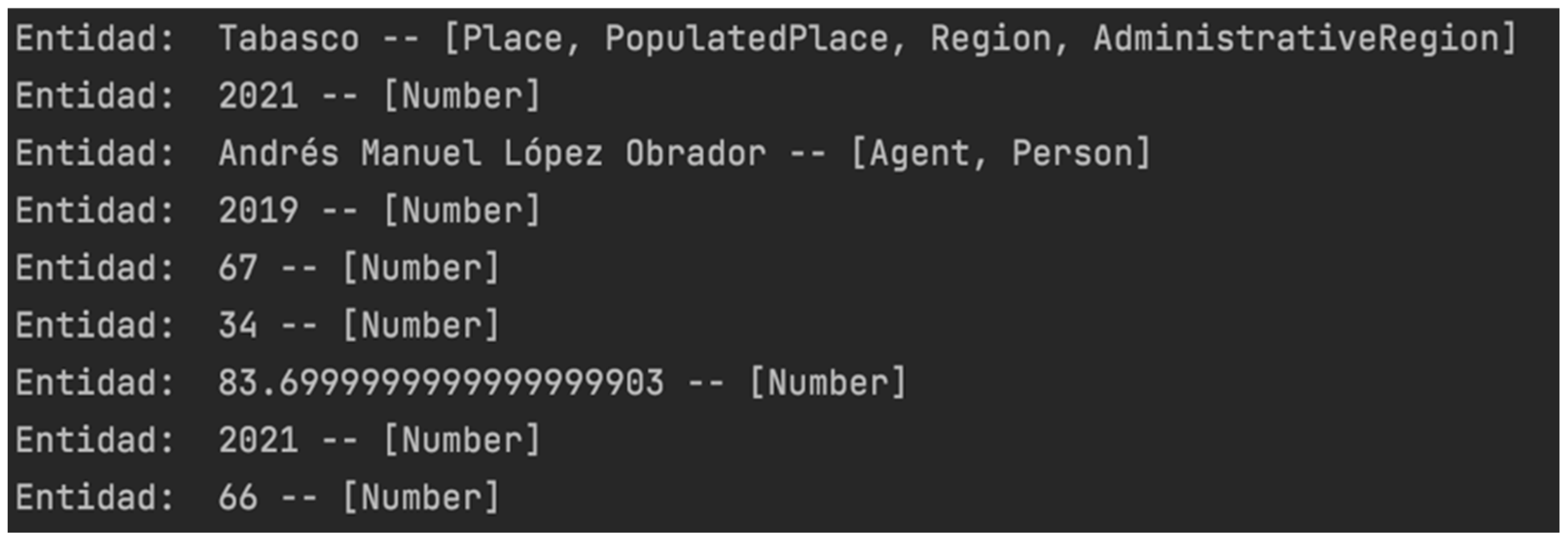
“De acuerdo a la evaluación promedio registrada por MITOFSKY en diciembre de 2021 para El Economista, el presidente López Obrador registró una aprobación promedio de 66% durante el último mes del 2021, la más alta desde febrero de 2019 cuando alcanzó 67%; en diciembre pasado la desaprobación presidencial promedio fue de 34 por ciento. Se identificó que por tipo de ocupación, los campesinos fueron quienes tuvieron el mayor porcentaje a favor del tabasqueño con 83.7 por ciento. Respecto de la ‘percepción de seguridad’, 41% de los encuestados opinó que está ‘igual’, 28.3% que está ‘peor’, 24.7% que está ‘mejor’, y 6% ‘no contestó’”.
- 2.
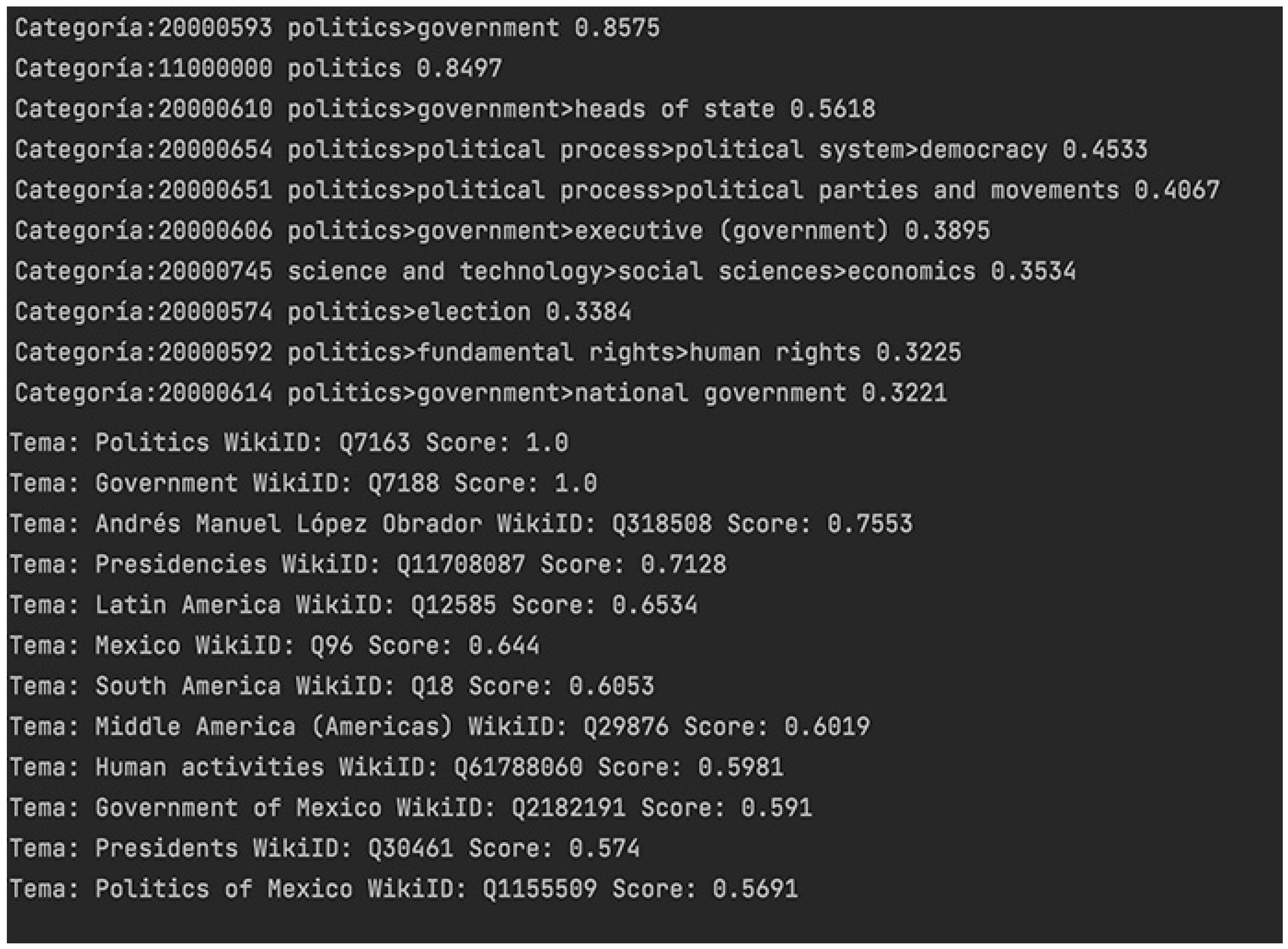
- The first stage is to implement NER and relation extraction analysis with the use of the TextRazor API. The results depicted in Figure 4 show the entities and the semantic relations. In Figure 5, the categorization and classification of the text based on the semantic identification of prominent key phrases and concepts related to the domain is shown. The number beside each category and topic is the matching score.
- 3.
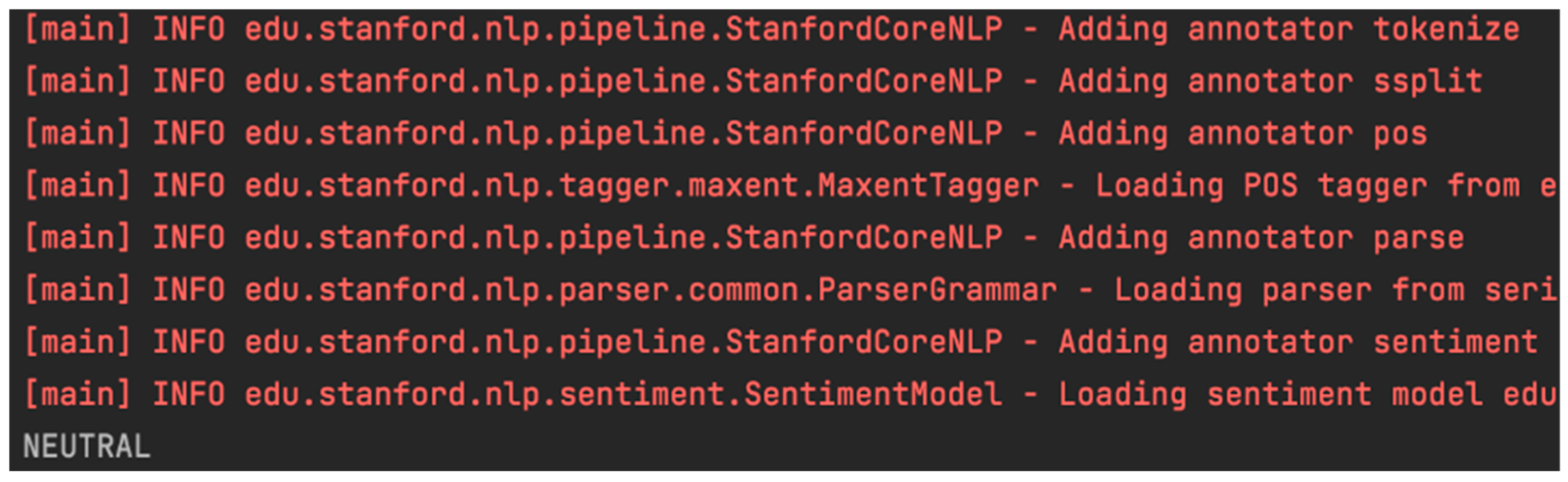
- Finally, sentiment analysis is applied with the Standford CoreNLP library obtaining three possible values: positive, neutral, or negative. For the text presented above, the content analysis result is “neutral” (see Figure 6).
3.4. Ontology Population and Validation
3.5. Resulting Knowledge Graph
4. Knowledge Graph Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kotler, P.; Levy, S.J. Broadening the Concept of Marketing. J. Mark. 1969, 33, 10–15. [Google Scholar] [CrossRef] [PubMed]
- Katz, R.S.; Mair, P. (Eds.) How Parties Organize: Change and Adaptation in Party Organizations in Western Democracies; Sage: New York, NY, USA, 1994; Volume 528, p. 375. [Google Scholar]
- Ingram, P.; Lees-Marshment, J. The anglicisation of political marketing: How Blair ‘out-marketed’ Clinton. J. Public Aff. 2002, 2, 44–56. [Google Scholar] [CrossRef]
- Perannagari, K.T.; Chakrabarti, S. Analysis of the literature on political marketing using a bibliometric approach. J. Public Aff. 2019, 20, e2019. [Google Scholar] [CrossRef]
- Trent, J.S.; Friedenberg, R.V.; Denton, R.E., Jr. Political Campaign Communication: Principles and Practices, 8th ed; Rowman & Littlefield Publishers: Lanham, MD, USA, 2015. [Google Scholar]
- Coto, M.A.A.; Adell, Á. Marketing Político 2.0: Lo que todo Candidato Necesita Saber para Ganar las Elecciones; Gestión 2000: Barcelona, Spain, 2011. [Google Scholar]
- Kirchner, A.E.L.; Juárez, S.B.; Vite, L. Marketing Político, 1st ed.; Cengage Learning: Queretaro, Mexico, 2011. [Google Scholar]
- Borgesius, F.J.Z.; Möller, J.; Kruikemeier, S.; Fathaigh, R.; Irion, K.; Dobber, T.; Bodo, B.; De Vreese, C. Online Political Microtargeting: Promises and Threats for Democracy. Utrecht Law Rev. 2018, 14, 82. [Google Scholar] [CrossRef]
- Studer, R.; Benjamins, V.; Fensel, D. Knowledge engineering: Principles and methods. Data Knowl. Eng. 1998, 25, 161–197. [Google Scholar] [CrossRef]
- Ehrlinger, L.; Wöß, W. Towards a Definition of Knowledge Graphs. CEUR Workshop Proceedings; CEUR-WS. 2016, Volume 1695. Available online: http://ceur-ws.org/Vol-1695/paper4.pdf (accessed on 23 May 2022).
- Shadbolt, N.; Berners-Lee, T.; Hall, W. The Semantic Web Revisited. IEEE Intell. Syst. 2006, 21, 96–101. [Google Scholar] [CrossRef]
- García-Sánchez, F.; García-Díaz, J.A.; Gómez-Berbís, J.M.; Valencia-García, R. Financial Knowledge Instantiation from Semi-structured, Heterogeneous Data Sources. In Computer Science On-line Conference; Springer: Cham, Switzerland, 2019; Volume 764, pp. 103–110. [Google Scholar] [CrossRef]
- Somodevilla, M.J.; Ayala, D.V.; Pineda, I. An Overview on Ontology Learning Tasks. In Computación y Sistemas; Instituto Politecnico Nacional: Mexico City, Mexico, 2018; pp. 137–146. [Google Scholar] [CrossRef]
- Petasis, G.; Karkaletsis, V.; Paliouras, G.; Krithara, A.; Zavitsanos, E. Ontology Population and Enrichment: State of the Art. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2011; Volume 6050, pp. 134–166. [Google Scholar] [CrossRef]
- Lubani, M.; Noah, S.A.M.; Mahmud, R. Ontology population: Approaches and design aspects. J. Inf. Sci. 2018, 45, 502–515. [Google Scholar] [CrossRef]
- Iyer, V.; Mohan, L.; Bhatia, M.; Reddy, Y.R. A Survey on Ontology Enrichment from Text. In Proceedings of the 16th International Conference on Natural Language Processing, Hyderabad, India, 18–21 December 2019; pp. 1–10. [Google Scholar]
- Drumond, L.; Girardi, R. A survey of ontology learning procedures. CEUR Workshop Proc. 2008, 427, 1–13. [Google Scholar]
- Kondylakis, H.; Papadakis, N. EvoRDF: Evolving the exploration of ontology evolution. Knowl. Eng. Rev. 2018, 33, e12. [Google Scholar] [CrossRef]
- Faria, C.; Serra, I.; Girardi, R. A domain-independent process for automatic ontology population from text. Sci. Comput. Program. 2014, 95, 26–43. [Google Scholar] [CrossRef]
- Guedea-Noriega, H.H.; García-Sánchez, F. Construcción de una Ontología para Marketing Político. Tecnol. Educ. 2020, 7, 38–44. [Google Scholar] [CrossRef]
- Scammell, M. Political Marketing: Lessons for Political Science. Political Stud. 1999, 47, 718–739. [Google Scholar] [CrossRef]
- Juárez, J. Hacia un estudio del marketing político: Limitaciones teóricas y metodológicas. Espiral 2003, 9, 60–95. [Google Scholar]
- Moore, C. Propaganda Prints: A History of Art in the Service of Social and Political Change; A&C Black: London, UK, 2010. [Google Scholar]
- Ganduri, R.N.; Reddy, E.L.; Reddy, T.N. Social Media as a Marketing Tool for Political Purpose and Its Implications on Political Knowledge, Participation, and Interest. Int. J. Online Mark. 2020, 10, 21–33. [Google Scholar] [CrossRef]
- Jain, A.; Kumar, A.; Dash, M.K. Information technology revolution and transition marketing strategies of political parties: Analysis through AHP. Int. J. Bus. Inf. Syst. 2015, 20, 71. [Google Scholar] [CrossRef]
- Antoniades, N. Political Marketing Communications in Today’s Era: Putting People at the Center. Society 2020, 57, 646–656. [Google Scholar] [CrossRef]
- Hoppe, T.; Humm, B.; Reibold, A. Semantic Applications; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- Pinto, F.M.; Marques, A.; Santos, M.F. Ontology-supported database marketing. J. Database Mark. Cust. Strat. Manag. 2009, 16, 76–91. [Google Scholar] [CrossRef][Green Version]
- Guedea-Noriega, H.H.; García-Sánchez, F. SePoMa: Semantic-Based Data Analysis for Political Marketing. In Technologies and Innovation. CITI 2018. Communications in Computer and Information Science; Springer: Cham, Switzerland, 2018; Volume 883, pp. 199–213. [Google Scholar] [CrossRef]
- Fenz, S. Supporting Complex Decision Making by Semantic Technologies. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2020; Volume 12123, pp. 632–647. [Google Scholar] [CrossRef]
- Morente-Molinera, J.; Cabrerizo, F.; Mezei, J.; Carlsson, C.; Herrera-Viedma, E. A dynamic group decision making process for high number of alternatives using hesitant Fuzzy Ontologies and sentiment analysis. Knowl.-Based Syst. 2020, 195, 105657. [Google Scholar] [CrossRef]
- Cutrona, V.; De Paoli, F.; Košmerlj, A.; Nikolov, N.; Palmonari, M.; Perales, F.; Roman, D. Semantically-Enabled Optimization of Digital Marketing Campaigns. In International Semantic Web Conference; Springer: Cham, Switzerland, 2019; pp. 345–362. [Google Scholar] [CrossRef]
- Noriega, H.H.G.; Sanchez, F.G. Semantic (Big) Data Analysis: An Extensive Literature Review. IEEE Lat. Am. Trans. 2019, 17, 796–806. [Google Scholar] [CrossRef]
- Cotfas, L.-A.; Roxin, I.; Delcea, C. Semantic search in social media analysis. In Proceedings of the 18th International Conference on Informatics in Economy, Education, Research and Business Technologies, Bucharest, Romania, 30–31 May 2019; pp. 37–42. [Google Scholar] [CrossRef]
- Sebei, H.; Taieb, M.A.H.; Ben Aouicha, M. SNOWL model: Social networks unification-based semantic data integration. Knowl. Inf. Syst. 2020, 62, 4297–4336. [Google Scholar] [CrossRef]
- Milić, P.; Veljković, N.; Stoimenov, L. Semantic Technologies in e-government: Toward Openness and Transparency. In Smart Technologies for Smart Governments; Springer: Cham, Switzerland, 2018; pp. 55–66. [Google Scholar] [CrossRef]
- Ahmed, J.; Ahmed, M. Ontological Based Approach of Integrating Big Data: Issues and Prospects. In ICDSMLA 2019; Springer: Singapore, 2020; pp. 365–378. [Google Scholar] [CrossRef]
- Caione, A.; Paiano, R.; Guido, A.L.; Fait, M.; Scorrano, P. Technological tools integration and ontologies for knowledge extraction from unstructured sources: A case of study for marketing in agri-food sector. In Proceedings of the Creating Global Competitive Economies: 2020 Vision Planning and Implementation—Proceedings of the 22nd International Business Information Management Association Conference, IBIMA 2013, Rome, Italy, 13–14 November 2013; pp. 225–236. [Google Scholar]
- Alazemi, N.; Al-Shehab, A.J.; Alhakem, H.A. Semantic-Based E-Government Framework Based on Domain Ontologies: A Case of Kuwait Region. J. Theor. Appl. Inf. Technol. 2018, 96, 2557–2566. [Google Scholar]
- Laney, D. 3D Data Management: Controlling Data Volume, Velocity, and Variety Application Delivery Strategies. 2001. Available online: https://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf (accessed on 23 May 2022).
- Rossi, R.; Hirama, K. Characterizing Big Data Management. In Proceedings of the InSITE 2015: Informing Science + IT Education Conferences, Tampa, FL, USA, 29 June–5 July 2015. [Google Scholar] [CrossRef]
- Beydoun, G.; Hoffmann, A.; Breis, J.T.F.; Béjar, R.M.; Valencia-García, R.; Aurum, A. Cooperative Modelling Evaluated. Int. J. Cooperative Inf. Syst. 2005, 14, 45–71. [Google Scholar] [CrossRef]
- Asim, M.N.; Wasim, M.; Khan, M.U.G.; Mahmood, W.; Abbasi, H.M. A survey of ontology learning techniques and applications. Database 2018, 2018, bay101. [Google Scholar] [CrossRef] [PubMed]
- Wimalasuriya, D.C.; Dou, D. Ontology-based information extraction: An introduction and a survey of current approaches. J. Inf. Sci. 2010, 36, 306–323. [Google Scholar] [CrossRef]
- Ontotext, What Is a Knowledge Graph?|Ontotext Fundamentals. 2020. Available online: https://www.ontotext.com/knowledgehub/fundamentals/what-is-a-knowledge-graph/ (accessed on 19 December 2021).
- Barrasa, J.; Hodler, A.E.; Webber, J. Knowledge Graphs: Data in Context for Responsive Businesses, 1st ed.; O’Reilly Media: Newton, MA, USA, 2021. [Google Scholar]
- Kertkeidkachorn, N.; Ichise, R. T2KG: A Demonstration of Knowledge Graph Population from Ttext and Its Challenges. CEUR Workshop Proceedings; CEUR-WS. 2018, Volume 2293, pp. 110–113. Available online: http://ceur-ws.org/Vol-2293/jist2018pd_paper9.pdf (accessed on 23 May 2022).
- Yoo, S.; Jeong, O. Automating the expansion of a knowledge graph. Expert Syst. Appl. 2019, 141, 112965. [Google Scholar] [CrossRef]
- Xu, J.; Kim, S.; Song, M.; Jeong, M.; Kim, D.; Kang, J.; Rousseau, J.F.; Li, X.; Xu, W.; Torvik, V.I.; et al. Building a PubMed knowledge graph. Sci. Data 2020, 7, 1–15. [Google Scholar] [CrossRef]
- Salahdine, F.; Kaabouch, N. Social Engineering Attacks: A Survey. Futur. Internet 2019, 11, 89. [Google Scholar] [CrossRef]
- Guzmán-Guzmán, X.; Núñez-Valdez, E.R.; Vásquez-Reynoso, R.; Asencio, A.; García-Díaz, V. SWQL: A new domain-specific language for mining the social Web. Sci. Comput. Program. 2021, 207, 102642. [Google Scholar] [CrossRef]
- Freelon, D. Computational Research in the Post-API Age. Political Commun. 2018, 35, 665–668. [Google Scholar] [CrossRef]
- Sapountzi, A.; Psannis, K.E. Social networking data analysis tools & challenges. Futur. Gener. Comput. Syst. 2018, 86, 893–913. [Google Scholar] [CrossRef]
- Vargas-Vera, M.; Moreale, E.; Stutt, A.; Motta, E.; Ciravegna, F. MnM: Semi-Automatic Ontology Population from Text. In Ontologies; Springer: Boston, MA, USA, 2007; pp. 373–402. [Google Scholar] [CrossRef]
- Ayadi, A.; Samet, A.; Beuvron, F.D.B.D.; Zanni-Merk, C. Ontology population with deep learning-based NLP: A case study on the Biomolecular Network Ontology. Procedia Comput. Sci. 2019, 159, 572–581. [Google Scholar] [CrossRef]
- Pech, F.; Martinez, A.; Estrada, H.; Hernandez, Y. Semantic Annotation of Unstructured Documents Using Concepts Similarity. Sci. Program. 2017, 2017, 7831897. [Google Scholar] [CrossRef]
- Achichi, M.; Bellahsene, Z.; Ienco, D.; Todorov, K. Towards Linked Data Extraction from Tweets. In EGC: Ex-traction et Gestion des Connaissances; Hermann-Editions: Paris, France, 2015; pp. 383–388. [Google Scholar]
- Bereta, K.; Papadakis, G.; Koubarakis, M. Ontop4theWeb: SPARQLing the Web On-the-fly. In Proceedings of the 2021 IEEE 15th International Conference on Semantic Computing, ICSC 2021, Laguna Hills, CA, USA, 27–29 January 2021; pp. 268–271. [Google Scholar] [CrossRef]
- Ait-Mlouk, A.; Vu, X.-S.; Jiang, L. WINFRA: A Web-Based Platform for Semantic Data Retrieval and Data Analytics. Mathematics 2020, 8, 2090. [Google Scholar] [CrossRef]
- Noy, N.F.; McGuinness, D.L. Ontology Development 101: A Guide to Creating Your First Ontology. Available online: https://protege.stanford.edu/publications/ontology_development/ontology101.pdf (accessed on 29 July 2020).
- W3C, OWL 2 Web Ontology Language Document Overview (Second Edition). 2012. Available online: https://www.w3.org/TR/owl2-overview/ (accessed on 16 March 2019).
- Chen, H.; Cao, G.; Chen, J.; Ding, J. A Practical Framework for Evaluating the Quality of Knowledge Graph. In China Conference on Knowledge Graph and Semantic Computing; Springer: Singapore, 2019; pp. 111–122. [Google Scholar] [CrossRef]
- Gao, J.; Li, X.; Xu, Y.E.; Sisman, B.; Dong, X.L.; Yang, J. Efficient knowledge graph accuracy evaluation. Proc. VLDB Endow. 2019, 12, 1679–1691. [Google Scholar] [CrossRef]
- Wang, X.; Chen, L.; Ban, T.; Usman, M.; Guan, Y.; Liu, S.; Wu, T.; Chen, H. Knowledge graph quality control: A survey. Fundam. Res. 2021, 1, 607–626. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
|
|
|
|
|
| 1 | 2 | 3 | 4 | 5 |
| 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guedea-Noriega, H.H.; García-Sánchez, F. Integroly: Automatic Knowledge Graph Population from Social Big Data in the Political Marketing Domain. Appl. Sci. 2022, 12, 8116. https://doi.org/10.3390/app12168116
Guedea-Noriega HH, García-Sánchez F. Integroly: Automatic Knowledge Graph Population from Social Big Data in the Political Marketing Domain. Applied Sciences. 2022; 12(16):8116. https://doi.org/10.3390/app12168116
Chicago/Turabian StyleGuedea-Noriega, Héctor Hiram, and Francisco García-Sánchez. 2022. "Integroly: Automatic Knowledge Graph Population from Social Big Data in the Political Marketing Domain" Applied Sciences 12, no. 16: 8116. https://doi.org/10.3390/app12168116
APA StyleGuedea-Noriega, H. H., & García-Sánchez, F. (2022). Integroly: Automatic Knowledge Graph Population from Social Big Data in the Political Marketing Domain. Applied Sciences, 12(16), 8116. https://doi.org/10.3390/app12168116